1. Introduction
The safety of maritime navigation is threatened by numerous risk factors, including adverse weather conditions, navigational obstacles, and technical malfunctions, among others. The rapid development of the global shipping industry, coupled with the rise of unmanned surface ships and intelligent industries, has increased the number and variety of ships, making maritime navigation safety more complex [
1]. To better mitigate accident risks, ensure navigation safety, and enhance the efficiency of maritime traffic management, effective and accurate detection of ships has become a key research field.
In recent years, with the advancement of infrared technology, infrared object detection has gradually become a research focus. Infrared images, formed by capturing the infrared radiation of objects, possess advantages that are irreplaceable by visible images. These advantages include all-weather capabilities and strong adaptability to complex environments, addressing the limitations of visible images, which are susceptible to environmental factors and struggle with imaging under low-light conditions [
2]. Infrared imaging finds widespread applications in various fields such as military, agriculture, medicine and transportation.
Traditional infrared object detection methods include wavelet transform [
3], template matching [
4], and contrast mechanism-based methods [
5], among others. However, these methods have limited accuracy, as they rely on manually designed features. Domain expertise and experience are required to manually select and design features for representing targets. These features often struggle to capture advanced semantic information on complex targets, resulting in poor generalization and limited adaptability to changes in target size. This inadequacy hinders their ability to effectively meet the requirements of ship detection tasks.
The rapid development of deep learning technology has led to powerful feature extraction capabilities, significantly outperforming traditional algorithms in detection performance. This advancement has been widely applied across various fields, such as semantic segmentation [
6], keypoint detection [
7], and image dehazing [
8], further demonstrating its versatility and effectiveness in tackling complex tasks. Convolutional neural network (CNN)-based object detection algorithms excel at automatically learning hierarchical feature representations from raw pixel data, which enables them to detect and localize objects with high accuracy and robustness. Compared to traditional methods, which rely on manually designed features, CNNs can automatically learn and extract complex and abstract features, thereby overcoming the limitations of these methods.
For ship detection, Wen et al. [
9] proposed a multi-scale, single-shot detector (MS-SSD) and introduced a scale-aware scheme, which demonstrated excellent performance for small targets while performing less effectively for larger ones. Zhan et al. [
10] proposed an edge-guided structure-based object detection network named EGISD-YOLO for infrared ship detection. Li et al. [
11] designed a complete YOLO-based ship detection method (CYSDM) for thermal infrared remote sensing ship detection in complex backgrounds, providing a reference for large-scale and all-weather ship detection. Yuan et al. [
12] proposed a multitype feature perception and refined network (MFPRN) combining a fast Fourier module and a lightweight multilayer perceptron. This method effectively reduces false detections, but it has a large number of parameters and high computational costs. Although these methods have innovated feature extraction and designed detectors suitable for ship detection, they primarily focus on extracting features from the images without fully utilizing the inherent characteristics of the targets. For example, information such as the shape, motion patterns, and thermal radiation characteristics of the ships is not adequately considered, leading to missed and false detections.
CNN-based detection algorithms have made certain progress in the task of infrared ship detection, but there are still some challenges that need to be overcome. Ship targets in infrared images often exhibit weak features, especially small ones, lacking clear shapes and texture details. The limited recognizable features contribute to increased uncertainty in detection results. Therefore, it is necessary to enhance the extraction of these limited features. Additionally, ships vary greatly in size and have irregular shapes, further limiting the robustness of infrared ship detection. Moreover, the intrinsic characteristics of ship targets can be fully incorporated, enabling more precise and reliable feature extraction tailored to the unique traits of these objects. To address the aforementioned challenges, this paper proposes the PJ-YOLO, which uses YOLOv8 [
13] as the baseline. The main contributions of this paper are as follows:
- (1)
We propose a novel PJ-YOLO network for infrared ship detection. It integrates prior knowledge auxiliary loss, which leverages the unique brightness distribution characteristics between ships and backgrounds in infrared images as prior knowledge, and also incorporates a joint feature extraction module and a residual deformable attention module.
- (2)
To address the challenge of weak and elusive features in infrared images, particularly for small ship targets, we construct a joint feature extraction module to enhance feature extraction ability by utilizing channel-differentiated features, context-aware information, and global information. This module effectively captures subtle characteristics of ship targets.
