1. Introduction
Using mobile observation platforms for adaptive regional ocean data collection is a crucial approach for capturing dynamic ocean element variations and plays a key role in improving the accuracy of the marine environment numerical prediction system [
1]. AUVs, with their capability to carry observation instruments, sustain long-duration underwater operations, enable fast data transmission, and exhibit high autonomy, have become widely used mobile ocean observation platforms [
2]. AUV formations provide an effective solution to overcome the limitations of a single AUV in ocean observation and hold great potential for various applications [
3]. As a crucial component of the ocean observation network, formations extend the spatiotemporal coverage of data collection and integrate sensors to deliver multi-dimensional environmental insights. Compared to a single AUV, multi-AUVs offer broader mission coverage, enhanced system robustness, and improved fault tolerance, making them more efficient and reliable in complex ocean environments.
In practical observation missions, multi-AUVs operate for extended periods in dynamic and complex 3D marine environments, often affected by ocean currents. Moreover, static and dynamic obstacles in the observation area constantly pose a threat to navigation safety. Additionally, the high manufacturing and maintenance costs of AUVs result in elevated costs for obtaining observation data. Therefore, designing an optimal observation strategy for multi-AUVs under complex observation constraints is an urgent problem to address. The aim of this strategy is to make effective use of limited AUV resources by strategically planning observation points, maximizing the utilization of ocean currents, avoiding obstacles, and collecting key environmental data, thus improving observation efficiency.
Researchers have developed a variety of methods for adaptive observation path planning, including Dijkstra’s algorithm, A*, Artificial Potential Field (APF), and rapidly-exploring random tree (RRT) algorithms. In [
4], Namik et al. framed the AUV path planning problem within an optimization framework and introduced a mixed-integer linear programming solution. This method was applied to adaptive path planning for AUVs to achieve the optimal path. Zeng [
5] combined sampling point selection strategies, information heuristics, and the RRT algorithm to propose a new rapid-exploration tree algorithm that guides vehicles to collect samples from research hotspot areas. Although these methods are relatively straightforward to implement, they depend on accurate modeling of the entire environment, limiting their use to small-scale, deterministic scenarios. When the environment changes, the cost function must be recalculated, and as the problem size increases, the search space expands exponentially. This often results in reduced performance and a higher risk of converging to local optima. Furthermore, these approaches are not well suited for real-time applications in harsh marine environments.
To overcome these limitations, researchers have explored biologically inspired bionic algorithms such as ant colony optimization (ACO), particle swarm optimization (PSO), and neural network-based methods. Zhou et al. [
6] proposed adaptive sampling path planning for AUVs, considering the temporal changes in the marine environment and energy constraints. They applied a particle swarm optimization algorithm combined with fuzzy decision-making to address the multi-objective path optimization problem. However, as the number of AUVs increased, these methods faced the challenge of rapidly escalating computational complexity. Ferri et al. [
7] introduced a “demand-based sampling” method for planning the underwater glider formation path tasks, which accommodates different sampling strategies. They integrated this approach with a simulated annealing optimizer to solve the minimization problem, and the experimental results demonstrated the approach’s effectiveness in glider fleet task planning. Hu et al. employed the ACO algorithm to generate observation strategies for AUVs [
8,
9]. By introducing a probabilistic component based on pheromone concentration when selecting sub-nodes, they expanded the algorithm’s search range [
10]. While these intelligent bionic methods offer significant advantages in handling complex environments, they still exhibit strong environmental dependency, high subjectivity, and a tendency to get trapped in local optima, often resulting in planning outcomes that do not meet practical requirements.
In recent years, advancements in artificial intelligence have driven increasing interest in applying DRL to environmental observation path planning [
11]. Once trained, DRL-based path planning methods enable AUVs to intelligently navigate their surroundings, making informed decisions that efficiently guide them toward target areas. These methods typically generate outputs used to select the most effective actions from the available set [
12]. With these capabilities, DRL-based path planning has emerged as a highly effective solution for overcoming the challenges associated with multi-AUV observations in uncertain, complex and dynamic marine environments [
13].
Deep Q-Network (DQN) [
14] is a seminal reinforcement learning algorithm that integrates Q-learning [
15] with deep neural networks [
16] to tackle challenges in continuous state spaces. Yang et al. [
17] effectively utilized DQN for efficient path planning under varying obstacle scenarios, improving AUV path planning success rates in complex marine environments. While DQN performs reasonably well in simple environments, its limitations become evident in more complex settings. First, DQN struggles to capture the dynamic characteristics of complex marine environments. Second, it suffers from low sample efficiency—its original random sampling mechanism in the experience replay buffer results in a homogeneous training dataset, restricting exploration. Additionally, because DQN uses the same network architecture and parameters for both reward computation and action selection, it often leads to overestimated predictions, causing ineffective training and slowing convergence.
To address the challenges encountered with DQN in practical applications, researchers have conducted extensive studies and proposed a series of improvements. Wei et al. [
3] enhanced the DQN network structure to tackle the path planning problem for glider formations in uncertain ocean currents. Zhang et al. [
18] innovatively introduced the DQN-QPSO algorithm by combining DQN with quantum particle swarm optimization. Its fitness function comprehensively accounts for both path length and ocean current factors, enabling the effective identification of energy-efficient trajectories in underwater environments. Despite these advancements, DQN often overestimates Q-values during training. To address this issue and improve performance, Hasselt et al. [
19] introduced Double DQN (DDQN). Building on this approach, Long et al. [
20] proposed a multi-scenario, multi-stage fully decentralized execution framework. In this framework, agents combine local environmental data with a global map, enhancing the algorithm’s collision avoidance success and generalization ability. Liu et al. [
21] incorporated LSTM units with memory capabilities into the DQN algorithm, proposing an Exploratory Noise-based Deep Recursive Q-Network model. Wang et al. [
22] introduced D3QN, an algorithm that integrates Double DQN and Dueling DQN to effectively mitigate overestimation and improve stability. Xi et al. [
23] optimized the reward function in D3QN to address the problem of path planning for AUVs in complex marine environments that include 3D seabed topography and local ocean current information. Although this adaptation allows for planned paths with shorter travel time, the resulting paths are not always smooth.
However, despite significant progress, applying DRL to multi-AUV adaptive observation strategy formulation in complex marine environments remains a challenging task. In real-world applications, prior environmental knowledge is often incomplete [
24]. Due to the limited detection range of sensors, it is crucial to enable multi-AUV systems to efficiently learn and make well-informed decisions in partially observable, dynamic environments while relying on limited prior information.
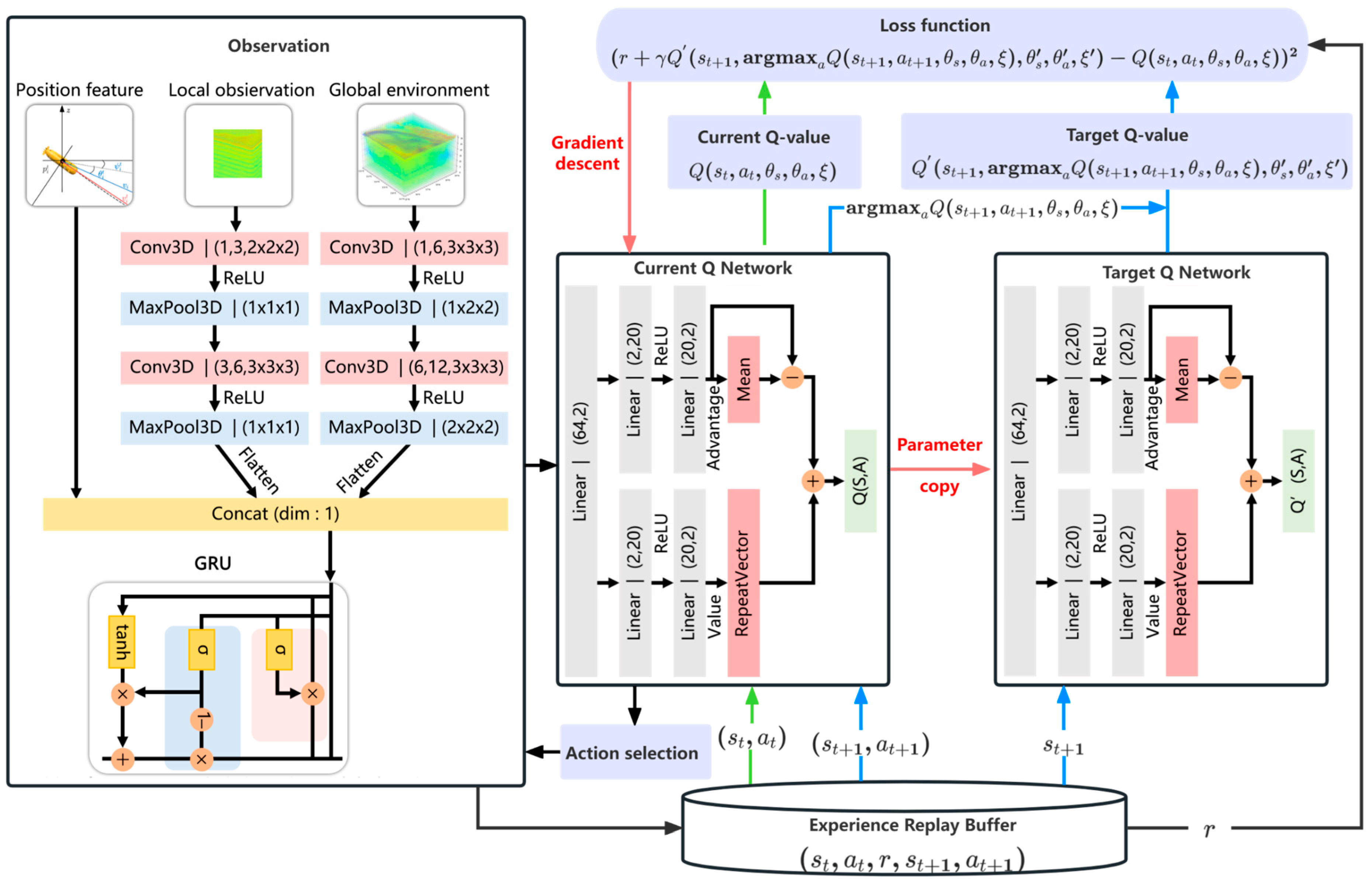
To tackle the aforementioned challenges, we propose an optimized adaptive observation strategy for multi-AUV systems based on an improved D3QN algorithm. This approach aims to enable multi-AUV systems to perform safe, efficient, and energy-efficient observations in dynamic 3D marine environments, while accounting for complex constraints such as ocean currents as well as dynamic and static obstacles. The main contributions of this study are as follows:
We model the adaptive observation process for multi-AUV systems in a dynamic 3D marine environment as a partially observable Markov decision process (POMDP) and develop a DRL framework based on D3QN. By leveraging the advantages of DRL algorithms, which facilitate direct interaction with the marine environment to guide AUV platforms in adaptive observation, we address challenges such as modeling complexities, susceptibility to local optima, and limited adaptability to dynamic environments, ultimately enhancing observation efficiency.
