Aggregation of Linked Data in the Cultural Heritage Domain: A Case Study in the Europeana Network †

 ,
,  and
and
Abstract
1. Introduction
- For those already making available linked data through their digital libraries, the process of sharing metadata with cultural heritage aggregators would not require much additional effort, since they could simply provide the linked data that they already make available for other purposes.
- For those that are not yet publishing linked data, setting-up the technological infrastructure for cultural heritage aggregation based on linked data, would be more beneficial, because, in addition, they would benefit from wider interoperability with other application cases than aggregation, and possibly with other domains besides cultural heritage.
1.1. Characterization of Metadata Aggregation in Cultural Heritage, and the Specific Case of Europeana
- Cultural heritage is divided in subdomains: Libraries, Museums, Archives, and Galleries.
- All subdomains apply their own resource description data models, norms and practices.
- Not all subdomains have a significant definition of standards-based solutions for description of cultural heritage resources, or they are only adopted by a few institutions. Libraries have traditionally established cooperation within its domain to enable shared services for bibliographic data. For archives and museums, however, the existing norms and standards have resulted from more recent cooperation.
- Interoperable information systems and data models are not common across subdomains. Within each of the subdomain, however, interoperable systems are frequently found. The interoperability is sometimes established within a country, and also at a wider international level, particularly in the subdomains of libraries and archives.
- XML-Schema data models are the basis of most of the adopted standards. Interoperable data models defined for relational data are not commonly found.
- The adoption of new technologies is not very agile, and may not be systematic in the early stages (for example, we have observed this aspect in the application of structured data in the Web by cultural heritage institutions [4]). Organizations operate with limited financial resources to invest in information technology innovation.
1.2. Related Work
2. Materials and Methods
2.1. Requirements
- Requirement R1—Data providers must be able to provide a linked data resource providing metadata about their dataset.
- Requirement R2—Data providers must be able to specify complete datasets or only some subset(s), because parts of the complete dataset may be out-of-scope, or not compliant, with aggregation for Europeana.
- Requirement R3—Data providers must be able to specify machine-actionable licensing statements regarding their metadata (we use the term ‘machine-actionable’ throughout this article because for automatic processing, a solution requires more than machine-readable metadata; it requires data that contains sufficient semantics for the functionality to be performed by software). Since it is not always the case that all resources in a dataset have the same associated license, data providers should be able to specify the license both for the complete dataset, and for each individual metadata resource.
