1. Introduction
In the early days of containerization, ports were considered monopolistic due to their strategic locations and port traffic concentration. The advent of containerization changed the operational perceptions of ports from a monopolistic standpoint to an era of fierce competition within neighboring ports [
1]. This competition made port performance a benchmark of a port’s competitive outcome and necessitated ports in paying keen attention to port performance indicators, productivity, and efficiency [
2]. While this has boosted the performance of most ports worldwide and in Africa in particular, some ports have nevertheless suffered in performance and have barely achieved the benefits of maritime trade despite their strategic locations [
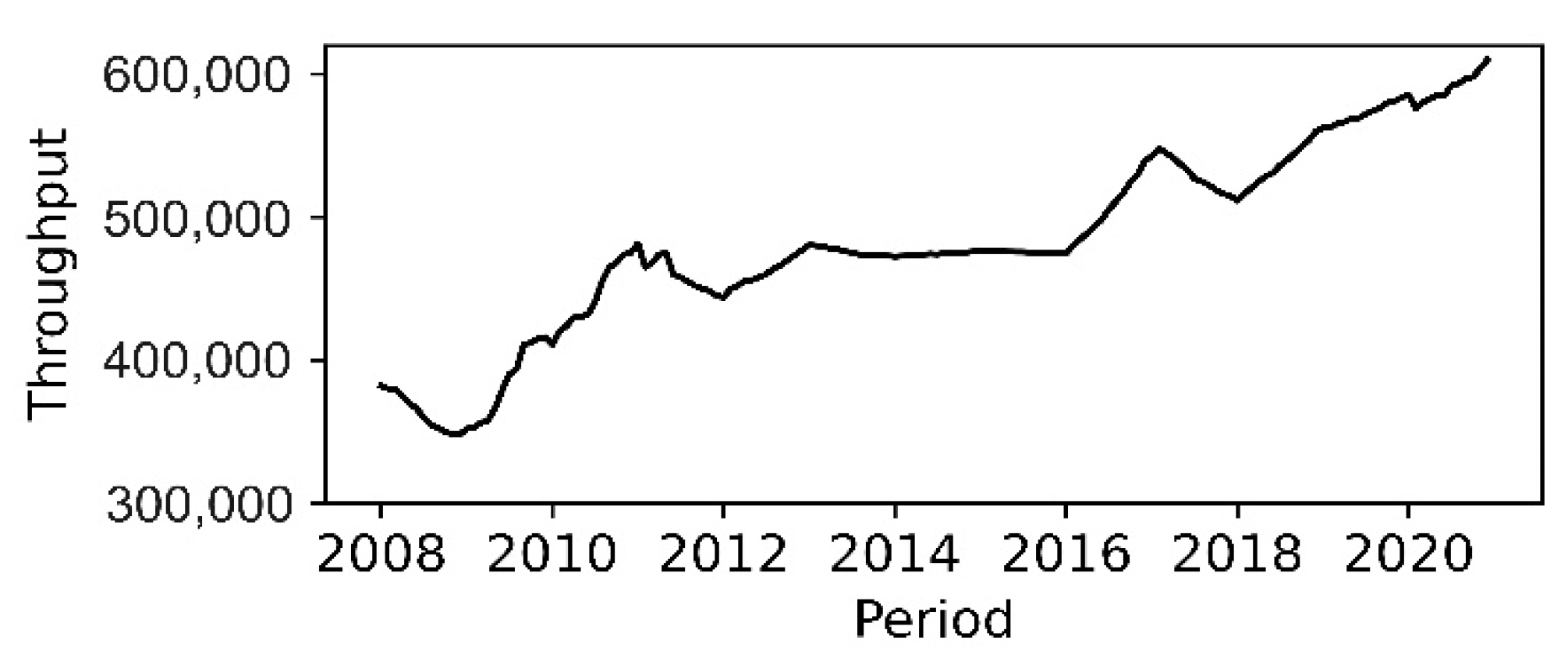
3]. The shipping connectivity index in African countries is amongst the lowest in the world. Countries located at the corners of the continent are the best-connected countries because they are situated at crossroads where international shipping routes connect to hub ports [
3]. Such countries include Cameroon, Morocco, Egypt, South Africa, Togo, Djibouti, Nigeria, and Mauritania. However, prior studies [
4] provide substantial literature to show how some of these ports, especially those located in sub-Saharan and Central Africa, are the most inefficient ports. UNCTAD [
5] classified aspects of the cargo dwell time of the ports as an indicator of port performance, defined as the time between container discharge and exit from the port, which exceeds 21 days on average compared to less than a week in European ports. The Douala port system is not keeping up with the rising cargo volume and international trade or other technological practices that facilitate trade due to the port’s shallow water depth of about 11 m, its location towards a tight city center, and other port operations inefficiencies that hinder growth projects [
6].
UNCTAD recently updated its port performance scorecard that was first drafted in 2012 as part of its port training program to benchmark port performance indicators (PPIs) and assist port managers with best practices in port assessments [
5]. Amongst these indicators, berth and cargo operations had the most substantial mean influence on port performance between 2015 and 2019, showing their importance as PPI benchmarks. Forecasting container throughput (CT) from these key PPIs will help the port make informed port planning decisions to treat port performance bottlenecks with the urgency it deserves. Port performance’s definition, therefore, entails a sequence of moves related to vessel stay at berth, the pace of loading/unloading freight, and the nature of storage and inland transport efficiency in and out of the port area.
The remainder of the article has the following structure: a succinct literature review is explored in
Section 2.
Section 3 presents the materials and methods of the study.
Section 4 describes the empirical study, while the results, analysis, and stochastic processes are deduced in
Section 5. Finally, discussions, conclusions, and future directions are outlined in
Section 6.
2. Literature Review
Since the initiation of container throughput forecasting in the 1980s, numerous studies have continuously proposed methods and model adjustments to achieve accuracy in container throughput forecasting. These methods can be divided into benchmark models, nonlinear modeling methods, and hybrid forecasting models. First, benchmark methods: Sepulveda-Rojas et al. [
7] applied an adjusted moving average for a model selection criterion in throughput forecasting, saving time spent on model testing. Rashed et al. [
8] applied the ARIMA model for container throughput forecast in the port of Antwerp, resulting in ARIMAX as an output series that is more accurate for throughput forecasting. Wang and Phan [
9] utilized the grey model (GM) to model cargo throughput in Kaohsiung port, where they used a modified residual of the GM (1, 1)—Fourier residual modification GM (1, 1)—to improve performance accuracy. Chen et al. [
10] applied a Grey–Markov model for container throughput forecast in Fujian Province, which proved their proposed draft as an accurate throughput forecasting model. Schulze and Prinz [
11] made a comparative study on SARIMA and Holt–Winters exponential smoothing to forecast container transshipment in Germany, where the SARIMA model outperformed Holt–Winters exponential smoothing in forecasting accuracy. Second, nonlinear modeling methods: Mark and Yang [
12] applied approximate least squares support vector machines (ALSSVMs) to model Hong Kong container throughput, where the results verified the superiority of the proposed model over the standard support vector machine (SVM). Chen and Chen [
13] utilized genetic programming (GP) for forecasting Taiwan’s primary port throughput, where they verified the accuracy of the proposed method in throughput forecasting. Third, Hybrid models: Xie et al. [
14] applied a hybrid least square support vector machine model (LSSVM) for container throughput forecasting in Shanghai and Shenzhen ports, where the hybrid model proved to be better than single models, while the LSSVM proved to model non-linearities in port time series. Niu et al. [
15] proposed a hybrid variational mode decomposition (VMD), autoregressive integrated moving average (ARIMA), hybridizing grey wolf optimization (HGWO), and support vector regression for container throughput forecasts. The built method outperformed the comparison models in prediction accuracy. Xiao et al. [
16] proposed a hybrid model based on improved optical swarm optimization and feed-forward neural networks (IPSO-FNNs) to model non-stationary time series in port throughput forecasting.
