1. Introduction
As marine exploration develops, AUVs are being used for a variety of tasks, including marine surveys, demining, and bathymetry data collection in marine and riverine environments [
1]. AUV trajectory tracking control is a prerequisite for achieving most advanced tasks. However, the actual operating scenarios of AUVs are usually complex, diverse, and unpredictable. The tracking controller will be affected by highly nonlinear vehicle dynamics and external time-varying disturbances. These effects make the dynamics of an AUV difficult to measure or difficult to measure in the underwater environments being investigated, causing various uncertainties [
2]. Therefore, designing a robust AUV tracking controller is a meaningful and challenging problem.
In previous studies, model-based control methods have been widely adopted due to their intuitiveness and reliability. Yang et al. combined neural networks and AUV control to realize AUV adaptive terminal sliding mode trajectory tracking [
3]. The work of Khodayari et al. [
4] combined fuzzy control and a PID controller; used Mamdani fuzzy rules to adjust PID parameters; and applied this to speed, depth, and heading control. Liang et al. [
5] proposed an adaptive robust control system using backstepping and sliding mode control, realizing AUV three-dimensional path tracking under the conditions of parameter uncertainty and external interference. Zhang et al. transformed the tracking control problem into a standard convex quadratic programming problem that is easy to calculate online, and designed a tracking controller based on the model predictive control (MPC) method. Simulations were conducted under two different three-dimensional trajectories to verify the feasibility and robustness of the algorithm. The design of the above method relies on accurate AUV dynamic and kinematic models. The control performance depends on the accuracy of the model. When there are errors in the model, the control performance will significantly decrease.
In recent years, deep reinforcement learning (DRL) [
6], as an emerging method for solving optimal control problems for nonlinear systems, has shown great potential for a variety of robot control tasks, such as underwater robots and unmanned aerial vehicles. Compared with traditional controllers, DRL has less precise requirements for system modeling, and the controller converges through interaction with and exploration of the environment. Wu et al. [
7] proposed a DRL controller based on the deterministic policy gradient theorem, which showed better results than nonlinear model predictive control (NMPC) and linear quadratic Gaussian (LQG) methods in experiments. Sun et al. [
8] designed a three-dimensional path tracking controller based on the deep deterministic policy gradient (DDPG) algorithm, and effectively reduced the steering frequency by using the rudder angle and its change rate as new terms in the reward function. Furthermore, in order to enable the controller to observe ocean current disturbances and adjust output, an ocean current disturbance observer was proposed. Du et al. [
9] proposed a DRL control strategy based on a reference model, introducing a reference model into the actor–critic structure to provide a smoothed reference target for the DRL model, giving the controller improved robustness, while eliminating response overshoot and control command saturation. When training DRL-based reinforcement learning controllers, there may be sparse reward and local convergence issues. Mao et al. [
10] proposed a multi-agent GAIL (MAG) algorithm based on generative adversarial imitation, enabling AUVs to overcome the difficulty of slow initial training of a network. Shi et al. [
11] improved experience replay rules and used an experience replay buffer to store and destroy samples, so that time series samples could be used to train neural networks. Experimental results showed that the algorithm had a fast and stable learning effect. Palomeras et al. [
12] proposed an AUV control architecture and used an actor–critic reinforcement learning algorithm in the reaction layer. The AUV using this control structure successfully completed vision-based cable following in a real scenario. Meanwhile, Liu et al. [
13] modeled a pipeline following problem as an end-to-end mapping from an image to AUV velocity, and used proximal policy optimization (PPO) to train their network. However, most current DRL methods only conduct training in an ideal simulation environment, ignoring the dynamic differences between a training environment and a working environment. An AUV is a nonlinear time-varying system, and the underwater environment has a fluid force interferences that is difficult to model. Therefore, the performance of models trained in simulation environments often decreases in the real environments, which is called the “reality gap” [
14].
In order to close this gap, domain randomization has become a common approach, i.e., randomizing certain parameters of the training environment during training. For example, Peng et al. [
15] randomly selected several environmental parameters at the beginning of each round of training: connecting rod mass, joint damping, ice hockey mass, table height, etc. Andrychowicz et al. [
16] not only randomized the physical parameters in a simulation environment, but also modeled additional effects specific to the robotic arm and accelerated policy convergence through large-scale distributed training. Tan et al. [
17] believed that the information transmission delay that exists in reality but does not exist in a simulation is the reason for the oscillation of a simulation strategy in a real environment, and this delay was also simulated. The parameter range of the domain randomization method relies on artificial prior knowledge. The wider the parameter range, the more robust the strategy, and the worse the control performance; therefore, domain randomization is a compromise that trades optimality for robustness. Another common way to overcome the reality gap is to introduce context into a DRL model. Yu et al. [
18] utilized a fully connected network to map recent interaction history sequence data into model parameters, and used the network output as part of the DRL model input. Zhou et al. [
19] used an interaction strategy alone to interact with the environment to generate the most informative trajectory. Ball et al. [
20] defined context variables as the ratio of state changes and implemented online context learning through a simple linear model, allowing the algorithm to be generalized to environments with changing dynamics. Compared with domain randomization, context-based methods can achieve online adaptation to an environment, but parameters such as the scope of the training environment and the length of the context need to be measured experimentally to accurately represent the real environment. The model performance still relies on human priors. Rusu et al. [
21] proposed a progressive neural network (PNN), which uses a laterally connected network architecture to extract correlations between tasks, effectively improving the training efficiency while avoiding catastrophic forgetting, and applied it to a pixel-driven robot control problem [
22]. However, the number of parameters of the PNN increases as the amount of tasks increases, and it is suitable for migration tasks between a small number of static environment tasks in the field of robot control. Each of the above methods has certain drawbacks, and they have been little applied in the field of AUV control.
To solve the above problems, this study combines the context concept and a PNN structure with the DRL algorithm, takes the context generated by embedding networks as part of the input to the policy network, and performs two-stage training based on the PNN architecture, so that the proposed method has the dual advantages of robustness to disturbances and fast adaptation. The main contributions of this study are as follows.
Context is introduced into the DRL controller through embedding networks. In the decision-making process, the embedding networks map the interaction history sequences onto latent variables representing the context, thus taking the current environment information as part of the decision-making factors, which gives the model the ability to adapt to the environment online.
A PNN-based training architecture is formulated. The DRL model utilizes the PNN’s property of lateral connectivity to quickly adapt to new working environments and transfer between different dynamical environments.
Several experiments were designed to validate the performance of the proposed method. These included tracking experiments for step signals, robustness experiments for various external disturbances, and adaptability experiments where the dynamics were changed.
The rest of this paper is organized as follows:
Section 2 presents the mathematical equations for the kinematics and dynamics model of the AUV system and briefly introduces the PPO model;
Section 3 explains the structure and flow of the proposed algorithm;
Section 4 presents the results of testing the proposed method in various environments and comparing the results with the results of the other algorithms; and, finally,
Section 5 gives the conclusions and an outlook for the future.
3. Proposed Method
3.1. Context-Based Policy Architecture
Previous reinforcement-learning-based controllers have typically only used the error vector at the current time as the state [
27,
28]. However, this approach limits the model’s ability to effectively infer the trend of environmental changes, resulting in excellent control performance only in the dynamic of training environments.
