Weakly Supervised Learning for Evaluating Road Surface Condition from Wheelchair Driving Data

 ,
,
Abstract
1. Introduction
- •
- This paper proposes a novel method for evaluating road surface conditions via weakly supervised learning that uses wheelchair acceleration data and its positional information as weak supervision.
- •
- The proposed method is evaluated using actual wheelchair driving data. We applied a weak supervision design and visually demonstrate that the proposed method learns subtle and detailed representations of road surface conditions.
- •
- The representations that the proposed method learns were found to be discriminative for a road surface classification task. In a semi-supervised setting, the proposed method outperforms a fully supervised method that uses manually annotated labels to learn representations of road surface conditions.
2. Related Work
3. Methodology
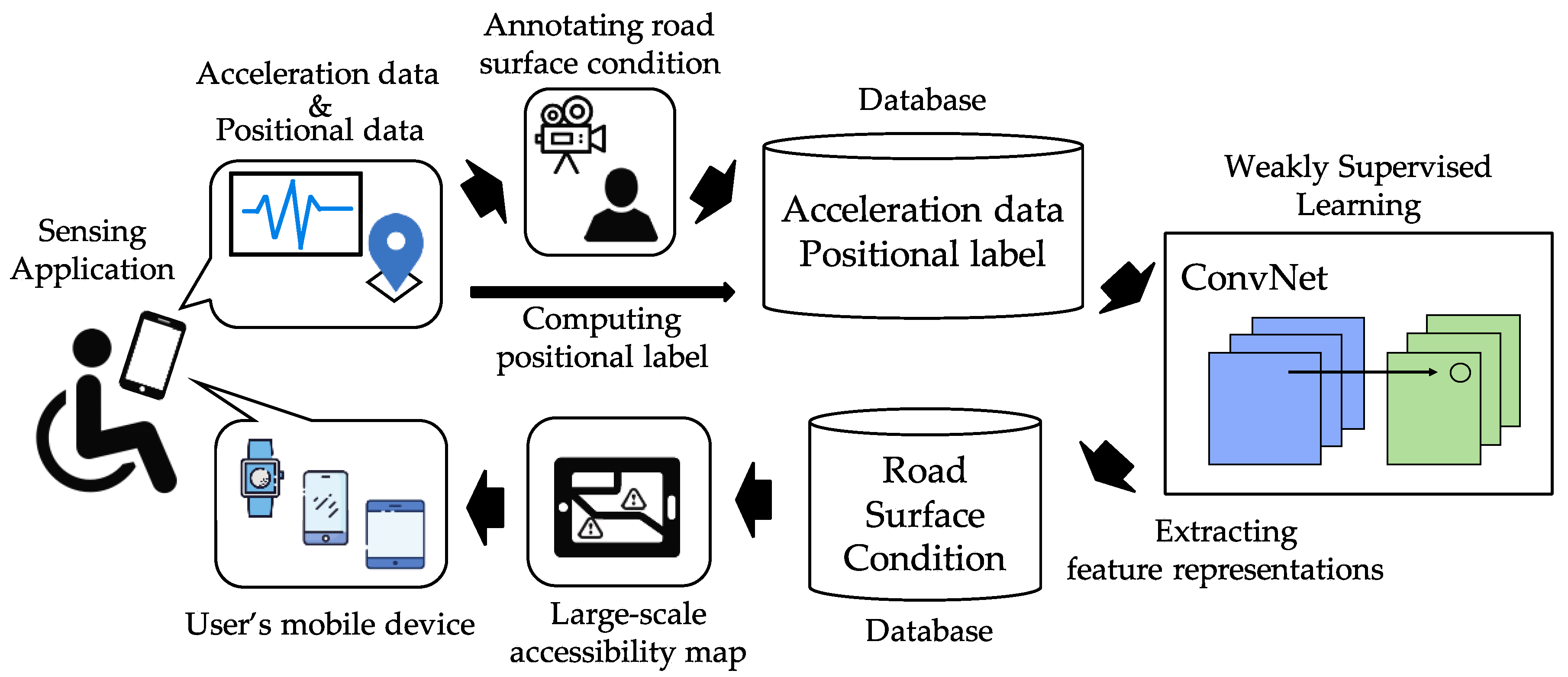
3.1. Proposed System
3.2. Dataset
3.3. Generating Weak Supervision from Positional Information
3.4. Training ConvNet to Predict the Position from Acceleration Data
3.4.1. Preprocessing
3.4.2. The Proposed ConvNet Model
3.4.3. Position Prediction
4. Results
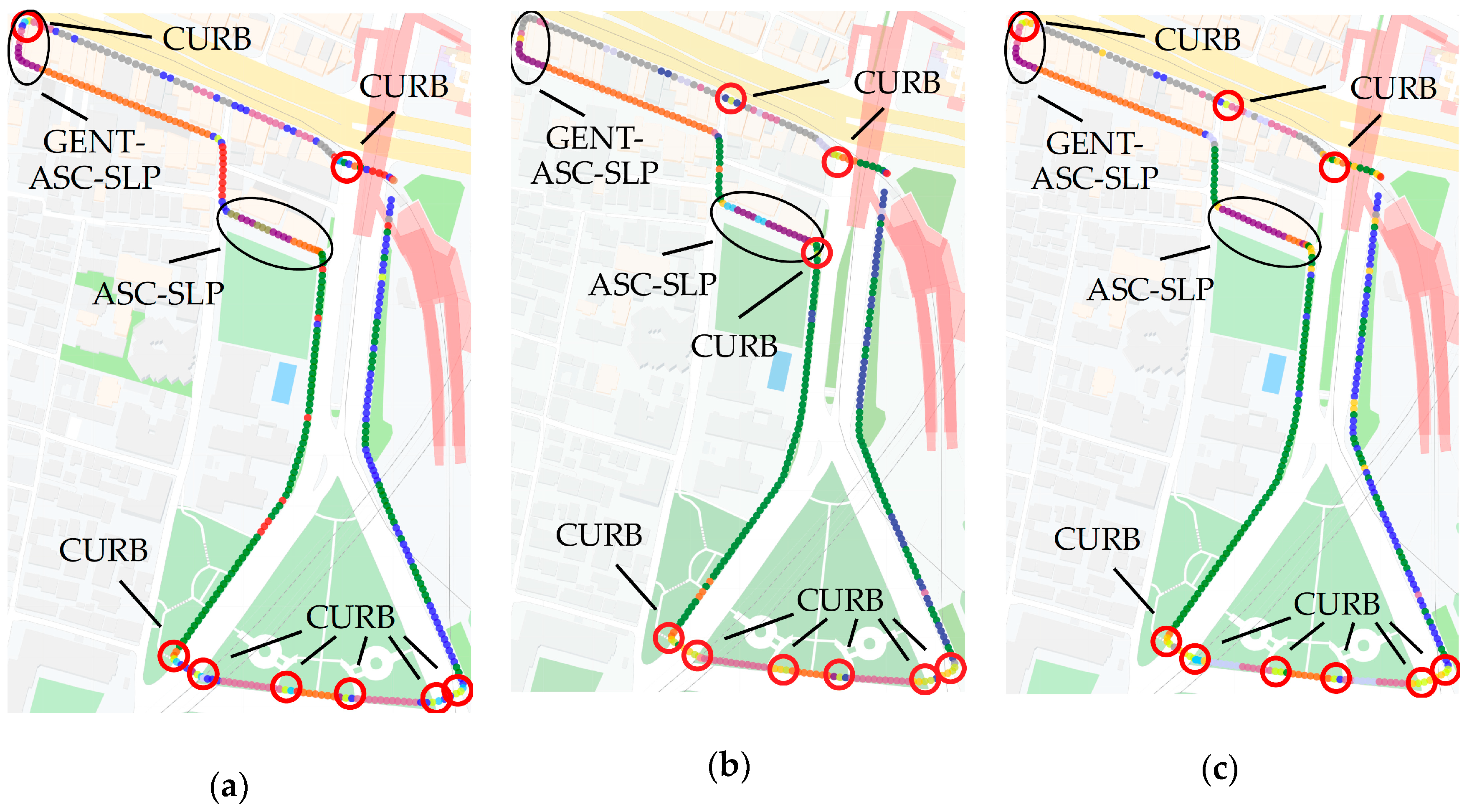
4.1. Qualitative Evaluation of the Learned Representation
4.1.1. Evaluation Procedure
4.1.2. Analysis of Grid Width Condition
