
Multi-AUV Hunting Strategy Based on Regularized Competitor Model in Deep Reinforcement Learning



Abstract
1. Introduction
- (i)
- Integrating the Competitor Model into the Objective Function. By introducing a binary stochastic variable, denoted as ‘optimality’ (o), this study transforms the strategy modeling of a single agent interacting with other agents into a probabilistic inference problem. The likelihood variational lower bound for achieving optimality is derived as a new objective function for MARL, while the strategies of competitors are modeled using a regularization approach. The competitor model can more accurately learn the strategies of other agents, improve the training efficiency of MARL, and achieve faster convergence.
- (ii)
- Training within a Competitive Game Framework. When converging to a Nash equilibrium, each intelligent agent selects its optimal strategy given a fixed competitor strategy to maximize its own gains. Applying the same reinforcement learning model to both competing sides enables diverse simulation experiments and improves the generalization ability of training.
2. Maximum Entropy Reinforcement Learning Algorithm Based on Regularized Competitor Model
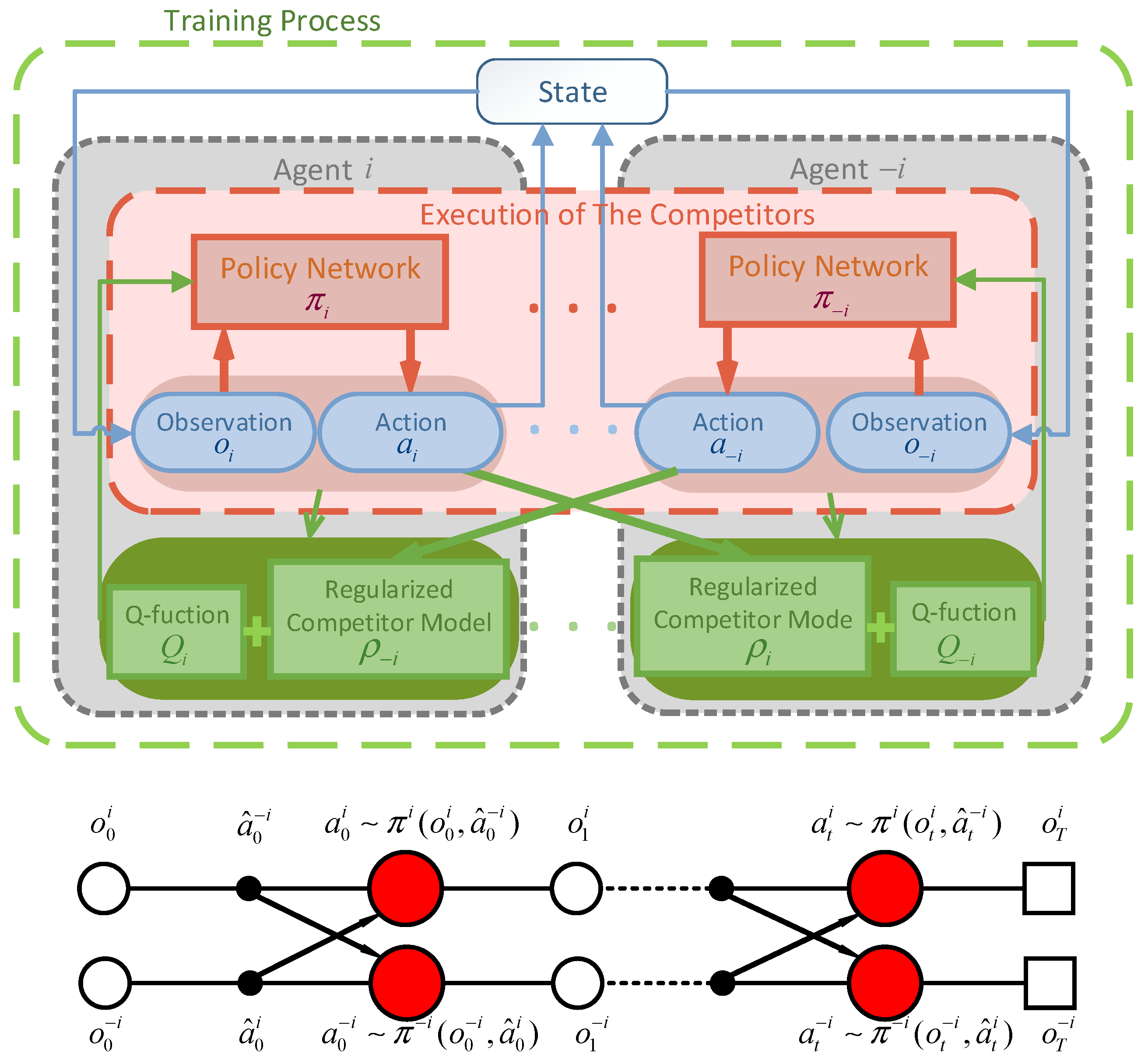
2.1. The Proposed Framework
2.2. Competitive Games
2.3. Regularized Competitor Model
2.4. Regularized Competitor Model with Maximum Entropy Objective Actor-Critic (RCMAC)
3. Multi-AUV Hunting with RCMAC
3.1. Environmental State Description
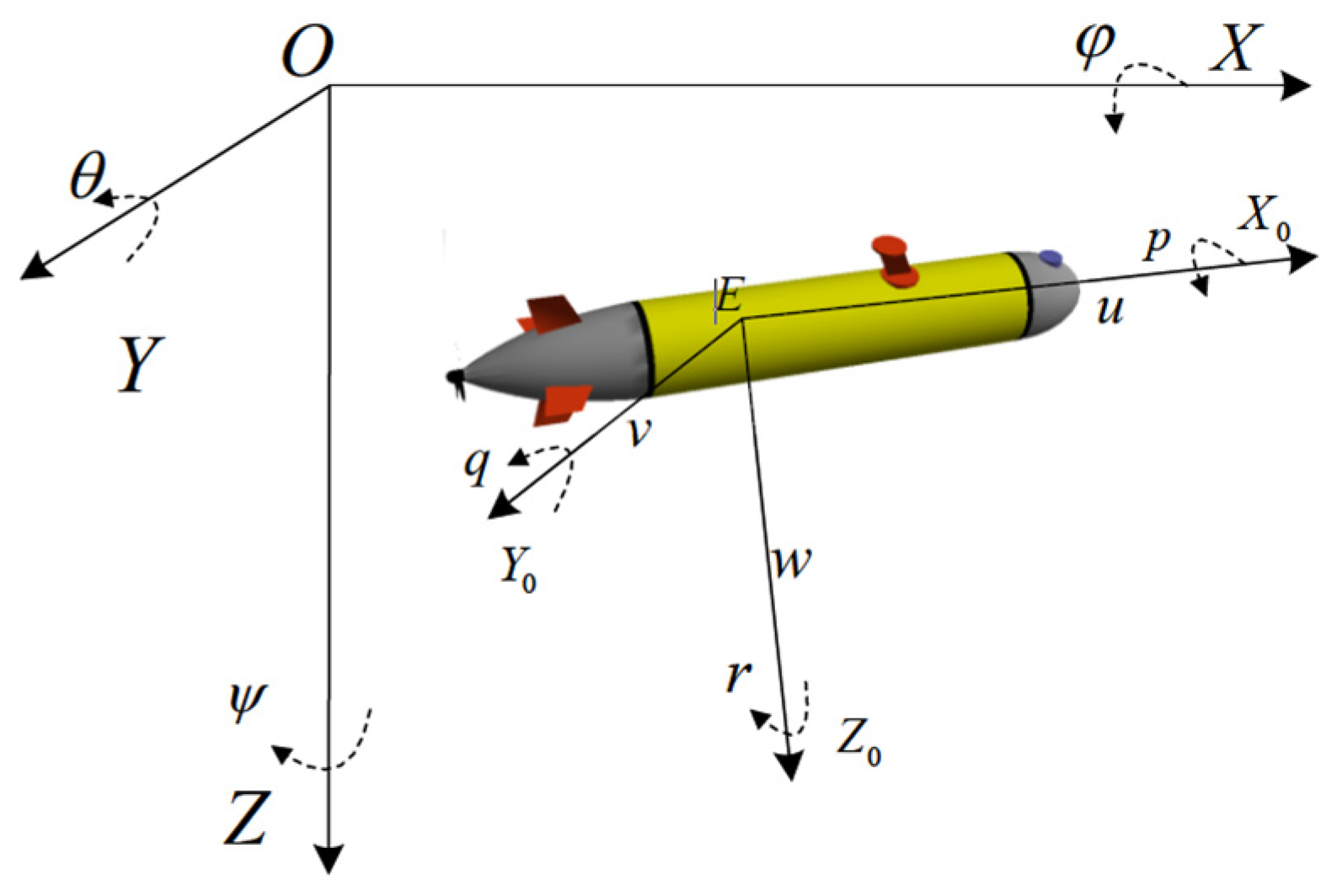
3.1.1. AUV Motion Model
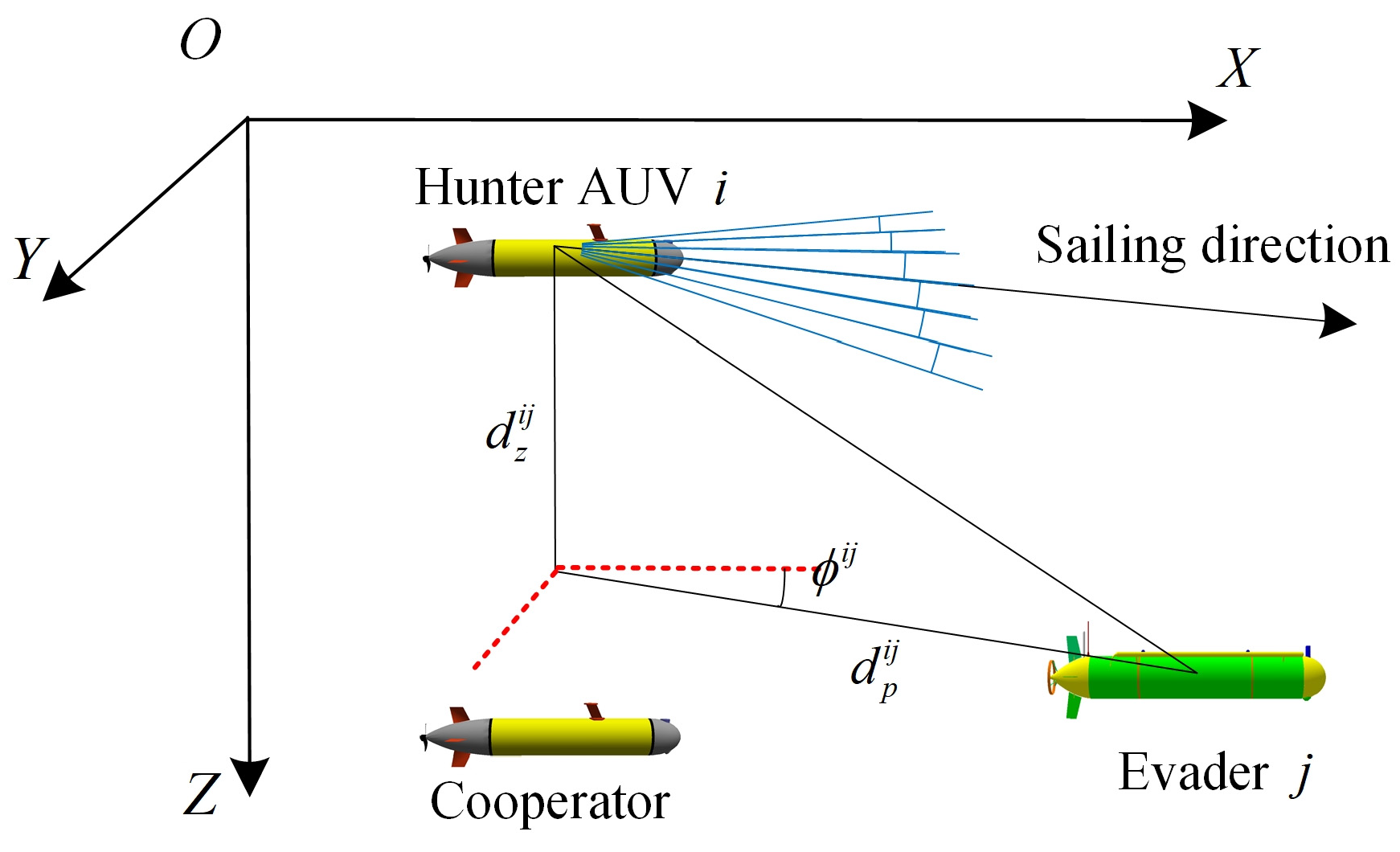
3.1.2. State of the Competitors (Including Cooperators and the Evader)
3.2. Criteria for a Successful Hunting Progress
- The distance between the center of the hunting formation and the evader is less than a threshold (5 m);
- The distance between the hunting AUVs and the evader is less than a threshold (10 m);
- There exists at least one hunting AUV with a distance of less than 1 m from the evader.
