1. Introduction
As digitization spreads into all areas of business and social life, the pressure on software development organizations is growing. The sheer amount of code being created, and the increasing complexity of software systems, fuels the need for new methods and tools to support the software development process.
A widely adopted framework addressing the challenges of the modern software delivery lifecycle is the DevOps model [
1], which is founded on the principles of continuous integration, continuous delivery, and continuous testing. Both the wisdom of the crowd and academic evidence [
2] speak for the efficiency of DevOps practice, but adopting DevOps brings its own challenges, including a significant increase in the volume and frequency of testing. In fact, on a large-scale project it is not feasible to implement DevOps without test automation—and writing automated test cases is time- and resource-consuming. Not surprisingly, automated test case generation methods are being actively studied. In general, to generate unit test cases, existing approaches use information extracted from other software artifacts, such as code under test, specification models, or execution logs [
3].
State-of-the-art test generation tools can significantly improve test coverage; however, it has been shown that their fault detection potential is problematic: many faulty code portions are never executed, or are executed in such a way that defects are not detected [
4]. These tools stem from the tradition of research on code analysis and code generation that is concerned with formal semantics and structural information about the code. Such research takes advantage of the formality, consistency, and unequivocalness of programming languages—that is, the properties that distinguish source code from natural languages. A more recent research trend switches the focus to