
Prediction of Water Saturation from Well Log Data by Machine Learning Algorithms: Boosting and Super Learner


 ,
,  ,
,
Abstract
1. Introduction
2. Methodology
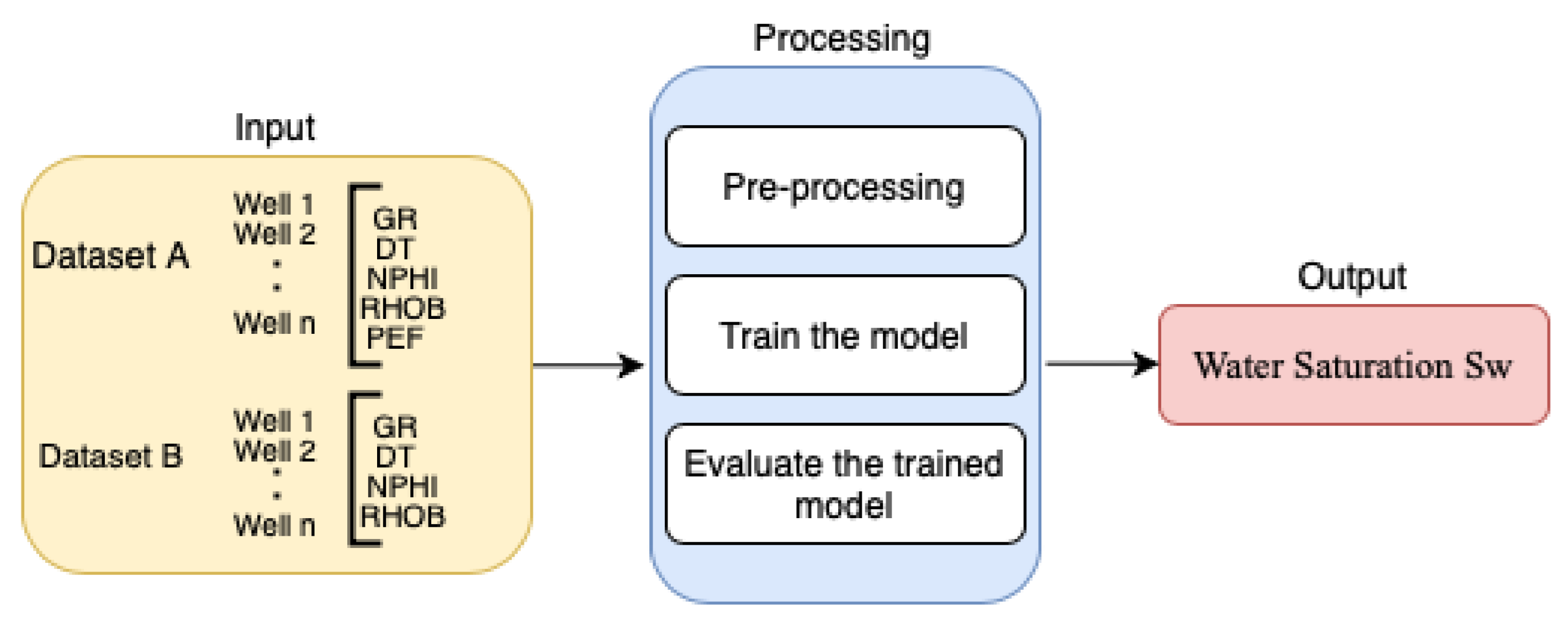
2.1. Dataset Preparation
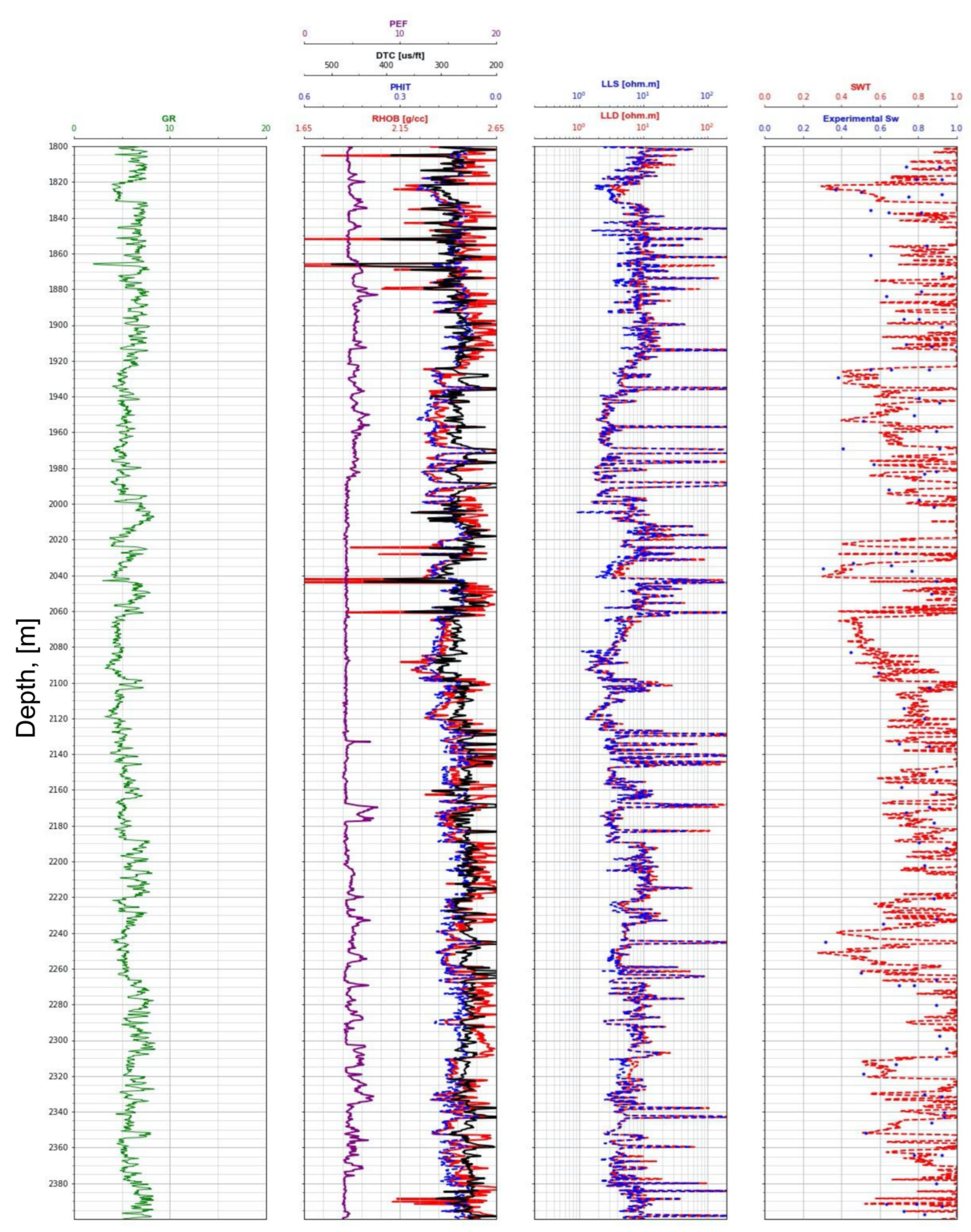
2.2. Calculating Water Saturation
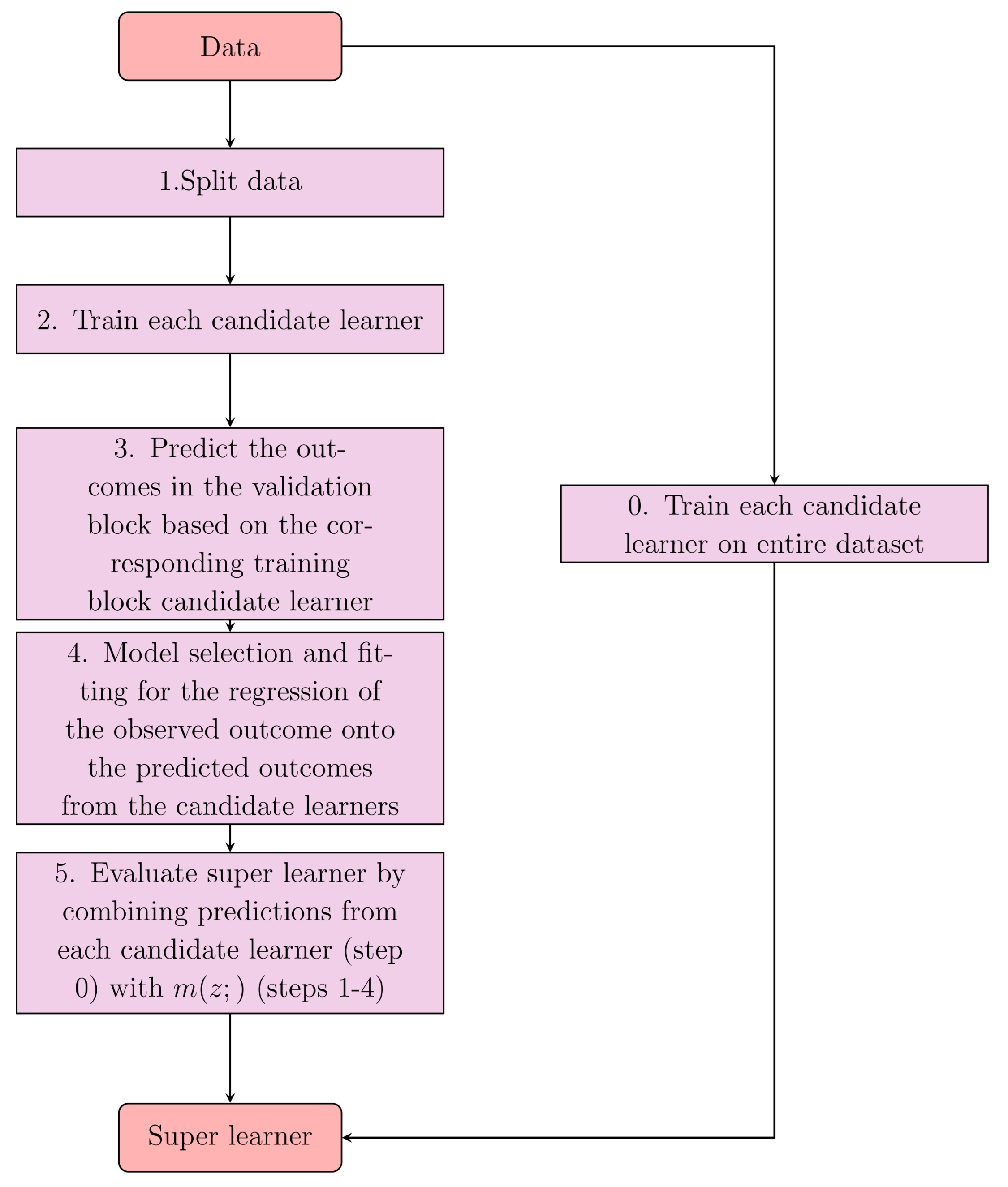
2.3. Methods
2.3.1. Models
- Defining Weights: ;
- For each i, define the training data to a weak learner using weights and determine the weighted error
- ,
- For each i, estimate weights for predictors as:
- Updated data wights for each i to N (N is the number of learner);
- Adjust weak learner for data test (x) as output.
