HOLMeS: eHealth in the Big Data and Deep Learning Era

 ,
,  ,
,  , , and
, , and 
Abstract
1. Introduction
- Patient trustiness, meaning that the system should represent a clinician (therefore, human-like interaction models may be provided with the aim of minimizing any kind of bias);
- Massive data handling, since a diagnostic by images produces huge amounts of data (not only structured as 3D volumes) [18];
- Legal responsibility for mistakes in acting or non-acting in an optimal way should be addressed by any clinical systems.
- On one hand, we introduce a general big data architecture which is useful to several eHealth applications;
- on the other hand, we present a particular instance/implementation of such an architecture—the HOLMeS (health online medical suggestions) system—for supporting the prevention of chronic diseases within the CMO (centro medico oplonti) diagnostic center (we note that this activity was performed in the context of a joint research project between the Data Life Research Consortium and the Department of Electrical Engineering and Information Technology of University of Naples), whose main novelty lies on:
- -
- the adoption of a new human–machine interaction paradigm where a machine learning algorithm, deployed on a big data computing cluster, provides online medical suggestions through a chat-bot module;
- -
- the training of the chat-bot in the medical domain using a deep learning approach, thus overcoming limitations of a biased interaction between users and software.
2. Related Work
- Knowledge-based CDSSs consist of three parts: A mechanism to communicate (GUI), which allows the system to show the results to the user as well as submit the input to the system; a knowledge-base (KB), which contains a set of rules and associations; the inference engine (IE), which combines the rules from the knowledge-base with the patients’ data.
- Nonknowledge-Based CDSSs, based on a machine learning system which allows learning from past experiences (ground truth) and/or finds patterns in clinical data; among the most common types of nonknowledge-based systems are supervised machine learning algorithms (as for developing computer-aided diagnosis systems [20,21]) and unsupervised machine learning algorithms (such as clustering or genetic algorithms).
- GYANT (www.gyant.com): Using artificial intelligence, GYANT is able to analyze symptoms and provide recommendations tied to the user answer, with full medical explanations. The result is not a real diagnosis but provided in terms of a follow-up to be held.
- Babylon Health (www.babylonhealth.com): It is a health service provider able to connect patients and doctors using mobile messaging and a video functionality allowing users to obtain drug prescriptions, consult health specialists, and book exams with nearby facilities. It is provided with a nonfree subscription paradigm with a web-oriented and mobile-oriented GUI. Its novelty is in the communication protocol, but it does not enable any machine learning or artificial intelligence algorithms. In the last update (2016), an AI-like feature was released, providing prescreening feedback on the user health condition.
- Brook (www.brook.org.uk): Logging all health-related data may be a long and boring procedure. Book makes this procedure as simple as messaging and uses mobile phone notifications for quick and easy updates. Brook was borne as a disease-specific application allowing to control sugar-safe zones in patients with diabetes. Today, it represents a general-level application able to keep a logbook of our health data with a specific focus on food habits and lifestyle.
- Forksy (www.getforksy.com): It is defined as a robot-coach that supports the users in improving their eating habits. The chat-bot starts talking about some personal information to estimate a proper calorie limit. During the day, Forksy sends a message asking what users ate or drank and keeps it all in a food diary. Finally, Forksy provides a personal nutritional assessment to improve: Digestion, sleep, brain and cognitive performance, and productive hours per day.
3. Big Data Tools Supporting eHealth Applications
3.1. Apache Spark Cluster
3.1.1. Hadoop Distributed File System
- Hardware failure, since it has to run over hundreds or thousands of commodity server machines;
- Streaming data access, since applications that use HDFS usually need batch processing and, thus, hight throughput is preferred over low access latency;
- Large data, supporting tens of millions of files, each of a size in gigabytes to terabytes;
- Simple coherency model, in order to simplify application access policies, since many applications usually need a write-once-read-many access model for files;
- Portability both across heterogeneous hardware and software, in order to sustain its usage and diffusion.
3.1.2. MapReduce
- The map step, which filters and sorts data (for example sorting patient by age, arranging a different queue for each possible age value);
- The reduce step, which summarizes the data (for example, counting the number of patients in each queue, producing the age frequencies).
