
Underwater Object Detection Algorithm Based on Adding Channel and Spatial Fusion Attention Mechanism


Abstract
1. Introduction
2. Overview of Improved Network Structure
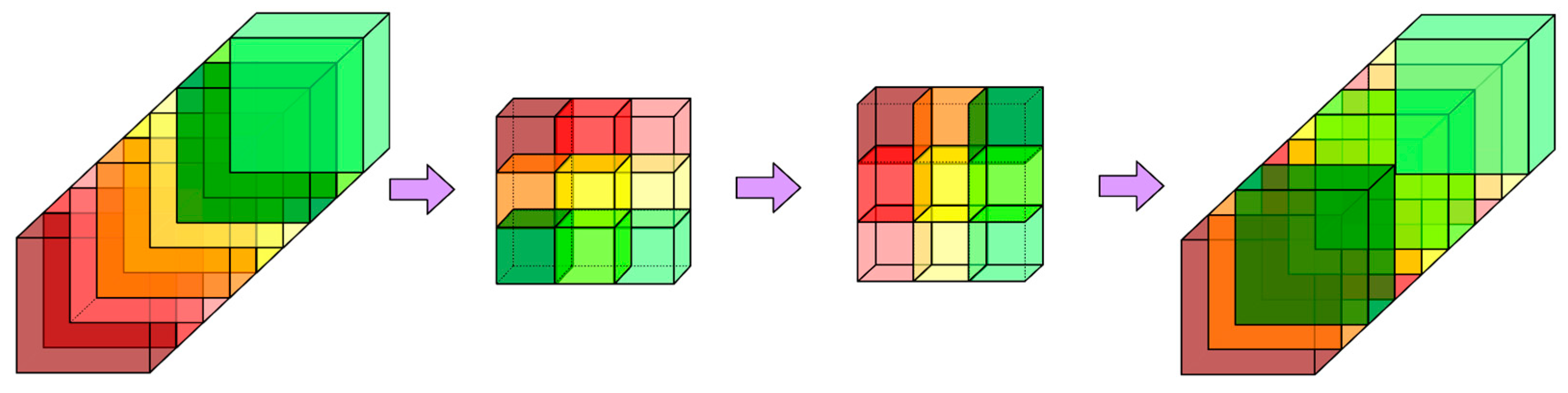
2.1. Channel and Spatial Fusion Attention Principle
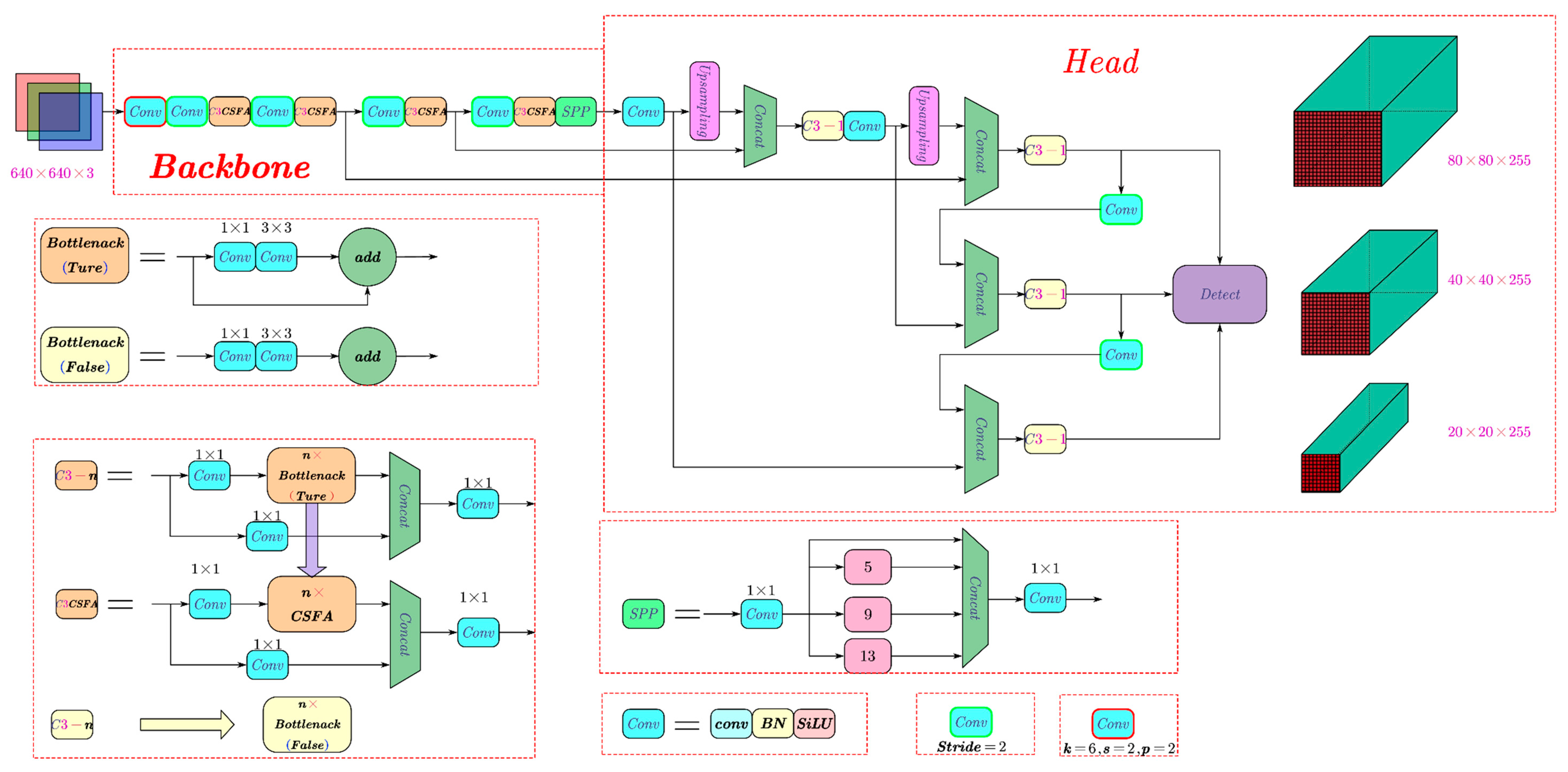
2.2. Improved YOLOv5 Network Structure
3. Model Analysis
3.1. Data Set
3.2. Evaluation Metrics
3.3. Model Training
4. Experimental Results
4.1. Experimental Environment
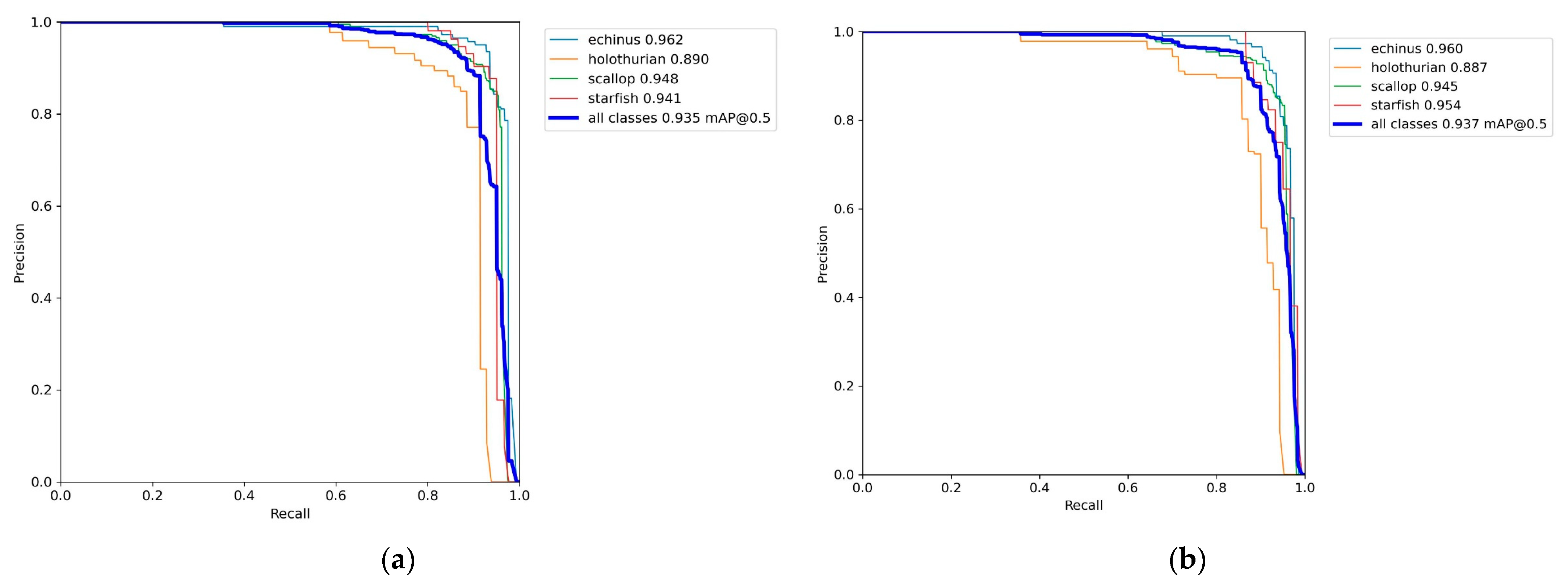
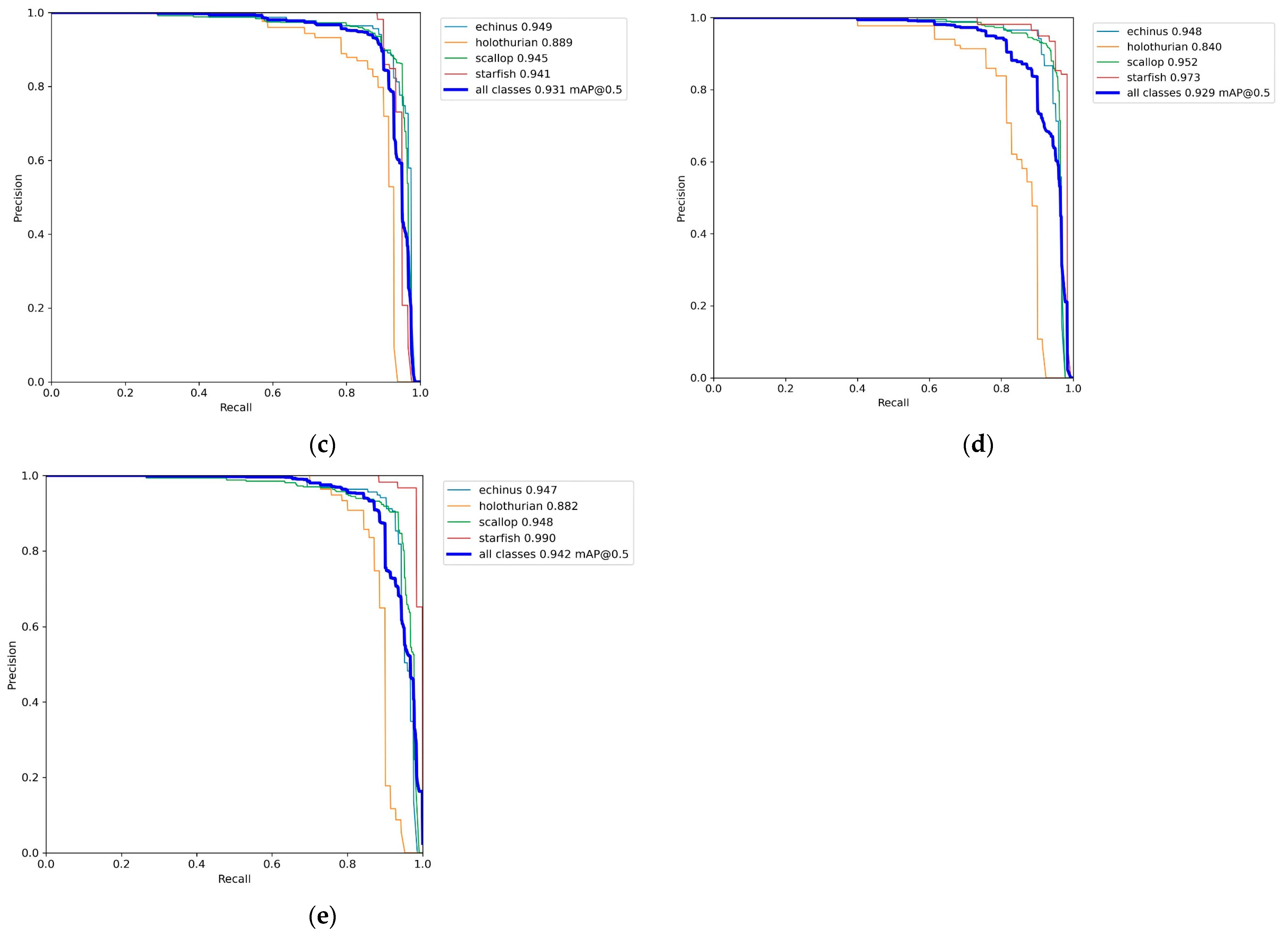
4.2. Ablation Experiment
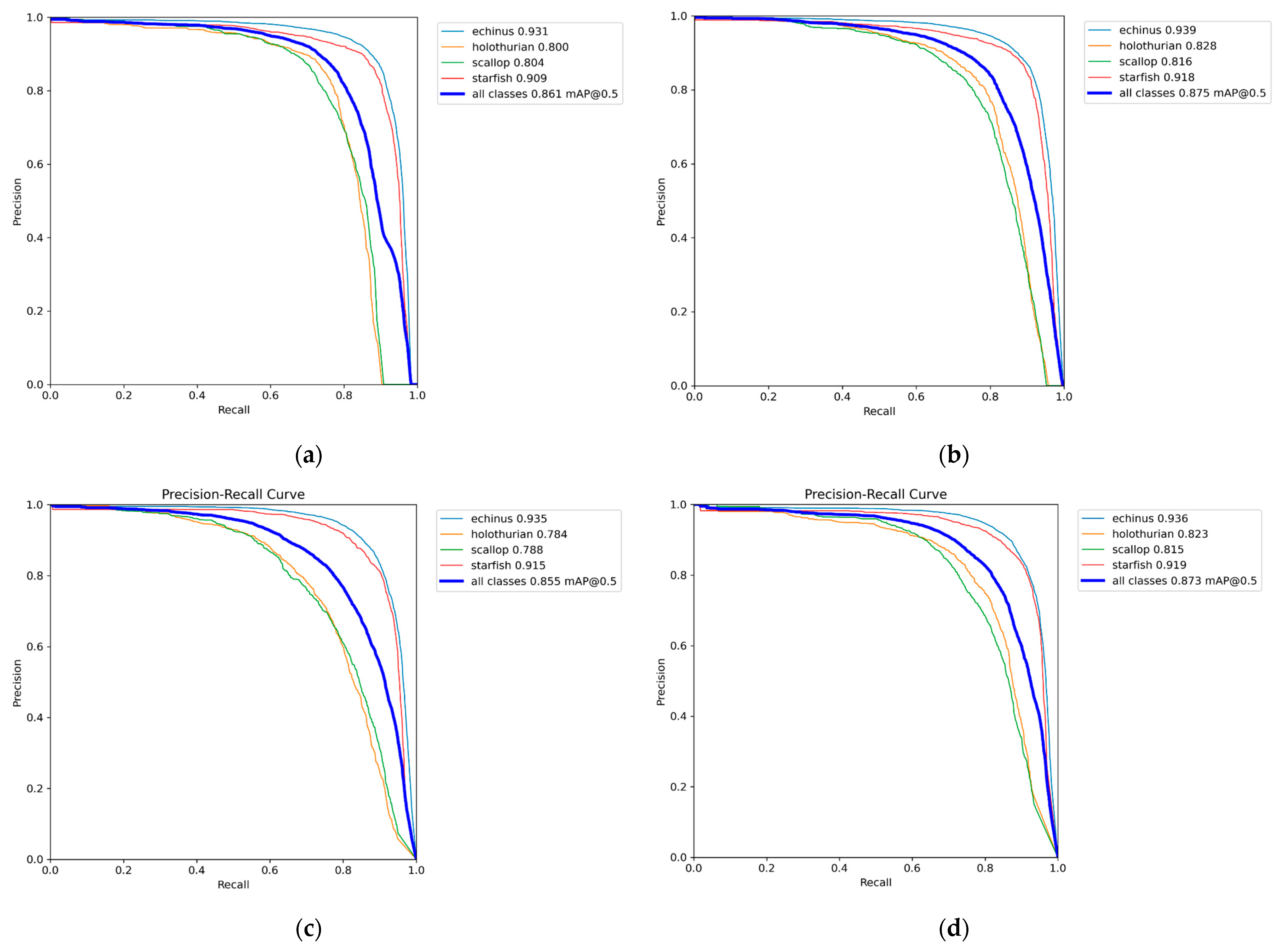
4.3. Comparison with Other Models
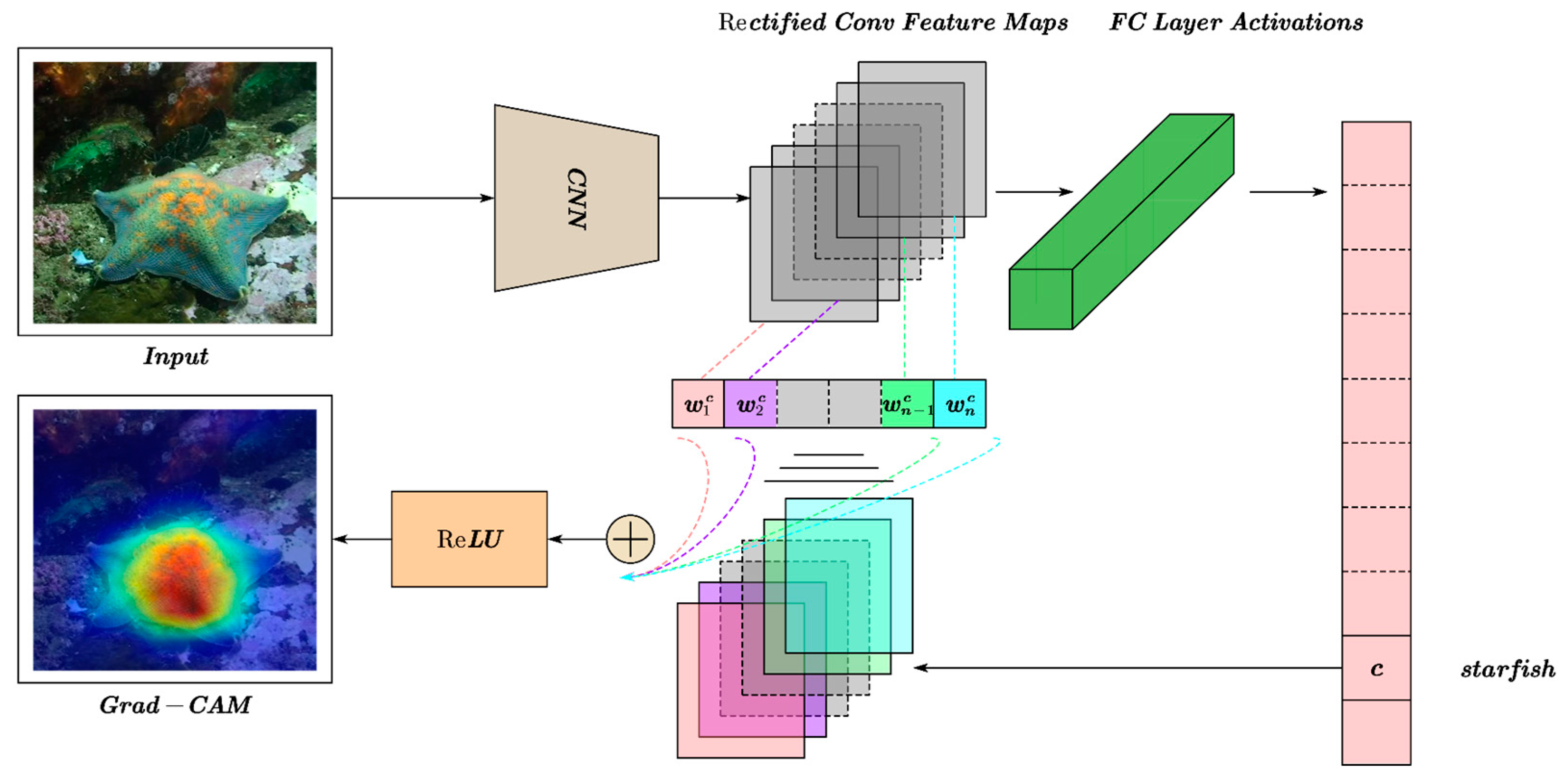
4.4. Grad-CAM Visualization
4.5. Analysis of Detection Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, T.; Zhang, Q.; Zhang, Y.; Sun, Y.; Fan, Y. Dynamic Modeling and Simulation Analysis of Underwater Manipulator with Large Arms. Chin. Hydraul. Pneum. 2021, 45, 25–32. [Google Scholar]
- Fan, Z.; Ha, Z. Underwater Manipulator Motion Spatial Analysis and Tracking Algorithm Optimization. Mach. Electron. 2020, 38, 67–73. [Google Scholar]
