
Detection Method of Marine Biological Objects Based on Image Enhancement and Improved YOLOv5S


Abstract
1. Introduction
2. Related Work
3. Image Enhancement Algorithm
3.1. Contrast Ratio
3.2. Histogram Equalization
3.3. Local Processing
3.4. Contrast Limit
4. The Improved YOLOv5S Object Detection Model
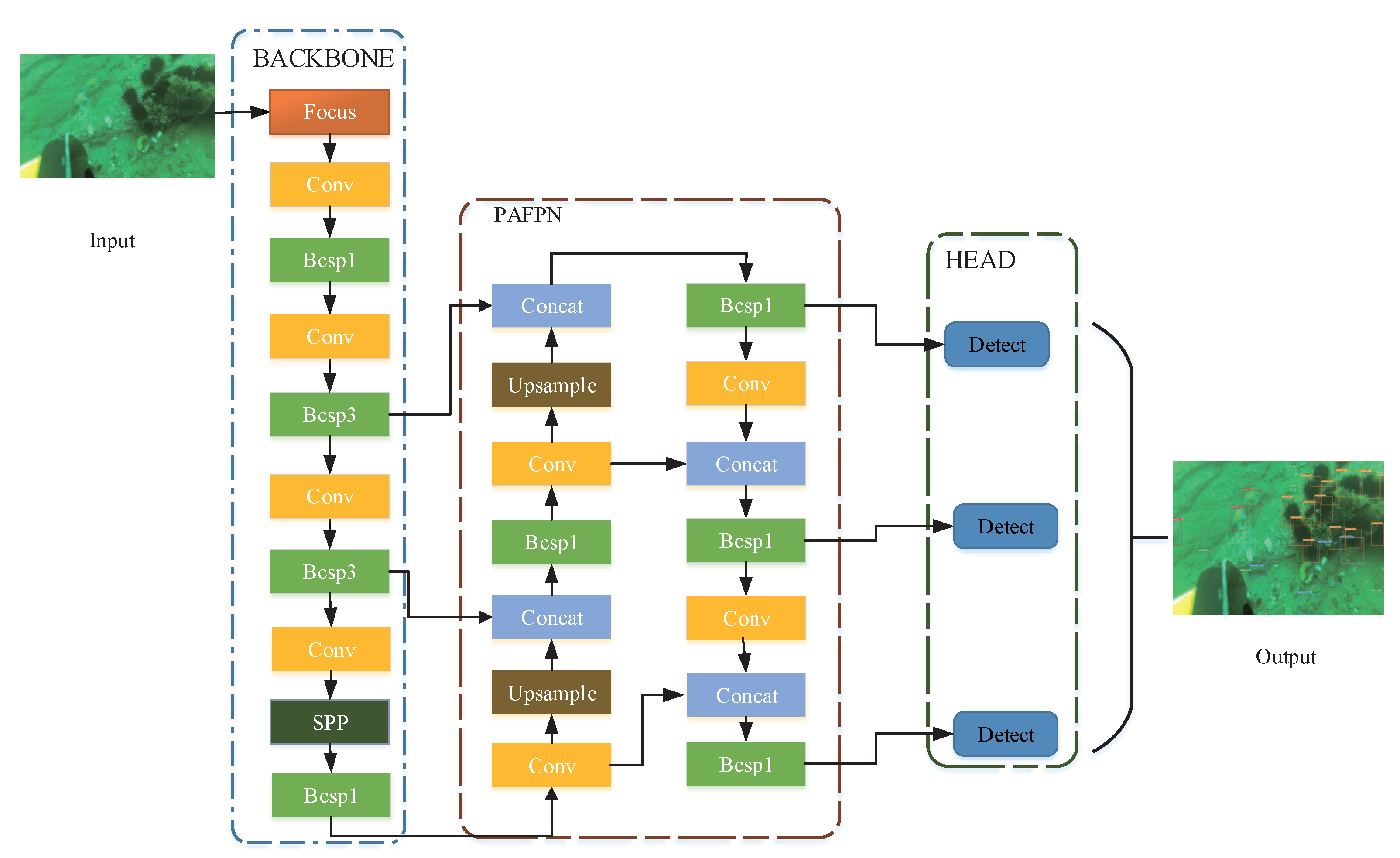
4.1. YOLOv5S
4.2. Improvement Strategy
| Algorithm 1: Soft non-maximum suppression. |
 |
5. Experimental Research and Result Analysis
5.1. Dataset Establishment
5.2. Model Training
5.3. Experimental Results
5.3.1. Validation of Image Enhancement
5.3.2. Validation of Improved Algorithm
5.3.3. Comparison of Detection Effects of Different Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AHE | Adaptive histogram equalization |
| CLAHE | Contrast-limited adaptive histogram equalization |
| CA | CACoordinate attention |
| ASFF | Adaptive spatial feature fusion |
| NMS | Non-maximum suppression |
| Soft-NMS | Soft non-maximum suppression |
| FPS | Frames per second |
| AP | Average precision |
| CNN | Convolutional neural network |
References
- McLellan, B.C. Sustainability assessment of deep ocean resources. Procedia Environ. Sci. 2015, 28, 502–508. [Google Scholar] [CrossRef]
- Lu, H.; Dong, W.; Li, Y.; Li, J.; Humar, I. CONet: A Cognitive Ocean Network. Wirel. Commun. IEEE 2019, 26, 90–96. [Google Scholar] [CrossRef]
- Lu, H.; Uemura, T.; Wang, D.; Zhu, J.; Huang, Z.; Kim, H. Deep-Sea Organisms Tracking Using Dehazing and Deep Learning. Mob. Netw. Appl. 2018, 25, 1008–1015. [Google Scholar] [CrossRef]
- Zhou, J.C.; Zhang, D.H.; Zhang, W.S. Classical and state-of-the-art approaches for underwater image defogging: A comprehensive survey. Front. Inf. Technol. Electron. Eng. 2020, 21, 1745–1769. [Google Scholar] [CrossRef]
- Kuanar, S.; Mahapatra, D.; Bilas, M.; Rao, K.R. Multi-path dilated convolution network for haze and glow removal in nighttime images. Vis. Comput. 2021, 38, 1121–1134. [Google Scholar] [CrossRef]
- J, Z.; Liu, Z.; Zhang, W.; Zhang, W. Underwater image restoration based on secondary guided transmission map. Multimed. Tools Appl. 2021, 80, 7771–7788. [Google Scholar]
- Wang, Y.; Song, W.; Fortino, G.; Qi, L.; Zhang, W.; Liotta, A. An Experimental-based Review of Image Enhancement and Image Restoration Methods for Underwater Imaging. IEEE Access 2019, 2019, 140233–140251. [Google Scholar] [CrossRef]
- Wang, R.; Wang, Y.; Zhang, J.; Fu, X. Review on Underwater Image Restoration and Enhancement Algorithms. In ICIMCS ’15: Proceedings of the 7th International Conference on Internet Multimedia Computing and Service; Association for Computing Machinery: New York, NY, USA, 2015; p. 6. [Google Scholar]
