
Underwater-Yolo: Underwater Object Detection Network with Dilated Deformable Convolutions and Dual-Branch Occlusion Attention Mechanism

 , , ,
, , ,
Abstract
1. Introduction
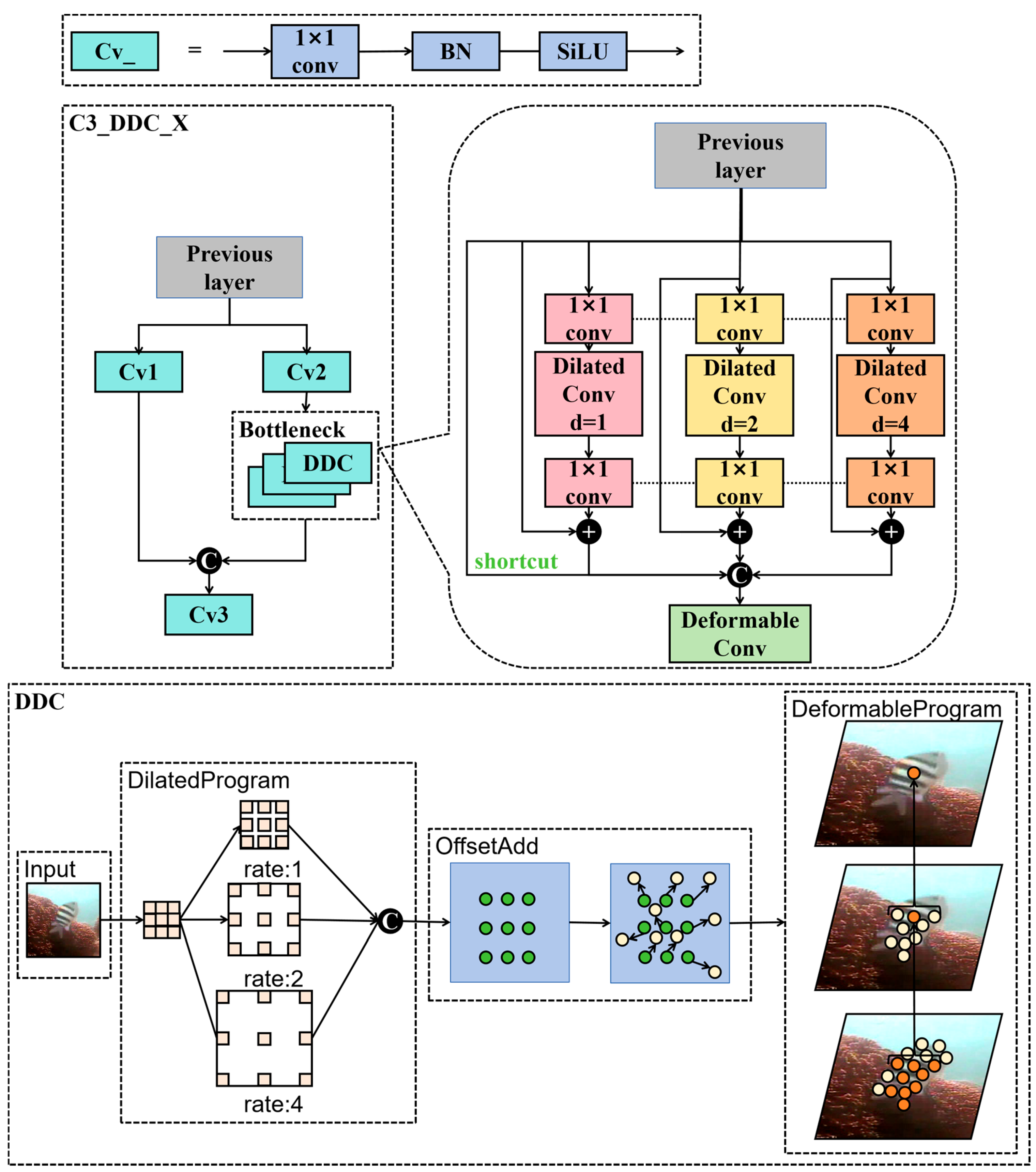
- Novel backbone network design: This study introduces a new backbone network that employs scalable deformable convolutions as the primary feature extraction layer. Compared with existing state-of-the-art single-stage networks, this design increases the receptive field without adding computational overhead, enabling the network to detect objects of varying scales and flexibly adapt to changes in object shape and position. This improves detection accuracy, particularly for unstructured and irregular targets.
