A Two-Stage Particle Swarm Optimization Algorithm for Wireless Sensor Nodes Localization in Concave Regions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Research Significance
1.2. Research Status
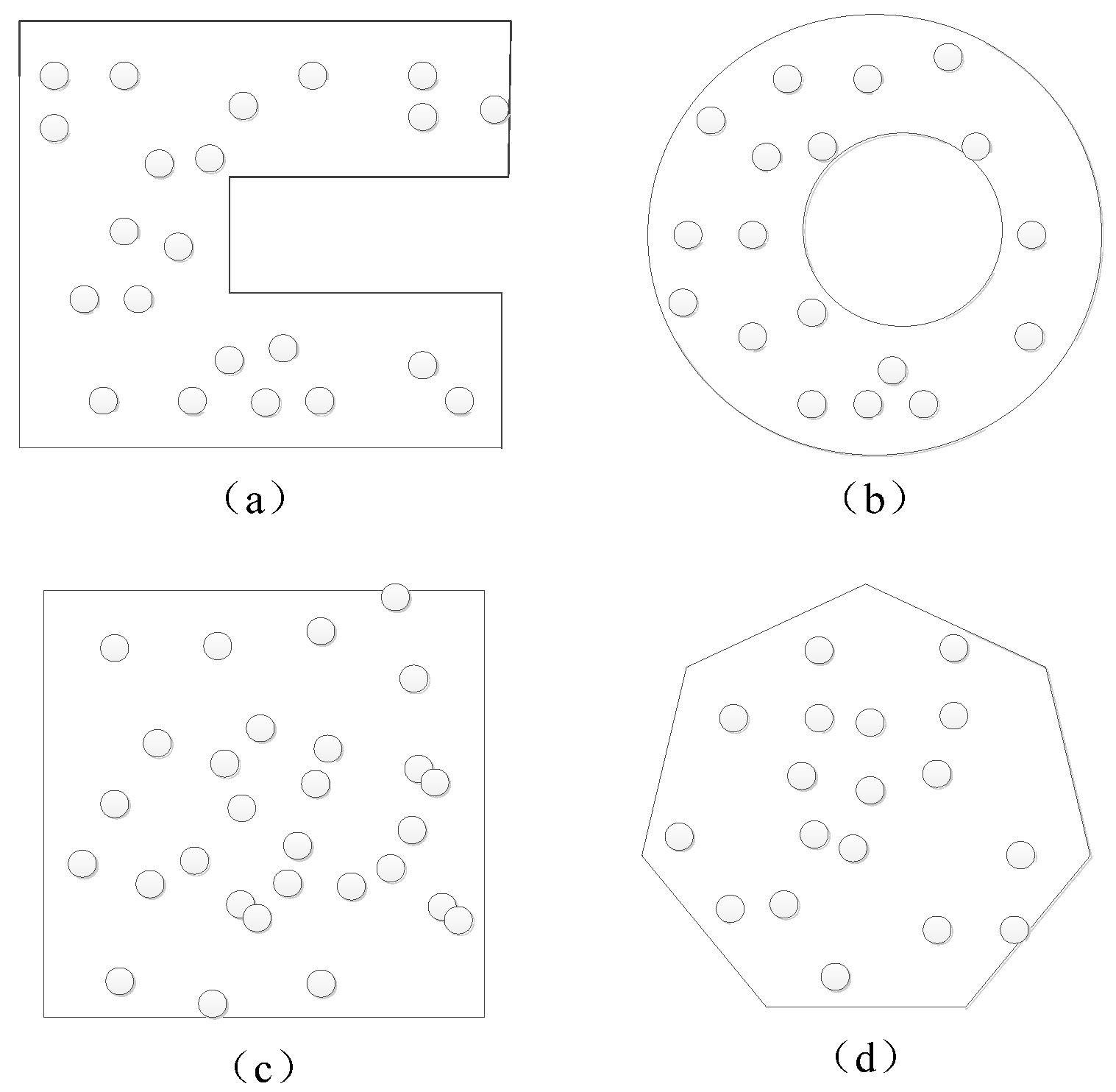
2. Initial Localization of Unknown Nodes
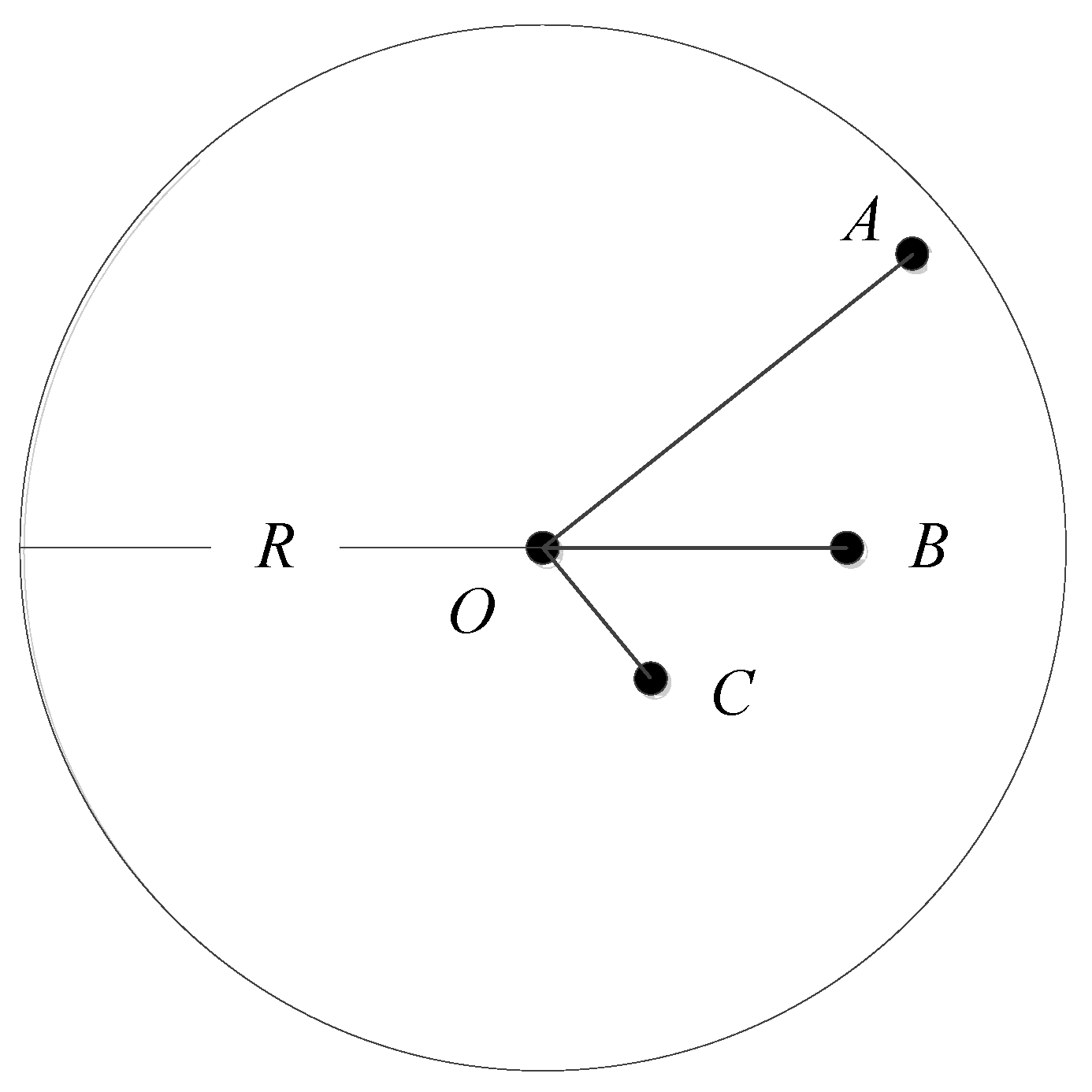
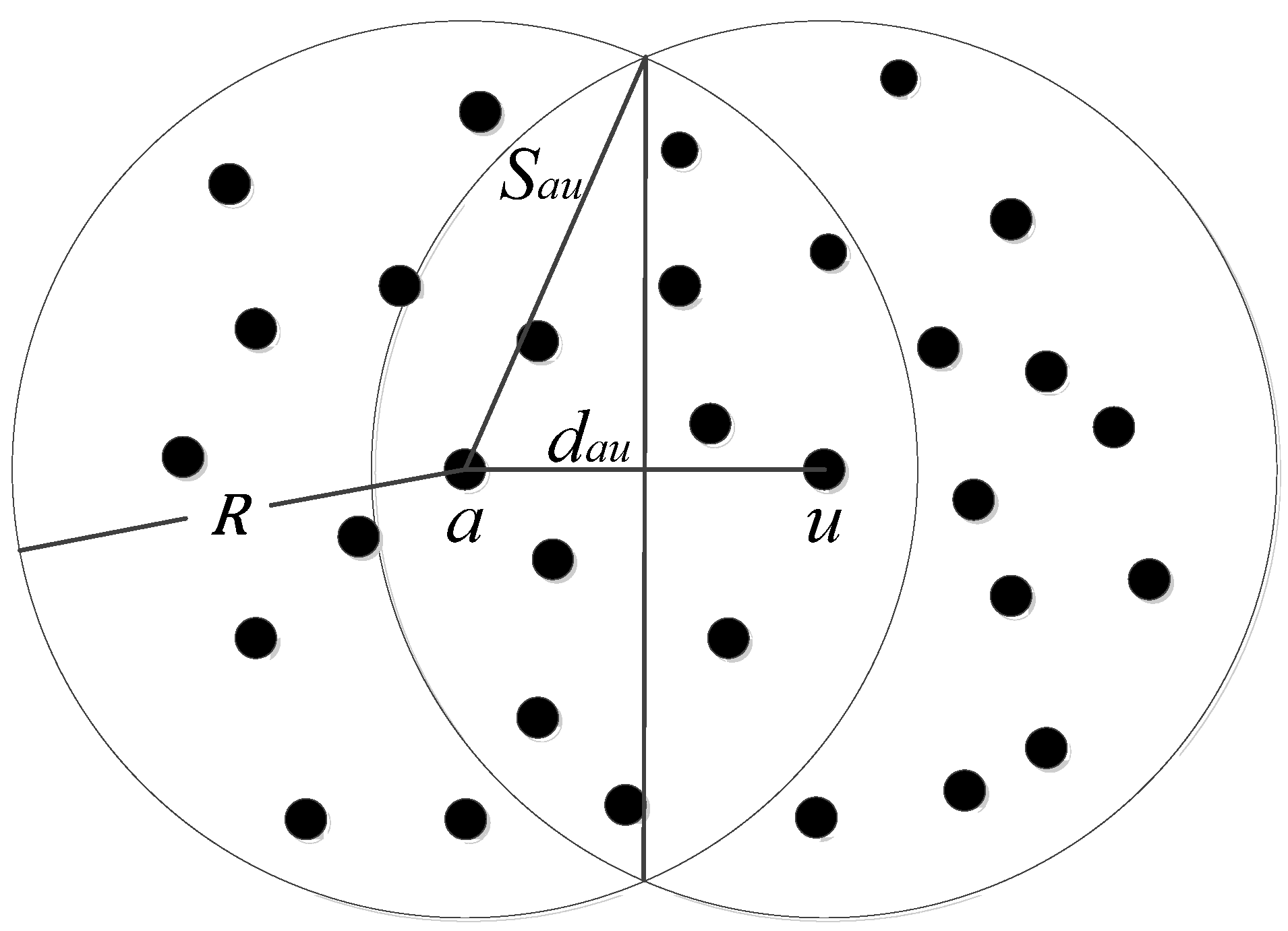
2.1. Calculate the Euclidean Distance of One Hop Based on the Intersection Ratio
2.2. Judge Whether the Multi-Hop Shortest Path between Beacon Nodes Is Affected by Concave Boundary
2.2.1. Judgment Method
- Calculate the distance between beacon nodes and . Divide by the communication radius to obtain the true shortest path intersection ratio between beacon nodes .