- Mliki, H.; Dammak, S.; Fendri, E. An improved multi-scale face detection using convolutional neural network. Signal Image Video Process. 2020, 14, 1345–1353. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Rodríguez, J.G. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Dimitri, G.M.; Spasov, S.; Duggento, A.; Passamonti, L.; Lió, P.; Toschi, N. Multimodal and multicontrast image fusion via deep generative models. Inf. Fusion 2022, 88, 146–160. [Google Scholar] [CrossRef]
- Wang, X.; Yang, J. Marathon athletes number recognition model with compound deep neural network. Signal Image Video Process. 2020, 14, 1379–1386. [Google Scholar] [CrossRef]
- Liang, Z.; Wang, Y.; Ding, X.; Mi, Z.; Fu, X. Single Underwater Image Enhancement by Attenuation Map Guided Color Correction and Detail Preserved Dehazing. Neurocomputing 2021, 425, 160–172. [Google Scholar] [CrossRef]
- Han, F.; Yao, J.; Zhu, H.; Wang, C. Underwater Image Processing and Object Detection Based on Deep CNN Method. J. Sens. 2020, 2020, 1–20. [Google Scholar] [CrossRef]
- Jian, M.; Liu, X.; Luo, H.; Lu, X.; Dong, J. Underwater image processing and analysis: A review. Signal Process. Image Commun. 2021, 91, 116088. [Google Scholar] [CrossRef]
- Anwar, S.; Li, C. Diving deeper into underwater image enhancement: A survey. Signal Process. Image Commun. 2020, 89, 115978. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization—ScienceDirect. In Graphics Gems; Elsevier: Amsterdam, The Netherlands, 1994; pp. 474–485. [Google Scholar]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- HeK, M.; SunJ, T.X.O. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341. [Google Scholar]
- Carlevaris-Bianco, N.; Mohan, A.; Eustice, R.M. Initial results in underwater single image dehazing. In Oceans 2010 Mts/IEEE Seattle; IEEE: Piscataway, NJ, USA, 2010; pp. 1–8. [Google Scholar]
- Wang, Y.; Liu, H.; Chau, L.P. Single underwater image restoration using adaptive attenuation-curve prior. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 65, 992–1002. [Google Scholar] [CrossRef]
- Shin, Y.S.; Cho, Y.; Pandey, G.; Kim, A. Estimation of ambient light and transmission map with common convolutional architecture. In OCEANS 2016 MTS/IEEE Monterey; IEEE: Piscataway, NJ, USA, 2016; pp. 1–7. [Google Scholar]
- Wang, K.; Hu, Y.; Chen, J.; Wu, X.; Zhao, X.; Li, Y. Underwater image restoration based on a parallel convolutional neural network. Remote Sens. 2019, 11, 1591. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Priyadharsini, R.; Sharmila, T.S. Object detection in underwater acoustic images using edge based segmentation method. Procedia Comput. Sci. 2019, 165, 759–765. [Google Scholar] [CrossRef]