statistical semantics. This exciting alternative can be now fully explored thanks to the much-increased availability of source-code resources stored in online open source repositories. It has been argued that large source-code corpora exhibit similar statistical properties to those of natural language corpora [
5], and indeed, statistical language models developed for Natural Language Processing (NLP) have proved to be efficient when applied to programming languages [
6].
However, even billions of lines of code scraped from online repositories are not sufficient to satisfy the training requirements for some types of tasks. Many applications—such as code generation from natural language descriptions, code search by natural language queries, or automated code documentation—require joint processing of natural languages and programming languages. This means that the source-code corpora used for training these systems need to be appropriately annotated with natural language descriptions. The main challenge here is the acquisition of fine-grained natural language annotations that accurately and consistently describe the semantics of code.
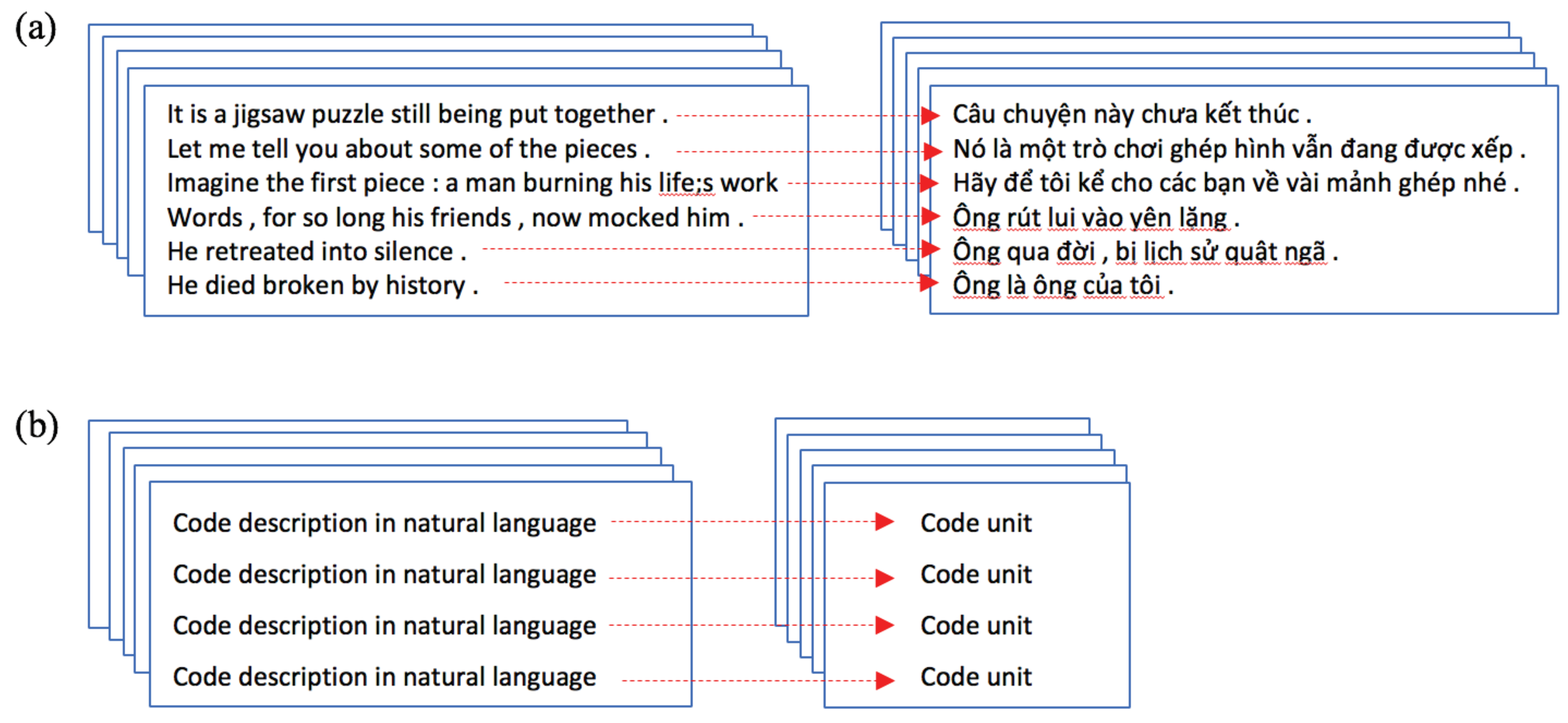
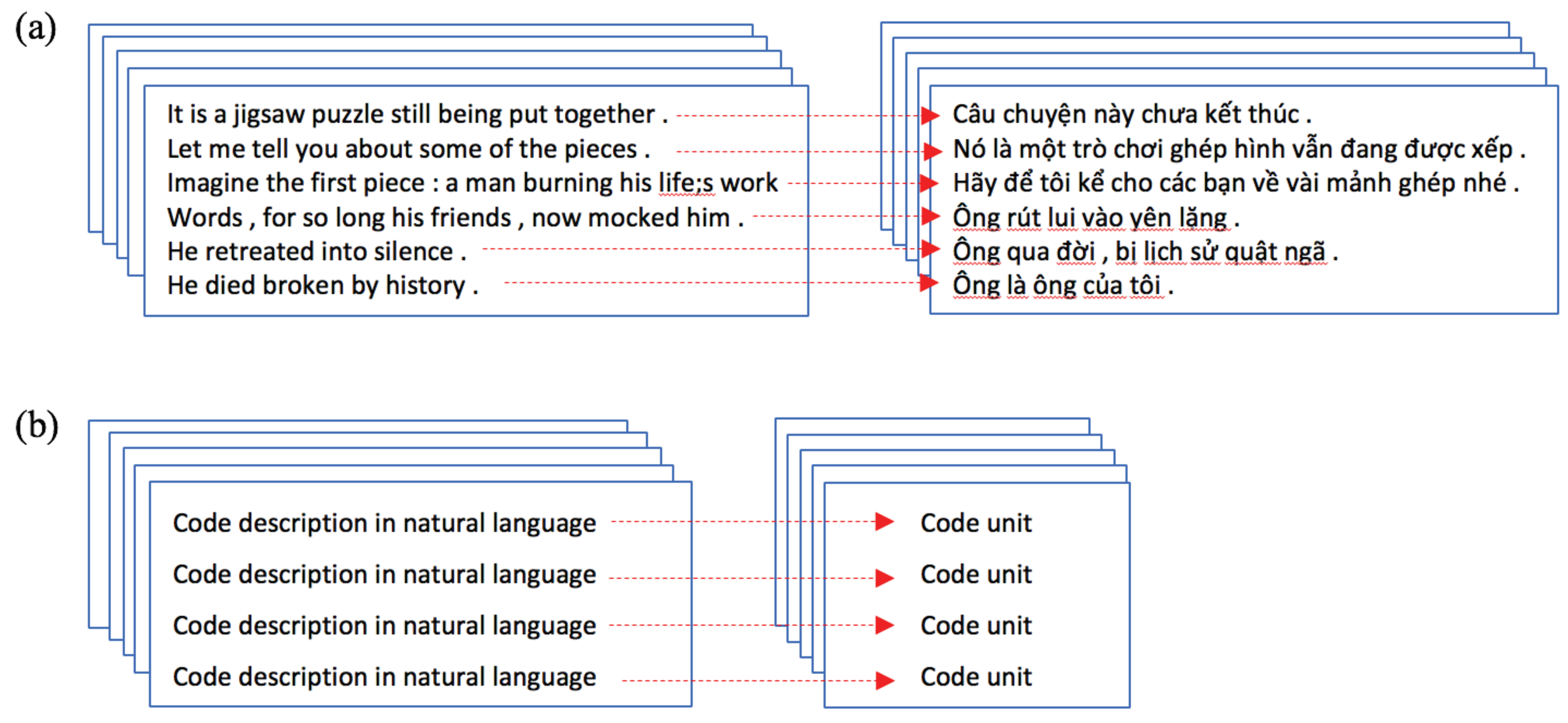
As a concrete example, statistical translation models used in NLP require training on parallel corpora—also called
bi-texts—in which many sentences written in a source language are aligned with their translations in a target language. A schematic example of a parallel corpus with aligned sentences in natural languages is presented in
Figure 1a. To apply statistical translation models to source code—that is, to train a model capable of mapping textual sequences to sequences of source code—it is necessary to obtain a
text-code parallel corpus in which a large number of code units are aligned with their descriptions in natural language (
Figure 1b).