- According to Formula (11), figure out the distance of each hop. The distance of each hop on the multi-hop shortest path between beacon nodes is summed to obtain the multi-hop path distance (Multi-Hop Distance), and then divided by the communication radius , Obtain the intersection ratio of the multi-hop shortest path between beacon nodes. If there is:it is determined that the multi-hop shortest path between beacon nodes is not affected by the concave boundary; otherwise, it is affected by the concave boundary.
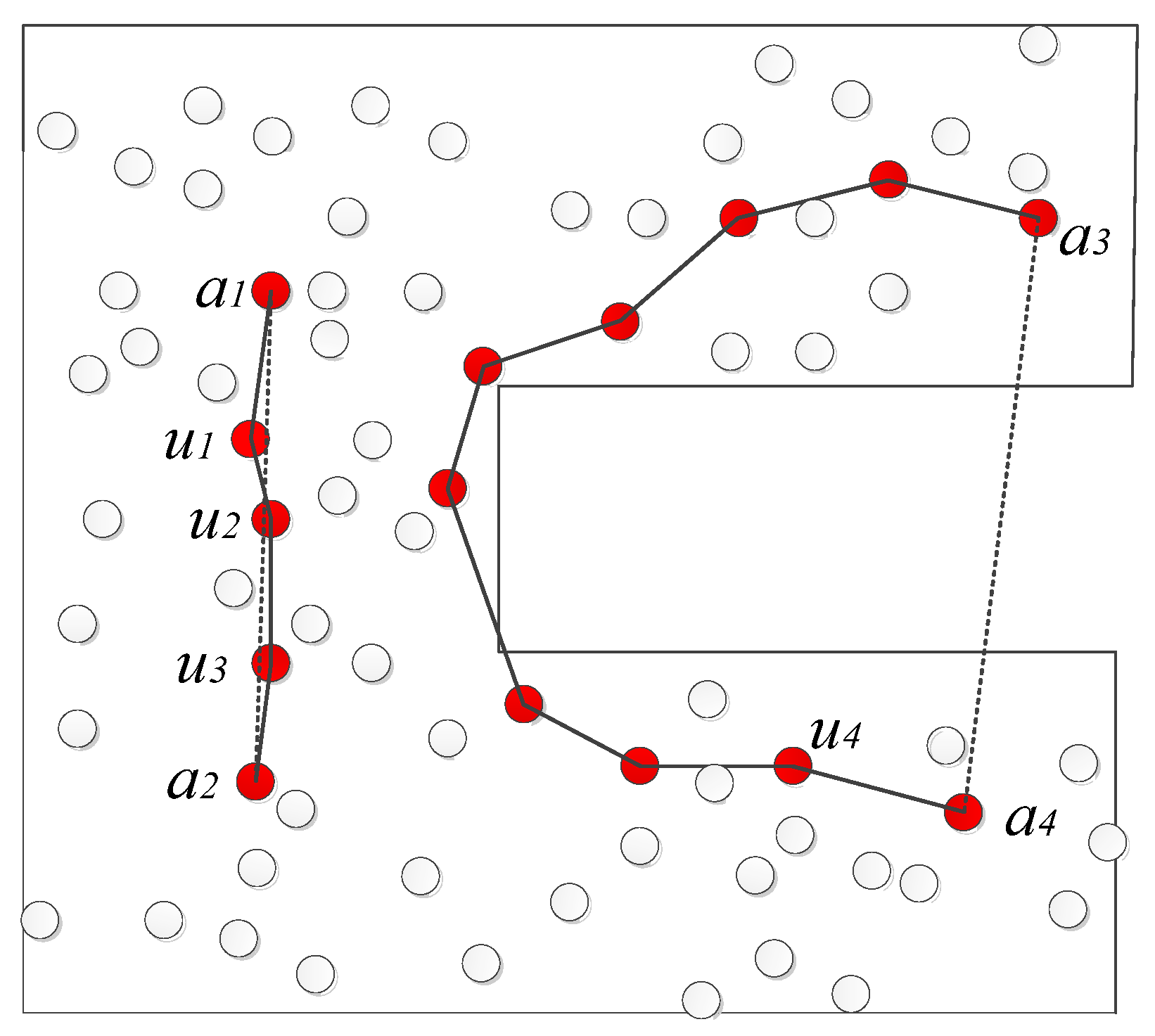
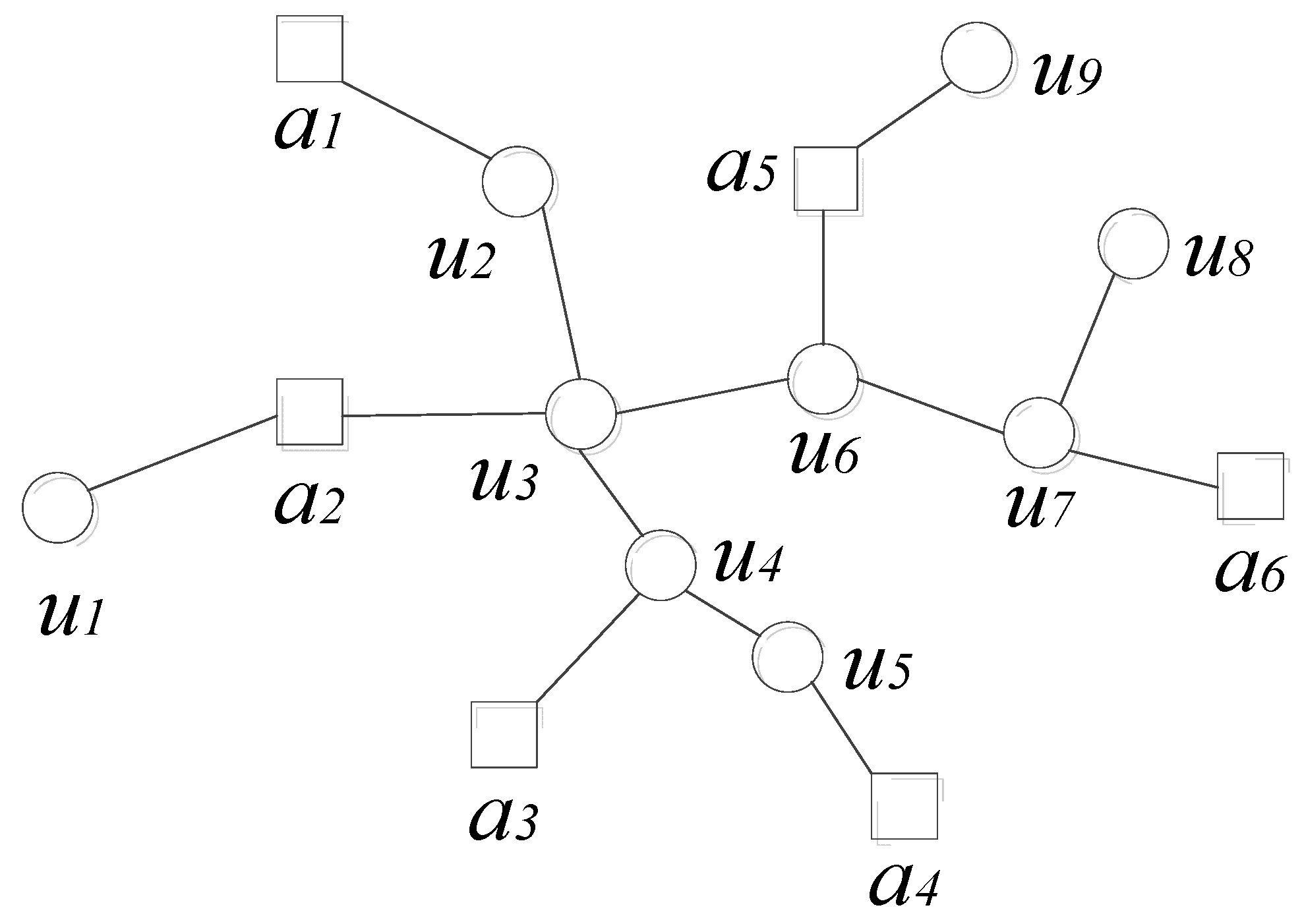
2.2.2. Similar Path Search Algorithm
- Find the multi-hop shortest path of the target unknown node to . Record this sensor nodes passed by the path into set .
- Find the multi-hop shortest paths from the remaining beacon nodes which are in the WSN to node , and record the nodes passed by these paths into the sets .
- Calculate the Ochiai coefficients of and respectively.
- Arrange the Ochiai coefficient values obtained in step 3 in descending order. If the coefficient value corresponding to is the largest, the multi-hop shortest path from to is taken as the most similar path Most Similar Path (MSP) of the target unknown node to .
2.3. Calculate Distance and Estimate Location
2.3.1. Calculate Distance
2.3.2. Location Calculation of Unknown Nodes
3. Improved PSO Algorithm
- Initialize particle population. The difference between the two-stage localization algorithm and other localization algorithms is that the initial position of the particle population is not completely random when locating the unknown node [14], but is limited to a specific circle. The center of the circle is the localization result of node obtained in the first stage. The radius is the maximum value of all non-similar path lengths of the unknown node in the ranging stage. The calculation formula of is:That is, the initial location of the particle population is randomly generated within the circle, assigning the initial speed of all particles to 0, and the maximum iteration to 100.
- Figure out the fitness function value of every particle base on Formula (30).
