A Noise Study of the PSW Signature Family: Patching DRS with Uniform Distribution †



Abstract
1. Introduction
Our Contribution and Paper Organization
2. Background
2.1. Lattice Theory
2.2. Lattice Problems
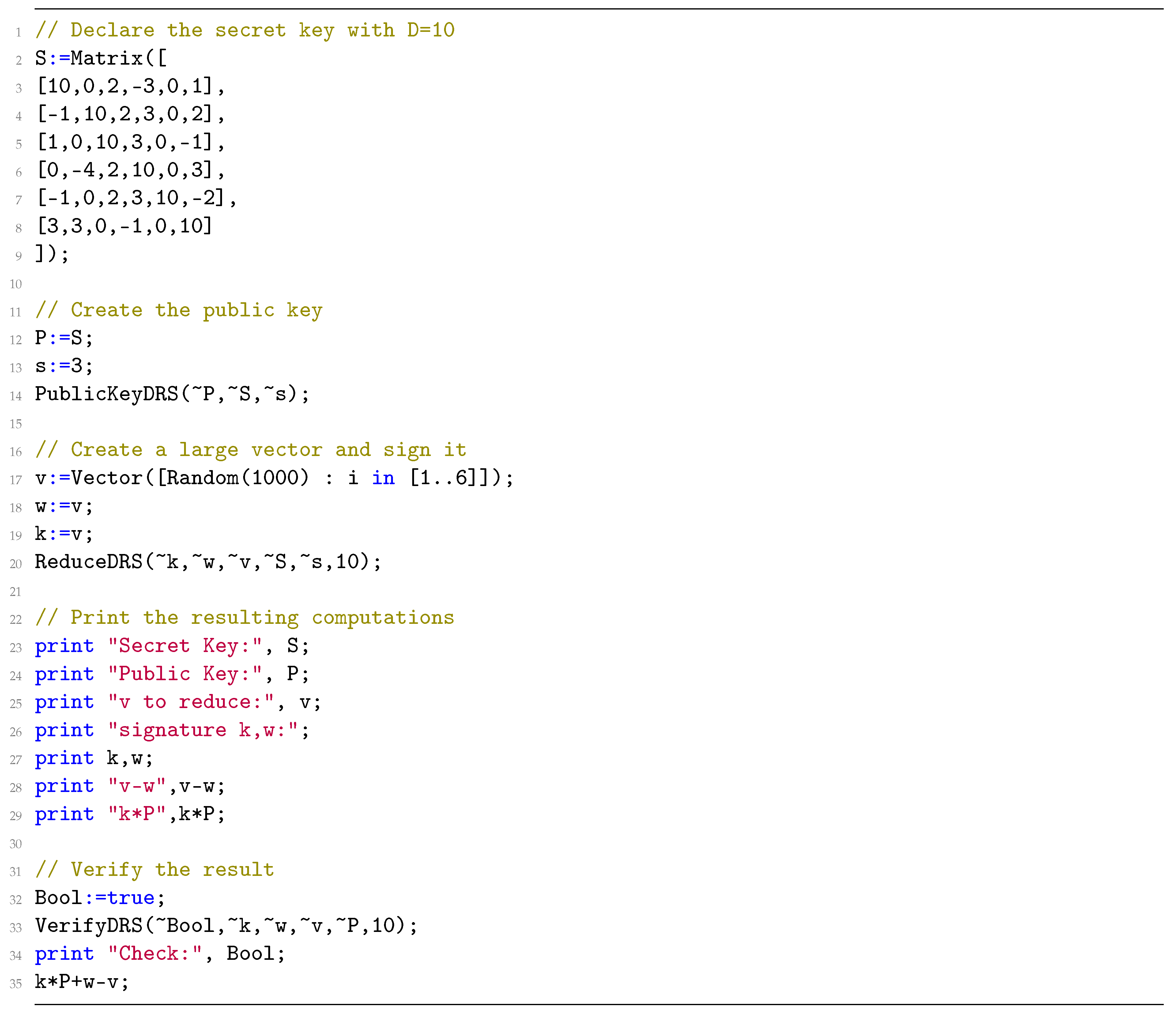
3. The Theoretical Framework of Plantard–Susilo–Win
3.1. Before PSW: Lattices for Number Representation
| and in base k would give |
3.2. Spectral Radius and Eigenvalues
3.3. The Original PSW Framework
| Algorithm 1 Approximate vector reduction algorithm |
| Require: A vector , two matrices such that and is diagonal invertible. |
| Ensure: such that and . |
| 1: |
| 2: while do |
| 3: |
| 4: |
| 5: return w |
| Algorithm 2 PSW vector reduction algorithm |
| Require:, such that and is diagonal invertible. |
| Ensure: such that and . |
| 1: |
| 2: |
| 3: while do |
| 4: |
| 5: |
| 6: |
| 7: for to do |
| 8: |
| 9: if then |
| 10: |
| 11: return w |
3.3.1. Setup
- Pick a random matrix with “low” values.
