1. Introduction
The Web and social network services play a central role to bring individuals with common interests closer. However, such close interaction enables the occurrence of illicit events. Criminals use the Web for various activities, such as building virtual communities, mobilization, provisioning information, online training, disseminating their services or ideals, recruiting new members, and financing and mitigating risks. In practice, Web content and its communication capabilities provide advantages for planning and executing criminal acts [
1]. On the other hand, the Web can benefit the development of software tools and mechanisms to support the investigation and the prevention of criminal acts.
Several countries, such as Brazil, have seen a fast increase in crime rates in the last few decades [
2]. This leads to difficulties in dealing with criminal occurrences in a timely and effectively way. To this end, automated services are necessary for both the prevention and investigative processes [
3]. Nevertheless, it is still necessary to research more efficient methods to analyze the criminal content in the context of social networks [
4], such as the analysis and detection of intentions related to crimes [
5]. It is desirable, for example, to distinguish between who is inducing a person to commit a crime and who is commenting on a crime announced by the media. Therefore, automated analysis of users’ intentions in social network posts can support investigators to understand the goals of the posts.
Automated analysis of user’s intentions described in natural language posts remains an open challenge. According to Wu et al. [
6], the language used in social networks is short and informal, which represents a computational challenge for automated mechanisms. The use of slang, such as those expressed by criminals, incorporates complexity in designing effective computational algorithms. In this investigation, we refer to the dialect of (cyber) criminal as Criminal Slang Expression (CSE).
The identification and classification of crimes mediated by the Web are hard tasks. There is a huge amount of Web content as unstructured data, which makes it arduous to analyze manually [
7]. The complexity is even higher when people use CSE, which is not formally defined. It is used to hinder others from understanding. This produces a “secret” language, which can be used in conjunction with data encryption (out of the scope of this paper) [
8]. Despite the use of complex cryptography techniques [
9,
10], which is not always viable, criminals use marginal/group CSE for a more restricted communication to a specific group. In addition, the volume and velocity of crimes execution committed with the support of the Web (e.g., drug trafficking and terrorism) [
11] make it harder to deal with this problem.
Literature presents lexical dictionaries aiming to represent CSE. For instance, Mota [
12] presented an extensive work with CSE used in Rio de Janeiro, Brazil. These dictionaries are mostly built to support human (criminal investigators) in interpreting CSE. Nevertheless, formal models suited to represent CSE that can be interpreted by computers are still needed. Such models should provide flexible and expansive constructions because CSEs are in constant evolution. According to Agarwal and Sureka [
13], only lexical dictionaries are not enough for building automatic intention detection mechanisms. Automated detection using an exclusively lexical approach proved to be flawed [
14], requiring the adoption of multiple techniques, such as Machine Learning (ML) ones.
Techniques and improvements in the area of categorizing emotions and feelings (that addresses intentions indirectly) have been explored (cf.
Section 3). However, literature shows that evaluation and representation of criminal intentions in natural language texts are rare. In this context, there is a lack of further studies exploring the use of linguistic fundamentals of intention analysis in written texts, such as Semiotics [
15] and Speech Act Theory (SAT) [
16,
17].
In this paper, we present a framework for selecting and classifying social network posts with CSE. We combine Semantic Web technologies and ML algorithms to this end. The Semantic Web provides computer interpretable models [
