1. Introduction
The cyber security toolkit (CyberSecTK) is a simple Python library for preprocessing and feature extraction of cyber-security-related data. As the digital universe expands, more and more data need to be processed using automated approaches. For instance, the statistics [
1] show a rapid growth in internet of things (IoT) devices. Currently, there are over 12 billion devices that can connect to the internet, and it was predicted to reach 14.2 billion in 2019. According to the publication announcement on the Worldwide Semiannual Internet of Things Spending Guide forecast [
2], a 13.6% compound annual growth rate (CAGR) is expected over the 2017–2022 period with an estimated investment of 1.2 trillion US dollars by 2022. The proliferation of the IoT will lead to new challenges in the near future. According to [
1], the growth of IoT devices usage will lead to an important problem, which will make it difficult for smart environment operators to ascertain IoT devices within their networks and monitor their operations. The Mirai botnet [
3] is an example of risks to IoT devices. This denial of service attack is a wake-up call to the IoT industry, which is possible if IoT devices are not secured. Security of IoT devices, in this example, will be key. GHOST [
4], an EU Horizon 2020 Research and Innovation funded project, develops an architecture to safeguard home IoT environments with personalized real-time risk control measures to mitigate cyber security events. The system modules a network and data flow analysis (NDFA) to build a profile builder (PB) based on network activities, which in turn notifies a risk engine (RE) to act in order to secure the smart-home IoT ecosystem. Abnormal behavior detection is one of the crucial components in our daily life interaction with IoT environments and devices.
In recent years, cyber security professionals have seen opportunities to use machine learning (ML) approaches to help process and analyze their data. The challenge is that cyber security experts do not have necessary artificial intelligence (AI) trainings to apply ML techniques to their problems. One key aspect is that they do not know how to extract features from cyber-security-related data and to preprocess a data set for ML applications. According to He et al. [
5], a deep learning approach is more efficient to analyze the IoT device network traffic within an edge computing environment. The edge computing helps to scale down the size of intermediate data, which is smaller in size compared to input data resulting from efficient feature extraction. An effective AI system trains to learn techniques based on its featured data set. Data preprocessing and feature selection are the steppingstones in ML techniques. Tohari et al. [
6] developed a technique based on a combined correlation-based features selection (CFS) technique and particle swarm optimization (PSO) to perform feature selection. The model was designed to analyze the network traffic for intrusion detection systems (IDSs) and achieve high-accuracy prediction. The goal of this library is to help bridge this gap. In particular, we proposed the development of a toolkit in Python that can process the most common types of cyber security data. This will help cyber experts to implement a basic ML pipeline from beginning to end. The proposed research work is our first attempt to achieve this goal. The presented toolkit is a suite of program modules, data sets, and tutorials on YouTube [
7], supporting research and teaching in cyber security and defense.
In this paper, we discussed a toolkit for cyber security and ML. In particular, our goal was to provide ways of extracting features from cyber-security-related data for ML applications. The library provides functions and data examples that show different extracted features and associated reasons. We have been developing a library for feature extraction of cyber-security-related data, so it is ready for ML with other libraries like Keras [
8], TensorFlow [
9], and sklearn [
10]. The library in its current form has functions to extract features from Wi-Fi data, standard transmission control protocol/internet protocol (TPC/IP) data, malware related logs, etc.
Libraries are very valuable tools to help AI practitioners to implement their applications. There are many important libraries for data science with Python such as TensorFlow [
9], sklearn [
10], and pandas [
11]. Domain-specific libraries have been used widely in the past and have proven valuable to improve efficiency in the development of ML applications. A good example of a domain-specific library of note is the natural language toolkit (NLTK) [
12]. This library helps linguists, data scientists, and others to more efficiently process texts for ML applications. The aim of our proposed library is similar but for cyber security data.
Whereas for NLTK the main source of data was text and language, the main source of data for cyber-security-related problems must be identified. The main sources of data traditionally have been network data in the form of network packet capture protocols (PCAPs), log data, and system files. In [
13], Calix and Sankaran looked at network data to address their cyber security problems. In these studies [
14], the researchers looked at malware data. Other possibilities include phishing [
15], biometrics [
16], etc.
Feature extraction algorithms aim to extract or engineer meaningful features from their media. These features usually create vector spaces and need to have certain properties related to data distribution, normalization, and dimensionality [
17]. Common problems with extracting features from network data are shown as following: differentiating the types of packets, dealing with encryption, and processing payloads. Most network-related studies focus on a specific type of packet (Internet Control Message Protocol (ICMP) or TCP) [
13] and usually exclude a payload or treat it separately [
18].
