
A Lightweight Network Based on Multi-Scale Asymmetric Convolutional Neural Networks with Attention Mechanism for Ship-Radiated Noise Classification

 ,
,  , and
, and
Abstract
1. Introduction
- The multi-scale convolutional learning structure extracts multi-scale features from Mel spectrograms, improving accuracy and adaptability in various acoustic signal scenarios.
- The asymmetric convolution with horizontal and vertical kernels reduces parameters. Meanwhile, the asymmetric convolution can extract more stable low-frequency line spectrum features, which is beneficial for revealing the deep features of ship attributes.
- The improved ECA attention mechanism fuses multi-scale features and emphasizes crucial features. To our knowledge, it is the first time that an ECA attention block has been introduced into the underwater acoustic target recognition field.
2. Materials and Methods
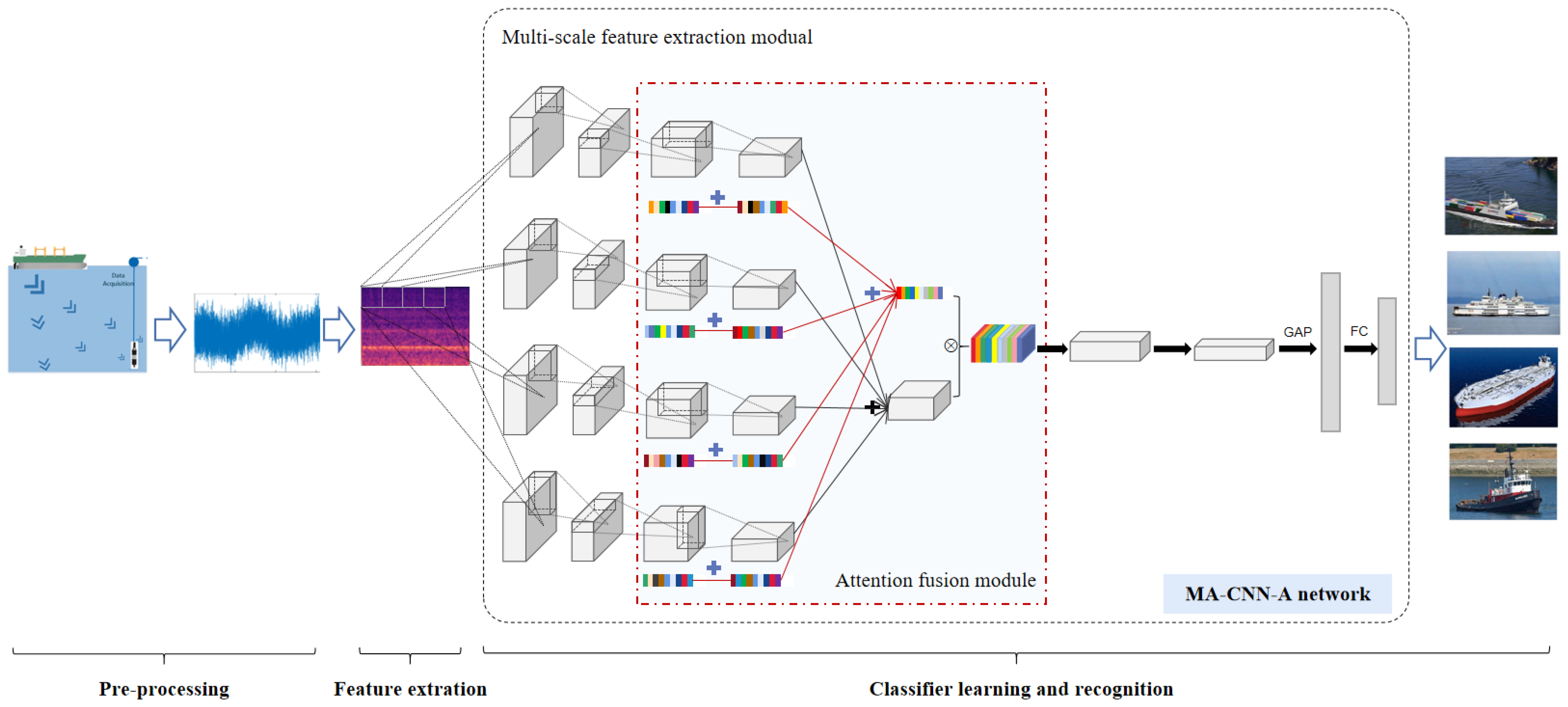
2.1. System Overview
- Data pre-processing. The sonar array initially captures ship-radiated noise. In this phase, array signal processing techniques (such as beamforming) strengthen the signals in target directions while reducing interference and noise from other sources.
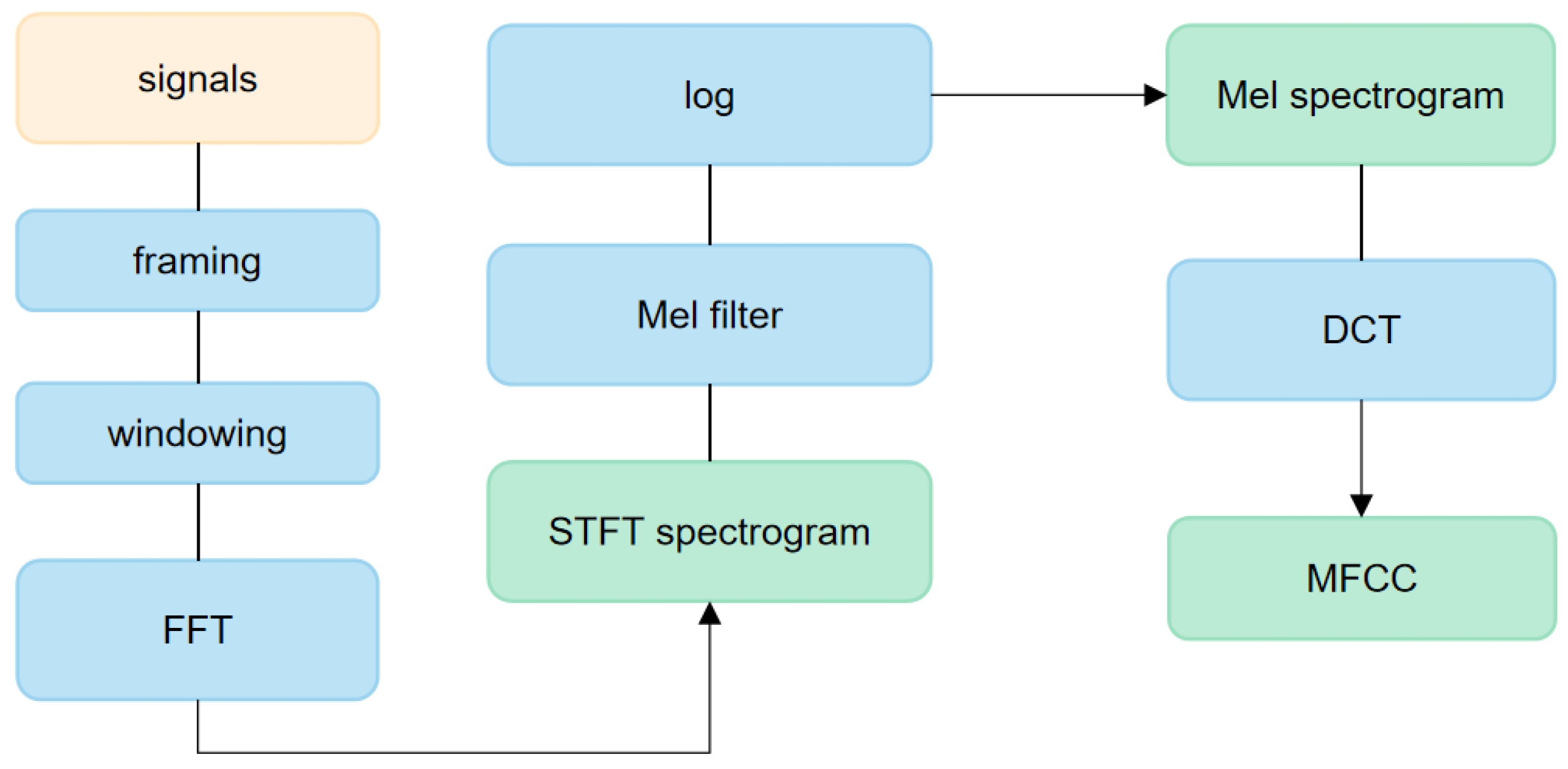
- Feature extraction. The audio signals are subsequently framed and converted into two-dimensional Mel spectrograms using Mel filters.
- Classifier learning and recognition. The Mel spectrograms are fed into the MA-CNN-A model. The MA-CNN-A will extract the detailed features and fuse the dominant feature weights by multi-scale asymmetric convolution and attention mechanisms. Finally, the fully connected layer with softmax is used as the classifier layer to obtain the predicted category label.