6], which are useful for representing semantic relations between domain concepts. Law and security concepts [
3,
18,
19,
20], for instance, can be better interpreted (by human and computers) through the formal representation using ontologies. We chose to use an ontology to describe aspects related to the language used to commit criminal acts. The use of ontologies allows us to describe relationships and make inferences to determine weights related to suspicious messages, which cannot be represented by simple vocabularies, or other less structured knowledge representation systems. In addition, ontologies are expandable and interoperable models on the Web, which can be (re)used by other Web systems.
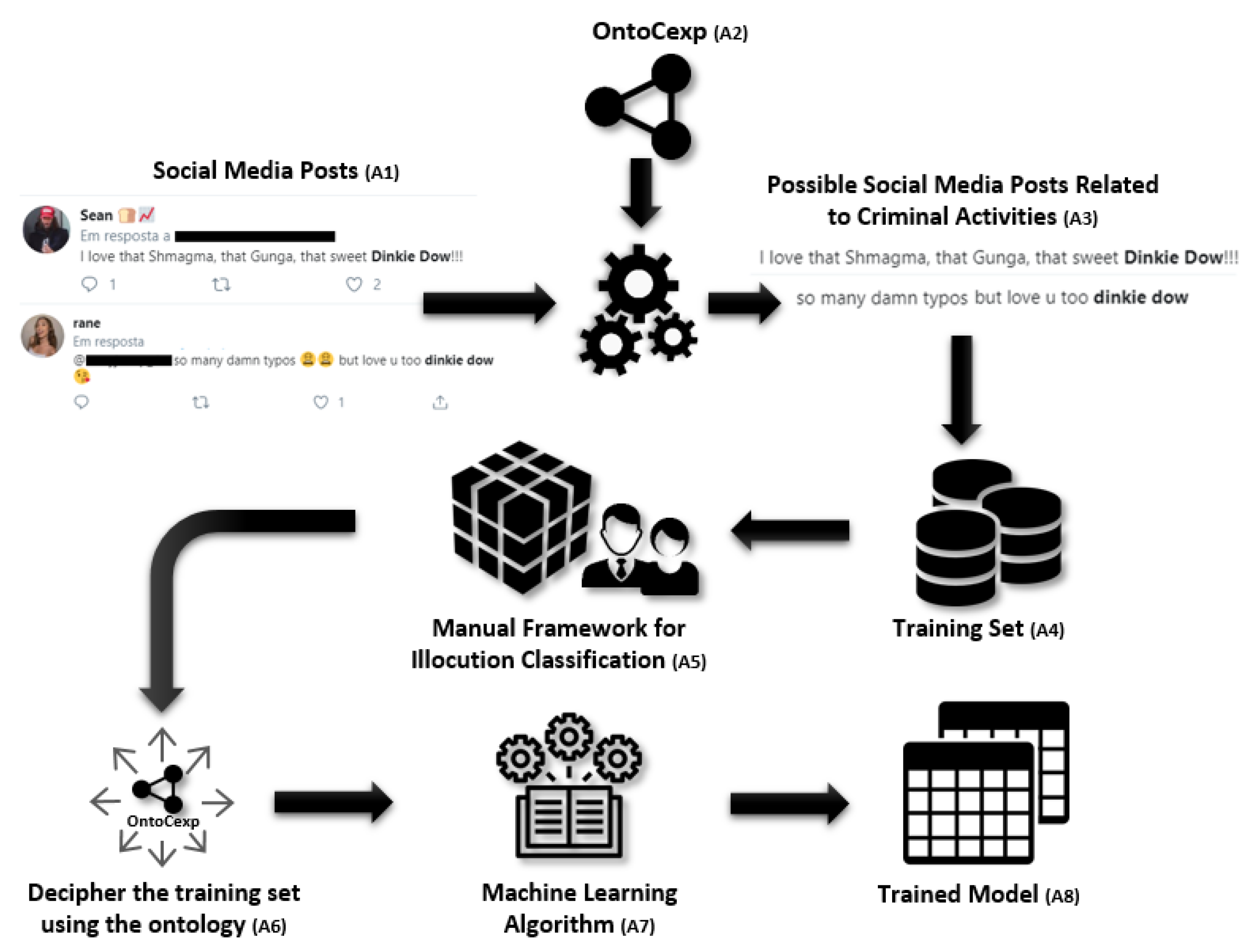
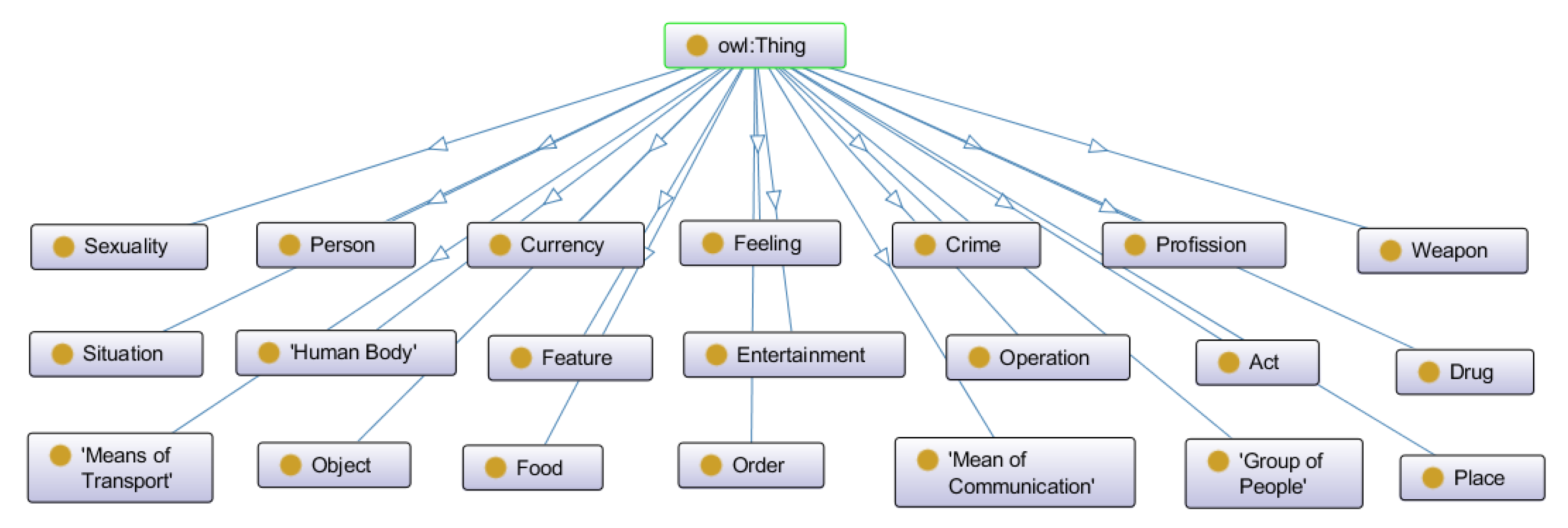
Our work proposes the Ontology-Based Framework for Criminal Intention Classification (OFCIC). The solution explores automatic classification models and algorithms applied to short textual messages to help in the detection of digital criminal acts. We propose the Ontology of Criminal Expressions (OntoCexp) [
21] to provide a formal and extensible model for representing CSE on social networks. The framework OFCIC uses the ontology OntoCexp for selecting potentially crime related posts, as well as to automatically decipher the posts. The ML techniques are used for automatically classifying the posts according to an intention classification framework [
22,
23].
Our solution provides computational mechanisms and a software prototype to support investigators in the task of selecting potential criminal posts and filter them according to a predefined intention classes from SAT. This work contributes and differs from other studies by proposing a hybrid framework, which uses fundamentals, concepts, and techniques from Semantic Web, Semiotics, SAT, and ML. It uniquely addresses intention classification (using SAT) of social media posts using CSE. Our solution is useful to assist human investigators in law enforcement agencies in the detection and analysis of suspicious social media posts. It allows for selecting and ranking posts from social media according to inferred suspicious level and intention.
This investigation is applied and evaluated in an empirical study on Twitter®. Based on 8,835,290 tweets analyzed, 702 tweets were filtered from this set using the framework and used as our ML training and test dataset. A prototype software tool provides functionalities for recovering potential criminal tweets (using the OntoCexp) and for filtering classified posts according to intention classes.
The remainder of this article is organized as follows:
Section 2 introduces the theoretical and methodological background by including key concepts;
Section 3 presents the related work;
Section 4 details the OFCIC framework, including the OntoCexp;
Section 5 presents our experimental evaluation with Twitter;
Section 6 discusses the achieved results; finally,
Section 7 concludes the paper.
3. Related Work
This section presents a literature review, which aims at answering the following research question: “What are the approaches to computationally assess and represent the intent of criminals in posts written in natural language using slang?”. The review was methodologically based on Kitchenham’s guide [
54].
In our methodology, a preliminary and exploratory investigation based on the research question was carried out aiming at obtaining the necessary inputs for the literature review, resulting in: (i) research parameters; (ii) scope of the search; (iii) scientific search databases; (iv) keywords; (v) search fields (e.g., title, abstract, manuscript). As we expected to identify advances and contributions in recent years, the search period was considered from 2014 to 2019 considering the fact that the research question addresses relatively recent research issues. We used the following search string: “(ontology OR thesaurus OR taxonomy OR vocabulary) AND (intention OR semiotics OR “speech acts”) AND (crime OR criminal)”. The syntax was adapted to each scientific search database.
