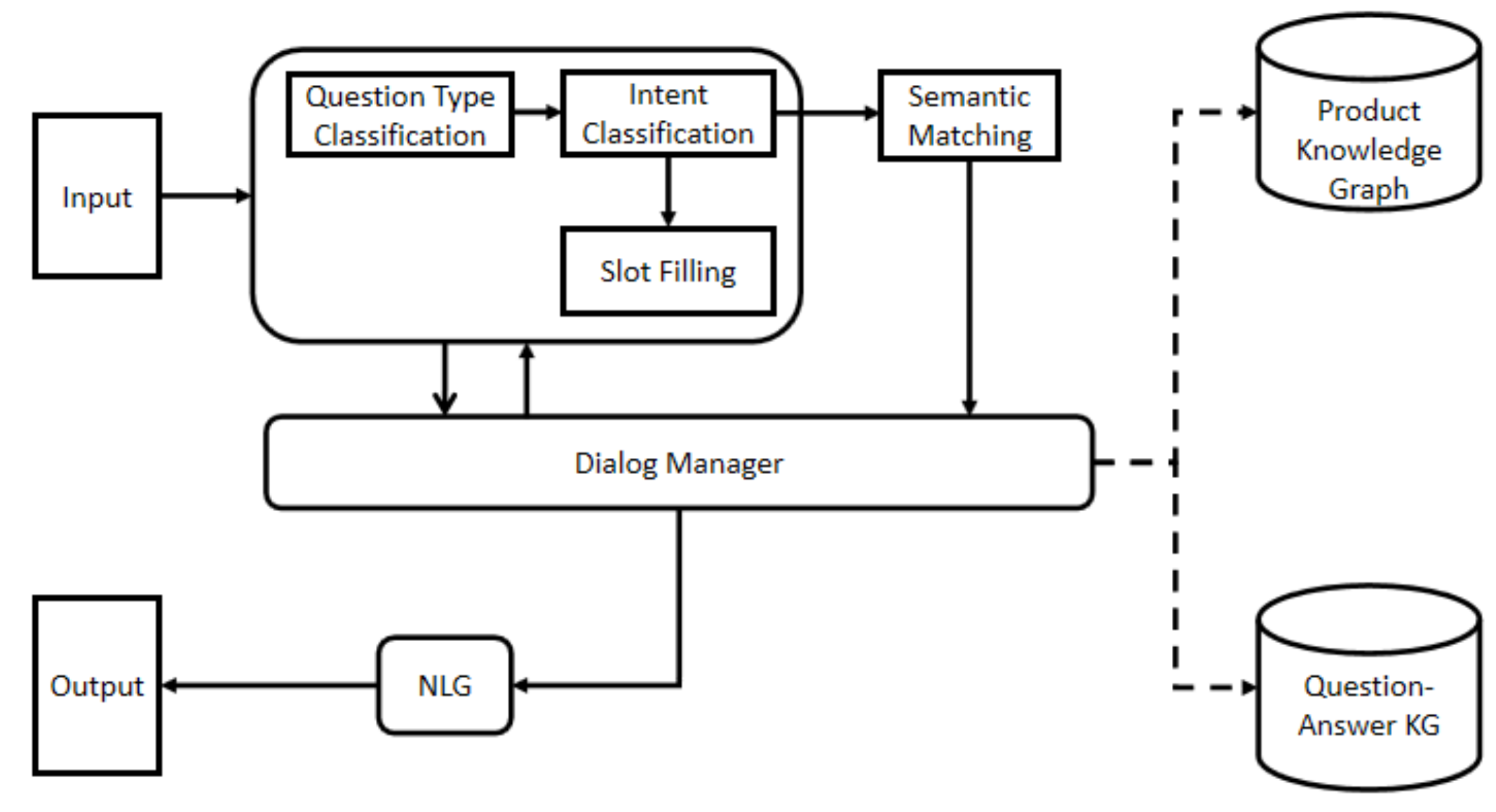
4.3. Semantic Matching
We assume that the QA pair with the highest semantic similarity to the question expressed in turn (and previous turns) will be of the highest utility to the user. After question type and intent category classification we obtain an initial set of candidates, , by retrieving all QA pairs from the knowledge base that are relevant to the question type and intent category. Following a common information retrieval approach, we then used a pairwise scoring function to sort by utility, where .
