
A Real-Time Ship Detector via a Common Camera


Abstract
:1. Introduction
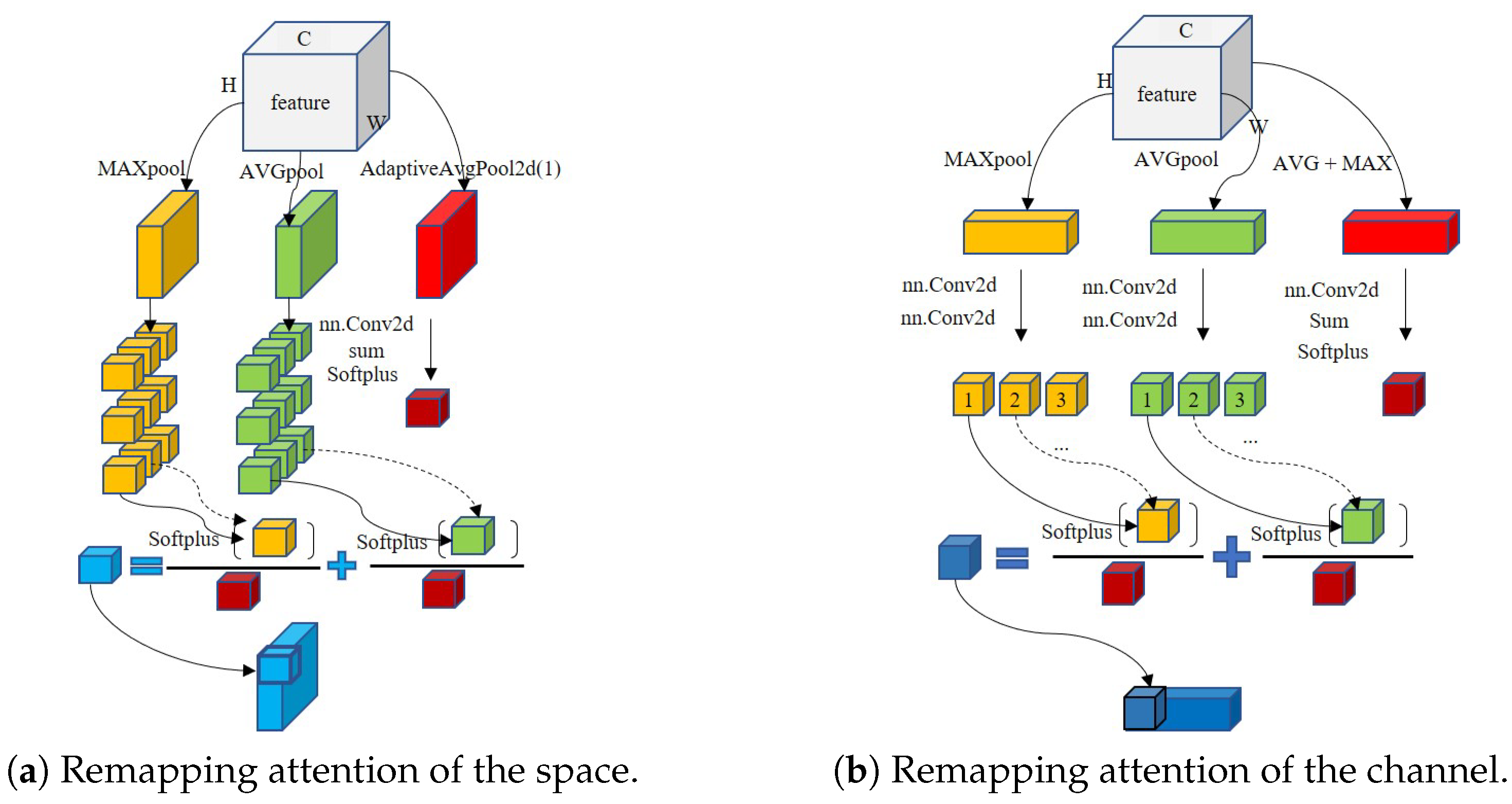
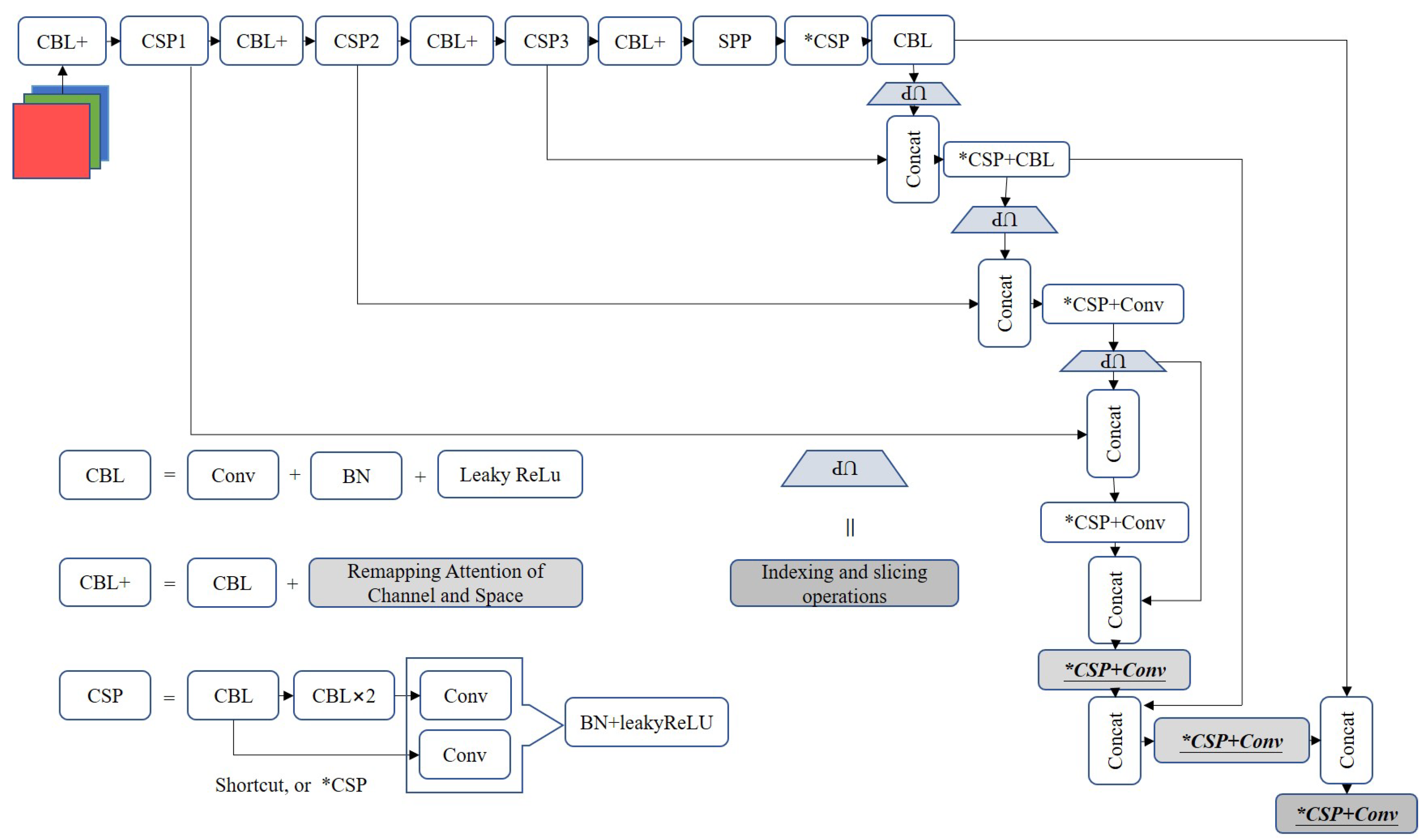
- We propose a real-time ship detector which is built on fast U-Net and remapping attention proposed. The fast U-Net offered adopts pixel period insertion to prompt the inference when multiple testing batches are set and decrease the number of training parameters. Remapping attention is specifically introduced to remap global features to local calculations, which is conducive to increasing the robustness in actual rain and fog scenes;
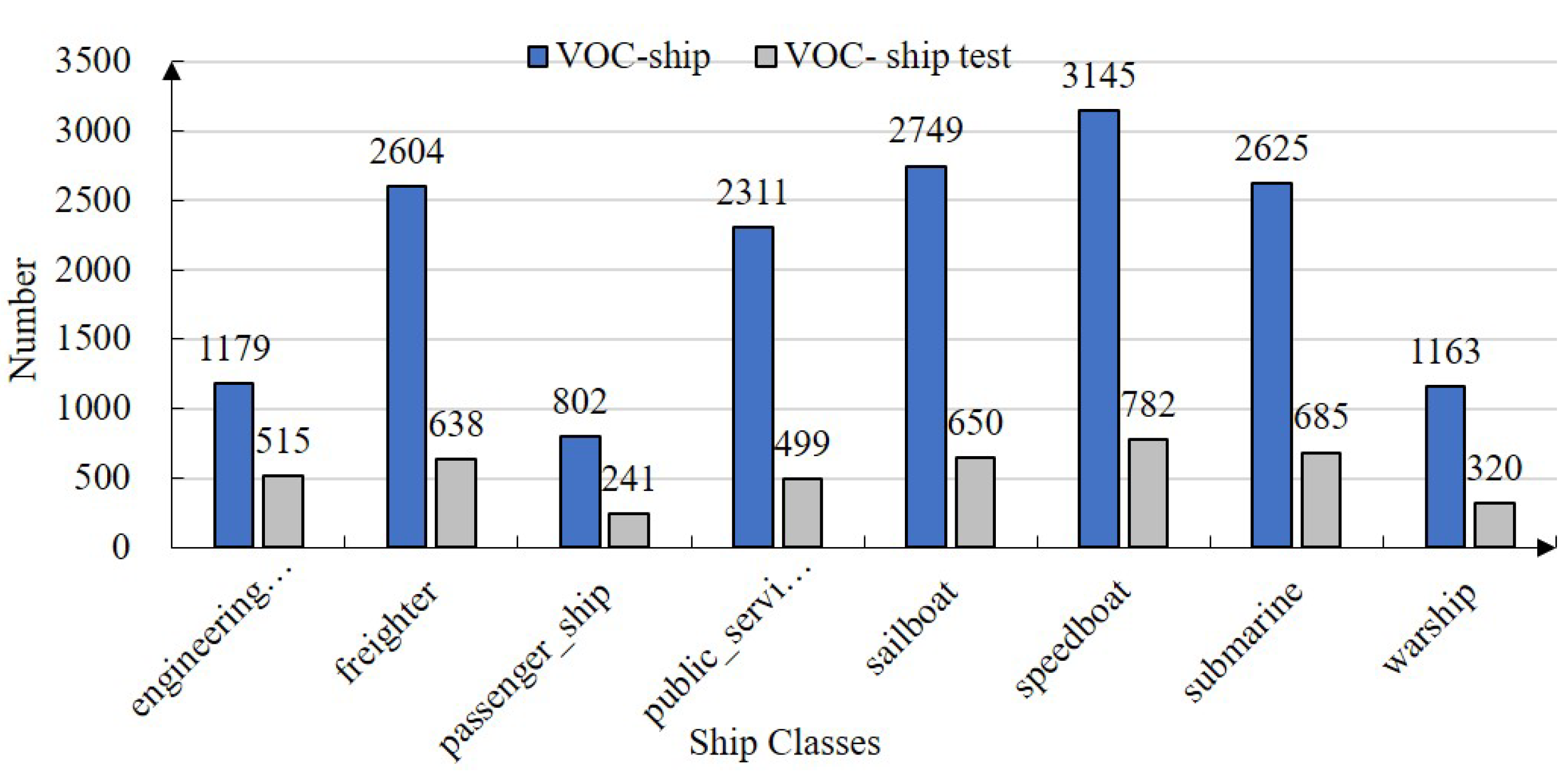
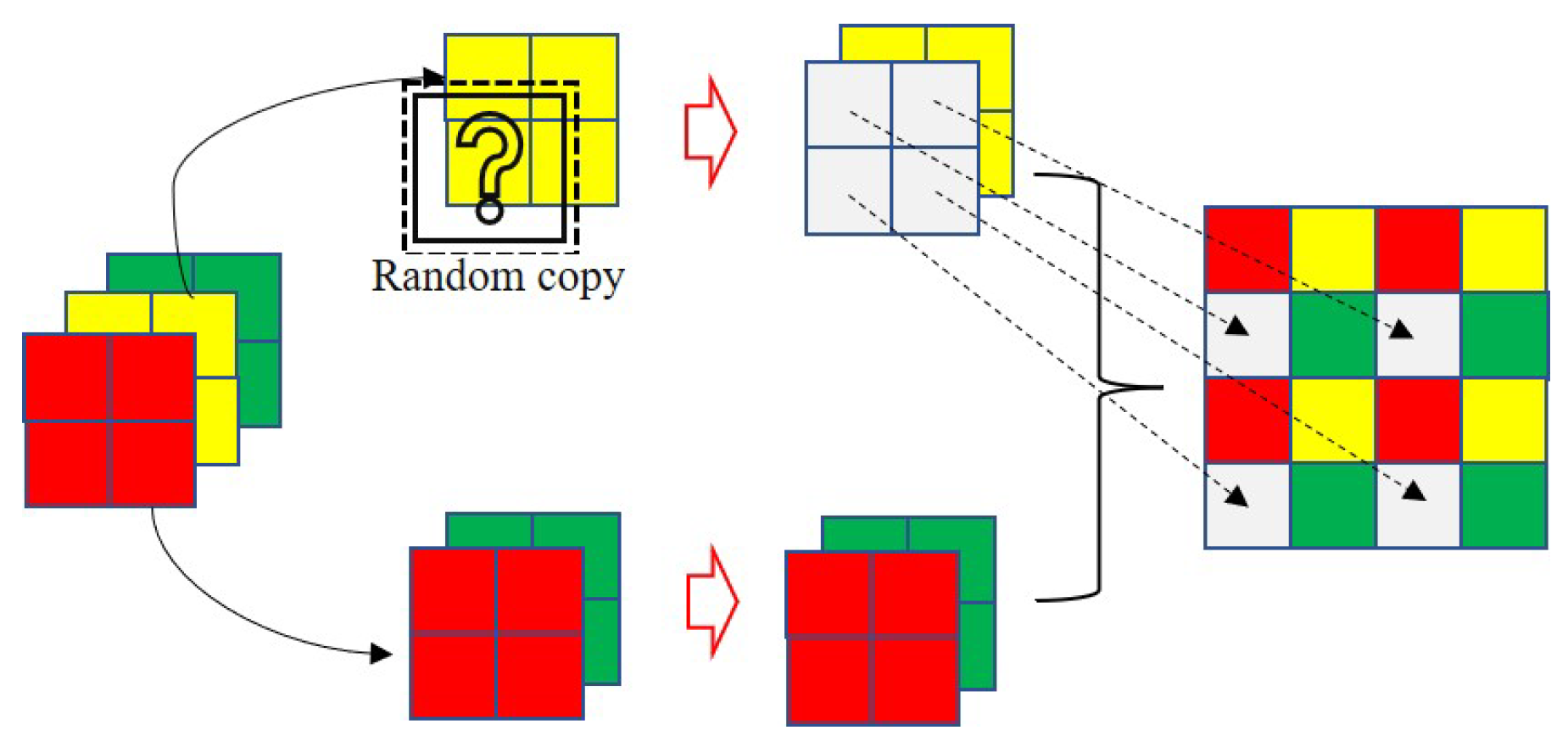
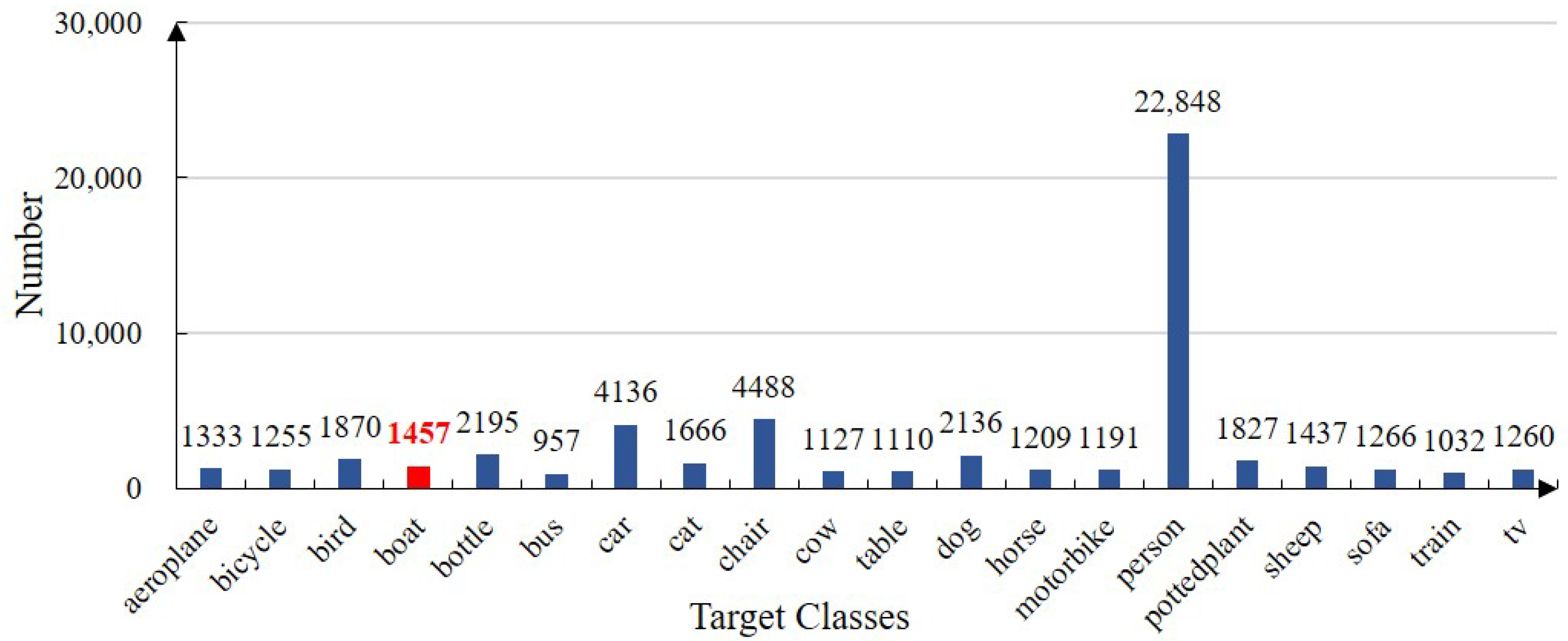
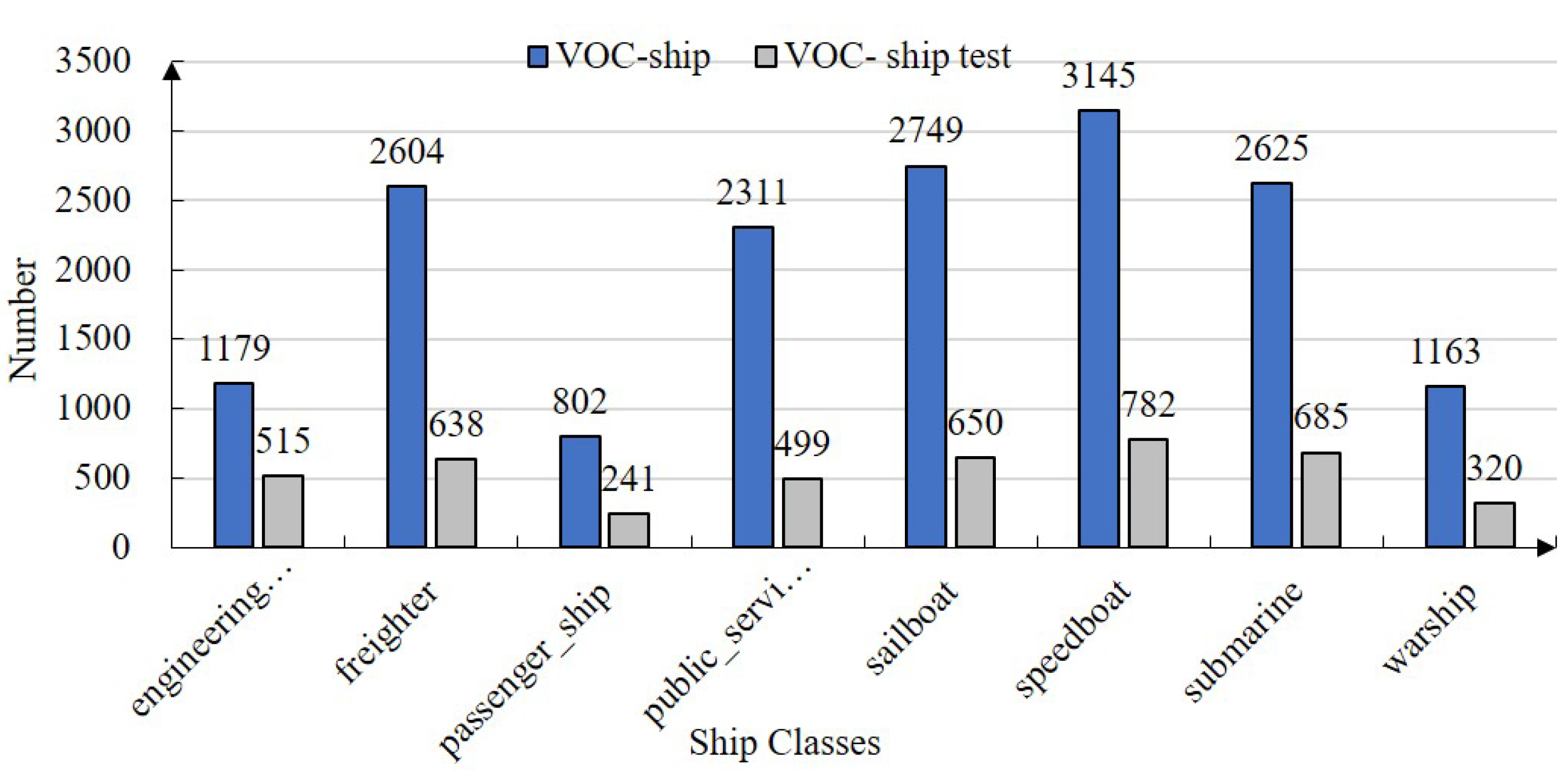
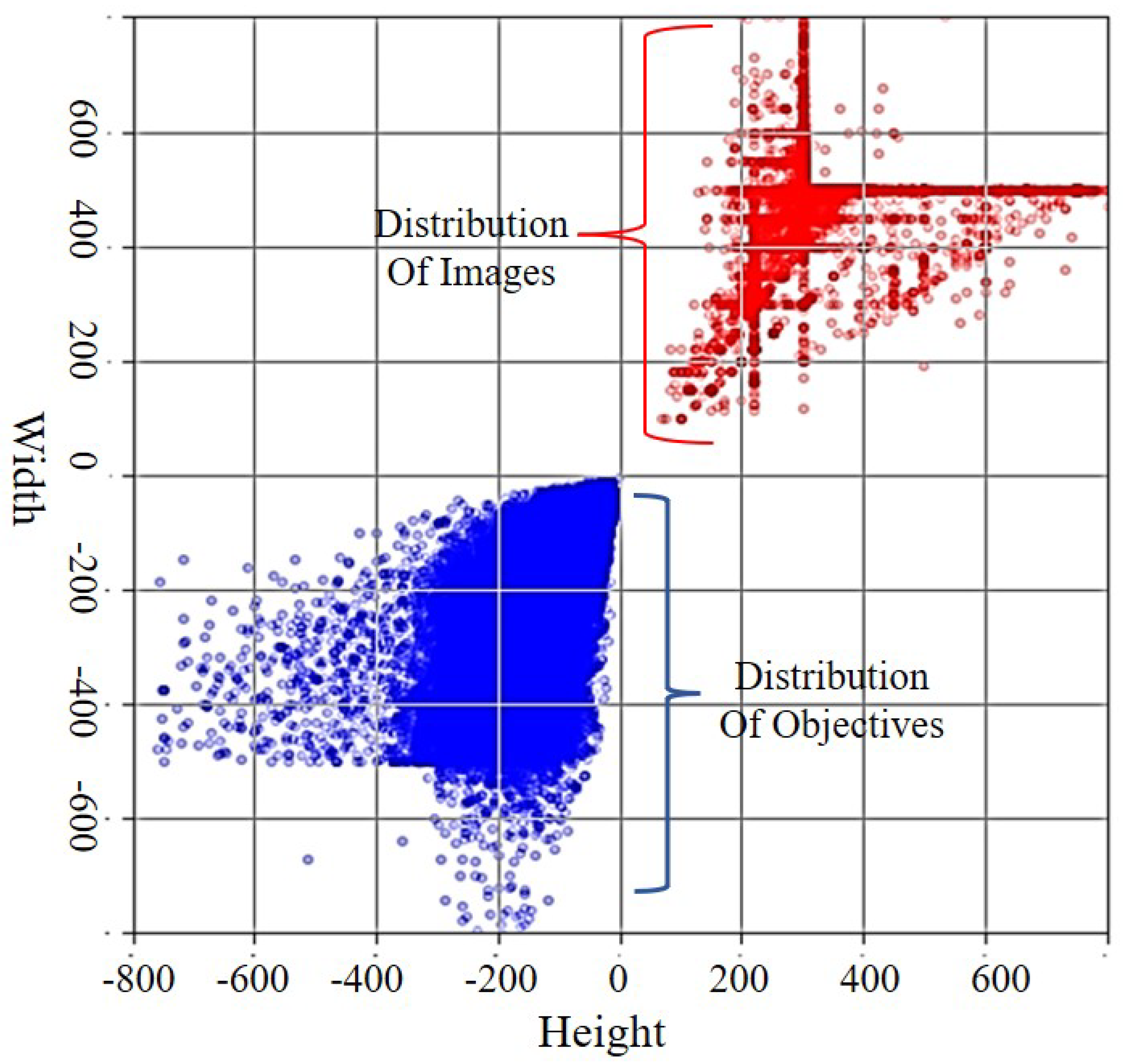
- We offer a ship dataset containing more than 14,000 images and data augmentation for the diversity of detecting backgrounds. The ship dataset provided alleviates the dataset’s lack of multiple ship classes. The data augmentation of the crossing-background randomly selects the targets copied to the new background, promoting the value of ship datasets and background diversity;
- We develop a rain–fog dataset containing 500 samples of pure rain–fog backgrounds. The pure images are collected from non-artificially synthesised scenes and the real world. This dataset is suitable for quantitatively validating ship detectors and testing the practical effects in marine environments.
2. Related Works
2.1. Traditional Ship Detectors
2.2. Modern Ship Detectors