- Update the and base on the Formulas (32) and (33):
- According to Formulas (27), (28) and (34), the coordinates and speed of each particle are updated. The smaller the ω value, the stronger local search capability. The larger the value of ω, the stronger global search capability. Because the optimization is based on the existing results, the particles need strong local search capability, and there is no requirement for the global search ability of the particles [15]. So it will be designed as a function that gradually decreases as the times of iterations increases. That is, as the times of iterations increases, the local optimization ability of the particles is gradually increased. Lots of experiments have proved that the highest localization accuracy is obtained when and . is the current inertia factor.
- If , the algorithm ends, and the is taken as the final coordinate of the target unknown node. Otherwise, perform step 2.
- Select the next unknown node and operate step 1.
| Algorithm 1 The Improved PSO Algorithm |
| 1: 2: Initial population, 3: , , , 4: for 5: for 6: figure out the value of every particle 7: if 8: 9: else 10: endif 11: if 12: 13: else 14: endif 15: 16: 17: 18: output 19: endfor 20: endfor |
4. Experiment Results and Analysis
4.1. The Impact of Beacon Node Ratio on Localization Results and Execution Time of Algorithm
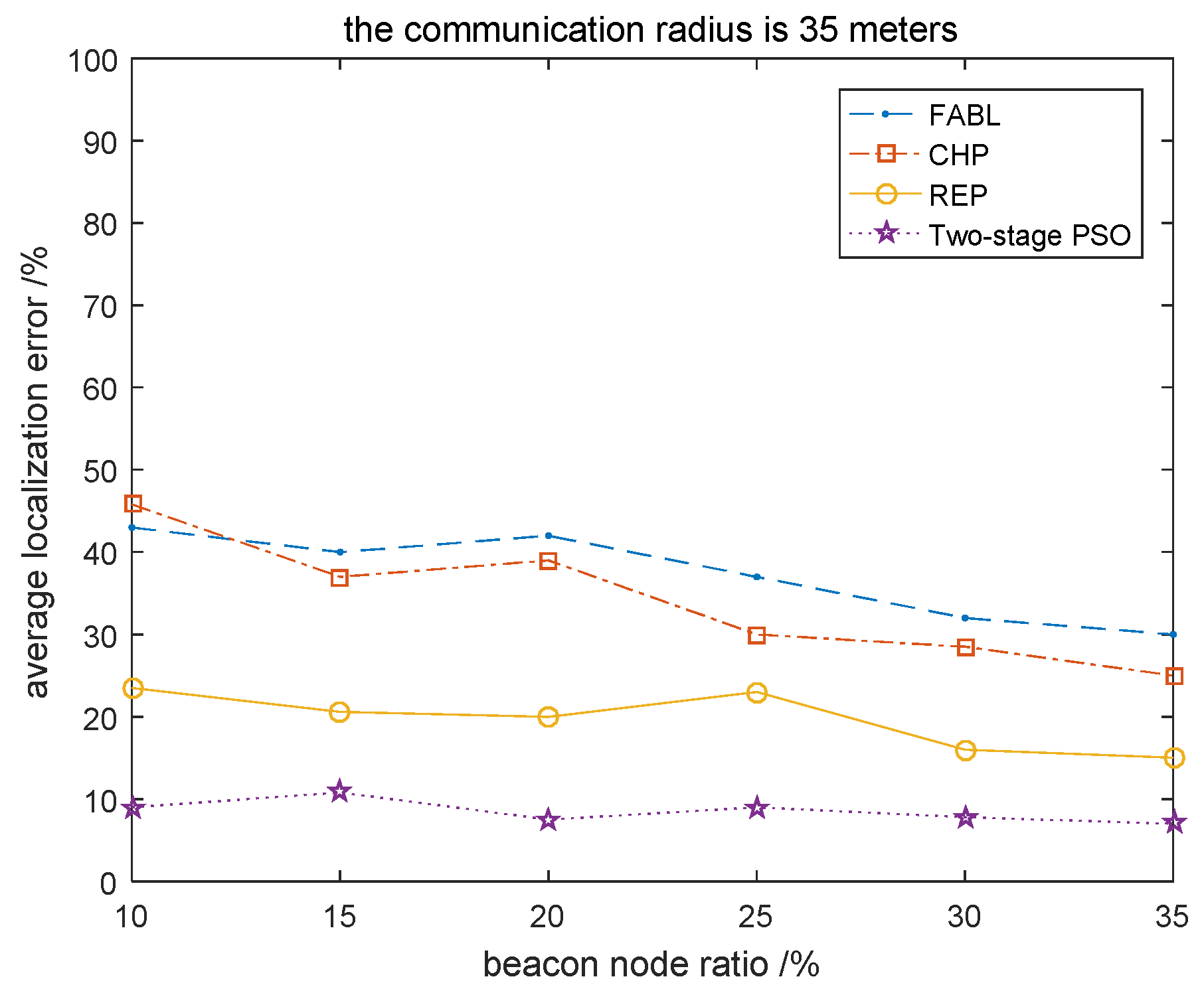
4.1.1. Relationship between Beacon Node Ratio and Localization Results
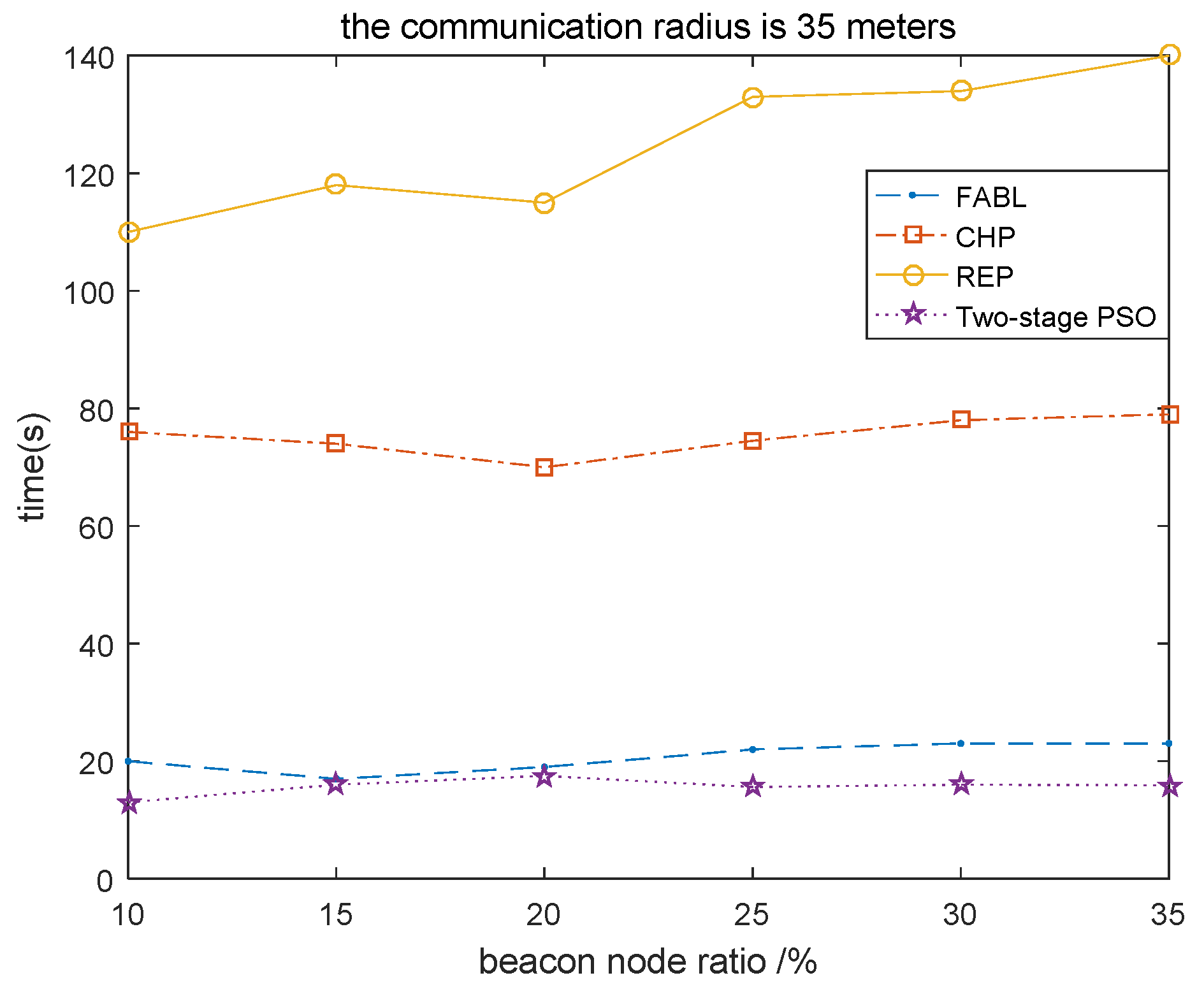
