An Intelligent Spam Detection Model Based on Artificial Immune System

 , ,
, ,  ,
, 
Abstract
1. Introduction
1.1. Common Threats
1.2. Architecture of an Email
1.3. Complexities Caused by Spam Emails
1.4. Shortcomings of Non-Automated Spam Filtration Methods
1.5. The Benefits of Our Proposed Machine Learning Based Approach
2. Related Work
3. Proposed Methodology
Negative Selection Algorithm (NSA) Illustrated
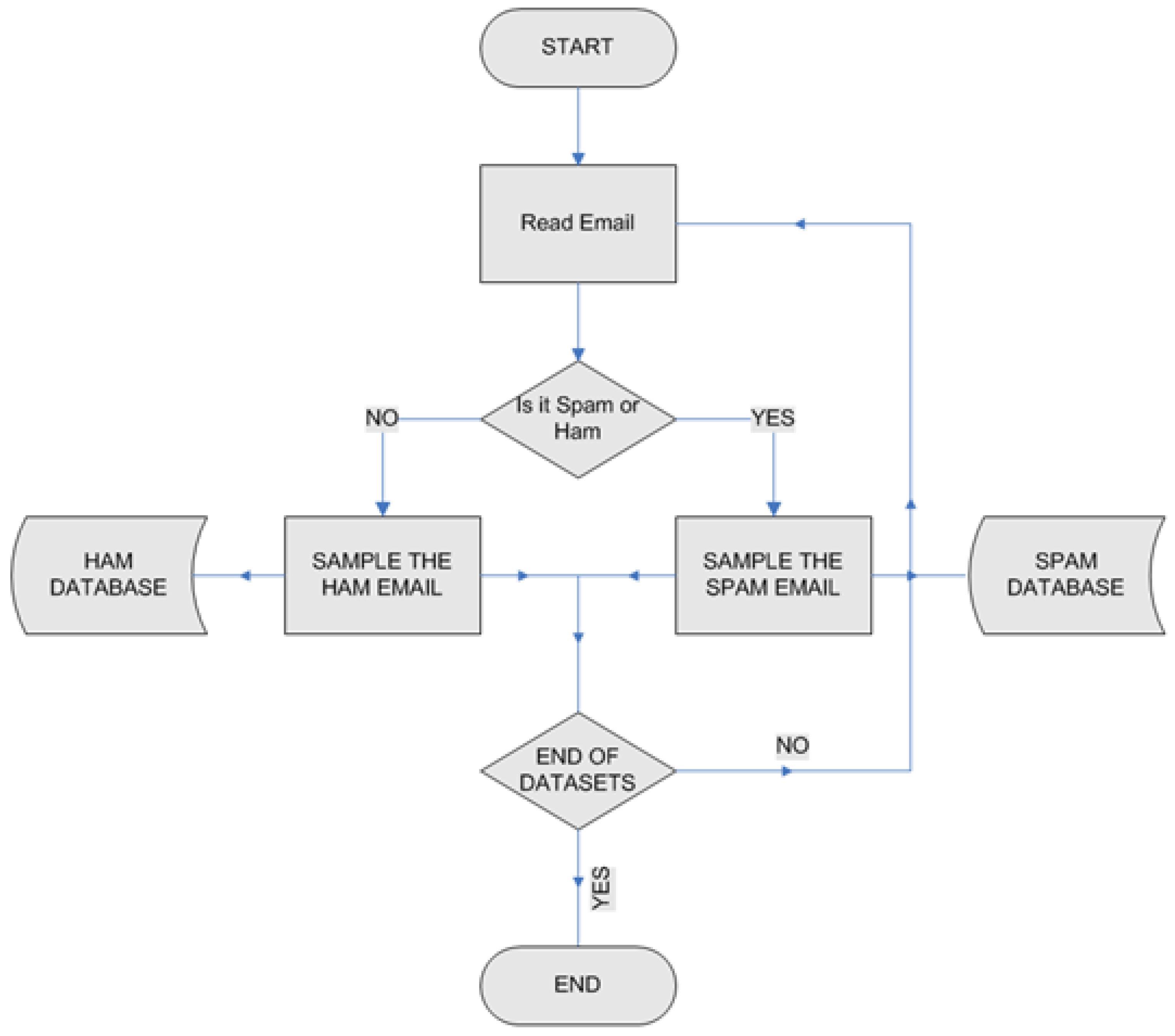
4. Design of the Framework
4.1. Training Phase
- To begin with, the datasets need to be identified by the framework as either HAM or SPAM.Corresponding pseudocode:
- Input: SPAM and HAM database
- Define Spam and Ham as containers for SPAM (non-self) and HAM (self) categories of datasets.