- Dual-branch occlusion-handling attention mechanism (GLOAM): To improve the detection of densely packed targets, the GLOAM module combines global feature extraction (using the Vision Transformer) and local feature extraction (via a depthwise–pointwise convolutional architecture) for powerful local feature extraction. The dual-branch attention mechanism assigns appropriate weights to both global and local components, effectively handling the relationship between objects and their background while enhancing the detection of occluded objects.
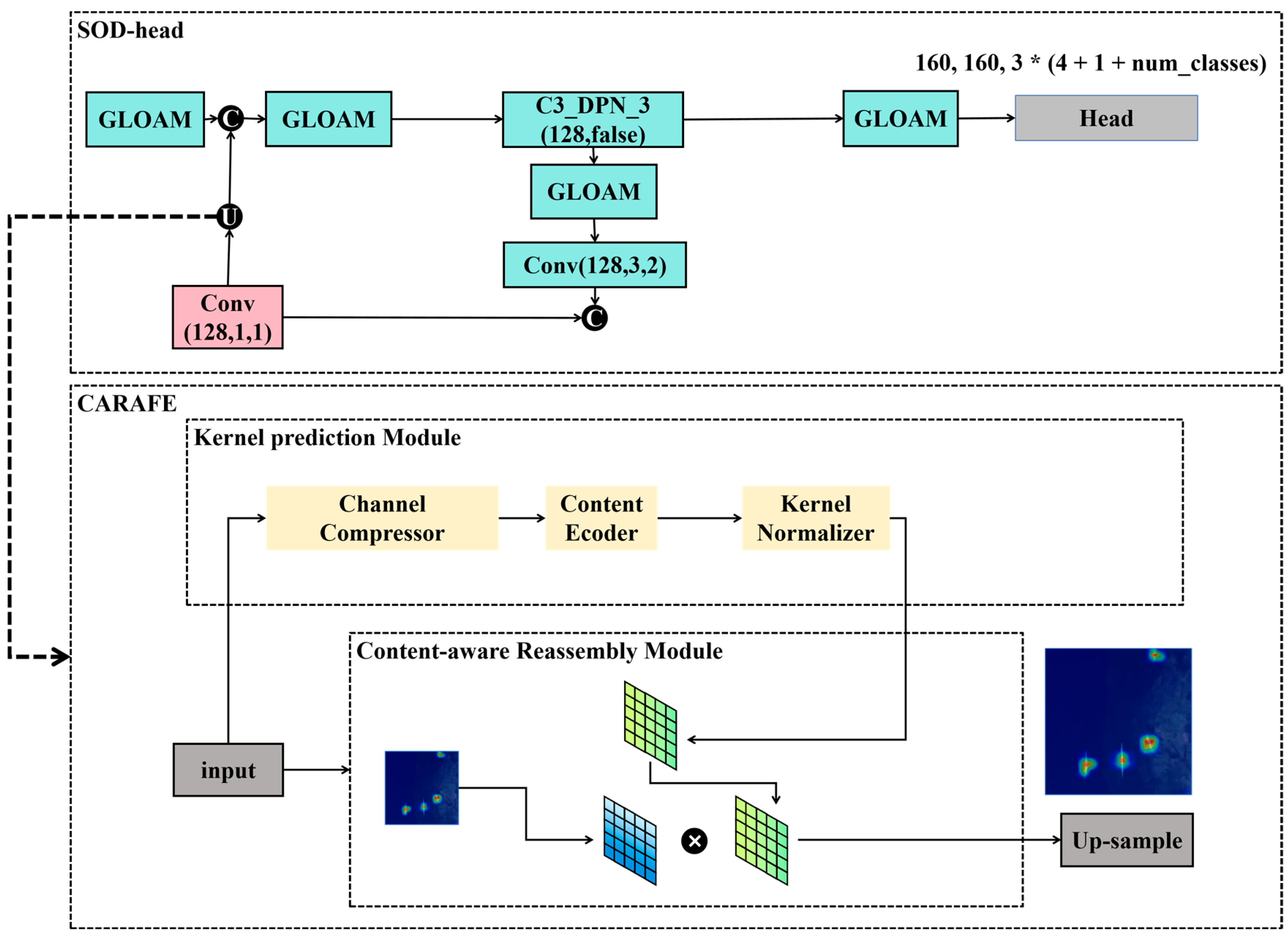
- Enhanced feature utilization with CARAFE up-sampling and Small-Object Detection Layer: To maximize the use of feature outputs from the backbone network and reduce information loss, the CARAFE up-sampling module is integrated into the detection network, enriching semantic information. Additionally, a specialized Small-Object Detection head (SOD-layer) is constructed, leveraging the GLOAM module to enhance the detection of densely clustered small targets.