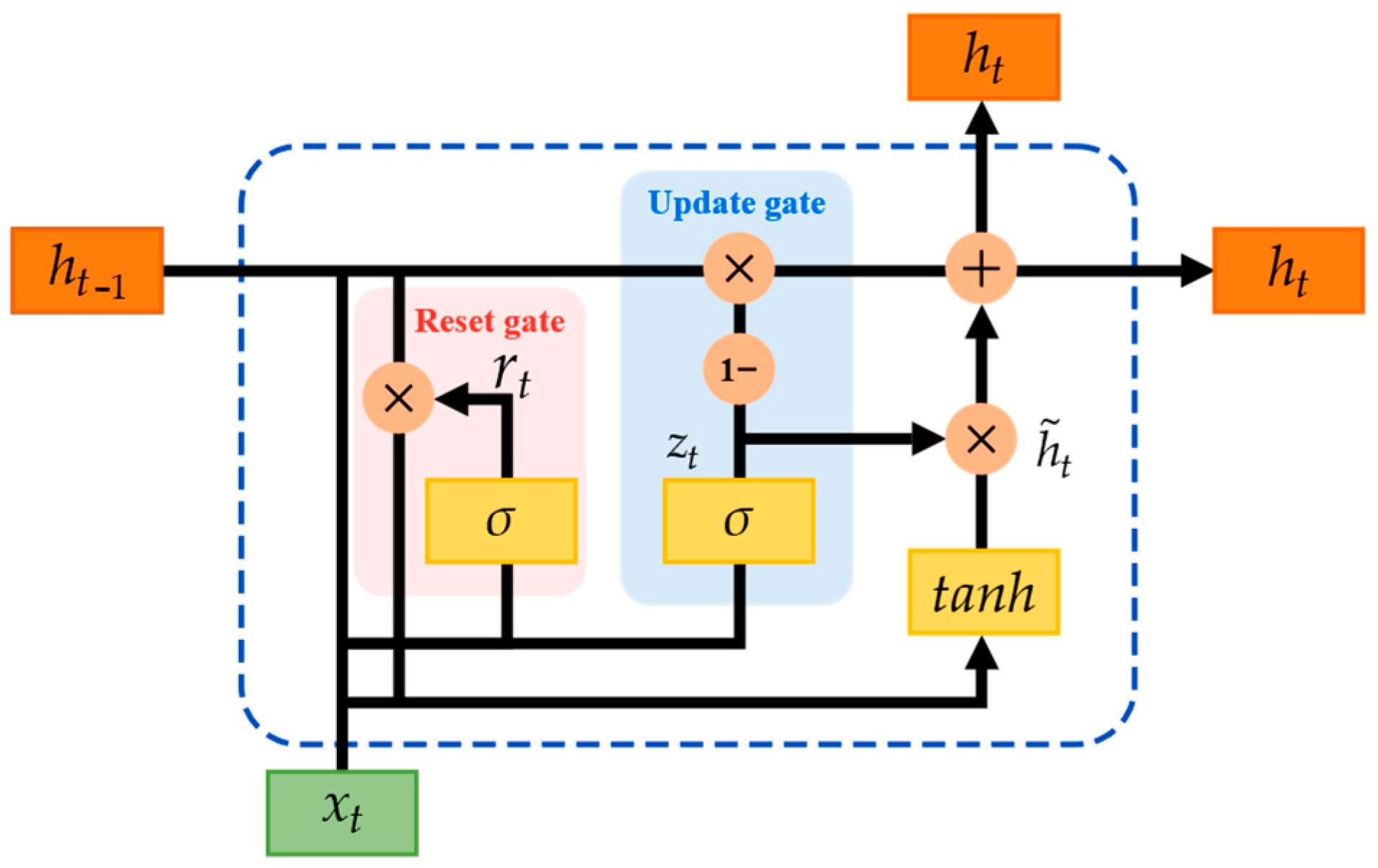
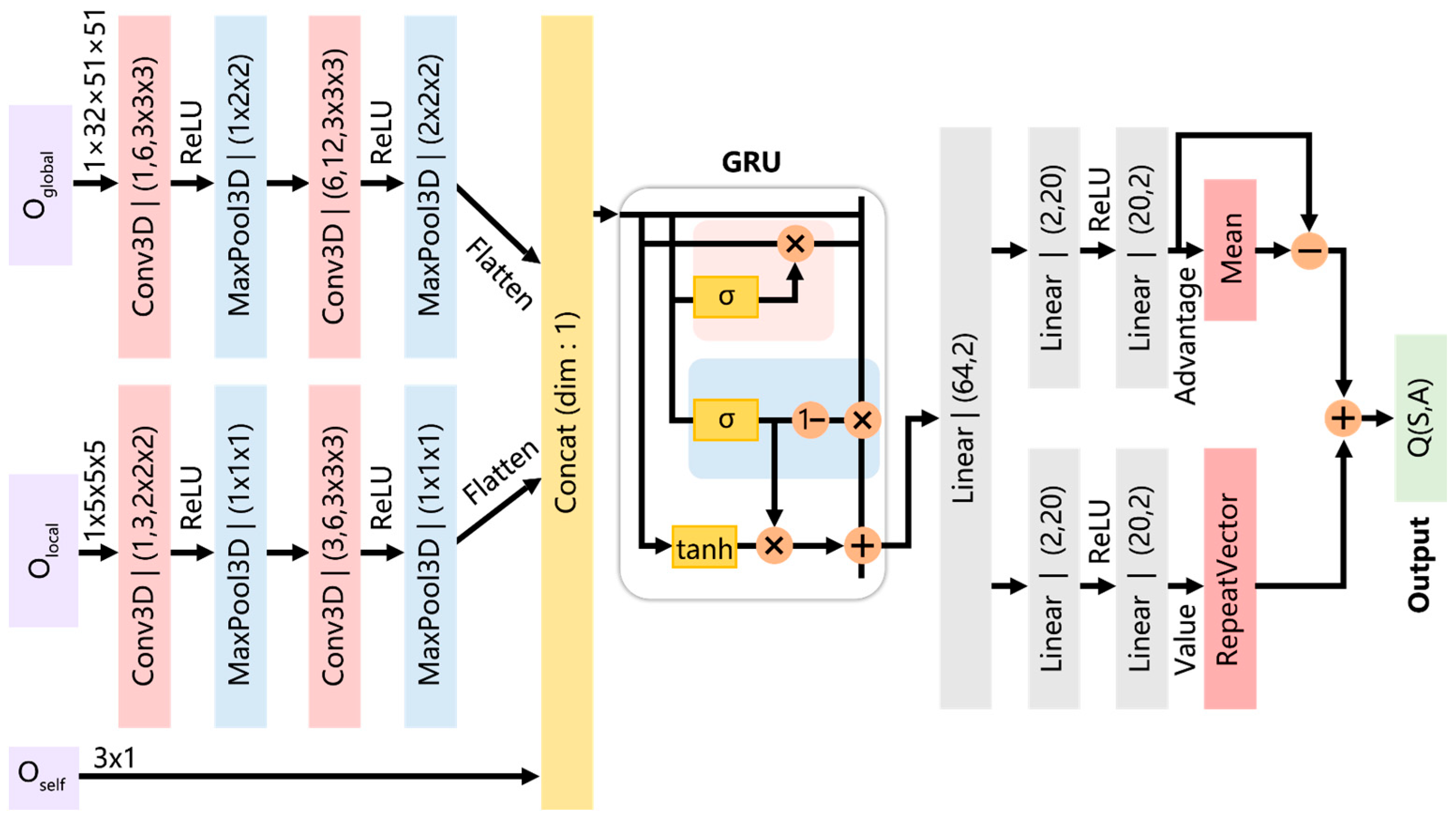
To overcome the challenges of partial observability and the complex dynamic 3D marine environment encountered during real-world observations, we introduce a GRU-enhanced variant of the traditional D3QN algorithm, termed GE-D3QN. This enhancement accelerates the convergence of average rewards and enables state-space prediction, allowing multiple AUVs to enhance observation efficiency while effectively leveraging ocean currents to reduce energy consumption and avoid unknown obstacles.