Malware detection is another problem, for which we want to apply ML approaches. There are several challenges, however, such as dealing with polymorphic viruses [
14]. Malware usually consists of code that multiplies, makes copies of itself and can deliver a payload. Detecting it can be challenging. Traditionally, static malware analysis through the use of hashing of files has been an approach to dealing with it. Polymorphic malware can evade hashing techniques by changing every copy of a new malware instance. To address polymorphic malware detection, a set of techniques referred to as dynamic malware analysis have been used.
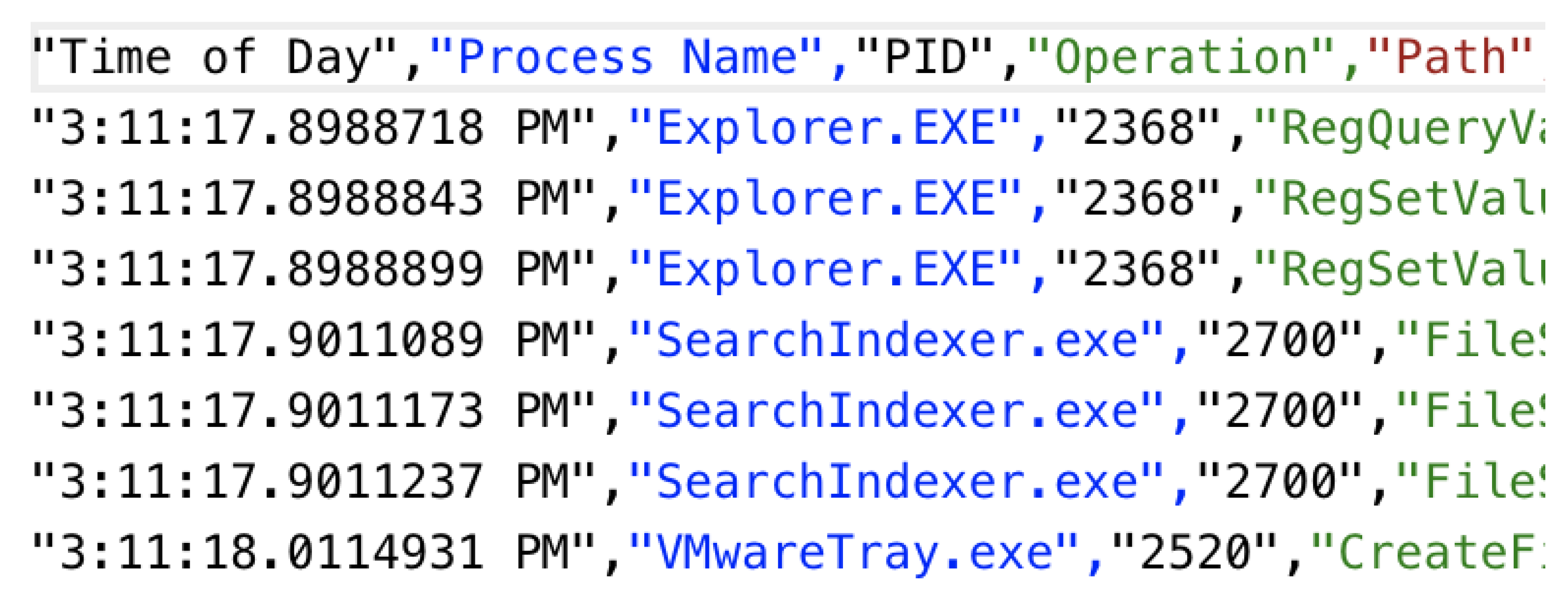
Dynamic approaches need malware to run in a sandbox environment and collect the dynamic behavior of the malware. This dynamic behavior consists, usually, of system calls, registry edits, network connections, access of dynamic link libraries (DLLs), etc. A basic pipeline for this was to take the dynamic malware, run it through an emulator, obtain log files of the behavior and extract features from the logs for ML purposes [
14]. According to Hamed et al. [
19], a components-based approach enables an easier comparison of methods. Where an intrusion detection system (IDS) can be analyzed in three major phases: preprocessing, detection, and empirical evaluation. For example, a network’s physical, datalink, and network packet header’s information can be useful to extract features to analyze network behavior. This can be useful to detect anomalies within a network. A malware image analysis technique in [
20] was used to classify, detect and analyze particular malware based on image texture analysis. The visualization technique converts the sample malware’s executable file into binary strings of 0′s and 1′s as a vector, which is then converted into two-dimensional images. The image is further compared in terms of factors such as creation, techniques, execution environment, propagation media, and negative impacts. A behavior-based malware-detection ML technique was also discussed in [
21]. The combined malware and benign instance of the data set from Windows’ portable executable (PE) binaries file is processed online to generate dynamic analysis reports. This is then further used for feature selection and analyzed based on available Weka classifiers. One of the proposed modules in our library was designed to process and extract features from log files (e.g., features from dynamic