4.1.3. Comparison with Fully Supervised Method
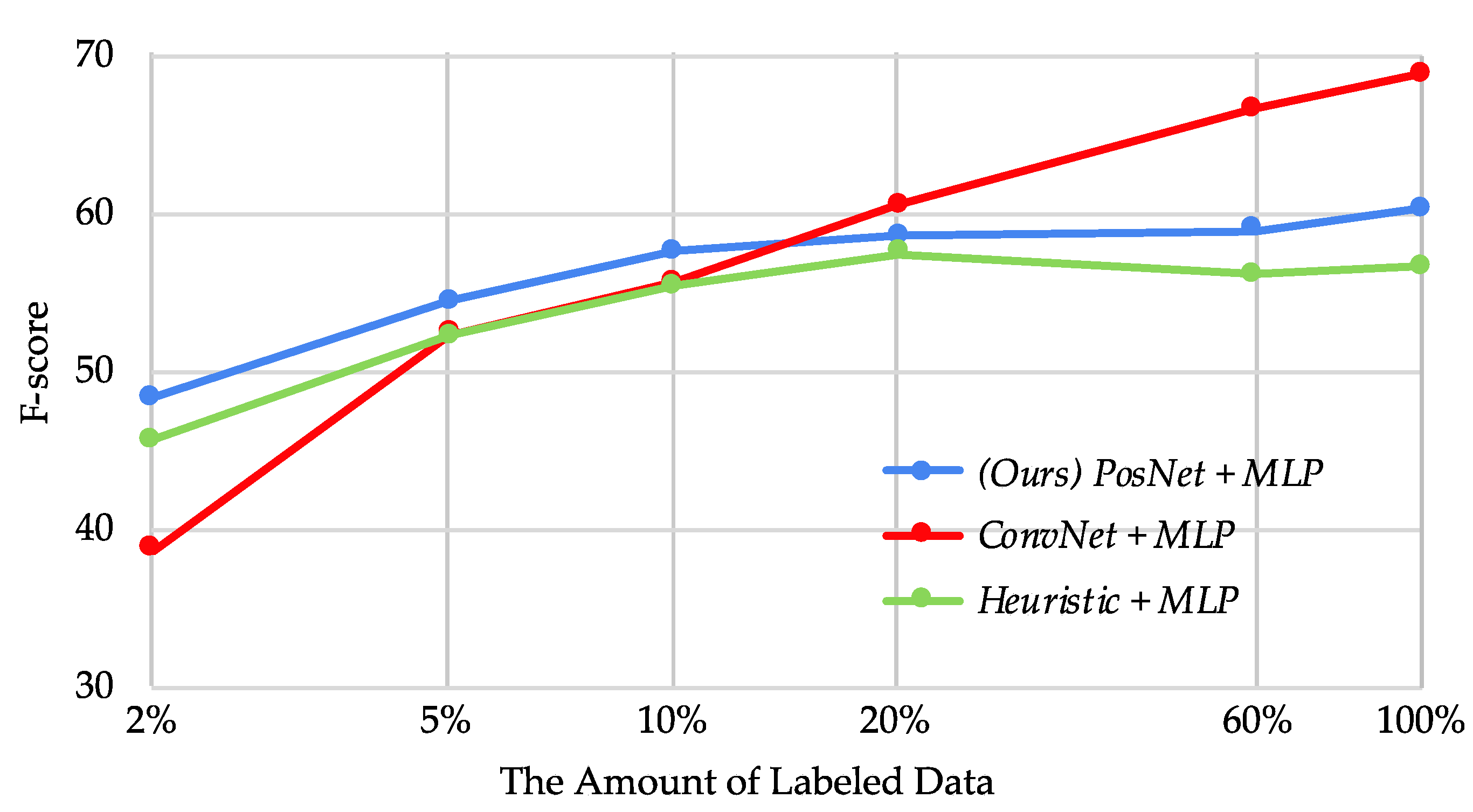
4.2. Quantitative Evaluation of the Learned Representation
4.2.1. Implementation Details
4.2.2. Comparison Result
4.2.3. Semi-Supervised Setting
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A



References
- Laakso, M.; Sarjakoski, T.; Sarjakoski, L.T. Improving accessibility information in pedestrian maps and databases. Cartogr. Int. J. Geogr. Inf. Geovis. 2011, 46, 101–108. [Google Scholar] [CrossRef]
- Matthews, H.; Beale, L.; Picton, P.; Briggs, D. Modelling access with GIS in urban systems (MAGUS): Capturing the experiences of wheelchair users. Area 2003, 35, 34–45. [Google Scholar] [CrossRef]
- Karimi, H.A.; Zhang, L.; Benner, J.G. Personalized accessibility map (PAM): A novel assisted wayfinding approach for people with disabilities. Ann. GIS 2014, 20, 99–108. [Google Scholar] [CrossRef]
- Ponsard, C.; Snoeck, V. Objective accessibility assessment of public infrastructures. In Proceedings of the 10th International Conference on Computers Helping People with Special Needs, Linz, Austria, 11–13 July 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 314–321. [Google Scholar] [CrossRef]
