Tangled String for Multi-Timescale Explanation of Changes in Stock Market


Abstract
:1. Introduction: Problem Definition
2. TS for a Stock Price Sequence
2.1. Origins of TS and the Data Market
- Requirement R1: collect information useful for decision making
- Method M1: obtain a high impact message in a sequence and relate it to external information
- Data for realizing M1: {DJ1: log text of communication, DJ2: information about disasters}
- Requirement R2: explain events in the tipping points of consumer behaviors in the market
- Method M2: detect a high impact event by TS and relate it with external information to explain the causality
- Data for realizing M2: {DJ3: log of consumptions or purchase history, DJ4: social events and news}
2.2. TS Algorithm
| Algorithm 1. Original version algorithm of TS algorithm (Revised from [23] without changing the meaning) |
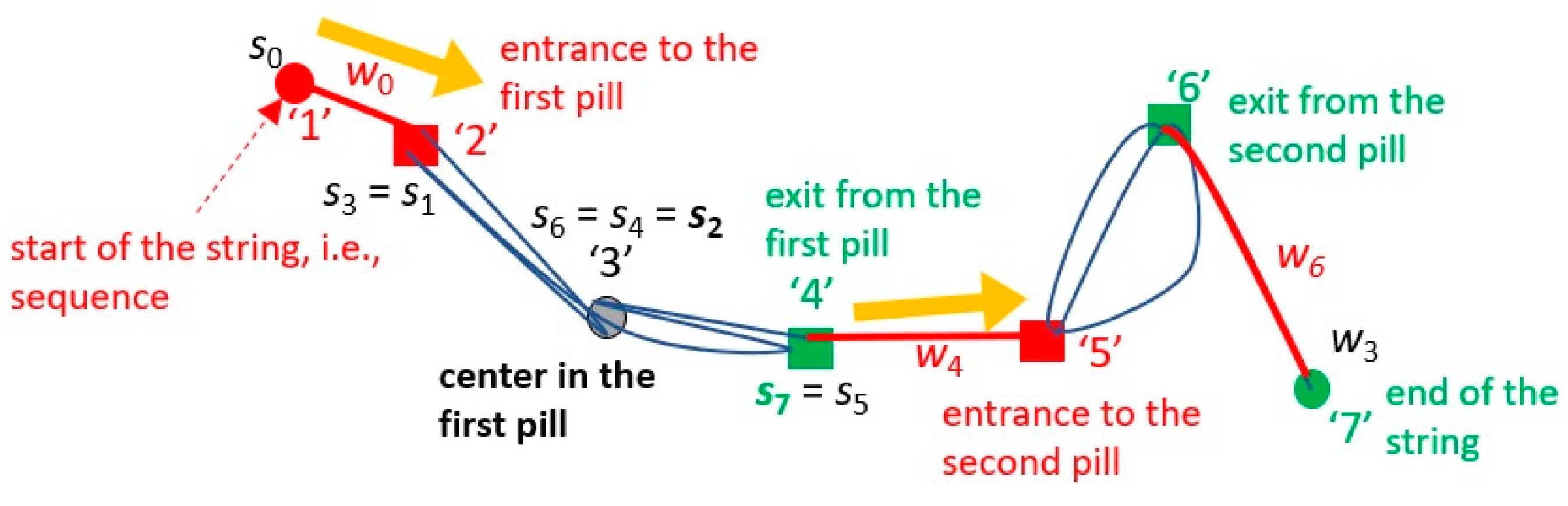
| Initial setting: String = {s1, …, … si, …sj, …, …, sL}, Wires = {w1-w2-w3-…-wL−1} where wi = si−si+1 represents the edge connecting the adjacent pair of tokens for i = 1 to L: pill(si) = si where pill(s) represents the pill including event s. weight(si) = 0 For W, a preset window, execute the cycles below: For i = W + 1 to L: Neighbors (si, W) = {si-W, si-W+1, …, …, si-1} if ∃sj(<i) ∈ Neighbors(si, W) {token(si) = token(sj)}: j = min{j|sj ∈ Neighbors(si, W), token(si) = token(sj)} r(si) = r(sj) #place si at r(sj), the same position as sj Wires = Wires\{wj-wj+1-…-wi-2} # cut the subsequence from sj to si-1 from Wires pill(si) = … = pill (sj+1) = pill (sj) # put all the events on the loop made by si and sj in the same pill pill_weight(sj) += i − j # the length of the loop is added to the weight of event sj