- (3)
Considering the multiscale nature of ship targets, a residual deformable attention module is designed within the higher layers of the backbone network, which effectively integrates multi-scale information to significantly enhance detail capture and improve detection performance.
The remainder of this paper is organized as follows:
Section 2 reviews related works.
Section 3 describes the overall framework of PJ-YOLO and its modules.
Section 4 presents comparative experiments and analyses on the infrared ship datasets. Finally,
Section 5 provides the conclusion.
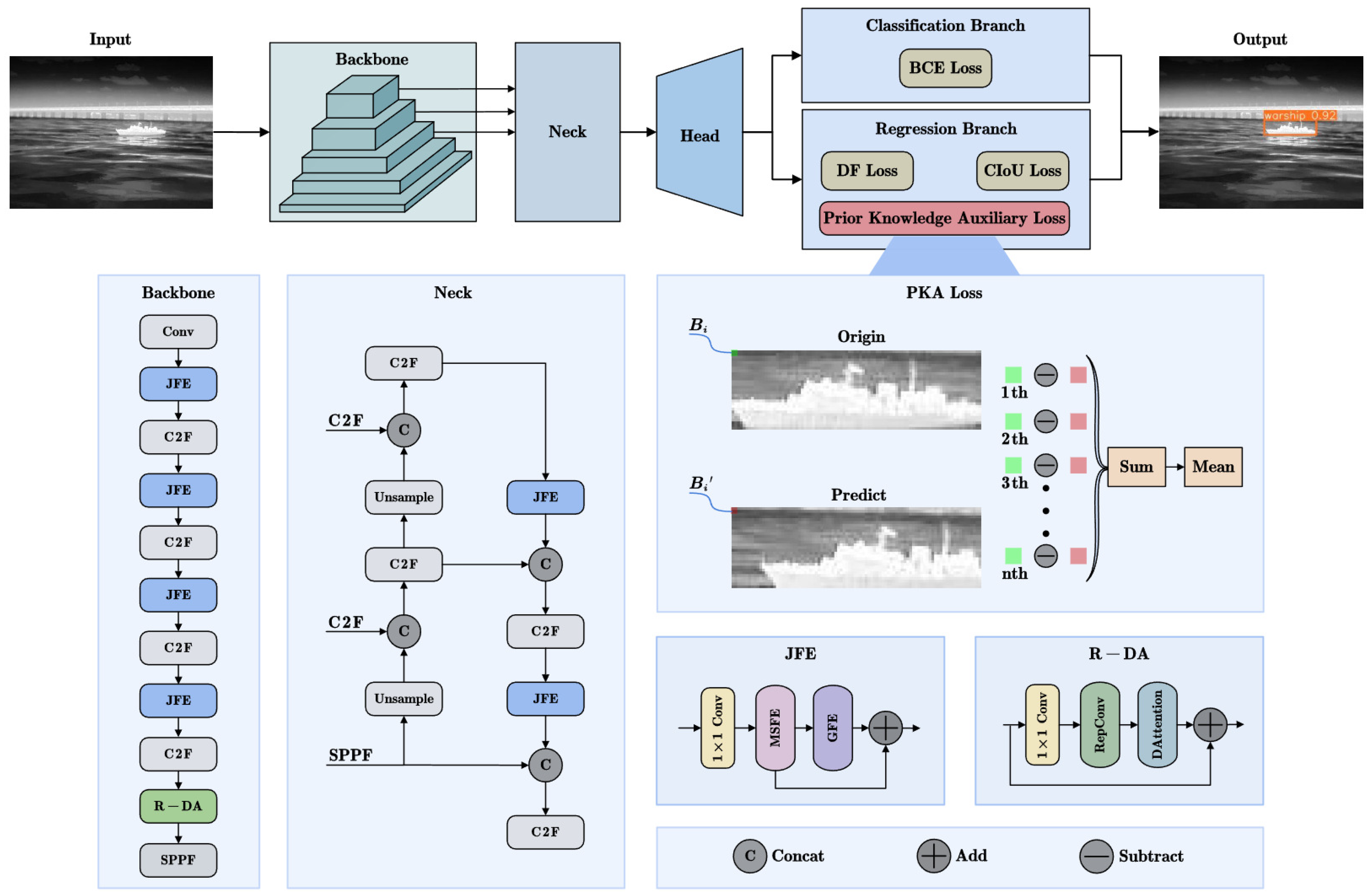
3. Proposed Method
The overall architecture of the proposed PJ-YOLO is shown in
Figure 1. In this network, the backbone and neck parts incorporate the joint feature extraction (JFE) module, which enhances feature extraction from multiple dimensions by integrating channel-differentiated features, context-aware information, and global information. This module is particularly effective in capturing subtle characteristics of ship targets, especially in scenarios with weak features or small targets. To better integrate multi-scale information, a residual deformable attention (R-DA) module is introduced in the high layers of the backbone, improving the model’s robustness to scale variations and complex backgrounds. Additionally, considering the significant brightness difference between ships and their backgrounds, an infrared ship prior knowledge auxiliary loss is designed. This loss function utilizes the prior knowledge of brightness distribution differences to guide the network in accurately locating targets, effectively reducing false alarms and missed detections. By combining the JFE module, R-DA module, and prior knowledge auxiliary loss, PJ-YOLO achieves an optimal balance between accuracy and speed, demonstrating strong potential for practical applications in infrared ship detection tasks.
