
MTP-YOLO: You Only Look Once Based Maritime Tiny Person Detector for Emergency Rescue


Abstract
1. Introduction
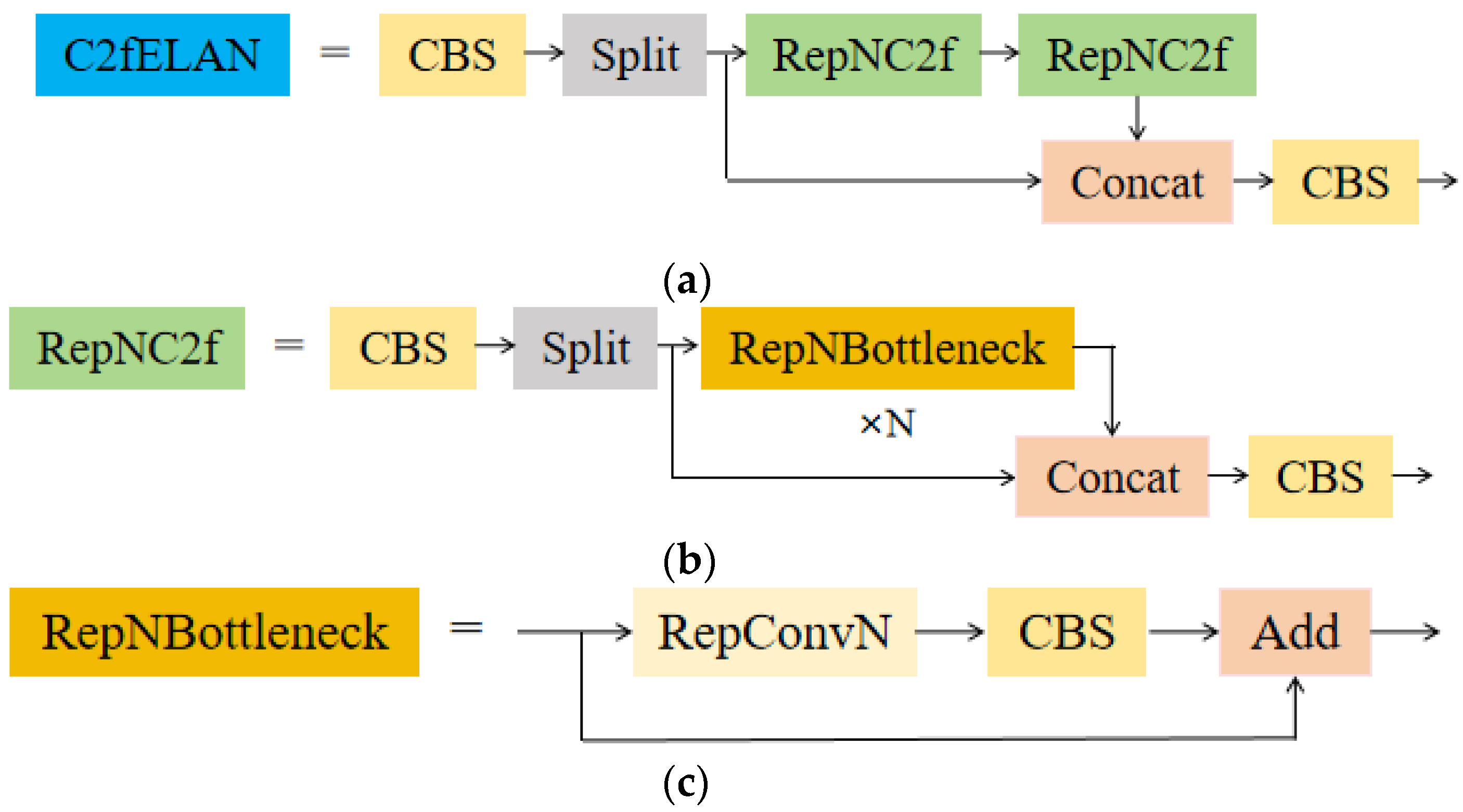