in the pill else r(si) = r(si-1) + a {r(si-1)−r(si-2)} # place si in the extension of the line from si-1 to si (a: a real constant) end if End For For each pill sent, sext = the first and the last event in pill weight(sent) =weight(sext) = ext – ent # assign the pill size as the weight of each event on a wire End For |
| Algorithm 2. An extension of TS for dealing with basket data; TS for basket-set data |
| Initial setting: String = {#n1, s1, s2, …, #n2, s.., …, s.., …, #nT, …, sL}, where #n: the delimiter for each time t. Wires = {w1-w2-w3-…-wT} where wj is {#nj-s … -smj (just before #nj+1)} for each s in String: pill(s) = wj where sj is a member of wj weight(s) = 0 For W, a preset window, execute the cycles below: For each si in String/{#n1, #n2, …, #nT}: Neighbors (si, W) = ∪ wk-W+1, …, wk where si is a member of wk. if ∃sj (<i) ∈Neighbors(si, W) s.t. token(si) = token(sj): j = min{j|sj ∈Neighbors(si, W), s.t. token(si) = token(sj)} r(si) = r(sj) #place si at r(sj), the same position as sj Wires = Wires\{wp-…-wk-1} where sj is a member of wp. pill(s) = pill (sj) for all s in {si} ∪ all s in {wp, …, wk-1} pill_weight(sj) += i−j # the length of the loop is added to the weight of event sj in the pill else r(si) = r(si-1) + a {r(si-1)−r(si-2)} #place si in the extension of the line from si-1 to si (a: a real constant) end if End For For each pill sent, sext = the first and the last event in pill weight(sent) = weight(sext) = ext−ent # assign the pill size as the weight of each event on a wire End For |
2.3. Explanation by TS Approach
- (1)
- (2)
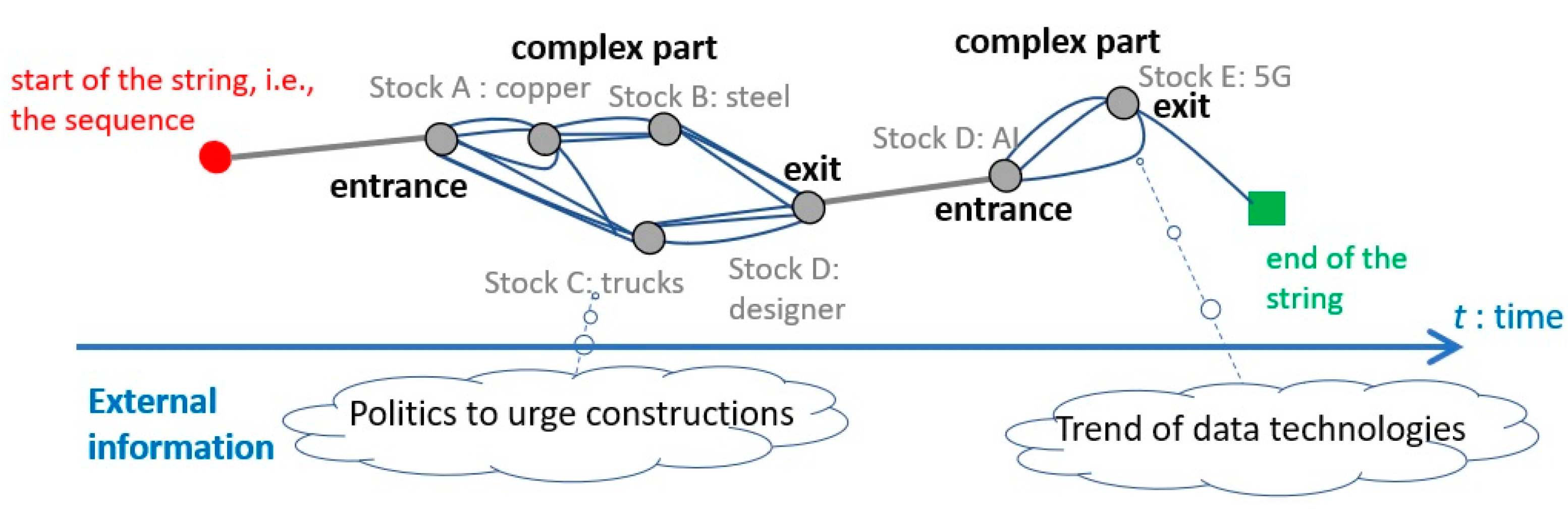
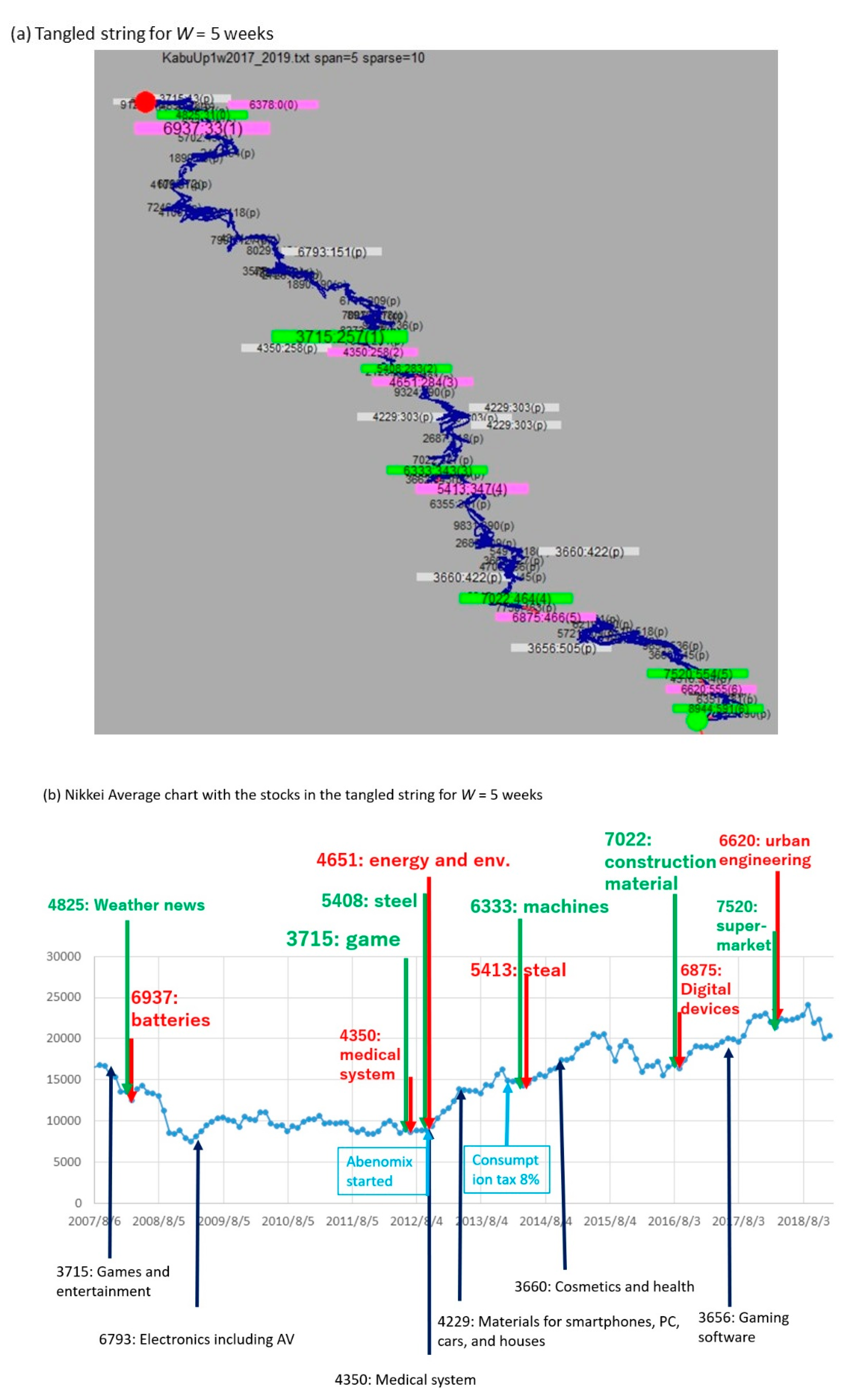
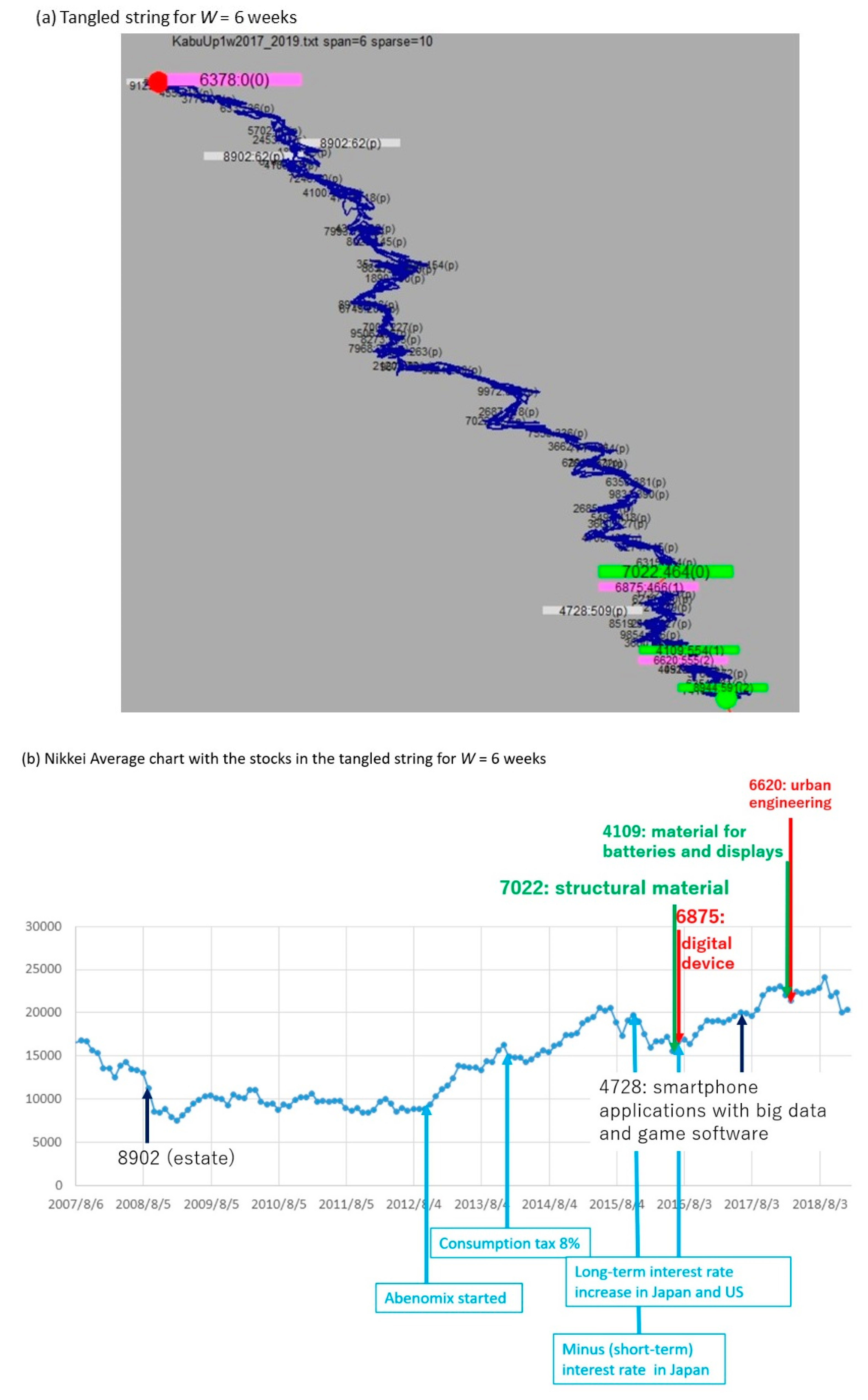
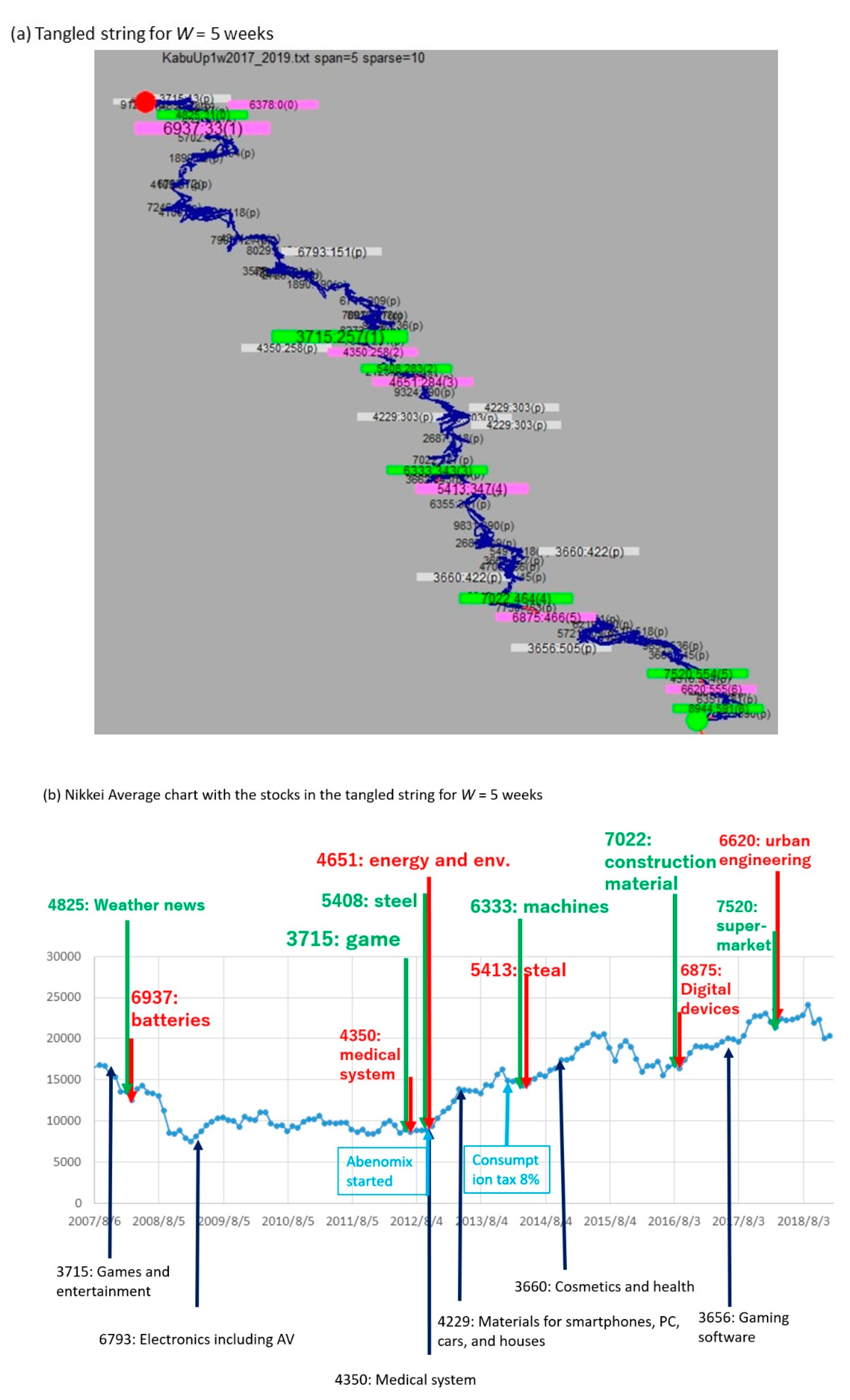
