1. Introduction
Data is an integral part of the current business and technology world. Every day, different organizations are producing a massive amount of data also known as “big data”. This “big data” analysis has attracted much attention to many organizations and researchers because it can assist in making strategic decisions and creating new knowledge. Product pricing for the open market place, investment risk estimation, mining customers’ spending/buying behaviors, credit card usage patterns, health issues, and so on are some common example of big data analytics. Designing a new framework for collecting, storing and analyzing this “big data” is undoubtedly a challenging task.
In the current IT era, multiple organizations dealing with similar kind of services want to perform analysis on their joint databases. It is often referred to as multi-party computation or analysis. This analysis may involve data-mining, querying over the joint dataset, data classification, statistical decision making, etc. [
1,
2]. Since the business applications contain sensitive data, such as personal health-related data or financial data, unveiling these data can potentially violate individual privacy and lead to significant financial loss to the organizations. Therefore, organizations do not want to disclose their data to anyone. However, when multiple organizations want to conduct a data-mining operation jointly, they are willing to get the result from the union of their databases without disclosing their sensitive data.
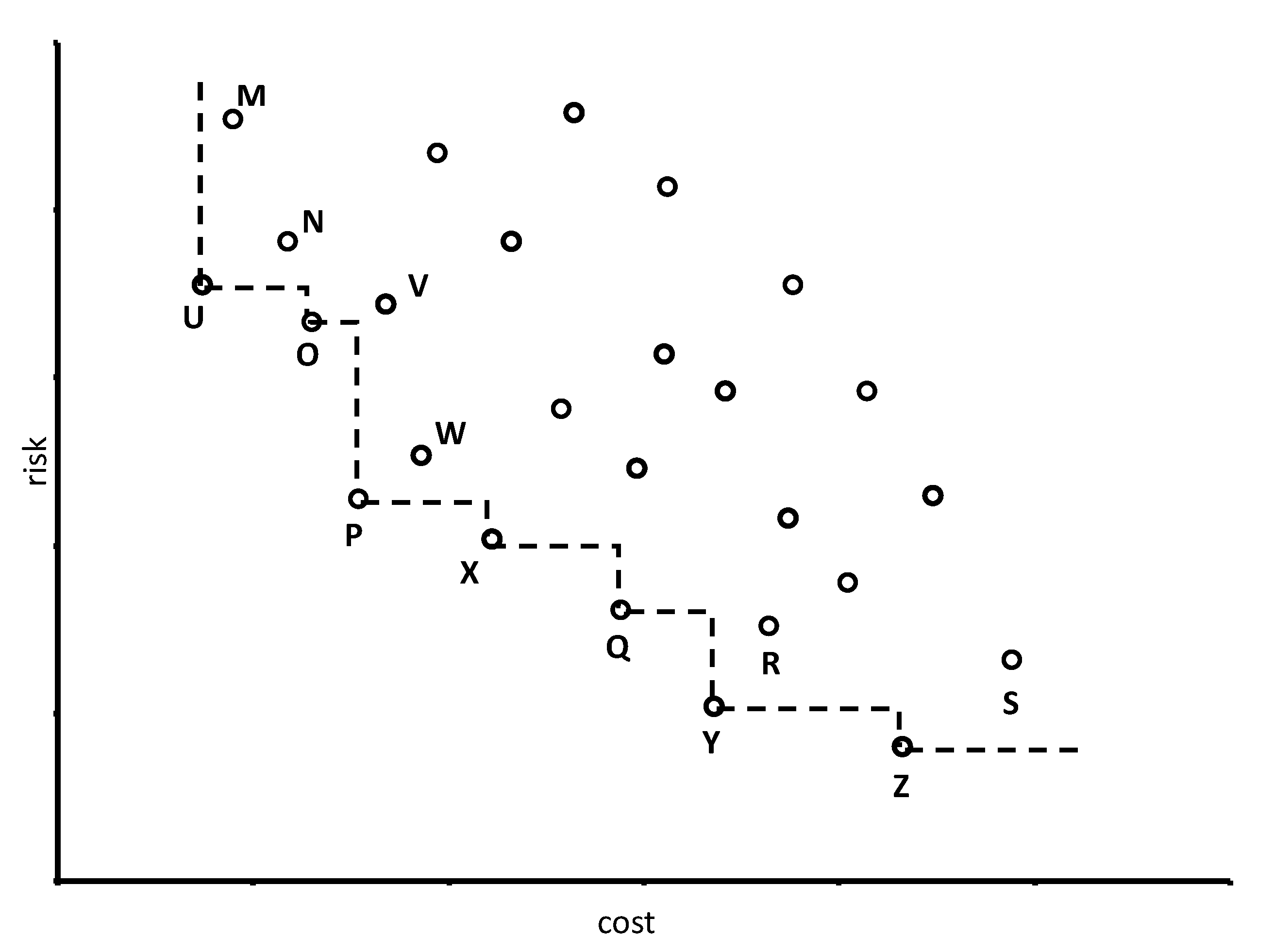
On the other hand, the skyline query is one of the popular methods for selecting representative objects from a large dataset. It retrieves a set of representative objects, each of which is not dominated by any other object within the database. For example, let us consider the issue of financial investment: an investor usually wants to purchase the stock that can minimize the commission costs and predicted risks. As a result, the target can be formalized as finding the skyline stock with minimal cost and minimal risk.