- Sahoo, A.; Dwivedy, S.K.; Robi, P.S. Advancements in the field of autonomous underwater vehicle. Ocean Eng. 2019, 181, 145–160. [Google Scholar] [CrossRef]
- Carlucho, I.; De Paula, M.; Wang, S.; Petillot, Y.; Acosta, G.G. Adaptive low-level control of autonomous underwater vehicles using deep reinforcement learning. Robot. Auton. Syst. 2018, 107, 71–86. [Google Scholar] [CrossRef]
- Ullah, I.; Chen, J.; Su, X.; Esposito, C.; Choi, C. Localization and Detection of Targets in Underwater Wireless Sensor Using Distance and Angle Based Algorithms. IEEE Access. 2019, 7, 45693–45704. [Google Scholar] [CrossRef]
- Yang, M.; Hu, J.; Li, C.; Rohde, G.; Du, Y.; Hu, K. An in-depth survey of underwater image enhancement and restoration. IEEE Access 2019, 7, 123638–123657. [Google Scholar] [CrossRef]
- Han, M.; Lyu, Z.; Qiu, T.; Xu, M. A review on intelligence dehazing and color restoration for underwater images. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 1820–1832. [Google Scholar] [CrossRef]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Han, J.; Zhou, J.; Wang, L.; Wang, Y.; Ding, Z. FE-GAN: Fast and Efficient Underwater Image Enhancement Model Based on Conditional GAN. Electronics 2023, 12, 1227. [Google Scholar] [CrossRef]