By conducting a series of comparative experiments and performing data assimilation on the results, we validated the effectiveness of the proposed method, demonstrating its superiority over similar algorithms in key performance indicators such as safety, energy consumption, and observation efficiency.
To evaluate the impact of different numbers of AUV platforms on observation performance, experiments were conducted with three, five, and seven AUVs performing observation tasks simultaneously in three distinct marine environmental scenarios. A centralized training and decentralized execution approach was used, with the AUVs employing a fully cooperative observation strategy. The results indicated that while the quality of data assimilation improved with the number of AUVs, diminishing returns were observed as the number of platforms increased.
The notations used in this paper are listed in
Table A1, and the subsequent sections are organized as follows:
Section 2 introduces the mathematical model for multi-AUV adaptive observation, the modeling of the observational background fields, and the relevant background knowledge of DRL.
Section 3 then provides a detailed explanation of the implementation of the proposed method. In
Section 4, we conduct a series of simulation experiments and analyze the results. Finally,
Section 5 summarizes the main contributions of this work and explores potential directions for future research.
2. Preliminaries and Problem Formulation
2.1. Problem Description
This study selects the sea area between 112° E–117° E and 15° N–20° N, extending from the surface to the seabed, as the target observation field. The temperature distribution within this region serves as the sampling data. Given the vast three-dimensional nature of the oceanic environment, areas with significant temperature variations hold greater observational value [
10]. To maximize the effectiveness of AUV data collection, this study prioritizes sampling based on temperature gradients.
This section will explain the adaptive observation framework and the verification process of observation results, as well as the statement of multi-AUV adaptive ocean observation path planning.
2.1.1. Adaptive Observation Framework
Accurate information on marine environmental elements is crucial for refined ocean research. Due to the dynamic nature of the marine environment, combining numerical modeling with direct observation via AUV platforms is a key approach to obtaining reliable and effective ocean data. Data assimilation utilizes the consistency of temporal evolution and physical properties to integrate ocean observations with numerical modeling, preserving the strengths of both and enhancing forecasting system performance.
The planning and design of an adaptive observation strategy for AUVs, leveraging assimilation techniques and ocean model prediction systems, is illustrated in
Figure 1. The process begins with the Princeton Ocean Model (POM), which generates daily ocean temperature simulations for the target sea area. Specifically, a five-day simulated sea surface temperature dataset serves as the prior background field for AUV operations in this study. Subsequently, the D3QN algorithm is employed to optimize the AUVs’ observation paths, ensuring efficient acquisition of ocean temperature data. The collected data are then assimilated using a coupled method based on the particle filter system described in [
25], refining marine environment analysis and forecasting. This assimilation process enhances the predictive accuracy of the forecasting system, which then produces updated analysis and forecast data. These updates, in turn, guide the dynamic adjustment of the AUVs’ observation paths. This iterative cycle of data collection, assimilation, and path optimization enables continuous adaptation, ensuring that the AUVs’ observation strategy remains responsive to evolving ocean conditions.
2.1.2. Multi-AUV Adaptive Observation Path Planning
The objective of the multi-AUV adaptive marine observation strategy is to find the optimal observation path for the AUVs, maximizing the collection of ocean temperature gradient data in a 3D dynamic ocean environment affected by ocean currents, while considering the constraints of collision avoidance between AUVs and obstacle avoidance.
First, we introduce the multi-AUV systems model. Assume that the system consists of
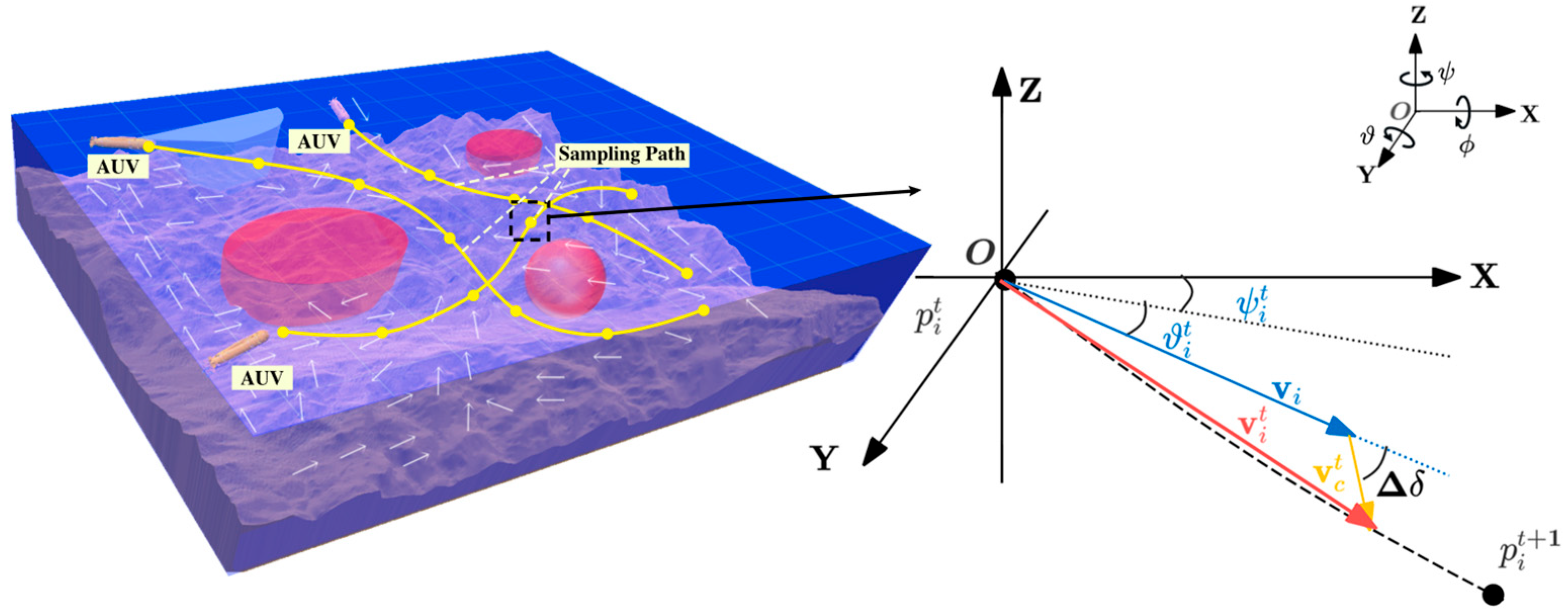
homogeneous AUVs, each equipped with sensors to gather environmental data. As illustrated in
Figure 2, an AUV’s state in the Cartesian coordinate system is defined as follows:
Here,
denotes the AUV’s position state vector, encompassing its 3-D coordinates
along with the following Euler angles: roll angle
, pitch angle
, and yaw angle
. The velocity vector
includes the velocity components along the surge (longitudinal), sway (lateral), and heave (vertical) directions. Taking into account the effects of ocean currents
while disregarding lateral motion and roll dynamics, the AUV’s kinematic model can be simplified as follows:
Then, the Euler angles can be calculated as follows:
Thus, the state of the AUV can be effectively described solely by its position and translational velocity. Additionally, to mitigate the high energy costs associated with frequent acceleration and deceleration, we assume that its speed remains constant.
The schematic diagram of adaptive observation path planning for multi-AUVs is shown in
Figure 2. In a 3D dynamic marine environment with obstacles
, a team of
-AUVs are deployed, each traveling at a constant speed
from the initial position
. Each AUV samples regions with higher temperature gradients
within its observation range
, while ensuring safe navigation and fully utilizing ocean currents to reduce energy consumption. The objective is to find a path
for each AUV that maximizes the temperature gradient at the sampling points by the end of the mission. Here,
,
denotes the total number of sampling points along the observation path, and
denotes the endpoint of the
-th AUV. The path from
to
for the
-th AUV can be expressed as follows:
In Equation (4), and represent the pitch and yaw angles of the -th AUV platform at the -th sampling point, where is the time step. Given the assumed AUV speed and fixed observation interval, controlling and enables the motion control of the AUV, thereby facilitating the planning of the observation path.
