Crowdsourcing the Paldaruo Speech Corpus of Welsh for Speech Technology


Abstract
1. Introduction
1.1. Challenges for Speech Technology and Low-Resource Languages
1.2. Spoken Welsh
1.3. Welsh Language Technologies
- Welsh language speech technology.
- Computer-assisted translation.
- Conversational artificial intelligence.
- To collect data from speakers from all major Welsh dialect areas, including data from native and non-native speakers of Welsh.
- To collect data which covers a representative sample of the most common sounds in the language.
2. Materials and Methods
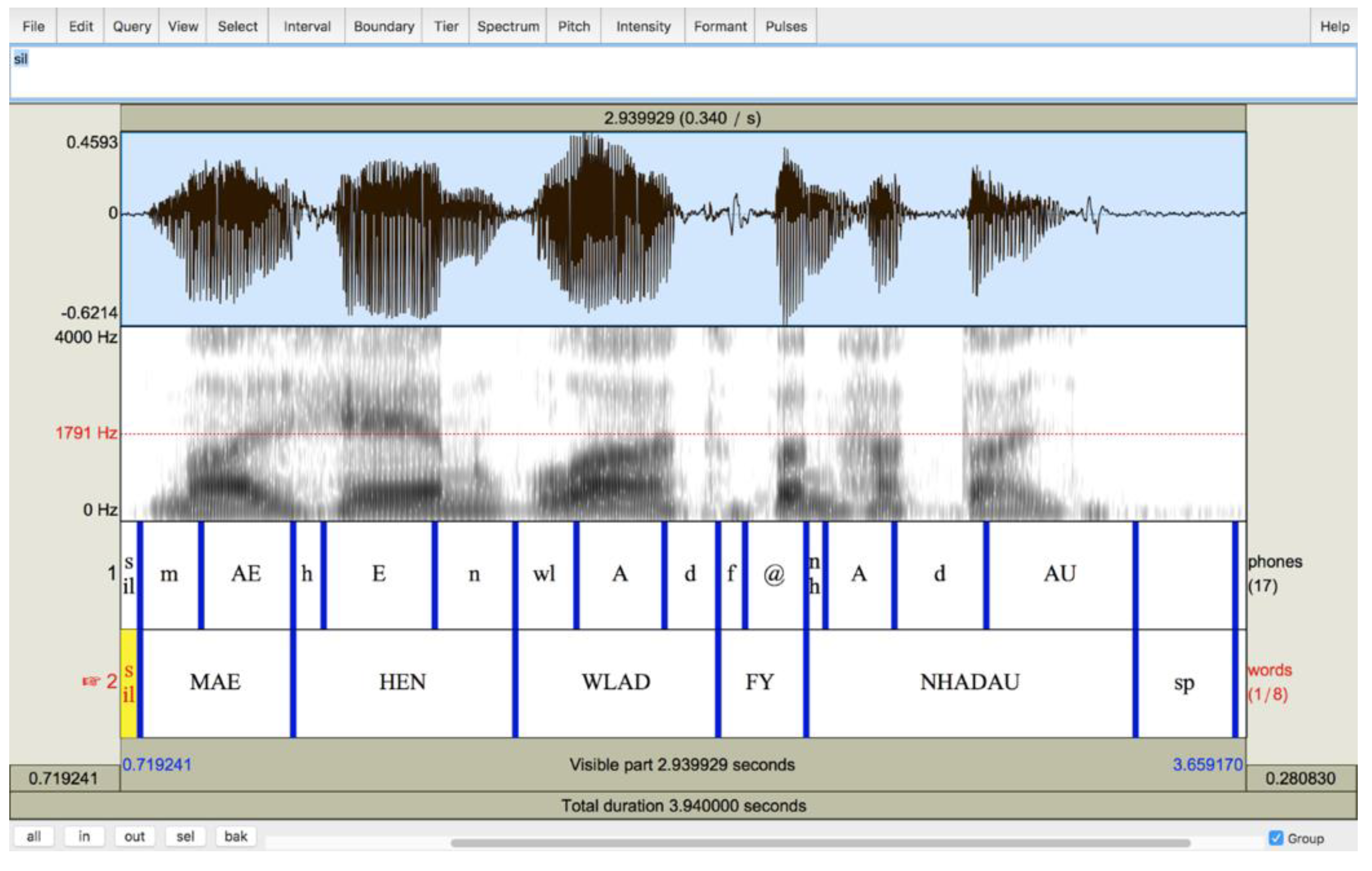
2.1. The Paldaruo App
2.2. Prompt Design
2.3. Data Collection
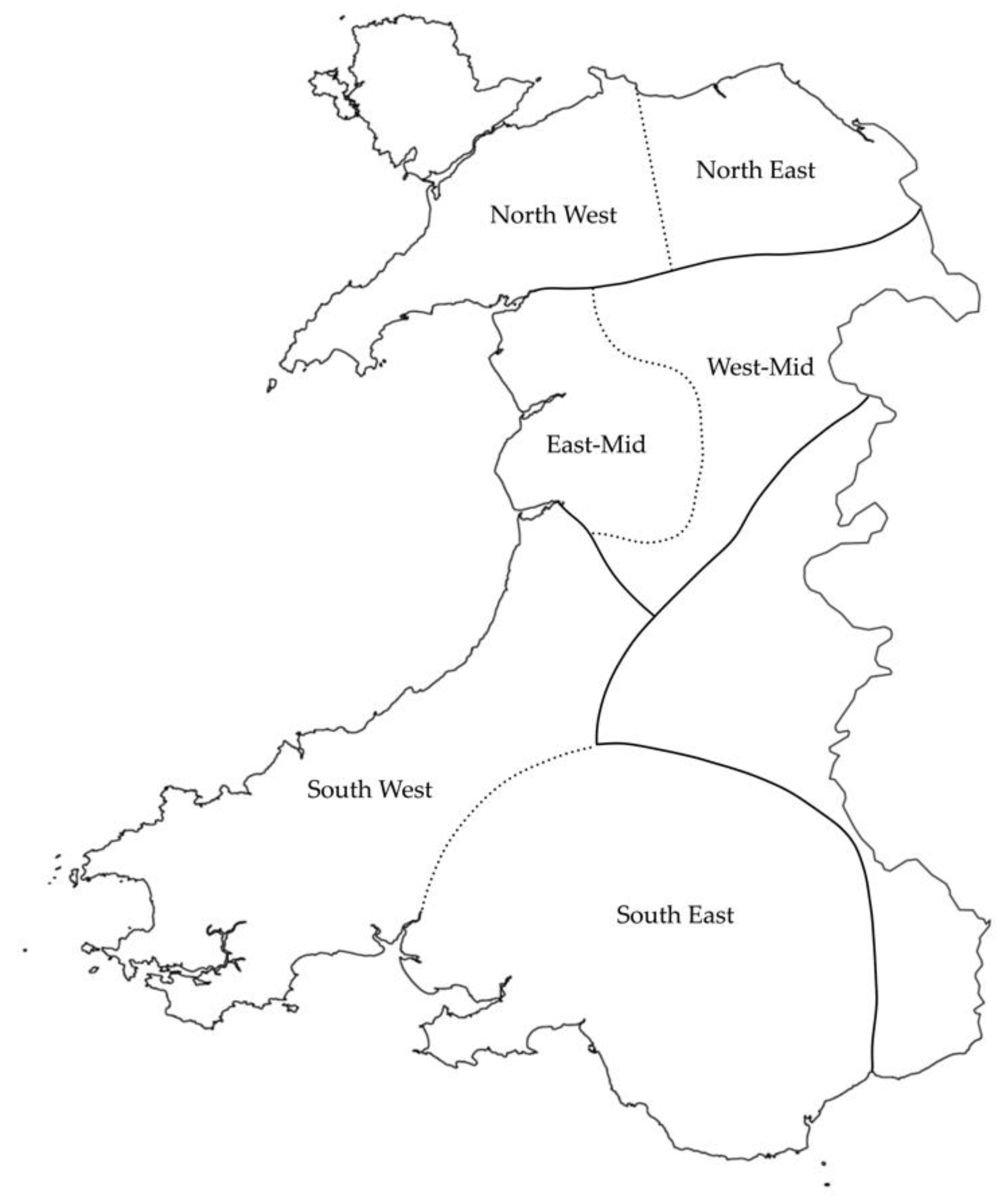
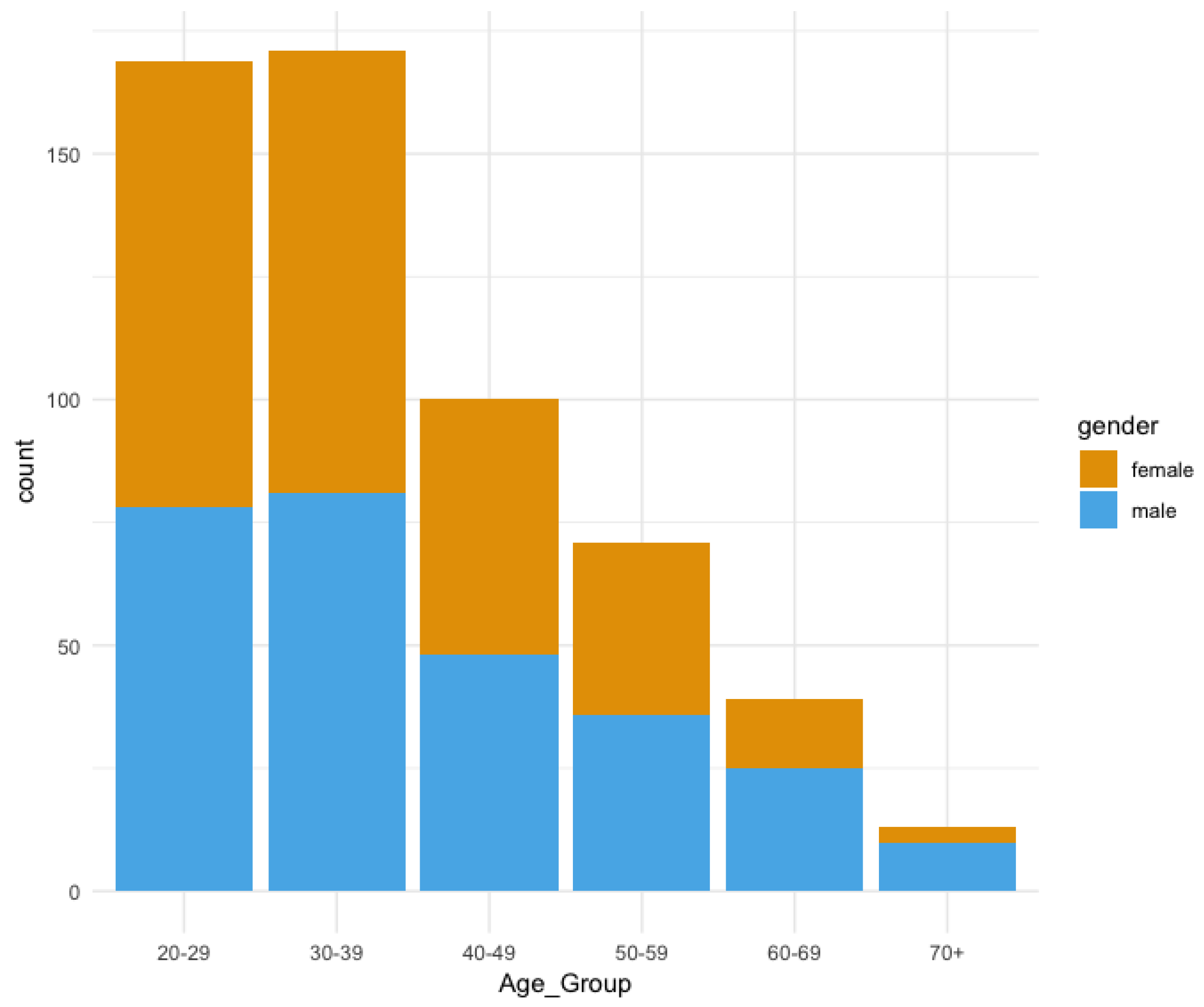
