A Survey of Deep Learning Methods for Cyber Security

Abstract
1. Introduction
2. Shallow Learning vs. Deep Learning
3. Deep Learning Methods Used in Cyber Security
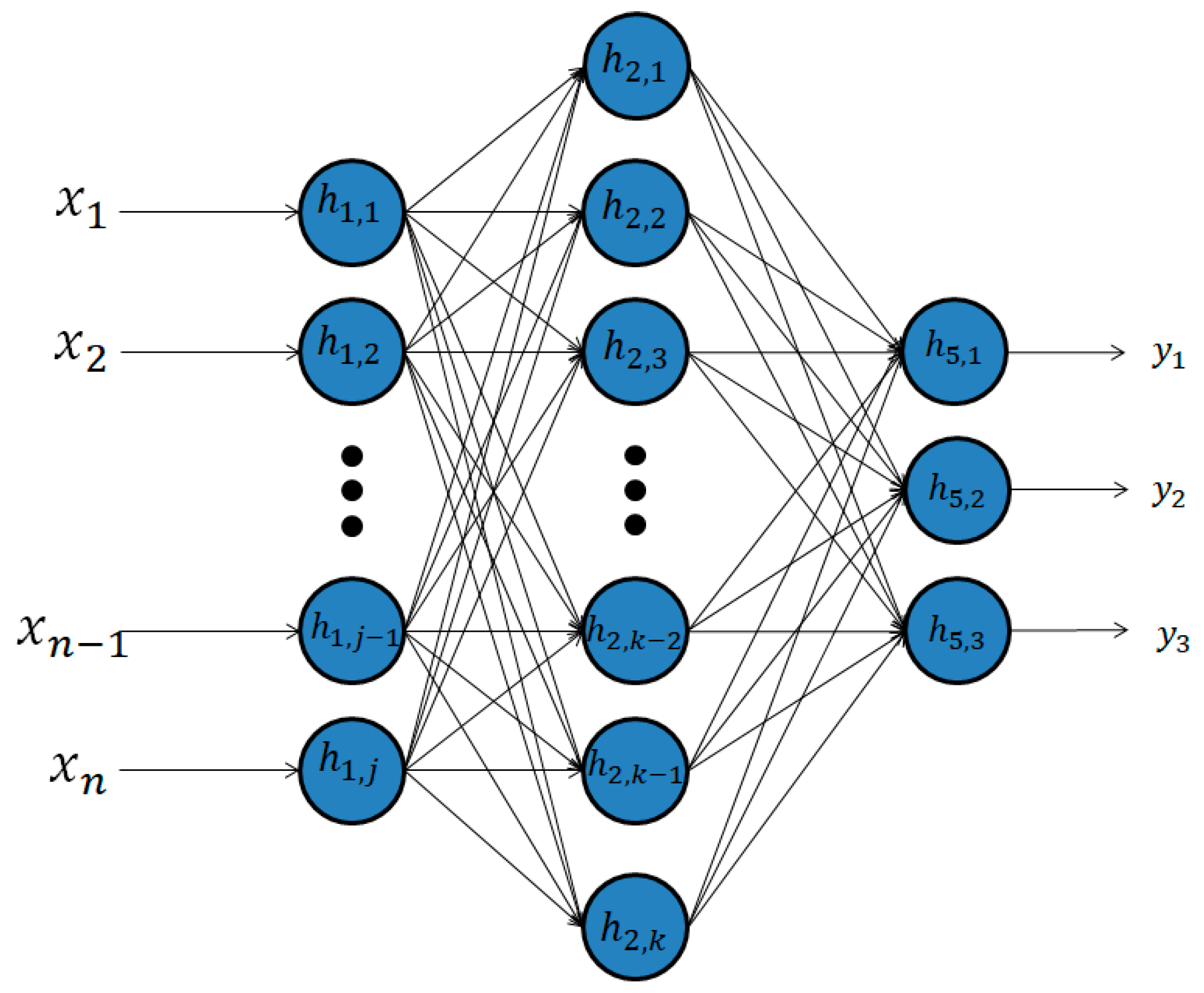
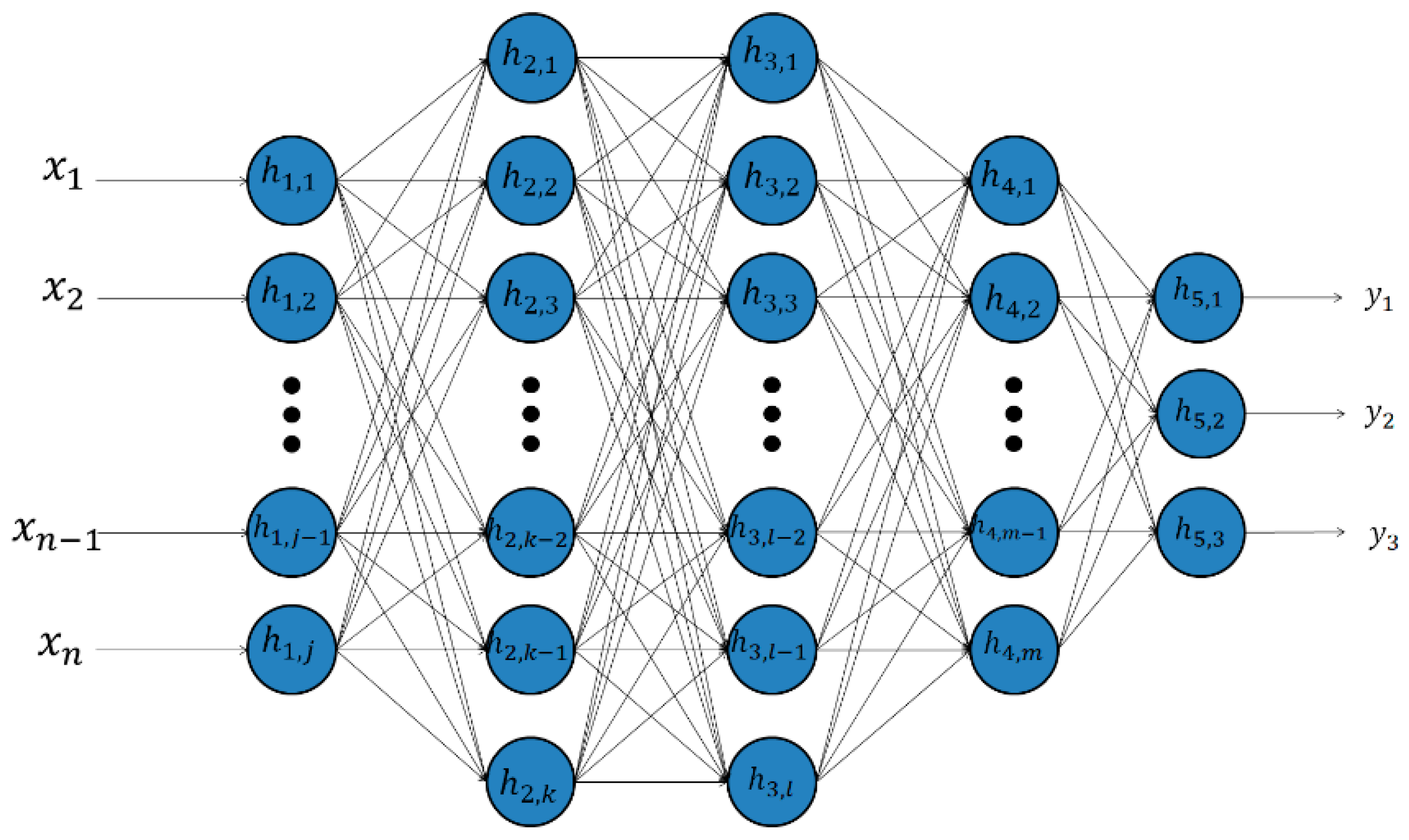
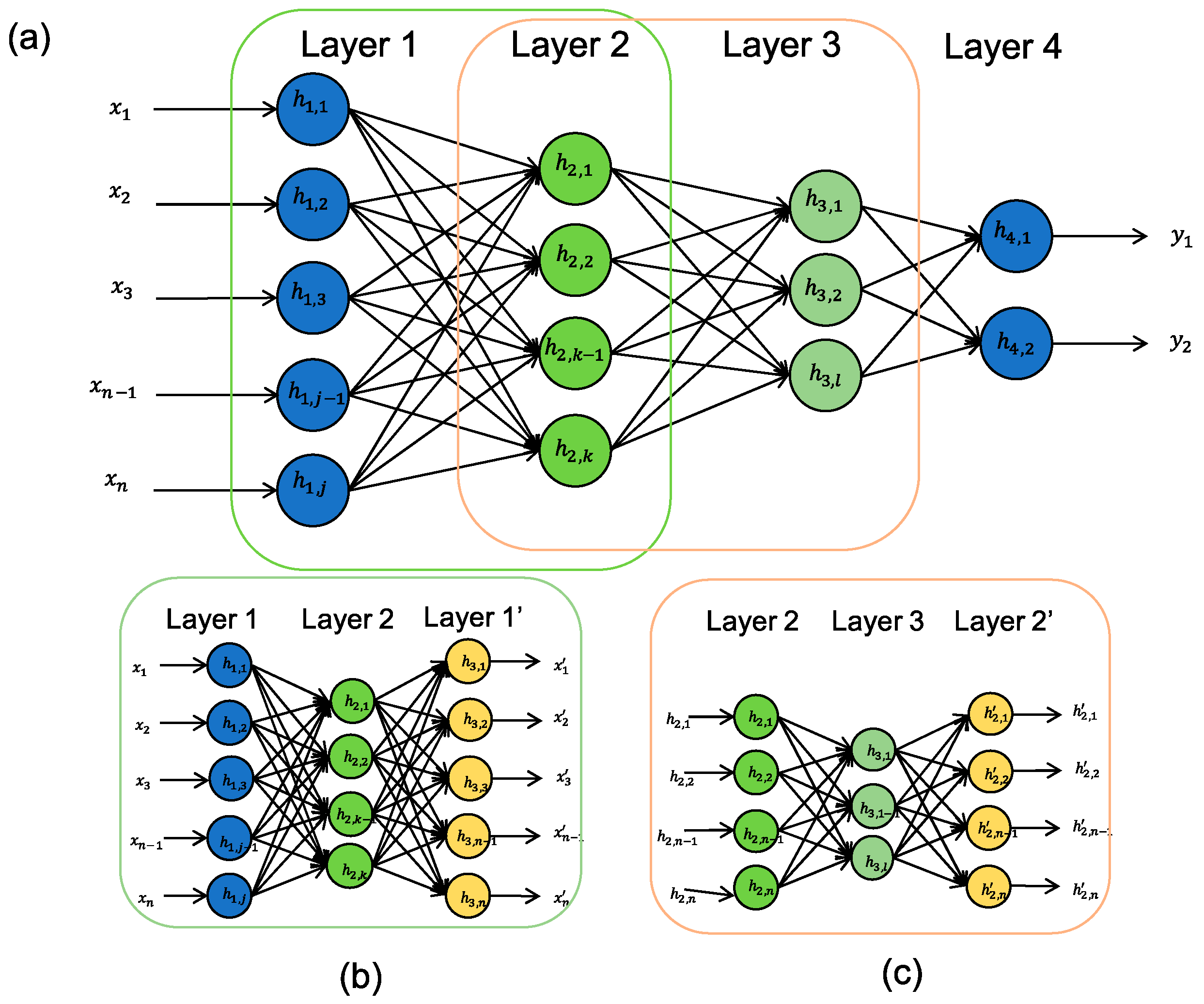
3.1. Deep Belief Networks
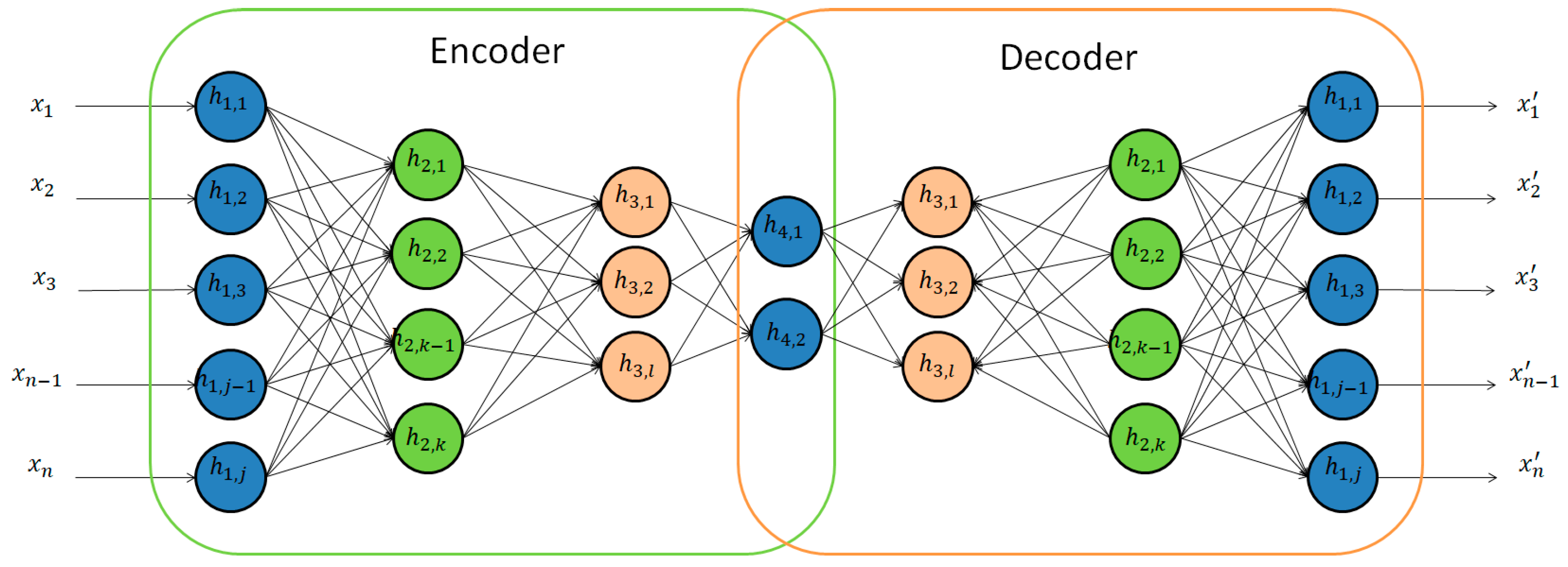
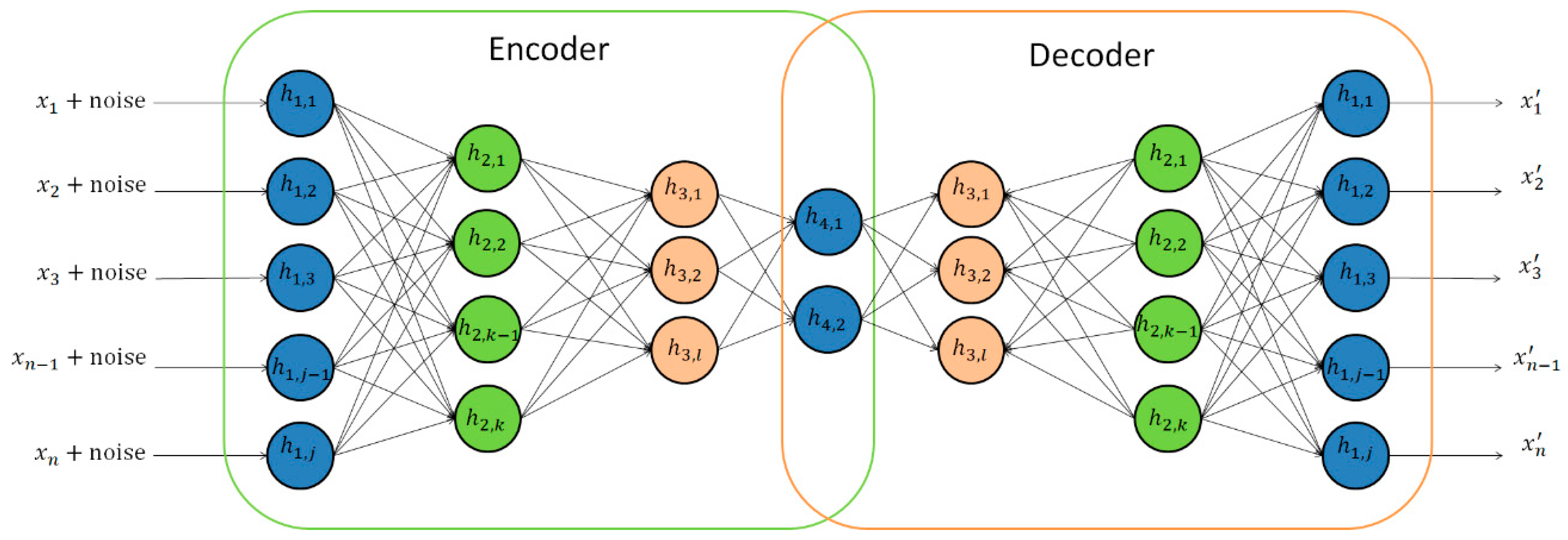
3.1.1. Deep Autoencoders
3.1.2. Restricted Boltzmann Machines
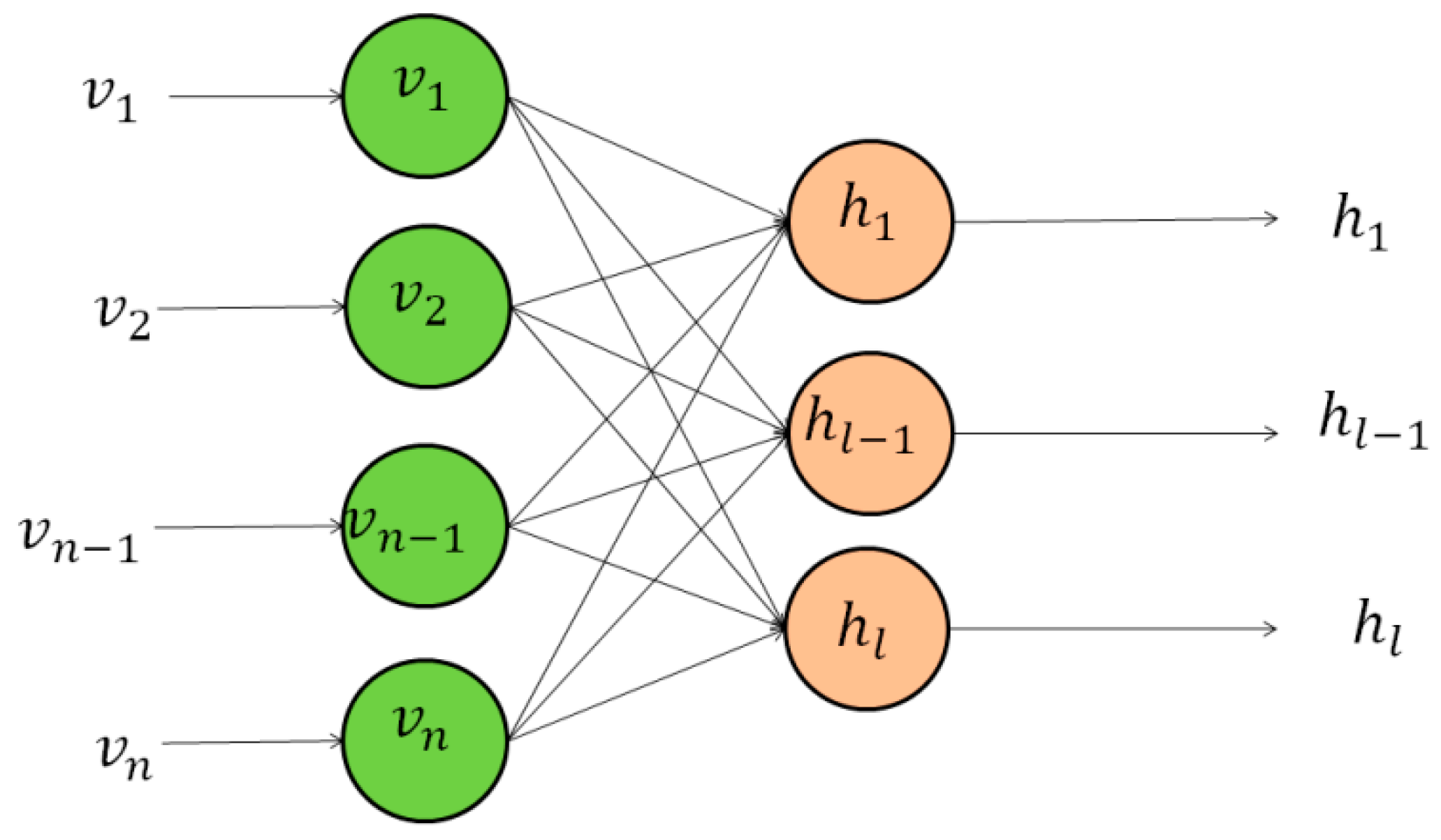
3.1.3. DBNs or RBMs or Deep Autoencoders Coupled with Classification Layers
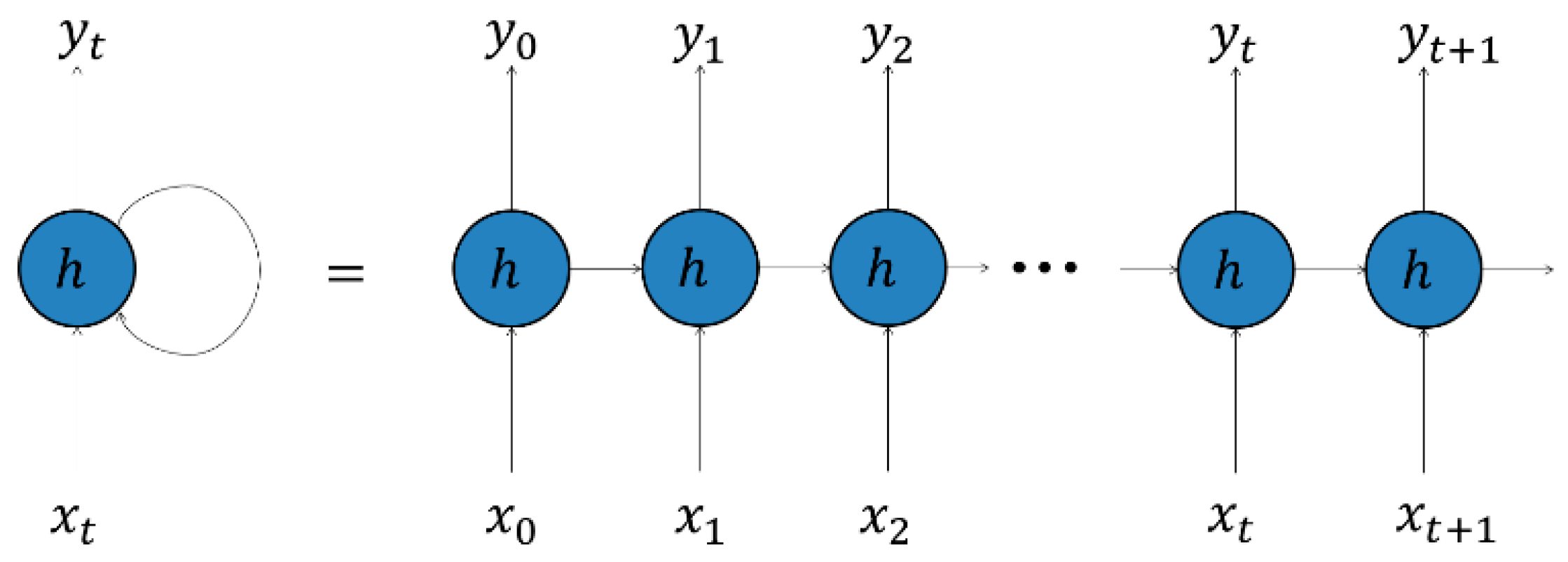
3.2. Recurrent Neural Networks
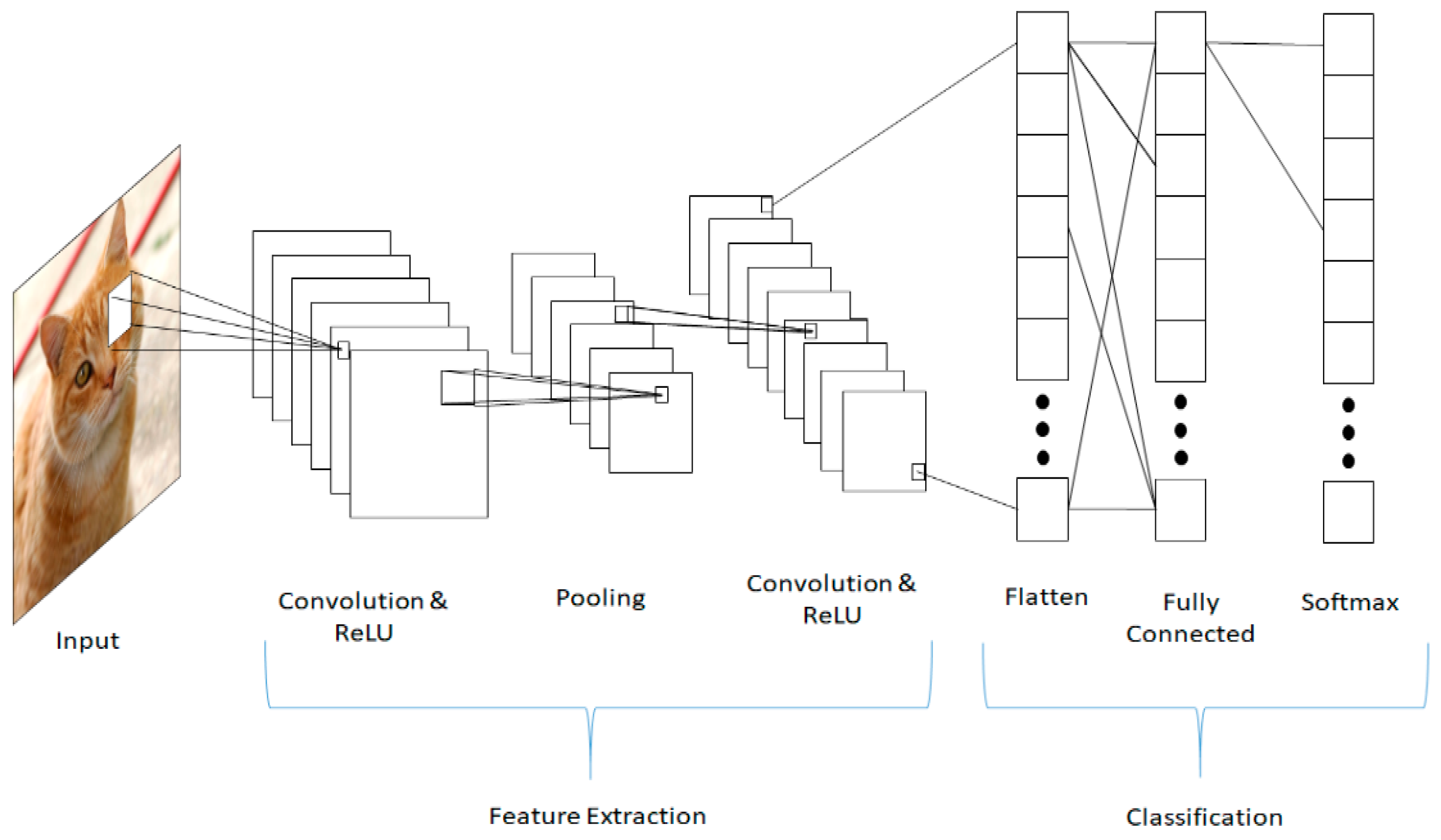
3.3. Convolutional Neural Networks
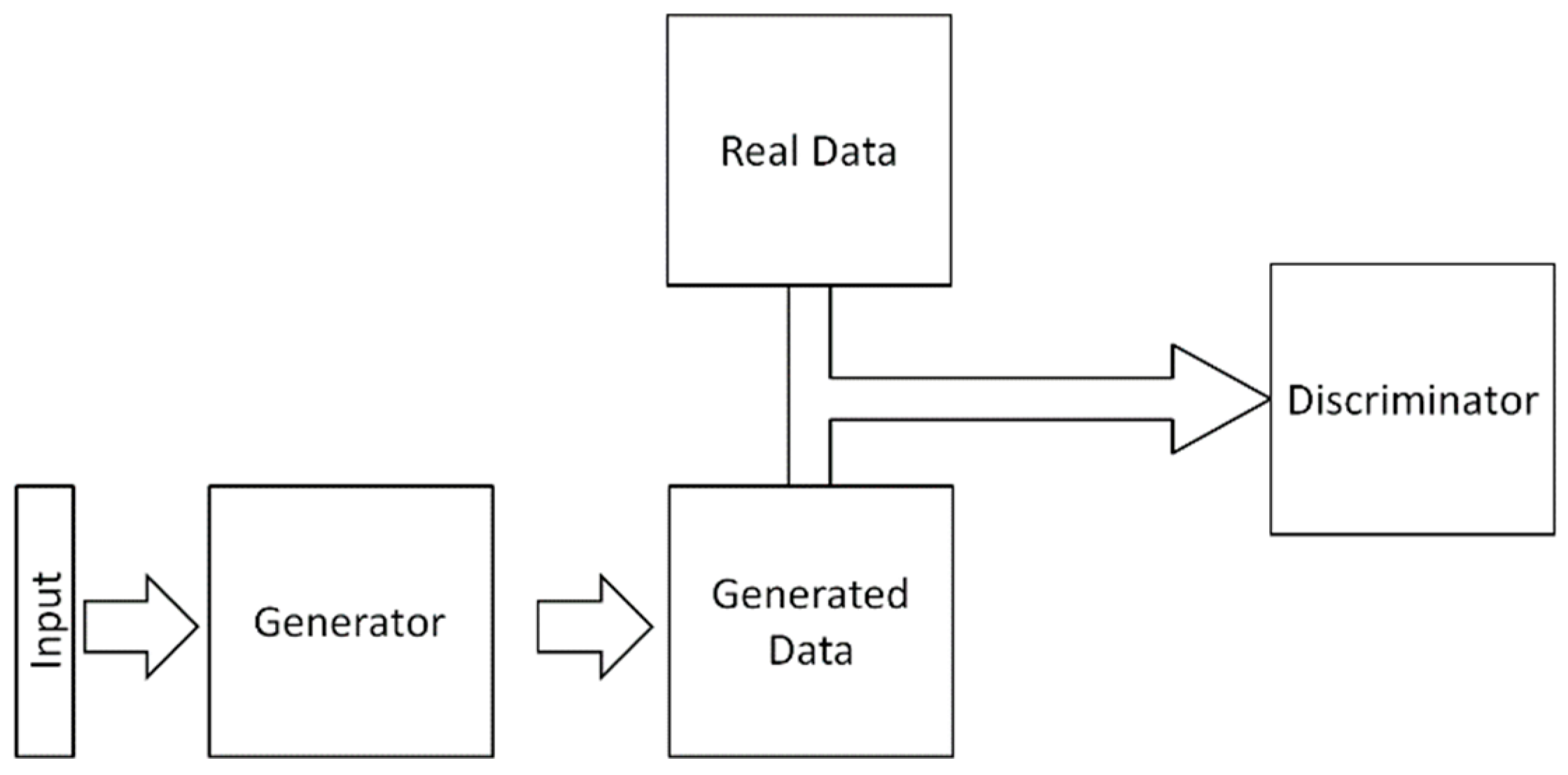
3.4. Generative Adversarial Networks
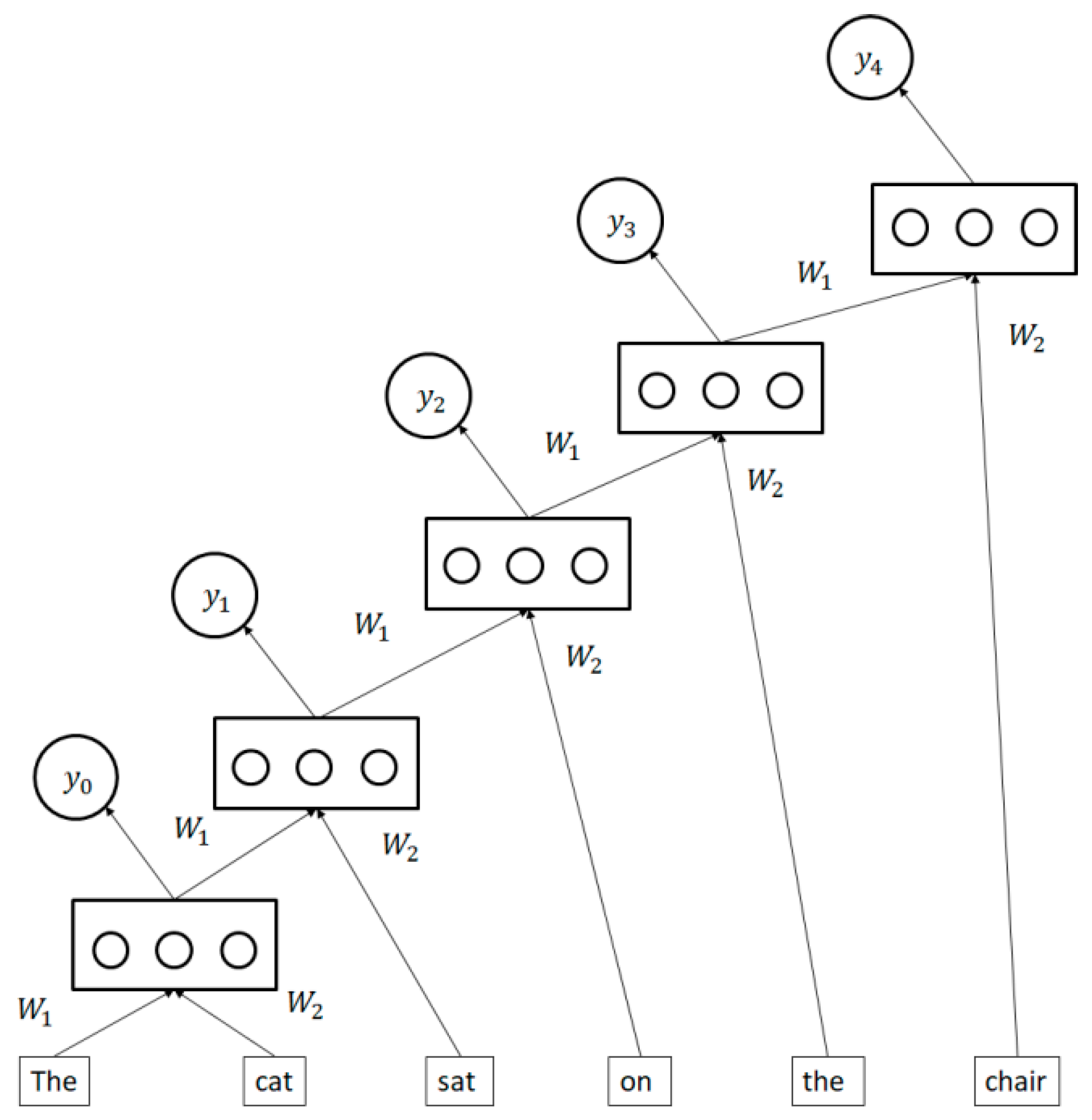
3.5. Recursive Neural Networks
4. Metrics
5. Cybersecurity Datasets for Deep Learning
6. Cyber Applications of Deep Learning Methods
6.1. Malware
6.1.1. Detection
6.1.2. Classification
6.2. Domain Generation Algorithms and Botnet Detection
6.3. Drive-By Download Attacks
6.4. Network Intrusion Detection
6.5. File Type Identification
6.6. Network Traffic Identification
6.7. SPAM Identification
6.8. Insider Threat Detection
6.9. Border Gateway Protocol Anomaly Detection
6.10. Verification If Keystrokes Were Typed by a Human
6.11. User Authentication
6.12. False Data Injection Attack Detection
7. Observations and Recommendations
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Buczak, L.; Guven, E. A Survey of Data Mining and Machine Learning Methods for Cyber Security. IEEE Commun. Surv. Tutor. 2016, 18, 1153–1176. [Google Scholar] [CrossRef]
- Nguyen, T.T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Garcia-Teodoro, P.; Diaz-Verdejo, J.; Maciá-Fernández, G.; Vázquez, E. Anomaly-based network intrusion detection: Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Sperotto, A.; Schaffrath, G.; Sadre, R.; Morariu, C.; Pras, A.; Stiller, B. An overview of IP flow-based intrusion detection. IEEE Commun. Surv. Tutor. 2010, 12, 343–356. [Google Scholar] [CrossRef]
- Wu, S.X.; Banzhaf, W. The use of computational intelligence in intrusion detection systems: A review. Appl. Soft Comput. 2010, 10, 1–35. [Google Scholar] [CrossRef]
- Torres, J.M.; Comesaña, C.I.; García-Nieto, P.J. Machine learning techniques applied to cybersecurity. Int. J. Mach. Learn. Cybern. 2019, 1–14. [Google Scholar]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine Learning and Deep Learning Methods for Cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Apruzzese, G.; Colajanni, M.; Ferretti, L.; Guido, A.; Marchetti, M. On the effectiveness of machine and deep learning for cyber security. In Proceedings of the 2018 10th IEEE International Conference on Cyber Conflict (CyCon), Tallinn, Estonia, 29 May–1 June 2018; pp. 371–390. [Google Scholar]