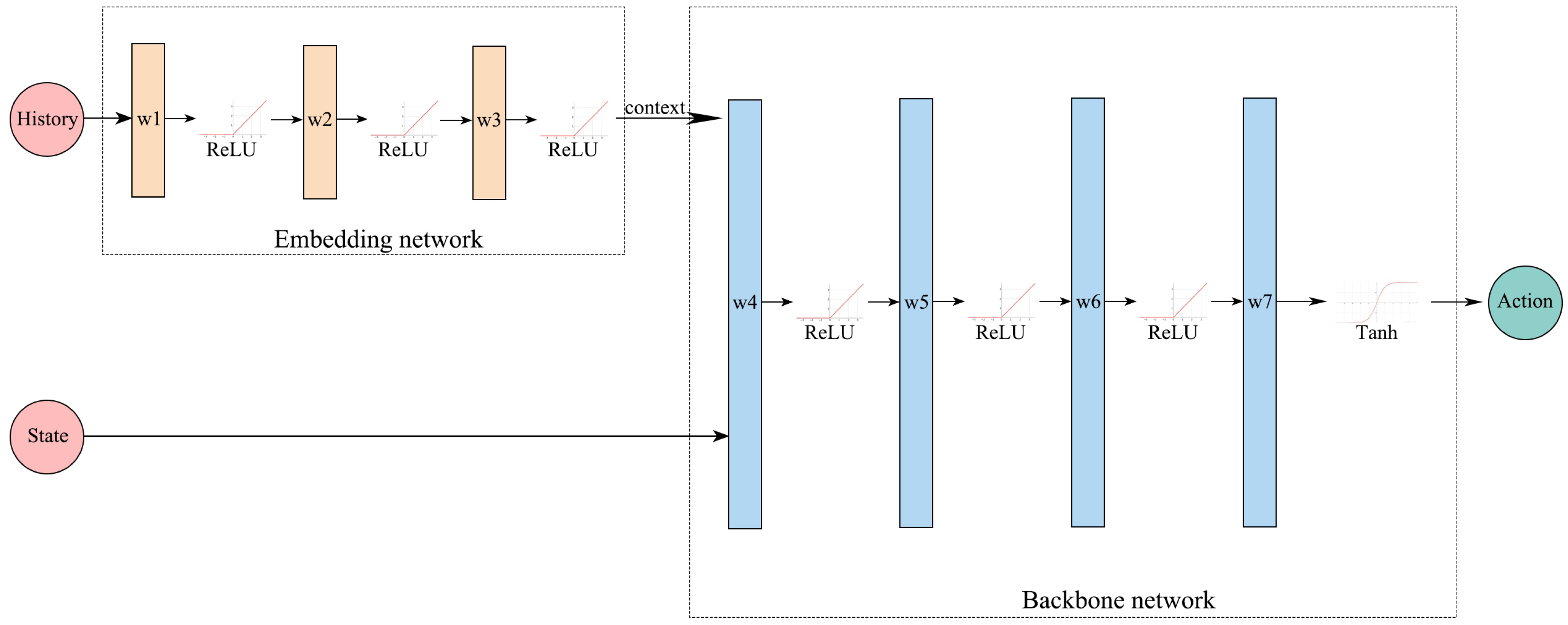
Figure 4 shows that in this research, an embedding network is articulated at the input of the policy network to introduce context into the PPO model. This embedding network implicitly maps the motion trajectory sequences to contextual variables, thus including environmental information as part of the decision-making factors. The design has two main advantages: (1) Firstly, the context generated by the embedding network enables the policy to adapt to the environment online. (2) The training of the embedding network is integrated with the backbone network and the training process is more efficient compared to the alternating optimization approach [
20].
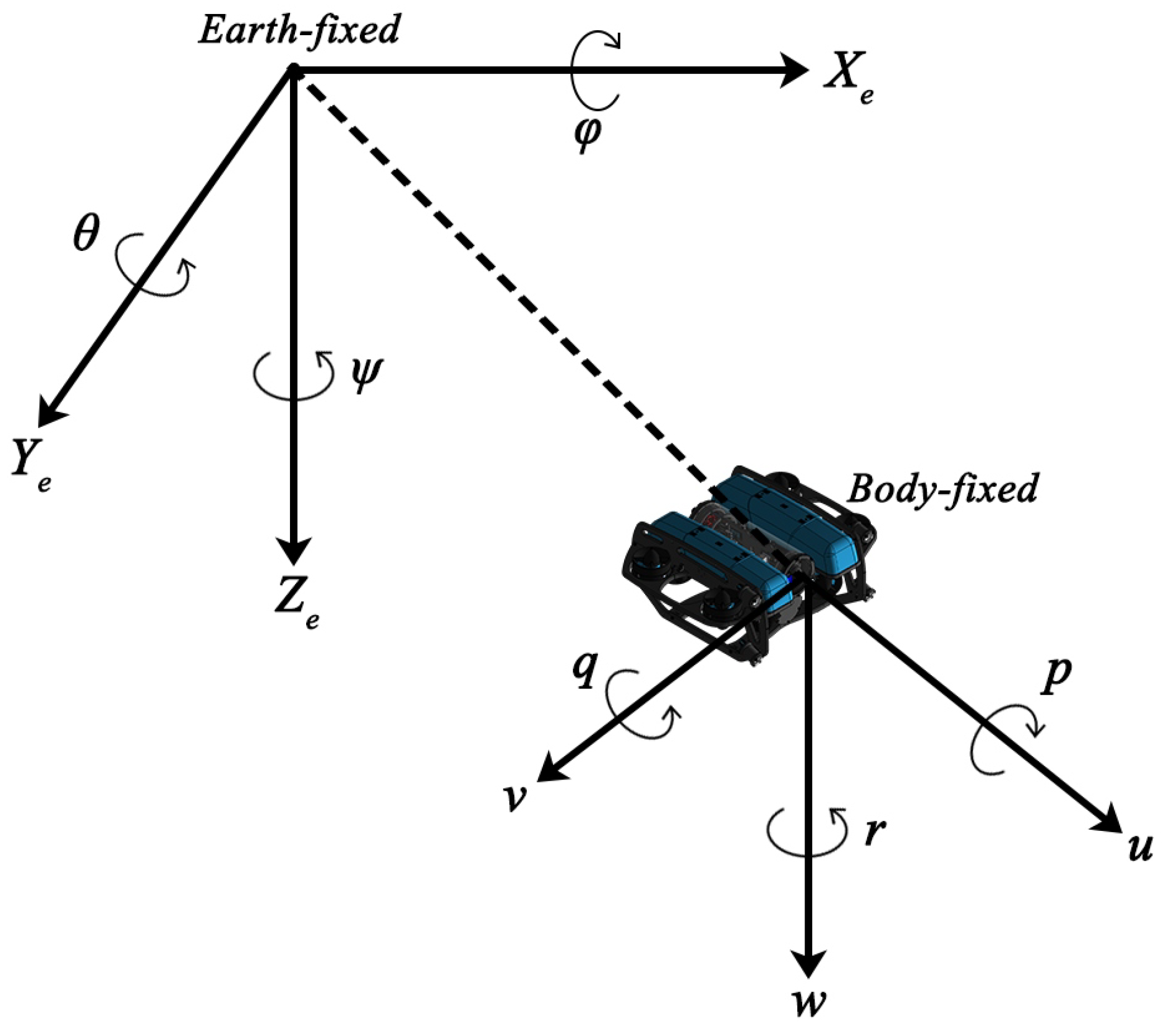
The input of the policy contains two parts, the current state vector
and the sequence of motion trajectory
History, where
is the state acquired by the AUV at the current moment
t. Based on the task definition in
Section 2.3,
,
and
are the position error and velocity in the direction of
and
, and
w and
v are the velocity in the direction of
and
, respectively. Since the AUV model in this research is intrinsically stable in roll and pitch, the tracking control of roll and pitch can be neglected [
29]. For a general torpedo body AUV, we propose to include angles in the state vector to describe the direction of the relative motion velocity. The motion track sequence
consists of a sequence of states and actions in past moments:
,
N is the size of window. The action
u is defined as the propulsive force received in the sway direction and the heave direction:
. The input dimension of the embedding network is
, while the input dimension of the policy network is
. The output dimension of the policy network is four, representing the mean and variance of the normal distributions of
Y and
Z. The critic network comprises three hidden layers that take the current state as input, and the output is a scalar value. Both the policy and the critic networks have 64 neurons in each hidden layer.
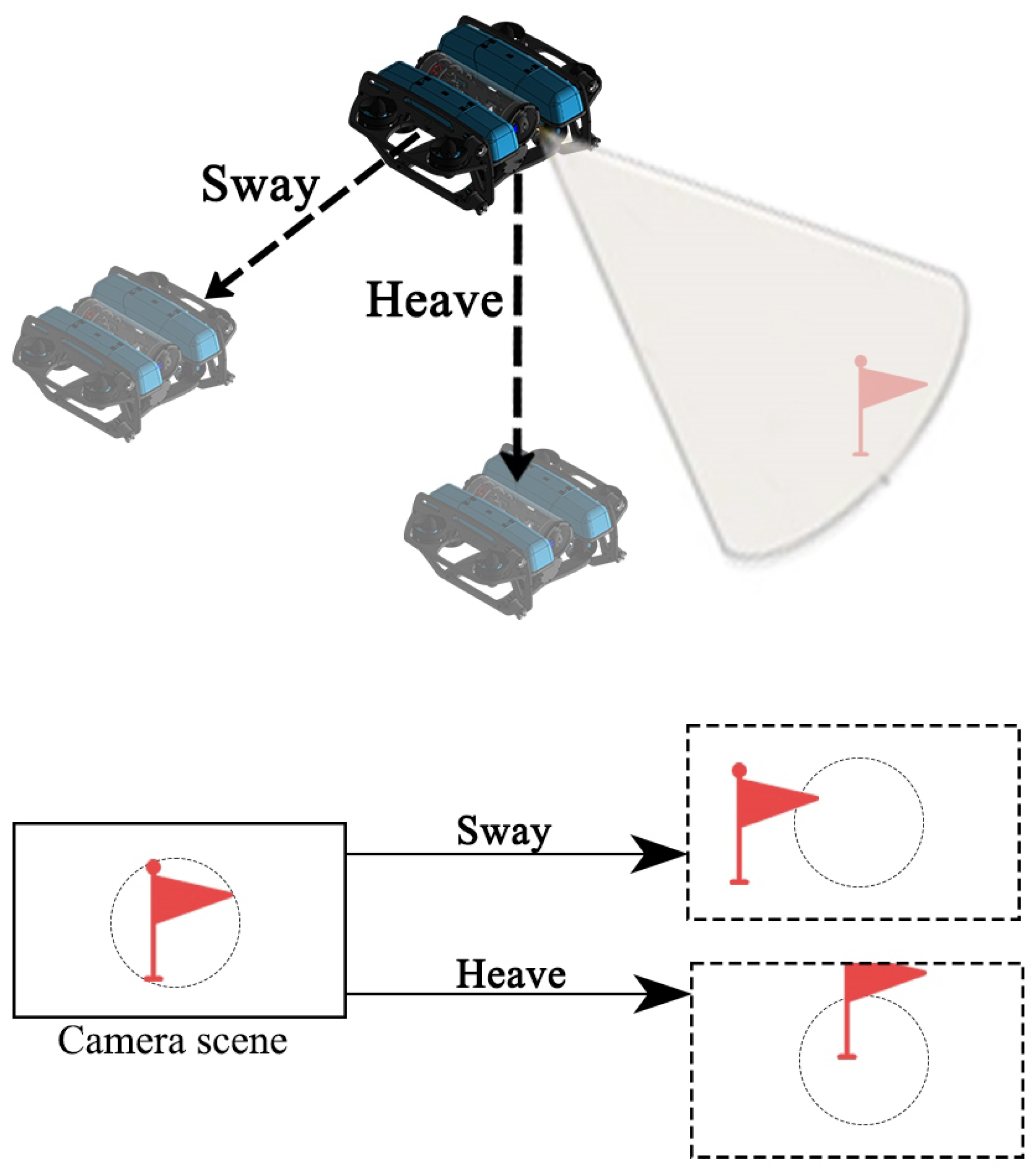
For the AUV target tracking task, not only the absolute error and response time of the system, but also the amount of overshooting and energy loss, should be considered. Therefore, the design reward function is mathematically expressed as follows:
The first term of the reward function is used to motivate the controller to reduce the error as quickly as possible to achieve a fast response to the position error. The second term motivates the controller to produce a smaller control amount to avoid overshooting, as well as to output limit values. and are scaling factors, which are used to adjust the weights of these two items.
