1. Introduction
Synthetic Aperture Radar (SAR) is a kind of active microwave imaging system that operates effectively under all weather conditions, offering multi-angle, long-distance monitoring capabilities that are superior to optical remote sensing systems, which are influenced by light intensity and weather. SAR employs pulse compression technology and synthetic aperture principles to produce high-resolution images across both distance and azimuth dimensions. Operating on similar principles to SAR, ISAR uses a broadband radar signal for high-resolution imaging. The technique involves synthesizing a virtual aperture through the relative motion between the radar and the target, enhancing the azimuthal imaging angle to capture detailed images of non-cooperative moving targets. This process concludes with the coherent processing of the received radar echoes to achieve sharp azimuthal resolution.
Proposed by Prickett and Chen [
1] in 1980 and developed into a focused system by 1957 in the United States, SAR technology has evolved significantly. Parallel developments in ISAR during the early 1980s, notably by C. C. Chen and others [
2], enhanced its capabilities for imaging non-cooperative aircraft. This led to broader applications in military reconnaissance and marine traffic monitoring, with subsequent advancements by the U.S. Naval Laboratory and Texas Instruments expanding its use under various sea conditions. Today, ISAR is integral not only to military applications but also to civilian maritime operations, being capable of delivering critical data for strategic defense systems across multiple dimensions.
Synthetic Aperture Radar (SAR) is typically used for imaging stationary targets from fixed platforms, which allows for the precise measurement of the platform’s motion parameters. However, SAR often falls short in scenarios involving non-cooperative moving targets, such as those encountered in maritime security. This inadequacy leads to the utilization of Inverse Synthetic Aperture Radar (ISAR) for the more effective imaging of these challenging targets. ISAR can provide high-resolution imaging in all weather conditions and at all times of day, covering multiple dimensions. This makes it a vital tool for identifying and tracking aircraft, ships, missiles, satellites, and other targets over long distances, playing a crucial role in strategic defense systems.
ISAR target recognition is more commonly used for aircraft due to their distinct contour characteristics, whereas ship target recognition is less common and more challenging due to the complex structure of ships and demanding imaging conditions. Sea clutter, unpredictable ship motion, and difficulties in timing the data collection significantly hinder accurate ship imaging. These challenges are compounded by the complex and large structure of ships compared to aircraft, which complicates the identification process.
To address these issues, new algorithms have been developed to enhance ship target recognition, aiding early warning and defense strategies for military targets at sea. As global maritime dynamics evolve, the importance of obtaining accurate information on sea surface movements grows, not only for military purposes but also for civilian applications such as maritime traffic management. This underscores the dual significance of ship target identification for both national defense and civil use.
ISAR image recognition consists of two steps: target feature extraction and target classifier design, in which feature extraction directly affects the final imaging performance and classification accuracy. Feature extraction is a key step in the subsequent ISAR imaging of ship targets. This process is achieved by first localizing the target within broad-range imaging maps and, then extracting its corresponding echo signal for refined processing. Meanwhile, ISAR 2D images contain rich target feature information. Key features such as ship size, shape, and structure, extracted from ship ISAR images, can be used for ship identification. The feature extraction of ships plays an important role in their recognition, and the extracted features allow subsequent classifiers to process these data more effectively and improve the recognition capability. In addition, low-dimensional feature vectors can be extracted from otherwise high-dimensional data, allowing the original data to be converted into a meaningful representation, helping the algorithm to process these data better and improve the recognition speed.
In recent years, deep learning has performed well in target recognition; it can automatically learn features from input image data, reducing the cost of labor and the impact of subjectivity due to human involvement. Hierarchical feature learning allows for the extraction of more efficient features, and the extracted features are also robust to noise. More and more scholars are applying deep learning to ISAR target recognition. Since ship targets often have more complex backgrounds, different resolutions, and multi-scale characteristics, how to extract them effectively is a key step in the application. In order to achieve stable performance for target recognition in both regular conditions and special environments, J Zhang et al. [
3] proposed a method that combines the attribute scattering center with the optimized VGGNet, which obtains the features in amplitude images and ultimately improves the accuracy of recognition. The work of Seong-Jae Hong et al. [
4] shows that, by designing the M2Det deep learning model for data preprocessing, the signal-to-noise ratio of the training samples can be effectively improved to enhance the performance of subsequent detection. Yuanrui Sun [
5] proposed a SPAN strong scattering point annotation network to improve the presence of multiple strong scattering points in the SAR image, the unique features of points, and limitations in ships’ appearance profile information. Yang Liu [
6] designed an SLS-CNN network to complete the segmentation of the target and background, mainly by detecting the thermal map and angular features of spectral residuals. Yue Guo [
7] designed a BiFPN network that fuses CBAM and BiFPN. Chushi Yu [
8] designed a BiFPN network architecture with YOLOV5 as the backbone network, which obtained better detection performance than YOLOV5 by fusing the above mechanisms. Fang Xie [
9] designed a lightweight network YOLO-CASS based on YOLOV5, which has significantly improved efficiency and performance and has the potential to be used in real-time detection applications. Tianwen Zhang [
10] also designed a Quad-FPN network to enhance feature extraction efficiency, which was tested in comparison with other methods; the qualitative and quantitative experimental results revealed that Quad-FPN could achieve better detection performance compared with other detection networks. Zhonghua Hong [
11] designed a multi-scale bounding box for adapting samples with different resolutions via target detection, and the effectiveness was verified in a dataset with mixed remote sensing data and optical images. Chen Chen [
12] proposed a neural network with an adaptive calibration mechanism for detecting multi-scale and arbitrary direction ship targets. The introduction of the RNMS method can be adapted to scenarios with multiple ship targets aligned. Guoxu Yan [
13] designed the lightweight detector LssDet and introduced the CSAT module as an attentional module, which can enhance the model’s attention to the trans-parapet region and model the long-term dependence between the channel and the spatial information. Lei Liu [
14] proposed using a multi-scale neural network MS-FCN to segment coastal and ocean backgrounds. This study also designed a rotatable DR-Box for labeling targets, which can achieve accurate target detection and background localization. Yunlong Gao [
15] incorporated the attention mechanism based on YOLOv4 to enhance the signal-to-noise ratio of the training image samples through a TAM network and then designed the CAM attention module, focusing on enhancing the acquisition of features of multi-size targets. Yan Zhao [
16] proposed a two-stage ARPN network, which can effectively improve the detection performance of multi-scale ship targets; this study also involved, designing the sensing field. Convolutional attention modules RFB and CBAM can enhance the feature extraction performance while suppressing the effect of interference. Dong Li [
17] focused on the detection of multi-scale targets in multi-scale targets or the presence of target rotation, as well as complex background situations where ship detection methods cannot achieve satisfactory performance; a novel multidimensional domain deep learning network for ISAR ship detection was developed to exploit complementary features in the spatial and frequency domains. Jingyu Cui [
18] proposed a fast-thresholding neural network for ship target detection. Mainly used for detecting ship targets with different scales against a large background, a lightweight thresholding neural network TNN was designed to learn the image’s grey scale information to segment the targets in the background in greyscale. Jiao Jiao [
19] proposed a training parameter adaptive tuning mechanism based on the master-RCNN backbone network for ship target detection in multi-scene and multi-scale cases and obtained significant results in target detection. Hughes [
20] proposed a pseudo-twin convolutional neural network architecture; the proposed network architecture effectively addresses the fragment correspondence problem in both high-resolution optical and SAR remote sensing images. Experimental results demonstrate its high prediction accuracy, confirming the twinning network’s effectiveness for radar image analysis.