2. Related Work
2.1. Common Underwater Object Detection
2.2. Underwater Small-Target Detection
2.3. Detection of Densely Occluded Underwater Targets
2.4. Literature Analysis
- Limited receptive field and adaptability: The relatively small receptive fields of convolutional kernels in existing algorithms constrain their ability to adapt to variations in target shape and position. This limitation significantly reduces their effectiveness in detecting objects in complex underwater environments, where targets can vary widely in scale and form.
- Insufficient feature extraction capability: Current algorithms struggle to effectively capture both global and local features, resulting in suboptimal performance, especially in multi-scale target detection. This issue is particularly pronounced when dealing with small or densely packed objects, as these models often fail to fully exploit the information available in feature layers, leading to inaccuracies in detection.
- Ineffective attention mechanisms: Existing attention mechanisms face substantial difficulties in distinguishing densely packed targets, complex shapes, and unstructured environments. In clusters of densely packed objects, visual overlap often occurs, making it hard for the model to focus on individual targets. For objects with intricate shapes, current mechanisms often fail to capture the full range of shape diversity, reducing recognition accuracy. Additionally, in unstructured environments, such as natural underwater scenes, the models struggle to differentiate targets from complex and dynamic backgrounds, further complicating detection tasks.
3. Proposed Method
3.1. Overall Structure of Underwater-Yolo
3.2. Dilated Deformable Convolution
3.3. Dual-Branch Occlusion Attention Mechanism
3.4. SOD-Layer
3.5. Anchor Point Selection Strategy
4. Experiment
4.1. Experimental Setup
4.1.1. Implementation Details
4.1.2. Datasets
- (1)
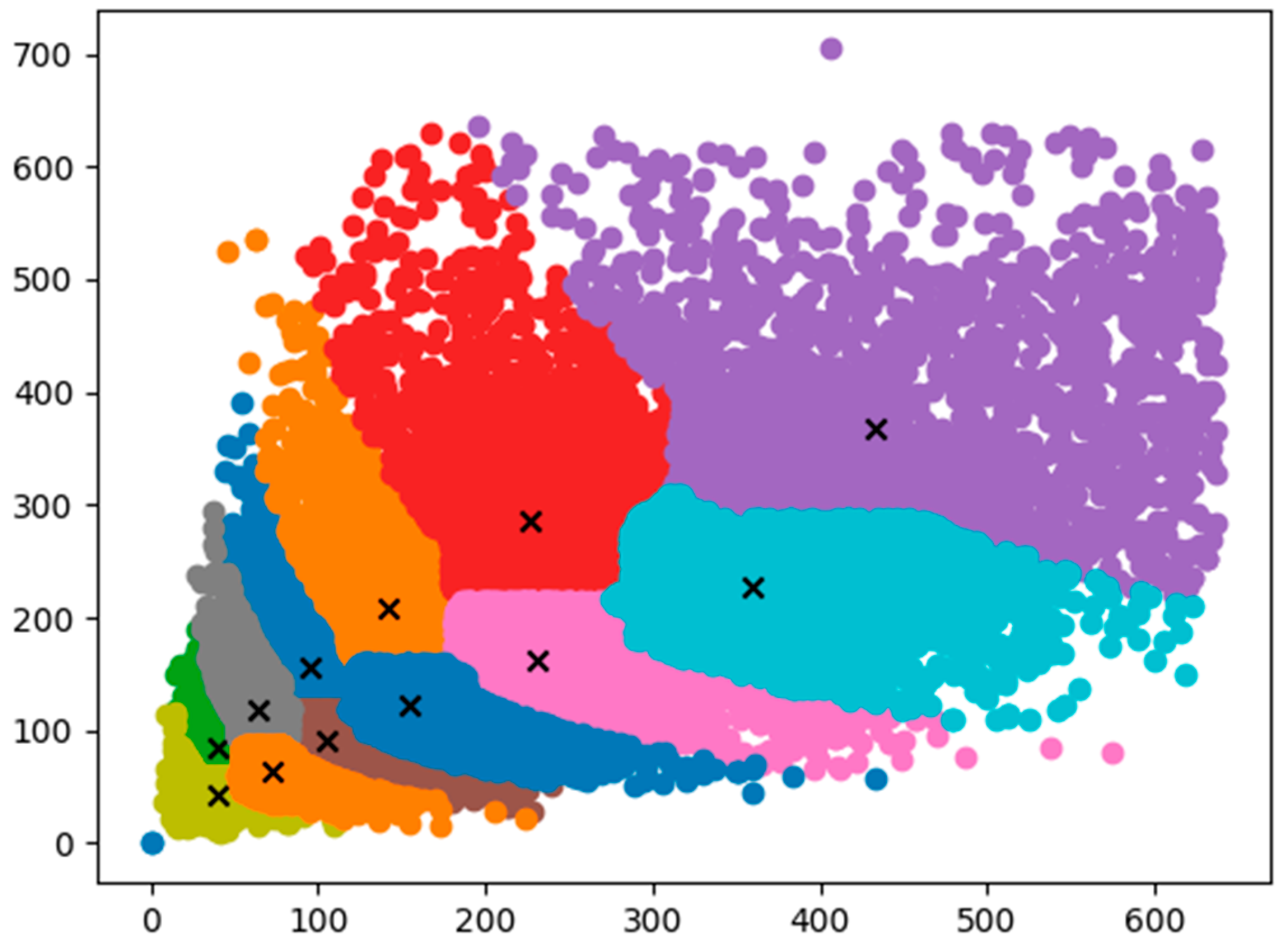
- Definition of density feature of target
- (2)
- Definition of small feature of target
4.2. Comparison of Heatmaps Between CSP-DDC and Other Backbone Networks
4.3. Visual Comparison of Underwater-YOLO
4.4. Limitation Experiments
4.5. Ablation Experiments
- CSP-DDC is specifically designed for detecting unstructured small targets, enhancing the model’s ability to detect these small targets by improving its receptive field.
- GLOAM primarily addresses occlusion issues between targets in dense scenes, aiding the model in more accurately identifying and localizing targets in complex environments.
- The SOD-layer is a feature extraction layer tailored for small targets, specifically aimed at enhancing the model’s recognition capabilities for small-sized objects.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Er, M.J.; Chen, J.; Zhang, Y.; Gao, W. Research challenges, recent advances, and popular datasets in deep learning-based underwater marine object detection: A review. Sensors 2023, 23, 1990. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Fang, X.; Pan, M.; Yuan, L.; Zhang, Y.; Yuan, M.; Lv, S.; Yu, H. A marine organism detection framework based on the joint optimization of image enhancement and object detection. Sensors 2021, 21, 7205. [Google Scholar] [CrossRef] [PubMed]
