1. Introduction
Autonomous underwater vehicles (AUV) usually use the Inertial Navigation System (INS) as their primary navigation device, but INS requires regular calibration to be able to perform long-term missions. In underwater situations, traditional navigation methods (e.g., GPS) are greatly limited due to the complexity and variability of the underwater environment [
1,
2,
3]. In contrast, the Gravity-Aided Inertial Navigation System (GAINS) is an advanced technology used for underwater navigation that enables highly accurate position estimation without emitting or receiving signals. To achieve this objective, GAINS utilizes a specially designed navigation algorithm to compare the gravimeter’s measurements of gravity anomalies at the current position with the stored gravity field data to effectively correct the INS position [
4,
5,
6,
7].
As the variability of the gravity field significantly affects the performance of GAINS [
8,
9], the use of gravity navigation in order to make path planning for UAVs is crucial.In this regard, previous researchers have explored several characteristics to describe the gravity field information, such as variance, roughness, slope, coefficient of variation, fractal dimensions, and their combination to determine the efficiency of using the gravity field for navigation [
10,
11,
12]. Based on empirical thresholds, the gravity map is divided by its characteristics into two categories: informative (suitable for positioning) and non-informative (not suitable for positioning) [
13]. Then, by treating non-informative areas as obstacles, the path planning problem can be transformed into a sequence optimization problem [
14,
15]. There are many optimization methods available to solve this problem, including genetic algorithms, simulated annealing algorithms, ant colony algorithms, particle swarm algorithms, etc. [
16,
17,
18,
19,
20]. However, the assumption that non-informative areas are restricted regions and entering these areas will result in significant positioning errors does not apply to UAV navigation situations. For example, flat areas are not suitable for gravity navigation, but there are no real obstacles, and, even relying solely on INS, it is possible to safely navigate through them. Furthermore, research suggests that areas suitable for positioning based on local characteristics are typically discrete and small, making it difficult to find connected informative areas [
13,
21,
22,
23]. As a result, it is impossible to use obstacle avoidance path planning methods for path planning in any sea area, especially when the starting or target points are surrounded by non-informative regions.
The main purpose of the planning method in this study is to find a path that minimizes the positioning error between the starting and ending points and can be carried out in any sea area. It is necessary to compare the filtering results along different trajectories to determine the optimality of the planned path. The posterior Cramér-Rao bound (PCRB) integrates information from kinetics and measurement models; therefore, it comprises all sensor-obtained gravity field information without the need for actually implementing the filtering algorithm [
24,
25,
26,
27,
28,
29,
30]. A* algorithm is one of the most common heuristic search algorithms, swiftly investigating a possible set of solutions for a given issue using heuristic search techniques, focusing more on the end answer than on sub-problems, which enables it to produce pathways fast and with improved results [
31,
32]. This study uses PCRB as the cost function of A*, precisely fusing the path planning and navigation filter estimation results. The characteristics of the gravity fields at departure and destination are not limitations on the proposed path-planning method. This study doe not add distance directly to the cost or heuristic function like most shortest path trajectory designs do. Instead, the distance factor is included in the INS error divergence variance. Hence, this method can plan the quickest path while maintaining positioning accuracy.
The following is the arrangement of this paper:
Section 2 derives the PCRB model of GAINS, and
Section 3 combines PCRB with A* to form the PCRB-based A* path planning method. In
Section 4, two simulation tests were conducted to prove the optimality of the two planned paths. Finally, conclusions are given in
Section 5.
2. PCRB for Gravity-Aided Navigation System
In most cases, GAINS is modeled as a hidden Markov model (HMM), as shown in
Figure 1, i.e., the observation depends only on the state of the Markov chain at that moment, independent of the other states; the current moment state is related only to the previous moment.
The mathematical model of GAINS can be reduced to the following two discrete-time equations.The first equation describes the evolution of the state vector, i.e., the INS error propagation process
where
is the state vector indicating the carrier position.
represents the state increment of INS.
represents the state noise from IMU measurement error, Gaussian distribution, and with covariance matrix
.
The second equation describes the observed values of the gravity sensor and the comparison with the reference map values by interpolation
where
is the measurement of the gravimeter at time
t, and
h denotes the interpolation method of the gravity sensors model combined with the reference data map, usually sampling bilinear or Kriging interpolation.
denotes the measurement noise of the geophysical sensor, which is assumed to be additive Gaussian white noise.
denotes the reference data mapping error. Considering this error covariance depending on the location, the variance matrix of the total observation error is modeled as (3) [
33].
where
includes a combination of sensor measurements and map uncertainty.
is the map spatial resolution, and
is the map mapping error variance.
is the variance of the local gravity anomaly.
is the inverse of the square of the correlation distance, and
is the gravimeter measurement error variance.