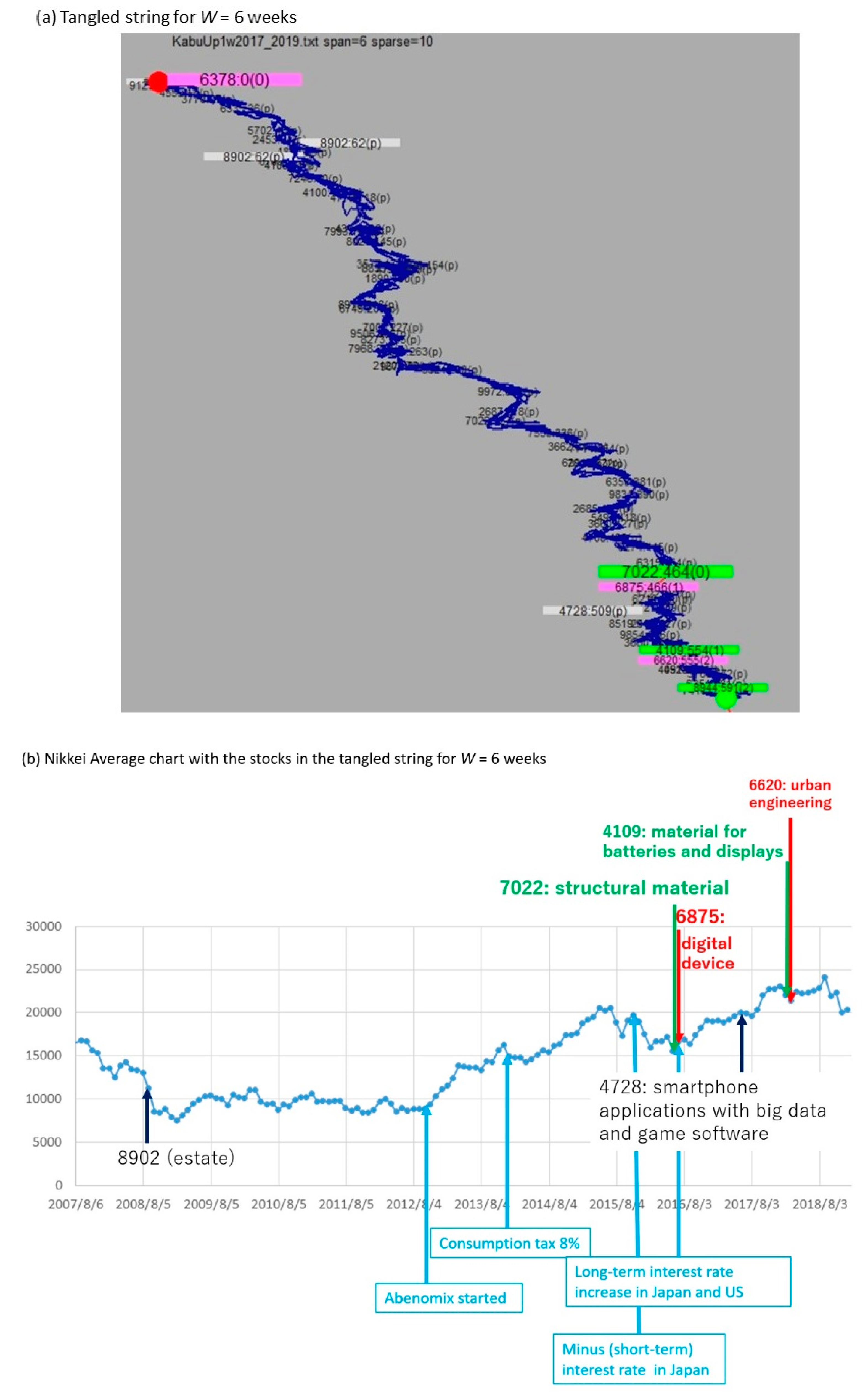
- From the string, choose large pills that have a tangled structure as complex parts in Figure 1. This is because a large complex pill corresponds to a trend that includes a set of frequent events occurring under various subsequences.
- (3)
- Explain the events at the nodes found in (1) above and the complex pills chosen in (2) above, correlating closely located events in the string with real events in the external information such as the user’s experience, common sense, and news. This part should be a free externalization of subjective ideas, rather than adherence to objective facts, in order to collect various explanations of possible causalities.
3. Results
3.1. Data on Up-Pricing Stocks
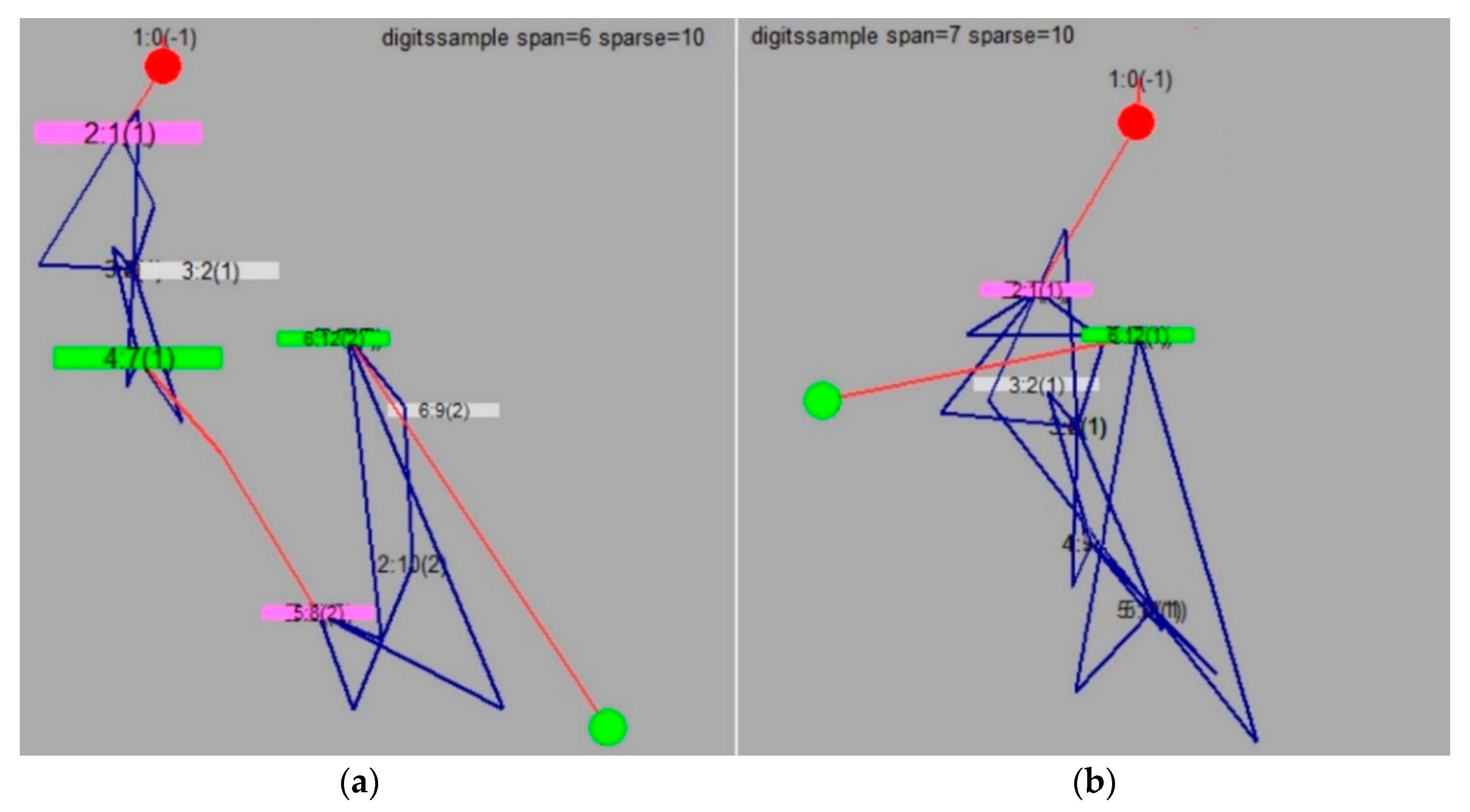
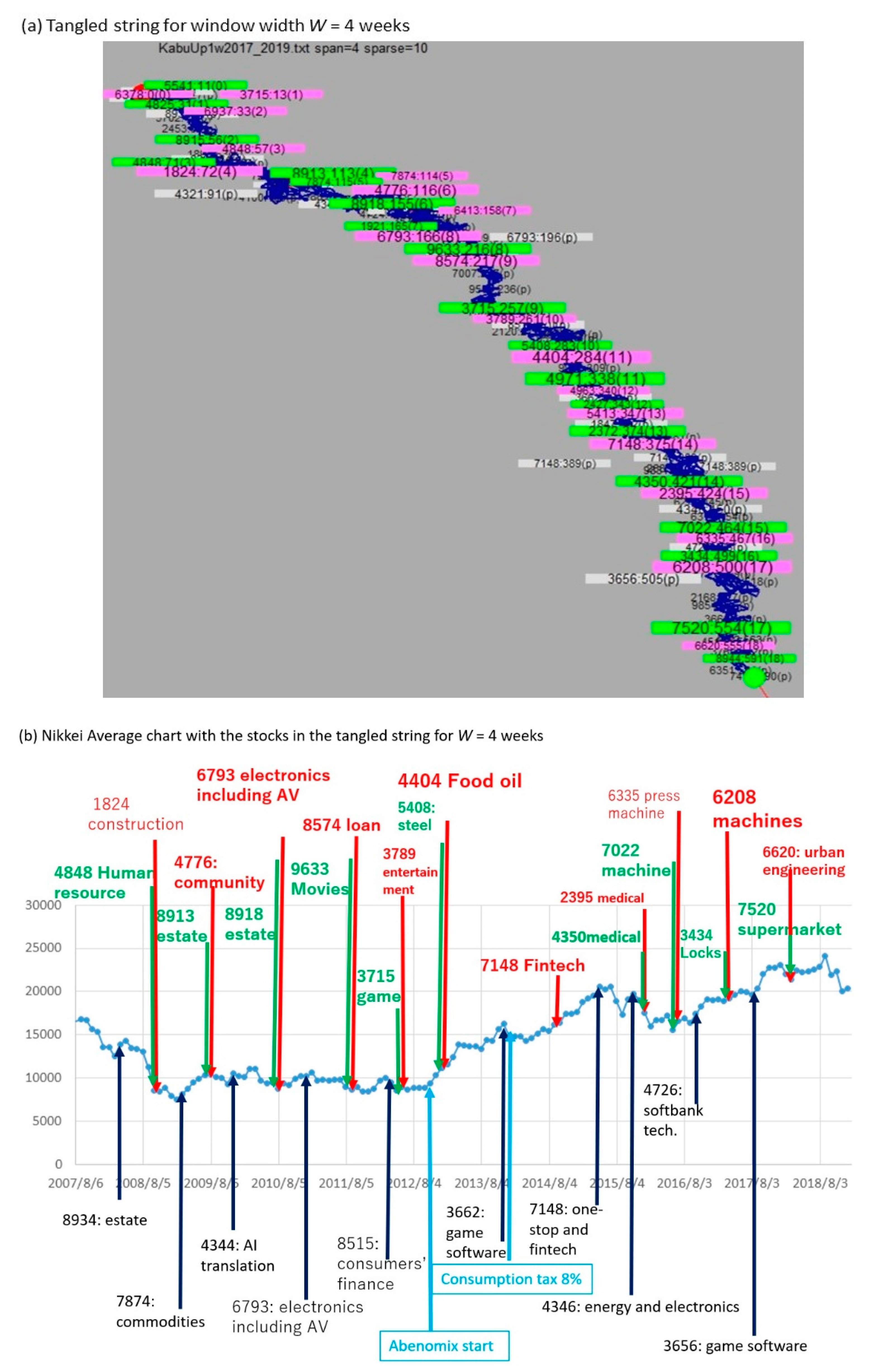
3.2. TS Visualization with Changing the Window Width W