- Peng, F.; Miao, Z.; Li, F.; Li, Z. S-FPN: A shortcut feature pyramid network for sea cucumber detection in underwater images. Expert Syst. Appl. 2021, 182, 115306. [Google Scholar] [CrossRef]
- Shi, P.; Xu, X.; Ni, J.; Xin, Y.; Huang, W.; Han, S. Underwater biological detection algorithm Based on improved faster-RCNN. Water 2021, 13, 2420. [Google Scholar] [CrossRef]
- Chen, J.; Er, M.J.; Zhang, Y.; Gao, W.; Wu, J. Novel dynamic feature fusion stragegy for detection of small underwater marine object. In Proceedings of the 2022 5th International Conference on Intelligent Autonomous Systems (ICoIAS), Dalian, China, 23–25 September 2022; pp. 24–30. [Google Scholar]
- Yu, Y.; Zhao, J.; Gong, Q.; Huang, C.; Zheng, G.; Ma, J. Real-time underwater maritime object detection in side-scan sonar images based on transformer-YOLOv5. Remote Sens. 2021, 13, 3555. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight underwater object detection based on yolo v4 and multi-scale attentional feature fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Gao, J.; Zhang, Y.; Geng, X.; Tang, H.; Bhatti, U.A. PE-Transformer: Path enhanced transformer for improving underwater object detection. Expert Syst. Appl. 2024, 246, 123253. [Google Scholar] [CrossRef]
- Chen, D.; Gou, G. SFDet: Spatial to frequency attention for small-object detection in underwater images. J. Electron. Imaging 2024, 33, 023057. [Google Scholar] [CrossRef]
- Li, X.; Yu, H.; Chen, H. Multi-scale aggregation feature pyramid with cornerness for underwater object detection. Vis. Comput. 2024, 40, 1299–1310. [Google Scholar] [CrossRef]
- Qu, S.; Cui, C.; Duan, J.; Lu, Y.; Pang, Z. Underwater small target detection under YOLOv8-LA model. Sci. Rep. 2024, 14, 16108. [Google Scholar] [CrossRef]
- Chen, G.; Mao, Z.; Wang, K.; Shen, J. HTDet: A hybrid transformer-based approach for underwater small object detection. Remote Sens. 2023, 15, 1076. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, W.; Du, X.; Yan, Z. Underwater small target detection based on yolox combined with mobilevit and double coordinate attention. J. Mar. Sci. Eng. 2023, 11, 1178. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, F.; Wang, S.; Dong, J.; Li, N.; Ma, H.; Wang, X.; Zhou, H. SWIPENET: Object detection in noisy underwater scenes. Pattern Recognit. 2022, 132, 108926. [Google Scholar] [CrossRef]
- Qi, S.; Du, J.; Wu, M.; Yi, H.; Tang, L.; Qian, T.; Wang, X. Underwater small target detection based on deformable convolutional pyramid. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 7–13 May 2022; pp. 2784–2788. [Google Scholar]
- Ji, X.; Chen, S.; Hao, L.-Y.; Zhou, J.; Chen, L. FBDPN: CNN-Transformer hybrid feature boosting and differential pyramid network for underwater object detection. Expert Syst. Appl. 2024, 256, 124978. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y.; Wang, J.; Li, Y. An Underwater Dense Small Object Detection Model Based on YOLOv5-CFDSDSE. Electronics 2023, 12, 3231. [Google Scholar] [CrossRef]