Although these studies were valuable in their respective methods, they were primarily based on univariate data structures. They forecasted throughput based solely on throughput’s lag observations, which might not be enough for an accurate forecast that provides insights required to improve critical port performance indicators (PPIs). As the financial crisis has made port time series volatile and nonlinear, benchmark methods fail to model this non-linearity due to their built-in linear assumptions on time series [
14]. Simultaneously, the solid pre-assumptions and time series component adjustments made by benchmark models limit their ability to model nonlinear interactions with crisp accuracy. Additionally, there is limited research in the literature for port throughput forecasts based on multivariate data structures. Few studies, such as [
17,
18], forecasted port throughput from a multivariate predictor variable consisting of GDP, import/export and GDP, output value, and net export, respectively. Gosasang et al. [
17] verified the performance accuracy of the MLP model over regression models in throughput forecasting, while [
18] applied a genetic algorithm and backpropagation neural network (GA-BPNN) on Guangdong Province port throughput; the results show that their proposed model outperforms traditional methods in throughput forecasting. Additionally, [
19] modeled port throughput from socio-economic factors through a novel multivariate adaptive regression adaptive spline and a robust v-support vector regression model (MARS-RSVR). Tang et al. [
20] applied the socio-economic growth projection factors for container throughput forecasting in the port of Shanghai and Lianyungang.
Evidence from the prior literature proves that the focus of container throughput forecasting based on multivariate data structures was on socio-economic and growth projection factors such as supporting industry output, economic status of the nation, import and export, GDP, interest rate, and growth projection factors. Tally [
21] noted that in evaluating the performance of a port, its actual and optimum throughput is compared, where an increase in throughput towards the optimum over time is considered an improvement in port performance and contrarywise. Thus, port performance can also be defined as a function of throughput. Tally [
22] divided a port’s optimum throughput into engineering and economic throughput, whereby the former constitutes the actual throughput that a port can physically accommodate under certain constraints (port KPIs), while the latter represents the optimum throughput a port can handle based on socio-economic factors. A port needs to find leverage to identify and prioritize measures to improve its KPIs to attain growth opportunities, competitive advantage and become attractive to cargo providers (shippers and shipping lines). Recent studies focusing on cargo port choice determinants from shipping lines’ and shippers’ perspectives shed a brighter light on factors affecting a port’s performance (as a function of throughput). Omoke and Onwuegbuchunam [
23], in the case of West African ports, deduced factors such as berth productivity, storage capacity, gate wait time, and ship turnaround time as critical for port performance, while in a global perspective, [
24] deduced factors: terminal charges, terminal service quality, intermodal transport availability, nautical accessibility, hinterland connection, port reputation, and terminal operations. Even more studies [
25,
26,
27] focused on defining the determinants of a port’s performance (as a function of throughput) for achieving port attractiveness and competitiveness in the perspective of cargo port providers (shippers and shipping lines) also proposed similar factors related to port operations. Besides, evidence from a recent port performance scorecard overview UNCTAD [
3], depicting key benchmark port performance indicators (human resources, gender, vessel operations, cargo operations, environment, finance, and economic), proves that berth and cargo operations had the most significant mean influence on port performance (as a function of throughput) from 2015–2019. Therefore, it is crucial to model port throughput from a new angle—port operations factors. This paper is the first to appear in the literature to explore port operations factors for container throughput modeling. It will provide insights to assist port management in spooning out port bottlenecks, improving efficiency, attaining competitive advantage, and port attractiveness for cargo port choice criteria (shippers and carriers). This study will also provide a steppingstone for further research in the field of port performance and container throughput forecasting.
The focus of this study is summarized in three points. First, to forecast the engineering optimal throughput of Douala port from multivariate predictor variables associated with port operations through RF and MLP. Second, to provide an interpretation of the stochastic process and complex interactions between the predictor and response variables through feature importance by permutation and partial dependency plots. Third, to provide a hypothesis testing through four model evaluation criteria and seven competing models based on univariate and multivariate data structures. Results indicate that RF is a potential candidate for forecasting the engineering optimal throughput of Douala port, which can reduce uncertainty and provide leverage for port managers and stakeholders to spot and improve weak key performance indicators.
3. Materials and Methods
Our models’ framework—RF, MLP and a developed hybrid RF-MLP—is described briefly in the sub-sections that follow:
Section 3.1 describes Random Forest,
Section 3.2 describes multilayer perceptron, and
Section 3.3 describes the developed hybrid model based on random forest and multilayer perceptron.
3.1. Random Forest
Random forest is a supervised ML algorithm that uses an ensemble method for regression and classification tasks. An ensemble is a method by which the RF model obtains an accurate prediction by averaging many independent weak decision tree predictions. The accuracy of an ensemble over individual members depends mainly on two necessary conditions. The individual tree members’ accuracy must be better than random guessing, and their errors made on unseen data must be uncorrelated or diverse [
28].
The principle of RF is to consolidate a multitude of de-correlated trees on a separate set of observations [
29], each of which is constructed using a bootstrap sample withdrawn from the original sample feature and a subset of parts and the average of the predictions of trees in the forest becomes the output of the model. This process is termed bootstrap aggregating or bagging. The main point in bootstrap aggregating is to reduce the variance by averaging the different approximately unbiased models in the forest. Some ensemble benefits, such as decreasing correlation through randomization, are exploited during bagging. The bias of the bagged trees always remains the same as that of the individual trees. Breiman and Cutler [
30] explained that reducing the correlation between trees dramatically reduces the variance, and overfitting is minimized as more trees are added. Overfitting is shared equally amongst the trees in the forest, thus limiting the generalized error. Perhaps a valuable characteristic of random forests is the out-of-bag (OOB) sample:
. During bagging, to generate a train set for the ensemble members, observations are set aside and not used for training in the ensemble. This set is the out-of-bag sample. The generalization error is computed from this OOB sample. Random forests regressions’ measure of the goodness-of-fit is the R2 value, calculated from the random forests’ OOB mean squared error
, and the dependable variable variance
, as shown in Equation (1) [
28].
For the learning process of random forest.
For to (size of the ensemble). Extract a bootstrap sample data of size from the training data sample. Grow a tree draw another bootstrapped sample by iteratively repeating the following steps for each node until a minimum node size is reached.
Select variables at random from the variables.
Pick the best variable/split-point in the .
Split the node into two baby nodes.
Output the total of trees }. To predict a new point , see Equation (2). The essential parameters here are the number of trees in forest K, and the number of randomly chosen variables at each split H. Experimenting is the recommended method in determining the number of trees for the model. The RF algorithm models such that, given an input and a labeled output the algorithm (RF) tries to learn and approximate its underlying mapping function, such that with new data it can predict the target output based on what it learned from the data it was fed. For nonlinear models, higher-order variable interactions are taken into consideration, and as such, one cannot make assumptions that an increase in one variable will adeptly lead to an increase in the response variable in the same direction. The multifaceted nature of variable interactions in nonlinear models adds complexities to their interpretation. The partition of individual trees in the forest to extend an ensemble means that each sub-tree has a local prediction value independent of its tree neighbors. Averaging the ensemble to obtain the forest prediction locks the algorithm in a black box along with interpretability.
