Hadoop Performance Analysis Model with Deep Data Locality †

Abstract
:1. Introduction
2. Overview of Hadoop and Data Locality with Literature Reviews
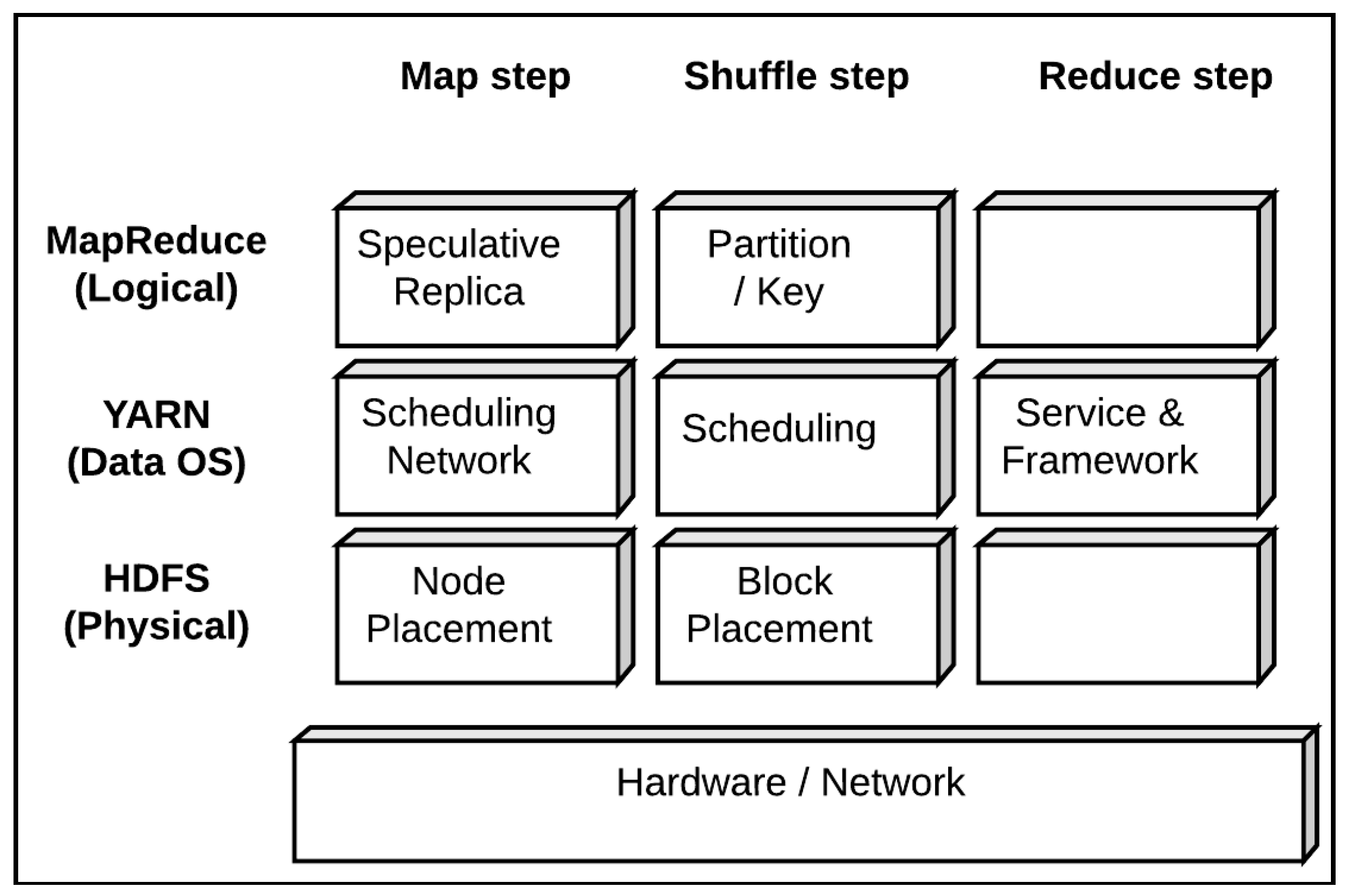
2.1. Hadoop System
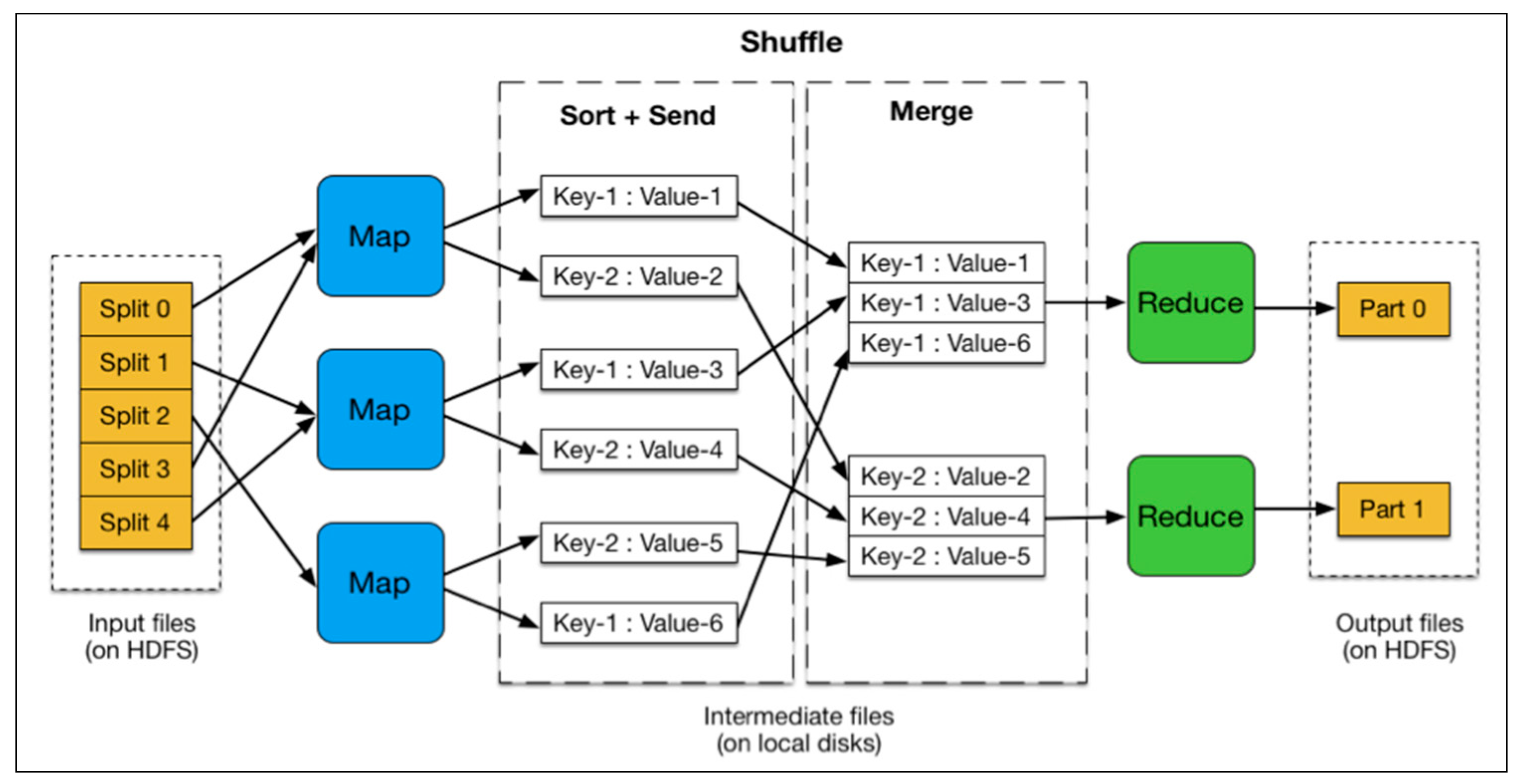
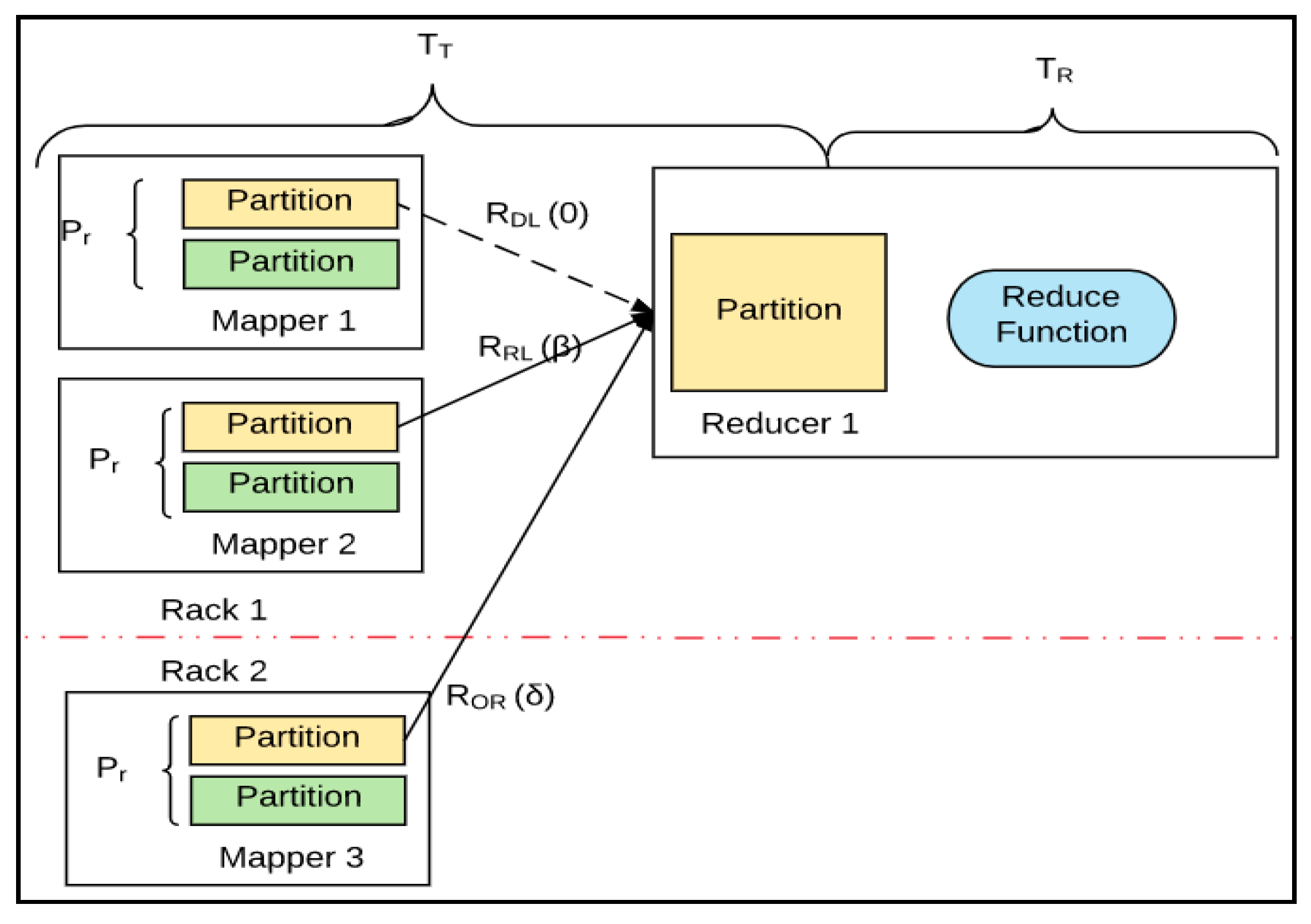
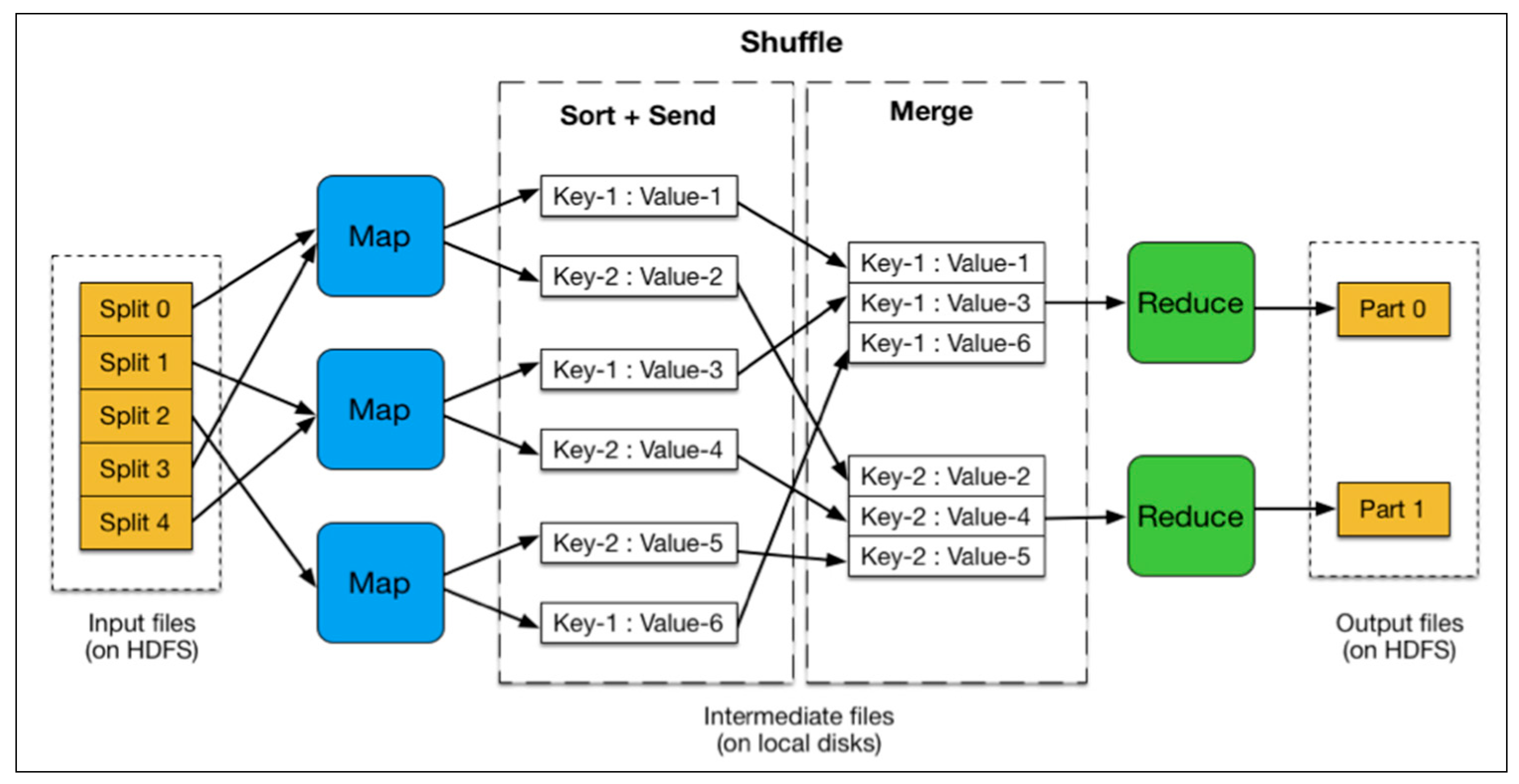
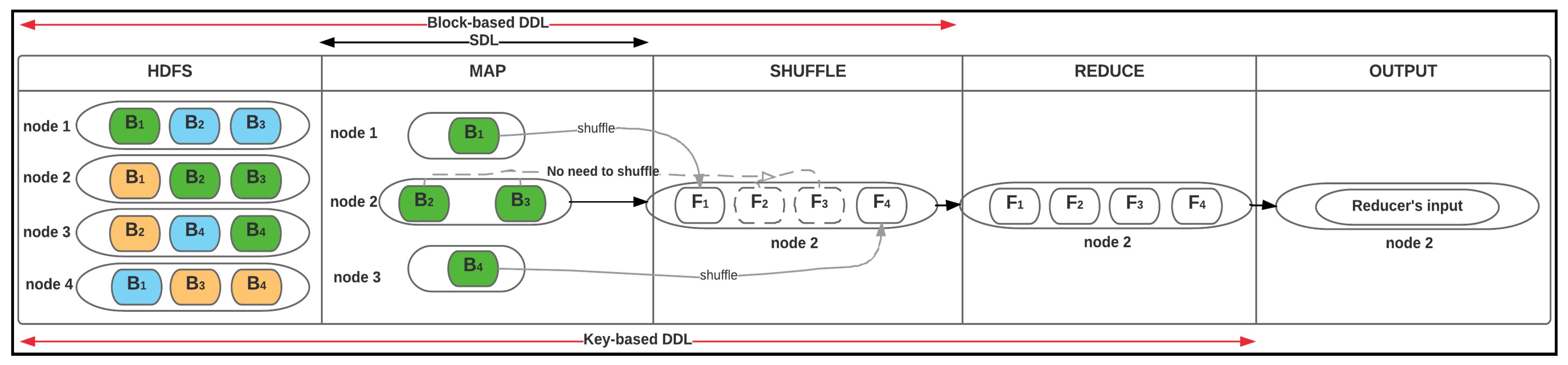
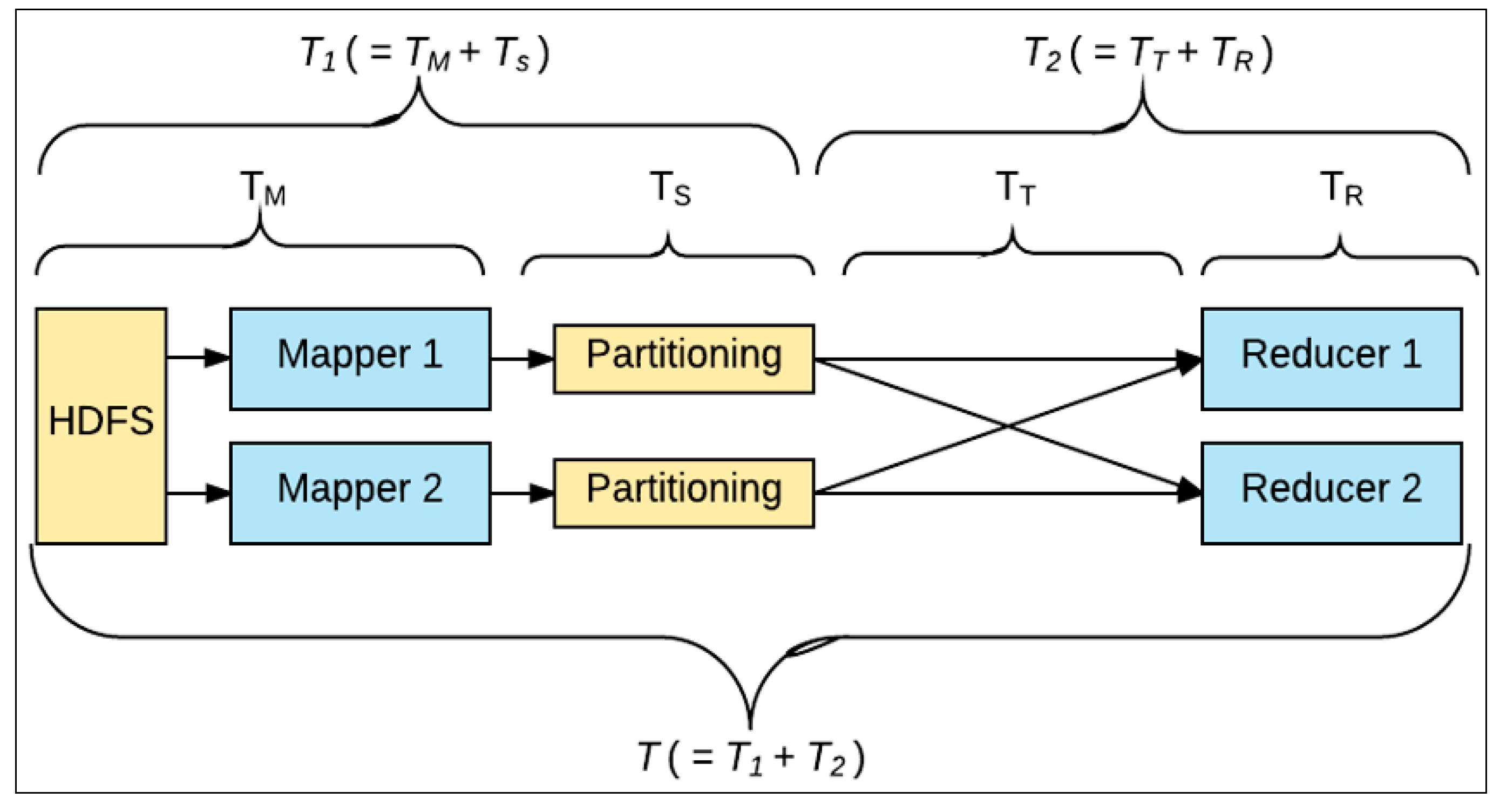
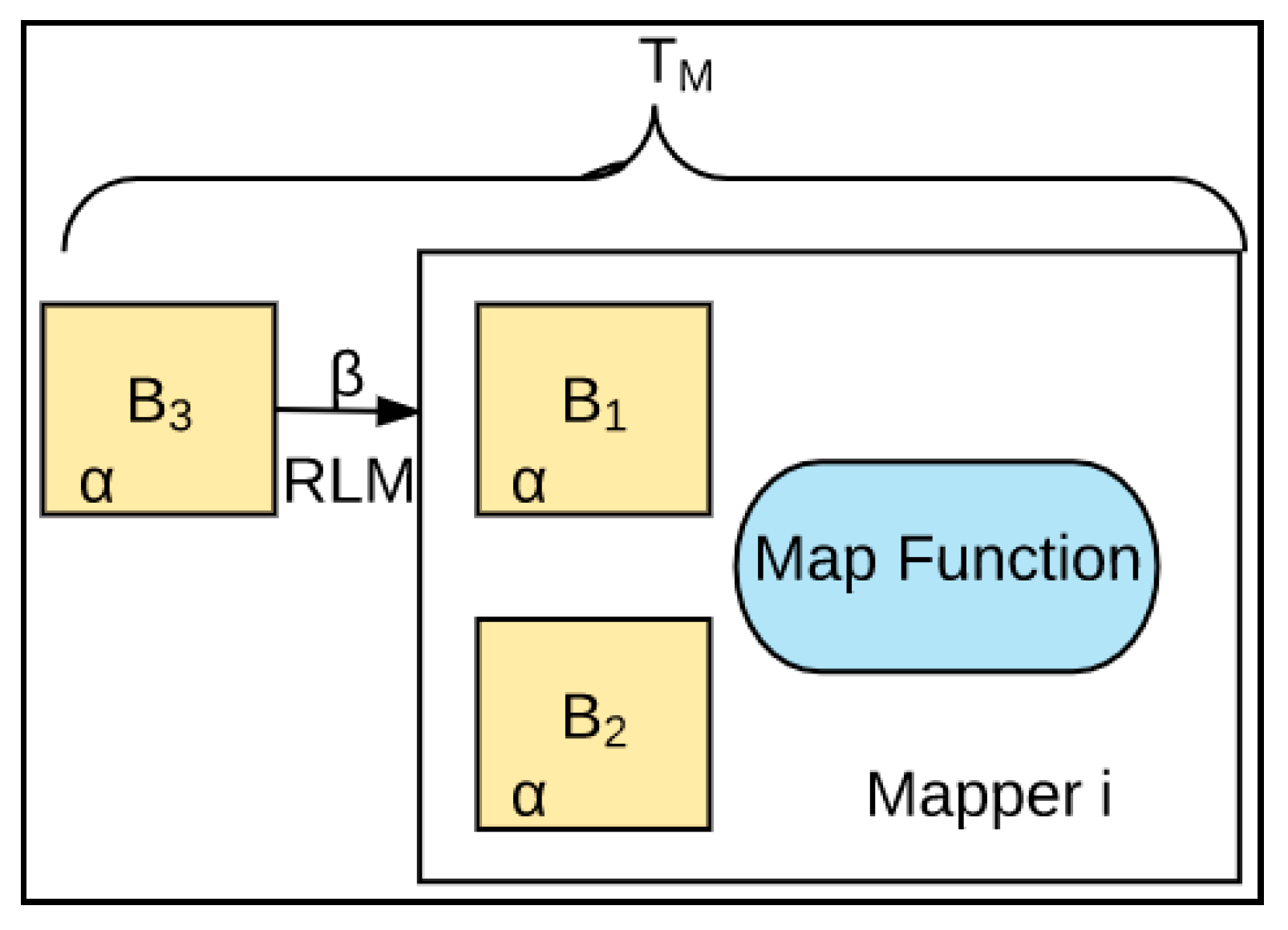
- Map: Mappers in containers execute the task using the data block in slave nodes. This is a part of the actual data manipulation for the job requested by the client. All mappers in the containers execute the tasks in parallel. The performance of the mapper depends on scheduling [10,12], data locality [16,17], programmer skills, container’s resources, data size and data complexity.
