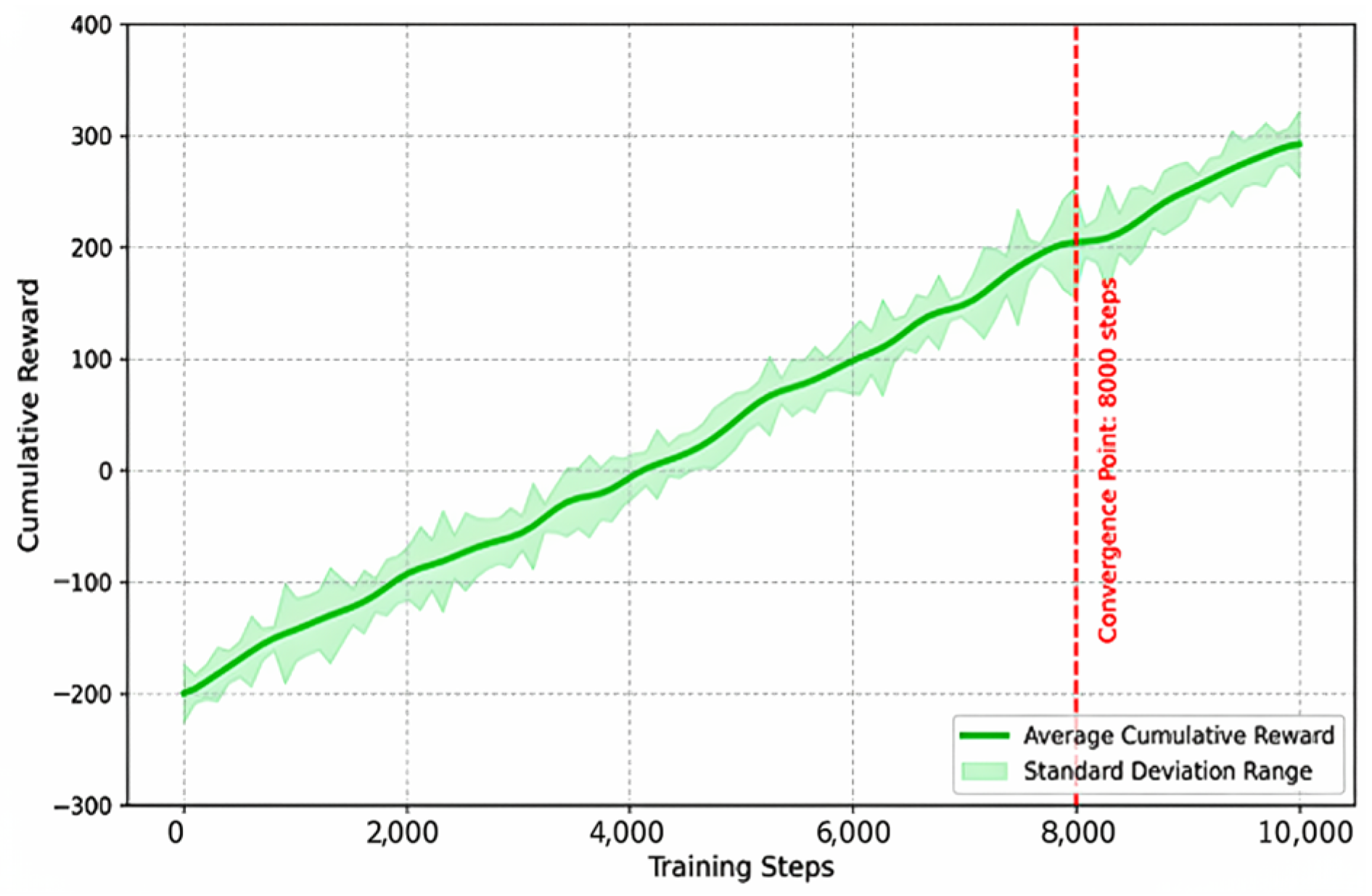
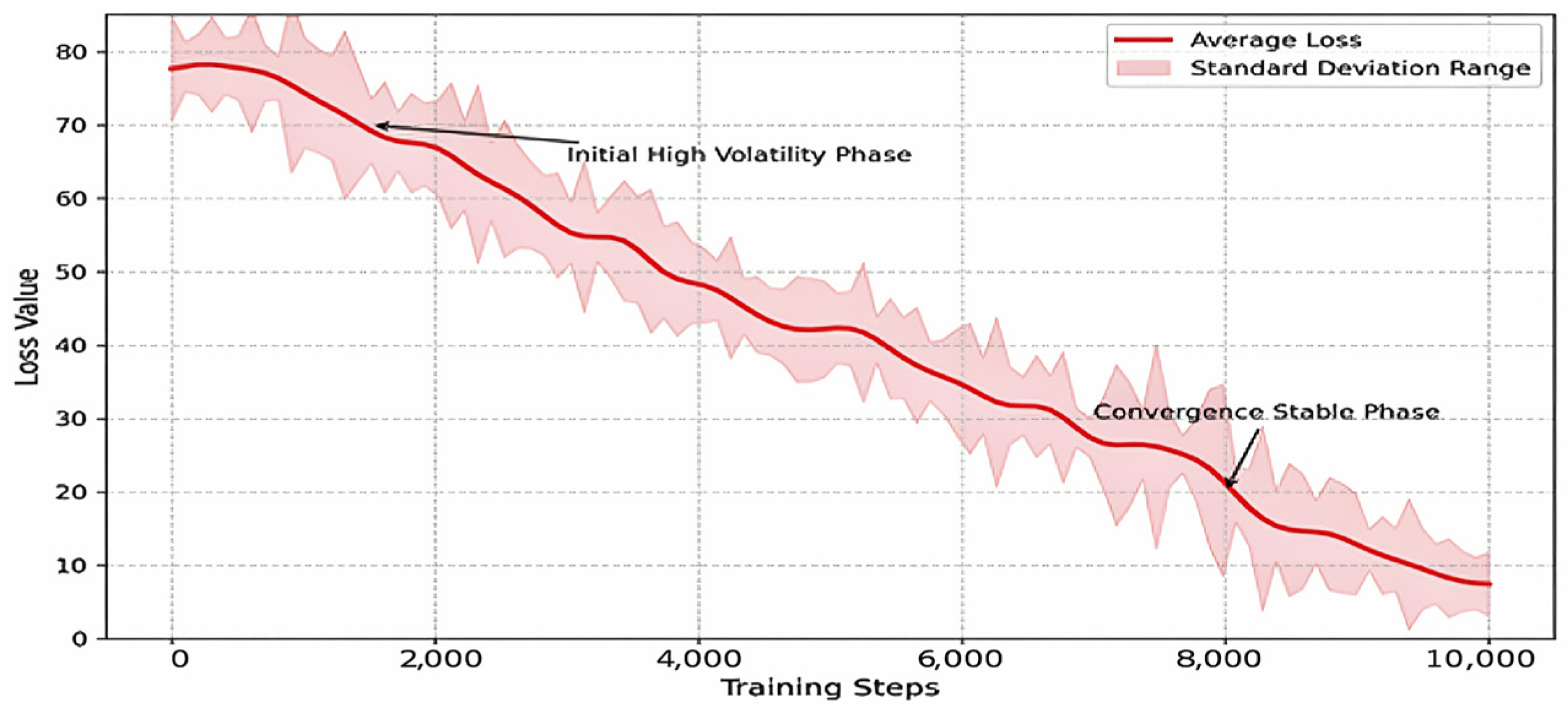
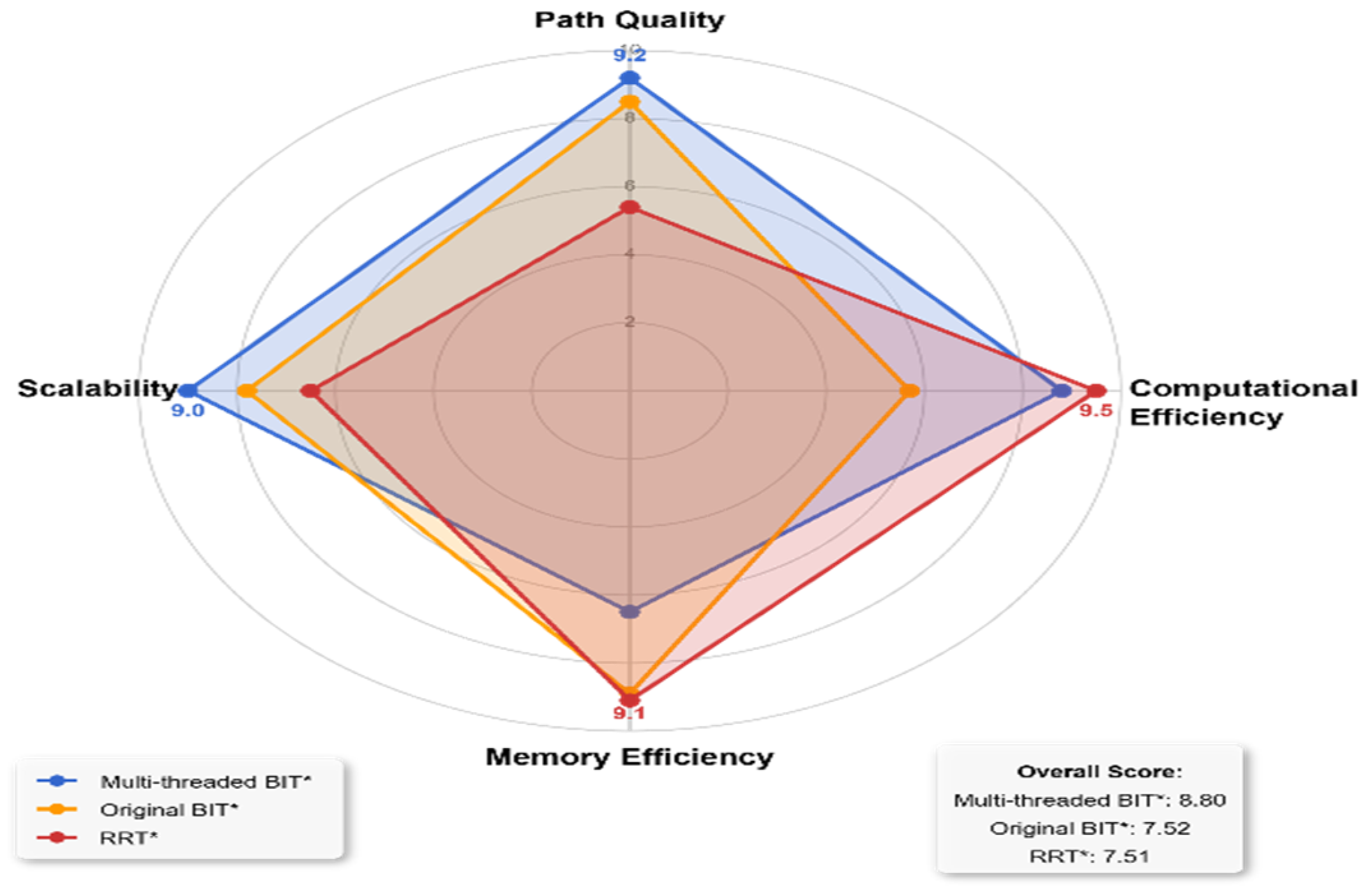
This study proposes a novel hybrid path planning strategy suitable for complex inland river environments. This strategy deeply integrates the high efficiency of the MEO-BIT* model in global path search and energy optimization with the powerful capabilities of the Deep Q-Network (DQN) algorithm in handling dynamic environments and learning complex decision-making behaviors. This hybrid strategy aims to provide high-quality initial paths and heuristic information through synergistic action. At the same time, DQN performs local, real-time path adjustments and dynamic obstacle avoidance. This significantly enhances the autonomous navigation efficiency and robustness of intelligent marine vehicles in complex dynamic environments, all while ensuring navigation safety and path economy. To achieve this, the model’s design incorporates efficient mathematical modeling methods. It optimizes DQN’s learning and planning performance in dynamic environments through specific reward mechanisms and network structures, ensuring the practicality of the final generated navigation solutions.
The successful training and performance of the MEO-BIT* + DQN hybrid model critically depend on the reasonable setting of a series of initialization parameters, among which the neural network weight initialization and experience replay buffer-related parameters of the DQN module are critical.
Initial weight states significantly impact training for the DQN model’s Q-Network and Target Q-Network. This study uses a standard normal distribution random initialization (mean 0, standard deviation 0.01) to break symmetry, prevent local optima, and promote effective learning. While employed here, more advanced methods, such as Xavier or He initialization, could be explored in future work to maintain activation value means and variances better across layers, mitigating vanishing/exploding gradients, and accelerating convergence.
2.3.2. Experience Replay Buffer Settings
Methods such as Xavier and He are used to initialize weights cleverly so that the gradients do not vanish or explode—they ensure that the output variance is consistent across layers. This improves efficiency and ensures stability during training. The correct initialization method depends on the problem so that it converges quickly.