Figure 1 shows a sample plot diagram of stock records along with their costs and risks. If we want to provide a suitable suggestion list for our clients using skyline query, the result will be
. From
Figure 1, it is obvious that no other object, within the given sample dataset, can dominate those seven objects. Therefore, they are in the skyline result. The skyline query attracts consistent attention in database research, due to its applications in decision making as well as analytics.
Like other data analysis applications, the distributed skyline computation certainly can benefit the participating organizations by producing skyline objects set from the joint database of the organizations. However, such computation also depends on managing data security and privacy challenges, especially for the skyline computation from the distributed multi-party databases. So far, several algorithms have been proposed for skyline computation, some of them are designed in a distributed computing environment and able to handle “big data” [
3,
4,
5]. However, none of them considered database privacy issues.
Let us assume that several organizations have done surveys about commission cost and risk prediction where each of the organization has collected the same kind of privacy information from their customers/clients. This information is sensitive since the privacy of client information is a vital responsibility for each organization. Therefore, one organization does not want to disclose the dataset to other organization. Hence one organization cannot compute global skyline on organizations’ union databases but only compute skyline query of its own, although all parties (organizations) are willing to get the skyline result from their combined databases. In conventional skyline computation algorithm, it is not possible to get skyline query result without disclosing the objects’ attributes value to others.
When concerning the privacy of the database objects in a distributed multi-party computation environment, most of the existing work on privacy-preserving skyline computation focused on the secure comparison of encrypted values owned by participating organizations [
6,
7,
8,
9]. Although these frameworks can preserve the data objects privacy, they are not much suitable concerning computational efficiency. In our previous work [
10], we introduced MapReduce framework-based secure ordering of database objects on each attribute in a semi-honest computation environment. Then computes the skyline by using the dominance relationship among the order of multi-party’s objects on each attribute. Although it is more efficient compared to secure comparison-based skyline query, it requires several rounds of ID encryption and decryption by the individual parties on each attribute of the database objects for creating the order of the objects. It also needs several rounds of data sorting by the coordinator on each dimension of the database objects. In this regard, our previous work consumes a significant amount of time for preparing the secure object order on each attribute. We also included the MapReduce framework only for sorting numeric values. However, using the MapReduce framework just for object ordering does not seem to be wise, since the framework itself requires a significant amount of time for inter-node communication and managing the process execution among multiple nodes.
In this work, we introduced an extended approach of [
10] that can process the distributed object order more efficiently in a semi-honest computation environment; at the same time, it preserves the privacy of individual objects. In this extended work, we incorporate Paillier cryptosystem [
11] for transforming the objects attributes value without changing the order of the objects on each attribute; where each participating party securely prepare encrypted object order on each attribute in collaboration with other participating parties. Then computes skyline from the order of the objects attribute value on each dimension without obtaining the original attributes’ value of the objects.
The remaining part of this paper is organized as follows.
Section 2 reviews the related work.