3.1. Joint Feature Extraction Module
In infrared ship images, the available target features are limited, and it is particularly difficult to identify and obtain relevant features for small infrared targets. Therefore, a joint feature extraction (JFE) module has been designed to enhance feature extraction capability across multiple dimensions, including channel, context-aware, and global information. The structure of the JFE module is shown in
Figure 2. The number of channels in the feature map is adjusted through a 1 × 1 convolution followed by multi-scale and global feature extraction using Multi-Scale Feature Extractor (MSFE) and Global Feature Extractor (GFE), respectively, with subsequent feature fusion. The residual connection designed after the MSFE facilitates the flow of information between network layers.
The MSFE consists of two branches, each designed to enhance the network’s focus on differentiated features and better capture context-aware information. The first branch is implemented with Self-Calibrated Convolution (SCConv) [
32]. Similar to regular convolutions, SCConv separates each channel of the convolution. However, SCConv channels are responsible for specific functions or information. Through dual mapping in the original scale space features and the downsampling latent space features, the network focuses on differentiated features, enhancing channel feature extraction capabilities. The second branch is achieved through three dilated convolutions with different dilation rates. By introducing dilation into the convolutional kernels, the receptive field is expanded, allowing for better capture of context information and strengthening the extraction of spatial features. Compared to regular convolutions, dilated convolutions maintain the same receptive field size while reducing the number of parameters and computational load. Finally, the features extracted from both branches are fused. This process can be expressed as follows:
where
x is the input feature, and
,
, and
represent dilated convolutions with dilated coefficients of 1, 3, and 5, respectively.
The GFE first processes the input by applying ReLU activation subsequent to both global max-pooling and global average-pooling operations. Global max-pooling captures the most prominent features by selecting the maximum value from each feature map, effectively highlighting the most significant characteristics of the image. In contrast, global average-pooling computes the average value of each feature map, maintaining the overall distribution of features and retaining the global context of the image. Finally, the activated features are processed by a fully connected layer, which integrates the salient and global information, thereby guiding the fusion of multi-scale features and improving the overall feature representation. This procedure can be represented as follows:
where
x is the input feature.
3.2. Residual Deformable Attention Module
To enhance the model’s focus on objects of varying scales and improve the network’s perception of critical features, an attention module is designed in the high layers of the backbone network. This aims to better capture the features of the targets.