- Requirement R4—Data providers must provide a machine-actionable specification of the available mechanisms, and their respective access information, to harvest the dataset or to download it in a standard distribution format.
- Requirement R5—The aggregator must be able to apply fully automatic methods to harvest or download the linked data datasets specified by its data providers.
- Constraint C1—All data communications between data providers and the aggregator must be done with standard technologies of the Semantic Web and linked data.
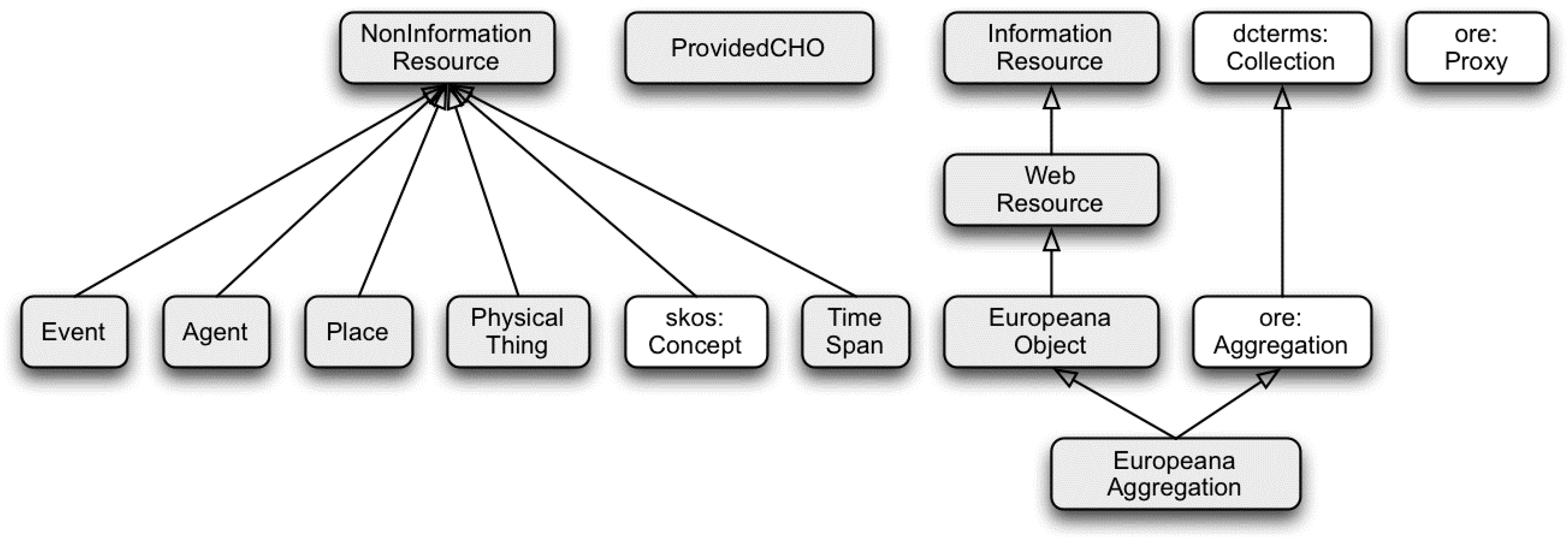
- Constraint C2—The final data model of the aggregated metadata must be EDM, because EDM is the data model that all Europeana systems, and many of its aggregators, are built on (note that at Europeana, EDM supports more than the metadata aggregation infrastructure; for example, EDM is underlying its information retrieval engine, end-user portal, APIs and other systems for data distribution). Other data models, and vocabularies not used in EDM, may be used in the intermediate steps of the aggregation’s workflow, however.
- Constraint C3—The solution must simplify the requirements for data providers to provide data to cultural heritage networks. The technical requirements should have low barriers for adoption by data providers and allow the re-use of existing linked data resources available at data providers, and which are compliant with the requirements of the cultural heritage network.
- Constraint C4—The manual effort required for the aggregators should not increase with a new solution. The data integration work required from linked data sources should be automated as much as possible in order to decrease, or at least maintain, the current operational costs of the cultural heritage networks.
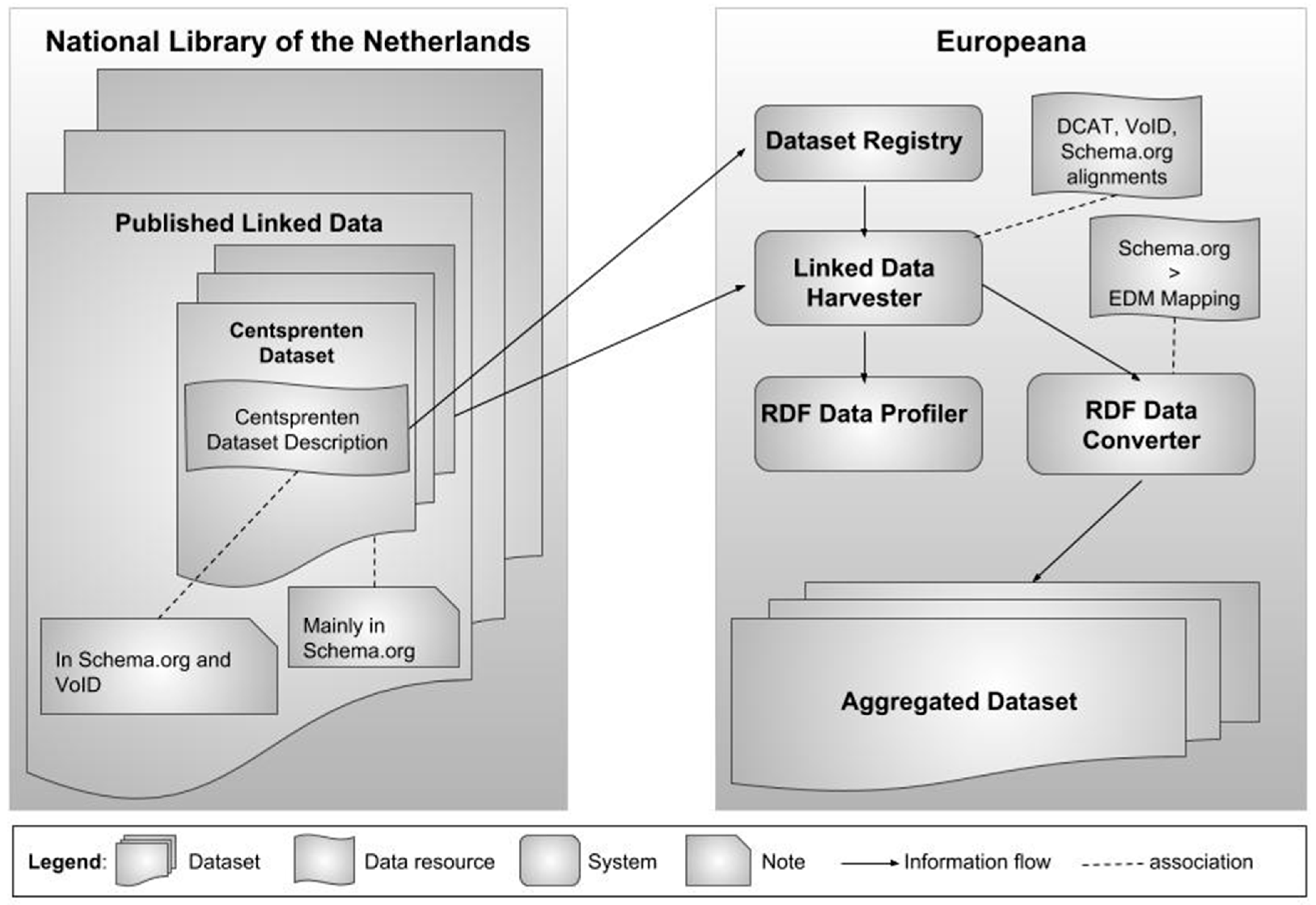
2.2. Workflow
- Publish dataset description—The data provider describes its dataset as a linked data RDF resource. It contains descriptive information about the cultural heritage content covered by the dataset and technical details about how the dataset can be collected by the aggregator.
- Register the dataset’s URI—The data provider notifies the aggregator of the availability of its dataset for aggregation. This notification consists of at least the URI of the dataset’s RDF description that is created in the first activity, from which the aggregator may collect the information he requires to process the dataset.
- Harvest dataset—The dataset is harvested by the aggregation system. The system follows the instructions for automatic dataset collection defined in the dataset’s RDF description.
- Profile dataset—The aggregator creates a data profile of the harvested dataset, supported by tools that analyze the aspects of the dataset relevant for performing its aggregation and integration into the central dataset. A dataset’s profile allows the aggregator to detect deficiencies in the dataset and notify the data provider about them. The profile also supports the assessment of the effort (regarding specific data preparation tasks) required for the next steps of the workflow.