Under the assumption of additive Gaussian white noise,
and
, are assumed to be independent of each other, and independent of
. (1) and (2) explicitly determine the joint probability distribution
of
and
at any moment
t with a known
.
where
refers to the probability density of the variables described in the parameters of
p. The derivation of (4) makes use of the Markov property of the model, i.e.,
, and
.
PCRB is a lower bound on the mean squared error (MSE) of a deterministic parameter estimate in parameter estimation, defined as the variance of any unbiased estimate being at least larger than the inverse of the Fisher information. Whenever the estimate
is based on the sequence
, the mean square error for any unbiased estimator
should satisfy the following condition.
where
is the Fisher information matrix.
where
denotes the joint probability density of
and
. Here and below, ∇ is the operator of the first order derivative, and
is the operator of the second order derivative.
Let
denote the PCRB of the state
determined for a given measurement
. By decomposing the lower bound (5) into subblocks, the estimated covariance of
is lower bounded by the lower right block of
, i.e.,
Correspondingly,
Insert (4) into (8) to get the recursive update
where
denotes the block matrix of zero entries of appropriate dimensionality.
Comparing with (9), it follows that
Under the assumption that the noise
and
of (1) and (2) are zero-mean Gaussian and invertible covariance matrices,
and
, respectively, therefore,
where
and
are constants. Thus, in the Equation (11),
where
and
is the gradient of
at the true position at time
t. In the above derivation, the expectation of both the measurement noise and the position is 0, so the expectation
is computed only at the current true position.
Bringing the Equations (14)–(16) into the Equation (11) gives
The derivation of (17) makes use of the Woodbury matrix identity [
34].
in (17) is only related to the position and represents the gravity information obtained from the map, and the square root of the trace of this matrix is used as the scalar navigation information map.
A further expansion of Equation (17) using the Woodbury matrix identity gives a more interesting form
(20) and (21) constitute the recursive form of the PCRB for the state estimation in GAINS, where (20) is the one-step prediction covariance and (21) is the posterior filter covariance.
By linearizing the model, the recursive PCRB is consistent with the Riccati recursion of the error covariance of the Kalman filter for the system. This also indicates that the Kalman filter can obtain the optimal solution under the assumption of linear system models, and its state covariance can reach the PCRB.
3. A* Algorithm Path Planning Design Based on PCRB
The A* algorithm is a heuristic search algorithm that is recursive in nature and can follow certain steps, starting from the original state and gradually searching to the optimal solution. The A* algorithm uses the overhead G between nodes in the graph, and a heuristic function H related to the current task to find the optimal path.
where,
is the valuation function of a node, which indicates the combined priority of that node considered in the selection of node
n.
denotes the actual generation value from the starting point to the current node.
denotes the cost estimate of the current node to the target point, which is the prediction function.
The computation in PCRB is in the time domain and the A* algorithm works in the spatial domain. To facilitate the combination of PCRB with the A* algorithm, the coordinates at
t time are assumed to be
n. Correspondingly, the estimated position PCRB in
n coordinates is
. The INS position error dispersion is assumed to be time-dependent only, and the coefficient of linear drift of the position error variance with time is
. Denote the Euclidean distance from the current point
to the parent node
by
, and denote the distance from the current point to the target node by
to denote the Euclidean distance from the current point to the target node.
The position error uncertainty of INS grows linearly over a certain time period, and the relationship between
and distance is as follows.
where
is the average velocity of the carrier during the sampling interval.
The main goal of this paper is to identify the path that minimizes the total posterior filtering errors of navigation at each current waypoint. We accomplish this by using the PCRB
at the present position
n as the cost function
for the current node in the A algorithm.
(26) represents the navigation error covariance of the one-step prediction, and (27) represents the correction of the one-step prediction by the posterior information from the reweighted force measurement to obtain the PCRB. Obviously the
matrix is a square matrix whose diagonal elements represent the error variance in two orthogonal directions,
X direction (eastward) and
Y direction (northward). In this paper, the sum of the traces of the PCRB of the localization error at each point on the trajectory is used as a metric to quantify the navigation accuracy of this path, i.e.,
where
means trace operation.