In summary, the multi-AUV adaptive ocean observation path planning is formalized as the following maximization problem:
where
represents the AUV’s endurance constraint;
and
denote the minimum pitch and yaw angles, respectively; and
and
indicate the corresponding maximum limits.
2.2. Modeling and Processing of Observational Background Fields
AUVs select areas with significant temperature gradients for observation and sampling, while avoiding obstacles such as islands, the seabed, and other hazards within the target sea area to ensure safe navigation. Additionally, the platform optimally leverages ocean current data to enhance temperature sampling efficiency. As a result, AUVs primarily focus on factors such as temperature gradients, underwater topography, obstacles, and ocean current information in the observation area. This study utilizes three-dimensional ocean temperature forecast data generated by the POM-based marine environment analysis and forecasting system, along with dynamic ocean current fields as prior background information, with temperature data serving as the primary observation target.
2.2.1. 3D Ocean Environment Forecasting and Data Processing
The POM, renowned for its high resolution, straightforward principles, and three-dimensional spatial characteristics, provides precise simulations of ocean conditions in estuaries and coastal regions. As one of the most widely used ocean models [
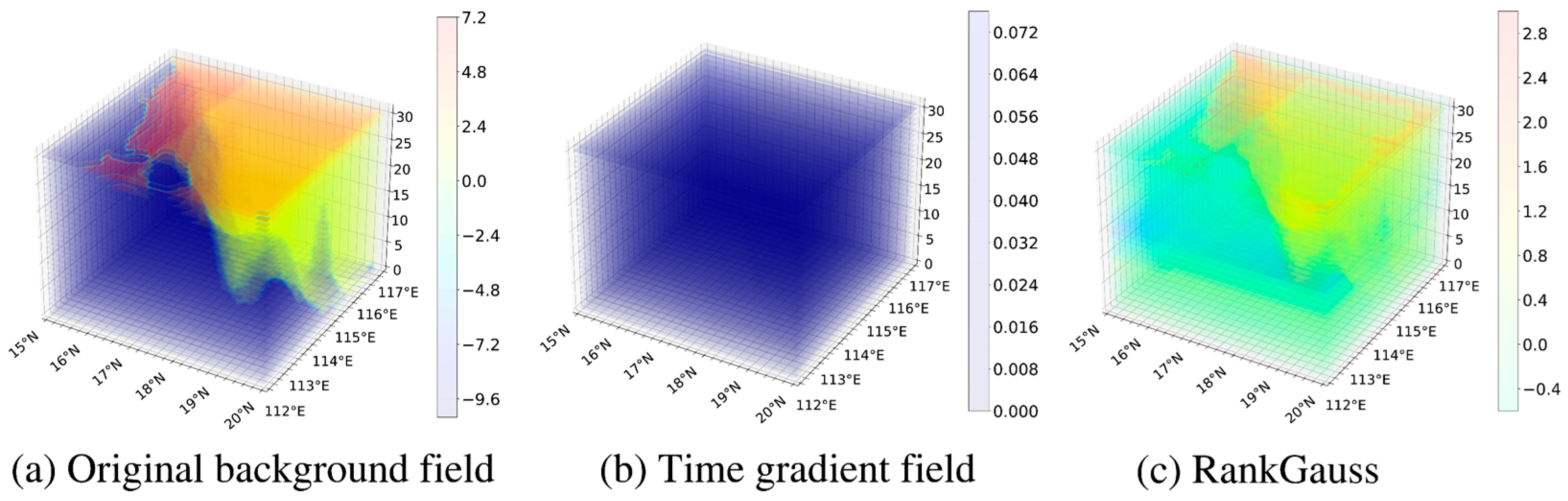
26], this study uses the POM to forecast the marine environment in the observation area over the next five days. The dataset features a horizontal resolution of 1/6°, 32 vertical layers, and a temporal resolution of 6 h. The observation area extends from 112° E to 117° E and 15° N to 20° N. The spatial distribution of the forecasted sea surface temperature at a given time is illustrated in
Figure 3a. To distinguish land from ocean temperature data, land areas are assigned a value of −10.
According to the literature [
27], RankGauss preprocessing is particularly effective for training agents using 3D sea surface temperature data. Consequently, we apply the RankGauss method to process the observed marine area data. Using the POM, we forecasted 11 sets of data for the next 6 days. The AUV collects data every 6 h, resulting in 21 observations over the 6-day period. First, the 11 original data sets are interpolated to create 21 new sets. Next, these 21 sets undergo RankGauss preprocessing to generate the global ocean background field. Finally, the time gradient is computed from these 21 sets, yielding 20 gradient sets, which are also preprocessed using RankGauss.
Figure 3 illustrates the complete data processing workflow, including the original data, the time gradient data, and the RankGauss-processed outputs.
2.2.2. Ocean Currents Modeling
AUVs routinely operate in complex and dynamic marine environments, where ocean currents have a significant impact, particularly on their kinematic parameters and trajectories. In terms of AUV planning, ocean currents inevitably affect the AUV’s trajectory during operation [
23]. In a real 3D marine environment, their effects cannot be ignored, especially regarding observation time and energy consumption. When the influence of ocean currents exceeds the adjustment range of the AUV platform, the platform cannot control effectively, significantly increasing energy consumption.
Ocean currents vary with depth, and to reach sampling points within the designated observation time, AUVs must strategically navigate by leveraging favorable currents and avoiding unfavorable ones through depth adjustments, such as diving or surfacing [
28]. Current data can be obtained through various methods, such as ocean hydrographic observatories, satellite remote sensing technology, and current meters. Some of these datasets are widely recognized for their applications in marine research. The dataset used in this study is the China Ocean ReAnalysis version 2 (CORAv2.0) [
29] reanalysis dataset from the National Ocean Science Data Center (NOSDC). It provides daily average data for 2021 with a spatial resolution of 1/10°. To match the 1/6° resolution of the POM model, the CORAv2.0 data are downsampled from their original 1/10° resolution. The temporal resolution is also improved from 24-h to 6-h updates.
As shown in
Figure 4, the observed background field consists of 3D regional ocean temperature gradient data from the marine environment numerical prediction system that incorporates ocean currents.
2.3. Deep Reinforcement Learning
The Markov decision process (MDP) serves as a fundamental framework for modeling sequential decision-making problems and forms the theoretical basis of reinforcement learning. In an MDP, state transitions are determined solely by the current state. However, real-world environments rarely adhere to the ideal assumptions of MDPs. In contrast, the POMDP provides a rigorous mathematical framework for sequential decision-making under uncertainty [
30]. POMDPs do not assume that the agent has access to the true underlying state, which is a practical assumption for real-world systems, as AUVs typically have limited information about the underlying target phenomena and even their own state in practice. Consequently, the multi-AUV observation problem can be framed as a POMDP.
A POMDP is commonly represented by the tuple . In this formulation, represents the state space, the action space, and the observation space. The transition function determines the probability of transitioning to state when action is taken in state , expressed as . Likewise, the observation function represents the probability of receiving observation once the agent executes action and transitions to state . The reward function determines the expected immediate reward that an agent receives after performing action in state . In infinite-horizon settings, a discount factor is employed to guarantee that the overall expected reward remains finite. Ultimately, the goal is to derive an optimal policy that maximizes the expected cumulative reward over the trajectory.
In practical applications, optimally solving POMDPs is computationally challenging. However, various DRL algorithms can provide feasible solutions. DRL enables agents to interact with the environment and learn through feedback in the form of rewards or penalties. DRL provides a powerful framework for adaptive observation strategy optimization. By learning to optimize actions to maximize ocean environment information gain, DRL-based systems can adaptively and efficiently explore unknown environments.
DRL integrates reinforcement learning with the powerful function approximation capabilities of deep neural networks. In DRL, deep neural networks serve as models to estimate or optimize policies and value functions in POMDP problems. DQN is one of the most renowned DRL methods, employing deep neural networks to approximate the value function. It utilizes Q-learning to generate Q-network samples, effectively aligning the estimated Q-value with the target Q-value. To achieve this, a loss function is formulated, and the network parameters are refined using gradient descent via backpropagation. The target Q-value is computed as follows:
where
and
denote the weighting parameters of the neural network and the target network, respectively. Additionally,
represents the action with the highest Q-value. In this work, the agent aims to maximize cumulative rewards from the environment using the Q-value and execute the optimal policy through
. The DQN loss function is expressed as follows:
Here, denotes the expected value, calculated as an average over all possible state transitions in the loss function.
