Fastai: A Layered API for Deep Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Applications
2.1. Vision









2.2. Text


2.3. Tabular

2.4. Collaborative Filtering

2.5. Deployment
3. High-Level API Design Considerations
3.1. High-Level API Foundations
- Getting the source items,
- Splitting the items into the training set and one or more validation sets,
- Labelling the items,
- Processing the items (such as normalization), and
- Optionally collating the items into batches.




3.2. Incrementally Adapting PyTorch Code

3.3. Consistency Across Domains
4. Mid-Level APIs
4.1. Learner
4.2. Two-Way Callbacks
- A callback should be available at every single point that code can be run during training, so that a user can customise every single detail of the training method;
- Every callback should be able to access every piece of information available at that stage in the training loop, including hyper-parameters, losses, gradients, input and target data, and so forth;
- Every callback should be able to modify all these pieces of information, at any time before they are used, and be able to skip a batch, epoch, training or validation section, or cancel the whole training loop.

Case Study: Generative Adversarial Network Training Using Callbacks
- Freeze the generator and train the critic for one (or more) step by:
- −
- getting one batch of “real” images;
- −
- generating one batch of “fake” images;
- −
- have the critic evaluate each batch and compute a loss function from that, which rewards positively the detection of real images and penalizes the fake ones;
- −
- update the weights of the critic with the gradients of this loss.
- Freeze the critic and train the generator for one (or more) step by:
- −
- generating one batch of “fake” images;
- −
- evaluate the critic on it;
- −
- return a loss that rewards positively the critic thinking those are real images;
- −
- update the weights of the generator with the gradients of this loss.
- begin_fit: Initialises the generator, critic, loss functions, and internal storage
- begin_epoch: Sets the critic or generator to training mode
- begin_validate: Switches to generator mode for showing results
- begin_batch: Sets the appropriate target depending on whether it is in generator or critic mode
- after_batch: Records losses to the generator or critic log
- after_epoch: Optionally shows a sample image
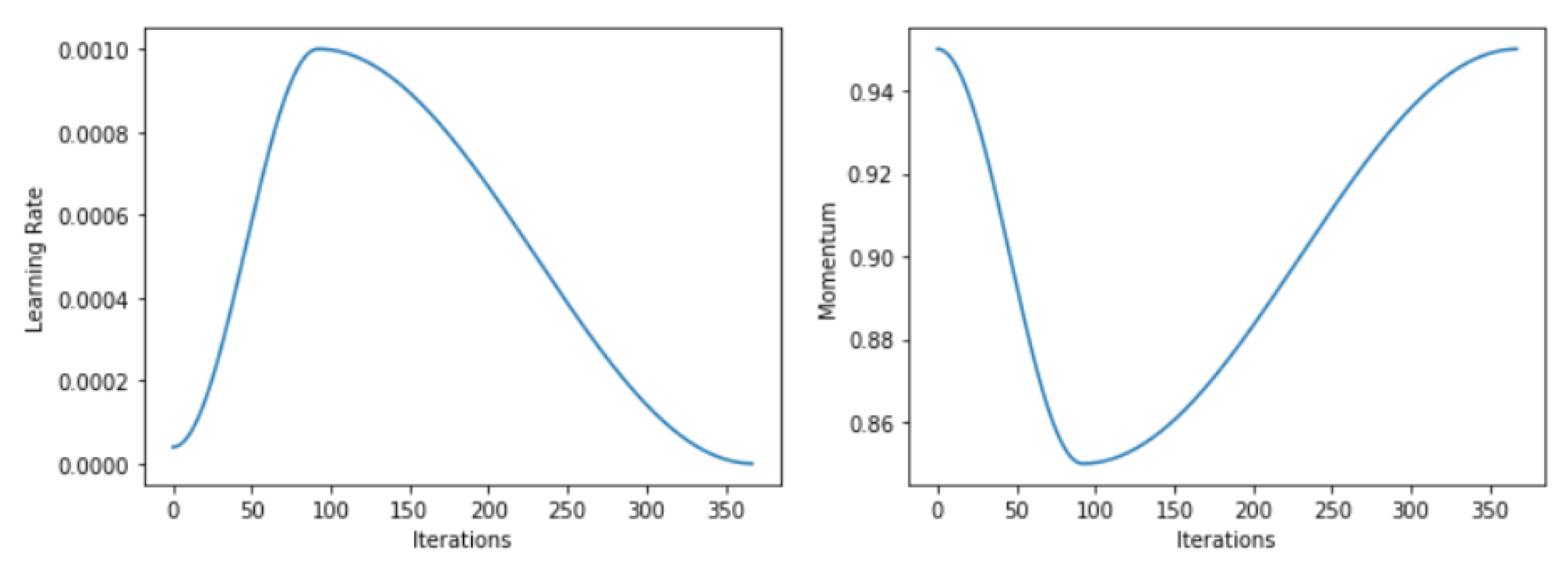
4.3. Generic Optimizer
- stats, which track and aggregate statistics such as gradient moving averages;
- steppers, which combine stats and hyper-parameters to update the weights using some function.