With the urgent need for practical applications, many scholars have also explored real-time application settings. Tianwen Zhang [
21] designed a HyperLi-Net ultra-lightweight network and proposed five external modules to achieve high accuracy: namely, the Multi-Receptive Field Module (MRF-Module), Dilated Convolutional Module (DC-Module), Channel and Spatial Attention Module (CSAModule), Feature Fusion Module (FF-Module), and Feature Pyramid Module (FP-Module). Five internal mechanisms are also used to achieve high speed, i.e., Region Free Model (RF-Model), Small Kernel (S-Kernel), Narrow Channel (N-Channel), Separable Convolution (Separa-Conv), and Bulk Normalized Fusion (BNFusion). Significant improvements in accuracy and speed can be achieved. Tianwen Zhang [
22] improved the detection speed by meshing the input image based on the YOLO model and using depth separable convolution. A new network structure, G-CNN, is proposed, which is mainly composed of a backbone convolutional neural network (B-CNN) and a detection convolutional neural network (D-CNN). It can achieve efficient real-time detection and identification. Mingming Zhu [
23] designed a highly efficient and accurate ship target detector by optimizing the network, balancing speed and accuracy, which was verified in experiments. Yao Chen [
24] proposed an end-to-end ship detection method using Darknet-53 as the backbone network to extract the ship’s complex background and offshore scene. Target features were extracted from complex backgrounds and offshore scenes, and a balanced network with detection efficiency and robustness was obtained. Shexiang Jiang [
25] proposed DWSC-YOLO inspired by YOLOv5 and MobileNetV3 to reduce the loss of accuracy caused by the lightweight neural network. To improve the accuracy and reduce the loss of convolutional neural networks, heterogeneous convolution and the experimental results show that the model can obtain excellent detection results with few computational resources and low costs. Tianwen Zhang [
26] proposed a novel ISAR ship detection method, mainly using a depth-separable convolutional neural network (DS-CNN) to adapt to the demands of high real-time applications. The method integrates a multi-scale detection mechanism, a crosstalk mechanism, and an anchor box mechanism and establishes a new lightweight, high-speed SAR ship detection network architecture. A DS-CNN consisting of deep convolution (D-Conv2D) and pointwise convolution (P-Conv2D) is used instead of the traditional convolutional neural network (C-CNN). Xiao Tang [
27] designed a DBW-YOLO network based on YOLOv7-tiny and enhanced the feature extraction accuracy by designing a feature extraction enhancement network, the BiFormer attention network, and introducing feature extraction accuracy. Feature extraction accuracy also introduced a dynamic attention mechanism to improve the model’s generalization ability.
These classification and parsing results are also important for practical applications in detecting ship targets. Xuning Liu [
28] proposed a concatenated CNN to improve the effectiveness of multi-scene classification by combining the recognition and verification models of CNN to address the lack of rich labeling information and the relatively homogeneous remote sensing images in remote sensing. J. Anil Raj [
29] constructed a deep learning model for one-shot learning that can improve the classification accuracy in response to the low data availability for specific categories of large ships. Jinglu He [
30] extended DenseNet to MR SAR ship classification. He proposed a multi-task learning framework to extract better deep features, in which softmax logarithmic loss and triplet joint loss are minimized to achieve the more efficient MR ship classification of SAR images. Z Xue [
31] proposed a new spectral-spatial Siamese network (S3Net)-based lightweight twin network for the recognition of hyperspectral images in response to the problem that training labels is time-consuming and laborious, which can easily make the deep learning model fall into overfitting; the study achieved better results. To solve the problem of limited spatial target recognition in the case of small samples, Yi Yang [
32] proposed the triple attention mechanism of the transformer, marking the dependency between the samples and the target, improving the recognition accuracy, and verifying the algorithm’s effectiveness.
Most models for deep learning usually require many training samples. However, for ISAR ship images, due to the non-cooperative nature of the target and the uncertainty of the target’s motion state, it is difficult to obtain sufficient real-world samples of ISAR images in most cases. As a result, with fewer training data, most deep learning models are prone to overfitting phenomena in the ISAR ship image recognition problem, and it is not easy to obtain stable and accurate results. Therefore, it is important to study deep-learning-based ISAR ship image recognition to address the small sample situation of ISAR ship images.
To address the above issues, this study builds a hybrid dataset by fusing the SSDD dataset with its own dataset. The data enhancement technique is adopted to effectively expand the number of samples, while the attention mechanism is also introduced to improve feature extraction performance. Focusing on the problems of insufficient target detection accuracy and high false alarm rates in traditional algorithms, we proposes a novel ISAR ship detection framework, named CIDNet, with the following main contributions:
C1: A super-resolution preprocessing module is introduced to enhance the edge details of small ships and suppress noise interference effectively.
C2: An Edge-Aware Feature Learning (EAFL) module improves the contrast of ship edges and facilitates fine-grained feature extraction.
C3: An Adaptive Follower Attention Network (AFAN) combines global attention with dynamic tracking to maintain robustness in complex scenes.
The remainder of the article is organized as follows.
Section 2 briefly reviews the related work.
Section 3 explains the proposed method for the fusion of adaptive annotation following network and edge-aware feature learning.
Section 4 illustrates the proposed ISAR ship target dataset.
Section 5 presents the experiment results and discussion. Finally, we describe the conclusions of the general statement of the study in
Section 6.
3. Proposed Methodology
3.1. Overview of Model Architecture
Most existing deep learning models use CNNs [
47] and self-attention mechanisms [
48] to improve the accuracy and efficiency of target detection through optimization strategies such as feature extraction [
49], region suggestion [
50], and the integration of contextual information [
51]. However, due to the limitations of these models in extracting details of smaller-sized targets and dynamic scene adaptation, the detection accuracy is usually unsatisfactory in complex environments. Especially in SAR image target detection, traditional algorithms such as Faster R-CNN [
52] are not sensitive enough to achieve the feature extraction of smaller-sized targets; this can easily lead to target loss, despite the introduction of region suggestion networks. In addition, traditional methods combining convolutional neural networks and self-attention mechanisms lack the integration of temporal information when dealing with rapidly changing targets, resulting in poor performance in high-noise or low-contrast backgrounds, making it difficult to achieve stable detection results.
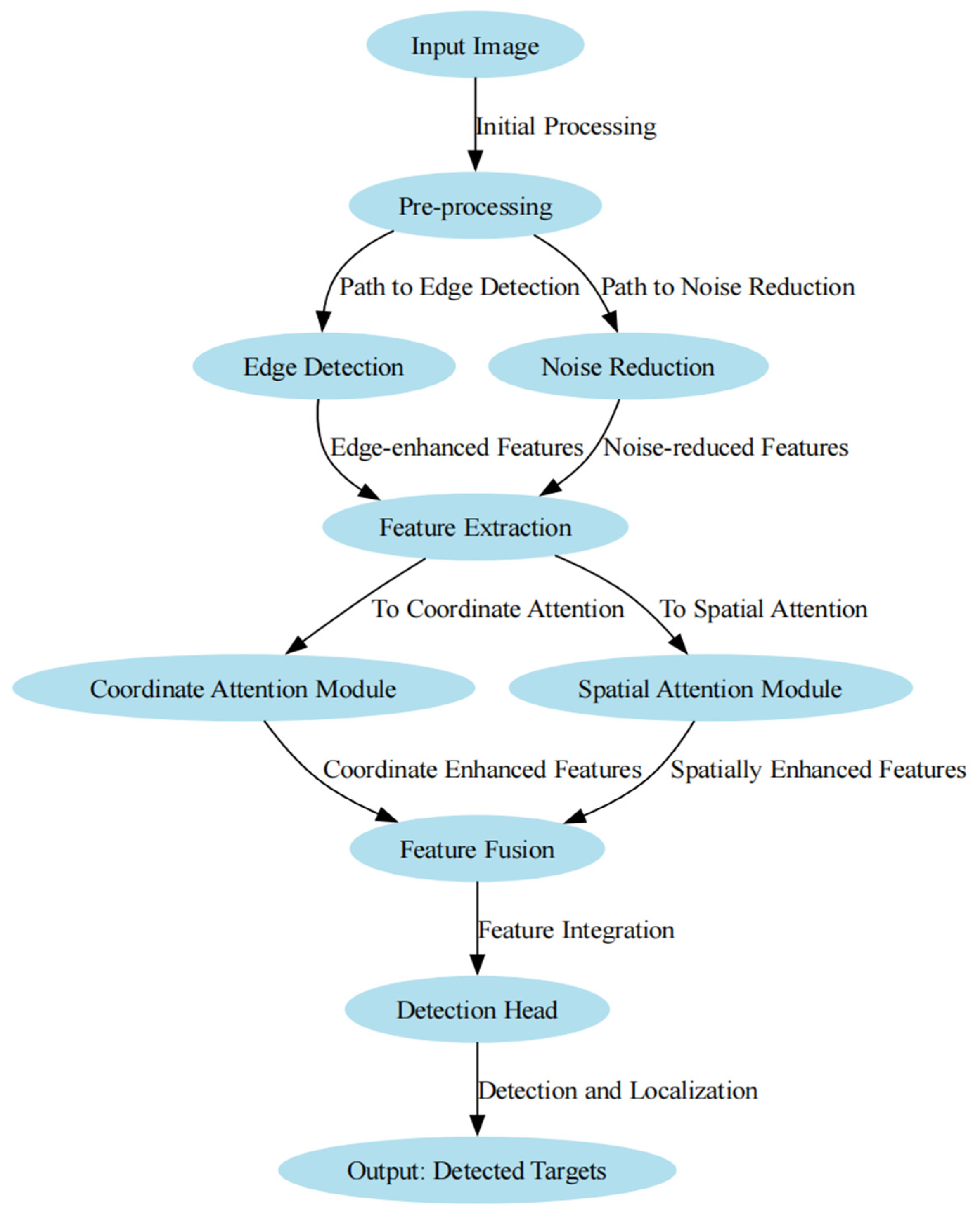
The input layer design of the CIDNet model proposed in this study is mainly a preprocessing session, which aims to achieve the super-resolution processing of ship targets in ISAR images to enhance the image resolution and also introduces a noise suppression algorithm in the preprocessing stage to reduce the impact of noise on the robustness of detection. After the preprocessing step, the network enters the feature extraction stage. The coordinated attention module is implemented by target-directed attention and enhanced feature expression; then, the spatial attention module is completed by global context integration and dynamic feature adjustment. CIDNet constitutes a multifunctional integrated detection head after the feature fusion stage, and the final output layer provides feature maps with different resolutions through multiscale detection, which can simultaneously detect targets of different sizes. This layer provides the bounding box of the target through confidence scores. Post-processing algorithms such as Non-Maximum Suppression (NMS) are also added to the output layer to ensure the accuracy of the output results.
