Abstract
Seed potatoes without sprouts usually need to be manually selected in mechanized production, which has been the bottleneck of efficiency. A fast and efficient object recognition algorithm is required for the additional removal process to identify unqualified seed potatoes. In this paper, a lightweight deep learning algorithm, YOLOv8_EBG, is proposed to both improve the detection performance and reduce the model parameters. The ECA attention mechanism was introduced in the backbone and neck of the model to more accurately extract and fuse sprouting features. To further reduce the model parameters, Ghost convolution and C3ghost were introduced to replace the normal convolution and C2f blocks in vanilla YOLOv8n. In addition, a bi-directional feature pyramid network is integrated in the neck part for multi-scale feature fusion to enhance the detection accuracy. The experimental results from an isolated test dataset show that the proposed algorithm performs better in detecting sprouts under natural light conditions, achieving an mAP0.5 of 95.7% and 91.9% AP for bud recognition. Compared to the YOLOv8n model, the improved model showed a 6.5% increase in mAP0.5, a 12.9% increase in AP0.5 for bud recognition, and a 5.6% decrease in the number of parameters. Additionally, the improved algorithm was applied and tested on mechanized sorting equipment, and the accuracy of seed potato detection was as high as 92.5%, which was sufficient to identify and select sprouted potatoes, an indispensable step since only sprouted potatoes can be used as seed potatoes. The results of the study can provide technical support for subsequent potato planting intelligence.
1. Introduction
The potato, which is not only highly productive but also rich in nutritional value, is the fourth major staple food after wheat, rice, and maize. Its yield and quality have a direct impact on agricultural production efficiency and food security [1,2,3]. In potato production, the quality and germination of seed potatoes are critical to final yields and crop health. Identification of seed potato sprouts is a critical step in ensuring the quality of seed potatoes, helping farmers detect sprouting issues in a timely manner and optimize planting and management strategies [4]. However, traditional manual identification methods are time-consuming and labor-intensive, and susceptible to human bias, leading to inaccurate identification results.
In previous research, edge extraction analysis methods based on image enhancement have been widely used for anomaly detection and quality inspection in industrial assembly lines due to their low computational requirements [5,6,7,8,9,10]. These methods were among the earliest machine vision techniques applied to potato sprout eye identification. Lv et al. [11] extracted the bud eye region by performing boundary connectivity region rejection after applying direct texture transformation to grayscale images through filtering. Digital imaging technologies based on image texture features, given their rich descriptive capabilities, have also been explored by researchers for potato sprout eye recognition. Based on the reconstruction of sprout eye features in the HSI space, Hou Jialin et al. [12] proposed a recognition method using S-component cross-sectional curves and their first-order derivatives as features, effectively characterizing just-sprouted, sprouted, short-type, and narrow-elongated sprouts. Meng et al. [13] constrained the reconstruction of the HSI space to simple potato samples without backgrounds by combining edge detection methods, and further developed a recognition method by utilizing the S-component features of sprout eye regions. However, traditional imaging methods require high sample cleanliness. Due to the non-standardized morphology and high variability of agricultural products, these methods exhibit significant limitations, often resulting in serious misjudgments when non-sprouting phenomena, such as broken skin, color spots, insect eyes, soil, and mechanical damage, randomly appear on the surface of seed potatoes.
With the rapid advancement of computer vision technologies and deep learning algorithms, image recognition-based methods have increasingly become a major research focus in crop management [14,15]. Zhao et al. [16] proposed a nondestructive method for detecting external defects in potatoes by combining machine learning with hyperspectral technology, achieving 93% accuracy in distinguishing healthy, black-skinned, and green-skinned potatoes. Zhang et al. [17] developed an improved version of the VGG16S network, integrating the CBAM attention mechanism with a Leaky ReLU activation function, achieving 97.87% accuracy in potato leaf disease detection. The model achieved 97.87% accuracy in potato leaf disease detection. As the YOLO (You Only Look Once) series of object detection algorithms has continued to evolve, YOLO models have been widely adopted for agricultural product quality assessment and disease detection, demonstrating superior real-time recognition speeds and high detection accuracy [18,19,20,21]. Li et al. [22] employed an improved YOLOv5s model for detecting sowing omissions in potatoes, achieving increases of 2.28, 3.09, and 0.28 percentage points in precision, recall, and mAP, respectively. Che et al. [23] proposed a model named YOLO-SBWL for real-time dynamic monitoring of corn seed defects, which combines the SimAM attention mechanism with the YOLOv7 network and employs a weighted bi-directional feature pyramid network. This model achieved a 97.21% mean average precision, an improvement of 2.59% over the original network, while reducing GFlops by 67.16%, thus successfully realizing dynamic real-time monitoring of corn seeds. Zhang et al. [24] proposed an improved YOLOv5s model for identifying the sprout eyes of seed potatoes. By incorporating the CBAM attention mechanism and a weighted BiFPN structure and replacing the conventional head with an efficient Decoupled Head to better separate regression and classification tasks, the model achieved improvements of 0.9 and 1.7 percentage points in precision and recall, respectively, compared to the original model.
Although deep learning methods have been extensively researched in the field of crop detection, their application to potato seed sprout detection remains in its early stages [25,26]. In the potato planting, it is necessary to screen seed potatoes for successful sprout development after cutting to ensure that only seed potatoes with strong growth potential enter the sowing process [27,28,29]. Based on this need, this paper proposes an improved YOLOv8 model for detecting potato seed sprouts, termed YOLOv8_EBG (E-ECA, B-BiFPN, G-Hyper-Ghost). Specifically, an image acquisition system was developed to detect sprouts on seed potatoes. The ECA mechanism was integrated into both the backbone and neck of YOLOv8n to enhance feature extraction and multi-scale fusion capabilities. Additionally, Ghost convolution was employed to replace traditional convolution operations, and the C2f module was replaced with C3Ghost, thereby achieving model lightweighting, reducing the number of parameters, and improving inference speed. Furthermore, a BiFPN block was incorporated into the neck of YOLOv8n, improving feature fusion efficiency and model accuracy. Finally, the YOLOv8_EBG model’s performance was comprehensively evaluated through ablation studies and comparative experiments, and practical validation was conducted on potato seed sorting equipment to assess the improved network’s real-world performance.