- Xu, X.; Liu, Y.; Lyu, L.; Yan, P.; Zhang, J. MAD-YOLO: A quantitative detection algorithm for dense small-scale marine benthos. Ecol. Inform. 2023, 75, 102022. [Google Scholar] [CrossRef]
- Liu, K.; Peng, L.; Tang, S. Underwater object detection using TC-YOLO with attention mechanisms. Sensors 2023, 23, 2567. [Google Scholar] [CrossRef]
- Li, J.; Liu, C.; Lu, X.; Wu, B. CME-YOLOv5: An efficient object detection network for densely spaced fish and small targets. Water 2022, 14, 2412. [Google Scholar] [CrossRef]
- Mathias, A.; Dhanalakshmi, S.; Kumar, R. Occlusion aware underwater object tracking using hybrid adaptive deep SORT-YOLOv3 approach. Multimed. Tools Appl. 2022, 81, 44109–44121. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13029–13038. [Google Scholar]
- Li, J.; Wang, C.; Huang, B.; Zhou, Z. ConvNeXt-backbone HoVerNet for nuclei segmentation and classification. arXiv 2022, arXiv:2202.13560. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zheng, G.; Songtao, L.; Feng, W.; Zeming, L.; Jian, S. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Author | Algorithm | Limitations |
|---|---|---|---|
| Common underwater object detection | Shi, P. et al. (2021) [4] | Faster-RCNN algorithm for underwater detection, utilizing ResNet, BiFPN, EIoU, and K-means++ for better feature extraction and scale integration. | Challenges in detecting small and densely packed organisms, as well as handling occlusion, due to the inherent limitations of the IoU-based bounding-box and anchor generation techniques. |
| Zhang, M et al. (2021) [7] | Lightweight underwater object detection method based on MobileNet v2, YOLOv4, and attentional feature fusion (AFFM). | Struggles with small-target detection and occlusion due to limited feature extraction for densely packed targets. | |
| Underwater small-target detection | Gao, J. et al. (2024) [8] | Path-augmented Transformer detection framework enhances semantic details of small-scale underwater targets. | Struggles with densely occluded underwater objects, lacking robust feature selection in cluttered scenes. |
| Chen, D. et al. (2024) [9] | SFDet employs a spatial-to-frequency domain attention mechanism optimized for small-object detection in underwater images. | Struggles with dense occlusion handling due to the focus on spatial and frequency domains. | |
| Li, X. et al. (2024) [10] | Multi-scale aggregation feature pyramid with cornerness for enhanced detection and recall of small underwater objects. | Struggles with dense occlusion, possibly due to limited contextual integration between closely packed targets. | |
| Qu, S. et al. (2024) [11] | YOLOv8-LA with LEPC module, AP-FasterNet, and CARAFE up-sampling. | Struggles with densely occluded targets despite improvements, due to the inherent challenges of detecting small, closely spaced underwater objects. | |
| Chen, G. et al. (2023) [12] | HTDet introduces a hybrid Transformer-based network with a fine-grained feature pyramid and test-time augmentation for efficient small-object detection underwater. | The model struggles with dense occlusions in dynamic marine environments due to the complex nature of underwater imagery. | |