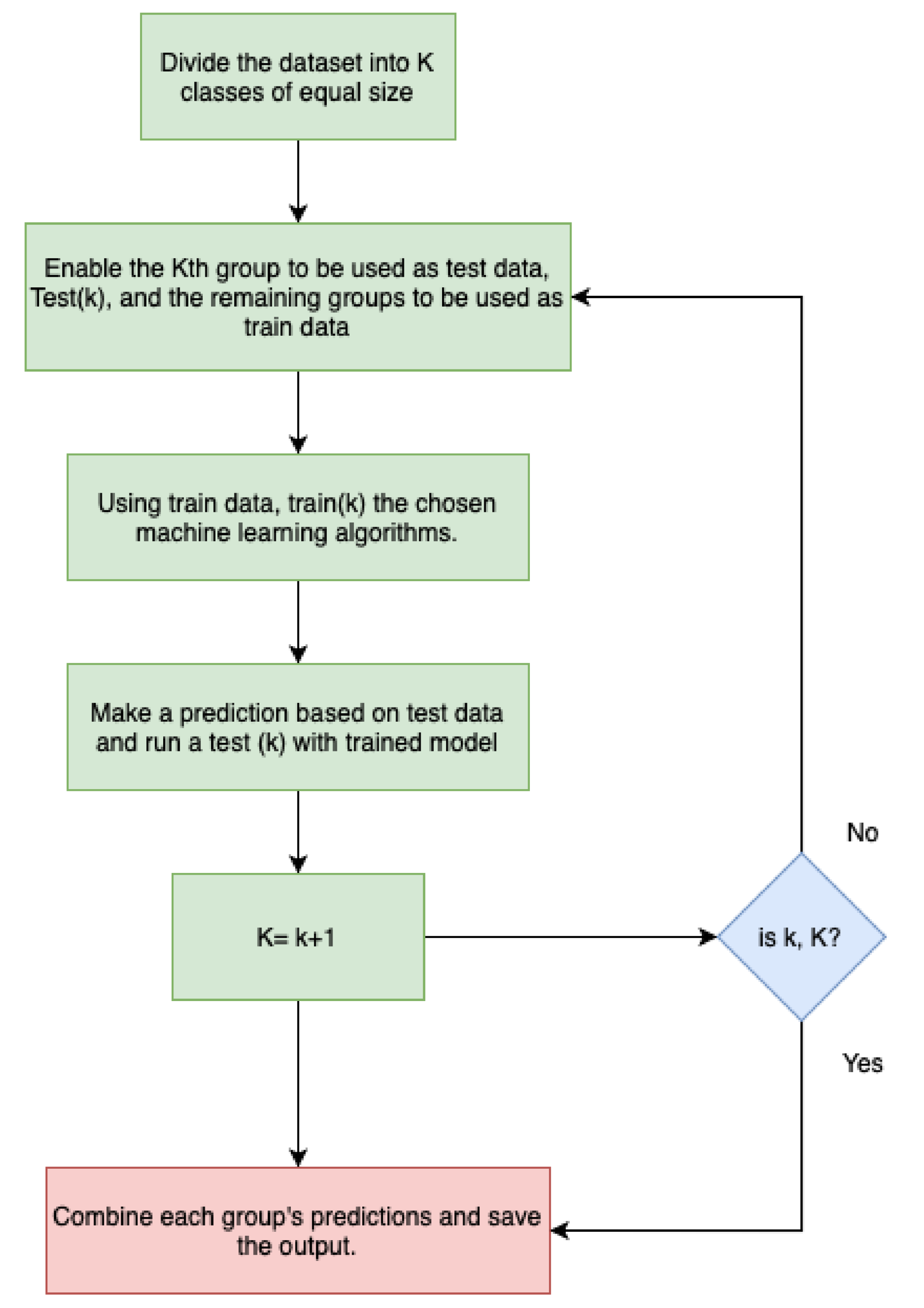
2.3.2. Model Evaluation
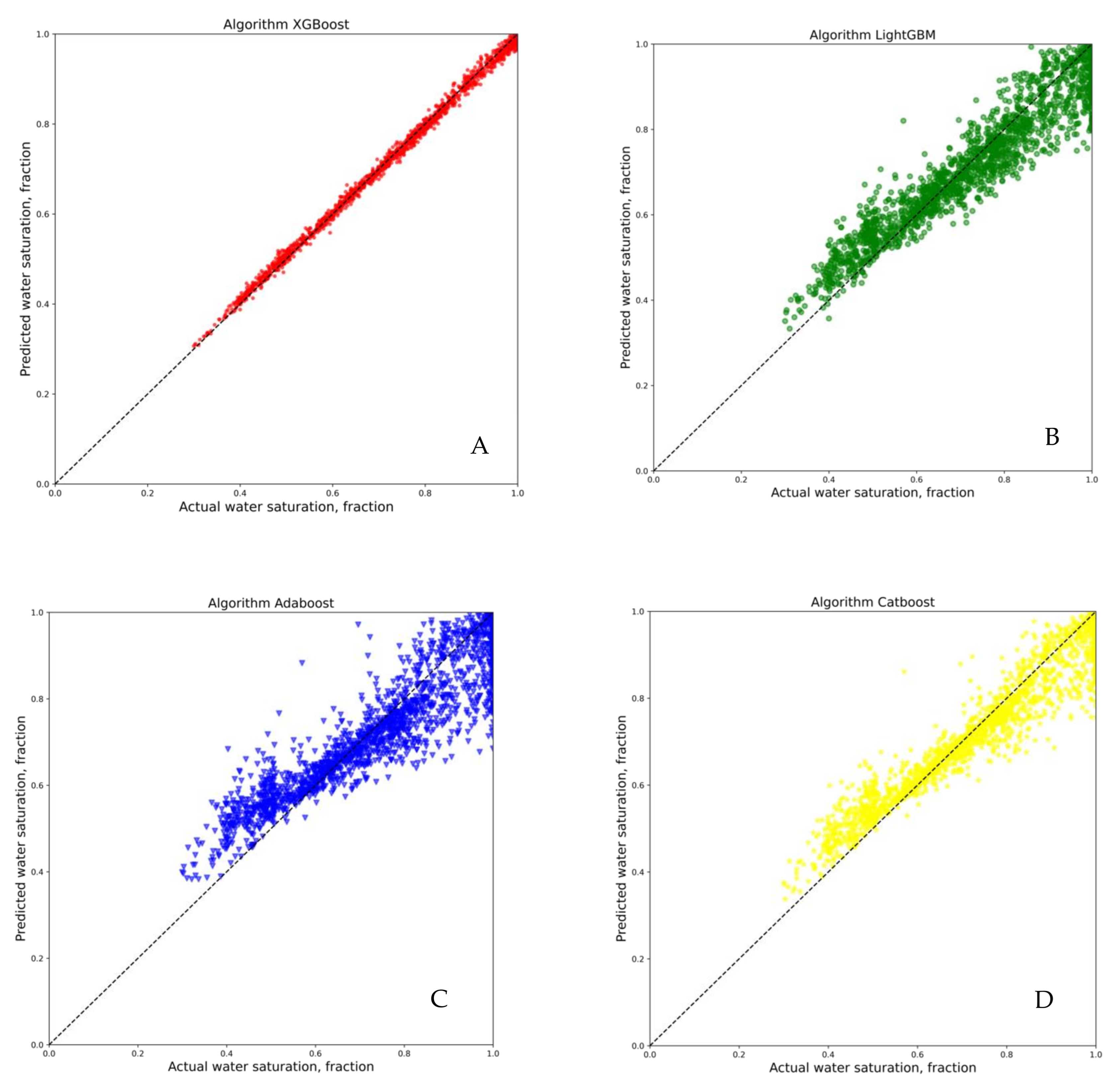
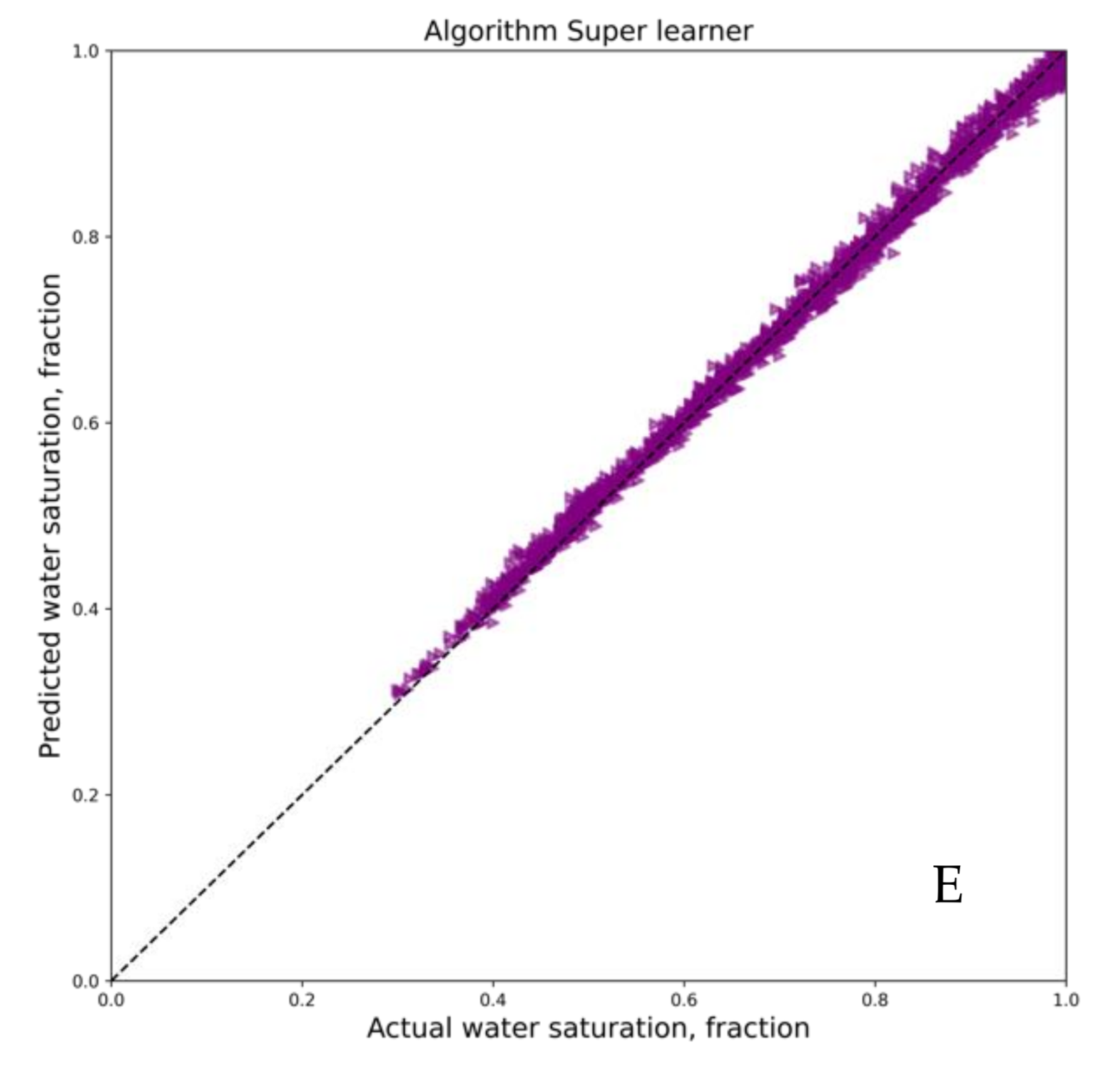
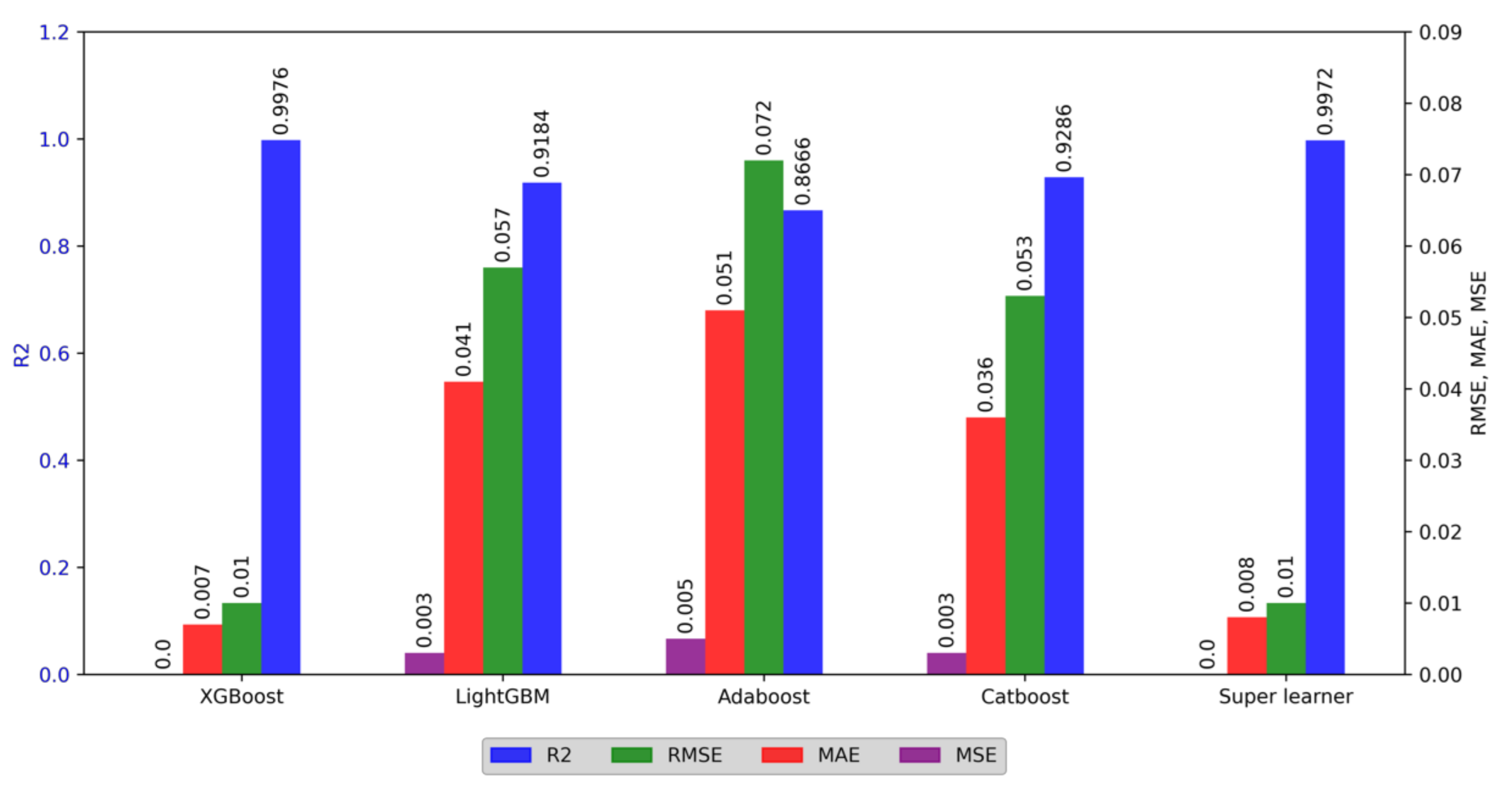
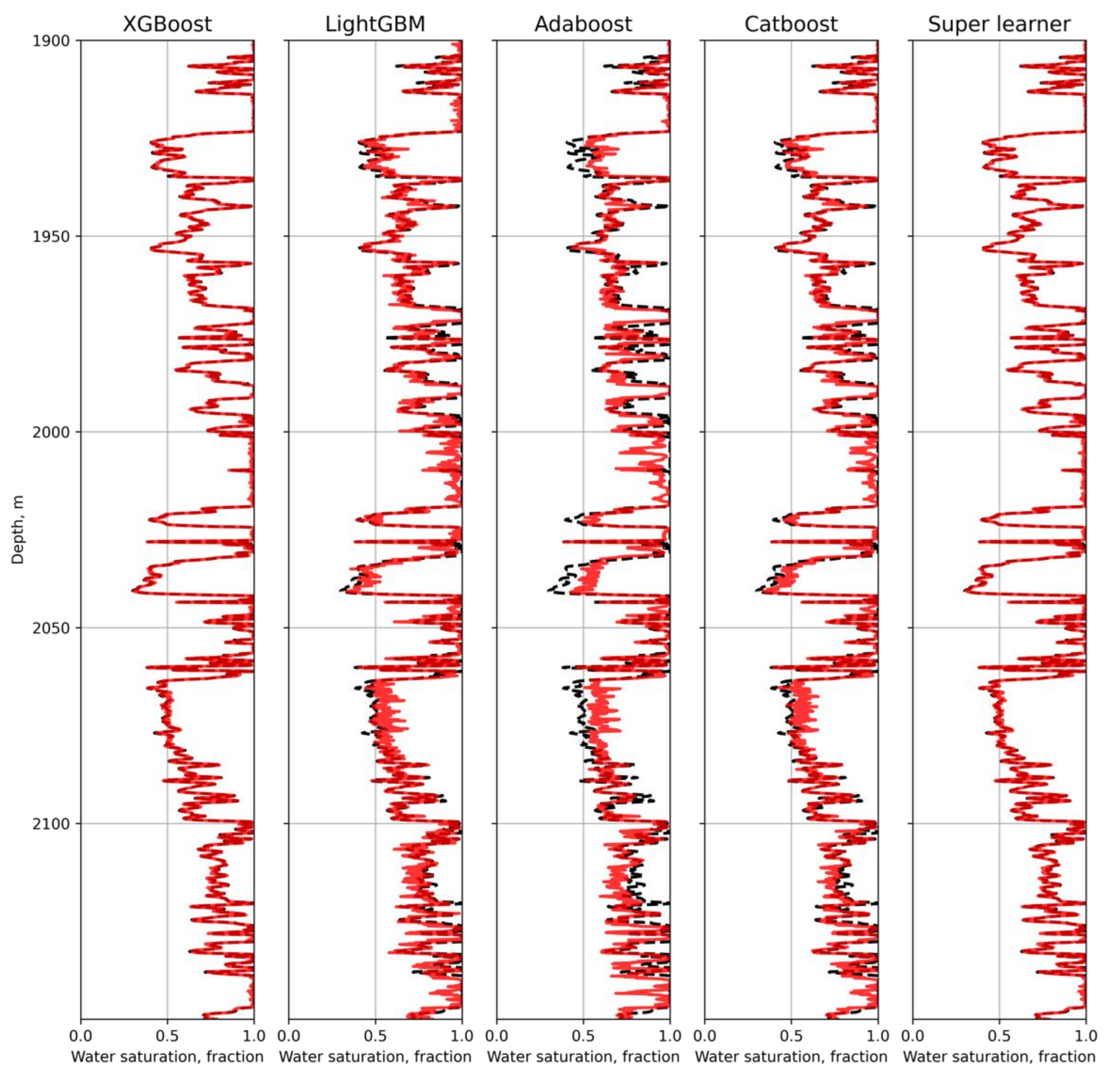
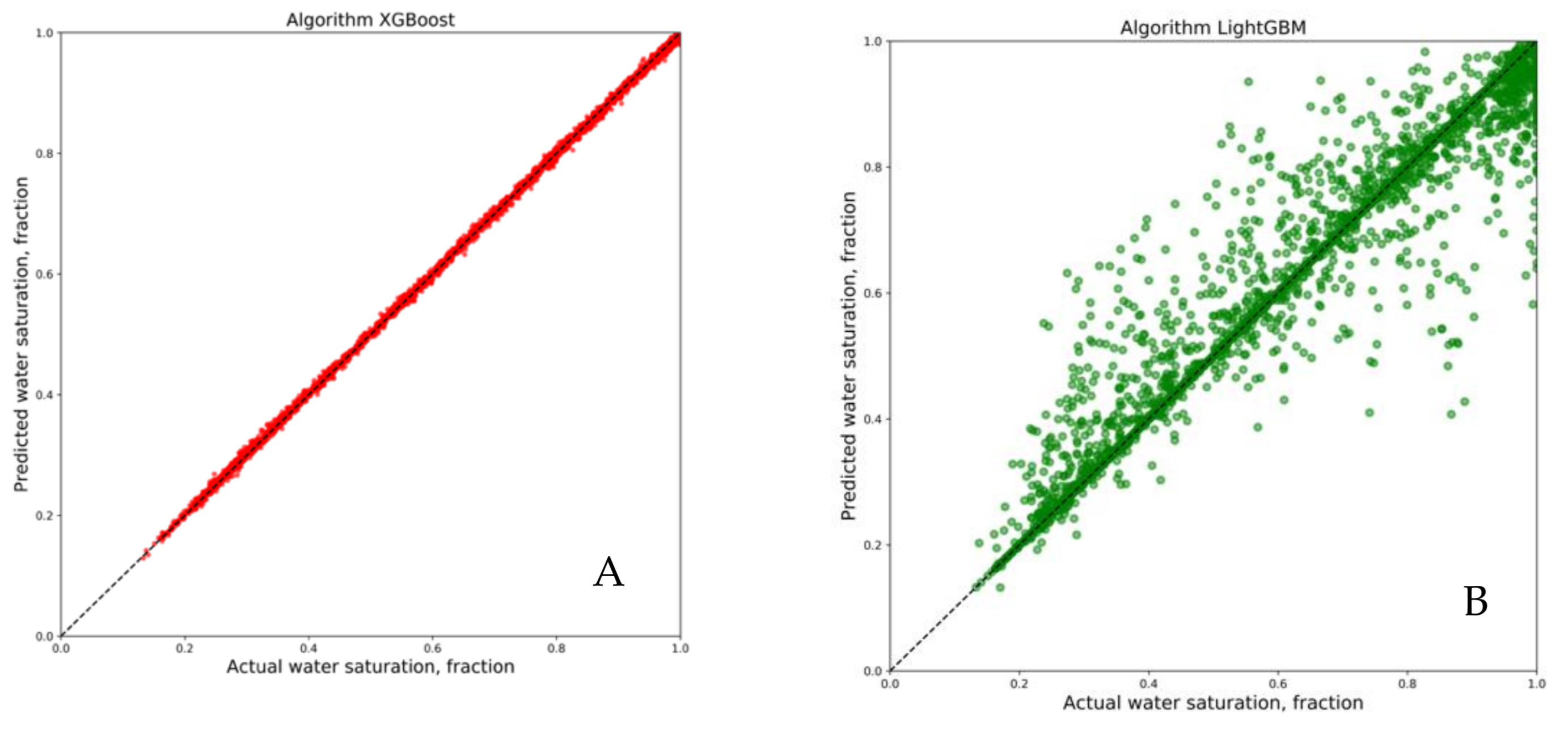
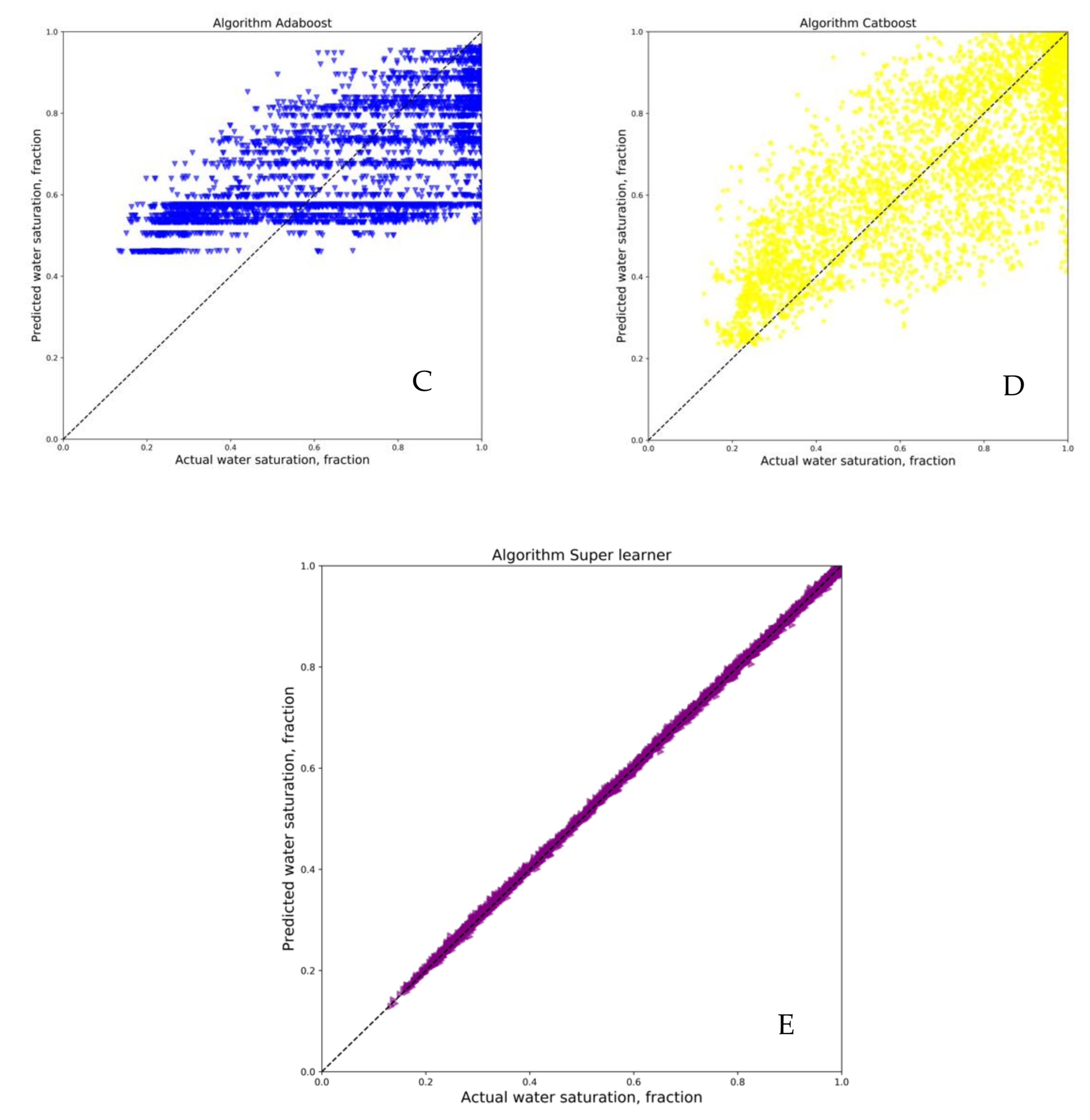
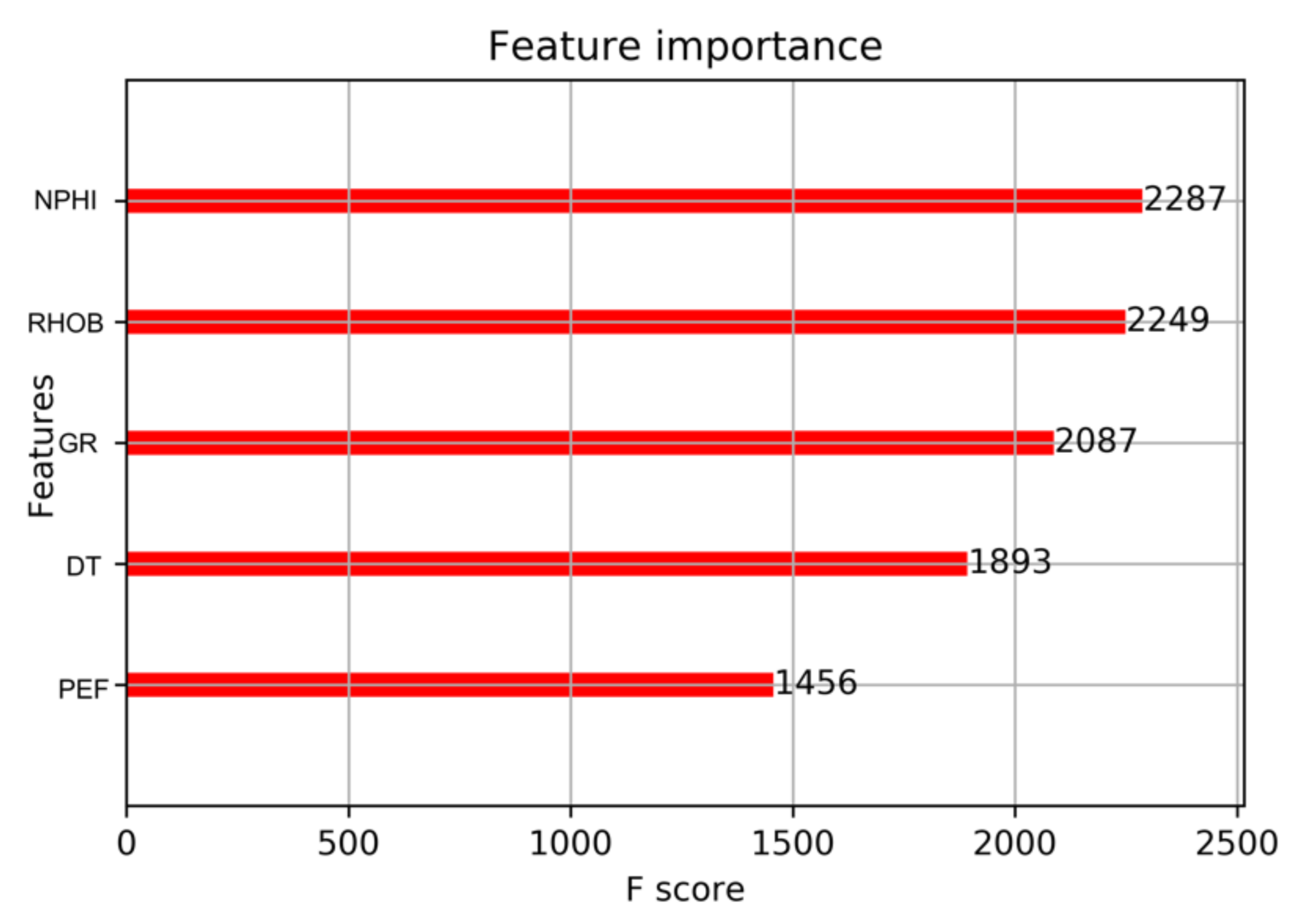
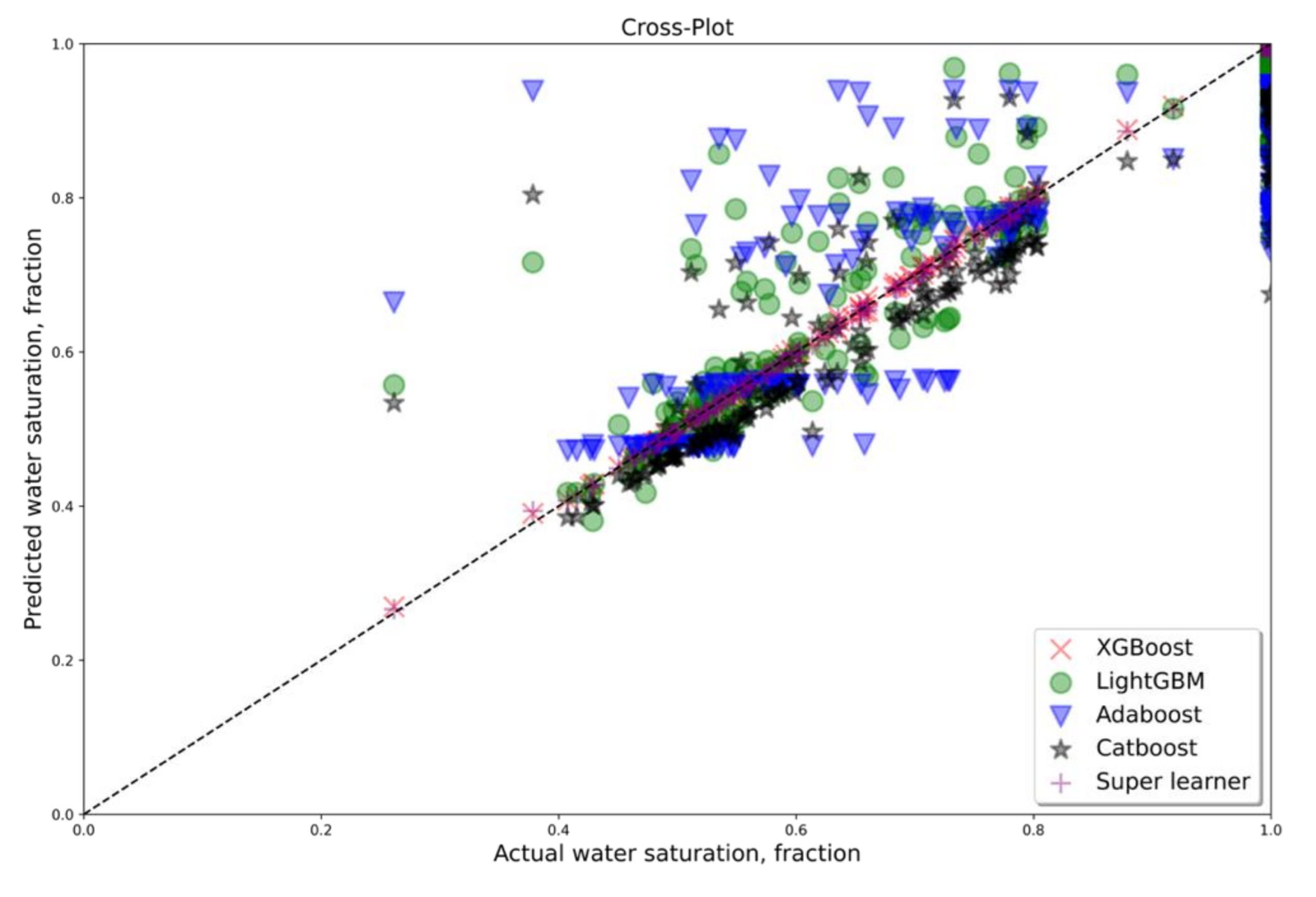
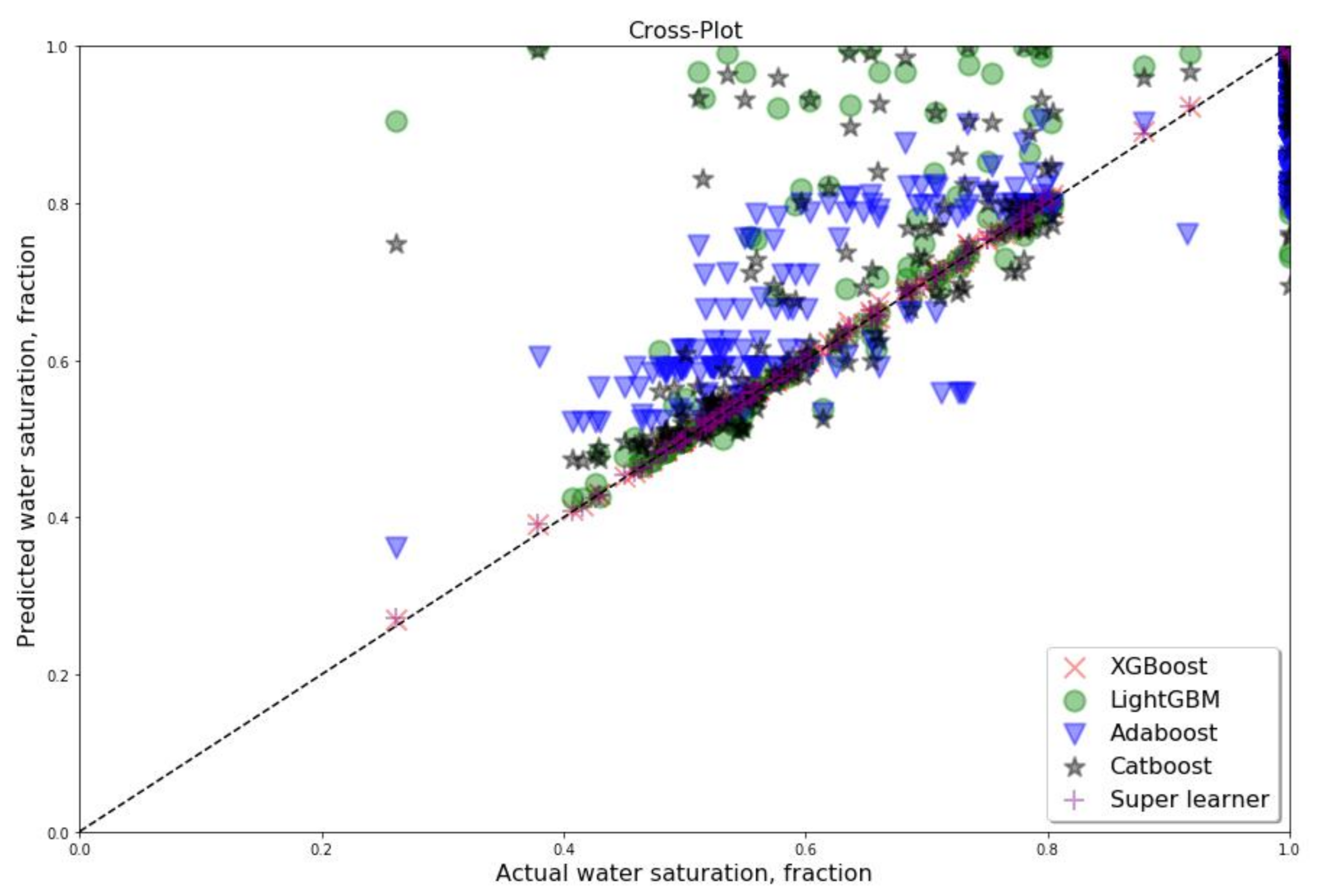
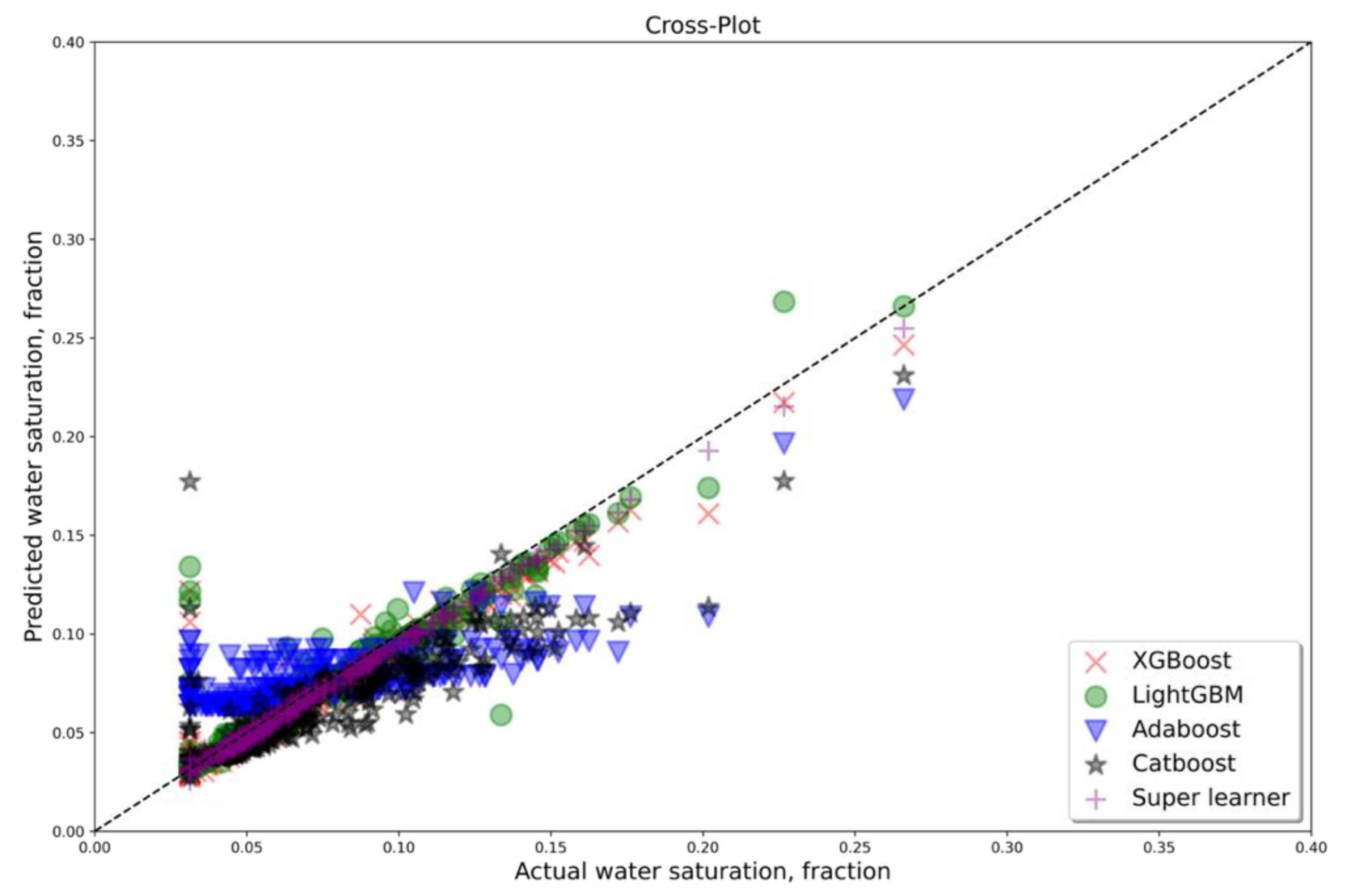
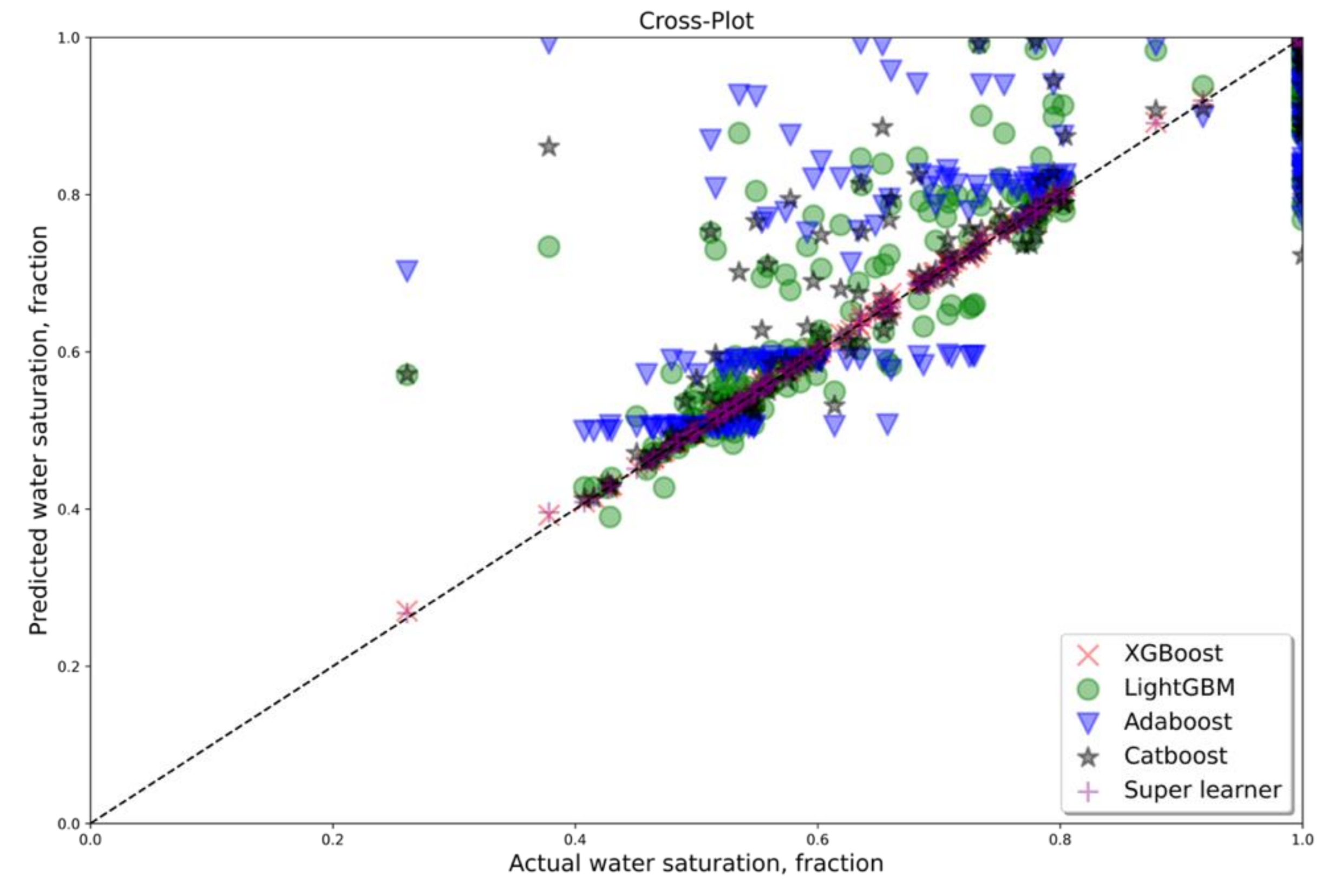
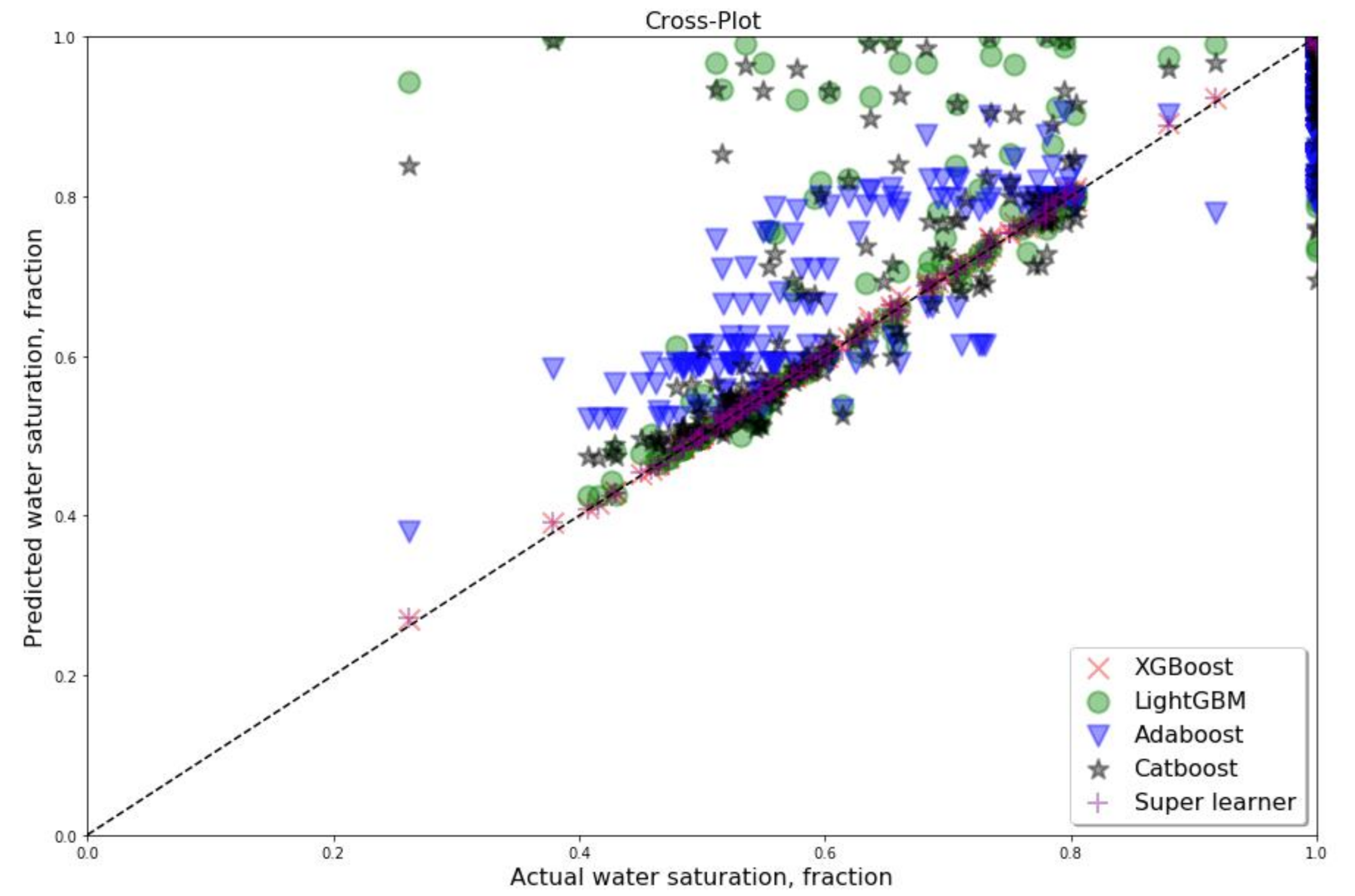
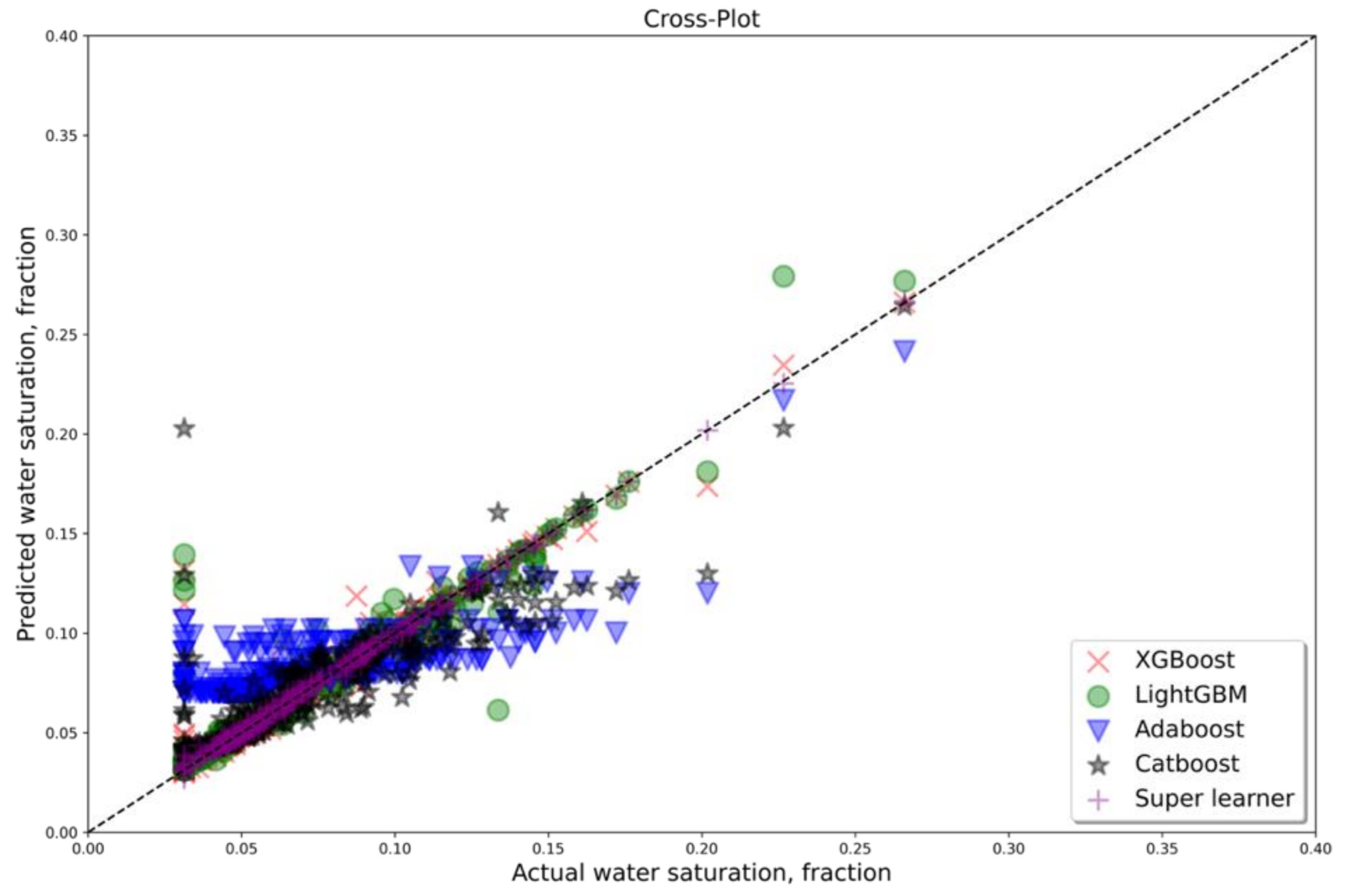
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Cross Plots for All Well, Which Were Considered as Testing for Dataset A with Five Features (PEF Included)



Appendix B. Cross Plots for All Wells, Which Were Considered as Testing for Dataset B with Four Features (PEF Excluded)



References
- Moradzadeh, A.; Bakhtiari, M.R. Methods of water saturation estimation: Historical perspective. J. Pet. Gas Eng. 2011, 3, 45–53. [Google Scholar]
- Awolayo, A.; Ashqar, A.; Uchida, M.; Salahuddin, A.A.; Olayiwola, S.O. A cohesive approach at estimating water saturation in a low-resistivity pay carbonate reservoir and its validation. J. Pet. Explor. Prod. Technol. 2017, 7, 637–657. [Google Scholar] [CrossRef]
- Archie, G.E. The Electrical Resistivity Log as an Aid in Determining Some Reservoir Characteristics. Trans. AIME 1942, 146, 54–62. [Google Scholar] [CrossRef]