3.3. Reward Functions of the Hunters
3.3.1. Cooperating Rewards
3.3.2. Hunting Rewards
3.3.3. Finishing Rewards
3.4. Reward Functions of the Evader
3.5. Competitive Training Process
| Algorithm 1 RCMAC in Multi-AUV Hunting |
|
4. Simulation Results
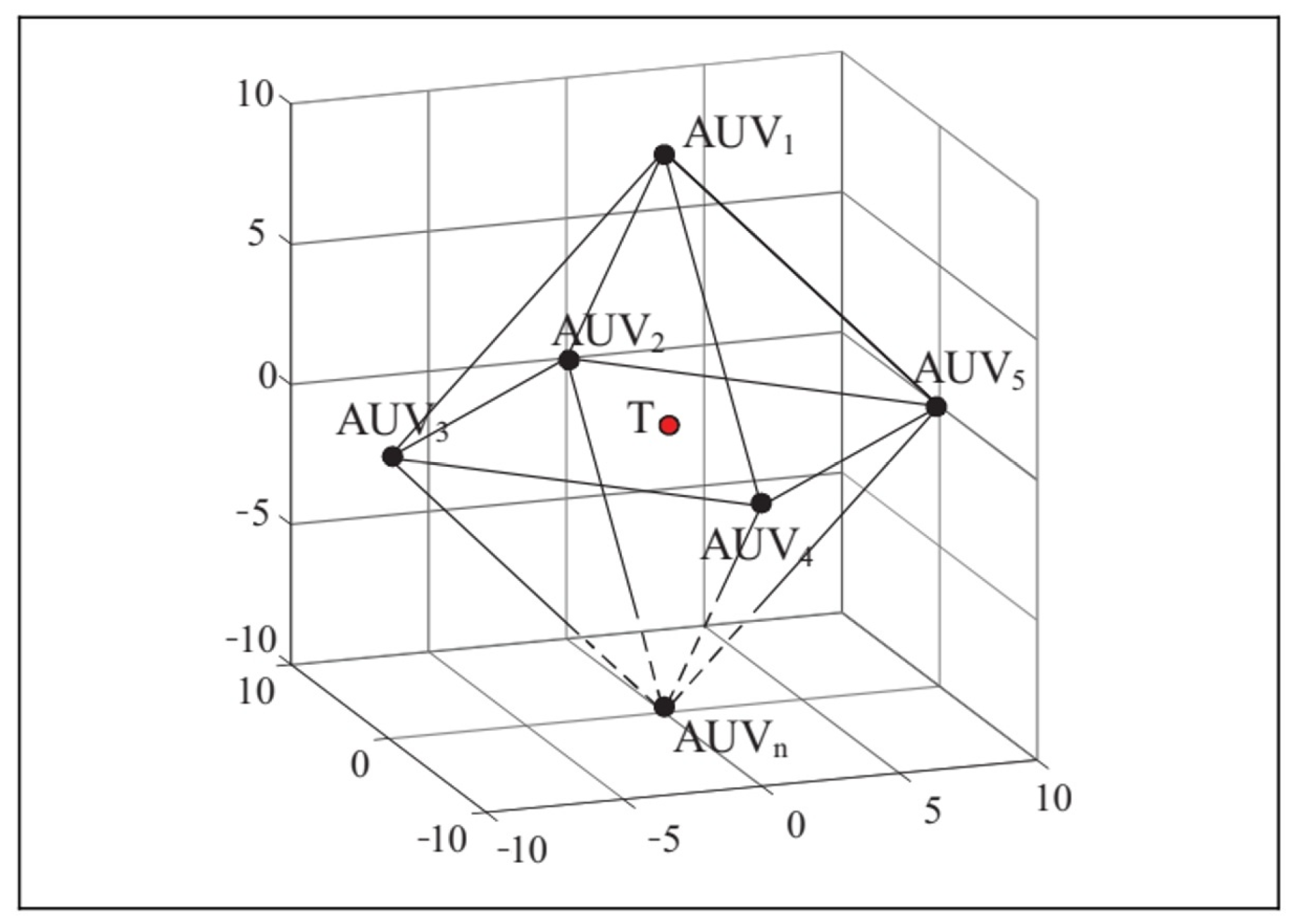
4.1. Experimental Environment and Training Parameters
4.2. Performance and Analysis
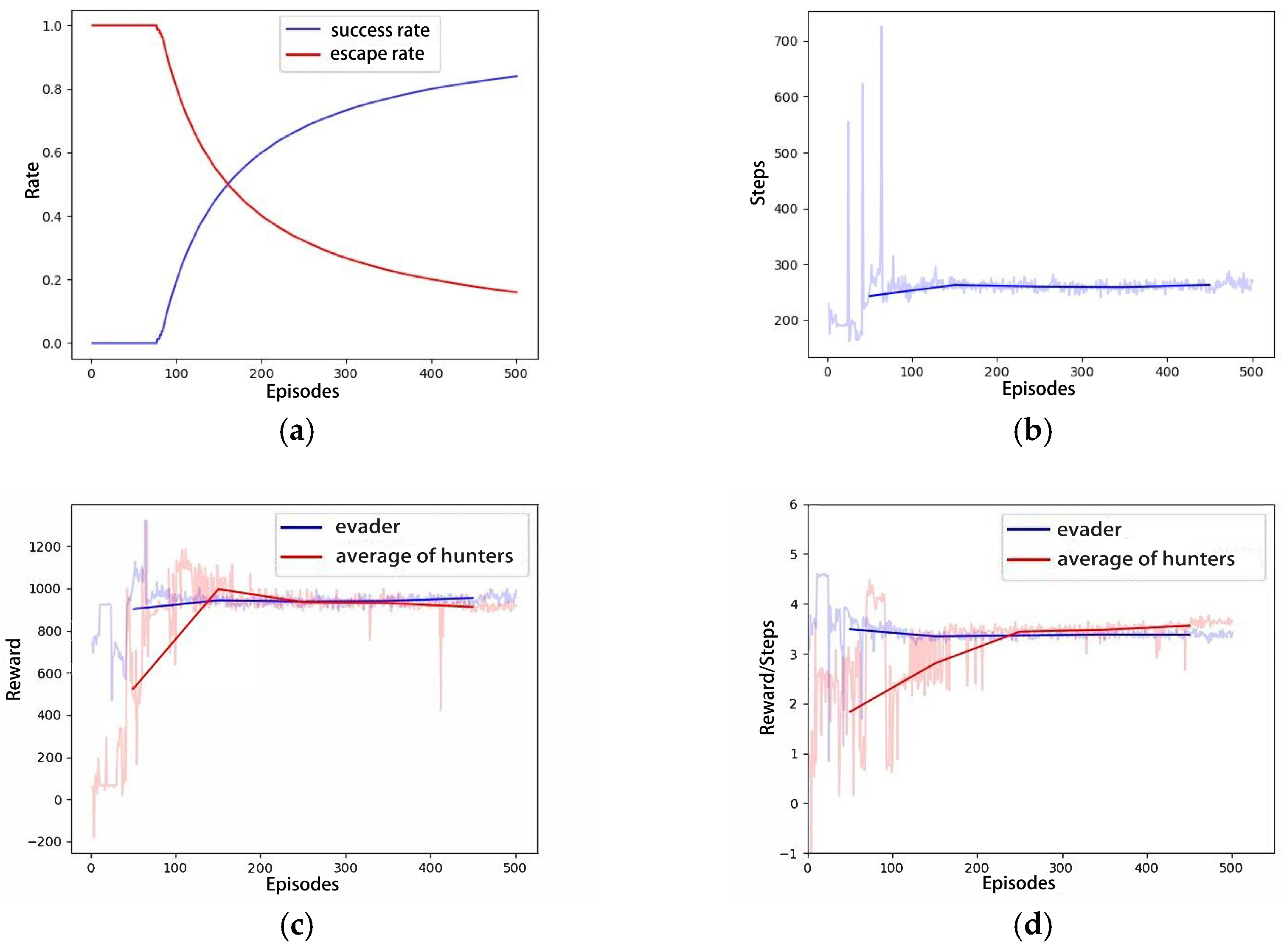
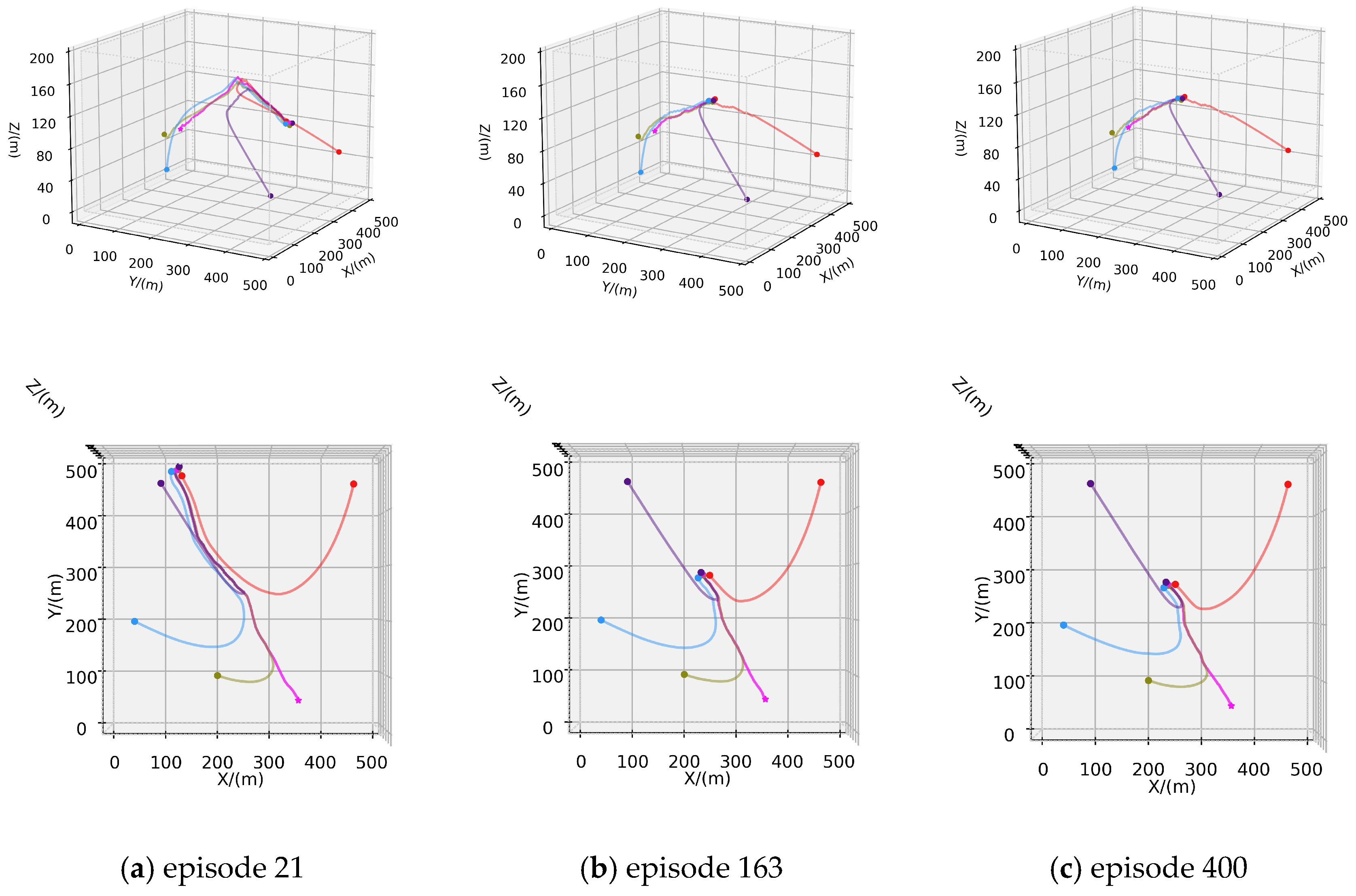
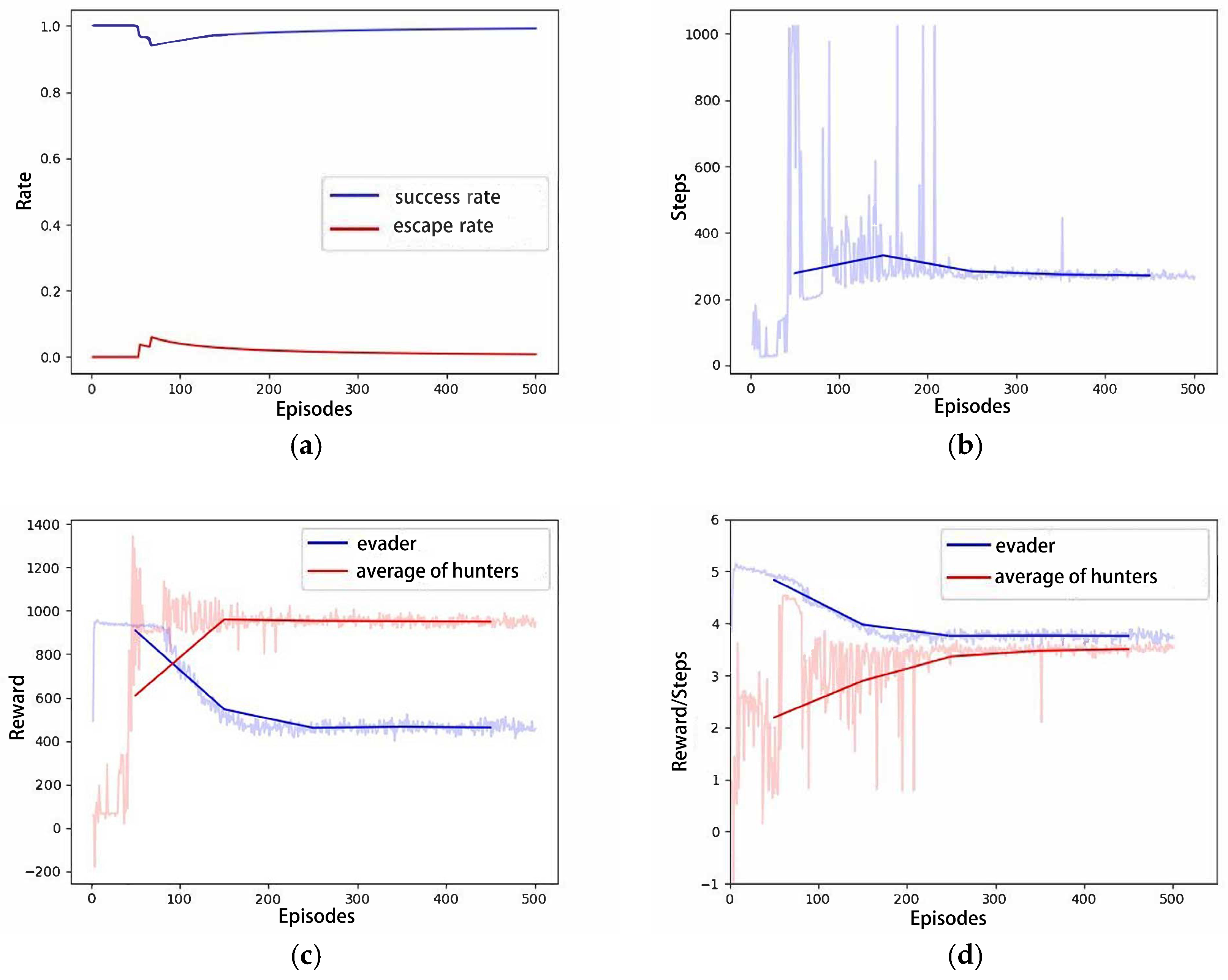
4.2.1. Scenario A: One Hunter–One Evader Game
4.2.2. Scenario B: Four Hunters–One Evader Game
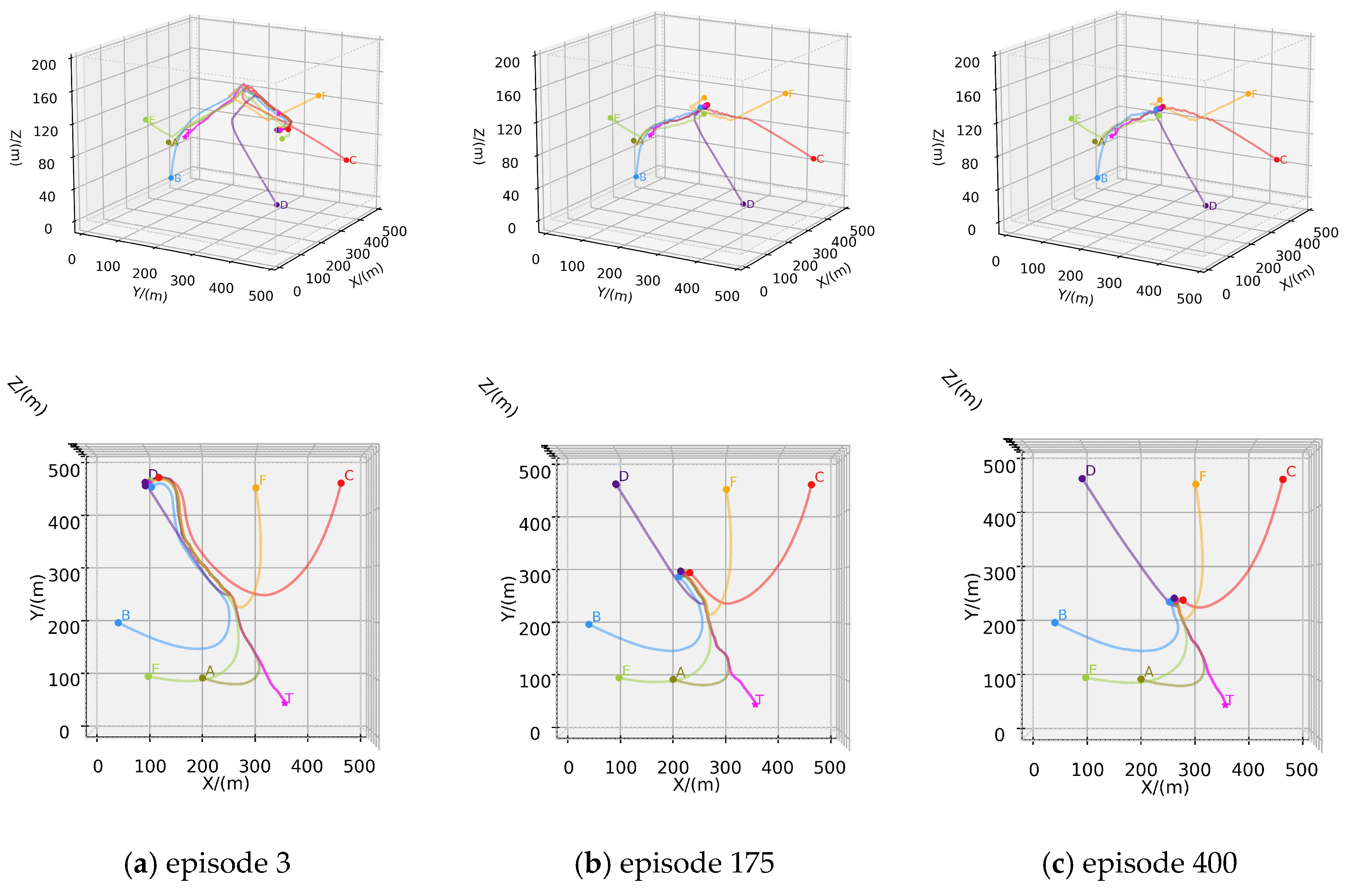
4.2.3. Scenario C: Six Hunters–One Evader Game
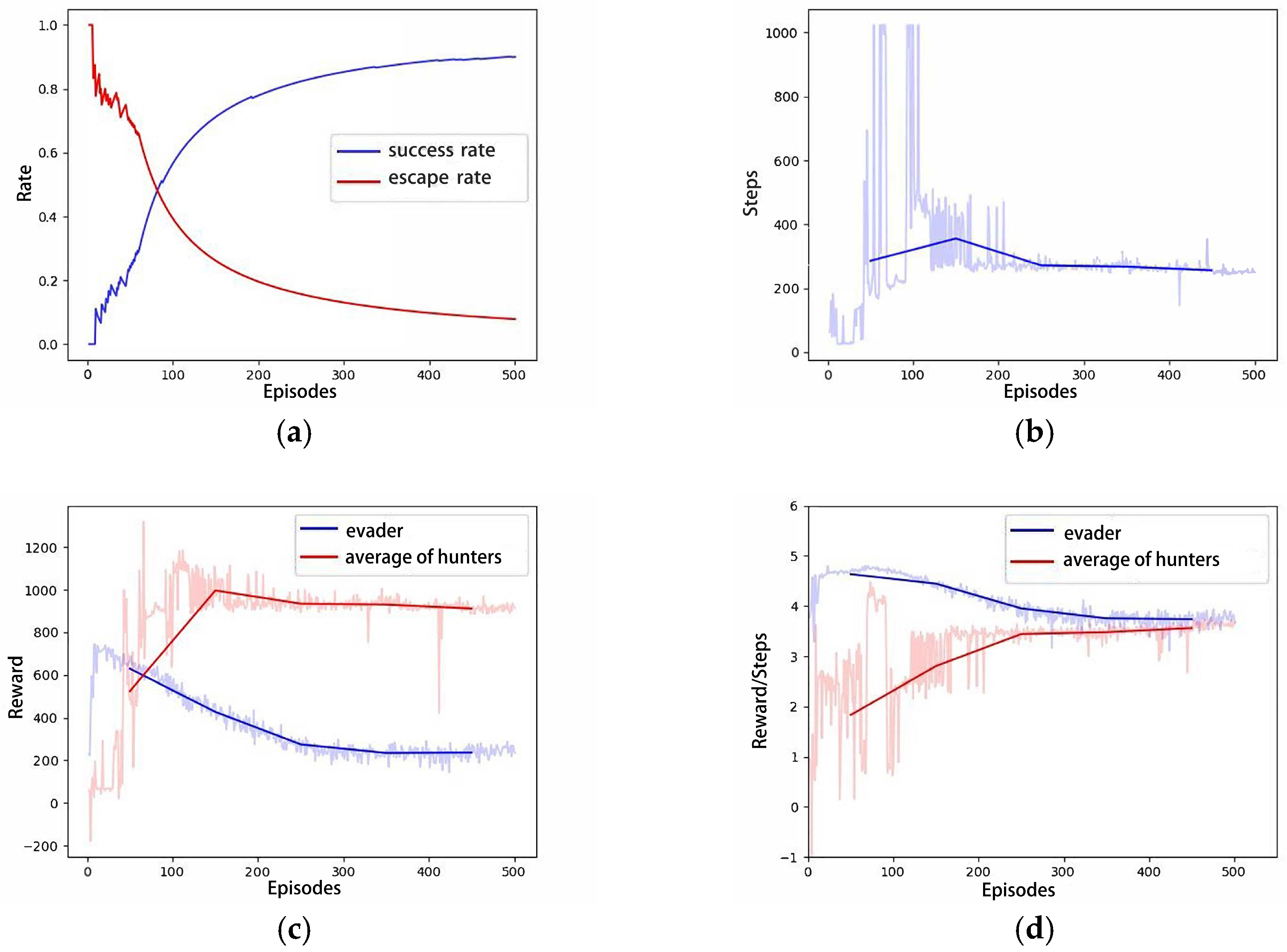
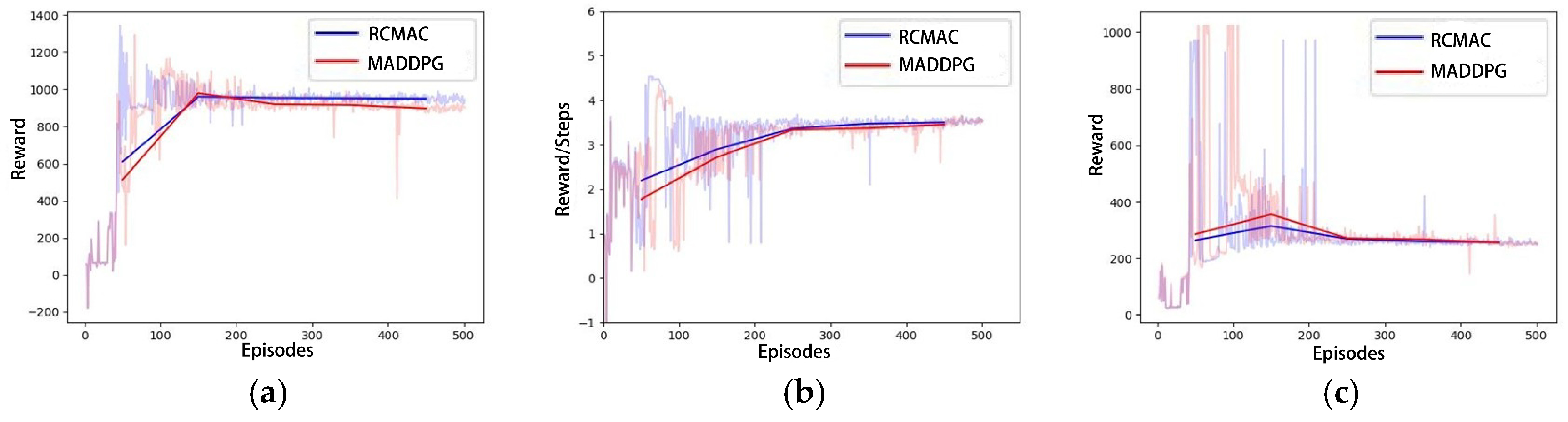
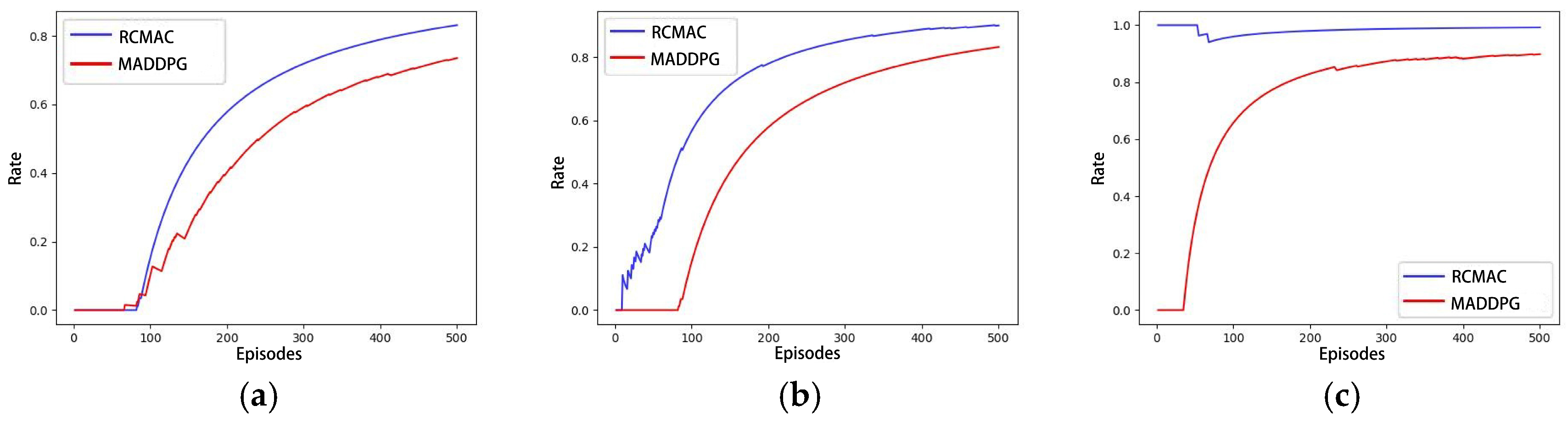
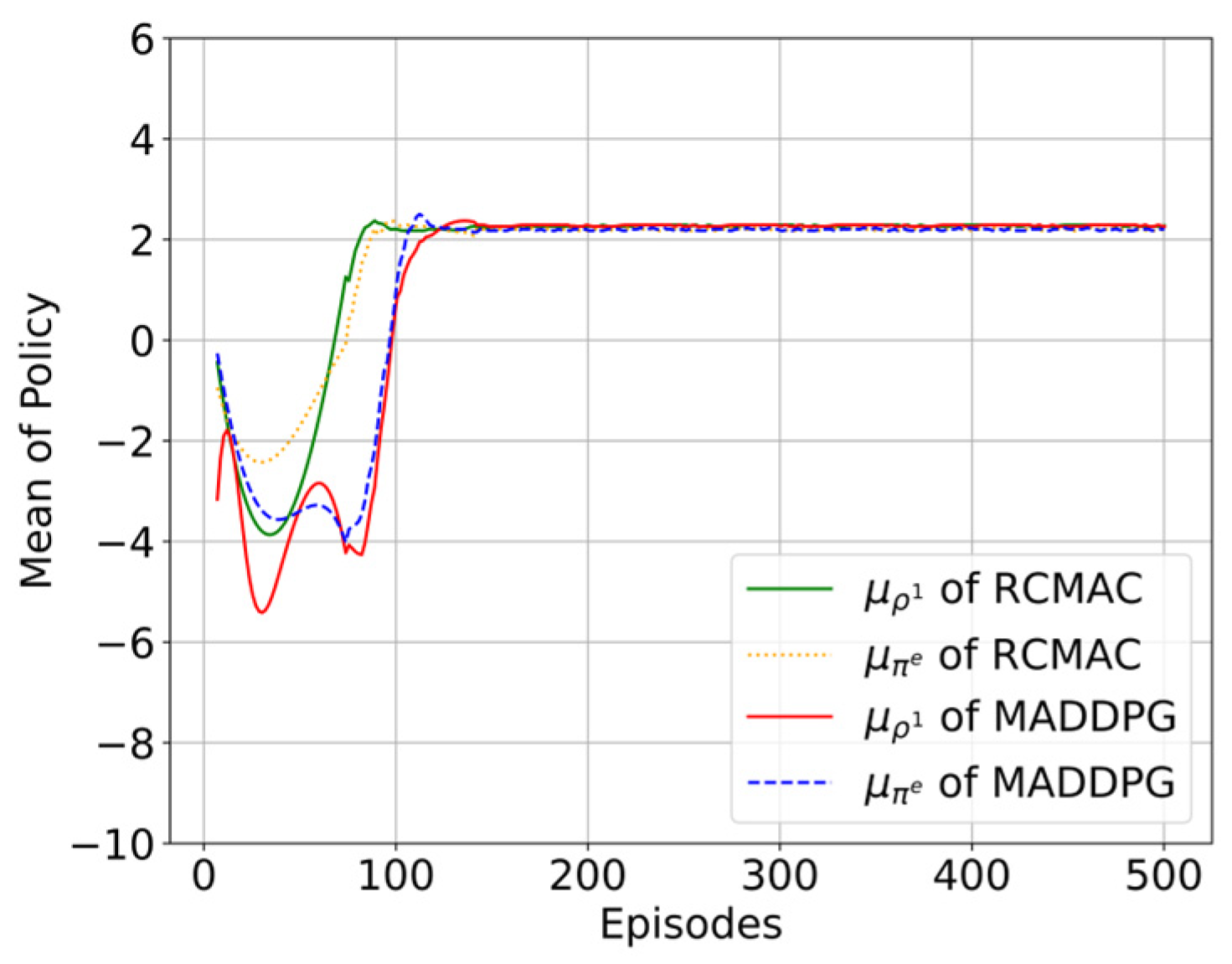
4.2.4. Performance Comparison with MADDPG
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUV | Autonomous Underwater Vehicle |
| RCM | Regularized Competitor Model |
| RCMAC | Regularized Competitor Model with Maximum Entropy Objective Actor-Critic |
| DRL | Deep Reinforcement Learning |
| MARL | Multi-Agent Reinforcement Learning |
| DDPG | Deep Deterministic Policy Gradient |
| MADDPG | Multi-Agent Deep Deterministic Policy Gradient |
| CTDE | centralized training and decentralized execution |
