
A New Compression and Storage Method for High-Resolution SSP Data Based-on Dictionary Learning


Abstract
:1. Introduction
2. Theory and Method
2.1. Mathematical Foundation of Dictionary Learning
2.1.1. Sparse Coding
- Set iteration time , residual , preset sparsity T, dictionary matrix , index sequence vector , matrix and original vector .
- Compute , select the element with the largest absolute value in , and denote its row number as and add it to .
- Add to the new last column of matrix , and compute the sparse coefficient vector .
- Compute the residual . If meets the accuracy requirements or , stop and generate by using the elements in as the row index to fill in the values in into the corresponding rows of the vector in turn, and filling all the remaining positions with 0. Otherwise, , and go to step 2.
2.1.2. Dictionary Update
2.2. Method and Process of 3D Ocean Sound Speed Data Compression
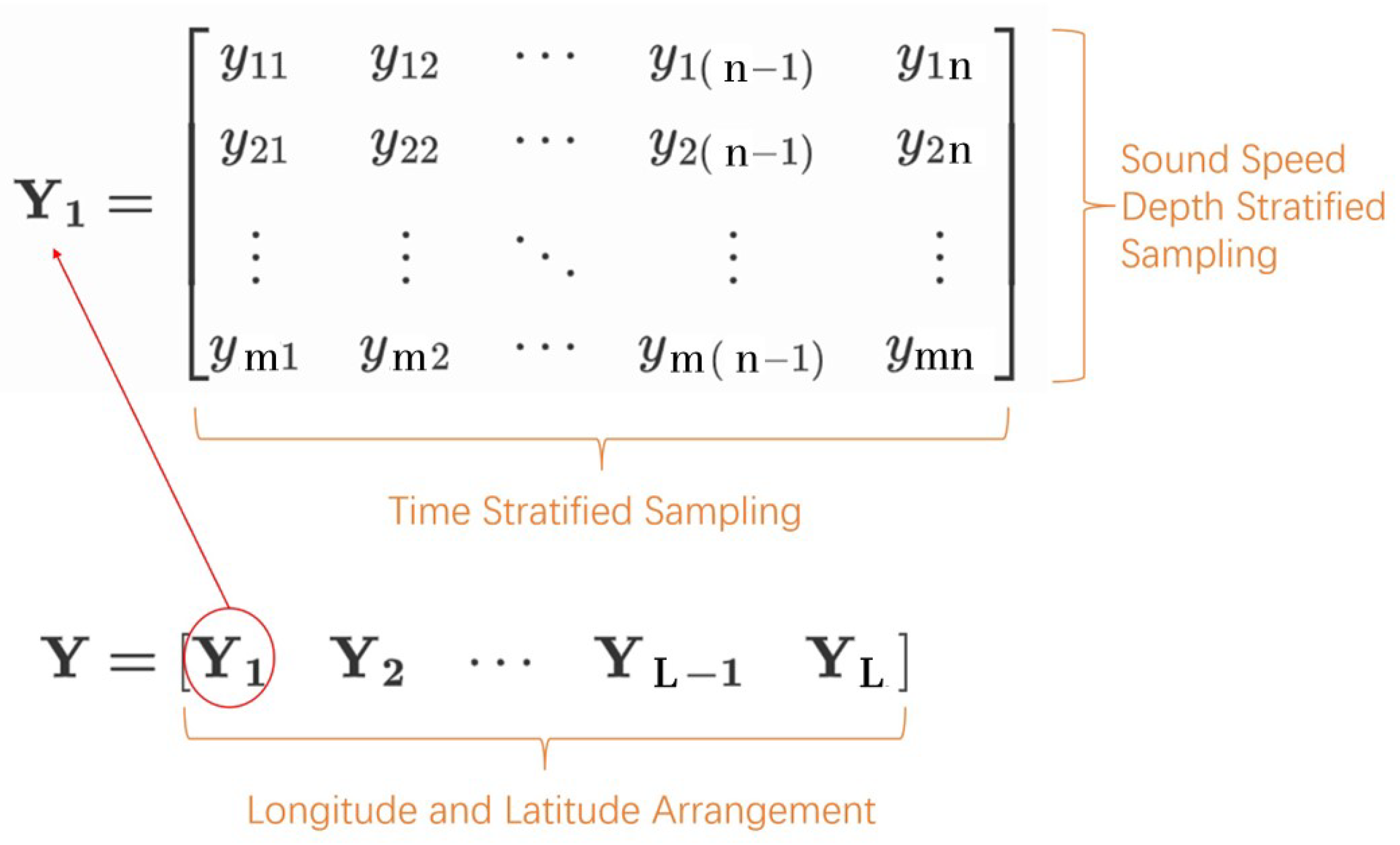
2.2.1. Data Preprocessing
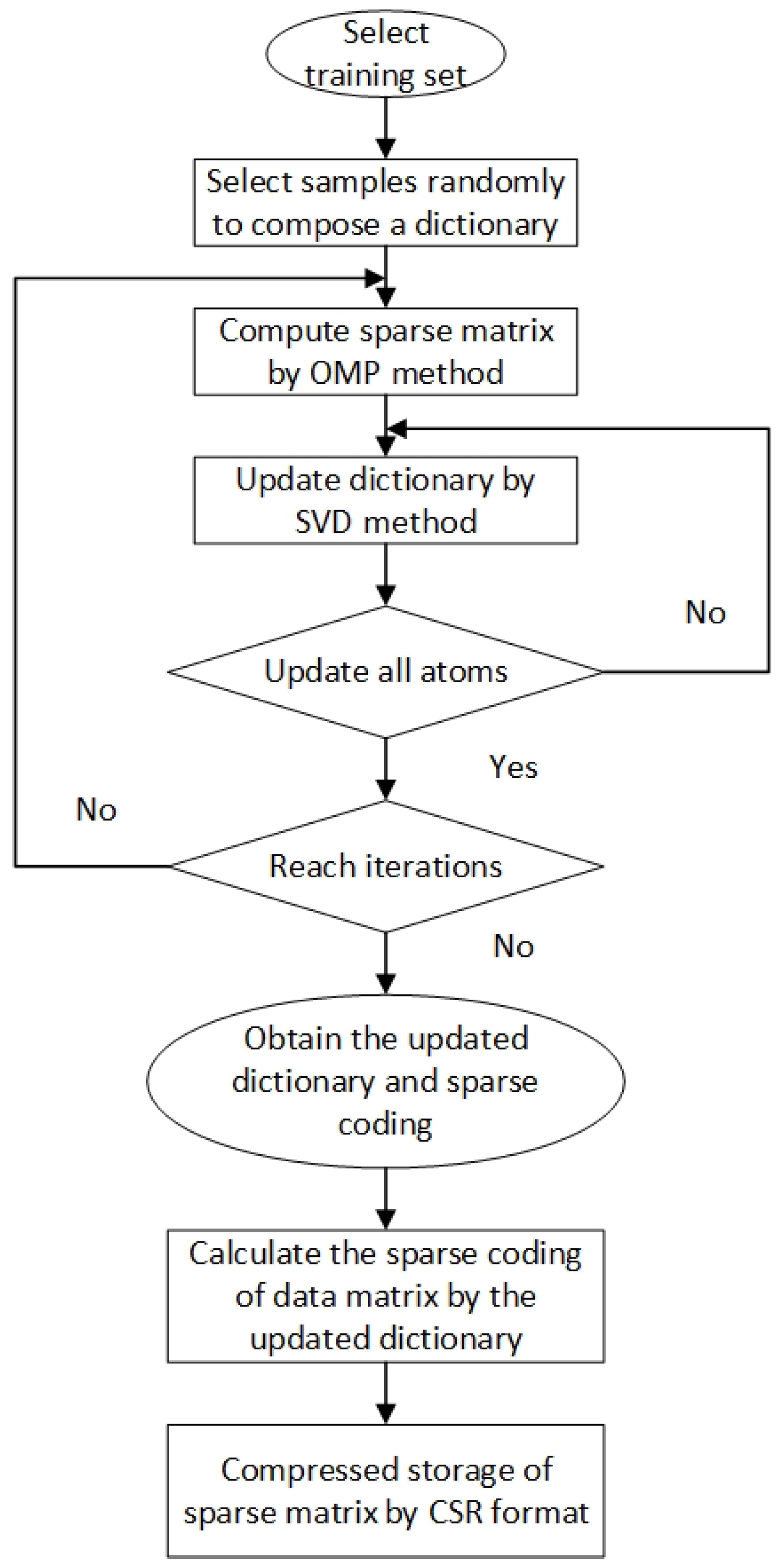
2.2.2. Dictionary Learning
2.2.3. CSR Storage
2.3. Performance Evaluation Method
2.3.1. Compression Ratio
2.3.2. Recovered Data Error
3. Numerical Results and Analysis
3.1. Influence of Each Parameter in the Algorithm
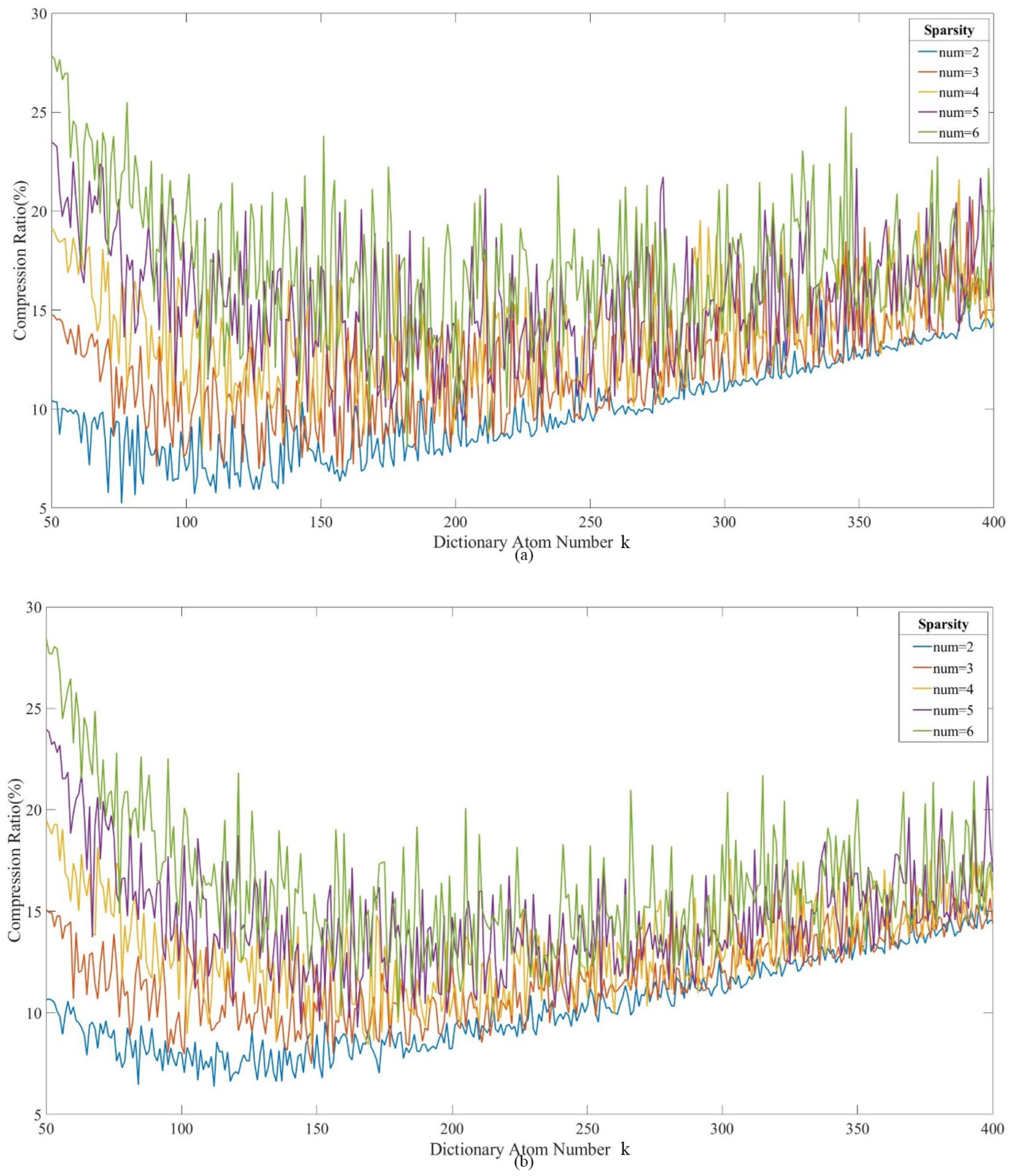
3.1.1. Actual Impact of Parameters on the Compression Ratio
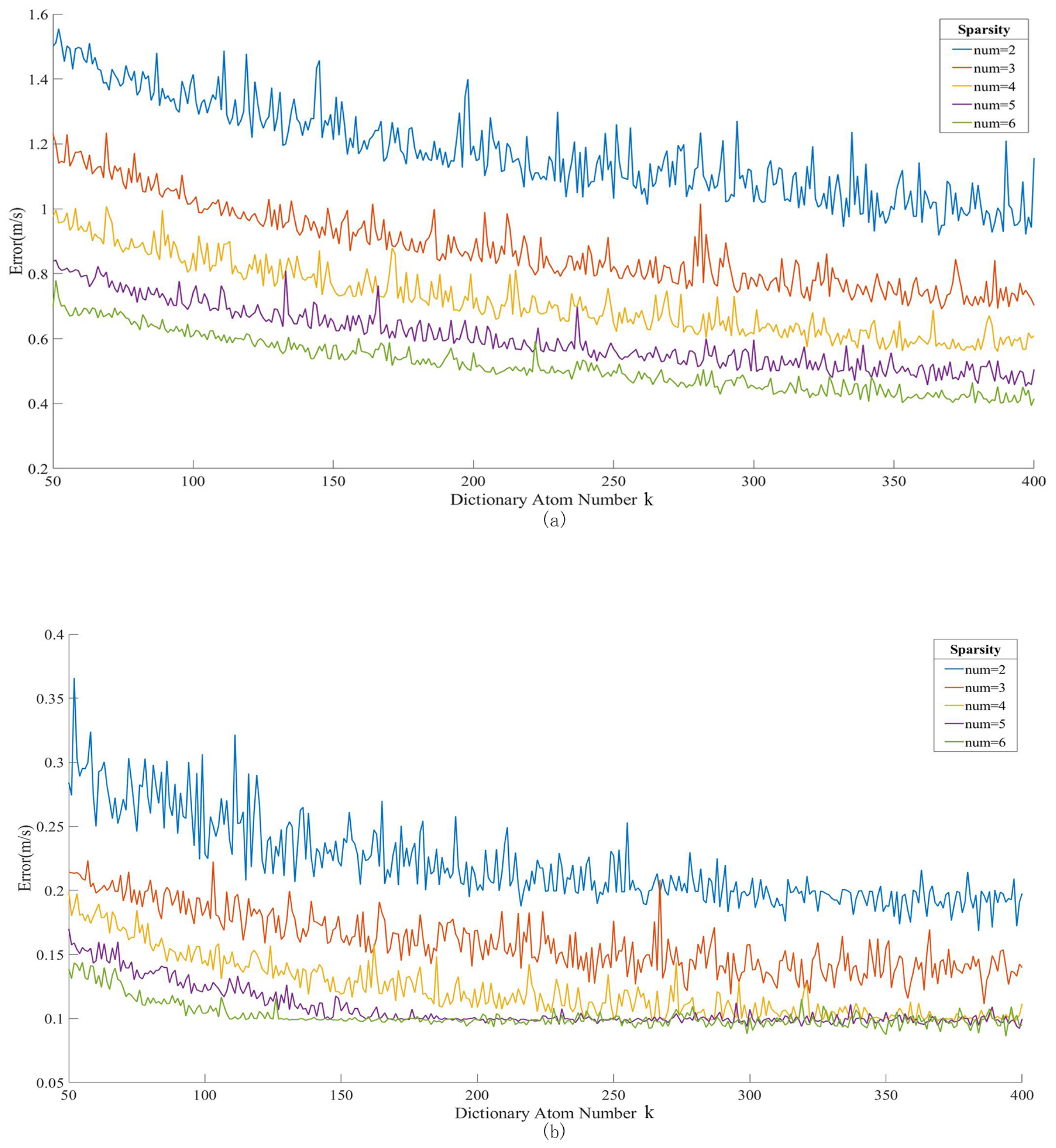
3.1.2. Actual Influence of Parameters on the Error of Recovered Data