- Hara, K. Scalable methods to collect and visualize sidewalk accessibility data for people with mobility impairments. In Proceedings of the Adjunct Publication of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; ACM: New York, NY, USA, 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Cardonha, C.; Gallo, D.; Avegliano, P.; Herrmann, R.; Koch, F.; Borger, S. A crowdsourcing platform for the construction of accessibility maps. In Proceedings of the 10th International Cross-Disciplinary Conference on Web Accessibility, Rio de Janeiro, Brazil, 13–15 May 2013; ACM: New York, NY, USA, 2013; p. 26. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar] [CrossRef]
- Eriksson, J.; Girod, L.; Hull, B.; Newton, R.; Madden, S.; Balakrishnan, H. The pothole patrol: Using a mobile sensor network for road surface monitoring. In Proceedings of the 6th International Conference on Mobile Systems, Applications, and Services, Breckenridge, CO, USA, 17–20 June 2008; ACM: New York, NY, USA, 2008; pp. 29–39. [Google Scholar] [CrossRef]
- Allouch, A.; Koubâa, A.; Abbes, T.; Ammar, A. Roadsense: Smartphone application to estimate road conditions using accelerometer and gyroscope. IEEE Sens. J. 2017, 17, 4231–4238. [Google Scholar] [CrossRef]
- Swan, M. The quantified self: Fundamental disruption in big data science and biological discovery. Big Data 2013, 1, 85–99. [Google Scholar] [CrossRef]
