
Underwater Biological Detection Based on YOLOv4 Combined with Channel Attention

Abstract
:1. Introduction
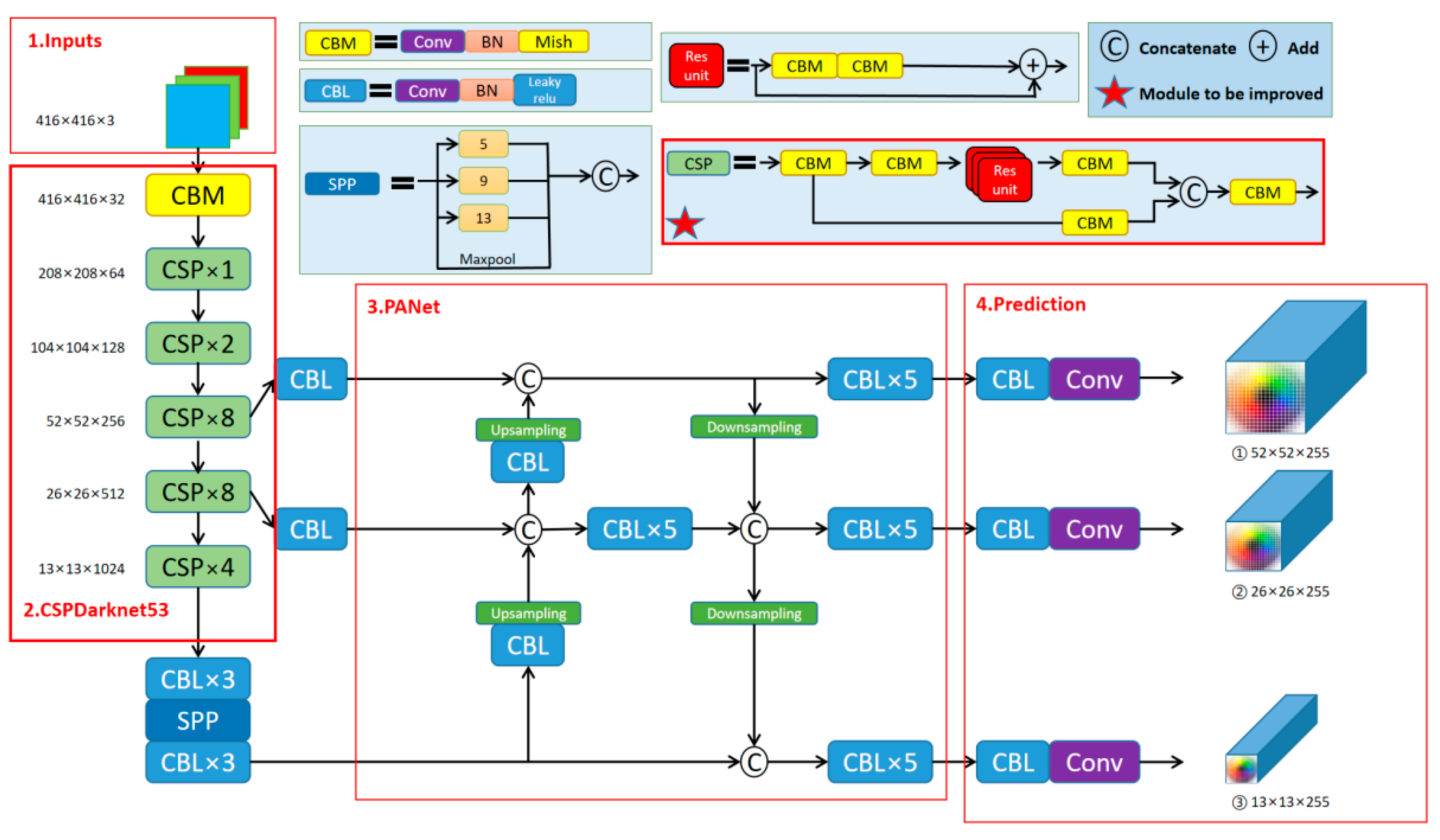
2. Model Structure
2.1. Basic Model
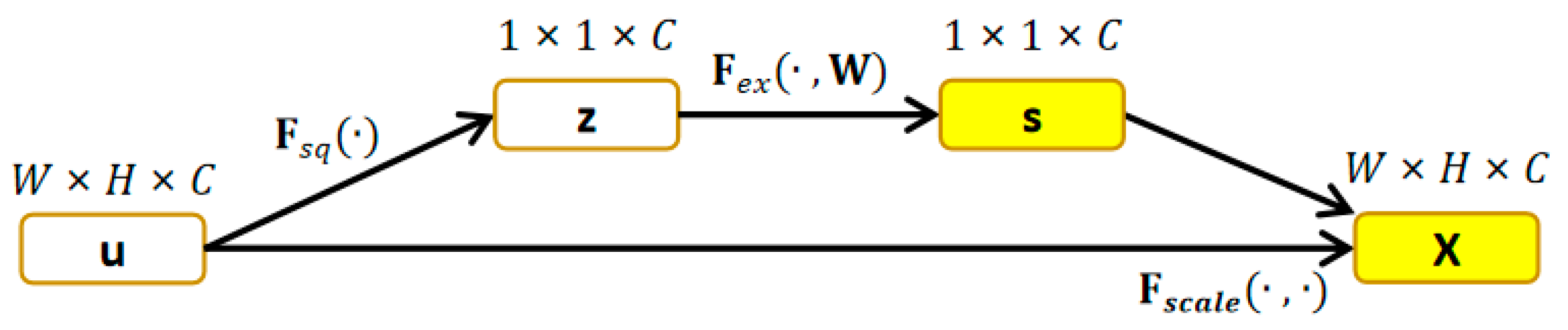
2.2. Channel Attention
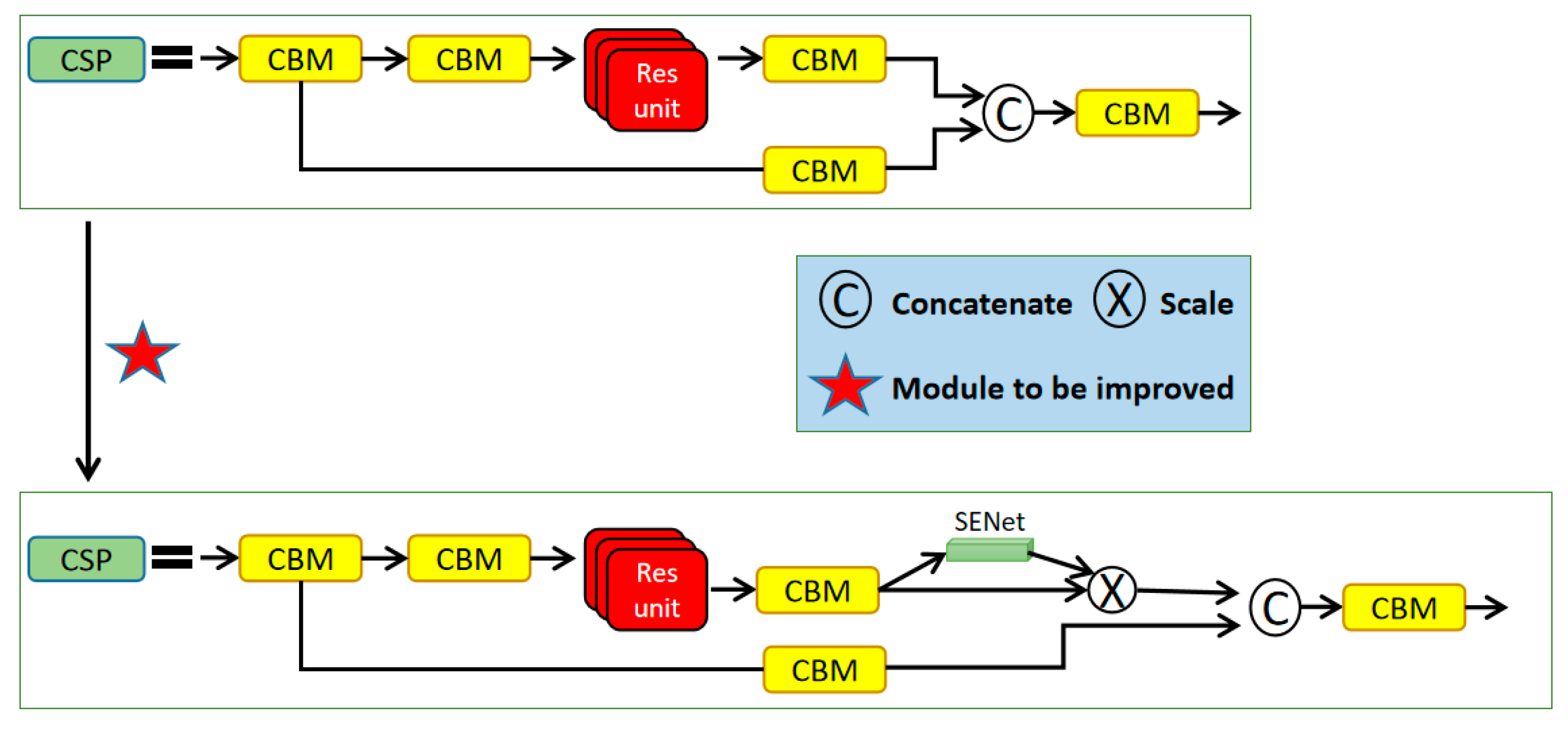
2.3. Proposed Model
3. Experiment and Analysis
3.1. Datasets
3.2. Experimental Details
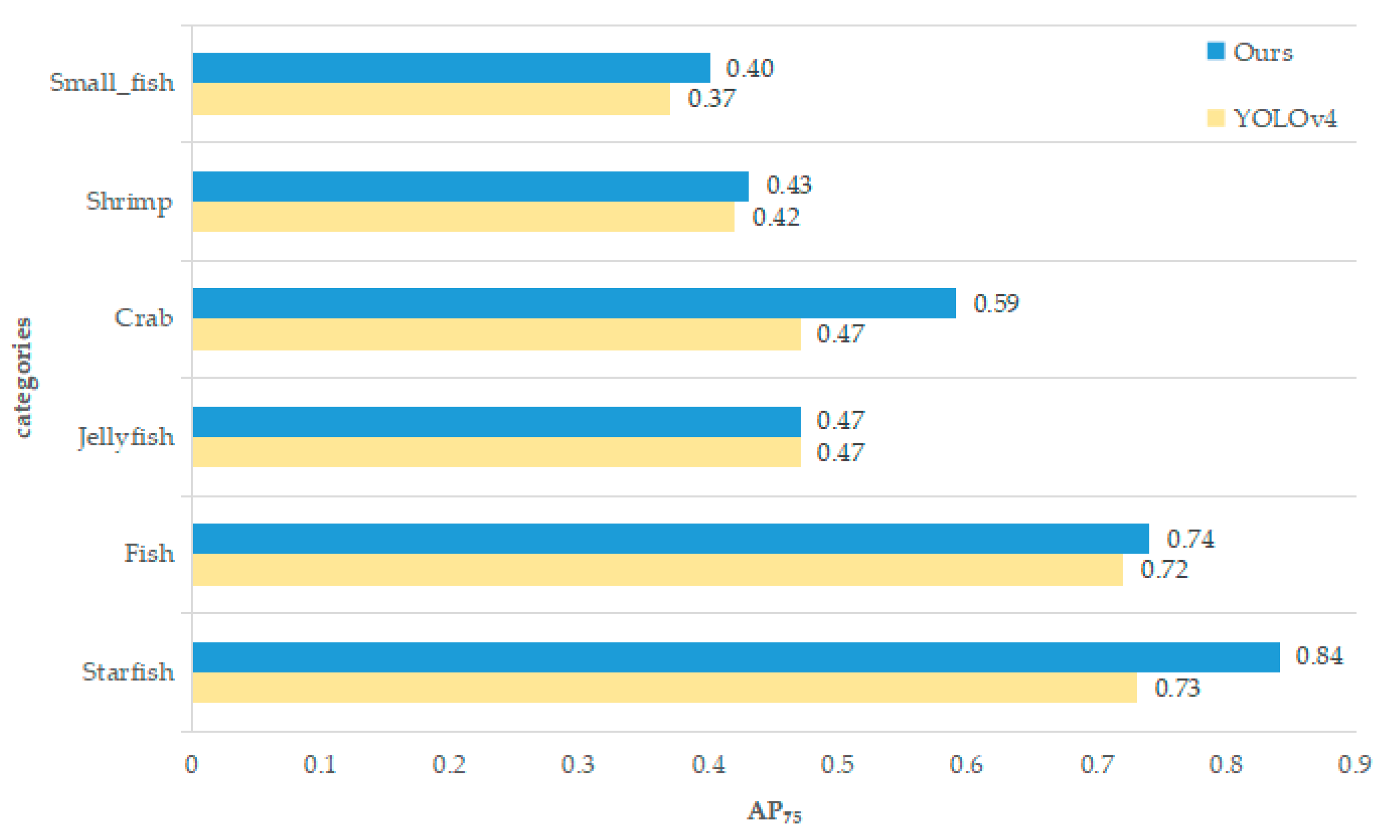
3.3. Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Christensen, J.H.; Mogensen, L.V.; Galeazzi, R.; Andersen, J.C. Detection, localization and classification of fish and fish species in poor conditions using convolutional neural networks. In Proceedings of the 2018 IEEE/OES Autonomous Underwater Vehicle Workshop (AUV), Porto, Portugal, 6–9 November 2018. [Google Scholar]
- Fouad, M.M.M.; Zawbaa, H.M.; El-Bendary, N.; Hassanien, A.E. Automatic nile tilapia fish classification approach using machine learning techniques. In Proceedings of the 13th International Conference on Hybrid Intelligent Systems (HIS 2013), Gammarth, Tunisia, 4–6 December 2013; pp. 173–178. [Google Scholar]