The heuristic function is the expected navigation error for the increase of the current position to the target position. Based on the fact that the INS position error can be considered as linearly divergent in the short term, the heuristic function is set to
Assuming that the current node is n and the actual cost is , the complete computation steps of for its child node are as follows.
- (1)
Calculate the distance from the child node to the target node according to Equation (24), and bring in Equation (29) to calculate the estimated value .
- (2)
The distance from the child node to the parent node is calculated according to Equation (23) and brought into Equation (25) to get .
- (3)
Substitute into Equation (26) to get then bring (28) to calculate of the child nodes.
- (4)
Combining the obtained
and
,
The A* algorithm controls the points in the map by setting the open list and close list, and the pseudo code table of PCRB-based A* path planning algorithm is shown in Algorithm 1.
| Algorithm 1 The PCRB-base A* path planning algorithm |
Add the start point s to the open list and set the initial value . Repeat the following procedure: - (1)
Iterate through the open list to find the node with the smallest F value and use it as the current node n to be processed. - (2)
Move the node to be processed to the close list. - (3)
For each of 8 grid points adjacent to the current node:
- i
Ignore if it is already in the closed list; - ii
If it is not in the open list, add it and set the current node as its parent, recording the F, G and H values of this node; - iii
If it is already in the open list, check if this path (i.e., via the current node to this node) is better. Using the trace of G as a reference, a smaller value indicates that this path has a smaller localization covariance. If so, set its parent node to the current node and recalculate its G value and F value. The open list is sorted by F values and needs to be reordered after the change.
- (1)
Stop, when
- (i)
The endpoint is added to the open list, and the path is found at this point. - (ii)
The find focus fails and the open list is empty, when there is no path.
- (2)
Let and deal with the next node.
Starting from the end point, each node moves along its parent node until the start point, saving the path. |
4. Simulation
The numerical gravity map of the simulation shown in
Figure 2 is derived from the global ocean gravity field
model produced by Sandwell’s team [
35], and the accuracy of the gravity field of the selected experimental region is better than
mGal. The maximum gravity anomaly in the region is
mGal and the minimum is
mGal. The gravity anomaly is highly undulating and contains various topographic features such as peaks, slopes, and flats, which are suitable for path planning analysis. Since the actual horizontal distances of longitude and
latitude of
are different, this paper projects the earth coordinate system to the geographic coordinate system, and the spatial resolution of the interpolated map is 1 km.
The measure of trajectory performance uses the Root Mean Square Error (RMSE), which is the square root of the ratio of the square of the deviation of the predicted value from the true value to the number of observations
n.
where
is the estimated value of the trajectory coordinates,
is the true value of the trajectory coordinates, and
N is the number of Monte Carlo experiments.
The estimated position
is calculated by the SITAN algorithm, which is essentially an extended Kalman filter algorithm [
5,
36]. The state error propagation of SITAN can be simply modeled as (32).
where
is the position error of INS, i.e.,
.
SITAN uses random linearization techniques to fit linear observation models.
where coefficients for
can be obtained from the following
(34) and (35) describe the process of calculating the observation matrix
H for gravity anomaly data. The variables used are as follows:
, which represents the grid of the INS indicator position on the digital gravity map;
, which is the gravity anomaly extracted from the digital map based on the INS indicated position;
, which is the gravity anomaly measured in real-time;
which is the spacial resolution of the digital map; and
L, which represents the number of grid points in the length of the fitted interval. Generally, a more accurate INS indicator position leads to a smaller INS confidence interval, resulting in a more precise linearized observation model.
For comparison, the following method [
31,
37] (hereinafter named method1) is used to calculate the informative areas.
where
and
are the sum of the squares of the gravity anomaly differences between point
and its adjacent points within a distance of
k in the latitude and longitude directions. When
,
is used as a criterion for determining the informative areas, as shown in
Figure 3.
In order to implement method1 in the A* algorithm, the following design was carried out:
The meaning of (39) is to use the distance from the current point to the goal point as the heuristic function . (40) represents a cost function of 0 in the informative areas and 1 in the non-informative areas, rather than being treated as obstacles.