- Compute
- Compute H be the HNF of .
3.3.2. Sign
- Hash a message m into a random vector such that
- Apply the PSW-vector reduction into x and save its output w.
3.3.3. Verify
- Check if .
- Check if .
3.3.4. Claimed Structural Security
4. The Original DRS Scheme
4.1. Setup
4.1.1. Secret Key Generation
- D, the large diagonal coefficient. This is a basic component in the PSW-framework. However, D is fixed equal to n before key generation and not ad-hoc.
- , the number of occurences per vector of the “big” noise , and is the lowest positive number such that . The reasoning behind this parameter is to thwart combinatorial attacks which relies on finding the position of the values B.
- B, the value of the “big” noise, and is equal to . It is a coefficient that is chosen large to increase the size of the shortest vector in the norm . The purpose of this coefficient was to increase the security of the scheme against pure lattice reduction attacks.
- , the number of values per vector, is equal to . is a constant that will be defined later. The role of those small 1 is to increase the perturbation within each coefficient position per vector when applying the PSW vector reduction algorithm.
| Algorithm 3 Secret key generation | |
| Require: A random seed x | |
| Ensure: A secret key | |
| 1: | |
| 2: | |
| 3: | ▹ Sets the randomness via x |
| 4: [D,,, 0, …, 0] | ▹ Sets initial rotating vector |
| 5: | ▹ Shuffle non-D positions randomly |
| 6: for ; ; do | |
| 7: | ▹ Set diagonals coefficient D |
| 8: for ; ; do | |
| 9: | ▹ Set others with random signs |
| 10: | |
| 11: return x, S | |
4.1.2. Public Key Generation
- Construct T in a fast manner, from a large combinatorial set.
- Bound the coefficients of , making sure computations do not overflow.