Section 3 discusses the notions and basic properties of skyline and Paillier cryptosystem. We briefly explain our secure skyline computation problem and proposed system model in
Section 4. In
Section 5, we specify the detailed algorithm with proper examples and analysis. Next, we discuss the privacy and security of our proposed framework in
Section 6. We experimentally explain the efficiency of our algorithms in
Section 7 under a variety of settings. Finally,
Section 8 concludes this work.
Throughout this paper, we have used the hexadecimal number system for describing our proposed algorithm.
5. Privacy-Preserving Multi-Party Secure Skyline Computation Algorithm
In this section, we provide details of the proposed algorithm. It consists of eight steps.
Local skyline computation.
Fix the bit-slice length and maximum bit-length of substitute vector element.
Paillier key-pair generation.
Generate and share the encrypted substitute vectors.
Combine the encrypted substitute vectors.
Encrypt the object order and resultant dataset generation.
Decrypt the objects order and global skyline computation.
Qualified global skyline objects identification.
Figure 3 describes the simplified block-diagram of our proposed privacy-preserving skyline computation model. Where we use one coordinator and
p is the number of participating parties. Each
represents the substitute vector generated by
, and
represents the encrypted substitute vector of
, where each element of
is encrypted using the Paillier public key.
5.7. Decrypt the Objects Order and Global Skyline Computation
After receiving the dataset with the encrypted disguised order of the local skyline objects on each attribute, the coordinator decrypts them by using Paillier private key, and obtain the transformed value of local skyline objects without changing their relative order.
Table 10 illustrates the sample database with encrypted data obtained from individual parties. The transformed order value of the objects’ attributes on each dimension after decryption, where each value in column
for
obtained by decrypting each encrypted value in column
. This process can be represented by the following equation:
Here we discuss the procedure of obtaining for , where the original attribute value is . Let’s assume the value of substitute vector elements and for hexadecimal value generated by and are and , respectively. Similarly, and for .
After encrypting with , and obtain and . Therefore, using homomorphic addition property, both parties can obtain the combine encrypted substitute vector element for as .
Since, for our running example. Hence, for , . By using the same equation computes . Proceeding in the same way of obtaining combine encrypted substitute vector element for , both parties can get for .
Finally, by adding the encrypted substitute vector elements for original attribute value , can produce the encrypted order value as .
After decryption, the coordinator uses the object order on each attribute for computing global skyline query. From
Table 10, we observe that according to the transformed value of the objects secure attribute value, any other objects within the dataset do not dominate the dataset objects with
IDs
. It can be confirmed from column
and
. Therefore, the coordinator computes the skyline result as
. Since each
representing the object with
ID, hence the result is also correct according to their original attributes value, as illustrated in
Figure 2. After computing the global skyline objects set
the coordinator sends the encrypted
IDs of qualified
objects to all participating parties.
7. Experiments
In this section, we evaluate the performance and effectiveness of our proposed framework. We used four identical computers connected with Cisco Catalyst 2960-X Series Gigabit Switch for the experimental setup. Out of the four computers one was considered to be the coordinator and other three computers as individual parties containing private datasets. Each of the computers has an Intel® Core™ i5-6500 3.20 GHz CPU and 8 GB memory. We used the 64-bit Ubuntu 16.04 operating system for our experiment. We compiled the source codes of the program under Java V8 and executed the program under Java™ 1.8.0 Runtime Environment. We generated synthetic datasets for evaluating the performance of our proposed framework. Each attribute value of the synthetic datasets was randomly picked from 32-bit unsigned integer. For the proposed study, we put our focus on the performance of generating secure object order targeting skyline computation from the privacy-preserved multi-party databases without unveiling the original attributes’ value of the objects to anyone. For evaluating the efficiency of our model, we considered that all participating parties begin to generate the encrypted substitute vectors and compute there local skyline objects set simultaneously after obtaining the Pallier public key, Paillierpk from the coordinator.
From our experiment, we found that the significant time consumes for computing the local skyline objects set, for generating encrypted substitute vector and for combining the vectors generated by individual parties. However, since the individual parties compute the local skyline objects set from their plain dataset without any security protocol, the local skyline computation time remain same either for non-secured distributed skyline computation or for privacy-preserved multi-party skyline computation. We also comprehensively compared the complexity of our proposed framework with the frameworks proposed in [
6,
10].