- Sort/Spill: The output pair which is emitted by the mapper is called partition. The partition is stored and sorted in the key/value buffer in the memory to process the batch job. The size of the buffer is configured by resource tracker and when its limit is reached, the spill is started.
- Shuffle: The key/value pairs in the spilled partition are sent to the reduce nodes based on the key via the network in this step. To increase the network performance, researchers have approached it from software defined network (SDN) [18], remote direct memory access (RDMA) [19], and Hadoop configurations [20], etc.
- Reduce: The slave nodes process the merged partition set to make a result of the application. The performance of reduce depends on scheduling [10,12], locality [16,17], programmer skills, container resources, data size, and data complexity, as was the case in the map step. However, unlike in the map step, the reduce step can be improved by in-memory computing [5,21,22,23].
- Output: The output of reduce nodes is stored at HDFS on the slave nodes.
2.2. Hadoop Locality Research
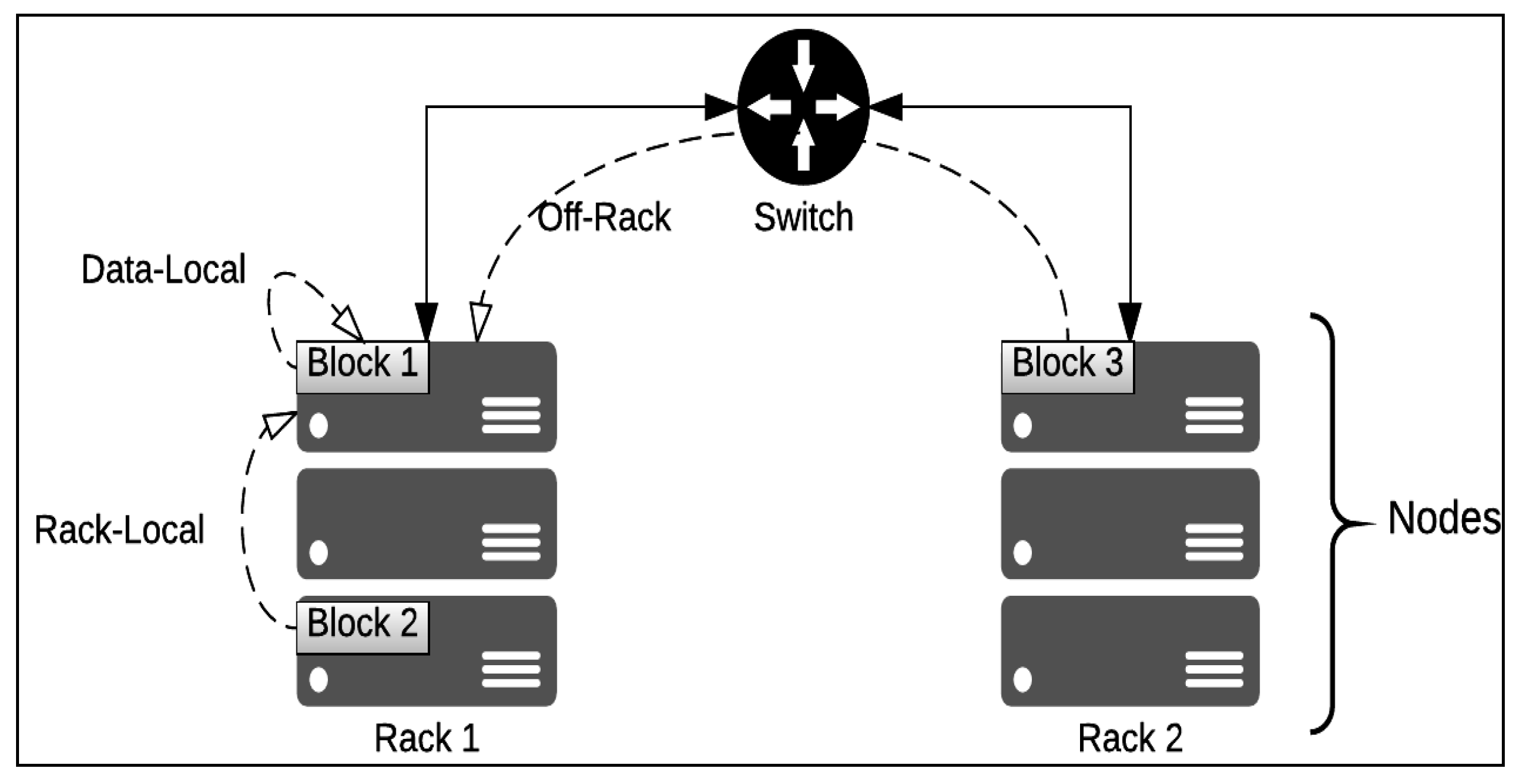
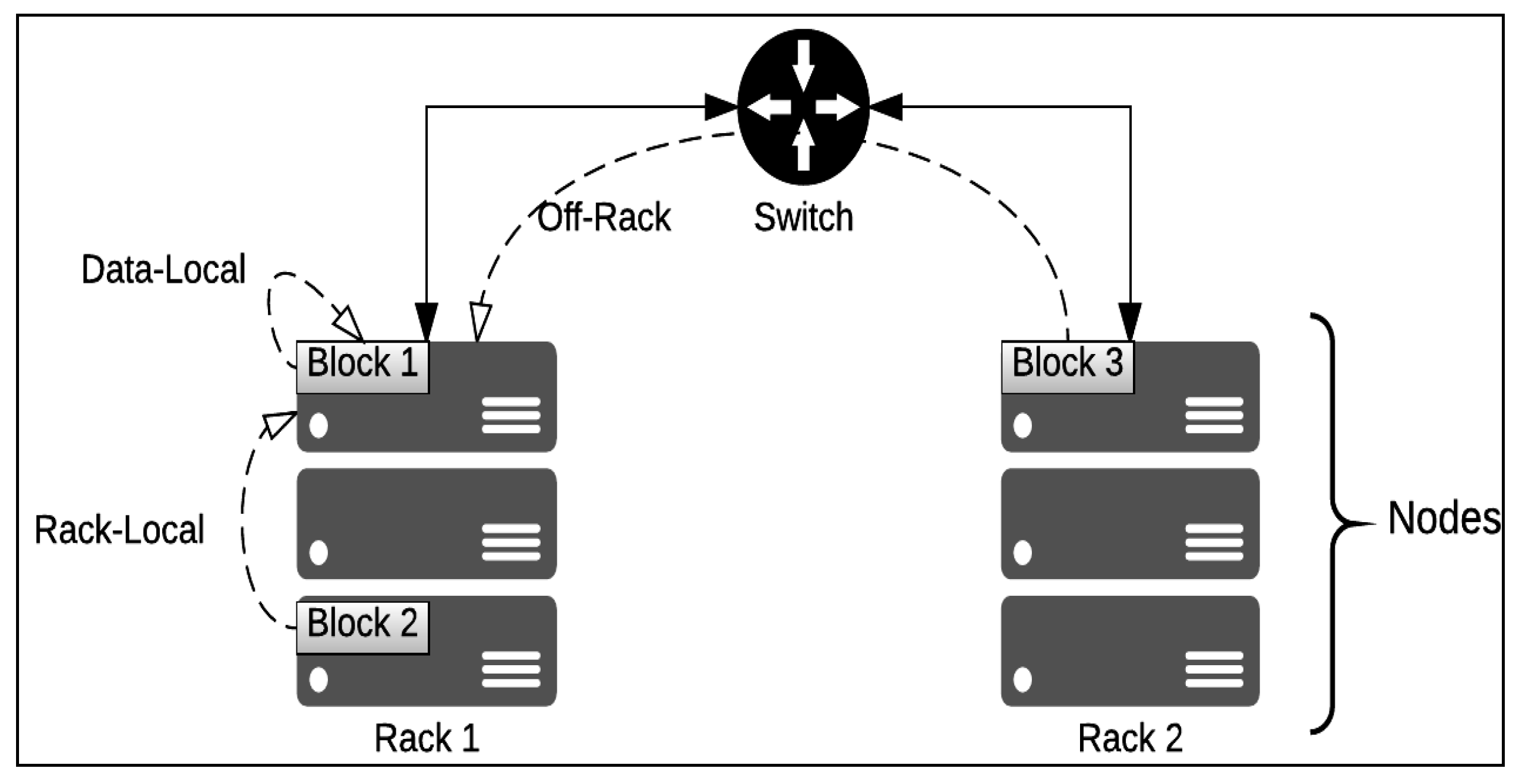
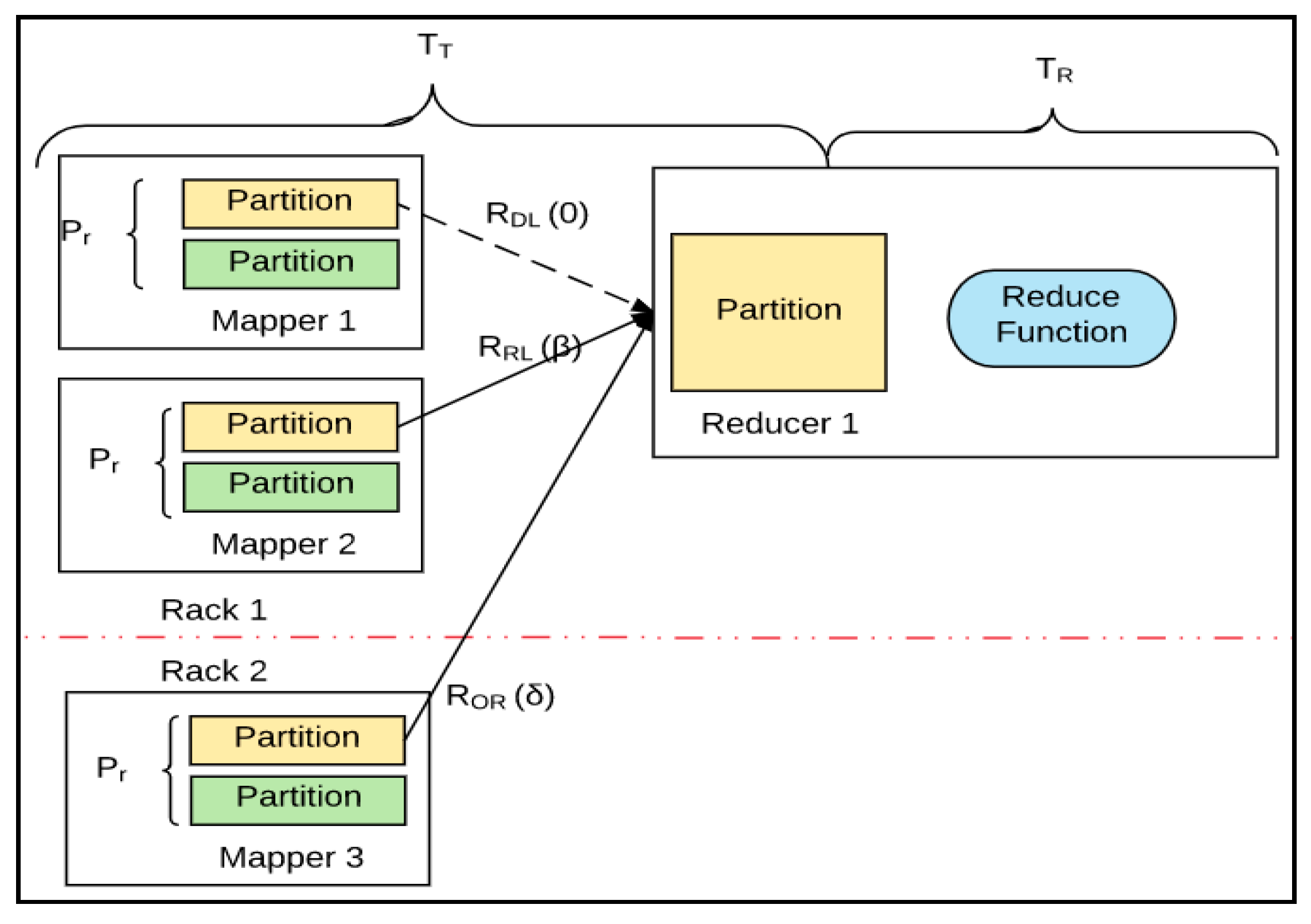
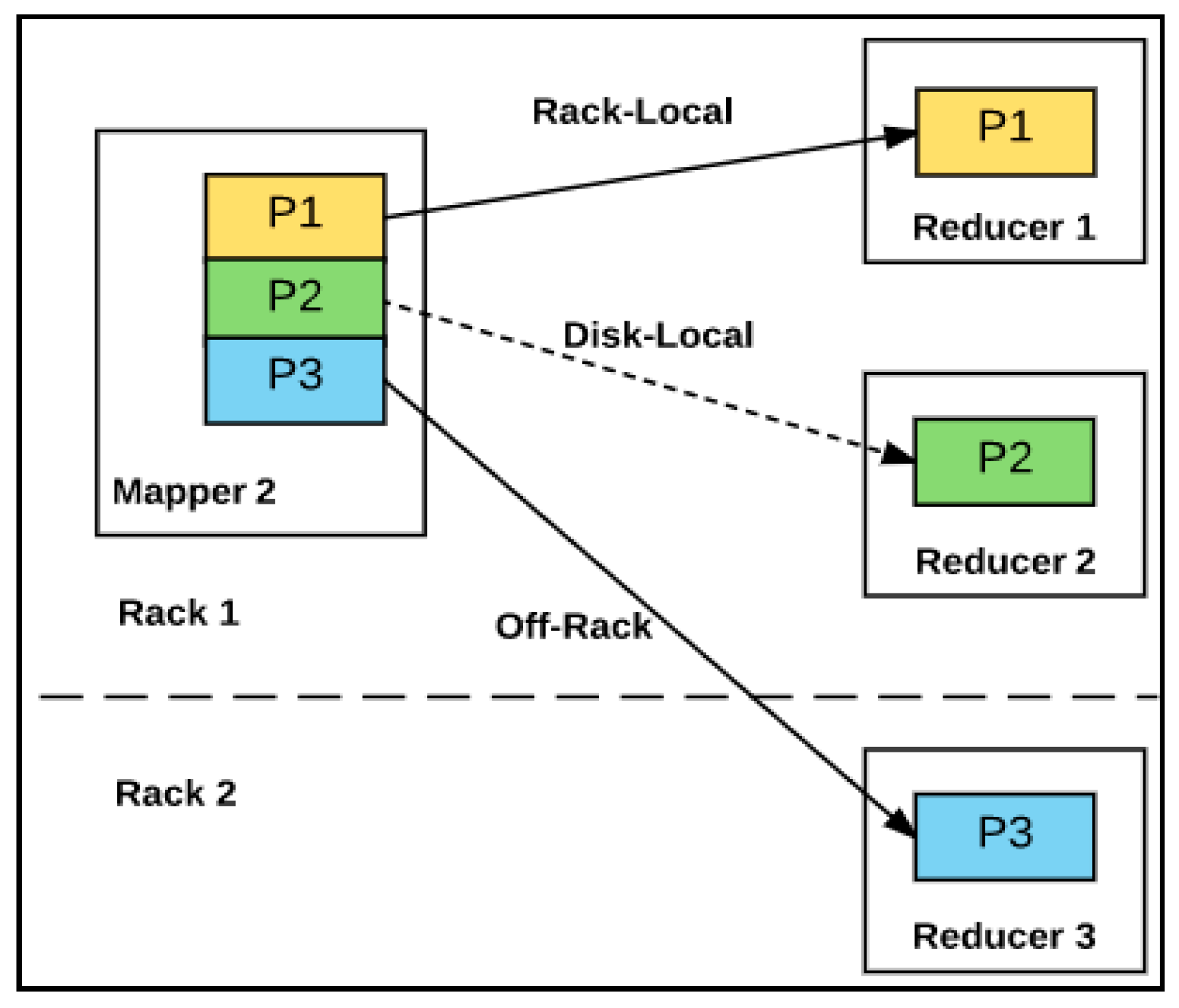
2.3. Hadoop Data Locality in Map Stage
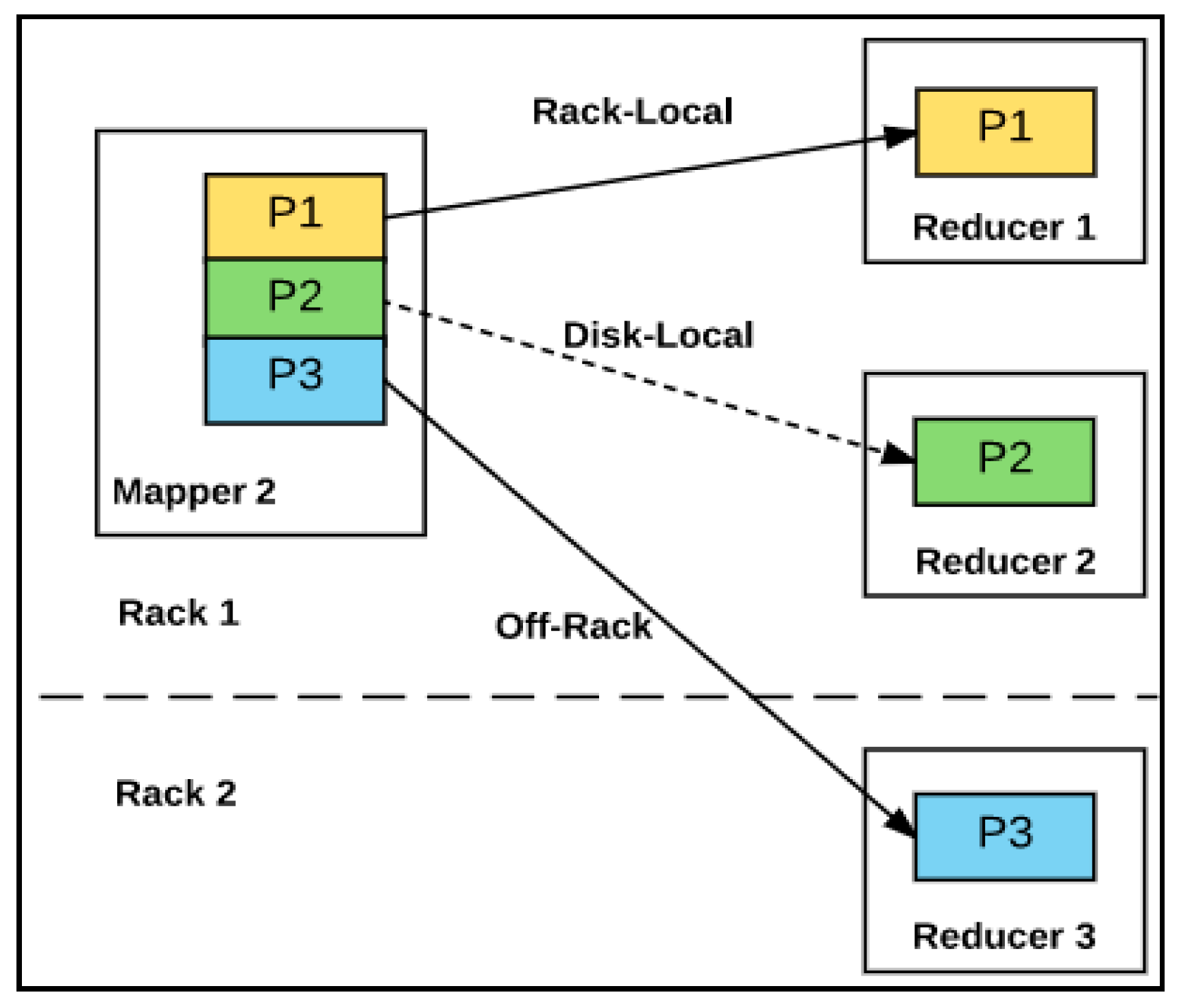
- Local disk (data-local map): The data block is on the local disk.
- In-rack disk (rack-local map): The data block is on another node on the same rack.
- Off-rack disk: The data block is not on the same rack, but another rack.