- Make sure is hard to reconstruct.
| Algorithm 4 Public key generation | |
| Require: the reduction matrix, a random seed x | |
| Ensure:P such that and | |
| 1: | |
| 2: | ▹ Sets the randomness via x |
| 3: for ; ; do | |
| 4: | ▹ Shuffle the rows of P |
| 5: for ; ; do | |
| 6: | |
| 7: | ▹ “Random” linear combinations |
| 8: | |
| 9: | |
| 10: return P |
4.2. Signature
| Algorithm 5 Sign: Coefficient reduction first, validity vector then | |
| Require:, the secret seed and diagonal dominant matrix | |
| Ensure:w with , and k with | |
| 1: v, , | |
| 2: while do | ▹ Apply the PSW vector reduction |
| 3: | |
| 4: | ▹ Ensure |
| 5: | |
| 6: mod n | |
| 7: | ▹ Set randomness identical to Setup |
| 8: for ; ; do | ▹ Transform into |
| 9: | |
| 10: for ; ; do | |
| 11: | |
| 12: | |
| 13: | |
| 14: | |
| 15: return | |
4.3. Verification
| Algorithm 6 Verify | |
| Require:, P the public key | |
| Ensure: Checks and | |
| 1: if then | ▹ Checks |
| 2: return FALSE | |
| 3: | |
| 4: | |
| 5: | |
| 6: while do | ▹ Verification per block of size |
| 7: | ▹ Get the smallest sized remainder |
| 8: | |
| 9: if then | ▹ Check block |
| 10: return FALSE | |
| 11: | ▹ Update values for next iteration |
| 12: | |
| 13: if then | |
| 14: return FALSE | |
| 15: return TRUE |
5. On the Security of the Public Key
5.1. Li, Liu, Nitaj and Pan’s Attack on a Randomized Version of the Initial PKC’08
5.2. Yu and Ducas’s Attack on the DRS Instantiation of the Initial Scheme of PKC’08
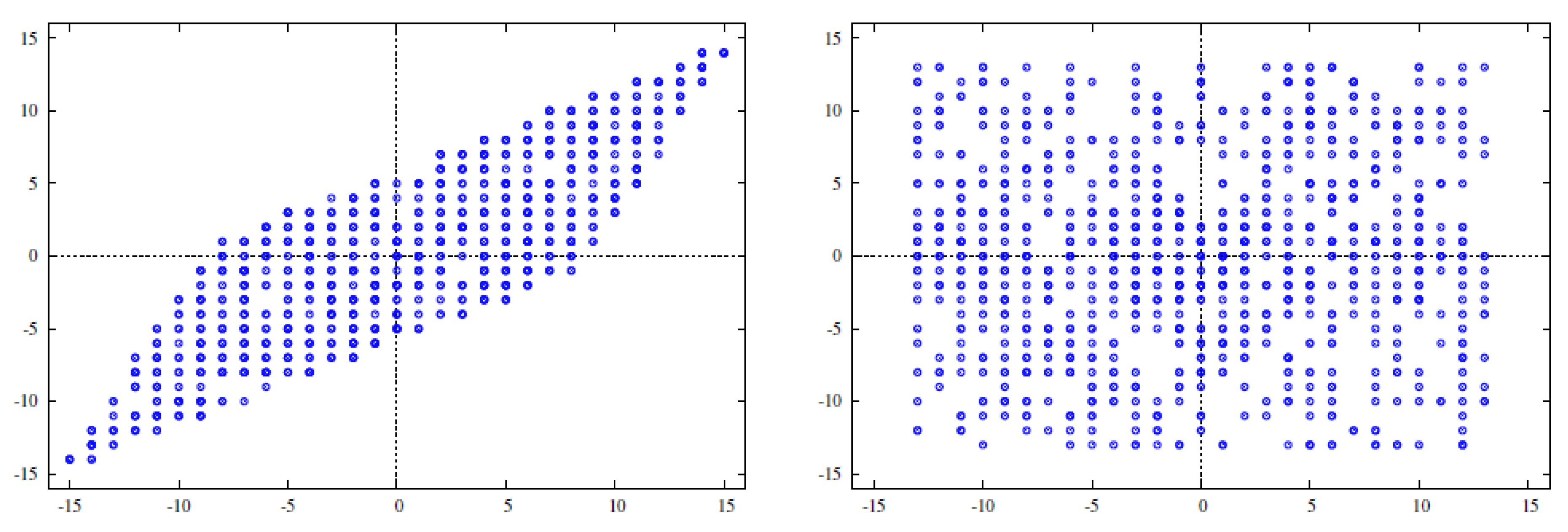
6. New Setup
- Creates a cumulative frequency distribution table from [31].
- Use the table to sample uniformly a number of zeroes.
- Sampling uniformly within the n-ball of with a fixed number of zeroes.