Figure 1 shows a schematic of the workflow of the proposed Edge-Aware Feature Learning (EAFL) method and Adaptive Following Attention Network (AFAN). The figure also shows the feature enhancement architecture based on EAFL and the adaptive following mechanism of AFAN, where EAFL contains several key sub-modules corresponding to
Section 3.2: namely an edge detection and noise suppression module, a multiscale feature fusion module with coordinate attention and spatial attention, and a dynamic target prioritization mechanism for detecting the head.
In the dataset preprocessing stage, we utilize its dataset to enhance the detectability of ship targets in low-contrast and complex backgrounds using adaptive preprocessing methods. In particular, we apply an image enhancement algorithm to perform meticulous edge enhancement and noise reduction operations on the original image to enhance the ship target’s boundary clarity and detail information. In addition, the preprocessing phase contains data extension techniques to expand the diversity of the dataset through various data enhancement means, such as flipping, rotating, and scaling, to facilitate the better adaptation of the model to different scenarios and environmental changes and thus improve the generalization performance.
In the backbone of the detection network, we add a coordinate attention module [
53] in the feature extraction stage to capture the relative positional relationship of the target in different coordinate systems, making the model’s understanding of the target’s position more accurate. In the feature fusion process, a spatial attention mechanism is introduced to enable the model to focus on the edge information of important regions and suppress background noise interference. This dual-attention design works synergistically in the model backbone and feature fusion phases, substantially improving the model’s detection ability in complex backgrounds. Meanwhile, an adaptive dynamic prioritization mechanism is embedded in the detection head, enabling the model to adjust its attention to ship targets in real time.
3.2. Adaptive Focusing Attention Network
Traditional models such as YOLO [
54] and DETR [
55] perform well when dealing with target detection in static images. However, they often struggle to achieve accurate tracking and recognition when the target is in complex motion or the background is rapidly changing. That is because these models are mainly used to process single-frame images and cannot integrate information between successive frames, leading to poor performance in real-time small-amplitude tracking. Although some advanced models have begun to introduce spatio-temporal information to improve the detection of dynamic targets, these attempts usually fail to fuse information in the temporal dimension effectively; otherwise, the processing methods are too complex, affecting the real-time performance of the models. To address the above problems, we propose the Adaptive Follower Attention Network (AFAN) approach.
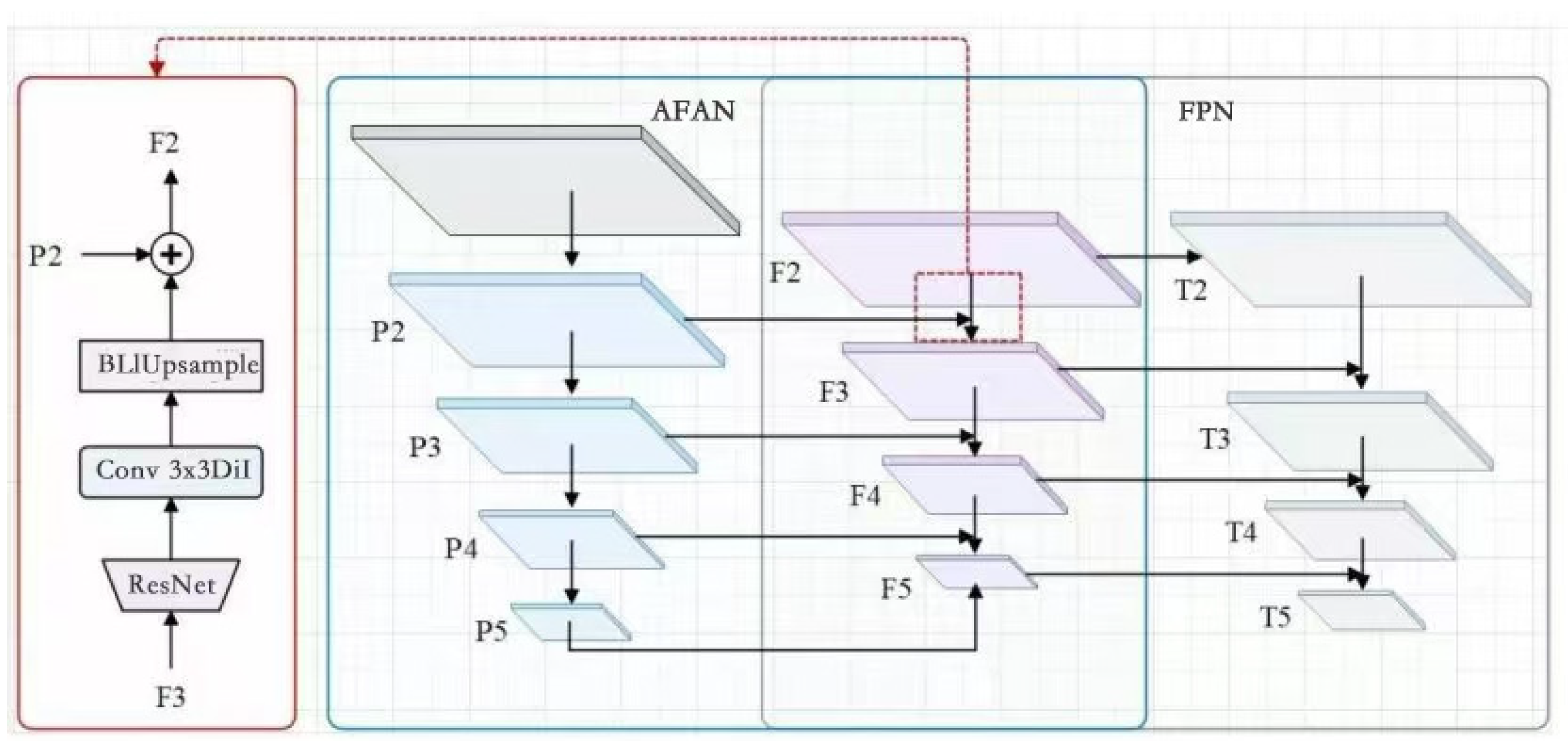
Figure 2 illustrates the structure of AFAN (Adaptive Follower Attention Network) as applied to a target detection network, with a particular emphasis on how it can be integrated with a multi-scale Feature Pyramid Network (FPN) and other network components to optimize target detection. The left part of the figure (red border) illustrates how the model goes from the base features (F3) through the ResNet block first, extracting the deeper features through residual concatenation to make the gradient propagation more stable. Subsequently, features are further extracted by a convolution operation (3 × 3 convolution combined with null convolution, Conv 3 × 3 Dil), and a higher-resolution feature map is generated via a bilinear interpolation upsampling (BLIUpsample) operation (P2). Eventually, the feature map undergoes feature fusion to generate the F2 layer, which provides optimized inputs for subsequent modules.