2. Materials and Methods
2.1. Image Sample Acquisition
In the experiment, an image acquisition system was constructed, consisting of a food conveyor belt, a camera, an illumination source, and a camera mount. The camera used was an MV-CS050-10UC model, with an image resolution of 1920*1080 pixels. To ensure more comprehensive image acquisition of the potato samples, such that potatoes occupied more than 50% of the image area, the distance between the camera and the potatoes was adjusted in advance. The image acquisition setup is shown in Figure 1.
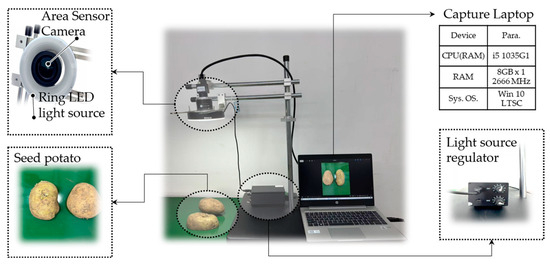
Figure 1.
The picture of Image Capture Devices.
The experimental materials selected for this study included a total of 1023 seed potatoes from six potato varieties bred in the Northeast monoculture region, as shown in Figure 2. All samples were provided by the College of Agriculture, Northeast Agricultural University. The selected seed potatoes were developed through genetic selection and breeding, exhibiting stable genetic traits and consistent growth and yield performance across multiple growth cycles, thereby ensuring the reproducibility and reliability of the experimental data. For variety selection, all six seed potato varieties were chosen from those used in fully mechanized potato production, aligning directly with the research objectives of this study. After screening, a total of 631 images of seed potatoes from the six varieties were collected, yielding 5024 sample points in total. All images were saved in JPG format.

Figure 2.
Dataset of six potato pictures.
2.2. Dataset Construction
The seed potato samples collected in this study were divided into two categories: seed potato and sprouts. Sprouts were further classified into terminal sprouts and lateral sprouts. The terminal sprout is the main growth point of the potato tuber, typically germinating earlier and producing thicker shoots that are most likely to develop into full potato plants. The terminal bud is located at the top of the potato, opposite to the tuber umbilicus. As shown in Figure 3, terminal buds are generally larger and more developed than other buds, with lengths ranging from a few millimeters to about one centimeter. They often occur in clusters and are conical or tapered in shape, thicker at the base and narrowing toward the tip. Terminal buds are usually darker in color, appearing pale green, pink, or purple depending on the variety, and tend to deepen in color as they develop.
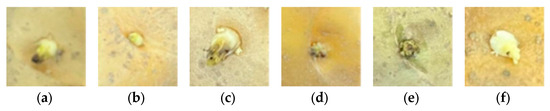
Figure 3.
Six types of potato sprouts: (a) refers to the buds of Helan 15, (b) to the buds of Benxi88-5, (c) to the buds of Jin Mandi, (d) to the buds of Jinmanti7, (e) to the buds of Xisen6 and (f) to the buds of Jinmandi1.
Lateral buds are located along the lateral parts of the potato tuber and are irregularly distributed across its surface. As shown in Figure 4, lateral buds are generally smaller than terminal buds, typically measuring no more than a few millimeters in length. They are ovate or oval in shape, shorter and more rounded than terminal buds. Their surface is relatively smooth, and their texture is softer compared to that of terminal buds. The color of lateral buds is similar to that of terminal buds within the same variety but is slightly lighter, typically appearing pale green or pale white; purple coloration is rarely observed.

Figure 4.
The typical morphology of the buds of seed potatoes.
The resulting image was imported into Make Sense, and the seed potatoes and the sprouts on top of the seed potatoes (including terminal and lateral sprouts) were labeled in the image. After the data annotation, we divided the dataset into training, validation, and test sets in a 7:1:2 ratio, as shown in Table 1.

Table 1.
Dataset partitioning.
2.3. Data Augmentation
Data augmentation is a technique used to generate new training data by applying various transformations and extension operations to existing datasets [30]. It is a critical method in machine learning, particularly in deep neural network-based model training, aimed at improving model generalization and reducing the risk of overfitting.
Firstly, there is significant individual variation in the appearance and location of sprouting points on seed potato pieces, which can differ markedly under varying lighting conditions and camera angles. Data augmentation simulates these potential variations, exposing the model to a broader range of sample differences during training and enhancing its generalization capability. Secondly, although the dataset construction process described above attempted to include as many different potato pieces and bud forms as possible, it remains difficult to ensure an even distribution of features such as size, color, and shape across the dataset. Data augmentation can help balance the dataset by replicating and transforming a limited number of minority class samples, thereby improving the model’s ability to recognize all categories. Finally, as the constructed image samples were captured under specific visual sensor conditions, there is a risk that the model could overfit to the noise and fine-grained details in the training data. By generating diverse training samples through data augmentation, the model is encouraged to learn more generalized features, thus mitigating overfitting.
In this study, four categories of data augmentation techniques, namely, color transformation, spatial transformation, artificial noise addition, and sample transformation, were introduced to extend the dataset. Figure 5 illustrates the effect of applying a single and more extreme augmentation scenario. The composition of the dataset after data enhancement is shown in Table 2 below.

Figure 5.
Data-enhanced graphic presentation used in this study.
Table 2.
Composition of the dataset after data enhancement.
