Exploring West African Folk Narrative Texts Using Machine Learning


Abstract
:1. Introduction
How Can Machine Learning and Natural Language Processing be Used to Identify, Analyze, and Generate West African Folk Tales?
2. Theoretical Background
2.1. European Narrative Theories
2.2. African Narrative Theories
3. Corpus Construction
- -
- Type A corpora: 0.5 MB West African, 0.5 MB Western European
- -
- Type B corpora: 1.1 MB West African, 1.1 MB Western European
4. Experiment 1: Text Generation
4.1. Introduction
4.2. Experimental Setup
4.2.1. Data Preprocessing
4.2.2. Training the Model
4.3. Results
4.4. Human Evaluation
4.4.1. Survey Setup
4.4.2. Survey Results
4.5. Discussion
5. Experiment 2: Text Classification
5.1. Introduction
5.2. Related Work
5.3. Experimental Setup
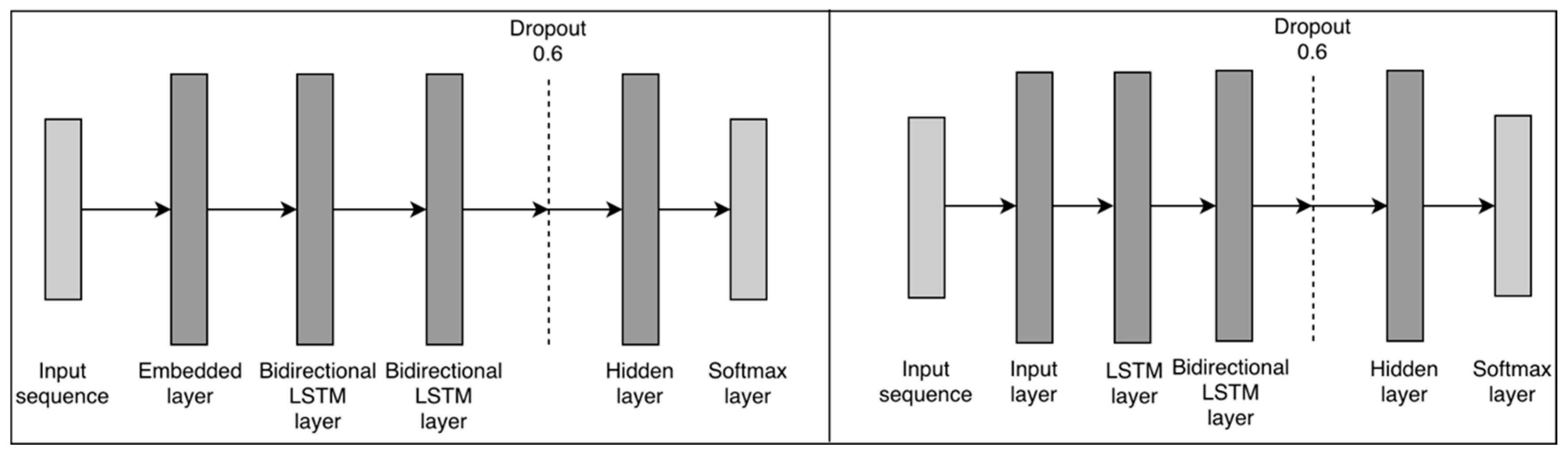
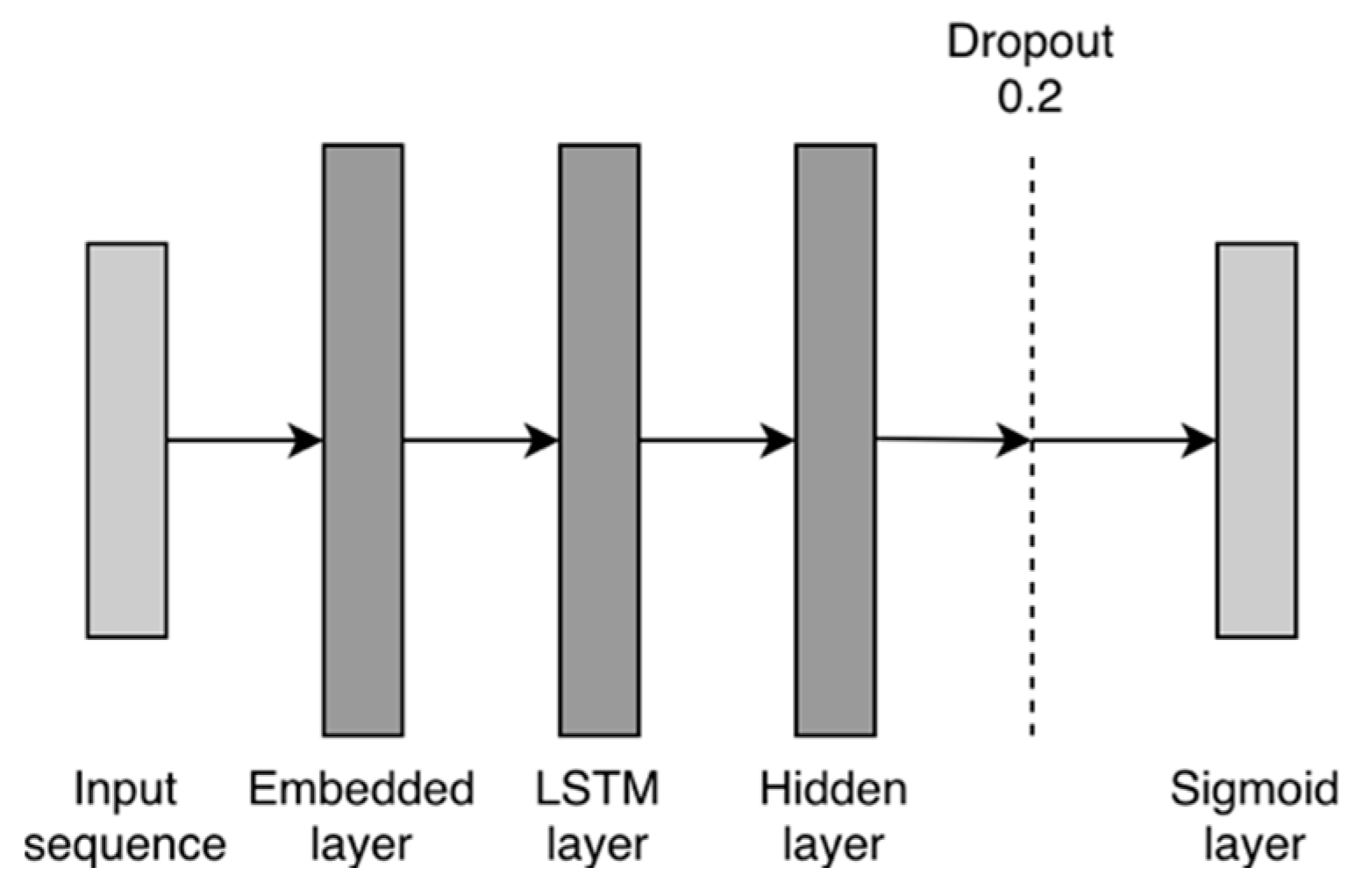
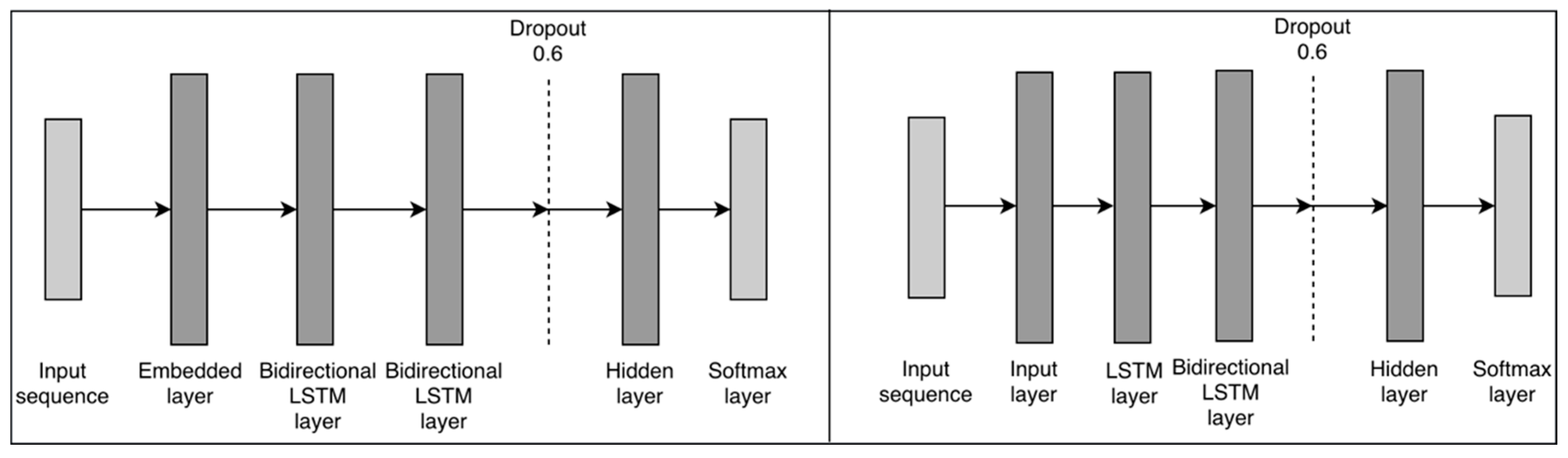
5.3.1. LSTM Classifier
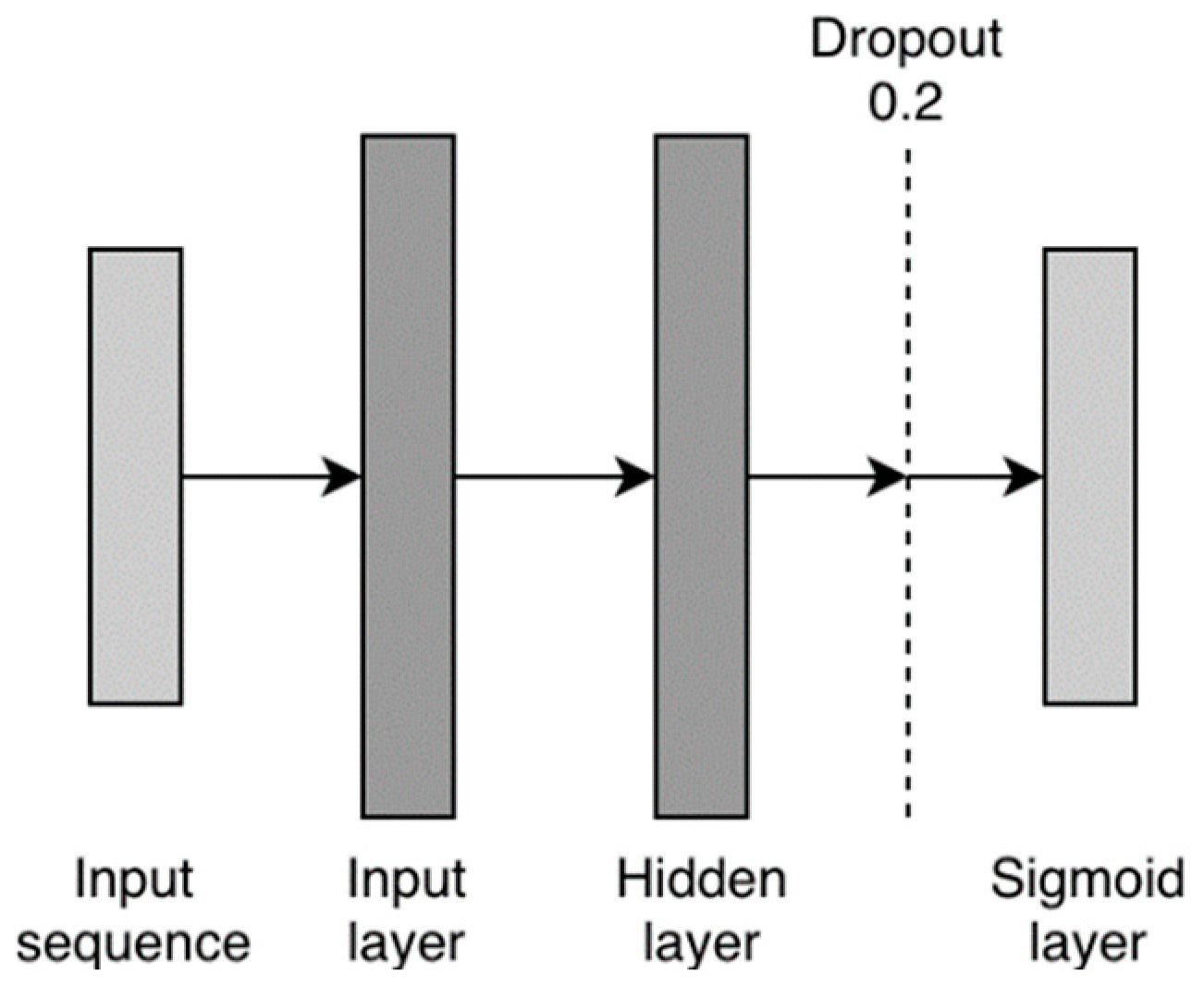