2.3. Ship Datasets
3. Methodologies
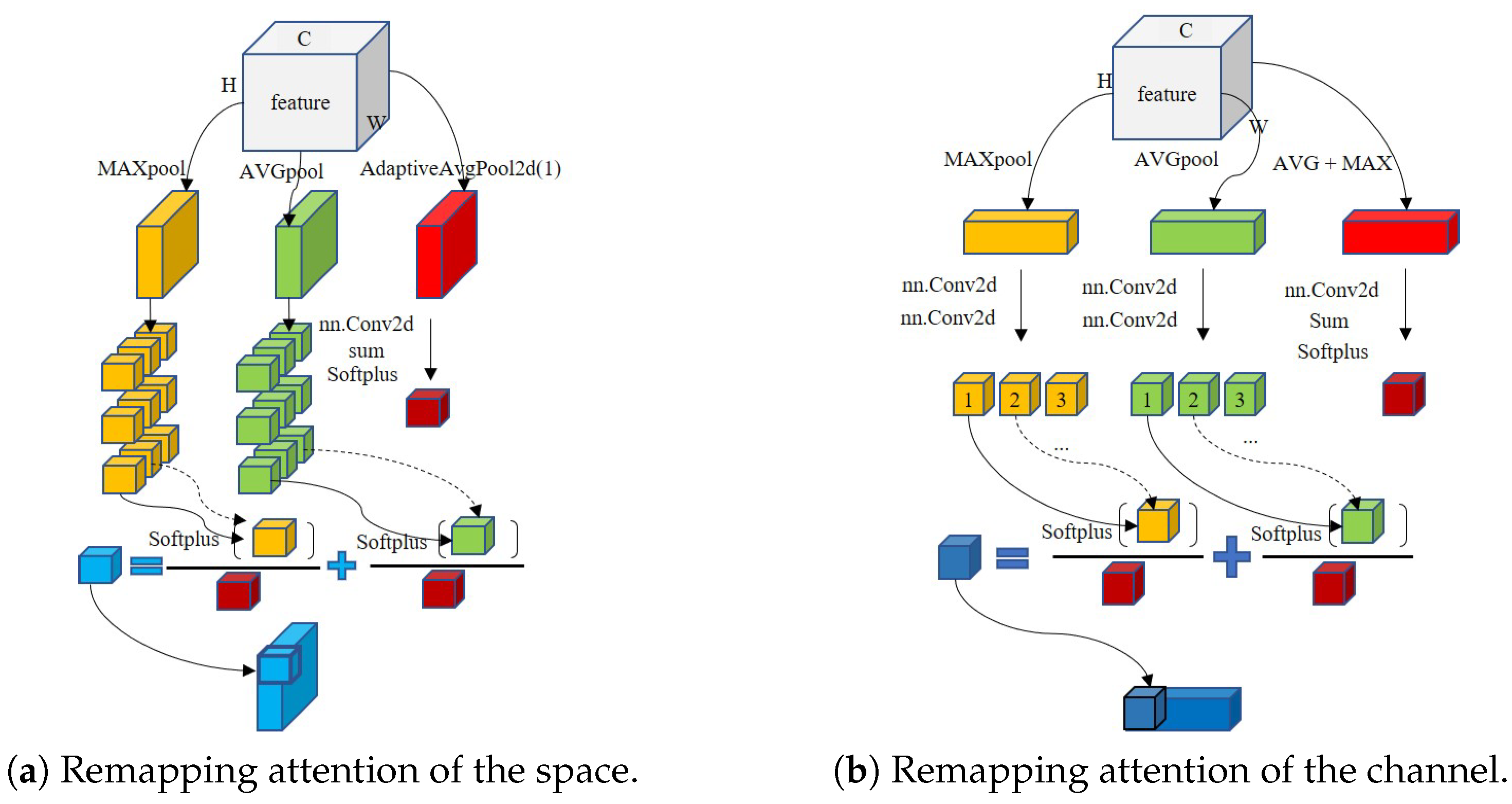
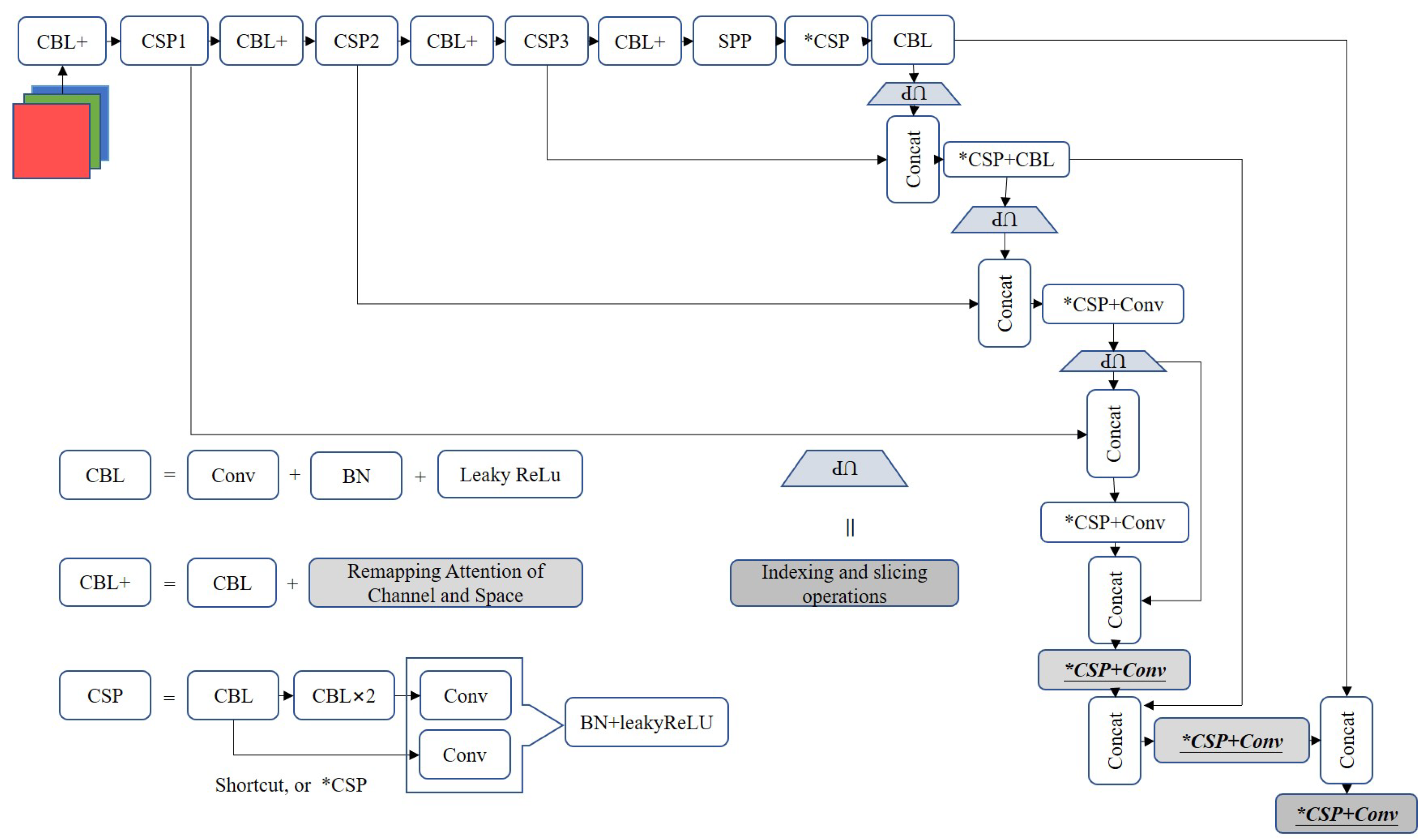
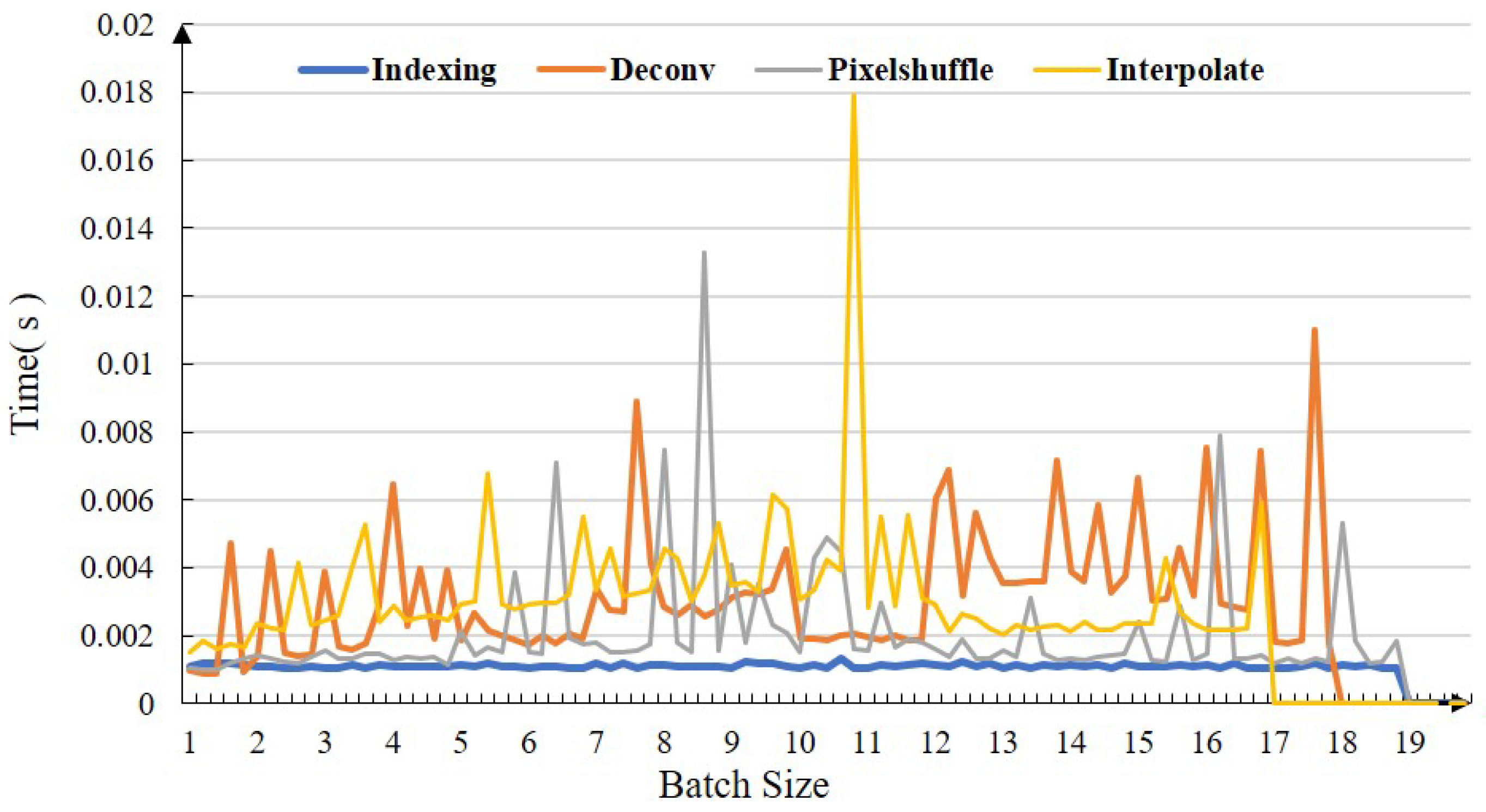
3.1. Remapping Attention and Fast U-Net
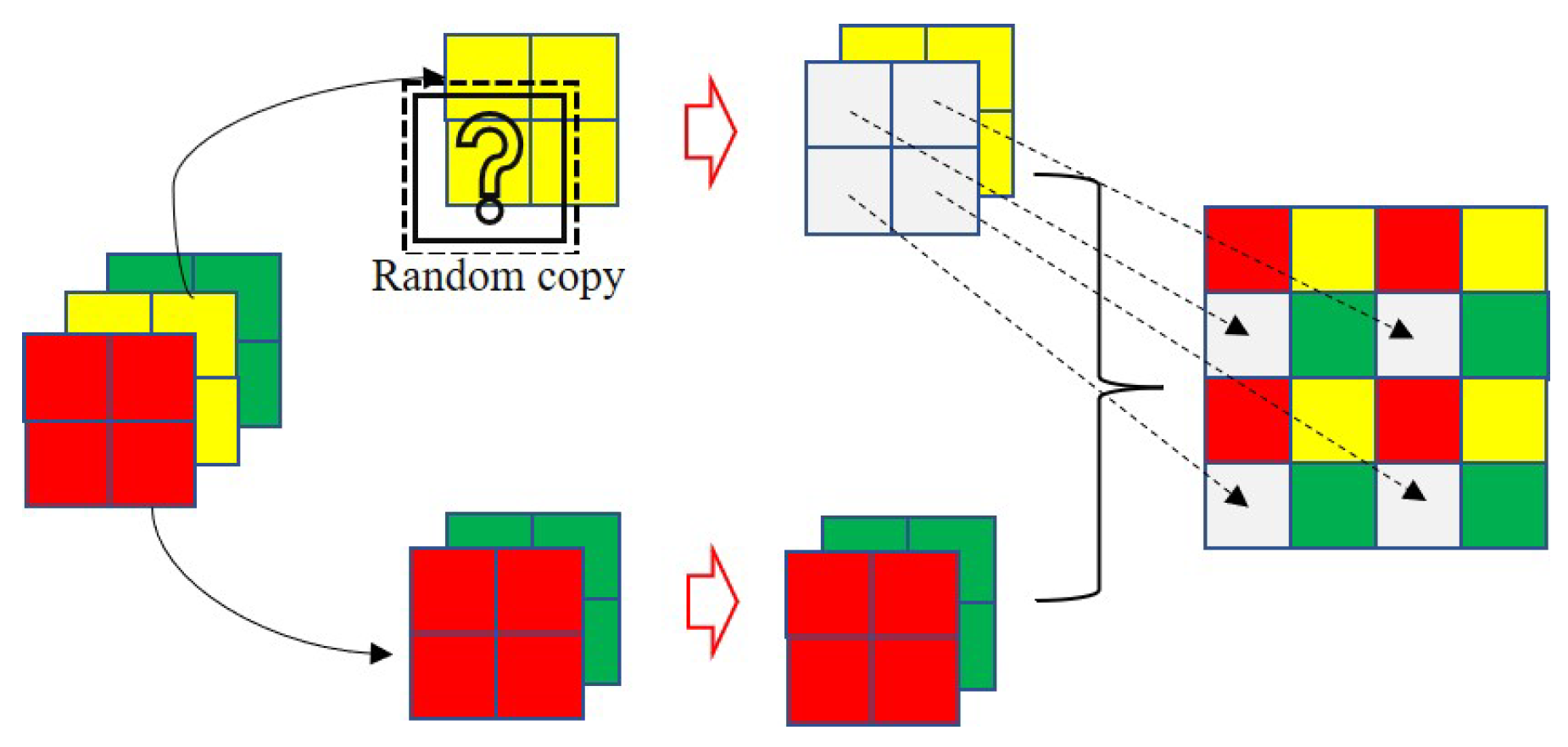
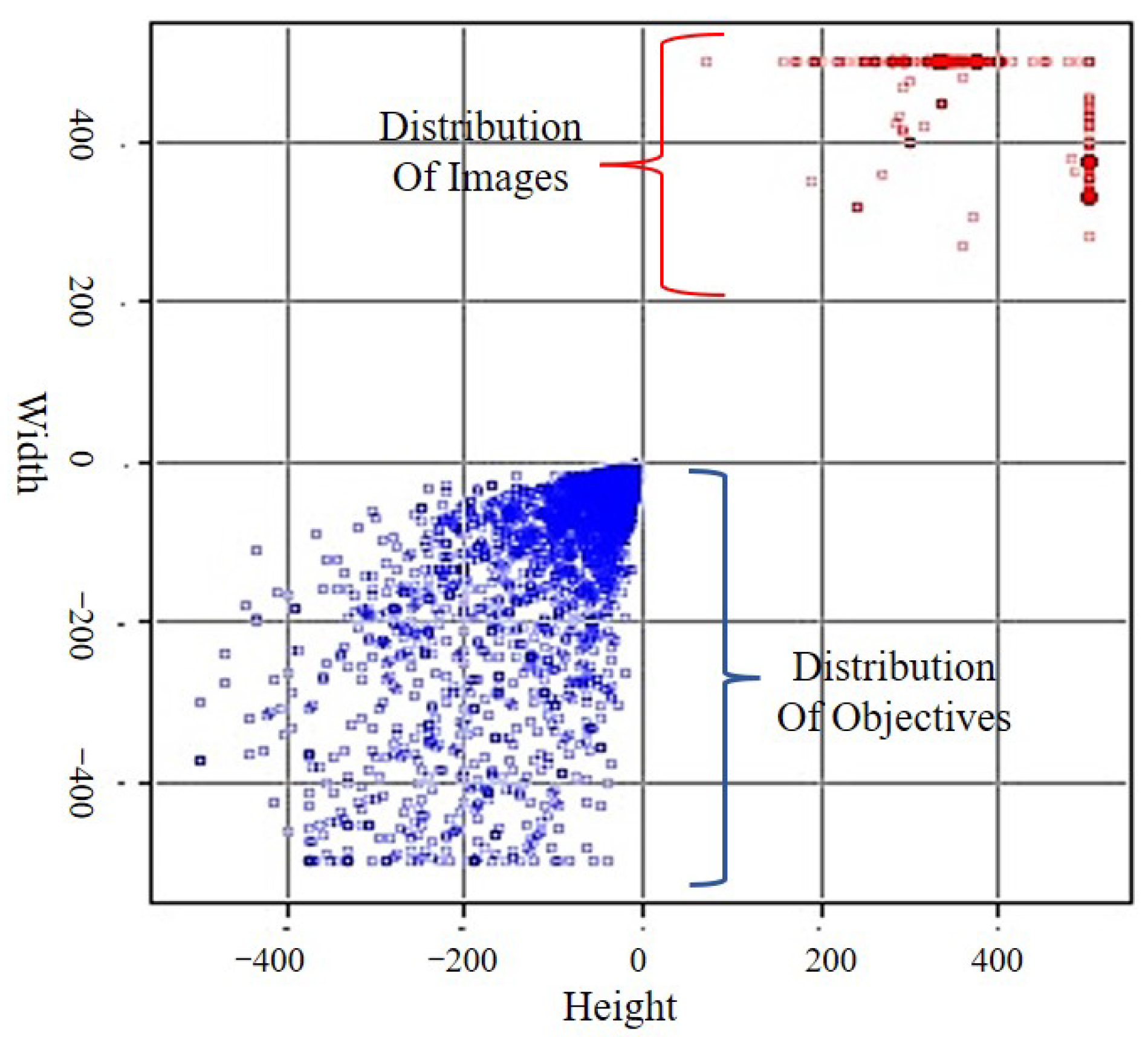
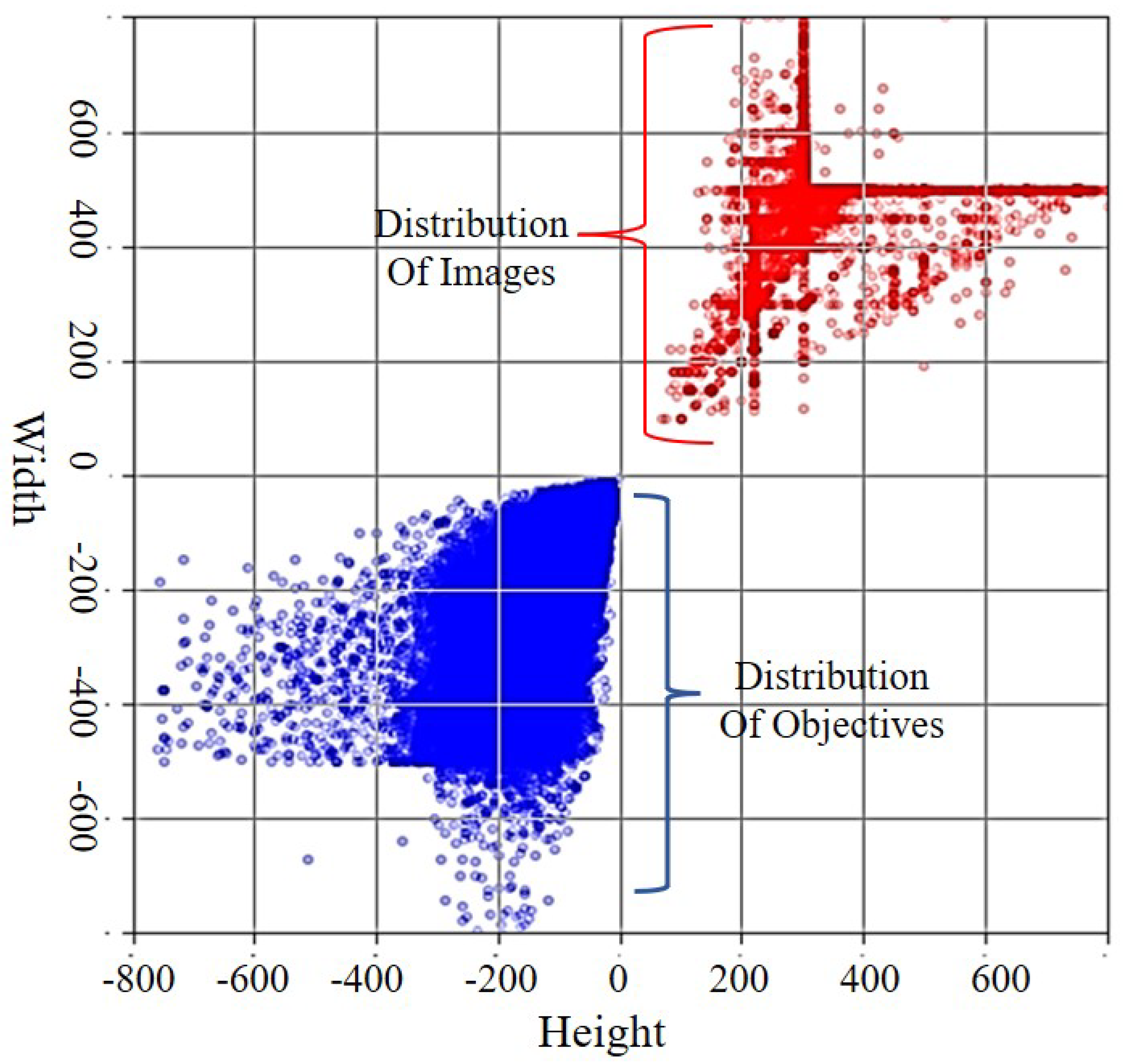
3.2. The Ship Dataset and Data Augmentation
3.3. The Rain-Fog Dataset
4. Experiments and Results
4.1. Experimental Setting
4.1.1. Experimental Conditions
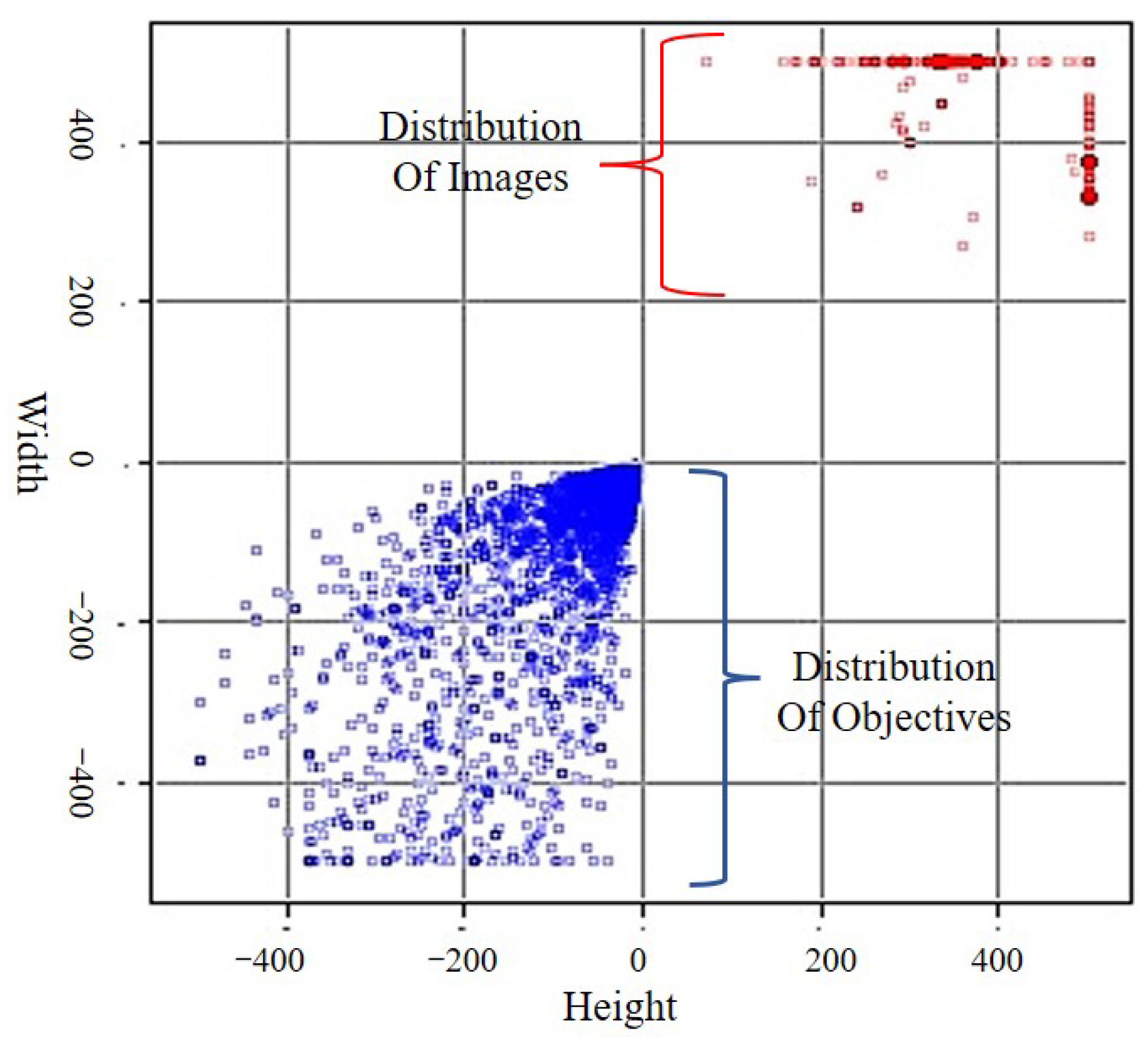
4.1.2. Datasets
4.1.3. Parameter Setting
4.1.4. Data Augmentation
4.1.5. Metrics
4.2. Results
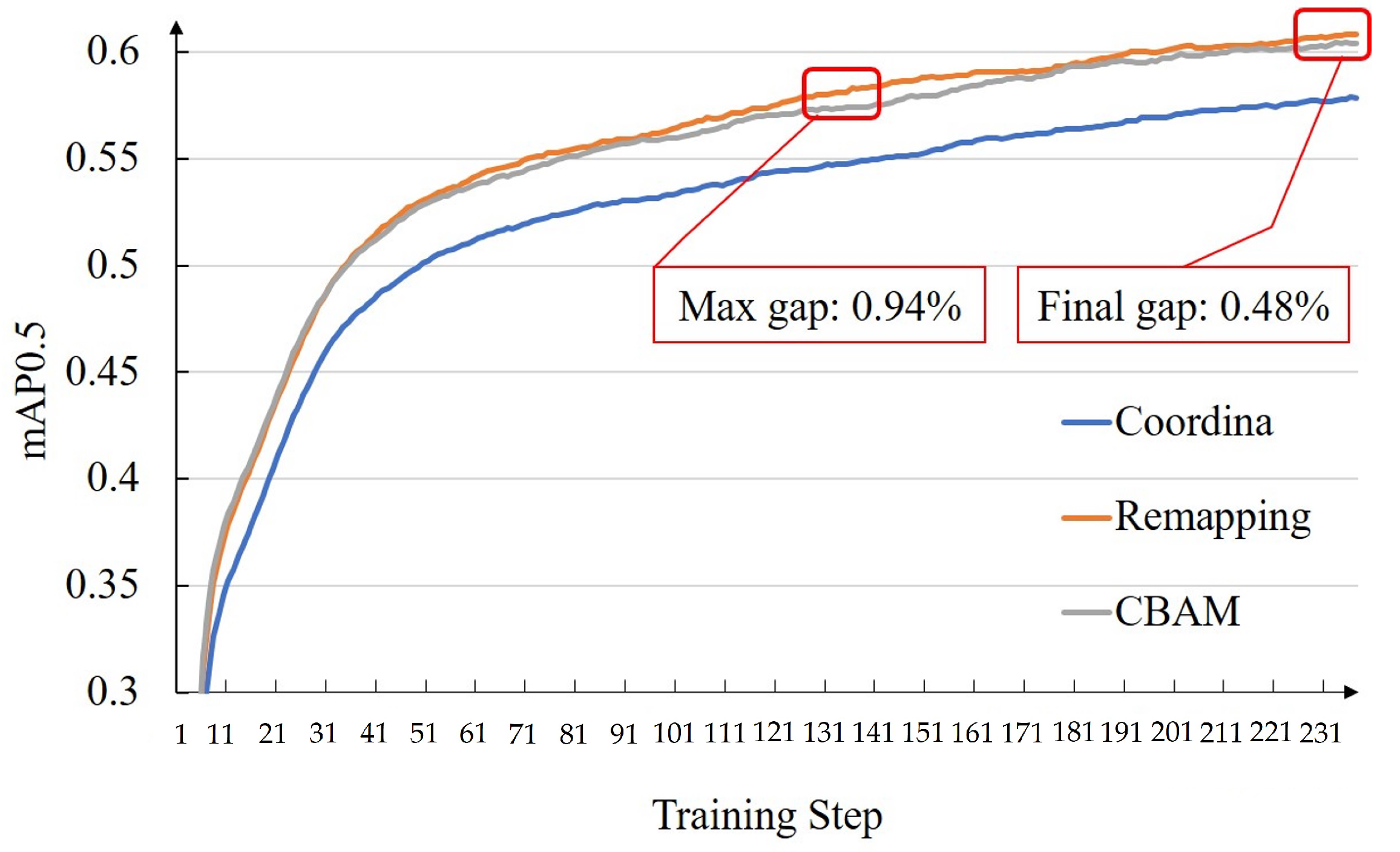
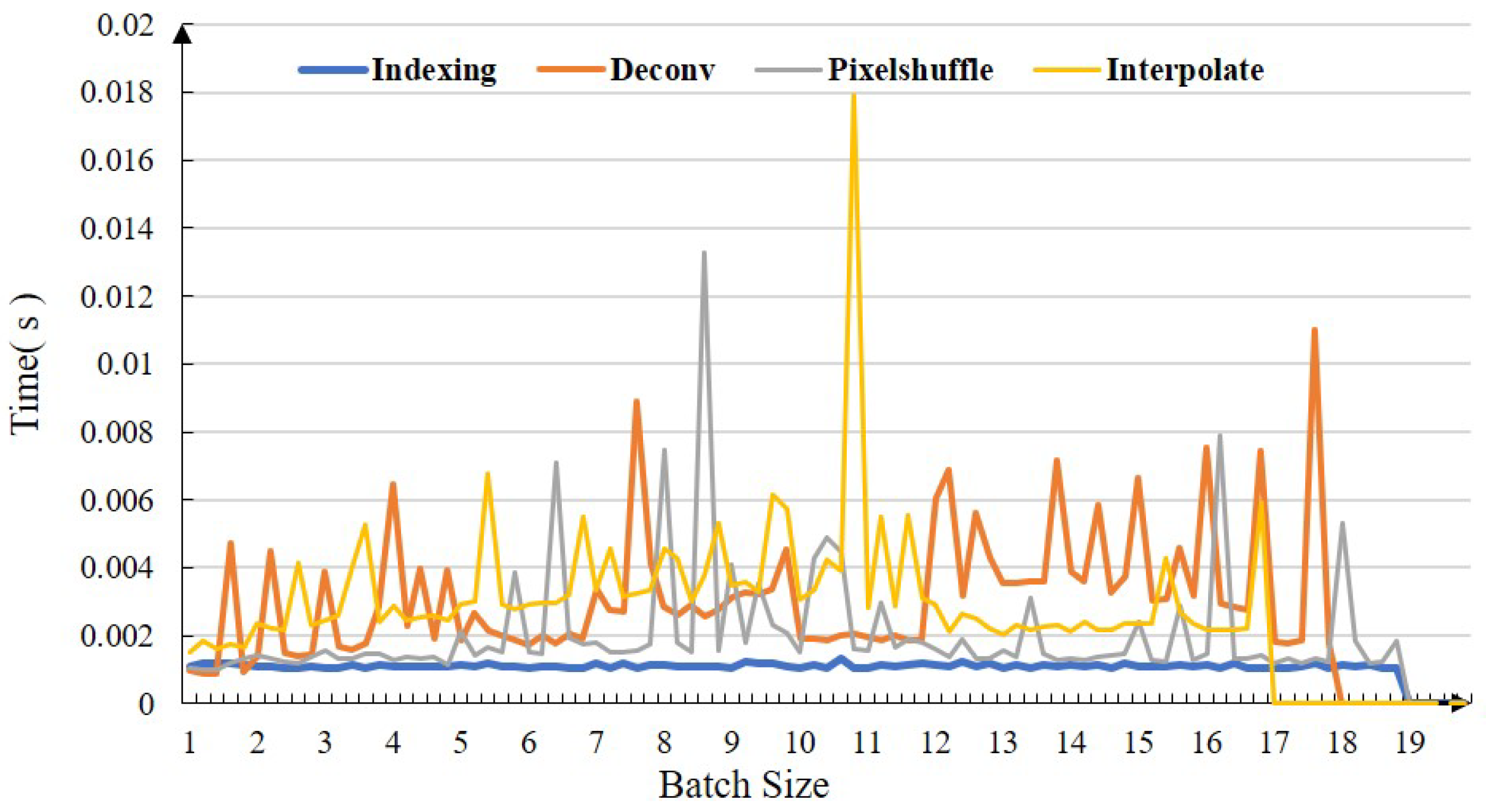
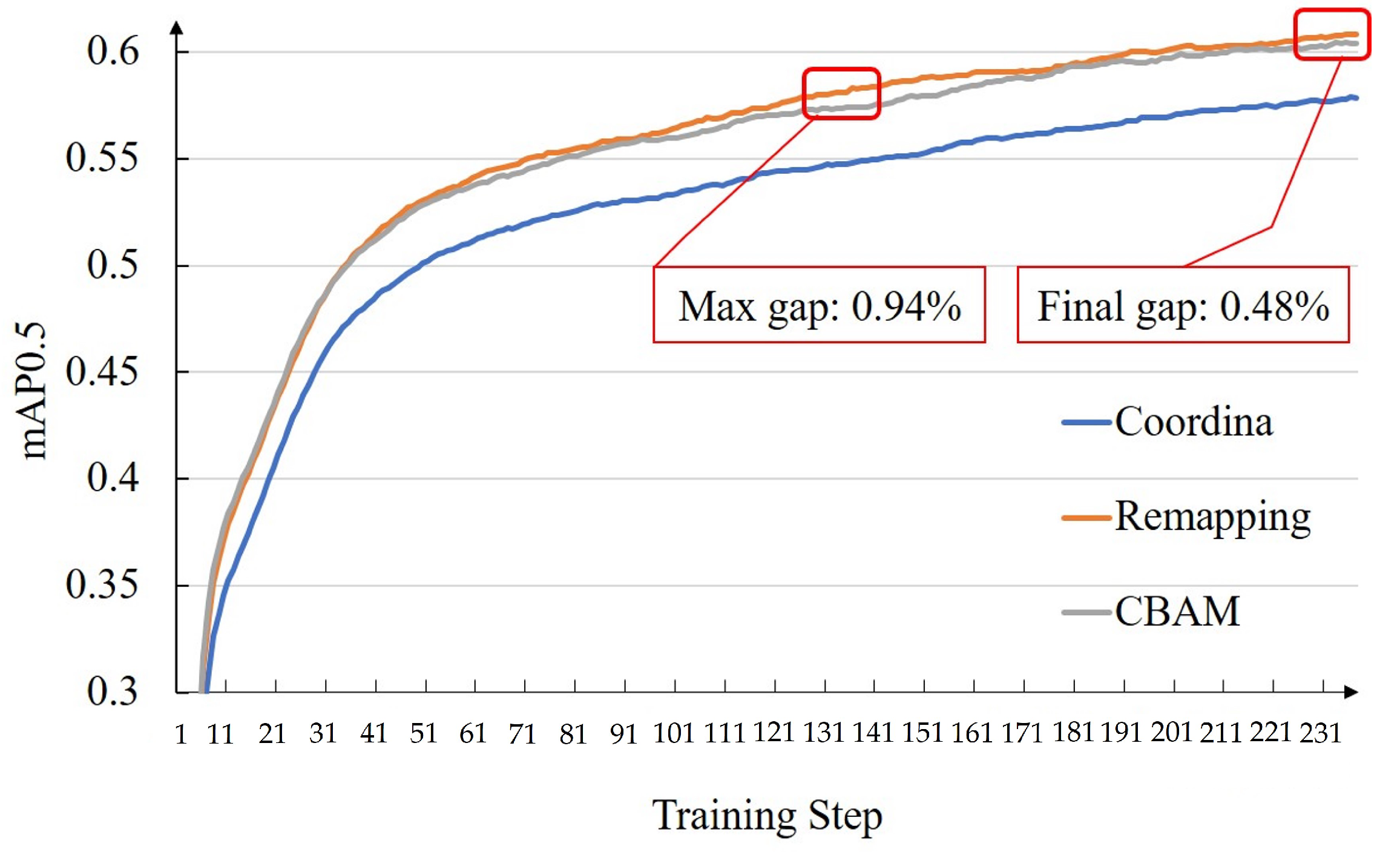
4.2.1. Influence of the Remapping and Fast U-Net
4.2.2. The Comparison of Ship Detectors
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


References
- Xiao, R.; Jianga, S.; Zhongb, J. Status and Development Trend of Active Sub-arrays Structure Design in Active Phased Array Antenna. IOP Conf. Ser. Mater. Sci. Eng. 2020, 914, 012038. [Google Scholar] [CrossRef]
- Wang, X.; Li, G.; Zhang, X.P.; He, Y. A Fast CFAR Algorithm Based on Density-Censoring Operation for Ship Detection in SAR Images. IEEE Signal Process. Lett. 2021, 28, 1085–1089. [Google Scholar] [CrossRef]
- Gao, F.; He, Y.; Wang, J.; Hussain, A.; Zhou, H. Anchor-free convolutional network with dense attention feature aggregation for ship detection in SAR images. Remote Sens. 2020, 12, 2619. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Caon, M.; Ros, P.M.; Martina, M.; Bianchi, T.; Magli, E.; Membibre, F.; Ramos, A.; Latorre, A.; Kerr, M.; Wiehle, S.; et al. Very low latency architecture for earth observation satellite onboard data handling, compression, and encryption. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 7791–7794. [Google Scholar]
- Solari, L.; Del Soldato, M.; Raspini, F.; Barra, A.; Bianchini, S.; Confuorto, P.; Casagli, N.; Crosetto, M. Review of satellite interferometry for landslide detection in Italy. Remote Sens. 2020, 12, 1351. [Google Scholar] [CrossRef]
- Krišto, M.; Ivasic-Kos, M.; Pobar, M. Thermal object detection in difficult weather conditions using YOLO. IEEE Access 2020, 8, 125459–125476. [Google Scholar] [CrossRef]
- Wang, N.; Li, B.; Wei, X.; Wang, Y.; Yan, H. Ship Detection in Spaceborne Infrared Image Based on Lightweight CNN and Multisource Feature Cascade Decision. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4324–4339. [Google Scholar] [CrossRef]
- Liu, R.W.; Yuan, W.; Chen, X.; Lu, Y. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, S.H.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 9656–9665. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Naddaf-Sh, S.; Naddaf-Sh, M.M.; Kashani, A.R.; Zargarzadeh, H. An Efficient and Scalable Deep Learning Approach for Road Damage Detection. In Proceedings of the 8th IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5602–5608. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Wang, S.L.; Bai, M.; Mattyus, G.; Chu, H.; Luo, W.J.; Yang, B.; Liang, J.; Cheverie, J.; Fidler, S.; Urtasun, R.; et al. TorontoCity: Seeing the World with a Million Eyes. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3028–3036. [Google Scholar] [CrossRef]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford RobotCar dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Volume 8693, pp. 740–755. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Wang, M.; Li, C.; Yu, Q. Ship Detection Based on Neighboring Information Fusion. J.-Xiamen Univ. Nat. Sci. 2007, 46, 645. [Google Scholar]
- Xu, F.; Liu, J.; Zeng, D.; Wang, X. Detection and identification of unsupervised ships and warships on sea surface based on visual saliency. Opt. Precis. Eng. 2017, 25, 1300–1311. [Google Scholar]
- Borghgraef, A.; Barnich, O.; Lapierre, F.; Van Droogenbroeck, M.; Philips, W.; Acheroy, M. An evaluation of pixel-based methods for the detection of floating objects on the sea surface. EURASIP J. Adv. Signal Process. 2010, 2010, 1–11. [Google Scholar] [CrossRef]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A universal background subtraction algorithm for video sequences. IEEE Trans. Image Process. 2010, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Jodoin, P.M.; Konrad, J.; Saligrama, V. Modeling background activity for behavior subtraction. In Proceedings of the 2nd ACM/IEEE International Conference on Distributed Smart Cameras, Palo Alto, CA, USA, 7–11 September 2008; pp. 1–10. [Google Scholar]
- Hu, W.C.; Yang, C.Y.; Huang, D.Y. Robust real-time ship detection and tracking for visual surveillance of cage aquaculture. J. Vis. Commun. Image Represent. 2011, 22, 543–556. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Arshad, N.; Moon, K.S.; Kim, J.N. An Adaptive Moving Ship Detection and Tracking Based on Edge Information & Morphological Operations. In Proceedings of the International Conference on Graphic and Image Processing (ICGIP), Cairo, Egypt, 1–3 October 2011; Volume 8285. [Google Scholar] [CrossRef]
- Fefilatyev, S.; Goldgof, D.; Shreve, M.; Lembke, C. Detection and tracking of ships in open sea with rapidly moving buoy-mounted camera system. Ocean Eng. 2012, 54, 1–12. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.Z.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z.H. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar] [CrossRef]
- Zhao, P.; Meng, C.; Chang, S. Single stage ship detection algorithm based on improved VGG network. J. Optoelectron Laser 2019, 30, 719–730. [Google Scholar]
- Wang, T.Y.; Yang, X.; Xu, K.; Chen, S.Z.; Zhang, Q.; Lau, R.W.H.; Soc, I.C. Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12262–12271. [Google Scholar] [CrossRef]
- Yang, W.; Tan, R.T.; Feng, J.; Guo, Z.; Yan, S.; Liu, J. Joint rain detection and removal from a single image with contextualized deep networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1377–1393. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.Y.; Huang, J.B.; Zeng, D.L.; Huang, Y.; Ding, X.H.; Paisley, J. Removing rain from single images via a deep detail network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1715–1723. [Google Scholar] [CrossRef]