3. Potato Seed Potato Sprout Identification Network
3.1. YOLOv8 Network Model
The main framework of the YOLOv8 network consists of the backbone, neck, and head [31]. Among them, the backbone references the CSPDarkNet network, and unlike YOLOv5, YOLOv8 uses C2f (CSPlayer_2Conv) instead of the C3 module to enhance the gradient flow. In the neck part, YOLOv8‘s neck uses a PAN-FPN similar to YOLOv5’s PAN-FPN, called dual-stream FPN, which is efficient and fast. In the head part, YOLOv8 uses the Decoupled Head, which separates the regression branch from the prediction branch, and converges faster and better. In addition, YOLOv8 abandons the previous Anchor-Base and uses the Anchor-Free structure, which is the most significant change of YOLOv8 compared with the previous YOLO models. YOLOv8 provides five different models, YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l and YOLOv8x, to accommodate diverse inspection needs. The detection performance of these models for potato seed sprouts in the selected dataset of this study is presented in Table 3.
Table 3.
Performance comparison of five YOLOv8 models.
According to the results presented in Table 3, the YOLOv8n model demonstrates superior computational efficiency and exhibits favorable characteristics for deployment on mobile devices. Based on these considerations, we selected YOLOv8n as the baseline model for subsequent modifications in this study.
3.2. YOLOv8 Network Improvements
Although the YOLOv8 network demonstrates excellent performance in object detection accuracy and processing speed, it encounters persistent challenges in small object recognition within complex environments. Specifically, in our potato seed tuber sprout detection task, the target sprouts typically occupy only a minimal portion of the overall image. Furthermore, residual soil clods adhering to the seed tubers create additional interference for computer vision systems. These factors collectively contribute to suboptimal detection speed and accuracy that require further enhancement.
YOLOv8 uses the traditional convolution in the backbone module, which is more powerful and capable of extracting complex features, but it is more computationally intensive and generates more parameters for the operation. In this study, the convolution in layers 2, 4, and 6 in backbone are replaced with GhostConv, and the C2f module is replaced with C3ghost. By combining GhostConv and C3 module to build efficient convolutional layers, the network reduces the large amount of computation and storage requirements while maintaining better accuracy, which can be used in embedded devices. The module for extracting features in YOLOv8 is mainly C2f. With the increase in convolutional layers, C2f becomes inaccurate for feature extraction, and the extracted feature data are easily lost. As a result, the model is likely to have detection errors or target omissions, leading to accuracy degradation when recognizing small targets. In this study, the ECA attention mechanism is added after each C2f in the neck part of YOLOv8 to adaptively adjust the weights of each channel, and BiFPN is used to improve the feature fusion efficiency. The improved YOLOv8_EBG network structure is shown in Figure 6.
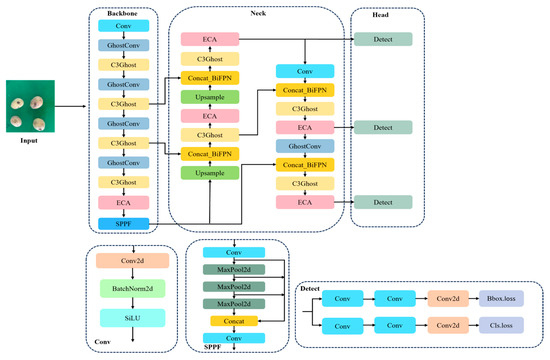
Figure 6.
Improvement of YOLOv8_EBG structural framework diagram.
3.2.1. Hyper-Ghost
For sprout detection of seed potato, detection speed is as important as accuracy [32,33]. In this study, GhostConv and C3ghost were introduced in YOLOv8n’s backbone instead of the traditional convolution and C2f to form the Hype Ghost module to ensure that the model accuracy is not lost without reducing the number of parameters in the model.
The schematic diagram of GhostConv is shown below in Figure 7. For an input of size X, where C is the number of input channels and H and W are the height and width of the input feature map. GhostConv first goes through a standard convolutional layer to generate the base feature map . As shown in Equation (1):
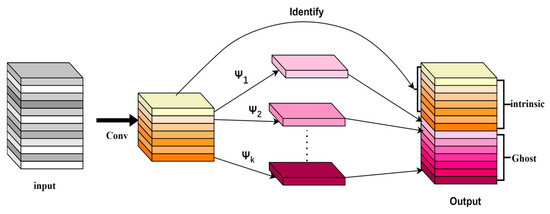
Figure 7.
GhostConv module. In the figure, Ψ represents the linear transformation.
This convolution operation is a smaller convolution kernel and generates a relatively small number of feature map channels, as shown in the figure below. If the number of input feature map channels is 12, then the number of feature map channels generated by this convolution operation step is 6.
GhostConv then generates more Ghost feature maps from the base feature map through k linear operations Ψ. The purpose of this step is to generate a large number of features with a small number of computations. The process of generating the Ghost feature map can be represented as shown in Equation (2).
In this case, G is a lightweight operator module, and deep separable convolution is used in this study.
Ultimately, the output of GhostConv is a feature map obtained by combining the base feature map and the Ghost feature map. As shown in Equation (3).
where denotes the feature map stitching operation.
Compared with C2f, the primary advantages of C3ghost lie in its superior computational efficiency and lightweight architecture. This enhancement stems from its GhostNet-inspired design paradigm, which strategically minimizes redundant computational operations to optimize memory utilization and thereby boost overall computational performance. Furthermore, C3ghost exhibits remarkable hardware adaptability, particularly in resource-constrained environments, with its efficient and lightweight characteristics conferring significant competitive advantages.
While C2f has achieved certain progress in computational optimization, comparative analyses demonstrate that C3ghost outperforms in three critical aspects: computational efficiency, memory optimization, and cross-platform adaptability. These technical merits endow C3ghost with greater potential for deployment in resource-limited scenarios. The architectural schematic of C3ghost is presented in Figure 8.
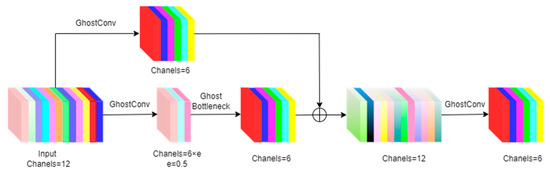
Figure 8.