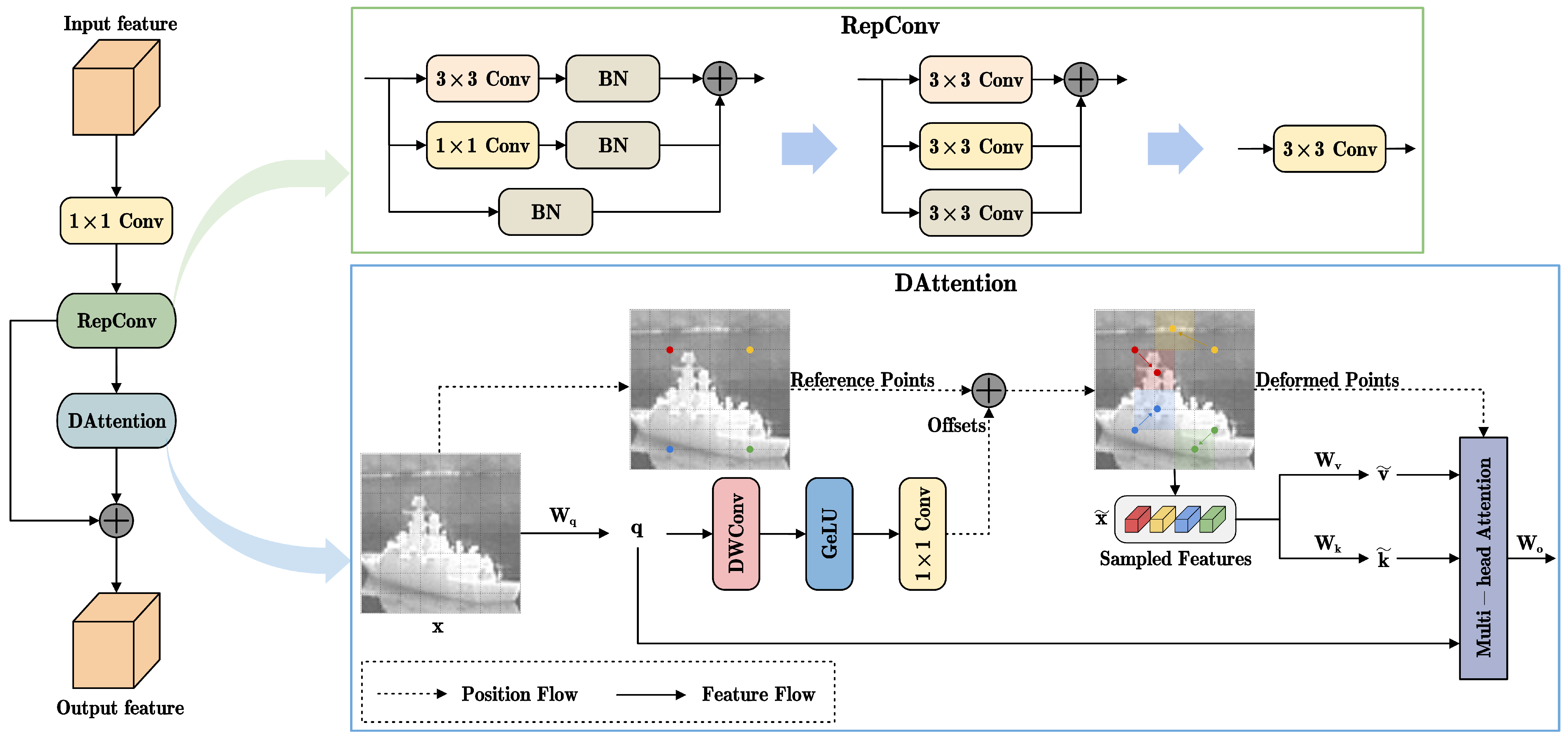
The structure of the residual deformable attention (R-DA) module is shown in
Figure 3. The input features first pass through 1 × 1 convolution for cross-channel aggregation. Then, RepConv [
33] reparameterization is applied to enhance inference speed without degrading accuracy. Finally, the features pass through DAttention [
34], with a residual connection introduced. The inclusion of the residual connection helps retain the original feature information, preventing the loss of important details and semantic information during feature transmission. This makes the network easier to train and addresses potential issues of information loss and gradient vanishing in attention modules. By establishing a connection between the attention module and the residual connection, the network can more accurately learn and utilize key features.
The main motivation of RepConv is to transform as many convolutions as possible into 3 × 3 convolutions, aiming to improve inference speed. As shown in
Figure 3, the simplification process of RepConv involves unifying convolutions of different sizes into a single 3 × 3 convolution, followed by an equivalent merging of the batch normalization (BN) parameters into the 3 × 3 convolution. This equivalent merging method converts the mean and variance of BN into the weights and biases of the convolution, allowing for a single convolution operation during inference and thereby improving inference efficiency.