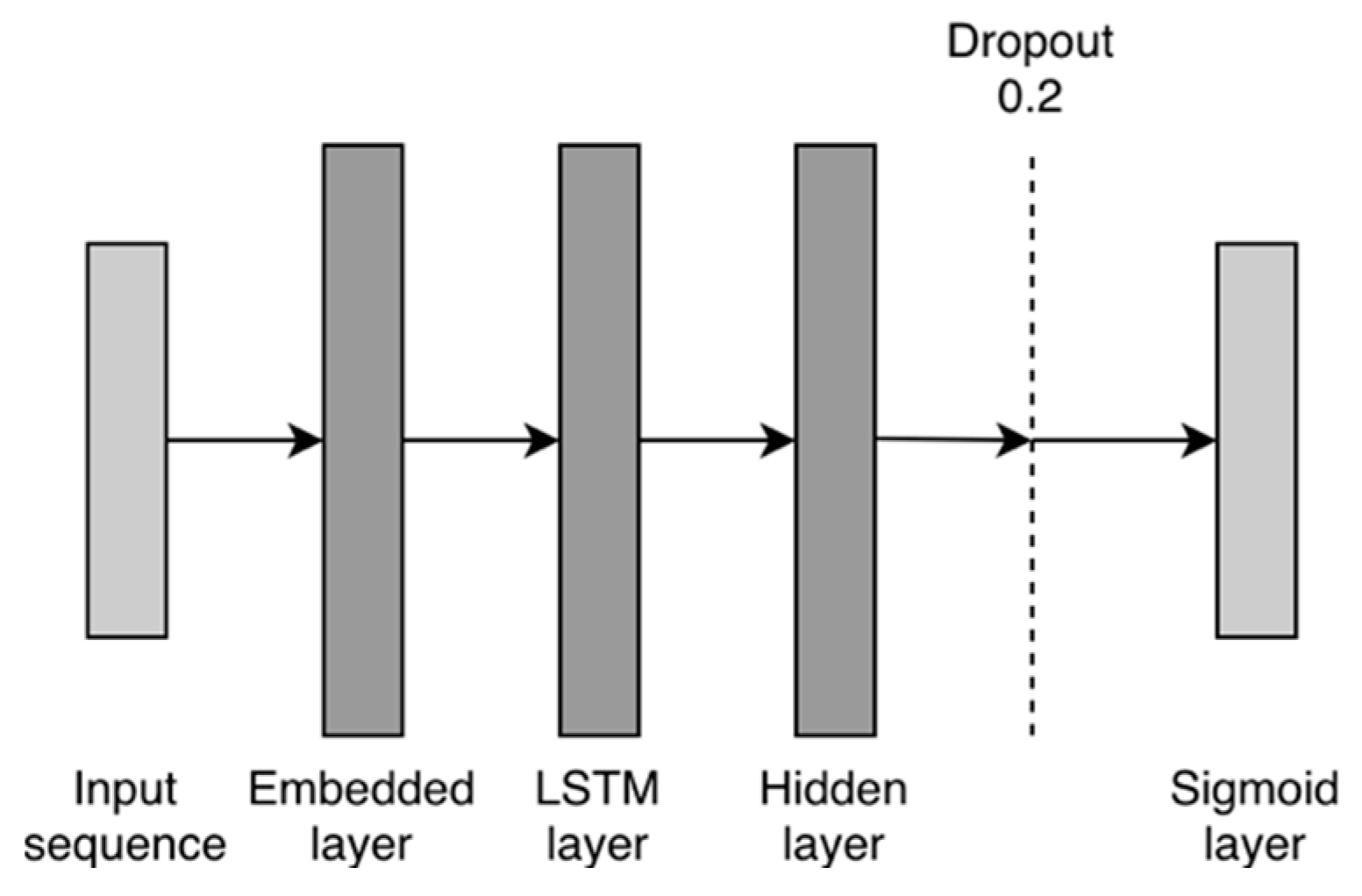
5.3.2. Bag-of-Words Classifier
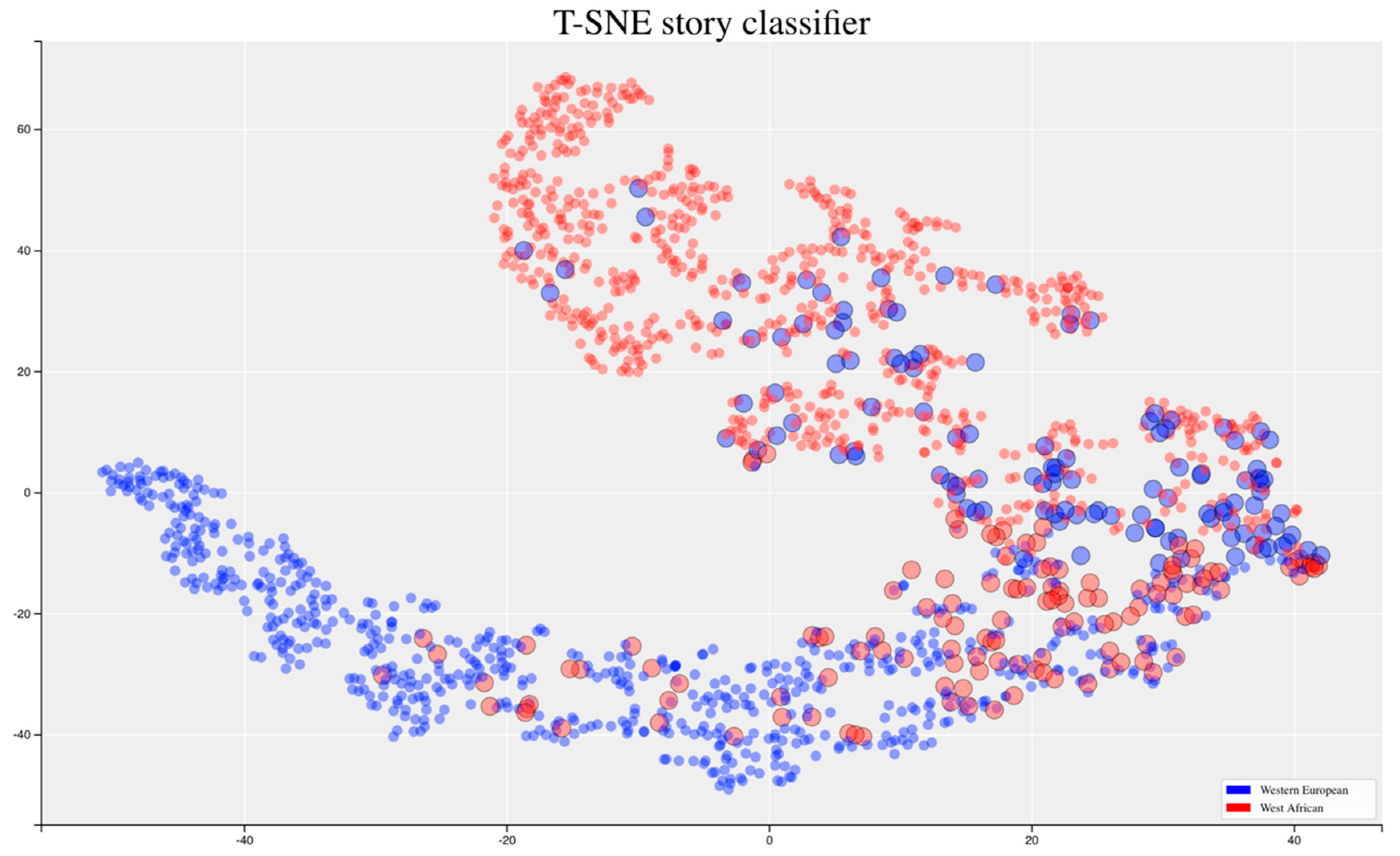
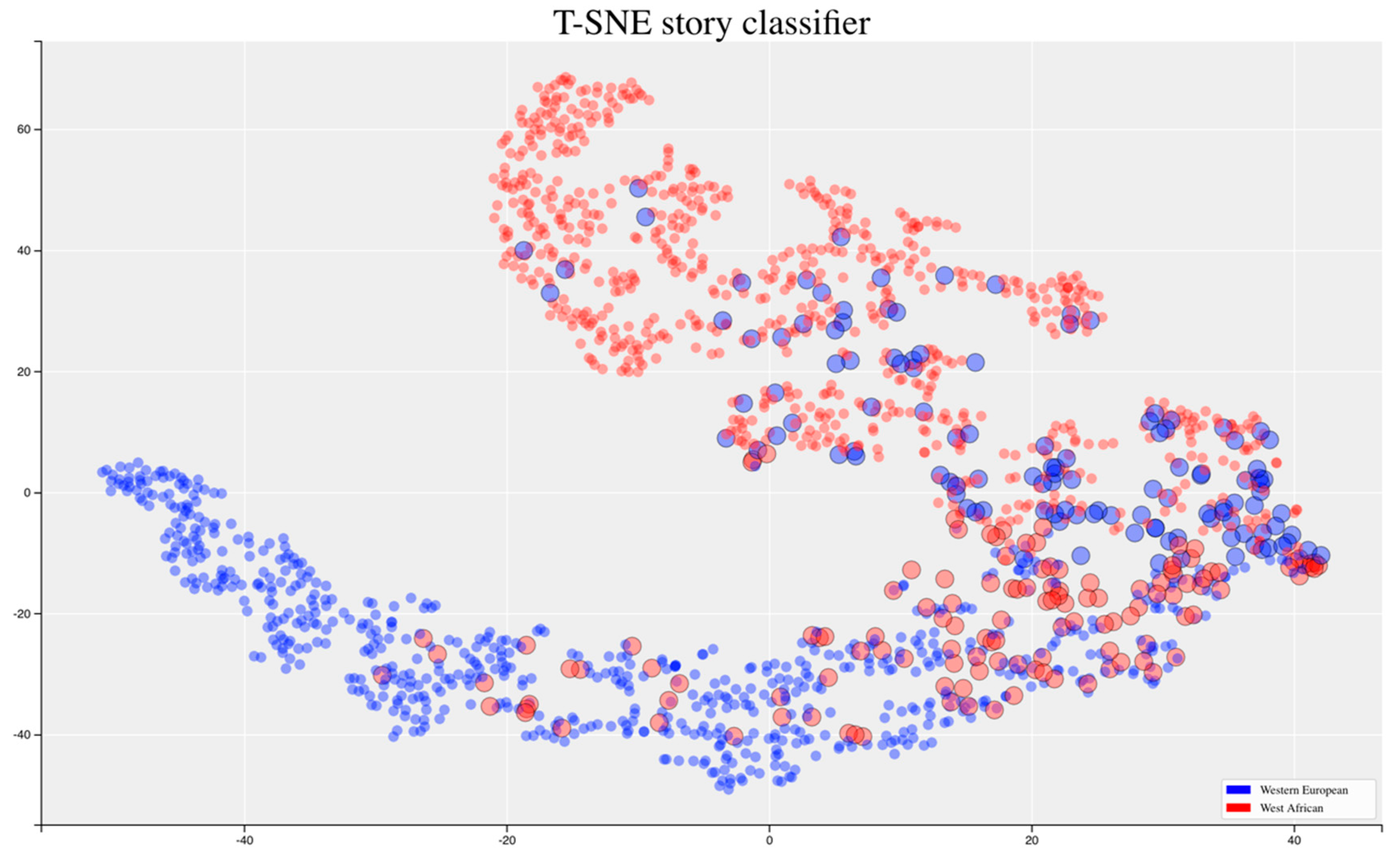
5.4. Comparison of the Results
5.5. Discussion Experiment 2
6. Experiment 3: Narrative Structure Analysis
6.1. Introduction
6.2. Related Work
6.3. Experimental Setup
Classification of Narrative Structures
- -
- Naïve Bayes (NB) is the simplest classifier based on Bayes’ rule, calculating the fraction of times a word appears among all words in a set of documents. Although NB is seen as relatively old compared to newer and more complex algorithms, it still performs well in many text classification tasks.