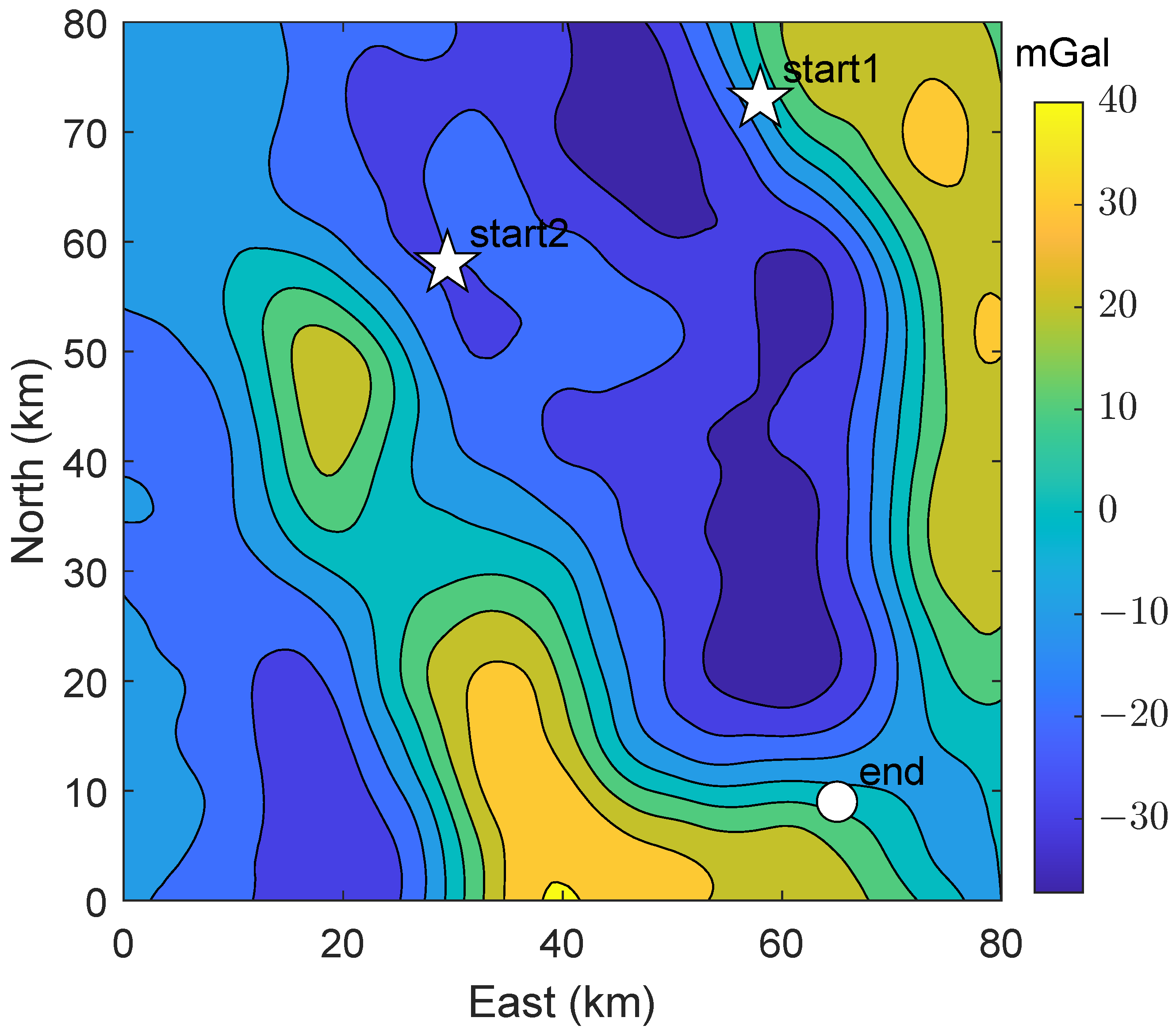
4.1. Test 1
The starting point of Test 1 in the planned path is located at
(start1 in
Figure 2). The point is located within the slope area, where contour lines are densely distributed. The ending point, on the other hand, has coordinates of
.
Table 1 lists the simulation conditions.
The background in
Figure 4 is the
contour filling map calculated from Equation (19) in spatial domain, i.e.,
where
is the slope vector of the gravity field, and
is the variance of the gravity measurement error at position
n.
represents the information of gravity anomaly fields in a small area that GAINS can collect. That is, a large
means a small value of positioning error. A comparison between this and the gravity anomaly contours in
Figure 2 reveals that regions with denser contours correspond to larger
, which indicates that gravity navigation is more advantageous in these areas. In addition, compared with
Figure 3, areas with large
(i.e., dark colored areas) are basically consistent with the informative areas determined by method1, indicating that
can quantify the informative areas.
