
Dual-CycleGANs with Dynamic Guidance for Robust Underwater Image Restoration



Abstract
1. Introduction
2. Related Work
2.1. Light Filed Map
2.2. CycleGAN
3. Proposed Framework
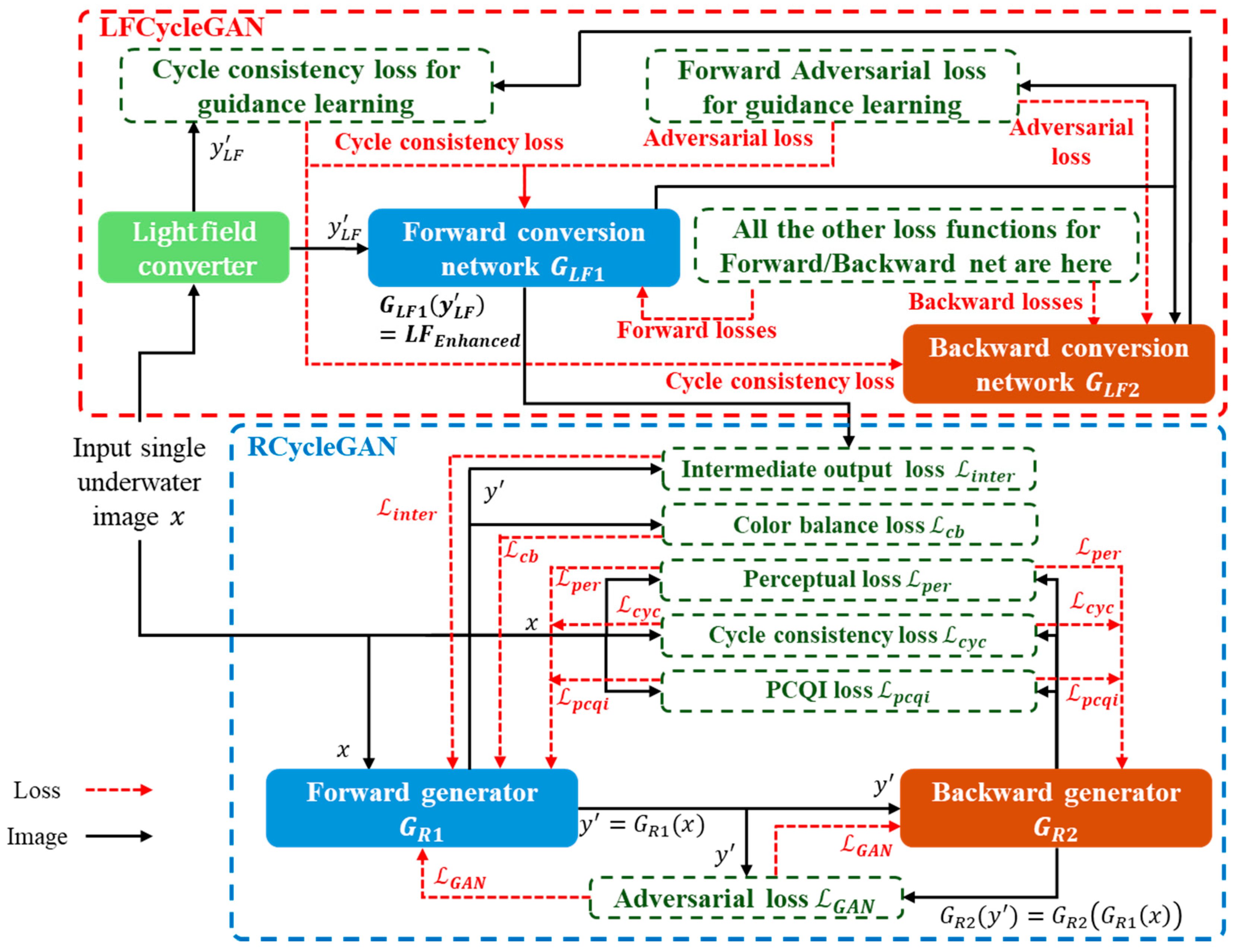
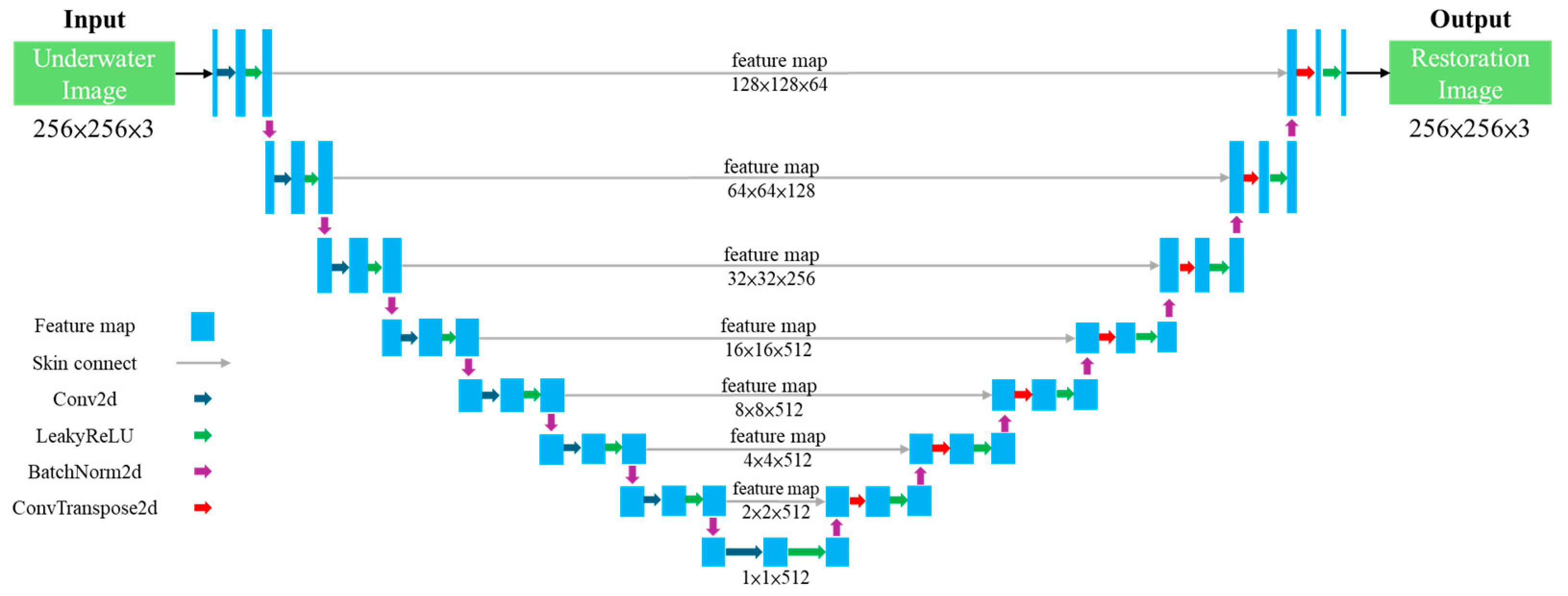
3.1. Dual-CycleGAN
3.2. Loss Design in RCycleGAN and LFCycleGAN
4. Experimental Results
4.1. Quantitative Comparisons
4.2. Qualitative Comparisons
4.3. Ablation Study
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peng, L.; Zhu, C.; Bian, L. U-Shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Z.; Xu, Z.; Zheng, Z.; Ma, F.; Wang, Y. Enhancement of underwater images through parallel fusion of transformer and CNN. J. Mar. Sci. Eng. 2024, 12, 1467. [Google Scholar] [CrossRef]
- Yeh, C.-H.; Lin, C.-H.; Lin, M.-H.; Kang, L.-W.; Huang, C.-H.; Chen, M.-J. Deep learning-based compressed image artifacts reduction based on multi-scale image fusion. Inf. Fusion 2021, 67, 195–207. [Google Scholar] [CrossRef]
- Yeh, C.-H.; Lai, Y.-W.; Lin, Y.-Y.; Chen, M.-J.; Wang, C.-C. Underwater image enhancement based on light field guided rendering network. J. Mar. Sci. Eng. 2024, 12, 1217. [Google Scholar] [CrossRef]
- Chiang, Y.-W.; Chen, Y.-C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2012, 21, 1756–1769. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, J.; Pang, Y.; Chen, S.; Wang, J. Single underwater image restoration by blue-green channels dehazing and red channel correction. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016; pp. 1731–1735. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Bekaert, P. Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2018, 27, 379–393. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Dudhane, A.; Hambarde, P.; Patil, P.W.; Murala, S. Deep underwater image restoration and beyond. IEEE Signal Process. Lett. 2020, 27, 675–679. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.J.; Luo, P.; Sattar, J. Simultaneous enhancement and super-resolution of underwater imagery for improved visual perception. arXiv 2020, arXiv:2002.01155. [Google Scholar]
- Naik, A.; Swarnakar, A.; Mittal, K. Shallow-uwnet: Compressed model for underwater image enhancement (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021. [Google Scholar]