- Wickramasinghe, C.S.; Marino, D.L.; Amarasinghe, K.; Manic, M. Generalization of Deep Learning for Cyber-Physical System Security: A Survey. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 745–751. [Google Scholar]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.; Du, X.; Guizani, M. A Survey of Machine and Deep Learning Methods for Internet of Things (IoT) Security. arXiv, 2018; arXiv:1807.11023. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Hebb, D.O. The Organization of Behavior; John Wiley Sons, Inc.: New York, NY, USA, 1949. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Hinton, G.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Fukushima, K. Cognitron: A self-organizing multilayered neural network. Biol. Cybern. 1975, 20, 121–136. [Google Scholar] [CrossRef] [PubMed]
- Jarrett, K.; Kavukcuoglu, K.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Ranzato, M.; Boureau, Y.L.; LeCun, Y. Sparse feature learning for deep belief networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2008; pp. 1185–1192. [Google Scholar]
- Ranzato, M.; Huang, F.J.; Boureau, Y.L.; LeCun, Y. Unsupervised learning of invariant feature hierarchies with applications to object recognition. In Proceedings of the CVPR’07 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Benigo, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2007; pp. 153–160. [Google Scholar]
- Mohamed, A.R.; Dahl, G.E.; Hinton, G. Acoustic modeling using deep belief networks. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 14–22. [Google Scholar] [CrossRef]
- Sarikaya, R.; Hinton, G.E.; Deoras, A. Application of deep belief networks for natural language understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 778–784. [Google Scholar] [CrossRef]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- El Hihi, S.; Bengio, Y. Hierarchical recurrent neural networks for long-term dependencies. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1996; pp. 493–499. [Google Scholar]
- Sutskever, I. Training Recurrent Neural Networks; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference Machine Learning, Atlanta, GA, USA, 15 February 2013; pp. 1310–1318. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 3104–3112. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv, 2014; arXiv:1406.1078. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv, 2014; arXiv:1409.0473. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1990; pp. 396–404. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ning, F.; Delhomme, D.; LeCun, Y.; Piano, F.; Bottou, L.; Barbano, P.E. Toward automatic phenotyping of developing embryos from videos. IEEE Trans. Image Process. 2005, 14, 1360–1371. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K.J. Phoneme recognition using time-delay neural networks. In Readings in Speech Recognition; Elsevier: Amsterdam, The Netherlands, 1990; pp. 393–404. [Google Scholar]