3.1.3. Spark.ML and ML Pipelines
3.2. Databricks
3.3. Watson
4. System Description
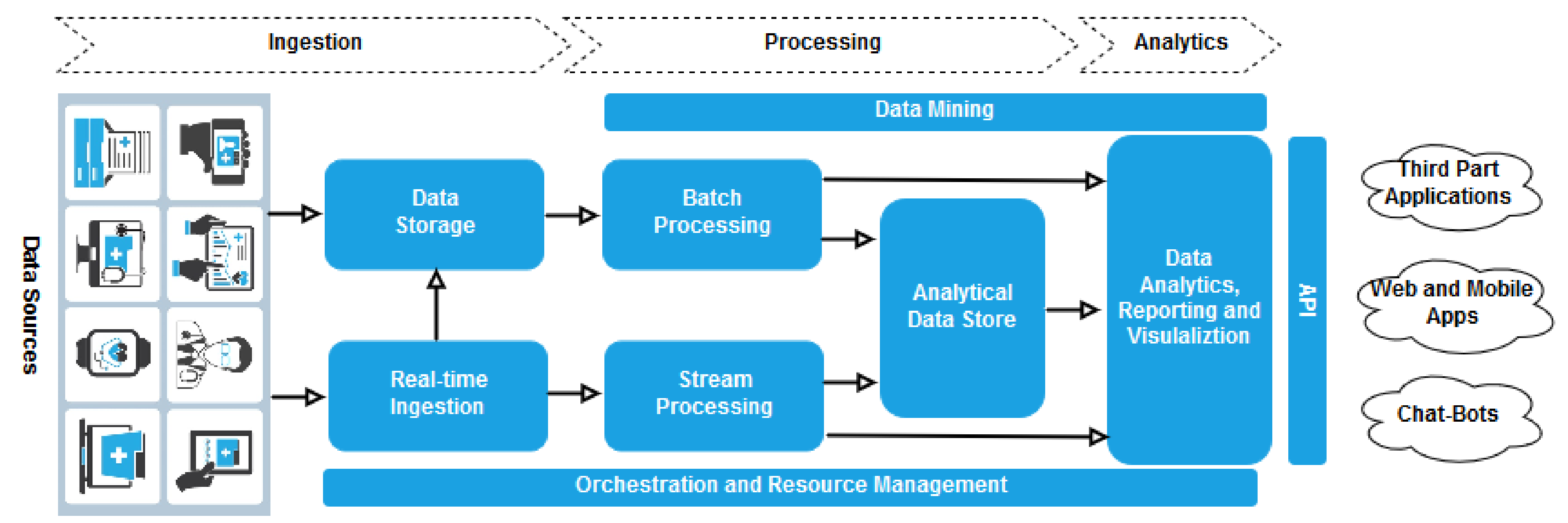
4.1. System Overview
- Data are processed using long-running batch jobs to filter, aggregate, and otherwise prepare the data themselves for analysis (batch processing);
- After capturing real-time messages, the architecture has to process them by filtering, aggregating, and otherwise preparing the data for analysis (strema processing).
4.2. Implementation Details
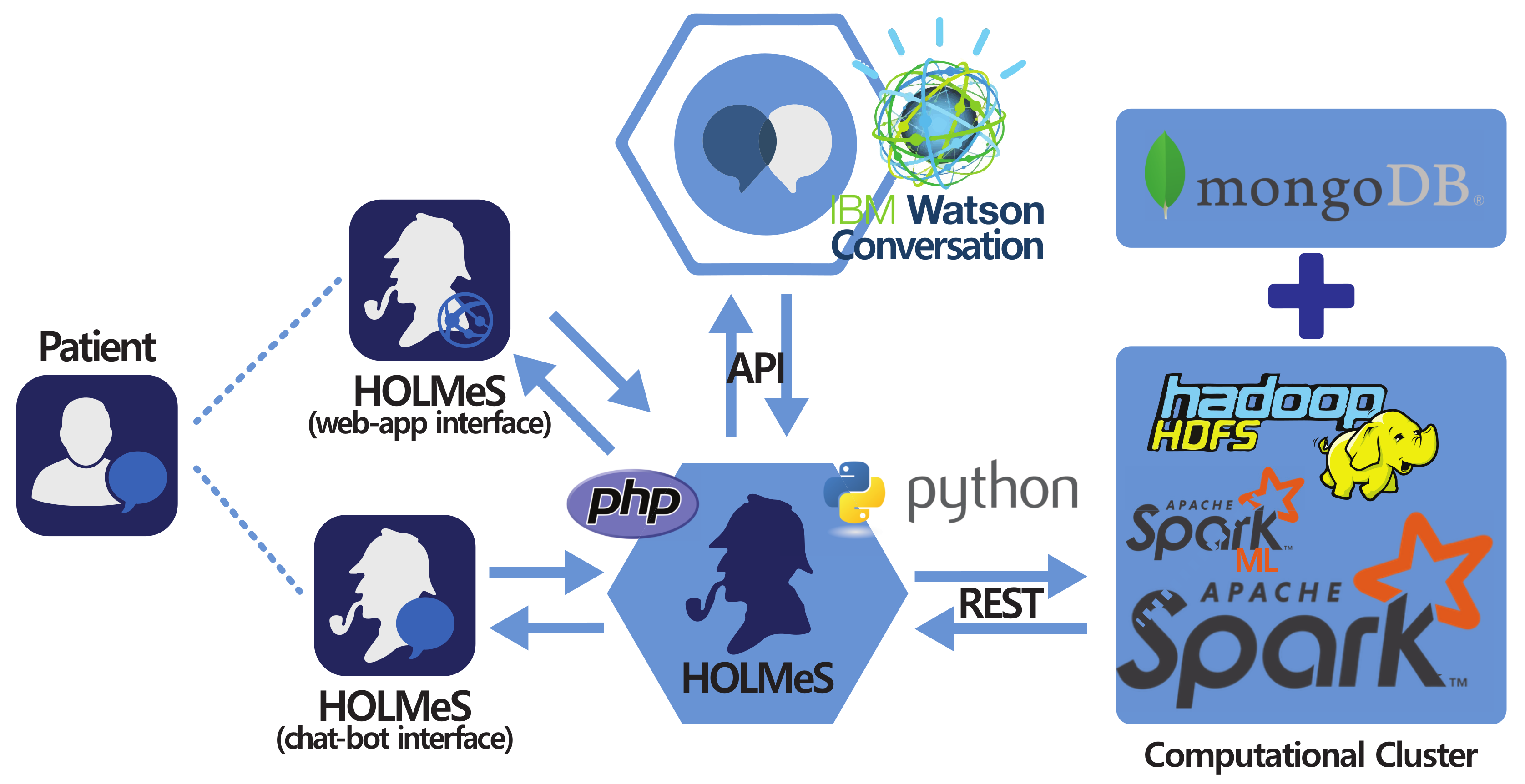
- The HOLMeS Application is the HOLMeS system core. Written in Python, it implements the main logic and orchestrates module communications and functions. In particular, it communicates with the user through the chat-bot, interpreting their requests using the functionalities provided by the Watson conversation API, managing requests and responses between the patient and application modules in order to provide to the user with whom it is interacting (through the chat-bot or through the web-app) with the result of the machine learning algorithms with respect to the possibility of having a disease.