6.1. Picking the Random Vectors
| Algorithm 7 Secret key table precomputation | |
| Require: all initial parameters | |
| Ensure: the table sum | |
| 1: | |
| 2: | |
| 3: | |
| 4: for ; ; do | ▹ Loop over the norm |
| 5: for ; ; do | ▹ Loop over possible non-zeroes |
| 6: | |
| 7: | |
| 8: for ; ; do | ▹ Construct array from T |
| 9: | |
| 10: | |
| 11: return |
| Algorithm 8 KraemerBis | |
| Require: all initial parameters and a number of zeroes z | |
| Ensure: a vector v with z zeroes and a random norm inferior or equal to D | |
| 1: | |
| 2: | ▹ Pick randomly elements |
| 3: for ; ; do | |
| 4: | |
| 5: for ; ; do | |
| 6: | |
| return v | |
| Algorithm 9 New secret key generation | |
| Ensure: all initial parameters and another extra random seed x | |
| Require: the secret key | |
| 1: | |
| 2: | |
| 3: | ▹ Set randomness |
| 4: for ; ; do | |
| 5: | ▹ Get the number of zeroes |
| 6: | |
| 7: for ; ; do | ▹ Randomly switch signs |
| 8: | |
| 9: | ▹ Permutes everything |
| 10: | |
| 11: return | |
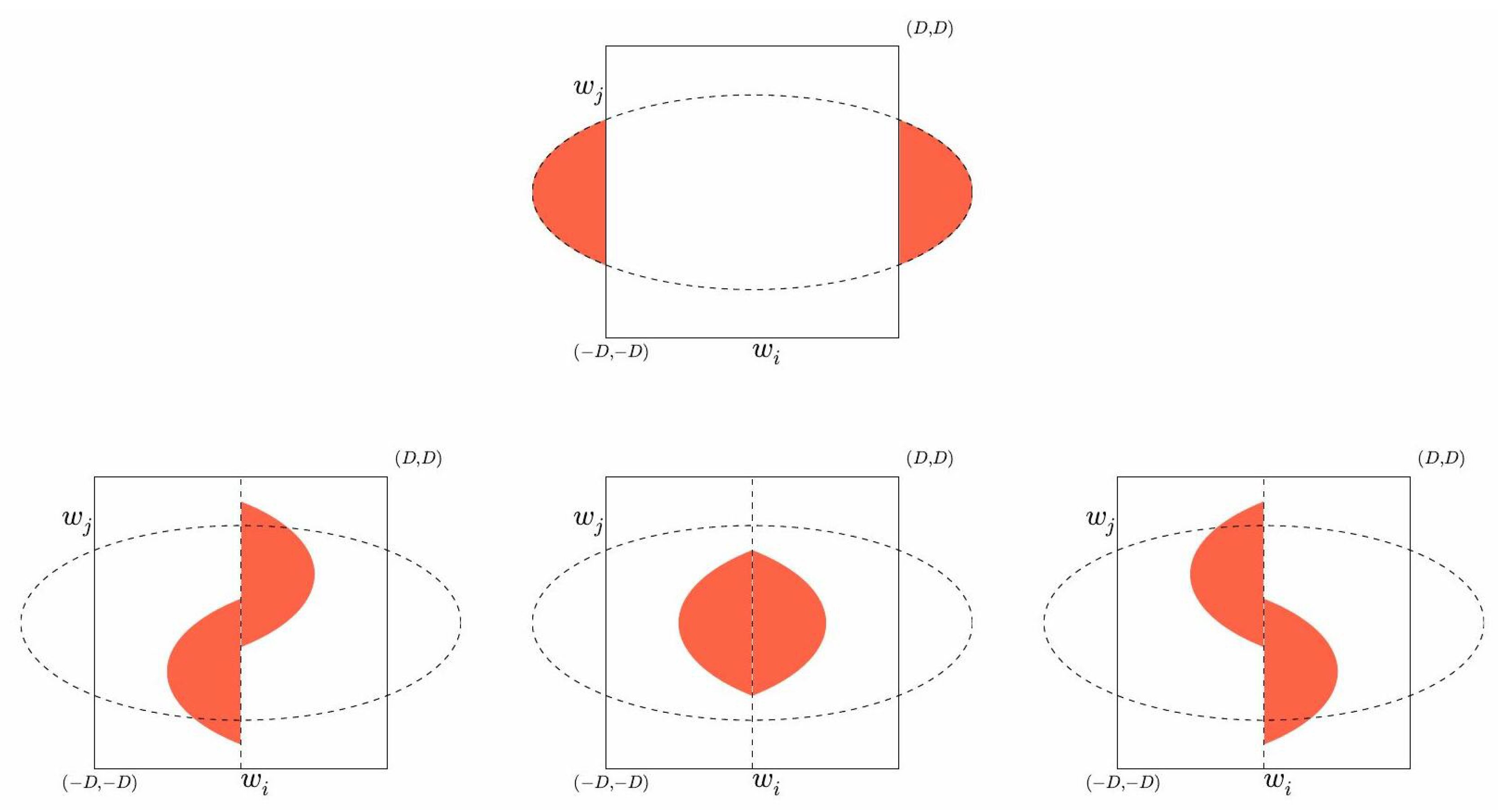
6.2. A Slightly More General Termination Proof
- m is the message we want to reduce, which we update step by step
- M is the noise matrix (so is the i-th noise row vector).