- Qian, R.; Tan, R.T.; Yang, W.H.; Su, J.J.; Liu, J.Y. Attentive Generative Adversarial Network for Raindrop Removal from A Single Image. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2482–2491. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detectors | Backbone | ImgSize | FPS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| SSD300 [15] | VGG16 | 300 | 43.2 | 0.251 | 0.431 | 0.258 | 0.066 | 0.259 | 0.414 |
| Faster RCNN [12] | ResNet-50 | 1000 | 9.4 | 0.398 | 0.592 | 0.435 | 0.218 | 0.426 | 0.507 |
| RetinaNet [47] | ResNet-101 | 800 | 5.1 | 0.378 | 0.575 | 0.408 | 0.202 | 0.411 | 0.492 |
| CenterNet [48] | Hourglass-104 | 512 | 4.2 | 0.449 | 0.624 | 0.481 | 0.256 | 0.474 | 0.574 |
| EfficientDet [21] | EfficientDet-B0 | 512 | 62.3 | 0.338 | 0.525 | 0.358 | 0.12 | 0.383 | 0.512 |
| YOLOv4s [19] | CSPDarknet-53 | 416 | 38.0 | 0.412 | 0.628 | 0.443 | 0.204 | 0.444 | 0.56 |
| YOLOv5s [20] | CSPDarknet-53 | 640 | 69.9 | 0.369 | 0.561 | 0.4 | 0.196 | 0.413 | 0.457 |
| YOLOv5s_Unet | CSPDarknet-53 | 640 | 59.0 | 0.393 | 0.582 | 0.431 | 0.23 | 0.432 | 0.466 |
| YOLOv5s_Coord_Unet | CSPDarknet-53 | 640 | 48.7 | 0.396 | 0.587 | 0.433 | 0.232 | 0.436 | 0.468 |
| YOLOv5s_CBAM_Unet | CSPDarknet-53 | 640 | 45.87 | 0.424 | 0.615 | 0.465 | 0.254 | 0.462 | 0.512 |
| YOLOv5s_ReMap_Unet | CSPDarknet-53 | 640 | 43.5/263.2 | 0.425 | 0.617 | 0.465 | 0.251 | 0.463 | 0.513 |
| YOLOv5s_ReMap_FastUnet | CSPDarknet-53 | 640 | 40.3/278.4 | 0.425 | 0.617 | 0.465 | 0.251 | 0.463 | 0.513 |
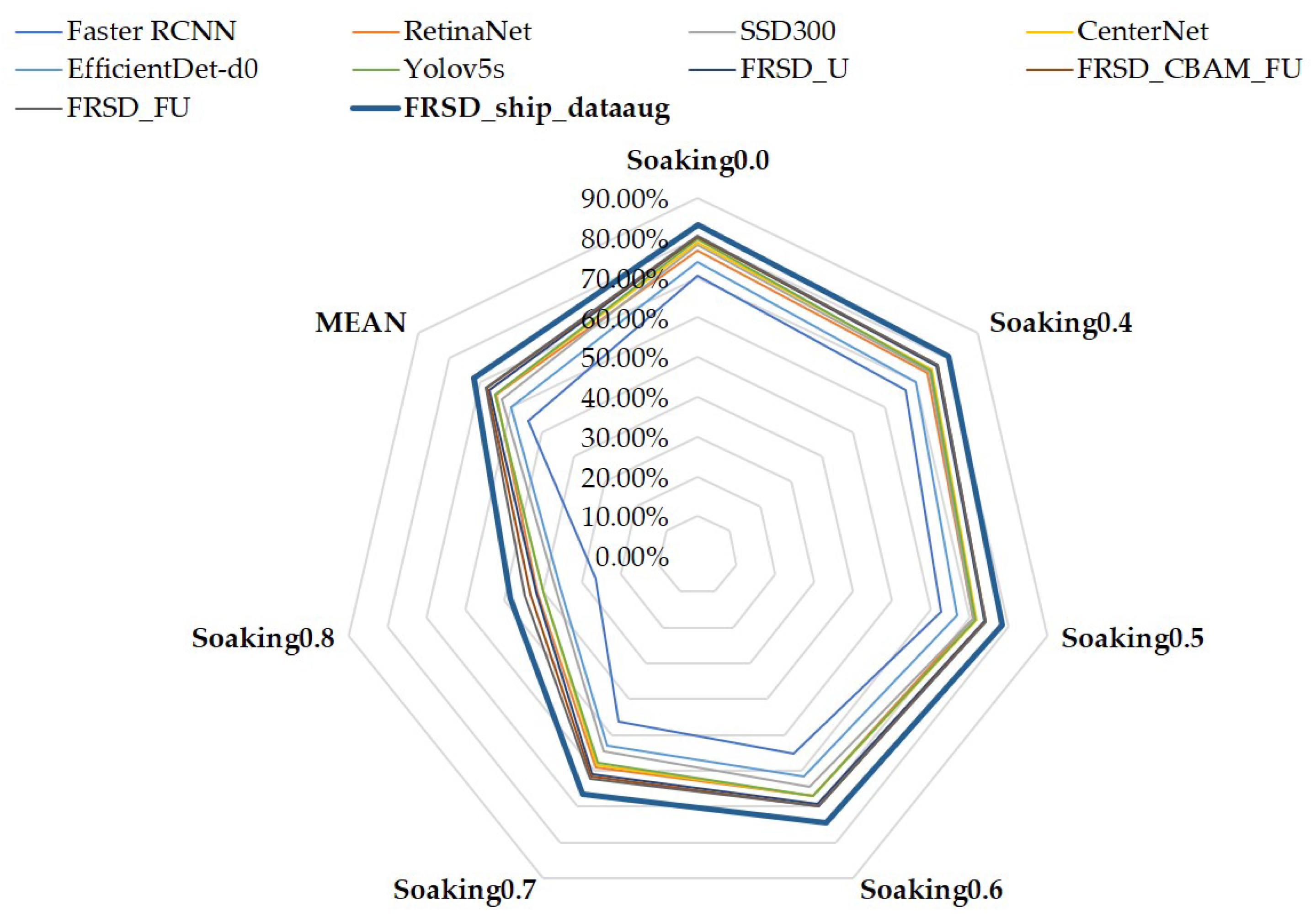