We considered all returned articles from all databases, except the Google Scholar. Due to the scope of this database (indexing of other databases), the first 100 articles were considered (The google scholar returned thousands of results in a relevance order. As no relevant titles were found between the 100th and 200th results, we decided to stop the evaluation in the 100th paper). The initial search obtained a total of 1876 articles; 289 articles from Springer Link, 346 from IEEE Xplore, 763 from Science Direct, 378 from ACM Digital Library, and 100 from Google Scholar.
The inclusion and exclusion criteria were defined by three of the authors in an iterative process of reading articles (in the exploratory search) and proposing criteria until reaching consensus. We detail the Inclusion (I) and Exclusion (E) criteria as follows:
I1—Research on analysis of intentions in natural language over social networks;
I2—Research on analysis of encrypted language (e.g., slang);
I3—Studies that use the Speech Act theory or Semiotics for analysis of encrypted languages;
I4—Studies exploring ontologies to represent knowledge about criminal acts;
E1—Articles written in languages other than English and Portuguese;
E2—Articles that are not related to intention or emotion analysis in addition to at least one of the following themes: ciphered language analysis, speech acts theory, ontologies, and semiotics;
E3—Articles that are not related to computing or multidisciplinary with computing;
E4—Texts other than scientific publications;
E5—Summary papers with less than four pages that do not have the depth or relevant results; and
E6—Systematic Reviews and Books (Paper collection books had their articles evaluated individually).
Twenty-four articles were excluded due to duplicate results from the scientific databases. The remaining articles were submitted to the inclusion and exclusion criteria. The first evaluation considered the title, abstract, and keywords. Forty-two articles were categorized as papers with the possibility of adherence to the research theme, and they were fully evaluated according to the criteria. Three researchers analyzed the selected articles and prepared the final list by consensus after discussion. During this evaluation, eight studies were identified as non-adherent and six papers were classified as literature reviews related to the theme.
In the following, we present a synthetic analysis of results concerning the 27 selected studies organized by two main categories.
Section 3.1 describes solutions based on Lexicon Dictionary and Ontology for intent analysis.
Section 3.2 presents ML-based solutions.
Section 3.3 discusses the key findings on the related work.
3.2. Machine Learning and Mixed Learning based Solutions
Among the 27 evaluated studies, 22 use ML techniques as a core element in the proposals aiming to identify intentions and emotions (e.g., hate and depression) in texts written in natural language. The main ML techniques identified were Neural Networks and SVM. Some studies were considered mixed as they made use of ontologies with machine learning. We present a summary of the found studies.
Garcia-Diaz et al. [
51] defined the process of emotion extraction as “opinion mining”, which consists of using natural language processing and computational linguistics. The data mining process takes place in five steps, namely: selection, preprocessing, transformation, data mining, and interpretation. In preprocessing of tweets, user names and user quotes were converted to an identifier to ensure anonymity. The fourth step is responsible for generating the output that should be worked out using Naive Bayes. According to the authors, the accuracy of the ML sentiment analysis classifiers was improved by using expert domain-specific knowledge from social networks.
A process of detecting depression in natural language messages was proposed in Losada et al. [
59]. The study consisted of four steps: (1) selection of the text origin; (2) data extraction; (3) prediction, which consists in analyzing the message history of a given user; and (4) text classification by using a Logistic Regression algorithm.
A categorization of misogyny types was proposed by Anzovino et al. [
60]. The main objective was to detect misogyny in messages posted on Twitter, by using ML and NLP for classifying tweets as misogynistic. In Waseem et al. [
57], ML techniques were used with multiple intermediate processing tasks to improve assertiveness. Similar to the results obtained by Garcia-Diaz et al. [
51], this process presented improvement of results but loss of time performance. Agarwal and Sureka [
13] proposed a lexical dictionary to assist the detection of racism in posts on Tumblr. A linguistic analysis was performed by using two APIs (Alchemy Document Sentiment and IBM Watson Tone Analyzer). Five categories of sentiment were proposed: joy, fear, sadness, anger, and disgust. The authors experimented the techniques: Random Forest, Decision Tree, and Naive Bayes. The results showed the superiority of the Random Forest technique for this task. In a similar task related to hate speech detection, Zhang et al. [
50] explored a deep neural network based method by combining Convolutional Neural Networks (CNN) and Gated Recurrent Networks (GRN). In their evaluation, such proposition performed superior to SVM, SVM+, and CNN.
The recognition of sarcasm is a hard task, due to lack of context, use of slang, and rhetorical questions. In Ghosh et al. [
61], the detection of sarcasm in social networks and discussion forums was investigated by using SVM and Long Short-Term Memory (LSTM). In their study, LSTM obtained better results than SVM.
Classification techniques were used by Justo et al. [
62] (rule-based classification and Naive Bayes) in the identification of sarcasm and malice in comments posted in social networks. Although initially seeming similar, sarcasm and malice are distinct in the form of detection. For sarcasm detection, it is necessary to know the domain and include characteristics (e.g., context) for better evaluation. In their study, other techniques for sarcasm detection were added, namely: lexical categories using n-Grams and sentiment detection through semantics.
Appling et al. [
63] studied the use of linguistic techniques and discriminatory model to detect fraud in texts. One of the linguistic techniques used was the amount of words used in a given text to affirm something. A greater than average amount of that user indicates the possibility of fraud. This technique relies on the prior knowledge of the posts made by the user. In a similar task related to fraud, Hu and Wang [
52] proposed a mathematical model for using with Naive Bayes. Their comparative study showed the superiority of Naive Bayes when compared to a Decision Tree algorithm.
In Dhouioui and Akaichi [
29], text mining was used to classify conversations by means of lexical dictionaries and extraction of behavioral characteristics. They proposed a combination of techniques for enhancing the detection of sexual predators. A comparison was conducted to analyze SVM and Naive Bayes. In this context, SVM demonstrated better performance. Three lexical dictionaries were developed, namely: (i) Emoticons; (ii) English language contractions; and (iii) Terms commonly used for communication via SMS.
Semantic Role Labeling (SRL) was used in Barreira et al. [
64] for forensic analysis of text messages extracted from mobile devices. According to the authors, the combination of linguistic techniques and ML achieved better accuracy than when these techniques were used separately. A Random Forest and Bagging based technique was proposed by Levitan et al. [
65] for the detection of fraud in video speeches. The audio transcription was required for application of the proposed technique. According to the authors, the adoption of a lexical dictionary might improve the outcome.
An approach to cyberbullying detection by means of ML techniques was proposed by Raisi et al. [
66]. After selecting a pair of users, tweets were scanned to identify bullying. This approach was restricted to environments where the access to the messages exchanged between those involved was allowed.