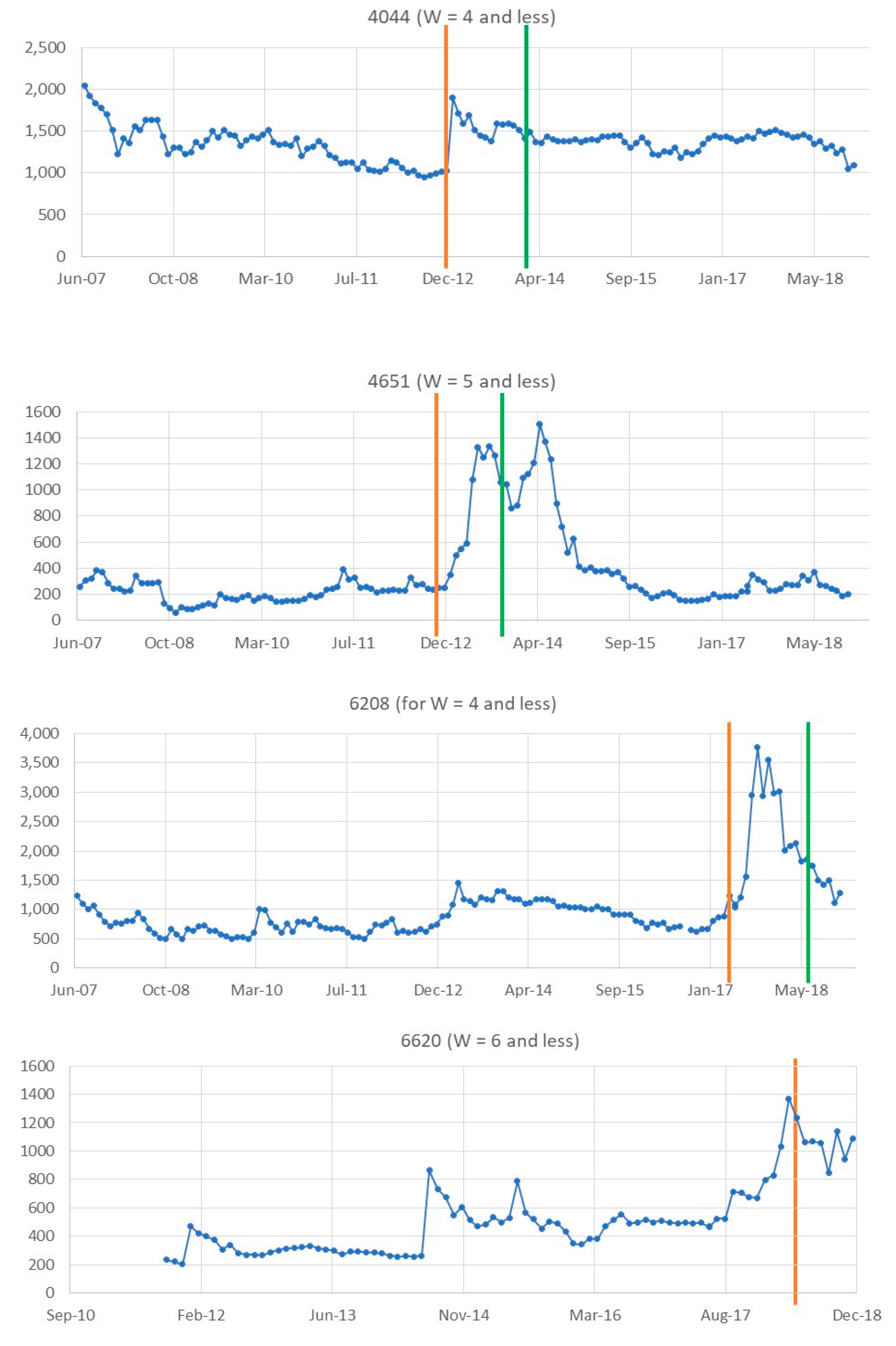
3.3. Change in Stock Price and the Two Types of Change Points in TS
4. Discussions
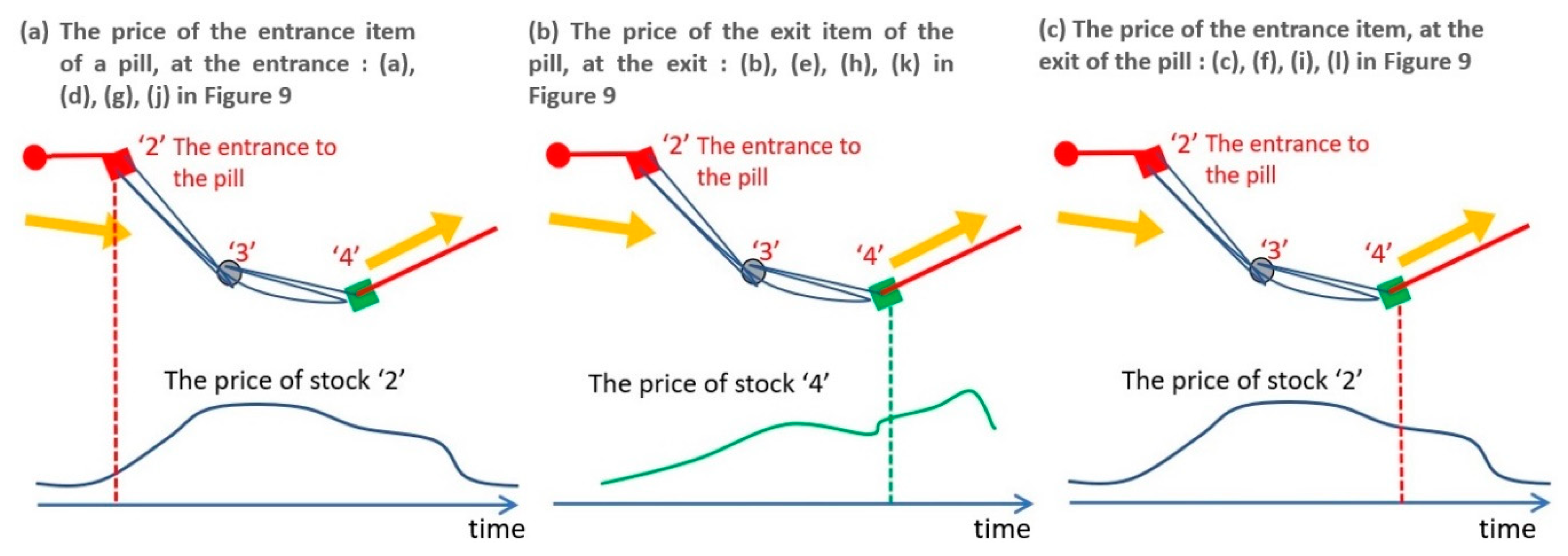
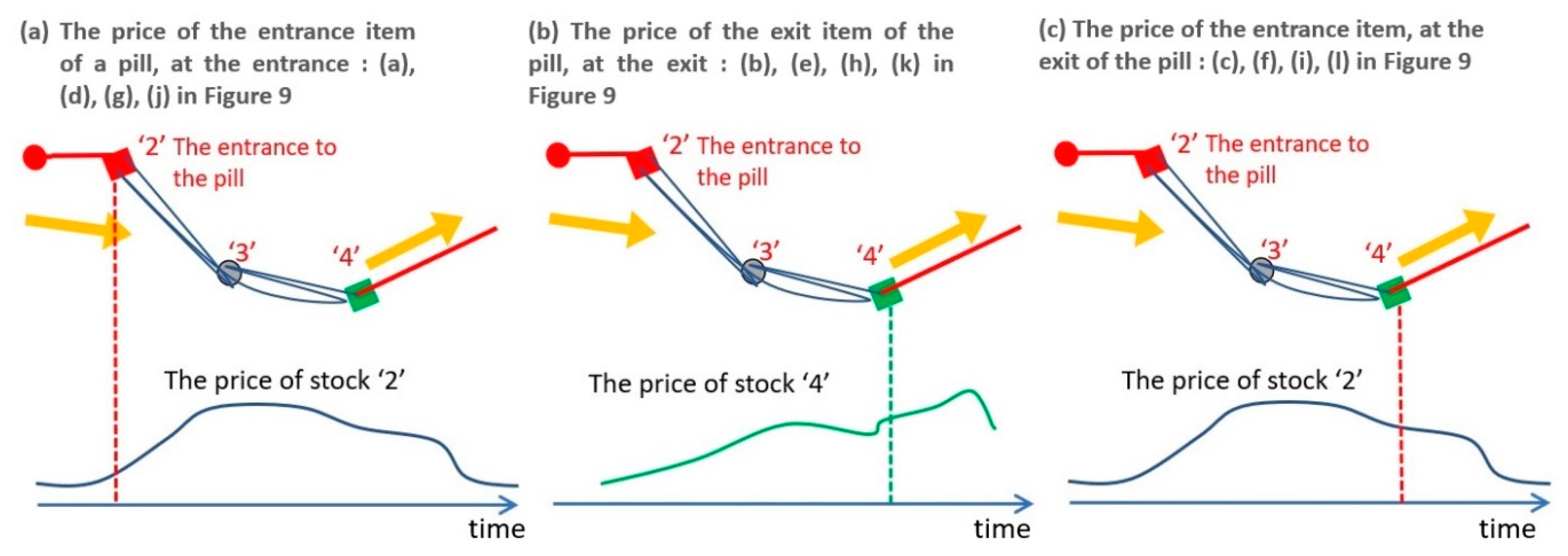
- (1)
- A trend starts at the entrance of a pill and continues during the pill. As a result, the price of the stock at the entrance of a pill continues to increase during the trend (Figure 9a,d,g,i).
- (2)
- The impact of the stock that appears at the exit fades in a short time because the trend disappears when the pill disappears. As a result, the price of the stock at the exit of a pill increases once but decreases sooner than the stock at the entrance (Figure 9b,e,h,k).
- (3)
- A trend ends at the exit of a pill. As a result, the price of the stock at the entrance of a pill decreases soon after the exit of the same pill (Figure 9c,f,I,l).