Aligned corpora for statistical machine translation (MT) of two natural languages (bi-text datasets) can be gathered from existing collections of translated texts. However, obtaining a parallel corpus for a natural language coupled with a programming language (a text-code dataset) is much less straightforward.
The question of what should be the nature and level of detail of the natural language descriptions provided in such a corpus does not have a definite answer and requires more investigation. Nonetheless, it seems reasonable to assume that the practical value of a text-code corpora depends on the following properties:
Size, and the potential to scale in size in the future, is of particular importance for deep learning models which require large amounts of training data.
Acquisition cost, in terms of human effort and the complexity of the procedure.
Level of noise in the acquired data.
Granularity of the natural language descriptions.
Several recent studies have proposed more or less sophisticated methods of obtaining text-code corpora (see
Section 2). The proposed methods vary in terms of the properties listed above, but regardless their practical value, none of them are applicable to the testing domain. The main contribution of this paper is a novel method of automatically synthetizing large text-code datasets containing textual descriptions of single testing tasks, each matched with the code implementing that task. Moreover, in this paper we demonstrate that machine learning models trained on our datasets can generate complete, compilable, and semantically relevant automated test cases based on quasi-natural language descriptions of testing tasks. These results were obtained using a neural MT model [
7] designed for learning from bi-text corpora, in which the degree of equivalence between source and target languages is very high. We find that this off-the-shelf neural MT architecture performs well on our code-text corpora, which suggests that the quasi-natural language descriptions obtained using our approach are precise and consistent enough to allow direct translation to code.
There are two aspects of the potential implications of the presented work. First, from the perspective of the testing community, we present an efficient, inexpensive, and scalable method for annotating test code with textual descriptions. The availability of such annotated datasets can accelerate the application of the latest advances in machine learning to the testing domain. Second, from the perspective of research on applying statistical models to source code, our datasets may provide better insight into the desired characteristics of text and code sequences in a training corpus. Understanding what type of annotations works well or what is the optimal translation unit for the source code may be valuable for researchers concerned with synthesizing text-code datasets.
The remainder of this article is organized as follows.
Section 2 provides an overview of existing solutions for text-code corpora acquisition. In
Section 3 we provide the rationale of our approach and explains how it works.
Section 4 describes in detail the procedure of synthesizing training corpora used in our experiments.
Section 5 presents the experimental setup and the results of training a neural MT model on a text-code dataset generated using our method. In
Section 6 we discuss the results, and
Section 7 concludes the paper.
2. Related Work
In this section, we do not attempt to show the full range of techniques of matching natural language descriptions to code that have been proposed throughout the literature. Rather, our aim is to investigate which approaches can yield datasets that meet the training needs of statistical text-code language models. Thus, the focus of this review is on studies which are explicitly concerned with applying language models to source code, and which provide some evidence for the performance of text-code language models trained on the proposed datasets.
The performance of the many of the models covered in this review, and indeed the models we present later in the paper, are evaluated using BLEU [
8]. BLEU is a de facto standard measure for MT. BLEU compares machine output with human-authored ground-truth translation, and scores how close they are to each other, on a scale from 0 to 100, with 100 indicating a hypothetically perfect translation. In the context of source-code generation from text input, BLEU is calculated by comparing the output of the model to the source-code ground truth from the corpus.