DQN calculates the target Q-value by selecting the maximum Q-value at each step using the
-greedy algorithm, which can lead to overestimation of the value function. To address this issue, algorithms such as DDQN [
19] and D3QN [
22] have been proposed. The learning strategy of D3QN is more efficient, and its performance has been proven in many applications. In this paper, we use D3QN to implement adaptive observation strategy planning in multi-AUV scenarios.
4. Simulation Results and Discussions
Based on the multi-AUV adaptive observation strategy developed in the above research, we set up several simulation scenarios to validate the effectiveness of the proposed method. Additionally, to demonstrate the superiority of the GE-D3QN algorithm proposed in this study, we incorporated the widely-used RNN and LSTM networks with the D3QN algorithm, forming the RE-D3QN and LE-D3QN algorithms. Comparison experiments were then conducted using D3QN, RE-D3QN, and LE-D3QN as benchmark algorithms.
The simulation experiments in this study were conducted on a system equipped with an Intel Core™ i7-12700F CPU (Intel Corporation, Santa Clara, CA, USA) and an NVIDIA GeForce RTX 3070 graphics card (8GB GDDR6), accompanied by 16GB DDR4 system memory. The algorithm was developed using Python 3.11 and PyTorch 2.0.1.
4.1. Parameter Setting
The initial hyperparameter settings for the algorithm are based on relevant literature [
23,
36,
37]. The learning rate
controls the magnitude of weight updates during backpropagation of the neural network. If
is too high, it can lead to large updates and unstable convergence; conversely, if it is too low, it slows convergence speed and reduces learning performance. To improve convergence, this study uses the Adam optimizer with a learning rate of
. The discount factor
, which governs the agent’s emphasis on future rewards and ranges between 0 and 1, is set to 0.9 to ensure a balanced consideration of immediate and long-term rewards. To encourage exploration and avoid local optima, the initial exploration rate is set to 1.0 and gradually decreases with a decay factor of 0.995. Over multiple training episodes, the exploration rate stabilizes at 0.05.
The exploration rate stabilizes at 0.05. The experience pool capacity is set to . The batch size, which defines the number of samples randomly selected per iteration, balances update consistency with computational efficiency. Based on available memory, it is set to 64. Each batch is reused four times for parameter updates to maximize data efficiency, though excessive reuse may lead to overfitting.
The experimental results indicate that after 4000 training episodes, performance stabilizes. Thus, the total number of training episodes is set to 5000 for a comprehensive evaluation of different algorithms. The main algorithm parameters are summarized in
Table 1.
The experimental environment is a 3D dynamic ocean background field generated by the POM model. Background data spanning six consecutive days are used, with updates every 6 h. Each training session includes 21 samples collected by the AUV platform. Each algorithm undergoes training in 50 groups, with 5000 episodes per group.
4.2. Scenario 1: Multi-AUV Observation Path Planning in Marine Environment Without Currents
This section presents a multi-AUV collaborative observation experiment in a current-free environment (i.e., the background field constructed in
Section 2.2.1). Four algorithms—D3QN, RE-D3QN, LE-D3QN, and GE-D3QN—are used to perform collaborative observations in this environment. The experiment consists of five AUV platforms, each navigating at a speed of 7 km/h, whose initial positions are listed in
Table 2.
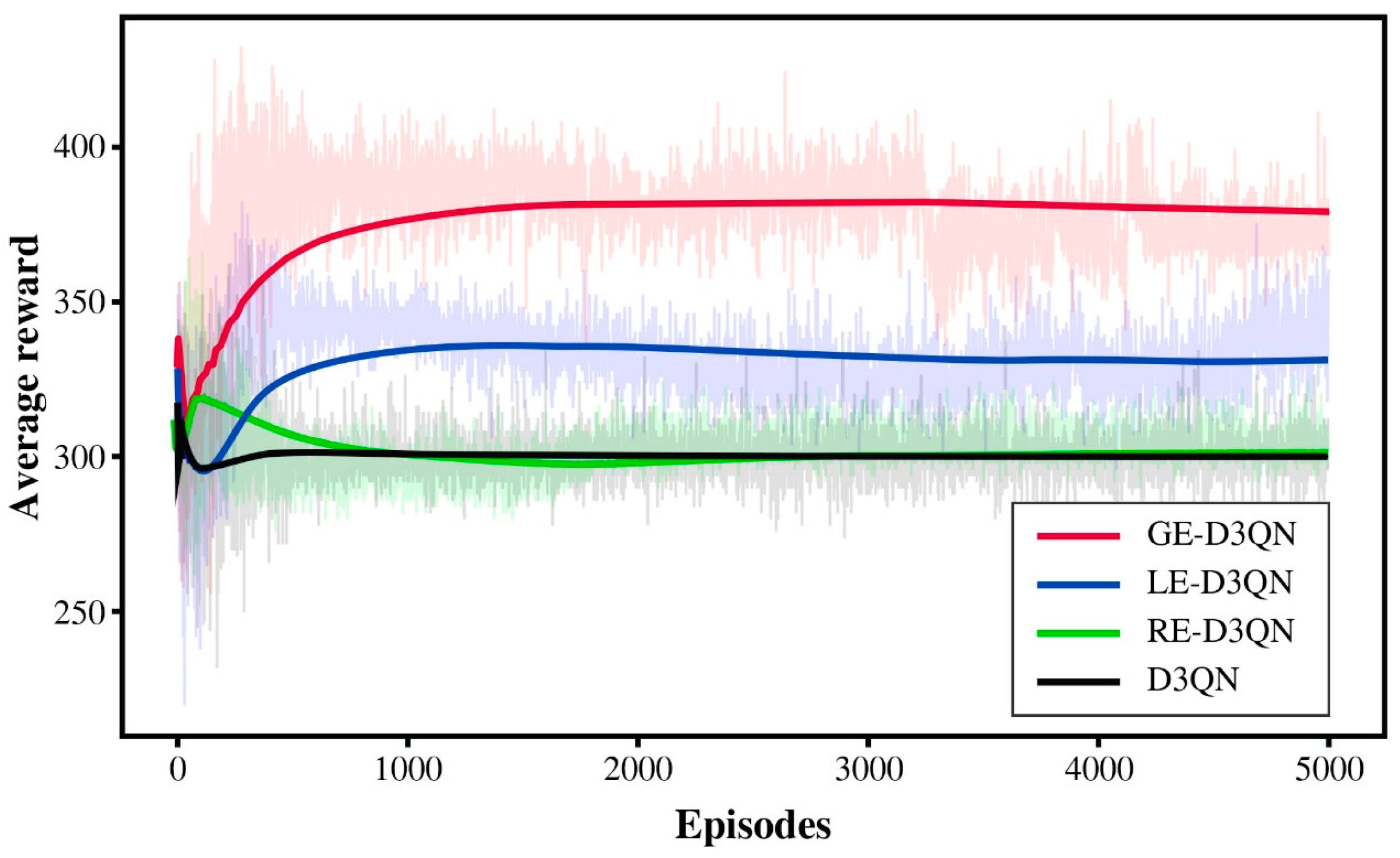
As shown in
Figure 8, after the initial phase of random exploration, the reward value of the D3QN algorithm follows a slow upward trend. However, in subsequent rounds of exploration, its training performance improves at a sluggish pace and eventually falls into a local optimum.
In contrast, the RE-D3QN algorithm benefits from the memory function of the neural network, allowing it to achieve a relatively high reward value during the initial exploration phase. However, as training progresses, the model increasingly learns interference signals, leading to a decline in reward value after the initial exploration stage. Consequently, the total reward value of the five agents stabilizes around 300, with no significant fluctuations.
Meanwhile, LE-D3QN, with its integrated forget gate mechanism, gradually filters out unimportant interference information during training, thereby maintaining better learning performance. GE-D3QN, leveraging its unique gated parameter adjustment mechanism, continuously optimizes its gating parameters during exploration to adapt to environmental changes, resulting in superior training outcomes.
Analyzing the reward curves of the four algorithms, LE-D3QN and GE-D3QN demonstrate relatively stable learning trends with a continuous upward trajectory. Notably, after 3000 episodes, GE-D3QN experiences a brief decline in reward value but quickly rebounds. This suggests that the algorithm retains its exploratory capability even when trapped in a local optimum, allowing it to break through and further enhance the optimization of the observation strategy.