- HOLMeS chat-bot is the module dedicated to interacting with the user in order to let them feel more conformable. The bot is designed to understand different kinds of chat interactions, from formal writing to more handy ones. It is one of the HOLMeS system entry points and interacts with the user to let them choose the required service. It is also intended to kindly ask the user for required information (such as age, height, weight, smoking status, and so on), just as a human physician would.
- HOLMeS web-app is the interface dedicated to performing the medical interview via dynamic web forms. The forms change the question fields according to the previous answers, minimizing the interaction while maximizing the quality of the information. The results are provided by bar plots and gauges. Although the web-form interfaces are not as comfortable as a chat-bot, they offer a suitable means for Internet browsers and mobile devices (via mobile-ready interfaces).
- IBM Watson provides the service needed to establish a written conversation, simulating human interactions, through its conversation APIs. Main features include natural language processing and text mining through machine learning approaches (in particular, convolutional neural networks and support vector machines).
- Computational cluster implements the decision making logic on the basis of the described big data architecture. It uses the Apache Spark cluster executed over the Databricks infrastructures, in order to be fast and scalable enough to be effectively used in a very big clinical scenario, where many requests from different patients come together, ensuring a response time comparable to that of a human physician. It uses machine learning algorithms from Spark ML library, previously trained on many clinical features, in order to predict the expected occurrence probability for different diseases. Finally, the storage service is delegated to Hadoop HDFS and to Mongo DB for storing patient clinical records.
- Providing general information about itself or the affiliated medical centre;