Pandey et al. [
67] developed an approach for categorization of intentions. Their approach was based on a linear model of logistic regression and CNN in addition to being supported by distributional semantic. Three categories of intentions were formulated: accusation, confirmation, and sensationalism.
Most investigations aim to detect events that have already occurred [
68]. Escalante et al. [
68] proposed an approach to detect intent to commit fraud and aggression on social network posts. During the detection process, an analysis of documents which were categorized by ML algorithms is performed. Profiles and subprofiles were used to support the detection process. The profile is defined by the same two dimension vectors containing words (3-grams) and their classifications. The adoption of subprofiles allows the evaluation of multiple classes, as it considers the diversity of domains.
Mundra et al. [
69] studied embedding learning as a technique based on neural networks for classification of idiomatic expressions in microblogs (e.g., Twitter). In addition, the Latent Dirichlet Allocation and Collaborative representation classifiers were evaluated [
5]. According to the authors, a crime intention detection system should combine more than one ML technique.
Characteristics of sounds emitted in voice communication were explored for detecting mood and user dialect [
70]. Fourier parameters support detection and later categorization of mood and dialect; SVM was used in categorization. Recurrent Neural Network (RNN) and Distributed Time Delay Neural Network (DTDNN) were further evaluated, but in neither scenario were they superior to SVM. A predictive model was proposed by Aghababaei and Makrehchi [
71] for predicting crime in a given area by analyzing posts from Twitter. The model combined public FBI data in some states of the United States with tweets of the most active users and the older registered accounts. Due to the lack of data in supervised learning, the authors proposed to automatically annotate tweets with labels inferred from crime trends. These annotations were the basis to automatically create training examples to be used by prediction models.
ML techniques were used in Park et al. [
72] to create an ontology. According to the authors, semantic knowledge acquired by means of ontology allows a better understanding and categorization of phishing attacks (attempt to obtain personally identifiable information). Another study aimed at understanding the difference in behavior and users’ intention when compared to socialbots on Twitter [
73]. They extracted bag-of-words feature sets represented as TF-IDF (Term Frequency-Inverse Document Frequency). These sets were used to compare bot and human tweets. Then, they applied sentiment analysis using the LabMT tool to better understand the nature of words used by bots and humans.
3.3. Discussion on Related Work
We identified techniques aimed at categorizing emotions that address intentions indirectly. Studies addressing further evaluation and representation of users’ intentions in texts written in natural language are very scarce. Most of the analyzed investigations use machine learning to evaluate sentiment. Natural language processing techniques are explored in the approaches proposed in [
52,
58,
60,
62,
63,
64,
74,
75]; data mining and semantic analysis are used in [
51]. In general, the studies presented better assertiveness measures in the categorization of sentiment using complementary approaches (e.g., semantic descriptors with ML) as compared with a single one. Although this represents a decrease of response time, the benefits of adopting complementary techniques may outweigh the computational cost.
The probabilistic classifiers are reliable, but they strongly rely on the size of the training base. Some of these classifiers are not suitable for real-time data analysis, making preprocessing an indispensable task for better accuracy. This preprocessing usually demands a high computational cost [
51]. The approach proposed by Garcia-Diaz et al. [
51] revealed gain in performing postprocessing where improved classifier accuracy was achieved by applying domain-specific knowledge.
The study presented by Anzovino et al. [
60] obtained better results by using Token N-Grams in combination with SVM. In [
63], the authors point out the benefits of adopting linguistics features in combination with ML techniques.
The adoption of multiple techniques for detecting intentions and sentiment proved to be a promising practice. The use of semantics (e.g., ontologies) in conjunction with these techniques is still an open research area of study, which requires continuous efforts for obtain advancements.
The exclusive use of a lexical dictionary presented drawbacks in [
72]. This characteristic was not present when using ontologies for semantic analysis of texts written in natural language. The use of NLP techniques used in conjunction with ontologies demonstrated good results in [
74], reaching an accuracy of 86%.
Although emotion and sentiment are strongly related to intentions, studies focusing specifically on intentions are rare, particularly those with consistent theoretical underpinnings about the understanding of intentions. For example, only the study presented by Hu and Wang [
52] explicitly used the speech act theory, despite the importance of this theory to the problem of meaning in linguistics and philosophy.