- the means that update and do not appear as this done in a separate function stat;
- the authors do not provide the full definition of the function they use (it depends on undefined parameters), the code below is based on the official TensorFlow implementation.
4.4. Generalized Metric API

4.5. Fastai.Data.External
4.6. Funcs_kwargs and DataLoader
4.7. Fastai.Data.Core
4.8. Layers and Architectures
5. Low-Level APIs
- Pipelines of transforms: Partially reversible composed functions mapped and dispatched over elements of tuples
- Type-dispatch based on the needs of data processing pipelines
- Attaching semantics to tensor objects, and ensuring that these semantics are maintained throughout a Pipeline
- GPU-optimized computer vision operations
- Convenience functionality, such as a decorator to make patching existing objects easier, and a general collection class with a NumPy-like API.
5.1. PyTorch Foundations
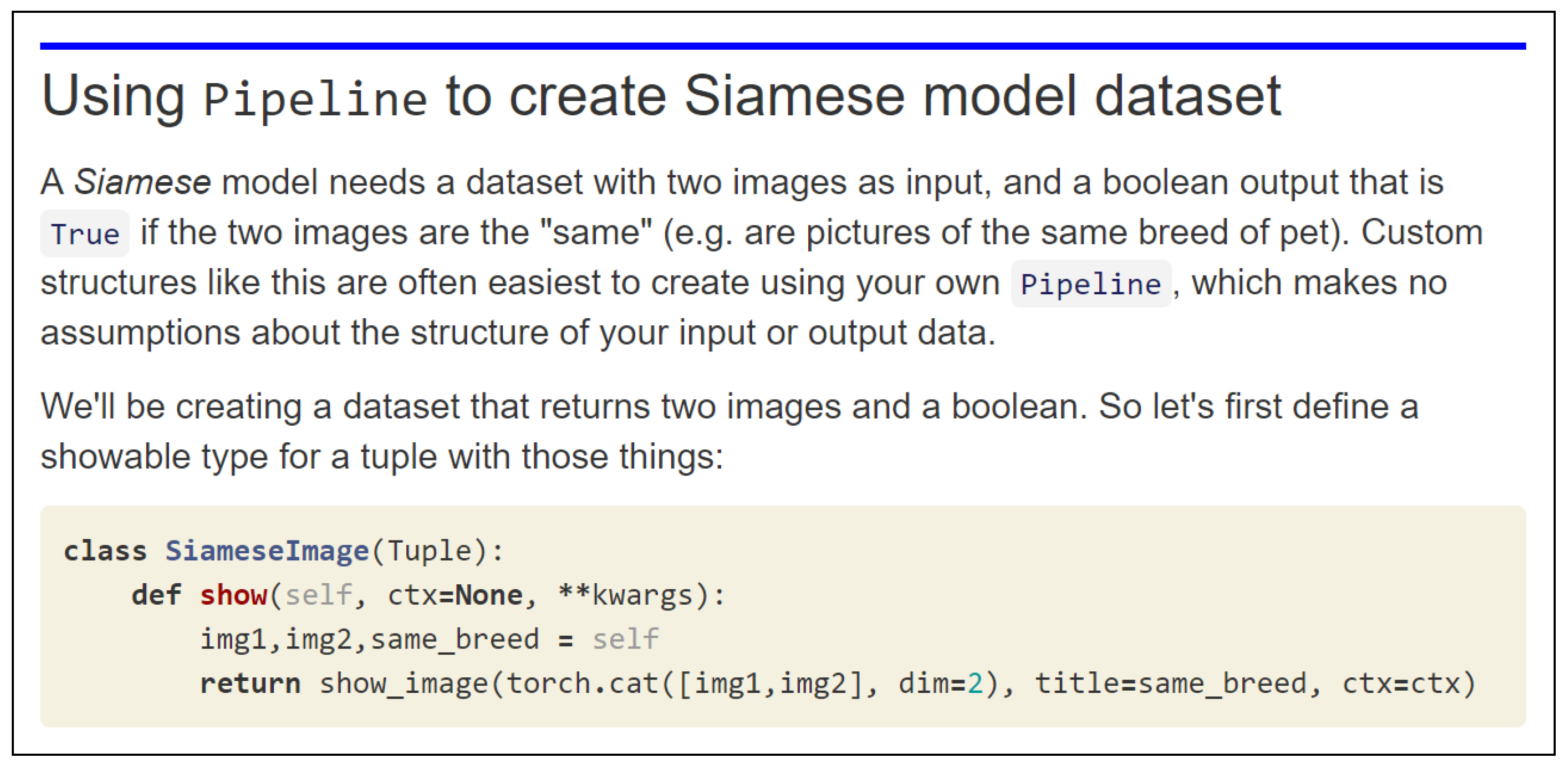
5.2. Transforms and Pipelines
5.3. Type Dispatch