Therefore, the RF model stems from producing accuracy and practical implementation at the expense of interpretability. In a dynamic sense, one way to open the black box of random forest predictions to close the gap in interpretability with traditional models is by computing how independent features lead to a specific prediction, as every prediction can be presented as the sum of feature contributions. This is performed through feature importance by permutation, whereby the values of single variables of interest are shuffled, and a change in model accuracy is computed. A variable is important if shuffling its values decreases the model’s accuracy. For the variable importance measure based on permutation,
according to [
28] is shown in Equation (3), where
is the OOB sample while the
variable is permuted. The average of these important measures in individual trees to ensembles of trees is shown in Equation (4).
A significance threshold (zero) is defined once variable importance measures are obtained to determine the significance of variables describing the response [
28]. One approach is to exclude unimportant variables below the threshold. However, this method is said to be computationally costly as it necessitates the creation of several forests to obtain a distribution of the important measures.
The interactions of predictor variables in a multivariate structure add complexities to the model interpretation of influence. Interpreting the dependence of the response variable on independent predictor variables is considered to understand the stochastic process inherent in variable contributions to the outcome. Breiman and Cutler [
30] suggested the partial dependence plots (PDPs) as a method of exploring what influence a variable of interest exerts on a response in any predictive model. Consider a dataset which includes
observations
, of a response variable
, for
, along with
covariate samples denoted
for
and
. The predictor model,
, is generated in the form shown in Equation (5).
For a single covariate , and all other covariates not included in , the predictor model above can be summarized as .
Friedman’s partial dependence plots, in the case of a single variable of interest
is obtained over a range of
values, where
are values of covariates in
, as shown in Equation (6).
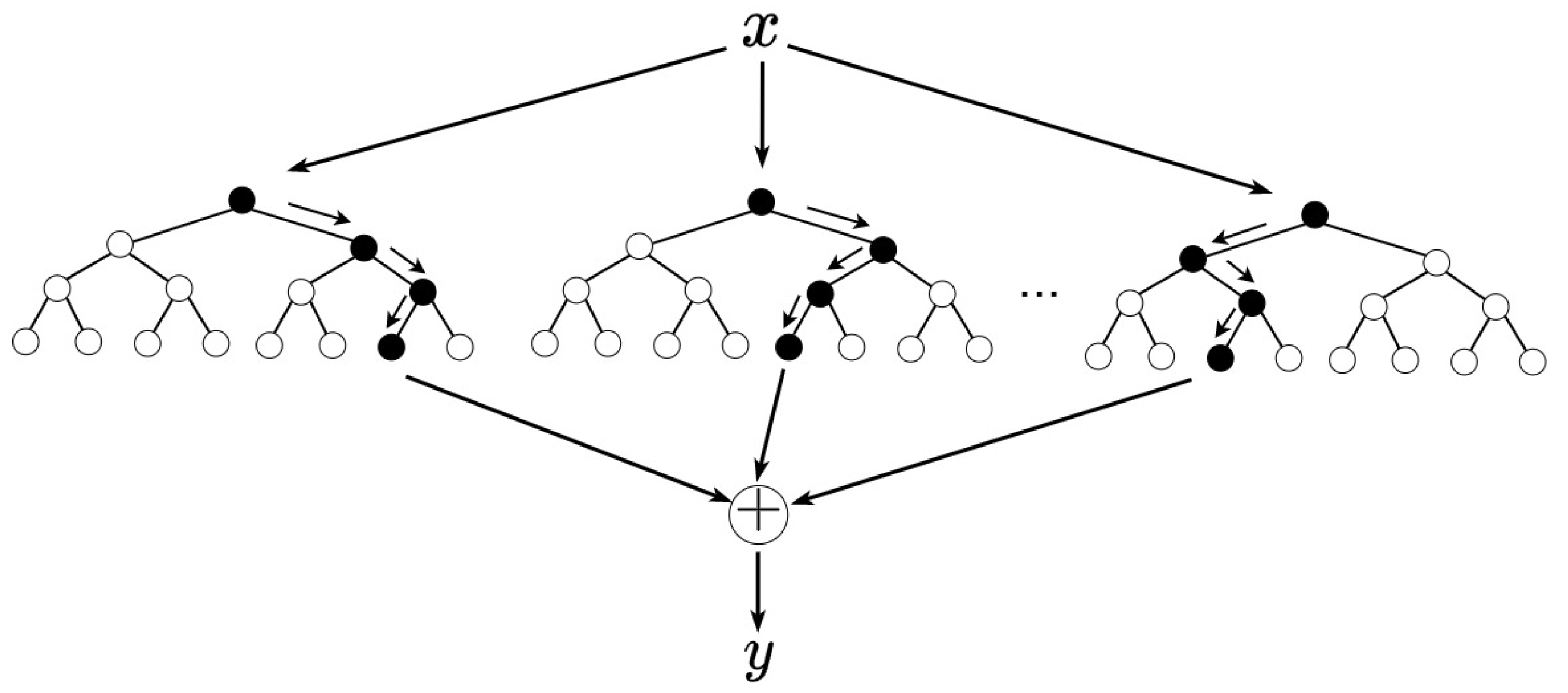
The partial dependence plot’s ability to investigate the nonlinear influence of predictor variables on the response is directly related to the model’s ability to approximate the input data’s underlying mapping. A schematic of an RF model is shown in
Figure 1, depicting data movement by bagging through independent trees in the forest.
3.2. Multilayer Perceptron
MLP is a kind of artificial neural network developed through recursive functions and logical assumptions by an experimental study of neurons’ interconnections in a physical system. Thus, it replicates the human brain’s neural network structure. MLP is used for both regression and classification tasks and usually consists of artificial neurons, which transmit signals between each other. When a neuron receives a signal, it processes it and signals downstream neurons connected to it. Neurons are organized into layers called the input layer, hidden layer, and output layer. Neural networks have been applied to problems ranging from gene prediction and the classification of cancers to speech recognition. The adeptness of neural networks is that they can be used as a prediction/assessment or analytical model in solving just about any problem. One benefit of MLP applications is that they may be more accurate when modeling from complicated natural systems with a large sample size. The more complex the system (large sample size), the more accurate the model becomes. Examples of its application include but are not limited to: Kourounioti et al. [
17] in predicting the dwell time of import containers in the port, [
17] compared the autoregressive integrated moving average (ARIMA) model with the artificial neural network (ANN) model for container throughput forecasting which resulted in the ANN outperforming the ARIMA in forecasting accuracy.
The mechanism of the feed-forward network is that each neuron receives a noted input
and then random weights are initialized, denoted with
. The inputs are then multiplied with the weights plus the bias
, an activation function is added to propagate the output of the first layer to the next layer in the network, as shown in Equations (7) and (8), where
is the weight of each node,
is the input variable and
, the bias of each node (neuron),
f is the activation function applied to every neuron,
is the number of inputs from the incoming layer, and
is the counter from 1 to
. Every layer in the model is represented as in Equation (8). The weights connect the neurons in the layers while the bias—a constant donated as 1, ensures the inputs propagates to the next layer. The activation function—ReLu, as shown in Equation (9)—is applied to every node.
The rectified linear function (ReLu) works to transform an input (
) to the maximum of (0) or the input itself (
). Since a neuron cannot propagate to the preceding neuron with an output of zero, the bias
ensures it fires forward by adding a value to it, denoted as 1. The output:
is used as input in downstream nodes, while the process repeats iteratively depending on the number of hidden layers. After an epoch (a complete forward propagation from input to output layer), we compute the error by obtaining the difference of the residuals. The weights update is performed through backpropagation if the error is still large. The Adam solver is used as an optimization algorithm for the model. The objective of Adam is to minimize a given loss function as close to
as possible. The error function (difference of the residuals) is defined as shown in Equation (10).
where
is the observed value and
is the predicted value of the training set instance
. Weight optimization is performed by applying the chain rule of differential calculus. Weights are updated going backward from the output, hence the term backpropagation. The first weight from the output layer is updated by finding the derivative of the loss function in respect to the model output multiplied by the model output in respect to the weight. This is formulated as shown in Equation (11), while the weights in the second layer going backward are updated as shown in Equation (12). Each weight
is then iteratively updated as shown in Equation (13).