analysis). In its simplest form, the dynamic malware analysis module can treat each log file per malware (or goodware) sample as a text file (similar to how a natural language document would be treated). From there, a simple bag of words approach can be explored, and this is the most basic analysis that can be implemented. Once the features are extracted, to complete the pipeline, the data must be preprocessed and normalized, ML models are built, and results must be analyzed to evaluate performance. Our library interacts well with standard sklearn and TensorFlow functions to complete the ML pipeline. The point of this library is to bring together modules for feature extraction in the domain of cyber security. Whenever possible, we use existing libraries/dependencies to manipulate raw data. For example, we use Python Scapy functions to process network packets. Libraries like sklearn do not have specific modules to extract features from cyber data. Therefore, our proposed library can be used to extract features from cyber data and those extracted features can then be used for ML applications using other tools such as TensorFlow, and sklearn. This library is a work in progress, and more features can be added in the future by incorporating new modules.
The structure of this paper is as follows: first, an introduction of the library and its need was shown. This section was followed by methods and results. Finally, the discussion of results and future work were presented.
2. Materials and Methods
The library consists of simple Python scripts for feature extraction and some tutorial materials for research and teaching of ML for cyber security. The code for the library is available from GitHub via the link in [
22]. The library focuses mainly on two types of data, which are network data and malware-related data. For the network data, we provide examples of how to extract data from Wi-Fi data and from regular network data. All inputs are assumed to be PCAP files. The library uses the Python Scapy [
23] library to extract the network features. The outputs are comma-separated values (CSV) files that contain features and their values. Currently, we are focusing on TCP packets and the basic wireless local area network (LAN) link-layer headers without looking into the payloads. As we extend the library, we will explore modules for payload extraction. Payload data are more challenging, because they are more diverse. One common way of looking at payload data is to think of them as documents in language. Therefore, NLP types of approaches can be considered. To preserve confidentiality of data transferred, packets are usually encrypted. Analyzing encrypted packets for ML can be very challenging and is currently not addressed by the library directly. However, according to [