A. Encrypted Substitute Vector Generation and Combining: We studied the runtime for encrypted substitute vector generation process according to the algorithm described in
Section 5.4, which will be executed by each participating party simultaneously. Since the length of the substitute vector increases twice with each increase of the bit-slice length, the process runtime of generating the unique random numbers within a given range and encrypting the substitute vector elements also increases. However, using the larger bit-slice length reduces the number of partitions for splitting the attribute value to transform the attribute value and thus also reduces the number of the required substitute vector. For example, a 32-bit attribute value can be substitutable by using two vectors of 16-bit-slice length, but it requires three vectors to substitute using the vector of 11-bit-slice length. We examined runtime with varied bit-slice length from 10 to 16.
Figure 4a shows the effect of encrypted substitute vector generation process with different bit-slice length.
We also studied the process execution time for joining the encrypted substitute vectors using homomorphic addition property according to
Section 5.5. In this regard, we examined the runtime of combining three substitute vectors generated by three participating parties for varied bit-slice length. Our experimental result is illustrated in
Figure 4b.
B. Privacy-Preserving Multi-Party Skyline Computation: To evaluate the performance of our proposed framework, we assumed that each participating party computes local skyline from the equal amount of data tuples. We evaluate the performance of our proposed framework for different data distribution and the varied number of objects’ dimension. For both experiments, we varied each participating parties’ tuples number from 10 k to 50 k.
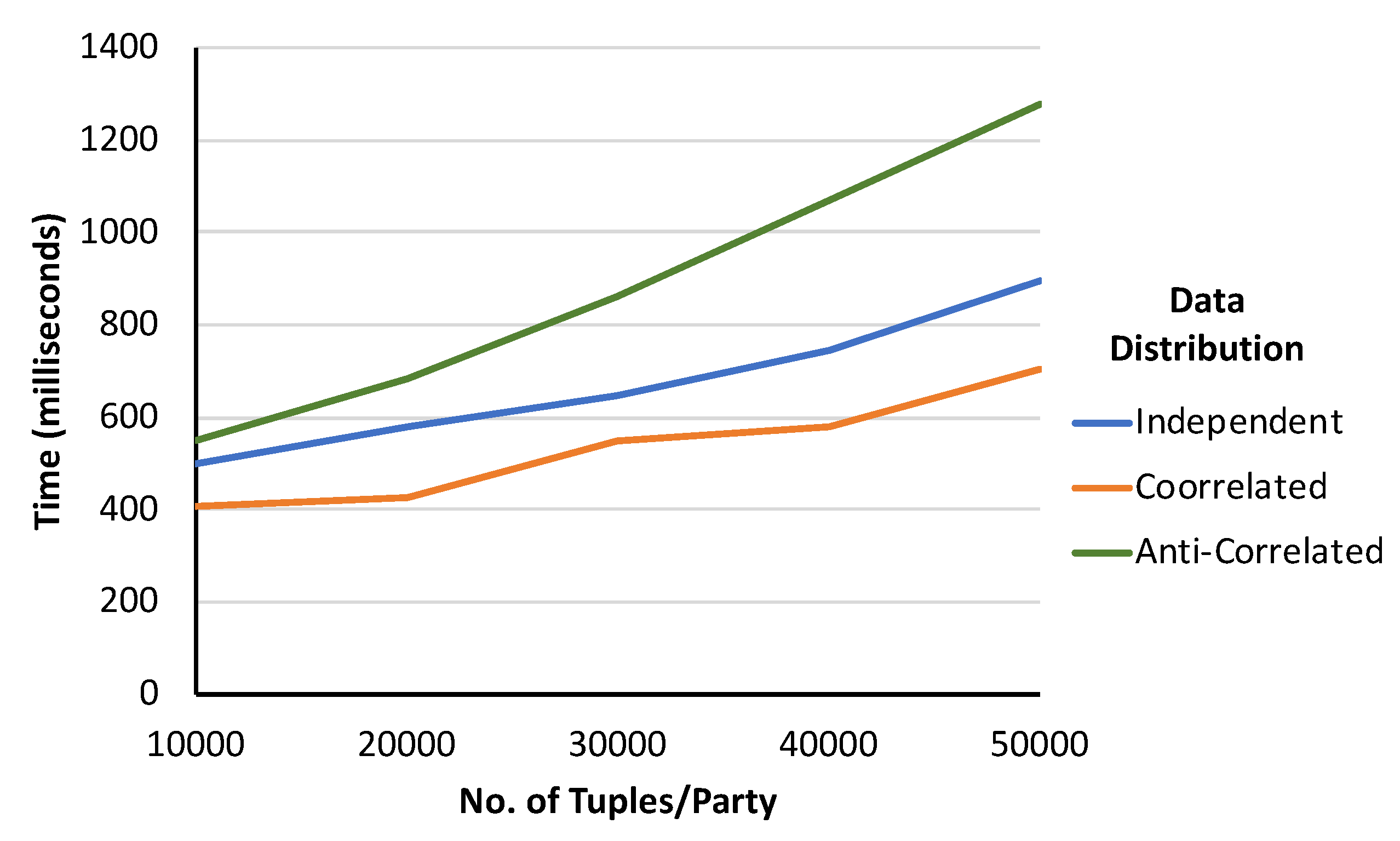
To conduct this experiment, we used three different types of data distribution. They are correlated, anti-correlated, and independent distributions. As shown in
Figure 5, this framework is affected by data distribution. We found that the framework is more efficient for the correlated dataset and less efficient for the anti-correlated dataset. However, the performance for independent dataset lies in between the performance for the anti-correlated and correlated dataset.
Figure 6 illustrates the effect of data dimension for computing skyline. We varied the data dimension from 2 to 6. Since the number of required encrypted substitute vector along with the number of comparisons and the amount of qualified local skyline objects increases with the vector dimension, the process execution time also increases. The results of our experiment also reflect it.
C. Comparison with Existing Privacy-Preserving Multi-party Skyline Computation Frameworks: The framework proposed in [