- D is the signature bound for which the condition has to be verified. We note the i-th diagonal coefficient of the secret key S.
6.3. On Exploiting the Reduction Capacity for Further Security
6.4. Ensuring the Termination of PSW
| For , . |
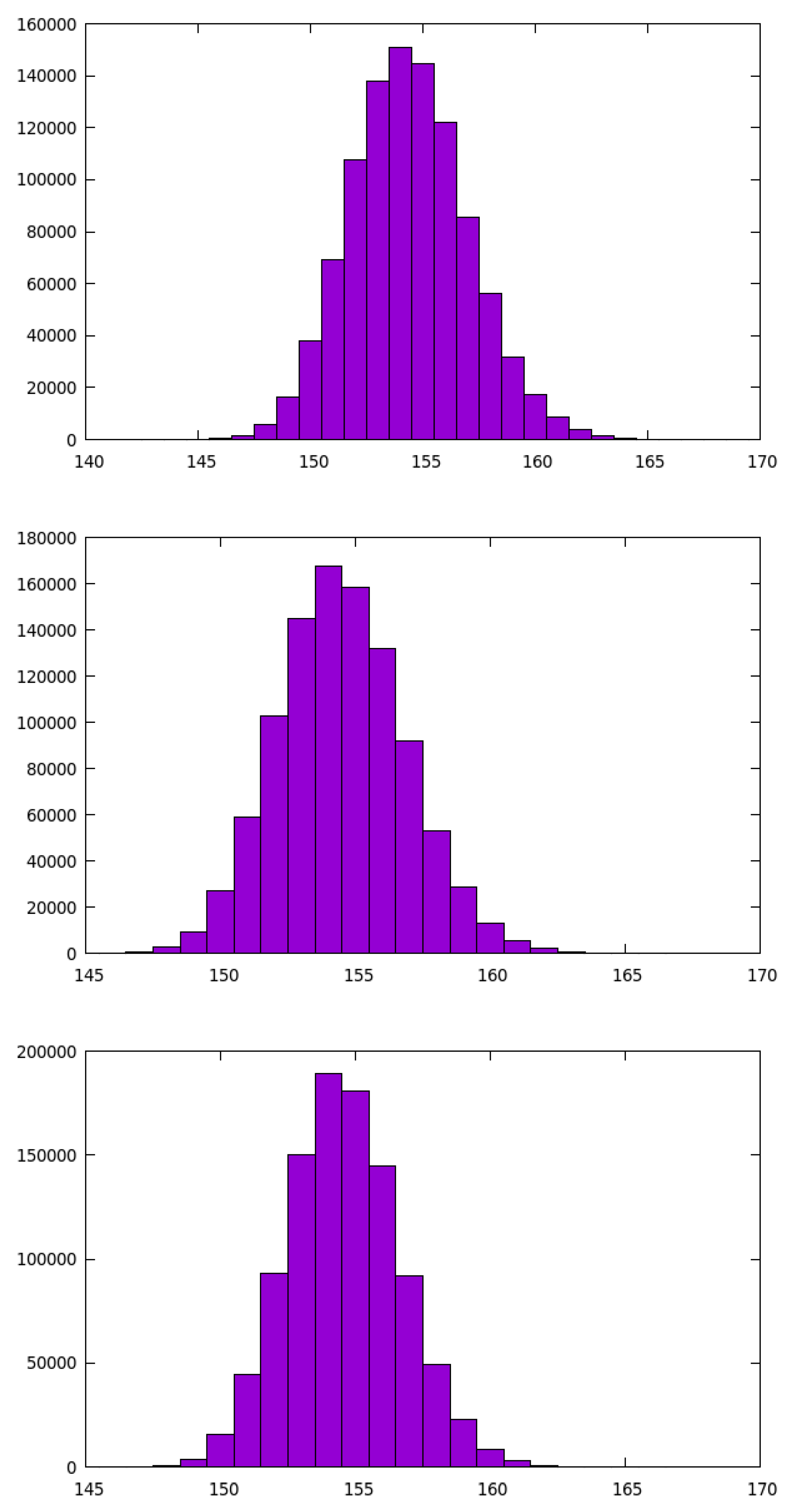
6.5. Setup Performance
7. Security Estimates
7.1. -Based Attack
7.2. Expected Heuristic Security Strength
7.3. A Note on the Structure of Diagonally Dominant Lattices
- ,
- ,
- allow us to exclude where the problem is just equivalent to SBP.