- Once the datasets have been appropriately marked, the features of SPAM or HAM emails need to be identified. Words and keywords along with the frequency of their occurrence are stored in appropriate databases. In the case of spam emails, certain word-combinations are also stored.
Corresponding pseudocode:
Read SPAM or HAM datasets
a. For input i = 1 to length of datasets:
b. Read email(i)
c. Sample words and keywords
d. Record words along with their frequency
e. If a word or combination of consecutive words (a keyword) has appeared before, then update its frequency in the SPAM and HAM databases
f. EndFor - Repeat step 1 (a–f) whenever new datasets are available to further train or update the database.
Corresponding pseudocode:
Read SPAM datasets
a. For input i = 1 to length of datasets:
b. Select the words or combinations
c. Check Token Database for the selection at 1.b.
d. If found == TRUE
e. Goto step 1.a.
f. Else, frequency is greater than set threshold
g. copy the word to Token Database
h. EndIf
i. EndFor
4.2. Enron Dataset Findings
4.3. Structure of the Datasets
5. Detection Stages
5.1. Blocked IP Database
5.2. Token Database
5.3. SPAM and HAM Database
6. Email Scanning Algorithm
- The email is preprocessed to be checked against the Token Database, the Blocked IP database, and finally the SPAM database.
- To reduce the processing time some of the helping verbs, such as am, is, are, was, were, be, being, been, do, did, didn’t etc. have been removed.
- The whole email is then converted into lower case to reduce the complexity of checking the words in all their possible combinations of upper and lower case. For instance, one of the most common spam words ‘viagra’ can come in many varieties such as Viagra, vIagra, viaGRa, etc. In fact there could be 64 possible forms (26) of the word Viagra. A human can process all those different forms and usually interprets them similarly but for the computer these are all different words. Converting to lower case reduces the processing overhead and improves the time efficiency.
- Extra spaces are also removed along with some special characters to reduce extra checks as explained above, e.g., ‘Viagra’, ‘Viagra’, ‘Viagra’, ‘Viagra’, etc., they are all different words to the computer. Hence, removing leading and trailing spaces and lowering the case will reduce processing complexity.
- The email is evaluated using three different detectors. The first one identifies whether the source IP address matches to that of the blacklisted IP address or if anywhere in the content of the email body, such an IP address is mentioned.
- In the second detector, words within the email body is matched against a pre-designed confirmed spam token database, and if a word does get matched, then the email is flagged as spam.
- In the third detector, each line of the email is evaluated to determine if it contains any spam word from a SPAM dataset built from training the confirmed spam emails. If 30% of the lines of the email contains any spam word, then the email is flagged as spam email.
6.1. Detector # 1—Source Check
Corresponding pseudocode:
|
6.2. Detector # 2—Token Database
Corresponding pseudocode:
|
6.3. Detector # 3—SPAM and HAM Database
Corresponding pseudocode:
|
7. Results and Discussion
8. Future Endeavors
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tschabitscher, H. How Many Emails Are Sent Every Day. 2015. Available online: https://www.lifewire.com (accessed on 11 June 2019).