Perhaps the most straightforward solution to creating a dataset of aligned text and code is reported in [
9], where a software engineer was hired to manually annotate 18,000 Python statements with pseudo-code. This approach is neither scalable nor cheap, but the study provides interesting insights. The dataset was used to train a phrase-based and a tree-to-string SMT models to generate pseudo-code from source code. The tree-to-string model outperformed the phrase-based model by a large margin (BLEU score of 54 compared to 25), suggesting that correct code-to-text mapping necessitates parsing program structure, and even line-by-line, noise-less descriptions are not sufficient to support a plain phrase-based translation model.
For the work reported in [
10] two text-code datasets, one containing Java and the other Python code, were created. In both datasets the code units were aligned with descriptions that combine structured and unstructured text. These datasets were used to train a neural model which generated code from a mix of natural language and structured inputs. The model achieved an impressive performance of 65.6 BLEU scores. Furthermore, the authors trained two neural translation models as baselines, one augmented with their structured attention mechanism. The augmented translation model outperformed the plain translation model on both datasets (BLEU scores of 50 and 44 compared to 34 and 29).
The remaining papers included in this review use a Big Data approach. This research follows two main directions: one toward exploiting Big Code (primarily GitHub (
https://github.com)), and the other toward mining programming-related Q&A websites, primarily StackOverflow (
https://stackoverflow.com).
The Big Code route involves scraping API documentation (
Javadoc, Python
docstrings) from online source-code repositories, and using it as natural language description of code fragments. The research reported in [
11] created a massive parallel corpus of over 7.5 million API sequences annotated with excerpts from
Javadoc. These API sequences are not raw code sequence, they are rather parsed representations of general API usage. Consequently, a neural MT model trained on this corpus would not generate code, instead given some description of required functionality it would produce hints on the APIs that can be used. This model was augmented with information on API importance, and achieved BLEU score of 54.
Another corpus exploiting API documentation [
12] consists of over 150,000 Python function bodies annotated with
docstrings. The authors used a back-translation approach [
13] to extend this corpus with a synthetic dataset of 160,000 entries. The performance of a (non-augmented) neural translation model trained on the extended corpus was low (BLEU score of 11).
The second route—assembling datasets from user queries matched to code fragments mined from Q&A websites—has recently attracted a lot of attention. In [
14], two training corpora were created from C# snippets extracted from responses to StackOverflow and Dot Net Perls questions, and matched with the titles of these questions. Furthermore, general-purpose engine queries that produced clicks to the questions were added as alternative natural language descriptions. A bi-modal source-code language model trained on the resulting dataset was evaluated in terms of retrieval capability. The model had much better performance when retrieving natural language descriptions (with code snippets as queries) compared with retrieving code snippets, with NL descriptions as queries (Mean Reciprocal Rank of 0.44 as compared to 1.18).
Datasets collected from Q&A websites are large, and have the potential to grow as new questions and answers are added to the websites, but the level of noise in the data is very high. Queries can have irrelevant or very informal titles, and the code snippets are often incomplete and non-compilable. This problem was partly addressed in [
14], by applying simple heuristics, but other researchers deemed this approach insufficient and proposed extracting quality datasets from noisy Q&A corpora by applying machine learning models, trained on human-annotated seed datasets, as filters. For example, in one study after collecting C# and SQL snippets produced in response to questions posted on StackOverflow and paired with the titles of these questions, the authors manually annotated a small subset of data and trained a semi-supervised classifier to filter out titles that were irrelevant to the corresponding code snippet [
15]. The resulting cleaned corpora (containing over 66,000 pairs for C# and 32,000 of SQL) were used to training a neural MT model for code summarization (that is, for generating text from code, not code from text), which achieved BLEU scores of 20.5 (C#) and 18.4 (SQL).
Systematic mining of question-code datasets retrieved from Stack Overflow was the main focus of two other studies. In [
16], user queries matched with Python and SQL code snippets were subject to a series of cleaning steps. First, a logistic regression classifier (with human-engineered features) was trained to select questions of type "how-to-do-it", in which the user provides a scenario and asks how to implement it. Next, a subset of over 5000 question-code pairs was manually annotated by hired students who judged whether a snippet constitutes a standalone solution to the corresponding question. A novel model, called the Bi-View Hierarchical Neural Network, was trained on the annotated data and used to select over 147,500 Python and 119,500 SQL question-code pairs, to be included in the final dataset (
https://github.com/LittleYUYU/StackOverflow-Question-Code-Dataset).