By updating backward,
is the output,
to
are the weights on the first hidden layer,
is the output of the first hidden layer,
to
are the weights in the second hidden layer, and
is a new weight,
. The old weight and the constant
is the learning rate which decides the length of steps towards a minimum for each iteration. While updating weights by backpropagation, the propagated error is also considered. Therefore, for each hidden layer, the backpropagated error values are computed as shown in Equations (14) and (15).
Here,
is the weight from the successive nodes,
is the weights connecting the current node
, and successive node
and
is the output of the current node. Thus, the backpropagated error
, and
is the input value of the predecessor node,
.
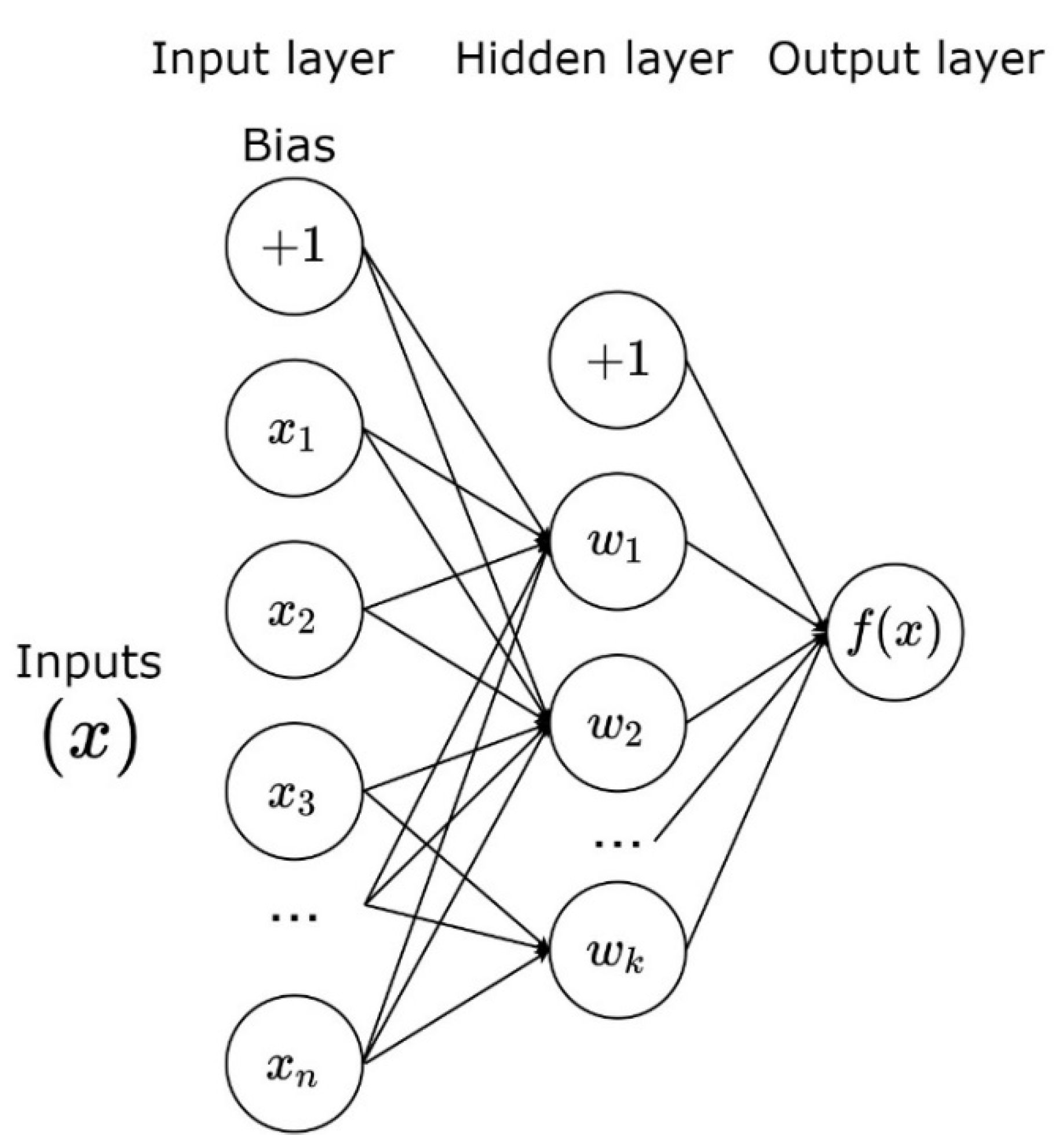
Figure 2 shows a schematic of a multilayer perceptron with input features,
, bias
, weights
and output
—where
is the activation function applied in every node.
3.3. RF—MLP
Both RF and MLP models have been used in prior research to model linear and nonlinear interactions with success. However, both models still have inherent drawbacks and are not suitable for all situations. For example, despite RF strengths in general resistance to overfitting, handling missing data, computing variable importance measures, and partial dependencies to describe variable interactions [
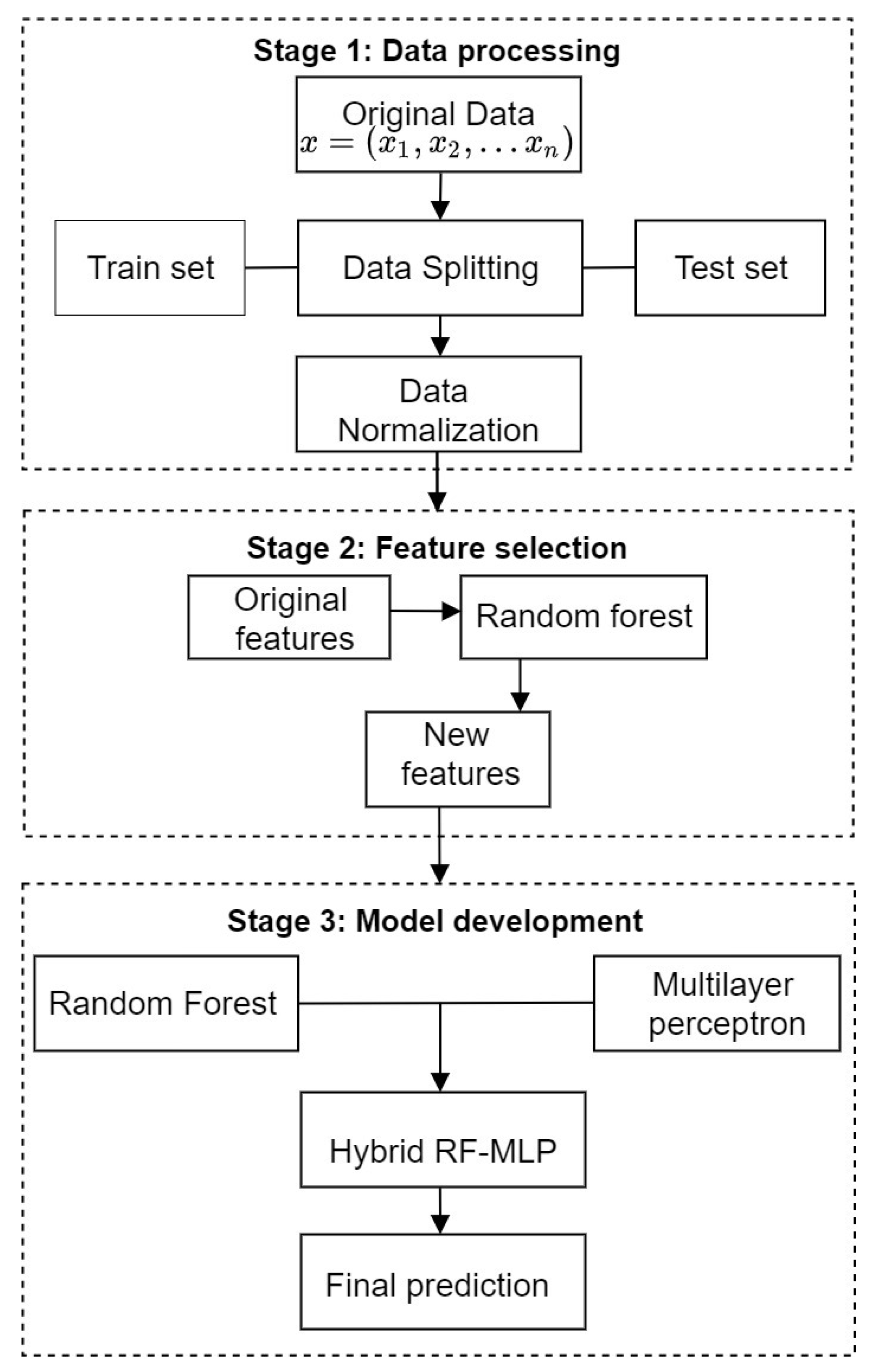
30], the RF algorithm might change considerably with a slight change in the data, making them easy to overfit. On the other hand, MLP performance in throughput modeling depends mainly on the data’s size and noise level. Thus, aggregating both models’ strengths could lead to the capture of differential underlying patterns that could improve performance accuracy. A schematic of the coupling of hybrid RF-MLP is shown in
Figure 3.