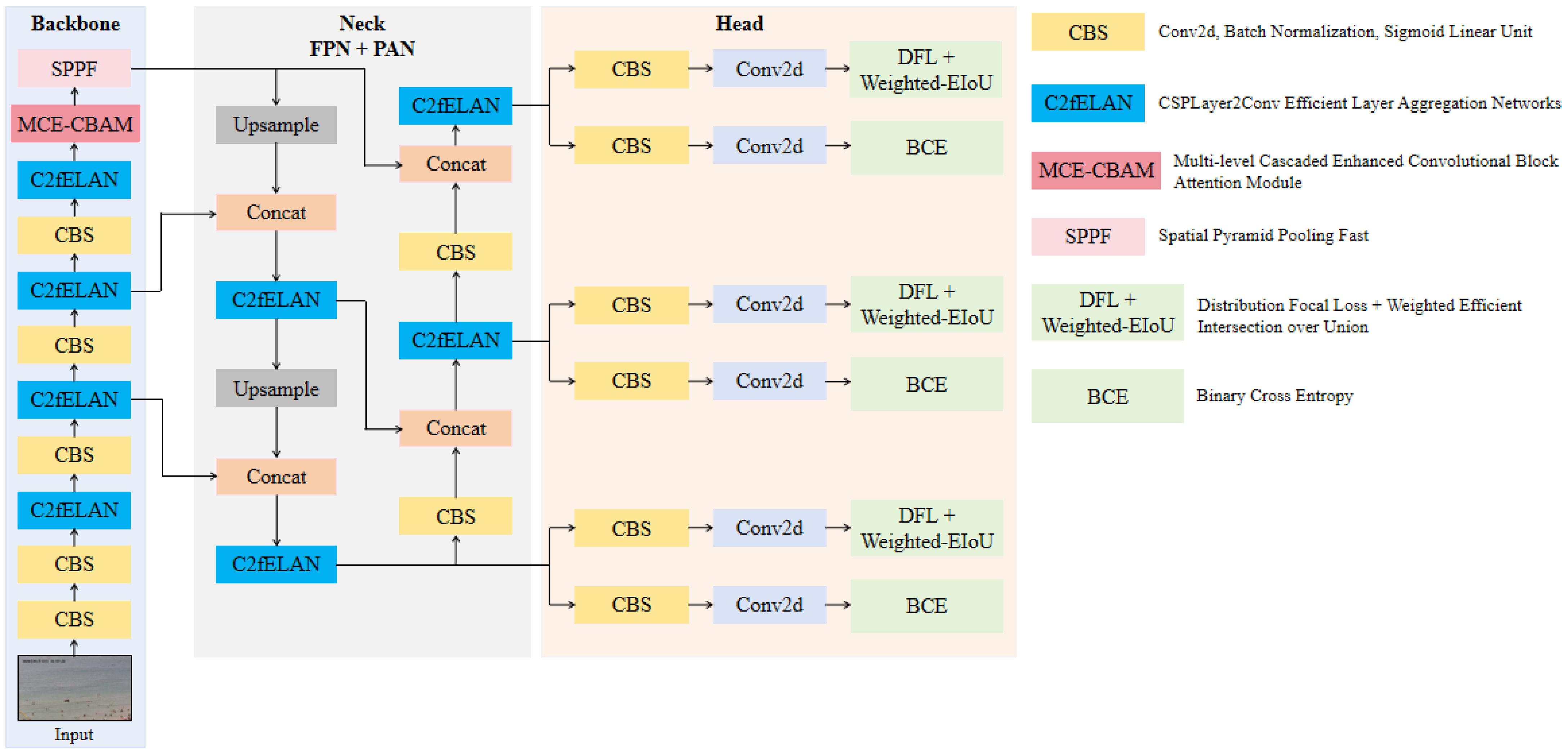
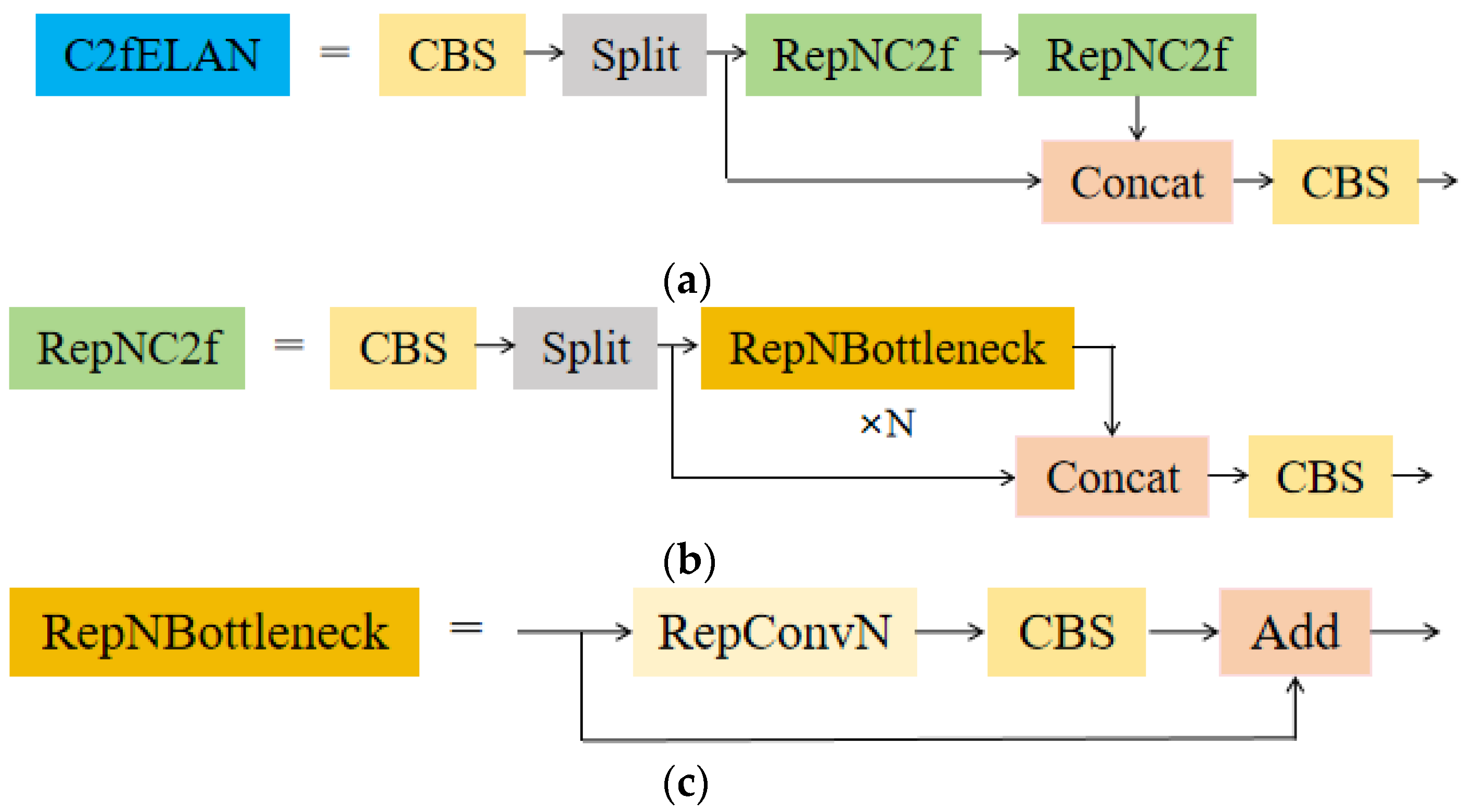
- We designed a new feature extraction module called C2fELAN to better retain tiny object information and reduce information loss during forward propagation, allowing the model to use this information to detect tiny objects and overcome the challenges of tiny object detection.