2.2. Feature Preparing
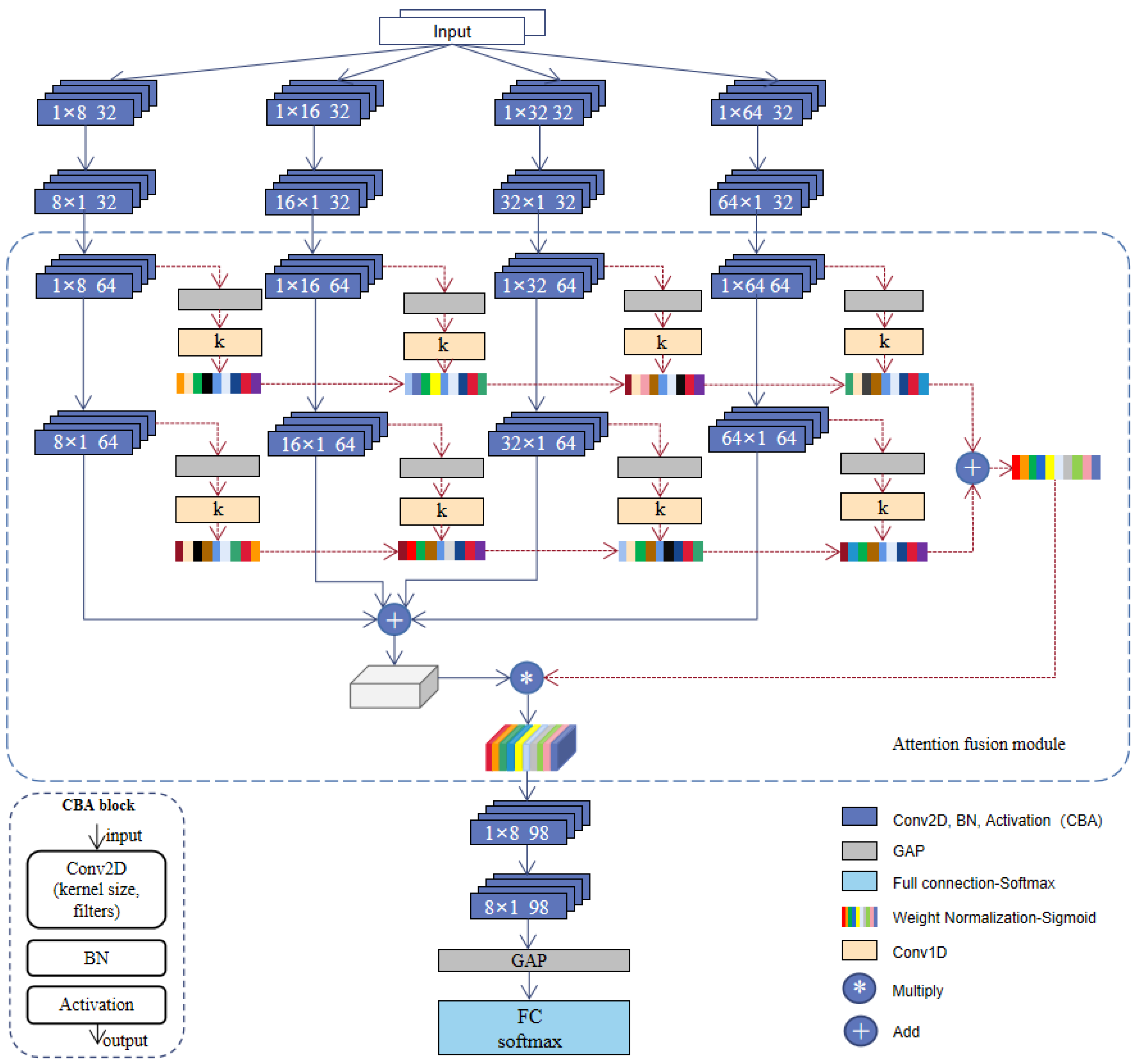
2.3. MA-CNN-A Model
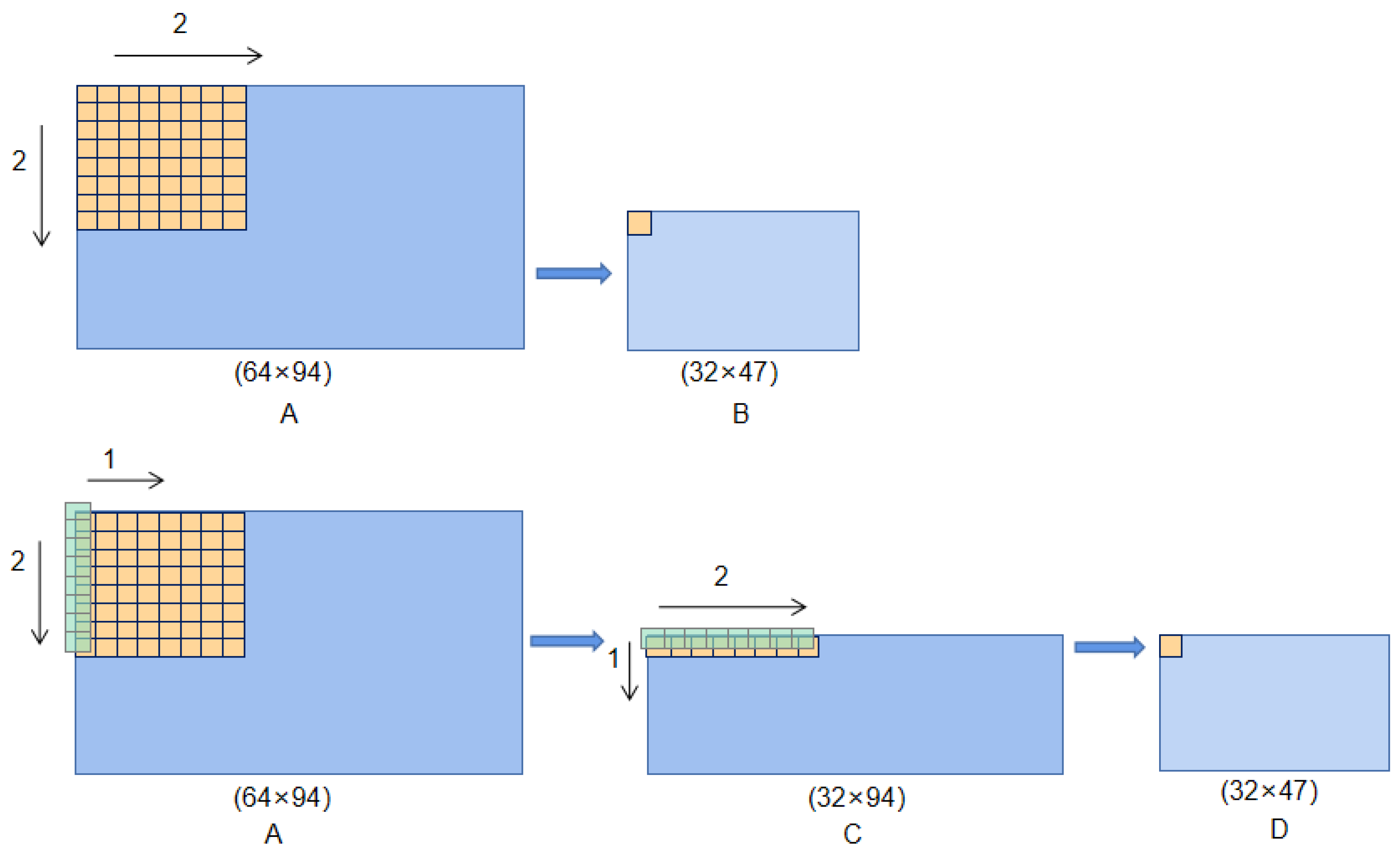
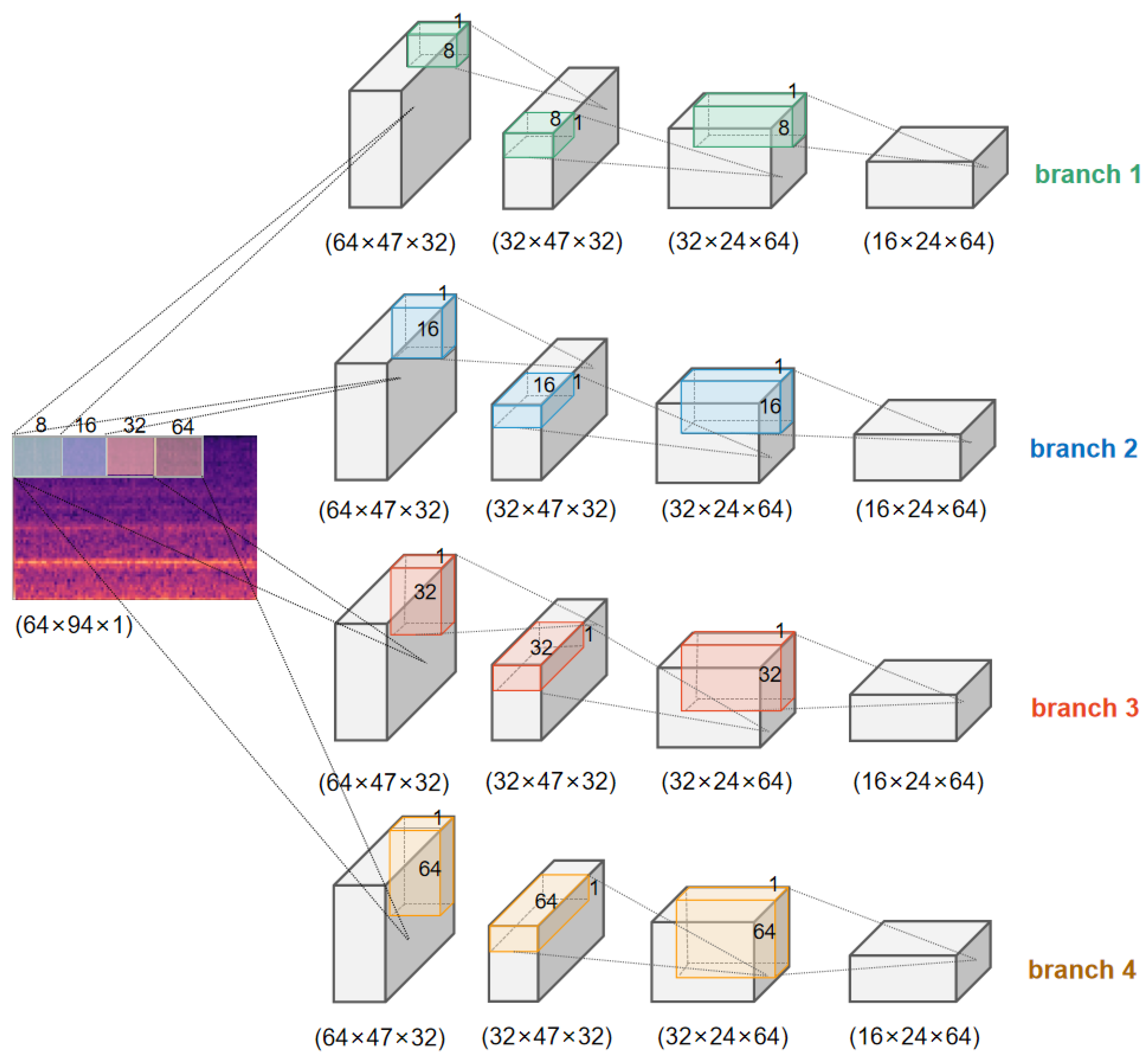
2.3.1. Multi-Scale Asymmetric Diverse Feature Extraction Backbone
- Each region of feature map B perceives each region of feature map A.
- Each region of feature map C perceives every region of feature map A.
- Each region of feature map D perceives every region of feature map C.
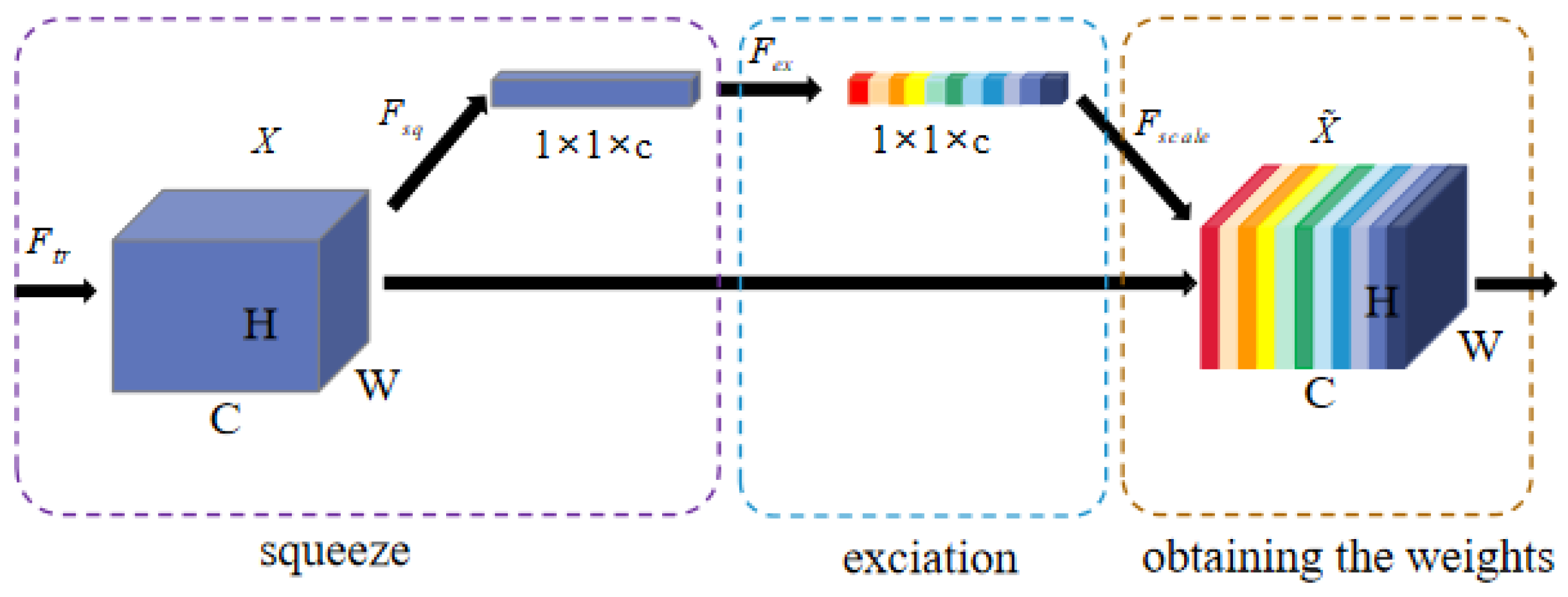
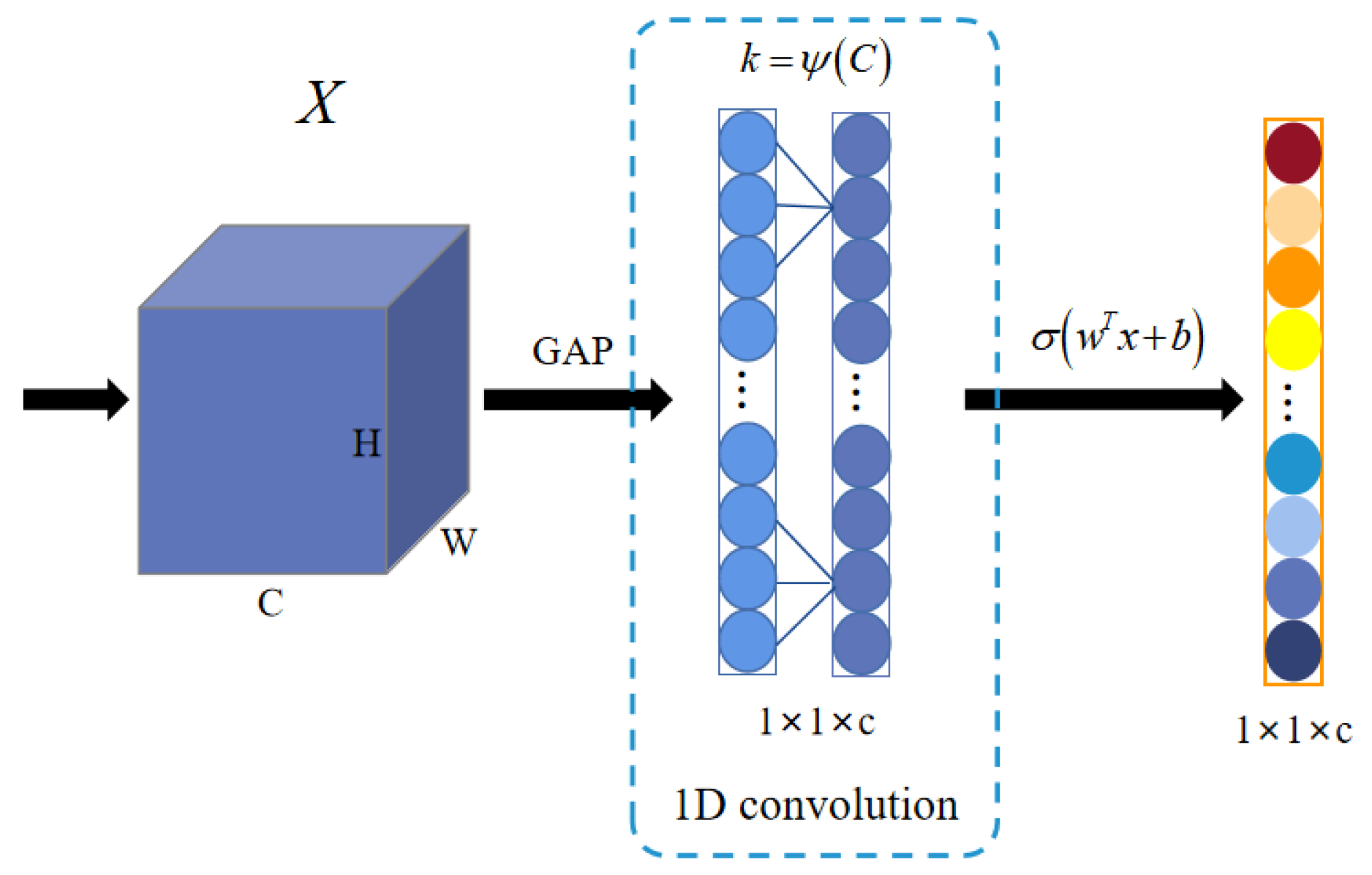
2.3.2. Attention Mechanism-Based Multi-Scale Feature Fusion
3. Experiment Setup
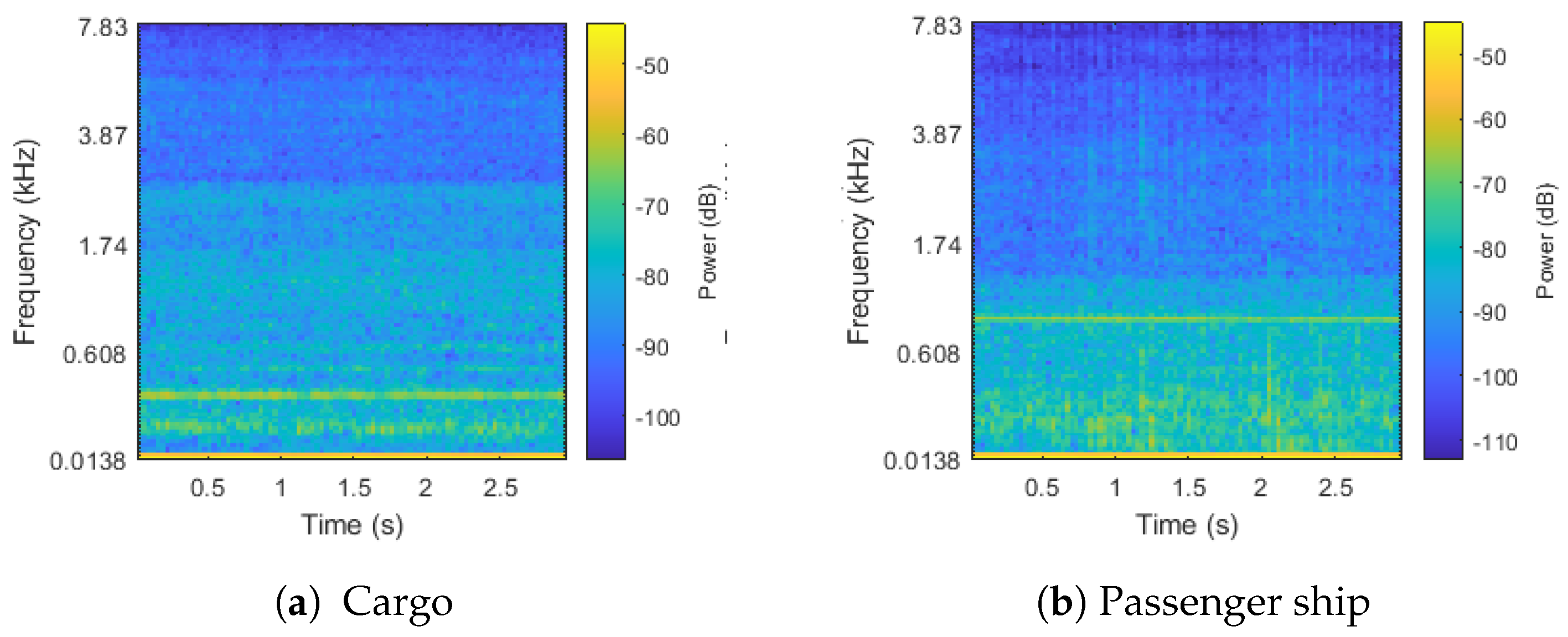
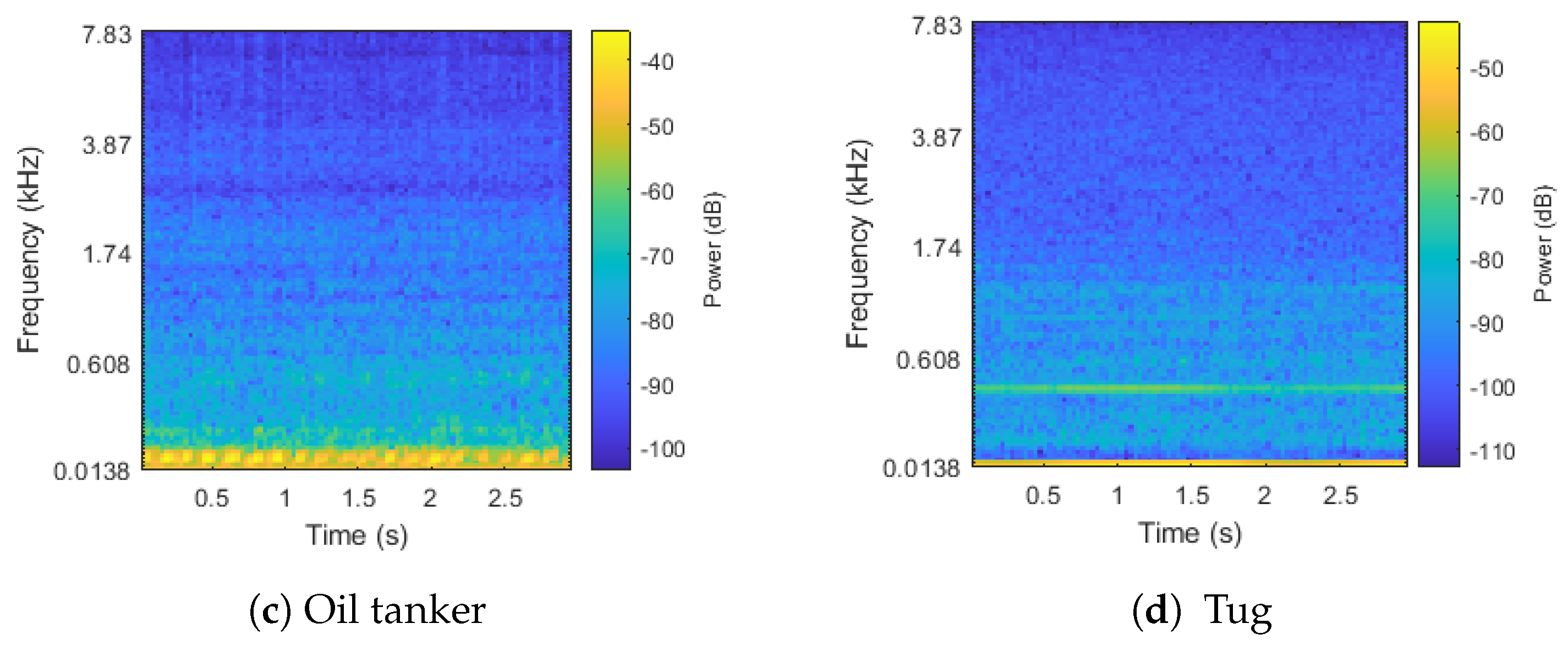
3.1. Dataset
3.2. Parameters Setup
3.3. Evaluation Metric
3.4. Comparative Methods
4. Experiment Results and Analysis
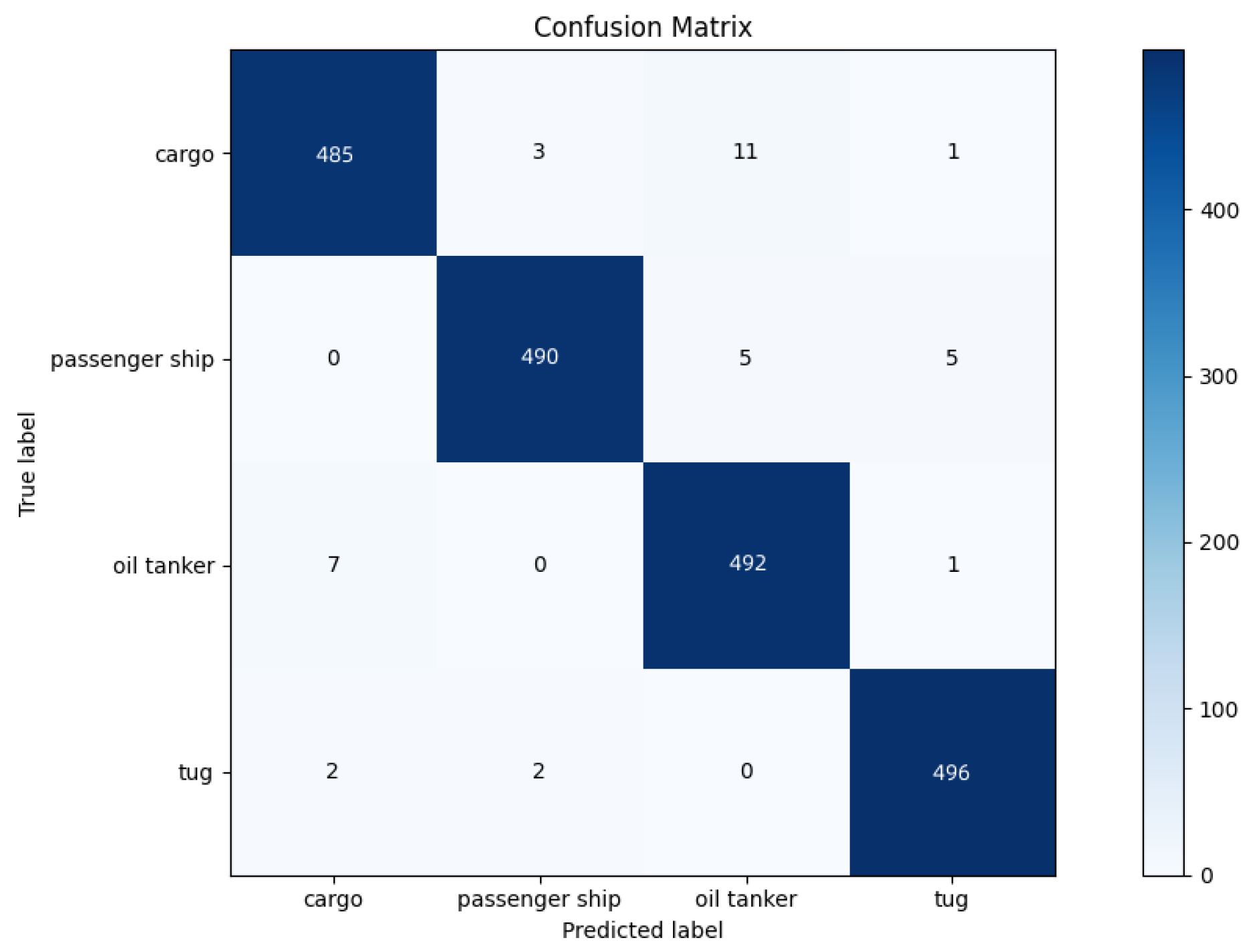
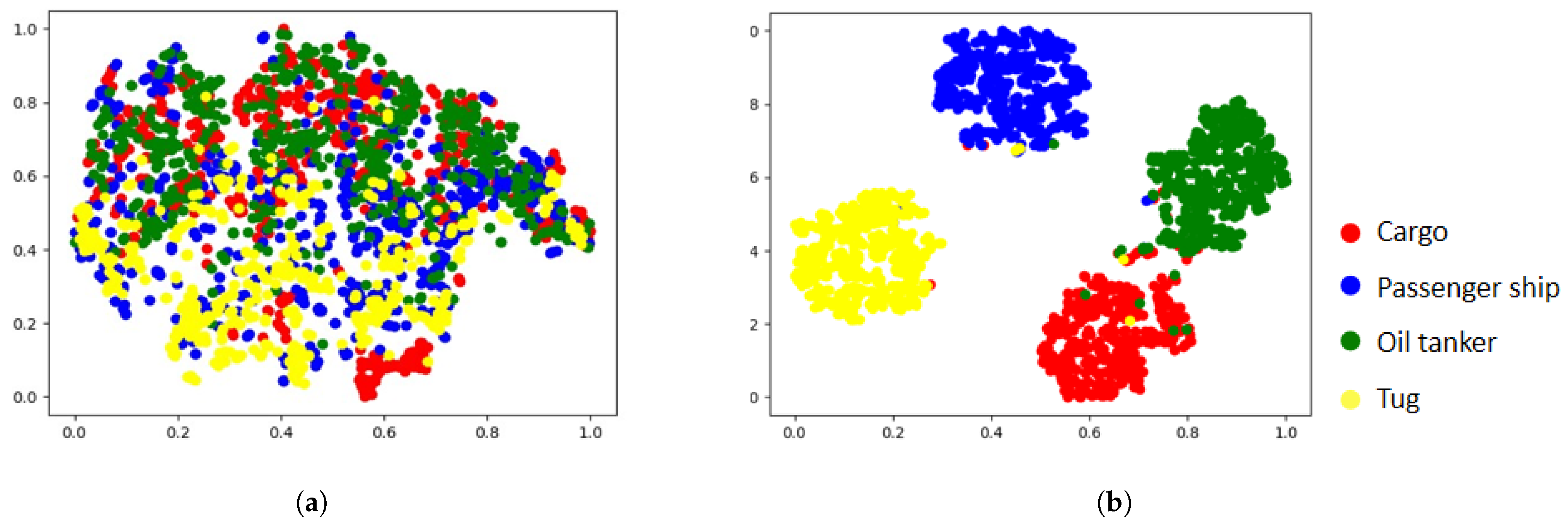
4.1. The Result of MA-CNN-A Model
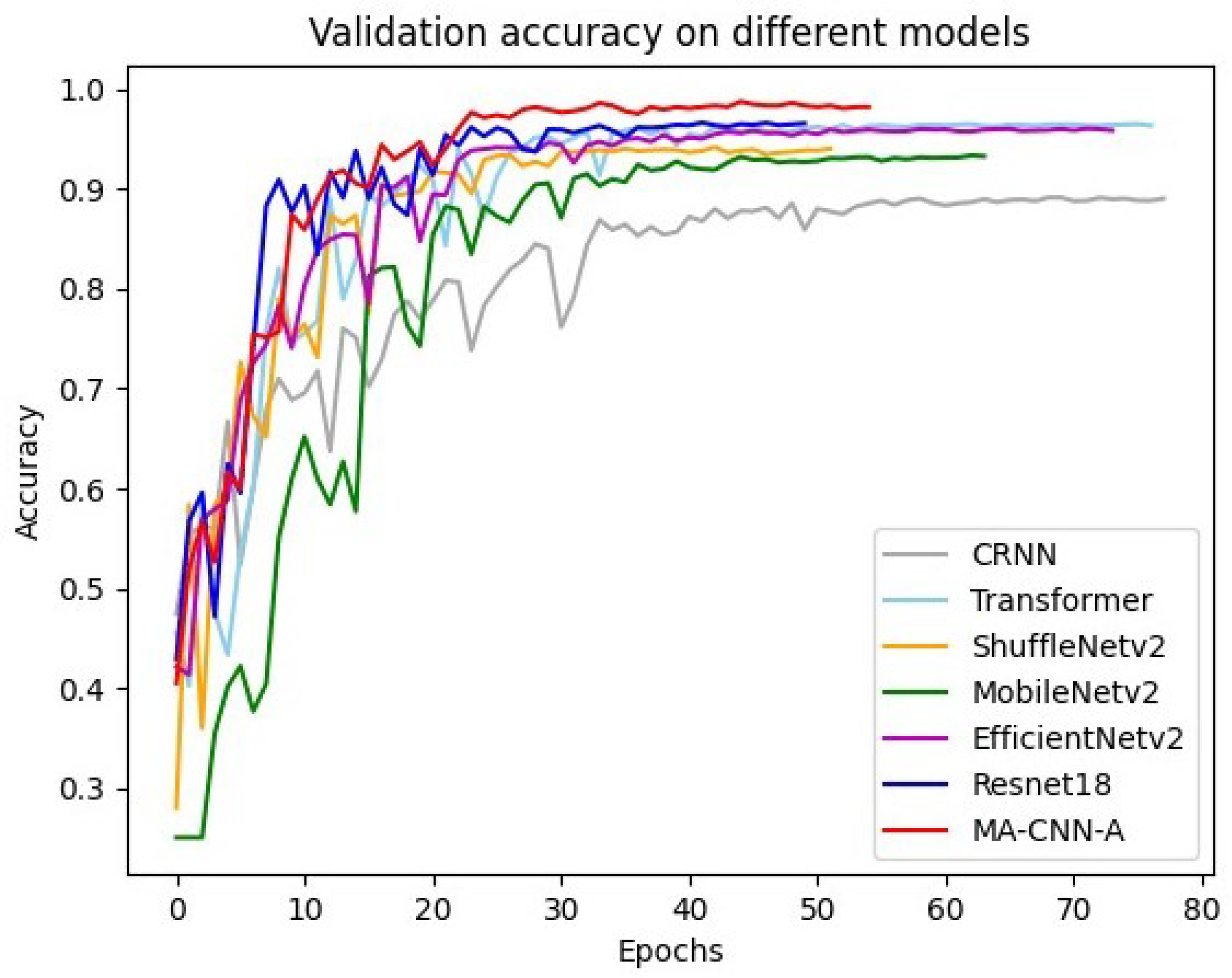
4.2. Comparison of Different Methods
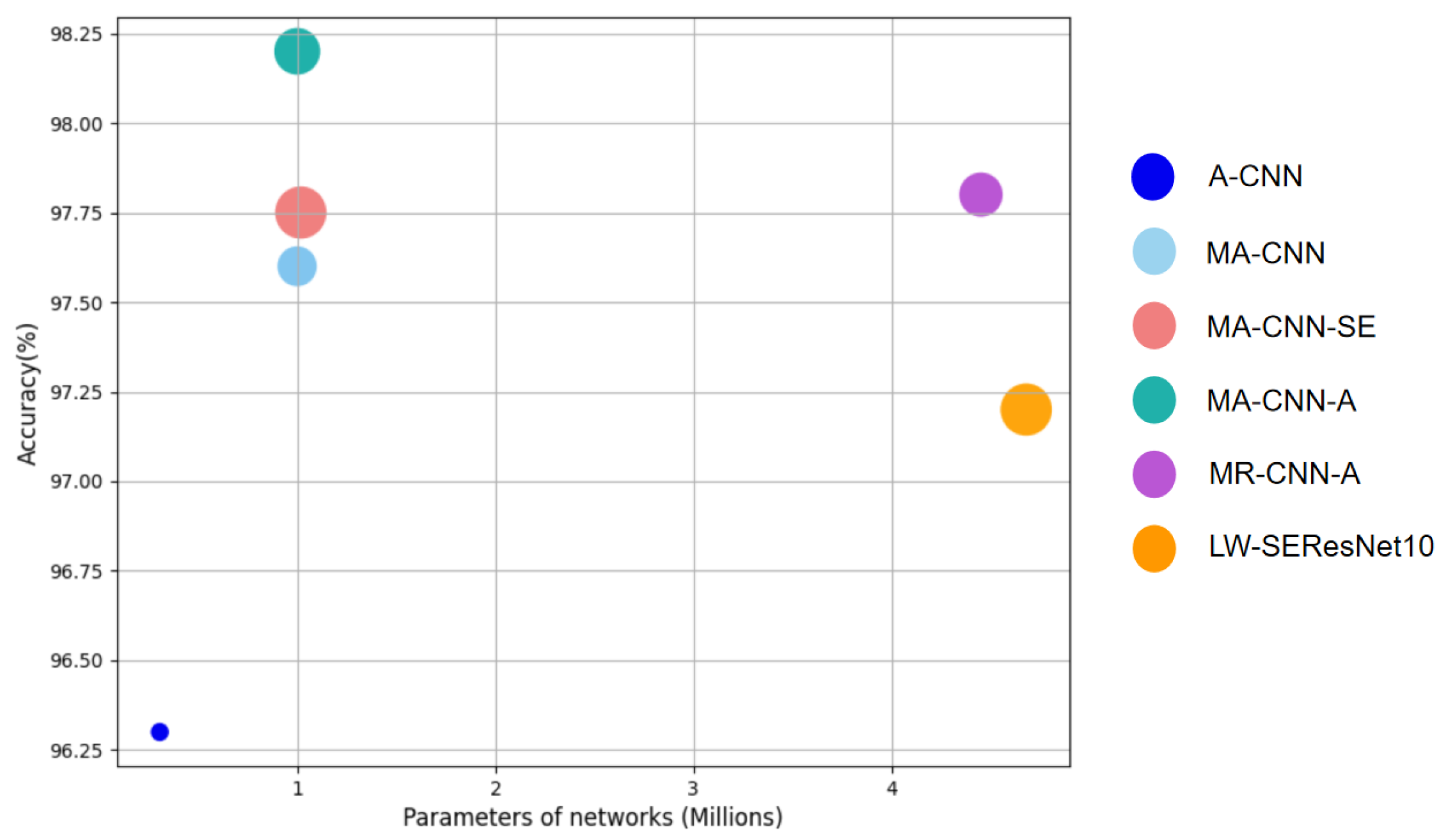
4.3. Ablation Experiments
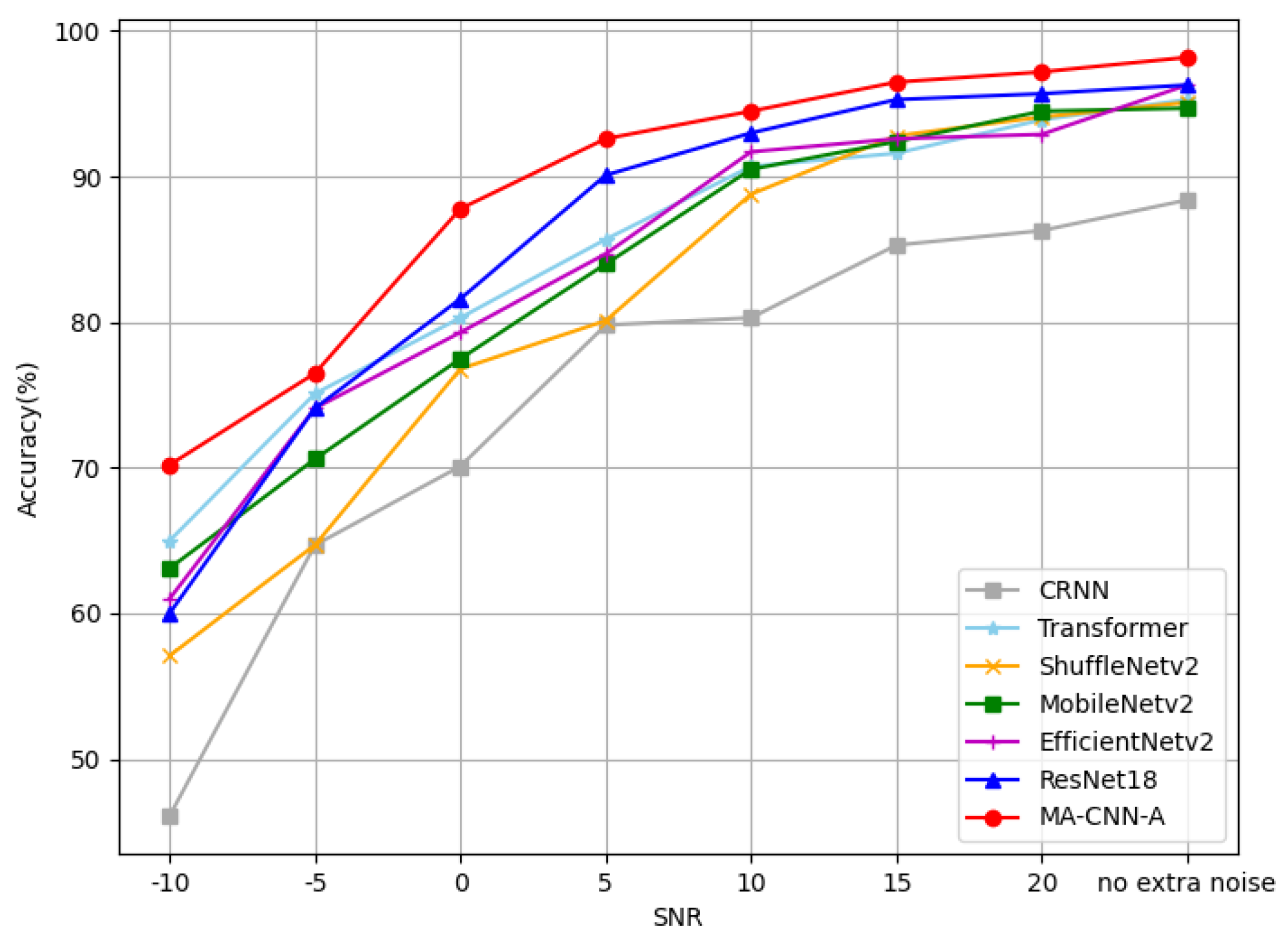
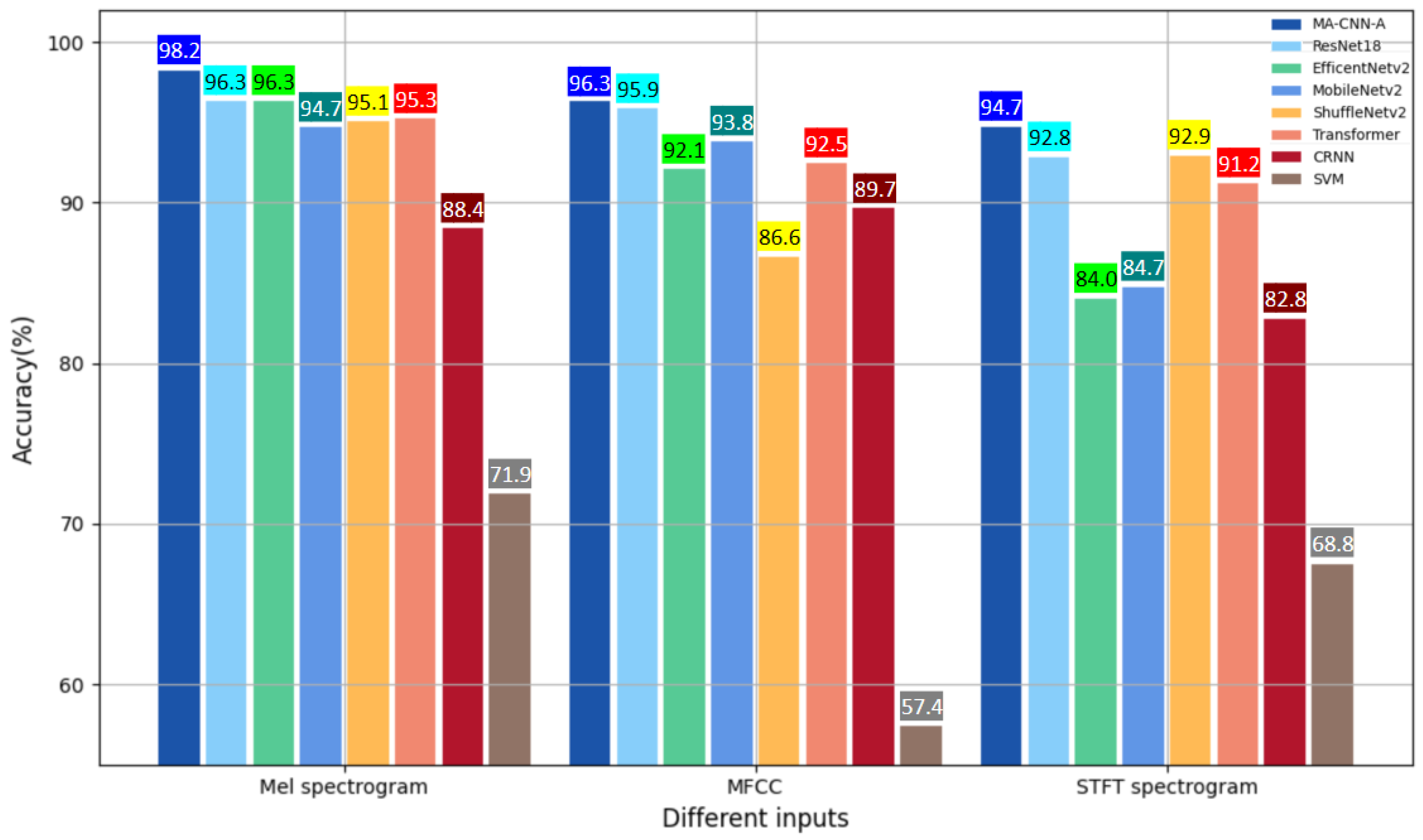
4.4. Robustness Test
4.4.1. Test on Low SNR
4.4.2. Performance of Different Features
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ke, X.; Yuan, F.; Cheng, E. Integrated optimization of underwater acoustic ship-radiated noise recognition based on two-dimensional feature fusion. Appl. Acoust. 2020, 159, 107057. [Google Scholar] [CrossRef]
- Li, Y.; Li, Y.; Chen, X.; Yu, J. Denoising and feature extraction algorithms using NPE combined with VMD and their applications in ship-radiated noise. Symmetry 2017, 9, 256. [Google Scholar] [CrossRef]
- Li, J.; Yang, H. The underwater acoustic target timbre perception and recognition based on the auditory inspired deep convolutional neural network. Appl. Acoust. 2021, 182, 108210. [Google Scholar] [CrossRef]