In stage one, we carried out data processing, where the original data were split into two subsets: the train set (80%), and test set (20%). The split data were then normalized to obtain a mean closer to zero for achieving faster convergence (speed up learning), and to ensure the min and max disparity in the input features were regarded to a similar extent by the model. The formula for normalization is shown in Equation (17) below.
where
is the normalized value for
X is the training set, while
max(X) and
min(X) determine the maximum and minimum values of the training set.
In stage two, we explored feature selection. First, the original features were trained with the random forest model (RF), then new features were created through a significance threshold determination criterion that quantifies the importance of the original features in function estimation. The feature importance measures were obtained by permuting the values of the original features, one at a time (see
Section 3.1). Once feature importance measures were generated, a significance threshold (which was set to 0.0 for this study) determined the new features by eliminating truly unimportant variables below the threshold value. The new features imply a significant association between predictor and response. The mathematical theory of the RF model and feature permutation importance is described in
Section 3.1.
At the third stage, the hybrid model was developed based on random forest (RF), and multilayer perceptron. The new features, depicting significant association with the response,
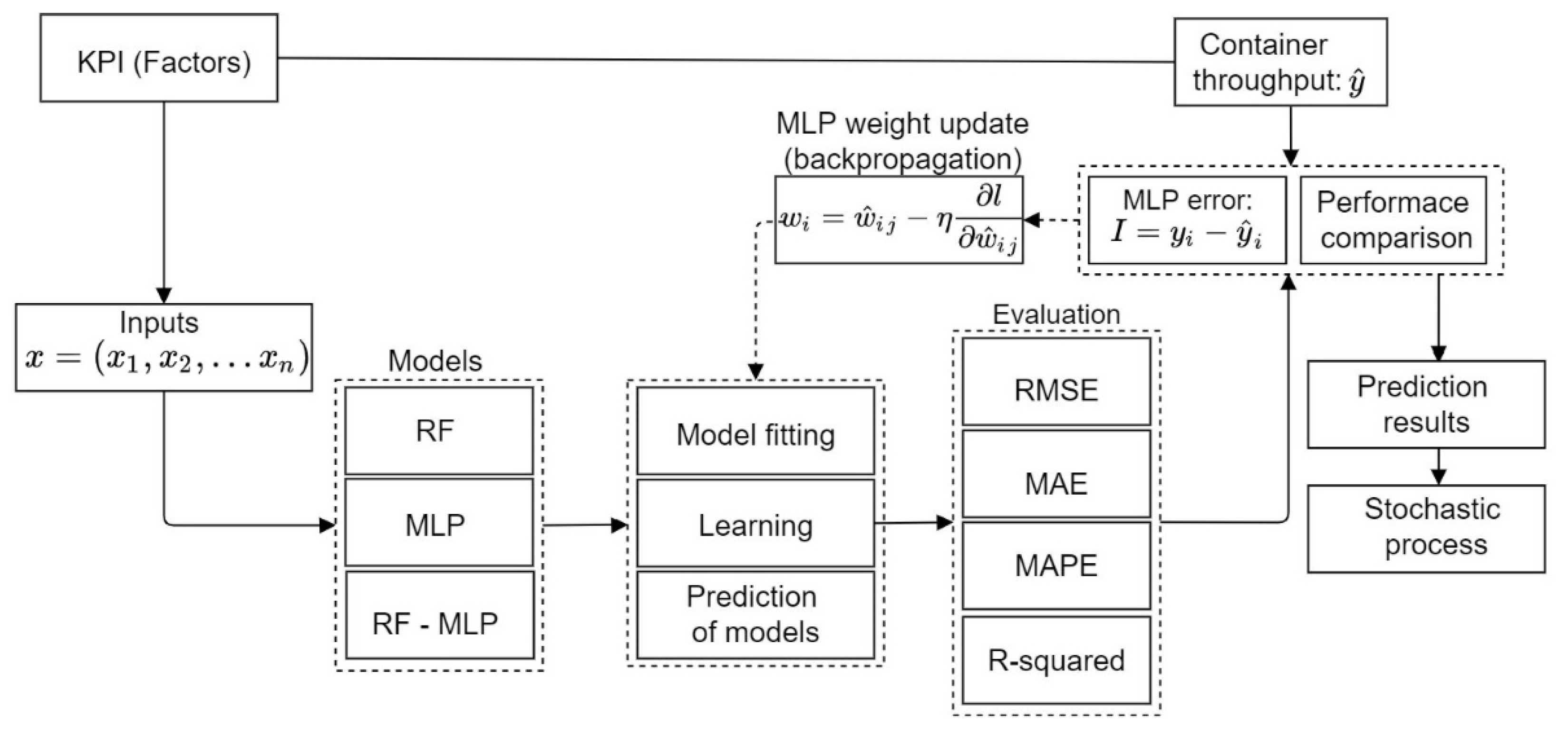
, were used to construct training patterns for RF-MLP. The train set of the new features was used to fit the model to study the underlying mapping with known inputs and outputs, then the performance from the train set fit was estimated on new data (test set or holdout data) with unknown target values. The resulting test set error was then assessed through four error metrics: r squared, NRMSE, MAE, and MAPE. A schematic of the entire study is shown in
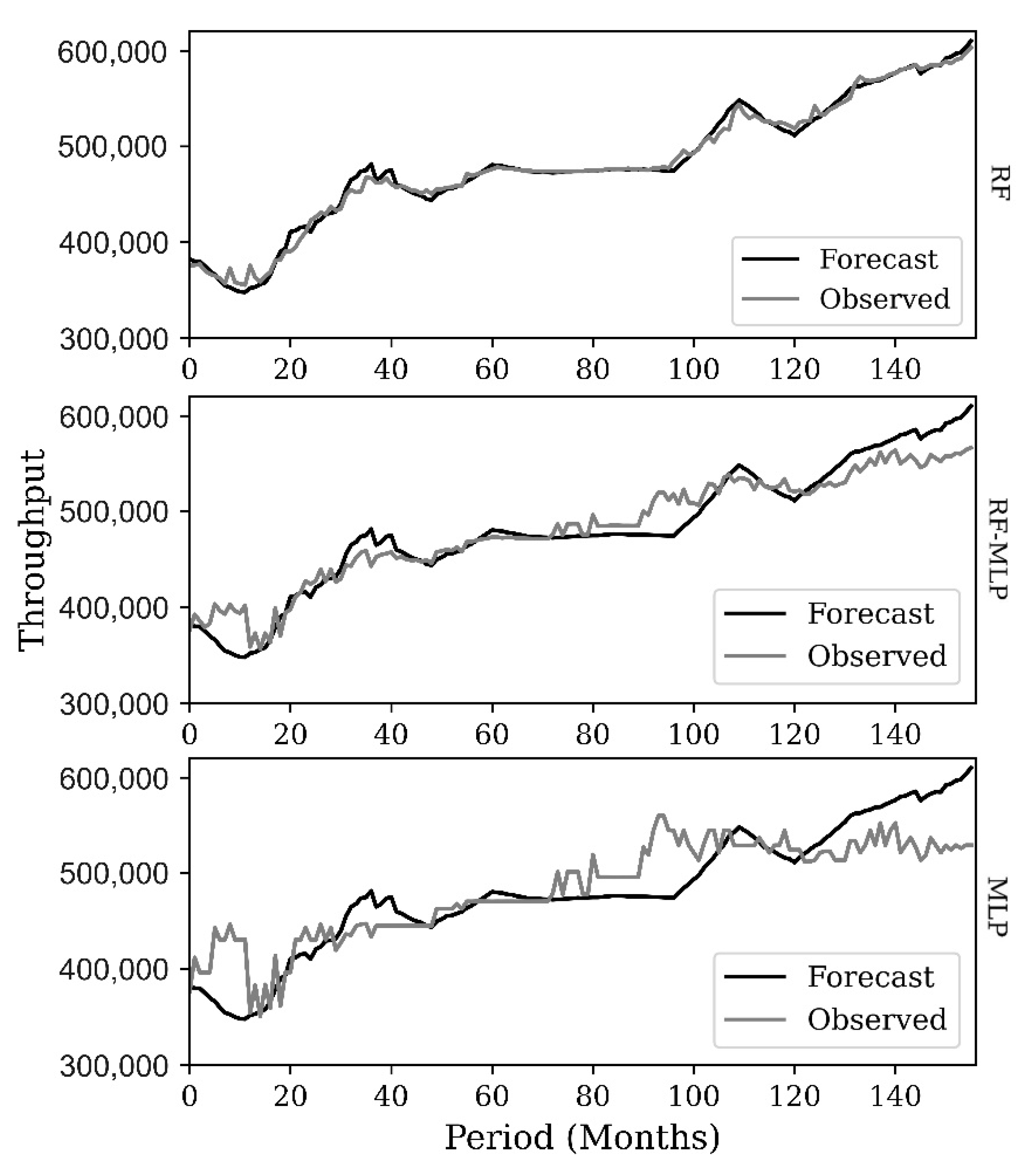
Figure 4, below.
6. Discussions and Conclusions
Port throughput forecasting is imperative in port management. It is a valuable and essential aid to planning, and planning is the foundation of efficient port operations. Amongst the very few studies in the container throughput modeling literature on multivariate time series, socio-economic, and growth projection factors, i.e., with factors such as GDP, interest rate, import/export, total