- Archie, G.E. Electrical Resistivity an Aid in Core-Analysis Interpretation. AAPG Bull. 1947, 31, 350–366. [Google Scholar] [CrossRef]
- Archie, G.E. Introduction to Petrophysics of Reservoir Rocks. AAPG Bull. 1950, 34, 943–961. [Google Scholar] [CrossRef]
- Archie, G.E. Classification of carbonate reservoir rocks and petrophysical considerations. Aapg Bull. 1952, 36, 278–298. [Google Scholar]
- Shao, W.; Chen, S.; Eid, M.; Hursan, G. Carbonate log interpretation models based on machine learning techniques. In Proceedings of the SPWLA 60th Annual Logging Symposium, The Woodlands, TX, USA, 15–19 June 2019. [Google Scholar] [CrossRef]
- Bukar, I.; Adamu, M.B.; Hassan, U. A machine learning approach to shear sonic log prediction. In Proceedings of the SPE Nigeria Annual International Conference and Exhibition, Lagos, Nigeria, 5 August 2019. [Google Scholar]
- Anifowose, F.; Ewenla, A.O.; Eludiora, S.I. Prediction of Oil and Gas Reservoir Properties using Support Vector Machines. In Proceedings of the IPTC 2012: International Petroleum Technology Conference, Bangkok, Thailand, 7–9 February 2012; p. cp-280. [Google Scholar]
- Fattahi, H.; Karimpouli, S. Prediction of porosity and water saturation using pre-stack seismic attributes: A comparison of Bayesian inversion and computational intelligence methods. Comput. Geosci. 2016, 20, 1075–1094. [Google Scholar] [CrossRef]
- Mardi, M.; Ghasemalaskari, M.K. Application of Artificial Neural Networks in Water Saturation Prediction in from Iranian Oil Field. In Proceedings of the GeoBaikal 2010—First International Scientific and Practical Conference, Irkutsk, Russia, 15–20 August 2010; p. cp-248. [Google Scholar]