- (1)
Other Hyperparameter Settings
The practical training of the DQN module relies on carefully selected hyperparameters. In this study, the key hyperparameters were set as follows, with specific values detailed in
Table 1:
Discount Factor (γ): Set to 0.9. This balances immediate and future rewards and is suitable for goal-oriented path planning tasks.
Learning Rate: Initially set to 0.001, using the Adam optimizer to ensure convergence speed and training stability.
Exploration Rate (ϵ): Initial ϵ = 0.9, ϵ Decay = 0.995, ϵ Min = 0.1. This strategy aims to balance extensive exploration in the early stages with exploiting known optimal strategies later while maintaining adaptability to dynamic environmental changes.
Experience Replay Buffer Size: Set to 20,000 to store a sufficiently diverse set of experiences and break data correlations.
Batch Size: Set to 32 to balance the accuracy of gradient estimation with computational efficiency.
Target Network Update Frequency: Updated every 200 training steps to stabilize the Q-value learning process.
Also included is a description of the neural network architecture; the Q-network uses a fully connected neural network with an input layer, two hidden layers, and an output layer. The two hidden layers contained 256 neurons and used ReLU (Rectified Linear Unit) as the activation function. The number of neurons in the output layer is the same as the dimension of the action space, and the activation function is not used to output the Q-value directly.
We use the Mean Squared Error (MSE) as the loss function to calculate the difference between the target Q-value and the predicted Q-value to update the weights of the online network.
In addition to the learning rate, other key information about the optimizer is provided. For example: “We use the Adam optimizer for network training, its learning rate is listed in
Table 1, and the other parameters (e.g.,
) are set by default in the PyTorch library (version 2.5.1).”
These hyperparameter settings combine standard practices in reinforcement learning with preliminary experimental adjustments tailored to the path planning problem of this study.