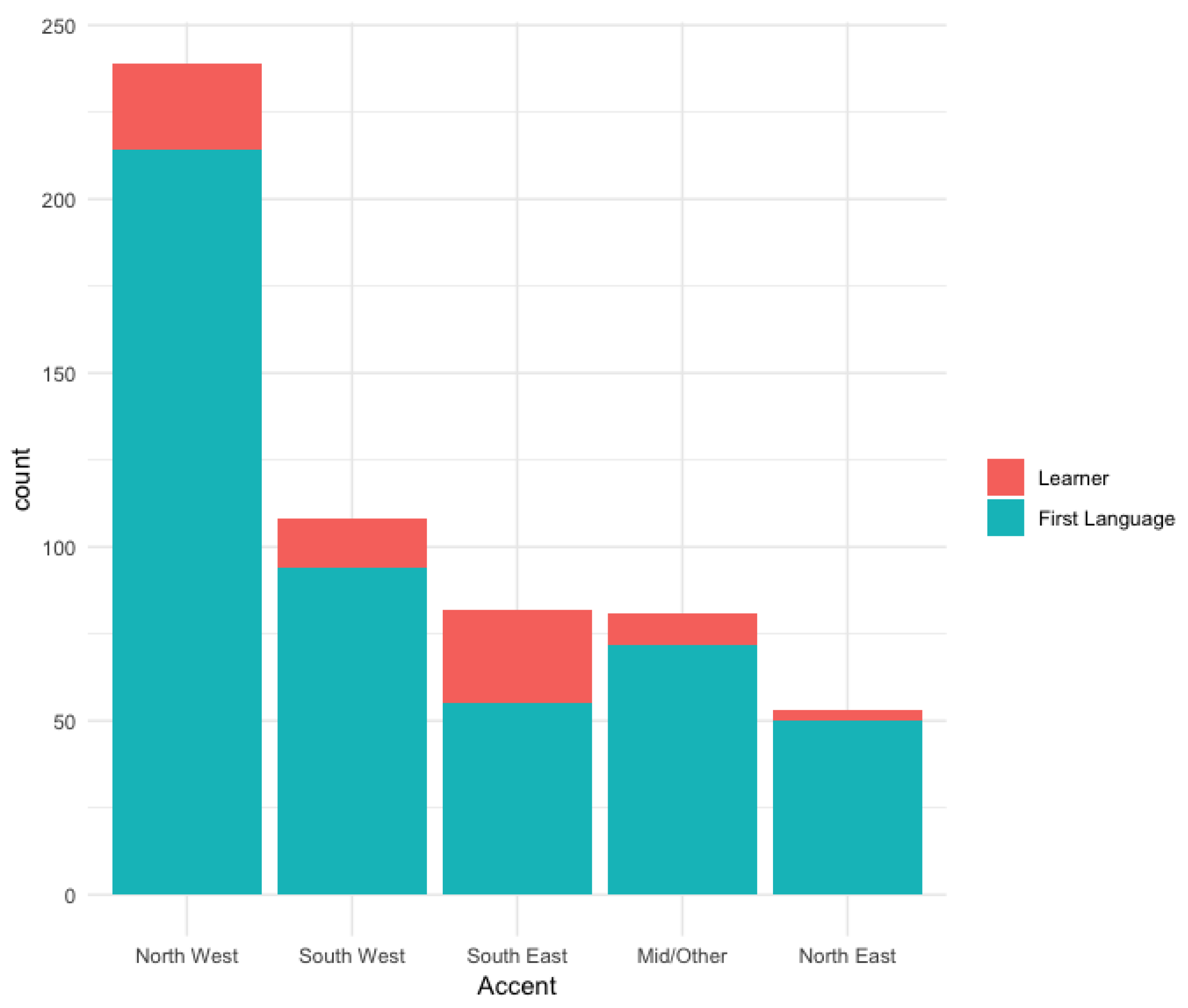
3. Corpus Analysis
Technical Specifications and Use of the Paldaruo Corpus
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Language in England and Wales: 2011; Office for National Statistics: South Wales, UK, 2013.