As shown in
Figure 4, following the proposed method, the planned path intersects the region with maximum information. However, the trajectory planned by method1 roughly follows the contour of the informative areas, rather than the center. Furthermore, the planned trajectory is smoother than the trajectory of method1, which is beneficial for heading control. In order to determine the optimality of the planned path, in addition to the path of method1 and the shortest path, we established several equidistant curves for comparison. Five additional curves were labeled as L1, L2, … curves, L5, from left to right, with a horizontal distance of 3.5 km between them.
We conducted Monte-Carlo simulations 100 times with the same parameters as those listed in
Table 1. Each trajectory was divided into 100 sampling points by equal Euclidean distances.
Figure 5 provides a comparison of the localization accuracy achieved using different trajectories in Test 1. As can be seen from
Figure 5, the RMSE of all paths decreases rapidly during the initial stage since the starting point 1 is located in a region with high
values. Among them, due to L4 and L5 towards the east heading in the initial stage, where the
value there is relatively small, there is a slower RMSE descent of the trajectory in these two compared to other trajectories. Although the planned trajectory does not maintain the lowest RMSE throughout the entire path, it can be seen in the
Figure 6 that the total RMSE of the planned trajectory is the smallest.
A noteworthy phenomenon is that even though L1 deviates from areas with high values, or even has a segment in the trajectory that is in a very small region, it still achieves a lower RMSE. One possible reason is that its path is short, so the divergence of the INS is small. The positioning accuracy is the comprehensive result of INS divergence and gravity-assisted correction, which cannot be determined solely by or the characteristic parameters of informative areas.
4.2. Test 2
Test 1 indicates that the RMSE of all trajectories decreases rapidly during the initial phase because the starting point is located in informative areas. Test 2 changed the starting point to
(start2 in
Figure 2), situated at a relatively gentle seabed. As shown in
Figure 7, this location has a smaller
value, indicating that less gravity information can be used at the initial position. Consistent with test 1, in
Figure 7, the black curve represents the planned trajectory, the gray curve represents the direct trajectory, and the blue curve represents the method1 trajectory. Similarly, we also designed L1–L5 as a comparison, with a horizontal spacing of approximately 5.5 km. Due to the distance from the informative areas, method1 fails at this test and only implements the shortest path planning of the A* algorithm without passing through any informative areas.
The simulation parameter settings are the same as
Table 1.
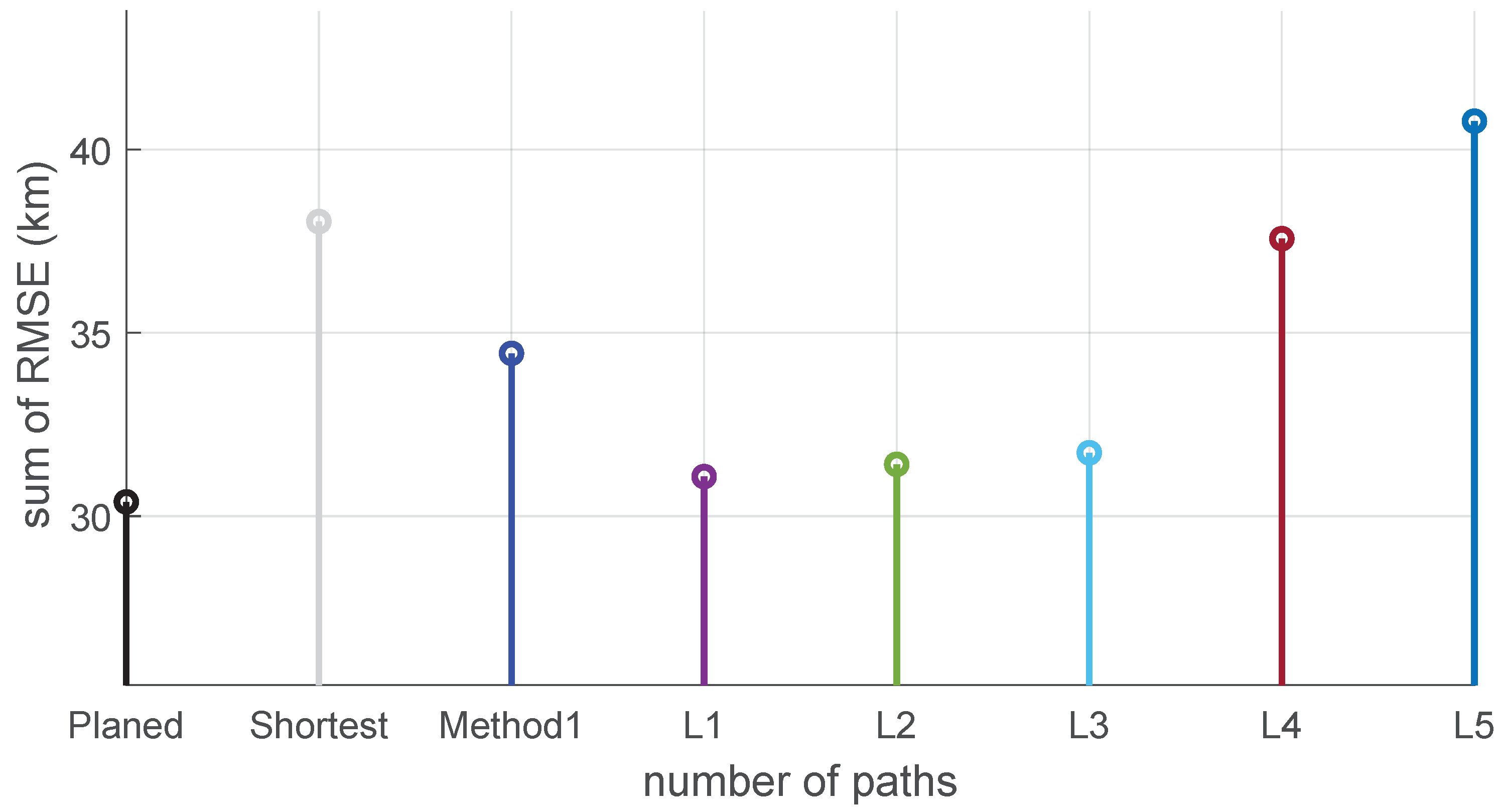
Figure 8 shows the RMSE of the position error for these trajectories, and the sum of RMSE values for each trajectory is presented in