2.4. Hadoop Data Locality beyond Map Stage
2.5. Proposed Approach
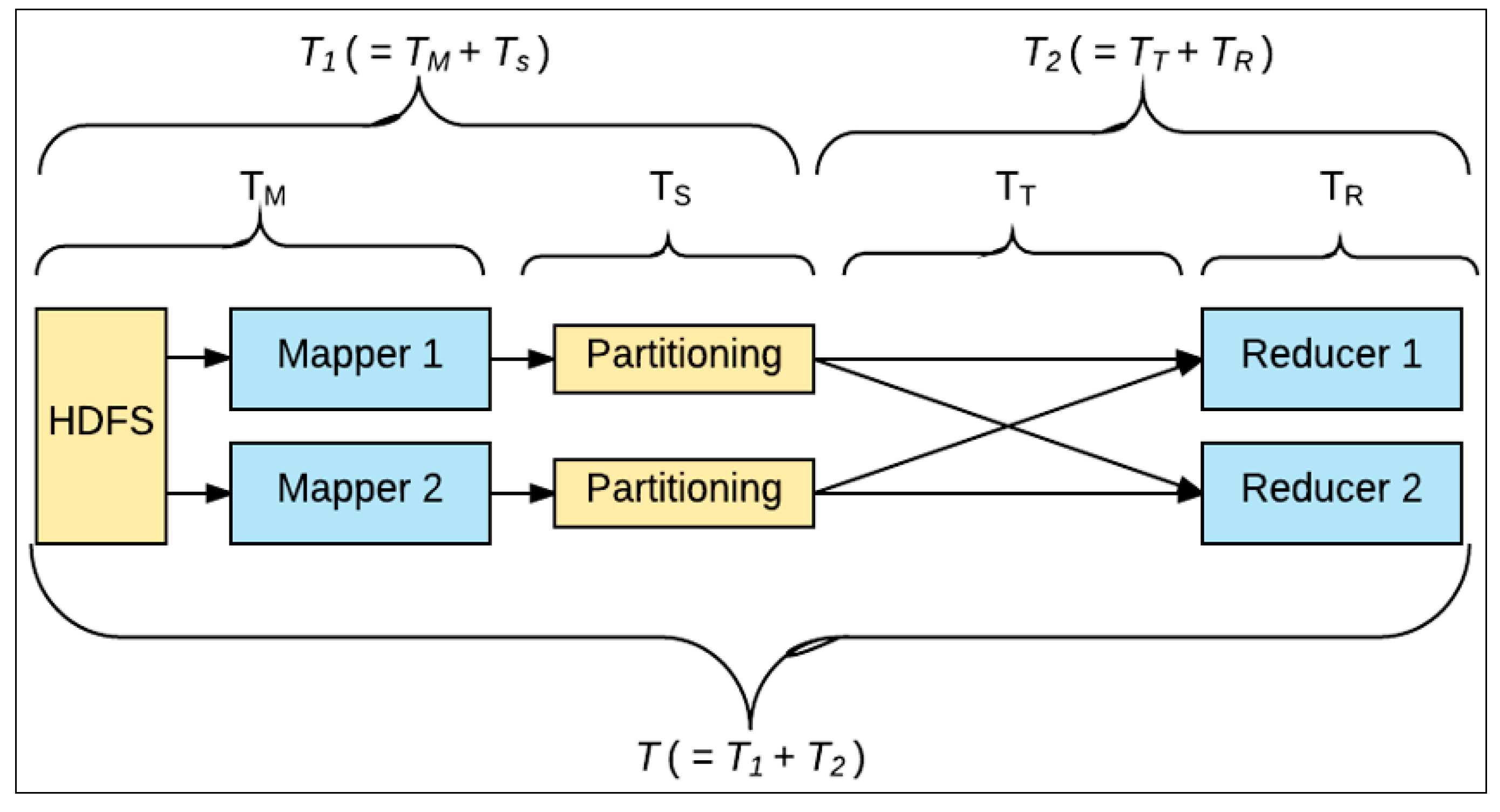
3. Analyzing Hadoop Performance
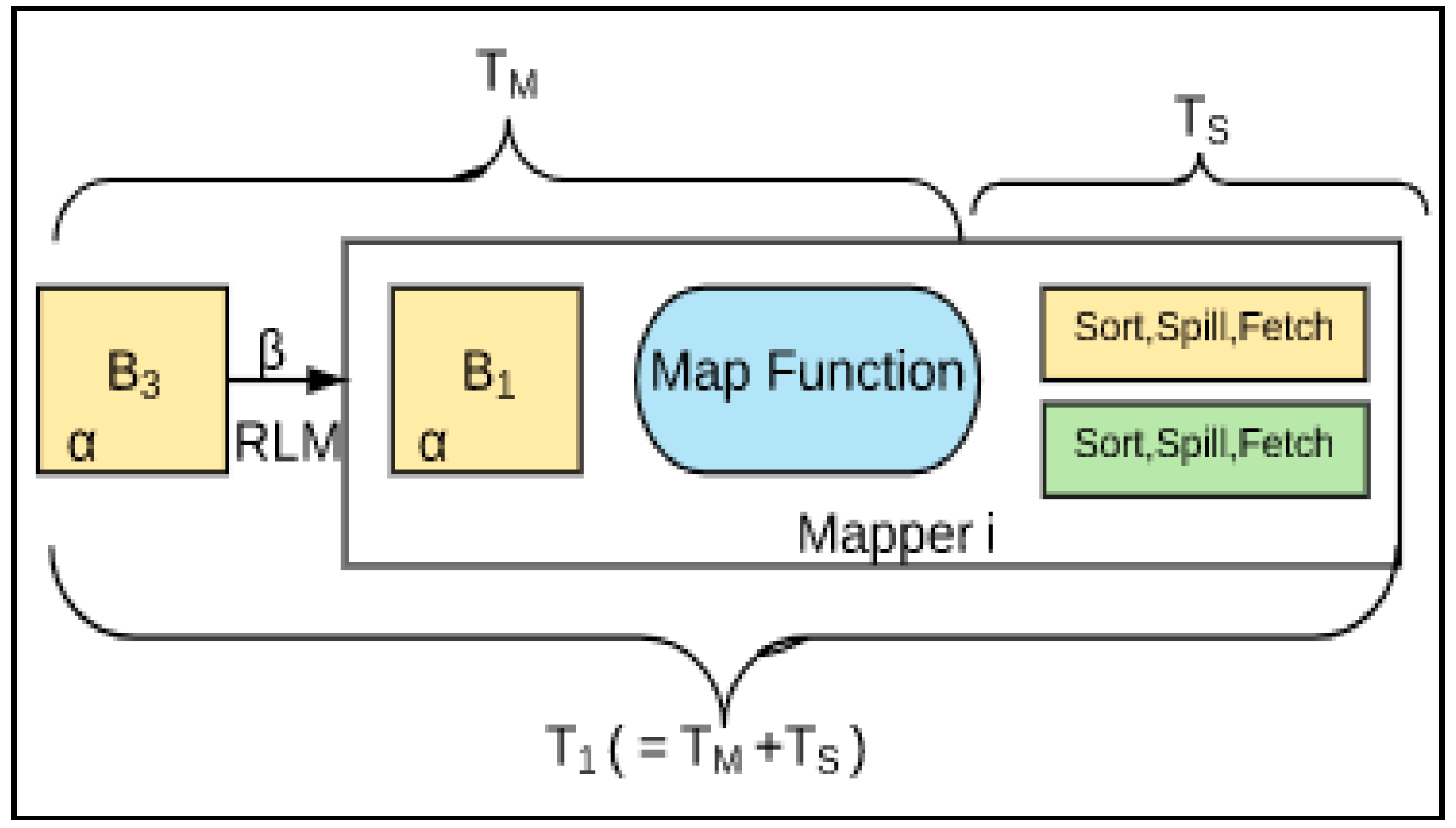
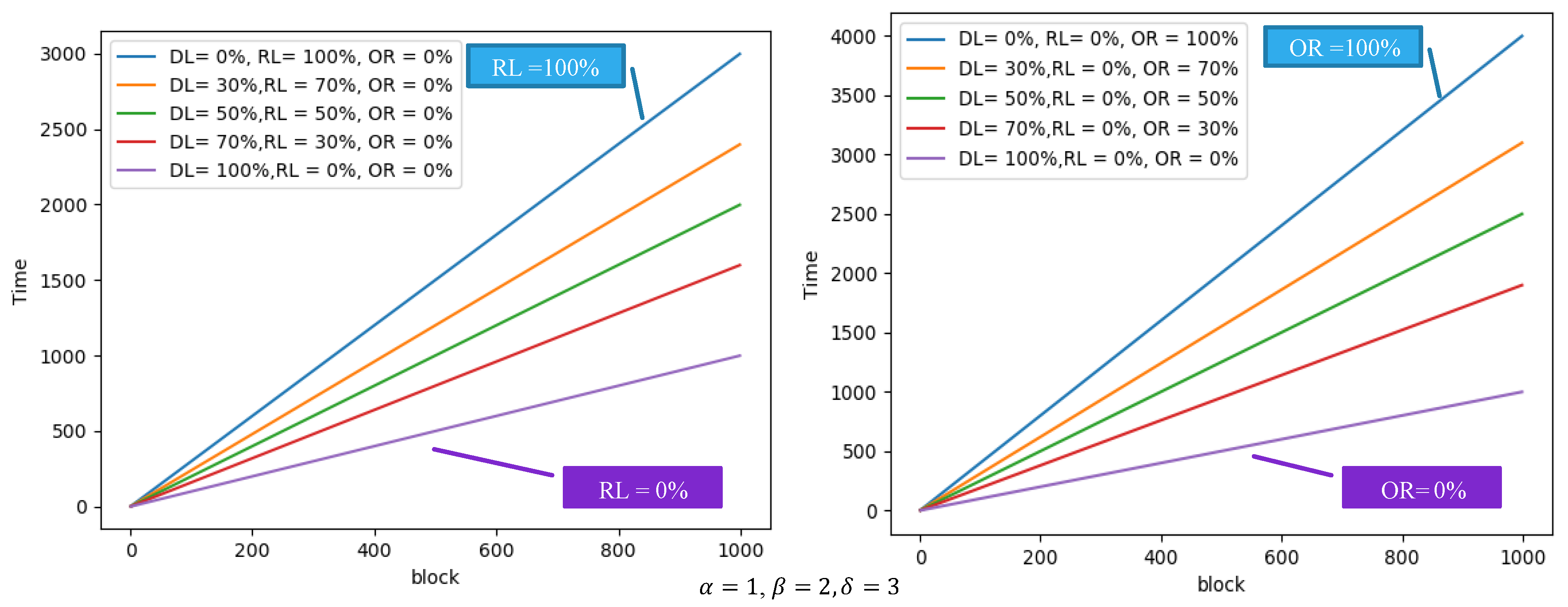
3.1. First Stage (T1)
3.2. Second Stage (T2)
3.3. Total Hadoop Processing Time (T)
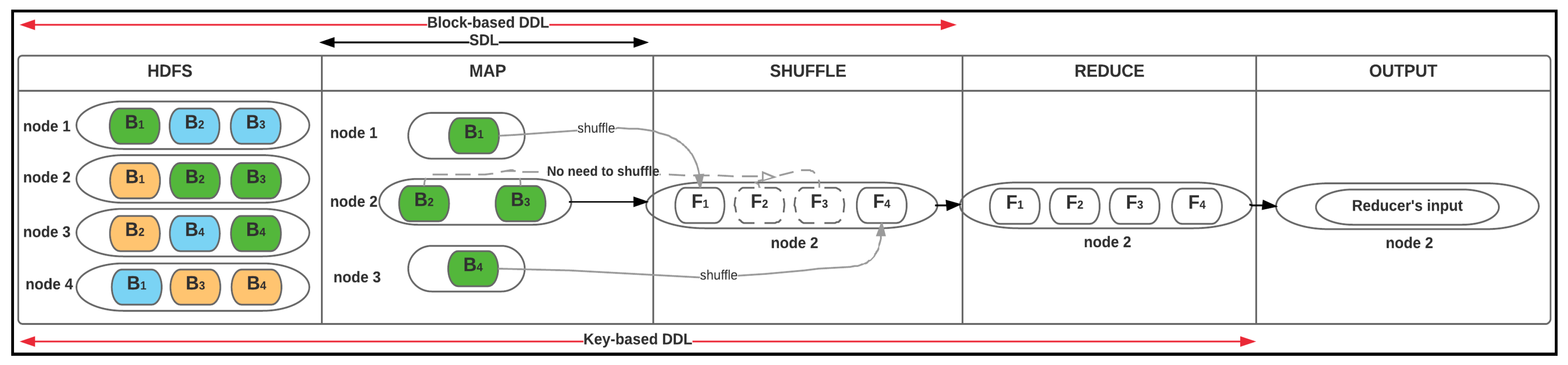
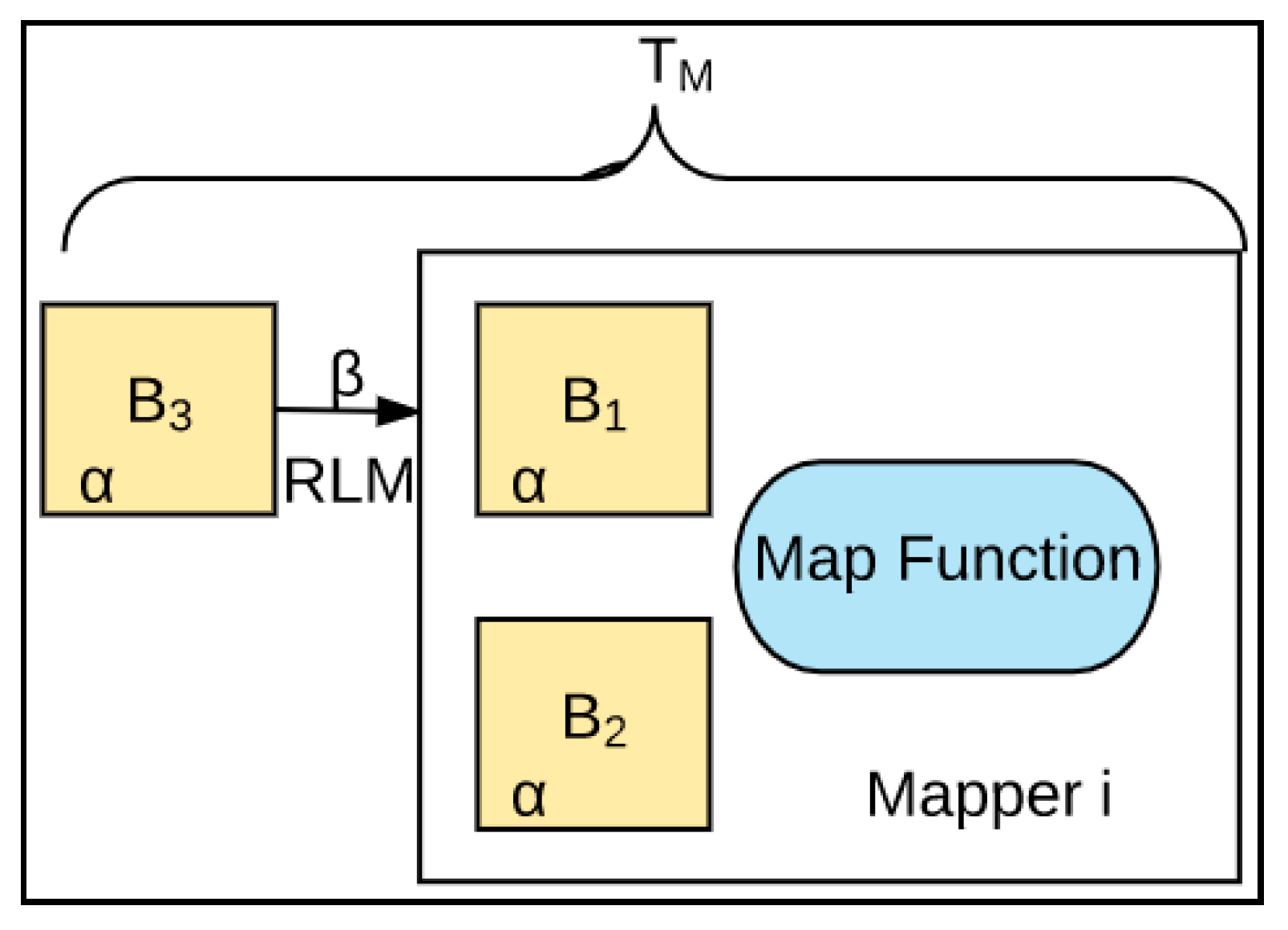
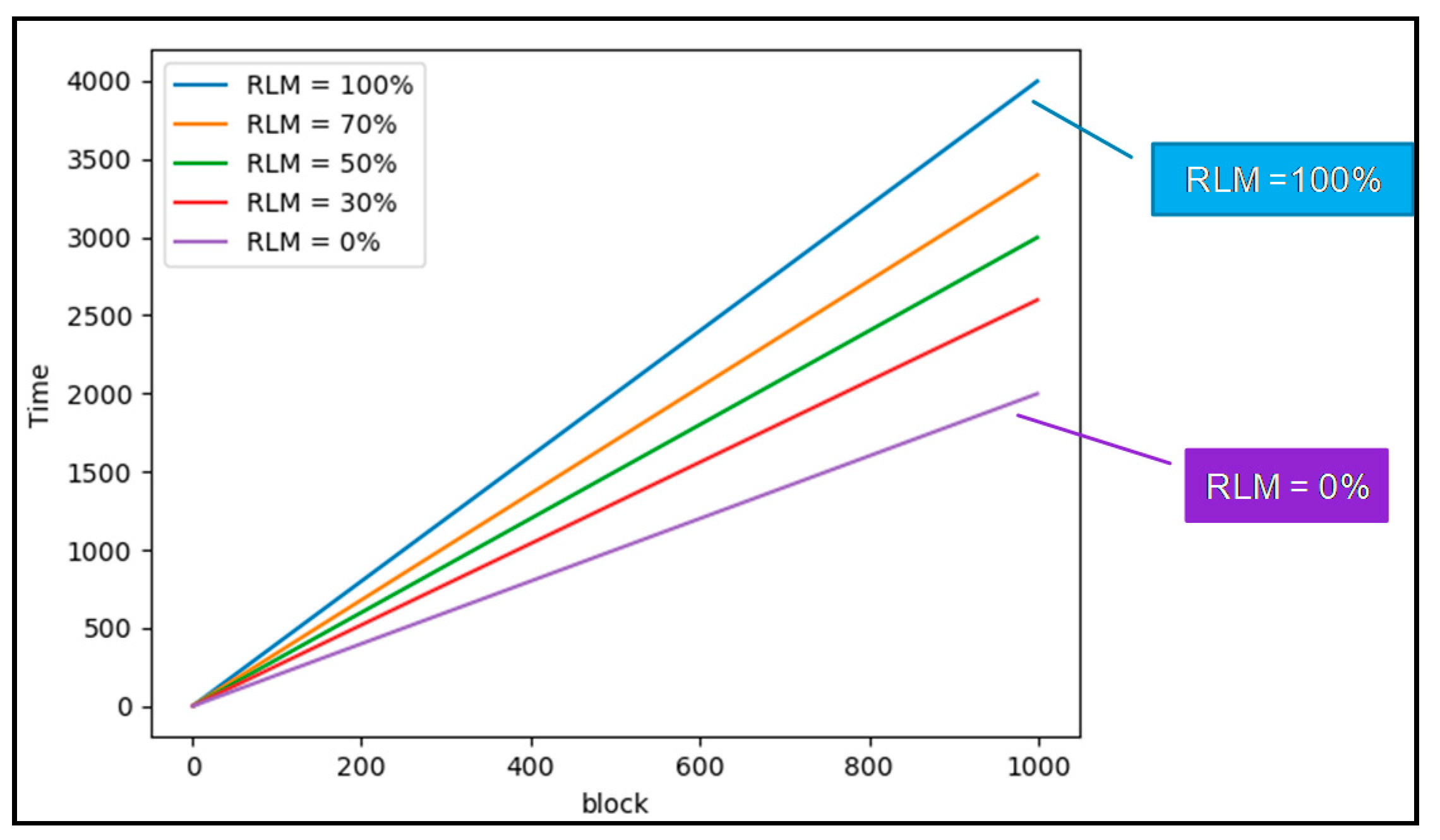
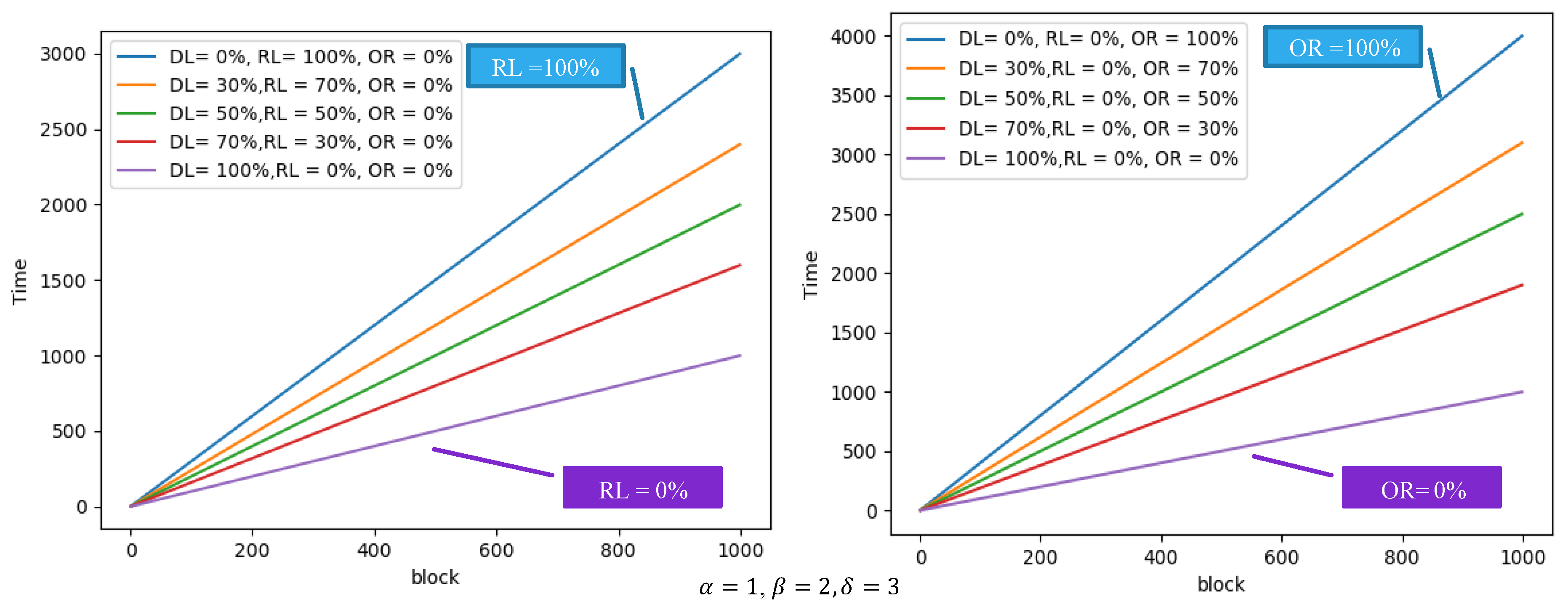
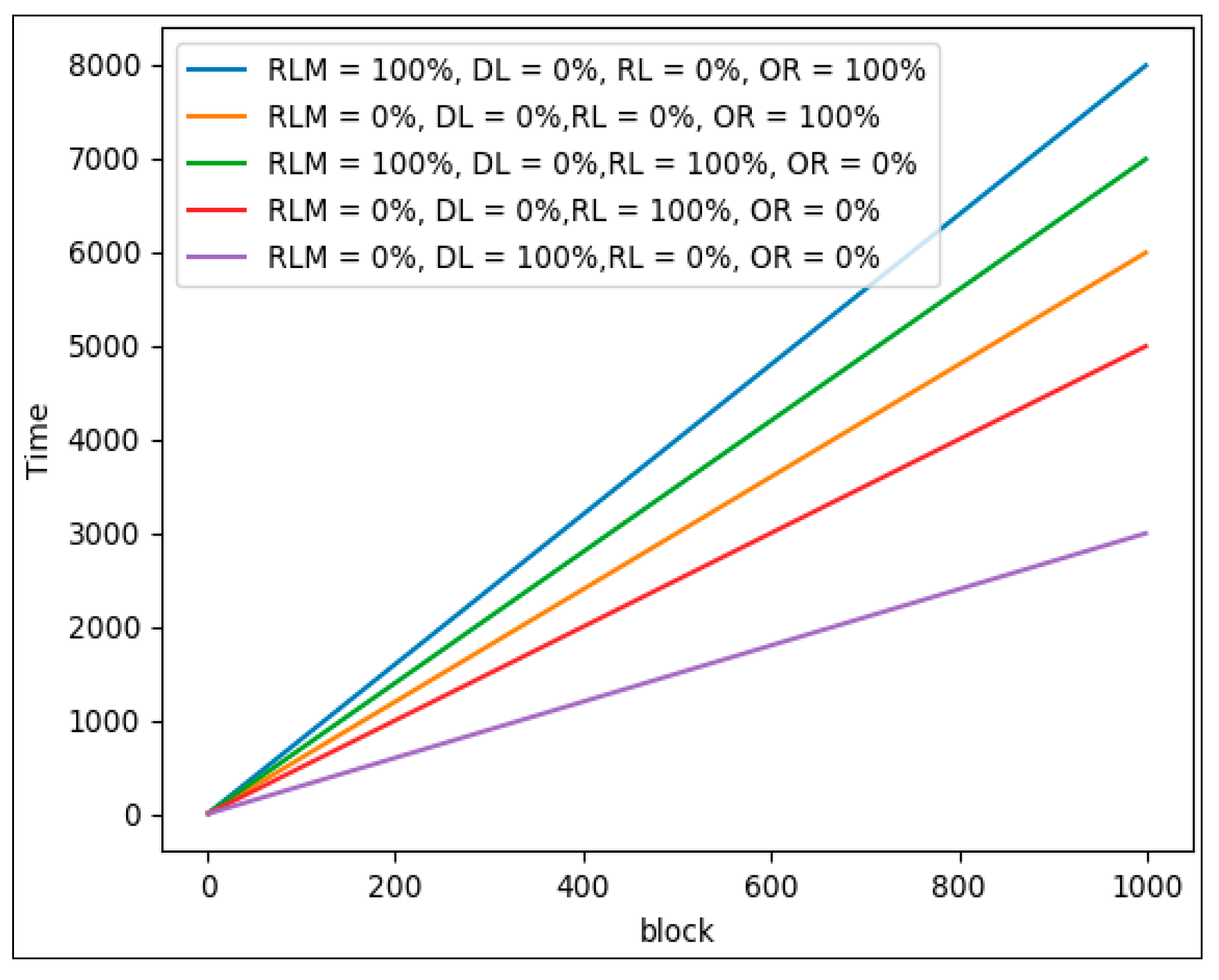
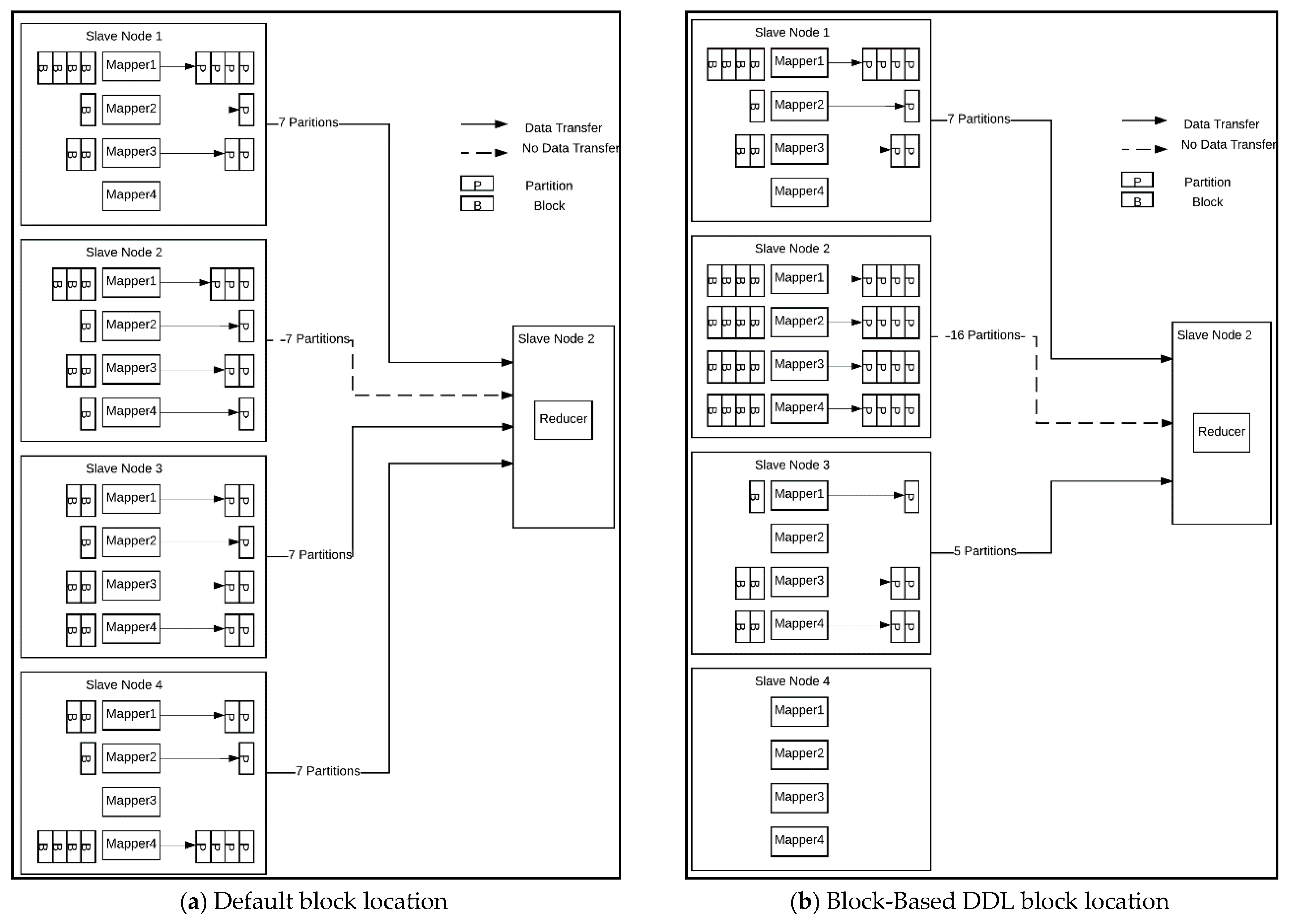
4. Deep Data Locality
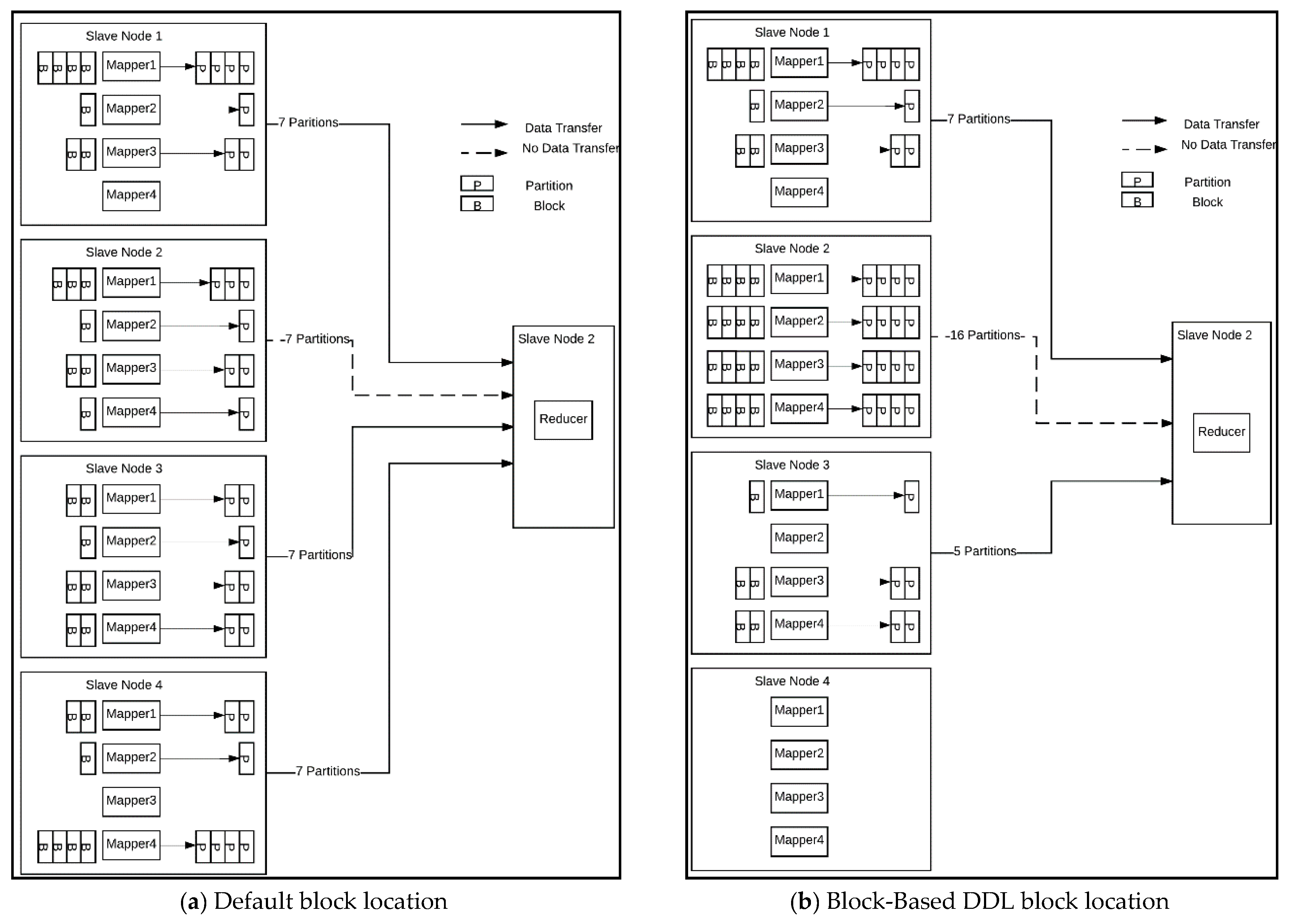
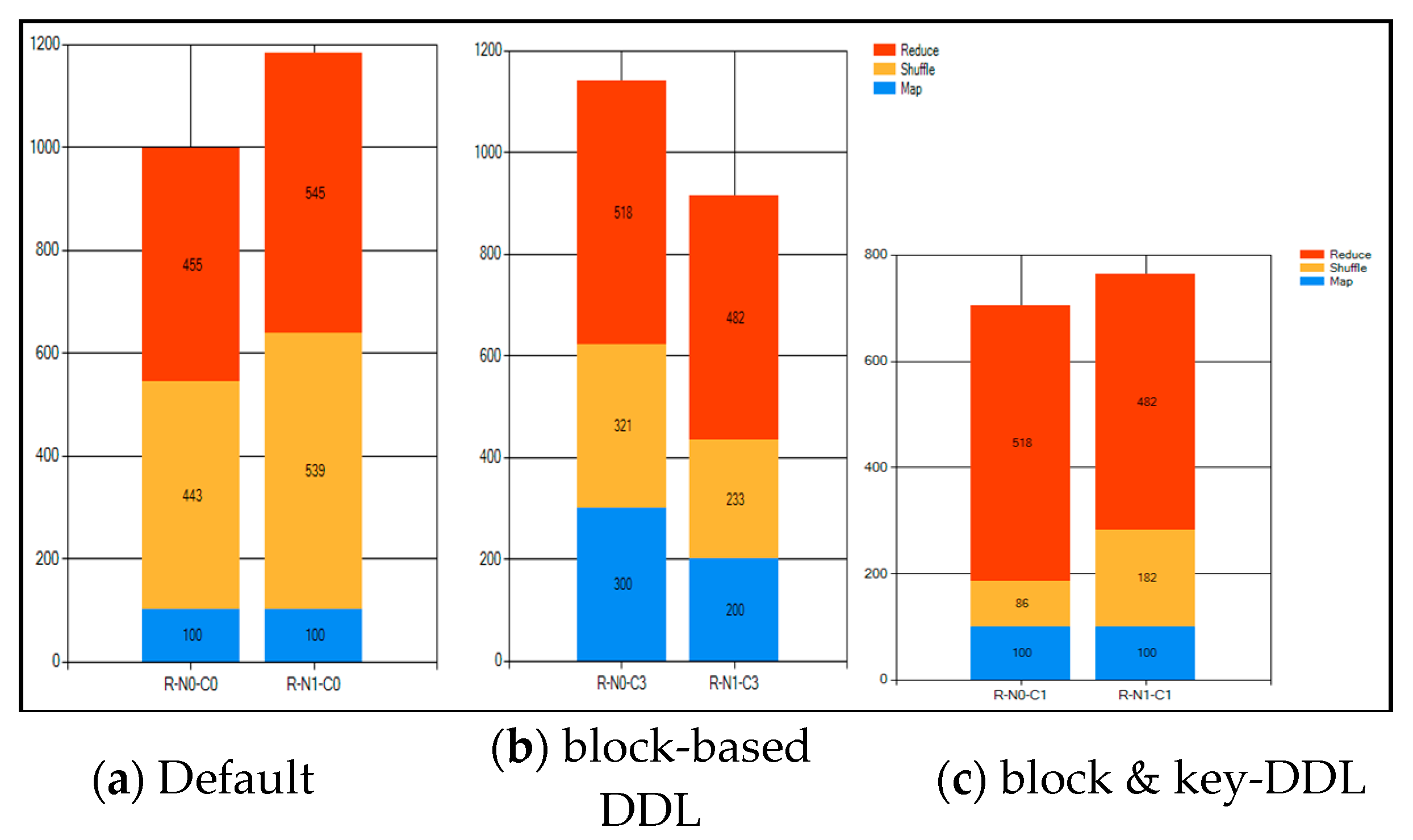
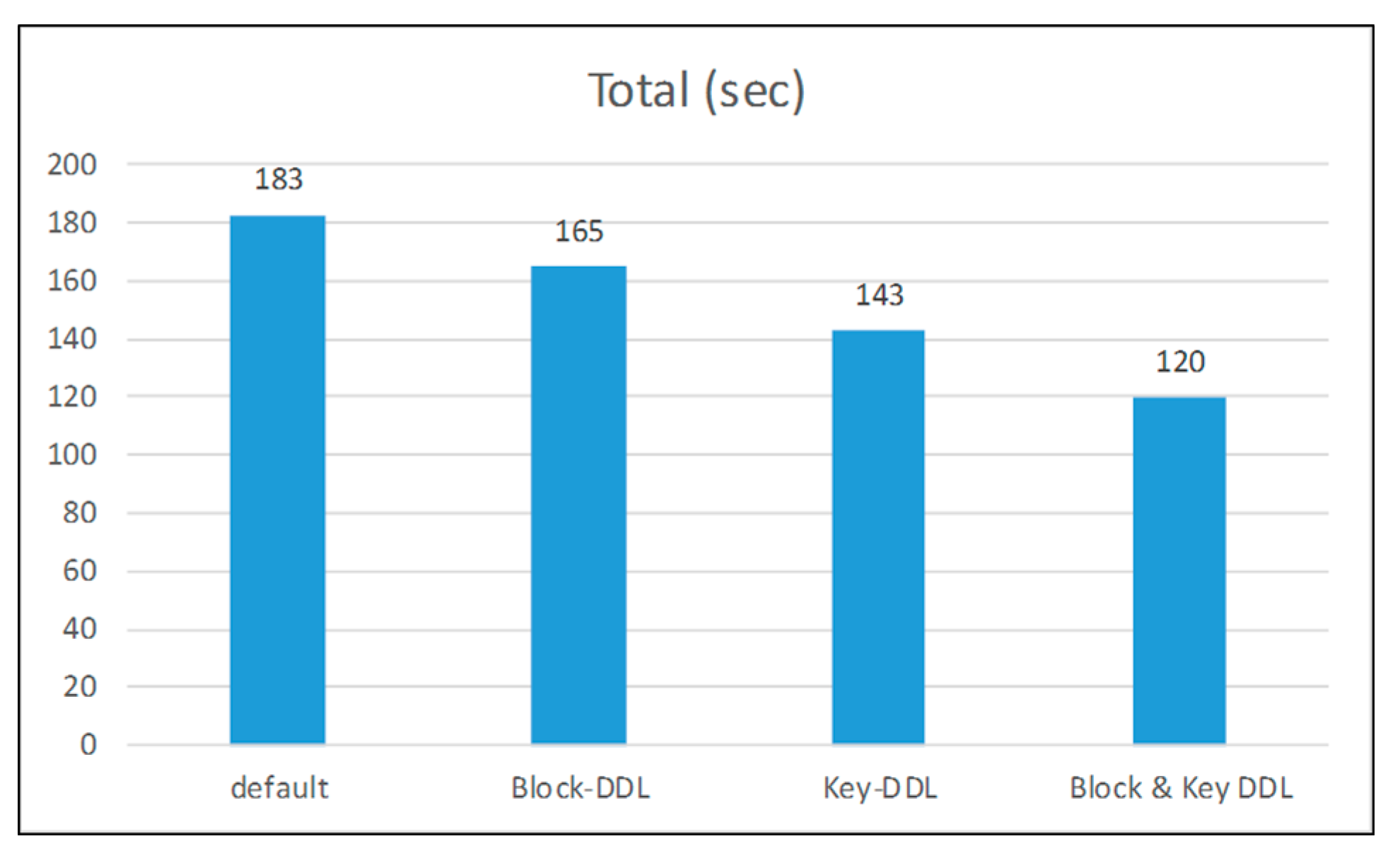
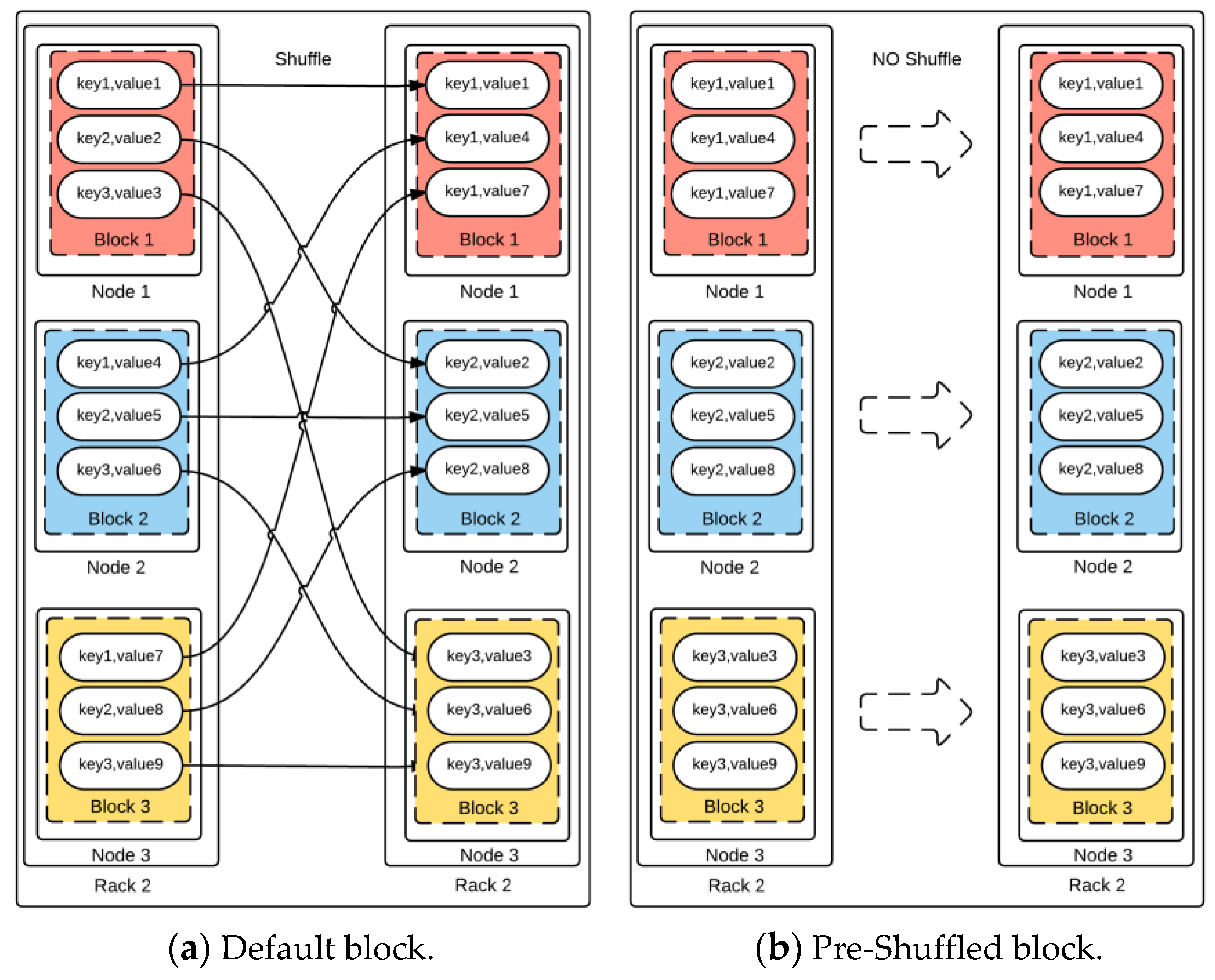
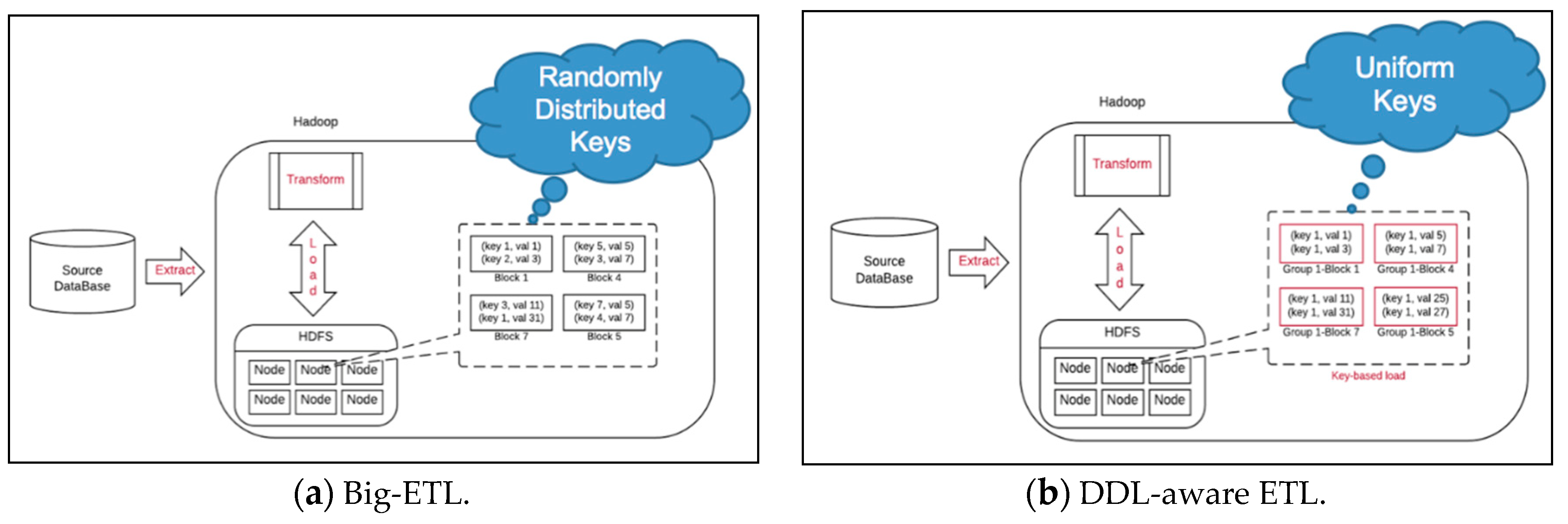
4.1. Block-Based DDL
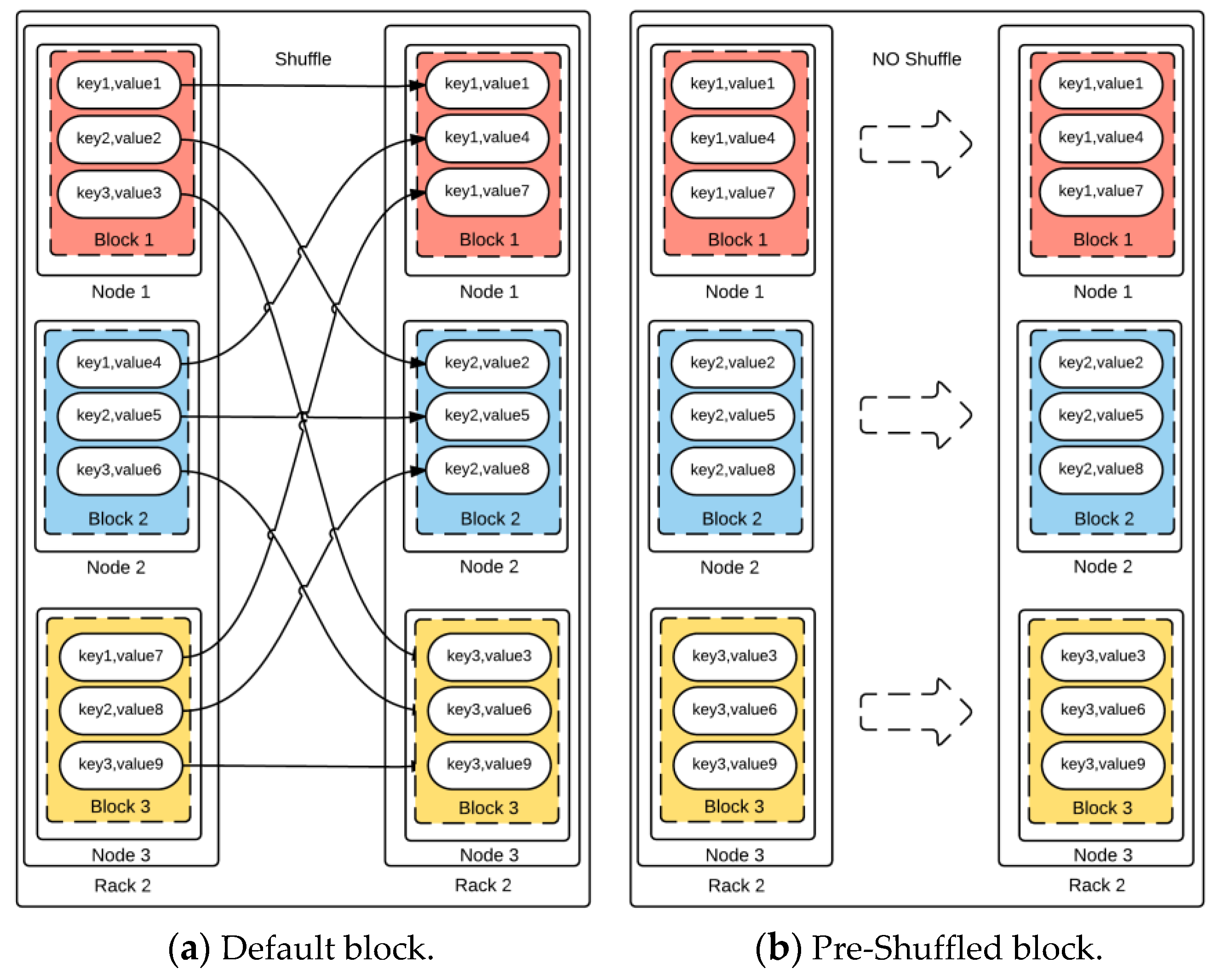
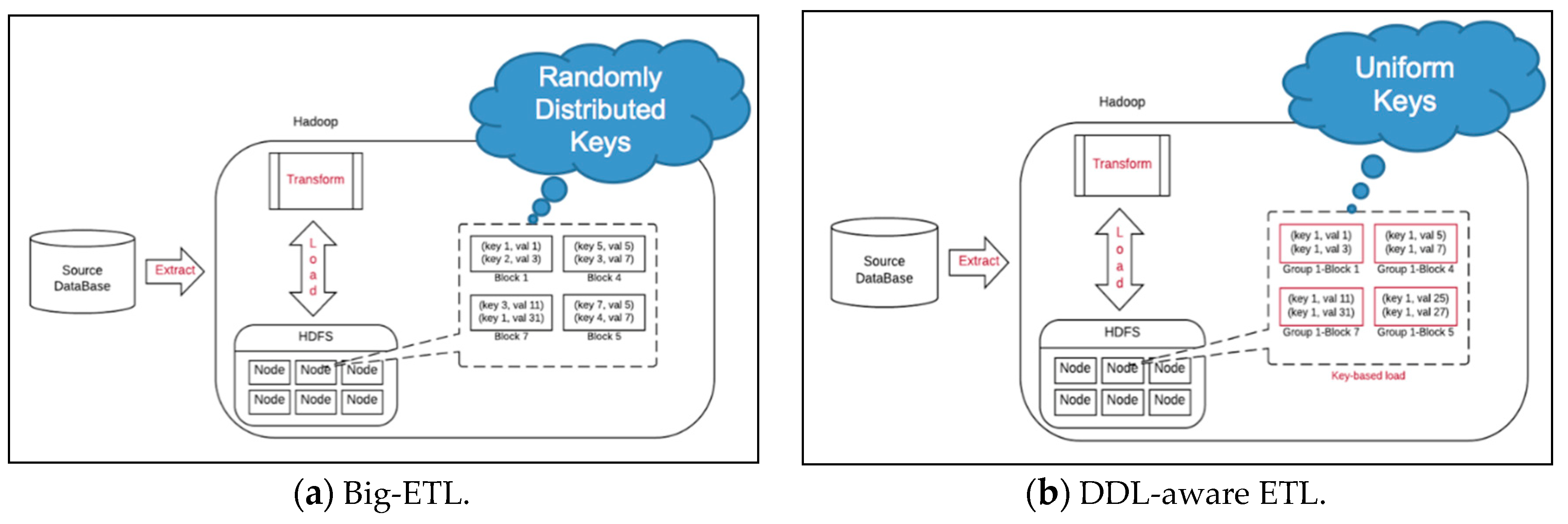
4.2. Key-Based DDL
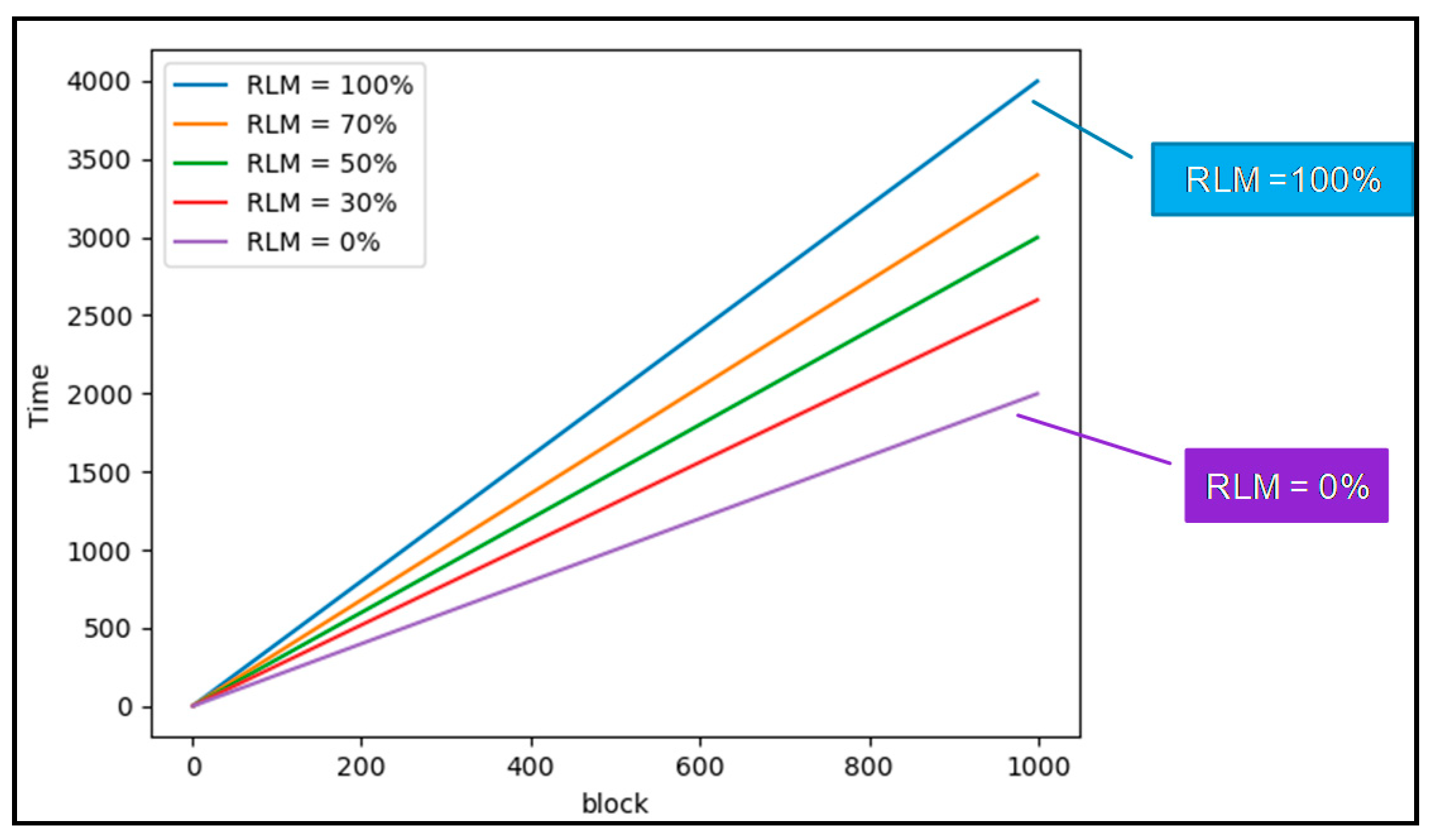
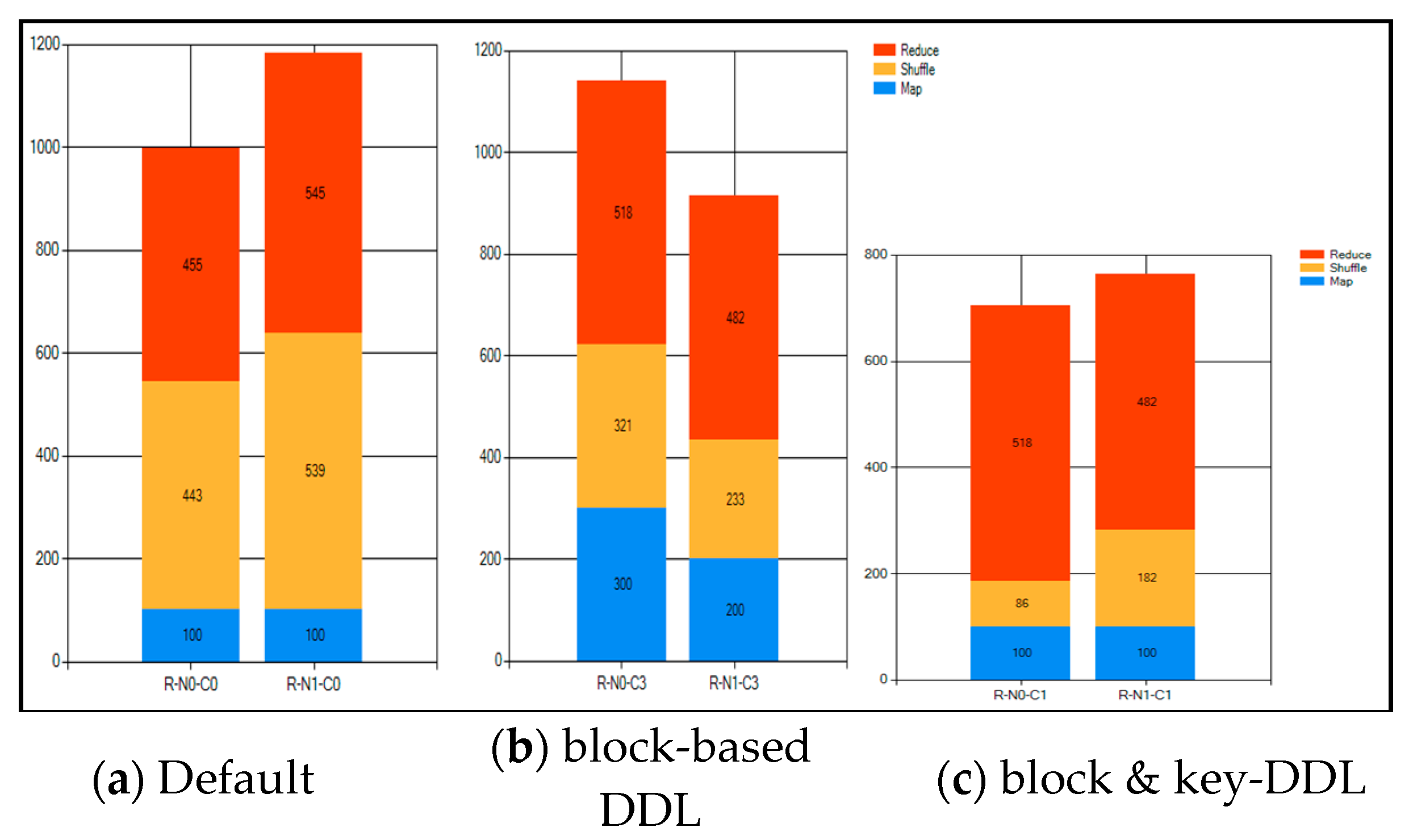
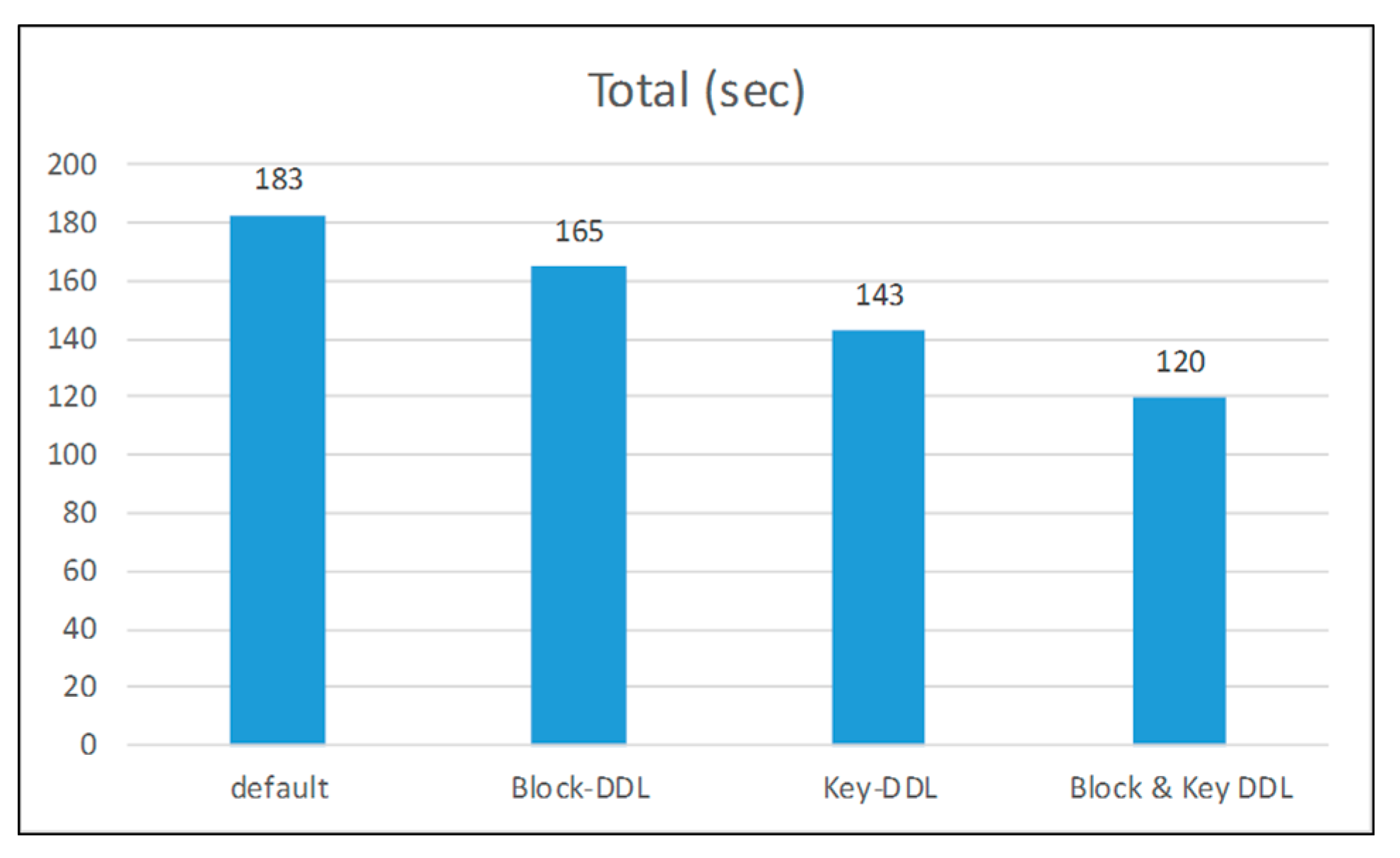
5. Performance Testing
5.1. Hadoop Performance Test on Cloud
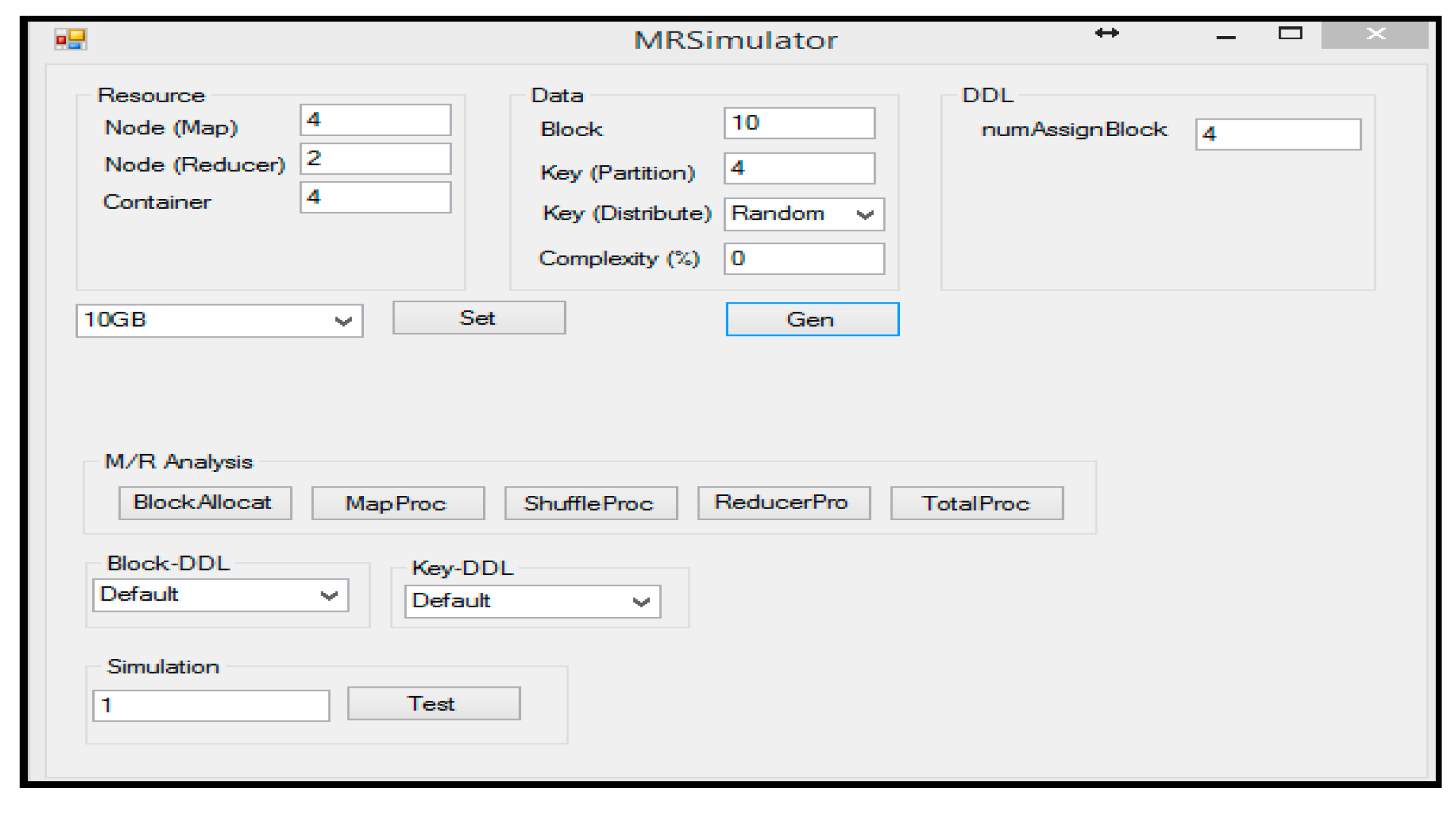
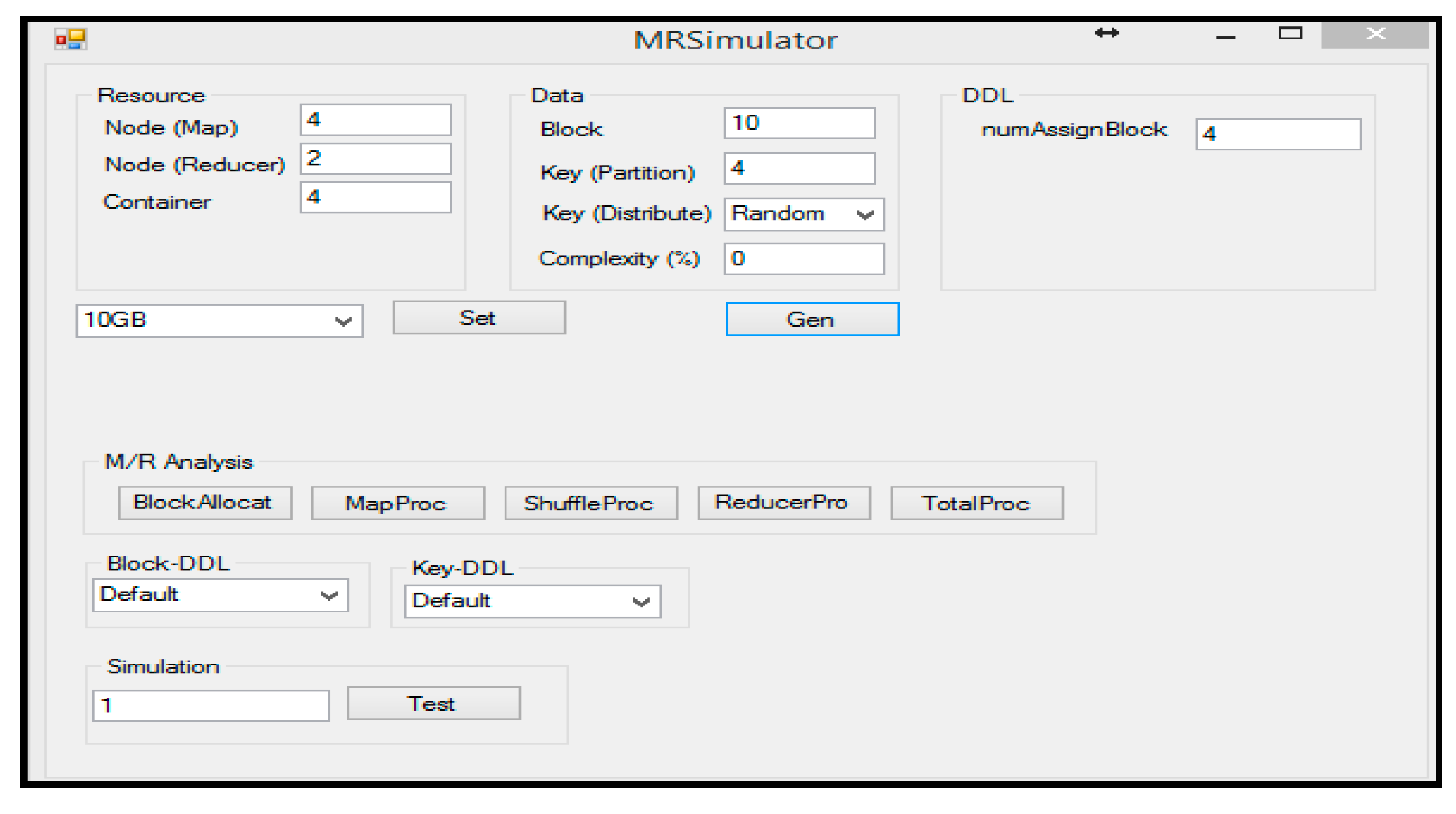
5.2. Hadoop Performance Test on Simulator
5.3. Hadoop Performance Test on Hardware Implementation
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Gantz, J.; Reisel, D. The Digital Universe in 2020: Big Data, Bigger Digital Shadows, and Biggest Growth in the Far East. Available online: https://www.emc.com/collateral/analyst-reports/idc-digital-universe-united-states.pdf (accessed on 10 June 2019).
- Hadoop. Available online: http://hadoop.apache.org/ (accessed on 10 June 2019).
- Hadoop YARN. Available online: https://hadoop.apache.org/docs/r2.7.1/hadoop-yarn/hadoop-yarn-site/YARN.html (accessed on 10 June 2019).
- Apache Storm. Available online: http://storm.apache.org/ (accessed on 10 June 2019).
- Apache Spark. Available online: http://spark.apache.org/ (accessed on 10 June 2019).
- Apache HBase. Available online: https://hbase.apache.org/ (accessed on 10 June 2019).