| Sun, Y. et al. (2023) [13] | Underwater target detection model using MobileViT, YOLOX, and a new double-coordinate attention (DCA) mechanism to enhance feature extraction and improve detection accuracy. | The model still faces challenges in dense occlusion scenarios where small targets are easily lost due to complex underwater conditions. | |
| Chen, L. et al. (2022) [14] | SWIPENET with Curriculum Multi-Class Adaboost (CMA) targets underwater object detection, enhancing small-object detection and noise robustness. | The approach may struggle in environments with densely occluded targets, where distinguishing between overlapping objects and noisy backgrounds remains challenging. | |
| Qi, S. et al. (2022) [15] | The proposed Underwater Small-Target Detection (USTD) network employs a Deformable Convolutional Pyramid (DCP) and Phased Learning for domain generalization. | Struggles with highly occlusive environments and managing diverse, dense underwater scenarios without further adaptation. | |
| Detection of densely occluded underwater targets | Ji, X. et al. (2024) [16] | FBDPN employs a CNN–Transformer hybrid, enhancing feature interaction across scales for better underwater object detection. | Struggles with handling unstructured small targets due to limited refinement between closely spaced multi-scale features. |
| Wang, J. et al. (2023) [17] | YOLOv5-FCDSDSE, enhanced with CFnet structure, Dyhead technology, a small-object detection layer, and SE attention mechanism for optimized underwater object detection. | Struggles with highly unstructured environments despite improvements in scale, space, and task perception. | |
| Xu, X. et al. (2023) [18] | MAD-YOLO, an enhanced YOLOv5 with VOVDarkNet for feature extraction, AFC-PAN for feature fusion, and SimOTA for improved occlusion handling. | While effective for blurred, dense, and small-scale objects, it may struggle with extremely noisy underwater conditions or highly complex occlusions. | |
| Liu, K. et al. (2023) [19] | TC-YOLO network combines YOLOv5s with Transformer self-attention, adaptive histogram equalization, and optimal transport label assignment for underwater object detection. | Potential limitations in handling unstructured small targets due to complex underwater imaging conditions and inherent algorithm constraints. | |
| Li, J. et al. (2022) [20] | An improved CME-YOLOv5 network integrates the coordinate attention mechanism and the C3CA module with expanded detection layers and the EIOU loss function to enhance detection of densely spaced fish and small targets. | The model struggles with dynamic identification and accurate detection in highly unstructured underwater environments where occlusion and density vary significantly. | |
| Mathias, A. et al. (2022) [21] | Hybrid Adaptive DeepSORT-YOLOv3 (HADSYv3) combines YOLOv3 for detection and adaptive deep SORT with LSTM for tracking occluded underwater objects. | Struggles with highly unstructured small targets due to reliance on fixed-size anchor boxes in YOLOv3 and potential scale variations. |