For robot motion control, differences in dynamics resulting from modeling errors or external environmental forces can be represented as generalized forces
on the right-hand side of the dynamics equations. Valassakis et al. [
30] proposed the use of generalized forces to describe modeling errors, which have a better profile and manipulability than randomizing environmental parameters and performed better in experiments. Therefore, this study created diverse training environments by sampling generalized forces. Specifically, before the start of each episode,
and
were sampled twice from a uniform distribution:
,
, where
and
are the limit values of the sampling interval. As shown in
Figure 5, the two sampled values were connected by a folded line to form a generalized force function that varied during one episode. The aim of this design was to simulate sudden and gradual changes in dynamics, as well as maintaining constant dynamics in the training environment.
3.2. Progressive Network Training Mechanism
In order to build effective context mappings, i.e., to allow context information to characterize a wide variety of environments, it is first necessary to generate a large number of different training environments. A common approach is to use domain randomization, which generates environments randomly by sampling environmental parameters in a distribution [
19].
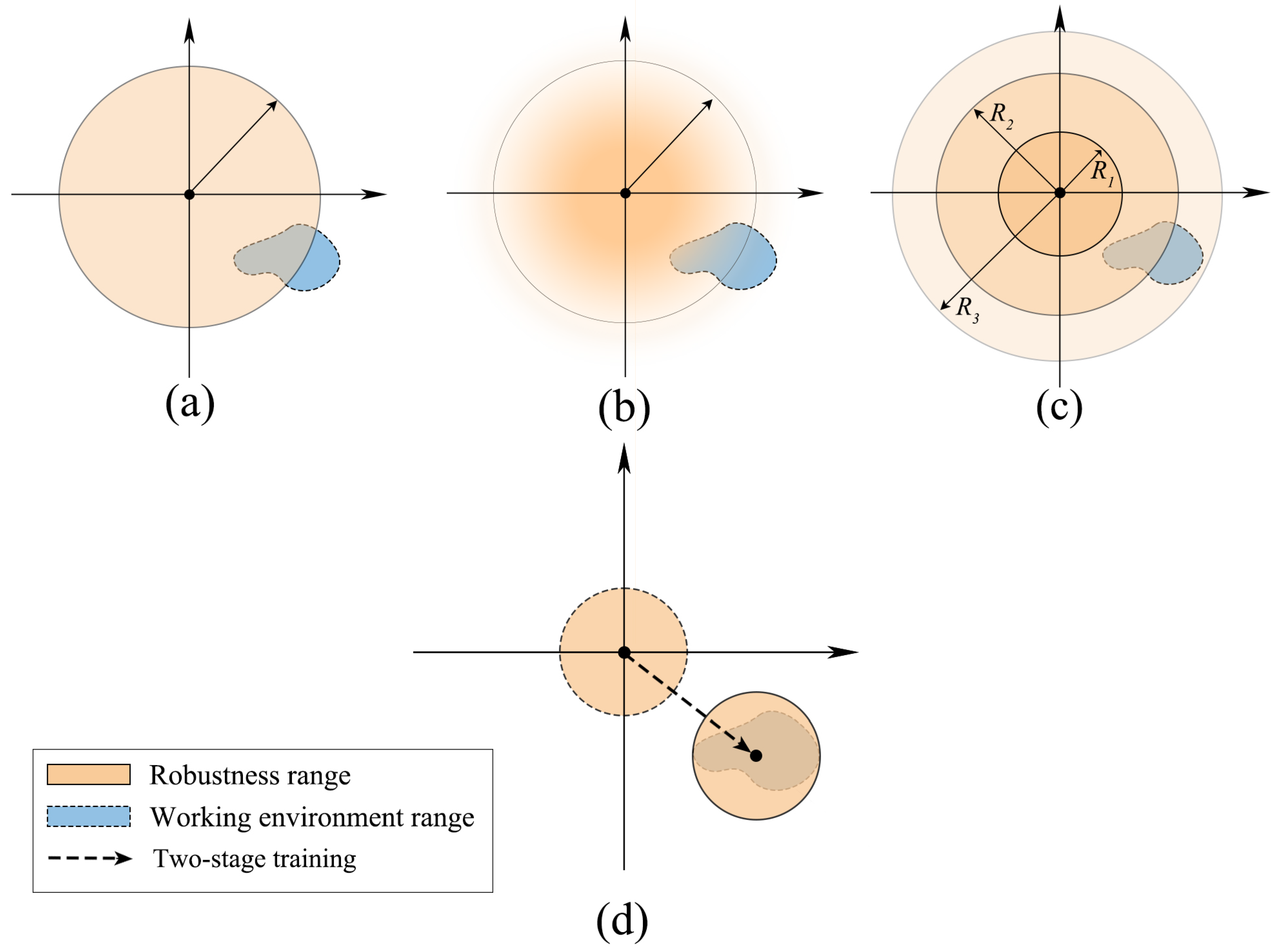
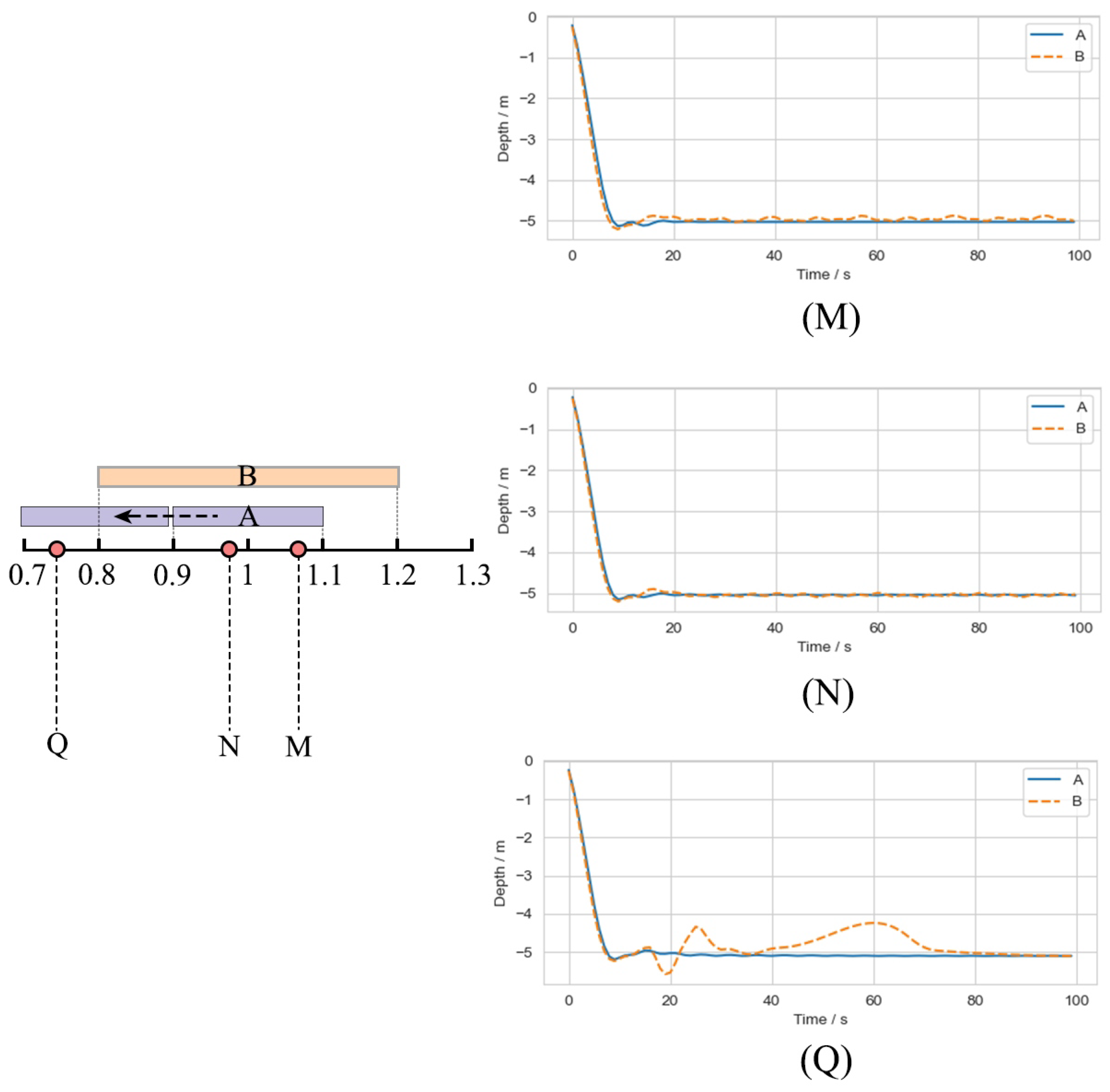
Figure 6 shows a hyperplane representing the range of dynamics, with the origin at the center of the training environment’s dynamics and the orange region indicating the model’s range of robustness. The darker the color, the better the control performance of the model. In general, the dynamics of a real working environment is not fixed but varies within a certain range, so the dynamics range of the working environment is a region rather than a point in
Figure 5.