- Zhou, J.; Liu, Q.; Jiang, Q.; Ren, W.; Lam, K.-M.; Zhang, W. Underwater camera: Improving visual perception via adaptive dark pixel prior and color correction. Int. J. Comput. Vis. 2023, 1–19. [Google Scholar] [CrossRef]
- Pramanick, A.; Sur, A.; Saradhi, V.V. Harnessing multi-resolution and multi-scale attention for underwater image restoration. arXiv 2024, arXiv:2408.09912. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2018, 3, 387–394. [Google Scholar] [CrossRef]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial network. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Guo, Y.; Li, H.; Zhuang, P. Underwater image enhancement using a multiscale dense generative adversarial network. IEEE J. Ocean. Eng. 2020, 45, 862–870. [Google Scholar] [CrossRef]
- Cong, R.; Yang, W.; Zhang, W.; Li, C.; Guo, C.-L.; Huang, Q.; Kwong, S. PUGAN: Physical model-guided underwater im-age enhancement using GAN with dual-discriminators. IEEE Trans. Image Process 2023, 32, 4472–4485. [Google Scholar] [CrossRef] [PubMed]
- Ye, T.; Chen, S.; Liu, Y.; Ye, Y.; Chen, E.; Li, Y. Underwater light field retention: Neural rendering for underwater imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 488–497. [Google Scholar]
- Rahman, Z.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. In Proceedings of the IEEE International Conference on Image Processing, Lausanne, Switzerland, 16–19 September 1996; Volume 3, pp. 1003–1006. [Google Scholar]
- Chang, B.; Zhang, Q.; Pan, S.; Meng, L. Generating handwritten chinese characters using cyclegan. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 199–207. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv 2017, arXiv:1701.04862. [Google Scholar]
- Srivastava, A.; Valkov, L.; Russell, C.; Gutmann, M.-U.; Sutton, C. Veegan: Reducing mode collapse in gans using implicit variational learning. In Advances in Neural Information Processing Systems 30; Long Beach Convention & Entertainment Center: Long Beach, CA, USA, 2017. [Google Scholar]
- Li, W.; Fan, L.; Wang, Z.; Ma, C.; Cui, X. Tackling mode collapse in multi-generator gans with orthogonal vectors. Pattern Recognit. 2021, 110, 107646. [Google Scholar] [CrossRef]
