1. Introduction
As a new idea of artificial intelligence in recent years, granular computing is a relatively modern theory in simulating human beings thinking and problem solving [
1,
2,
3]. One of the fundamental tasks of granular computing is to explore an efficient information granulation method, in order to build multilevel granular structures [
4]. Among the many approaches of information granulation [
5,
6,
7,
8], cluster analysis is perhaps one of the most widely used ones [
9]. The fundamental objective of clustering is to discover the underlying structure of a data set. In general, the structure means that similar samples are assigned to the same cluster while dissimilar samples are assigned to different clusters. The lack of prior knowledge makes clustering analysis remain a very challenging problem. Research on clustering algorithm has received much attention and a number of clustering methods have been developed over the past decades.
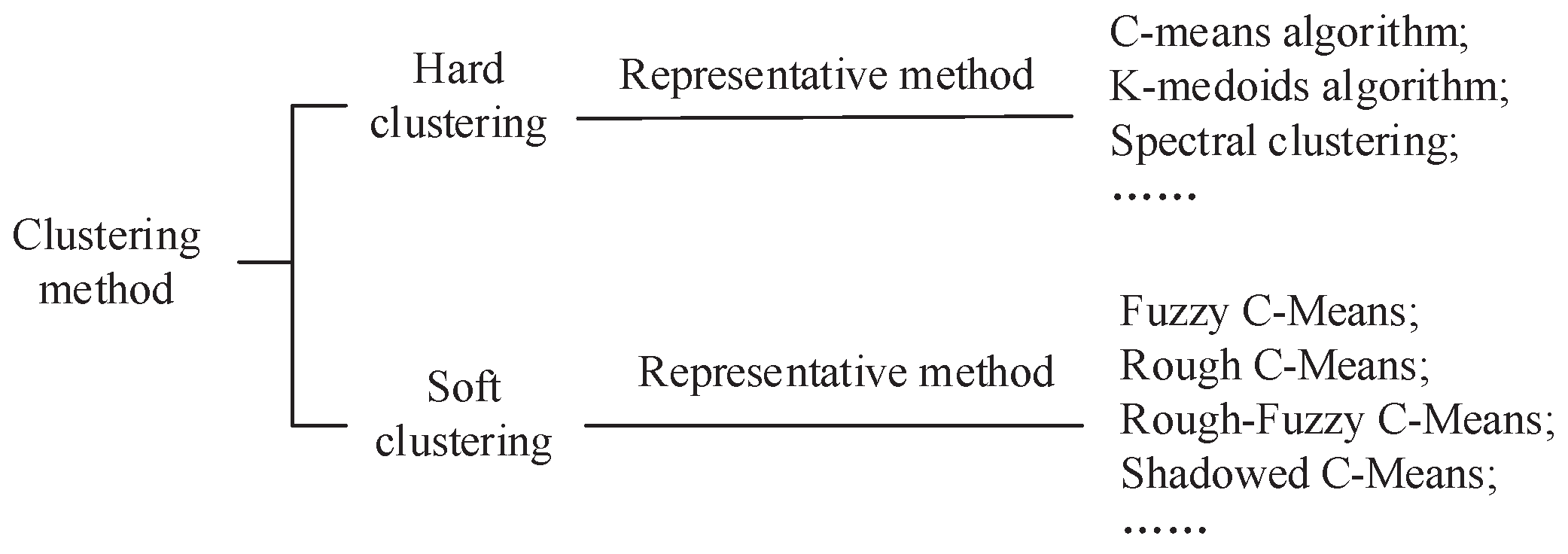
The various methods for clustering can be divided into two categories: hard clustering and soft clustering. Hard clustering methods, such as c-means [
10] and spectral clustering [
11], are based on an assumption that a cluster is represented by a set with a crisp boundary. That is, a data point is either in or not in a specific cluster. The requirement of a sharp boundary leads to easy analytical results, but may not adequately show the fact that a cluster may not have a well-defined boundary. Furthermore, it is not the best way to divide the uncertain objects into one cluster.
In order to relax the constraint of hard clustering methods, many soft clustering methods were proposed for different application backgrounds. Fuzzy sets are a well known generalization of crisp sets, which were first introduced by Zadeh [
12]. Incorporating fuzzy sets into c-means clustering, Bezdek [
13] proposed fuzzy c-means (FCM), which assumes that a cluster is represented by a fuzzy set that models a gradually changing boundary. Another effective tool for uncertain data analysis is rough set theory [
14], which uses a pair of exact concepts, called the lower and upper approximations, to approximate a rough (imprecise) concept. Based on the rough set theory, Lingras and West [
15] introduced rough c-means (RCM) clustering, which describes each cluster not only by a center, but also with a pair of lower and upper bounds. Incorporating membership in the RCM framework, Mitra et al. [
16] put forward a rough-fuzzy c-means (RFCM) clustering method. Shadowed set, proposed by Pedrycz [
17], provides an alternate mechanism for handling uncertainty. As a conceptual and algorithmic bridge between rough sets and fuzzy sets, shadowed set has been successfully used for clustering analysis, resulting in shadowed c-means (SCM) [
18]. A brief classification of existing clustering methods can be shown in
Figure 1.