Figure 6a,b show the effect of sampling from uniform and normal distributions, respectively. Sampling from a normal distribution will make the model fully trained near the center of the dynamics, while the effect of a uniform distribution is more average.
Figure 6c illustrates that a wider range of environments characterized by the context requires a larger training range to cover the unknown dynamics of the working environment, provided that the model size and the definition of the context remain the same. In order for the context mapping to cover the unknown dynamics of the working environment, a larger training range needs to be used, trading optimality for robustness.
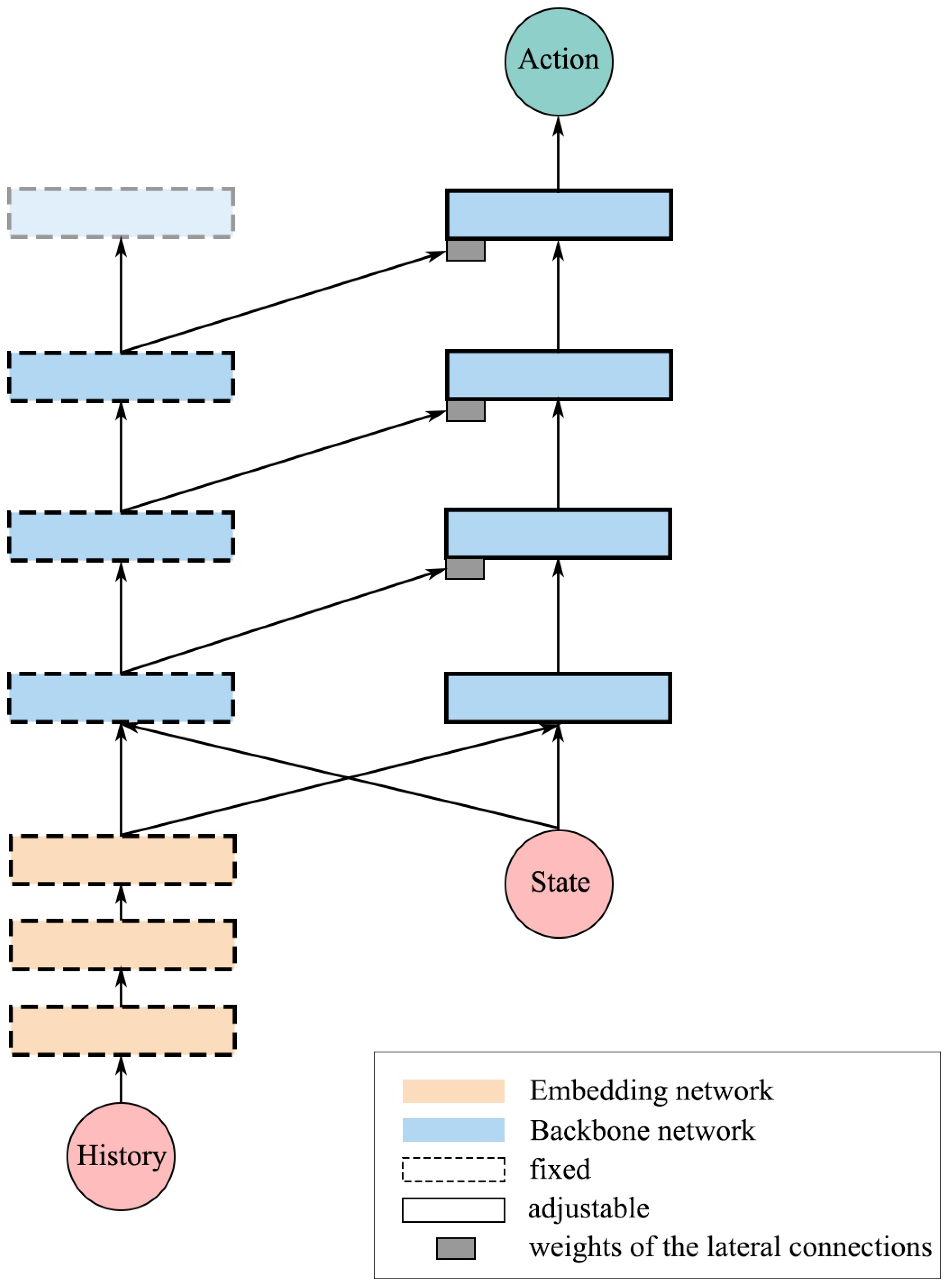
In order to solve the above problems, this study utilizes progressive neural networks to transfer the DRL model across various dynamics, as shown in
Figure 7. The model comprises two network columns, with the left column representing the trained network and the right column representing the network that is to be optimized in the working environment. When trained in a working environment, the parameters of the left column are fixed, and the right column receives outputs from the network layers of the left column through lateral connections. These lateral connections enable the right column to extract useful features from the left column, which are adapted to the training environment, thus accelerating the learning process. As mentioned earlier, the work environment can vary within a certain range, making it impractical to add new columns whenever the environment changes. Therefore, the parameters of the embedding network are directly copied and fixed to enable the model to adapt online to small disturbances in the work environment.