output value, fixed asset investment, and population size had been employed to model the optimal economic throughput of a port. This paper is the first to appear in the literature to explore port KPIs associated with port operations for modeling the optimal engineering throughput of a port. This study offers insightful knowledge that assists a port in optimizing bottlenecks in port. Therefore, it is vital to achieve accuracy and interpretability in throughput forecasting. Additionally, while the importance of improving port KPIs is common knowledge in the logistics field, countries such as Cameroon and other developing nations fail to confront this issue with the urgency it deserves. Port KPIs have increasingly become central to every port’s performance, which is why it is crucial to understand which of these indicators affect or contribute to a port’s growth.
6.1. Implications
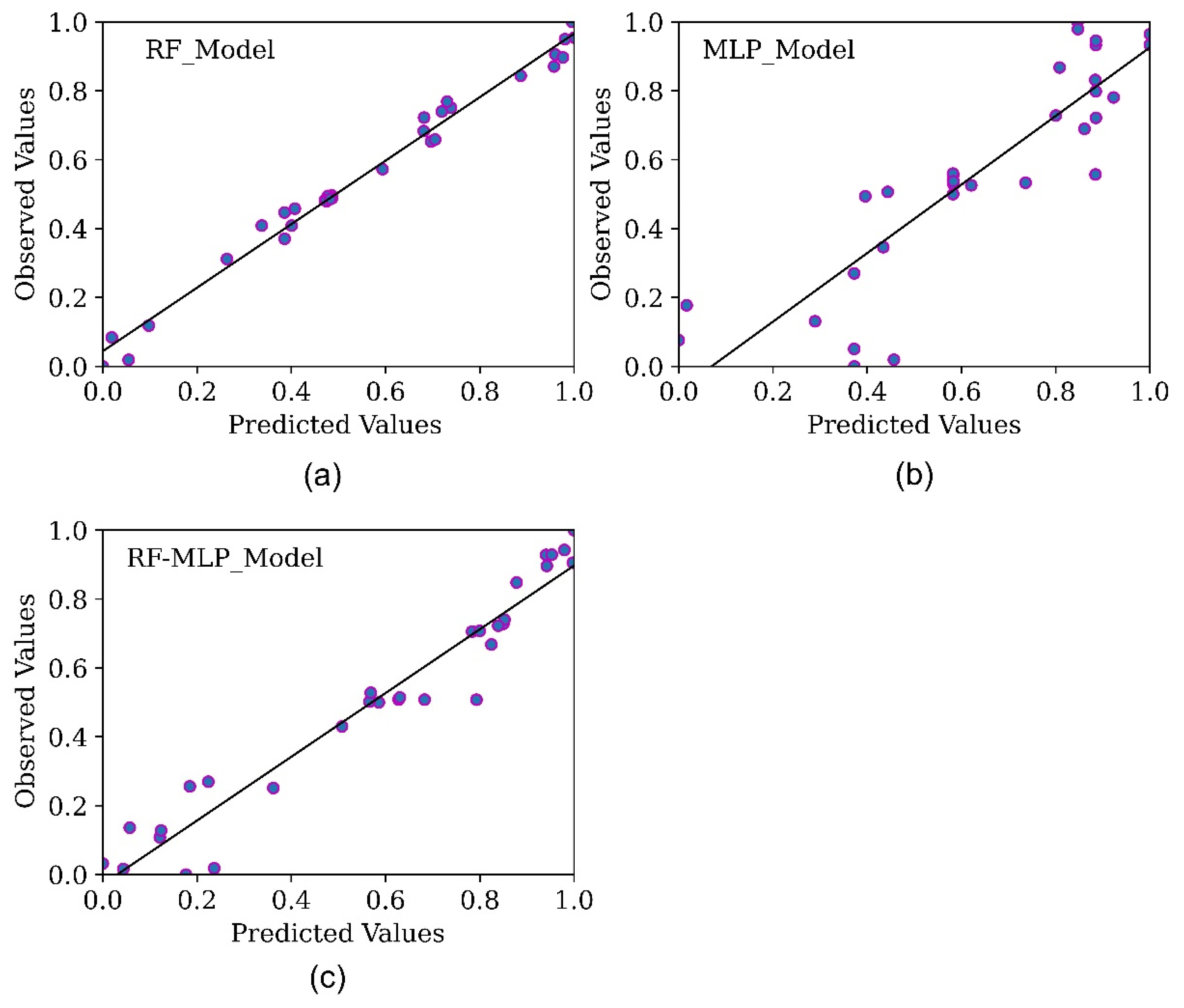
This study explored models—RF, MLP and RF-MLP—for port throughput forecasting and emphasized modeling from a multivariate process variable on KPIs associated with port operations. Performance comparison with other throughput modeling methods is also provided. All models, both proposed and comparison models, were applied in their basic form. The results imply that the RF model is effective with multivariate variables in forecasting the optimal engineering container throughput of Douala port for two reasons. First, it decreases the correlation between process variables through randomization by employing random split selection during bagging. Second, its complex nature lets it capture the complexities and higher-order variable interactions inherent in port time series, which is interpreted through feature importance and partial dependence plots. With its complex nature, the RF model is a potential candidate for forecasting the optimal engineering throughput of a port. The strength of the RF model is also inherent in the hybrid RF-MLP model results on the R2 value (goodness-of-fit)—0.9487, as aggregating their advantages enhances the prediction accuracy of the MLP model based on the R2 score from 0.7565 to 0.9487, respectively. Besides, its relatively small number of tunable parameters, automatic handling of missing data, generalization errors, and resistance to overfitting make it less complicated and easy for application. Based on the findings of this study, the proposed variables can be applied to similar studies to assist port management in improving their KPIs and overall efficiency.