24], an encrypted wireless network packet can still be analyzed using the link-layer header information. In this paper, we used the same approach to extract features from wireless network packets.
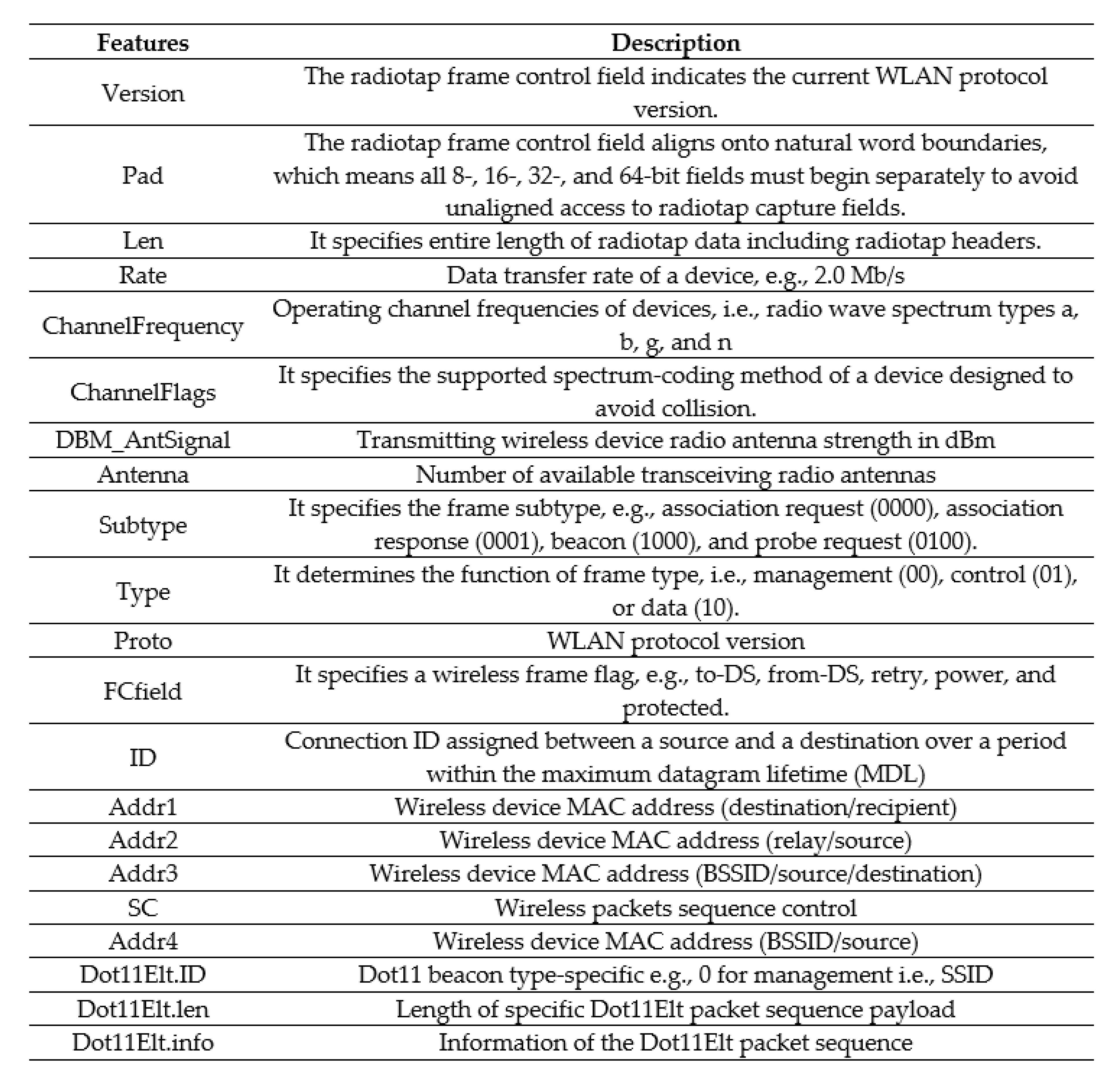
Figure 1 shows an example of a wireless LAN frame.
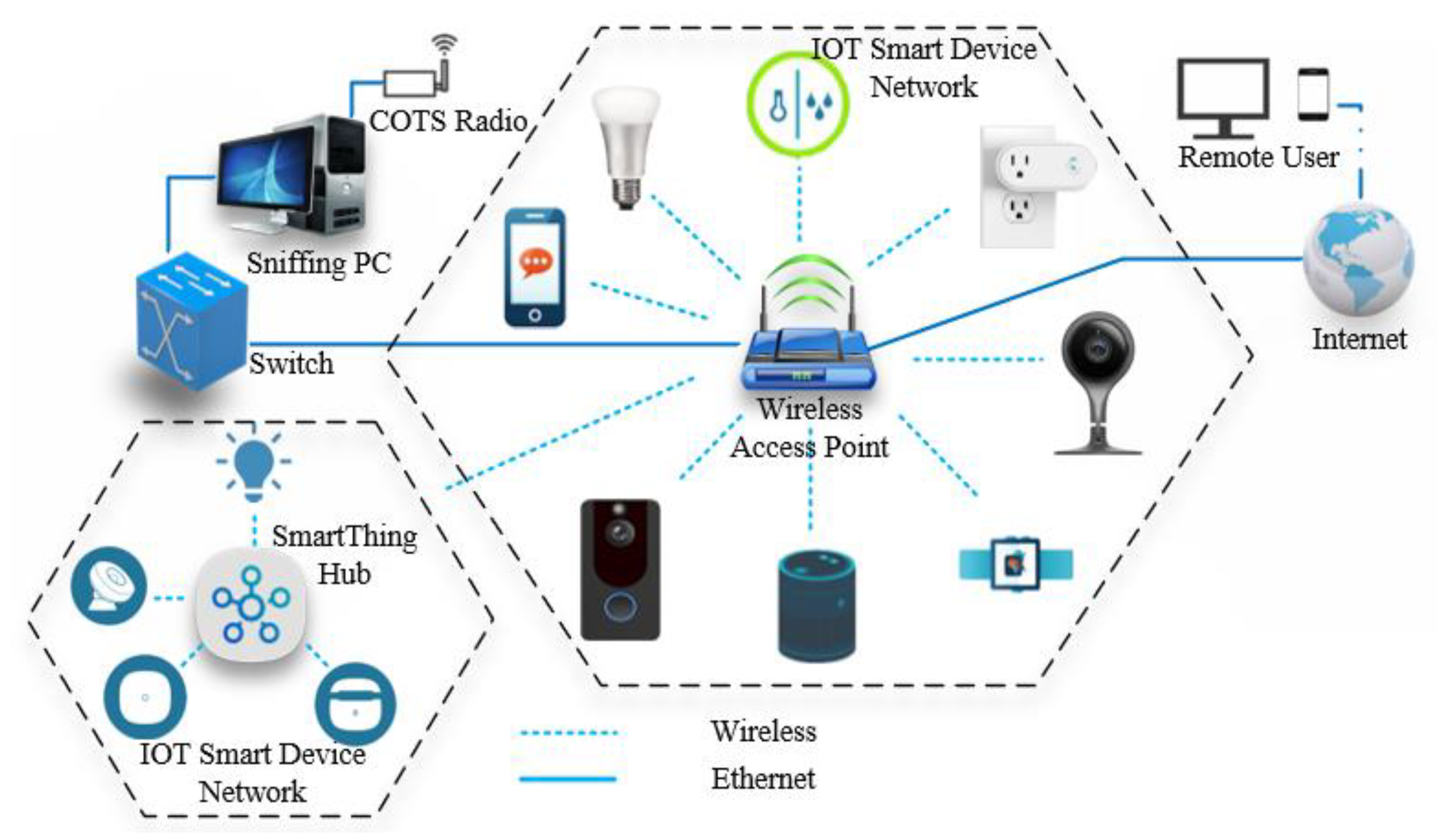
The wireless network packets to test our modules were collected within a simple testbed lab environment, where multiple IoT devices were connected to an access point (AP).
Figure 2 illustrates the lab setup environment. The research work focused on collecting wireless packets as an initial approach to feature extraction. The sample data set is available for the library. A commercial off-the-shelf (COTS) radio receiver was used in monitor mode, to passively eavesdrop the wireless network traffic within a controlled lab environment. We preferred the monitor mode over the promiscuous mode due to its capabilities to identify hidden APs, which can passively listen to the wireless network traffic without associating to the network. With this approach, features can be directly extracted based on nonencrypted link-layer header information.
For example, a sample IoT wireless LAN data set contains 21 features with 94 instances as a proof of concept to test the cyber security toolkit. We used Python Scapy [
23], an open-source Python library, to collect the wireless network traffic and further extract features using the proposed library based on Scapy’s built-in library support.
Scapy is handy to use in terms of its built-in functions and support community. The user can simply dump network packets and parse them through different layered information within each packet for further analysis. Similarly, Aircrack-ng [
25], an open-source Wi-Fi network security toolset, was used to set up a wireless network adaptor in monitoring mode, before we started capturing the wireless network traffic within our testbed lab environment to create a data set.