4.1.2. Relationship between Beacon Node Ratio and Execution Time of Algorithm
4.2. The Impact of Node Communication Radius on Localization Results and Execution Time of Algorithm
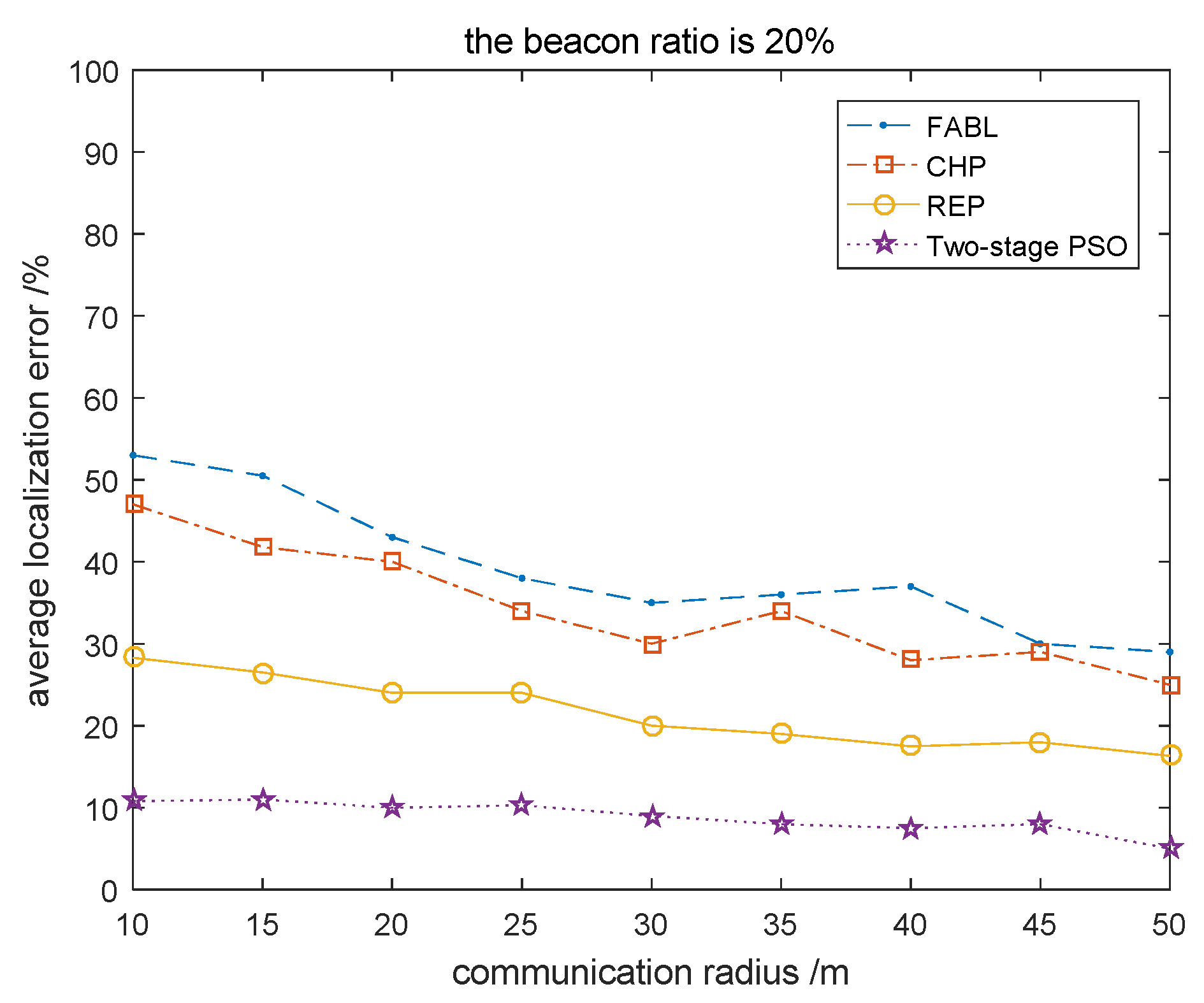
4.2.1. Relationship between Node Communication Radius and Localization Results
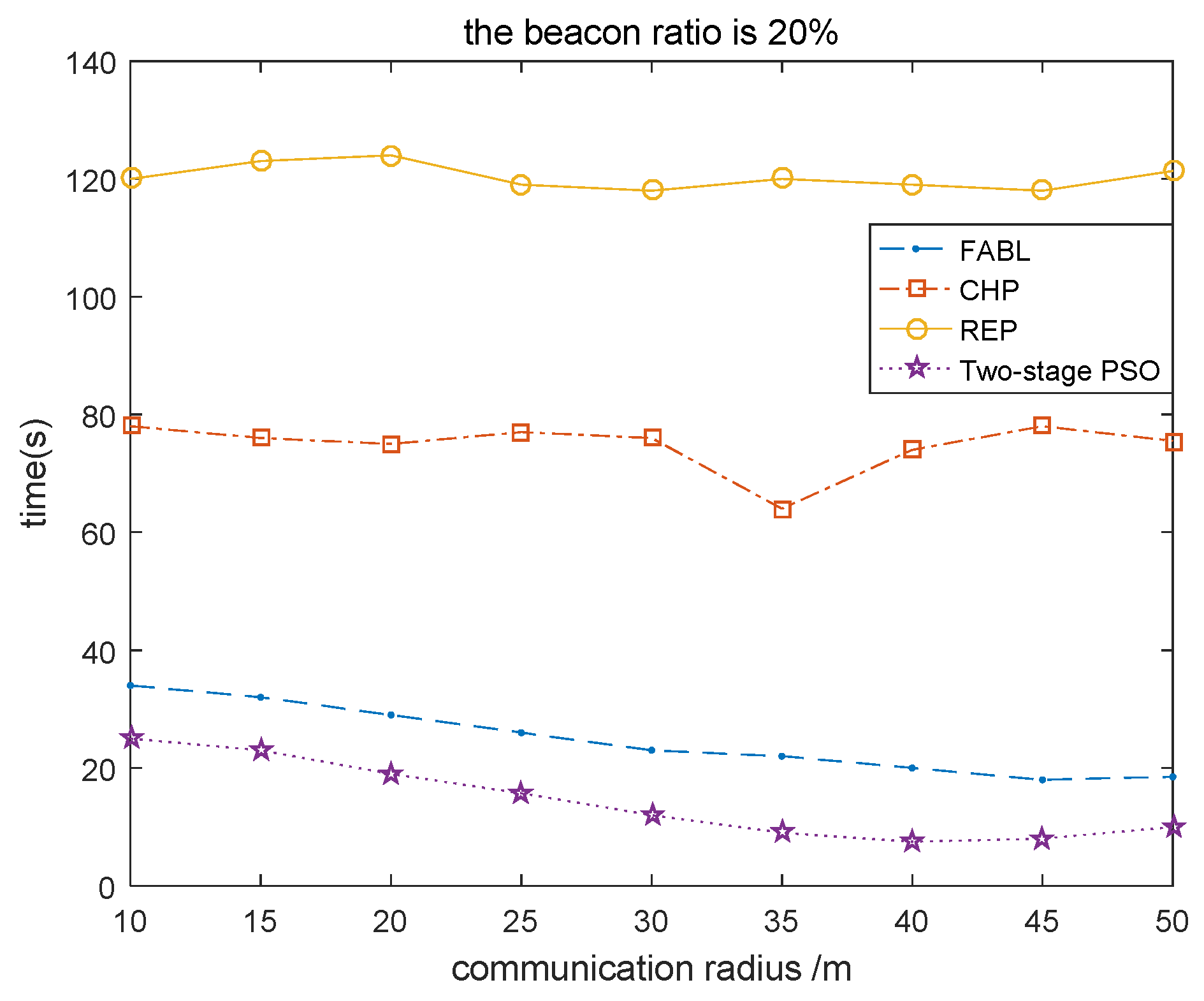
4.2.2. Relationship between Communication Radius and Execution Time of Algorithm
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Asma, M.; Mohammed, F.; Nabila, L. Wireless sensor networks localization algorithms: A comprehensive survey. Int. J. Comput. Netw. Commun. 2013, 5, 45–64. [Google Scholar]
- Li, M.; Liu, Y. Rendered path: Range-free localization in anisotropic sensor networks with holes. In Proceedings of the 13th Annual ACM International Conference on Mobile Computing and Networking, Montreal, QC, Canada, 9–14 September 2007; pp. 51–62. [Google Scholar]
- Lim, H.; Hou, J.C. Distributed localization for anisotropic sensor networks. ACM Trans. Sens. Netw. 2009, 5, 1–26. [Google Scholar] [CrossRef]
- Li, J.; Zhang, J.M.; Liu, X.D. A weighted DV-HOP localization scheme for wireless sensor networks. In Proceedings of the 8th International Conference on Embedded Computing and Communication, Dalian, China, 25–27 September 2009; pp. 269–272. [Google Scholar]
- Anup, K.P.; Li, Y.W.; Takuro, S. Friendly anchor based range free localization (FABL) in anisotropic wireless sensor network. In Proceedings of the 26th European Conference on Solid-State Transducers, Kraków, Poland, 9–12 September 2012. [Google Scholar]