TF-IDF
TF-IDF means term frequency-inverse document frequency. Our first baseline computes S with a TF-IDF weighted bag-of-words representation of and to estimate the semantic relatedness by cosine similarity between the feature vectors of the QA pair, , and the user turn, .
WMD
The second baseline leverages the semantic information of distributed word representations [
26]. To this end, we replace the tokens in
and
with their respective embeddings and then compute the word mover distance [
27] between the embeddings.
SMN
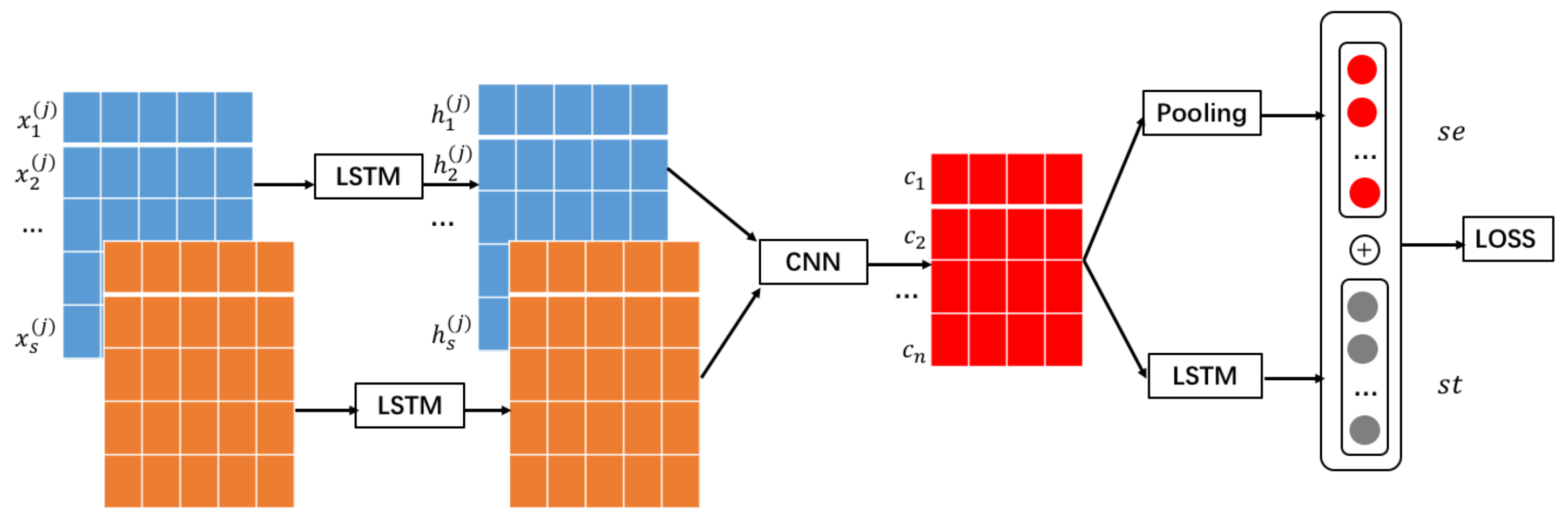
In addition to the baselines we use a sequential matching network (SMN) [
20], which treats semantic matching as a classification task. The SMN first represents
and
by their respective sequence of word embeddings
and
before encoding both separately with a recurrent network, a gated recurrent unit (GRU) [
28] in this case. A word-word similarity matrix
and a sequence-sequence similarity matrix
is constructed from
and
, and important matching information is distilled into a matching vector
via a convolutional layer followed by max-pooling.
is further projected using a fully connected layer followed by a softmax.