For our Wi-Fi IoT data example, the library’s module extracts features from wireless network traffic-based PCAP files. The module parses the wireless network layer information using Scapy functions and extracts features based on a predefined list into a final CSV file. In its simplest form, each packet becomes an instance or sample of the output CSV file. The procedure, for this example’s feature extraction approach, is summarized in Algorithm 1 (
Figure 3), where IOTwireless.csv is a labeled data set file. Sniff is a Scapy built-in function to control network packets, and it allows users to pass a function with an argument “prn” to perform custom actions. The variable Labels represents the feature labels list to be extracted from the input PCAP file. Dot11 and Dot11Elt are wireless frame layers, which hold information about the connected wireless network. Dot11 and Dot11Elt are layer fields and are the values associated within each packet with the labels defined in Labels.
The malware module focuses on data collected via dynamic analysis (e.g., running a virus in a sandbox through an emulator). The emulator generates logs of the behavior of the malware that is processed for feature extraction. Each log is treated as a document, and its content is treated as words. With this view of the data, features can be extracted using a bag of words approach.
Evaluation
Evaluating a module statistically can be challenging given that we need to assess, in a way, how the code was written and if it is useful to the user. We settled on evaluating the use of some of the modules as part of a class. In particular, we used modules for malware feature extraction and for network data analysis. As part of the class, we also recorded videos and created a virtual machine (VM), data sets, lectures, and labs. We assessed the whole course together and did not focus on a specific module of the library. The survey was conducted to assess the content arrangement and design of the course and to obtain direct feedback on the learning experience. The data came from 19 students who attended classes during the summer of 2019. The open-source learning module was designed to be a week-long ML course for cyber security professional. The course was provided for professionals with a basic knowledge of network security and coding. Most of students in the course possessed very advanced programming skills. The learning module consists of 7 data sets distributed in 15 lectures and 10 labs. All the code modules are implemented in Python and tested in an Ubuntu virtual machine. The VM has many libraries already preinstalled and can be downloaded from [
7].