| SAC | Soft Actor-Critic |
References
- Ma, T.; Lyu, J.; Yang, J.; Xi, R.; Li, Y.; An, J.; Li, C. CLSQL: Improved Q-Learning Algorithm Based on Continuous Local Search Policy for Mobile Robot Path Planning. Sensors 2022, 22, 5910. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Sun, H.; Guo, L. Potential Field Hierarchical Reinforcement Learning Approach for Target Search by Multi-AUV in 3-D Underwater Environments. Int. J. Control 2020, 93, 1677–1683. [Google Scholar] [CrossRef]
- Wang, G.; Wei, F.; Jiang, Y.; Zhao, M.; Wang, K.; Qi, H. A Multi-AUV Maritime Target Search Method for Moving and Invisible Objects Based on Multi-Agent Deep Reinforcement Learning. Sensors 2022, 22, 8562. [Google Scholar] [CrossRef] [PubMed]
- Mao, Y.; Gao, F.; Zhang, Q.; Yang, Z. An AUV Target-Tracking Method Combining Imitation Learning and Deep Reinforcement Learning. J. Mar. Sci. Eng. 2022, 10, 383. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhao, M.; Wang, C.; Wei, F.; Qi, H. A Method for Underwater Human–Robot Interaction Based on Gestures Tracking with Fuzzy Control. Int. J. Fuzzy Syst. 2021, 23, 2170–2181. [Google Scholar] [CrossRef]
- Wu, C.; Dai, Y.; Shan, L.; Zhu, Z. Date-Driven Tracking Control via Fuzzy-State Observer for AUV under Uncertain Disturbance and Time-Delay. J. Mar. Sci. Eng. 2023, 11, 207. [Google Scholar] [CrossRef]
