2. Background
Honest researchers and field workers can affirm that, despite careful design, meticulous planning, and continuous monitoring of execution, data collection does not always happen the way it should. No matter how carefully one goes about it, there always seems to be errors of one kind or another in the collected data [
15,
16,
17]. Unforeseen challenges or delays in data collection could be due to issues related to the means of collection (e.g., telephone lines are out of order on the day that collection was planned to start), logistics (e.g., the bus that was supposed to bring volunteers to a suitable location broke down on the way), the attitude or literacy levels of potential participants, and so forth. The NCHLT speech project was no exception in this regard, and despite the fact that the project was successfully executed, not everything went exactly as planned.
During the project speech, data was collected using a smartphone application [
11]. The initial version of the app used a prompt counter to select a unique subset of prompts for each recording session. However, this value was stored in memory and was sometimes accidentally reset as fieldworkers cleared recording devices. This resulted in some subsets of the data being recorded multiple times while other subsets were never selected. The app was subsequently updated to support random selection of prompts from the larger vocabulary, and additional, more diverse data was collected in some languages. To meet the project specifications, the majority of the repeated prompts were excluded from the subset of the data that was released as the NCHLT Speech corpus.
It is often said that “there is no data like more data”, and given the modeling capabilities of some recent acoustic modeling techniques, the question arose whether the data that was excluded from the official NCHLT corpus could be used to improve modeling accuracy. In this paper, we therefore investigate the potential of the additional or auxiliary data to improve acoustic models of the languages involved, given current best practices.
While the results of many studies seem to confirm that “there really is no data like more data”, the “garbage in, garbage out” principle also holds: using poor quality data will result in poor models, no matter how much of it is available. Poor models will ultimately yield poor results. One of the aims of our investigation was thus to quantify, to some extent, the quality of the utterances in the auxiliary datasets and to exclude potential “garbage” from the pool of additional data.
Basic verification steps were included in the NCHLT data collection protocol to identify corrupt and/or empty files. In the current study, we also used forced alignment to identify recordings that did not match their prompts. A phone string corresponding to the expected pronunciation of each prompt was generated, and if a forced alignment between the phone string and the actual acoustics failed, the utterance was not included in the auxiliary data. For the remaining prompts, we used a phone-based dynamic programming (PDP) scoring technique [
18,
19] to quantify the degree of acoustic match between the expected and produced pronunciations of each prompt and to rank them accordingly. Consequently, transcription errors or bad acoustic recording conditions could be filtered out based on an utterance level measure.
Baseline automatic speech recognition (ASR) results for both the Hidden Markov Model Toolkit (HTK) [
20] and Kaldi [
21] toolkits were published when the NCHLT Speech corpus was released. The Kaldi implementation of Subspace Gaussian Mixture Models (SGMMs) yielded the best results [
4]. Subsequent experiments using one of the languages (Xho) showed that substantial gains can be achieved over the initial baseline if the acoustic models are implemented using deep neural networks (DNNs) [
22]. Similar observations were made for the Lwazi telephone corpus [
23] and DNNs optimized using sequence-discriminative training within a state-level minimum Bayes risk criterion. However, according to recent studies, time delay neural networks (TDNN) [
24,
25] and long short-term memory (LSTM) acoustic models outperform DNN-based models [
26].
A model architecture that combines TDNNs and bi-directional LSTMs (BLSTMs) yielded the best results in a preliminary study on the auxiliary NCHLT data [
19]. BLSTMs process input data in both time directions using two separate hidden layers. In this manner, they preserve both past and future context information [
27]. The interleaving of temporal convolution and BLSTM layers has been shown to model future temporal context effectively [
28]. When BLSTMs are trained on limited datasets, configurations with more layers (as many as five) outperform similar systems with fewer layers (three or less). Larger training sets (approaching 100 h of data) obtain even better performance using six layers [
29].
Ongoing research aims to incorporate deeper TDNNs since it is known that more layers have significantly improved the performance of image recognition tasks [
30]. However, the gate mechanism in LSTMs still seems to have utility to selectively train TDNNs by emphasizing the more important input dimensions for a particular piece of audio [
31]. In this paper, we report results obtained using TDNN-F acoustic models, which have recently been demonstrated to be effective in resource-constrained scenarios [
32]. Apart from reducing the number of parameters (and connections) of a single layer, the singular-value decomposition operation also proves effective with deeper network architectures. In particular, it has been found that tuning the TDNN-F networks resulted in networks with as many as 11 layers [
32]. The best Kaldi Librispeech chain model example recipe used in this study contained as many as 17 layers (
Section 4.1).