5.4. Object-Oriented Semantic Tensors
5.5. GPU-Accelerated Augmentation
5.6. Convenience Functionality



6. Nbdev
- Python modules are automatically created, following best practices such as automatically defining __all__ with exported functions, classes, and variables
- Navigate and edit code in a standard text editor or IDE, and export any changes automatically back into your notebooks
- Automatically create searchable, hyperlinked documentation from your code (as seen in Figure 12; any word surrounded in backticks will by hyperlinked to the appropriate documentation, a sidebar is created in the documentation site with links to each of module, and more
- Pip installers (uploaded to pypi automatically)
- Testing (defined directly in notebooks, and run in parallel)
- Continuous integration
- Version control conflict handling
7. Related Work
8. Results and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Howard, J.; Gugger, S. Deep Learning for Coders With Fastai and PyTorch: AI Applications Without a PhD, 1st ed.; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2020. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 14 February 2020).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Howard, J.; Ruder, S. Fine-tuned Language Models for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. NIPS Autodiff Workshop. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 14 February 2020).
- Oliphant, T. NumPy: A Guide to NumPy; Trelgol Publishing: Spanish Fork, UT, USA, 2006. [Google Scholar]
- Clark, A. Python Imaging Library (Pillow Fork). Available online: https://github.com/python-pillow/Pillow (accessed on 14 February 2020).
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 11–17 July 2010; pp. 51–56. [Google Scholar]
- Coleman, C.; Narayanan, D.; Kang, D.; Zhao, T.; Zhang, J.; Nardi, L.; Bailis, P.; Olukotun, K.; Zaharia, C. DAWNBench: An End-to-End Deep Learning Benchmark and Competition. Training 2017, 100, 102. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 22–24 June 2009. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A.; Jawahar, C.V. Cats and Dogs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Smith, L.N. A disciplined approach to neural network hyper-parameters: Part 1—learning rate, batch size, momentum, and weight decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and Recognition Using Structure from Motion Point Clouds. ECCV 2008, 1, 44–57. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association For Computational Linguistics: Human Language Technologies; Association for Computational Linguistics: Portland, ON, USA, 2011; pp. 142–150. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Kudo, T. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. arXiv 2018, arXiv:1804.10959. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Eisenschlos, J.; Ruder, S.; Czapla, P.; Kadras, M.; Gugger, S.; Howard, J. MultiFiT: Efficient Multi-lingual Language Model Fine-tuning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar] [CrossRef]