- Nagamine, K.; Iwasawa, Y.; Matsuo, Y.; Yairi, E.I. An estimation of wheelchair user’s muscle fatigue by accelerometers on smart devices. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2015 ACM International Symposium on Wearable Computers, Osaka, Japan, 7–11 September 2015; ACM: New York, NY, USA, 2015; pp. 57–60. [Google Scholar] [CrossRef]
- Plötz, T.; Hammerla, N.Y.; Olivier, P. Feature learning for activity recognition in ubiquitous computing. In Proceedings of the International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; Volume 22, pp. 1729–1734. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Yairi, E.I.; Takahashi, H.; Watanabe, T.; Nagamine, K.; Fukushima, Y.; Matsuo, Y.; Iwasawa, Y. Estimating Spatiotemporal Information from Behavioral Sensing Data of Wheelchair Users by Machine Learning Technologies. Information 2019, 10, 114. [Google Scholar] [CrossRef]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef]
- Zimmermann-Janschitz, S. Geographic Information Systems in the context of disabilities. J. Access. Des. All 2018, 8, 161–192. [Google Scholar] [CrossRef]
- Yairi, E.I.; Igi, S. Geographic Information System for Pedestrian Navigation with Areas and Routes Accessibility. J. Inf. Process. 2005, 46, 2940–2951. (In Japanese) [Google Scholar]
- Development Specification for Spatial Network Model for Pedestrians. Available online: http://www.mlit.go.jp/common/001244374.pdf (accessed on 3 November 2019). (In Japanese).