- Hamada, G.M.; Elshafei, M.A.; Adernian, A.M. Functional Network Softsensor for Determination of Porosity and Water Saturation in Sandstone Reservoirs. In Proceedings of the 72nd EAGE Conference and Exhibition incorporating SPE EUROPEC 2010, Barcelona, Spain, 14–17 June 2010; p. cp-161. [Google Scholar]
- Movahhed, A.; Bidhendi, M.N.; Masihi, M.; Emamzadeh, A. Introducing a method for calculating water saturation in a carbonate gas reservoir. J. Nat. Gas Sci. Eng. 2019, 70, 102942. [Google Scholar] [CrossRef]
- Mohammadi, A. Determination of Stone Groups of Asmari Formation Reservoir Based on Petrophysical Logs Using Fuzzy Logic Method. Master’s Thesis, University Tehran, Tehran, Iran, 2004. [Google Scholar]
- Sheremetov, L.; Martinez-Munoz, J.; Chi-Chim, M. Soft-computing method-ology for prediction of water saturation in fractured carbonate reservoirs. In Proceedings of the 80th EAGE Conference and Exhibition 2018, Copenhagen, Denmark, 11–14 June 2018; pp. 1–5. [Google Scholar]
- Negara, A.; Jin, G.; Agrawal, G. Enhancing rock property prediction from conventional well logs using machine learning technique-case studies of conventional and unconventional reservoirs. In Proceedings of the Abu Dhabi International Petroleum Exhibition & Conference, Abu Dhabi, United Arab Emirates, 7–10 November 2016. [Google Scholar]