- prevents insanely large M where D does not matter.
- prevents heuristically easier cases.
7.4. A Small Density Comparison with Ideal Lattices
8. Conclusions and Open Questions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A







References
- NIST. NIST Kicks Off Effort to Defend Encrypted Data From Quantum Computer Threat; NIST: Gaithersburg, MI, USA, 2016.
- Shor, P.W. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. Siam J. Comput. 1997, 26, 1484–1509. [Google Scholar] [CrossRef]
- Minkowski, H. Geometrie der Zahlen; B.G. Teubner: Leipzig, Germany, 1896. [Google Scholar]
- Ajtai, M. Generating hard instances of lattice problems. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing; ACM: New York, NY, USA, 1996; pp. 99–108. [Google Scholar]
- Goldreich, O.; Goldwasser, S.; Halevi, S. Public-key cryptosystems from lattice reduction problems. In Proceedings of the Annual International Cryptology Conference; Springer: Berlin, Germany, 1997; pp. 112–131. [Google Scholar]
- Nguyen, P. Cryptanalysis of the Goldreich-Goldwasser-Halevi cryptosystem from crypto’97. In Proceedings of the Annual International Cryptology Conference; Springer: Berlin, Germany, 1999; pp. 288–304. [Google Scholar]
- Fischlin, R.; Seifert, J.P. Tensor-based trapdoors for CVP and their application to public key cryptography. In Cryptography and Coding; Springer: Berlin, Germany, 1999; pp. 244–257. [Google Scholar]
- Micciancio, D. Improving lattice based cryptosystems using the Hermite normal form. In Cryptography and Lattices; Springer: Berlin, Germany, 2001; pp. 126–145. [Google Scholar]
- Paeng, S.H.; Jung, B.E.; Ha, K.C. A lattice based public key cryptosystem using polynomial representations. In International Workshop on Public Key Cryptography; Springer: Berlin, Germany, 2003; pp. 292–308. [Google Scholar]
- Sloane, N.J.A. Encrypting by Random Rotations. In Cryptography, Proceedings of the Workshop on Cryptography Burg Feuerstein, Germany, 29 March–2 April 1982; Beth, T., Ed.; Springer: Berlin/Heidelberg, Germany, 1983; pp. 71–128. [Google Scholar]
- Regev, O. New lattice-based cryptographic constructions. J. ACM 2004, 51, 899–942. [Google Scholar] [CrossRef]
- Gama, N.; Izabachene, M.; Nguyen, P.Q.; Xie, X. Structural lattice reduction: Generalized worst-case to average-case reductions and homomorphic cryptosystems. In Annual International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2016; pp. 528–558. [Google Scholar]
- NIST. Post-Quantum Cryptography Standardization; NIST: Gaithersburg, MI, USA, 2018.
