1. Introduction
Terrestrial resources are insufficient to meet the demands of human development. Thus, the development of marine resources, which cover 71% of the Earth’s surface [
1], is crucial. Underwater robots are vital for exploring these resources, where underwater optical images serve as the “eyes” of these robots, providing essential data and information for researchers [
2].
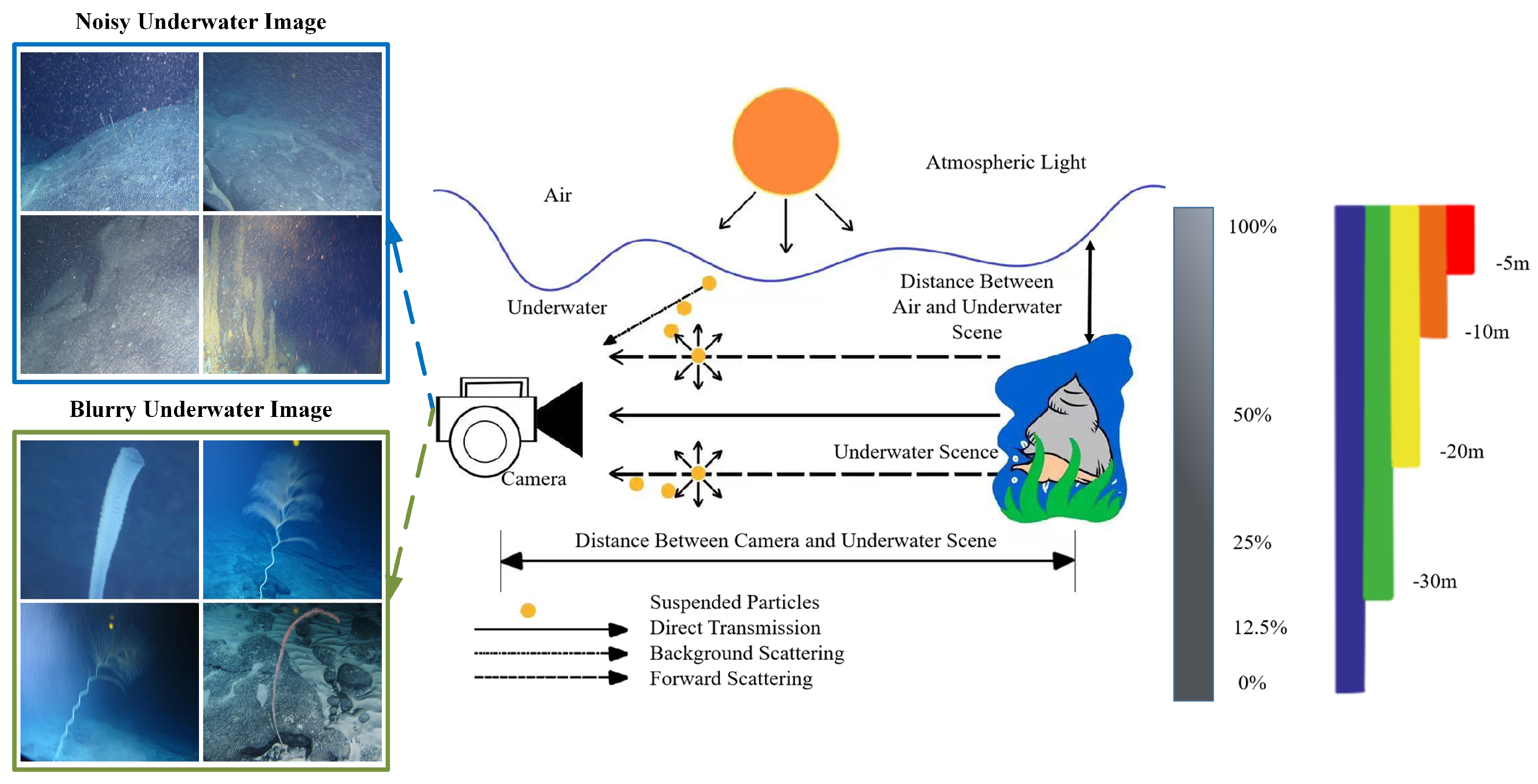
The underwater imaging environment is influenced by factors such as marine organisms, suspended particles, and poor lighting conditions, which makes it more complex than imaging on land. Underwater images often exhibit a low contrast, color distortion, and blurred details [
3]. The movement of underwater robots can further exacerbate these issues, particularly due to particles, including marine organisms, floating feces, suspended sediments, and other inorganic matter. These particles vary in size, shape, and transparency. Scattering occurs when underwater light encounters small particles and is reflected back to the camera, resulting in a low contrast and blurriness in the captured images, as shown in
Figure 1. Underwater optical images exhibit color distortion and are influenced by many impurities and motion blur. Consequently, these images cannot be directly used for target detection and require additional restoration.
The underwater environment is complex and dynamic, with suspended particles, light scattering, and light absorption, leading to color distortion and low contrast. The environment is also often accompanied by marine snow noise caused by plankton or sediment particles. Therefore, multiple issues must be simultaneously considered when dealing with severely degraded underwater optical images under complex lighting conditions, including the removal of marine snow noise, the restoration of blurring, and the basic color correction task. However, most of the existing methods focus on solving one problem at a time. Therefore, these isolated techniques struggle to maintain consistency when addressing multiple degradation factors simultaneously, and consequently, they do not achieve the desired visual results [
4].