- (2)
Reward Function Design
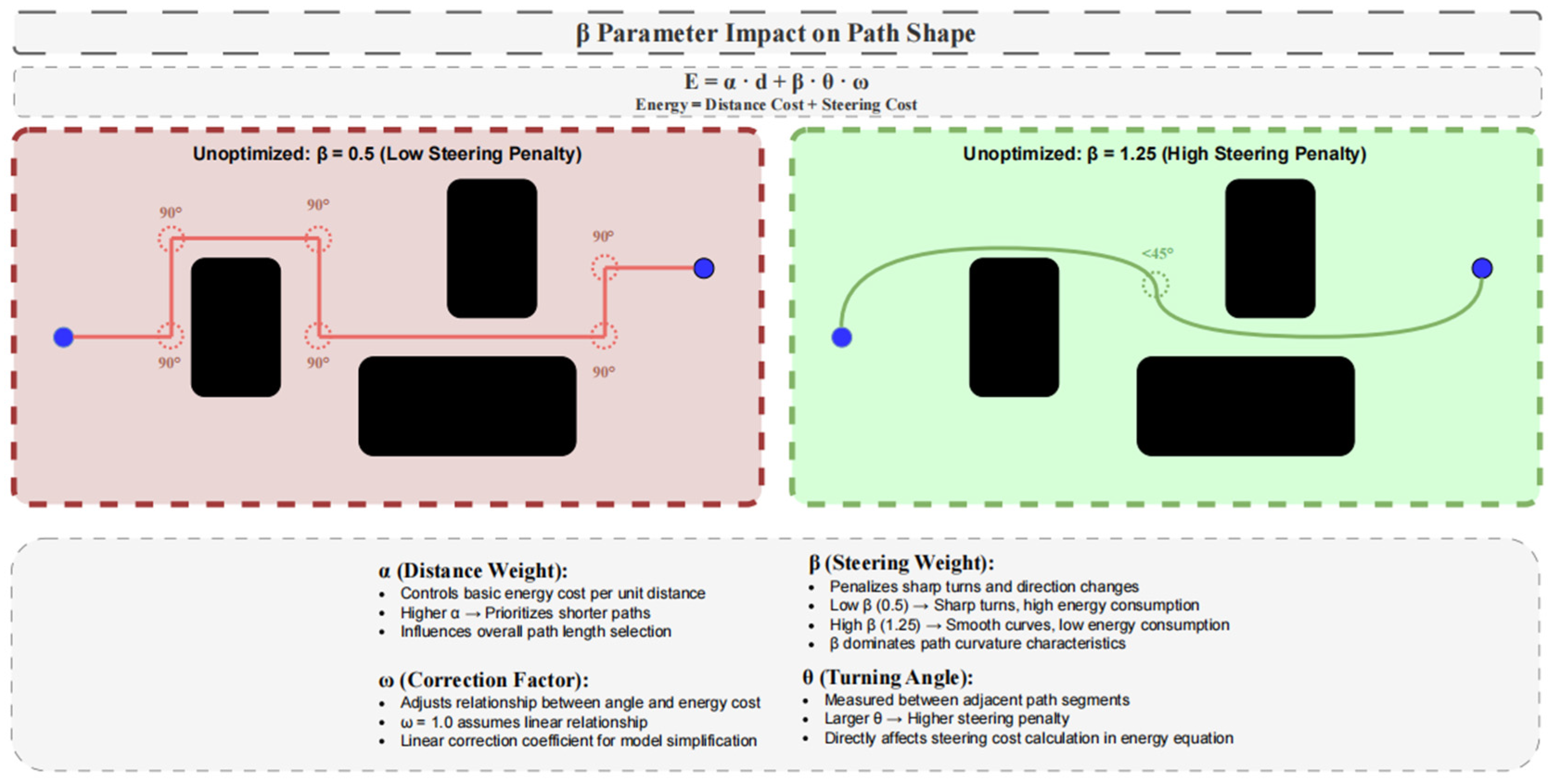
The reward function in reinforcement learning needs to show the vessel’s safety, energy, and general efficiency; then, the ship can learn effective strategies combined with map and path sample output by improved BIT* algorithm.
From a safety perspective, the vessel must avoid collisions and complete its navigation task. Therefore, we adopt the following safety reward to prevent collisions:
When the ship sails into a black square (collision), the reward is:
Considering the navigation efficiency, the ship should minimize costs except for collision and task completion. Therefore, the reward is based on the ship’s good learning routing and improved BIT* algorithm:
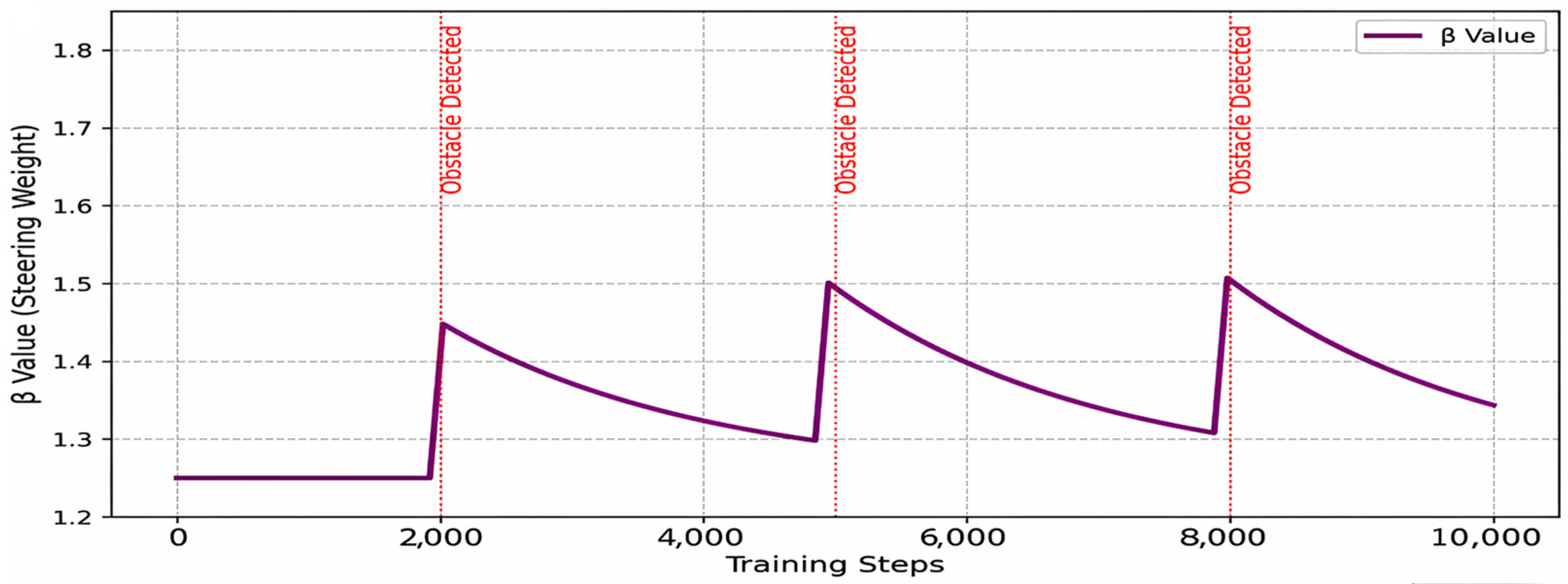
For BIT* path planning, to encourage the vessel to plan (take actions leading to larger states: forward state), we decrease the reward value with a constant decreasing speed against its decreasing weight. The set target reward does matter in our chosen navigation policy through channels; we can easily and quickly get good policies with low rewards. However, we will be greedy and pay for that since we neglect safety or choose a bigger one, leading to wide explorations instead of making the best results slow to achieve. That is why rewarding choices have much to do with it. Upon reaching the finishing line, the penalty value is:
The decision model is implemented using TensorFlow (version 2.16.1) and Python 3.9.