- Wu, J.; Song, C.; Ma, J.; Wu, J.; Han, G. Reinforcement Learning and Particle Swarm Optimization Supporting Real-Time Rescue Assignments for Multiple Autonomous Underwater Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6807–6820. [Google Scholar] [CrossRef]
- Cao, X.; Zuo, F. A Fuzzy-Based Potential Field Hierarchical Reinforcement Learning Approach for Target Hunting by Multi-AUV in 3-D Underwater Environments. Int. J. Control 2021, 94, 1334–1343. [Google Scholar] [CrossRef]
- Chen, M.; Zhu, D. A Novel Cooperative Hunting Algorithm for Inhomogeneous Multiple Autonomous Underwater Vehicles. IEEE Access 2018, 6, 7818–7828. [Google Scholar] [CrossRef]
- Chen, L.; Guo, T.; Liu, Y.; Yang, J. Survey of Multi-Agent Strategy Based on Reinforcement Learning. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 604–609. [Google Scholar]
- Orr, J.; Dutta, A. Multi-Agent Deep Reinforcement Learning for Multi-Robot Applications: A Survey. Sensors 2023, 23, 3625. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Xu, X. Hunting Algorithm for Multi-AUV Based on Dynamic Prediction of Target Trajectory in 3D Underwater Environment. IEEE Access 2020, 8, 138529–138538. [Google Scholar] [CrossRef]