The blue area in the middle shows the AFAN module’s working process in detail. The AFAN module receives feature maps at different levels (e.g., P2 to P5) and significantly optimizes the accuracy and efficiency of target detection through processing, such as feature extraction [
56], an attention-based mechanism (CBAM) [
57], multi-head self-attention [
58], and feature fusion. The AFAN module can effectively capture target area information while suppressing background noise by performing dynamic feature focusing between multi-level feature maps.
The right part of the figure shows how the features are fed into the multi-scale feature pyramid network (FPN) after being processed by the AFAN module. The FPN receives the feature maps (F2 to F5) generated by the AFAN module and processes and synthesizes the feature maps at different scales. Eventually, the FPN generates multi-level output feature maps (T2 to T5), which provide efficient and accurate support for the final classification and localization of the target detection task. The network achieves an efficient process from essential feature extraction to optimized multi-scale target detection through inter-module integration.
3.2.1. Dynamic Structure of the BETR Model
BETR is a self-attentive mechanism for dealing with global dependencies in images using Transformer, which uses a feature pyramid network (FPN) [
59] or similar structural models for integrating different scales. Due to the problem that targets are easily lost in complex backgrounds [
60] in traditional target detection algorithms, we base our investigations on the BETR model, improve and integrate the BETR model, and propose a new Adaptive Follow-Attention Network (AFAN), which accomplishes the optimization of the dynamic structure and the attention mechanism:
AFAN introduces a dynamic feature adjustment layer for the BETR model [
61], which can automatically adjust the feature processing flow according to the complexity of the image content. For example, for a scene containing multiple target images with small sizes and fast-changing poses, the dynamic feature adjustment layer increases the features’ local sensitivity and spatiotemporal resolution.
Within the BETR architecture, AFAN enhances the encoder’s capabilities by implementing a conditional tuning strategy. This strategy dynamically optimizes attention weights and feature extraction methods for each layer of the encoder based on real-time scene analysis. Such optimizations allow BETR to maintain high accuracy and speed, even as the scene dynamics change, by focusing computational resources where they are most needed. AFAN’s innovative application of inter-layer attentional dynamic connectivity in the BETR model is a mechanism that allows the model to dynamically adjust the information flow between different layers based on the characteristics of the target.
AFAN further extends BETR’s functionality by introducing a mechanism for dynamic information flow adjustment between different network layers. This inter-layer attentional connectivity allows the network to flexibly adjust its internal information processing pathways based on target characteristics, enhancing the ability to maintain continuity in target tracking over sequences of images.
Leveraging AFAN’s capabilities, BETR can actively track the visual focus of a target throughout an image sequence. This tracking is achieved by an adaptive attention focus mechanism that recalibrates based on prior detection results and predictions of the target’s future state. This continuous adjustment helps to maintain robust tracking performance, especially for moving targets such as ships, where position and state can change rapidly due to sea conditions.
AFAN, built on the BETR framework, incorporates specialized multi-head self-attention mechanisms that are fine-tuned for the dynamics of moving ship targets. These mechanisms enable a simultaneous focus on both the spatial and temporal dimensions of the target, thus significantly improving the model’s understanding of target motion patterns and trajectories. The integration of features across successive frames via a spatiotemporal feature fusion module enables BETR to predict and adapt to future target states effectively.
AFAN draws on the power of the BETR model, particularly its ability to deal with long-range dependencies in complex scenes. The BETR model is based on the Transformer architecture, which allows the model to capture global information in an image through self-attentive mechanisms. In AFAN, this architecture is optimized to focus on detecting ship targets. Based on BETR, AFAN adds multi-head self-attention mechanisms specifically designed for moving ship targets. It can simultaneously focus on the target’s position and state changes across time frames, thus improving the understanding of its motion patterns. In addition to spatial focus, AFAN innovates in the temporal dimension by integrating target features in successive frames to construct a complete target motion trajectory. This processing is achieved through a specially designed spatiotemporal feature fusion module that can process and utilize temporal information differences to predict the future state of the target.
3.2.2. Innovative Applications of Attention Mechanisms
AFAN further enhances the application of the attention mechanism based on the BETR model by introducing attention-directed feature optimization not only at the spatial level but also at every level of deep learning:
Dynamic Attention Adjustment: The attention weights are dynamically adjusted for each target’s motion characteristics and environmental context, prioritizing fast-moving targets or those with complex backgrounds. That is achieved through a dynamic learning network that adjusts attention distribution based on the target’s real-time state and environmental feedback.
Multiscale Feature Response: AFAN has devised a multiscale feature response mechanism that adjusts the model’s response to features at different levels of resolution. This multi-scale mechanism guarantees appropriate processing across all granularity levels, with particular emphasis on small target detection through fine-scale detailed analysis.
To adapt to changes in different environments and target states, AFAN implements a set of adaptive feature adjustment techniques. This includes:
Parameter adaptive tuning [
62]: the internal parameters of the model, such as the convolutional kernel size, number of layers, and type of activation function, are dynamically adjusted according to the environment and target data analyzed in real-time. This adaptive mechanism allows AFAN to maintain efficient performance under static conditions and in highly dynamic environments.
Feedback mechanism: a feedback loop [
63] is introduced to allow the model to adjust the processing strategy of subsequent frames according to the detection results of the previous frame, thus forming a continuous learning and adaptation process and enhancing the model’s responsiveness to dynamic changes. With these detailed techniques and implementation strategies, AFAN is theoretically advanced and effectively improves the detection accuracy of dynamic targets in ISAR imaging systems and the overall robustness of the system in practical applications.
3.3. Edge-Aware Feature Learning
Although feature-matching-based algorithms (e.g., SIFT [
64], SURF [
65]) perform well under the conditions of stable features and little change in the environment, these algorithms often have difficulty in finding enough stable feature points for effective matching in ISAR imaging due to the usually low contrast between the target and the background and the blurriness of the target features, which affects the accuracy of the detection. In solving these problems, we use the edge-aware feature learning (EAFL) method.
EAFL highlights the edge information of the target by applying high-frequency feature enhancement to the input image, making the edges and contours more distinct in the subsequent feature extraction process. This enhancement is usually realized by applying specific filters (e.g., Sobel [
66] or Laplacian [
67]) that capture the high-frequency portion of the image, thus improving the contrast between the target and the background. In the feature extraction stage, EAFL integrates an automatic edge detection module [
68], which starts working at the primary stage of the convolutional network to provide feature maps containing rich edge information for the subsequent layers. YOLOv10 can handle multi-scale features [
69], on which EAFL further optimizes the feature fusion strategy. During the feature fusion process, EAFL adopts a dynamic adjustment method to automatically adjust the fusion ratio of features in different layers according to the size and complexity of the target.
A module based on Convolutional Neural Networks and Attention Mechanisms, which is a key component of the Edge-Aware Feature Learning (EAFL) technique, is illustrated in
Figure 3. This module implements the enhancement of the edge features of an image through Average Pooling, Conv2d, Batch Normalization, Nonlinear Activation, and Sigmoid Activation Function [
70]. Through input and preprocessing, average pooling operation, feature fusion and enhancement, branching and attention mechanisms, and output and residual learning, we can significantly improve the recognition of image edges and textures using the EAFL module.
The core of the EAFL method is to enhance the detectability of ship targets in ISAR images using edge-aware techniques. This technique is based on edge detection theories in image processing, such as the Sobel operator or the Canny edge detection algorithm [
71]. Edge detection algorithms detect object boundaries by recognizing rapid changes in pixel brightness, which is especially important for small-sized targets with usually indistinct boundaries in ISAR images. By enhancing this edge information, the target can be made more visually salient and thus more easily recognized by subsequent detection algorithms.
After extracting the edge information, EAFL uses deep learning techniques for feature fusion. We aim to enhance the discriminative ability of the extracted features and improve detection accuracy in complex ISAR ship detection scenarios. Specifically, the proposed strategy first introduces a preprocessing module into the YOLOv10 [
72] architecture, where an improved Canny edge detection algorithm is applied to the input image. The thresholds and filter responses of the traditional Canny algorithm are optimized to adapt to the characteristics of SAR images, enabling the more precise extraction of ship boundary information against noisy backgrounds. The extracted edge features are subsequently integrated with the deep semantic features obtained from the backbone network.