Figure 9.
In addition to the planned trajectory, L1, L2, and L3 all cross the area with large
values on the left side in the initial stage, where L2 overlaps with the planned trajectory for a long time. In the magnified coordinate area, it can be seen that these four curves have a significantly faster descent speed at the beginning than the other four curves, including the straight line trajectory, method1 trajectory, L4, and L5. As shown in
Figure 9, among all trajectories, the sum of RMSE for L2 and L3 is close to the planned trajectory, but their path length is longer, and the planned path is still the optimal choice. Due to the neglect of the relative value of information in the path planning method based on informative areas, available gravity information below the set threshold is discarded, and the setting of the threshold is vague and empirical, and will not be applicable to any sea area. Therefore, as shown in
Figure 9, method1 exhibits the worst RMSE, even worse than the shortest path. On the contrary, the path planning method based on PCRB has clear information significance, considering not only the amount of gravity field information, but also the distance factor and INS drift rate, thus obtaining the optimal results.
4.3. The Impact of Changing the Measurement Noise on the Paths
In practice, the statistical characteristics of gyroscopes and accelerometers noise in inertial navigation systems are usually known and stable after careful calibration, so the process noise is stable. Therefore, the main factor to consider is the impact of gravity measurement errors. And since gravity measurement noise is affected by carrier motion, waves, and inaccurate map modeling, its variance is difficult to estimate accurately, so path planning should be considered to adapt to different measurement noise. The calculation of the sum of RMSE of two experimental trajectories is carried out by changing the standard deviation of the measurement noise
to obtain
Table 2.
In an overall view in
Table 2 and
Table 3, increasing the amount of measurement noise will increase the lower limit of positioning error, but will not change the ranking of the lower limit size of the curve, so the planned trajectory always has higher positioning accuracy than the other curves. Therefore, the planned trajectory is always optimal. And with the increase of the measurement noise, the improvement of the localization accuracy of the planned trajectory is more obvious. The optimality of the planned trajectory is not affected by gravimetric measurements, so that the planned trajectory can be navigated in one determined ocean mission to achieve the optimal navigation accuracy. In addition, the RMSE of a spatially close trajectory to the planned path is also close to the RMSE of the planned trajectory. Therefore, even if the real path deviates from the planned one by a small amount, it is possible to obtain a high positioning accuracy by gravity information.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}