Another complex method to mine high-quality aligned data from Stack Overflow was described in [
17]. First, the authors manually engineered a set of code structure features needed to determine the syntactic validity of a code snippet. Second, a subset of collected StackOverflow posts was manually annotated, using a carefully designed annotation procedure, to label specific elements in each post (intent, context, snippet), and to filter out non "how-to-do-it" questions. Next, a neural translation model was trained to learn "correspondence features"—that is, to learn the probability of the intent given a snippet, and the probability of the snippet given an intent. Finally, the calculated probabilities for each intent and snippet were fed to a logistic regression classifier as the correspondence features, together with the manually engineered structural features. After training, the classifier was used to create an automatically mined training corpus containing almost 600,000 intent-snippet pairs (
https://conala-corpus.github.io/). Given the small set of annotated data used for training the correspondence features, the authors acknowledged existing threats to validity, and provided an additional dataset of 3,000 examples manually curated by annotators. A baseline neural MT model trained on 100,000 examples from the automatically mined corpus combined with the curated data achieved BLEU score of 14.26. The performance of the model trained on curated data only was even lower (BLEU score 10.58).
7. Conclusions and Future Work
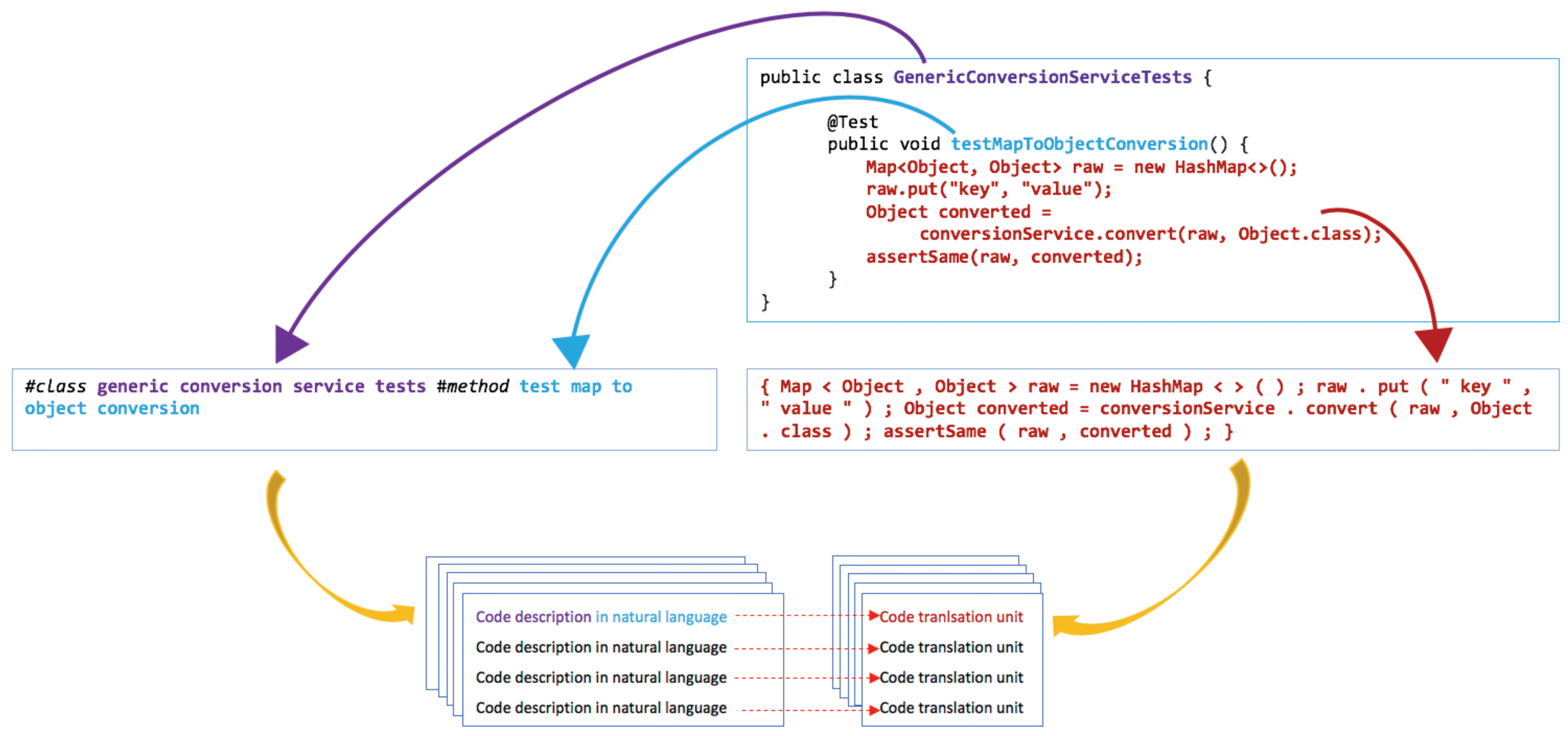
In this paper, we have presented a method that exploits the availability of source code in open software repositories to automatically construct an aligned text-code dataset. This method leverages self-documenting code—the software engineering practice of using meaningful class and function names to describe the functionality of program modules. Furthermore, we have demonstrated how datasets constructed in this way can be used to train (MT-inspired) text to source-code generation systems. Moreover, we have shown that it is feasible to use this machine translation-based code generation approach for automatic test case generation.