- R Open Source Projects. Available online: http://projects.revolutionanalytics.com/rhadoop/ (accessed on 10 June 2019).
- MATLAB MapReduce and Hadoop. Available online: http://www.mathworks.com/discovery/matlab-mapreduce-hadoop.html (accessed on 10 June 2019).
- Hadoop MapReduce. Available online: https://hadoop.apache.org/docs/r2.7.1/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html (accessed on 10 June 2019).
- Tang, S.; Lee, B.S.; He, B. DynamicMR: A Dynamic Slot Allocation Optimization Framework for MapReduce Clusters. IEEE Trans Cloud Comput. 2014, 2, 333–347. [Google Scholar] [CrossRef]
- Membrey, P.; Chan, K.C.C.; Demchenko, Y. A Disk Based Stream Oriented Approach for Storing Big Data. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems, San Diego, CA, USA, 20–24 May 2013; pp. 56–64. [Google Scholar]
- Hou, X.; Ashwin Kumar, T.K.; Thomas, J.P.; Varadharajan, V. Dynamic Workload Balancing for Hadoop MapReduce. In Proceedings of the Fourth IEEE International Conference on Big Data and Cloud Computing, Sydney, Australia, 3–5 December 2014; pp. 56–62. [Google Scholar]
- Hammoud, M.; Sakr, M.F. Locality-Aware Reduce Task Scheduling for MapReduce. In Proceedings of the Third IEEE International Conference on Cloud Computing Technology and Science, Athens, Greece, 29 November–1 December 2011; pp. 570–576. [Google Scholar]
- Dai, X.; Bensaou, B. A Novel. Decentralized Asynchronous Scheduler for Hadoop. Communications QoS, Reliability and Modelling Symp. In Proceedings of the 2013 IEEE Global Communications Conference, Atlanta, GA, USA, 9–13 December 2013; pp. 1470–1475. [Google Scholar]
- Zhu, H.; Chen, H. Adaptive Failure Detection via Heartbeat under Hadoop. In Proceedings of the IEEE Asia -Pacific Services Computing Conference, Jeju, Korea, 12–15 December 2011; pp. 231–238. [Google Scholar]
- Nishanth, S.; Radhikaa, B.; Ragavendar, T.J.; Babu, C.; Prabavathy, B. CoRadoop++: A Load Balanced Data Colocation in Radoop Distributed File System. In Proceedings of the IEEE 5th International Conference on Advanced Computing, ICoAC 2013, Chennai, India, 18–20 December 2013; pp. 100–105. [Google Scholar]