- Lu, R.; Li, Y.-C.; Li, Y.; Jiang, J.; Ding, Y. Multi-Agent Deep Reinforcement Learning Based Demand Response for Discrete Manufacturing Systems Energy Management. Appl. Energy 2020, 276, 115473. [Google Scholar] [CrossRef]
- Lowe, R.; WU, Y.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Tian, Z.; Wen, Y.; Gong, Z.; Punakkath, F.; Zou, S.; Wang, J. A Regularized Opponent Model with Maximum Entropy Objective. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Castillo-Zamora, J.J.; Camarillo-Gómez, K.A.; Pérez-Soto, G.I.; Rodríguez-Reséndiz, J.; Morales-Hernández, L.A. Mini-AUV Hydrodynamic Parameters Identification via CFD Simulations and Their Application on Control Performance Evaluation. Sensors 2021, 21, 820. [Google Scholar] [CrossRef] [PubMed]
- Rashid, T.; Samvelyan, M.; De Witt, C.S.; Farquhar, G.; Foerster, J.; Whiteson, S. Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. J. Mach. Learn. Res. 2020, 21, 1–51. [Google Scholar]
- Foerster, J.; Song, F.; Hughes, E.; Burch, N.; Dunning, I.; Whiteson, S.; Botvinick, M.; Bowling, M. Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 24 May 2019; pp. 1942–1951. [Google Scholar]
- Nayyar, A.; Mahajan, A.; Teneketzis, D. Decentralized Stochastic Control with Partial History Sharing: A Common Information Approach. IEEE Trans. Autom. Control 2013, 58, 1644–1658. [Google Scholar] [CrossRef]