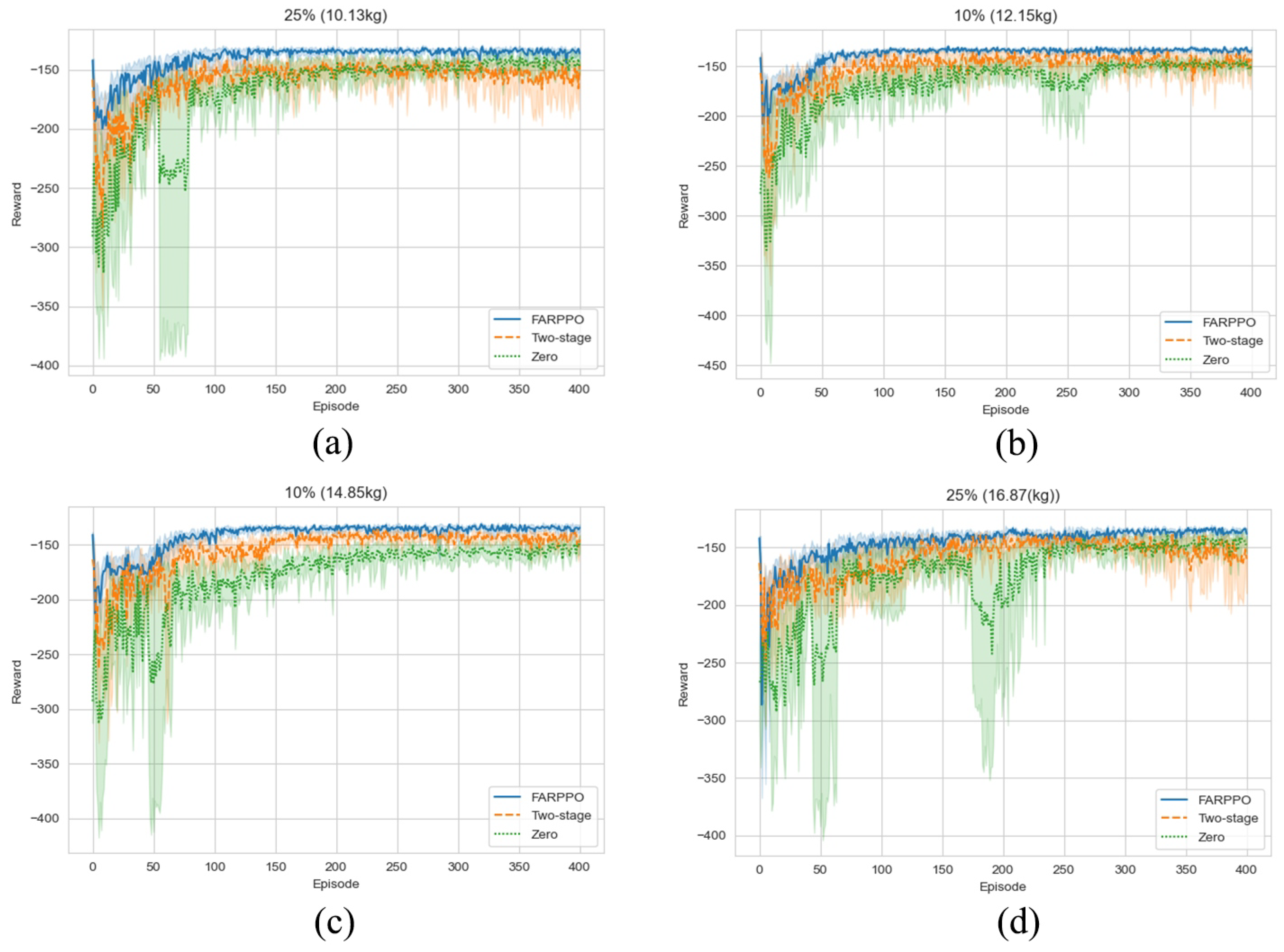
Figure 6d demonstrates that the two-stage training approach based on progressive network allows the model to transfer between very different dynamic environments, and the context-based policy architecture makes the model more robust to small perturbations.
3.3. Algorithm Process
A fast adaptive robust PPO (FARPPO) algorithm is proposed by combining a context-based policy architecture with a progressive network training mechanism. The training environment was created by uniformly sampling the generalized forces
and
, a process known as domain randomization. We first initialized and fully trained a policy
, then initialized a policy
and connected it laterally as shown in
Figure 7. Finally, we trained FARPPO to convergence in the working environment. Algorithm 1 gives the main steps involved in the above process.
| Algorithm 1: FARPPO for the target tracking of the AUV |
| | Input: initial critic network parameters ; initial policy networks parameters ,; initial reply buffer B; the limit value of the sampling interval , |
| | Output: FARPPO policy network |
| 1 | for episode = 1:M do |
| 2 | | Sample environment from and |
| 3 | | Collect transitions from and store in B |
| 4 | | if B is full then |
| 5 | | | Compute GAE based on the current Value function |
| 6 | | | for Reuse_times = 1:N do |
| 7 | | | | Update policy network: |
| 8 | | | | Update critic network: |
| 9 | | | end |
| 10 | | | clear B |
| 11 | | end |
| 12 | end |
| 13 | Connect the two policy networks laterally as FARPPO according to Figure 7 |
| 14 | Frozen , initializes , clear B |
| 15 | Deploy FARPPO to the work environment |
| 16 | while not converged do |