- Gupta, S.; Pilli, E.S.; Mishra, P.; Pundir, S.; Joshi, RC. Forensic Analysis of Email Address Spoofing. In Proceedings of the 5th International Conference on Confluence 2014: NGIT Summit, Noida, India, 25–26 September 2014; pp. 898–904. [Google Scholar]
- Smadi, S.; Aslam, N.; Zhang, L. Detection of Phishing Emails Using Data Mining Algorithms. In Proceedings of the 9th International Conference on Software, Knowledge, Information Management and Applications, Kathmandu, Nepal, 15–17 December 2015; p. 4. [Google Scholar]
- Bratko, A.; Filipic, B.; Cormack, G.; Lynam, T.; Zupan, B. Spam filtering using statistical data compression models. J. Mach. Learn. Res. 2006, 7, 2673–2698. [Google Scholar]
- Jagatic, T.; Johnson, N.; Jakobsson, M.; Menczer, F. Social Phishing. Commun. ACM 2007, 50, 94–99. [Google Scholar] [CrossRef]
- Shan, T.L.; Narayana, G.; Shanmugam, B.; Azam, S.; Yeo, K.C.; Kannoorpatti, K. Heuristic Systematic Model Based Guidelines for Phishing Victims. In Proceedings of the IEEE Annual India Conference, Bangalore, India, 16–18 December 2016; pp. 1–6. [Google Scholar]
- Leung, C.; Liang, Z. An Analysis of the Impact of Phishing and Anti-Phishing Related Announcements on Market Value of Global Firms. Master’ Thesis, HKU, Pok Fu Lam, Hong Kong, 2009. [Google Scholar]
- Raad, N.; Alam, G.; Zaidan, B.; Zaidan, A. Impact of spam advertisement through e-mail: A study to assess the influence of the anti-spam on the email marketing. Afr. J. Bus. Manag. 2010, 4, 2362–2367. [Google Scholar]
- Al-Sharif, S.; Iqbal, F.; Baker, T.; Khattack, A. White-Hat Hacking Framework for Promoting Security Awareness. In Proceedings of the 8th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Larnaca, Cyprus, 21–23 November 2016. [Google Scholar]
- Ghafir, I.; Prenosil, V.; Hammoudeh, M.; Baker, T.; Jabbar, S.; Khalid, S.; Jaf, S. BotDet: A System for Real Time Botnet Command and Control Traffic Detection. IEEE Access 2018, 6, 38947–38958. [Google Scholar] [CrossRef]
- Foley, C. ABC Bus Companies, Inc.—Cyber Incident Notification. 2018. Available online: https://www.doj.nh.gov/consumer/security-breaches/documents/abc-bus-20180302.pdf (accessed on 24 May 2019).
- French Cinema Chain Fires Dutch Executives Over CEO Fraud. Available online: https://www.bankinfosecurity.com/blogs/french-cinema-chain-fires-dutch-executives-over-ceo-fraud-p-2681 (accessed on 25 May 2019).
- Laorden, C.; Ugarte-Pedrero, X.; Santos, I.; Sanz, B.; Nieves, J.; Bringas, P.G. Study on the effectiveness of anomaly detection for spam filtering. Inf. Sci. 2014, 277, 421–444. [Google Scholar] [CrossRef]
- Khan, M.I.; Faisal, F.; Azam, S.; Karim, A.; Shanmugam, B.; Boer, F.D. Using Blockchain Technology for File Synchronization. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Moscow, Russia, 15–16 November 2018; IOP: London, UK, 2019. in press. [Google Scholar]
- Vokerla, R.R.; Shanmugam, B.; Azam, S.; Karim, A.; Boer, F.D.; Jonkman, M.; Faisal, F. An Overview of Blockchain Applications and Attacks. In Proceedings of the International Conference on Vision Towards Emerging Trends in Communication and Networking (ViTECoN), Tamil Nadu, India, 30–31 March 2019. [Google Scholar]
- Hoon, K.S.; Yeo, K.C.; Azam, S.; Shunmugam, B.; Boer, F.D. Critical Review of Machine Learning Approaches to Apply Big Data Analytics in DDoS Forensics. In Proceedings of the 2018 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 4–6 January 2018. [Google Scholar]