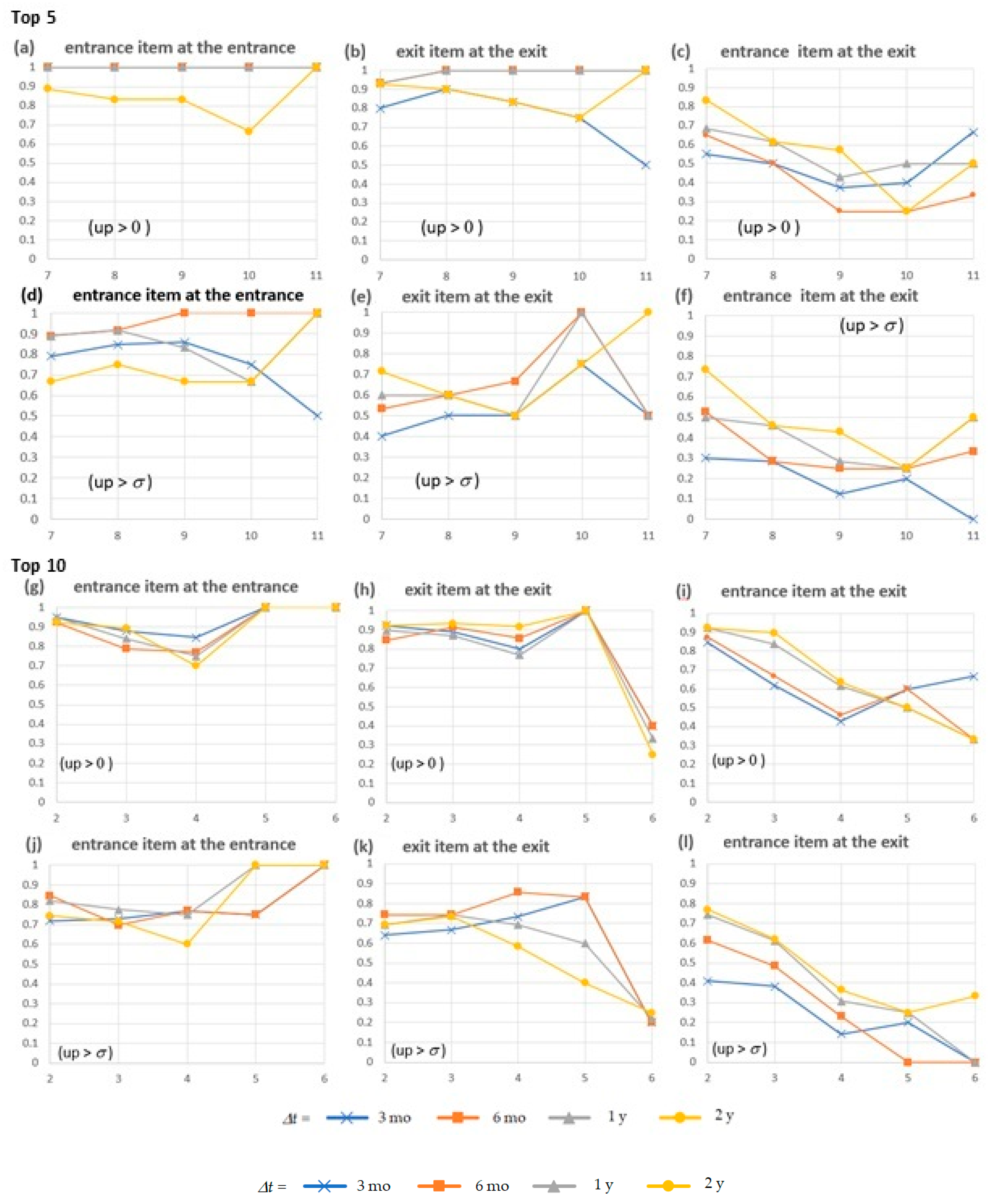
- (4)
- The stock tends to increase more for the shorter W because a short W means a reduced capacity to detect repeating events. Thus, only the entrances/exits of an especially high frequency of repetition in pills are obtained. However, even for a long W, the price of stocks appearing at the entrance increases continuously during the period of the trend (all in Figure 9).
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data Availability
References
- Jagtiani, J.; Lemieux, C. The Roles of Alternative Data and Machine Learning in Fintech Lending: Evidence from the Lending Club Consumer Platform; WP18-15; Lemieux Federal Reserve Bank of Chicago: Chicago, IL, USA, 2018. [Google Scholar] [CrossRef]
- Lux, T. The socio-economic dynamics of speculative markets: Interacting agents, chaos, and the fat tails of return distributions. J. Econ. Behav. Organ. 1998, 33, 143–165. [Google Scholar] [CrossRef]
- Lespagnol, V.; Rouchie, J. Trading Volume and Market Efficiency: An Agent Based Model with Heterogenous Knowledge about Fundamentals. HAL Archives-Ouvertes. 2014. Available online: https://halshs.archives-ouvertes.fr/halshs-00997573 (accessed on 15 March 2019).
- Ding, X.; Zhang, Y.; Liu, T.; Duan, J. Deep Learning for Event-Driven Stock Prediction. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2327–2333. [Google Scholar]
- Dash, R.; Dash, P.K. A hybrid stock trading framework integrating technical analysis with machine learning techniques. J. Financ. Data Sci. 2016, 2, 42–57. [Google Scholar] [CrossRef]
- Rajput, V.; Sarika Bobde, S. Stock market forecasting technique literature survey. Int. J. Comput. Sci. Mob. Comput. 2016, 5, 500–506. [Google Scholar]
- Cimino, M.G.C.A.; Bona, F.D.; Foglia, P.; Monaco, M.; Prete, C.A.; Vaglini, G. Stock price forecasting over adaptive timescale using supervised learning and receptive fields. In Proceedings of the 6th International Conference on Mining Intelligence and Knowledge Exploration, Cluj-Napoca, Romania, 20–22 December 2018; pp. 279–288. [Google Scholar] [CrossRef]
- Fama, E.F.; Fisher, L.; Jensen, M.C.; Roll, R. The Adjustment of Stock Prices to New Information. Int. Econ. Rev. 1969, 10, 1–21. [Google Scholar] [CrossRef]
- Foster, G. Stock Market Reaction to Estimates of Earnings per Share by Company Officials. J. Account. Res. 1973, 11, 25–27. [Google Scholar] [CrossRef]
- Yoon, S.; Suge, A.; Takahashi, H. Do news articles have an impact on trading?—Korean market studies with high frequency data. In New Frontiers in Artificial Intelligence, Proceedings of the JSAI-isAI Workshops, JURISIN, Tsukuba, Tokyo, 30 June 2018; Springer: Berlin, Germany, 2018; pp. 129–139. [Google Scholar] [CrossRef]
- Kaura, M.; Kanga, S. Market Basket Analysis: Identify the changing trends of market data using association rule mining. Procedia Comput. Sci. 2016, 85, 78–85. [Google Scholar] [CrossRef]
- Ohsawa, Y. Graph-Based Entropy for Detecting Explanatory Signs of Changes in Market. Rev. Socionetwork Strat. 2018, 12, 183–203. [Google Scholar] [CrossRef]
- Iwata, T.; Watanabe, S.; Yamada, T.; Ueda, N. Topic tracking model for analyzing consumer purchase behavior. In Proceedings of the 21st International Joint Conference on Artificial Intelligence (IJCAI), Pasadena, CA, USA, 22 July 2009; pp. 1427–1432. [Google Scholar]
- Abdulhakim, Q.; Alharbi, B.; Wang, S.; Zhang, X. A PCA-Based Change Detection Framework for Multidimensional Data Streams: Change Detection in Multidimensional Data Streams. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 935–944. [Google Scholar] [CrossRef]
- Kleinberg, J. Bursty and hierarchical structure in streams. Data Min. Knowl. Discov. 2003, 7, 373–397. [Google Scholar] [CrossRef]
- Fearnhead, P.; Liu, Z. Online Inference for Multiple Changepoint Problems. J. R. Stat. Soc. Ser. B 2007, 69, 589–605. [Google Scholar] [CrossRef]
- Hayashi, Y.; Yamanishi, K. Sequential network change detection with its applications to ad impact relation analysis. Data Min. Knowl. Discov. 2015, 29, 137–167. [Google Scholar] [CrossRef]
- Miyaguchi, K.; Yamanishi, K. Online detection of continuous changes in stochastic processes. Int. J. Data Sci. Anal. 2017, 3, 213–229. [Google Scholar] [CrossRef]
- Blei, D.; Lafferty, J.D. Dynamic Topic Models. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; Volume 23, pp. 113–120. [Google Scholar] [CrossRef]
- Li, W.; McCallum, A. Pachinko Allocation: DAG-Structured Mixture Models of Topic Correlations. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar] [CrossRef]
- Hua, J.; Huang, M.L.; Wang, G.; Zreika, M. Applying Data Visualization Techniques for Stock Relationship Analysis. Filomat 2018, 32, 1931–1936. [Google Scholar] [CrossRef]
- Shoemate, B. Stock Market Visualizations. 2015. Available online: https://www.benshoemate.com /2015/08/20/stock-market-visualizations/ (accessed on 20 March 2019).