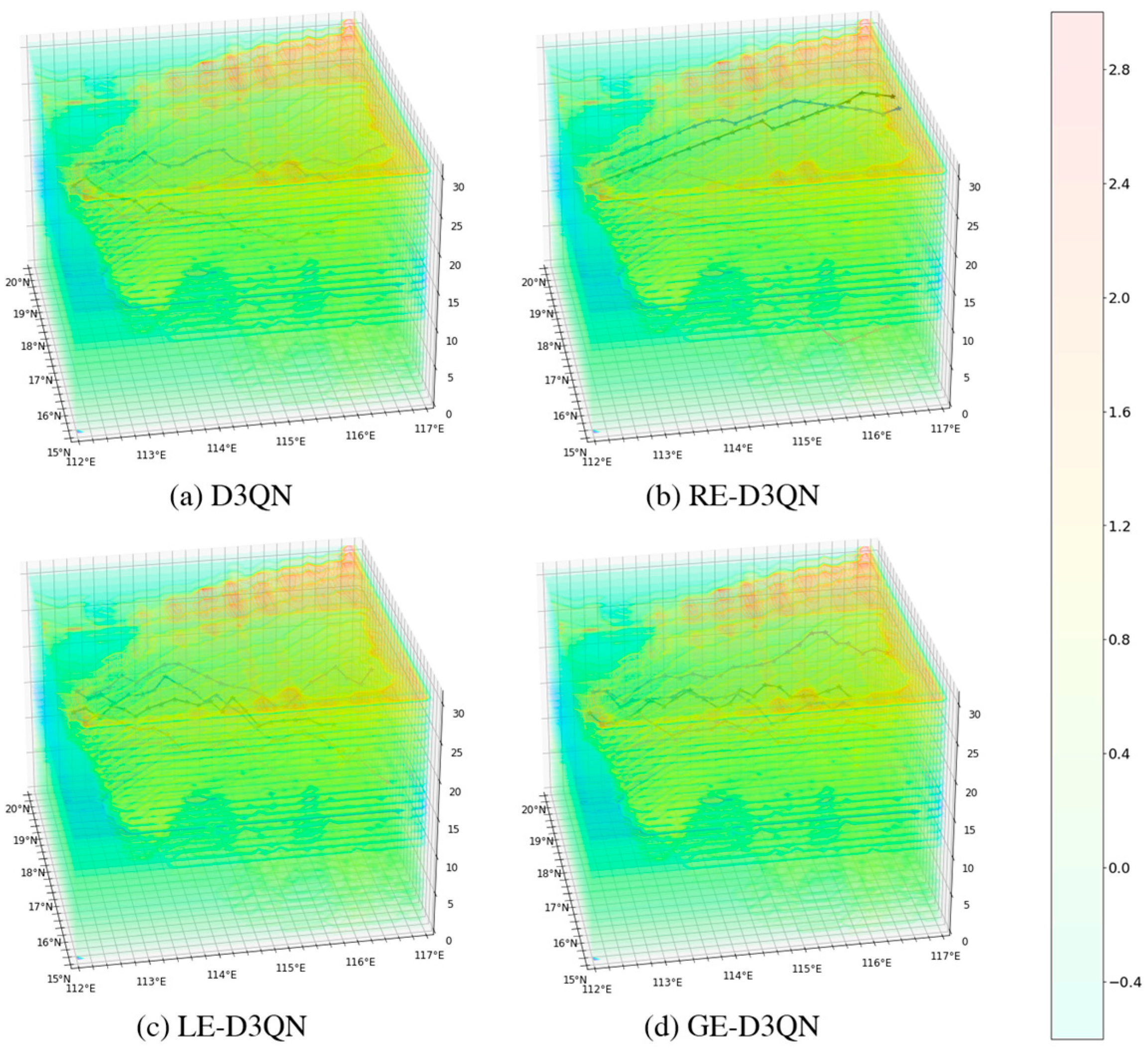
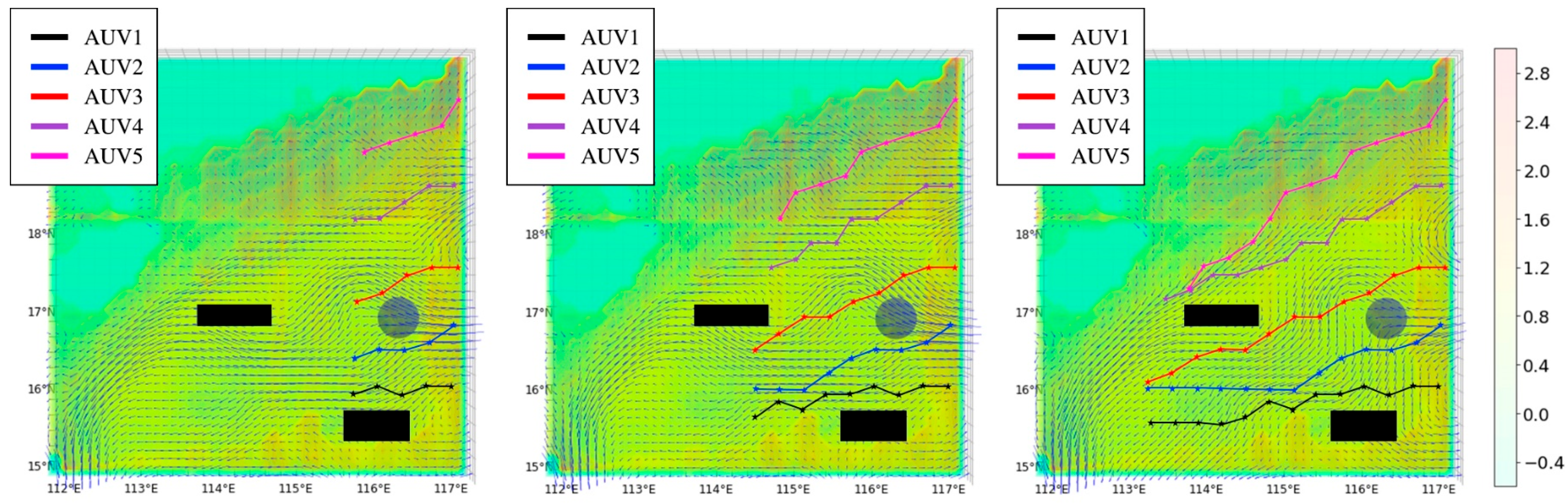
Figure 9 presents the observation paths that achieved the highest reward values after 5000 episodes for the four algorithms. The figure shows that the AUVs are capable of sampling regions with significant temperature differences. Among the five paths planned by each algorithm, the D3QN algorithm’s path appears relatively smooth, indicating insufficient exploration of the surrounding environment, which results in lower reward values. The RE-D3QN algorithm follows a straight-line exploration pattern, suggesting that it has fallen into a local optimum during discrete action selection. This occurs because a specific action previously yielded a high reward, causing the algorithm to repeatedly execute similar actions in subsequent path planning. In contrast, the paths planned by LE-D3QN and GE-D3QN are more intricate, demonstrating that these two algorithms can fully explore the surrounding environment and thus generate more optimal, high-reward paths.
A total of 50 training groups were conducted for the four algorithms—D3QN, RE-D3QN, LE-D3QN, and GE-D3QN. From these, the three best-performing datasets were selected. The observation strategies with the highest rewards were identified, and temperature data were collected from their respective sampling points. Subsequently, particle filtering was applied for data assimilation, using the Root Mean Square Error (RMSE) between forecasted and actual values as the evaluation criterion. A comparative analysis was then performed to assess the sampling performance of the four algorithms against random sampling, evaluating the impact of different observation strategies on improving the forecasting system’s performance. The RMSE calculation formula is as follows:
Here, represents the number of analysis steps used for the statistical computation, while and represent the ensemble mean corresponding to the model state and the true value, respectively.
As shown in
Table 3, with the RMSE of random sampling serving as the baseline for the forecasting system’s performance, the average RMSE for the three selected observation strategies was calculated, enabling a comparison of performance improvements across the four algorithms. The results indicate that D3QN, RE-D3QN, LE-D3QN, and GE-D3QN improved forecasting performance by 8.158%, 13.715%, 16.956%, and 19.540%, respectively. These findings demonstrate that employing the GE-D3QN algorithm for observation strategy design significantly enhances the accuracy and effectiveness of the ocean forecasting system.
4.3. Scenario 2: Multi-AUV Observation Path Planning in Marine Environment with Ocean Currents
This section simulates the collaborative observation of multi-AUVs under the influence of ocean currents. Dynamic ocean currents (as described in
Section 2.2.2) were introduced into the background field, with their direction and speed varying over time. To evaluate the observation efficiency of multi-AUVs in this environment, we conducted experiments using four algorithms: D3QN, RE-D3QN, LE-D3QN, and GE-D3QN, under ocean current perturbations. Due to the stronger currents near the sea surface, the starting positions of the AUVs were set close to the surface to better capture the ocean current variations, as detailed in
Table 4.