| 17 | | Collect transitions from and store in B |
| 18 | | if B is full then |
| 19 | | | Compute GAE based on the current Value function |
| 20 | | | for Reuse_times = 1:N do |
| 21 | | | | Update policy network: |
| 22 | | | | Update critic network: |
| 23 | | | end |
| 24 | | end |
| 25 | end |
| 26 | return |
3.4. Computational Complexity Analysis
We analyzed the time computational complexity of the FARPPO algorithm using big O notation denoted by .
Initialize the network parameters, such that the number of each network parameter is N. The time complexity required for initialization is . In the main loop, the key steps include environment sampling, data collection and storage, updating the policy and critic network, and emptying the cache area, such that the number of iterations of the main loop is M and the state dimension is S. The time complexity required for a single main loop is , this can be simplified as , so the overall time complexity is ; the time complexity of the policy network combination and parameter freezing part is , in the training phase, the main loop is trained continuously until convergence, each time. The key steps include the environmental interaction and the experience of the reuse and updating, so that the convergence and the number of iterations required is T, and then the time complexity is . Synthesizing the above analysis, the total time complexity of the whole algorithm is , This can be simplified as . where N: number of network parameters; S: dimensions of the state space; M: number of iterations in training phase 1; T: number of iterations required for convergence in the deployment phase.