- Merity, S.; Keskar, N.S.; Socher, R. Regularizing and Optimizing LSTM Language Models. arXiv 2017, arXiv:1708.02182. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:abs/1910.03771. [Google Scholar]
- De Brébisson, A.; Simon, É.; Auvolat, A.; Vincent, P.; Bengio, Y. Artificial Neural Networks Applied to Taxi Destination Prediction. arXiv 2015, arXiv:1508.00021. [Google Scholar]
- Guo, C.; Berkhahn, F. Entity Embeddings of Categorical Variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. Adv. Neural Inf. Process. Syst. 2008, 2008, 1257–1264. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. 2015, 5, 19:1–19:19. [Google Scholar] [CrossRef]
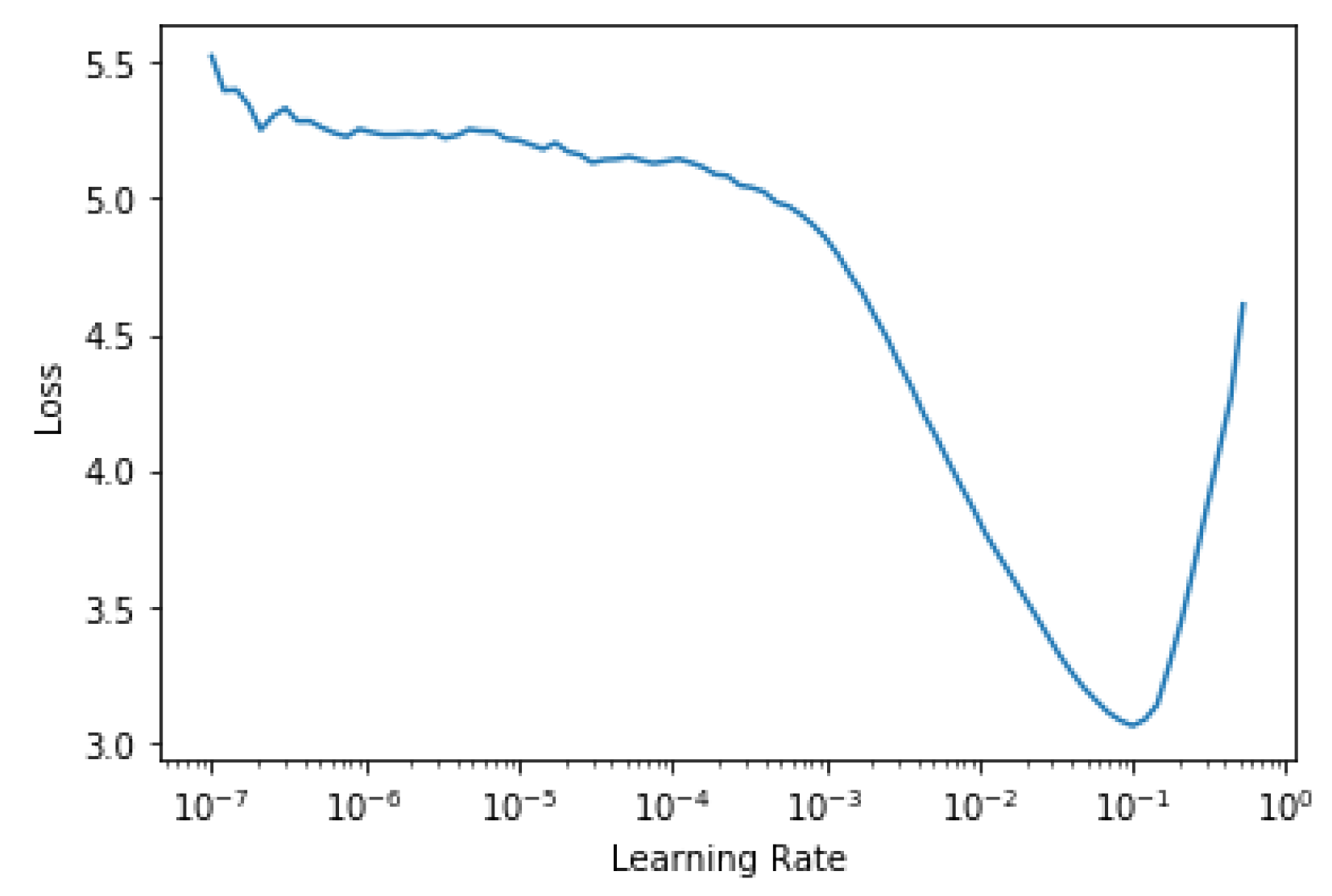
- Smith, L.N. No More Pesky Learning Rate Guessing Games. arXiv 2015, arXiv:1506.01186. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. 2010. Available online: http://yann.Lecun.Com/exdb/mnist (accessed on 14 February 2020).
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Massa, F.; Chintala, S. Torchvision. Available online: https://github.com/pytorch/vision/tree/master/torchvision (accessed on 14 February 2020).
- Girshick, R.; Radosavovic, I.; Gkioxari, G.; Dollár, P.; He, K. Detectron. 2018. Available online: https://github.com/facebookresearch/detectron (accessed on 14 February 2020).
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. Fairseq: A Fast, Extensible Toolkit for Sequence Modeling. arXiv 2019, arXiv:1904.01038. [Google Scholar]
- Zhang, H.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed Precision Training. 2017. Available online: http://xxx.lanl.gov/abs/1710.03740 (accessed on 14 February 2020).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- You, Y.; Li, J.; Hseu, J.; Song, X.; Demmel, J.; Hsieh, C. Reducing BERT Pre-Training Time from 3 Days to 76 Minutes. arXiv 2019, arXiv:1904.00962. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 17–19 June 1997. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 18–21 June 2018. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conf. Comput. Vision Pattern Recog. (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 28 July 2017. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. CoRR 2018. Available online: http://xxx.lanl.gov/abs/1812.01187 (accessed on 14 February 2020).
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. 2019. Available online: http://xxx.lanl.gov/abs/1908.08681 (accessed on 14 February 2020).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Python Core Team. Python: A Dynamic, Open Source Programming Language, Python Software Foundation, Python version 3.7; Python Core Team: Cham, Switzerland, 2019. [Google Scholar]