- Das, A.; Kumar, A.; Bahl, R. Marine vessel classification based on passive sonar data: The cepstrum-based approach. IET Radar Sonar Nav. 2013, 7, 87–93. [Google Scholar] [CrossRef]
- Liu, J.; He, Y.; Liu, Z.; Xiong, Y. Underwater target recognition based on line spectrum and support vector machine. In Proceedings of the 2014 International Conference on Mechatronics, Control and Electronic Engineering (MCE-14), Hainan, China, 17–19 October 2014; pp. 79–84. [Google Scholar]
- Meng, Q.; Yang, S.; Piao, S. The classification of underwater acoustic target signals based on wave structure and support vector machine. J. Acoust. Soc. Am. 2014, 136 (Suppl. 4), 87–93. [Google Scholar] [CrossRef]
- Seok, J.; Bae, K. Target classification using features based on fractional Fourier transform. IEICE Trans. Inf. 2014, 97, 2518–2521. [Google Scholar] [CrossRef]
- Azimi-Sadjadi, M.R.; Yao, D.; Huang, Q.; Dobeck, G.J. Underwater target classification using wavelet packets and neural networks. IEEE Trans. Neural Netw. 2000, 11, 784–794. [Google Scholar] [CrossRef] [PubMed]
- van Haarlem, M.P.; Wise, M.W.; Gunst, A.W.; Heald, G.; McKean, J.P.; Hessels, J.W.; Reitsma, J. LOFAR: The low-frequency array. Astron. Astrophys. 2013, 556, A2. [Google Scholar] [CrossRef]
- Pezeshki, A.; Azimi-Sadjadi, M.R.; Scharf, L.L. Undersea target classification using canonical correlation analysis. Ocean Eng. 2007, 32, 948–955. [Google Scholar] [CrossRef][Green Version]
- Wang, S.; Zeng, X. Robust underwater noise targets classification using auditory inspired time–frequency analysis. Appl. Acoust. 2014, 78, 68–76. [Google Scholar] [CrossRef]
- Lim, T.; Bae, K.; Hwang, C.; Lee, H. Classification of underwater transient signals using MFCC feature vector. In Proceedings of the 2007 9th International Symposium on Signal Processing and Its Applications, Sharjah, United Arab Emirates, 12–15 February 2007; pp. 1–4. [Google Scholar]