3.1.3. Selection of Compression Performance Parameters
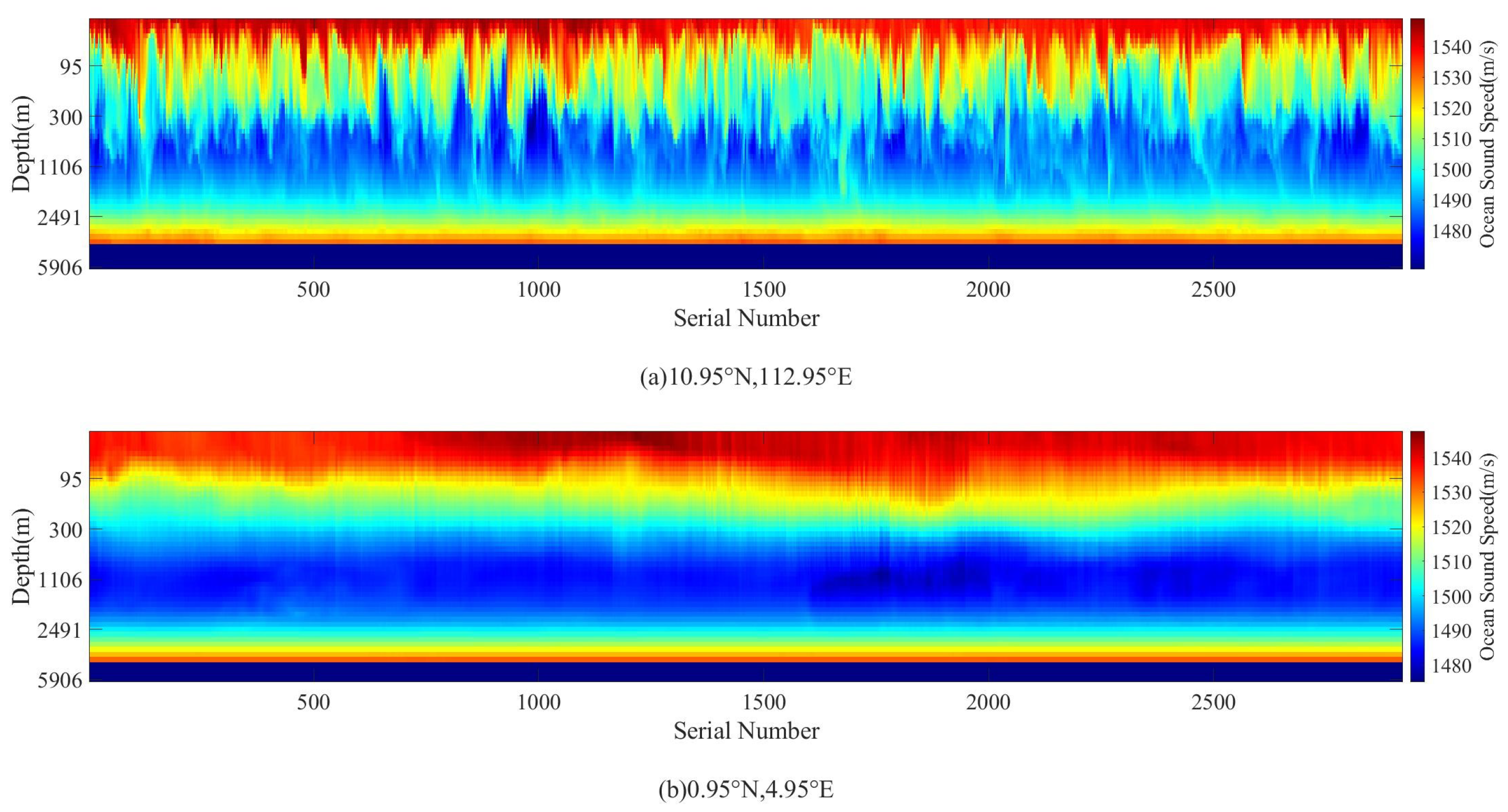
3.2. Impact of Data Matrix Organization on Performance
3.2.1. Spatio-Temporal Structure
3.2.2. Spatial Discrete Structure
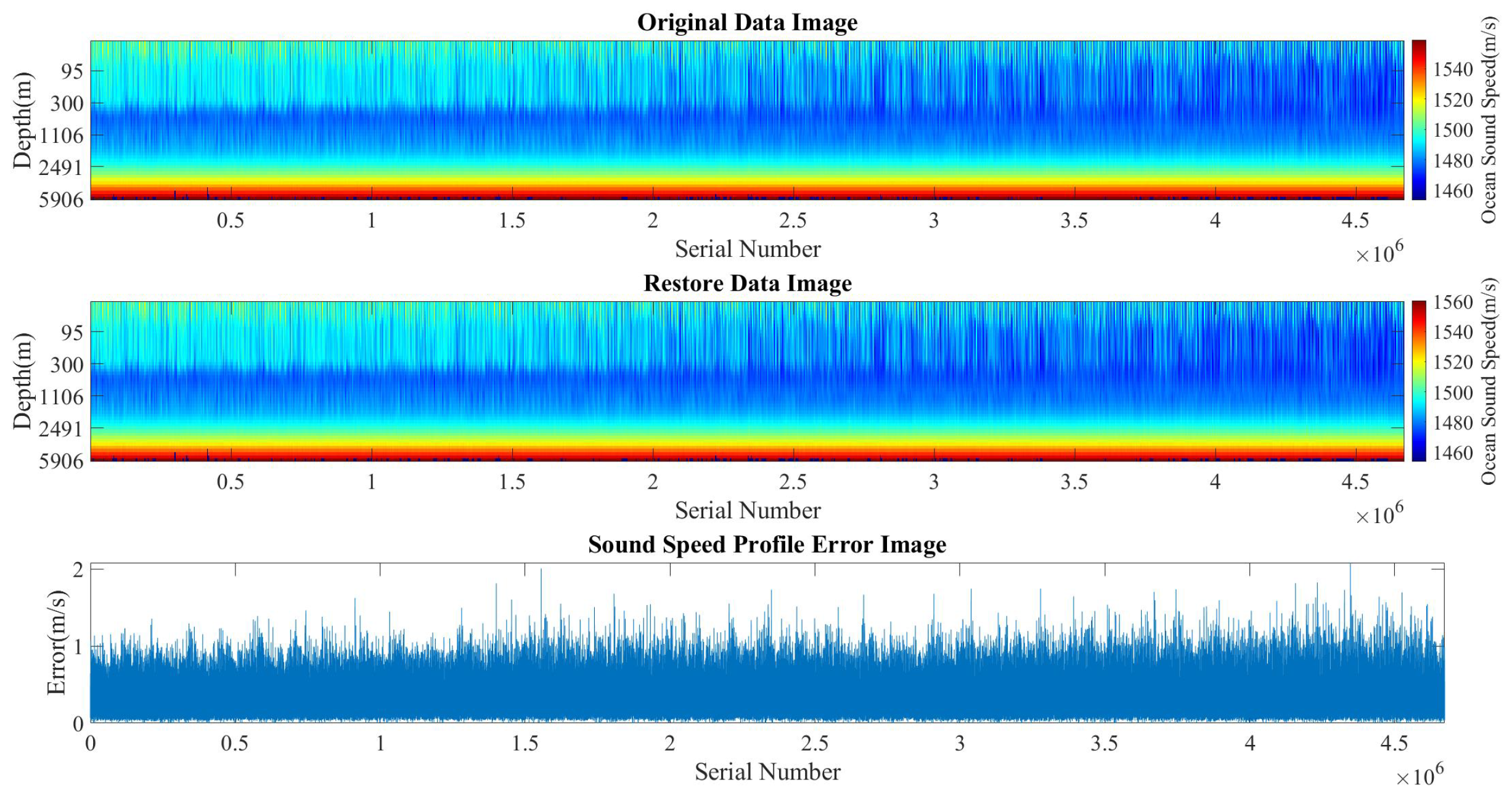
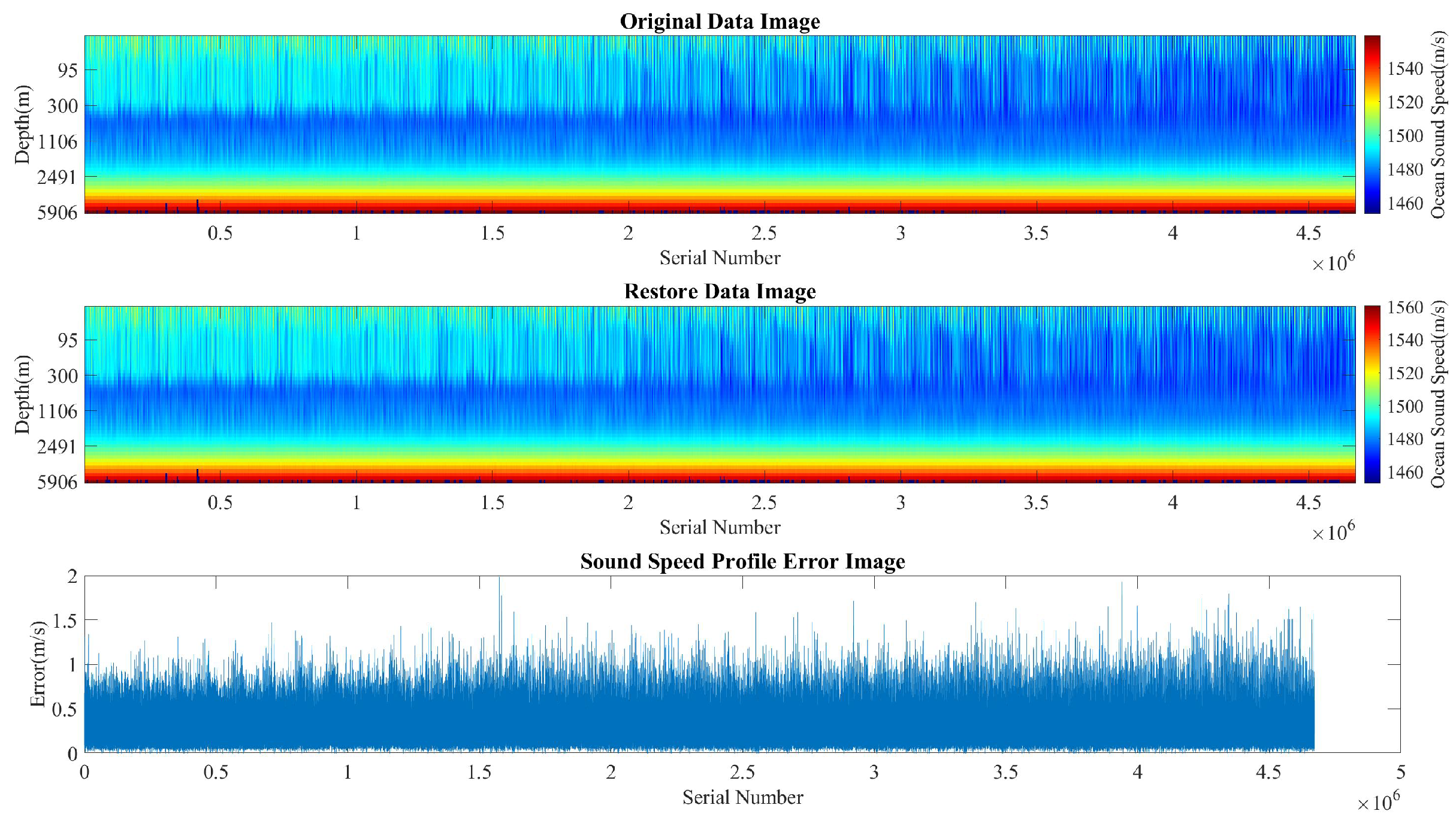
3.2.3. Performance Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tosic, I.; Frossard, P. Dictionary learning. IEEE Signal Process. Mag. 2011, 28, 27–38. [Google Scholar] [CrossRef]
- Bianco, M.; Gerstoft, P. Dictionary learning of sound speed profiles. J. Acoust. Soc. Am. 2017, 141, 1749–1758. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuo, Y.; Kiang, J. Estimation of range-dependent sound-speed profile with dictionary learning method. IET Radar Sonar Navig. 2020, 14, 194–199. [Google Scholar] [CrossRef]