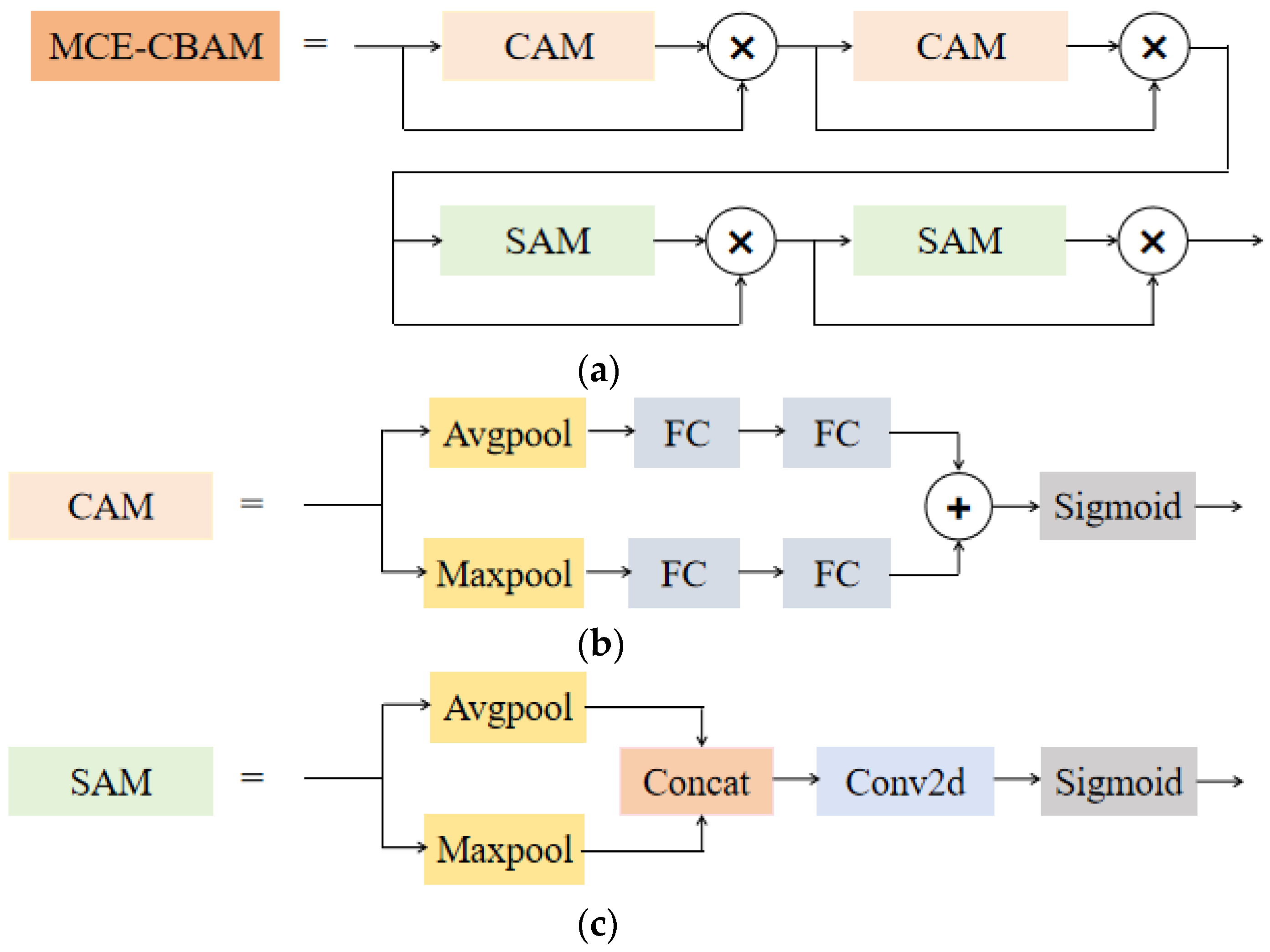
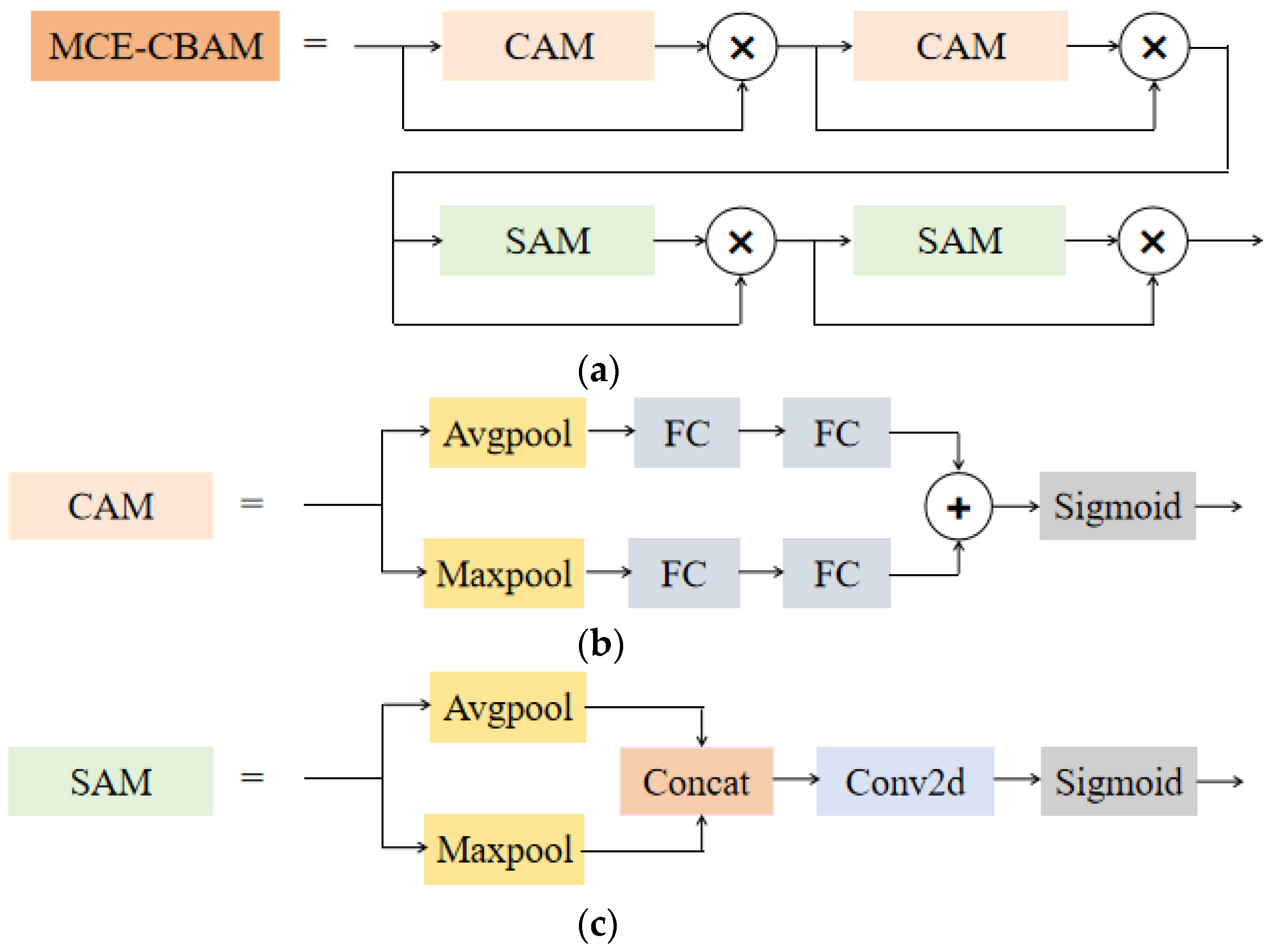
- We adopted the Multi-level Cascaded Enhanced CBAM to obtain a more focused attention distribution, allowing the model to attach importance to areas where the important features of tiny objects exist and learn more useful information.
- We proposed a new bounding box regression loss function called Weighted EIoU Loss to solve the problem of tiny objects having different sensitivities to position and scale deviation and boost the model’s performance in identifying tiny persons.
2. Related Work
2.1. Object Detection
2.2. Tiny Object Detection
3. Method
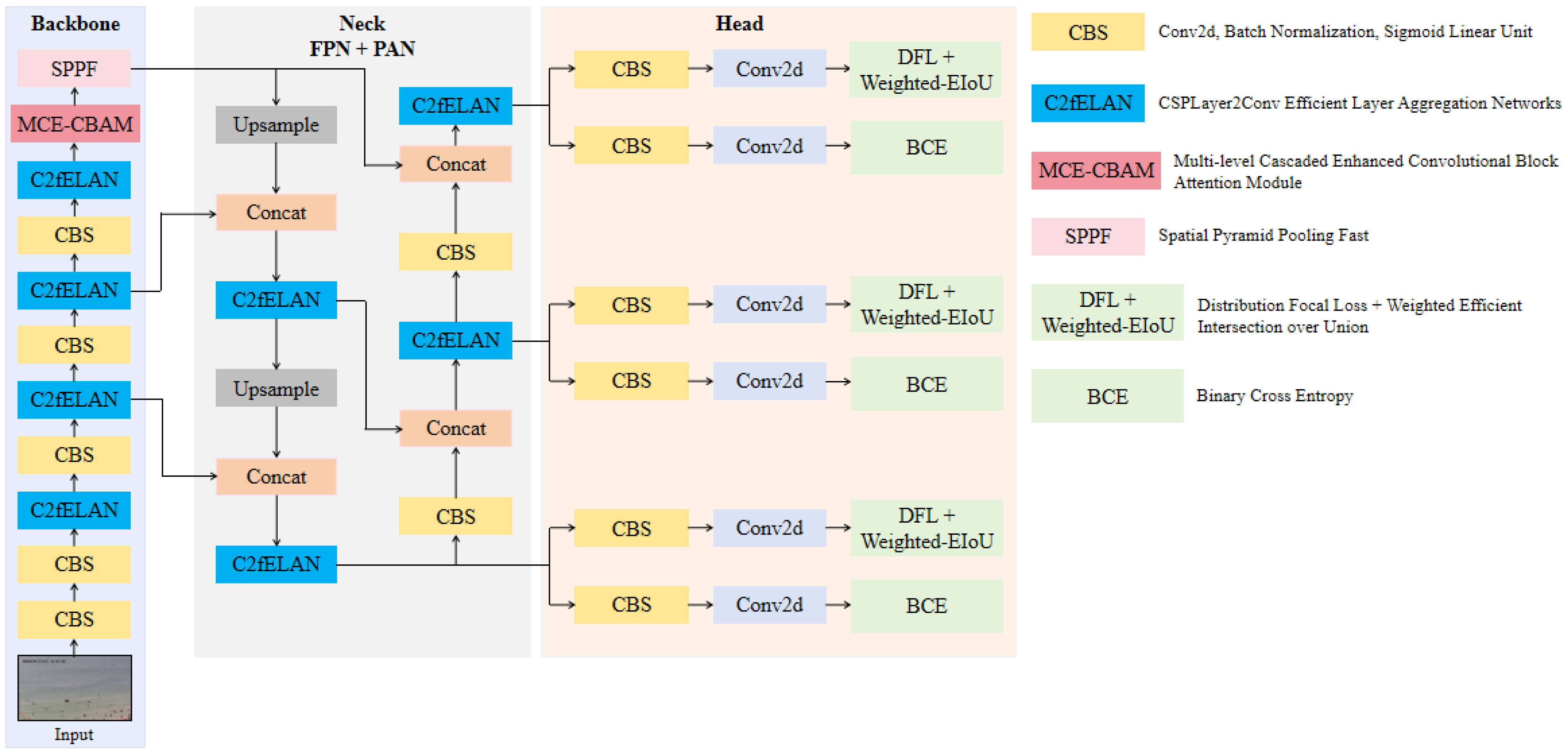
3.1. Overview of MTP-YOLO
3.2. C2fELAN Module
3.3. Multi-Level Cascaded Enhanced CBAM Module
3.4. Weighted-EIoU Loss
4. Experiment
4.1. Datasets and Experimental Settings
4.2. Comparison of Different Weight Values for Weighted EIoU
4.3. Algorithm Comparison
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MTP-YOLO | you only look once based maritime tiny person detector |