Furthermore, datasets designed for the multi-task restoration of complex underwater optical images are lacking. In particular, when dealing with varying lighting conditions, marine snow noise levels, and water composition, existing datasets lack the diversity required to represent diverse, complex scenarios, limiting the generalizability of current research [
5].
Existing methods for restoring underwater optical images typically focus on color correction and enhancement rather than addressing impurity occlusion and blurriness in real underwater images. Moreover, the lack of publicly available datasets further complicates the restoration process [
6]. To address these challenges, Mei et al. [
7] proposed the Underwater Image Enhancement Benchmark Dataset (UIEBD-Snow dataset) to explore underwater optical image restoration involving impurities. However, datasets for restoring underwater images affected by motion blur are lacking.
Underwater image restoration is challenging, requiring color correction, impurity removal, and compensation for motion blur [
8]. From a global perspective, restoration can be divided into two main parts: impurity removal and image enhancement. With the widespread application of deep learning technology, most underwater image enhancement and restoration methods often rely on pure convolutional neural network (CNN) structures or U-shape Transformer structures. A CNN offers several advantages. However, its small receptive field makes it challenging to capture global features. Conversely, visual Transformers, such as U-shape Transformers, have been used for restoration tasks in underwater imaging tasks based on their ability to capture global information [
9]. However, Transformers often lack the translation invariance and local correlation characteristics of a CNN, consequently requiring a large volume of training data to surpass CNN’s performance. Therefore, combining the Transformer with a CNN to optimize their advantages and preserve global and local features is promising. Ordinary Transformer visual entities vary considerably because different shooting angles of the same object can lead to notable differences in binary images. Additionally, the performance of visual Transformers may vary across different scenarios. When dealing with high-resolution, pixel-dense images, the Vision Transformer model incurs a computational cost proportional to the square of the pixels due to self-attention [
10].
Given the above background, this article introduces TFCNet, a network that integrates CNN-based local features and Transformer-based global representations. TFCNet incorporates the Transformer for encoding and CNN for decoding. TFCNet considerably enhances the quality of underwater image restoration by combining the Transformer’s focus on global information with the CNN’s ability to use underlying image features. Simultaneously, we propose an additional underwater image restoration dataset, UIEBD-Blur, by building on the UIEBD-Snow dataset to account for blurring. TFCNet has demonstrated promising results using the UIEBD-Snow and UIEBD-Blur datasets and can concurrently perform color correction, denoising, and deblurring for underwater images. In summary, the contributions of this article include the following:
- 1.
This paper proposes TFCNet, a multi-task restoration method for underwater optical images, which is based on a hybrid architecture. It integrates a Swin Transformer-based encoder module with spatial adaptivity to efficiently capture global image features. The decoder module, comprising a CNN without activation functions, reduces computational complexity.
- 2.
This paper introduces the UIEBD-Blur dataset, which was specifically designed for motion blur recovery in underwater optical images. Experiments using the UIEBD-Blur and UIEBD-Snow datasets demonstrated that TFCNet achieved superior visual outcomes in marine snow noise removal and color correction.
- 3.
This study validated the feasibility of TFCNet in enhancing and restoring complex underwater optical images and its superiority to other methods. Ablation experiments further investigated the effectiveness of the hybrid architecture by evaluating the contributions of the Transformer-based encoder and CNN-based decoder within the framework.
2. Related Works
In underwater image restoration research, scholars focus on image enhancement and color correction techniques. These techniques can be categorized into three main types: model-free, model-based, and deep learning-based methods. K. Iqbal et al. [
11] proposed an unsupervised color correction method for enhancing underwater images. This method is based on color balancing and contrast correction of the RGB and HSI color models. Hitam et al. [
12] introduced the CLAHE method, which combines results from the RGB and HSV color models using Euclidean norms. Fu et al. [
13] developed a widely used classical method based on retinex. Drews et al. [
14] proposed Underwater DCP (UDCP), which applies adaptive DCP to estimate underwater scene transmission. Peng et al. [
15] introduced Generalized DCP (GDCP) for image restoration, incorporating adaptive color correction into the image formation model. In addition, Mei et al. [
16] proposed a method based on the optical geometric properties. These methods enhance underwater image details; however, they often excessively amplify noise and distort colors, occasionally resulting in over-enhancement. Fu et al. [
17] proposed a network based on probabilistic methods to obtain the enhancement distribution for degraded underwater images. Li et al. [
18] developed WaterGAN, a network based on the generative adversarial network (GAN), to generate datasets of underwater images using air and depth pairings. These datasets are used for the unsupervised pipeline-based color correction of underwater images. Wang et al. [
19] introduced UWdepth, a self-supervised model that obtains depth information from underwater scenes using monocular sequences. This depth information is subsequently used to enhance underwater images. Fabbri et al. [
20] developed UGAN, a GAN-based model, to improve underwater image quality. Han et al. [
21] designed their method by leveraging contrastive learning and generative adversarial networks to maximize the mutual information between raw and restored images. Islam et al. [
22] presented a model based on conditional generative adversarial networks to enhance underwater images in real time. In addition, Zhou et al. [
23] researched underwater image enhancement using deep learning techniques.
However, existing methods for enhancing underwater images only address color correction and do not fully satisfactorily restore underwater images degraded by visual impurities. This remains a challenge in the field. A few methods are available for removing impurities and blurring from underwater images, and even fewer methods can simultaneously enhance the image.