- Sainath, T.N.; Mohamed, A.R.; Kingsbury, B.; Ramabhadran, B. Deep convolutional neural networks for LVCSR. In Proceedings of the 2013 IEEE International Conference Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 8614–8618. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Zhang, X.; LeCun, Y. Text understanding from scratch. arXiv, 2015; arXiv:1502.01710. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv, 2016; arXiv:1609.04802. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv, 2016; arXiv:1605.05396. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; van der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Pollack, J.B. Recursive distributed representations. Artif. Intell. 1990, 46, 77–105. [Google Scholar] [CrossRef]
- Goller, C.; Kuchler, A. Learning task-dependent distributed representations by backpropagation through structure. Neural Netw. 1996, 1, 347–352. [Google Scholar]
- Bottou, L. From machine learning to machine reasoning. arXiv, 2011; arXiv:1102.1808. [Google Scholar]
- Socher, R.; Lin, C.C.; Manning, C.; Ng, A.Y. Parsing natural scenes and natural language with recursive neural networks. In Proceedings of the 28th International Conference Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 129–136. [Google Scholar]
- Socher, R.; Pennington, J.; Huang, E.H.; Ng, A.Y.; Manning, C.D. Semi-supervised recursive autoencoders for predicting sentiment distributions. In Proceedings of the Conference Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 151–161. [Google Scholar]
- Socher, R.; Huang, E.H.; Pennin, J.; Manning, C.D.; Ng, A.Y. Dynamic pooling and unfolding recursive autoencoders for paraphrase detection. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2011; pp. 801–809. [Google Scholar]
- KDD Cup 99. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 23 February 2019).
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications (CISDA), Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- The CTU-13 Dataset. Available online: https://stratosphereips.org/category/dataset (accessed on 23 February 2019).
- Alexa Top Sites. Available online: https://aws.amazon.com/alexa-top-sites/ (accessed on 23 February 2019).
- Bambenek Consulting—Master Feeds. Available online: http://osint.bambenekconsulting.com/feeds/ (accessed on 23 February 2019).
- DGArchive. Available online: https://dgarchive.caad.fkie.fraunhofer.de/site/ (accessed on 23 February 2019).
- Google Play Store. Available online: https://play.google.com/store (accessed on 23 February 2019).
- VirusTotal. Available online: https://virustotal.com (accessed on 23 February 2019).
- Contagio. Available online: http://contagiodump.blogspot.com/ (accessed on 23 February 2019).
- Comodo. Available online: https://www.comodo.com/home/internet-security/updates/vdp/database.php (accessed on 23 February 2019).
- Zhou, Y.; Jiang, X. Dissecting android malware: Characterization and evolution. In Proceedings of the 2012 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–23 May 2012; pp. 95–109. [Google Scholar]
- VirusShare. Available online: http://virusshare.com/ (accessed on 23 February 2019).
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C.E.R.T. DREBIN: Effective and Explainable Detection of Android Malware in Your Pocket. NDSS 2014, 14, 23–26. [Google Scholar]
- Microsoft Malware Classification (BIG 2015). Available online: https://www.kaggle.com/c/ malware-classification/data (accessed on 23 February 2019).