- Irfan, M.; Zheng, J.; Ali, S.; Iqbal, M.; Masood, Z.; Hamid, U. DeepShip: An underwater acoustic benchmark dataset and a separable convolution based autoencoder for classification. Appl. Acoust. 2021, 183, 115270. [Google Scholar] [CrossRef]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena-Gimenez, A. ShipsEar: An underwater vessel noise database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Da, L.; Zhang, Y.; Hu, Y. Integrated neural networks based on feature fusion for underwater target recognition. Appl. Acoust. 2021, 182, 108261. [Google Scholar] [CrossRef]
- Yang, H.; Li, J.; Sheng, M. Underwater acoustic target multi-attribute correlation perception method based on deep learning. Appl. Acoust. 2022, 190, 108644. [Google Scholar]
- Hu, G.; Wang, K.; Peng, Y.; Qiu, M.; Shi, J.; Liu, L. Deep learning methods for underwater target feature extraction and recognition. Comput. Intell. Neurosci. 2018, 2018, 1214301. [Google Scholar] [CrossRef]
- Dai, W.; Dai, C.; Qu, S.; Li, J.; Das, S. Very deep convolutional neural networks for raw waveforms. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 421–425. [Google Scholar]
- Yang, H.; Li, J.; Shen, S.; Xu, G. A deep convolutional neural network inspired by auditory perception for underwater acoustic target recognition. Sensors 2019, 19, 1104. [Google Scholar] [CrossRef] [PubMed]
- Hong, F.; Liu, C.; Guo, L.; Chen, F.; Feng, H. Underwater acoustic target recognition with a residual network and the optimized feature extraction method. Appl. Acoust. 2021, 11, 1442. [Google Scholar] [CrossRef]
- Tian, S.; Chen, D.; Wang, H.; Liu, J. Deep convolution stack for waveform in underwater acoustic target recognition. Sci. Rep. 2021, 11, 9614. [Google Scholar] [CrossRef]
