
Sample Augmentation Method for Side-Scan Sonar Underwater Target Images Based on CBL-sinGAN

Abstract
1. Introduction
2. Methods
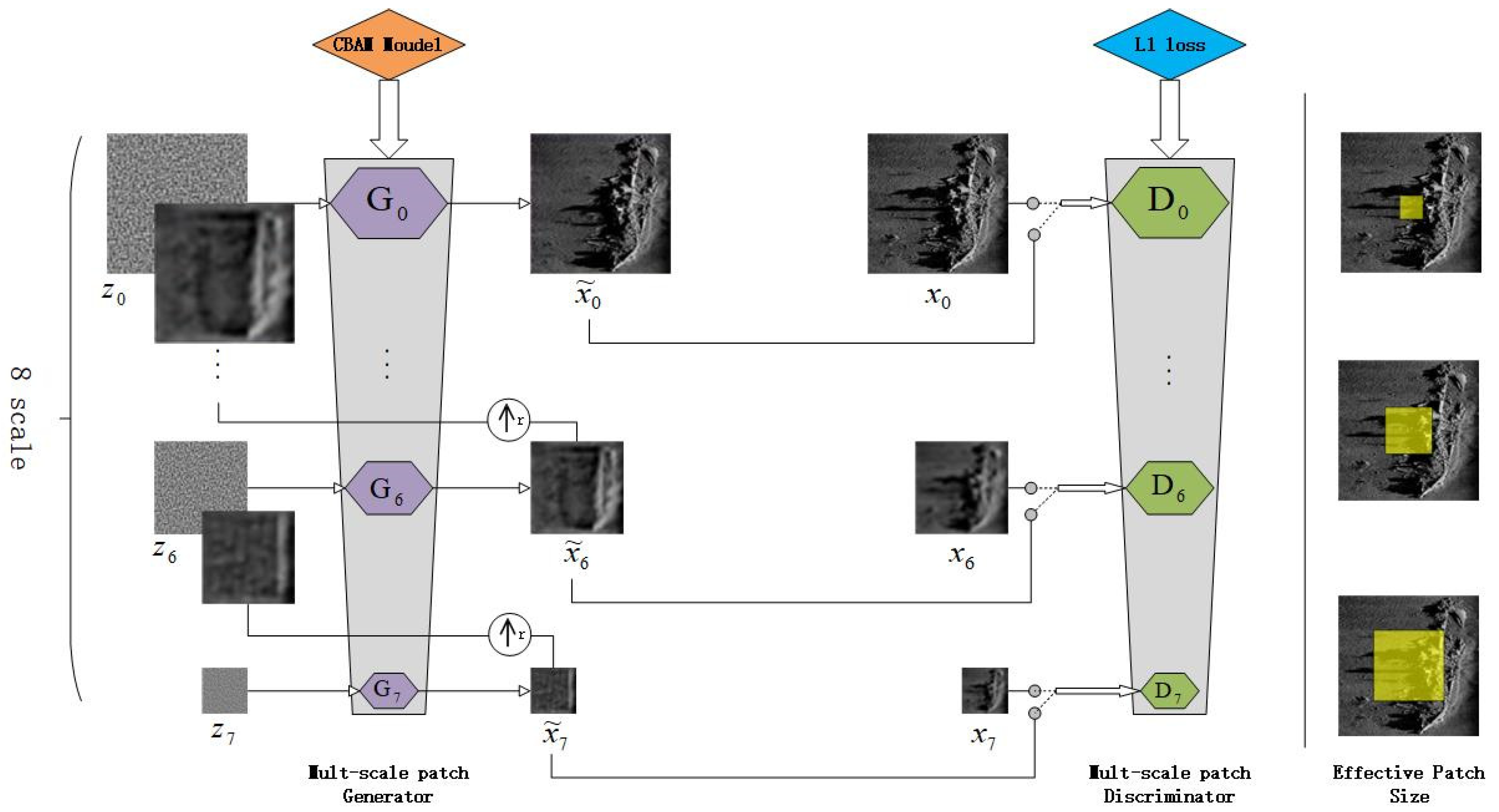
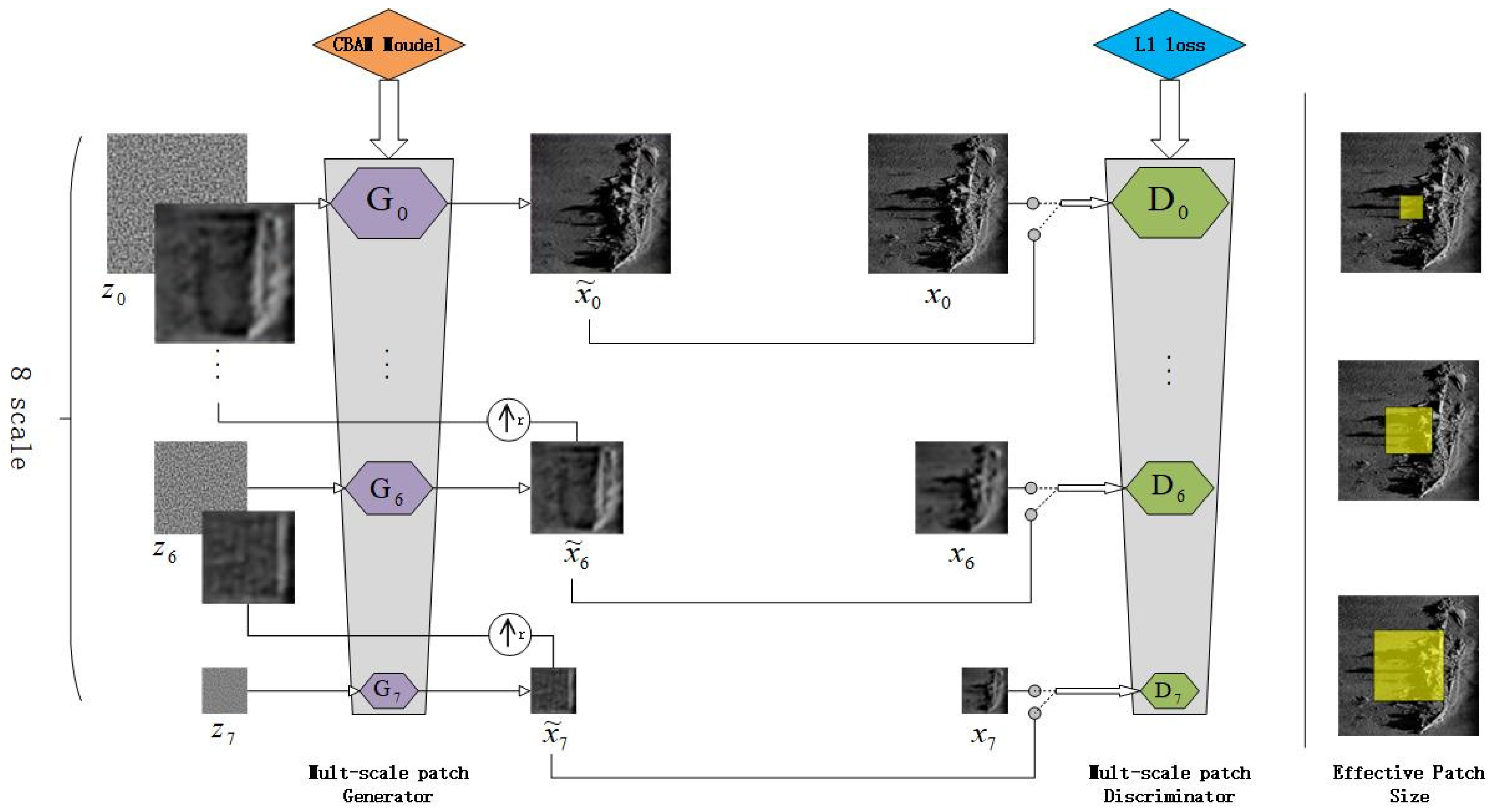
2.1. The Basic Structure of CBL-sinGAN
2.2. The Multi-Scale Architecture of the SinGAN Module
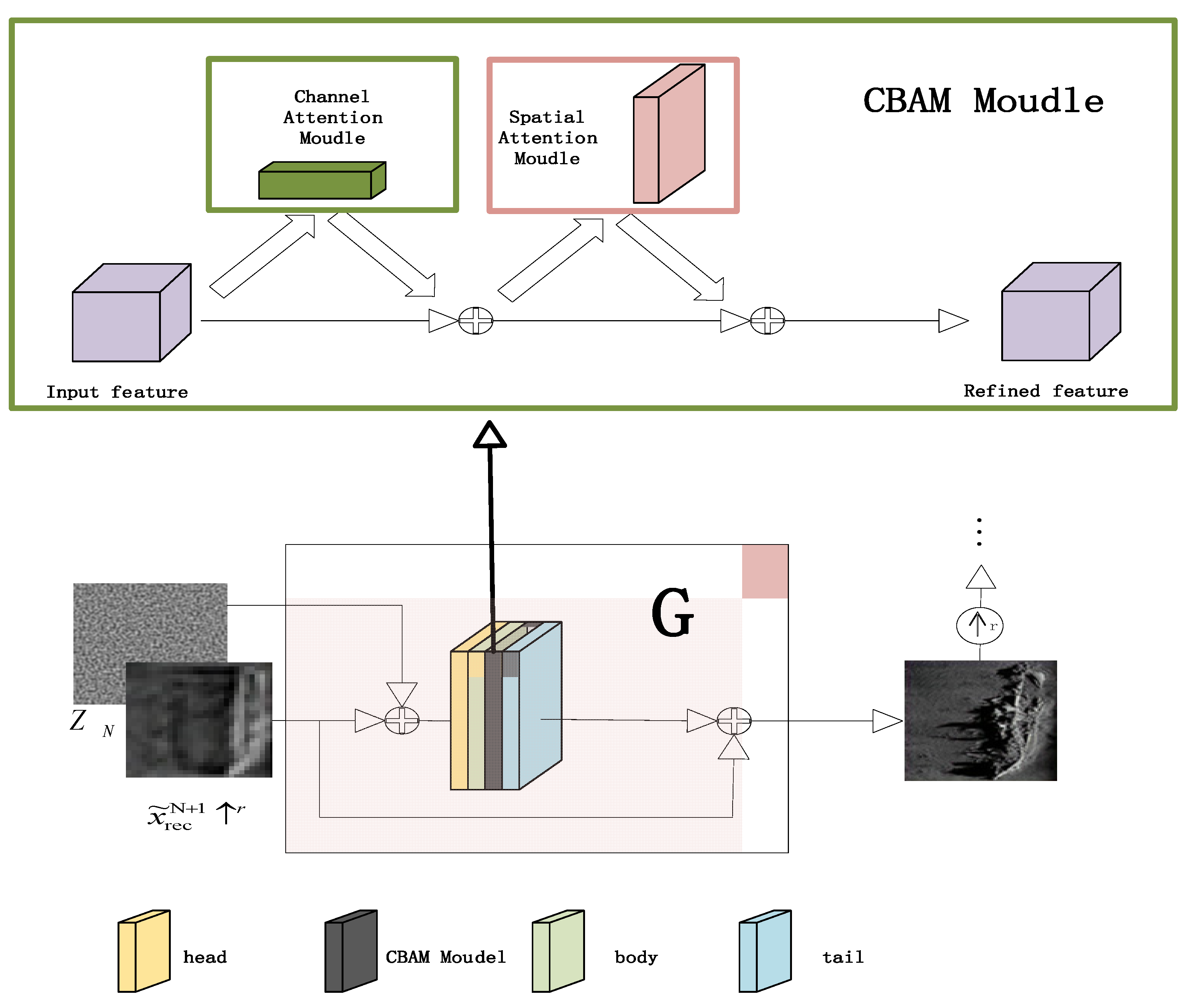
2.3. Generator Based on the CBAM Model
2.4. Discriminator Based on L1 Loss Function
3. Experimental Validation
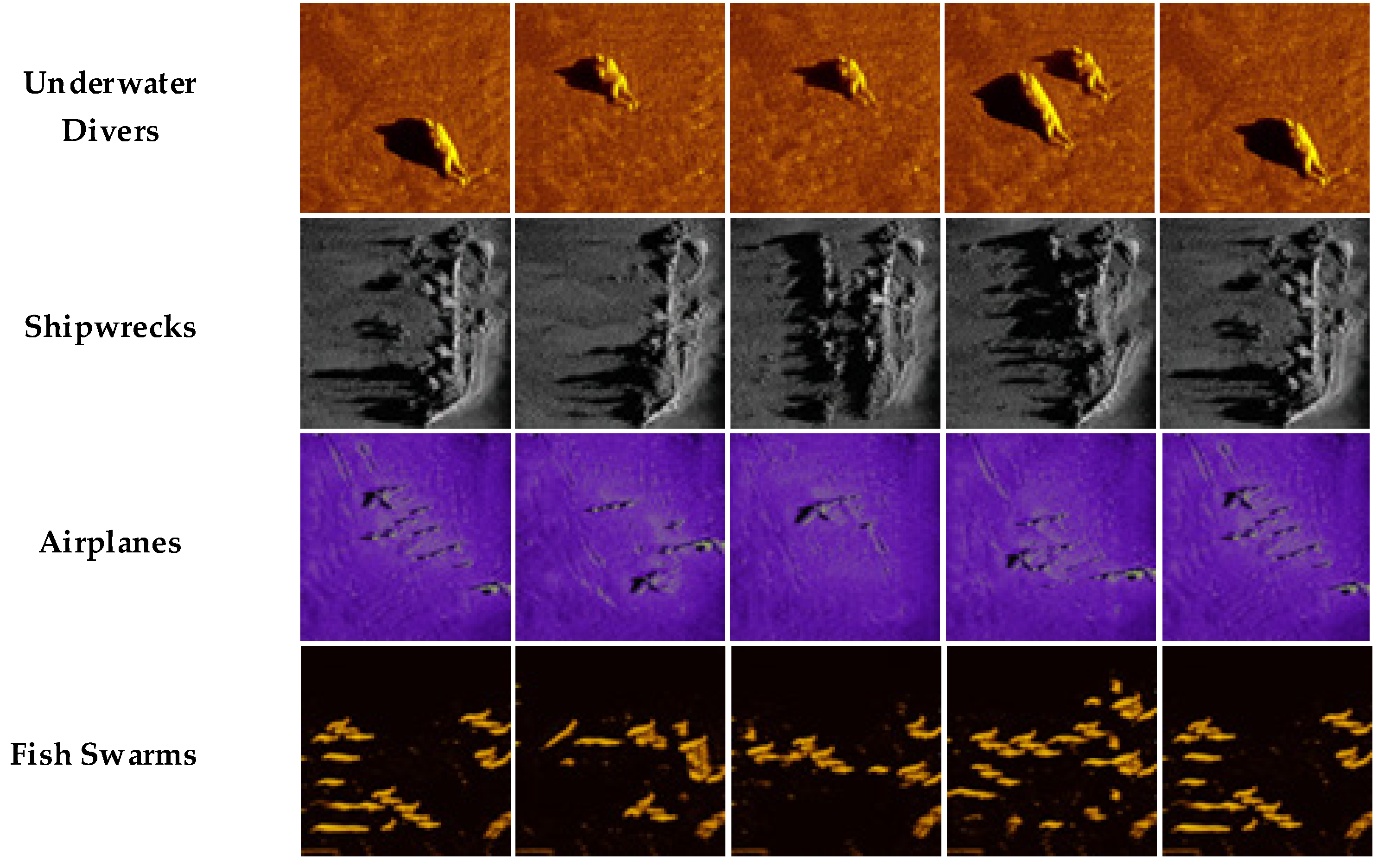
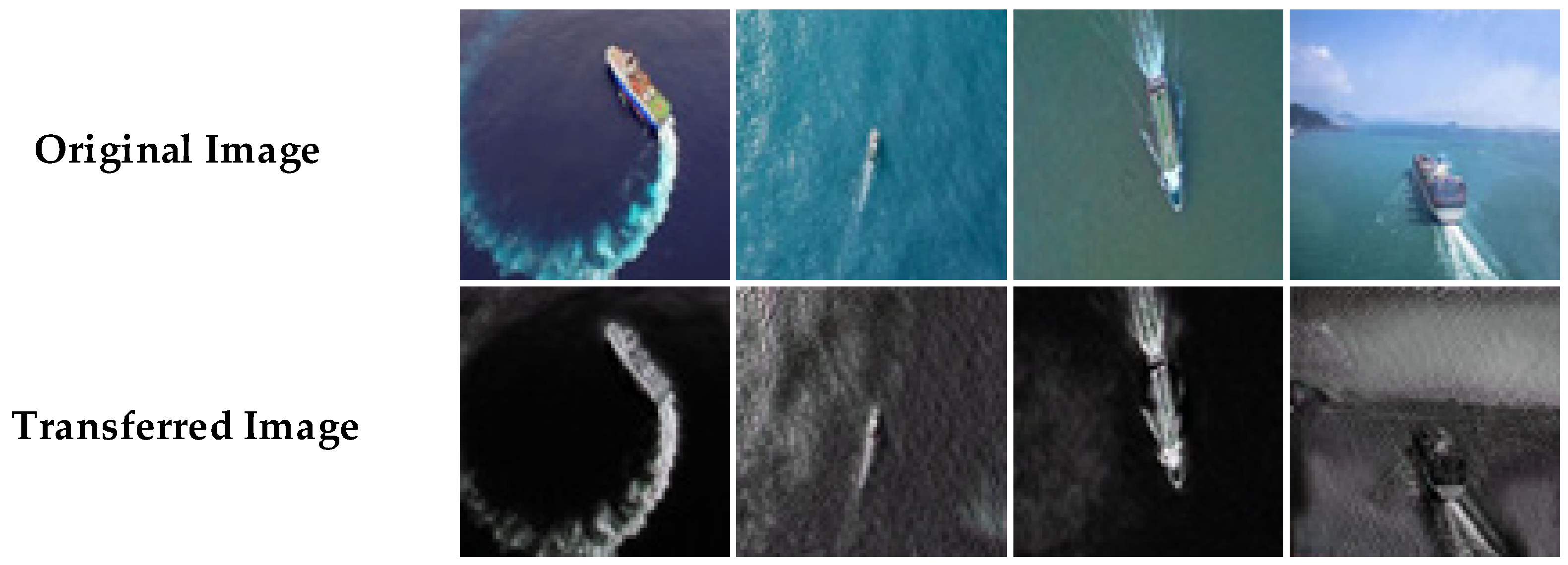
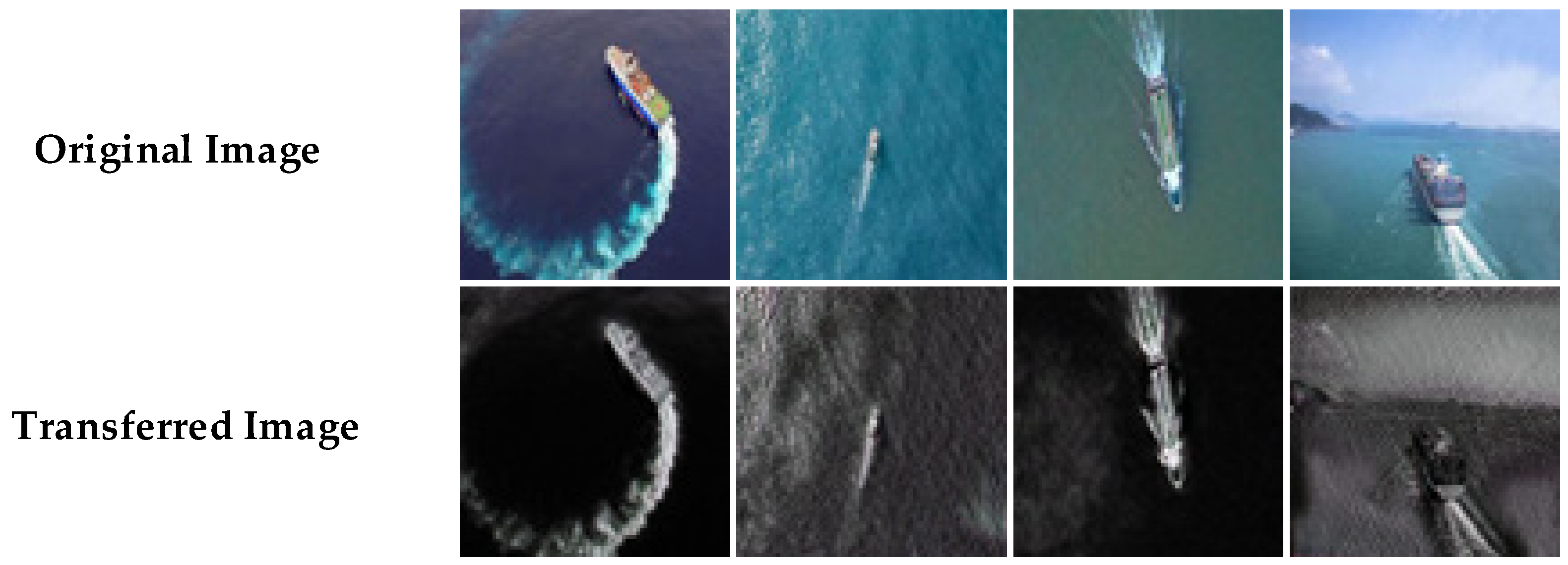
3.1. Dataset Description and Experimental Equipment Parameters
3.2. Evaluation Metrics
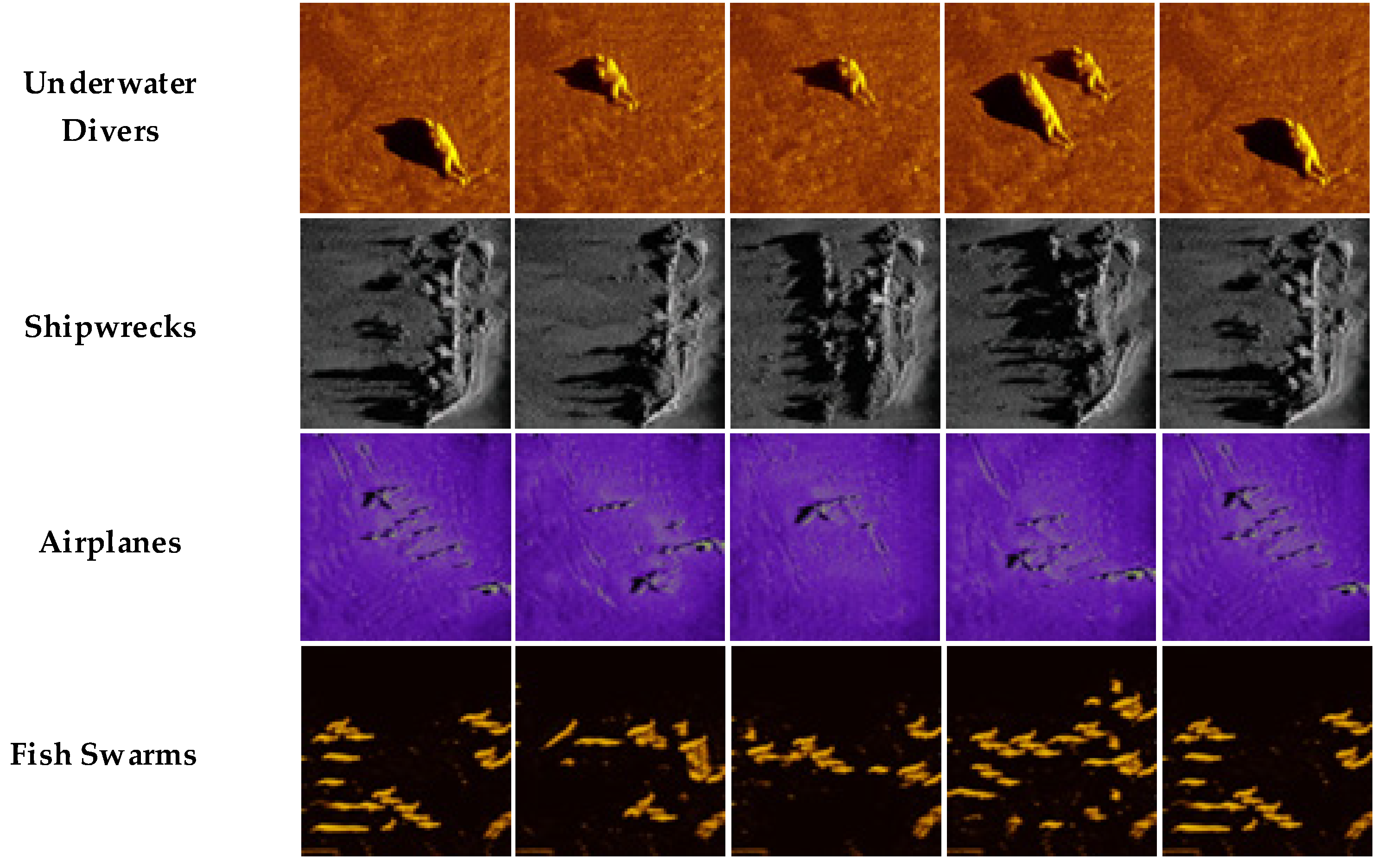
3.3. Analysis of Augmented Image Quality
3.4. Performance of the Model on Object Detection
4. Discussion