6] applies the pairwise secure comparison of the objects’ attributes for computing dominance relationship between two participating parties’ objects. Therefore, the complexity of the algorithm increases with the number of participating parties, since each local skyline object of a party needs to be securely compared with other parties local skyline objects set separately. The author proposed to generate the homomorphic encryption key-pair twice for each comparison of the two private objects using the LAHE scheme. The complexity of the Fast Secure Integer Comparison (FSIC) protocol used by the framework depends on the maximum length of the attribute value in the number of bits. Furthermore, it also requires five rounds of information exchange between each pair of the participating parties for each comparison of their local skyline objects.
On the other hand, our proposed framework is comparatively less dependent on the number of participating parties. The coordinator generates the homomorphic encryption key-pair only for one time for the whole process. And our framework does not employ secure comparison protocol like [
6]. Moreover, it just requires six rounds of data exchange for the entire computation process: at the beginning between the coordinator and the participating parties for sharing the public encryption key. After that, three rounds communication requires between the participating parties for fixing the bit-slice length, for sharing the encrypted substitute vector and merging the individual parties’ local skyline objects’ encrypted order on each attribute. Then, another round of communication required for sending the merged set of local skyline objects’ encrypted order to the coordinator. The final round of data communication needed between the coordinator and the participating parties, for sharing the encrypted
s of the globally qualified skyline objects. Although it requires to transmit a large amount of data during the sharing of each party’s encrypted substitute vector, it is negligible compared to five rounds of information exchange for each dominance relationship comparison of two parties’ objects.
The method proposed in [
10] is also scalable for any number of participating parties, although it requires multiple rounds of data interchange between the participating parties with the coordinator based on the number of slices of each attribute value and the number of dimension of the objects for preparing the order of the objects on each attribute. It also requires multiple rounds of sorting by the coordinator, and partial order merging by the individual parties for generating objects’ order securely on each attribute. On the other hand, our present work does not need several rounds of data exchange, data sorting and partial order merging like [
10]. Besides that, we consider using homomorphic encrypted substitute vector to transform the objects’ attributes value securely without altering their order on each attribute.
Therefore, we claim that the proposed algorithm is more efficient and robust in terms of computation and communication complexity.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}