Following this, a customized Feature Pyramid Network (FPN) is employed to fuse multi-scale feature maps generated from different levels of the network. The FPN effectively aggregates high-level semantic information and low-level detailed features, which is particularly beneficial for detecting ship targets with varying sizes. In addition, the feature fusion process incorporates a Coordinate Attention (CA) mechanism to strengthen the sensitivity of the spatial position information, allowing the model to better capture the relative location of ship targets. A Spatial Attention (SA) mechanism is further utilized to focus on key regions of the feature maps, dynamically adjusting the attention weights based on the importance of local features.
Moreover, the Edge-Aware Feature Learning (EAFL) module is designed to refine the feature representation by enhancing edge contours and suppressing background interference. The fused feature maps, enriched with edge information, semantic context, and attention-enhanced features, are jointly optimized in an end-to-end learning manner. The attention layers within the fusion module specifically adjust the weight distribution of different feature components based on edge strength, ensuring that the model prioritizes the target regions with clear boundaries while reducing the impact of noise. The attention layer, in particular, adjusts the weights of the components of the feature map based on edge strength, ensuring that the model focuses on potential target regions with well-defined edges.
- 1.
Verification process for edge strength
Edge intensity verification is a method used to assess the contrast between the target region and the background by simulating and analyzing the superposition of different gradients in an image. In the experiment, the calculation of edge intensity is based on the gradient variation in the pixel values in the image, which reflects the transition region between the target and the background. The effectiveness of the edge detection algorithm can be visually assessed by calculating the edge intensity of the target region and comparing it to the noise level of the background region. If the calculation results show that the edge intensity of the target region is significantly higher than the noise level of the background region, this indicates that the edge detection step has successfully distinguished the target from the background, thus effectively improving the image’s contrast.
Specifically, the process of edge strength verification includes the following key steps: first, the gradient magnitude of each pixel in the image is calculated by gradient operators (e.g., Sobel, Prewitt, or Canny operators), and these gradient magnitudes reflect the strength of the edges in the image. Next, the gradient magnitudes of the target and background regions are statistically analyzed by calculating their mean and standard deviation, respectively. If the gradient magnitude of the target region is significantly higher than that of the background region, and the gradient magnitude of the background region is mainly concentrated in the lower noise level range, the edge detection algorithm enhances the contrast between the target and the background. In this study, we compute the gradient using the Sobel operator:
where
is the input image, and
and
denote the gradient in the horizontal and vertical directions, respectively. The edge intensity is obtained by calculating the gradient magnitude:
In addition, comparative experiments can be conducted to verify the effectiveness of edge strength further to observe the changes in the image before and after edge detection. For example, in the image without edge detection, the boundary between the target and the background may be blurred and difficult to distinguish clearly. Meanwhile, after the edge detection process, the edge of the target region becomes sharper, and the background noise is effectively suppressed, which significantly improves the visual effect of the image and the accuracy of information extraction.
- 2.
Proof of enhancement of the Coordinate Attention Module
The coordinate attention module is used to reinforce edge information in a specific region of the image. We define the coordinate attention weights
:
where
is the coordinate weight matrix, and
F is the feature map. By calculating the coordinate attention weights, the importance of each region on the feature map can be obtained and the highly weighted regions can be enhanced by focusing on them.
Weighting the target area
:
By comparing the intensity of features after coordinate enhancement with the intensity of features without enhancement, the enhancement effect of coordinate attention can be quantified and verified to significantly improve the target region’s saliency.
- 3.
Proof of the focusing effect of the spatial attention module
The spatial attention module is used to reinforce the spatial distribution of salient targets in an image. We define the spatial attention weights
:
where
is the weight of spatial attention, with adjustment by the activation function sigmoid. The feature map after spatial attention processing is:
Computational analysis: By comparing the feature strengths before and after spatial enhancement and comparing the response differences between target and non-target regions, the effectiveness of the spatial attention module in focusing on targets can be assessed. In the numerical simulation, the enhanced region should significantly exceed the non-enhanced region to ensure that spatial attention can effectively focus on important targets.
- 4.
Validation of feature fusion and output
In the final feature fusion stage, EAFL combines coordinate-enhanced features with spatially enhanced features:
The target detection enhancement effect of EAFL can be verified by experimentally simulating the intensity distribution of the fused features, especially the detection scores in the target region. If the target detection accuracy and recall of the fused features are significantly improved, it proves that the feature fusion of EAFL is indeed effective.
Network training and optimization: The entire EAFL network is trained with the ISAR image dataset, including targets in multiple environments and under different dynamic conditions. High-performance GPUs and automated hyper-parameter tuning techniques are utilized to fine-tune the network’s learning rate, loss function, and optimizer settings to ensure optimal detection performance in real-world applications.
4. Building the Dataset
The dataset used in this paper comprises a mixture of actual flight-to-sea ISAR imaging processing results and the SSDD dataset. The images are mainly regional images containing ship targets and complex backgrounds on the sea surface, and the ship targets in the images present different states due to different sea conditions, as shown in
Figure 4. Specifically, there are three main challenges for the ISAR dataset. The first is image scatter due to ship micro-movements (e.g., transverse/longitudinal rocking). The second is target energy attenuation during long-range detection due to low signal-to-noise ratios (Low-SNR). Moreover, the Doppler spectrum broadens under complex sea conditions, which raises the problem of coupled interference in the time-frequency domain. For SSDD datasets, side-view imaging leads to ship geometry distortions (e.g., bow/tail blurring). Moreover, there is a high percentage of small targets: a large number of small fishing boats (pixel area < 30 × 30) are present in the near-shore scene. In addition, dynamic sea surface echoes (e.g., at wind speeds > 10 m/s) can mask weak target signals.
In order to increase the generalization ability of the model training, a data augmentation method was used to make the data as diverse as possible. In contrast, the number of data samples increased. This studymainly uses random scaling, rotation, flipping, cropping, changing contrast, and Mosaic for data augmentation. The dataset contains 2604 images, including ISAR images with different resolutions, polarizations, sea states, and sea areas, which is conducive to training the model’s ship detection effect under different sea conditions. The dataset exhibits a balanced class distribution, with no significant skewness observed across categories. Specifically, the sample sizes for each class, i.e., ship, boat, and container ship, are approximately equal. Compared with traditional pixel-level segmentation methods, the anchor box-based labeling strategy adopted in CIDNet offers significant advantages in handling noise interference and dynamic background variations in ISAR ship images. Pixel-level segmentation methods require precise annotations of target boundaries, which are easily affected by background noise, sea clutter, and low-contrast regions, often leading to inaccurate segmentation in real maritime environments. In contrast, the anchor box labeling approach provides a more robust representation by focusing on the overall spatial position and size of the target, rather than relying on fine-grained pixel details. This strategy reduces the sensitivity of the model to edge noise and allows the detection framework to generalize more effectively across varying sea conditions and complex backgrounds, allowing the target detection method to deal with various real-time and complex environments.
5. Experiments and Analysis
5.1. Performance Evaluation Indicators
To comprehensively and fairly evaluate CIDNet’s performance with other comparative models in the ISAR ship target detection task, evaluation metrics such as mean accuracy (mAP), recall, false detection rate (FAR), inference time, and frame rate (FPS) are used. The method’s performance is evaluated by quantifying the model’s detection effect in different scenarios. The detailed definitions of each metric and its calculation formula are given below.
- 1.
Mean Average Precision, mAP
Mean Average Precision () is one of the most commonly used evaluation metrics in target detection tasks and is calculated as the average of the detection accuracies of all categories. Specifically, mAP measures how well the model matches the predicted bounding box with the actual bounding box under different thresholds (usually, the threshold).
(Intersection over Union) is used to measure the degree of overlap between the predicted bounding box and the true bounding box and is calculated as:
where
denotes the area of the projected bounding box,
denotes the area of the real bounding box,
denotes their overlap, and
denotes their concatenation. Thresholds of
, such as 0.5 and 0.95, are usually set as criteria for matching targets.
Average precision (
) is the area under the precision curve (i.e., the area of the precision-recall curve) for a single category at multiple
thresholds. It is calculated by averaging the precision under different
thresholds:
where R is a different threshold under multiple recalls, and
is the precision at each recall rate.
is the average
AP value across all categories:
where
is the total number of categories in the target detection task and
is the average accuracy of the targets in category
i.