- Bulusu, N.; Heidemann, J.; Estrin, D. GPS-less low-cost outdoor localization for very small devices. IEEE Pers. Commun. 2000, 7, 28–34. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L. Research on DV-Hop algorithm based on quantum particle swarm optimization. Comput. Technol. Dev. 2018, 28, 81–85. [Google Scholar]
- Ahmad, T. Energy EC: An artificial bee colony optimization based energy efficient cluster leader selection for wireless sensor networks. J. Inf. Optim. Sci. 2020, 41, 587–597. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2003, 69, 46–61. [Google Scholar] [CrossRef]
- Lee, W.S.; Kim, N.G. Omnidirectional Distance Estimation using ultrasonic in Wireless Sensor Networks. J. Inst. Internet Broadcast. Commun. 2009, 9, 85–91. [Google Scholar]
- Al-Salti, F.; Alzeidi, N.; Day, K. Localization Schemes for Underwater Wireless Sensor Networks: Survey. Int. J. Comput. Netw. Commun. 2020, 12, 113–130. [Google Scholar] [CrossRef]
- Zhou, Q.; Leydesdorff, L. The Normalization of Occurrence and Co-Occurrence Matrices in Bibliometrics Using Cosine Similarities and Ochiai Coefficients. J. Assoc. Inf. Sci. Technol. 2015, 67, 2805–2814. [Google Scholar] [CrossRef]
- Xue, D. Research on range-free location algorithm for wireless sensor network based on particle swarm optimization. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 1–8. [Google Scholar] [CrossRef]
- Sivasakthiselvan, S.; Nagarajan, V. A new localization technique for node positioning in wireless sensor networks. Clust. Comput. 2018, 22, 4027–4034. [Google Scholar] [CrossRef]