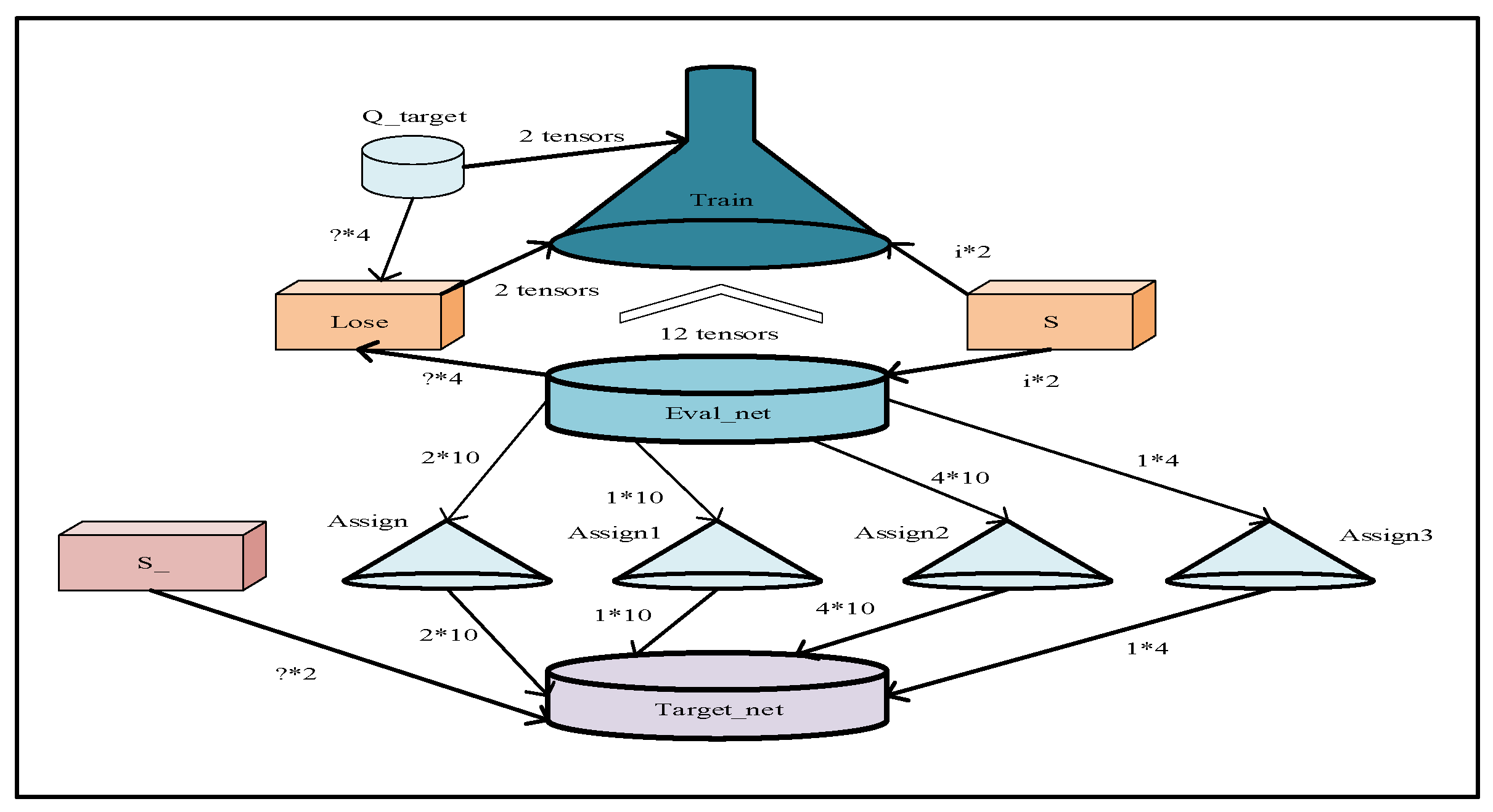
Figure 4 illustrates the trained DQN’s network architecture.
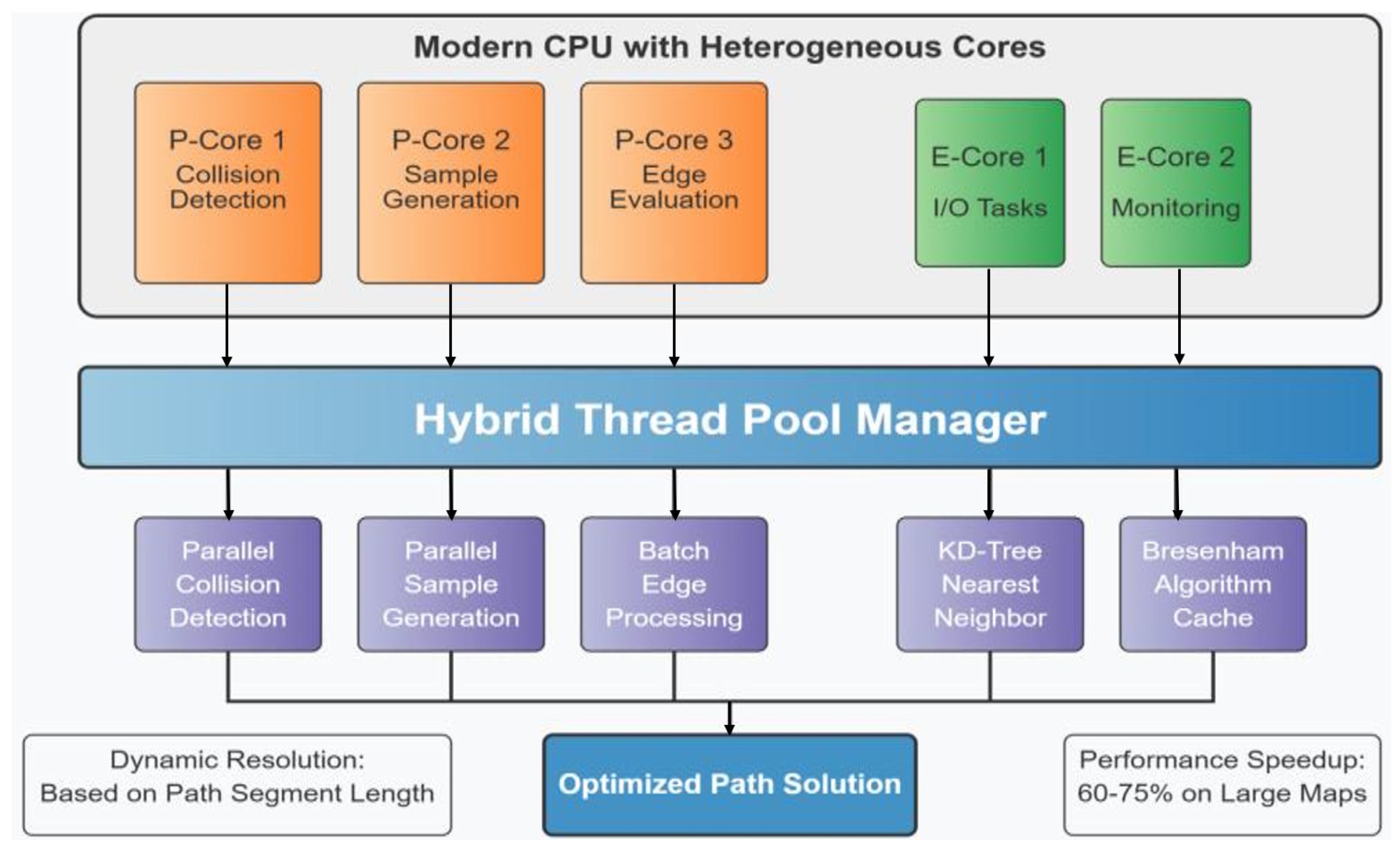
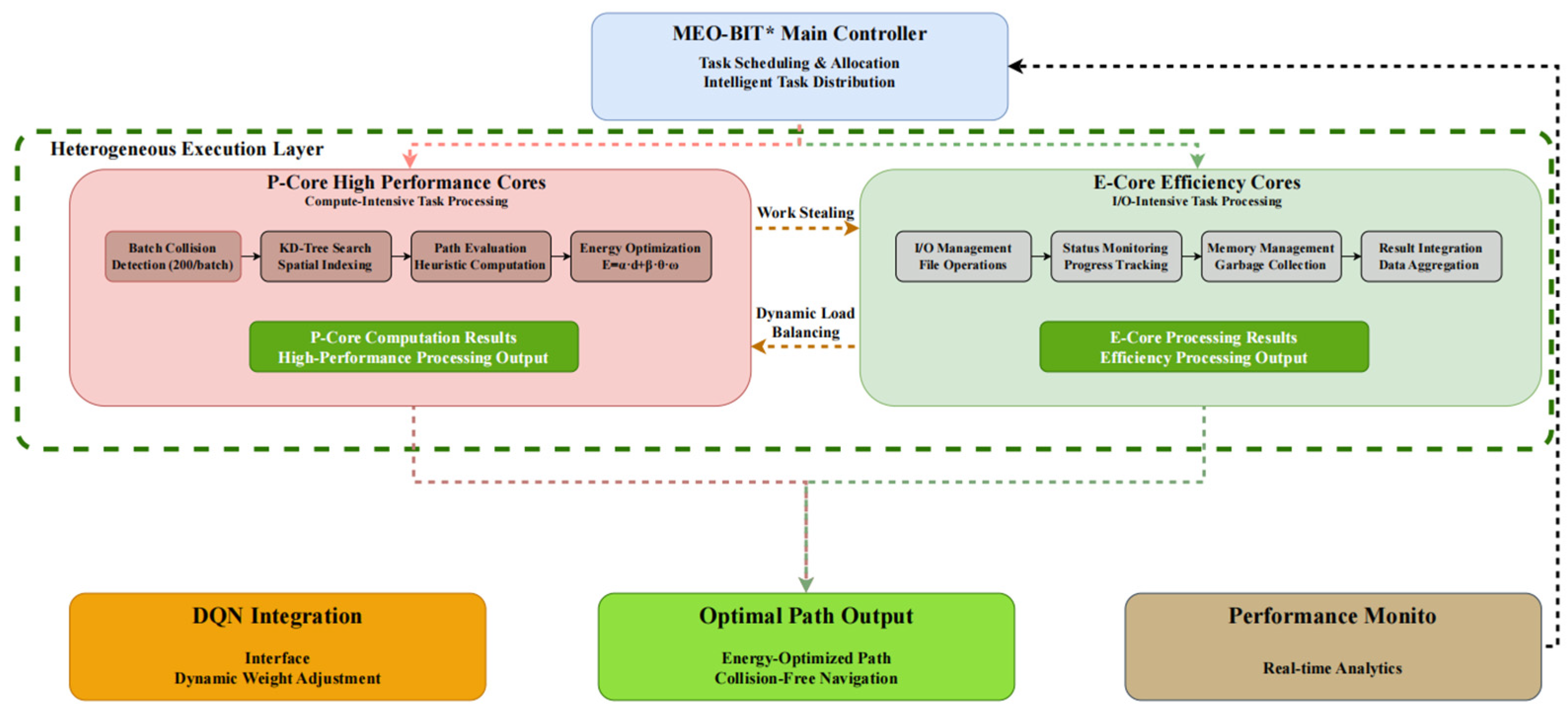
Figure 4 illustrates the Deep Q-Network (DQN) architecture proposed in this paper. The network consists of an Input Layer, Hidden Layer 1, Hidden Layer 2, and an Output Layer. The numerical value “256” in the figure indicates that each hidden layer contains 256 neurons. The network is designed to handle the state representation information provided by MEO-BIT* (see
Section 2.4.1 and
Section 2.3.2 State Space Definitions for details, 36 dimensions in total). The hidden layer uses the ReLU (Rectified Linear Unit) activation function for nonlinear transformation. The number of neurons in the output layer corresponds to the action-spatial dimension (five discrete actions are defined in this paper), and the Q-value estimation of each action is directly output. Processor core division: The heterogeneous processors used in this article (such as the Intel Core i7-14700H) include P-Cores and E-Cores. P-Cores have higher clock frequencies and stronger single-threaded performance, making them suitable for computationally intensive tasks such as forward inference in DQNs, complex collision detection, and path evaluation in MEO-BIT*; E-cores optimize power consumption and are suitable for handling lightweight tasks such as data I/O, status monitoring, and partial thread management in the background or with high parallelism and low latency requirements. The multi-threaded parallelism mechanism of the MEO-BIT* algorithm (
Section 2.1.2) allocates different types of computing tasks to the most appropriate cores (P-cores or E-cores) through intelligent task scheduling and load balancing to optimize overall energy efficiency and computing throughput.
DQN integrates reinforcement learning with deep learning, approximating optimal Q-values through parallel online and target networks. The online network outputs state-action Q-values, processed by two fully connected layers, with target network parameters updated periodically. This design stabilizes training for offline learning models, providing sufficient information for optimal policy function calculations for each sampled state. The model is then retrained online, enabling other vessels to obtain all information samples, receive rewards, and evaluate actions based on expected average gain for further updates.