- Elshater, Y.; Martin, P.; Rope, D.; McRoberts, M.; Statchuk, C. A Study of Data Locality in YARN. In Proceedings of the IEEE International Congress on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 174–181. [Google Scholar]
- Qin, P.; Dai, B.; Huang, B.; Xu, G. Bandwidth-Aware Scheduling with SDN in Hadoop: A New Trend for Big Data. IEEE Syst. J. 2015, 11, 1–8. [Google Scholar] [CrossRef]
- Lu, X.; Islam , N.S.; Wasi-ur-Rahman, M.; Jose, J.; Subramoni, H.; Wang, H.; Panda, D.K. High-Performance Design of Hadoop RPC with RDMA over InfiniBand. In Proceedings of the 42nd IEEE International Conference on Parallel Processing, Lyon, France, 1–4 October 2013; pp. 641–650. [Google Scholar]
- Basak, A.; Brnster, I.; Ma, X.; Mengshoel, O.J. Accelerating Bayesian network parameter learning using Hadoop and MapReduce. In Proceedings of the 1st International Workshop on Big Data, Streams and Heterogeneous Source Mining: Algorithms, Systems, Programming Models and Applications, Beijing, China, 12 August 2012; pp. 101–108. [Google Scholar]
- Iwazume, M.; Iwase, T.; Tanaka, K.; Fujii, H.; Hijiya, M.; Haraguchi, H. Big Data in Memory: Benchimarking In Memory Database Using the Distributed Key-Value Store for Machine to Machine Communication. In Proceedings of the 15th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Beijing, China, 30 June–2 July 2014; pp. 1–7. [Google Scholar]
- SAP HANA. Available online: http://hana.sap.com/abouthana.html (accessed on 10 June 2019).
- Islam, N.S.; Wasi-ur-Rahman, M.; Lu, X.; Shankar, D.; Panda, D.K. Performance Characterization and Acceleration of In-Memory File Systems for Hadoop and Spark Applications on HPC Clusters. In Proceedings of the International Conference on Big Data, IEEE Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 243–252. [Google Scholar]
- Hadoop HDFS. Available online: https://issues.apache.org/jira/browse/HDFS/ (accessed on 10 June 2019).
- Lee, S. Deep Data Locality on Apache Hadoop. Ph.D. Thesis, The University of Nevada, Las Vegas, NV, USA, 10 May 2018. [Google Scholar]