- Aitchison, J.W.; Carter, H. A Geography of the Welsh Language, 1961–1991; University of Wales Press: Cardiff, UK, 1994; ISBN 978-0-7083-1236-0. [Google Scholar]
- Besacier, L.; Barnard, E.; Karpov, A.; Schultz, T. Automatic speech recognition for under-resourced languages: A survey. Speech Commun. 2014, 56, 85–100. [Google Scholar] [CrossRef]
- Kurimo, M.; Enarvi, S.; Tilk, O.; Varjokallio, M.; Mansikkaniemi, A. Modeling under-resourced languages for speech recognition. Lang. Resour. Eval. 2017, 51, 961–987. [Google Scholar] [CrossRef]
- Crystal, D. Language Death; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Cormack, M. The media and language maintenance. In Minority Language Media: Concepts, Critiques and Case Studies; Cormack, M., Hourigan, N., Eds.; Multilingual Matters: Clevedon, UK, 2007; pp. 52–68. [Google Scholar]
- Pretorius, L.; Soria, C. Introduction to the special issue. Lang. Resour. Eval. 2017, 51, 891–895. [Google Scholar] [CrossRef]
- Ceberio Berger, K.; Gurrutxaga Hernaiz, A.; Baroni, P.; Hicks, D.; Kruse, E.; Quochi, V.; Russo, I.; Salonen, T.; Sarhimaa, A.; Soria, C. Digital Language Survival Kit: The DLDP Recommendations to Improve Digital Vitality. Available online: http://wp.dldp.eu/wp-content/uploads/2018/09/Digital-Language-Survival-Kit.pdf (accessed on 24 July 2019).
- Estellés-Arolas, E.; González-Ladrón-de-Guevara, F. Towards an integrated crowdsourcing definition. J. Inf. Sci. 2012, 38, 189–200. [Google Scholar] [CrossRef]
- Eskenazi, M. The basics. In Crowdsourcing for Speech Processing: Applications to Data Collection, Transcription and Assessment; Eskenazi, M., Levow, G., Meng, H., Parent, G., Suendermann, D., Eds.; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- McGraw, I. Collecting Speech from Crowds. In Crowdsourcing for Speech Processing: Applications to Data Collection, Transcription and Assessment; Eskenazi, M., Levow, G., Meng, H., Parent, G., Suendermann, D., Eds.; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Jones, G. The distinctive vowels and consonants of Welsh. In Welsh Phonology: Selected Readings; Ball, M.J., Jones, G., Eds.; University of Wales Press: Cardiff, UK, 1984; pp. 40–64. [Google Scholar]
- Mayr, R.; Davies, H. A cross-dialectal acoustic study of the monophthongs and diphthongs of Welsh. J. Int. Phon. Assoc. 2011, 41, 1–25. [Google Scholar] [CrossRef]
- Ball, M.J.; Williams, B.J. Welsh Phonetics; Edwin Mellen Press: New York, NY, USA, 2001. [Google Scholar]
- Awbery, G.M. Phonotactic constraints in Welsh. In Welsh Phonology: Selected Readings; Ball, M.J., Jones, G., Eds.; University of Wales Press: Cardiff, UK, 1984; pp. 65–104. [Google Scholar]
- Rees, I.W. Phonological Variation in Mid-Wales. Stud. Celt. 2015, 45, 149–174. [Google Scholar]
- Mayr, R.; Morris, J.; Mennen, I.; Williams, D. Disentangling the effects of long-term language contact and individual bilingualism: The case of monophthongs in Welsh and English. Int. J. Biling. 2017, 21, 245–267. [Google Scholar] [CrossRef]
- Durham, M.; Morris, J. (Eds.) Sociolinguistics in Wales; Palgrave Macmillan: London, UK, 2017; ISBN 978-1-137-52897-1. [Google Scholar]
- Morris, J. Sociophonetic variation in a long-term language contact situation: /l/-darkening in Welsh-English bilingual speech. J. Socioling. 2017, 21, 183–207. [Google Scholar] [CrossRef]
- Prys, M. Style in the vernacular and on the radio: code-switching and mutations as stylistic and social markers in Welsh. Ph.D. Thesis, Prifysgol Bangor University, Bangor, UK, 2016. [Google Scholar]
- Davies, P.; Deuchar, M. Auxiliary deletion in the informal speech of Welsh–English bilinguals: A change in progress. Lingua 2014, 143, 224–241. [Google Scholar] [CrossRef]
- Borsley, R.D.; Tallerman, M.; Willis, D. The Syntax of Welsh; Cambridge Syntax Guides; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Welsh Government. Cymraeg 2050: A Million Welsh Speakers; Welsh Government: Cardiff, UK, 2017.