4.1. The Unique Advantages and Comparative Analysis of CBL-sinGAN
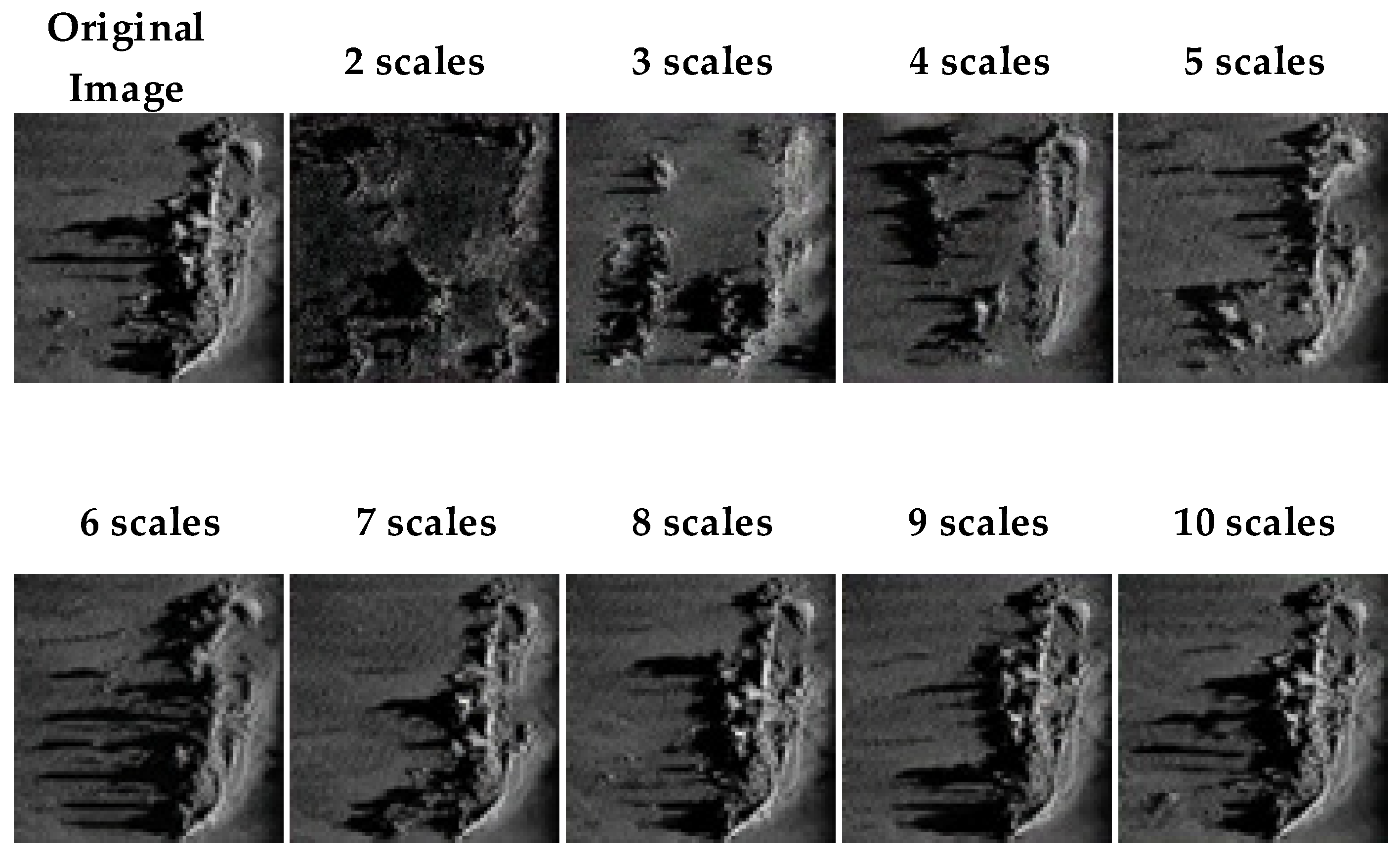
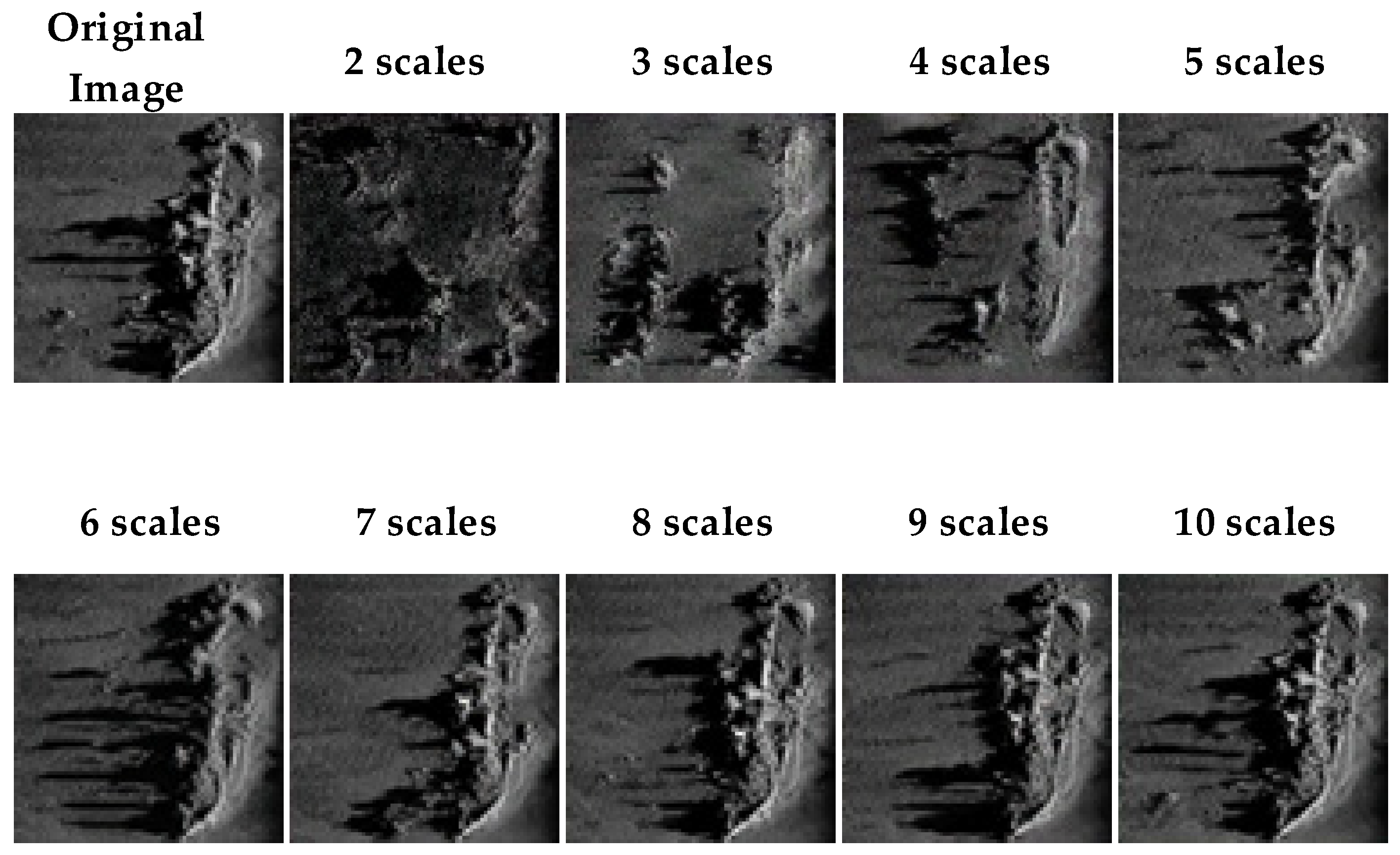
4.2. Scale Selection in Image Generation
4.3. Ablation Experiment and Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Buscombe, D. Shallow water benthic imaging and substrate characterization using recreational-grade side scan-sonar. Environ. Model. Softw. 2017, 89, 1–18. [Google Scholar] [CrossRef]
- Flowers, H.J.; Hightower, J.E. A novel approach to surveying sturgeon using side-scan sonar and occupancy modeling. Mar. Coast. Fish. 2013, 5, 211–223. [Google Scholar] [CrossRef]
- Johnson, S.G.; Deaett, M.A. The application of automated recognition techniques to side-scan sonar imagery. IEEE J. Ocean. Eng. J. Devoted Appl. Electr. Electron. Eng. Ocean. Environ. 1994, 19, 138–144. [Google Scholar] [CrossRef]