- Yairi, E.I.; Nara, H.; Igi, S. The GIS for improving accessibility of routes and areas, and its practical use by community of residents. Trans. Hum. Interface Soc. 2005, 7, 463–475. (In Japanese) [Google Scholar]
- Yairi, E.I.; Igi, S. Research on Ubiquitous System for Mobility Support of the Elderly and Disabled and Its Technology Transfer to Industry. J. Inf. Process. 2007, 48, 770–779. (In Japanese) [Google Scholar]
- Koga, M.; Izumi, S.; Matsubara, S.; Morishita, K.; Yoshioka, D. Development and verification of navigation system to support wheelchair user activity in urban areas. IADIS Int. J. WWW/Internet 2015, 13, 43–56. [Google Scholar]
- Kuo, T.S.; Tseng, K.S.; Yan, J.W.; Liu, Y.C.; Frank Wang, Y.C. Deep aggregation net for land cover classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 252–256. [Google Scholar] [CrossRef]
- Rakhlin, A.; Davydow, A.; Nikolenko, S. Land Cover Classification from Satellite Imagery with U-Net and Lovász-Softmax Loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 262–266. [Google Scholar] [CrossRef]
- Mohan, P.; Padmanabhan, V.N.; Ramjee, R. Nericell: Rich monitoring of road and traffic conditions using mobile smartphones. In Proceedings of the 6th ACM International Conference on Embedded Networked Sensor Systems, Raleigh, NC, USA, 5–7 November 2008; ACM: New York, NY, USA, 2008; pp. 323–336. [Google Scholar] [CrossRef]
- Yu, J.; Zhu, H.; Han, H.; Chen, Y.J.; Yang, J.; Zhu, Y.; Chen, Z.; Xue, G.; Li, M. Senspeed: Sensing driving conditions to estimate vehicle speed in urban environments. IEEE Trans. Mob. Comput. 2016, 15, 202–216. [Google Scholar] [CrossRef]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional neural networks for human activity recognition using mobile sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar] [CrossRef]
- Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI), Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; ACM: New York, NY, USA, 2015; pp. 1307–1310. [Google Scholar] [CrossRef]
- Rad, N.M.; Furlanello, C. Applying deep learning to stereotypical motor movement detection in autism spectrum disorders. In Proceedings of the IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 1235–1242. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.C.; Vincent, P. Unsupervised feature learning and deep learning: A review and new perspectives. arXiv 2012, arXiv:1206.5538. [Google Scholar]
- Längkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Is object localization for free?-weakly-supervised learning with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 685–694. [Google Scholar] [CrossRef]
- Agrawal, P.; Carreira, J.; Malik, J. Learning to see by moving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 37–45. [Google Scholar] [CrossRef]
- Owens, A.; Wu, J.; McDermott, J.H.; Freeman, W.T.; Torralba, A. Ambient sound provides supervision for visual learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 801–816. [Google Scholar] [CrossRef]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised Representation Learning by Predicting Image Rotations. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- You, Z.; Raich, R.; Fern, X.Z.; Kim, J. Weakly Supervised Dictionary Learning. IEEE Trans. Signal Process. 2018, 66, 2527–2541. [Google Scholar] [CrossRef]
- Zhang, A.; Cebulla, A.; Panev, S.; Hodgins, J.; Torre, F.D.L. Weakly-supervised Learning for Parkinson’s Disease Tremor Detection. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Seogwipo, Korea, 11–15 July 2017; pp. 143–147. [Google Scholar] [CrossRef]