- Eriavbe, F.E.; Okene, U.O. Machine learning application to permeability prediction using log & core measurements: A realistic work ow application for reservoir characterization. In Proceedings of the SPE Nigeria Annual International Conference and Exhibition, Lagos, Nigeria, 5–7 August 2019. [Google Scholar]
- Al-Bulushi, N.; King, P.; Blunt, M.; Kraaijveld, M. Development of artificial neural network models for predicting water saturation and fluid distribution. J. Pet. Sci. Eng. 2009, 68, 197–208. [Google Scholar] [CrossRef]
- Saumya, S.; Naqeeb, I.; Vij, J.; Khambra, I.; Kumar, A. Saturation Forecast Using Machine Learning: Enabling Smarter Decision-Making Capabilities. In Proceedings of the Abu Dhabi International Petroleum Exhibition & Conference, Society of Petroleum Engineers, Abu Dhabi, United Arab Emirates, 12 November 2019. [Google Scholar]
- Mollajan, A.; Memarian, H. Estimation of water saturation from petrophysical logs using radial basis function neural network. J. Tethys 2013, 1, 156–163. [Google Scholar]
- Gholanlo, H.H.; Amirpour, M.; Ahmadi, S. Estimation of water saturation by using radial based function artificial neural network in carbonate reservoir: A case study in Sarvak formation. Petroleum 2016, 2, 166–170. [Google Scholar] [CrossRef]
- Aliouane, L.; Ouadfeul, S.-A.; Djarfour, N.; Boudella, A. Petrophysical parameters estimation from well-logs data using multi-layer perceptron and radial basis function neural networks. In Proceedings of the International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 730–736. [Google Scholar]