- Sijia, S.; Hangfang, Z. Sparse Representation of Sound Speed Profiles Based on Dictionary Learning. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics, Chengdu, China, 17–19 October 2020. [Google Scholar]
- Qianqian, L.; Khan, S.; Fanlin, Y. Compressive acoustic sound speed proile estimation in the Arabian Sea. J. Acoust. Soc. Am. 2020, 43, 603–620. [Google Scholar]
- Pali, M.; Rurtz, S.; Schnass, K. Average performance of OMP and thresholding under dictionary mismatch. IEEE Signal Process. Lett. 2022, 29, 1077–1081. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Rubinstein, R.; Bruckstein, A.; Elad, M. Dictionaries for sparse representation modeling. Proc. IEEE 2010, 98, 1045–1057. [Google Scholar] [CrossRef]
- Mun, S.; Yazid, H. Performance analysis on dictionary learning and sparse representation algorithms. Multimed. Tools Appl. 2022, 81, 16455–16476. [Google Scholar]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; pp. 40–44. [Google Scholar]
- Huang, K.; Aviyente, S. Sparse representation for signal classification. Adv. Neural Inf. Process. Syst. 2007, 19, 609. [Google Scholar]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2691–2698. [Google Scholar]
- Chen, S.; Donoho, D.; Saunders, M. Atomic decomposition by basis pursuit. SIAM J. Sci. Comput. 1999, 20, 33–61. [Google Scholar] [CrossRef]