- Qi, Q.; Zhang, Y.; Tian, F.; Wu, Q.J.; Li, K.; Luan, X.; Song, D. Underwater Image Co-Enhancement with Correlation Feature Matching and Joint Learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1133–1147. [Google Scholar] [CrossRef]
- Gao, Y.; Yang, L.; Gao, P. Research on object detection algorithm based on yolov3. Control. Instrum. Chem. Ind. 2021, 48, 581–588. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 38, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Zhang, S. An underwater fish object detection method based on Faster R-CNN and image enhancement. J. Dalian Ocean. Univ. 2020, 35, 612–619. [Google Scholar]
- Song, S.; Zhu, J. Research on underwater biological object recognition based on mask R-CNN and transfer learning. Comput. Appl. Res. 2020, 37, 386–391. [Google Scholar]
- Chen, Y.Y.; Gong, C.Y.; Liu, Y.Q. Fish recognition method based on FTVGG16 convolutional neural network. Trans. Chin. Soc. Agric. Mach. 2019, 50, 223–231. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1483–1498. [Google Scholar] [CrossRef]
- Zeng, L.; Sun, B.; Zhu, D. Underwater target detection based on Faster R-CNN and adversarial occlusion network. Eng. Appl. Artif. Intell. 2021, 100, 104190. [Google Scholar] [CrossRef]
- Liu, J.; Liu, S.; Xu, S.; Zhou, C. Two-Stage Underwater Object Detection Network Using Swin Transformer. IEEE Access 2022, 10, 117235–117247. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. Eur. Conf. Comput. Vis. 2016, 14, 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Xu, J.; Dou, Y.; Zheng, Y. An underwater object recognition and tracking method based on YOLO-V3 algorithm. Chin. J. Inert. Technol. 2020, 28, 129–133. [Google Scholar]
- Mao, G.; Weng, W.; Zhu, J.; Zhang, Y.; Wu, F.; Mao, Y. Shallow sea biological detection model based on improved YOLO-V4 network. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 152–158. [Google Scholar]
- Chen, L.; Zheng, M.; Duan, S.; Luo, W.; Yao, L. Underwater Target Recognition Based on Improved YOLOv4 Neural Network. Electronics 2021, 10, 1634. [Google Scholar] [CrossRef]