- Wen, Y.; Yang, Y.; Luo, R.; Wang, J.; Pan, W. Probabilistic Recursive Reasoning for Multi-Agent Reinforcement Learning. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Davies, I.; Tian, Z.; Wang, J. Learning to Model Opponent Learning. In Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Zhu, Q.; Başar, T. Decision and Game Theory for Security; Springer: Fort Worth, TX, USA, 2013; pp. 246–263. [Google Scholar]
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement Learning with Deep Energy-Based Policies. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 6–11 August 2017; pp. 1352–1361. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft Actor-Critic Algorithms and Applications. arXiv 2019, arXiv:1812.05905. [Google Scholar]
- Wei, E.; Wicke, D.; Freelan, D.; Luke, S. Multiagent Soft Q-Learning. arXiv 2018, arXiv:1804.09817. [Google Scholar]
- Danisa, S. Learning to Coordinate Efficiently through Multiagent Soft Q-Learning in the Presence of Game-Theoretic Pathologies. Master’s Thesis, University of Cape Town, Cape Town, Western Cape, South Africa, September 2022. [Google Scholar]
- Fjellstad, O.-E.; Fossen, T.I. Position and Attitude Tracking of AUV’s: A Quaternion Feedback Approach. IEEE J. Ocean. Eng. 2002, 19, 512–518. [Google Scholar] [CrossRef]