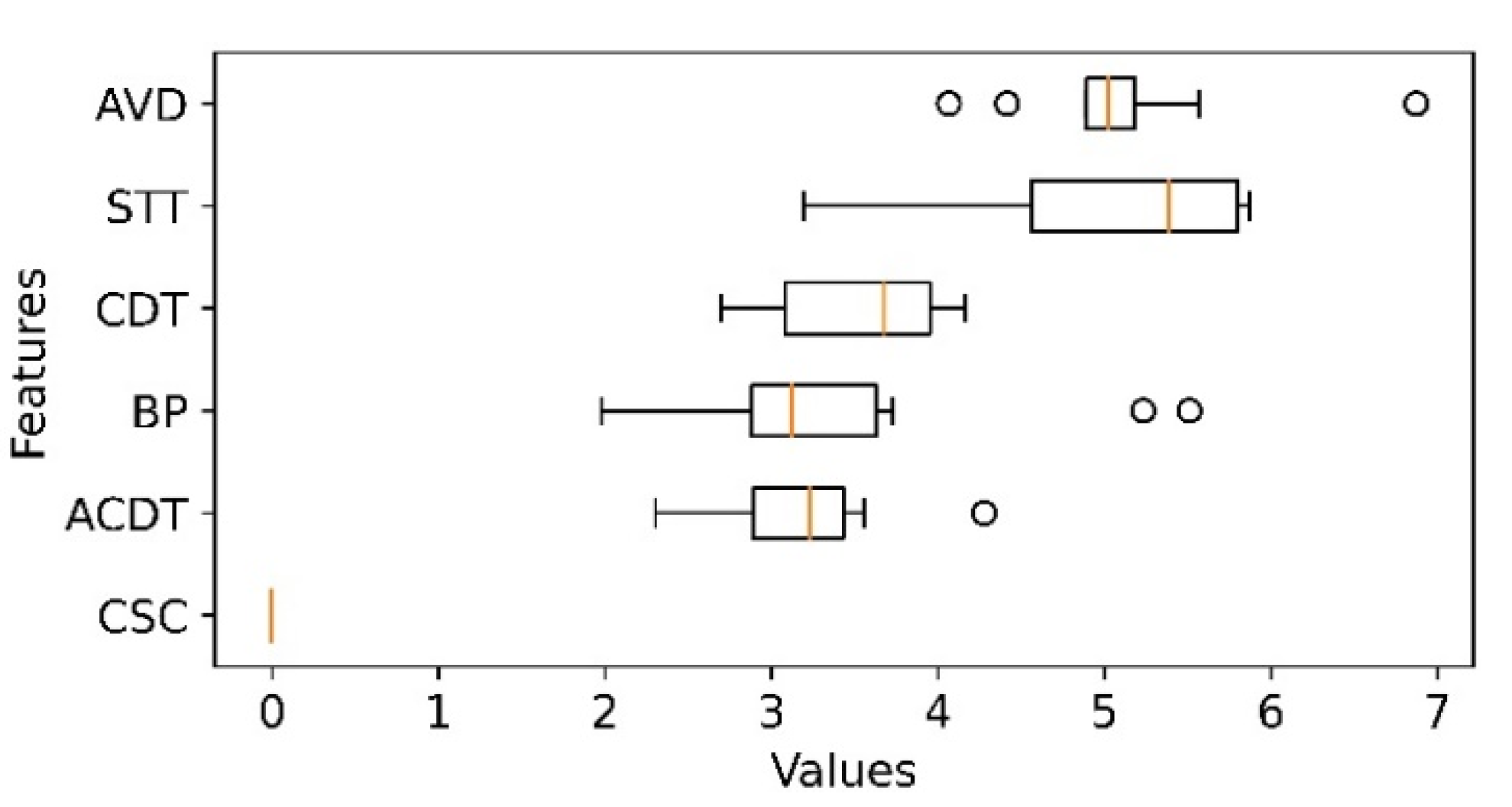
In today’s world, ‘uncertainty is opportunity.’ The forecasting task is a type of prediction that helps map out that uncertainty by exploring the underlying mapping of past and current data. This allows organizations to carry out an objective quality assessment—to consider the possibilities for better decision making with fewer risks. This study’s findings will provide significant insights to the port management of Douala in engaging in port planning and development projects in improving their port KPIs, which will potentially lead to improving port attractiveness and attaining international competitive objectives. Practically, from the obtained results, the RF feature permutation importance (see
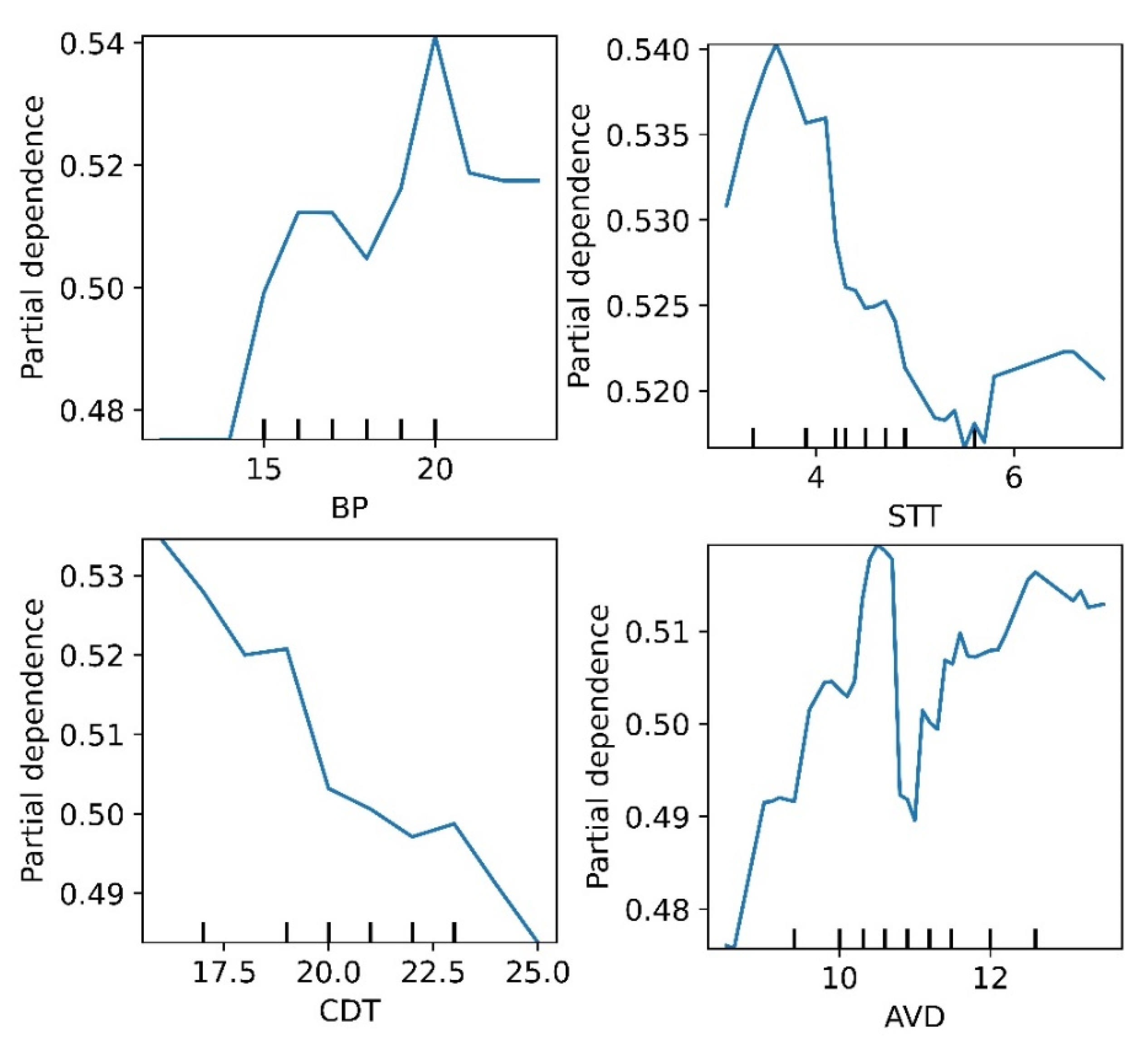
Figure 7) portrays the contribution of vessel draft (AVD), ship turnaround time (STT), container dwell time (CDT), and berth productivity (BP) in order of merit as the most important predictor variables for the models’ forecast. These variables should be the most vital to port management when engaging in port development projects. The PDPs on the four most important predictor variables of interest (AVD, STT, CDT and BP) further depicts how much improvement should be made on each predictor variable to attract more container throughput to the port. For instance, according to the PDPs (see
Figure 8), AVD should be improved to 13 m through intensive dredging projects, berth/crane productivity to 20 container moves per hour by enforcing more terminal equipment, and CTD should be reduced to under 10 days by implementing new fiscal regime reforms, as [