MPCNN
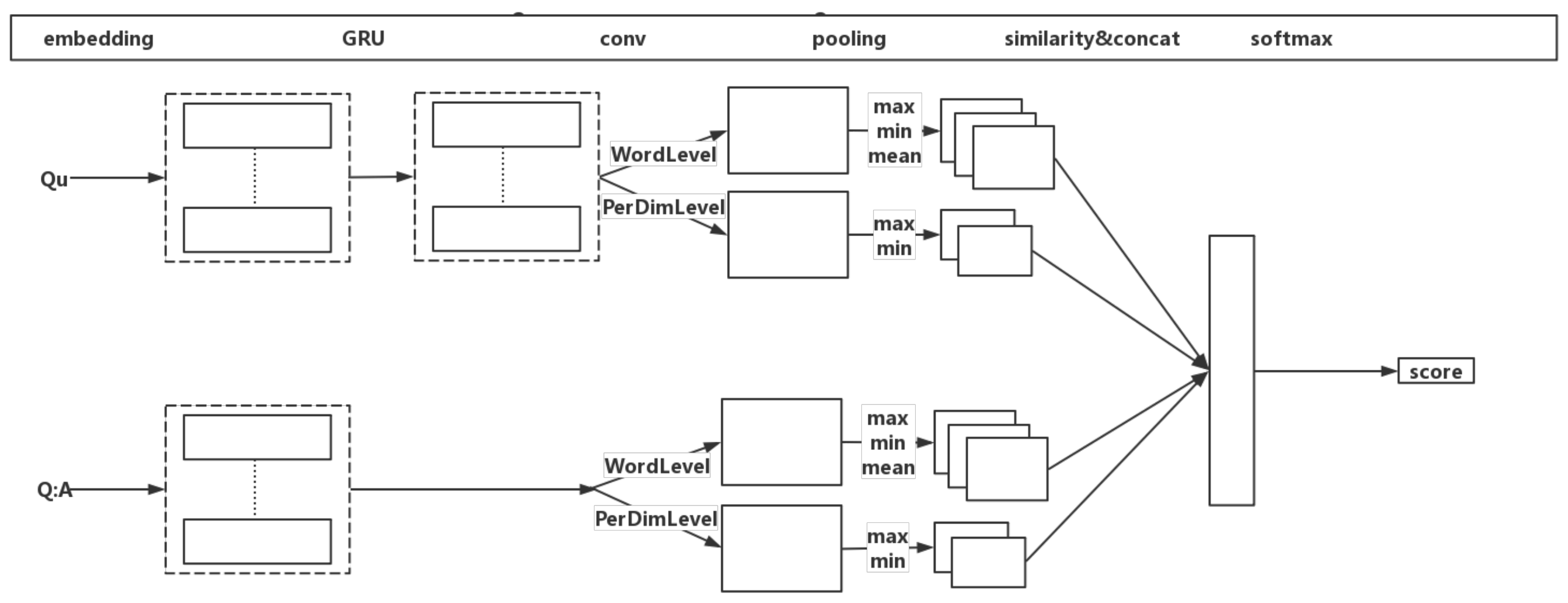
In this section, we present innovative solutions that incorporate multi-info and context information of user questions into multi-perspective CNN(MPCNN) to fulfill question paraphrase identification. The architecture of model is shown in
Figure 4. Our model has two same subnetworks that processing
and
in parallel after getting context by GRU.
(1) Multi-info
To the data,
is quite long but
in our QA-KB is short and contains less information. Besides, the
is quite long and contains some information that related to
. In this work, we concat
and
of QA-KB then to compute S(
,
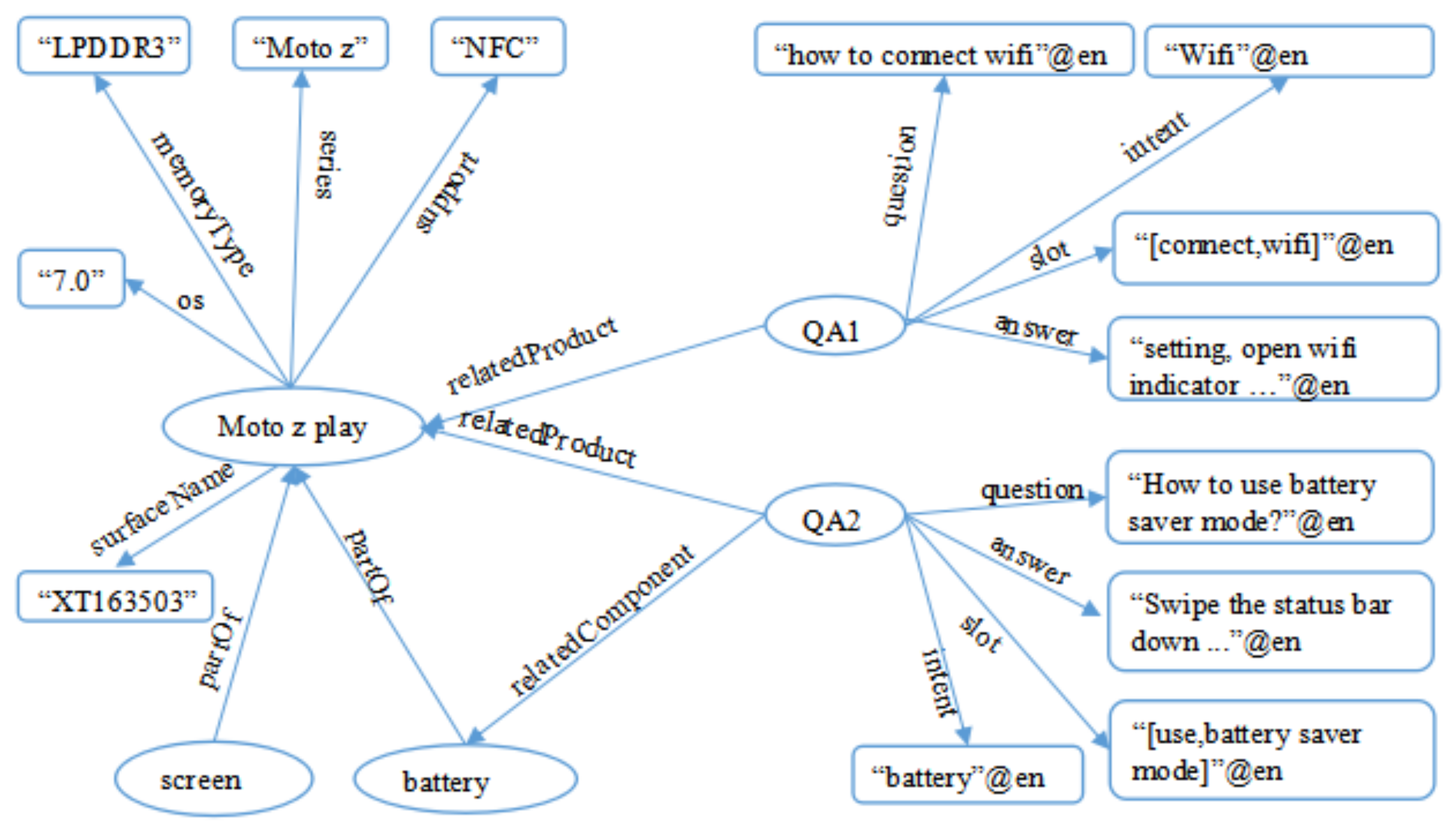
). User queries are always concerned with a specific product but some related standard questions for different products may be the same in the QA-KB. For example in
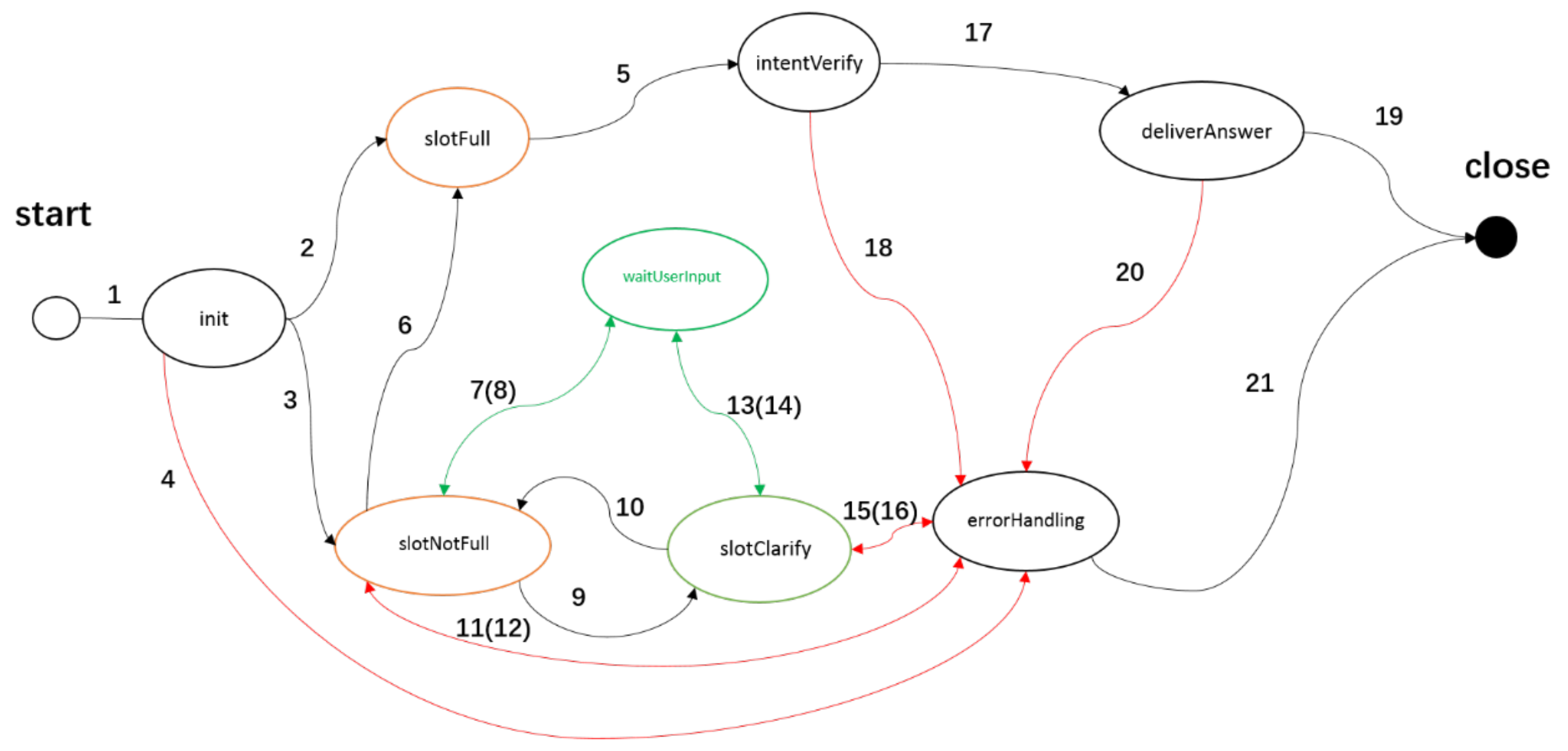
Figure 1 “moto g3” is a mobile name. For a same question, if the product of the question is different, it will influence the matching result. We replace these specific mobiles by the same word “Mobile” directly. In this paper, we use the product-KB and CRF (Conditional Random Field) algorithm to recognize the mobile from
. The left part of