- Tian, S.; Chen, D.; Fu, Y.; Zhou, J. Joint learning model for underwater acoustic target recognition. Knowl. Based Syst. 2023, 260, 110119. [Google Scholar] [CrossRef]
- Liu, F.; Shen, T.; Luo, Z.; Zhao, D.; Guo, S. Underwater target recognition using convolutional recurrent neural networks with 3-D Mel-spectrogram and data augmentation. Appl. Acoust. 2021, 178, 107989. [Google Scholar] [CrossRef]
- Ibrahim, A.K.; Chérubin, L.M.; Zhuang, H.; Schärer Umpierre, M.T.; Dalgleish, F.; Erdol, N.; Dalgleish, A. An approach for automatic classification of grouper vocalizations with passive acoustic monitoring. J. Acoust. Soc. Am. 2018, 143, 666–676. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Xue, L.; Zeng, X.; Jin, A. A novel deep-learning method with channel attention mechanism for underwater target recognition. Sensors 2022, 22, 5492. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Wang, X.; Liu, A.; Zhang, Y.; Xue, F. Underwater acoustic target recognition: A combination of multi-dimensional fusion features and modified deep neural network. Remote Sens. 2019, 11, 1888. [Google Scholar] [CrossRef]
- Zhu, P.; Zhang, Y.; Huang, Y.; Zhao, C.; Zhao, K.; Zhou, F. Underwater acoustic target recognition based on spectrum component analysis of ship radiated noise. Appl. Acoust. 2023, 211, 109552. [Google Scholar] [CrossRef]
- Lei, Z.; Lei, X.; Wang, N.; Zhang, Q. Present status and challenges of underwater acoustic target recognition technology: A review. Front. Phys. 2022, 10, 1044890. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4510–4520. [Google Scholar]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1911–1920. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Cai, H.; Zhu, L.; Han, S. Proxylessnas: Direct neural architecture search on target task and hardware. arXiv 2018, arXiv:1812.00332. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- Denton, E.L.