- Logeswaran, L.; Lee, H. An efficient framework for learning sentence representations. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Dau, H.A.; Begum, N.; Keogh, E. Semi-supervision dramatically improves time series clustering under dynamic time warping. In Proceedings of the 25th ACM International Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; ACM: New York, NY, USA, 2016; pp. 999–1008. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Liu, H.; Taniguchi, T.; Tanaka, Y.; Takenaka, K.; Bando, T. Visualization of driving behavior based on hidden feature extraction by using deep learning. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2477–2489. [Google Scholar] [CrossRef]
- Fukushima, Y.; Uematsu, H.; Mitsuhashi, R.; Suzuki, H.; Yairi, E.I. Sensing human movement of mobility and visually impaired people. In Proceedings of the 13th International ACM SIGACCESS Conference on Computers and Accessibility, Dundee, Scotland, UK, 24–26 October 2011; ACM: New York, NY, USA, 2011; pp. 279–280. [Google Scholar] [CrossRef]
- Nagamine, K.; Iwasawa, Y.; Yutaka, M.; Yairi, E.I. Physical Strain Evaluation of Manual Wheelchair Driving by Accelerometer. IEICE Trans. Inf. Syst. 2017, J100-D, 773–782. (In Japanese) [Google Scholar] [CrossRef]
- Iwasawa, Y.; Yairi, E.I. Life-logging of wheelchair driving on web maps for visualizing potential accidents and incidents. In Proceedings of the 12th Pacific Rim International Conference on Artificial Intelligence, Kuching, Malaysia, 3–7 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 157–169. [Google Scholar] [CrossRef]
- Iwasawa, Y.; Nagamine, K.; Yutaka, M.; Yairi, E.I. Road sensing: Personal sensing and machine learning for development of large scale accessibility map. In Proceedings of the 17th International ACM SIGACCESS Conference on Computers & Accessibility, Lisbon, Portugal, 26–28 October 2015; ACM: New York, NY, USA, 2015; pp. 335–336. [Google Scholar] [CrossRef]
- Iwasawa, Y.; Yairi, I.E.; Matsuo, Y. Combining human action sensing of wheelchair users and machine learning for autonomous accessibility data collection. IEICE Trans. Inf. Syst. 2016, E99-D, 115–124. [Google Scholar] [CrossRef]
- Takahashi, H.; Nagamine, K.; Iwasawa, Y.; Yutaka, M.; Yairi, E.I. Quantification of Road Condition from Wheelchair Sensing Data Using Deep Convolutional Neural Network. IEICE Trans. Inf. Syst. 2018, J101-D, 1009–1021. (In Japanese) [Google Scholar] [CrossRef]
- Takahashi, H.; Iwasawa, Y.; Nagamine, K.; Yairi, E.I. Study on data labeling method using GPS for DCNN learning to extract road surface characteristics from wheelchair sensing data. In Proceedings of the 32nd Annual Conference of the Japanese Society for Artificial Intelligence, Kagoshima, Japan, 5–8 June 2018; pp. 2502–2505. (In Japanese). [Google Scholar]
- Mora, H.; Gilart-Iglesias, V.; Pérez-del Hoyo, R.; Andújar-Montoya, M.D. A Comprehensive System for Monitoring Urban Accessibility in Smart Cities. Sensors 2017, 17, 1834. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Jones, G.R. Human friendly coordinates. GeoInformatics 2015, 18, 10–12. [Google Scholar]
- Ministry of Land, Infrastructure, Transport and Tourism, Commentary of Each Rule of Road Structure Ordinance. Available online: http://www.mlit.go.jp/road/sign/kouzourei_kaisetsu.html (accessed on 3 November 2019). (In Japanese).
