
Semi-Supervised Underwater Image Enhancement Method Using Multimodal Features and Dynamic Quality Repository


Abstract
1. Introduction
2. Related Works
2.1. Underwater Image Enhancement Methods
2.2. Semi-Supervised Approaches
2.3. Contrastive Learning
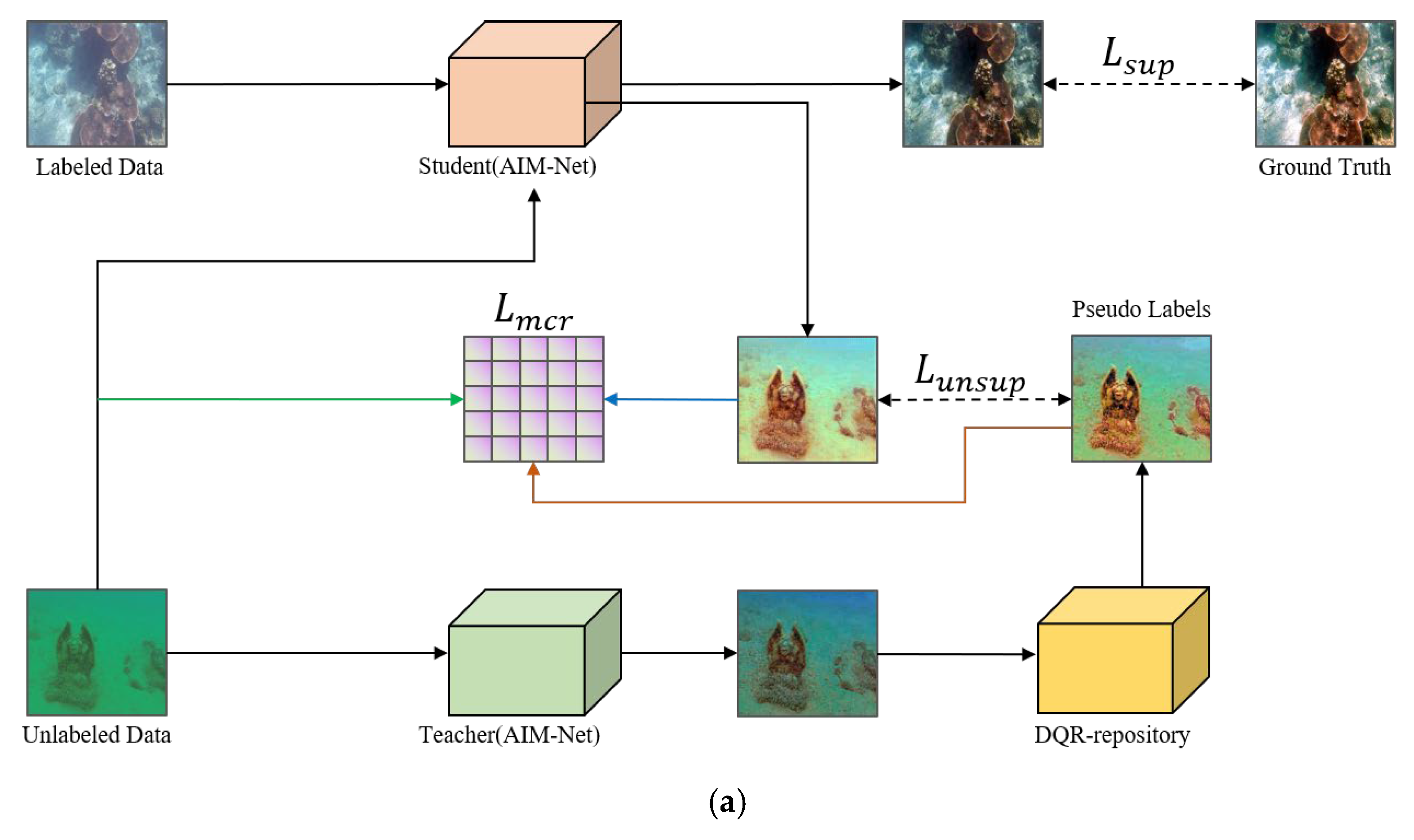
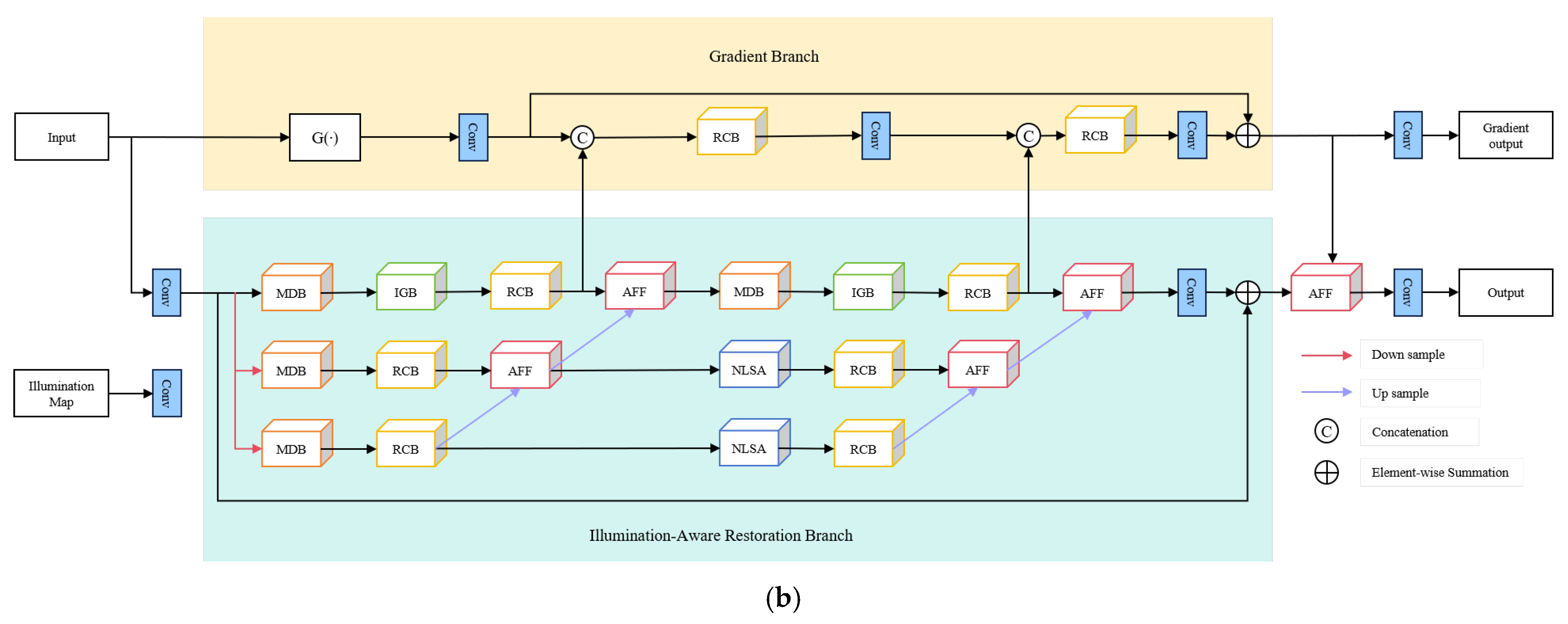
3. Methods
3.1. The Network Structure of MCR-UIE
3.2. Dynamic Quality and Reliability Repository
| Algorithm 1: Update of dynamic quality reliability repository |
| Require: NR-IQA method , Entropy metric , Local region split function ; Initialize: ; Sample a batch of unlabeled images from ; for each do Get teacher’s prediction: ; Get student’s prediction: ; Compute enhanced quality scores for , , and ; Split each prediction into local regions: using ; Compute NR-IQA scores of each region for teacher prediction: ; Compute NR-IQA scores of each region for student prediction: ; Compute NR-IQA scores of each region for existing reliable bank sample: . Aggregate regional scores with weighted mean for global score: if and then Replace the by ; end if end for |
3.3. Multimodal Contrastive Loss
3.3.1. VGG Feature Contrastive Loss
3.3.2. Edge Feature Contrastive Loss
3.3.3. Color Feature Contrastive Loss
3.3.4. Local Region Contrastive Loss
4. Experimental Results
4.1. Datasets and Settings
4.1.1. Software Configuration
4.1.2. Introduction to Dataset
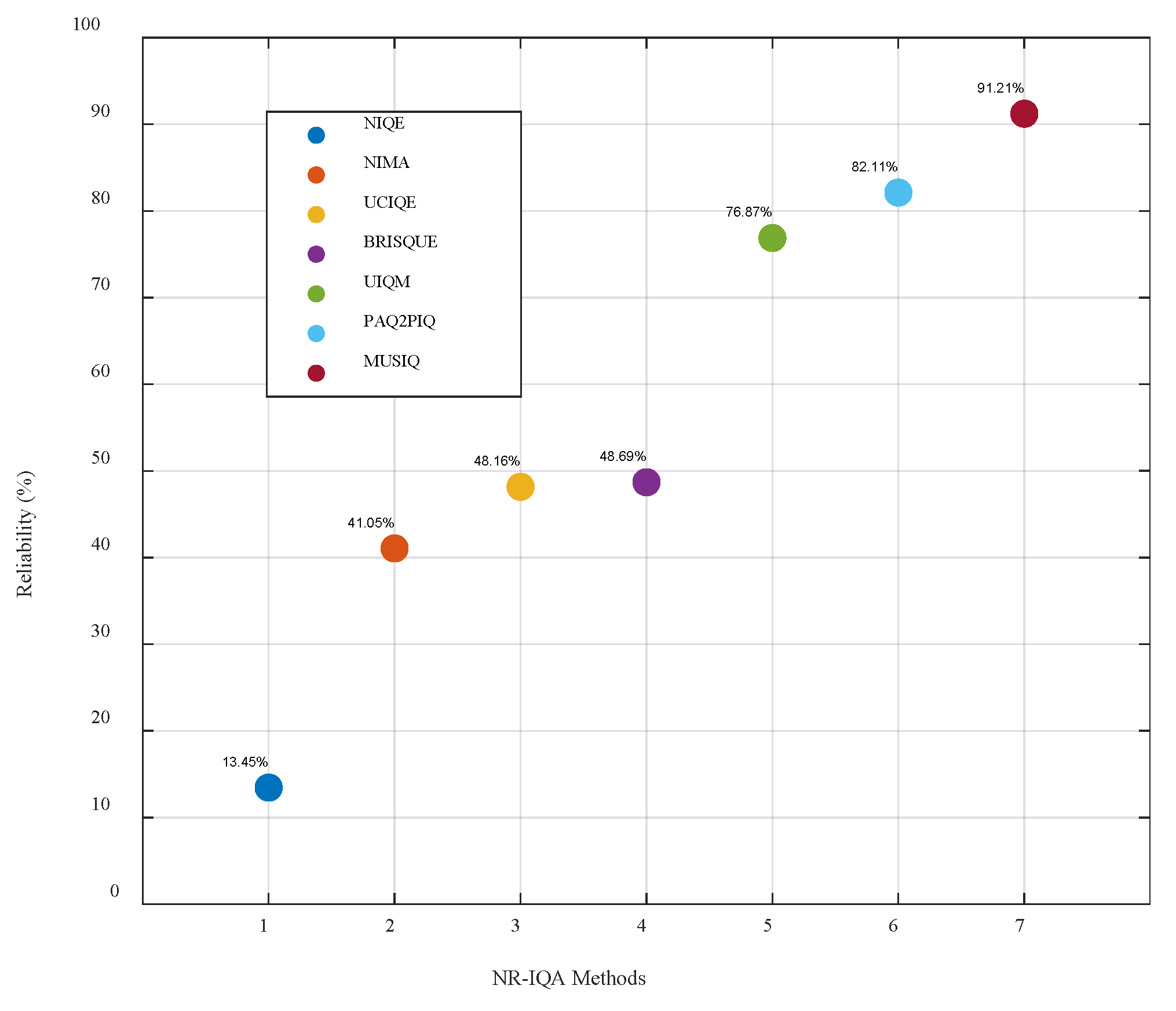
4.1.3. Evaluation Metrics