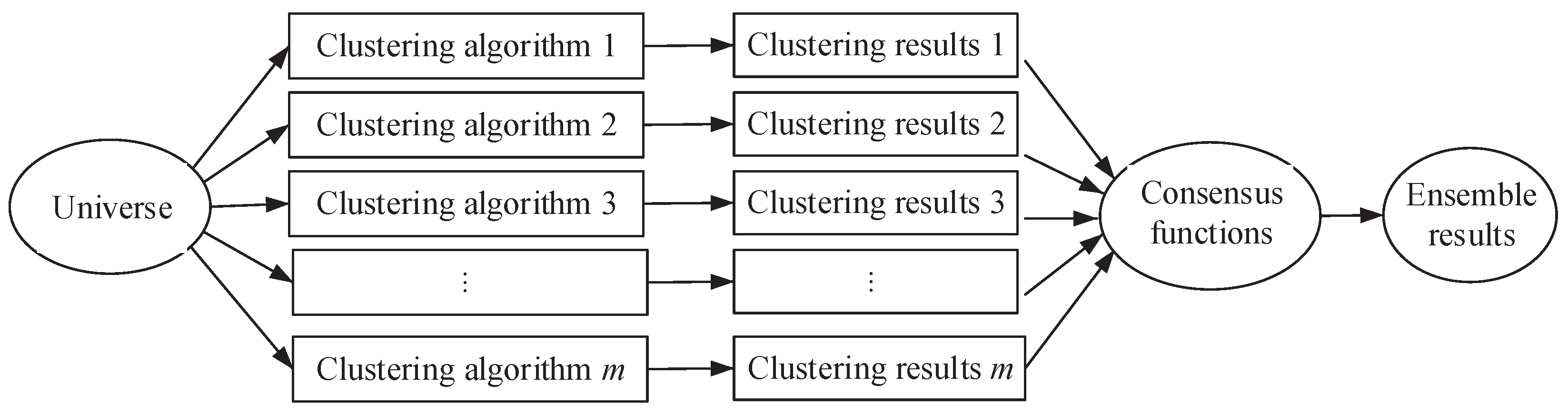
Although there are a lot of clustering methods, the performances of many clustering algorithms are critically dependent on the characteristics of the data set and the input parameters. Improper input parameters may lead to clusters that deviate from those in the data set. It has been accepted that a single clustering algorithm cannot handle all types of data distribution effectively. In order to solve this problem, Strehl and Ghosh [
19] proposed cluster ensemble algorithm, which combines multiple clusterings of a set of objects into one clustering result without accessing the original features of the objects. It has been shown that cluster ensemble is useful in many applications, such as knowledge-reuse [
20], multi-view clustering [
21], distributed computing [
22] and in improving the quality and robustness of clustering results [
23,
24,
25,
26].
Three-way decision as a separate filed of study for problem solving was proposed by Yao [
27,
28,
29,
30], which is an extension of the commonly used binary-decision model. The approach of three-way decisions divides the universe into the Positive, Negative and Boundary regions, which denote the regions of acceptance, rejection and non-commitment for ternary classifications, respectively. For the objects that partially satisfy the classification criteria, it is difficult to directly identify them without uncertainty. Instead of making a binary decision, we use thresholds on the degrees of satisfiability to make one of three decisions: accept, reject, or non-commitment. The third option may also be referred to as a deferment decision that requires further judgments. Three-way decisions have been proved to build on solid cognitive foundations and are a class of effective ways commonly used in human problem solving and information processing [
31]. Many soft computing models for leaning uncertain concepts, such as interval sets, rough sets, fuzzy sets and shadowed sets, have the tri-partitioning properties and can be reinvestigated within the framework of three-way decision [
30].
Hard clustering methods do not address satisfactorily the uncertain relationships between an element and a cluster. It is more reasonable in some applications that there may be three types of relationships between an element and a cluster, namely, belong-to fully, belong-to partially (i.e., also not belong-to partially), and not belong-to fully. In most of the existing studies, a cluster is represented by a single set and the set naturally divides the space into two regions. Objects belong to the cluster if they are in the set, otherwise they do not. Here, only two relationships are considered and we refer to these clustering methods based on such two-way decisions as hard clustering methods. In order to address the three types of relationships between a cluster and an object, three-way clustering has been proposed and studied [
32,
33,
34]. Three-way clustering uses two regions to represent a cluster, i.e., core region (Co) and fringe region (Fr) rather than one set. The core region is an area where the elements are highly concentrated of a cluster and fringe region is an area where the elements are loosely concentrated. There may be common elements in the fringe region among different clusters.