- 2.
Recall
This metric is used to measure the proportion of targets that are successfully detected by the model across all real targets, reflecting the leakage of the model. It is calculated as follows:
where TP (true positive) is the number of targets correctly detected by the model, and FN (false negative) is the number of true targets that the model fails to detect.
Recall reflects the model’s ability to reduce missed detections, with larger values indicating that the model has a smaller probability of missing detections in the detection task.
- 3.
False Alarm Rate, FAR
This is used to measure the proportion of background that the model incorrectly identifies as a target. The model sometimes incorrectly detects a target in a region without a target. It is calculated using the following formula:
where FP (false positive) is the number of regions where the model incorrectly detects a target, TN (true negative) is the number of areas correctly identified as non-targets by the model.
A lower value of false detection rate indicates that the model is more robust in dealing with complex backgrounds and noise interference.
- 4.
Inference Time
The inference time refers to the time in milliseconds (ms) the model requires to process an image. The inference time directly reflects the model’s real-time processing capability. It is calculated as:
where
is the total time required to process the entire test set, and
is the total number of images in the test set.
The shorter the inference time, the faster the processing speed of the representation model, which is crucial especially in real-time application scenarios.
- 5.
Frames Per Second, FPS
This indicates the number of image frames per second that the model can process, and it is usually used to measure the model’s real-time performance. The frame rate is calculated using the formula:
where the inference time is measured in milliseconds and the frame rate is measured in frames per second. The higher the frame rate, the more images the model is able to process per unit cycle in a real-time application.
5.2. Experimental Methods
The algorithm is validated using its own ISAR ship image dataset, and the results are compared and analyzed with those of other detection models. All models are trained and tested on the same hardware platform in the experiments to ensure comparable and fair results. Based on PyTorch 2.4.0, CUDA 12.5, and NVIDIA RTX 3080 for training, the MVCB-IR dataset was divided into training, validation, and testing sets with a ratio of 70% for training, 15% for validation, and the remaining 15% for final testing. The training set is used for the model to learn the features of different types of ships, the validation set is used to adjust the hyper-parameters in real-time during training, and the test set is used to evaluate the final performance of the model.
The same training strategy is used for all models to ensure that the models are trained under the same conditions and thus compare their performance.
Loss function: All target detection models use Binary Cross-Entropy Loss [
73] for the classification task, combined with IoU (Intersection over Union) loss to optimize bounding box regression [
74]. The CIDNet model specifically incorporates a loss function based on an attention mechanism to ensure the target region’s focus.
Training process: The model is trained over 100 epochs, with the complete training set used for each epoch. The performance metrics (mAP, recall, false detection rate, etc.) on the validation set are recorded after each epoch, which judge whether the hyperparameters need to be adjusted. Specifically, the initial learning rate was set to 0.001, and an automatic learning rate decay strategy was adopted, in which the learning rate was reduced by a factor of 0.1 if the validation performance, particularly the mAP value, did not improve within five consecutive epochs. The batch size was fixed at 16 to balance stable gradient updates and the efficient utilization of GPU memory resources. The total number of training epochs was set to 100, and the model’s performance on the validation set was evaluated after each epoch to guide parameter adjustments. During optimization, the Adam optimizer was employed to accelerate convergence and adaptively adjust the learning rate. To alleviate the risk of overfitting, especially in the detection of small-sized ship targets, L2 regularization was applied throughout the training process, and the Dropout technique was introduced in the feature extraction stage to improve the generalization capability by randomly deactivating some of the neurons. The loss function consisted of Binary Cross-Entropy Loss for classification tasks and IoU-Based Loss for bounding box regression, while an additional attention-guided loss component was incorporated to further enhance the model’s focus on the target regions in complex scenes.
The training process uses an automatic learning rate decay mechanism to gradually reduce the learning rate when the performance on the validation set does not improve. The batch size (batch size) for each training is set to 16, and gradient accumulation is used to balance the computational load, thus accelerating the training speed.
Regularization techniques were used during the training process to avoid the problem of overfitting the models, especially for detecting smaller-sized ship targets. All models use L2 regularization to prevent the models from overfitting the training data. In addition, the CIDNet model uses a Dropout mechanism in the feature extraction phase to enhance the robustness of the model, randomly discarding some of the neuron outputs and avoiding the model’s overdependence on specific features.
During the training process, a dynamic learning rate adjustment strategy is used. When the performance metrics (especially the mAP values) on the validation set do not improve within five consecutive epochs, the system automatically reduces the learning rate so that the model jumps out of the local optimum. This strategy ensures that the model can continue to optimize the parameters in the later stages of training, reducing performance fluctuations.
To ensure optimal model performance, the hyperparameters of each model are adjusted, and the batch size of all models is set to 16 to make full use of the hardware resources and to ensure the stability of the training process. The Adam optimizer is chosen to help the model converge quickly with its adaptive learning rate feature, and to avoid the overfitting problem during the training process. The initial learning rate is set to 0.001 and decayed after every 10 epochs to ensure the model is optimized gradually.
The dataset contains various types of ships, from small patrol boats to large cargo and passenger ships. This ship diversity helps the model to learn how to recognize and differentiate between various ship types and to classify and locate them effectively even when the visual features are not obvious. In addition to natural environmental factors, the dataset also artificially adds different levels of noise and interference to simulate various interference situations that may be encountered in actual operations, such as electronic interference, meteorological factors, etc.
5.3. Ablation Experiments
Ablation experiments with the CIDNet model were carried out in the absence of different factors. The baseline model uses pure YOLOv10 without adding any Adaptive Follower Attention Network (AFAN) or Edge-Aware Feature Learning (EAFL). Base+EAFL refers to the addition of the EAFL module to YOLOv10. Base+AFAN is the model that combines YOLOv10 with AFAN. Full CIDNet model refers to the fusion of YOLOv10, EAFL, and AFAN features on the traditional YOLOv10 algorithm.
The results of the comparative analysis of the different ablation models are given in
Table 1.
Impact of the Adaptive Follower of Attention Network: according to the results in the table, it can be determined that, after combining the Adaptive Follower of Attention Network (AFAN) into the original YOLOv10 model, the model’s mean average precision (mAP) is significantly improved, while the inference time is slightly increased. This result suggests that AFAN significantly enhances the model’s target detection ability in complex contexts by optimizing the attention mechanism, especially when dealing with smaller-sized ship targets. However, the introduction of AFAN also led to a slight increase in the false detection rate (FAR), which may be attributed to the model’s enhanced sensitivity to details when tracking dynamic targets, which, in turn, also improves the response to background noise to some extent.
It is noteworthy that, while the proposed CIDNet achieves a remarkable improvement in mean average precision (mAP), a slight increase in the false alarm rate (FAR) is also observed. This trade-off is primarily caused by the enhanced sensitivity of the model to small or ambiguous features, which improves target recall but may lead to additional false detections in highly complex scenes. However, in real-world maritime applications, particularly in scenarios involving early warning, surveillance, or search-and-rescue operations, higher recall and mAP are generally prioritized over a minimal increase in FAR. This is because the cost of missing critical ship targets is often more severe than the cost of handling false positives. Moreover, the slight increase in FAR can be effectively mitigated through post-processing techniques or human verification in practical systems, ensuring that CIDNet maintains both high detection accuracy and reliable applicability in diverse maritime environments.
Impact of edge-aware feature learning: the experimental results show that applying EAFL to the YOLOv10 model significantly improves the model’s mean average precision (mAP), although this also has an impact on the model’s inference time and FAR.
EAFL enables the CIDNet model to more accurately locate and identify real targets against complex backgrounds by enhancing the identifiability of image edges while suppressing the misclassification of non-target regions. In addition, the introduction of EAFL also enables the model to dynamically adjust its detection strategy according to the specific features of the scene, optimizing detection efficiency and accuracy, albeit at the cost of slightly increased inference times.
5.4. Comparative Results on the Dataset
Through dataset testing, the experimental results reveal the significant advantages of using CIDNet in SAR image ship target detection, especially in terms of minor ship target detection, noise immunity, and real-time processing capability. In this section, the performance of CIDNet as compared to the other three models (YOLOv10, Faster R-CNN, DETR) is demonstrated under various evaluation metrics, and the sample test results are shown in
Figure 5. The advantages of CIDNet in different scenarios are also analyzed using detailed data.