Figure 5 indicates the structure of the product-KB. In product-KB, every mobile has its surface names which are mined from the chat log.
Product-KB hardly contains all mobiles and their surface names so we use CRF to recognize the mobile names from the input user question as a supplement. There are two level features used in CRF, char level ngrames and word level ngrams. The maximum char level ngram is 6 and word level ngram is 3. By using the multi-info of product-KB and answer information, the precision of semantic matching is improved.
(2) Context Multi-Perspective CNN
After getting the multi-info, the input of our neural model are
and
. Given a user query
and a response candidate
, the model looks up an embedding table and represents
and
as
= [e
,e
,...,e
] and
= [e
,e
,...,e
] respectively, where e
and e
∈ R
are the embeddings of the
j-th word of
and
respectively.
L is the max length of two input sequences. Before feed into multi-perspective CNN,
is transformed to hidden vectors conM
by GRU. Suppose that conM
=
are the hidden vectors of
, then
is defined by
where
= 0,
and
are an update gate and a reset gate respectively,
is a sigmoid function, and
,
,
,
,
,
are parameters.
Because is not a sequential sentence the model only gets context information of and learns long-term dependencies by GRU. conM and are then processed by the same neural networks. The paper applies to both word level convolutional filters and embedding level convolutional filters. Word level filters operate over sliding windows while considering the full dimensionality of the word embeddings, like typical temporal convolutional filters. The embedding level filters focus on information at a finer granularity and operate over sliding windows of each dimension of the word embeddings. Embedding level filters can find and extract information from individual dimensions, while word level filters can discover broader patterns of contextual information. Both kinds of filters are allowed to extract more information for richer our model.
For every output vector of convolutional filter, the model converts it to a scalar by pooling layer. Pooling helps a convolutional model retain the most prominent and prevalent features, which is helpful for robustness our model. Max pooling is a widely used pooling layer, which applies max operation over the input vector and returns the maximum value. In addition to using max pooling, our model also uses min pooling and mean pooling.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}