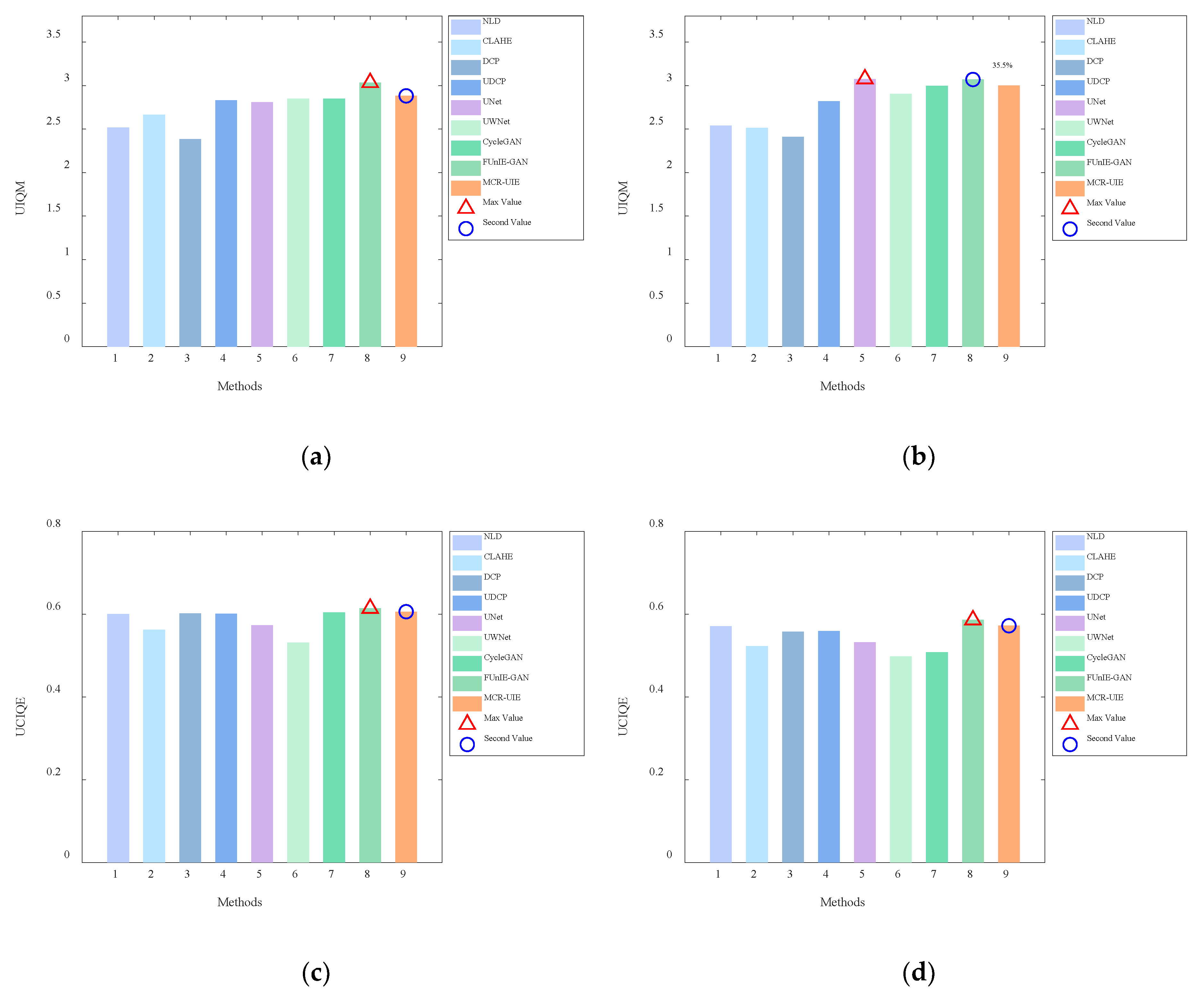
4.2. Enhanced Experiments on Public Datasets
4.3. Enhanced Experiments on Deep-Sea Cage Dataset
4.4. Ablation Experiments
4.5. Deployment Feasibility
4.6. Analysis of Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shuang, X.; Zhang, J.; Tian, Y. Algorithms for improving the quality of underwater optical images: A comprehensive review. Signal Process. 2024, 219, 109408. [Google Scholar] [CrossRef]
- Rout, D.K.; Kapoor, M.; Subudhi, B.N.; Thangaraj, V.; Jakhetiya, V.; Bansal, A. Underwater visual surveillance: A comprehensive survey. Ocean Eng. 2024, 309, 118367. [Google Scholar] [CrossRef]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2822–2837. [Google Scholar] [CrossRef]
- Galdran, A.; Pardo, D.; Picón, A.; Alvarez-Gila, A. Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 2015, 26, 132–145. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, T.; Dong, J.; Yu, H. Underwater image enhancement via extended multi-scale Retinex. Neurocomputing 2017, 245, 1–9. [Google Scholar] [CrossRef]
- Zuiderveld, K.J. Contrast limited adaptive histogram equalization. Graph. Gems 1994, 4, 474–485. [Google Scholar]
- Wen, Z.; Zhao, Y.; Gao, F.; Su, H.; Rao, Y.; Dong, J. NUAM-Net: A Novel Underwater Image Enhancement Attention Mechanism Network. J. Mar. Sci. Eng. 2024, 12, 1216. [Google Scholar] [CrossRef]