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. Adv. Neural Inf. Process. 2014, 27, 1269–1277. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Kingsbury, B. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Sheng, L.; Dong, Y.; Evgeniy, N. High-quality speech synthesis using super-resolution mel-spectrogram. arXiv 2019, arXiv:1912.01167. [Google Scholar]
- Tiwari, V. MFCC and its applications in speaker recognition. Int. J. Emerg. Technol. 2012, 1, 19–22. [Google Scholar]
- Tian, C.; Xu, Y.; Zuo, W.; Lin, C.W.; Zhang, D. Asymmetric CNN for image superresolution. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 3718–3730. [Google Scholar] [CrossRef]
- Lo, S.Y.; Hang, H.M.; Chan, S.W.; Lin, J.J. Efficient dense modules of asymmetric convolution for real-time semantic segmentation. In Proceedings of the ACM Multimedia Asia, Beijing, China, 15–18 December 2019; pp. 1–6. [Google Scholar]
- Jun, F.; Jing, L.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Shen, S.; Yang, H.; Li, J.; Xu, G.; Sheng, M. Auditory inspired convolutional neural networks for ship type classification with raw hydrophone data. Entropy 2018, 20, 990. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Feng, S.; Zhu, X. A Transformer-Based Deep Learning Network for Underwater Acoustic Target Recognition. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1505805. [Google Scholar] [CrossRef]
- Yang, S.; Xue, L.; Hong, X.; Zeng, X. A Lightweight Network Model Based on an Attention Mechanism for Ship-Radiated Noise Classification. J. Mar. Sci. Eng. 2023, 11, 432. [Google Scholar] [CrossRef]
- Ma, Y.; Liu, M.; Zhang, Y.; Zhang, B.; Xu, K.; Zou, B.; Huang, Z. Imbalanced underwater acoustic target recognition with trigonometric loss and attention mechanism convolutional network. Remote Sens. 2022, 14, 4103. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ship Type | No. of Ships | Total Recordings | Training Size | Validation Size | Test Size |