- Cheng, R. A survey: Comparison between Convolutional Neural Network and YOLO in image identification. J. Physics: Conf. Ser. 2020, 1453, 012139. [Google Scholar] [CrossRef]
- Pedersen, M.; Bruslund Haurum, J.; Gade, R.; Moeslund, T.B. Detection of marine animals in a new underwater dataset with varying visibility. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–7 June 2019; pp. 18–26. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Siddiqui, S.A.; Salman, A.; Malik, M.I.; Shafait, F.; Mian, A.; Shortis, M.R.; Harvey, E.S. Automatic fish species classification in underwater videos: Exploiting pre-trained deep neural network models to compensate for limited labelled data. ICES J. Mar. Sci. 2018, 75, 374–389. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1483–1498. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1804–02767. [Google Scholar]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2022, 1–33. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, R.; Ye, Q. Freeanchor: Learning to match anchors for visual object detection. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 147–155. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Yang, H.; Liu, P.; Hu, Y.; Fu, J. Research on underwater object recognition based on YOLOv3. Microsyst. Technol. 2021, 27, 1837–1844. [Google Scholar] [CrossRef]
- Song, Y.; He, B.; Liu, P. Real-time object detection for AUVs using self-cascaded convolutional neural networks. IEEE J. Ocean. Eng. 2019, 46, 56–67. [Google Scholar] [CrossRef]
- Salman, A.; Siddiqui, S.A.; Shafait, F.; Mian, A.; Shortis, M.R.; Khurshid, K.; Ulges, A.; Schwanecke, U. Automatic fish detection in underwater videos by a deep neural network-based hybrid motion learning system. ICES J. Mar. Sci. 2020, 77, 1295–1307. [Google Scholar] [CrossRef]
- Cao, S.; Zhao, D.; Liu, X.; Sun, Y. Real-time robust detector for underwater live crabs based on deep learning. Comput. Electron. Agric. 2020, 172, 105339. [Google Scholar] [CrossRef]
- Liu, Z.; Zhuang, Y.; Jia, P.; Wu, C.; Xu, H.; Liu, Z. A Novel Underwater Image Enhancement Algorithm and an Improved Underwater Biological Detection Pipeline. J. Mar. Sci. Eng. 2022, 10, 1204. [Google Scholar] [CrossRef]
- Kong, W.; Hong, J.; Jia, M.; Yao, J.; Cong, W.; Hu, H.; Zhang, H. YOLOv3-DPFIN: A dual-path feature fusion neural network for robust real-time sonar target detection. IEEE Sens. J. 2019, 20, 3745–3756. [Google Scholar] [CrossRef]