- Nosseir, A.; Khaled, N.; Islam, T. Intelligent Word-Based Spam Filter Detection Using Multi-Neural Networks. Int. J. Comput. Sci. Issues 2013, 10, 17–21. [Google Scholar]
- Aski, A.S.; Sourati, N.K. Proposed efficient algorithm to filter spam using machine learning techniques. Pac. Sci. Rev. A Nat. Sci. Eng. 2016, 18, 145–149. [Google Scholar] [CrossRef][Green Version]
- Feldman, R.; Fresko, M.; Kinar, Y.; Lindell, Y.; Liphstat, O.; Rajman, M.; Schler, Y.; Zamir, O. Text Mining at the Term Level. In Principles of Data Mining and Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 1998; pp. 65–73. [Google Scholar]
- Cohen, Y.; Gordon, D.; Hendler, D. Early detection of spamming accounts in large-Scale service provider networks. Knowl. Based Syst. 2018, 142, 241–255. [Google Scholar] [CrossRef]
- Idris, I.; Selamat, A.; Omatu, S. Hybrid email spam detection model with negative selection algorithm and differential evolution. Eng. Appl. Artif. Intell. 2014, 28, 97–110. [Google Scholar] [CrossRef]
- Ruano-Ordás, D.; Fdez-Riverola, F.; Méndez, J.R. Using evolutionary computation for discovering spam patterns from e-mail samples. Inf. Proc. Manag. 2018, 54, 303–317. [Google Scholar] [CrossRef]
- Akhawe, D.; He, W.; Li, Z.; Moazzezi, R.; Song, D. Clickjacking Revisited: A Perceptual View of UI Security. In Sergey Bratus & Felix; Lindner, F.X., Ed.; ‘WOOT’, USENIX Association: Berkeley, CA, USA, 2014. [Google Scholar]
- Dipti, Y.; Pawade, D.; Lahigude, A.; Reja, D. Review Report on Security Breaches Using Keylogger and Clickjacking. Int. J. Adv. Found. Res. Comput. 2015, 2, 55–59. [Google Scholar]
- Smadi, S.; Aslam, N.; Zhang, L. Detection of online phishing email using dynamic evolving neural network based on reinforcement learning. Dec. Support Syst. 2018, 107, 88–102. [Google Scholar] [CrossRef]
- Zhu, Y.; Tan, Y. Extracting Discriminative Information from E-Mail for Spam Detection Inspired by Immune System. In Proceedings of the IEEE Congress on Evolutionary Computation, Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Fahim, M.; Baker, T.; Khattak, A.; Shah, B.; Aleem, S.; Chow, F. Context Mining of Sedentary Behaviour for Promoting Self-Awareness Using a Smartphone. Sensors 2018, 18, 874. [Google Scholar] [CrossRef] [PubMed]
- Hayat, M.Z.; Basiri, J.; Seyedhossein, L.; Shakery, A. Content-Based Concept Drift Detection for Email Spam Filtering. In Proceedings of the 2010 5th International Symposium on Telecommunications, Tehran, Iran, 4–6 December 2010. [Google Scholar] [CrossRef]
- Byun, H.; Lee, S.W. Applications of Support Vector Machines for Pattern Recognition: A Survey. In Pattern Recognition with Support Vector Machines; Lecture Notes in Computer Science; Lee, S.W., Verri, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2388. [Google Scholar]
- Nizamani, S.; Memon, N.; Glasdam, M.; Nguyen, D.D. Detection of fraudulent emails by employing advanced feature abundance. Egypt. Inf. J. 2014, 15, 169–174. [Google Scholar] [CrossRef]
- Alsmadi, I.; Alhami, I. Clustering and classification of email contents. J. King Saud Univ. Comput. Inf. Sci. 2015, 27, 46–57. [Google Scholar] [CrossRef]
- Idris, I. Model and Algorithm in Artificial Immune System for Spam Detection. Int. J. Artif. Intell. Appl. 2012, 3, 83–94. [Google Scholar] [CrossRef]
- Brownlee, J. Clever Algorithms: Nature-inspired Programming Recipes. In Immune Algorithms; LuLu.com: Morrisville, NC, USA, 2012; pp. 270–284. [Google Scholar]
- Graham, P. A Plan for Spam. 2002. Available online: www.paulgraham.com/Spam.html (accessed on 21 February 2019).