Initialization at startup requires defining the action space (ship maneuver options) and the state space (vessel movement area data). Key initial settings include the learning rate, crucial for stable DNN parameter updates without numerical imbalance during cost value calculations. DQN utilizes an experience learning mode, where actions’ reward results are stored in memory (Replay Store), batched, and used for repeated interactions with the environment. This offline path planning application addresses small-sample and difficult-to-adjust issues in non-static, nonlinear conditions, enabling robust path generation around vessels in challenging scenarios (see
Table 2).
- (3)
Training Steps of the Hybrid Mode
The training process for the DQN decision model is illustrated in
Figure 5.
During the training process, the vessel’s current state information, S, in the aquatic environment, is first fed into the Q-Evaluation Network (Q Eval network), as depicted in the figure. The Q Eval network then outputs the Q-value for each action within the vessel’s action set. Following this, an action, A, is selected based on an ϵ-greedy policy and executed. After acting, the ship receives a reward, R, and its state transitions to S′. This quadruple (s, a, r, s′) is stored in the experience replay buffer.
The experience replay mechanism is a crucial technique in deep reinforcement learning. Random sampling from past experiences breaks the temporal correlation between samples, significantly improving learning stability. As shown on the right side of the figure, experiences are randomly sampled from the experience replay buffer and input into both the Q Eval and Q Target networks. The loss function is then calculated to update the Q Eval parameters, while the Q Target parameters are synchronized periodically in cycle c. This dual-network structure effectively mitigates the overestimation problem commonly found in Q-learning.
- (4)
Detailed coding about the state space
We designed a fixed-length state vector S with multiple information dimensions to enable the DQN agent to perceive the environment and make intelligent decisions fully. This vector is the only input to the DQN neural network. All values are normalized (e.g., scaled to [−1, 1] intervals) before being entered into the network to ensure the stability and efficiency of the training.
The state vector S consists of the following components:
Ego State: Contains the position and orientation of the AUV in the global coordinate system.
: three dimensions. θ is the heading angle of the AUV.
Goal Information: Contains the relative coordinates and distance of the final target point relative to the current position of the AUV.
: three dimensions. This helps the agent perceive the direction and distance of the target.