- Lindauer, B.; Glasser, J.; Rosen, M.; Wallnau, K.C.; ExactData, L. Generating Test Data for Insider Threat Detectors. JoWUA 2014, 5, 80–94. [Google Scholar]
- Glasser, J.; Lindauer, B. Bridging the gap: A pragmatic approach to generating insider threat data. In Proceedings of the 2013 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 23–24 May 2013; pp. 98–104. [Google Scholar]
- EnronSpam. Available online: https://labs-repos.iit.demokritos.gr/skel/i-config/downloads/enron-spam/ (accessed on 23 February 2019).
- SpamAssassin. Available online: http://www.spamassassin.org/publiccorpus (accessed on 23 February 2019).
- LingSpam. Available online: https://labs-repos.iit.demokritos.gr/skel/i-config/downloads/lingspam_ public.tar.gz (accessed on 23 February 2019).
- Yuan, Z.; Lu, Y.; Wang, Z.; Xue, Y. Droid-sec: Deep learning in android malware detection. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 371–372. [Google Scholar] [CrossRef]
- Yuan, Z.; Lu, Y.; Xue, Y. Droiddetector: Android malware characterization and detection using deep learning. Tsinghua Sci. Technol. 2016, 21, 114–123. [Google Scholar] [CrossRef]
- Pascanu, R.; Stokes, J.W.; Sanossian, H.; Marinescu, M.; Thomas, A. Malware classification with recurrent networks. In Proceedings of the 2015 IEEE International Conference Acoustics, Speech and Signal Process, (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 1916–1920. [Google Scholar]
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep learning for classification of malware system call sequences. In Proceedings of the Australasian Joint Conf. on Artificial Intelligence, Hobart, Australia, 5–8 December 2016; pp. 137–149. [Google Scholar]
- Tobiyama, S.; Yamaguchi, Y.; Shimada, H.; Ikuse, T.; Yagi, T. Malware detection with deep neural network using process behavior. In Proceedings of the IEEE 40th Annual Computer Software and Applications Conference (COMPSAC), Atlanta, GA, USA, 10–14 June 2016; Volume 2, pp. 577–582. [Google Scholar]
- Ding, Y.; Chen, S.; Xu, J. Application of Deep Belief Networks for opcode based malware detection. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3901–3908. [Google Scholar]
- McLaughlin, N.; del Rincon, J.M.; Kang, B.; Yerima, S.; Miller, P.; Sezer, S.; Safaei, Y.; Trickel, E.; Zhao, Z.; Doupe, A.; et al. Deep android malware detection. In Proceedings of the 7th ACM on Conference on Data and Application Security and Privacy, Scottsdale, AZ, USA, 22–24 March 2017; pp. 301–308. [Google Scholar]
- Hardy, W.; Chen, L.; Hou, S.; Ye, Y.; Li, X. DL4MD: A deep learning framework for intelligent malware detection. In Proceedings of the International Conference Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; p. 61. [Google Scholar]
- Benchea, R.; Gavriluţ, D.T. Combining restricted Boltzmann machine and one side perceptron for malware detection. In Proceedings of the International Conference on Conceptual Structures, Iasi, Romania, 27–30 July 2014; pp. 93–103. [Google Scholar]