Inspired by deformable convolutions, the DAttention focuses only on a set of key sampling points around a reference point, rather than processing all pixels in the image. This significantly reduces computational overhead while maintaining good performance. Given the input feature map, reference points are generated. To obtain the offset for each reference point, the feature map is linearly projected to the query token. The offset is generated by the offset network, and it is applied to the reference points. In the offset network, the input features are first captured by deep convolution to extract local features. Then, a GeLU activation function and a 1 × 1 convolution are applied to obtain the two-dimensional offset. After obtaining the reference points, local features are captured through bilinear interpolation and used as the input for both key
k and value
v. Subsequently, the operations of
q,
k, and
v follow the standard self-attention, with an additional relative position offset compensation. The process can be formulated as follows:
where
x and
represent input and sample features,
and
represent deformable key embeddings and value embeddings respectively, and
represents bilinear interpolation operation.
3.3. Loss Function
In object detection, the role of the loss function is to guide the optimization process by quantifying the difference between the model’s predictions and the ground truth, with the goal of enabling the model to accurately and robustly detect targets. Regression loss is a crucial component of object detection, as it guides the model in adjusting the predicted bounding boxes during training to more accurately locate the targets. We designed the Prior Knowledge Auxiliary Loss (PKA Loss), incorporating prior knowledge of infrared ships to guide the model in more accurately localizing ship targets based on brightness differences.
3.3.1. Loss Function of the Regression Branch
In vanilla YOLOv8, the regression branch includes the Distribution Focal Loss (DFL) and CIoU Loss functions. The DFL enables the network to quickly focus on the distribution of positions close to the target location, while the CIoU Loss improves upon the IoU Loss by enhancing the precision of the bounding box regression. The DFL is defined as follows:
where
and
present the values approaching the continuous label
y from the left and right sides, and
represents the Sigmoid output of the
i-th branch.
Compared to the IoU loss function, CIoU incorporates considerations of aspect ratio and center point distance in the penalty term. This allows for better adaptation to targets of varying scales and more accurately measures the overlap between the predicted bounding box and the ground truth bounding box. The definition of CIoU is as follows:
where
denotes ground truth bounding box,
denotes predicted bounding box,
v is used to measure the scale consistency between two bounding boxes, and
is the weighting coefficient.
b and
are predicted and ground truth bounding box centers,
represents Euclidean distance between the centers of the two boxes, and