- -
- Linear Support Vector Machine (SVM) is a popular algorithm of choice whenever the sample size is small. SVM is based on finding an ideal hyper-plane between two or more vectors. The features that are used to determine the final position of a document in the feature space, are words, of which the occurrences are counted. Since longer documents will have higher average count values than shorter ones, tf-idf values for each word are used as input, to place more emphasis on distinctive words.
- -
- Logistic Regression (LR) can be used for binary classification but is also well applicable in multi-class classification tasks. The method learns the probability of a sample belonging to a class by finding the optimal decision boundary that is best at separating the classes. It is similar to the NB classifier in that both aim to predict target y given x. The difference is that NB is a generative model, it first models the joint distribution of x and y before predicting P(y|x). LR, on the other hand, is a discriminative model, which directly predicts P(y|x) by learning the input to output mapping.
- -
- Word2Vec Logistic Regression (Word2Vec) is a pretrained model and uses the Gensim model available online. In Word2Vec, semantics play a role such that similar meaning words have similar word embeddings. In this case, the words are tokenized, and word vector averaging is applied to each word to find the importance of each word in a document. Then, the averages are fed to a Logistic Regression algorithm.
- -
- Term Frequency Logistic Regression (TF) counts the occurrence of each token and considers tokens occurring twice or more, with the exception of stop words. This is fed to a simple logistic regression classifier to perform the classification task.
6.4. Term Frequency of N-grams
6.5. Discussion Experiment 3
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lundby, K. Digital Storytelling, Mediatized Stories: Self-Representations in New Media; Peter Lang: Bern, Switzerland, 2008. [Google Scholar]
- Abbott, H.P. The Cambridge Introduction to Narrative; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Edosomwan, S.; Peterson, C.M. A History of Oral and Written Storytelling in Nigeria. In Commission for International Adult Education; ERIC: New Mexico, USA, 2016. [Google Scholar]
- Tang, P. Masters of the Sabar: Wolof Griot Percussionists of Senegal; Temple University Press: Philadelphia, PA, USA, 2007. [Google Scholar]
- Tuwe, K. The African oral tradition paradigm of storytelling as a methodological framework: Employment experiences for African communities in New Zealand. In Proceedings of the 38th AFSAAP Conference: 21st Century Tensions and Transformation in Africa, Melbourne, Australia, 28–30 October 2015. [Google Scholar]
- Grimm, J.; Grimm, W. The Original Folk and Fairy Tales of the Brothers Grimm: The Complete First Edition; Princeton University Press: Princeton, NJ, USA, 2014. [Google Scholar]
- Finnegan, R.H.; Finnegan, R.; Turin, M. Oral Literature in Africa; Oxford University Press: Oxford, UK, 1970; Volume 970. [Google Scholar]
- Propp, V. Morphology of the Folktale; University of Texas Press: Austin, TX, United States, 2010; Volume 9. [Google Scholar]
- Grasbon, D.; Braun, N. A morphological approach to interactive storytelling. In Proceedings of the CAST01, Living in Mixed Realities, Conference on Artistic, Cultural and Scientific Aspects of Experimental Media Spaces, Sankt Augustin, Germany, 21–22 September 2001; pp. 337–340. [Google Scholar]
- Chatman, S.B. Story and Discourse: Narrative Structure in Fiction and Film; Cornell University Press: Ithaca, NY, USA, 1980. [Google Scholar]
- Lucas, D.W. Aristotle Poetics; University of Chicago Press: Chicago, IL, USA, 1968. [Google Scholar]
- Brütsch, M. The three-act structure: Myth or magical formula? J. Screenwrit. 2015, 6, 301–326. [Google Scholar] [CrossRef]
- Campbell, J. The Hero with a Thousand Faces; New World Library: Novato, CA, USA, 2008; Volume 17. [Google Scholar]
- Vogler, C. The Writer’s Journey—Mythic Structure for Writers; Michael Wiese Productions: Studio City, CA, USA, 1998. [Google Scholar]
- Dickey, M.D. Game design narrative for learning: Appropriating adventure game design narrative devices and techniques for the design of interactive learning environments. Educ. Technol. Res. Dev. 2006, 54, 245–263. [Google Scholar] [CrossRef]