- Burguera, A.; Bonin-Font, F. On-line multi-class segmentation of side-scan sonar imagery using an autonomous underwater vehicle. J. Mar. Sci. Eng. 2020, 8, 557. [Google Scholar] [CrossRef]
- Chen, E.; Guo, J. Real time map generation using Side-scan sonar scanlines for unmanned underwater vehicles. Ocean Eng. 2014, 91, 252–262. [Google Scholar] [CrossRef]
- Shin, J.; Chang, S.; Bays, M.J.; Weaver, J.; Wettergren, T.A.; Ferrari, S. Synthetic Sonar Image Simulation with Various Seabed Conditions for Automatic Target Recognition. In Proceedings of the OCEANS 2022, Hampton Roads, VA, USA, 17–20 October 2022; pp. 1–8. [Google Scholar]
- Neupane, D.; Seok, J. A review on deep learning-based approaches for automatic sonar target recognition. Electronics 2020, 9, 1972. [Google Scholar] [CrossRef]
- Topple, J.M.; Fawcett, J.A. MiNet: Efficient deep learning automatic target recognition for small autonomous vehicles. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1014–1018. [Google Scholar] [CrossRef]
- Zhou, X.; Yu, C.; Yuan, X.; Luo, C. Deep Denoising Method for Side Scan Sonar Images without High-quality Reference Data. In Proceedings of the 2022 2nd International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 18–20 March 2022; pp. 241–245. [Google Scholar]
- Feldens, P.; Darr, A.; Feldens, A.; Tauber, F. Detection of boulders in side scan sonar mosaics by a neural network. Geosciences 2019, 9, 159. [Google Scholar] [CrossRef]
- Tang, Y.L.; Jin, S.H.; Bian, G.; Zhang, Y. Shipwreck target recognition in side-scan sonar images by improved YOLOv3 model based on transfer learning. IEEE Access 2020, 8, 173450–173460. [Google Scholar]