- Shafiee, S.; Kamangar, F. The Role of Dictionary Learning on Sparse Representation-Based Classification. In Proceedings of the PETRA ’13: Proceedings of the 6th International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes, Greece, 29–31 May 2013. [Google Scholar]
- LeBlanc, L.R.; Middleton, F.H. An underwater acoustic sound velocity data model. J. Acoust. Soc. Am. 1980, 67, 2055–2062. [Google Scholar] [CrossRef]
- Yang, M.; Zhang, L.; Feng, X.; Zhang, D. Fisher discrimination dictionary learning for sparse representation. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 543–550. [Google Scholar]
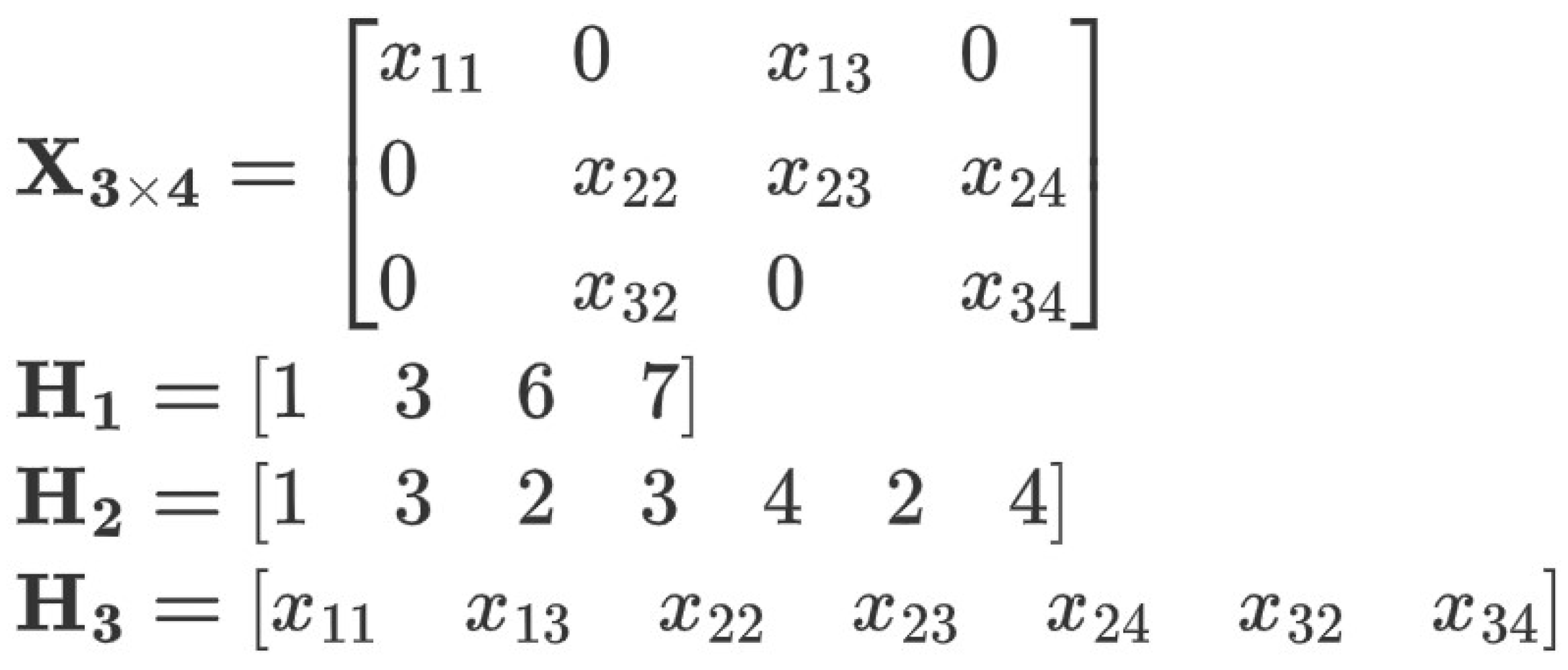

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Error (m/s) | Maximum Error (m/s) | Compression Rate (%) |