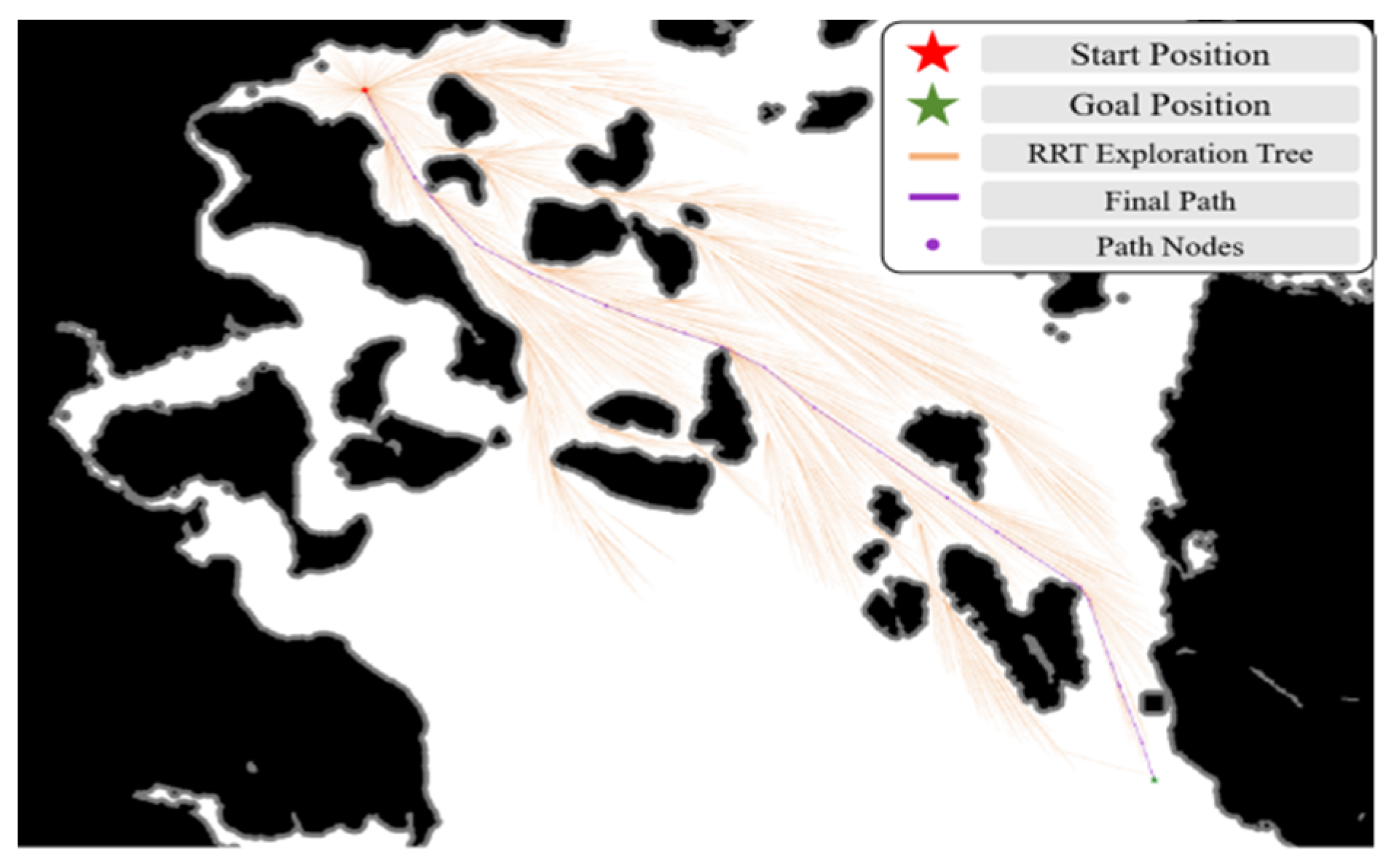
Global Path Guidance: From the global path information of MEO-BIT* planning, we select the coordinates of the following five closest waypoints relative to the AUV. This provides short- and medium-term heading guidance for DQN so its decision-making is consistent with the globally optimal path.
: 5 points × 2 dimensions/point = 10 dimensions. If less than five waypoints remain, they are filled with zero vectors.
Dynamic Obstacle Information: The information of the three nearest dynamic obstacles near the AUV sensed by the sensor. Each obstacle’s information includes its position and speed relative to the AUV.
for i = 1 to 3: 3 obstacles × 4 dimensions/Obstacles = 12 dimensions. This allows the Agent to predict collision risk. If there are less than three perceived obstacles, they are also filled with zero vectors.
Static Environment Perception: We use a lidar-like “tentacle” model to perceive static obstacles such as land. Virtual rays are emitted from the center of the AUV in eight fixed directions (front, front −45°, right, rear −45°, rear, rear +45°, left, front +45°), with the distance of each ray to a static obstacle included in the state.