Jiang et al. [
24] proposed a UDnNet network based on a GAN with skip connections to model the mapping relationship in underwater optical images contaminated by marine snow noise. This method generates marine-snow-free optical images from noisy inputs, partially suppressing noise. However, its limitations include high computational costs and lengthy training cycles. Sun et al. [
25] introduced a CNN called NR-CCNet, which incorporates a recurrent learning strategy and an attention mechanism to address marine snow noise. This approach reduces noise to some extent; however, its restoration performance remains unsatisfactory. Sun et al. [
26] developed a progressive multi-branch embedded fusion network to further improve the performance. This framework uses a dual-branch hybrid encoder–decoder module equipped with a triple attention mechanism to fuse distorted images and their sharpened versions, focusing on noisy regions and learning contextual features. It progressively learns a nonlinear mapping from degraded inputs, and the final output is refined and enhanced using a three-branch hybrid encoder–decoder module at each stage. Nevertheless, the multi-branch architecture increases the model complexity, and its effectiveness in marine snow noise removal remains limited because the network primarily targets underwater optical image enhancement.
Furthermore, image enhancement and restoration methods developed for atmospheric conditions also provide some valuable insights for marine snow noise removal.
The authors of [
27] advocated for a revised median filter as a potent approach to mitigate the effects of underwater contaminants on these images. DB-ResNet [
28] is a specialized structure, termed a “deep detail network”, which was specifically designed to remove natural raindrop patterns from captured images. A deep residual network (ResNet) is a parameter layer that encapsulates more complex image features and streamlines the network’s structure by reducing the mapping distance between the input and output features. Other authors [
29] proposed a progressive optimization residual network (Progressive ResNet (PRN)) and a progressive recurrent network (PReNet) for image de-raining. Ren et al. [
29] introduced PRN and a progressive recurrent network (PReNet) for image deraining. Maxim [
30] is the latest MLP-based U-Net backbone network that combines global and local perceptual fields and can be directly applied to high-resolution images. Restormer [
31] is an efficient Transformer that incorporates several pivotal enhancements in the design of its improved multi-head attention and feed-forward networks. Multi-stage progressive restoration network (MPRNet) [
32] is an innovative, collaborative design with a multi-stage structure aimed at learning the recovery features of degraded inputs while decomposing the entire recovery process. MPRNet learns context-dependent features using an encoder–decoder architecture and subsequently combines them with high-resolution branches that better preserve local information.
These methods are highly competitive in natural image restoration in the air; however, land-based and underwater imaging models cannot be used interchangeably. Sato et al. [
33] proposed an underwater image restoration dataset multi-scale residual block (MSRB), which only performs underwater image denoising and cannot perform color correction. Mei et al. [
7] proposed a lightweight baseline named UIR-Net, which simultaneously recovers and enhances underwater images while achieving notable recovery results. However, it still encounters limitations in color correction.
3. Method
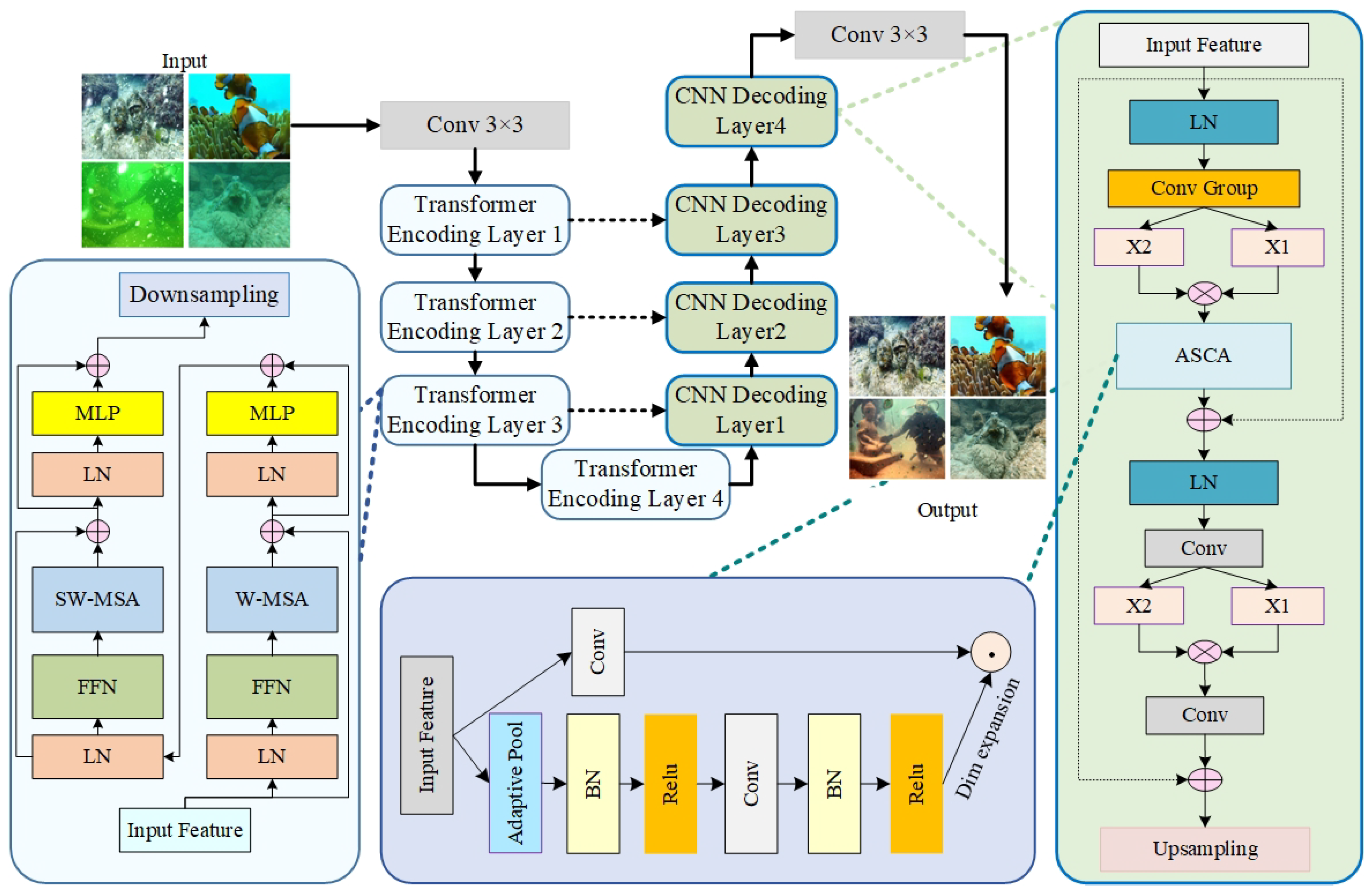
Achieving satisfactory results for complex underwater optical image enhancement and restoration tasks using either a single Transformer architecture or a single convolutional neural network (CNN) structure is challenging.