- Elshandidy, H. Available online: https://helshandidy.files.wordpress.com/2011/04/negativeselection1.png (accessed on 11 June 2019).
- Wanli, M.; Tran, D.; Sharma, D. A Novel Spam Email Detection System Based on Negative Selection. In Proceedings of the Fourth International Conference on Computer Sciences and Convergence Information Technology, Seoul, Korea, 24–26 November 2009; pp. 987–992. [Google Scholar]
- Chikh, R.; Chikhi, S. Clustered negative selection algorithm and fruit fly optimization for email spam detection. J. Ambient Intell. Humaniz. Comput. 2017, 10, 143–152. [Google Scholar] [CrossRef]
- Selamat, I.I.A. A Swarm Negative Selection Algorithm for Email Spam Detection. J. Comput. Eng. Inf. Tech. 2015, 4, 2. [Google Scholar]
- Zhou, Y.; Goldberg, M.; Ismail, M.; Wallace, W. Strategies for Cleaning Organizational Emails with an Application to Enron Email Dataset. In Proceedings of the 5th Conference North American Association for Computational Social and Organizational Sciences, Pittsburgh, PA, USA, 7–9 June 2007. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Spam | Number of Ham |
|---|---|---|
| Enron1 | 1513 | 3735 |
| Enron2 | 1496 | 4361 |
| Enron3 | 1500 | 4012 |
| Enron4 | 4500 | 1500 |
| Enron5 | 3675 | 1500 |
| Enron6 | 4500 | 1500 |
| Total | 17,184 | 16,608 |
| No | Key | Frequency |
|---|---|---|
| 1 | Viagra | 1177 |
| 2 | Sex | 333 |
| 3 | xanax | 262 |
| 4 | vicodin | 143 |
| 5 | discreet | 109 |
| 6 | casino | 86 |
| 7 | teen | 69 |
| 8 | unsolicited | 27 |
| 9 | Removal instructions | 20 |
| 10 | babes | 12 |
| 11 | financial freedom | 8 |
| 12 | offer expires | 5 |
| 13 | make money | 4 |
| 14 | work from home | 2 |
| 15 | mortgage rates | 1 |
| 16 | free gift | 1 |
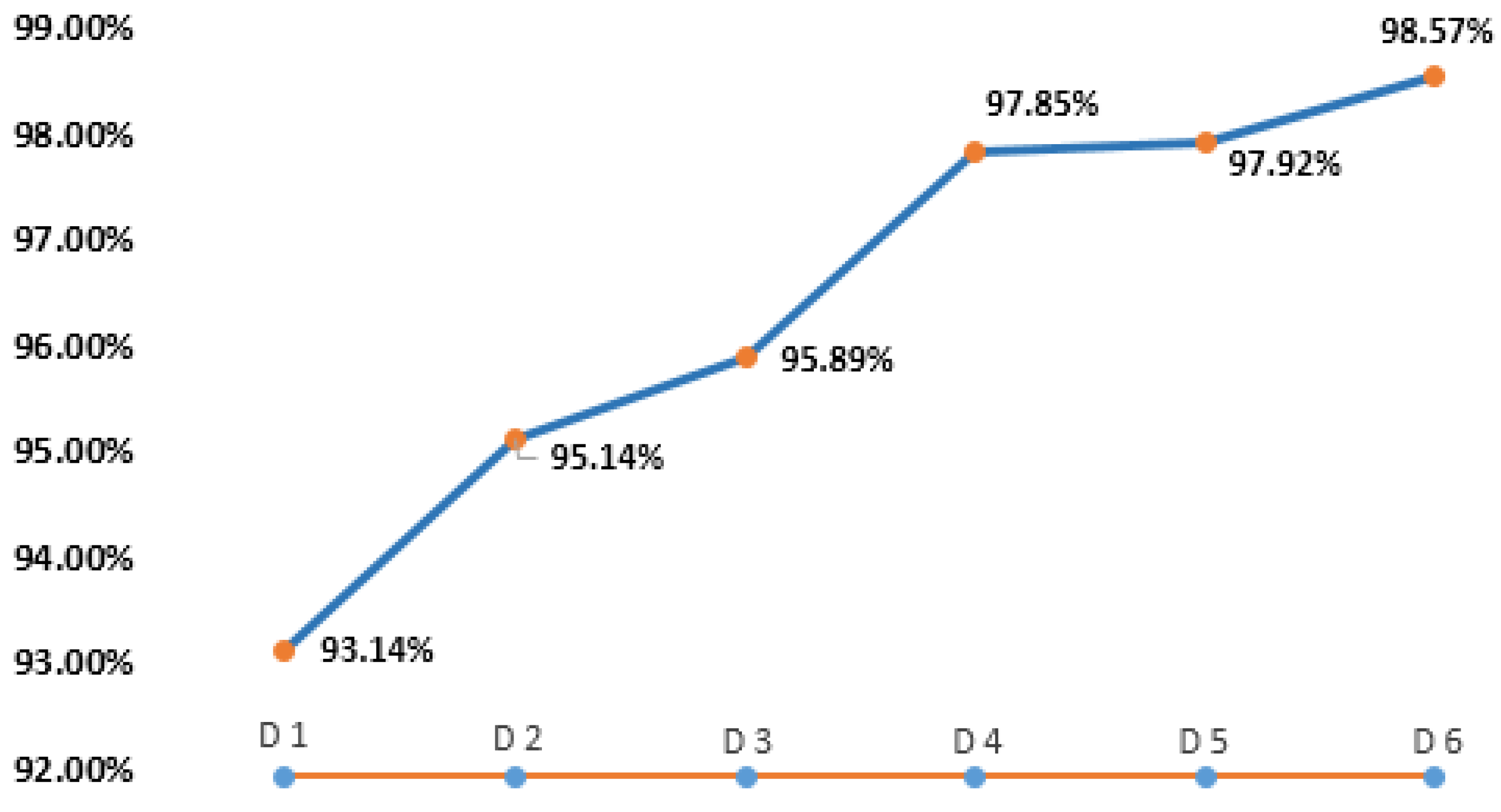
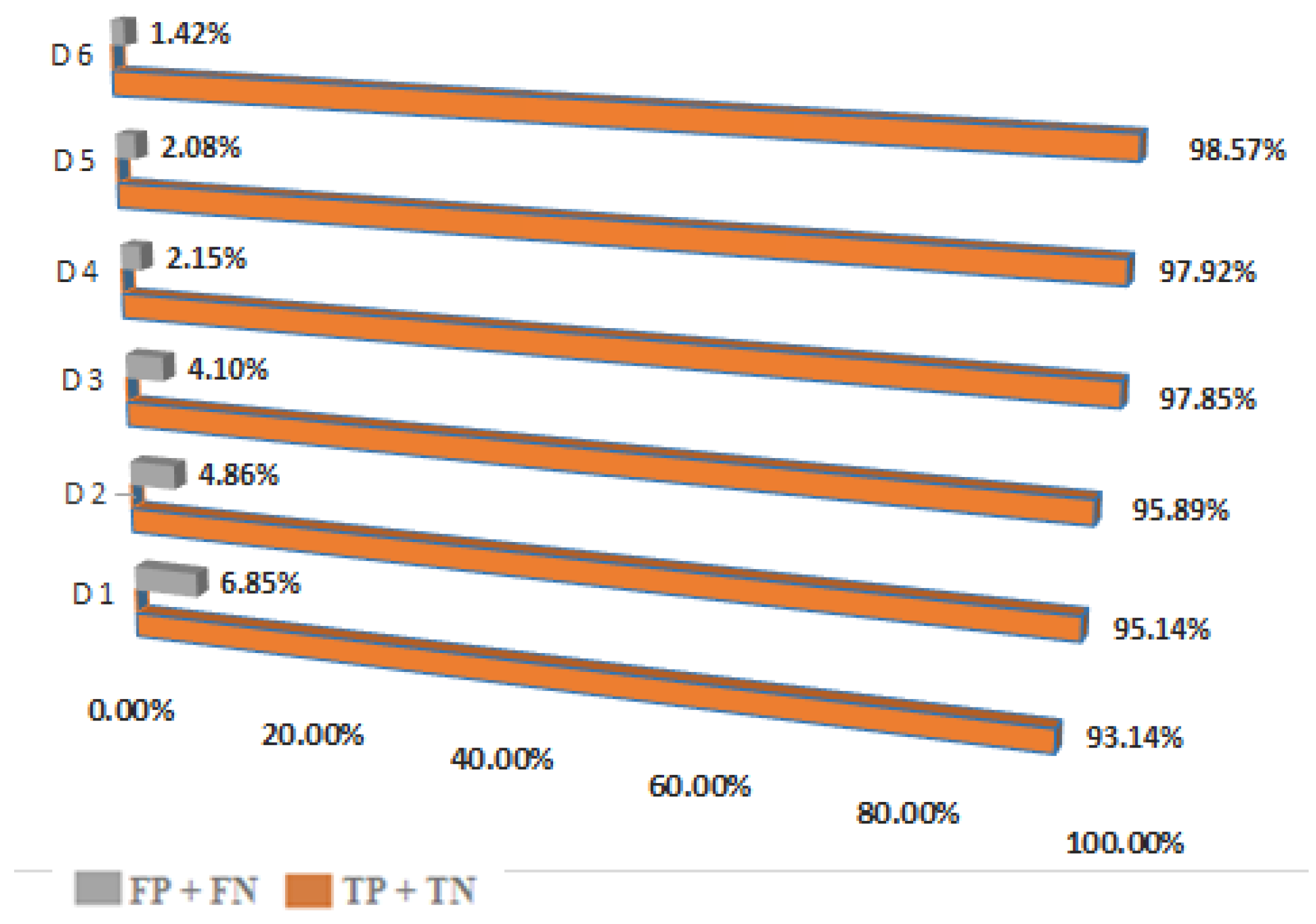
| Datasets | Trained by Number of Datasets | Total Email Scanned: 17,157 | |||
|---|---|---|---|---|---|
| TP + TN | FP + FN | TP + TN Percentage | FP + FN Percentage | ||
| 15,981 | 1176 | 93.14 | 6.85 | ||
| 16,323 | 834 | 95.14 | 4.86 | ||
| 16,453 | 704 | 95.89 | 4.10 | ||
| 16,789 | 368 | 97.85 | 2.15 | ||
| 16,801 | 357 | 97.92 | 2.08 | ||