- Xu, L.; Zhang, D.; Jayasena, N.; Cavazos, J. HADM: Hybrid analysis for detection of malware. In Proceedings of the SAI Intelligent Systems Conference, London, UK, 21–22 September 2016; pp. 702–724. [Google Scholar]
- Hou, S.; Saas, A.; Ye, Y.; Chen, L. Droiddelver: An android malware detection system using deep belief network based on API call blocks. In Proceedings of the International Conference Web-Age Information Manage, Nanchang, China, 3–5 June 2016; pp. 54–66. [Google Scholar]
- Zhu, D.; Jin, H.; Yang, Y.; Wu, D.; Chen, W. DeepFlow: Deep learning-based malware detection by mining Android application for abnormal usage of sensitive data. In Proceedings of the 2017 IEEE Symposium Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 438–443. [Google Scholar]
- Ye, Y.; Chen, L.; Hou, S.; Hardy, W.; Li, X. DeepAM: A heterogeneous deep learning framework for intelligent malware detection. Knowl. Inf. Syst. 2018, 54, 265–285. [Google Scholar] [CrossRef]
- Saxe, J.; Berlin, K. Deep neural network based malware detection using two dimensional binary program features. In Proceedings of the 10th International Conference Malicious and Unwanted Software (MALWARE), Washington, DC, USA, 20–22 October 2015; pp. 11–20. [Google Scholar]
- Weber, M.; Schmid, M.; Schatz, M.; Geyer, D. A toolkit for detecting and analyzing malicious software. In Proceedings of the 18th Annual Computer Security Applications Conference, Las Vegas, NV, USA, 9–13 December 2002; pp. 423–431. [Google Scholar]
- Shibahara, T.; Yagi, T.; Akiyama, M.; Chiba, D.; Yada, T. Efficient dynamic malware analysis based on network behavior using deep learning. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–7. [Google Scholar]
- Mizuno, S.; Hatada, M.; Mori, T.; Goto, S. BotDetector: A robust and scalable approach toward detecting malware-infected devices. In Proceedings of the 2017 IEEE International Conference Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar]
- Chen, Y.; Zhang, Y.; Maharjan, S. Deep learning for secure mobile edge computing. arXiv, 2017; arXiv:1709.08025. [Google Scholar]
- Hill, G.D.; Bellekens, X.J.A. Deep learning based cryptographic primitive classification. arXiv, 2017; arXiv:1709.08385. [Google Scholar]
- Dahl, G.E.; Stokes, J.W.; Deng, L.; Yu, D. Large-scale malware classification using random projections and neural networks. In Proceedings of the 2013 IEEE International Conference Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 3422–3426. [Google Scholar]
- Li, P.; Hastie, T.J.; Church, K.W. Very sparse random projections. In Proceedings of the 12th ACM SIGKDD International Conference Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 287–296. [Google Scholar]
- Li, P.; Hastie, T.J.; Church, K.W. Margin-constrained random projections and very sparse random projections. In Proceedings of the Conference on Learning Theory (COLT), Pittsburgh, PA, USA, 22–25 June 2006; pp. 635–649. [Google Scholar]
- Microsoft Security Essentials Product Information. Applies to: Windows 7. Available online: https://support.microsoft.com/en-us/help/18869/windows-7-security-essentials-product-information (accessed on 23 February 2019).