C3ghost schematic. The ⊕ in the diagram represent splices.
The GhostConv module demonstrates superior computational efficiency while preserving model accuracy through its innovative approach of minimizing redundant computations and generating virtual feature maps from existing features [34]. In the present study, the proposed Hyper Ghost module further enhances this capability, offering a computationally efficient solution specifically optimized for potato sprout detection tasks.
3.2.2. ECA
In the field of deep learning, especially in visual tasks, the attention mechanism has become a key technique to enhance the perceptual ability and interpretability of models, and an effective attention strategy can significantly enhance the ability of models to focus on important features [35,36,37]. The large number of Ghost Conv we introduced in 3.2.1 effectively realizes the lightweight of the model, which provides enough computational margin for us to introduce a reasonable attention mechanism, and at the same time, the attention mechanism is also an important way to compensate for the possible loss of computational accuracy caused by GhostConv.
In this study, the Efficient Channel Attention mechanism, a lightweight channel attention model designed for convolutional neural networks, is adopted, which originates from the optimization for the SE attention mechanism, which models the relationships between channels in a more efficient way to improve computational efficiency and performance, with the ability to adaptively adjust the weights of each channel [38]. The design concept of ECA is to optimize the feature representation and decision-making process of the network by minimizing the parameter introduction and computational cost while effectively capturing the complex dependencies between channels. This complex dependency, by integrating ECA, can offset the accuracy degradation due to the limited computation of Ghost Conv with little increase in computation power.
The structure of the ECA module is shown in Figure 9. For an input with dimensions (, , ), the ECA first performs a global average pooling to obtain a weight vector = {} of the same dimensions as the number of input channels, and the weight coefficients . As shown in Equation (4).
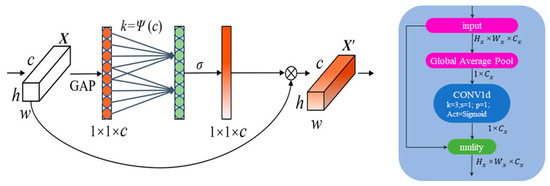
Figure 9.
ECA Attention Mechanism Schematic.
In Equation (4), is the pixel value of channel c at the corresponding position in the input feature map. The result obtained by global average pooling extraction is called the description vector element of channel c, which is used to express the importance weight of each channel.
In the SE mechanism, the above results are activated after two fully connected layers to obtain the channel weights, but the ECA mechanism omits the complex fully connected layers and directly applies the one-dimensional convolution to transformation to achieve the capture and learning based on the dependency relationship between the channel description vectors, and generates new channel weight vectors through the backpropagation process in the iterative process, which is expressed as in Equation (5):
In Equation (5), is the number of convolution kernels for one-dimensional convolution. In order to match the number of outputs of ω with the input channels, here the convolution process needs to comprehensively configure the step stride and boundary processing strategy to ensure that the processed output vector will be consistent with the number of channels of the original feature map, and to ensure that each channel has a corresponding output weight value.
For the vector ω generated by one-dimensional convolution in this process, the activation function is ultimately used for metric control, so that the weights of each channel are restricted to a fixed interval, and the attention mechanism uses a sigmoid function for activation before feeding the normalized weights back to the inputs in the form of multiplication. As shown in Equation (6):
where , the output adjusted by the ECA attention mechanism, carries convolutionally processed weights on top of ; σ denotes the sigmoid function, which provides a smooth and non-linear mapping that helps the network learn more complex patterns, allowing the attention mechanism to adjust the contribution of different channels in a more subtle way, helping the network to be able to pay attention to the characteristics of potato seed sprouts.
In this study, the attention mechanism is added to the backbone and neck parts, respectively. Adding the attention mechanism to the backbone can make the model better recognize the channel information of the buds in the feature extraction stage, thus improving the robustness of the overall model, and adding the attention mechanism to the SPPF of the YOLOv8 backbone The first layer can effectively improve the effectiveness and accuracy of SPPF when dealing with multi-scale features, and ECA can help the network to strengthen important features before multi-scale pooling in SPPF, optimizing the subsequent multi-scale fusion and target detection performance.
The neck part of YOLOv8 is important to improve the detection accuracy of the model on different scales and sizes of targets through multi-scale operations such as feature fusion, feature enhancement, and information transfer, and to maintain an efficient real-time detection capability by optimizing the amount of computation. By adding the ECA attention mechanism in the neck part, the network is able to better handle features of different scales and enhance the detection ability of multi-scale targets, which is especially important for bud detection.
3.2.3. BiFPN
BiFPN, the Bidirectional Feature Pyramid Network, is a neural network architecture for target detection and image segmentation. In computer vision tasks, Feature Pyramid Network (FPN) is a commonly used method to capture targets at different scales by constructing feature maps at different scales [39]. However, traditional FPNs have some drawbacks, such as inefficient feature fusion and insufficient information flow, etc. BiFPN overcomes these problems by introducing a bidirectional feature fusion mechanism and weighted feature fusion. The traditional FPN is unidirectional, i.e., it passes information from high-level feature maps to low-level feature maps. BiFPN, on the other hand, adds directional information transfer, i.e., transferring information from low-level feature maps to high-level feature maps. This bidirectional information flow makes the information fusion between feature maps more adequate. Moreover, in BiFPN, feature maps of different scales are assigned different weights when fused. These weights are learnable parameters, and the model will automatically adjust them during the training process to optimally fuse features of different scales.