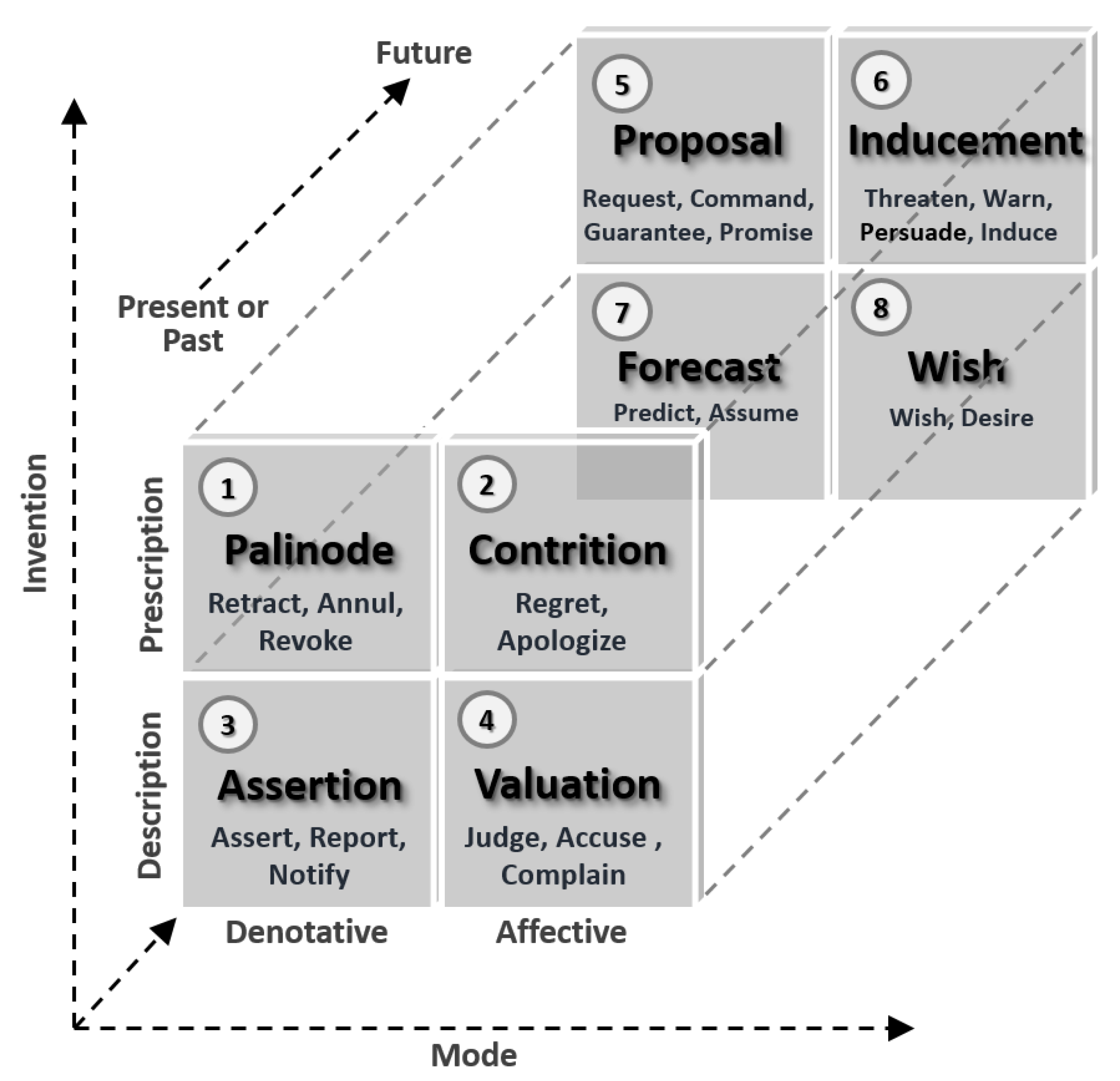
The perspective in which words are used to accomplish things has much to contribute, not only in the detection process, especially in establishing what one wants to detect. For example, illocutions (acts of speech or writing that constitute actions) may result in different pragmatic effects, depending on the interpretation of the speaker’s intentions. Thus, an illocution classification model can contribute to the definition of what we want to detect regarding ”user intentions”, such as committing crimes.
We also analyzed the linguistic foundations used in our related work, in particular semiotics and pragmatics studies. Although Semiotics was a search keyword, no studies analyzing posts related to intentions to commit crimes were obtained. Semiotics provides us a vast theoretical and methodological basis for understanding the use and interpretation of signs in computer systems [
76]. From the semiotics’ point of view, people communicate by sharing signs through multiple media.
The “Pragmatics” [
77] is a field of research that aims to understand the relationship between signs and people (Pragmatics can be understood as a subfield of semiotics (and linguistics), and it focuses on understanding the relationship of context and meaning, including intentions), being essential to identify the speaker’s intention. From this perspective, it is important to understand how signs influenced the communication process to identify the expression of criminal intent in social media posts.
Regarding the investigations on the realm of ontology-based social network analysis, a fuzzy ontology (T2FOBOMIE) was proposed by Ali et al. [
36] to support an opinion mining system, whereas our ontology (OntoCexp) supports the identification of criminal expressions in the ciphered language (informal posts and using slang) used by criminals. Ali et al. [
37] focused on the classification of reviews about a hotel and their characteristics. In our work, we aim to identify the intent to commit crimes in Twitter’s posts. Ali et al. [
38] aimed to filter web content and to identify and block access to pornography. They were not concerned with the use of slang, which is recurrent in pornography. In our approach, we aim to predict crimes, by looking for posts in the Twitter that contain expressions related to weapons, violence, cyber attacks, terrorism, etc.
Regarding ontology-based frameworks, in [
39], the authors used sentiment analysis in opinions to monitor transportation activities (accidents, vehicles, street conditions, traffic, etc.), whereas our focus is to detect specific intentions in social media. A recommendation system was proposed in [
40] aiming to suggest items with a polarity (positive or negative) to disabled users; we aim to identify criminals in social media to anticipate and avoid crimes. An approach for sentiment classification was proposed in [
41] to extract meaningful information on the domain of Transportation. Differently, our goal is to extract ciphered messages from criminals to support the detection of malicious acts. In [
39,
40,
41], the authors do not present solutions for slang assessment, nor take into account the use of sarcasm, which is very common in publications of social networks.
In this sense, we observe a lack of theories, methods, and tools for analyzing, representing and detecting criminal intention in social media posts—for example, studies on the interaction of users (human) with technological artifacts; analysis of linguistic aspects and their relationship to user behavior; and the application of advanced ML techniques.
Our proposed solution further advances the state-of-the-art in the automatic detection of criminal intention in social media natural language messages. Our ontology-based solution is suited to represent the target slang language to support the identification process in distinct tasks. We combine it with speech acts theory in the definition and implementation of ML-based mechanism for intention recognition in texts relying on illocution classes.
6. Discussion
Expression of intentions is a key element in human communication. This applies to criminal communication using social media. Criminals, like the rest of the population, take advantage of Web facilities and online social networks in their activities [
1]. Computational solutions considering data analysis can be used as a tool for criminal investigation and prevention. Currently, the huge quantity of message, speed, and complexity of the digital environment turns the manual search and analysis of posts from social networks with criminal content impracticable.
This work goes one step further towards the improvement of computational support in tasks considering criminal intentions of posts using criminal slang (deliberately or unintentionally ciphered messages). Our literature review demonstrated that existing investigations mostly emphasize sentiment analysis tasks. Indeed, there is a lack of software tools for analyzing, representing, and detecting criminal intention in social media posts (cf.
Section 3). Our literature review provided us with strategies on how to deal with the problem based on the careful analysis of related tasks. Existing studies (e.g., [
60,
63,
74]) showed that a strategy that combines techniques (e.g., ontologies and ML) is a more viable path to deal with our problem.