The next section of the paper describes the NCHLT data, as well as the extent of repetition in the auxiliary datasets. Subsequent sections introduce the techniques that were used to quantify the quality of the auxiliary recordings and present TDNN-F results for all 11 languages. The paper also includes experiments that were conducted to determine whether the acoustic models benefited from the inclusion of the auxiliary data in the training set. The recognition performance of models trained on different training sets was measured on out-of-domain datasets.
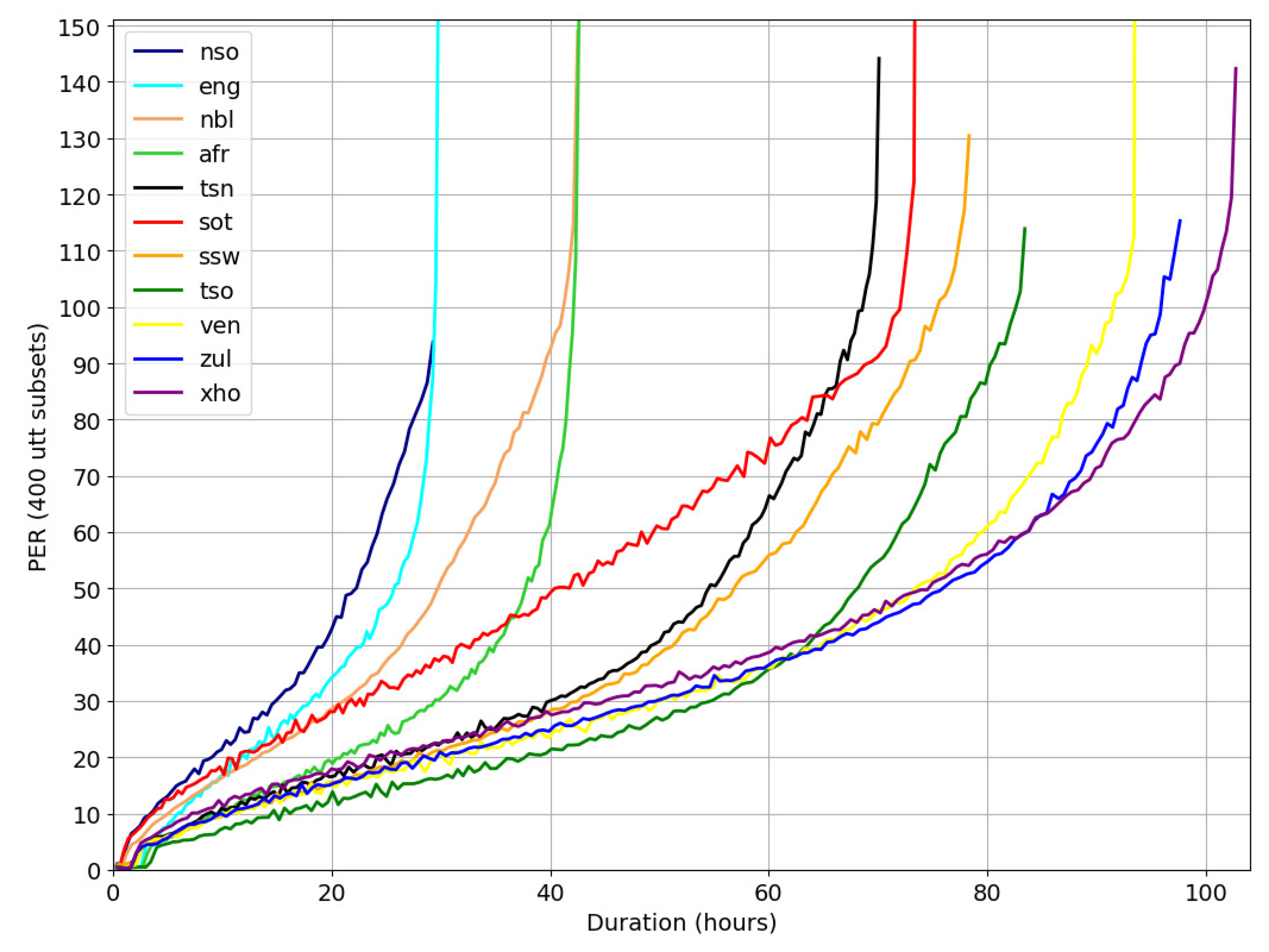
4. Experiments
This section presents ASR results obtained using the
NCHLT-clean training data, as well as extended training sets that include auxiliary data. The development and test sets described in
Section 3 were used throughout. Experiments were also conducted using cross-corpus validation data so that more general conclusions could be drawn from the results. The validation data was created during the Resources for Closely Related Languages (RCRL) project [
35] and comprises 330 Afr news bulletins that were broadcast between 2001 and 2004 on the local Radio Sonder Grense (RSG) radio station. The bulletins were purchased from the South African Broadcasting Corporation (SABC) and transcribed to create a corpus of around 27 h of speech data. For the experiments in this study, we used a previously-selected
h evaluation set containing 28 speakers (To obtain the phone sequences from the RSG orthography, we implemented the same procedure as for the NCHLT Afr system. After text pre-processing, G2P rules were applied to generate pronunciations for new words.).