: eight dimensions. This provides the agent with intuitive information about the distribution of free space around it. If there is no obstacle in one direction, it is set to the maximum perceived distance.
In summary, the total dimension of the state vector S is 3 (self) + 3 (target) + 10 (global path) + 12 (dynamic obstacles) + 8 (static environment) = 36 dimensions. Such a structured representation of the state provides a sufficiently rich and fixed information input to the DQN.
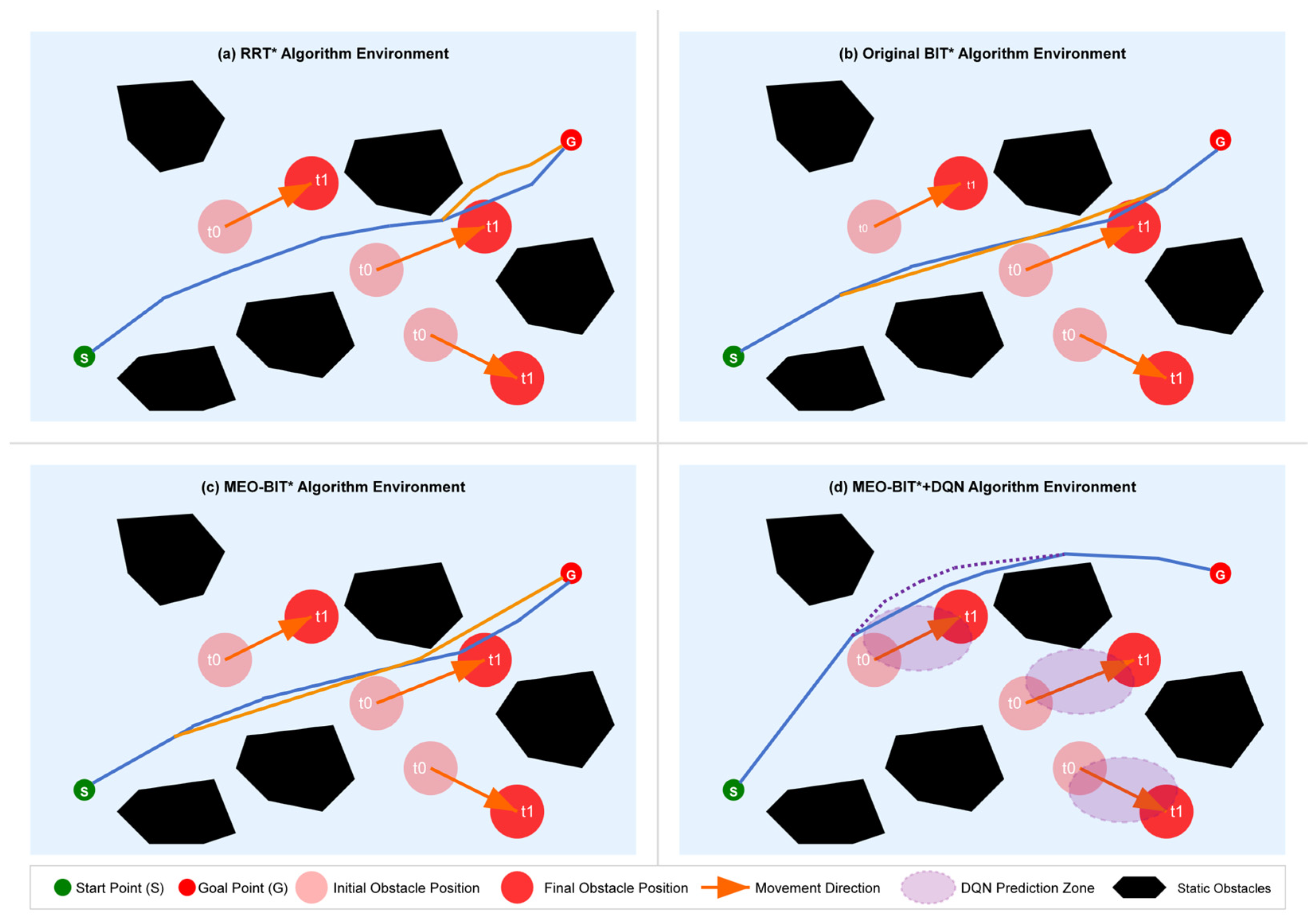
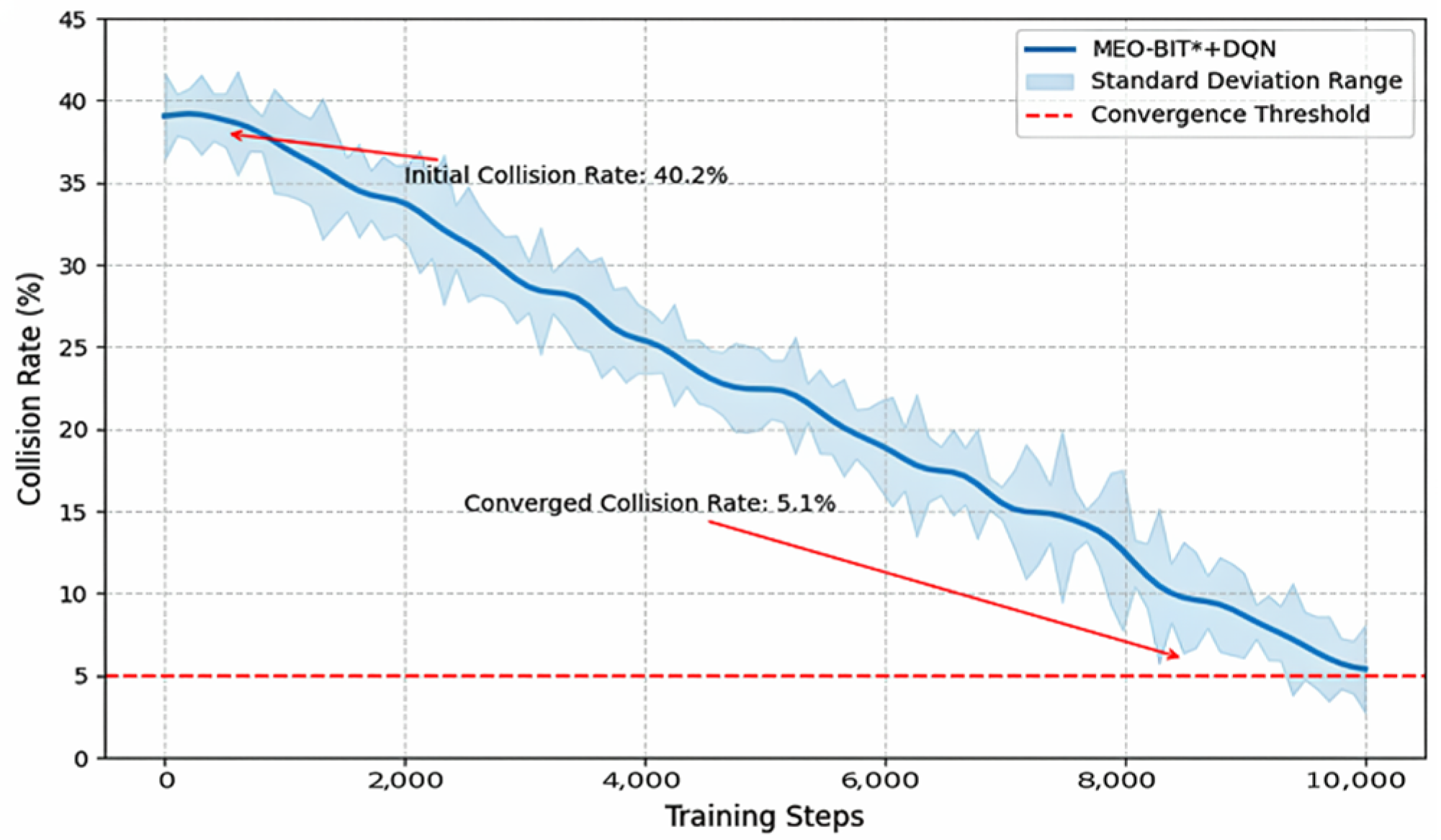
2.3.3. Modeling and Training Mechanism of Dynamic Obstacles
During DQN training, dynamic barriers are modeled in the following ways:
1. Each dynamic obstacle adopts a linear motion model, and its state update formula is:
where
is the preset velocity vector, and
are Gaussian noise terms with standard deviation
), simulating water flow disturbances and uncertainties.
2. Interaction mechanism
The state vector S for the DQN’s perceptual input consists of the relative position and velocity of the three nearest dynamic obstacles with respect to the AUV. Specifically, for each obstacle , we include (), resulting in a total of 3 × 4 = 12 dimensions.