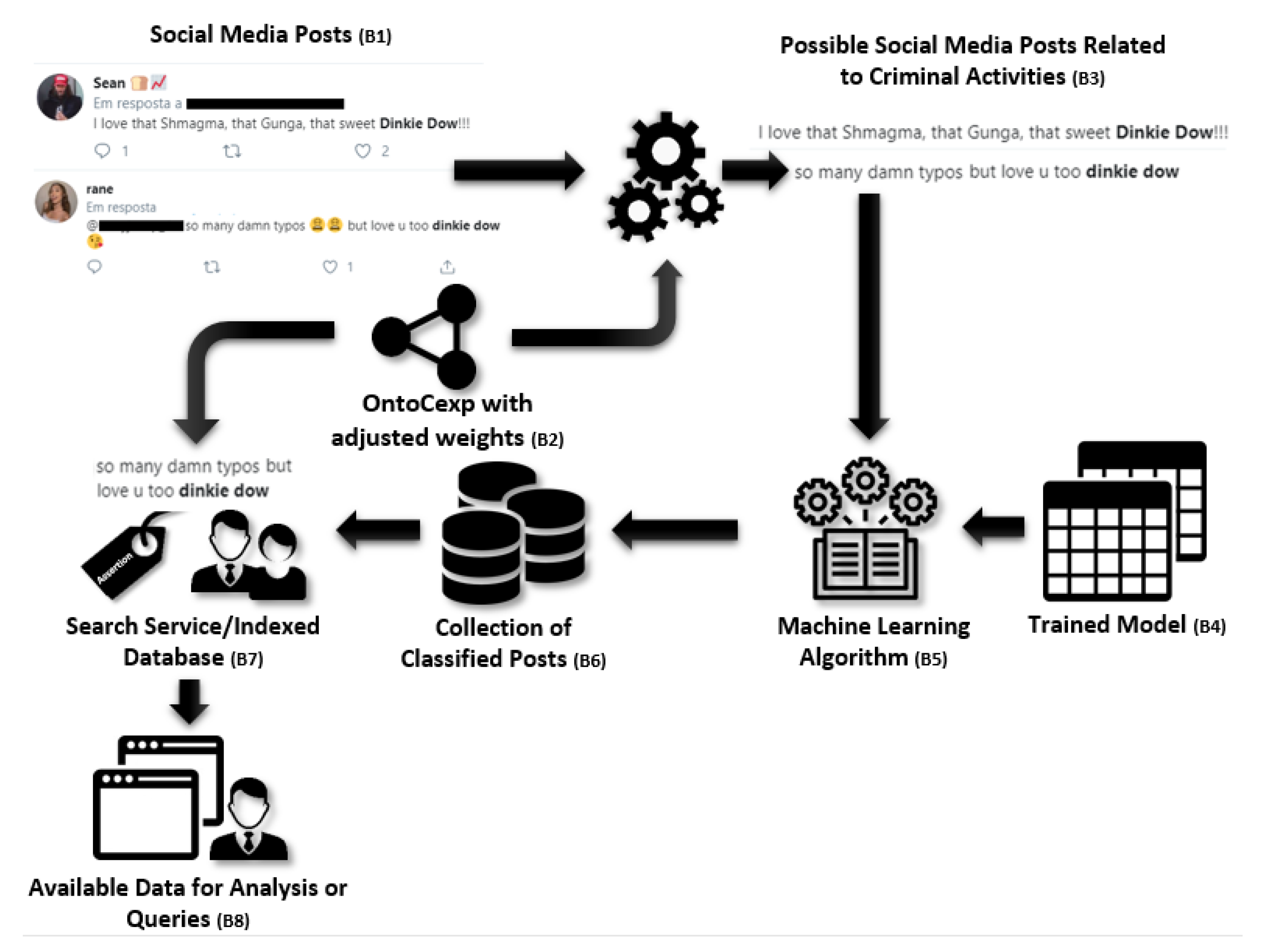
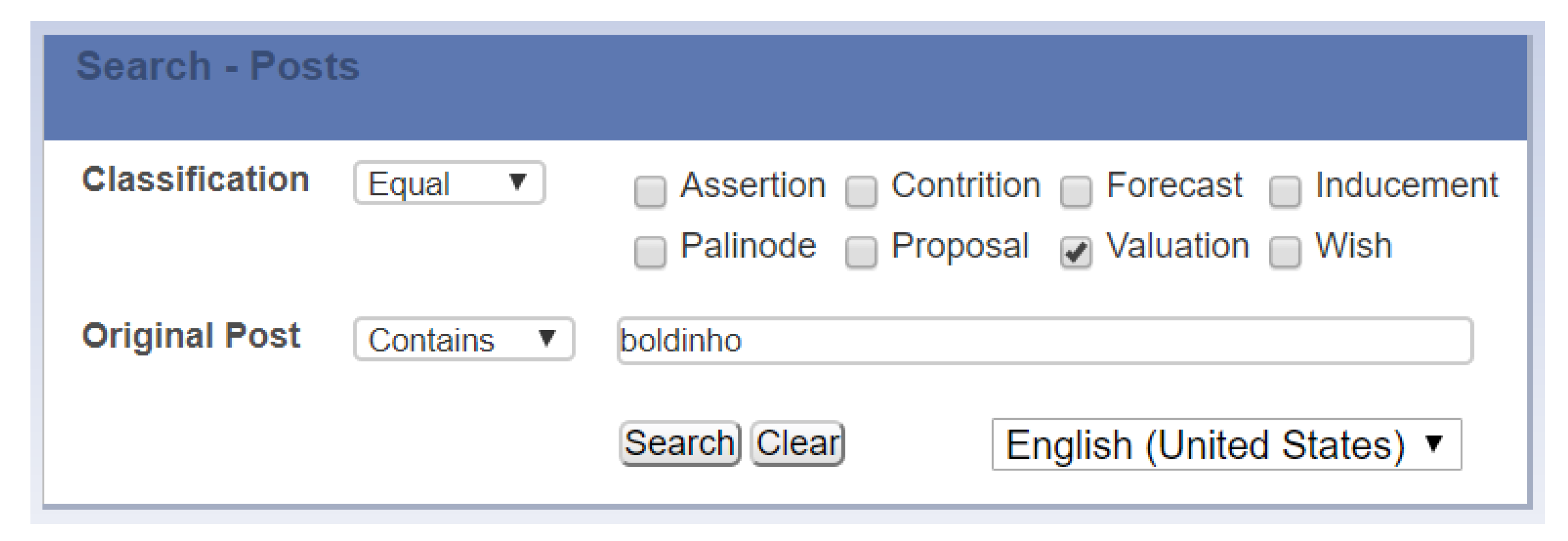
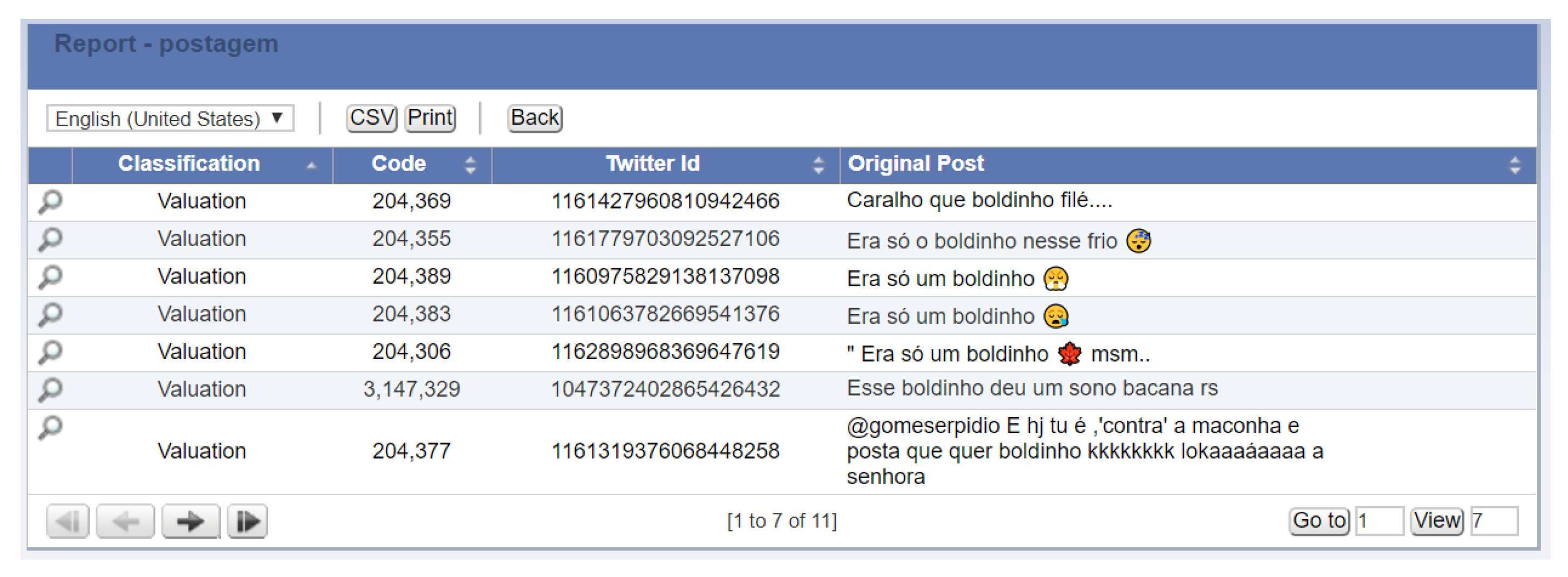
We proposed a framework (OFCIC) and defined an ontology (OntoCexp) to support the formal representation of criminal vocabulary. Our solution explored the OntoCexp ontology and ML techniques. This provided a viable way to build the SocCrime software prototype that automatically selects posts written using crime slang and translates them to “standard language”. The framework is suited to automatically classify posts’ intentions. In a simplified interface, users can choose keywords and illocution classes; then, the prototype returns a report with suspicious posts. Scenarios illustrated the differences in results when considering each class of illocution.
The OFCIC framework is complex and involves various steps and technologies. The extensive use of OFCIC may demand computational and human resources for its refined implementation, including key steps such as: (1) collection of social media posts for the construction of the training model; (2) adjustments to the weights of ontology terms and the definition of additional and improved rules to be used in the post selection; and (3) ML training (according to the technique used). However, it is important to note that this does not impact the scalability of the