In this way, the model is able to make better use of the information in each feature map and improve the overall feature representation [40]. Each time, features are fused from different layers, BiFPN dynamically adjusts the weights of the fusion between layers based on the learned parameters. In this way, the network can automatically learn how to better fuse information from different layers based on the characteristics of the data. Through this weighted fusion, the network is able to reduce the noise that may be caused by the bottom layer features and improve the representation of the higher layer features. Suppose that the feature map at a certain layer is , which is weighted and fused with the upper layer feature map and the lower layer feature map by a learnable weight matrix. Then the computation of the output feature map of a layer in BiFPN can be expressed as shown in Equation (7):
where are the weights obtained from learning, reflecting the importance of information flow from layer j to layer i. These weights are optimized by training data.
For each layer of the feature map, BiFPN not only relies on simple up-sampling or convolution operation but also exchanges and weights the information in multiple directions to obtain an optimal fusion result, as shown in Figure 10.
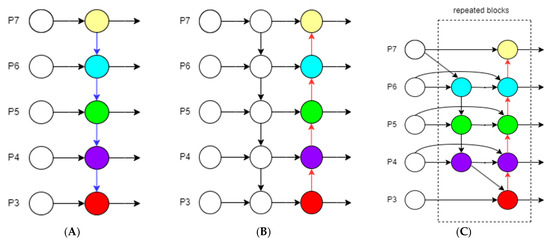
Figure 10.
(A) FPN structure; (B) PAN structure; (C) BiFPN structure.
3.3. Evaluation Metrics and Analysis Environment
In this study, the evaluation metrics used cover both performance assessment and complexity assessment of the model. For performance evaluation, four key metrics were chosen: precision, recall, mean Average Precision (mAP), and F1 score (F1-Score). Among them, precision is used to measure the accuracy of the model in positive case detection, and recall is used to assess the comprehensiveness of the model in positive case detection. The calculation of mAP is based on the average of the area under the precision-recall curve, whose evaluation interval is set from 0.5 to 0.95 in 0.05 incremental steps. As the IoU threshold increases, the overlap requirement between the predicted and real frames is enhanced accordingly, resulting in a decreasing trend in the AP value. For the potato and its sprout eye detection task characteristics, this study chooses mAP0.5 as the evaluation criterion, and this threshold achieves the best balance between localization accuracy and practical application requirements. Given that precision and recall present a contradictory relationship in many cases, F1-Score is introduced as a reconciled mean of the two to comprehensively assess the quality of the model. The value of the F1-Score ranges between 0 and 1, and the use of both precision and recall to comprehensively reflect the model’s performance. The specific calculation formula is as shown in Equations (8)–(10):
where is the number of true examples, is the number of false positive examples and is the number of false negative examples.
where P(r) is the precision corresponding to the recall rate r, the legal range of AP value is [0,1], a value closer to 1 represents the stronger comprehensive ability of the model, mAP is the average value of the detection ability of the model in multiple categories, the calculation formula is shown below:
where N is the total number of categories and is the average accuracy of the first category.
For the model complexity aspect, there are three metrics: Params, GFlops, and Size, which are calculated as shown in Equations (13) and (14):
The experimental environment configuration and key parameters for model construction are shown in Table 4.
Table 4.
Environment and tools of analysis and model building in paper.
3.4. Implementation Details
Intersection over Union (IoU) is a core metric used to evaluate the performance of object detection in the field of computer vision. It quantifies the spatial match between a predicted bounding box and the ground truth bounding box by calculating the ratio of the area of their overlapping region to the area of their union. The formula is presented as follows:
In the standard evaluation framework, the initial threshold is typically set at 0.5, with incremental steps of 0.05 up to 0.95. As the IoU threshold increases from 0.5 to 0.95, the criteria for correctly detected objects become progressively stricter. When the threshold is set to 0.5, an overlap of approximately 50% is sufficient to classify the detection as correct; however, when the threshold reaches 0.95, it requires a precise alignment of over 95% between the predicted and ground truth boxes. The AP performance as well as mAP performance of the YOLOv8n model for both sprouted and seed potatoes at the three key IoU thresholds (0.5, 0.75, and 0.95) are shown in Table 5.
Table 5.
Performance of the model under different IoU thresholds.
As can be seen in Table 5, there is a significant difference in the effect of variation in IoU threshold on potato sprout detection performance. When the IoU threshold was increased from 0.5 to 0.95, the AP value of seed potato detection hardly changed, realizing a strong stability. This is due to the fact that seed potato, as a large-sized target, has distinct morphological properties as well as rich textural information. In contrast, the AP value for bud detection plummets from 79% to 24%, which is due to the fact that buds are small targets, and the localization bias of a smile under the threshold requirement of a high IoU can lead to detection failure. Second, the low contrast features of the buds and the background are further amplified under strict IoU standards. Therefore, the IoU threshold of 0.5 was selected as more suitable for the detection of buds in this experiment.
4. Experimental Environment and Parameter Configuration
4.1. Comparison of Attention Mechanisms
To validate the effectiveness of the ECA attention mechanism selected in this study, model performance was compared under different attention mechanisms following the introduction of the GhostConv and BiFPN modules. All experiments were conducted under the same experimental conditions. The experimental results for seed potato sprout detection are presented in Table 6.
Table 6.
Comparison of four attention mechanisms.
As shown in the table above, using the same YOLOv8n template, the addition of CBAM, SimAM, and GAM attention mechanisms resulted in a reduction in the number of parameters but also led to decreases in both precision and recall to varying degrees. Specifically, precision decreased by 2.5%, 2.3%, and 2.9%, while mAP values decreased by 3.4%, 3.9%, and 2.1%, respectively. These results indicate that these attention mechanisms are not suitable for potato seed sprout recognition. In contrast, after introducing the ECA attention mechanism, the model not only reduced the number of parameters but also improved precision by 9.1% and increased the mAP value by 6.5% compared to the original YOLOv8n model. Additionally, among all the attention mechanisms evaluated, the model incorporating ECA exhibited the lowest GFLOPs value, the smallest model weight, and the fastest processing speed. These results fully demonstrate that the ECA attention mechanism outperforms the other mechanisms on the self-constructed dataset.