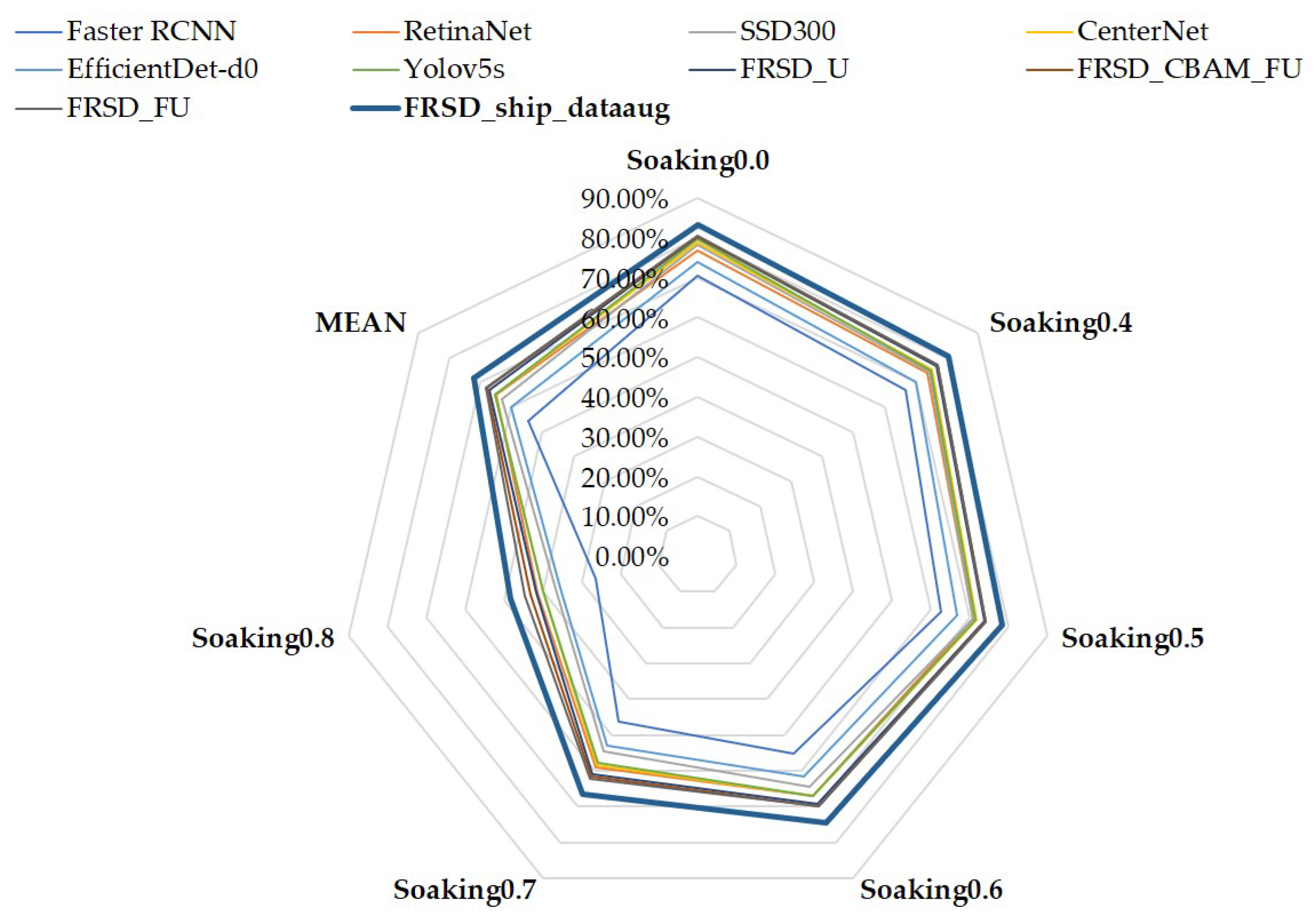
| Detectors | Imgsize | Soaking 0.0 | Soaking 0.4 | Soaking 0.5 | Soaking 0.6 | Soaking 0.7 | Soaking 0.8 | MEAN | DEV | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster RCNN [12] | 800 | 70.59% | 66.75% | 62.65% | 55.13% | 46.16% | 26.27% | 54.592% | 16.38% | 25.10 |
| RetinaNet [47] | 600 | 76.90% | 73.92% | 70.98% | 66.92% | 58.98% | 41.49% | 64.865% | 13.03% | 34.61 |
| SSD300 [15] | 300 | 78.30% | 74.40% | 70.90% | 64.50% | 54.40% | 36.70% | 63.20% | 15.45% | 66.02 |
| CenterNet [48] | 512 | 78.70% | 75.20% | 71.90% | 66.90% | 58.300% | 39.80% | 65.13% | 14.30% | 42.30 |
| EfficientDetd0 [21] | 512 | 74.00% | 70.10% | 66.80% | 61.50% | 52.80% | 35.50% | 60.12% | 14.13% | 36.40 |
| YOLOV4_ship [19] | 416 | 74.26% | 69.19% | 65.81% | 61.17% | 52.22% | 36.37% | 59.87% | 13.72% | 34.20 |
| YOLOV5s_ship [20] | 640 | 78.79% | 74.90% | 71.60% | 66.90% | 57.80% | 40.00% | 65.16% | 14.41% | 68.01 |
| FRSD_U | 640 | 80.10% | 76.70% | 73.90% | 69.10% | 60.90% | 41.80% | 67.08% | 14.07% | 43.61 |
| FRSD_CBAM_FU | 640 | 80.19% | 76.90% | 74.10% | 69.78% | 61.60% | 43.30% | 67.65% | 13.55% | 43.31 |
| FRSD_FU | 640 | 80.39% | 76.90% | 74.20% | 69.80% | 62.22% | 44.50% | 68.01% | 13.12% | 42.56 |
| FRSD_ship_dataaug | 640 | 83.15% | 80.70% | 78.40% | 74.50% | 66.60% | 48.40% | 71.958% | 12.91% | 42.56 |
| Detectors | Imgsize | Engi_ship | Freighter | Passe_ship | Public_ser | Sailboat | Speedboat | Submarine | Warship | Ship |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster RCNN [12] | 800 | 70.70% | 85.55% | 59.68% | 86.36% | 79.67% | 85.81% | 87.78% | 65.08% | 14.72% |
