
Crop-Free-Ridge Navigation Line Recognition Based on the Lightweight Structure Improvement of YOLOv8



Abstract
1. Introduction
2. Materials and Methods
3. Design and Analysis of Key Components
3.1. Improved YOLOv8 Network Model
3.1.1. MobileNetV4 Backbone Network
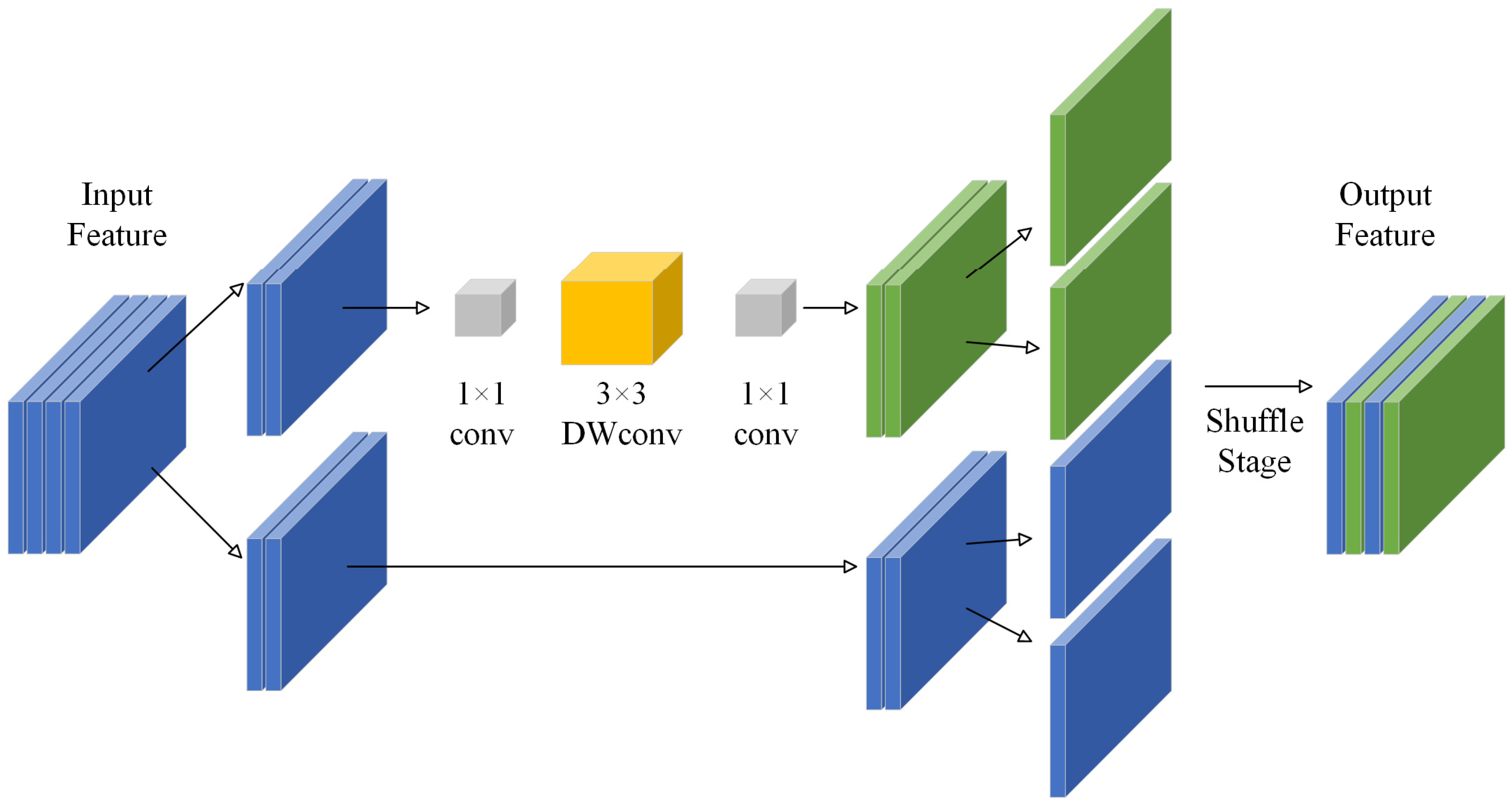
3.1.2. Shuffleblock
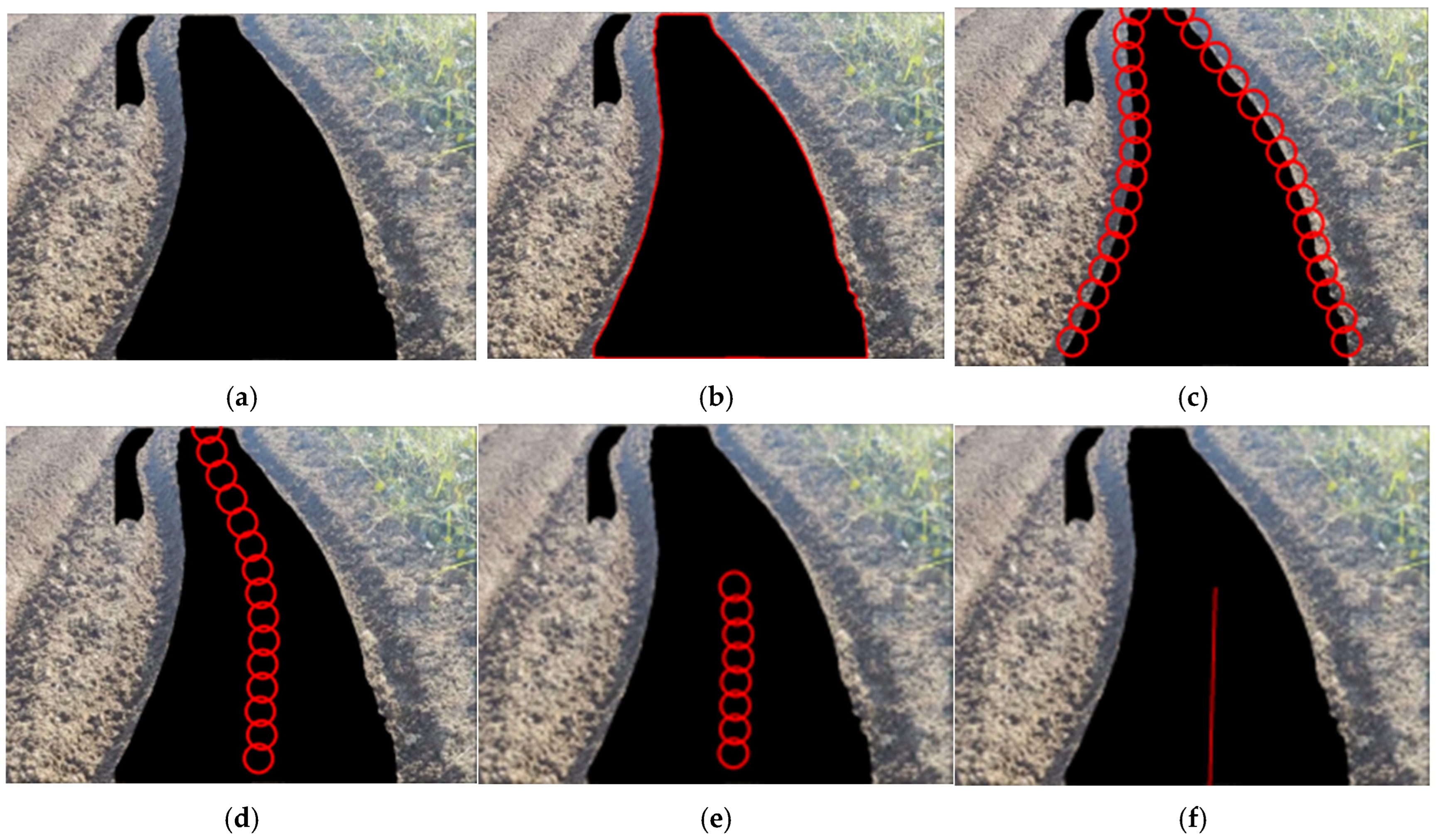
3.2. Navigation Line Extraction Method
4. Optimization of Cylinder Working Parameters
4.1. Model Training Platform Environment
4.2. Model Evaluation Indicators
4.3. Backbone Comparison Experiment and Ablation Experiment
4.4. Comparison of Commonly Used Models
4.5. Verification of the Navigation Line Prediction Effect
5. Discussion
6. Conclusions
- (1)
- The improved YOLOv8 model demonstrated superior performance compared to models such as Mask-RCNN, YOLACT++, YOLOv8, and YOLO11. Specifically, the Params and FLOPs of the model were reduced to 1.8 M and 8.8 G, respectively. At the same time, the detection frame rate of RTX3060 GPU was increased to 49.5 frames per second, which is 2.85 frames higher than the original model. In addition, while maintaining a high accuracy of 90.4%, we reduced the number of model parameters and the computation requirements, improved the detection frame rate, and provided a suitable method for the edge deployment of agricultural machinery.