- Welsh Government. Welsh Language Technology Action Plan; Welsh Government: Cardiff, UK, 2018.
- Welsh Government. Welsh-Language Technology and Digital Media Action Plan; Welsh Government: Cardiff, UK, 2013.
- Prys, D.; Williams, B.; Hicks, B.; Jones, D.B.; Ní Chasaide, A.; Gobl, C.; Carson-Berndsen, J.; Cummins, F.; Ní Chiosáin, M.; McKenna, J.; et al. WISPR: Speech Processing Resources for Welsh and Irish. In Proceedings of the SALTMIL Workshop at LREC 2004: First Steps for Language Documentation of Minority Languages: Computational Linguistic Tools for Morphology, Lexicon and Corpus Compilation, Lisbon, Portugal, 24 May 2004; pp. 68–71. [Google Scholar]
- Williams, B. Diphone synthesis for the Welsh language. In Proceedings of the 1994 International Conference on Spoken Language Processing, Yokahama, Japan, 18–22 September 1994; pp. 739–742. [Google Scholar]
- Williams, B. Text-to-speech synthesis for Welsh and Welsh English. In Proceedings of the Eurospeech 1995, Madrid, Spain, 18–21 September 1995; Volume 2, pp. 1113–1116. [Google Scholar]
- Williams, B. A Welsh speech database: Preliminary results. In Proceedings of the Eurospeech 1999, Budapest, Hungary, 5–9 September 1999; Volume 5, pp. 2283–2286. [Google Scholar]
- Language Technologies Unit. Paldaruo; Bangor University: Bangor, UK, 2019. [Google Scholar]
- Jones, D.B.; Cooper, S. Building Intelligent Digital Assistants for speakers of a Lesser-Resourced Language. In Proceedings of the LREC 2016 Workshop “CCURL 2016—Towards an Alliance for Digital Language Diversity”, Portorož, Slovenia, 23–28 May 2016; pp. 74–79. [Google Scholar]
- Prys, D.; Jones, D.B. Gathering Data for Speech Technology in the Welsh Language: A Case Study. In Proceedings of the LREC 2018 Workshop “CCURL 2018—Sustaining Knowledge Diversity in the Digital Age”, Miyazaki, Japan, 12 May 2018; pp. 56–61. [Google Scholar]
- BBC. Lansio adnodd Adnabod Lleferydd Cymraeg Newydd (Launching a New Welsh Speech Recognition Resource); BBC Cymru Fyw Website; BBC: London, UK, 2014. [Google Scholar]
- BBC. Speakers for Welsh Voice Recognition App Sought; BBC News Website; BBC: London, UK, 2014. [Google Scholar]
- S4C. Apêl am Leisiau i Helpu Adeiladu Adnodd Adnabod Lleferydd Cymraeg (Appeal for Voices to Help Create Welsh Speech Recognition Resource); S4C News; S4C: Wales, UK, 2014. [Google Scholar]
- Language Technologies Unit. Welsh National Language Technologies Portal; Bangor University: Bangor, UK, 2019. [Google Scholar]
- Williams, I. Challenges for Developing Speech Technology for Welsh; Plas Gregynog: Newtown, UK, 2017. [Google Scholar]
- Williams, I. Modelau Cyfrifiadurol ar Gyfer y Gymraeg (Computational Models for Welsh); Bangor University: Bangor, UK, 2017. [Google Scholar]
- Young, S.; Evermann, G.; Kershaw, D.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; Valtchev, V.; Woodland, P. The HTK Book; Version 3.2.; Cambridge University Engineering Department: Cambridge, UK, 2002. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi Speech Recognition Toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Big Island, HI, USA, 11–15 December 2011. [Google Scholar]
- DeepSpeech: A TensorFlow Implementation of Baidu’s DeepSpeech Architecture; Mozilla: Mountain View, CA, USA, 2019.
- Cooper, S.; Jones, D.B.; Prys, D. Developing further speech recognition resources for Welsh. In Proceedings of the First Celtic Language Technology Workshop at the 25th International Conference on Computational Linguistics, Dublin, Ireland, 23–29 August 2014; pp. 55–59. [Google Scholar]
- Lee, A.; Kawahara, T. Julius-Speech/Julius: Release 4.5. Available online: https://zenodo.org/record/2530396#.XTgW4Y8RXIU (accessed on 24 July 2019).