|---|---|---|---|---|---|
| Cargo | 69 | 110 | 3500 | 1000 | 500 |
| Passenger ship | 46 | 193 | 3500 | 1000 | 500 |
| Oil tanker | 133 | 240 | 3500 | 1000 | 500 |
| Tug | 17 | 70 | 3500 | 1000 | 500 |
| Feature | Dimension | Sampling Rate | N-fft | Hop Length |
|---|---|---|---|---|
| Melsp | 64 × 94 | 16 kHz | 1024 | 512 |
| Cargo | 98.1% | 97.0% | 97.6% |
| Passenger ship | 99.0% | 98.0% | 98.5% |
| Oil tanker | 96.9% | 98.4% | 97.6% |
| Tug | 98.6% | 99.2% | 98.9% |
| Overall average | 98.2% | ||
| Model | Accuracy (%) | Computation Time (s/epoch) | Inference Speed on GPU (fps) | Inference Speed on CPU (fps) | GFLOPs | No. Params (M) | Model Size (MB) |
|---|---|---|---|---|---|---|---|
| MA-CNN-A | 98.2% | 28 | 310.2 | 123.5 | 1.177 | 1.00 | 3.9 |
| ResNet18 [46] | 96.3% | 38 | 265.8 | 23.1 | 6.592 | 11.18 | 42.7 |
| EfficientNetv2 [47] | 96.3% | 110 | 49.8 | 41.5 | 0.708 | 20.34 | 78.0 |
| MobileNetv2 [32] | 94.7% | 36 | 267.7 | 86.9 | 0.073 | 2.26 | 12.3 |
| ShuffleNetv2 [48] | 95.1% | 39 | 168.4 | 143.5 | 0.029 | 1.20 | 4.7 |
| Transformer [49] | 95.3% | 35 | 230.8 | 101.1 | 4.134 | 2.55 | 9.0 |
| CRNN [24] | 88.4% | 42 | 108.4 | 50.6 | 6.240 | 6.81 | 24.2 |
| No. of Branches | Kernal Shape | Kernal Size | Stride | Accuracy | No. of Parameters (M) |
|---|---|---|---|---|---|
| One | Square | (8 × 8) | (2 × 2) | 95.5% | 0.54 |
| Asymmetric | (1 × 8) (8 × 1) | (1 × 2) (2 × 1) | 96.3% | 0.19 | |
| Two | Square | (8 × 8) (16 × 16) | (2 × 2) | 96.6% | 1.07 |
| Asymmetric | (1 × 8) (8 × 1) | (1 × 2) (2 × 1) | 97.0% | 0.30 | |
| (1 × 16) (16 × 1) | |||||
| Three | Square | (8 × 8) (16 × 16) | (2 × 2) | 97.3% | 3.12 |
| (32 × 32) | |||||
| Asymmetric | (1 × 8) (8 × 1) | (1 × 2) (2 × 1) | 97.4% | 0.53 | |
| (1 × 16) (16 × 1) | |||||
| (1 × 32) (32 × 1) | |||||