- 1.
Comparison of mAP metrics
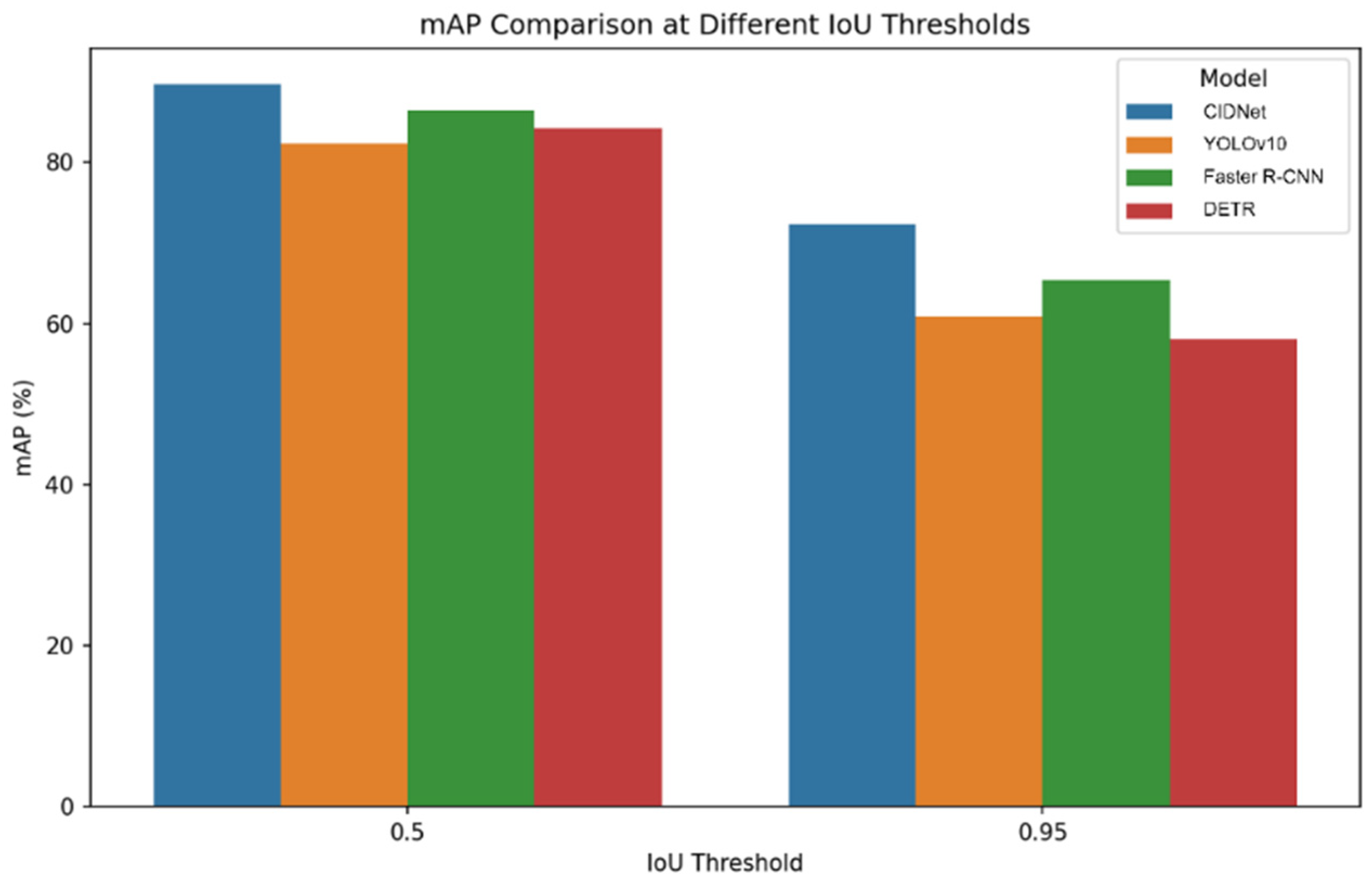
As shown in
Figure 6, CIDNet demonstrates excellent performance in terms of mean average precision (mAP), especially on the higher IoU threshold of 0.95, where its mAP reaches 72.3%. This is superior to YOLOv10’s 60.9%, Faster R-CNN’s 65.4%, and DETR’s 58.1%. This indicates that CIDNet’s ability to identify and locate targets accurately is superior to other models, and it is particularly suitable for application scenarios that require high-precision localization.
- 2.
Recall Results
Recall measures the extent to which the model misses detections, with a higher recall indicating a more significant proportion of targets successfully detected by the model.
As shown in
Figure 7, CIDNet also performs well in terms of the recall rate, reaching 88.1%, a performance metric significantly higher than YOLOv10’s 75.9%, Faster R-CNN’s 81.4%, and DETR’s 79.6%. The high recall rate means that CIDNet is even better at reducing missed detections, making it more reliable in security-sensitive applications.
- 3.
False Alarm Rate and Noise Interference Testing
As shown in
Figure 8, CIDNet shows a significant advantage in comparing the false detection rate (FAR) and noise interference resistance performance. Specifically, CIDNet’s FAR under standard conditions is 5.3%, while it only rises to 6.1% under noisy conditions, showing its strong resistance to noise. In comparison, YOLOv10’s false detection rate is 9.7% under normal conditions and rises to 12.8% under noisy conditions, indicating that it is prone to more false alarms in noisy environments. Faster R-CNN and DETR also show an increase in the false detection rate, from 7.2% and 8.1% under normal conditions to 8.5% and 10.9% under noisy conditions, respectively.
These data reveal the superiority of CIDNet over other models in terms of interference immunity, particularly in its ability to maintain a low false detection rate when dealing with noisy environments. CIDNet’s lower increase in false detection rates (less than 15%) compared to YOLOv10 and DETR (both with more than a 30% increase) signals that it is better suited for accurate target detection in complex and noisy contexts.
- 4.
FPS
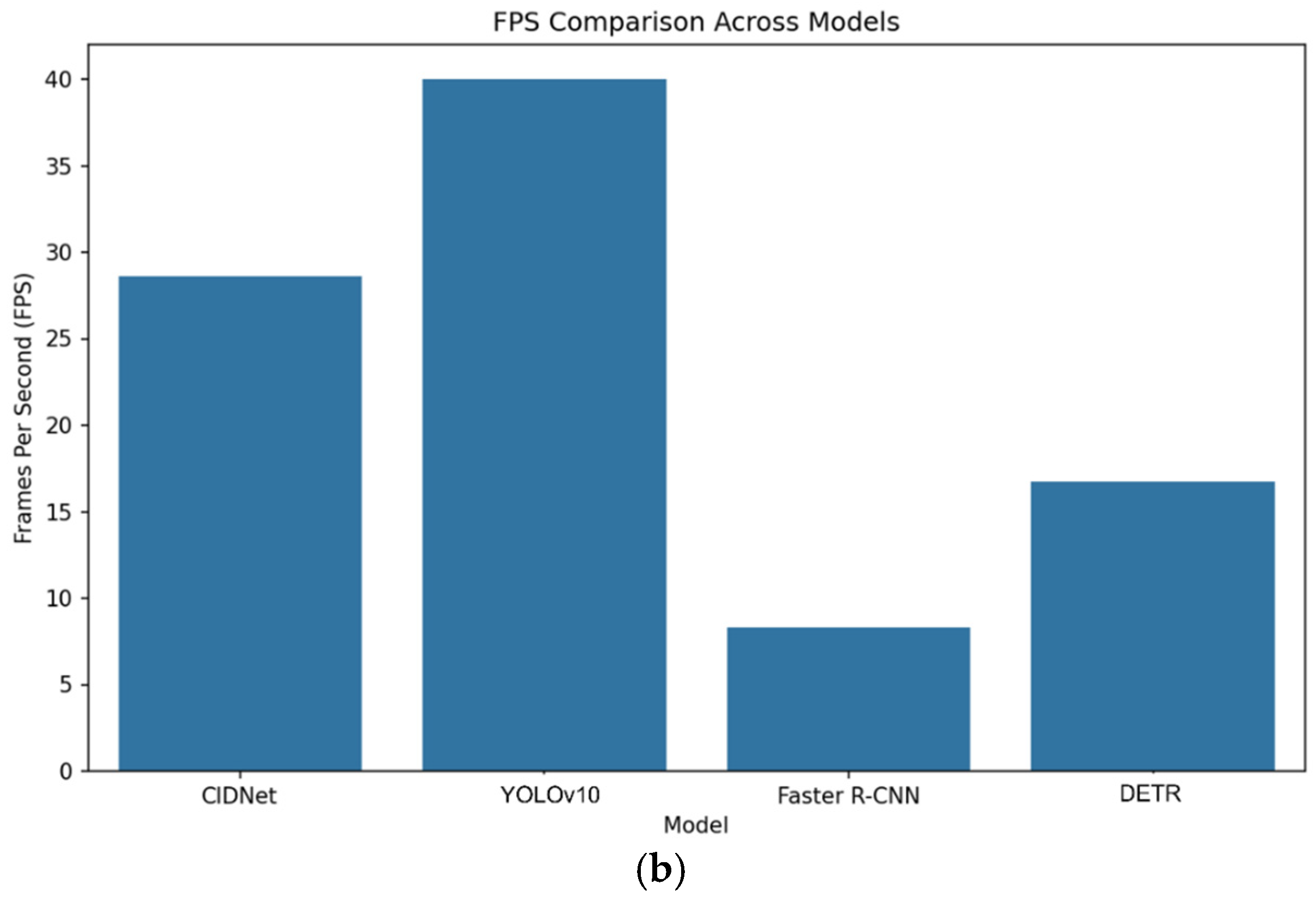
Reasoning time and frame rate are key metrics for measuring the model in real-time applications. A shorter inference time and higher frame rate indicate that the model is more adaptable in real-time scenarios.