- Tang, Y.; Li, H.; Zhang, W.; Bian, S.; Zhai, G.; Liu, M.; Zhang, X. Lightweight DETR-YOLO method for detecting shipwreck target in side-scan sonar. Syst. Eng. Electron. 2022, 44, 2427. [Google Scholar]
- Nguyen, H.-T.; Lee, E.-H.; Lee, S. Study on the classification performance of underwater sonar image classification based on convolutional neural networks for detecting a submerged human body. Sensors 2019, 20, 94. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, L.; Yu, D.; Li, H.; Liu, M.; Zhang, W. Sample Augmentation Method for Side-scan sonar Underwater Target Images Based on CSLS-CycleGAN. Syst. Eng. Electron. 2023, 45, 1–16. Available online: http://kns.cnki.net/kcms/detail/11.2422.TN.20230807.1406.002.html (accessed on 7 January 2024).
- Rajani, H.; Gracias, N.; Garcia, R. A Convolutional Vision Transformer for Semantic Segmentation of Side-Scan Sonar Data. arXiv 2023, arXiv:2302.12416. [Google Scholar] [CrossRef]
- Álvarez-Tuñón, O.; Marnet, L.R.; Antal, L.; Aubard, M.; Costa, M.; Brodskiy, Y. SubPipe: A Submarine Pipeline Inspection Dataset for Segmentation and Visual-inertial Localization. arXiv 2024, arXiv:2401.17907. [Google Scholar]
- Ge, Q.; Ruan, F.; Qiao, B.; Zhang, Q.; Zuo, X.; Dang, L. Side-scan sonar image classification based on style transfer and pre-trained convolutional neural networks. Electronics 2021, 10, 1823. [Google Scholar] [CrossRef]
- Huo, G.; Wu, Z.; Li, J. Underwater object classification in Side-scan sonar images using deep transfer learning and semisynthetic training data. IEEE Access 2020, 8, 47407–47418. [Google Scholar] [CrossRef]
- Li, C.; Ye, X.; Cao, D.; Hou, J.; Yang, H. Zero shot objects classification method of side scan sonar image based on synthesis of pseudo samples. Appl. Acoust. 2021, 173, 107691. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, L.; Jin, S.; Zhao, J.; Huang, C.; Yu, Y. AUV-Based Side-Scan Sonar Real-Time Method for Underwater-Target Detection. J. Mar. Sci. Eng. 2023, 11, 690. [Google Scholar] [CrossRef]
- Huang, C.; Zhao, J.; Yu, Y.; Zhang, H. Comprehensive Sample Augmentation by Fully Considering SSS Imaging Mechanism and Environment for Shipwreck Detection Under Zero Real Samples. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5906814. [Google Scholar] [CrossRef]
- Kim, S.; Kim, J.; Kim, T.; Heo, H.; Kim, S.; Lee, J.; Kim, J.H. Unpaired Panoramic Image-to-Image Translation Leveraging Pinhole Images. Available online: https://openreview.net/forum?id=bRm0rul3SZ (accessed on 7 January 2024).