- Cordonsky, I.; Rosenberg, I.; Sicard, G.; David, E.O. DeepOrigin: End-to-end deep learning for detection of new malware families. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Gibert, D. Convolutional Neural Networks for Malware Classification; Universitat Politècnica de Catalunya: Barcelona, Spain, 2016. [Google Scholar]
- David, O.E.; Netanyahu, N.S. Deepsign: Deep learning for automatic malware signature generation and classification. In Proceedings of the 2015 International Joint Conference Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Wang, X.; Yiu, S.M. A multi-task learning model for malware classification with useful file access pattern from API call sequence. arXiv, 2016; arXiv:1610.05945. [Google Scholar]
- Yousefi-Azar, M.; Varadharajan, V.; Hamey, L.; Tupakula, U. Autoencoder-based feature learning for cyber security applications. In Proceedings of the 2017 International Joint Conference Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3854–3861. [Google Scholar]
- Huang, W.; Stokes, J.W. MtNet: A multi-task neural network for dynamic malware classification. In Proceedings of the International Conference Detection of Intrusions and Malware, and Vulnerability Assessment, Donostia-San Sebastián, Spain, 7–8 July 2016; pp. 399–418. [Google Scholar]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial perturbations against deep neural networks for malware classification. arXiv, 2016; arXiv:1606.04435. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Anderson, H.S.; Woodbridge, J.; Filar, B. DeepDGA: Adversarially-tuned domain generation and detection. In Proceedings of the 2016 ACM Workshop on Artificial Intelligence and Security, Vienna, Austria, 28 October 2016; pp. 13–21. [Google Scholar]
- Woodbridge, J.; Anderson, H.S.; Ahuja, A.; Grant, D. Predicting domain generation algorithms with long short-term memory networks. arXiv, 2016; arXiv:1611.00791. [Google Scholar]
- Lison, P.; Mavroeidis, V. Automatic Detection of Malware-Generated Domains with Recurrent Neural Models. arXiv, 2017; arXiv:1709.07102. [Google Scholar]
- Mac, H.; Tran, D.; Tong, V.; Nguyen, L.G.; Tran, H.A. DGA Botnet Detection Using Supervised Learning Methods. In Proceedings of the 8th International Symposium on Information and Communication Technology, Nhatrang, Vietnam, 7–8 December 2017; pp. 211–218. [Google Scholar]
- Yu, B.; Gray, D.L.; Pan, J.; de Cock, M.; Nascimento, A.C.A. Inline DGA detection with deep networks. In Proceedings of the 2017 IEEE International Conference Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 683–692. [Google Scholar]
- Zeng, F.; Chang, S.; Wan, X. Classification for DGA-Based Malicious Domain Names with Deep Learning Architectures. Int. J. Intell. Inf. Syst. 2017, 6, 67–71. [Google Scholar] [CrossRef][Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-ResNet and the impact of residual connections on learning. AAAI 2012, 4, 4278–4284. [Google Scholar]
- Tran, D.; Mac, H.; Tong, V.; Tran, H.A.; Nguyen, L.G. A LSTM based framework for handling multiclass imbalance in DGA botnet detection. Neurocomputing 2018, 275, 2401–2413. [Google Scholar] [CrossRef]
- Torres, P.; Catania, C.; Garcia, S.; Garino, C.G. An Analysis of Recurrent Neural Networks for Botnet Detection Behavior. In Proceedings of the 2016 IEEE Biennial Congress of Argentina (ARGENCON), Buenos Aires, Argentina, 15–17 June 2016; pp. 1–6. [Google Scholar]
- McDermott, C.D.; Majdani, F.; Petrovski, A. Botnet detection in the internet of things using deep learning approaches. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Voas, J. Ddos in the iot: Mirai and other botnets. Computer 2017, 50, 80–84. [Google Scholar] [CrossRef]
- Shibahara, T.; Yamanishi, K.; Takata, Y.; Chiba, D.; Akiyama, M.; Yagi, T.; Ohsita, Y.; Murata, M. Malicious URL sequence detection using event de-noising convolutional neural network. In Proceedings of the 2017 IEEE International Conference Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar]
- Yamanishi, K. Detecting Drive-By Download Attacks from Proxy Log Information Using Convolutional Neural Network; Osaka University: Osaka, Japan, 2017. [Google Scholar]
- Gao, N.; Gao, L.; Gao, Q.; Wang, H. An intrusion detection model based on deep belief networks. In Proceedings of the 2014 2nd International Conference Advanced Cloud and Big Data (CBD), Huangshan, China, 20–22 November 2014; pp. 247–252. [Google Scholar]
- Nguyen, K.K.; Hoang, D.T.; Niyato, D.; Wang, P.; Nguyen, P.; Dutkiewicz, E. Cyberattack detection in mobile cloud computing: A deep learning approach. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Alrawashdeh, K.; Purdy, C. Toward an online anomaly intrusion detection system based on deep learning. In Proceedings of the 15th IEEE International Conference Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 195–200. [Google Scholar]
- Alom, M.Z.; Bontupalli, V.; Taha, T.M. Intrusion detection using deep belief networks. In Proceedings of the 2015 National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 June 2015; pp. 339–344. [Google Scholar]
- Dong, B.; Wang, X. Comparison deep learning method to traditional methods using for network intrusion detection. In Proceedings of the 8th IEEE International Conference Communication Software and Networks (ICCSN), Beijing, China, 4–6 June 2016; pp. 581–585. [Google Scholar]
- Li, Y.; Ma, R.; Jiao, R. A hybrid malicious code detection method based on deep learning. Methods 2015, 9, 205–216. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M. Network intrusion detection for cyber security using unsupervised deep learning approaches. In Proceedings of the 2017 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 27–30 June 2017; pp. 63–69. [Google Scholar]
- Coburg Intrusion Detection Dataset-001. Available online: https://www.hs-coburg.de/forschung-kooperation/forschungsprojekte-oeffentlich/ingenieurwissenschaften/cidds-coburg-intrusion-detection-data-sets.html (accessed on 23 February 2019).
- Abdulhammed, R.; Faezipour, M.; Abuzneid, A.; AbuMallouh, A. Deep and machine learning approaches for anomaly-based intrusion detection of imbalanced network traffic. IEEE Sens. Lett. 2018. [Google Scholar] [CrossRef]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. arXiv, 2018; arXiv:1802.09089. [Google Scholar]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the IEEE 2017 International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; pp. 712–717. [Google Scholar]
- Ixia Corporation, Ixia Breakpoint Overview and Specifications. 2016. Available online: https://www.ixiacom.com/products/breakingpoint (accessed on 23 February 2019).
- LeCun, Y.A.; Jackel, L.D.; Bottou, L.; Brunot, A.; Cortes, C.; Denker, J.S.; Drucker, H.; Guyon, I.; Muller, U.A.; Sackinger, E.; et al. Learning algorithms for classification: A comparison on handwritten digit recognition. In Neural Networks; World Scientific: London, UK, 1995; pp. 261–276. [Google Scholar]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection system. In Proceedings of the 9th EAI International Conference Bio-inspired Information and Communications Technologies (Formerly BIONETICS), New York, NY, USA, 3–5 December 2015; pp. 21–26. [Google Scholar]
- Ma, T.; Wang, F.; Cheng, J.; Yu, Y.; Chen, X. A Hybrid Spectral Clustering and Deep Neural Network Ensemble Algorithm for Intrusion Detection in Sensor Networks. Sensors 2016, 16, 1701. [Google Scholar] [CrossRef]
- Aminanto, M.E.; Kim, K. Deep Learning-Based Feature Selection for Intrusion Detection System in Transport Layer. Available online: https://pdfs.semanticscholar.org/bf07/e753401b36662eee7b8cd6c65cb8cfe31562.pdf (accessed on 23 February 2019).