To address these challenges, a hybrid architecture model is proposed in this study. This approach aims to maximize the local features and global representations by leveraging the strengths of the Transformer and CNN structures. The proposed multi-task restoration network, TFCNet, which is based on this hybrid architecture, is illustrated in
Figure 2.
3.1. The Overall Structure of TFCNet
TFCNet integrates the strengths of the Transformer and CNN models. Transformers focus on global information but often overlook details at low resolutions, which impedes the decoder’s ability to restore the pixel size, frequently leading to coarse results. Conversely, CNN models can effectively compensate for this limitation of Transformers. Thus, combining these two models presents greater advantages.
The entire TFCNet network adopts a hierarchical design encompassing eight stages. Initially, the encoder section serves as the core of TFCNet. Each stage begins by reducing the resolution of the input feature map through the Swin Transformer and downsampling layers, executing downsampling and progressively expanding the receptive field to capture global information. The encoder initially applies four stages of Swin Transformer structures to the input image, embedding image blocks obtained through the CNN into the feature map, necessitating positional encoding. Subsequently, the features extracted by the Transformer are passed on to the decoder, which uses conventional transposed convolution upsampling to restore the image pixels.
The overall processing pipeline is as follows: the underwater optical image requiring enhancement and restoration is the TFCNet network input. Considering the UIEBD-Blur dataset as an example, where represents the complex underwater optical image to be restored, the processing steps of the TFCNet encoder module can be simplified as follows:
The first-layer encoder module, based on the Swin Transformer architecture, is computed as follows:
The encoder modules in the second to fourth layers, based on the Swin Transformer architecture, are computed as follows:
where
W_
i represents the weight matrix of the
i-th layer encoder module based on the Swin Transformer architecture,
B_
i denotes the bias term of the
i-th layer encoder module, and
f_
i corresponds to the activation function of the
i-th layer encoder module.
Subsequently, the processing steps of the decoder module, which is based on the CNN architecture, can be simplified as follows:
The first-layer decoder module, based on the CNN architecture, is computed as follows:
The decoder modules in the second to fourth layers, based on the CNN architecture, are computed as follows:
where
represents the weight matrix of the
i-th layer decoder module based on the CNN architecture,
denotes the bias term of the
i-th layer decoder module, and
g_
i corresponds to the activation function of the
i-th layer decoder module.
The output layer of TFCNet is as follows:
where
W_
o is the weight matrix, and
B_
o is the bias of the output layer.
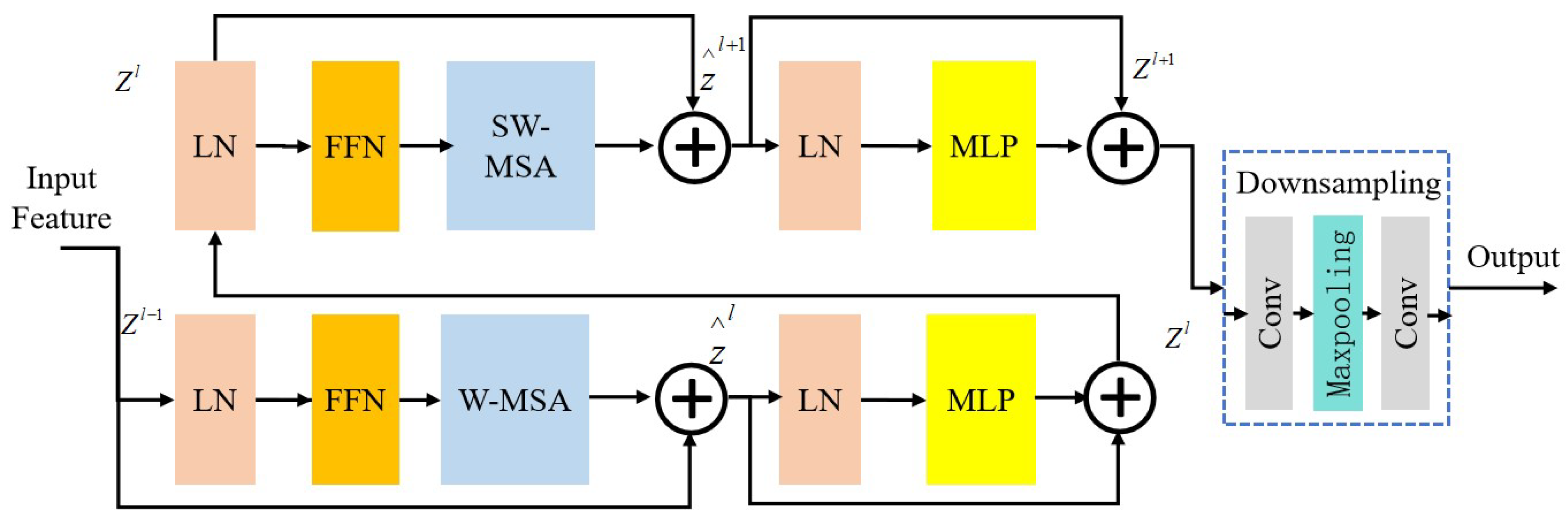
3.2. Encoding Network Design
The TFCNet network comprises four encoder modules based on the Swin Transformer structure and adopts a five-stage hierarchical design. Each stage progressively reduces the resolution of the input feature map and gradually expands the receptive field, akin to a CNN. The structure of the module, as
Figure 3 illustrates, includes layer normalization, feature fusion normalization, a multi-layer perceptron, and an attention mechanism module.