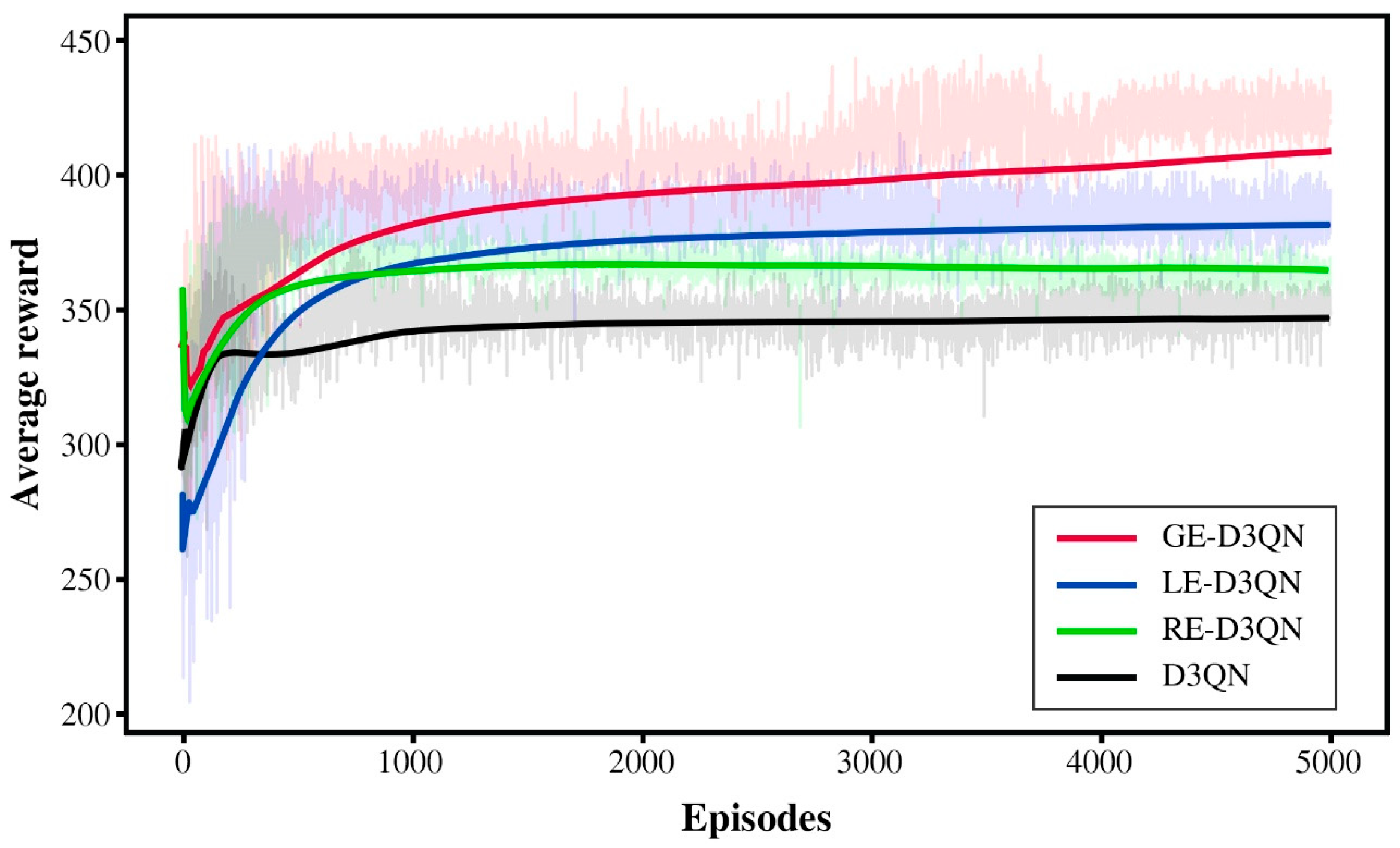
Figure 10 presents a comparison of the performance of four algorithms over 5000 episodes. The RE-D3QN and D3QN algorithms initially outperform LE-D3QN in learning efficiency but fail to enhance their exploration capability beyond 500 episodes. In contrast, the LE-D3QN algorithm starts with weaker performance but surpasses RE-D3QN and D3QN after 1000 episodes while maintaining its exploration capability. Overall, the GE-D3QN algorithm demonstrates the best training performance, effectively integrating dynamic ocean currents with observation tasks to achieve superior overall results.
Figure 11 illustrates the adaptive observation paths using the GE-D3QN algorithm in a dynamic ocean current background. As shown in the figure, AUV1, AUV2, and AUV3 depart from open waters, where most of the surrounding ocean currents align with their travel direction. The AUV platforms are able to effectively carry out observation tasks by utilizing the direction of the ocean currents. AUV4 and AUV5 are located in areas with more terrain obstacles and surrounding countercurrents. The AUV platforms can adjust their states based on the ocean currents, overcoming the constraints of the countercurrent zones and successfully performing observation tasks while avoiding collisions with the terrain.
Table 5 presents the evaluation results of various performance metrics for the observation paths of four algorithms in ocean current environments. After introducing the ocean current constraints, the observation strategies formulated by the four algorithms all improved the average observation speed of the AUVs compared to the initial speed (7 km/h), with increases of 7.29%, 9.86%, 12.57%, and 10.86%, respectively. This indicates that all algorithms are able to effectively utilize ocean current information to optimize the attitude angles of the AUVs, thereby improving observation efficiency.
Compared to the D3QN algorithm, the average reward per hour of RE-D3QN, LE-D3QN, and GE-D3QN increased by 7.55%, 10.79%, and 23.74%, respectively, demonstrating the superiority of recurrent neural networks in learning and utilizing ocean current information. Although D3QN exhibits the highest computational efficiency, it achieves the lowest rewards and falls short in terms of both travel distance and time compared to GE-D3QN. It is noteworthy that, while the observation strategy formulated by RE-D3QN achieved the fastest observation speed (7.88 km/h), its average travel length per task was the longest, resulting in only a 7.55% increase in the average reward per hour in the ocean environment. This suggests that a higher speed does not necessarily equate to better observation performance. Overall, GE-D3QN stands out with the shortest travel distance, optimal travel time, highest rewards, and acceptable computational time, making it particularly effective for devising observation strategies for AUVs in ocean current environments.
4.4. Scenario 3: Multi-AUV Observation Path Planning in Complex Marine Environments
Through the comparative experiments presented in
Section 4.2 and
Section 4.3, the superiority of the proposed GE-D3QN algorithm over LE-D3QN, RE-D3QN, and traditional D3QN algorithms has been validated. This section further demonstrates the applicability and effectiveness of the GE-D3QN algorithm in complex marine environments, including the influence of ocean currents and obstacles. In the experiment, the number of AUV platforms is set to five, with an initial navigation speed of 7 km/h. The initial positions of the AUVs are detailed in
Table 4. The AUV platforms rely on onboard sonar systems to perceive their surrounding environment and autonomously avoid obstacles.
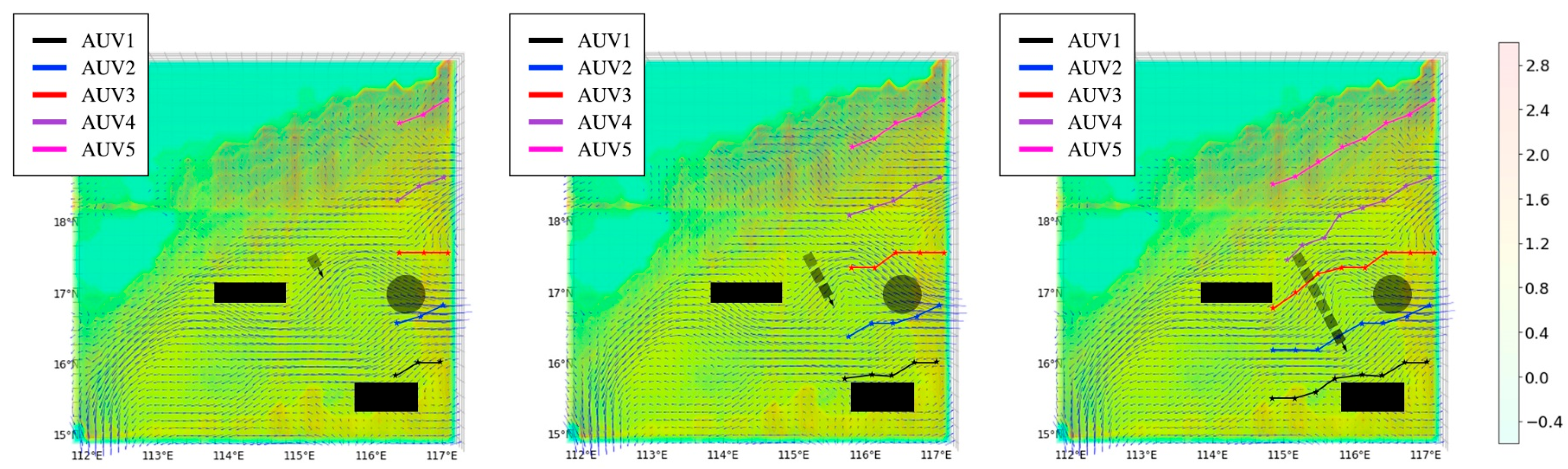
During marine observation missions, AUV platforms are not only influenced by seabed topography but also face potential threats from unexpected obstacles such as shipwrecks, large marine organisms, and other underwater military equipment. To enhance the realism of the simulation environment and better reflect actual ocean conditions, both static and dynamic obstacles are introduced in the observation area. For irregular static obstacles such as islands and reefs, a geometric modeling approach is employed, simplifying them into spherical and cuboid shapes. Spherical obstacles are used to reduce the complexity of modeling smaller irregular objects, while cuboid obstacles simplify the representation of larger irregular structures. Dynamic obstacles, such as ocean buoys and drifting objects, are modeled as cuboid obstacles moving in uniform linear motion. This approach ensures a more accurate simulation of real-world ocean scenarios, enhancing the algorithm’s adaptability to dynamic and unpredictable underwater environments.