- (2)
- The least-squares fitting algorithm used to extract navigation lines from the detection mask exhibited good performance, with an average initial deviation of 3.60 pixels and an average overall deviation of 2.10 pixels. It also demonstrated good anti-interference performance in the presence of fluctuations in the fitted data points, meaning that it can better meet the accuracy requirements of real-time detection in complex scenes involving agricultural machinery.
7. Future Work
- (1)
- We will continue to explore the factors affecting the recognition frame rate and further improve the recognition efficiency of the method;
- (2)
- We will further study the relationship between deep network model structures and recognition accuracy in crop-free-ridge environments while maintaining the existing parameter and computational complexity, reducing or even improving recognition accuracy losses;
- (3)
- Based on specific usage scenarios, we will conduct research on the deployment platform to implement real-time ridge line recognition using onboard methods.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, S.; Liu, J.; Jin, Y.; Bai, Z.; Liu, J.; Zhou, X. Design and Testing of an Intelligent Multi-Functional Seedling Transplanting System. Agronomy 2022, 12, 2683. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, G.; Qi, Y.; Yang, T.; Jin, C. Research Progress on Key Technologies of Agricultural Machinery Unmanned Driving System. J. Intell. Agric. Mech. 2022, 3, 27–36. [Google Scholar]
- Jin, Y.; Liu, J.; Xu, Z.; Yuan, S.; Li, P.; Wang, J. Development Status and Trend of Agricultural Robot Technology. Int. J. Agric. Biol. Eng. 2021, 14, 1–19. [Google Scholar] [CrossRef]
- Luo, X.; Liao, J.; Zang, Y.; Qu, Y.; Wang, P. The Development Direction of Agricultural Production in China: From Mechanization to Intelligence. China Eng. Sci. 2022, 24, 46–54. [Google Scholar] [CrossRef]
- Yin, J.; Wang, Z.; Zhou, M.; Wu, L.; Zhang, Y. Optimized Design and Experiment of the Three-Arm Transplanting Mechanism for Rice Potted Seedlings. Int. J. Agric. Biol. Eng. 2021, 14, 56–62. [Google Scholar] [CrossRef]
- Wang, X.; Han, X.; Mao, H.; Liu, F. Visual Navigation Path Detection of Greenhouse Tomato Ridges Based on Least Squares Method. J. Agric. Mach. 2012, 43, 161–166. [Google Scholar]
- Jiang, G.; Wang, X.; Wang, Z.; Liu, H. Wheat Rows Detection at the Early Growth Stage Based on Hough Transform and Vanishing Point. Comput. Electron. Agric. 2016, 123, 211–223. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, X.; Zhao, R.; Chen, Y.; Liu, X. Navigation Line Extraction Method for Broad-Leaved Plants in the Multi-Period Environments of the High-Ridge Cultivation Mode. Agriculture 2023, 13, 1496. [Google Scholar] [CrossRef]
- Li, H.; Lai, X.; Mo, Y.; He, D.; Wu, T. Pixel-Wise Navigation Line Extraction of Cross-Growth-Stage Seedlings in Complex Sugarcane Fields and Extension to Corn and Rice. Front. Plant Sci. 2025, 15, 1499896. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Liu, D. 3D Autonomous Navigation Line Extraction for Field Roads Based on Binocular Vision. J. Sens. 2019, 2019, 6832109. [Google Scholar] [CrossRef]
- Kneip, J.; Fleischmann, P.; Berns, K. Crop edge detection based on stereo vision. Robot. Auton. Syst. 2020, 123, 103323. [Google Scholar] [CrossRef]
- Liu, J.; He, M.; Xie, B.; Peng, Y.; Shan, H. Rapid Online Method and Experiment of Autonomous Navigation Robot for Trellis Orchard. J. Agric. Eng. 2021, 37, 12–21. [Google Scholar]
- Ji, W.; Gao, X.; Xu, B.; Pan, Y.; Zhang, Z.; Zhao, D. Apple Target Recognition Method in Complex Environment Based on Improved YOLOv4. J. Food Process Eng. 2021, 44, e13866. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, Z.; Ali, S.; Yang, N.; Fu, S.; Zhang, Y. Multi-Class Detection of Cherry Tomatoes Using Improved Yolov4-Tiny Model. Int. J. Agric. Biol. Eng. 2023, 16, 225–231. [Google Scholar]