| 16,912 | 245 | 98.57 | 1.42 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saleh, A.J.; Karim, A.; Shanmugam, B.; Azam, S.; Kannoorpatti, K.; Jonkman, M.; Boer, F.D. An Intelligent Spam Detection Model Based on Artificial Immune System. Information 2019, 10, 209. https://doi.org/10.3390/info10060209
Saleh AJ, Karim A, Shanmugam B, Azam S, Kannoorpatti K, Jonkman M, Boer FD. An Intelligent Spam Detection Model Based on Artificial Immune System. Information. 2019; 10(6):209. https://doi.org/10.3390/info10060209
Chicago/Turabian StyleSaleh, Abdul Jabbar, Asif Karim, Bharanidharan Shanmugam, Sami Azam, Krishnan Kannoorpatti, Mirjam Jonkman, and Friso De Boer. 2019. "An Intelligent Spam Detection Model Based on Artificial Immune System" Information 10, no. 6: 209. https://doi.org/10.3390/info10060209
APA StyleSaleh, A. J., Karim, A., Shanmugam, B., Azam, S., Kannoorpatti, K., Jonkman, M., & Boer, F. D. (2019). An Intelligent Spam Detection Model Based on Artificial Immune System. Information, 10(6), 209. https://doi.org/10.3390/info10060209