Reward function (Equations (6)–(8)):
Collision penalty (trigger condition: Euclidean distance between AUV and obstacle ≤ safe radius).
Safe navigation rewards (γ is the discount factor, n is the number of steps) to encourage efficient obstacle avoidance.
3. Training environment generation
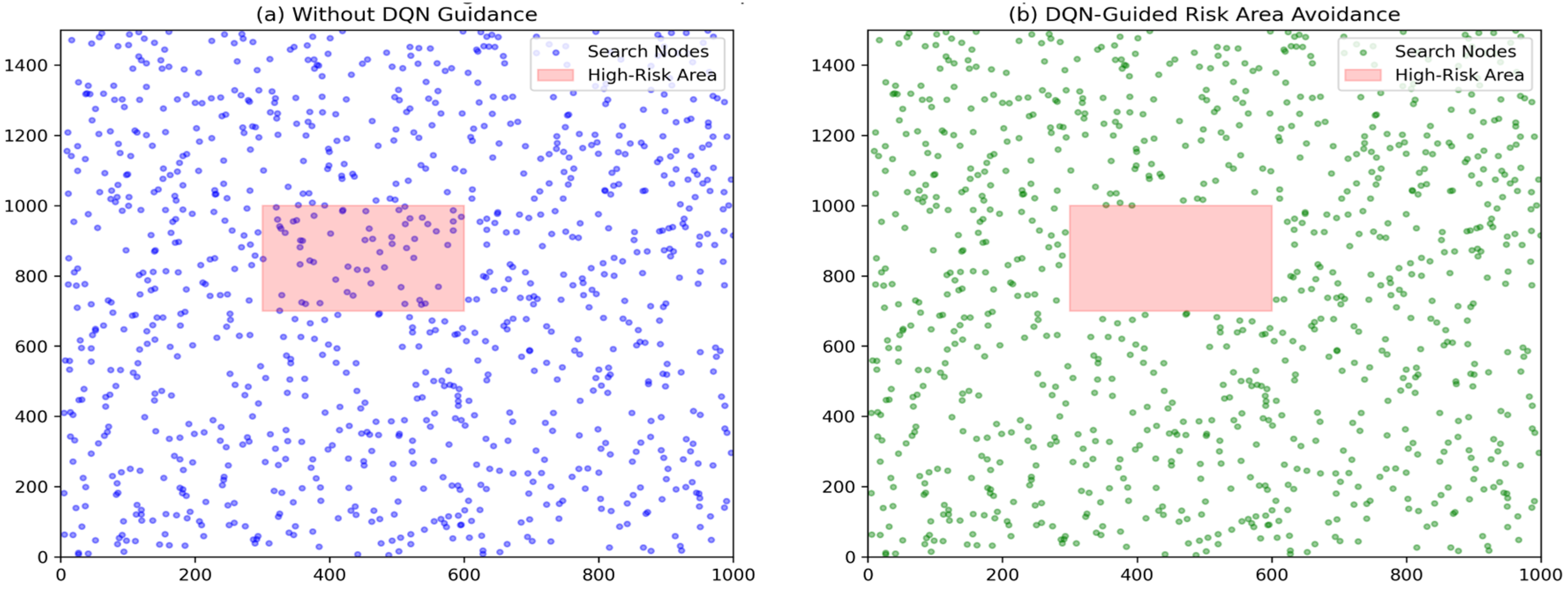
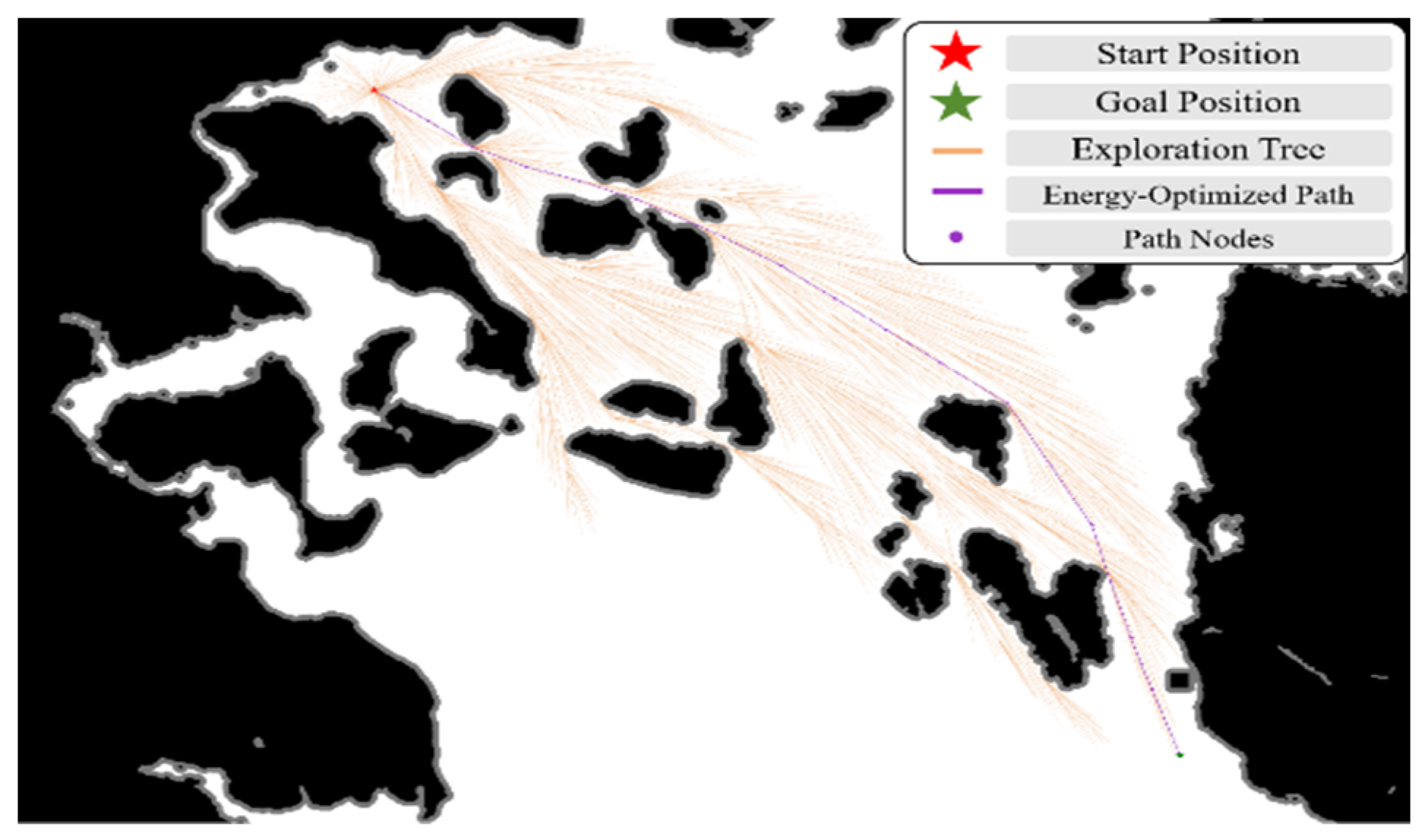
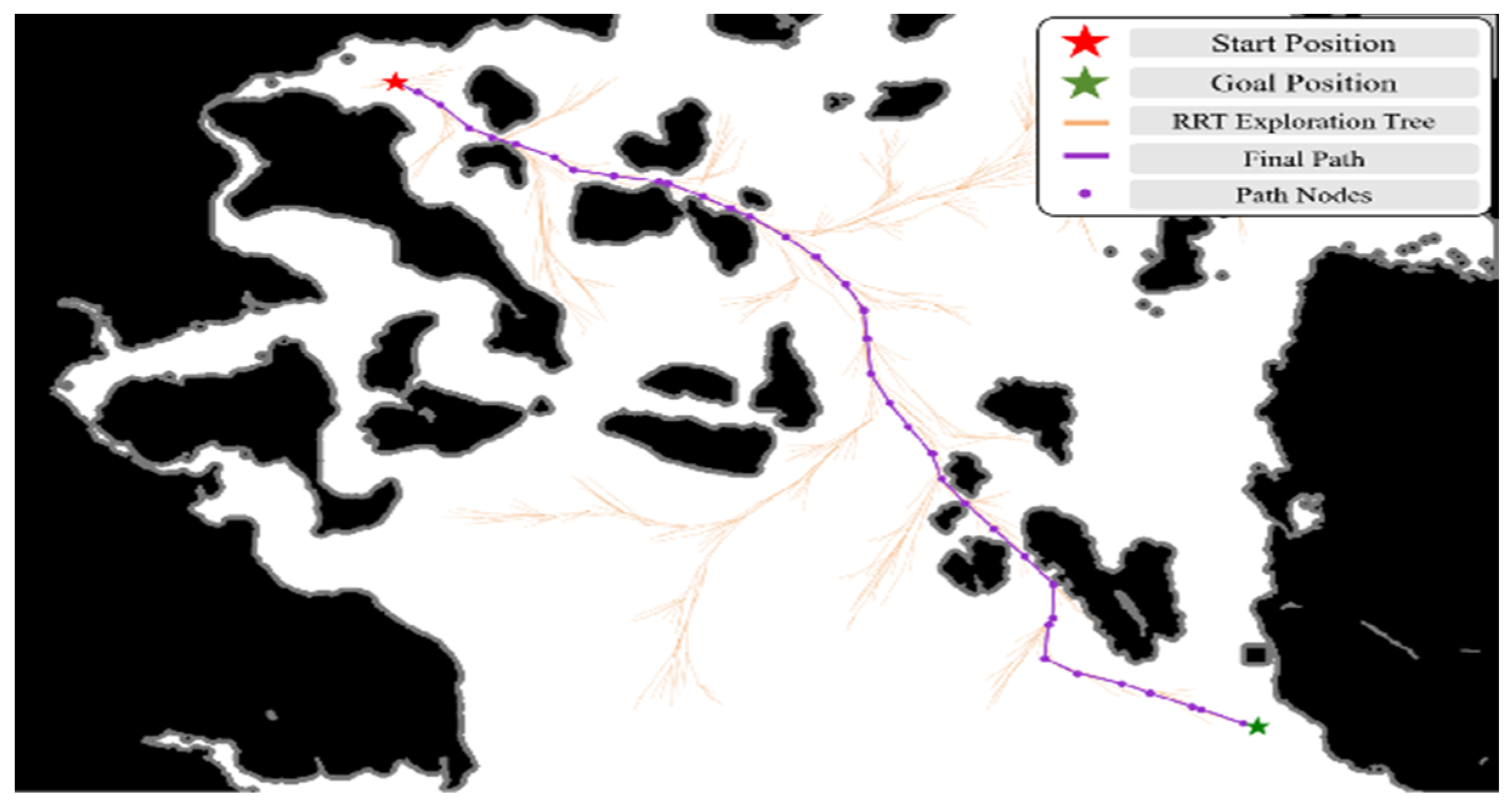
Ten randomly generated dynamic obstacles are superimposed on the Achao waterway map, their initial positions and speed directions are evenly and randomly distributed, and the speed amplitude is fixed at 1.5 pixels/second (about 0.3 times the actual speed). Reset the obstacle trajectory every 5 s to ensure that the training covers a variety of dynamic scenarios (see
Section 3.3.1).
4. Collaborative obstacle avoidance decision-making
DQN realizes active obstacle avoidance instead of passive replanning by predicting the obstacle motion trend (based on the velocity information in the state vector) and outputting the steering action in real time (such as the heading angle adjustment in Equation (5)).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}