| RetinaNet [47] | 600 | 81.58% | 93.31% | 69.60% | 90.35% | 86.35% | 91.79% | 87.58% | 77.72% | 13.80% |
| SSD300 [15] | 300 | 84.37% | 88.77% | 78.08% | 88.61% | 82.22% | 87.31% | 90.21% | 85.10% | 20.47% |
| CenterNet [48] | 512 | 77.60% | 91.70% | 75.00% | 92.50% | 85.70% | 90.50% | 92.50% | 81.90% | 20.05% |
| EfficientDetd0 [21] | 512 | 74.10% | 90.40% | 66.40% | 89.10% | 87.30% | 89.80% | 88.10% | 72.70% | 11.30% |
| YOLOV5s_ship [20] | 640 | 71.10% | 92.00% | 72.20% | 91.79% | 88.10% | 91.40% | 94.20% | 84.40% | 23.90% |
| FRSD_ship_dataaug | 640 | 84.70% | 94.20% | 80.60% | 93.70% | 89.20% | 93.90% | 95.01% | 85.80% | 26.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, P.; Yu, X.; Chen, Z.; Liang, Y. A Real-Time Ship Detector via a Common Camera. J. Mar. Sci. Eng. 2022, 10, 1043. https://doi.org/10.3390/jmse10081043
Zhao P, Yu X, Chen Z, Liang Y. A Real-Time Ship Detector via a Common Camera. Journal of Marine Science and Engineering. 2022; 10(8):1043. https://doi.org/10.3390/jmse10081043
Chicago/Turabian StyleZhao, Penghui, Xiaoyuan Yu, Zongren Chen, and Yangyan Liang. 2022. "A Real-Time Ship Detector via a Common Camera" Journal of Marine Science and Engineering 10, no. 8: 1043. https://doi.org/10.3390/jmse10081043
APA StyleZhao, P., Yu, X., Chen, Z., & Liang, Y. (2022). A Real-Time Ship Detector via a Common Camera. Journal of Marine Science and Engineering, 10(8), 1043. https://doi.org/10.3390/jmse10081043