4] found that long cargo dwell times at Douala port are because of the fiscal pressure from port management. Finally, STT should be reduced to a minimum of 2 days by increasing the number of berths or length of container quay. Sheikholeslami et al. [
34] found that increasing the length of quay reduces wait times of container ships by applying a simulation-based analysis.
6.2. Limitations and Suggestions
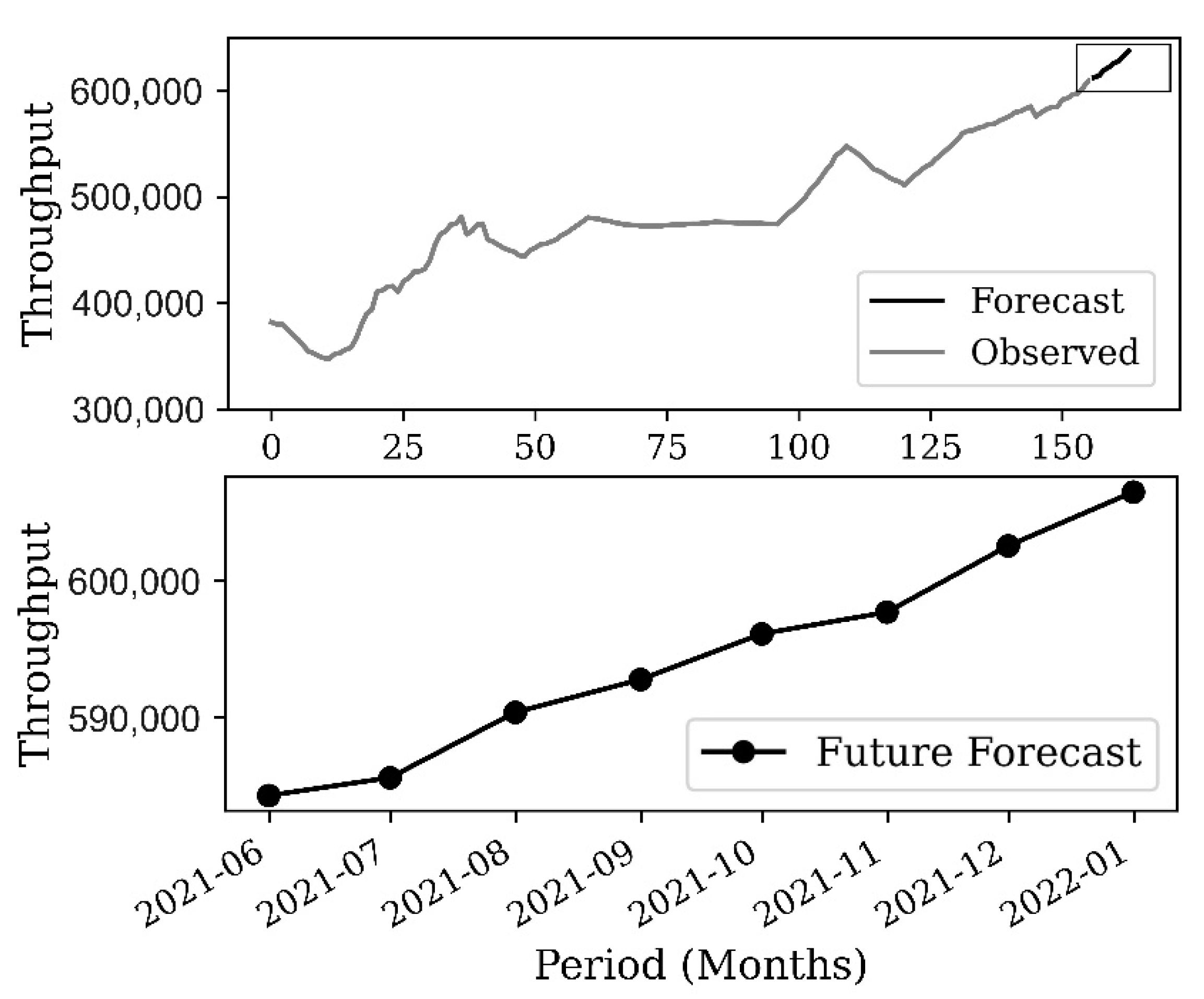
These results must be interpreted with caution, and a few limitations should be borne in mind. First, initially, we only considered a few factors due to data unavailability and we did not consider other competing benchmark models for comparison. Second, the ML models in this study were applied in their primary forms without modifications proposed in prior research; this is because the focus of the study was on a new variable application which should become a steppingstone for future studies. Third, the RF model applied in this study has a limitation to extrapolation, which is why we only considered a short-term throughput forecast. Due to the different data distributions and sample sizes inherent in container throughput time series, model applications across different datasets often give differential results. Therefore, for future directions, more port operations factors, external factors constituting regional center and hinterland connectivity index, and model modifications should be included and compared with even more competing benchmark models. For the different data distributions, to obtain a reliable forecasting result, trials should be focused on finding models that fit best given the data distribution or sample size.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}