- MapR. Available online: https://www.mapr.com/products/product-overview/shark (accessed on 10 June 2019).
- Lee, S.; Jo, J.-Y.; Kim, Y. Survey of Data Locality in Apache Hadoop. In Proceedings of the 4th IEEE/ACIS International Conference on Big Data, Cloud Computing, and Data Science Engineering (BCD), Honolulu, HI, USA, 29–31 May 2019. [Google Scholar]
- Lee, S.; Jo, J.-Y.; Kim, Y. Key based Deep Data Locality on Hadoop. In Proceedings of the IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 3889–3898. [Google Scholar]
- Lee, S.; Jo, J.-Y.; Kim, Y. Performance Improvement of MapReduce Process by Promoting Deep Data Locality. In Proceedings of the 3rd IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 292–301. [Google Scholar]
- IBM, InfoSphere Data Stage. Available online: https://www.ibm.com/ms-en/marketplace/datastage (accessed on 10 June 2019).
- Oracle. Data Integrator. Available online: http://www.oracle.com/technetwork/middleware/data-integrator/overview/index.html (accessed on 10 June 2019).
- Informatica. PowerCenter. Available online: https://www.informatica.com/products/data-integration/powercenter.html#fbid=uzsZzvdWlvX (accessed on 10 June 2019).
- DataStream. TeraStream. Available online: http://datastreamsglobal.com/ (accessed on 10 June 2019).
- Cloudlab. Available online: https://www.cloudlab.us/ (accessed on 10 June 2019).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Constant Symbol | Definition | Time Symbol | Definition |
|---|---|---|---|
| α | Processing time for one block | T1 | Processing time of First Stage (TM + TS) |
| β | Transferring time of one block under Rack-Local | TM | Processing time of Map function |
| TS | Processing time of Sort, Spill, Fetch in Shuffle | ||
| δ | Transferring time of one block under Off-Rack | T2 | Processing time of Second Stage (TT + TR) |
| TT | Processing time of Transfer in Shuffle | ||
| γ | Processing time of Sort, Spill and Fetch for one block | TR | Processing time of Reduce function |
| T | Total processing time of Hadoop |