- Lei, F.; Tang, F.; Li, S. Underwater Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- Qiang, W.; He, Y.; Guo, Y.; Li, B.; He, L. Research on underwater object detection algorithm based on improved SSD. J. Northwestern Polytech. Univ. 2020, 38, 747–754. [Google Scholar] [CrossRef]
- Zhao, X.; Yu, S.; Li, Q.; Yan, Y.; Zhao, Y. Underwater object detection algorithm based on attention mechanism. J. Yangzhou Univ. Nat. Sci. 2021, 24, 62–67. [Google Scholar]
- Wei, X.; Yu, L.; Tian, S.; Feng, P.; Ning, X. Underwater target detection with an attention mechanism and improved scale. Multimed. Tools Appl. 2021, 80, 33747–33761. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1–12. [Google Scholar]
- Zou, Z.; Gai, S.; Da, F.; Li, Y. Occluded pedestrian detection algorithm based on attention mechanism. Acta Opt. Sin. 2021, 41, 157–165. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- YOLO by Ultralytics, version 5.0.0; Ultralytics: Washington, USA, 10 June 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 27 February 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. Eur. Conf. Comput. Vis. 2014, 37, 346–361. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- YOLO by Ultralytics, version 8.0.0; Ultralytics: Washington, USA, 10 January 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 13 May 2023).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Epochs | Batch Size | Learning Rate | Weight Decay | Momentum |
|---|---|---|---|---|
| 500 | 16 | 0.01 | 0.005 | 0.9 |
| Model | P (%) | R (%) | mAP@0.5 (%) |
|---|---|---|---|
| YOLOv5 | 91.2 | 88.9 | 93.5 |
| YOLOv5+SE | 92 | 87.2 | 93.7 |
| YOLOv5+CA | 93 | 87.7 | 93.1 |
| YOLOv5+CBAM | 91.1 | 89.6 | 92.9 |
| YOLOv5+CSFA(ours) | 94.2 | 87.8 | 94.2 |
| Model | AP (%, Holothurian) | AP (%, Echinus) | AP (%, starfish) | AP (%, Scallop) | mAP@0.5 (%) |
|---|---|---|---|---|---|
| RCNN [12] | 68.2 | 80.4 | 78.9 | 69.3 | 74.2 |
| Fast RCNN [13] | 70.5 | 82.3 | 81.4 | 71.4 | 76.4 |
| Faster RCNN [14] | 74.1 | 85.5 | 84.4 | 75.2 | 79.8 |
| YOLOv3 [31] | 73.3 | 84.6 | 83.3 | 74.4 | 78.9 |
| YOLOv3+SENet [29] | 78 | 89.2 | 87.1 | 78.5 | 83.2 |
| YOLOv4 [41] | 78.2 | 90.7 | 86.4 | 78.3 | 83.4 |
| YOLOv5 [37] | 80 | 93.1 | 90.9 | 80.4 | 86.1 |
| YOLOv6 [42] | 78.4 | 93.5 | 91.5 | 78.8 | 85.5 |