Two acoustic modeling recipes were followed to build all acoustic models.
Section 4.1 describes the experimental setup. Since the focus of the current work was primarily on acoustic modeling, recognition performance was quantified in terms of phone recognition results (
Section 4.2) in all experiments. In principle, improved phone recognition should translate to better word recognition results for a well-defined transcription task. Word recognition experiments were not included, because of the very limited amount of text corpora available for most of the NCHLT languages. After establishing a new baseline (
Section 4.3), further data augmentation work using both
Aux1 and
Aux2 data was carried out. The selection criteria for auxiliary datasets (
Section 4.4 and
Section 4.5) allowed us to test the utility of the additional data with current acoustic modeling techniques. This section ends with cross-corpus validation experiments for a specific set of models
Section 4.6.
Author Contributions
The individual contributions of the authors were as follows: conceptualisation, F.d.W. and J.B.; data curation, J.B.; formal analysis, J.B. and F.d.W.; funding acquisition, F.d.W.; investigation, J.B.; methodology, J.B. and F.d.W.; project administration, J.B. and F.d.W.; resources, F.d.W.; software, J.B.; supervision, F.d.W.; validation, F.d.W.; visualisation, F.d.W. and J.B.; writing-original, F.d.W. and J.B.; writing-review and editing, F.d.W. and J.B.
Funding
This research was funded by the South African Centre for Digital Language Resources (SADiLaR,
https://www.sadilar.org/).
Acknowledgments
The authors are indebted to Andrew Gill of the Centre for High Performance Computing for providing technical support.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; nor in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| Afr | Afrikaans |
| AST | African Speech Technology |
| ASR | Automatic speech recognition |
| Aux | auxiliary |
| BLSTM | bi-directional LSTM |
| DAC | Departments of Arts and Culture |
| DACST | Department of Arts Culture Science and Technology |
| DNN | deep neural network |
| DST | Department of Science and Technology |
| Eng | English |
| G2P | grapheme-to-phoneme |
| HTK | Hidden Markov Model Toolkit |
| LDC | linear discriminant analysis |
| LSTM | long short-term memory |
| MLLT | maximum likelihood linear transform |
| Nbl | isiNdebele |
| NCHLT | National Centre for Human Language Technology |
| Nso | Sepedi |
| PDP | phone-based dynamic programming |
| PER | phone error rate |
| SABC | South African Broadcasting Corporation |
| RCRL | Resources for Closely Related Languages |
| RSG | Radio Sonder Grense |
| SADiLaR | South African Centre for Digital Language Resources |
| SAMPA | Speech Assessment Methods Phonetic Alphabet |
| SAT | speaker adaptive training |
| SGMM | subspace Gaussian mixture models |
| Sot | Sesotho |
| Ssw | Siswati |
| TDNN | time delay neural networks |
| TDNN-F | factorized time delay neural networks |
| Tsn | Setswana |
| Tso | Xitsonga |
| Ven | Tshivenda |
| WER | word error rate |
| WSJ | Wall Street Journal |
| Xho | isiXhosa |
| Zul | isiZulu |
References
- Roux, J.C.; Louw, P.H.; Niesler, T. The African Speech Technology Project: An Assessment. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC’04), Lisbon, Portugal, 1 January 2004; pp. 93–96. [Google Scholar]
- Badenhorst, J.; Heerden, C.V.; Davel, M.; Barnard, E. Collecting and evaluating speech recognition corpora for 11 South African languages. Lang. Resour. Eval. 2011, 3, 289–309. [Google Scholar] [CrossRef]
- Calteaux, K.; de Wet, F.; Moors, C.; van Niekerk, D.; McAlister, B.; Sharma-Grover, A.; Reid, T.; Davel, M.; Barnard, E.; van Heerden, C. Lwazi II Final Report: Increasing the Impact of Speech Technologies in South Africa; Technical Report; CSIR: Pretoria, South Africa, 2013. [Google Scholar]