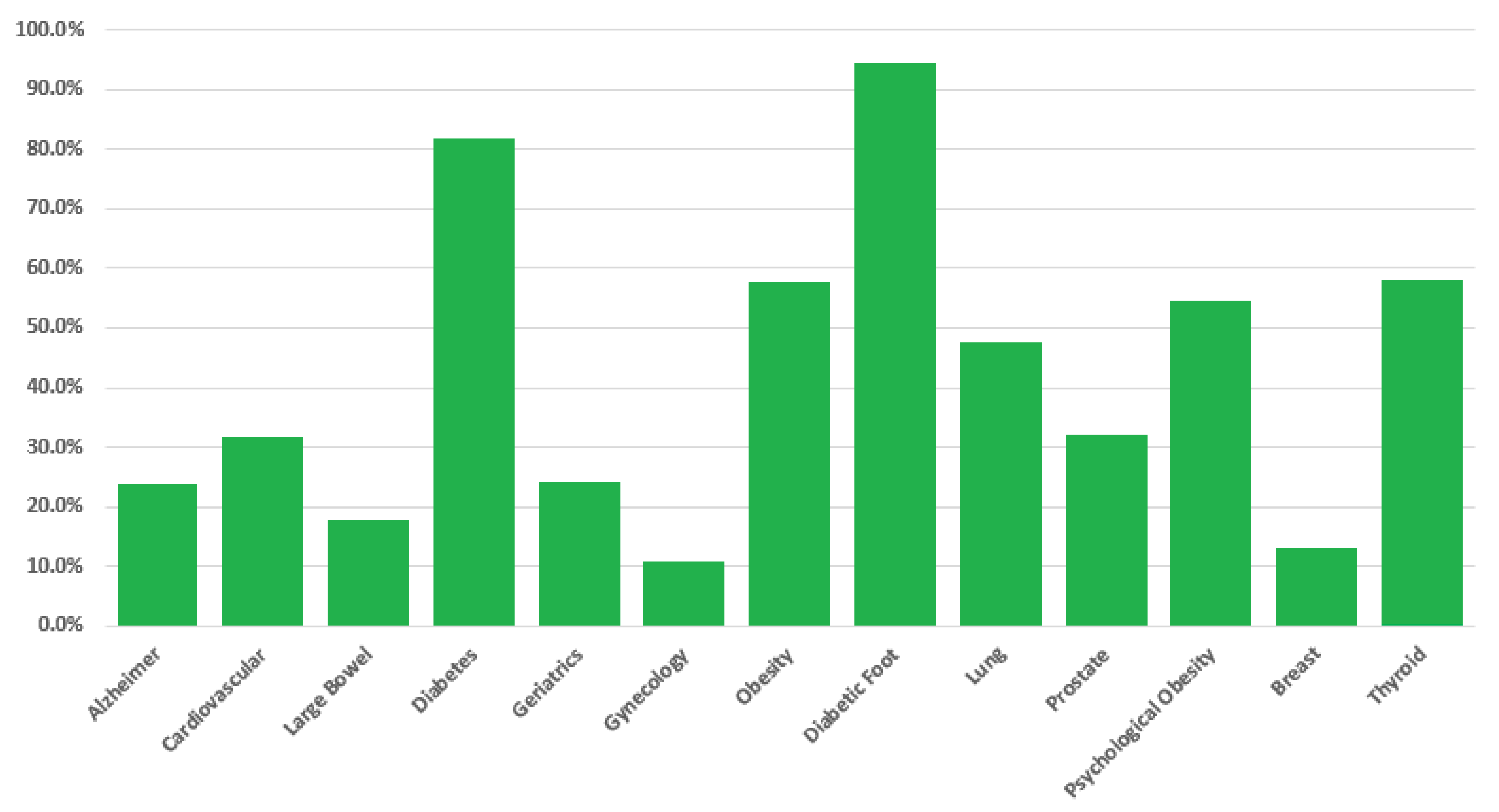
- Collecting general patient information in order to provide general prevention pathways indications among different disease (the result is provided in terms of probabilities, per each prevention pathway, of a positive response to each of the screening procedures);
- Collecting detailed patient information (clinical, examination results and so on) in order to evaluate the needs of a specific disease prevention partway (the result is provided in terms of probability of a positive response to the screening procedure);
- Booking a de-visu examination with the affiliated medical centre.
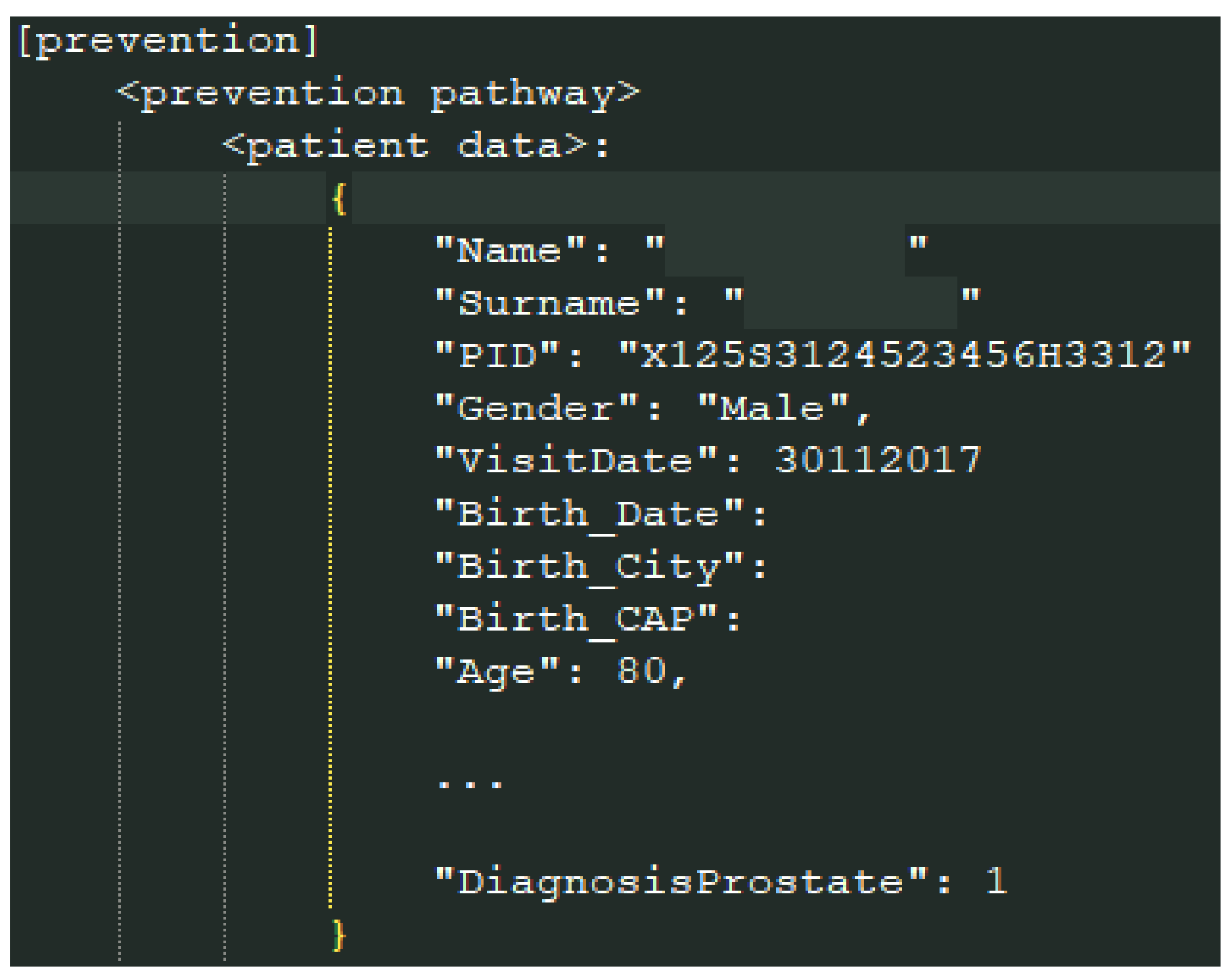
4.3. Data Storage
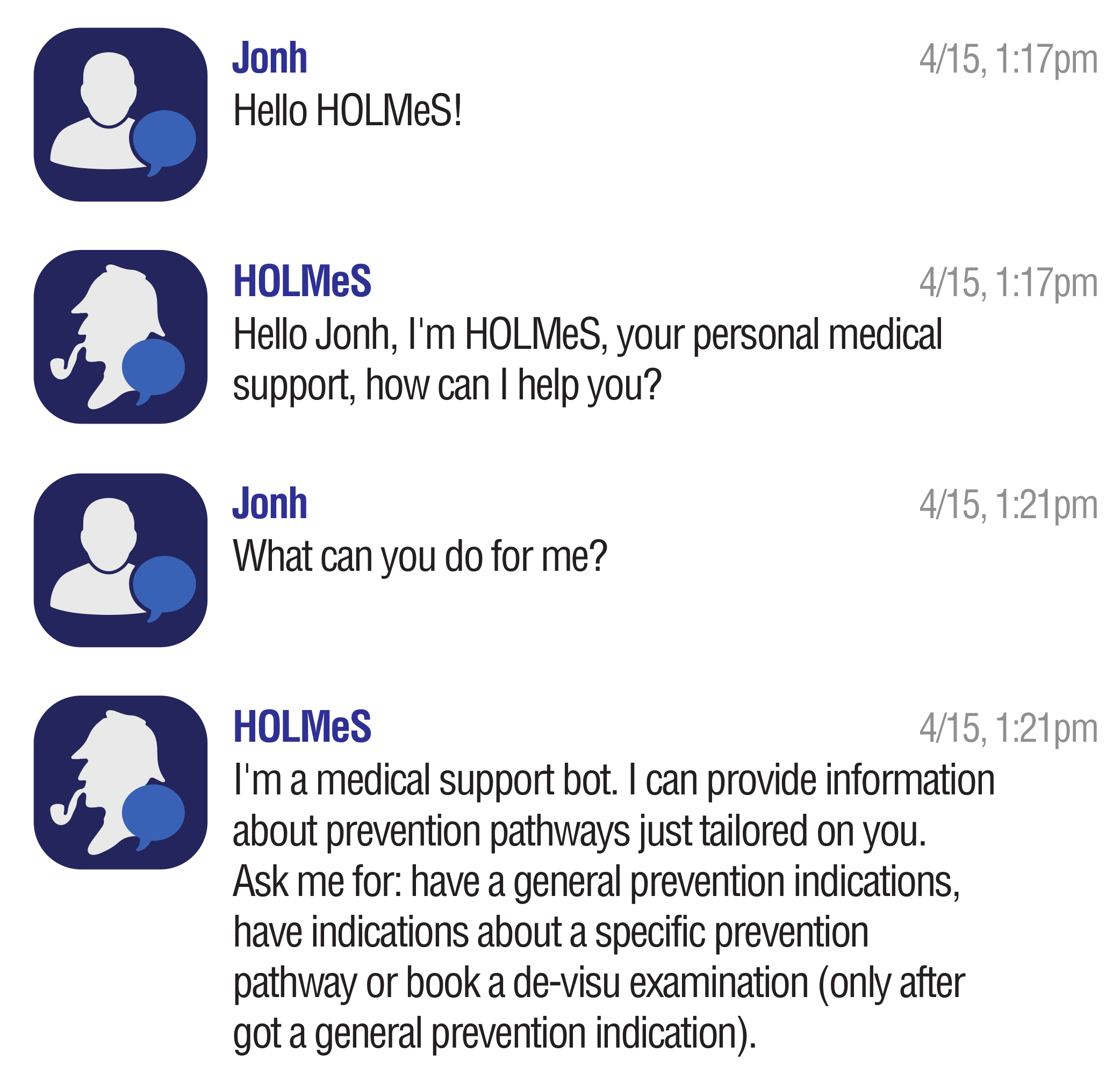
4.4. Chat-Bot Interaction Skills
- #greetings: To handle the initial conversation preamble;
- #book: To describe actions as reserving a de-visu examination;
- #get: To ask to receive something, such as prevention pathway indications or information about the centre;
- #put: To catch the intent of giving the required information to the system.