- Zhang, B.; Fang, J.; Li, Y.; Wang, Y.; Zhou, Q.; Wang, X. GFRENet: An Efficient Network for Underwater Image Enhancement with Gated Linear Units and Fast Fourier Convolution. J. Mar. Sci. Eng. 2024, 12, 1175. [Google Scholar] [CrossRef]
- Zhao, S.; Mei, X.; Ye, X.; Guo, S. MSFE-UIENet: A Multi-Scale Feature Extraction Network for Marine Underwater Image Enhancement. J. Mar. Sci. Eng. 2024, 12, 1472. [Google Scholar] [CrossRef]
- Yang, J.; Zhu, S.; Liang, H.; Bai, S.; Jiang, F.; Hussain, A. PAFPT: Progressive aggregator with feature prompted transformer for underwater image enhancement. Expert Syst. Appl. 2025, 262, 125539. [Google Scholar] [CrossRef]
- Xiang, D.; He, D.; Sun, H.; Gao, P.; Zhang, J.; Ling, J. HCMPE-Net: An unsupervised network for underwater image restoration with multi-parameter estimation based on homology constraint. Opt. Laser Technol. 2025, 186, 112616. [Google Scholar] [CrossRef]
- Fu, F.; Liu, P.; Shao, Z.; Xu, J.; Fang, M.M.-G. A multi-scale evolutionary generative adversarial network for underwater image enhancement. J. Mar. Sci. Eng. 2024, 12, 1210. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, K.; Wei, H.; Chen, W.; Zhao, T. Underwater image quality optimization: Researches, challenges, and future trends. Image Vis. Comput. 2024, 146, 104995. [Google Scholar] [CrossRef]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Huang, S.; Wang, K.; Liu, H.; Chen, J.; Li, Y. Contrastive semi-supervised learning for underwater image restoration via reliable bank. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18145–18155. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Bekaert, P. Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2017, 27, 379–393. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.-H.; Li, G.; Kwong, S.; Li, C. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Kar, A.; Dhara, S.K.; Sen, D.; Biswas, P.K. Zero-shot single image restoration through controlled perturbation of koschmieder’s model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16205–16215. [Google Scholar]
- Wang, K.; Hu, Y.; Chen, J.; Wu, X.; Zhao, X.; Li, Y. Underwater image restoration based on a parallel convolutional neural network. Remote Sens. 2019, 11, 1591. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Miyato, T.; Maeda, S.-i.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.-L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Wang, Y.; Wang, H.; Shen, Y.; Fei, J.; Li, W.; Jin, G.; Wu, L.; Zhao, R.; Le, X. Semi-supervised semantic segmentation using unreliable pseudo-labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4248–4257. [Google Scholar]
- Wang, L.; Yoon, K.-J. Semi-supervised student-teacher learning for single image super-resolution. Pattern Recognit. 2022, 121, 108206. [Google Scholar] [CrossRef]
- Zhu, H.; Han, X.; Tao, Y. Semi-supervised advancement of underwater visual quality. Meas. Sci. Technol. 2020, 32, 015404. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Liang, D.; Li, L.; Wei, M.; Yang, S.; Zhang, L.; Yang, W.; Du, Y.; Zhou, H. Semantically contrastive learning for low-light image enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 1555–1563. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10551–10560. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Han, J.; Shoeiby, M.; Malthus, T.; Botha, E.; Anstee, J.; Anwar, S.; Wei, R.; Armin, M.A.; Li, H.; Petersson, L. Underwater image restoration via contrastive learning and a real-world dataset. Remote Sens. 2022, 14, 4297. [Google Scholar] [CrossRef]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5148–5157. [Google Scholar]
- Liu, Y.; Zhu, L.; Pei, S.; Fu, H.; Qin, J.; Zhang, Q.; Wan, L.; Feng, W. From synthetic to real: Image dehazing collaborating with unlabeled real data. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 50–58. [Google Scholar]
- Heo, B.; Chun, S.; Oh, S.J.; Han, D.; Yun, S.; Kim, G.; Uh, Y.; Ha, J.-W. Adamp: Slowing down the slowdown for momentum optimizers on scale-invariant weights. arXiv 2020, arXiv:2006.08217. [Google Scholar]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef] [PubMed]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Naik, A.; Swarnakar, A.; Mittal, K. Shallow-uwnet: Compressed model for underwater image enhancement (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 15853–15854. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]


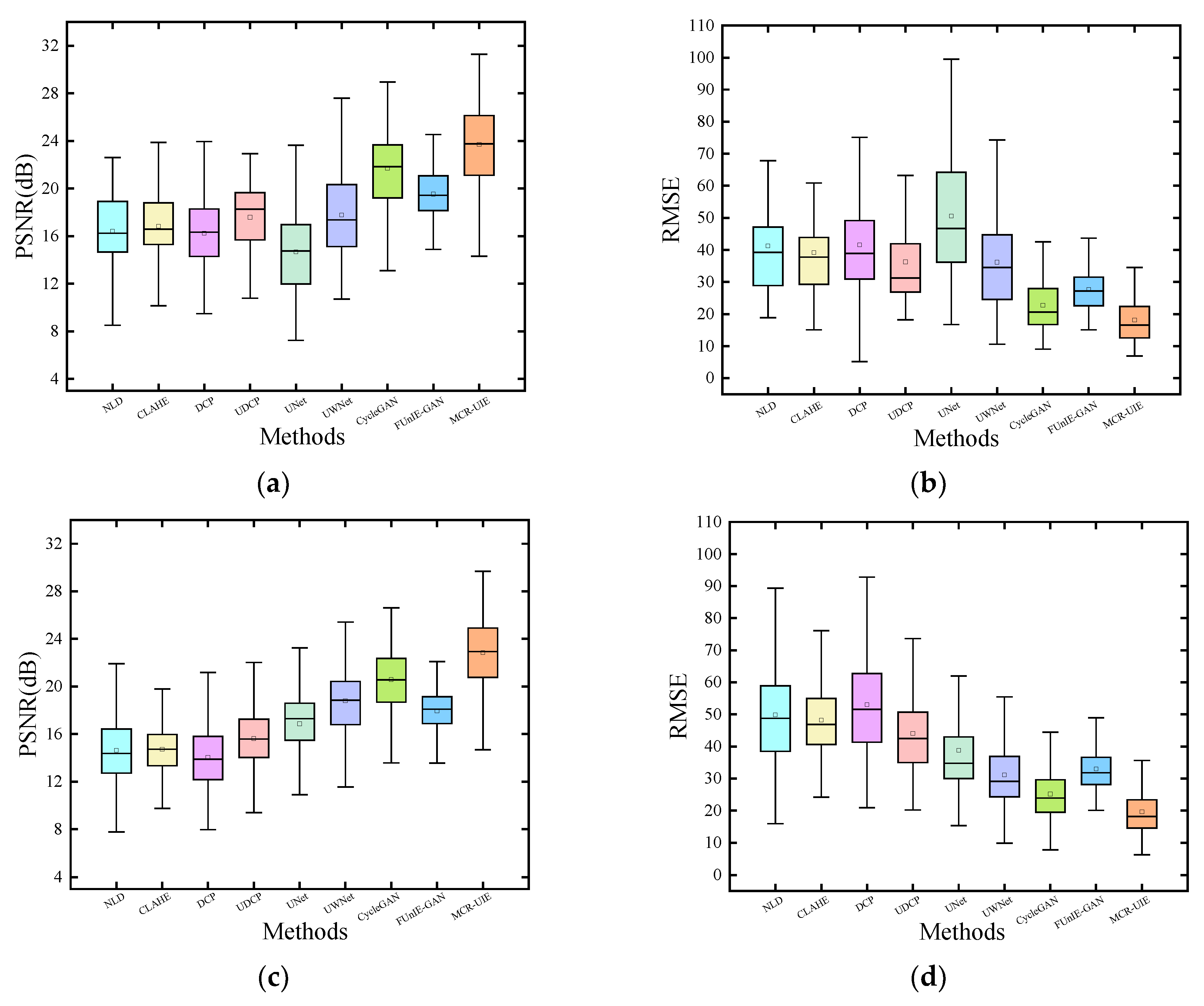






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | UIEB | LSUI | ||||