- Prithi, S.; Sumathi, S. LD2FA-PSO: A novel Learning Dynamic Deterministic Finite Automata with PSO algorithm for secured energy efficient routing in Wireless Sensor Network. Ad. Hoc. Netw. 2020, 97, 102024. [Google Scholar] [CrossRef]
- Meng, Y.; Zhi, Q.; Zhang, Q.; Lin, E. A Two-Stage Wireless Sensor Grey Wolf Optimization Node Location Algorithm Based on K-Value Collinearity. Math. Probl. Eng. 2020, 2020, 1–10. [Google Scholar]
- Najib, Y.N.B.A.; Daud, H.; Aziz, A.A. Singular Value Thresholding Algorithm for Wireless Sensor Network Localization. Mathematics 2020, 8, 437. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, Y.; Zhi, Q.; Zhang, Q.; Yao, N. A Two-Stage Particle Swarm Optimization Algorithm for Wireless Sensor Nodes Localization in Concave Regions. Information 2020, 11, 488. https://doi.org/10.3390/info11100488
Meng Y, Zhi Q, Zhang Q, Yao N. A Two-Stage Particle Swarm Optimization Algorithm for Wireless Sensor Nodes Localization in Concave Regions. Information. 2020; 11(10):488. https://doi.org/10.3390/info11100488
Chicago/Turabian StyleMeng, Yinghui, Qianying Zhi, Qiuwen Zhang, and Ni Yao. 2020. "A Two-Stage Particle Swarm Optimization Algorithm for Wireless Sensor Nodes Localization in Concave Regions" Information 11, no. 10: 488. https://doi.org/10.3390/info11100488
APA StyleMeng, Y., Zhi, Q., Zhang, Q., & Yao, N. (2020). A Two-Stage Particle Swarm Optimization Algorithm for Wireless Sensor Nodes Localization in Concave Regions. Information, 11(10), 488. https://doi.org/10.3390/info11100488