- @HOLMeS: “holmes”, ”you”, ”system”;
- @HOLMeS_functionalities: ”functionalities”, ”skills”, capabilites”;
- @clinical_centre: ”CMO”, ”centre”, ”clinical”;
- @address, ”address”, ”location”, ”position”;
- @de_visu_examination: ”visit”, ”appointment”, ”medical consult”;
- @specific_pathway_examination: ”specific visit”, ”specific examination”, ”specific pathway”;
- @general_pathway_examination: ”general visit”, ”general examination”, ”general pathway”;
- @age: ”age”, ”years”, ”years old”;
- @sex: ”gender”, ”sex”, ”sexuality”;
- @birthday: ”birthday”, ”BD”;
- @height: ”height”, ”highness”;
4.5. The Machine Learning Algorithm
- Improved scalability, since classifiers can be easily distributed over a cluster to accommodate a growing amount of user requests;
- Reduced computational time, since the schema is highly parallelizable because different classifier predictions can be evaluated in parallel;
- High maintainability, since any single classifier can be adapted, corrected or improved without any impact on any other system components;
- High upgradability, since a new classifier can be easily added to make HOLMeS able to deal with any new desired diseases.
- General-level prevention evaluation, in which the user can query the HOLMeS system, through the chat bot, in order to have the first medical prevention advice, submitting some simple clinical features, such as age, height, weight, living place, smoking status, some disease familiarity, and so on.
- Specific disease prevention evaluation, in which a user can query the HOLMeS System, through the chat bot, in order to have more detailed prevention advice about a specific disease by submitting more specific features, such as results examination, blood pressure, respiratory and heart rate, oxygen saturation, body temperature, and so on.
4.6. General Functionalities
- The user wants information about the affiliated medical centre;
- The user asks for general information about the system and its functionalities;
- The patient desires to obtain general-level evaluation about the available prevention pathways;
- The patient desires to obtain detailed indications about a specific disease prevention pathway (only after a general survey has been carried out);
- The patient wants a de-visu examination (only after a general survey has been carried out).
4.7. Dataset
5. Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Buyya, R.; Yeo, C.S.; Venugopal, S. Market-oriented cloud computing: Vision, hype, and reality for delivering it services as computing utilities. In Proceedings of the 10th IEEE International Conference on High Performance Computing and Communications, 2008. HPCC’08, Dalian, China, 25–27 September 2008; pp. 5–13. [Google Scholar]
- Bryant, R.; Katz, R.H.; Lazowska, E.D. Big-Data Computing: Creating Revolutionary Breakthroughs in Commerce, Science and Society, 2008. Available online: https://www.immagic.com/eLibrary/ARCHIVES/GENERAL/CRA_US/C081222B.pdf (accessed on 21 January 2019).