In addition to the fundamental Swin Transformer module, a feature fusion normalization module is incorporated to further refine the layer-normalized features. Specifically, the image features processed via layer normalization undergo max and average pooling to extract high-frequency and global features, respectively. These features are then fused through stacking and convolutional operations. Subsequently, a sigmoid function is applied to obtain feature weight information, which is used to derive the feature information after suppressing the marine snow noise.
The computational workflow of each Swin Transformer-based encoder module in the TFCNet network is detailed as follows:
where
represents the window-based multi-head self-attention operation,
denotes the min-max normalization, and
corresponds to the layer normalization.
where
MLP() represents the multi-layer perceptron operation.
where
represents the shifted window-based multi-head self-attention operation.
where
and
represent the output features of the attention mechanism modules in each module. Finally, after further downsampling operations, the corresponding feature information is the output.
3.3. Decoding Network Design
The system becomes correspondingly complex because the complex multi-task restoration of underwater optical images necessitates simultaneous color correction, marine snow noise elimination, and blur restoration. Under such circumstances, nonlinear activation functions, such as Sigmoid, ReLU, GELU, and Softmax, are not essential [
34]. Moreover, these nonlinear activation functions can be replaced by multiplication or directly removed. This ensures effective image enhancement and restoration and reduces the computational cost of the network. Guided by this concept, the TFCNet network constructs the decoder module based on a baseline network that does not require activation functions [
34].
Figure 4 reveals that in this decoder module, the structure before upsampling has eliminated the nonlinear functions. The Gated Linear Units, which can introduce nonlinear computations, are replaced by the product of two feature maps, denoted as
ϕ and
θ. This reduces the computational complexity of the decoder module to a certain degree, thereby enhancing the efficiency of TFCNet.
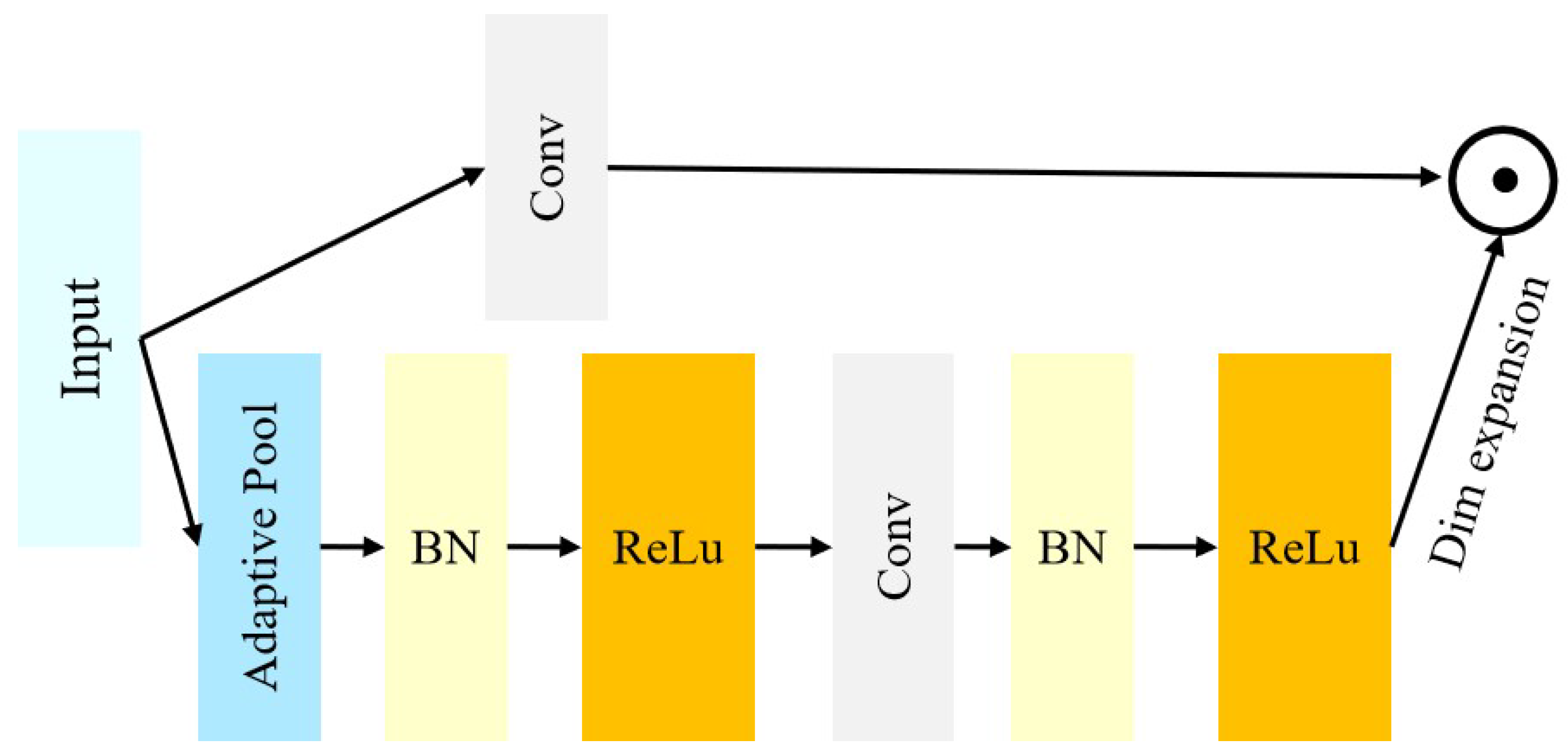