- Align data model and vocabularies—The aggregator analyzes the data model and vocabularies used by the linked data of the data provider, and compares them with the reference data model it uses (typically EDM or a profile thereof). As a result of this analysis, the aggregator sets any alignments necessary between the two models. In cases where the data provider’s linked data is based on EDM, no alignments are necessary, unless one of the existing extensions of EDM is used. The alignment task is supported by the report resulting from the profiling of the dataset and by software tools for data alignment and data integration.
- Convert dataset—The system converts the harvested linked data to the data model used in the central aggregated dataset. The conversion follows the data model alignments defined in the previous activity. The resulting EDM data is inspected by the aggregator according to the relevant validation and data quality assurance practices.
- Integrate dataset—The linked data aggregation system transfers the converted dataset to the regular ingestion systems of the aggregator. The dataset in EDM will then be processed by the regular data integration workflow of the aggregator, which is independent of the initial harvesting method applied for the dataset.
2.3. Pilot Setup
3. Results
3.1. Dataset Description
3.2. Dataset Registry
3.3. Linked Data Harvester
- Based on crawling through root resources—in this option, data providers use the property void:rootResource pointing to entry points that allow the crawler to reach the resources that describe the cultural heritage objects. One or more root resources can be specified, and they may refer directly to the URIs of cultural heritage objects.
- Based on downloading a distribution—by using this option, data providers have the possibility to use the classes and properties of any of the vocabularies, given that all three support this mechanism. The downloadable distribution must be available as RDF files using one well known serialization for RDF.
3.4. RDF Data Profiler
3.5. Schema.org to Europeana Data Model Mapping
3.6. RDF Data Converter
4. Discussion
- Adoption by data providers—During the pilot, the implementation of the requirements was always done without much effort from the KB. Also, in the process, the KB was able to reuse its previous linked data work. The example of the KB, however, cannot represent all cultural heritage data providers, since not all of them have previous experience with linked data. Institutions without in-house knowledge of linked data are likely to find the requirements more challenging, since they will need to employ many of the techniques underlying linked data technology. Another observation is that the freedom to apply another data model to represent the cultural heritage objects was a motivation for the KB. In this case Schema.org was a good motivation for KB since it is capable to reach wider audiences than EDM, particularly through internet search engines.