- Piantadosi, G.; Marrone, S.; Sansone, M.; Sansone, C. A Secure OsiriX Plug-In for Detecting Suspicious Lesions in Breast DCE-MRI. In Algorithms and Architectures for Parallel Processing; Springer International Publishing: Berlin, Germany, 2013; pp. 217–224. [Google Scholar]
- Piantadosi, G.; Marrone, S.; Sansone, M.; Sansone, C. A secure, scalable and versatile multi-layer client–server architecture for remote intelligent data processing. J. Reliab. Intell. Environ. 2015, 1, 173–187. [Google Scholar] [CrossRef]
- Pérez, A.; Gojenola, K.; Casillas, A.; Oronoz, M.; de Ilarraza, A.D. Computer aided classification of diagnostic terms in spanish. Expert Syst. Appl. 2015, 42, 2949–2958. [Google Scholar] [CrossRef]
- Arsene, O.; Dumitrache, I.; Mihu, I. Expert system for medicine diagnosis using software agents. Expert Syst. Appl. 2015, 42, 1825–1834. [Google Scholar] [CrossRef]
- Winters, B.; Custer, J.; Galvagno, S.M.; Colantuoni, E.; Kapoor, S.G.; Lee, H.; Goode, V.; Robinson, K.; Nakhasi, A.; Pronovost, P.; et al. Diagnostic errors in the intensive care unit: A systematic review of autopsy studies. BMJ Qual. Saf. 2012, 21, 894–902. [Google Scholar] [CrossRef] [PubMed]
- Tehrani, A.; Lee, H.; Mathews, S.; Shore, A.; Makary, M.; Pronovost, P. Diagnostic Errors More Common, Costly and Harmful Than Treatment Mistakes; John Hopkins Medicine: Baltimore, Maryland, 2013. [Google Scholar]
- Ongenae, F.; Claeys, M.; Dupont, T.; Kerckhove, W.; Verhoeve, P.; Dhaene, T.; De Turck, F. A probabilistic ontology-based platform for self-learning context-aware healthcare applications. Expert Syst. Appl. 2013, 40, 7629–7646. [Google Scholar] [CrossRef]
- Della Mea, V. What is e-Health: The death of telemedicine? J. Med. Internet Res. 2001, 3, e22. [Google Scholar] [CrossRef] [PubMed]
- Oh, H.; Rizo, C.; Enkin, M.; Jadad, A. What is eHealth? A systematic review of published definitions. J. Med. Internet Res. 2005, 7, e1. [Google Scholar] [CrossRef] [PubMed]
- Healy, J. Implementing e-Health in developing countries: Guidance and principles. In ICT Applications and Cyber Security Division (CYB). Policies and Strategies Department. [Monografía en Internet]; International Telecommunication Union: Geneva, Switzerland, 2008. [Google Scholar]
- Ball, M.J.; Lillis, J. E-health: Transforming the physician/patient relationship. Int. J. Med. Inform. 2001, 61, 1–10. [Google Scholar] [CrossRef]
- Eysenbach, G.; Diepgen, T.L. The role of e-health and consumer health informatics for evidence-based patient choice in the 21st century. Clin. Dermatol. 2001, 19, 11–17. [Google Scholar] [CrossRef]
- O’donoghue, J.; Herbert, J. Data management within mHealth environments: Patient sensors, mobile devices, and databases. J. Data Inf. Qual. 2012, 4, 5. [Google Scholar] [CrossRef]
- Marrone, S.; Piantadosi, G.; Fusco, R.; Petrillo, A.; Sansone, M.; Sansone, C. A Novel Model-Based Measure for Quality Evaluation of Image Registration Techniques in DCE-MRI. In Proceedings of the 2014 IEEE 27th International Symposium on Computer-Based Medical Systems, New York, NY, USA, 27–29 May 2014; pp. 209–214. [Google Scholar]
- Piantadosi, G.; Marrone, S.; Fusco, R.; Petrillo, A.; Sansone, M.; Sansone, C. Data-driven selection of motion correction techniques in breast DCE-MRI. In Proceedings of the 2015 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Torino, Italy, 15–18 May 2015; pp. 273–278. [Google Scholar]
- Marrone, S.; Piantadosi, G.; Fusco, R.; Petrillo, A.; Sansone, M.; Sansone, C. Breast segmentation using Fuzzy C-Means and anatomical priors in DCE-MRI. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 1472–1477. [Google Scholar]
- Berner, E.S. Clinical Decision Support Systems; Springer: Berlin, Germany, 2007. [Google Scholar]
- Marrone, S.; Piantadosi, G.; Fusco, R.; Petrillo, A.; Sansone, M.; Sansone, C. Automatic Lesion Detection in Breast DCE-MRI. In Image Analysis and Processing (ICIAP); Springer: Berlin/Heidelberg, Germany, 2013; pp. 359–368. [Google Scholar]
- Piantadosi, G.; Fusco, R.; Petrillo, A.; Sansone, M.; Sansone, C. LBP-TOP for Volume Lesion Classification in Breast DCE-MRI. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9279, pp. 647–657. [Google Scholar]
- Buchanan, B. Rule based expert systems. In The MYCIN Experiments of the Stanford Heuristic Programming Project; Wiley Online Library: Hoboken, NJ, USA, 1984. [Google Scholar]
- Musen, M.A.; Middleton, B.; Greenes, R.A. Clinical decision-support systems. In Biomedical Informatics; Springer: Cham, Switzerland, 2014; pp. 643–674. [Google Scholar]
- Aronson, A.R. DiagnosisPro: The ultimate differential diagnosis assistant. JAMA 1997, 277, 426–426. [Google Scholar] [CrossRef]
- Khosla, V. Technology Will Replace 80% of What Doctors Do. Available online: http://tech.fortune.cnn.com/2012/12/04/technology-doctors-khosla/ (accessed on 1 September 2018).