- Ohsawa, Y.; Hayashi, T. Tangled string for sequence visualization as fruit of ideas in innovators marketplace on data jackets. Intell. Decis. Technol. 2016, 10, 235–247. [Google Scholar] [CrossRef]
- Ohsawa, Y. Tangled String Diverted for Evaluating Stock Risks: A by Product of Innovators Marketplace on Data Jackets. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015. [Google Scholar] [CrossRef]
- Ohsawa, Y.; Liu, C.; Hayashi, T.; Kido, H. Data jackets for externalizing use value of hidden datasets. Procedia Comput. Sci. 2014, 35, 946–953. [Google Scholar] [CrossRef]
- Ohsawa, Y.; Liu, C.; Suda, Y.; Kido, H. Innovators Marketplace on Data Jackets for Externalizing the Value of Data via Stakeholders’ Requirement Communication. In Proceedings of the AAAI 2014 Spring Symposium on Big Data Becomes Personal: Knowledge into Meaning, Stanford, CA, USA, 24 March 2014; Available online: https://www.aaai.org/ocs/index.php/SSS/SSS14/paper/viewFile/7676/7775 (accessed on 20 March 2019).
- Ohsawa, Y.; Ji, Q. Wire stretching for noise reduction in a visualized tangled string. In Proceedings of the Workshop on Chance Discovery, Data Synthesis, Curation and Data Market, IJCAI, Buenos Aires, Argentina, 26 July 2015; pp. 1–4. [Google Scholar]
- Chong, T.T.; Leung, K.W.; Yuen, A.H. Is the Rate-of-Change Oscillator Profitable? J. Investig. 2011, 20, 72–74. [Google Scholar] [CrossRef]
- Kritzman, M.; Li, Y.; Page, S.; Rigobon, R. Principal Components as a Measure of Systemic Risk. J. Portf. Manag. 2011, 37, 112–126. [Google Scholar] [CrossRef]
- Matsuura, N. Low Volatility Funds as the Focus of Investors’ Interest. Morningstar 2014. Available online: https://www.morningstar.co.jp/fund/analyst/2014/4q/MFA120141028 (accessed on 20 March 2019). (In Japanese).
- Japan Bond Tradikng, Co., Ltd. Long-Term JGB Yield. 2018. Available online: http://www.bb.jbts.co.jp/english/ marketdata/marketdata01 (accessed on 20 March 2019).
- Baklanova, V.; Berg, T.; Stemp, D. U.S. Long-Term Interest Rates Rise, But Remain Low; OFR Financial Markets Monitor; Office of Financial Research: Washington, DC, USA, 2017. Available online: https://www.financialresearch.gov/financial-markets-monitor/files/OFR-FMM-2017-01-13_Long-Term-Rates-Rise-But-Remain-Low.pdf (accessed on 20 March 2019).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. 1 | No. 2 | No. 3 | …, …, … | No. 10 | ||
|---|---|---|---|---|---|---|
| 6 July 2007 | #n | 6378 | 8061 | 2678 | …, …, … | 2687 |
| 13 July 2007 | #n | 1907 | 6850 | 6316 | …, …, … | 1898 |
| … | #n | … | … | … | …, … | …, … |
| … | #n | 1907 | 6378 | 7999 | …, …, … | 8934 |
| 4 January 2019 | #n | 4992 | 4344 | 6465 | …, …, … | 9501 |
| Top 5 | W = 7 | W = 8 | W =9 | W = 10 |
| 0.59 (13/22) | 0.67 (8/12) | 0.57 (4/7) | 0.6 (3/5) | |
| Top 10 | W = 3 | W = 4 | W = 5 | W = 6 |
| 0.55 (21/38) | 0.67 (12/18) | 0.83 (5/6) | 1.0 (2/2) |
| Δt | 3 mo. | 6 mo. | 12 mo. | 24 mo. | 3 mo. | 6 mo. | 12 mo. | 24 mo. |
|---|---|---|---|---|---|---|---|---|
| Top-5 | Entrances (red) | Exits (green) | ||||||
| decrease | 0 (0) | 0 (0) | 0 (0) | 0 | 0.097 (3) | 0 | 0 | 0 |
| increase | 1.0 (43) | 1.0 (39) | 1.0 (39) | 1.0 (34) | 0.90 (28) | 1.0 (34) | 1.0 (34) | 1.0 (31) |
| increase > σ | 0.16 (7) | 0.18 (7) | 0.18 (7) | 0.18 (6) | 0.097 (3) | 0.12 (4) | 0.059 (2) | 0.16 (5) |
| Top-10 | Entrances (red) | Exits (green) | ||||||
| decrease | 0.11 (4) | 0.19 (7) | 0.14 (5) | 0.12 (4) | 0.15 (6) | 0.11 (4) | 0.18 (6) | 0.09 (3) |
| increase | 0.89 (32) | 0.81 (29) | 0.85 (29) | 0.88 (27) | 0.85 (34) | 0.89 (34) | 0.82 (28) | 0.91 (30) |
| increase > σ | 0.75 (27) | 0.72 (26) | 0.79 (27) | 0.71(22) | 0.60 (24) | 0.69 (26) | 0.68 (23) | 0.67 (22) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ohsawa, Y.; Hayashi, T.; Yoshino, T. Tangled String for Multi-Timescale Explanation of Changes in Stock Market. Information 2019, 10, 118. https://doi.org/10.3390/info10030118
Ohsawa Y, Hayashi T, Yoshino T. Tangled String for Multi-Timescale Explanation of Changes in Stock Market. Information. 2019; 10(3):118. https://doi.org/10.3390/info10030118
Chicago/Turabian StyleOhsawa, Yukio, Teruaki Hayashi, and Takaaki Yoshino. 2019. "Tangled String for Multi-Timescale Explanation of Changes in Stock Market" Information 10, no. 3: 118. https://doi.org/10.3390/info10030118
APA StyleOhsawa, Y., Hayashi, T., & Yoshino, T. (2019). Tangled String for Multi-Timescale Explanation of Changes in Stock Market. Information, 10(3), 118. https://doi.org/10.3390/info10030118