- Shen, J.; Fan, T.; Tang, M.; Zhang, Q.; Sun, Z.; Huang, F. A biological hierarchical model based underwater moving object detection. Comput. Math. Methods Med. 2014, 2014, 609801. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Fu, L.; Liu, K.; Nian, R.; Yan, T.; Lendasse, A. Stable Underwater Image Segmentation in High Quality via MRF Model. In Proceedings of the OCEANS 2015 - MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–4. [Google Scholar]
- Shevchenko, V.; Eerola, T.; Kaarna, A. Fish detection from low visibility underwater videos. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1971–1976. [Google Scholar]
- Liu, S.; Li, X.; Gao, M.; Cai, Y.; Nian, R.; Li, P.; Yan, T.; Lendasse, A. Embedded Online Fish Detection and Tracking System via YOLOv3 and Parallel Correlation Filter. In Proceedings of the OCEANS 2018 MTS/IEEE, Charleston, SC, USA, 22–25 October 2018. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 January 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 January 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804. 02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 January 2017; pp. 2117–2125. [Google Scholar]
- Faster, R.C.N.N. Towards real-time object detection with region proposal networks. Adv. Neur. Inf. Process. Syst. 2015, 28, 2969239–2969250. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neur. Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Sung, M.; Yu, S.C.; Girdhar, Y. Vision based real-time fish detection using convolutional neural network. In Proceedings of the OCEANS 2017-Aberdeen, Aberdeen, UK, 19–22 June 2017. [Google Scholar]
- Wang, M.; Liu, M.; Zhang, F.; Lei, G.; Guo, J.; Wang, L. Fast classification and detection of fish images with YOLOv2. In Proceedings of the OCEANS-MTS/IEEE Kobe Techno-Oceans (OTO), Kobe, Japan, 28–31 May 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neur. Inf. Process. Syst. 2014, 27. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neur. Inf. Process. Syst. 2017, 30. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 January 2018; pp. 7132–7141. [Google Scholar]
- Pedersen, M.; Bruslund Haurum, J.; Gade, R.; Moeslund, T.B. Detection of marine animals in a new underwater dataset with varying visibility. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 January 2019; pp. 18–26. [Google Scholar]
- Bahnsen, C.H.; Møgelmose, A.; Moeslund, T.B. The aau multimodal annotation toolboxes: Annotating objects in images and videos. arXiv 2018, arXiv:1809.03171. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | Train | Val | Test | Total |