- Gervás, P. Propp’s Morphology of the Folk Tale as a Grammar for Generation. In 2013 Workshop on Computational Models of Narrative; Schloss Dagstuhl-Leibniz-Zentrum für Informatik GmbH, Dagstuhl Publishing: Saarbrücken/Wadern, Germany, 2013. [Google Scholar]
- Finlayson, M.A. Inferring Propp’s functions from semantically annotated text. J. Am. Folk. 2016, 129, 55–77. [Google Scholar] [CrossRef]
- Gervás, P.; Lönneker-Rodman, B.; Meister, J.C.; Peinado, F. Narrative models: Narratology meets artificial intelligence. In Proceedings of the International Conference on Language Resources and Evaluation. Satellite Workshop: Toward Computational Models of Literary Analysis, Genoa, Italy, 22–28 May 2006; pp. 44–51. [Google Scholar]
- Imabuchi, S.; Ogata, T. A story generation system based on Propp theory: As a mechanism in an integrated narrative generation system. In International Conference on NLP; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Berry, J.; Spears, R. West African Folktales; Northwestern University Press: Evanston, IL, USA, 1991. [Google Scholar]
- Iyasere, S.O. Oral tradition in the criticism of African literature. J. Mod. Afr. Stud. 1975, 13, 107–119. [Google Scholar] [CrossRef]
- Barthes, R. Le Degré zéro de L’écriture; Le Seuil: Paris, France, 2015. [Google Scholar]
- Gyasi, K.A. Writing as translation: African literature and the challenges of translation. Res. Afr. Lit. 1999, 30, 75–87. [Google Scholar] [CrossRef]
- Ninan, O.D.; Odéjobí, O.A. Theoretical issues in the computational modelling of Yorùbá narratives. In 2013 Workshop on Computational Models of Narrative; Schloss Dagstuhl—Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2013. [Google Scholar]
- Sackey, E. Oral tradition and the African novel. Mod. Fict. Stud. 1991, 37, 389–407. [Google Scholar] [CrossRef]
- Simmons, D.C. Analysis of cultural reflection in Efik folktales. J. Am. Folk. 1961, 74, 126–141. [Google Scholar] [CrossRef]
- Ficler, J.; Goldberg, Y. Controlling linguistic style aspects in neural language generation. arXiv 2017, arXiv:1707.02633. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2014. [Google Scholar]
- Bhardwaj, A.; Di, W.; Wei, J. Deep Learning Essentials: Your Hands-on Guide to the Fundamentals of Deep Learning and Neural Network Modeling; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Johnson, D.D. Generating polyphonic music using tied parallel networks. In Computational Intelligence in Music, Sound, Art and Design, Proceedings of the International Conference on Evolutionary and Biologically Inspired Music and Art, Amsterdam, The Netherlands, 19–21 April 2017; Springer: Amsterdam, The Netherlands, 2017; pp. 128–143. [Google Scholar]
- Manu, S.Y. Six Ananse Stories; Sedco Publishing Ltd.: Accra, Ghana, 1993. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-ninth AAAI Conference on Artificial Intelligence, Austin, Texas, USA, 25–30 January 2015. [Google Scholar]
- Nguyen, D.; Trieschnigg, D.; Meder, T.; Theune, M. Automatic classification of folk narrative genres. In Proceedings of the Workshop on Language Technology for Historical Text (s) at KONVENS 2012, Vienna, Austria, 19–21 September 2012. [Google Scholar]
- Trieschnigg, D.; Hiemstra, D.; Theune, M.; Jong, F.; Meder, T. An Exploration of Language Identification Techniques in the Dutch Folktale Database. In Proceedings of the Workshop on Adaptation of Language Resources and Tools for Processing Cultural Heritage (LREC 2012), Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-supervised sequence learning. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2015; pp. 3079–3087. [Google Scholar]
- Maaten, L.V.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Finlayson, M.M. Learning Narrative Structure from Annotated Folktales. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2012. [Google Scholar]
- Habel, C. Stories—An artificial intelligence perspective (?). Poetics 1986, 15, 111–125. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| West African | Western European | |
|---|---|---|
| Total no. folk tales | 252 | 490 |
| Total word count | 203,537 | 202,866 |
| Total no. characters | 857,590 | 855,097 |