The Adaptive Spatial Channel Attention (ASCA) mechanism was introduced to accelerate the convergence speed of the model, mitigate the risk of overfitting, and stabilize the model. Building on the SCA attention mechanism, a batch normalization layer was added between two convolutional layers, speeding up the convergence of the model and reducing the overfitting risk. Additionally, extra convolutional layers and ReLU activation functions were incorporated to enhance the model’s nonlinear expressive capacity and aid in extracting more complex features.
Figure 5 illustrates the ASCA mechanism.
X represents the input feature map, and denotes the number of channels. Divide the number of channels of the input feature map by 2 for in_channels and by 4 for mid_channels. W_i and represent the weight and bias of the i-th conventional layer, respectively, and BN_i represents the i-th batch normalization layer. Finally, ReLU stands for the ReLU activation function.
Adaptive average pooling:
The computation formula for the
i-th convolutional layer is as follows:
The
i-th batch normalization layer:
The
i-th ReLU activation function:
Output: .
3.4. Loss Function
Regarding the loss function, this article adopts the commonly used loss functions in underwater image restoration,
and
, as follows:
where
= 0.8 and
= 0.2.
The
loss (Mean Absolute Error (MAE)) is the mean distance between the predicted value
x of the model and the true value
y. We used the
loss to measure the pixel level loss between the reference network and the training results as follows:
The SSIM (structural similarity) loss is considered an indicator for luminance, contrast, and structure, incorporating human visual perception. We can obtain it as follows:
where
,
, and
are as follows:
Therefore, we can determine
as follows:
4. Experimental Datasets and Discussion
4.1. Introduction to the Experimental Datasets
Experimental comparative analysis was conducted on two datasets, UIEBD-Snow and UIEBD-Blur, to verify the effectiveness and generalizability of the proposed method, which a focus on the impurities and motion blur in the underwater image restoration process. Both datasets are based on the commonly used public dataset UIEBD [
35].
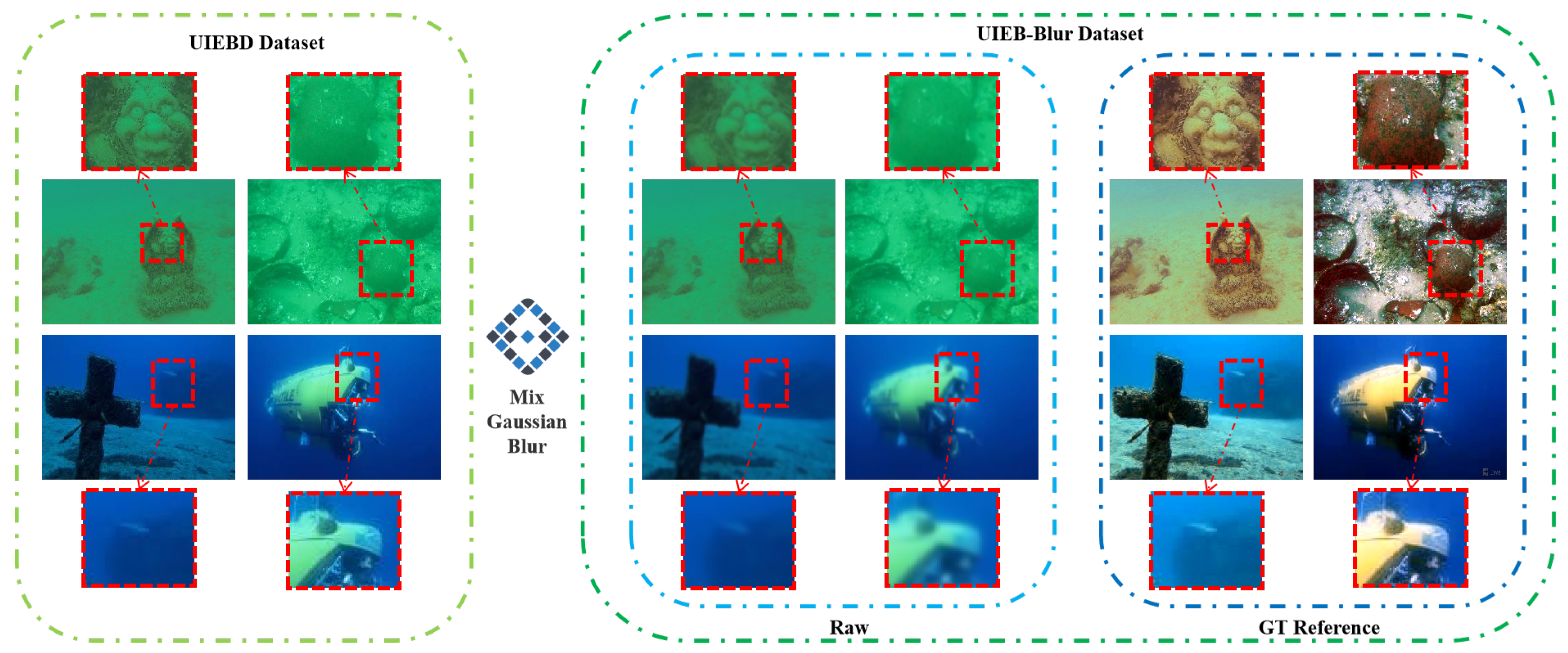
Figure 6 presents a schematic diagram of the UIEBD-Snow dataset construction.