- Wang, S.; Ma, K.; Yeganeh, H.; Wang, Z.; Li, W. A patch-structure representation method for quality assessment of contrast changed images. IEEE Signal Process. Lett. 2015, 22, 2387–2390. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on single image super-resolution: Dataset and study. In Proceeding of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Kinga, D.; Adam, J.B. A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | UFO-120 | EUVP | UIEB | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | UIQM | PSNR | SSIM | UIQM | PSNR | SSIM | UIQM | |
| Deep SESR | 27.15 | 0.84 | 3.13 | 25.25 | 0.75 | 2.98 | 19.26 | 0.73 | 2.97 |
| Shallow-UWnet | 25.20 | 0.73 | 2.85 | 27.39 | 0.83 | 2.98 | 18.99 | 0.67 | 2.77 |
| UGAN | 23.45 | 0.80 | 3.04 | 23.67 | 0.67 | 2.70 | 20.68 | 0.84 | 3.17 |
| WaterNet | 22.46 | 0.79 | 2.83 | 20.14 | 0.68 | 2.55 | 19.11 | 0.80 | 3.04 |
| PUGAN | 23.70 | 0.82 | 2.85 | 24.05 | 0.74 | 2.94 | 21.67 | 0.78 | 3.28 |
| Dual-CycleGAN | 25.23 | 0.84 | 3.06 | 27.39 | 0.91 | 2.97 | 22.12 | 0.85 | 3.26 |
| Method | FLOPs | Parameters |
|---|---|---|
| Deep SESR | 146.10 G | 2.46 M |
| Shallow-UWnet | 21.63 G | 0.22 M |
| UGAN | 38.97 G | 57.17 M |
| WaterNet | 193.70 G | 24.81 M |
| PUGAN | 72.05 G | 95.66 M |
| Dual-CycleGAN | 18.15 G | 54.41 M |
| UIEB | |||
|---|---|---|---|
| PSNR | SSIM | UIQM | |
| Complete Dual-CycleGAN | 22.12 | 0.85 | 3.26 |
| (w/o) | 20.81 | 0.82 | 2.99 |
| (w/o) | 20.75 | 0.84 | 2.96 |
| (w/o) | 20.8 | 0.84 | 2.96 |
| (w/o) | 20.88 | 0.84 | 2.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.-Y.; Huang, W.-J.; Yeh, C.-H. Dual-CycleGANs with Dynamic Guidance for Robust Underwater Image Restoration. J. Mar. Sci. Eng. 2025, 13, 231. https://doi.org/10.3390/jmse13020231
Lin Y-Y, Huang W-J, Yeh C-H. Dual-CycleGANs with Dynamic Guidance for Robust Underwater Image Restoration. Journal of Marine Science and Engineering. 2025; 13(2):231. https://doi.org/10.3390/jmse13020231
Chicago/Turabian StyleLin, Yu-Yang, Wan-Jen Huang, and Chia-Hung Yeh. 2025. "Dual-CycleGANs with Dynamic Guidance for Robust Underwater Image Restoration" Journal of Marine Science and Engineering 13, no. 2: 231. https://doi.org/10.3390/jmse13020231
APA StyleLin, Y.-Y., Huang, W.-J., & Yeh, C.-H. (2025). Dual-CycleGANs with Dynamic Guidance for Robust Underwater Image Restoration. Journal of Marine Science and Engineering, 13(2), 231. https://doi.org/10.3390/jmse13020231