|---|---|---|
| 0.4578 | 2.7455 | 13.45 |
| 0.4871 | 2.3451 | 13.22 |
| 0.4534 | 2.2457 | 12.47 |
| 0.4965 | 2.9874 | 11.87 |
| 0.4658 | 2.9122 | 13.45 |
| 0.4178 | 2.4257 | 12.49 |
| 0.4844 | 2.5567 | 11.51 |
| Average Error (m/s) | Maximum Error (m/s) | Compression Rate (%) |
|---|---|---|
| 0.3745 | 1.9545 | 16.28 |
| 0.3544 | 1.7253 | 15.11 |
| 0.3578 | 1.9877 | 15.87 |
| 0.3978 | 1.8878 | 15.23 |
| 0.3147 | 1.9652 | 14.78 |
| 0.3799 | 1.8532 | 15.26 |
| 0.3783 | 1.4558 | 13.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, K.; Wang, Y.; Xiao, W. A New Compression and Storage Method for High-Resolution SSP Data Based-on Dictionary Learning. J. Mar. Sci. Eng. 2022, 10, 1095. https://doi.org/10.3390/jmse10081095
Yan K, Wang Y, Xiao W. A New Compression and Storage Method for High-Resolution SSP Data Based-on Dictionary Learning. Journal of Marine Science and Engineering. 2022; 10(8):1095. https://doi.org/10.3390/jmse10081095
Chicago/Turabian StyleYan, Kaizhuang, Yongxian Wang, and Wenbin Xiao. 2022. "A New Compression and Storage Method for High-Resolution SSP Data Based-on Dictionary Learning" Journal of Marine Science and Engineering 10, no. 8: 1095. https://doi.org/10.3390/jmse10081095
APA StyleYan, K., Wang, Y., & Xiao, W. (2022). A New Compression and Storage Method for High-Resolution SSP Data Based-on Dictionary Learning. Journal of Marine Science and Engineering, 10(8), 1095. https://doi.org/10.3390/jmse10081095