- Masoudi, P.; Araabi, B.; Fa, T.A.; Memarian, H. Clustering as an efficient tool for assessing fluid content and movability by re-sistivity logs. In Proceedings of the Fourth International Mine and Mining Industries Congress & the Sixth Iranian Mining Engineering Conference, Tehran, Iran, October 2016. [Google Scholar]
- Mollajan, A. Application of local linear neuro-fuzzy model in estimating reservoir water saturation from well logs. Arab. J. Geosci. 2015, 8, 4863–4872. [Google Scholar] [CrossRef]
- Kapoor, G. Estimating Pore Fluid Saturation in an Oil Sands Reservoir Using Ensemble Tree Machine Learning Algorithms. Bachelor’s Thesis, Saint Mary’s University, Halifax, NS, Canada, 2017. [Google Scholar]
- Baziar, S.; Shahripour, H.B.; Tadayoni, M.; Nabi-Bidhendi, M. Prediction of water saturation in a tight gas sandstone reservoir by using four intelligent methods: A comparative study. Neural Comput. Appl. 2016, 30, 1171–1185. [Google Scholar] [CrossRef]
- Miah, M.I.; Zendehboudi, S.; Ahmed, S. Log data-driven model and feature ranking for water saturation prediction using machine learning approach. J. Pet. Sci. Eng. 2020, 194, 107291. [Google Scholar] [CrossRef]
- Kenari, S.A.J.; Mashohor, S. Robust committee machine for water saturation prediction. J. Pet. Sci. Eng. 2013, 104, 1–10. [Google Scholar] [CrossRef]
- Al-Amri, M.; Mahmoud, M.; Elkatatny, S.; Al-Yousef, H.; Al-Ghamdi, T. Integrated petrophysical and reservoir characterization work ow to enhance permeability and water saturation prediction. J. Afr. Earth Sci. 2017, 131, 105–116. [Google Scholar] [CrossRef]