- Barnard, E.; Davel, M.H.; van Heerden, C.; de Wet, F.; Badenhorst, J. The NCHLT speech corpus of the South African languages. In Proceedings of the 4th Workshop on Spoken Language Technologies for Under-Resourced Languages, St. Petersburg, Russia, 14–16 May 2014; pp. 194–200. [Google Scholar]
- De Wet, F.; Badenhorst, J.; Modipa, T. Developing speech resources from parliamentary data for South African English. Procedia Comput. Sci. 2016, 81, 45–52. [Google Scholar] [CrossRef][Green Version]
- Eiselen, R.; Puttkammer, M.J. Developing Text Resources for Ten South African Languages. In Proceedings of the Language Resource and Evaluation, Reykjavik, Iceland, 28 May 2014; pp. 3698–3703. [Google Scholar]
- Camelin, N.; Damnati, G.; Bouchekif, A.; Landeau, A.; Charlet, D.; Estève, Y. FrNewsLink: A corpus linking TV Broadcast News Segments and Press Articles. In Proceedings of the Language Resource and Evaluation, Miyazaki, Japan, 22 May 2018; pp. 2087–2092. [Google Scholar]
- Takamichi, S.; Saruwatari, H. CPJD corpus: Crowdsourced parallel speech corpus of japanese dialects. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC-2018), Miyazaki, Japan, 7–12 May 2018; pp. 434–437. [Google Scholar]
- Salimbajevs, A. Creating Lithuanian and Latvian speech corpora from inaccurately annotated web data. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC-2018), Miyazaki, Japan, 7–12 May 2018; pp. 2871–2875. [Google Scholar]
- Baumann, T.; Köhn, A.; Hennig, F. The Spoken Wikipedia Corpus collection: Harvesting, alignment and an application to hyperlistening. Lang. Resour. Eval. 2018, 1–27. [Google Scholar] [CrossRef]
- de Vries, N.J.; Davel, M.H.; Badenhorst, J.; Basson, W.D.; de Wet, F.; an Alta de Waal, E.B. A smartphone-based ASR data collection tool for under-resourced languages. Speech Commun. 2014, 56, 119–131. [Google Scholar] [CrossRef]
- Jones, K.S.; Strassel, S.; Walker, K.; Graff, D.; Wright, J. Multi-language speech collection for NIST LRE. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, 23–28 May 2016; pp. 4253–4258. [Google Scholar]
- Ide, N.; Reppen, R.; Suderman, K. The American National Corpus: More Than the Web Can Provide. In Proceedings of the Third International Conference on Language Resources and Evaluation (LREC’02), Las Palmas, Spain, 29–31 May 2002; pp. 840–844. [Google Scholar]
- Schalkwyk, J.; Beeferman, D.; Beaufays, F.; Byrne, B.; Chelba, C.; Cohen, M.; Kamvar, M.; Strope, B. “Your Word is my Command”: Google search by voice: A case study. In Advances in Speech Recognition; Springer: Boston, MA, USA, 2010; pp. 61–90. [Google Scholar]
- Cieri, C.; Miller, D.; Walker, K. Research Methodologies, Observations and Outcomes in (Conversational) Speech Data Collection. In Proceedings of the Second International Conference on Human Language Technology Research, San Diego, CA, USA, 24–27 May 2002; pp. 206–211. [Google Scholar]
- De Wet, F.; Louw, P.; Niesler, T. The design, collection and annotation of speech databases in South Africa. In Proceedings of the Pattern Recognition Association of South Africa (PRASA 2006), Bloemfontein, South Africa, 29 November–1 December 2006; pp. 1–5. [Google Scholar]
- Brümmer, N.; Garcia-Romero, D. Generative modeling for unsupervised score calibration. arXiv 2014, arXiv:1311.0707. [Google Scholar]
- Davel, M.H.; van Heerden, C.; Barnard, E. Validating Smartphone-Collected Speech Corpora. In Proceedings of the Third Workshop on Spoken Language Technologies for Under-resourced Languages, Cape Town, South Africa, 7–9 May 2012; pp. 68–75. [Google Scholar]
- Badenhorst, J.; Martinus, L.; De Wet, F. BLSTM harvesting of auxiliary NCHLT speech data. In Proceedings of the 2019 Southern African Universities Power Engineering Conference/Robotics and Mechatronics/Pattern Recognition Association of South Africa (SAUPEC/RobMech/PRASA), Bloemfontein, South Africa, 28–30 January 2019; pp. 123–128. [Google Scholar]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book. Revised for HTK Version 3.4. 2009. Available online: http://htk.eng.cam.ac.uk// (accessed on 27 June 2019).