As shown in
Figure 12 and
Figure 13, in complex marine environments, the multi-AUV systems based on GE-D3QN can sense obstacles in real time during the observation process and quickly adjust their strategies, selecting collision-free paths to efficiently collect ocean information. The analysis of how the observation strategy in such scenarios enhances the performance of the marine forecasting system will be further explored through the experiments presented in
Section 4.5.
4.5. Scenario 4: Multi-AUV Observation Path Planning with Varying Numbers in Three Different Marine Environments
To further examine the impact of collaborative observations using different numbers of AUVs under the GE-D3QN algorithm on the performance of the marine environment numerical prediction system, we conducted comparative experiments using three, five, and seven AUVs in background fields without ocean currents, with ocean currents, and with both ocean currents and dynamic/static obstacles. The starting positions of the AUVs are detailed in
Table 6.
As shown in
Figure 14, since all the experiments used the GE-D3QN algorithm, the reward curves exhibit similar fluctuations, plateauing around the 500th episode. With more agents, the seven-AUV scenario achieved the highest total reward due to increased data collection. However, in terms of average reward per AUV, the seven-AUV scenario performed worse, while the three-AUV scenario had the best observation efficiency. This suggests that while a greater number of AUVs enhances overall data collection, it does not necessarily improve the quality of individual observations. A smaller number of AUVs can yield more cost-effective data with lower resource consumption.
The assimilation technique processes observed data by integrating AUV path coordinates and collected sea temperature data into the assimilation system based on their respective layers. The RMSE between true and predicted values is then calculated, with the average RMSE across all layers representing the RMSE of the observation path. Data from observations by three, five, and seven AUVs were assimilated, and the experimental results are presented in
Table 7.
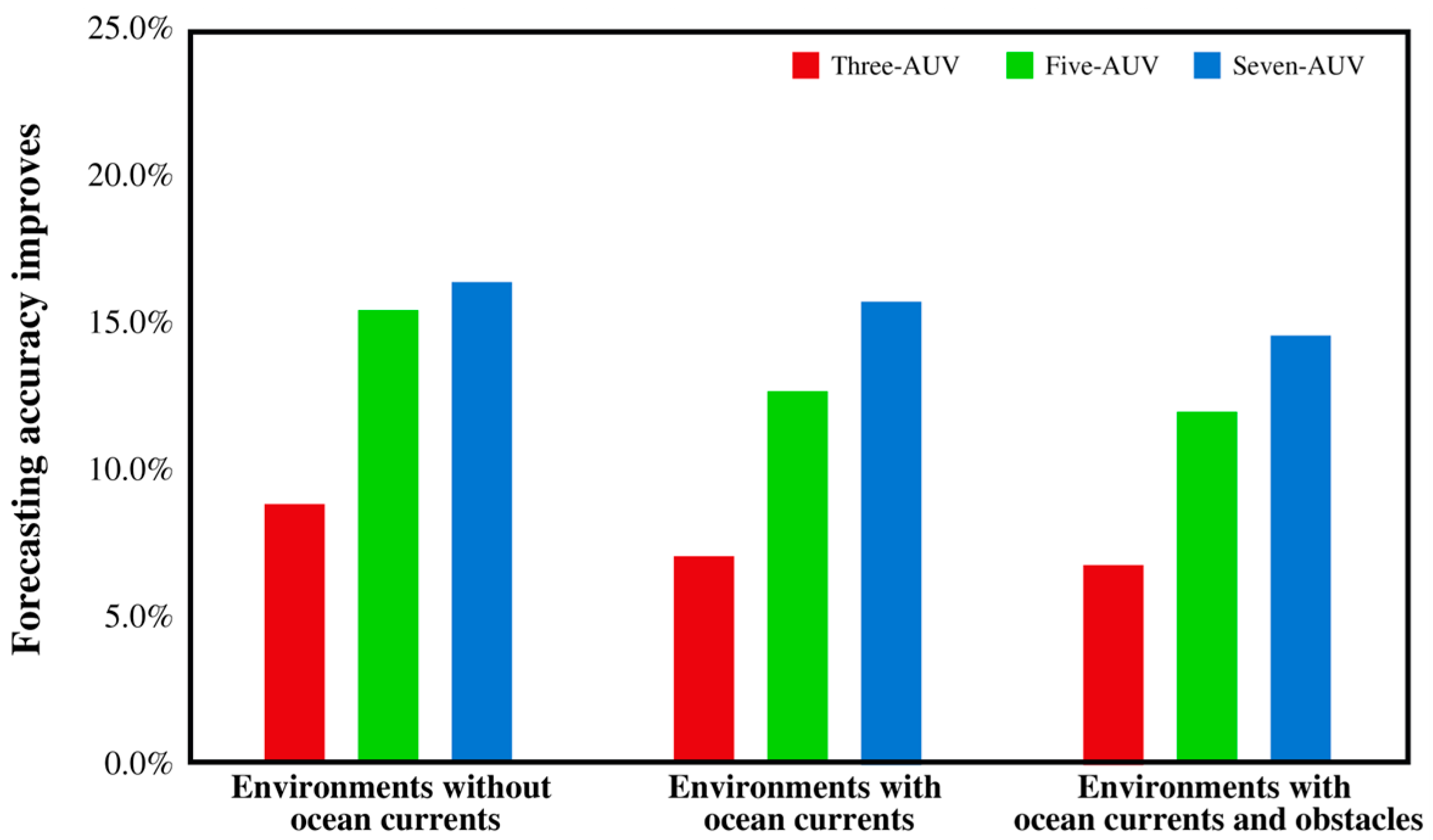
As shown in
Table 7 and
Figure 15, regardless of observation constraints, the seven-AUV experiment outperforms the three-AUV and five-AUV experiments in assimilation performance. The forecast accuracy improvements of the three-AUV experiment over random sampling are 8.851%, 7.083%, and 6.801%, respectively. For the five-AUV experiment, the improvements rise to 15.443%, 12.695%, and 11.997%, while the seven-AUV experiment achieves the highest gains at 16.401%, 15.757%, and 14.595%.
When AUVs operate without constraints, they achieve optimal observation performance, with steadily increasing reward values and minimal fluctuations. Introducing ocean current constraints forces the observation strategy to balance temperature gradients and energy consumption, prioritizing higher reward points within a limited time rather than maximizing observations at all costs. This leads to slightly lower reward values and a minor drop in assimilation performance across all three AUV formations. With both ocean currents and obstacles in the background field, the number of constraints increases, and obstacles may appear in high-gradient regions. To ensure observation safety, the algorithm avoids these areas, further reducing assimilation performance for all three AUV formations.
Moreover, increasing the number of AUVs from three to five improves the average RMSE of data assimilation experiments by 5.793% across all three background fields. However, increasing the number from five to seven yields only a 2.211% improvement, highlighting diminishing returns. While additional AUVs enhance data collection and assimilation accuracy, their marginal benefits decrease. Therefore, the number of AUVs should be optimized based on the required observation accuracy.
5. Conclusions
This study proposes an optimization method for multi-AUV adaptive observation strategies based on an improved D3QN algorithm. To address the challenges of tightly coupled environmental modeling and the difficulty of determining the optimal observation strategies in complex marine environments with traditional algorithms, we leverage the advantage of DRL algorithms, which autonomously interact with the environment to facilitate learning. The problem is formulated as a POMDP, and a DRL approach based on the D3QN framework is developed. To enhance the D3QN algorithm, we integrate a GRU network to overcome issues such as partial observability and the complexities of dynamic 3D marine environments. The main contributions are as follows: (1) The proposed method offers state-space prediction and rapid convergence, enabling AUVs to complete observation tasks efficiently while effectively leveraging ocean currents to reduce energy consumption and avoid unforeseen obstacles. (2) The simulation results demonstrate that the proposed GE-D3QN method significantly outperforms the D3QN, RE-D3QN, and LE-D3QN algorithms in complex marine environments, particularly regarding safety, energy consumption, and observation efficiency. (3) Experiments deploying three, five, and seven AUVs across three marine scenarios, combined with data assimilation analysis, reveal that while increasing the number of platforms improves forecasting accuracy, the improvement rate gradually diminishes, reflecting diminishing marginal returns. These findings validate the effectiveness and practicality of the proposed method for multi-AUV cooperative observation tasks.
Although this study has yielded promising outcomes, several limitations remain. First, under sparse reward conditions, achieving an optimal balance between team incentives and individual rewards is crucial for fostering effective collaboration among agents—a challenge that warrants further investigation. Second, extending the algorithm to larger-scale environments introduces significant issues in computational complexity and coordination, which will be a primary focus of our future work. Finally, validating the proposed algorithm in real marine settings is essential for confirming its practical applicability, and this remains a key objective for subsequent studies.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}