- Kamalyar, K. Using Artificial Neural Network for Predicting Water Saturation in an Iranian Oil Reservoir. In Proceedings of the 10th EAGE International Conference on Geoinformatics-Theoretical and Applied Aspects, Kyiv, Ukraine, 10–14 May 2011; p. cp-240. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting ma-chine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ganatra, A.P.; Kosta, Y.P. Comprehensive Evolution and Evaluation of Boosting. Int. J. Comput. Theory Eng. 2010, 2, 931–936. [Google Scholar] [CrossRef]
- Snieder, E.; Khan, U.T. A comprehensive evaluation of boosting algorithms for artificial neural network-based ow forecasting models. In Proceedings of the AGU Fall Meeting 2019, San Francisco, CA, USA, 9–13 December 2019. [Google Scholar]
- Gonzalez-Recio, O.; Jiménez-Montero, J.; Alenda, R. The gradient boosting algorithm and random boosting for genome-assisted evaluation in large data sets. J. Dairy Sci. 2013, 96, 614–624. [Google Scholar] [CrossRef]
- Deconinck, E.; Zhang, M.H.; Coomans, D.; Heyden, Y.V. Evaluation of boosted regression trees (brts) and two-step brt pro-cedures to model and predict blood-brain barrier passage. J. Chemom. 2007, 21, 280–291. [Google Scholar] [CrossRef]
- Ray, S. Quick Introduction to Boosting Algorithms in Machine Learning. Available online: https://www.analyticsvidhya.com/blog/2015/11/quick-introduction-boosting-algorithms-machine-learning/ (accessed on 1 January 2019).