A key differentiation between our approach and the methods discussed in
Section 2 is that the textual descriptions in our parallel corpora are not expressed in true natural language. In NLP, a lack of the naturalness is often considered a weakness, but in the context of the software testing domain, the quasi-natural language nature of the text in our generated datasets does not affect usability, because this language has been devised by the software developer community. This form of communication has a lot in common with Controlled Natural Languages [
23]: it uses simplified syntax but preserves most of the natural properties of its base language and can be intuitively understood. As elaborated on in
Section 6, this compliance by software developers with naming conventions results in consistent repeatable patterns within the generated datasets which make the learning task feasible. Furthermore, unlike previous attempts to leverage developer-defined descriptions of code [
11,
12], our approach can be applied to generating code that is not exposed as a public API and therefore lacks inline documentation. Admittedly, escaping one limitation (the restriction to code sourced from public APIs) comes at the cost of another limitation (the restriction to self-documenting code only).
We have demonstrated the feasibility of our approach within the software testing domain. Specifically, our experiments have been on the generation of unit test cases, which can be described in a single quasi-natural language sentence and which have relatively short code bodies. As a result, one open question that remains is whether our approach can be generalized to other (potentially more complex) code domains. This is a question we will address in future work. However, even with this potential limitation the current results are very worthwhile because the demand for automated tests in the modern software development cycle is very high, and we believe it is important to fill the gap in the availability of training data for developing test automation tools, even if the approach is not universal. The fact that existing neural translation models trained on this type of data can achieve satisfactory performance is evidence of the high quality of the text-code parallel corpora synthesized from class and function names. Indeed, we believe that the performance of these initial systems is at a level that permits the immediate application of our approach in the area of software engineering.
That said, the evaluation of the true value of the generated code requires far more effort. As pointed out in
Section 5, a BLEU score is an approximate indicator of the quality of translation of natural languages. We have not identified any empirical studies investigating the applicability of BLEU to source code, and therefore the results reported in this and other papers need to be treated with caution.
A more reliable evaluation would involve retrieving feedback from human users. Our current efforts are focused on developing a Test Recommendation Engine trained on the corpora extracted from self-documenting code. The Engine, which is a part of a Horizon 2020 project (
https://elastest.eu/), will be released publicly, and we have plans for the collaboration with several industry test teams to gather their feedback.
We envisage two use cases benefiting from automated test generation. The first one involves training a project-specific model, similar to the ones trained on the rx and sf datasets. The tools built using such a specialized model are likely to produce accurate test cases for the new code written as developers add or modify features in an already mature project. The second use case involves a generic model trained on multiple repositories. In this case, the predictions are likely to be less accurate (and so require some editing) but the model would still be of value for test teams working on new projects with a minimal codebase.
Author Contributions
Conceptualization, M.K. and J.D.K.; methodology, M.K.; software, M.K.; investigation, M.K; Writing—original draft preparation, M.K.; Writing—review and editing, J.D.K.; Supervision, J.D.K.
Funding
This work was partly funded by the EC project ElasTest, 731535 (H2020-ICT-2016-2017/H2020- ICT-2016-1, Research and Innovation Action). The work was also supported by the ADAPT Centre which is funded under the SFI Research Centres Programme (Grant 13/RC/2106) and is co-funded under the European Regional Development Fund.