The space complexity is mainly related to the number of network parameters and the size of the experience playback buffer, and when the number of network parameters in the assumption above is N, then the complexity is . Let the buffer size be set to B, assuming that the storage of state, action, reward, and other information requires space , where A is the dimension of the action space, so the space complexity is . The overall space complexity is . This indicates that the proposed algorithm is capable of being implemented in real-time operations.
The FARPPO algorithm involves multiple policy and value network update operations, especially internal nested loops, which increase the stability of the policy and the accuracy of the decision but also imply a high computational load. In order to prevent a combinatorial explosion from causing difficulties in solving the problem, we recommend that the number of state network parameters (N) be kept within the thousand-digit range, and that the number of state-space dimensions (S), the number of iterations in the training phase1 (M), and the number of iterations required for convergence in the deployment phase (T) be kept within the hundred-digit range.
5. Conclusions
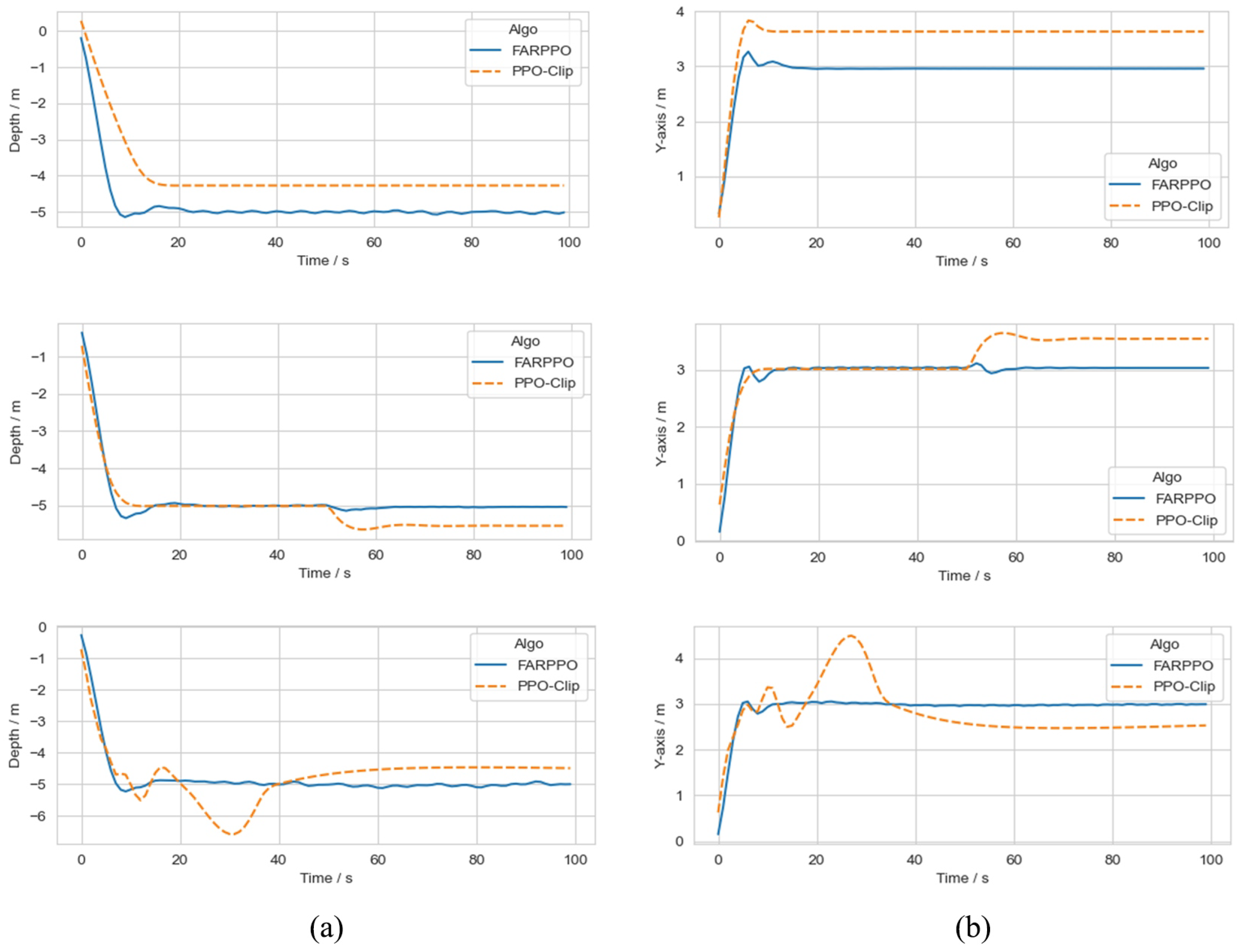
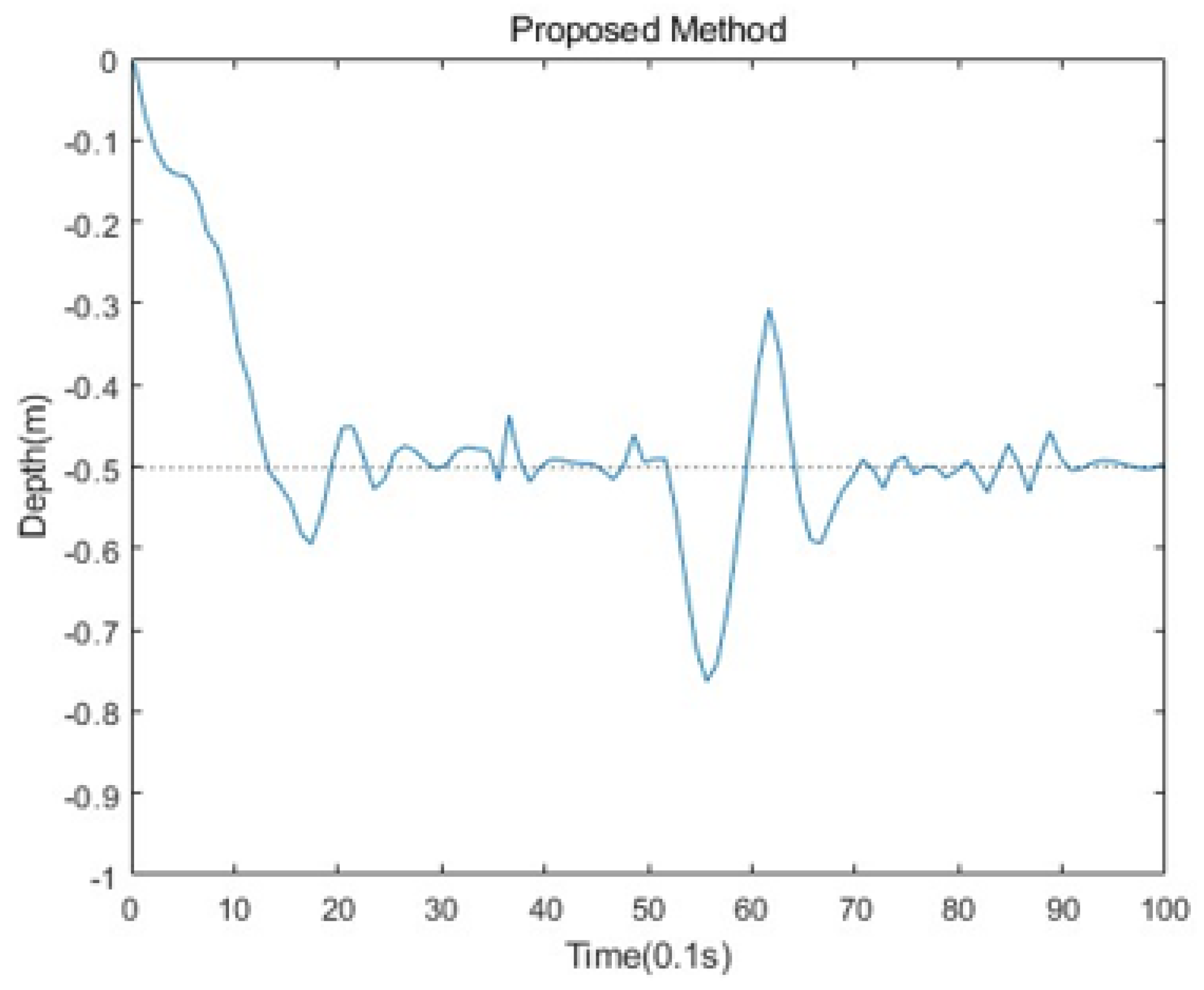
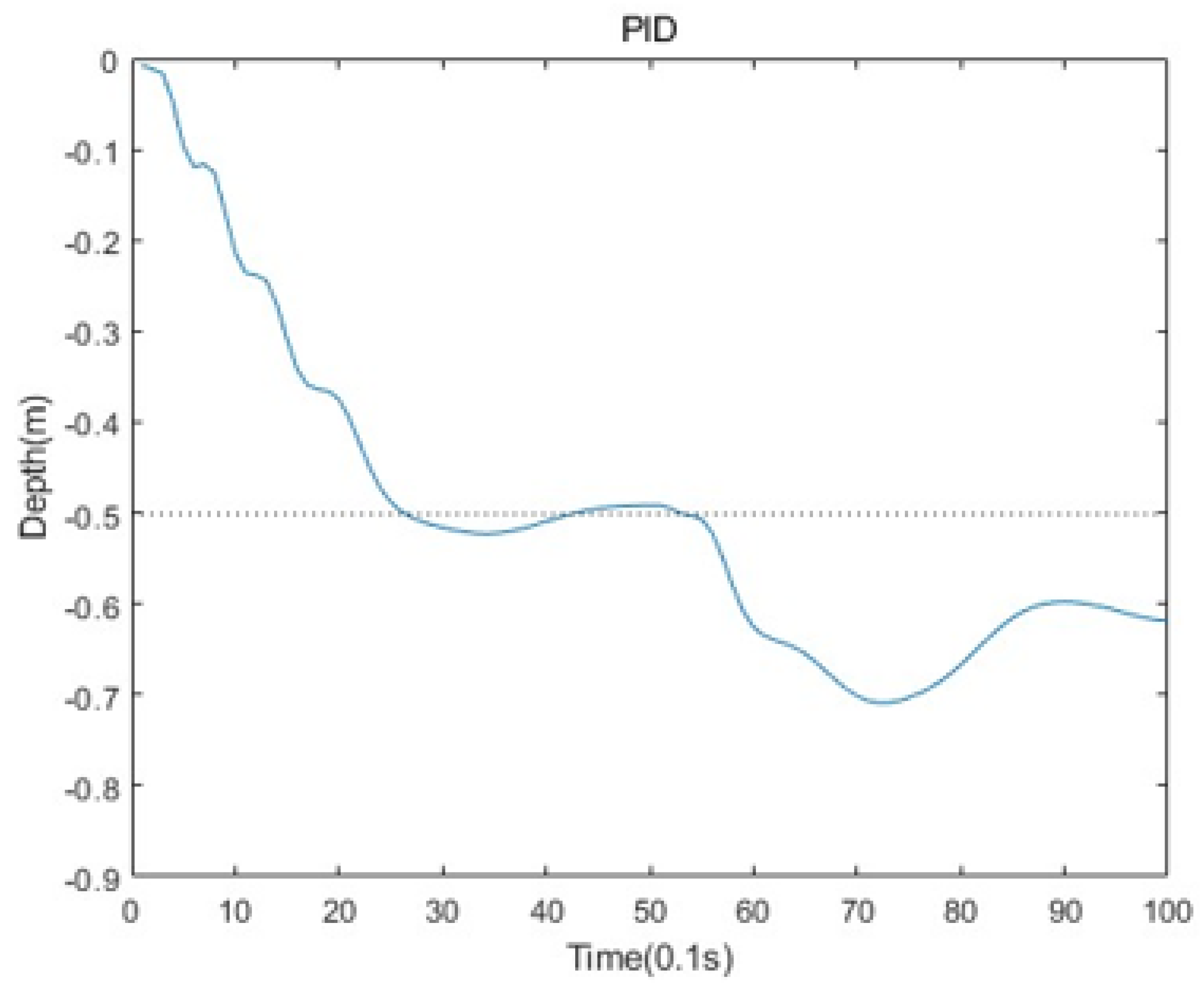
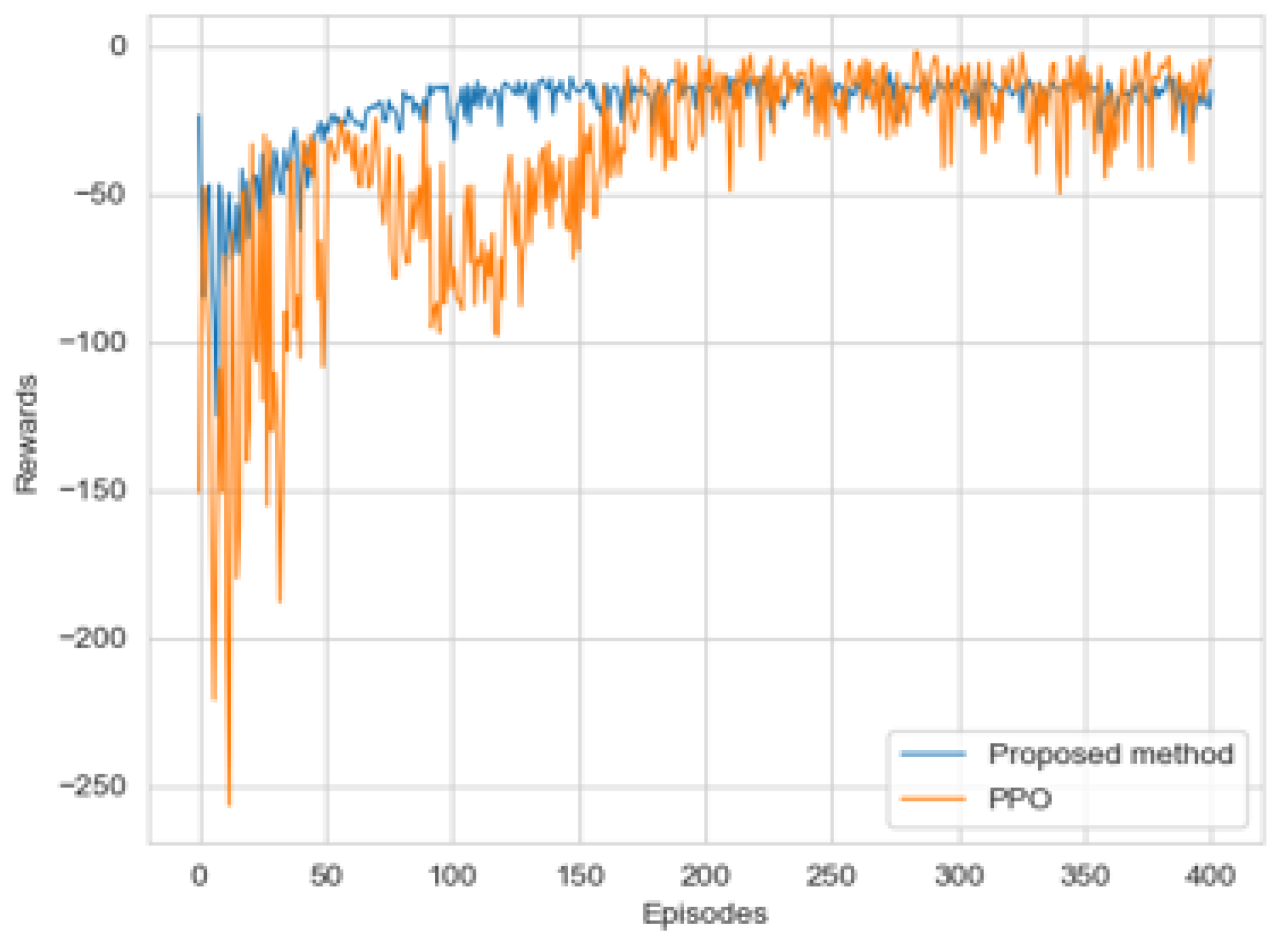
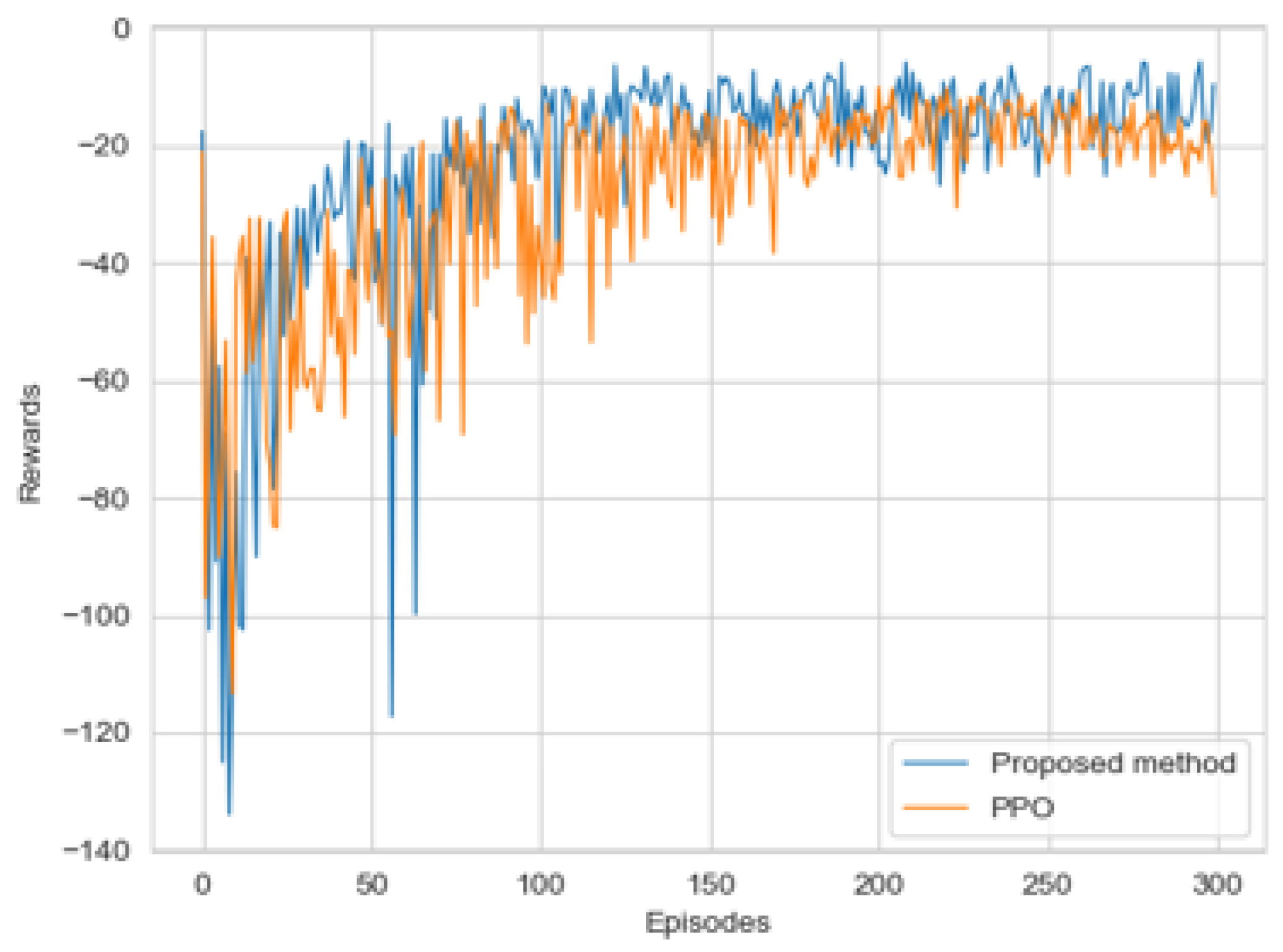
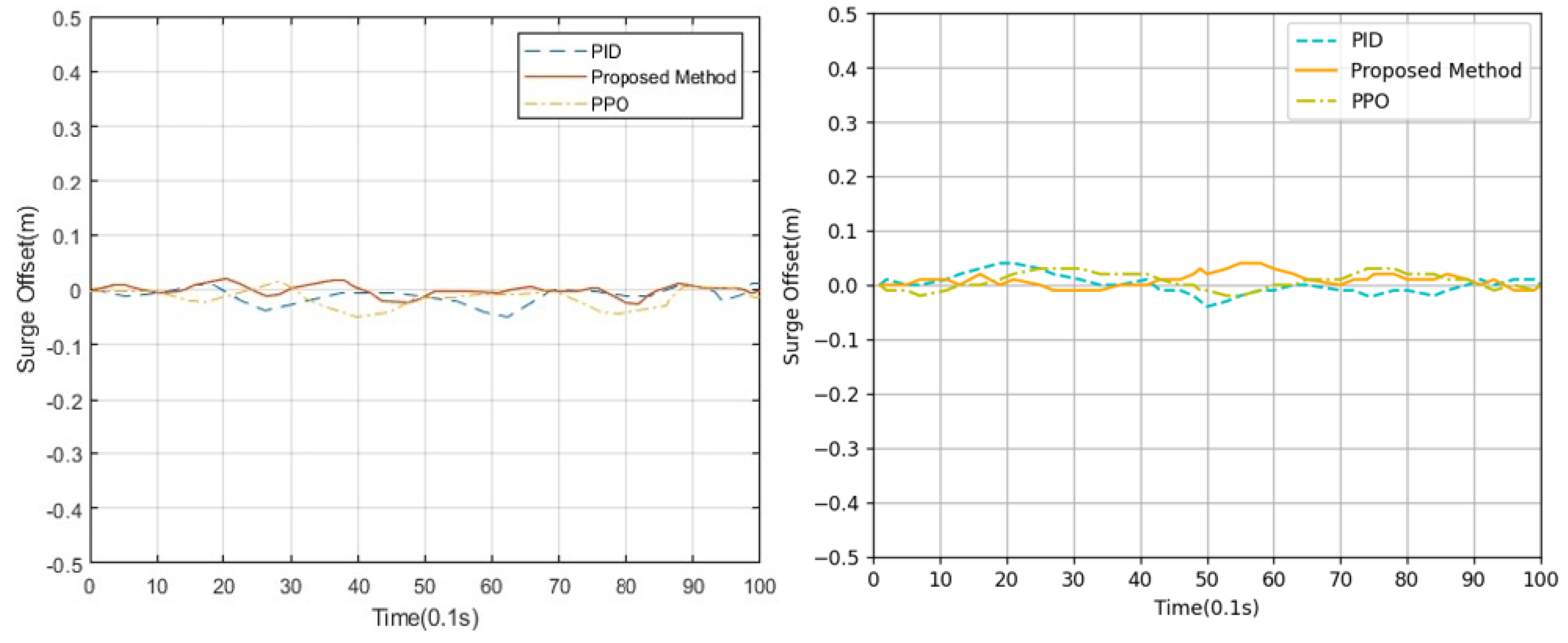
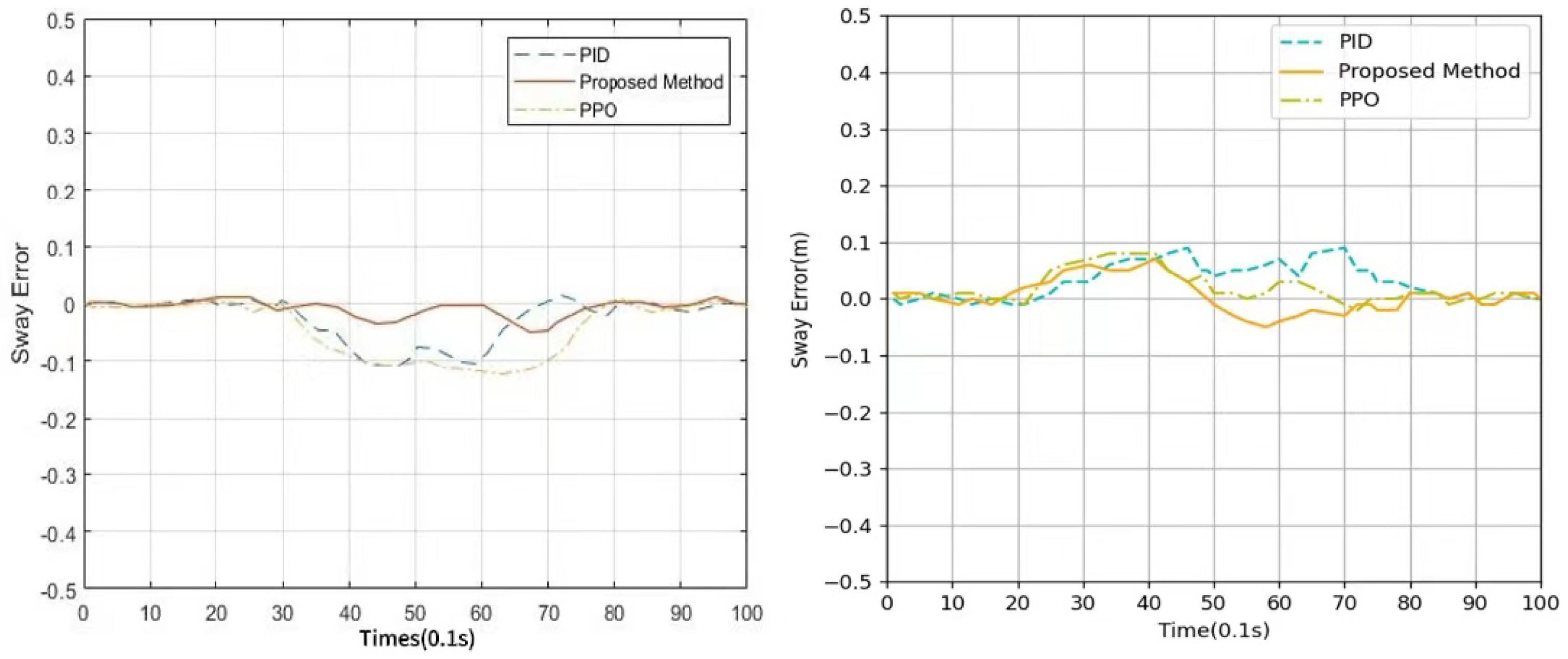
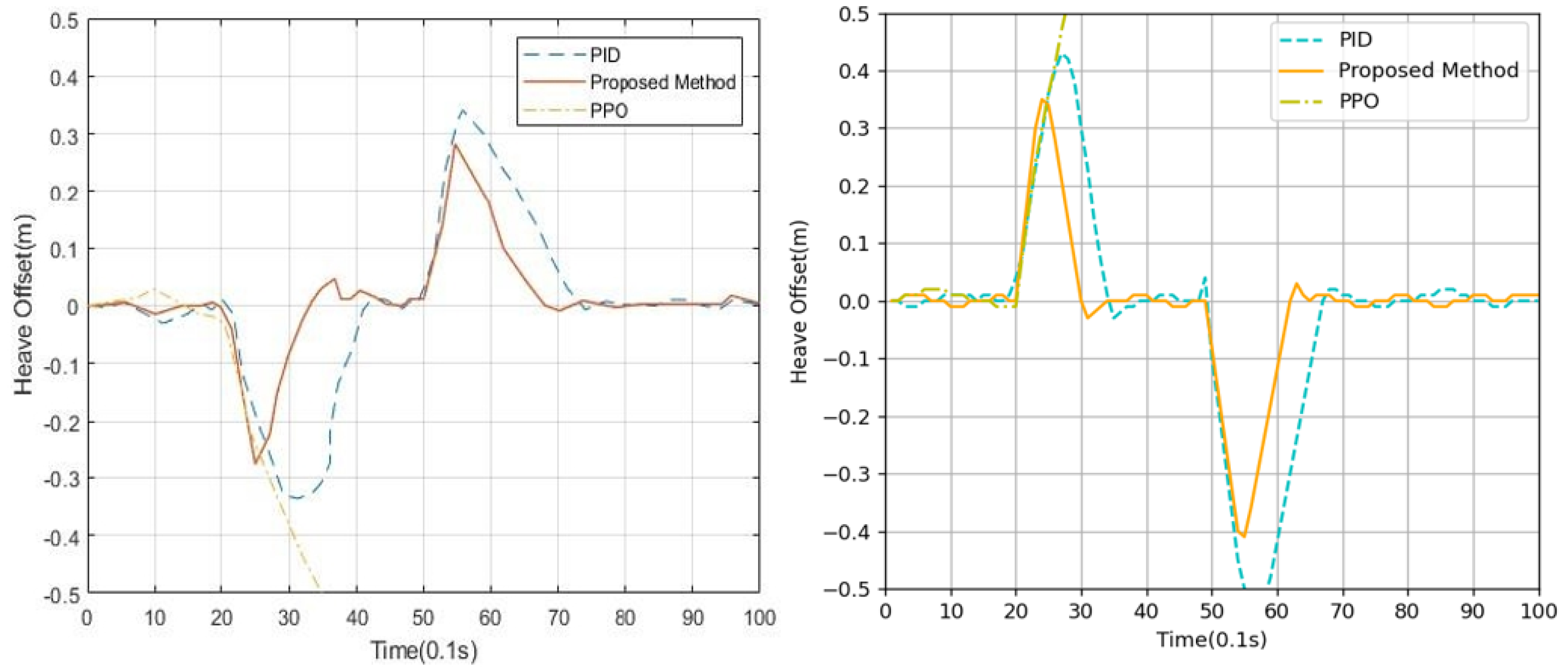