- Wang, J.; Gao, Z.; Zhang, Y.; Zhou, J.; Wu, J.; Li, P. Real-Time Detection and Location of Potted Flowers Based on a ZED Camera and a YOLO V4-Tiny Deep Learning Algorithm. Horticulturae 2021, 8, 21. [Google Scholar] [CrossRef]
- Zhao, S.; Peng, Y.; Liu, J.; Wu, S. Tomato Leaf Disease Diagnosis Based on Improved Convolution Neural Network by Attention Module. Agriculture 2021, 11, 651. [Google Scholar] [CrossRef]
- Zhou, J.; Geng, S.; Qiu, Q.; Shao, Y.; Zhang, M. A Deep-Learning Extraction Method for Orchard Visual Navigation Lines. Agriculture 2022, 12, 1650. [Google Scholar] [CrossRef]
- Yang, R.; Zhai, Y.; Zhang, J.; Zhang, H.; Tian, G.; Zhang, J.; Huang, P.; Li, L. Potato Visual Navigation Line Detection Based on Deep Learning and Feature Midpoint Adaptation. Agriculture 2022, 12, 1363. [Google Scholar] [CrossRef]
- Li, X.; Su, J.; Yue, Z.; Duan, F. Adaptive Multi-ROI Agricultural Robot Navigation Line Extraction Based on Image Semantic Segmentation. Sensors 2022, 22, 7707. [Google Scholar] [CrossRef]
- Ruan, Z.; Chang, P.; Cui, S.; Luo, J.; Gao, R.; Su, Z. A Precise Crop Row Detection Algorithm in Complex Farmland for Unmanned Agricultural Machines. Biosyst. Eng. 2023, 232, 1–12. [Google Scholar] [CrossRef]
- Yang, Y.; Zhou, Y.; Yue, X.; Zhang, G.; Wen, X.; Ma, B.; Chen, L. Real-time detection of crop rows in maize fields based on autonomous extraction of ROI. Expert Syst. Appl. 2023, 213, 118826. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, Z.; Xie, W.; Wang, C.; Wang, F. Research on Navigation Line Extraction Algorithm for Sanqi Ridge Based on Deeplab-MV3. J. Kunming Univ. Sci. Technol. (Nat. Sci. Ed.) 2023, 48, 95–106. [Google Scholar]
- Yu, J.; Zhang, J.; Shu, A.; Chen, Y.; Chen, J.; Yang, Y.; Tang, W.; Zhang, Y. Study of convolutional neural network-based semantic segmentation methods on edge intelligence devices for field agricultural robot navigation line extraction. Comput. Electron. Agric. 2023, 209, 107811. [Google Scholar] [CrossRef]
- Li, D.; Li, B.; Kang, S.; Feng, H.; Long, S.; Wang, J. E2CropDet: An Efficient End-to-End Solution to Crop Row Detection. Expert Syst. Appl. 2023, 227, 120345. [Google Scholar] [CrossRef]
- Gong, H.; Zhuang, W.; Wang, X. Improving the Maize Crop Row Navigation Line Recognition Method of YOLOX. Front. Plant Sci. 2024, 15, 1338228. [Google Scholar] [CrossRef]
- Kong, X.; Guo, Y.; Liang, Z.; Zhang, R.; Hong, Z.; Xue, W. A Method for Recognizing Inter-Row Navigation Lines of Rice Heading Stage Based on Improved ENet Network. Measurement 2025, 241, 115677. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO (Version 8.0.0) [Computer Software]. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 July 2024).
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4: Universal Models for the Mobile Ecosystem. In Proceedings of the European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 78–96. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2018; pp. 116–131. [Google Scholar]
- Wang, S.; Sun, G.; Zheng, B.; Du, Y. A Crop Image Segmentation and Extraction Algorithm Based on Mask RCNN. Entropy 2021, 23, 1160. [Google Scholar] [CrossRef]
- Huang, M.; Xu, G.; Li, J.; Huang, J. A Method for Segmenting Disease Lesions of Maize Leaves in Real Time Using Attention YOLACT++. Agriculture 2021, 11, 1216. [Google Scholar] [CrossRef]
- Hidayatullah, P.; Syakrani, N.; Sholahuddin, M.R.; Gelar, T.; Tubagus, R. YOLOv8 to YOLO11: A Comprehensive Architecture In-Depth Comparative Review. J. Appl. Eng. Technol. Sci. 2025, submitted.