- Gorman, K.; Howell, J.; Wagner, M. Prosodylab-Aligner: A Tool for Forced Alignment of Laboratory Speech. Can. Acoust. 2011, 39, 192–193. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer. Available online: http://www.fon.hum.uva.nl/praat/ (accessed on 24 July 2019).
- Cooper, S. A Resource for Exploring Socio-Phonetic Variation in Welsh: The Paldaruo Corpus; University of Glasgow: Glasgow, UK, 2015. [Google Scholar]
- Iosad, P. Bridging the Gap: Length and Tenseness in Brythonic Vowels; Institiúid Ard-Léinn Bhaile Átha Cliath: Dublin, Ireland, 2017. [Google Scholar]
- Language Technologies Unit. Paldaruo Source Code; Bangor University: Bangor, UK, 2019; Available online: https://github.com/techiaith/Paldaruo (accessed on 24 July 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prompt | Translation |
|---|---|
| lleuad, melyn, aelodau, siarad, ffordd, ymlaen, cefnogaeth, Helen | moon, yellow, members, talk, road, forward, support, Helen |
| gwraig, oren, diwrnod, gwaith, mewn, eisteddfod, disgownt, iddo | wife, orange, day, work, in, eisteddfod, discount, to him |
| rhybuddio, Elen, uwchraddio, hwnnw, beic, Cymru, rhoi, aelod | warn, Elen, upgrade, that, bike, Wales, give, member |
| lliw, yng Nghymru, gwneud, rownd, ychydig, wy, yn, llaes | colour, in Wales, make, round, few, egg, in, flaccid |
| hyn, newyddion, ar, roedd, pan, llun, melin, sychu | this, news, on, was, when, picture, mill, dry |
| Prompt | Translation |
|---|---|
| Beth ydy Cymraeg? | What is Welsh? |
| Beth oedd Yr Ail Ryfel Byd? | What was the Second World War? |
| Pwy oedd T. Llew Jones? | Who was T. Llew Jones? |
| Faint mae llaeth yn costio? | How much does milk cost? |
| Daeth wyau siocled yn boblogaidd adeg oes Fictoria | Easter eggs became popular during the Victorian period |
| Doedd dim cerbyn arall yn rhan o’r ddamwain | No other vehicles were involved in the accident |
| Mi fydd y broses yn debyg i etholiadau eraill | The process will be similar to other elections |
| Dw i wrth fy modd yn cerdded ac yn hoff iawn o natur | I’m in my element walking and am fond of nature |
| Mae unrhyw ddraenog sydd allan yng ngolau dydd angen help | Any hedgehog that is out in daylight needs help |
| Version 1 | Version 2 | Version 3 | Version 4 | Version 5 | |
|---|---|---|---|---|---|
| Date Published | 31 November 2014 | 15 July 2016 | 9 June 2017 | 16 November 2017 | 19 December 2018 |
| Audio Duration (hours) | 26 | 34 | 36 | 38 | 40 |
| Number of files | 8941 | 11,556 | 12,024 | 12,682 | 14,215 |
| Number of contributors | 383 | 487 | 506 | 536 | 564 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cooper, S.; Jones, D.B.; Prys, D. Crowdsourcing the Paldaruo Speech Corpus of Welsh for Speech Technology. Information 2019, 10, 247. https://doi.org/10.3390/info10080247
Cooper S, Jones DB, Prys D. Crowdsourcing the Paldaruo Speech Corpus of Welsh for Speech Technology. Information. 2019; 10(8):247. https://doi.org/10.3390/info10080247
Chicago/Turabian StyleCooper, Sarah, Dewi Bryn Jones, and Delyth Prys. 2019. "Crowdsourcing the Paldaruo Speech Corpus of Welsh for Speech Technology" Information 10, no. 8: 247. https://doi.org/10.3390/info10080247
APA StyleCooper, S., Jones, D. B., & Prys, D. (2019). Crowdsourcing the Paldaruo Speech Corpus of Welsh for Speech Technology. Information, 10(8), 247. https://doi.org/10.3390/info10080247