Acknowledgments
Magdalena Kacmajor would like to include special thanks to Micael Gallego Carrillo from Universidad Rey Juan Carlos in Madrid, who first brought her attention to self-documenting code as a possible source of training data.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CNL | Controlled Natural Language |
| DevOps | Development and Operations |
| ML | Machine Learning |
| MT | Machine Translation |
| NL | Natural Language |
| NLP | Natural Language Processing |
| NMT | Neural Machine Translation |
| PL | Programming Language |
| SMT | Statistical Machine Translation |
References
- Virmani, M. Understanding DevOps & bridging the gap from continuous integration to continuous delivery. In Proceedings of the 5th International Conference on the Innovative Computing Technology (INTECH 2015), Galicia, Spain, 20–22 May 2015; pp. 78–82. [Google Scholar] [CrossRef]
- Perera, P.; Silva, R.; Perera, I. Improve software quality through practicing DevOps. In Proceedings of the 2017 Seventeenth International Conference on Advances in ICT for Emerging Regions (ICTer), Colombo, Sri Lanka, 6–9 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Anand, S.; Burke, E.K.; Chen, T.Y.; Clark, J.; Cohen, M.B.; Grieskamp, W.; Harman, M.; Harrold, M.J.; McMinn, P.; Bertolino, A.; et al. An orchestrated survey of methodologies for automated software test case generation. J. Syst. Softw. 2013, 86, 1978–2001. [Google Scholar] [CrossRef]
- Shamshiri, S.; Just, R.; Rojas, J.M.; Fraser, G.; McMinn, P.; Arcuri, A. Do automatically generated unit tests find real faults? An empirical study of effectiveness and challenges (t). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 201–211. [Google Scholar] [CrossRef]
- Hindle, A.; Barr, E.T.; Gabel, M.; Su, Z.; Devanbu, P. On the naturalness of software. Commun. ACM 2016, 59, 122–131. [Google Scholar] [CrossRef]
- Allamanis, M.; Barr, E.T.; Devanbu, P.T.; Sutton, C.A. A Survey of Machine Learning for Big Code and Naturalness. ACM Comput. Surv. 2018, 51, 81. [Google Scholar] [CrossRef]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Oda, Y.; Fudaba, H.; Neubig, G.; Hata, H.; Sakti, S.; Toda, T.; Nakamura, S. Learning to generate pseudo-code from source code using statistical machine translation (T). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 574–584. [Google Scholar] [CrossRef]
- Ling, W.; Blunsom, P.; Grefenstette, E.; Hermann, K.M.; Kočiský, T.; Wang, F.; Senior, A. Latent Predictor Networks for Code Generation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 599–609. [Google Scholar] [CrossRef]
- Gu, X.; Zhang, H.; Zhang, D.; Kim, S. Deep API Learning. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016; pp. 631–642. [Google Scholar] [CrossRef]
- Miceli Barone, A.V.; Sennrich, R. A Parallel Corpus of Python Functions and Documentation Strings for Automated Code Documentation and Code Generation. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, Taiwan, 27 November–1 December 2017; pp. 314–319. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 86–96. [Google Scholar]
- Allamanis, M.; Tarlow, D.; Gordon, A.D.; Wei, Y. Bimodal Modelling of Source Code and Natural Language. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2123–2132. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Zettlemoyer, L. Summarizing Source Code using a Neural Attention Model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 2073–2083. [Google Scholar] [CrossRef]
- Yao, Z.; Weld, D.S.; Chen, W.P.; Sun, H. StaQC: A Systematically Mined Question-Code Dataset from Stack Overflow. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1693–1703. [Google Scholar] [CrossRef]
- Yin, P.; Deng, B.; Chen, E.; Vasilescu, B.; Neubig, G. Learning to mine aligned code and natural language pairs from stack overflow. In Proceedings of the 15th International Conference on Mining Software Repositories, Gothenburg, Sweden, 28–29 May 2018; pp. 476–486. [Google Scholar] [CrossRef]
- Martin, R.C. Clean Code: A Handbook of Agile Software Craftsmanship, 1st ed.; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv. 2014. Available online: https://arxiv.org/abs/1409.0473 (accessed on 15 February 2019).
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization, 2014. arXiv. 2014. Available online: https://arxiv.org/abs/1409.2329 (accessed on 15 February 2019).
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 103–111. [Google Scholar]
- Kuhn, T. A Survey and Classification of Controlled Natural Languages. Comput. Linguist. 2014, 40, 121–170. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}