- Zhou, M.; Xia, J.; Yang, F.; Zheng, K.; Hu, M.; Li, D.; Zhang, S. Design and Experiment of Visual Navigated UGV for Orchard Based on Hough Matrix and RANSAC. Int. J. Agric. Biol. Eng. 2021, 14, 176–184. [Google Scholar] [CrossRef]
- Yu, G.; Wang, Y.; Gan, S.; Xu, H.; Chen, J.; Wang, L. Improved DeepLabV3+ Algorithm for Extracting Navigation Lines in Crop Free Fields. J. Agric. Eng. 2024, 40, 168–175. [Google Scholar]
- Zhang, Y.; Wang, H.; Liu, J.; Zhao, X.; Lu, Y.; Qu, T.; Tian, H.; Su, J.; Luo, D.; Yang, Y. A Lightweight Winter Wheat Planting Area Extraction Model Based on Improved DeepLabv3+ and CBAM. Remote Sens. 2023, 15, 4156. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MobileNetV4 | ShuffleNetV2 | GhostNet | EfficientNet | Params/M | FLOPs/G | mAP/% | FPS |
|---|---|---|---|---|---|---|---|
| √ | × | × | × | 2.3 | 9.7 | 90.4 | 47.6 |
| × | √ | × | × | 2.2 | 2.4 | 87.2 | 73.5 |
| × | × | √ | × | 1.9 | 9.1 | 89.6 | 48.5 |
| × | × | × | √ | 7.5 | 9.5 | 96.2 | 29.5 |
| MobileNetV4 | Shuffleblock | Params/M | FLOPs/G | mAP/% | FPS |
|---|---|---|---|---|---|
| × | × | 3.2 | 12.1 | 96.3 | 46.7 |
| √ | × | 2.3 | 9.7 | 90.4 | 47.6 |
| × | √ | 2.8 | 11.2 | 95.0 | 47.4 |
| √ | √ | 1.8 | 8.8 | 90.4 | 49.5 |
| Model | Params/M | FLOPs/G | mAP/% | FPS |
|---|---|---|---|---|
| Mask-RCNN | 43.9 | 134.07 | 80.6 | 13.8 |
| YOLACT++ | 49.61 | 67.09 | 91.7 | 16.2 |
| YOLOv8 | 3.2 | 12.1 | 96.3 | 46.7 |
| YOLO11 | 2.8 | 10.4 | 95.2 | 43.7 |
| this study 1 | 1.8 | 8.8 | 90.4 | 49.5 |
| Scene 1 | Scene 2 | Scene 3 | Scene 4 | Scene 5 | Average | Total Average | Standard Deviation | t | p | |
|---|---|---|---|---|---|---|---|---|---|---|
| Initial deviation of this article | 4.31 | 2.84 | 1.07 | 1.48 | 8.34 | 3.60 | 4.26 | 4.01 | 2.77 | 0.01 |
| Initial deviation of RANSAC | 11.91 | 2.84 | 1.07 | 2.37 | 12.15 | 6.07 | 6.66 | 8.22 | ||
| Overall deviation of this article | 1.72 | 1.50 | 1.88 | 2.50 | 2.90 | 2.10 | 2.68 | 1.79 | 1.33 | 0.19 |
| Overall deviation of RANSAC | 3.08 | 1.50 | 1.88 | 2.64 | 2.94 | 2.41 | 3.00 | 1.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, R.; Hu, J.; Zhang, T.; Chen, X.; Liu, W. Crop-Free-Ridge Navigation Line Recognition Based on the Lightweight Structure Improvement of YOLOv8. Agriculture 2025, 15, 942. https://doi.org/10.3390/agriculture15090942
Lv R, Hu J, Zhang T, Chen X, Liu W. Crop-Free-Ridge Navigation Line Recognition Based on the Lightweight Structure Improvement of YOLOv8. Agriculture. 2025; 15(9):942. https://doi.org/10.3390/agriculture15090942
Chicago/Turabian StyleLv, Runyi, Jianping Hu, Tengfei Zhang, Xinxin Chen, and Wei Liu. 2025. "Crop-Free-Ridge Navigation Line Recognition Based on the Lightweight Structure Improvement of YOLOv8" Agriculture 15, no. 9: 942. https://doi.org/10.3390/agriculture15090942
APA StyleLv, R., Hu, J., Zhang, T., Chen, X., & Liu, W. (2025). Crop-Free-Ridge Navigation Line Recognition Based on the Lightweight Structure Improvement of YOLOv8. Agriculture, 15(9), 942. https://doi.org/10.3390/agriculture15090942