- Xi, J.; Ye, X.; Li, C. Sonar Image Target Detection Based on Style Transfer Learning and Random Shape of Noise under Zero Shot Target. Remote Sens. 2022, 14, 6260. [Google Scholar] [CrossRef]
- Li, B.Q.; Huang, H.N.; Liu, J.Y.; Li, Y. Optical image-to-underwater small target synthetic aperture sonar image translation algorithm based on improved CycleGAN. Acta Electon. Sin. 2021, 49, 1746. [Google Scholar]
- Bird, J.J.; Barnes, C.M.; Manso, L.J.; Ekárt, A.; Faria, D.R. Fruit quality and defect image classification with conditional GAN data augmentation. Sci. Hortic. 2022, 293, 110684. [Google Scholar] [CrossRef]
- Mikołajczyk, A.; Majchrowska, S.; Carrasco Limeros, S. The (de) biasing effect of gan-based augmentation methods on skin lesion images. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer Nature: Cham, Switzerland, 2022; pp. 437–447. [Google Scholar]
- Razavi, A.; Van den Oord, A.; Vinyals, O. Generating diverse high-fidelity images with vq-vae-2. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Xu, Y.; Ben, K.; Wang, T. Research on DCGAN Model Improvement and SAR Image Generation. Comput. Sci. 2020, 47, 93–99. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Jiang, Y.; Ku, B.; Kim, W.; Ko, H. Side-scan sonar image synthesis based on generative adversarial network for images in multiple frequencies. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1505–1509. [Google Scholar] [CrossRef]
- Steiniger, Y.; Kraus, D.; Meisen, T. Generating synthetic Side-scan sonar snippets using transfer-learning in generative adversarial networks. J. Mar. Sci. Eng. 2021, 9, 239. [Google Scholar] [CrossRef]
- Yang, Z.; Zhao, J.; Zhang, H.; Yu, Y.; Huang, C. A Side-Scan Sonar Image Synthesis Method Based on a Diffusion Model. J. Mar. Sci. Eng. 2023, 11, 1103. [Google Scholar] [CrossRef]
- Liu, W.; Piao, Z.; Tu, Z.; Luo, W.; Ma, L.; Gao, S. Liquid warping gan with attention: A unified framework for human image synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5114–5132. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, S.; Gao, C.; Cao, J.; He, R.; Feng, J.; Yan, S. Psgan: Pose and expression robust spatial-aware gan for customizable makeup transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5194–5202. [Google Scholar]
- Shaham, T.R.; Dekel, T.; Michaeli, T. Singan: Learning a generative model from a single natural image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4570–4580. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Li, X.; Hu, X.; Yang, J. Spatial group-wise enhance: Improving semantic feature learning in convolutional networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14; Springer International Publishing: Cham, Switzerland, 2016; pp. 702–716. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Huang, X.; Li, Y.; Poursaeed, O.; Hopcroft, J.; Belongie, S. Stacked generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5077–5086. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | FID | IS | MMD |
|---|---|---|---|
| plane | 127.7 | 3.923 ± 0.226 | 0.221 |
| People | 123.0 | 4.346 ± 0.197 | 0.217 |
| Fish | 152.6 | 4.965 ± 0.367 | 0.237 |
| Boat | 118.9 | 4.456 ± 0.300 | 0.139 |
| Group | Real Shipwreck Images | Augmented Shipwreck Images |
|---|---|---|
| 1 | 50 | - |
| 2 | - | 424 |
| 3 | 50 | 424 |
| Detection Images | 100 | - |
| Precision | Recall | AP0.5 | AP0.5:0.95 | |
|---|---|---|---|---|
| YOLOv5-1 | 90.0% | 91.2% | 0.924 | 0.546 |
| YOLOv5-2 | 94.8% | 95.8% | 0.958 | 0.593 |
| YOLOv5-3 | 94.9% | 96.0% | 0.961 | 0.61 |
| Detection Model/Group | 1 | 2 | 3 |
|---|---|---|---|
| YOLOv5n | 82.7% | 89.2% | 91.5% |
| YOLOv5s | 83.1% | 92.3% | 92.8% |
| YOLOv5m | 86.1% | 94.9% | 95.3% |
| YOLOv5x | 90.0% | 94.8% | 94.9% |
| Scale | FID | IS | MMD |
|---|---|---|---|
| 2 | 405.947 | 4.509 | 0.7412 |
| 3 | 368.951 | 4.378 | 0.4852 |
| 4 | 380.985 | 4.585 | 0.4600 |
| 5 | 274.182 | 4.563 | 0.3936 |
| 6 | 216.276 | 4.534 | 0.3349 |
| 7 | 204.740 | 4.522 | 0.3278 |
| 8 | 141.345 | 4.583 | 0.2496 |
| 9 | 183.675 | 4.512 | 0.2306 |
| 10 | 164.144 | 4.364 | 0.1901 |
| Group | CBAM Model | L1 Loss | FID | IS | MMD |
|---|---|---|---|---|---|
| 1 | - | - | 131.61 | 4.299 ± 0.285 | 0.169 |
| 2 | √ | - | 122.35 | 4.385 ± 0.210 | 0.154 |
| 3 | - | √ | 157.92 | 4.306 ± 0.275 | 0.261 |
| 4 | √ | √ | 118.89 | 4.456 ± 0.300 | 0.139 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, C.; Jin, S.; Bian, G.; Cui, Y.; Wang, M. Sample Augmentation Method for Side-Scan Sonar Underwater Target Images Based on CBL-sinGAN. J. Mar. Sci. Eng. 2024, 12, 467. https://doi.org/10.3390/jmse12030467
Peng C, Jin S, Bian G, Cui Y, Wang M. Sample Augmentation Method for Side-Scan Sonar Underwater Target Images Based on CBL-sinGAN. Journal of Marine Science and Engineering. 2024; 12(3):467. https://doi.org/10.3390/jmse12030467
Chicago/Turabian StylePeng, Chengyang, Shaohua Jin, Gang Bian, Yang Cui, and Meina Wang. 2024. "Sample Augmentation Method for Side-Scan Sonar Underwater Target Images Based on CBL-sinGAN" Journal of Marine Science and Engineering 12, no. 3: 467. https://doi.org/10.3390/jmse12030467
APA StylePeng, C., Jin, S., Bian, G., Cui, Y., & Wang, M. (2024). Sample Augmentation Method for Side-Scan Sonar Underwater Target Images Based on CBL-sinGAN. Journal of Marine Science and Engineering, 12(3), 467. https://doi.org/10.3390/jmse12030467