The comparison of mAP values across the four attention mechanisms is shown in Figure 11. As can be clearly seen from the figure, the combination of the baseline model with the ECA attention mechanism achieved a significantly higher mAP than the other models.
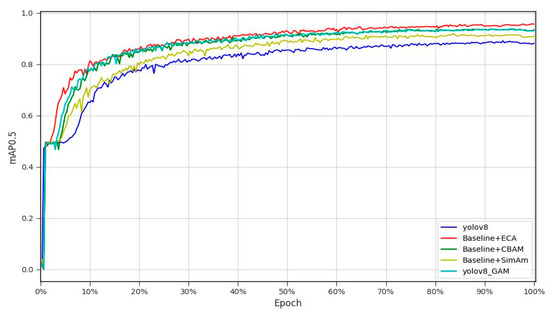
Figure 11.
Comparison of mAP0.5 attained in fusion experiments featuring distinct attention mechanisms.
4.2. Ablation Experiment
To verify the effectiveness of the improved model, ablation experiments were conducted in this study. The experimental results are shown in the following Table 7. YOLOv8_E denotes that the ECA attention mechanism is added to the backbone. YOLOv8_B denotes that the BiFPN structure is introduced into the backbone; YOLOv8_G denotes that the GhostConv is introduced to replace the Conv and the C3Ghost to replace the C2f module in the backbone. YOLOv8n_EB denotes the introduction of the ECA attention mechanism blocks and the BiFPN blocks; YOLOv8n_BG denotes the introduction of the BiFPN blocks and the GhostConv and the C3Ghost; YOLOv8_EG denotes the introduction of the ECA attention mechanism and the GhostConv and the C3Ghost; YOLOv8_EBG denotes the introduction of the ECA attention mechanism and BiFPN and GhostConv. The results of the potato sprout detection ablation experiments are shown in Table 7.
Table 7.
Ablation Experiment.
As shown in Table 7, the inclusion of the ECA attention mechanism in YOLOv8 resulted in a 1.3% increase in mAP for all sprout shapes and a 16.6% decrease in parameters. However, recall decreased by 1.2%, indicating occasional instances of missed sprout detection. The standalone BiFPN module reduced recognition accuracy by 1.8%, suggesting that its feature fusion mechanism comes at the expense of recognition accuracy. The GhostConv and C3Ghost implementations significantly reduced the parameters while maintaining comparable accuracy, suggesting that Hyper-Ghost is able to speed up detection without compromising accuracy.
The combined ECA-BiFPN integration effectively compensated for the accuracy loss introduced by BiFPN alone, resulting in substantial improvements in recognition performance. Similarly, the ECA-HyperGhost combination reduced model parameters while achieving higher accuracy than the standalone YOLOv8, YOLOv8_E, and YOLOv8_G models, confirming ECA’s ability to offset the precision loss associated with Hyper-Ghost. In contrast, the BiFPN-HyperGhost combination exhibited lower accuracy compared to the YOLOv8_EB model, further validating the superior performance of the ECA attention mechanism.
The combined YOLOv8_EBG model achieved the best overall results, with a 5.6% reduction in model parameters, a 1.1% reduction in GFLOPs, a 9.1% increase in sprout detection accuracy, and a 6.5% improvement in mAP for potato seed sprout identification. These findings suggest that the synergistic combination of ECA, BiFPN, and Hyper-Ghost provides the most effective solution for the potato eye recognition task.
In order to see more intuitively the difference between the improved YOLOv8_EBG model and the YOLOv8n model for extracting the features of potato seed sprouts, the same parameter settings were chosen in this study to compare the visualized thermograms of the two models. As shown in Figure 12, Figure 12A is the original image, B is the heat map output from the 21st layer of YOLOv8n, and C is the feature map output from the 21st layer of YOLOv8_EBG.

Figure 12.
Comparison of detection heat maps.
From Figure 12B, it can be clearly observed that the region of interest (ROI) captured by the YOLOv8n model for potato seed sprouts is relatively large. This indirectly indicates that a significant portion of the YOLOv8n model’s computational effort is redundant, contributing to a larger number of parameters. Moreover, the base YOLOv8n model misidentified potato skin areas as seed sprouts in Figure 12B, further illustrating that its recognition accuracy for small targets is suboptimal. In contrast, as shown in Figure 12C, the ROI identified by the improved YOLOv8_EBG model is much smaller and is concentrated precisely on the sprout regions, with almost no attention paid to non-sprouting areas. This suggests that the YOLOv8_EBG model proposed in this study achieves more accurate feature localization and focuses more effectively on the target features. Additionally, the improved model exhibits significantly better accuracy in detecting small targets compared to the baseline YOLOv8n model. The enhanced performance of the YOLOv8_EBG model can be attributed to the introduction of the ECA attention mechanism and the BiFPN module, which enhance feature extraction and multi-scale fusion capabilities for potato seed sprout detection. These results fully demonstrate the effectiveness of the improved YOLOv8_EBG model.
The comparison curves between the original YOLOv8n and the improved YOLOv8_EBG model are shown in Figure 13. Parts A, B, and C in Figure 13 represent the comparison between the precision, recall, and mAP0.5 between the original model and the improved model, respectively. It can be clearly seen from Figure 13 that the improved model is significantly better than the original model in terms of precision, recall, and mAP0.5.
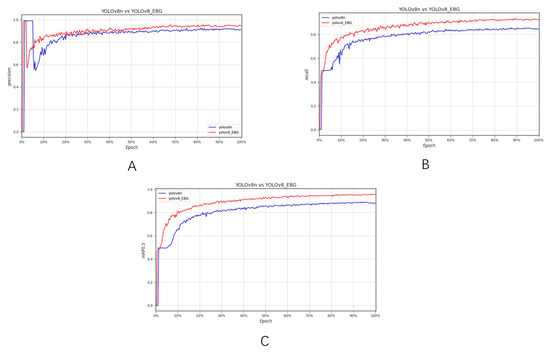
Figure 13.