c represents the diagonal distance of the smallest enclosing area that can simultaneously contain both boxes.
3.3.2. Prior Knowledge Auxiliary Loss
In nature, any object with a temperature above absolute zero (0 K) emits infrared radiation. Infrared images are formed by capturing the thermal radiation emitted by objects, resulting in different brightness levels corresponding to temperature differences. As shown in
Figure 4, the three scenarios all demonstrate a clear difference in brightness levels between the ship targets and their backgrounds. Ships in infrared images typically have higher temperatures compared to their background, such as water surfaces, making them appear brighter in infrared images. This characteristic can be leveraged to assist in object detection.
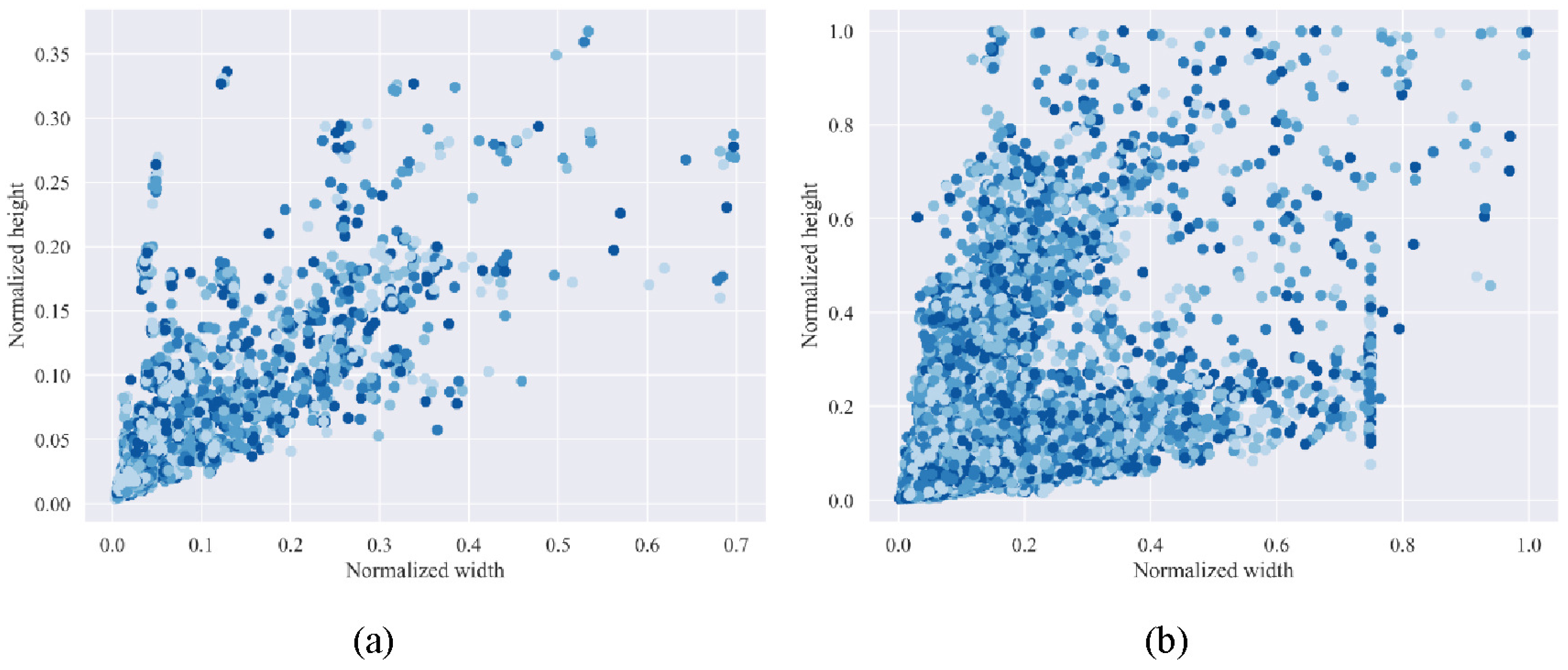
As shown in
Figure 5, the mean brightness of each target bounding box in the infrared ship image is displayed. It can be observed that there is a noticeable difference in the mean brightness between the ground truth (GT) bounding box and the predicted bounding box. Specifically, for ship (c), the brightness difference between the two boxes reaches 3.15. This significant difference in mean brightness indicates that the predicted bounding box does not fully align with the target, suggesting that some portions of the ship’s main body are not accurately captured within the predicted box. This misalignment leads to the observed discrepancy in average brightness. To address this issue, Prior Knowledge Auxiliary (PKA) Loss was designed by incorporating the brightness differences between the GT and predicted bounding boxes of infrared ships as prior knowledge. The PKA Loss is combined with the CIoU from vanilla YOLOv8 to form a new regression loss, named CPA Loss. The values obtained by normalizing the pixel values of the grayscale image to a range of 0 to 1 represent brightness. There is a significant difference in brightness distribution between the target and the background. This difference in brightness distribution is represented by the mean brightness. To ensure an accurate calculation of the mean brightness with an equal number of pixels in both target boxes, the width and height of the boxes are adjusted to be identical. As shown in
Figure 6, the green box represents the original bounding box, and the red box represents the predicted bounding box. By fixing the center points of the target boxes, the width and height are adjusted to the minimum values of the width and height of the two boxes, respectively. The pseudo-code of PKA Loss is shown in Algorithm 1.
| Algorithm 1: Pseudo-code of PKA Loss |
![Jmse 13 00226 i001]() |
The new regression loss, CPA Loss, is obtained by combining CIoU with the PKA Loss at different weight ratios:
where
represents the PKA Loss value,
is the brightness value of the predicted bounding box,
is the brightness value of the original bounding box,
is the pixel-level difference,
is the number of pixels in each bounding box,
is the number of pixels in each bounding box,
is the loss weight ratio, and
is the CIoU Loss value.