- Staudemeyer, R.C. Applying long short-term memory recurrent neural networks to intrusion detection. S. Afr. Comput. J. 2015, 56, 136–154. [Google Scholar] [CrossRef]
- Kim, J.; Kim, H. Applying recurrent neural network to intrusion detection with hessian free optimization. In Proceedings of the International Conference on Information Security Applications, Jeju Island, Korea, 20–22 August 2015; pp. 357–369. [Google Scholar]
- Kim, G.; Yi, H.; Lee, J.; Paek, Y.; Yoon, S. LSTM-Based System-Call Language Modeling and Robust Ensemble Method for Designing Host-Based Intrusion Detection Systems. arXiv, 2016; arXiv:1611.01726. [Google Scholar]
- Kim, J.; Kim, J.; Thu, H.L.T.; Kim, H. Long Short Term Memory Recurrent Neural Network Classifier for Intrusion Detection. In Proceedings of the 2016 International Conference Platform Technology and Service (PlatCon), Jeju, Korea, 15–17 February 2016; pp. 1–5. [Google Scholar]
- Krishnan, R.B.; Raajan, N.R. An intellectual intrusion detection system model for attacks classification using RNN. Int. J. Pharm. Technol. 2016, 8, 23157–23164. [Google Scholar]
- Yin, C.L.; Zhu, Y.F.; Fei, J.L.; He, X.Z. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Roy, S.S.; Mallik, A.; Gulati, R.; Obaidat, M.S.; Krishna, P.V. A Deep Learning Based Artificial Neural Network Approach for Intrusion Detection. In Proceedings of the International Conference Mathematics and Computing, Haldia, India, 17–21 January 2017; pp. 44–53. [Google Scholar]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep learning approach for network intrusion detection in software defined networking. In Proceedings of the 2016 International Conference Wireless Networks and Mobile Communication (WINCOM), Fez, Morocco, 26–29 October 2016; pp. 258–263. [Google Scholar]
- Chawla, S. Deep Learning Based Intrusion Detection System for Internet of Things; University of Washington: Seattle, WA, USA, 2017. [Google Scholar]
- Diro, A.A.; Chilamkurti, N. Deep learning: The frontier for distributed attack detection in Fog-to-Things computing. IEEE Commun. Mag. 2018, 56, 169–175. [Google Scholar] [CrossRef]
- Diro, A.A.; Chilamkurti, N. Distributed attack detection scheme using deep learning approach for internet of things. Future Gener. Comput. Syst. 2018, 82, 761–768. [Google Scholar] [CrossRef]
- Diro, A.A.; Chilamkurti, N. Leveraging LSTM Networks for Attack Detection in Fog-to-Things Communications. IEEE Commun. Mag. 2018, 56, 124–130. [Google Scholar] [CrossRef]
- Nadeem, M.; Marshall, O.; Singh, S.; Fang, X.; Yuan, X. Semi-Supervised Deep Neural Network for Network Intrusion Detection. Available online: https://digitalcommons.kennesaw.edu/ccerp/2016/Practice/2/ (accessed on 23 February 2019).
- Rasmus, A.; Berglund, M.; Honkala, M.; Valpola, H.; Raiko, T. Semi-supervised learning with ladder networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 3546–3554. [Google Scholar]
- Yu, Y.; Long, J.; Cai, Z. Network intrusion detection through stacking dilated convolutional autoencoders. Secur. Commun. Netw. 2017, 2017, 4184196. [Google Scholar] [CrossRef]
- The UNB ISCX 2012 Intrusion Detection Evaluation Dataset. Available online: http://www.unb.ca/cic/research/datasets/ids.html (accessed on 23 February 2019).
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Yu, Y.; Long, J.; Cai, Z. Session-Based Network Intrusion Detection Using a Deep Learning Architecture. In Modeling Decisions for Artificial Intelligence; Lecture Notes in Computer Science; Springer: Cham, Germany, 2017; Volume 10571, pp. 144–155. [Google Scholar]
- Kang, M.J.; Kang, J.W. Intrusion detection system using deep neural network for in-vehicle network security. PLoS ONE 2016, 11, e0155781. [Google Scholar] [CrossRef] [PubMed]
- Loukas, G.; Vuong, T.; Heartfield, R.; Sakellari, G.; Yoon, Y.; Gan, D. Cloud-based cyber-physical intrusion detection for vehicles using Deep Learning. IEEE Access 2018, 6, 3491–3508. [Google Scholar] [CrossRef]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, S. Intrusion detection in 802.11 networks: Empirical evaluation of threats and a public dataset. IEEE Commun. Surv. Tutor. 2015, 18, 184–208. [Google Scholar] [CrossRef]
- Aminanto, M.E.; Kim, K. Improving detection of Wi-Fi impersonation by fully unsupervised deep learning. In Proceedings of the International Conference on Information Security Applications, Jeju Island, Korea, 24–26 August 2017; pp. 212–223. [Google Scholar]
- Maimó, L.F.; Gómez, A.L.P.; Clemente, F.J.G.; Pérez, M.G. A self-adaptive deep learning-based system for anomaly detection in 5G networks. IEEE Access 2018, 6, 7700–7712. [Google Scholar] [CrossRef]
- Garcia, S.; Grill, M.; Stiborek, J.; Zunino, A. An empirical comparison of botnet detection methods. Comput. Secur. 2014, 45, 100–123. [Google Scholar] [CrossRef]
- Cox, J.A.; James, C.D.; Aimone, J.B. A signal processing approach for cyber data classification with deep neural networks. Procedia Comput. Sci. 2015, 61, 349–354. [Google Scholar] [CrossRef]
- Wang, Z. The Applications of Deep Learning on Traffic Identification; BlackHat: Washington, DC, USA, 2015. [Google Scholar]
- Lotfollahi, M.; Shirali, R.; Siavoshani, M.J.; Saberian, M. Deep Packet: A Novel Approach for Encrypted Traffic Classification Using Deep Learning. arXiv, 2017; arXiv:1709.02656. [Google Scholar]
- Wang, W.; Zhu, M.; Wang, J.; Zeng, X.; Yang, Z. End-to-end encrypted traffic classification with one-dimensional convolution neural networks. In Proceedings of the 2017 IEEE International Conference Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 43–48. [Google Scholar]
- ISCX VPN-nonVPN Encrypted Network Traffic Dataset. 2017. Available online: http://www.unb.ca/cic/research/datasets/vpn.html (accessed on 23 February 2019).
- Tzortzis, G.; Likas, A. Deep Belief Networks for Spam Filtering. in Tools with Artificial Intelligence. In Proceedings of the 2007 19th IEEE International Conference on ICTAI, Patras, Greece, 29–31 October 2007; Volume 2, pp. 306–309. [Google Scholar]
- Mi, G.; Gao, Y.; Tan, Y. Apply stacked auto-encoder to spam detection. In Proceedings of the International Conference in Swarm Intelligence, Beijing, China, 26–29 June 2015; pp. 3–15. [Google Scholar]
- Tuor, A.; Kaplan, S.; Hutchinson, B.; Nichols, N.; Robinson, S. Deep learning for unsupervised insider threat detection in structured cybersecurity data streams. arXiv, 2017; arXiv:1710.00811. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 8th IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Cheng, M.; Xu, Q.; Lv, J.; Liu, W.; Li, Q.; Wang, J. MS-LSTM: A multi-scale LSTM model for BGP anomaly detection. In Proceedings of the IEEE 24th International Conference Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–6. [Google Scholar]
- Kobojek, P.; Saeed, K. Application of recurrent neural networks for user verification based on keystroke dynamics. J. Telecommun. Inf. Technol. 2016, 3, 80–90. [Google Scholar]
- Shi, C.; Liu, J.; Liu, H.; Chen, Y. Smart user authentication through actuation of daily activities leveraging WiFi-enabled IoT. In Proceedings of the 18th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Chennai, India, 10–14 July 2017; ACM: New York, NY, USA, 2017; p. 5. [Google Scholar]
- He, Y.; Mendis, G.J.; Wei, J. Real-time detection of false data injection attacks in smart grid: A deep learning-based intelligent mechanism. IEEE Trans. Smart Grid 2017, 8, 2505–2516. [Google Scholar] [CrossRef]
- Roth, P. Introducing Ember: An Open Source Classifier and Dataset. 16 April 2018. Available online: https://www.endgame.com/blog/technical-blog/introducing-ember-open-source-classifier-and-dataset (accessed on 23 February 2019).