framework in use. Once the selection of the posts is performed using OntoCexp with the previously adjusted weights, the classification occurs based on the pre-trained model. The posts are included in a conventional search engine (which performs keyword-based retrieval), and the posts are filtered according to pre-classified list in linear time.
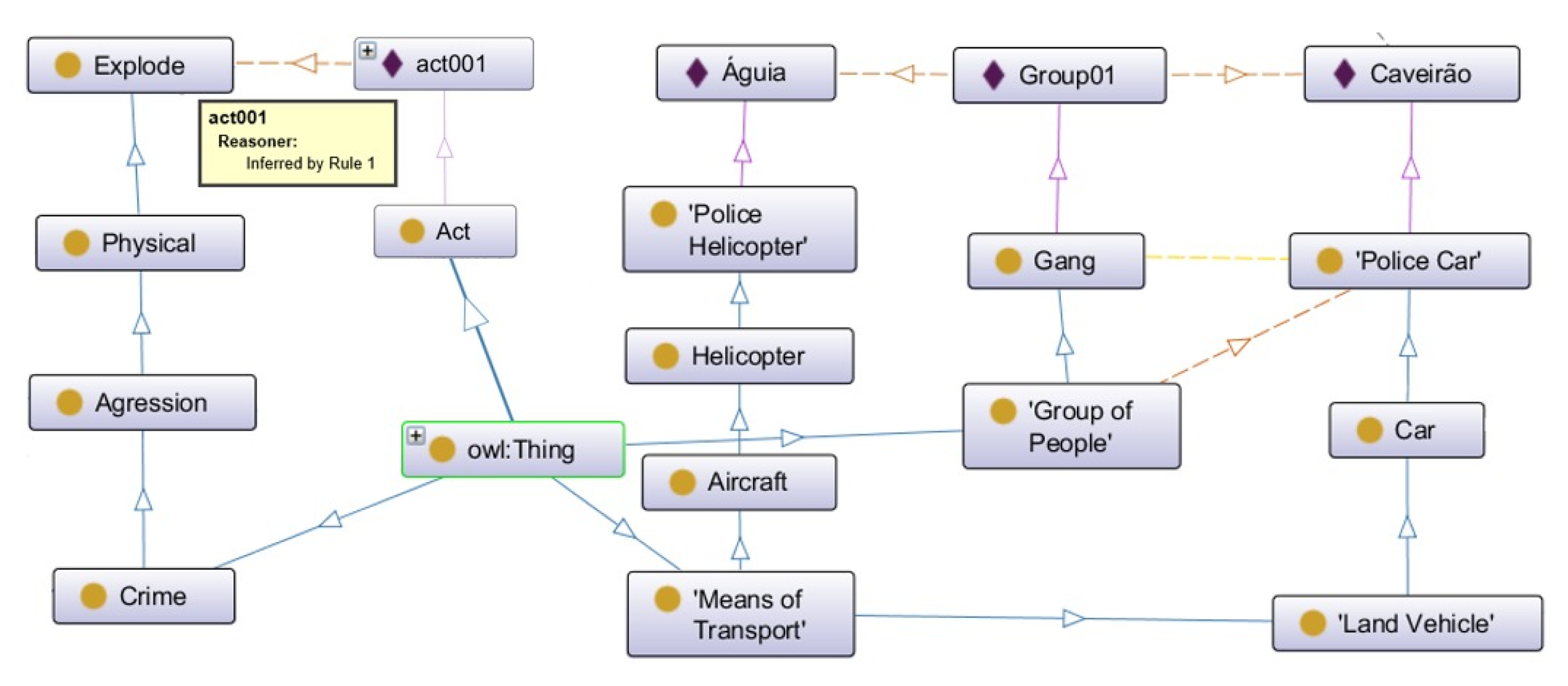
One key aspect to be considered is the long-term maintenance and evolution of the OntoCexp. The current version of the ontology presents 165 Classes, 635 individuals, 3410 Axioms, 1533 Logical Axioms, 848 Declaration Axioms, and 44 Object Properties, resulting in ALCHO(D) DL expressivity [
95]. Crime domain is dynamic and complex. CSE is constantly evolving and rationalized. CSEs described in Mota [
12] are a good starting point, and presented positive results by selecting relevant posts in our Twitter
® study. Nevertheless, the OntoCexp might be expanded (to represent other regional CSE) with adequate updating techniques. This includes the adjustments on the weights of the terms used by OFCIC. The ontology updating efforts are focused on the inclusion of new instances (i.e., new terms) and SWRL rules. Further studies on how to support (or automate) these tasks are needed. This might include, for instance, techniques for automatic ontology evolution.