|---|---|---|---|---|---|---|
| PSNR ↑ (dB) | SSIM ↑ | RMSE ↓ | PSNR ↑ | SSIM ↑ | RMSE ↓ | |
| NLD | 16.416 | 0.708 | 41.261 | 14.629 | 0.694 | 49.862 |
| CLAHE | 16.812 | 0.751 | 39.182 | 14.713 | 0.744 | 48.154 |
| DCP | 16.526 | 0.713 | 41.558 | 14.025 | 0.694 | 52.976 |
| UDCP | 17.478 | 0.752 | 36.284 | 15.613 | 0.756 | 43.976 |
| UNet | 14.668 | 0.706 | 50.550 | 16.851 | 0.772 | 38.738 |
| UWNet | 17.771 | 0.759 | 36.146 | 18.782 | 0.783 | 31.139 |
| CycleGAN | 21.723 | 0.795 | 22.694 | 20.570 | 0.784 | 25.124 |
| FUnIE-GAN | 19.524 | 0.784 | 27.584 | 17.948 | 0.777 | 32.951 |
| MCR-UIE | 23.698 | 0.851 | 18.089 | 22.835 | 0.865 | 19.612 |
| Method | UIQM ↑ | UCIQE ↑ | ||
|---|---|---|---|---|
| UIEB | LSUI | UIEB | LSUI | |
| NLD | 2.518 | 2.540 | 0.600 | 0.571 |
| CLAHE | 2.665 | 2.515 | 0.562 | 0.523 |
| DCP | 2.386 | 2.410 | 0.602 | 0.558 |
| UDCP | 2.829 | 2.821 | 0.601 | 0.559 |
| UNet | 2.810 | 3.075 | 0.573 | 0.532 |
| UWNet | 2.849 | 2.905 | 0.531 | 0.498 |
| CycleGAN | 2.850 | 2.997 | 0.604 | 0.508 |
| FUnIE-GAN | 3.033 | 3.069 | 0.614 | 0.586 |
| MCR-UIE | 2.881 | 3.000 | 0.606 | 0.572 |
| Method | UIEB | LSUI | ||||
|---|---|---|---|---|---|---|
| PSNR ↑ | SSIM ↑ | RMSE ↓ | PSNR ↑ | SSIM ↑ | RMSE ↓ | |
| Semi-base | 22.985 | 0.847 | 19.503 | 21.982 | 0.850 | 22.003 |
| Semi-base + DQR | 23.201 | 0.848 | 19.013 | 22.285 | 0.861 | 20.892 |
| Semi-base + MCL1 | 21.902 | 0.837 | 22.205 | 21.165 | 0.785 | 26.121 |