| Tiny | Small | Medium | Large |
|---|---|---|---|
| [39.67, 42.67] | [64.00, 118.52] | [154.00, 121.48] | [226.00, 286.22] |
| [40.67, 84.74] | [105.67, 90.07] | [141.67, 209.19] | [360.00, 226.37] |
| [72.00, 64.00] | [95.33, 157.04] | [231.00, 162.96] | [432.94, 368.59] |
| Light Intensity | Transparency | Depth of Field | |
|---|---|---|---|
| Min | 21 | 1.0 | 0.38 |
| Max | 210 | 1.0 | 555 |
| Mean | 101 | 1.0 | 24 |
| CSP-Darknet | Conv-Next-Small | Swim-Transformer-Tiny | CSP-DDC | |
|---|---|---|---|---|
| AP50 | 0.736 | 0.808 | 0.849 | 0.863 |
| AP75 | 0.506 | 0.578 | 0.625 | 0.653 |
| FLOPs | 79.963 G | 148.994 G | 79.914 G | 24.086 G |
| Parameter | 31.425 M | 53.039 M | 31.122 M | 8.706 M |
| YoloX-s | YoloV8-s | YoloV10-s | Resnet101+ DETR | Resnet101+ RT-DETR | Underwater-Yolo | |
|---|---|---|---|---|---|---|
| AP50 | 0.647 | 0.841 | 0.869 | 0.864 | 0.891 | 0.938 |
| AP75 | 0.566 | 0.605 | 0.629 | 0.649 | 0.722 | 0.889 |
| AP-small | 0.571 | 0.542 | 0.650 | 0.654 | 0.704 | 0.764 |
| FLOPs | 26.92 G | 28.853 G | 21.6 G | 208.95 G | 259.60 G | 26.858 G |
| Parameter | 8.968 M | 11.173 M | 7.2 M | 55.704 M | 76.12 M | 9.815 M |
| Resnet101+ DETR | Resnet101+ RT-DETR | Underwater-Yolo | |
|---|---|---|---|
| FLOPs | 208.95 G | 259.60 G | 26.858 G |
| Parameter | 55.704 M | 76.12 M | 9.815 M |
| FPS | 30 | 74 | 64 |
| GPU rate | 560.45 MB | 660.15 MB | 214.53 MB |
| Underwater-Yolo | CLfish-V1 | |||||
|---|---|---|---|---|---|---|
| Name | CSP-DDC | GLOAM | SOD-Layer | AP50↑ | AP75↑ | AP-small↑ |
| 3 | √ | √ | √ | 0.938 | 0.889 | 0.764 |
| 2 | × | √ | √ | 0.922 | 0.868 | 0.744 |
| 1 | × | × | √ | 0.888 | 0.826 | 0.709 |
| Baseline | × | × | × | 0.647 | 0.566 | 0.571 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zheng, B.; Chao, D.; Zhu, W.; Li, H.; Duan, J.; Zhang, X.; Zhang, Z.; Fu, W.; Zhang, Y. Underwater-Yolo: Underwater Object Detection Network with Dilated Deformable Convolutions and Dual-Branch Occlusion Attention Mechanism. J. Mar. Sci. Eng. 2024, 12, 2291. https://doi.org/10.3390/jmse12122291
Li Z, Zheng B, Chao D, Zhu W, Li H, Duan J, Zhang X, Zhang Z, Fu W, Zhang Y. Underwater-Yolo: Underwater Object Detection Network with Dilated Deformable Convolutions and Dual-Branch Occlusion Attention Mechanism. Journal of Marine Science and Engineering. 2024; 12(12):2291. https://doi.org/10.3390/jmse12122291
Chicago/Turabian StyleLi, Zhenming, Bing Zheng, Dong Chao, Wenbo Zhu, Haibing Li, Jin Duan, Xinming Zhang, Zhongbo Zhang, Weijie Fu, and Yunzhi Zhang. 2024. "Underwater-Yolo: Underwater Object Detection Network with Dilated Deformable Convolutions and Dual-Branch Occlusion Attention Mechanism" Journal of Marine Science and Engineering 12, no. 12: 2291. https://doi.org/10.3390/jmse12122291
APA StyleLi, Z., Zheng, B., Chao, D., Zhu, W., Li, H., Duan, J., Zhang, X., Zhang, Z., Fu, W., & Zhang, Y. (2024). Underwater-Yolo: Underwater Object Detection Network with Dilated Deformable Convolutions and Dual-Branch Occlusion Attention Mechanism. Journal of Marine Science and Engineering, 12(12), 2291. https://doi.org/10.3390/jmse12122291