| Symbol | Definition | Symbol | Definition |
|---|---|---|---|
| M | Number of Mapper in Map | Bi | Set of allocated blocks in Mapper (i), {b1, b2, …, bB} |
| R | Number of Reducer in Reduce | |Bi| | Total number of allocated blocks in Mapper (i) |
| RLMi | Number of Rack Local Map (RLM) in Mapper (i) | Pr | Ratio of Partition in Mapper, {P1, P2, …, Pr} |
| i | Mapper ID | RDL | Ratio of Disk-Local |
| j | Reducer ID | RRL | Ratio of Rack-Local |
| b | Block ID | ROR | Ratio of Off-Rack |
| Map (s) | Shuffle (s) | Total (min) | Map (s) | Shuffle (s) | Total (min) | Map (s) | Shuffle (s) | Total (min) | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Default-Job1-30G | 26 | 463 | 27 | Default-Job1-60G | 25 | 929 | 71 | Default-Job1-120G | 28 | 2345 | 165 |
| Default-Job2-30G | 30 | 431 | 27 | Default-Job2-60G | 27 | 906 | 76 | Default-Job2-120G | 32 | 1968 | 165 |
| LNBPP-Job1-30G | 22 | 292 | 21 | LNBPP-Job1-60G | 24 | 721 | 59 | LNBPP-Job1-120G | 24 | 1475 | 150 |
| LNBPP-Job2-30G | 20 | 328 | 25 | LNBPP-Job2-60G | 22 | 771 | 62 | LNBPP-Job2-120G | 25 | 1647 | 150 |
| Decrease Time (%) | 25% | 30.7% | 14.8% | Decrease Time (%) | 11.5% | 18.7% | 17.7% | Decrease Time (%) | 18.3% | 27.6% | 9% |
| Block-DDL | Key-DDL | Block& Key-DDL | |
|---|---|---|---|
| Default | 9.8% | 21.9% | 34.4% |
| Block-DDL | N/A | 13.3% | 27.3% |
| Key-DDL | N/A | N/A | 16.1% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Jo, J.-Y.; Kim, Y. Hadoop Performance Analysis Model with Deep Data Locality. Information 2019, 10, 222. https://doi.org/10.3390/info10070222
Lee S, Jo J-Y, Kim Y. Hadoop Performance Analysis Model with Deep Data Locality. Information. 2019; 10(7):222. https://doi.org/10.3390/info10070222
Chicago/Turabian StyleLee, Sungchul, Ju-Yeon Jo, and Yoohwan Kim. 2019. "Hadoop Performance Analysis Model with Deep Data Locality" Information 10, no. 7: 222. https://doi.org/10.3390/info10070222
APA StyleLee, S., Jo, J.-Y., & Kim, Y. (2019). Hadoop Performance Analysis Model with Deep Data Locality. Information, 10(7), 222. https://doi.org/10.3390/info10070222