This paper aims at presenting a three-way clustering method based on the results of hard clustering. The idea comes from cluster ensemble and three-way decision. Because different algorithms or different parameters for a hard algorithm may lead to different clustering results. It is hard to judge which structure best matches the real distribution without supervised information. Therefore, we integrate multiple clustering results and lead to a three way clustering algorithm. In the proposed algorithm, hard clustering methods are used to produce different clustering results and label matching is used to align each clustering result to a given order. Different from the other three-way clustering algorithms, which use evaluation functions to decide the core region and fringe region, we regard the intersection of the clusters with same order as the core region. The difference between the union and the intersection of the clusters with the same order are regarded as the fringe region of the specific cluster. Therefore, a three-way explanation of the cluster is naturally formed.
The present paper is based on, but substantially expands, our preliminary study reported in a conference paper [
35]. The study is organized into five sections. We start with brief preliminaries of the background knowledge in
Section 2. In
Section 3, we present the process of three-way ensemble clustering by two main steps. Experimental results are reported in
Section 4. We conclude the paper and point out some future research problems in
Section 5.
3. Three-Way Ensemble Clustering
By following ideas of cluster ensemble and three-way decision, we present a three-way ensemble clustering algorithm. In this section, we assume that the universal has been divided into k disjoint sets m times by existing hard clustering algorithms. We discuss how to design a valid consensus function to obtain a three-way clustering based on the hard clustering results.
We begin our discussion by introducing some notations. We suppose that
is a set of
n objects and
denotes
th clustering of
V, where
is a hard clustering results of
V, that is,
and
. The
k sets
are clusters of
. Although we have obtained the clustering results of
V,
cannot be directly used for the conclusion of the next stage due to the lack of priori category information. As an example, we consider the data set
and let
and
be three clusterings of
V which are shown in
Table 1. Although the objects are expressed in different orders, they represent the same clustering result. In order to combine the clustering results, the cluster labels must be matched to establish the correspondence between each one.
In general, the number of identical objects covered by the corresponding cluster labels should be the largest. The cluster labels can be registered based on this heuristic. Assume and are two hard clustering results of V. Each divides the data set into k clusters denoted by and , respectively. First, the numbers of identical objects covered by each pair of cluster labels and in the two clusters are recorded in the overlap matrix of . Then select the cluster label that covers the largest number of identical objects to establish the correspondence and remove the result from the overlap matrix. Repeat the above process until all the cluster labels have established the corresponding relationship.
When there are clustering results, we can randomly select one as the matching criterion and match the other clustering results with the selected results. The matching algorithm only needs to check the clustering results and and store the overlap matrix with the storage space of . The whole matching process is fast and efficient.
After all clustering labels match, all objects of
V can be divided into three types for a given label
j based on the results of labels matching:
From the above classifications, it can be seen that the objects in Type I are assigned to
th cluster in all clustering results. The objects of Type II are assigned to
th cluster in part of clustering results. The objects in Type III have no intersection with
th in each clustering result. Based on the ideas of three-way decision and three-way clustering, the elements in Type I are clearly attributable to the
th cluster and should be assigned to core region of
th cluster. The elements in Type II should be assigned to fringe region of
th cluster and all the elements in Type III should be assigned to trivial region of
th cluster. From the above discussion, we get the following strategy to obtain a three-way clustering by cluster ensemble.
The above clustering method is called a three-way ensemble clustering. The procedure of three-way ensemble clustering consists mainly of three steps.
Obtain a group of hard clustering results by using existing methods.
Randomly select one clustering result in step 1 as the matching criterion and match the other clustering results with the selected results
Compute the intersection of the clusters with the same labels and the difference between the union and the intersection of the clusters with the same labels.
The above procedure can be depicted by
Figure 3. Finally, we present Algorithm 1, which describes the proposed three-way ensemble clustering based on hard clustering results. In Algorithm 1, we choose the first clustering results
as matching criterion and match the other clustering results with
during label matching.
| Algorithm 1 Three-way ensemble clustering |
- 1:
Input: m hard clustering results - 2:
Output: Three-way ensemble re-clustering result - 3:
for each in do - 4:
for to k, to k do - 5:
overlap =Count ; //overlap is a matrix; //Count counts the number of same elements of and - 6:
end for - 7:
- 8:
while } do - 9:
=argmax(overlap// is the biggest element - 10:
//align to - 11:
Delete overlap - 12:
Delete overlap - 13:
- 14:
end while - 15:
end for - 16:
for to k do - 17:
Calculate Co - 18:
Calculate Fr - 19:
end for - 20:
return
|






{kind=link}
{kind=link}
{kind=link}