- Theano Development Team. Theano: A Python framework for fast computation of mathematical expressions. arXiv 2016, arXiv:1605.02688. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000. Available online: https://www.drdobbs.com/open-source/the-opencv-library/184404319 (accessed on 14 February 2020).
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A publishing format for reproducible computational workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas; Loizides, F., Schmidt, B., Eds.; IOS Press: Clifton, VA, USA, 2016; pp. 87–90. [Google Scholar]
- Dieleman, S.; Schlüter, J.; Raffel, C.; Olson, E.; Sønderby, S.K.; Nouri, D.; Maturana, D.; Thoma, M.; Battenberg, E.; Kelly, J.; et al. Lasagne: First Release; Zenodo: Geneva, Switzerland, 2015. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Luke Tierney. XLISP-STAT: A Statistical Environment Based on the XLISP Language (Version 2.0); Technical Report 28; School of Statistics, University of Minnesota: Minneapolis, MA, USA, 1989. [Google Scholar]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
- Raschka, S. MLxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J. Open Source Softw. 2018, 3. [Google Scholar] [CrossRef]
- Revay, S.; Teschke, M. Multiclass Language Identification using Deep Learning on Spectral Images of Audio Signals. arXiv 2019, arXiv:1905.04348. [Google Scholar]
- Koné, I.; Boulmane, L. Hierarchical ResNeXt Models for Breast Cancer Histology Image Classification. In International Conference Image Analysis and Recognition; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Elkins, A.; Freitas, F.F.; Sanz, V. Developing an App to interpret Chest X-rays to support the diagnosis of respiratory pathology with Artificial Intelligence. arXiv 2019, arXiv:1906.11282. [Google Scholar]
- Anand, S.; Mahata, D.; Aggarwal, K.; Mehnaz, L.; Shahid, S.; Zhang, H.; Kumar, Y.; Shah, R.R.; Uppal, K. Suggestion Mining from Online Reviews using ULMFiT. arXiv 2019, arXiv:1904.09076. [Google Scholar]
- Jeremy, H.; Sylvain, G. SwiftAI; Fast.ai, Inc.: Paris, France, 2019. [Google Scholar]












© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. https://doi.org/10.3390/info11020108
Howard J, Gugger S. Fastai: A Layered API for Deep Learning. Information. 2020; 11(2):108. https://doi.org/10.3390/info11020108
Chicago/Turabian StyleHoward, Jeremy, and Sylvain Gugger. 2020. "Fastai: A Layered API for Deep Learning" Information 11, no. 2: 108. https://doi.org/10.3390/info11020108
APA StyleHoward, J., & Gugger, S. (2020). Fastai: A Layered API for Deep Learning. Information, 11(2), 108. https://doi.org/10.3390/info11020108