- Wang, Z.; Sui, Y.; Qin, H.; Lu, H. State Super Sampling Soft Actor–Critic Algorithm for Multi-AUV Hunting in 3D Underwater Environment. J. Mar. Sci. Eng. 2023, 11, 1257. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Learning rate of all networks | 0.0003 |
| 0.97 | |
| Mini batch size | 256 |
| Replay buffer size M | 1024 |
| Training episode num | 5000 |
| Testing episode num | 500 |
| Max step num | 1024 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sui, Y.; Wang, Z.; Bai, G.; Lu, H. Multi-AUV Hunting Strategy Based on Regularized Competitor Model in Deep Reinforcement Learning. J. Mar. Sci. Eng. 2025, 13, 901. https://doi.org/10.3390/jmse13050901
Sui Y, Wang Z, Bai G, Lu H. Multi-AUV Hunting Strategy Based on Regularized Competitor Model in Deep Reinforcement Learning. Journal of Marine Science and Engineering. 2025; 13(5):901. https://doi.org/10.3390/jmse13050901
Chicago/Turabian StyleSui, Yancheng, Zhuo Wang, Guiqiang Bai, and Hao Lu. 2025. "Multi-AUV Hunting Strategy Based on Regularized Competitor Model in Deep Reinforcement Learning" Journal of Marine Science and Engineering 13, no. 5: 901. https://doi.org/10.3390/jmse13050901
APA StyleSui, Y., Wang, Z., Bai, G., & Lu, H. (2025). Multi-AUV Hunting Strategy Based on Regularized Competitor Model in Deep Reinforcement Learning. Journal of Marine Science and Engineering, 13(5), 901. https://doi.org/10.3390/jmse13050901