| Min. word count | 53 | 34 |
| Max. word count | 7878 | 3536 |
| Avg. word count | 804 | 421 |
| LSTM Type | Character-Level | Word-Level |
|---|---|---|
| Number of units | 100, 200 | 100, 200 |
| Sequence length | 7, 7 ∗ avg(word length), 50, 100 | 7, 50, 100 |
| Max. training epochs | 25, 50, 75, 100 | 5, 10, 25, 50 |
| Dropout | 0.2, 0.6 | 0.2, 0.6 |
| Batch size | 64, 128 | 64, 128 |
| West African | Western European | |
|---|---|---|
| 1 | Day 564 | Little 585 |
| 2 | Time 533 | Time 513 |
| 3 | Tortoise 526 | King 466 |
| 4 | King 485 | Day 379 |
| 5 | Little 482 | Fox 344 |
| 6 | Lion 430 | Wolf 309 |
| 7 | Told 393 | Home 279 |
| 8 | Water 390 | House 270 |
| 9 | People 385 | Wife 256 |
| 10 | Jacka l379 | Reynard 241 |
| Classifier Type | LSTM | Bag-of-Words |
|---|---|---|
| Number of units | 100, 200, 300 | - |
| Max. training epochs | 25, 50, 75, 100 | 5, 25, 50 |
| Dropout | 0.2, 0.4, 0.6 | 0.2, 0.4, 0.6 |
| Split in Half | Split at 25% | Split at 10% | ||||
|---|---|---|---|---|---|---|
| begin:mid:end | begin:end | begin:mid:end | begin:end | begin:mid:end | begin:end | |
| 1:1 | 1:2:1 | 1:1 | 1:8:1 | 1:1 | ||
| NB | - | 37.0% | 34.1% | 57.4% | 43.9% | 73.2% |
| SVM | - | 45.4% | 44.5% | 66.2% | 72.0% | 77.8% |
| LR | - | 48.8% | 45.0% | 67.3% | 71.4% | 77.3% |
| Word2Vec | - | 60.1% | 48.0% | 70.4% | 67.0% | 73.3% |
| TF | - | 55.0% | 53.0% | 70.5% | 74.8% | 77.9% |
| Split in Half | Split at 25% | Split at 10% | ||||
|---|---|---|---|---|---|---|
| begin:mid:end | begin:end | begin:mid:end | begin:end | begin:mid:end | begin:end | |
| 1:1 | 1:2:1 | 1:1 | 1:8:1 | 1:1 | ||
| NB | - | 59.5% | 43.5% | 63.4% | 50.4% | 66.1% |
| SVM | - | 65.5% | 51.3% | 75.2% | 66.3% | 77.0% |
| LR | - | 64.7% | 50.6% | 73.5% | 67.6% | 79.1% |
| Word2Vec | - | 64.2% | 52.6% | 69.0% | 69.4% | 75.6% |
| TF | - | 65.8% | 53.0% | 74.4% | 66.1% | 75.5% |
| 4-g | Term Frequency | 4-g | Term Frequency |
|---|---|---|---|
| once upon a time | 25 | once upon a time | 27 |
| upon a time there | 17 | upon a time there | 20 |
| a time there lived | 10 | a time there was | 17 |
| a long time ago | 9 | time there was a | 16 |
| time there lived a | 9 | there was once a | 14 |
| there was once a | 8 | once on a time | 12 |
| a time there was | 7 | there was a king | 6 |
| very long time ago | 6 | a long time ago | 5 |
| time there was a | 6 | a donkey and a | 5 |
| a very long time | 6 | a lion and a | 5 |
| there was a man | 6 | and was just doing | 4 |
| man and his wife | 5 | was a king who | 4 |
| once there was a | 5 | was just going to | 4 |
| long time ago in | 5 | caught sight of a | 4 |
| want to marry her | 5 | on a time a | 4 |
| 4-g | Term Frequency | 4-g | Term frequency |
|---|---|---|---|
| from that day on * | 8 | rest of their lives | 5 |
| and from that day * | 7 | that he had been | 5 |
| and that is why * | 7 | stop him eat him | 4 |
| ever since that time * | 5 | for rest of their | 4 |
| and that is how * | 4 | he said to himself | 4 |
| passed a law that | 4 | and they lived happily | 3 |
| that is reason why * | 3 | more than a match | 3 |
| that I bought for | 3 | as soon as he | 3 |
| for many years and * | 3 | fast as he could | 3 |
| gazelle that i bought | 3 | her that he had | 3 |
| that for future no | 3 | they lived happily together | 3 |
| since that time whenever * | 3 | fox laughed and said | 3 |
| what are you doing | 3 | told her that he | 3 |
| for future no one | 3 | said that he was | 3 |
| did not want to | 3 | that i did not | 3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lô, G.; de Boer, V.; van Aart, C.J. Exploring West African Folk Narrative Texts Using Machine Learning. Information 2020, 11, 236. https://doi.org/10.3390/info11050236
Lô G, de Boer V, van Aart CJ. Exploring West African Folk Narrative Texts Using Machine Learning. Information. 2020; 11(5):236. https://doi.org/10.3390/info11050236
Chicago/Turabian StyleLô, Gossa, Victor de Boer, and Chris J. van Aart. 2020. "Exploring West African Folk Narrative Texts Using Machine Learning" Information 11, no. 5: 236. https://doi.org/10.3390/info11050236
APA StyleLô, G., de Boer, V., & van Aart, C. J. (2020). Exploring West African Folk Narrative Texts Using Machine Learning. Information, 11(5), 236. https://doi.org/10.3390/info11050236