- Papazoglou, M.P.; Traverso, P.; Dustdar, S.; Leymann, F. Service-oriented computing: State of the art and research challenges. Computer 2007, 40. [Google Scholar] [CrossRef]
- Apache Spark. Apache Spark: Lightning-Fast Cluster Computing. Available online: http://spark.apache.org/ (accessed on 21 January 2019).
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. Mllib: Machine learning in apache spark. J. Mach. Learn. Res. 2016, 17, 1–7. [Google Scholar]
- Kakadia, D. Apache Mesos Essentials; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Vavilapalli, V.K.; Murthy, A.C.; Douglas, C.; Agarwal, S.; Konar, M.; Evans, R.; Graves, T.; Lowe, J.; Shah, H.; Seth, S.; et al. Apache hadoop yarn: Yet another resource negotiator. In Proceedings of the 4th Annual Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2013; p. 5. [Google Scholar]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Lake Tahoe, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Apache hadoop. Available online: http://hadoop.apache.org/ (accessed on 21 January 2019).
- Meng, X.; Bradley, J.; Sparks, E.; Venkataraman, S. ML Pipelines: A New High-Level API for MLlib. Databricks Blog. Available online: https://databricks.com/blog/2015/01/07/ml-pipelines-a-new-high-level-api-for-mllib.html (accessed on 1 November 2018).
- Databricks.com. Databricks. Available online: https://databricks.com/ (accessed on 1 November 2018).
- Ferrucci, D.; Levas, A.; Bagchi, S.; Gondek, D.; Mueller, E.T. Watson: Beyond jeopardy! Artif. Intell. 2013, 199, 93–105. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #Records | Age (AVG) | |
|---|---|---|
| Alzheimer | 176 | 68 |
| Cardiovascular | 299 | 55 |
| Large Bowel | 513 | 53 |
| Diabetes | 3955 | 60 |
| Geriatrics | 89 | 70 |
| Gynecology | 1344 | 46 |
| Obesity | 629 | 50 |
| Diabetic Foot | 1075 | 65 |
| Lung | 225 | 56 |
| Prostate | 1045 | 60 |
| Psychological Obesity | 388 | 50 |
| Breast | 5867 | 47 |
| Thyroid | 1128 | 46 |
| Total | 16,733 | 56 |
| General Pathway | Specific Pathway | |
|---|---|---|
| (First Level) | (Second Level) | |
| Alzheimer | 67.08% (± 0.06%) | 90.60% (± 0.06%) |
| Cardiovascular | 71.35% (± 0.06%) | 83.58% (± 0.06%) |
| Large Bowel | 58.07% (± 0.04%) | 90.16% (± 0.04%) |
| Diabetes | 78.94% (± 0.03%) | 81.21% (± 0.03%) |
| Geriatrics | 69.53% (± 0.09%) | 97.79% (± 0.09%) |
| Gynecology | 75.15% (± 0.03%) | 79.17% (± 0.03%) |
| Obesity | 81.80% (± 0.04%) | 80.20% (± 0.04%) |
| Diabetic Foot | 83.00% (± 0.03%) | 90.88% (± 0.03%) |
| Lung | 75.91% (± 0.06%) | 96.93% (± 0.06%) |
| Prostate | 83.68% (± 0.03%) | 98.82% (± 0.03%) |
| Psychological Obesity | 74.65% (± 0.06%) | 80.30% (± 0.06%) |
| Breast | 60.65% (± 0.03%) | 62.56% (± 0.03%) |
| Thyroid | 68.27% (± 0.03%) | 96.00% (± 0.03%) |
| Median | 74.65% | 86.78% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amato, F.; Marrone, S.; Moscato, V.; Piantadosi, G.; Picariello, A.; Sansone, C. HOLMeS: eHealth in the Big Data and Deep Learning Era. Information 2019, 10, 34. https://doi.org/10.3390/info10020034
Amato F, Marrone S, Moscato V, Piantadosi G, Picariello A, Sansone C. HOLMeS: eHealth in the Big Data and Deep Learning Era. Information. 2019; 10(2):34. https://doi.org/10.3390/info10020034
Chicago/Turabian StyleAmato, Flora, Stefano Marrone, Vincenzo Moscato, Gabriele Piantadosi, Antonio Picariello, and Carlo Sansone. 2019. "HOLMeS: eHealth in the Big Data and Deep Learning Era" Information 10, no. 2: 34. https://doi.org/10.3390/info10020034
APA StyleAmato, F., Marrone, S., Moscato, V., Piantadosi, G., Picariello, A., & Sansone, C. (2019). HOLMeS: eHealth in the Big Data and Deep Learning Era. Information, 10(2), 34. https://doi.org/10.3390/info10020034