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Hilton Waikoloa Village, Big Island, HI, USA, 11–15 December 2011. [Google Scholar]
- Badenhorst, J.; de Wet, F. The limitations of data perturbation for ASR of learner data in under-resourced languages. In Proceedings of the 2017 Pattern Recognition Association of South Africa and Robotics and Mechatronics (PRASA-RobMech), Bloemfontein, South Africa, 30 November–1 December 2017; pp. 44–49. [Google Scholar]
- van Heerden, C.; Kleynhans, N.; Davel, M. Improving the Lwazi ASR baseline. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 3534–3538. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the INTERSPEECH 2015 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3214–3218. [Google Scholar]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K.J. Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 328–339. [Google Scholar] [CrossRef]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Yu, Z.; Ramanarayanan, V.; Suendermann-Oeft, D.; Wang, X.; Zechner, K.; Chen, L.; Tao, J.; Ivanou, A.; Qian, Y. Using bidirectional LSTM recurrent neural networks to learn high-level abstractions of sequential features for automated scoring of non-native spontaneous speech. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 338–345. [Google Scholar]
- Peddinti, V.; Wang, Y.; Povey, D.; Khudanpur, S. Low latency acoustic modeling using temporal convolution and LSTMs. IEEE Signal Process. Lett. 2018, 25, 373–377. [Google Scholar] [CrossRef]
- Karafiat, M.; Baskar, M.K.; Vesely, K.; Grezl, F.; Burget, L.; Černocký, J.C. Analysis of multilingual BLSTM acoustic model on low and high resource languages. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5789–5793. [Google Scholar]
- Huang, X.; Zhang, W.; Xu, X.; Yin, R.; Chen, D. Deeper Time Delay Neural Networks for Effective Acoustic Modeling. J. Phys. Conf. Ser. 2019, 1229, 012076. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, W.; Chen, D.; Huang, X.; Liu, B.; Xu, X. Gated Time Delay Neural Network for Speech Recognition. J. Phys. Conf. Ser. 2019, 1229, 012077. [Google Scholar] [CrossRef]
- Povey, D.; Cheng, G.; Wang, Y.; Li, K.; Xu, H.; Yarmohammadi, M.; Khudanpur, S. Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 3743–3747. [Google Scholar]
- van der Westhuizen, E.; Niesler, T.R. Technical Report SU-EE-1501 An Analysis of the NCHLT Speech Corpora; Technical Report; Stellenbosh University of Zurich, Department of Electrical and Electronic Engineering: Stellenbosch, South Africa, 2015. [Google Scholar]
- Loots, L.; Davel, M.; Barnard, E.; Niesler, T. Comparing manually-developed and data-driven rules for P2P learning. In Proceedings of the 20th Annual Symposium of the Pattern Recognition Association of South Africa (PRASA), Stellenbosch, South Africa, 30 November–1 December 2009; pp. 35–40. [Google Scholar]
- de Wet, F.; de Waal, A.; van Huyssteen, G.B. Developing a broadband automatic speech recognition system for Afrikaans. In Proceedings of the INTERSPEECH 2011, 12th Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011; pp. 3185–3188. [Google Scholar]
- Peddinti, V.; Chen, G.; Povey, D.; Khudanpur, S. Reverberation robust acoustic modeling using i-vectors with time delay neural networks. In Proceedings of the INTERSPEECH 2015 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 2440–2444. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the INTERSPEECH 2015 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3586–3589. [Google Scholar]
- Povey, D. Kaldi Librispeech TDNN-F 1c Chain Model Example Recipe. Available online: https://github.com/kaldi-asr/kaldi/blob/master/egs/librispeech/s5/local/chain/tuning/run_tdnn_1c.sh (accessed on 27 June 2019).
- Povey, D. Kaldi Librispeech TDNN-F 1d Chain Model Example Recipe. Available online: https://github.com/kaldi-asr/kaldi/blob/master/egs/librispeech/s5/local/chain/tuning/run_tdnn_1d.sh (accessed on 27 June 2019).
- Cheng, G.; Peddinti, V.; Povey, D.; Manohar, V.; Khudanpur, S.; Yan, Y. An exploration of dropout with lstms. In Proceedings of the Interspeech, 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1586–1590. [Google Scholar]
- Jurafsky, D.; Martin, J. Speech Lang. Process.; Prentice Hall: Upper Saddle River, NJ, USA, 2000; pp. 153–199. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



{kind=link}