- Freung, Y.; Shapire, R. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J. Jpn. Soc. Artif. Intell. 1999, 14, 1612. [Google Scholar]
- Chen, T.; Guestrin, C. XGboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. Cat-Boost: Unbiased Boosting with Categorical Features. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 663–6648. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. arXiv 2017, preprint. arXiv:1706.09516. [Google Scholar]
- Al-Mudhafar, W.J. Integrating machine learning and data analytics for geostatistical characterization of clastic reservoirs. J. Pet. Sci. Eng. 2020, 195, 107837. [Google Scholar] [CrossRef]
- Subasi, A.; El-Amin, M.F.; Darwich, T.; Dossary, M. Permeability prediction of petroleum reservoirs using stochastic gradient boosting regression. J. Ambient. Intell. Humaniz. Comput. 2020, 1–10. [Google Scholar] [CrossRef]
- Erofeev, A.; Orlov, D.; Ryzhov, A.; Koroteev, D. Prediction of Porosity and Permeability Alteration Based on Machine Learning Algorithms. Transp. Porous Media 2019, 128, 677–700. [Google Scholar] [CrossRef]
- Zhang, L.; Zhan, C. Machine Learning in Rock Facies Classification: An Application of XGBoost. In Proceedings of the SEG Global Meeting Abstracts, Al Ain, United Arab Emirates, 9–12 October 2017; pp. 1371–1374. [Google Scholar] [CrossRef]
- Al-Mudhafar, W.; Jaber, A.K.; Al-Mudhafar, A. Integrating Probabilistic Neural Networks and Generalized Boosted Regression Modeling for Lithofacies Classification and Formation Permeability Estimation. In Proceedings of the OTC-27067-MS, the Offshore Technology Conference, Houston, TX, USA, 2–5 May 2016. [Google Scholar]
- Nielsen, D. Tree Boosting with Xgboost-Why Does Xgboost win “every” Machine Learning Competition? Master’s Thesis, NTNU, Trondheim, Norway, 2016. [Google Scholar]
- Van der Laan, M.J.; Polley, E.C.; Hubbard, A.E. Super Learner. U.C. Berkeley Division of Biostatistics Working Paper Series. 2014. Available online: Bepress.com/ucbbiostat/paper222 (accessed on 1 November 2007).
- Polley, E.C.; van der Laan, M.J. “Super Learner In Prediction”. U.C. Berkeley Division of Biostatistics Working Paper Series. Working Paper 266. 2010. Available online: https://biostats.bepress.com/ucbbiostat/paper266 (accessed on 1 January 2019).
- Amyx, J.; Bass, D.; Whiting, R.L. Petroleum Reservoir Engineering Physical Properties; McGraw-Hill: New York, NY, USA, 1960. [Google Scholar]
- Rokach, L. Decision forest: Twenty years of research. Inf. Fusion 2016, 27, 111–125. [Google Scholar] [CrossRef]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class AdaBoost. Stat. Its Interface 2009, 2, 349–360. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Kamrava, S.; Bai, T.; Sahimi, M. Machine learning in geo-and environmental sciences: From small to large scale. Adv. Water Resour. 2020, 103619. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Advances in Neural Information Processing Systems 30 (NIPS 2017). Available online: https://papers.nips.cc/paper/2017 (accessed on 1 January 2019).
- Gibert, K.; Sànchez-Marrè, M.; Izquierdo, J. A survey on pre-processing techniques: Relevant issues in the context of environmental data mining. AI Commun. 2016, 29, 627–663. [Google Scholar] [CrossRef]
- Sen, M. Srivastava, Regression Analysis: Theory, Methods, and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Layton, R. Learning Data Mining with Python; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Massaron, L.; Boschetti, A. Regression Analysis with Python; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms ∏ | Python Package | Package Version | Website of the Package |
|---|---|---|---|
| XGBoost | xgboost | 0.9.0 | https://xgboost.readthedocs.io/en/latest/index.html |
| Lightgbm | lightgbm | 2.3.2 | https://lightgbm.readthedocs.io/en/ |
| Adaboost | Adaboost | 0.23.1 | https://scikit-learn.org |
| Catboost | Catboost | 0.4 | https://catboost.ai |
| Random Forest | scikit-learn | 0.22.2 | https://scikit-learn.org/dev/index.html |
| Super learner | mlens | 0.1 | http://ml-ensemble.com |
| Algorithms | Hyperparameters Tuned | Search Interval | Optimal Values |
|---|---|---|---|
| XGBoost | Learning_rate Subsample Colsample_bytree max_depth n_estimators | 0.01–0.5 0.5–1 0.5–1 1–14 1000–4000 | 0.1 0.8 0.8 9 3000 |
| LightGBM | learning_rate num_leaves max_depth n_estimators | 0.01–0.5 3–95 1–14 1000–3000 | 0.1 70 7 2000 |
| Adaboost | Learning_rate n_estimators | 0.01–0.2 1500–3000 | 0.05 1600 |
| Catboost | Learning_rate depth iterations | 0.01–0.4 1–14 1500–3000 | 0.1 7 1800 |
| Algorithm | R2 | RMSE | MAE | MSE | ||||
|---|---|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | Training | Testing | |
| XGBoost | 0.997579 | 0.99325 | 0.009750 | 0.009934 | 0.007179 | 0.0078357 | 0.000095 | 0.000102 |
| LightGBM | 0.924810 | 0.918942 | 0.032930 | 0.035976 | 0.010999 | 0.011305 | 0.001084 | 0.001294 |
| Adaboost | 0.886684 | 0.866633 | 0.062433 | 0.051907 | 0.040370 | 0.050834 | 0.003897 | 0.005236 |
| Catboost | 0.957758 | 0.941368 | 0.026422 | 0.052927 | 0.004381 | 0.035912 | 0.000698 | 0.002801 |
| Super learner | 0.998828 | 0.997245 | 0.009591 | 0.010400 | 0.001567 | 0.007686 | 0.000092 | 0.000108 |
| Algorithm | R2 | RMSE | MAE | MSE | ||||
|---|---|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | Training | Testing | |
| XGBoost | 0.99481 | 0.993482 | 0.008164 | 0.008540 | 0.002921 | 0.003203 | 0.000066 | 0.000073 |
| LightGBM | 0.98391 | 0.982904 | 0.013047 | 0.013832 | 0.003913 | 0.004755 | 0.000172 | 0.000191 |
| Adaboost | 0.94261 | 0.932993 | 0.026952 | 0.027384 | 0.019823 | 0.022912 | 0.000726 | 0.000750 |
| Catboost | 0.93912 | 0.931926 | 0.027091 | 0.027601 | 0.011892 | 0.012272 | 0.000733 | 0.000762 |
| Super Learner | 0.99989 | 0.999727 | 0.001711 | 0.001748 | 0.001197 | 0.001230 | 0.0000029 | 0.000003 |
| Algorithms | XGboost | Adaboost | Superlearner | Catboost | Lightgbm |
|---|---|---|---|---|---|
| Run Time (s) | 530.462 | 322.011 | 466.198 | 630.198 | 301.622 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hadavimoghaddam, F.; Ostadhassan, M.; Sadri, M.A.; Bondarenko, T.; Chebyshev, I.; Semnani, A. Prediction of Water Saturation from Well Log Data by Machine Learning Algorithms: Boosting and Super Learner. J. Mar. Sci. Eng. 2021, 9, 666. https://doi.org/10.3390/jmse9060666
Hadavimoghaddam F, Ostadhassan M, Sadri MA, Bondarenko T, Chebyshev I, Semnani A. Prediction of Water Saturation from Well Log Data by Machine Learning Algorithms: Boosting and Super Learner. Journal of Marine Science and Engineering. 2021; 9(6):666. https://doi.org/10.3390/jmse9060666
Chicago/Turabian StyleHadavimoghaddam, Fahimeh, Mehdi Ostadhassan, Mohammad Ali Sadri, Tatiana Bondarenko, Igor Chebyshev, and Amir Semnani. 2021. "Prediction of Water Saturation from Well Log Data by Machine Learning Algorithms: Boosting and Super Learner" Journal of Marine Science and Engineering 9, no. 6: 666. https://doi.org/10.3390/jmse9060666
APA StyleHadavimoghaddam, F., Ostadhassan, M., Sadri, M. A., Bondarenko, T., Chebyshev, I., & Semnani, A. (2021). Prediction of Water Saturation from Well Log Data by Machine Learning Algorithms: Boosting and Super Learner. Journal of Marine Science and Engineering, 9(6), 666. https://doi.org/10.3390/jmse9060666