Detail blurring in underwater optical images is expressed as a blur effect along a direction, with the extent of blurring being related to underwater imaging conditions and the speed of the underwater vehicle. Gaussian blur is a uniform blur treatment without direction. However, a directional kernel (motion blur kernel) was created in this study and combined with Gaussian blur to achieve a directional Gaussian blur effect, thereby simulating motion blur. The Gaussian function is the core concept of Gaussian blur.
Figure 7 illustrates the entire dataset construction process.
4.2. Training Parameter Settings
During the experimental process, the dataset was partitioned into 80% for training, 10% for testing, and 10% for validation. All other deep learning-based comparison methods were trained and tested using this identical data-splitting ratio.
The TFCNet model is an end-to-end trained model configured to perform underwater optical image enhancement and restoration tasks, encompassing color correction, denoising, and deblurring. Specifically, the Adam optimizer with an initial learning rate of was used. Considering the model depth, the warm-up strategy gradually improved the learning efficiency. The network was trained on a image patch that was randomly cropped from training images. The batch size was 4. The learning rate was . The number of epochs was 200. The model was trained on one 4090 GPU, which could be completed in 4 h.
4.3. Comparison with State-of-the-Art Methods for Underwater Image Enhancement
4.3.1. Qualitative Evaluations
The proposed method enhances and restores complex underwater optical images, including color correction. The experimental comparison includes four methods designed for underwater optical image enhancement with demonstrated effectiveness: Deepwave [
36], PUIENet [
17], Shallow [
37], and FUnIE-GAN [
22]. Additionally, three state-of-the-art methods for general optical image enhancement and restoration, DGUNet [
38], MPRNet [
32], and UIRNet [
7], were included.
The comparative results of TFCNet and other methods on the UIEBD-Snow dataset in
Figure 8 reveal that the methods solely designed for underwater optical image enhancement were ineffective at eliminating marine snow noise in complex underwater optical images. These methods focus on color correction and achieved suboptimal results owing to the interference of the marine snow noise. In contrast, DGUNet [
38], MPRNet [
32], and UIRNet [
7] demonstrated some success in mitigating the marine snow noise while achieving satisfactory results in color correction. However, when examining the details compared with the ground truth data of UIEBD-Snow, the results processed by the TFCNet network aligned more closely with the reference ground truth, where it outperformed other comparative methods overall. Furthermore, the experimental results on the UIEBD-Snow dataset indicate that the methods that exclusively target underwater optical image enhancement were insufficient for restoring the complex underwater scenes.
Figure 9 illustrates that Deepwave [
36], PUIENet [
17], and Shallow [
37] demonstrated strong color correction capabilities while training the UIEBD-Blur dataset. However, these methods are limited when removing blur. MPRNet [
32], DGUNet [
38], and UIRNet [
7] improved the color correction and blur removal. Nevertheless, when considering the overall results, the output processed by the TFCNet network aligned more closely with the reference ground truth data provided by the UIEBD-Blur dataset, where it demonstrated superior performance.
A comprehensive comparative analysis of
Figure 8 and
Figure 9 reveals that TFCNet, leveraging its hybrid architecture, effectively enhanced and restored the complex underwater optical images on the UIEBD-Snow and UIEBD-Blur datasets. This included fundamental color correction, more challenging marine snow noise elimination, and blur restoration tasks.
4.3.2. Quantitative Evaluation
We used standard metrics, such as PSNR, SSIM, and RMSE, to validate the superiority of our approach for full-reference evaluation [
39]. The PSNR quantifies the pixel-level fidelity by measuring the logarithmic ratio between the maximum signal power and noise distortion, making it sensitive to the absolute error magnitude. The SSIM evaluates the perceptual quality through luminance, contrast, and structure comparisons, emphasizing local pattern preservation and visual perception. The RMSE provides a direct, interpretable measure of the average pixel-wise deviation, which is particularly useful for physical accuracy validation in scientific applications. Additionally, we used the UCIQE [
40] and UIQM for no-reference evaluation, which are commonly used for assessing underwater image quality. The UIQM combines colorfulness, sharpness, and contrast measures to predict human visual preferences, while the UCIQE focuses on color distribution properties.