- Plantard, T.; Sipasseuth, A.; Dumondelle, C.; Susilo, W. DRS: Diagonal Dominant Reduction for Lattice-Based Signature. PQC Standardization Process, Round 1 Submissions. 2018. Available online: https://csrc.nist.gov/Projects/Post-Quantum-Cryptography/Round-1-Submissions (accessed on 15 May 2019).
- Plantard, T.; Susilo, W.; Win, K.T. A digital signature scheme based on CVP max. In InInternational Workshop on Public Key Cryptography; Springer: Berlin/Heidelberg, Germany, 2008; pp. 288–307. [Google Scholar]
- Yu, Y.; Ducas, L. Learning Strikes Again: The Case of the DRS Signature Scheme. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Brisbane, Australia, 2–6 December 2018; pp. 525–543. [Google Scholar]
- Li, H.; Liu, R.; Nitaj, A.; Pan, Y. Cryptanalysis of the randomized version of a lattice-based signature scheme from PKC’08. In Proceedings of the Australasian Conference on Information Security and Privacy; Springer: Berlin/Heidelberg, Germany, 2018; pp. 455–466. [Google Scholar]
- Brualdi, R.A.; Ryser, H.J. Combinatorial Matrix Theory; Cambridge University Press: Cambridge, UK, 1991; Volume 39. [Google Scholar]
- Wei, W.; Liu, M.; Wang, X. Finding shortest lattice vectors in the presence of gaps. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 20–24 April 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 239–257. [Google Scholar]
- Ajtai, M.; Dwork, C. A public-key cryptosystem with worst-case/average-case equivalence. In Proceedings of the Twenty-Ninth Annual ACM Symposium on Theory of Computing; ACM: New York, NY, USA, 1997; pp. 284–293. [Google Scholar]
- Gama, N.; Nguyen, P.Q. Predicting lattice reduction. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2008; pp. 31–51. [Google Scholar]
- Liu, M.; Wang, X.; Xu, G.; Zheng, X. Shortest Lattice Vectors in the Presence of Gaps. IACR Cryptol. Eprint Arch. 2011, 2011, 139. [Google Scholar]
- Lyubashevsky, V.; Micciancio, D. On bounded distance decoding, unique shortest vectors, and the minimum distance problem. In CRYPTO 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 577–594. [Google Scholar]
- Babai, L. On Lovász’ lattice reduction and the nearest lattice point problem. Combinatorica 1986, 6, 1–13. [Google Scholar] [CrossRef]
- Bajard, J.C.; Imbert, L.; Plantard, T. Modular number systems: Beyond the Mersenne family. In International Workshop on Selected Areas in Cryptography; Springer: Berlin/Heidelberg, Germany, 2004; pp. 159–169. [Google Scholar]
- Plantard, T. Arithmétique modulaire pour la cryptographie. Ph.D. Thesis, 2005. Available online: https://documents.uow.edu.au/~thomaspl/pdf/Plantard05.pdf (accessed on 15 May 2019).
- Nguyen, P.Q.; Regev, O. Learning a parallelepiped: Cryptanalysis of GGH and NTRU signatures. J. Cryptol. 2009, 22, 139–160. [Google Scholar] [CrossRef]
- Ducas, L.; Nguyen, P.Q. Learning a zonotope and more: Cryptanalysis of NTRUSign countermeasures. In International Conference on the Theory and Application of Cryptology and Information Security; Springer: Berlin/Heidelberg, Germany, 2012; pp. 433–450. [Google Scholar]
- Gentry, C.; Peikert, C.; Vaikuntanathan, V. Trapdoors for hard lattices and new cryptographic constructions. In STOC 2008; ACM: New York, NY, USA, 2008; pp. 197–206. [Google Scholar]
- Pernet, C.; Stein, W. Fast computation of Hermite normal forms of random integer matrices. J. Number Theory 2010, 130, 1675–1683. [Google Scholar] [CrossRef]
- Serra-Sagristà, J. Enumeration of lattice points in l1 norm. Inf. Process. Lett. 2000, 76, 39–44. [Google Scholar] [CrossRef]