| YOLOv8 [43] | 82.3 | 93.6 | 91.9 | 81.5 | 87.3 |
| YOLOv5+CSFA(ours) | 82.8 | 93.9 | 91.8 | 81.6 | 87.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Xue, G.; Huang, S.; Liu, Y. Underwater Object Detection Algorithm Based on Adding Channel and Spatial Fusion Attention Mechanism. J. Mar. Sci. Eng. 2023, 11, 1116. https://doi.org/10.3390/jmse11061116
Wang X, Xue G, Huang S, Liu Y. Underwater Object Detection Algorithm Based on Adding Channel and Spatial Fusion Attention Mechanism. Journal of Marine Science and Engineering. 2023; 11(6):1116. https://doi.org/10.3390/jmse11061116
Chicago/Turabian StyleWang, Xingyao, Gang Xue, Shuting Huang, and Yanjun Liu. 2023. "Underwater Object Detection Algorithm Based on Adding Channel and Spatial Fusion Attention Mechanism" Journal of Marine Science and Engineering 11, no. 6: 1116. https://doi.org/10.3390/jmse11061116
APA StyleWang, X., Xue, G., Huang, S., & Liu, Y. (2023). Underwater Object Detection Algorithm Based on Adding Channel and Spatial Fusion Attention Mechanism. Journal of Marine Science and Engineering, 11(6), 1116. https://doi.org/10.3390/jmse11061116