| C2fELAN | cross stage partial layer with two convolutions efficient layer aggregation networks |
| MCE-CBAM | multi-level cascaded enhanced convolutional block attention module |
| W-EIoU | weighted efficient intersection over union |
| GELAN | generalized efficient layer aggregation networks |
| CBS | conv2d, batch normalization, sigmoid linear unit |
| SPPF | spatial pyramid pooling fast |
| DFL | distribution focal loss |
| BCE | binary cross entropy |
| RepNC2f | re-parameterization cross stage partial layer with two convolutions without identity connection |
| RepNBottleneck | re-parameterization bottleneck without identity connection |
| RepConvN | re-parameterization convolution without identity connection |
| RepConv | re-parameterization convolution |
| SiLU | sigmoid linear unit |
| CAM | channel attention module |
| SAM | spatial attention module |
| FC | Fully Connected layer |
References
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Shehzadi, T.; Hashmi, K.A.; Stricker, D.; Afzal, M.Z. Object Detection with Transformers: A Review. arXiv 2023, arXiv:2306.04670. [Google Scholar]
- Chen, G.; Wang, H.; Chen, K.; Li, Z.; Song, Z.; Liu, Y.; Chen, W.; Knoll, A. A Survey of the Four Pillars for Small Object Detection: Multiscale Representation, Contextual Information, Super-Resolution, and Region Proposal. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 936–953. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, Z.; Sun, J.; Xu, L.; Zhou, X. Illumination Adaptive Multi-Scale Water Surface Object Detection with Intrinsic Decomposition Augmentation. J. Mar. Sci. Eng. 2023, 11, 1485. [Google Scholar] [CrossRef]
- Yu, X.; Chen, P.; Wu, D.; Hassan, N.; Li, G.; Yan, J.; Shi, H.; Ye, Q.; Han, Z. Object Localization under Single Coarse Point Supervision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhou, Z.; Hu, X.; Li, Z.; Jing, Z.; Qu, C. A Fusion Algorithm of Object Detection and Tracking for Unmanned Surface Vehicles. Front. Neurorobot. 2022, 16, 808147. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO (Version 8.0.0) [Computer Software]. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 26 February 2024).