Comparison of results between YOLOv8_EBG and YOLOv8n: (A) Comparison of precision between YOLOv8_EBG and YOLOv8n; (B) Comparison of recall rate between YOLOv8_EBG and YOLOv8n; (C) Comparison of mAP0.5 between YOLOv8_EBG and YOLOv8n.
Considering that mAP0.5 provides only a comprehensive assessment of the overall detection performance for seed potatoes and their young sprouts, which differ significantly in category characteristics, this study further compared and analyzed the average precision (AP0.5) for each category before and after model optimization under an IoU threshold of 0.5. The specific experimental results are presented in Figure 14.
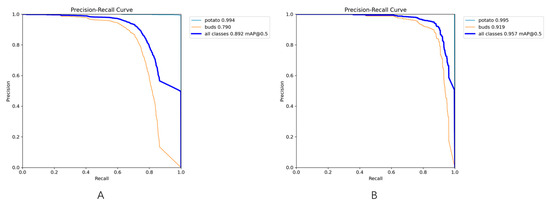
Figure 14.
Comparison of AP0.5 of potato seed potatoes and sprouts before and after algorithm optimization: (A)YOLOv8n; (B)YOLOv8_EBG.
As shown in Figure 14, a comparative analysis of the performance of the YOLOv8n model and the improved YOLOv8_EBG model reveals that the AP0.5 values of both are maintained at a high level of 99% in potato seed potato identification. This suggests that the experimental dataset used in this study (containing both sprouted and non-sprouted potato samples) has reached performance saturation on the recognition task for this category, and the improved algorithm fails to further enhance the recognition accuracy. For potato seed potato sprout identification, the AP0.5 value of the improved model was significantly improved from 79.0% to 91.2%, with an absolute improvement of 12.9 percentage points. This result shows that the proposed algorithmic improvement strategy exhibits significant performance optimization in the potato seed potato dataset constructed in this study, especially on the more challenging task of sprout identification.
4.3. Experiments Comparing the Performance of Different Models
In order to verify the comprehensive performance of the YOLOv8_EBG model proposed in this study, a comparison was conducted with six models, including YOLOv3-tiny, YOLOv5s, YOLOv8n, and YOLOv11n, among others. The comparison results are presented in Table 8.
Table 8.
Comparison of the performance of different models.
From Table 8, it can be observed that under the same conditions, namely identical training epochs, parameter settings, and dataset, the YOLOv8_EBG model proposed in this study has a smaller model weight compared to the other models. In terms of detection accuracy, YOLOv8_EBG outperforms the other four models. Additionally, the computational complexity, measured by GFLOPs, is lower for YOLOv8_EBG than for the remaining detection models, resulting in faster inference speed. Therefore, the YOLOv8_EBG model demonstrates a clear advantage in detection performance.
The results of the comparison experiments are illustrated in Figure 15. It can be clearly observed that the YOLOv3-tiny model exhibited missed detections of sprouts and lower accuracy for bud identification. Although YOLOv5s, YOLOv8n, and YOLOv11n achieved complete sprout detection without missed buds, their sprout recognition rates were comparatively lower than that of the improved YOLOv8_EBG model. All five models achieved recognition rates above 90% for potato tuber detection, demonstrating high accuracy for large target identification, which also appears to have reached the performance ceiling for the dataset used in this study.
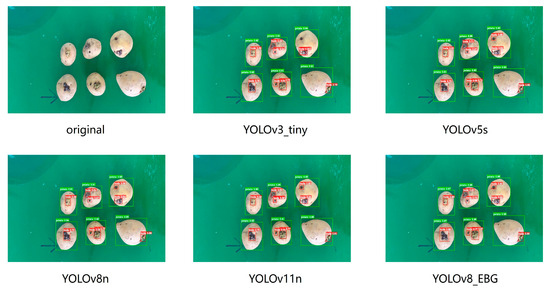
Figure 15.
Test results for different algorithms.
4.4. Performance Testing of Models on Potato Seed Potato Sorters
To verify the practical application performance of the improved YOLOv8_EBG model proposed in this study, a potato seed sorting test bed was constructed. The system consists of a three-channel conveyor belt, an industrial camera, a programmable logic controller (PLC), an air pump, a computer, and an elimination device. The specific structure is shown in Figure 16. The working process is as follows: the conveyor belt is divided into three channels, with Channels 1 and 3 serving as the feeding channels. Seed potatoes to be inspected are transported along the feeding channels. The industrial camera captures images of the seed potatoes, and the extracted image features are transmitted to a PC equipped with the pre-trained YOLOv8_EBG model. The model quickly identifies whether sprouts are present on the surface of the seed potatoes. The identification results are then transmitted to the PLC via RG45 communication. Based on the received information, the PLC controls the elimination device to reject seed potatoes that do not meet the planting requirements by diverting them to Channel 2.

Figure 16.
Automatic identification device for potato seed potato sprouts: In the figure, 1 is the feed channel 1, 2 is the reject channel, 3 is the feed channel 2, 4 is the trigger, 5 is the cylinder, 6 is the double-bar pneumatic valve, 7 is the fill light, 8 is the camera, 9 is the indicator light, 10 is the computer.