As shown in
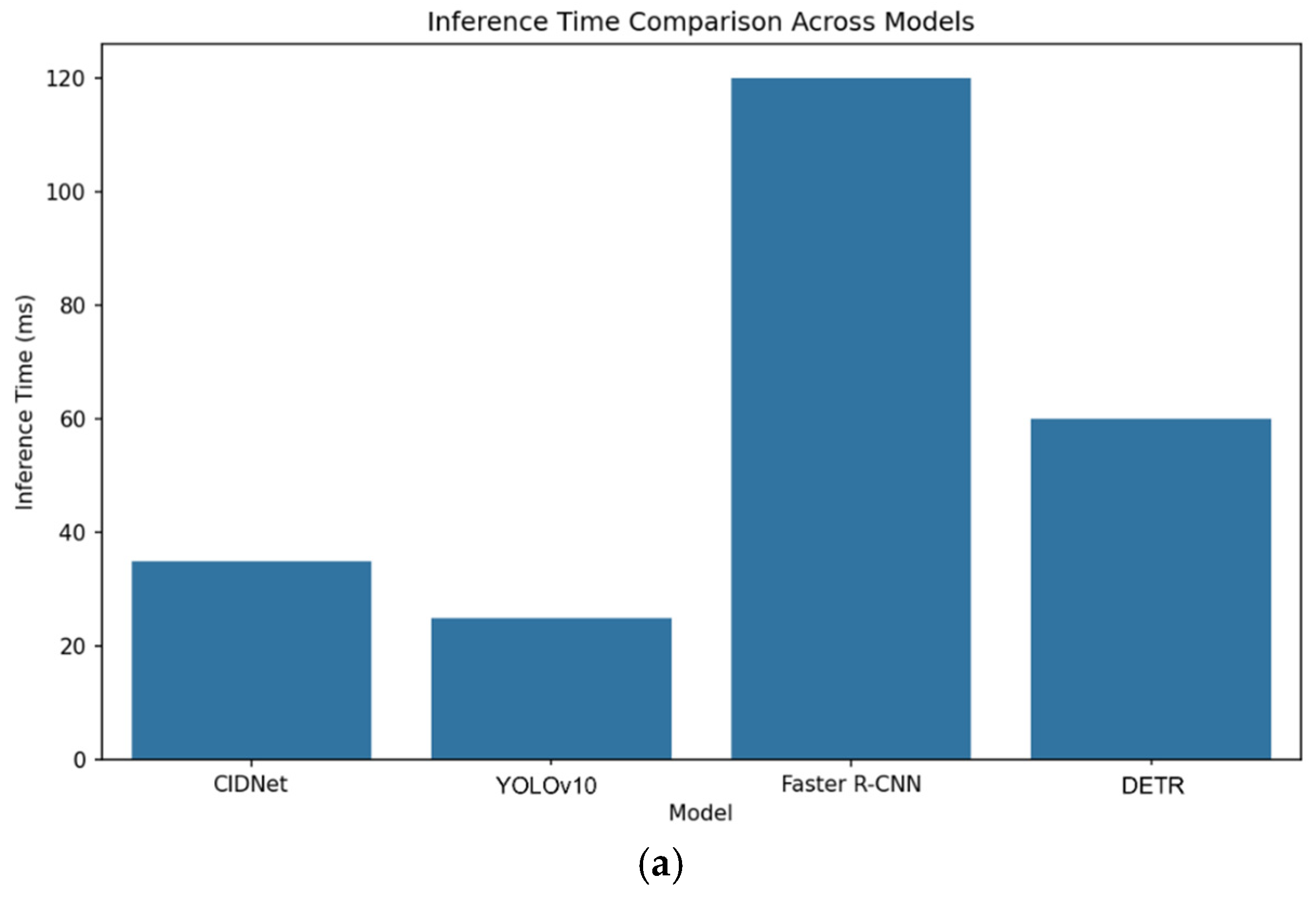
Figure 9a, based on the visual comparison of inference time, YOLOv10 has the shortest inference time, meaning it is the fastest in processing a single image. CIDNet’s inference time is slightly longer than that of YOLOv10 but significantly better than that of the Faster R-CNN and DETR. Although CIDNet is not the fastest, considering its higher accuracy, this inference time is still within the acceptable range.
Although CIDNet is slightly inferior to YOLOv10 (25 ms) in terms of inference time (35 ms), it still outperforms Faster R-CNN (120 ms) and DETR (60 ms). As shown in
Figure 9b, in terms of frame rate, CIDNet reaches 28.6 FPS, which is not as good as YOLOv10’s 40.0 FPS but significantly better than Faster R-CNN’s 8.3 FPS and DETR’s 16.7 FPS. This shows that, although it sacrifices some of its speed, CIDNet can provide high accuracy while maintaining a high frame rate and balancing speed and performance.
Overall, CIDNet outperforms YOLOv10, Faster R-CNN, and DETR regarding average accuracy, recall, and resistance to noise interference. However, it is slightly inferior to YOLOv10 regarding inference speed and frame rate. Compared to YOLOv10, CIDNet achieves an increase of 6.0% in mAP, 12.2% in recall, and 9.2% in the F1-score. Compared with Faster R-CNN, CIDNet shows improvements of 3.6% in mAP, 6.7% in recall, and 5.2% in the F1-score. Even against DETR, which focuses on global feature modeling, CIDNet demonstrates substantial gains of 8.9%, 8.5%, and 8.7% in mAP, recall, and F1-scores, respectively.
These experimental results clearly demonstrate that the proposed CIDNet significantly enhances target localization accuracy and detection robustness in complex ISAR ship detection scenarios. Specifically, the substantial improvement in recall indicates that CIDNet is more effective in reducing missed detections, while the superior F1-score reflects a balanced optimization between precision and recall, making CIDNet highly applicable to real-world maritime monitoring tasks where both accuracy and completeness of detection are critical. Taking the dataset used in this study as an example, for the problem of small ship movements in complex sea conditions, the core submodule AFAN proposed by CIDNet can dynamically track the target focus and adjust the attention mechanism in real time. Faced with coupling interference in the time-frequency domain, AFAN adapts to the dynamic changes in the scene and adjusts the feature extraction path adaptively to improve the stability of motion target detection. On the other hand, in order to improve the model’s small target detection abilities, the core submodule EAFL introduces an edge-aware learning module to enhance the details of target contours and suppress background noise. In multi-scale feature fusion, the dynamic weighting mechanism is used to highlight the target area, thereby improving the performance of small object detection.
CIDNet’s comprehensive performance allows it to be used in tasks requiring high accuracy and better real-time performance, especially in specialized areas such as ISAR ship target detection.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}