- Adoption by aggregators—We found that the implementation of the requirements was more demanding for the aggregator than for the data provider. Nowadays, the majority of aggregators operate based on XML solutions, while for a linked data workflow, aggregators need to deploy data processing software for RDF data. More knowledge in RDF may be necessary in organizations, especially for information technology departments and for data officers who need to align the linked data models in use by providers with the EDM required by Europeana. The impact on human resources would be especially important for the aggregators who do not yet need to align data models, because they require EDM from their providers and thus operate solely on EDM data.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity and Variety. META Group Research. Available online: https://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf (accessed on 29 May 2019).
- Lagoze, C.; van de Sompel, H.; Nelson, M.L.; Warner, S. The Open Archives Initiative Protocol for Metadata Harvesting, Version 2.0. Open Archives Initiative. Available online: http://www.openarchives.org/OAI/2.0/openarchivesprotocol.htm (accessed on 29 May 2019).
- Niggermann, E.; Cousins, J.; Sanderhoff, M. Europeana Business Plan 2018 ‘Democratizing Culture’. Europeana Foundation. Available online: https://pro.europeana.eu/files/Europeana_Professional/Publications/Europeana_Business_Plan_2018.pdf (accessed on 29 May 2019).
- Freire, N.; Calado, P.; Martins, B. Availability of Cultural Heritage Structured Metadata in the World Wide Web. In Connecting the Knowledge Commons—From Projects to Sustainable Infrastructure; Chan, L., Mounier, P., Eds.; OpenEdition Press: Marseille, France, 2019. [Google Scholar]
- Europeana Foundation. Definition of the Europeana Data Model v5.2.8. Available online: http://pro.europeana.eu/edm-documentation (accessed on 29 May 2019).
- Gradmann, S. Knowledge = Information in Context: On the Importance of Semantic Contextualisation in Europeana. Europeana Foundation. Available online: http://pro.europeana.eu/publication/knowledgeinformation-in-context (accessed on 29 May 2019).
- BBC. A Guide to the Research & Education Space for Contributors and Developers. Available online: https://bbcarchdev.github.io/inside-acropolis/ (accessed on 29 May 2019).
- DPLA. Metadata Application Profile, version 5.0. Digital Public Library of America. Available online: https://drive.google.com/file/d/1fJEWhnYy5Ch7_ef_-V48-FAViA72OieG/view (accessed on 29 May 2019).
- Berners-Lee, T. Linked Data Design Issues. W3C-Internal Document. Available online: http://www.w3.org/DesignIssues/LinkedData.html (accessed on 29 May 2019).
- Van de Sompel, H.; Michael, L.N. Reminiscing About 15 Years of Interoperability Efforts. D-Lib Mag. 2015, 21. [Google Scholar] [CrossRef]
- Richardson, L.; Ruby, S. Restful Web Services; O’Reilly: Boston, MA, USA, 2007. [Google Scholar]
- NISO. ResourceSync Framework Specification. National Information Standards Organization. Available online: http://www.niso.org/apps/group_public/download.php/12904/z39-99-2014_resourcesync.pdf (accessed on 29 May 2019).
- Simou, N.; Chortaras, A.; Stamou, G.; Kollias, S. Enriching and Publishing Cultural Heritage as Linked Open Data. In Mixed Reality and Gamification for Cultural Heritage; Springer: Cham, Switzerland, 2017; pp. 201–223. [Google Scholar]
- Hyvönen, E. Publishing and Using Cultural Heritage Linked Data on the Semantic Web. Synth. Lect. Semantic Web Theory Technol. 2012, 2. [Google Scholar] [CrossRef]
- Jones, E.; Seikel, M. Linked Data for Cultural Heritage; Facet Publishing: Cambridge, UK, 2016. [Google Scholar]
- Szekely, P.; Knoblock, C.A.; Yang, F.; Zhu, X.; Fink, E.E.; Allen, R.; Goodlander, G. Connecting the Smithsonian American Art Museum to the Linked Data Cloud. In Proceedings of the Semantic Web: Semantics and Big Data, Montpellier, France, 26–30 May 2013; pp. 593–607. [Google Scholar]
- Dragoni, M.; Tonelli, S.; Moretti, G. A Knowledge Management Architecture for Digital Cultural Heritage. J. Comput. Cult. Herit. 2017, 10, 3. [Google Scholar] [CrossRef]
- Meijer, E.; de Valk, S. A Distributed Network of Heritage Information. Available online: https://github.com/netwerk-digitaal-erfgoed/general-documentation/blob/master/Whitepaper%20A%20distributed%20network%20of%20heritage%20information.md (accessed on 15 June 2019).