This paper proposed a new algorithm, FARPPO, for controlling AUVs. Firstly, we established a mathematical model of the AUV motion system and describd the basic task settings. Then, we designed FARPPO, improving the network structure and training method to achieve the integration of the advantages of the two methods. The visually guided tracking control experiments were carried out based on YOLOv8 and YOLOv10, and it was found that the input message from YOLO had little effect on the FARPPO. Compared with the traditional reinforcement learning algorithm and the PID algorithm, which is the most widely used algorithm in engineering applications, the algorithm proposed in this study accomplished better tracking control of the target, which proved the effectiveness of the proposed algorithm in a real underwater environment and its practical engineering significance. Finally, step response experiments were conducted in various dynamic environments using FARPPO and the control algorithm to test their robustness and adaptability. The results indicated that the FARPPO algorithm could effectively resist environmental disturbances by adapting to the environment online through an embedding network based on motion history. The training mechanism based on the progressive network enabled the algorithm to quickly adapt to new dynamic environments, resulting in a significantly improved training speed and stability compared to the two-stage training method, providing a new approach to implementing DRL controllers for AUVs.
Although this study significantly improved the training speed and stability, most of the tests were conducted simulation environments, and unexpected problems may occur in applications under real marine environmental conditions. Future work and further research are required to determine the degree of generalization of this algorithm in various environmental scenarios.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}