- Smith, N.A.; Tromble, R.W. Sampling Uniformly From the Unit Simplex; Johns Hopkins University: Baltimore, MD, USA, 2004. [Google Scholar]
- Knuth, D.E.; Graham, R.L.; Patashnik, O.; Liu, S. Concrete Mathematics; Adison Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Derzko, N.; Pfeffer, A. Bounds for the spectral radius of a matrix. Math. Comput. 1965, 19, 62–67. [Google Scholar] [CrossRef]
- Wilkinson, J.H. The Algebraic Eigenvalue Problem; Clarendon: Oxford, UK, 1965; Volume 662. [Google Scholar]
- Bartels, R.H.; Stewart, G.W. Solution of the matrix equation AX+ XB= C [F4]. Commun. ACM 1972, 15, 820–826. [Google Scholar] [CrossRef]
- Golub, G.; Nash, S.; Van Loan, C. A Hessenberg-Schur method for the problem AX+ XB= C. IEEE Trans. Autom. Control 1979, 24, 909–913. [Google Scholar] [CrossRef]
- Householder, A.S. The Theory of Matrices in Numerical Analysis; Courier Corporation: Chelmsford, MA, USA, 1964. [Google Scholar]
- Kannan, R. Minkowski’s convex body theorem and integer programming. Math. Oper. Res. 1987, 12, 415–440. [Google Scholar] [CrossRef]
- Van de Pol, J.; Smart, N.P. Estimating key sizes for high dimensional lattice-based systems. In Proceedings of the IMA International Conference on Cryptography and Coding; Springer: Berlin/Heidelberg, Germany, 2013; pp. 290–303. [Google Scholar]
- Hoffstein, J.; Pipher, J.; Schanck, J.M.; Silverman, J.H.; Whyte, W.; Zhang, Z. Choosing parameters for NTRUEncrypt. In Proceedings of the Cryptographers’ Track at the RSA Conference; Springer: Cham, Switzerland, 2017; pp. 3–18. [Google Scholar]
- Chen, Y.; Nguyen, P.Q. BKZ 2.0: Better lattice security estimates. In Proceedings of the InInternational Conference on the Theory and Application of Cryptology and Information Security; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–20. [Google Scholar]
- The FPLLL Team. FPLLL, a Lattice Reduction Library. Available online: https://github.com/fplll/fplll (accessed on 15 May 2019).
- Sipasseuth, A.; Plantard, T.; Susilo, W. Improving the security of the DRS scheme with uniformly chosen random noise. In Proceedings of the Australasian Conference on Information Security and Privacy; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Computational Algebra Group. U.o.S. 2018. Available online: https://magma.maths.usyd.edu.au/calc/ (accessed on 15 May 2019).
- PARI Group. U.o.B. PARI-GP. 2018. Available online: https://pari.math.u-bordeaux.fr/gp.html (accessed on 15 May 2019).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | 912 | 1160 | 1518 |
| OldDRS | 2.871 | 4.415 | 7.957 |
| NewDRS | 31.745 | 63.189 | 99.392 |
| Dimension | R | ||||
|---|---|---|---|---|---|
| 1108 | 1 | 24 | 28 | < | |
| 1372 | 1 | 24 | 28 | < | |
| 1779 | 1 | 24 | 28 | < |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sipasseuth, A.; Plantard, T.; Susilo, W. A Noise Study of the PSW Signature Family: Patching DRS with Uniform Distribution †. Information 2020, 11, 133. https://doi.org/10.3390/info11030133
Sipasseuth A, Plantard T, Susilo W. A Noise Study of the PSW Signature Family: Patching DRS with Uniform Distribution †. Information. 2020; 11(3):133. https://doi.org/10.3390/info11030133
Chicago/Turabian StyleSipasseuth, Arnaud, Thomas Plantard, and Willy Susilo. 2020. "A Noise Study of the PSW Signature Family: Patching DRS with Uniform Distribution †" Information 11, no. 3: 133. https://doi.org/10.3390/info11030133
APA StyleSipasseuth, A., Plantard, T., & Susilo, W. (2020). A Noise Study of the PSW Signature Family: Patching DRS with Uniform Distribution †. Information, 11(3), 133. https://doi.org/10.3390/info11030133