- Bahnsen, A.C.; Torroledo, I.; Camacho, L.D.; Villegas, S. DeepPhish: Simulating Malicious AI. In Proceedings of the Symposium on Electronic Crime Research, San Diego, CA, USA, 15–17 May 2018. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | |||
|---|---|---|---|
| Malicious | Benign | ||
| Actual Class (ground truth) | Malicious | True Positive (TP) | False Negative (FN) |
| Benign | False Positive (FP) | True Negative (TN) | |
| DL Method | Citation | No. of Times Cited (as of 10/8/2018) | Cyber Security Application | Dataset Used |
|---|---|---|---|---|
| Autoencoder | Hardy et al. [83] | 20 | Malware Detection | Comodo Cloud Security Center [66] |
| Autoencoder | Wang and Yiu [102] | 8 | Malware Classification | Public malware API call sequence dataset [138] |
| Autoencoder | Javaid et al. [130] | 77 | Intrusion Detection | KDDCUP 1999 [57] |
| Autoencoder | Ma et al. [134] | 20 | Intrusion Detection | KDDCUP 1999 [57] |
| Autoencoder | Aminanto and Kim [135] | 1 | Intrusion Detection | KDDCUP 1999 [57] |
| Autoencoder | Abeshu and Chilamkurti [145] | 9 | Intrusion Detection | NSL-KDD [58] |
| Autoencoder | Chawla [144] | 0 | Intrusion Detection (IoT) | Simulated from Open Car Test-bed and Network Experiments |
| Autoencoder | Cox, James, and Aimone [160] | 8 | File Type Identification | Internal Dataset |
| Autoencoder | Wang [161] | 58 | Network Traffic Identification | Honeypot dataset derived internally |
| Autoencoder | Lotfollahi et al. [162] | 12 | Network Traffic Identification | ISCX VPN-nonVPN traffic dataset [164] |
| Autoencoder | Mi, Gao, and Tan [166] | 12 | Spam identification | EnronSpam [73], PU1, PU2, PU3, PU4 |
| Autoencoder | Aminanto and Kim [155] | 3 | Impersonation Attacks | AWID [156] |
| Autoencoder | Diro and Chilamkurti [147] | 9 | Intrusion Detection | NSL-KDD [58] |
| Autoencoder | Shi et al. [171] | 20 | User Authentication | Custom |
| Autoencoder | Yousefi-Azar et al. [103] | 11 | Intrusion Detection Malware Detection | NSL-KDD [58], Microsoft Malware Classification Challenge [70] |
| Autoencoder | Abdulhammed et al. [128] | 0 | Intrusion Detection | CIDDS-001 [127] |
| Autoencoder (Ladder Networks) | Nadeem et al. [148] | 3 | Intrusion Detection | KDD 1999 [57] |
| Autoencoder RBM | Alom and Taha [126] | 3 | Intrusion Detection | KDD 1999 [57] |
| Autoencoder | Mirsky et al. [129] | 12 | Intrusion Detection | Custom |
| CNN | Gibert [100] | 13 | Malware Classification | Microsoft Malware Classification Challenge [70] |
| CNN | Zeng, Chang, and Wan [112] | 1 | DGA | Alexa [60], Private Dataset |
| CNN | Yamanishi [119] | 1 | Drive-by Download Attack | KDD 1999 [57] |
| CNN | McLaughlin et al. [82] | 24 | Malware Detection | Genome Project [67], McAfee Labs |
| CNN | Wang et al. [130] | 17 | Intrusion Detection | CTU-13 [59], IXIA [131] |
| CNN | Wang et al. [163] | 9 | Traffic Identification | ISCX VPN–non-VPN traffic dataset [164] |
| CNN | Shibahara et al. [118] | 3 | Drive-by Download Attack | Malware domain list, Malware Bytes, Alexa [60], honeypot setup |
| CNN RNN | Kolosnjaji et al. [79] | 63 | Malware Detection | Virus Share [68], Maltrieve Private |
| CNN RNN | Tobiyama et al. [80] | 26 | Malware Detection | Unknown |
| CNN RNN | Mac et al. [110] | 1 | DGA | Alexa [60], OSINT [61] |
| CNN RNN | Yu et al. [111] | 5 | DGA | Alexa [60], DGArchive [62] |
| CNN (dilated) Autoencoder | Yu et al. [150] | 4 | Intrusion Detection | CTU-UNB [59,151,152], Contagio-CTU-UNB [152] |
| CNN (Dynamic) | Hill and Bellekens [94] | 1 | Malware Detection | Unknown |
| DNN | Saxe and Berlin [89] | 127 | Malware Detection | Jotti commercial malware feed Invincea‘s private data |
| DNN | Mizuno et al. [92] | 2 | Malware Infected Device Detection | Traffic data from malware, verified by TrendMicro or Kaspersky; campus network traffic data; samples from Malwr, MalShare, and VirusShare |
| DNN | Dahl et al. [95] | 163 | Malware Classification | Internal Microsoft dataset |
| DNN | Grosse et al. [105] | 96 | Malware Classification | DREBIN [69] |
| DNN | Cordonsky et al. [99] | 0 | Malware Classification | Unknown |
| DNN | Huang and Stokes [104] | 42 | Malware Classification | Microsoft corporation provided dataset |
| DNN | Roy et al. [142] | 14 | Intrusion Detection | KDDCUP 1999 [57] |
| DNN | Tang et al. [143] | 59 | Intrusion Detection for SDN | Generated from a Cooja network simulator |
| DNN | Diro and Chilamkurti [146] | 27 | Intrusion Detection | NSL-KDD [58] |
| DNN RNN | Tuor et al. [166] | 25 | Insider Threat | CERT Insider Threat Dataset v6.2 [71,72] |
| Autoencoders (Denoising) | David and Netanyahu [101] | 39 | Malware Classification | C4 Security dataset |
| GAN | Anderson, Woodbridge and Filar [107] | 23 | DGA | Alexa [60] |
| RBM | Alrawashdeh and Purdy [122] | 16 | Intrusion Detection | KDDCUP 1999 [57] |
| RNN | Pascanu et al. [78] | 87 | Malware Detection | Internal Microsoft dataset |
| RNN | Shibahara et al. [91] | 11 | Malware Detection | Virus Total [64], Alexa [60] |
| RNN | Woodbridge et al. [108] | 16 | DGA | Alexa [60], OSINT [61] |
| RNN | Lison and Mavroeidis [109] | 4 | DGA | Alexa [60], DGArchive [62], OSINT [61] |
| RNN | Tran et al. [114] | 5 | DGA | Alexa [60], OSINT [61] |
| RNN | Torres et al. [115] | 17 | DGA | Malware Capture Facility Project Dataset |
| RNN | Kim et al. [139] | 47 | Intrusion Detection | KDDCUP 1999 [57] |
| RNN | Kim and Kim [137] | 11 | Intrusion Detection | KDDCUP 1998 [57], ADFA-LD, and UNM data sets |
| RNN | Kim et al. [138] | 12 | Intrusion Detection | KDDCUP 1999 [57] and additional, original data |
| RNN | Loukas et al. [155] | 2 | Intrusion Detection (Vehicles) | Custom |
| RNN | Cheng et al. [169] | 11 | Border Gateway Protocol Anomaly Detection | Custom |
| RNN | Kobojek and Saeed [170] | 6 | Keystroke Verification | Custom |
| RNN | McDermott, Majdani, and Petrovski [116] | 0 | Intrusion Detection (IoT) | Custom |
| RNN | Krishnan and Raajan [140] | 11 | Intrusion Detection | KDD 1999 [57] |
| RNN | Staudemeyer [136] | 23 | Intrusion Detection | KDD 1999 [57] |
| RNN | Yin et al. [141] | 36 | Intrusion Detection | NSL-KDD [58] |
| RBM | Yuan et al. [76] | 104 | Malware Detection | Contagio [65] Google Play Store [63] |
| RBM | Yuan et al. [77] | 66 | Malware Detection | Contagio [65] Genome Project [67] Google Play Store [63] |
| RBM | Hou et al. [86] | 12 | Malware Detection | Comodo Cloud [66], Security Center |
| RBM | Xu et al. [85] | 9 | Malware Detection | Google play store [63] Virus share [68] |
| RBM | Benchea and Gavriluţ [84] | 4 | Malware Detection | Self-generated dataset |
| RBM | Zhu et al. [87] | 5 | Malware Detection | Genome Project [67] VirusTotal [64] DREBIN [69] Google Play [63] |
| RBM | Ye et al. [88] | 8 | Malware Detection | Comodo Cloud [66], Security Center |
| RBM | Gao et al. [120] | 46 | Intrusion Detection | NSL-KDD [58] |
| RBM | Alom, Bontupalli, and Taha [123] | 31 | Intrusion Detection | KDD 1999 [57] |
| RBM | Dong and Wang [124] | 22 | Intrusion Detection | NSL-KDD [58] |
| RBM | Kang and Kang [154] | 59 | Intrusion Detection (Vehicles) | Custom |
| RBM | Nguyen et al. [121] | 1 | Intrusion Detection | NSL-KDD [58] KDDCUP 1999 [57] UNSW-NB15 |
| RBM | Tzortzis and Likas [165] | 21 | Spam Identification | EnronSpam [73] SpamAssassin [74] LingSpam [75] |
| RBM | He, Mendis, and Wei [172] | 34 | False Data Injection | Custom |
| RBM | Chen et al. [93] | 3 | Malware Detection (Mobile Edge Computing) | Unknown |
| RBM | Ding, Chen, and Xu [81] | 6 | Malware Detection | Unknown |
| RBM Autoencoder | Li, Ma, and Jiao [125] | 28 | Intrusion Detection | KDD 1999 [57] |
| RBM RNN | Maimó et al. [158] | 4 | Intrusion Detection (5G) | CTU-13 [59] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berman, D.S.; Buczak, A.L.; Chavis, J.S.; Corbett, C.L. A Survey of Deep Learning Methods for Cyber Security. Information 2019, 10, 122. https://doi.org/10.3390/info10040122
Berman DS, Buczak AL, Chavis JS, Corbett CL. A Survey of Deep Learning Methods for Cyber Security. Information. 2019; 10(4):122. https://doi.org/10.3390/info10040122
Chicago/Turabian StyleBerman, Daniel S., Anna L. Buczak, Jeffrey S. Chavis, and Cherita L. Corbett. 2019. "A Survey of Deep Learning Methods for Cyber Security" Information 10, no. 4: 122. https://doi.org/10.3390/info10040122
APA StyleBerman, D. S., Buczak, A. L., Chavis, J. S., & Corbett, C. L. (2019). A Survey of Deep Learning Methods for Cyber Security. Information, 10(4), 122. https://doi.org/10.3390/info10040122