| Semi-base + MCL2 | 22.282 | 0.840 | 21.145 | 21.784 | 0.845 | 22.309 |
| Semi-base + MCL3 | 22.562 | 0.844 | 20.355 | 22.030 | 0.853 | 21.817 |
| Semi-base + MCL4 | 21.898 | 0.836 | 22.670 | 19.826 | 0.835 | 30.048 |
| Semi-base + MCL | 22.759 | 0.838 | 20.977 | 22.356 | 0.849 | 23.151 |
| MCR-UIE | 23.698 | 0.851 | 18.089 | 22.835 | 0.865 | 19.612 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, M.; Li, G.; Hu, Y.; Liu, H.; Hu, Q.; Huang, X. Semi-Supervised Underwater Image Enhancement Method Using Multimodal Features and Dynamic Quality Repository. J. Mar. Sci. Eng. 2025, 13, 1195. https://doi.org/10.3390/jmse13061195
Ding M, Li G, Hu Y, Liu H, Hu Q, Huang X. Semi-Supervised Underwater Image Enhancement Method Using Multimodal Features and Dynamic Quality Repository. Journal of Marine Science and Engineering. 2025; 13(6):1195. https://doi.org/10.3390/jmse13061195
Chicago/Turabian StyleDing, Mu, Gen Li, Yu Hu, Hangfei Liu, Qingsong Hu, and Xiaohua Huang. 2025. "Semi-Supervised Underwater Image Enhancement Method Using Multimodal Features and Dynamic Quality Repository" Journal of Marine Science and Engineering 13, no. 6: 1195. https://doi.org/10.3390/jmse13061195
APA StyleDing, M., Li, G., Hu, Y., Liu, H., Hu, Q., & Huang, X. (2025). Semi-Supervised Underwater Image Enhancement Method Using Multimodal Features and Dynamic Quality Repository. Journal of Marine Science and Engineering, 13(6), 1195. https://doi.org/10.3390/jmse13061195