In terms of survey methods and survey data, we followed standard approaches such as in [
26]. The survey contained 17 questions, including questions of satisfaction with materials prepared in class, surveys of satisfaction with teaching content and materials, and analysis of teaching results. In addition, participants could write down their other feelings or concerns about the course.
All of the questions in the survey, except for the final comment, used a Likert scale, for a range of 1 to 5.
Table 1 shows the scale meanings of the survey answers, and
Table 2 demonstrates the survey questions.
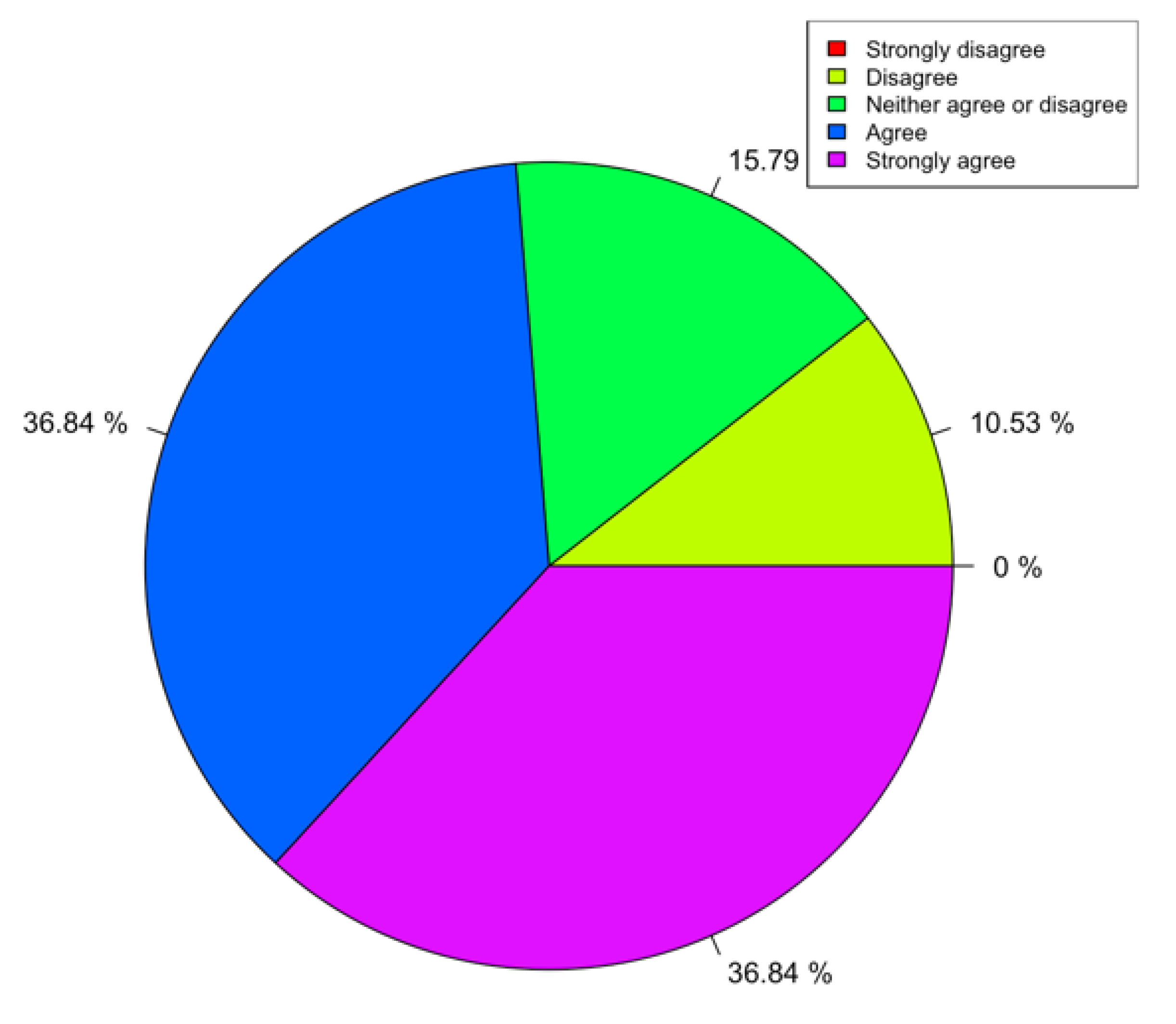
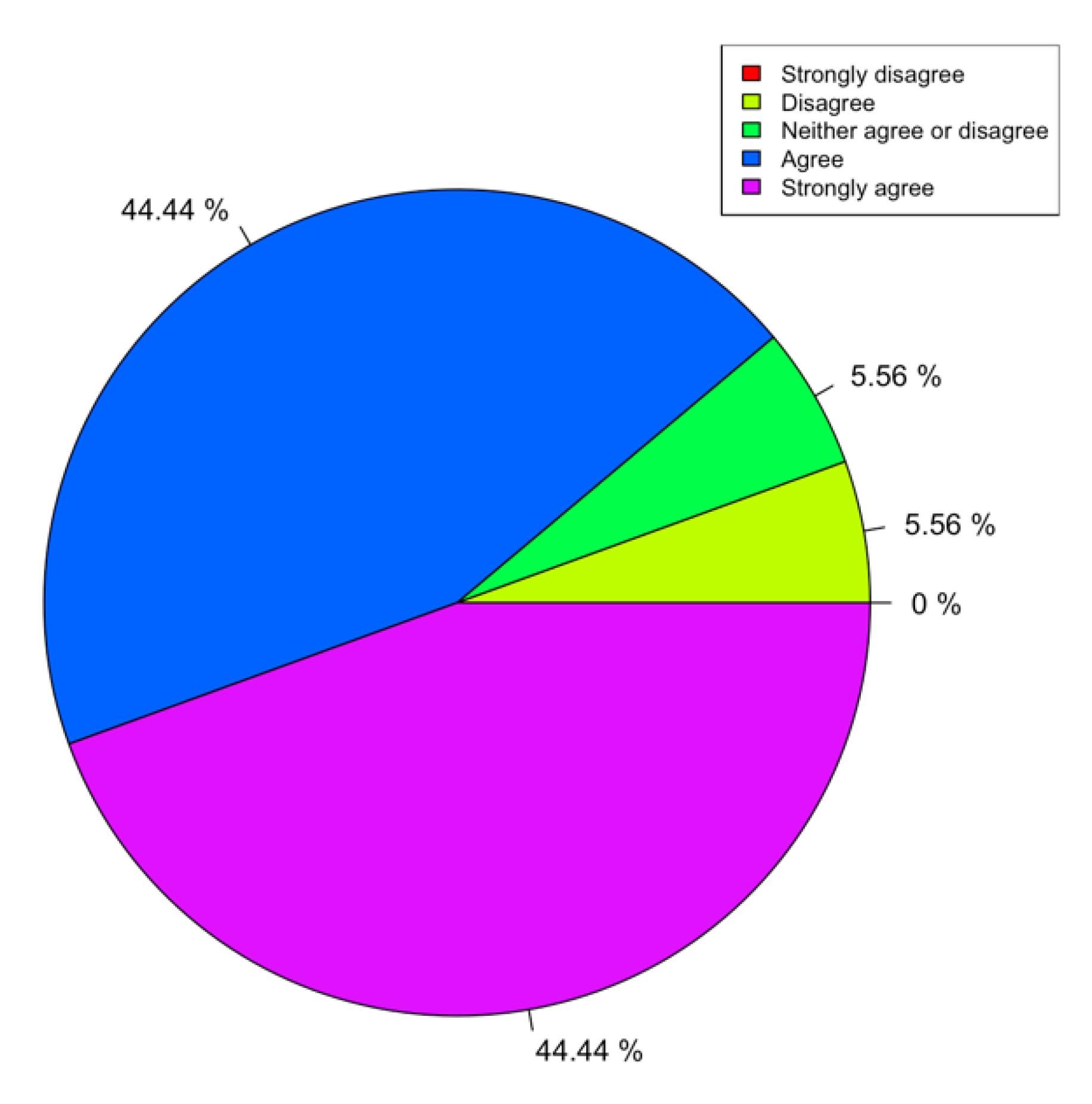
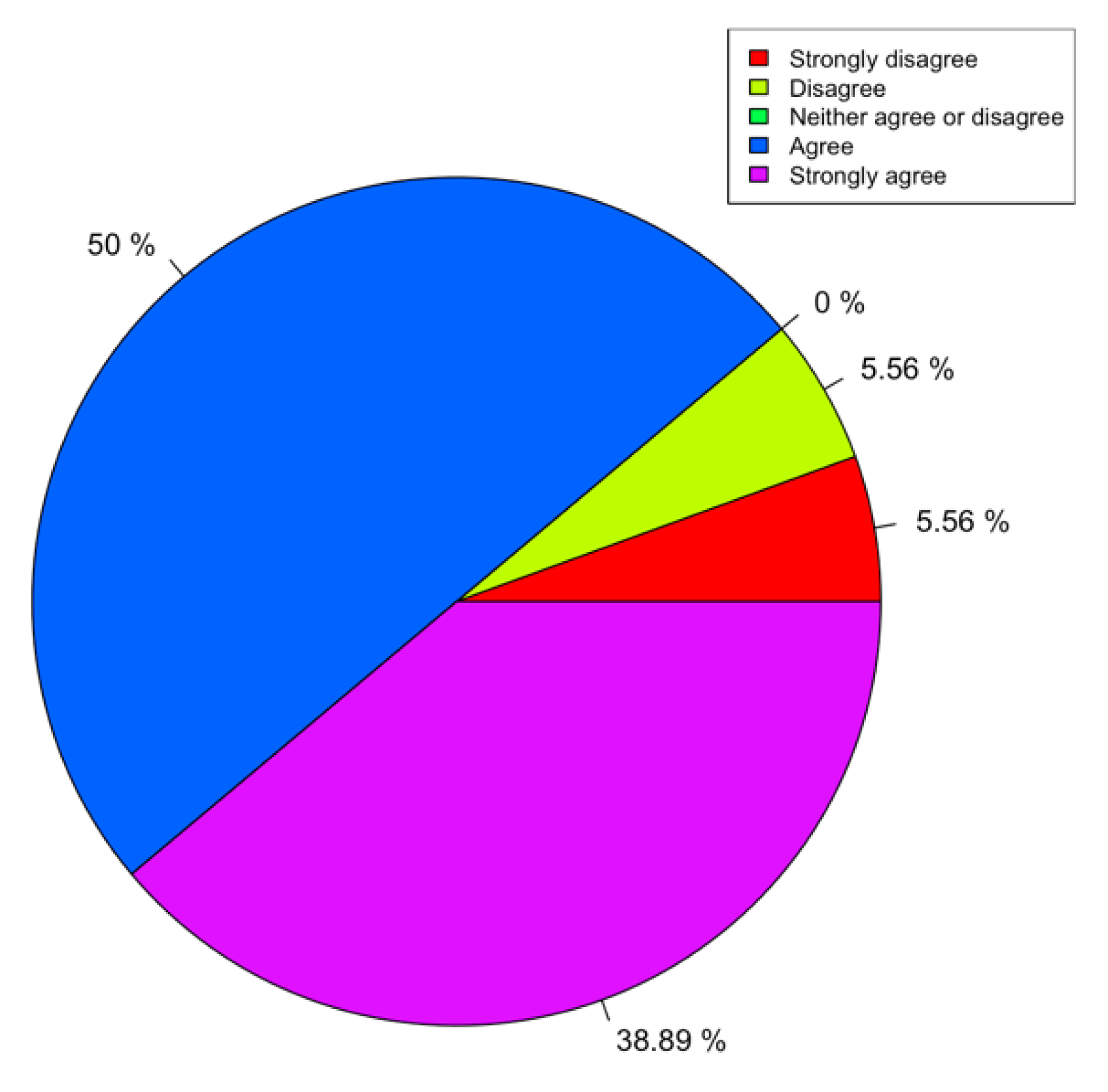
Given that this is a library/coding module, it can be difficult to present statistical results of its usefulness and usability. Given that these modules were used in a class run in the summer of 2019, we used the results of the course surveys as an indirect assessment of these materials. In particular, we emphasized those questions that were more pertinent to the library itself. We presented a full list of questions for completion. For our purposes, we focused on question 12 (Q12), in particular, which we felt was the most relevant to assess our module/library.
Through statistical analysis of the survey data with the R language, we presented some issues of note. This paper tried to find out the relationship between course materials, course content, and course satisfaction, so as to help optimize the materials and meet the needs of target groups.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
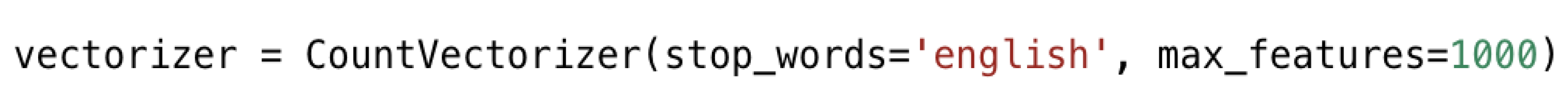{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}