The conducted case study with Twitter® shows, in practice: (1) the viability of the framework execution; (2) the expressiveness and utility of the ontology; and (3) the analysis of effectiveness in applying the ML techniques in our context. Although a relatively large number (8,835,290) of tweets was considered for the case study, this study must be expanded to include a larger time window. This may result in more tweets used for ML training and adjusting the weight of terms in the ontology. This may reach better results and an expanded study of this subject. In addition, aspects such as CSE regionalism and studies in other countries/languages can be executed.
This study can be expanded to other online social networks. Other social media, for example, with more restricted communication channel can be used by criminals in other ways. Studies with these networks can contribute to the evolution and refinement of our framework and ontology. It is important to mention that Twitter® maintains a public access API, which facilitated the study reported in this article.
Another aspect to be discussed is the effectiveness of the investigated ML techniques. The best ML configurations presented F1-score around
(in the cross validation). This number is close to those obtained in [
96] for special education domain, which uses elaborated sentences written in standard language (consider a more formal written style without slang).
We highlight some aspects in the analysis of the obtained results concerning the ML models. First, the results refer to a multiclass classification with eight classes, which makes the classification problem harder as compared with typical binary classification problems. The individual results of the classes show that, in specific situations, in which the user is interested in a specific class, this number is higher, for example, was obtained for the inducement class. In these cases, we can improve the results by using multiple binary classification, i.e., a class is individually trained against the others. We obtained of general F1-Score by combining GloVe and ANN techniques. In this case, the user cannot select multiple classes at once.
Results can be further improved by increasing our training set. In addition, 704 tweets may be too little for the cross validation, especially when we consider that some classes have very few (e.g., contrition) or no samples (e.g., palinode). Despite the balancing techniques explored in our investigation (SMOTE [
92]), larger and balanced training sets may enhance the achieved results. Long-term studies should provide larger and further representative training sets.
In addition, other approaches, such as the use of CNN and RNN, already trained in the transfer learning technique can be explored to improve the ML results. For example, we can investigate how to improve the results by combining CNN and GRU techniques [
50]. One approach would be to use trained CNN/RNN (with millions of messages) for sentiment analysis, and use in conjunction with other classifiers. Other approaches, such as transforming vectors (result of word embedding) into images and using ML solutions for this purpose, can be explored. We emphasize that the trained networks available for binary classification are more abundant than 8 classes classification, and their suitability to the problem of intention classification is the subject of future research.
We found positive results with the use of deciphered phrases by the applied ontology as compared with original phases. In general, deciphered phrases increased the score by 0.02–0.09 in most of the configurations assessed. Considering experimental results obtained with cross-validation (
Table 2), we obtained
of increase on average from
to
(around 13% of improvement) (The Student’s
t-test (two dependent paired samples, with distribution close to the normal curve) including all configuration values of
Table 2 resulted on
and
p-value < 0.0001 (two-tailed), showing significant improvement considering
significance level (i.e., 99% of confidence)). When we consider the best configuration (may be the most interesting in practice), we obtained
, from
to
using SVM Word2Vec_skip 0.01/1 (around 24% of improvement), which is not negligible in terms of increasing the measures of ML techniques. A plausible explanation to this fact is that the word embedding algorithms were trained for Portuguese messages (in the standard form). The main fact that justifies this translation is its potential of reusing techniques developed for standard writing language, enabling new possibilities in long-term research.
Our research adopted a word-by-word translation strategy, which explored the structure of the OntoCexp. This ontology can be combined with advanced translation techniques, which combines ontologies with statistical and ML techniques. This can result in improved translation and the increase of the ML scores. This strategy requires additional research focused on translation of slang and ciphered text to the standard ones. Therefore, the obtained results can be considered a baseline for an OFCIC framework implementation, which provides room for improvements in further research. The efforts to maintain the ontology as well as alternatives to minimize these efforts must be investigated when comparing future translation techniques.
The SocCrime prototype showed the viability of the OFCIC execution and use. Additional evaluations of the use of the framework in practical settings are still required. In fact, how it influences the practice of human investigators and their impacts should come from a long-term study, which requires a system in production and agreements with law enforcement agencies. From a practical point of view, one of the challenges is to increase the obtained results from the ML techniques. The overall result around is relatively low, and even individual class results (it may be what matters in practice and are higher, as discussed) may not be the expected for law enforcement agencies. However, the illocution classification is an additional tool to provide filtering and ranking options for suspicious messages selected by the framework. Despite the current results, these tools can be useful in practice when we consider the huge number of social network posts, which makes manual assessment practically impossible. In addition, investigators may be frequently interested only in highly suspicious posts, which are in the first positions of the rank and are more likely to be recovered by the framework, due to the occurrence of CSE.
Finally, we indicate that this is a pioneering and promising study on how ontologies and ML techniques improve the support for the analysis of intentions of social media posts, making use of CSE. The results obtained from the conducted case study point out the viability of the framework, with immediate contributions in the selection of suspicious messages from social network posts. This article opened further research directions for improving each part of our solutions (framework, ontology, ML, and prototype).

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}