|---|---|---|---|---|
| Fish | 2622 | 307 | 312 | 3241 |
| Small_fish | 7722 | 1024 | 809 | 9555 |
| Crabs | 415 | 76 | 57 | 548 |
| Shrimp | 5206 | 665 | 667 | 6538 |
| Jellyfish | 520 | 55 | 62 | 637 |
| Starfish | 4100 | 501 | 492 | 5093 |
| Total | 20,585 | 2628 | 2399 | 25,612 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, A.; Yu, L.; Tian, S. Underwater Biological Detection Based on YOLOv4 Combined with Channel Attention. J. Mar. Sci. Eng. 2022, 10, 469. https://doi.org/10.3390/jmse10040469
Li A, Yu L, Tian S. Underwater Biological Detection Based on YOLOv4 Combined with Channel Attention. Journal of Marine Science and Engineering. 2022; 10(4):469. https://doi.org/10.3390/jmse10040469
Chicago/Turabian StyleLi, Aolun, Long Yu, and Shengwei Tian. 2022. "Underwater Biological Detection Based on YOLOv4 Combined with Channel Attention" Journal of Marine Science and Engineering 10, no. 4: 469. https://doi.org/10.3390/jmse10040469
APA StyleLi, A., Yu, L., & Tian, S. (2022). Underwater Biological Detection Based on YOLOv4 Combined with Channel Attention. Journal of Marine Science and Engineering, 10(4), 469. https://doi.org/10.3390/jmse10040469