- Vander Sande, M.; Verborgh, R.; Hochstenbach, P.; Van de Sompel, H. Towards sustainable publishing and querying of distributed Linked Data archives. J. Documentation 2018, 74, 195–222. [Google Scholar] [CrossRef]
- Freire, N.; Manguinhas, H.; Isaac, A.; Robson, G.; Howard, J.B. Web technologies: A survey of their applicability to metadata aggregation in cultural heritage. Inf. Serv. Use J. 2018, 37, 4. [Google Scholar]
- Freire, N.; Robson, G.; Howard, J.B.; Manguinhas, H.; Isaac, A. Metadata Aggregation: Assessing the Application of IIIF and Sitemaps within Cultural Heritage. In Proceedings of the Research and Advanced Technology for Digital Libraries, Thessaloniki, Greece, 18–21 September 2017. [Google Scholar]
- Freire, N.; Charles, V.; Isaac, A. Evaluation of Schema.org for Aggregation of Cultural Heritage Metadata. In Proceedings of the Semantic Web (ESWC 2018), Heraklion, Crete, Greece, 3–7 June 2018. [Google Scholar]
- Google Inc.; Yahoo Inc. Microsoft Corporation and Yandex, “About Schema.org”, n.d. Available online: http://schema.org/docs/about.html (accessed on 29 May 2019).
- Wallis, R.; Isaac, A.; Charles, V.; Manguinhas, H. Recommendations for the application of Schema.org to aggregated Cultural Heritage metadata to increase relevance and visibility to search engines: The case of Europeana. Code4Lib J. 2017, 36, 12330. [Google Scholar]
- Freire, N.; Meijers, E.; Voorburg, R.; Isaac, A. Aggregation of cultural heritage datasets through the Web of Data. Procedia Comput. Sci. 2018, 137, 120–126. [Google Scholar] [CrossRef]
- Alexander, K.; Cyganiak, R.; Hausenblas, M.; Zhao, J. Describing Linked Datasets with the VoID Vocabulary. W3C Interest Group Note. Available online: https://www.w3.org/TR/void/ (accessed on 29 May 2019).
- Maali, F.; Reikson, J. Data Catalog Vocabulary (DCAT). W3C Recommendation. Available online: https://www.w3.org/TR/vocab-dcat/ (accessed on 29 May 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Requirement | DCAT | Schema.org | VoID |
|---|---|---|---|
| Class for ‘Dataset’ | dcat:Dataset | Schema:Dataset | void:Dataset |
| Title of the dataset | dcterms:title | schema:name | dcterms:title |
| Class for Distribution | dcat:Distribution (associated with the dataset with dcat:distribution) | schema:DataDownload (associated with the dataset with schema:distribution) | A Distribution class is not defined by VoID. The distribution is represented as properties of the dataset |
| Dataset level license | dcterms:license | schema:license | dcterms:license |
| Downloadable distribution | dcat:download URL dcat:mediaType | schema:contentUrl schema:encodingFormat | void:dataDump void:feature void:TechnicalFeature |
| Listing of URIs | Not (yet) supported in DCAT | Not supported in Schema.org | void:rootResource |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Freire, N.; Voorburg, R.; Cornelissen, R.; de Valk, S.; Meijers, E.; Isaac, A. Aggregation of Linked Data in the Cultural Heritage Domain: A Case Study in the Europeana Network. Information 2019, 10, 252. https://doi.org/10.3390/info10080252
Freire N, Voorburg R, Cornelissen R, de Valk S, Meijers E, Isaac A. Aggregation of Linked Data in the Cultural Heritage Domain: A Case Study in the Europeana Network. Information. 2019; 10(8):252. https://doi.org/10.3390/info10080252
Chicago/Turabian StyleFreire, Nuno, René Voorburg, Roland Cornelissen, Sjors de Valk, Enno Meijers, and Antoine Isaac. 2019. "Aggregation of Linked Data in the Cultural Heritage Domain: A Case Study in the Europeana Network" Information 10, no. 8: 252. https://doi.org/10.3390/info10080252
APA StyleFreire, N., Voorburg, R., Cornelissen, R., de Valk, S., Meijers, E., & Isaac, A. (2019). Aggregation of Linked Data in the Cultural Heritage Domain: A Case Study in the Europeana Network. Information, 10(8), 252. https://doi.org/10.3390/info10080252