| Four | Square | (8 × 8) (16 × 16) | (2 × 2) | 96.3% | 11.72 |
| (32 × 32) (64 × 64) | |||||
| Asymmetric | (1 × 8) (8 × 1) | (1 × 2) (2 × 1) | 97.6% | 1.00 | |
| (1 × 16) (16 × 1) | |||||
| (1 × 32) (32 × 1) | |||||
| (1 × 64) (64 × 1) | |||||
| Five | Square | (8 × 8) (16 × 16) | (2 × 2) | 97.3% | 45.80 |
| (32 × 32) (64 × 64) | |||||
| (128 × 128) | |||||
| Asymmetric | (1 × 8) (8 × 1) | (1 × 2) (2 × 1) | 97.6% | 1.92 | |
| (1 × 16) (16 × 1) | |||||
| (1 × 32) (32 × 1) | |||||
| (1 × 64) (64 × 1) | |||||
| (1 × 128) (128 × 1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, C.; Yan, S.; Yao, T.; Yu, Y.; Pan, G.; Liu, L.; Wang, M.; Bai, J. A Lightweight Network Based on Multi-Scale Asymmetric Convolutional Neural Networks with Attention Mechanism for Ship-Radiated Noise Classification. J. Mar. Sci. Eng. 2024, 12, 130. https://doi.org/10.3390/jmse12010130
Yan C, Yan S, Yao T, Yu Y, Pan G, Liu L, Wang M, Bai J. A Lightweight Network Based on Multi-Scale Asymmetric Convolutional Neural Networks with Attention Mechanism for Ship-Radiated Noise Classification. Journal of Marine Science and Engineering. 2024; 12(1):130. https://doi.org/10.3390/jmse12010130
Chicago/Turabian StyleYan, Chenhong, Shefeng Yan, Tianyi Yao, Yang Yu, Guang Pan, Lu Liu, Mou Wang, and Jisheng Bai. 2024. "A Lightweight Network Based on Multi-Scale Asymmetric Convolutional Neural Networks with Attention Mechanism for Ship-Radiated Noise Classification" Journal of Marine Science and Engineering 12, no. 1: 130. https://doi.org/10.3390/jmse12010130
APA StyleYan, C., Yan, S., Yao, T., Yu, Y., Pan, G., Liu, L., Wang, M., & Bai, J. (2024). A Lightweight Network Based on Multi-Scale Asymmetric Convolutional Neural Networks with Attention Mechanism for Ship-Radiated Noise Classification. Journal of Marine Science and Engineering, 12(1), 130. https://doi.org/10.3390/jmse12010130