In the experimental evaluation using the UIEBD-Snow dataset in
Table 1, the highest score is highlighted in red, and the second-highest score is highlighted in blue. The results processed using the TFCNet network had the best values in the PSNR, SSIM, and RMSE metrics, where it outperformed other methods. TFCNet did not attain the highest score or the second-highest score in the UIQM and UICQE metrics; nonetheless, its performance remained close to the highest score. The four methods, namely, Deepwave [
36], PUIENet [
17], Shallow [
37], and FUnIE-GAN [
22], demonstrated distinct advantages when evaluated using the UIQM and UICQE metrics. However, when reference images are available, the UIQM and UCIQE prioritize perceptual enhancements over physical fidelity, often assigning higher scores to artificially processed images despite significant deviations from the ground truth, where handcrafted features fail to capture the structural distortions measurable by the SSIM or RMSE. In addition, combined with a qualitative analysis, these methods are limited to underwater optical image enhancement and are ineffective in marine snow noise elimination tasks, making them unsuitable for underwater optical image multi-task restoration. In contrast, the TFCNet network excels in these scenarios, producing cleaner, more natural results with fine-grained textures, as shown in
Figure 8.
In evaluating the experimental results of the UIEBD-Blur dataset, as in
Table 2, the highest score is highlighted in red, and the second-highest score is highlighted in blue. TFCNet demonstrated exceptional performance, surpassing other methods in the PSNR, SSIM, and RMSE. It achieved the second-highest score in the UIQM metric. TFCNet did not achieve the highest or second-highest score in the UICQE metric compared with Deepwave [
36] and PUIENet [
17]. Nonetheless, its results were close to the highest score. Combined with the performance
Figure 9 illustrates, TFCNet performed the best, where it effectively restored underwater optical images with motion blur.
Qualitative and quantitative analyses were conducted on the experimental results using the UIEBD-Snow and UIEBD-Blur datasets. Based on the comprehensive analysis of
Figure 8 and
Figure 9 and
Table 1 and
Table 2, our method considerably color-corrected and eliminated impurity and motion blur for underwater images, demonstrating practical relevance.
4.4. Ablation Study
Ablation experiments were conducted by designing four comparative models with approximately the same number of parameters to validate the effectiveness of the Swin Transformer-based encoder module and the activation-free CNN-based decoder module. These models include a Vision Transformer-based encoder combined with a CNN-based encoder, a pure CNN-based encoder–decoder structure, an original Swin Transformer-based encoder–decoder structure, and the proposed TFCNet network proposed in this paper.
A visual study was performed on the UIEBD-Snow dataset for a qualitative analysis.
Figure 10 reveals that the model combining a Vision Transformer-based encoder with a CNN-based encoder did not effectively learn the mapping relationships, where it exhibited shallow learning capabilities during training and testing and performed poorly on challenging samples. The pure CNN-based encoder–decoder structure struggled to model the mapping between color and target images, which left considerable room for improvement in detail restoration. Combining the original Swin Transformer-based encoder with the CNN-based decoder improved the enhancement and restoration of underwater optical images to some extent; however, its overall performance remained measurably inferior to TFCNet.
As in
Table 3, TFCNet demonstrated substantial performance improvements over other combinations, with increases of approximately 0.5 and 0.01 in the PSNR and SSIM, respectively. The results obtained using TFCNet’s hybrid architecture, combined with the visual performance in
Figure 10, were more aligned with human visual perception and restored the complex underwater optical images better.
To validate the design efficacy of the proposed CNN decoder in TFCNet, here we performed ablation experiments by substituting the decoder module with two alternatives, MPRNet [
32] and UIRNet [
7]. As demonstrated in
Figure 11 and
Table 4, the proposed TFCNet exhibited superior performance in both the qualitative and quantitative assessments.
4.5. Application Testing
This section involves application tests using the training results from the TFCNet network on the UIEBD-Snow and UIEBD-Blur datasets to validate the effectiveness of TFCNet.
Initially, we focused on assessing a subset of images from the MSRB dataset [
33], which is used for marine snow noise elimination in underwater optical imagery, along with its extended version, the MSIRB dataset [
7].
Figure 12 illustrates the evaluation results, which involve real underwater optical images affected by marine snow noise.
Figure 12 reveals that the TFCNet method accomplished color correction in underwater optical images while also eliminating marine snow noise to a degree in the MSRB and MSIRB datasets. However, a closer examination revealed that the evaluation results of the TFCNet method on the MSRB dataset were less satisfactory than those obtained using the MSIRB dataset. This discrepancy can be attributed to the limitations in the datasets. When the morphology of marine snow noise does not align with the marine snow models in the dataset, the noise elimination is constrained, which is an issue that necessitates further in-depth research in future studies.
In addition, this section selected some complex underwater optical images that exhibited genuine marine snow noise and blurring phenomena for testing, with the results depicted in
Figure 13. As illustrated, TFCNet performed color correction on underwater optical images (images (a) and (b)) while simultaneously mitigating the marine noise to some extent. However, the noise elimination effect was suboptimal for the densely concentrated dynamic turbidity presented in image (b). Furthermore, for images (c) and (d), TFCNet achieved color correction in the underwater optical imagery while partially addressing the blurring effects. Nevertheless, it remained limited in restoring severe motion blur, as exemplified in image (d).
In summary, TFCNet demonstrated commendable performance on the UIEBD-Snow and UIEBD-Blur datasets. Nonetheless, the processing outcomes for real-world images revealed certain inadequacies. This observation underscores the inherent limitations of the UIEBD-Snow and UIEBD-Blur datasets discussed in this section, indicating a need for further refinement and enhancement in subsequent research.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}