- Sung, M.; Cho, H.; Kim, T.; Joe, H.; Yu, S.C. Crosstalk removal in forward scan sonar image using deep learning for object detection. IEEE Sens. J. 2019, 19, 9929–9944. [Google Scholar] [CrossRef]
- Hu, W.C.; Wu, H.T.; Zhang, Y.F.; Zhang, S.H.; Lo, C.H. Shrimp recognition using ShrimpNet based on convolutional neural network. J. Ambient. Intell. Humaniz. Comput. 2020, 1–8. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Shen, Z. YOLO-Submarine Cable: An Improved YOLO-V3 Network for Object Detection on Submarine Cable Images. J. Mar. Sci. Eng. 2022, 10, 1143. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP50 (%) | AP50 (%) | AP (%) | |||
|---|---|---|---|---|---|---|
| Holothurian | Echinus | Scallops | Starfish | |||
| IMAGE | 83.8 | 93.0 | 87.5 | 92.3 | 88.3 | 51.2 |
| CLAHE | 87.4 | 93.0 | 90.1 | 93.2 | 90.9 | 53.7 |
| DCP | 85.7 | 93.2 | 89.2 | 92.0 | 89.5 | 52.8 |
| ACE | 86.3 | 92.7 | 89.7 | 93.7 | 90.2 | 53.1 |
| RGHS | 86.1 | 92.9 | 88.9 | 93.0 | 89.7 | 53.4 |
| Model | ASFF | Soft-NMS | CA | AP50(%) | AP(%) |
|---|---|---|---|---|---|
| YOLOv5S | 90.9 | 53.7 | |||
| ✓ | 92.8 | 59.3 | |||
| ✓ | ✓ | 93.6 | 60.7 | ||
| ✓ | ✓ | ✓ | 94.9 | 62.8 |
| Model | AP50(%) | AP(%) | Size | FPS |
|---|---|---|---|---|
| Faster R-CNN | 90.8 | 61.7 | 41.2 M | 23 |
| Cascade R-CNN | 90.4 | 63.8 | 68.4 M | 18 |
| FreeAnchor | 91.8 | 63.1 | 36.1 M | 26 |
| RetinaNet | 89.9 | 58.1 | 36.17 M | 26 |
| FCOS | 85.8 | 48.0 | 31.8 M | 17 |
| FSAF | 89.6 | 57.4 | 36.2 M | 26 |
| YOLOv3 | 93.8 | 63 | 283.4 M | 34 |
| YOLOv4 | 92.7 | 59.2 | 256.3 M | 47 |
| YOLOv5S | 90.9 | 53.7 | 14.2 M | 83 |
| 94.9 | 62.8 | 20.4 M | 82 | |
| YOLOv5M | 94.5 | 65.5 | 42.5 M | 59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Fan, Y.; Cai, Z.; Lyu, Z.; Ren, W. Detection Method of Marine Biological Objects Based on Image Enhancement and Improved YOLOv5S. J. Mar. Sci. Eng. 2022, 10, 1503. https://doi.org/10.3390/jmse10101503
Li P, Fan Y, Cai Z, Lyu Z, Ren W. Detection Method of Marine Biological Objects Based on Image Enhancement and Improved YOLOv5S. Journal of Marine Science and Engineering. 2022; 10(10):1503. https://doi.org/10.3390/jmse10101503
Chicago/Turabian StyleLi, Peng, Yibing Fan, Zhengyang Cai, Zhiyu Lyu, and Weijie Ren. 2022. "Detection Method of Marine Biological Objects Based on Image Enhancement and Improved YOLOv5S" Journal of Marine Science and Engineering 10, no. 10: 1503. https://doi.org/10.3390/jmse10101503
APA StyleLi, P., Fan, Y., Cai, Z., Lyu, Z., & Ren, W. (2022). Detection Method of Marine Biological Objects Based on Image Enhancement and Improved YOLOv5S. Journal of Marine Science and Engineering, 10(10), 1503. https://doi.org/10.3390/jmse10101503