- Bersch, S.D.; Azzi, D.; Khusainov, R.; Achumba, I.E.; Ries, J. Sensor Data Acquisition and Processing Parameters for Human Activity Classification. Sensors 2014, 14, 4239–4270. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Esterman, M.; Tamber-Rosenau, B.J.; Chiu, Y.C.; Yantis, S. Avoiding non-independence in fMRI data analysis: Leave one subject out. Neuroimage 2010, 50, 572–576. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1094–1096. [Google Scholar]
- Cao, H.; Nguyen, M.N.; Phua, C.; Krishnaswamy, S.; Li, X. An integrated framework for human activity classification. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; ACM: New York, NY, USA, 2012; pp. 331–340. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grid Width (m) | 3 | 4 | 5 |
|---|---|---|---|
| Number of classes | 581 | 403 | 310 |
| Color Title | Blue | Green | Light Blue | Light Green | Purple | Grey | Light Purple | Yellow-Green | Orange |
|---|---|---|---|---|---|---|---|---|---|
| Color code | #3333FF | #339933 | #66CCFF | #66FF33 | #993399 | #999999 | #CC6699 | #DDFF00 | #FF6700 |
| Method | F-score | Accuracy (%) | F-score | Accuracy (%) |
|---|---|---|---|---|
| Without Smoothing | With Smoothing | |||
| Raw + k-NN | 28.2 | 75.5 | 26.4 | 74.9 |
| MV + k-NN | 45.0 | 69.9 | 45.6 | 73.2 |
| Heuristic + SVM | 51.9 | 80.3 | 51.8 | 80.7 |
| Heuristic + MLP | 56.5 | 78.2 | 56.3 | 78.9 |
| (Ours) PosNet + SVM | 57.7 | 80.4 | 59.8 | 82.1 |
| (Ours) PosNet + MLP | 60.2 | 80.4 | 61.2 | 82.4 |
| ConvNet + SVM | 62.6 | 82.5 | 67.4 | 85.2 |
| ConvNet + MLP | 68.7 | 84.7 | 71.3 | 86.4 |
| Method | Per-Class F-Score | Per-Class Precision (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Slope | Curb | TI | Oths | Slope | Curb | TI | Oths | |
| Raw + k-NN | 15.8 | 7.93 | 3.10 | 86.1 | 31.2 | 59.8 | 14.2 | 76.2 |
| MV + k-NN | 35.8 | 42.9 | 18.8 | 82.5 | 40.9 | 42.5 | 18.8 | 82.9 |
| Heuristic + SVM | 19.6 | 63.2 | 35.8 | 89.1 | 49.1 | 70.2 | 46.9 | 85.1 |
| Heuristic + MLP | 26.7 | 65.6 | 46.4 | 87.3 | 43.3 | 66.6 | 48.9 | 88.7 |
| (Ours) PosNet + SVM | 41.2 | 68.5 | 32.5 | 88.7 | 59.0 | 73.6 | 44.0 | 84.9 |
| (Ours) PosNet + MLP | 49.6 | 67.9 | 34.1 | 88.9 | 52.4 | 71.6 | 38.9 | 87.2 |
| ConvNet + SVM | 43.6 | 71.3 | 44.4 | 90.8 | 61.4 | 65.2 | 49.1 | 90.4 |
| ConvNet + MLP | 51.1 | 77.8 | 54.2 | 91.6 | 55.5 | 78.1 | 58.0 | 90.9 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Watanabe, T.; Takahashi, H.; Iwasawa, Y.; Matsuo, Y.; Eguchi Yairi, I. Weakly Supervised Learning for Evaluating Road Surface Condition from Wheelchair Driving Data. Information 2020, 11, 2. https://doi.org/10.3390/info11010002
Watanabe T, Takahashi H, Iwasawa Y, Matsuo Y, Eguchi Yairi I. Weakly Supervised Learning for Evaluating Road Surface Condition from Wheelchair Driving Data. Information. 2020; 11(1):2. https://doi.org/10.3390/info11010002
Chicago/Turabian StyleWatanabe, Takumi, Hiroki Takahashi, Yusuke Iwasawa, Yutaka Matsuo, and Ikuko Eguchi Yairi. 2020. "Weakly Supervised Learning for Evaluating Road Surface Condition from Wheelchair Driving Data" Information 11, no. 1: 2. https://doi.org/10.3390/info11010002
APA StyleWatanabe, T., Takahashi, H., Iwasawa, Y., Matsuo, Y., & Eguchi Yairi, I. (2020). Weakly Supervised Learning for Evaluating Road Surface Condition from Wheelchair Driving Data. Information, 11(1), 2. https://doi.org/10.3390/info11010002