5. Conclusions
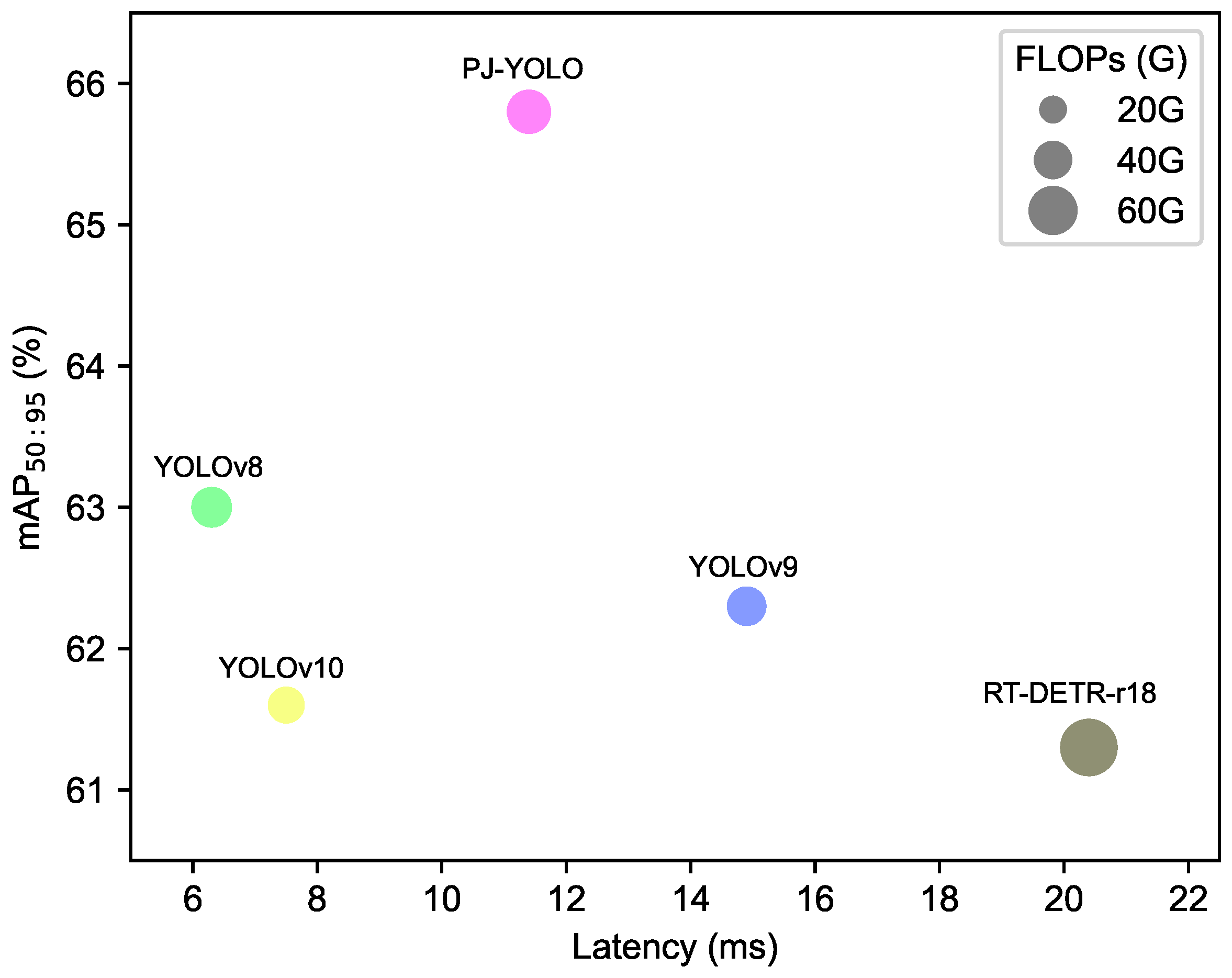
In this paper, we proposed a PJ-YOLO for infrared ship detection, which is dedicated to improving detection performance. In the feature extraction stage, a joint feature extraction module was designed to enhance the extraction of effective features from multiple dimensions. To enhance the model’s focus on targets of different scales, we introduced a residual deformable attention mechanism at the high level of the backbone network, improving the capture of target features. Additionally, we designed a prior auxiliary loss using prior knowledge of infrared ship brightness distribution to more accurately locate targets, enhancing the model’s robustness and improving target localization accuracy. Extensive experiments on the SFISD dataset and the InfiRray Ships dataset validate that PJ-YOLO significantly improves the detection accuracy of infrared ships.
Future research will focus on lightweighting the network structure to enhance FPS while maintaining high detection accuracy, thereby improving operational efficiency and reducing computational resource consumption. To achieve this, we will explore techniques such as network pruning, model lightweighting, operator optimization, and knowledge distillation. Additionally, to enhance the model’s generalization capability, we will also focus on collecting a more diverse set of infrared ship images, aiming to ensure that it maintains stable and efficient performance across various real-world conditions.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}