- Lim, J.-S.; Astrid, M.; Yoon, H.-J.; Lee, S.-I. Small Object Detection using Context and Attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized Feature Pyramid for Object Detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA,, 18–23 June 2018. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia (MM ‘16), Association for Computing Machinery, New York, NY, USA, 15–19 October 2016. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. arXiv 2021, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | mAP@0.5 | |
|---|---|---|---|
| 1.0 | 0.767 | 0.579 | 0.675 |
| 1.5 | 0.750 | 0.573 | 0.665 |
| 2.0 | 0.769 | 0.580 | 0.680 |
| 2.5 | 0.773 | 0.590 | 0.688 |
| 3.0 | 0.776 | 0.596 | 0.691 |
| Methods | Precision | Recall | mAP@0.5 | mAP@[0.5,0.9] |
|---|---|---|---|---|
| Faster RCNN | - | - | 0.498 | 0.211 |
| YOLOv5 | 0.791 | 0.583 | 0.665 | 0.284 |
| YOLOv6 | - | - | 0.491 | 0.228 |
| YOLOv7 | 0.784 | 0.628 | 0.663 | 0.245 |
| SSD | 0.272 | 0.052 | 0.057 | - |
| FCOS | - | - | 0.581 | 0.313 |
| YOLOv8 | 0.758 | 0.578 | 0.674 | 0.315 |
| YOLOv9 | 0.767 | 0.597 | 0.690 | 0.331 |
| DETR | - | - | 0.189 | 0.050 |
| MTP-YOLO (Ours) | 0.776 | 0.596 | 0.691 | 0.331 |
| Faster RCNN | YOLOv5 | YOLOv6 | YOLOv7 | SSD |
|---|---|---|---|---|
| 315.0 M | 13.8 M | 38.8 M | 284.7 M | 90.6 M |
| FCOS | YOLOv8 | YOLOv9 | DETR | MTP-YOLO |
| 244 M | 21.5 M | 116.7 M | 474 M | 56.9 M |
| Methods | Precision | Recall | mAP@0.5 |
|---|---|---|---|
| Baseline | 0.758 | 0.578 | 0.674 |
| Baseline + C2fELAN | 0.771 | 0.597 | 0.689 |
| Baseline + C2fELAN + MCE-CBAM | 0.775 | 0.596 | 0.690 |
| Baseline + C2fELAN + MCE-CBAM + W-EIoU | 0.776 | 0.596 | 0.691 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; Li, S.; Liu, Z.; Zhou, Z.; Zhou, X. MTP-YOLO: You Only Look Once Based Maritime Tiny Person Detector for Emergency Rescue. J. Mar. Sci. Eng. 2024, 12, 669. https://doi.org/10.3390/jmse12040669
Shi Y, Li S, Liu Z, Zhou Z, Zhou X. MTP-YOLO: You Only Look Once Based Maritime Tiny Person Detector for Emergency Rescue. Journal of Marine Science and Engineering. 2024; 12(4):669. https://doi.org/10.3390/jmse12040669
Chicago/Turabian StyleShi, Yonggang, Shaokun Li, Ziyan Liu, Zhiguo Zhou, and Xuehua Zhou. 2024. "MTP-YOLO: You Only Look Once Based Maritime Tiny Person Detector for Emergency Rescue" Journal of Marine Science and Engineering 12, no. 4: 669. https://doi.org/10.3390/jmse12040669
APA StyleShi, Y., Li, S., Liu, Z., Zhou, Z., & Zhou, X. (2024). MTP-YOLO: You Only Look Once Based Maritime Tiny Person Detector for Emergency Rescue. Journal of Marine Science and Engineering, 12(4), 669. https://doi.org/10.3390/jmse12040669