In this study, sprout detection experiments were conducted by selecting 100 seed potatoes with smooth surfaces and 100 seed potatoes with soil attached to their surfaces. Each group included 90 seed potatoes with sprouts and 10 seed potatoes without sprouts. The experimental results are presented in Table 9. From the experimental data, it can be observed that for seed potatoes with smooth surfaces, all mainstream YOLO series target detection models achieved detection accuracies above 80% when identifying sprouted seed potatoes. Specifically, the accuracies of YOLOv8n, YOLOv11n, and the improved YOLOv8_EBG model were 83.6%, 85.1%, and 92.5%, respectively. This indicates that these models, particularly the improved YOLOv8_EBG, demonstrate superior performance in sprout detection tasks. For seed potatoes with soil attached to the surface, although detection accuracies decreased across all models, the improved YOLOv8_EBG model continued to show outstanding performance, achieving an accuracy of 91.4%. This was 9.7%, 11.2%, 9.3%, and 7.9% higher than that of YOLOv3-tiny, YOLOv5s, YOLOv8n, and YOLOv11n, respectively. The primary reason for this difference is that sprouts are small targets, and YOLO-based models are susceptible to interference from soil during target detection, leading to failures in identifying soil-covered sprouts. The improved YOLOv8_EBG model enhances the focus on sprout features by suppressing redundant soil-related features, thereby improving detection accuracy for sprouted seed potatoes. Combined with the practical needs of seed potato screening, particularly in reducing seed potato wastage and achieving comprehensive sprout detection, the improved YOLOv8_EBG model demonstrates higher accuracy and F1 scores under the same conditions, aligning well with the practical requirements for seed potato screening before planting.
Table 9.
Performance testing of different models on the experimental setup.
5. Discussion
Although the YOLOv8_EBG algorithm has made significant progress in the targeted research direction and outperforms existing models in terms of performance, there are still several limitations in this study. First, the robustness of the model in highly dynamic real-world scenarios, such as illumination fluctuations, partial occlusion, and irregularities in bud morphology, requires further validation. The current model was trained on a single batch of potato samples collected in a controlled laboratory environment, comprising 1023 samples across six varieties commonly cultivated in northern China. However, representative varieties widely grown in southern China (e.g., Favorita, Min Potato Series, Yun Potato Series) were not included, potentially limiting the model’s varietal generalization capability. Second, although data diversity was improved through augmentation techniques, it remains challenging to adequately capture the wide variability in potato sprout morphology and environmental conditions due to the limited size of the original dataset. Finally, the performance of the model is highly dependent on a customized image acquisition system, the specific configuration of which may not be easily transferable to diverse real-world application scenarios. This dependency could limit the generalizability and scalability of the model in broader agricultural contexts.
The seed potato sorting equipment developed in this study has not yet been validated in real production environments. Although the device demonstrated strong performance in sorting tests on non-training set samples under laboratory conditions, its applicability in real-world production scenarios and the robustness of the embedded algorithm still require further evaluation. Therefore, future research should focus on testing the device’s performance in operational environments and implementing optimizations to address potential challenges, such as environmental interference and device stability issues.
To further enhance the generalization ability and practical applicability of the model, future work should prioritize expanding the dataset to include a broader range of geographic varieties—such as the Chinese Potato Series, Min Potato Series, and Yun Potato Series commonly cultivated in southern China—as well as samples collected under diverse environmental conditions (e.g., variations in lighting and shading). In addition, optimizing the compatibility and robustness of the hardware system will be critical to ensuring stable model performance across different application scenarios. The mature application of this automated sorting technology is expected to significantly reduce manual labor intensity and enhance potato production efficiency, thereby providing reliable technical support for intelligent seed potato sorting in smart agriculture.
6. Conclusions
In this study, a fast and accurate network model was proposed for sprout detection in seed potatoes during pre-planting handling. The ECA module was integrated into both the backbone and neck of YOLOv8n to enhance detection accuracy. GhostConv was employed to replace standard convolution layers, and C3Ghost was utilized to substitute the C2f module, effectively reducing the number of model parameters while maintaining detection accuracy and achieving model lightweighting. Additionally, the BiFPN module was introduced to replace the FPN-PAN structure in YOLOv8n, enabling bidirectional feature fusion and improving the retention of multi-scale feature information within the model.
Ablation experiments show that the improved YOLOv8_EBG model has a greater improvement in recognition speed and recognition accuracy compared with the original YOLOv8n model, and the size of the improved model is reduced compared with the original model. Comparative experimental results show that the multi-proposed YOLOv8_EBG model improves the accuracy of potato seed potato sprout recognition and optimizes the recognition of small target sprouts. It achieves higher performance with a smaller memory footprint compared to other mainstream target detection models.
Author Contributions
Conceptualization, Y.L. and J.F.; Methodology, Y.L.; Software, Y.L. and J.L.; Validation, Z.Z. and Q.Z. Writing—original draft, Y.L.; Writing—review and editing, Q.Z., J.L., and J.F. All authors will be informed about each step of manuscript processing, including submission, revision, revision reminder, etc., via emails from our system or assigned Assistant Editor. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Science Foundation of Heilongjiang Province, grant number LH2023C031.
Institutional Review Board Statement
Not applicable. For studies not involving humans or animals.
Data Availability Statement
Data available on request due to restrictions, e.g., privacy or ethical: The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sohel, A.; Shakil, M.S.; Siddiquee, S.M.T.; Marouf, A.A.; Rokne, J.G.; Alhajj, R. Enhanced Potato Pest Identification: A Deep Learning Approach for Identifying Potato Pests. IEEE Access 2024, 12, 172149–172161. [Google Scholar] [CrossRef]
- Yuan, B.; Li, C.; Wang, Q.; Yao, Q.; Guo, X.; Zhang, Y.; Wang, Z. Identification and Functional Characterization of the RPP13 Gene Family in Potato (Solanum tuberosum L.) for Disease Resistance. Front. Plant Sci. 2025, 15, 1515060. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, A.; Fating, A.; Darvankar, M.; Patil, A.; Kapse, Y. Potato Leaf Disease Identification with Multi-Stage Approach: A Comparative Study. In Proceedings of the 2023 IEEE Pune Section International Conference (PuneCon), Piscataway, NJ, USA, 14–16 December 2023; IEEE: Pune, India, 2023; pp. 1–5. [Google Scholar]
- Zhu, X.; Li, W.; Zhang, N.; Jin, H.; Duan, H.; Chen, Z.; Chen, S.; Wang, Q.; Tang, J.; Zhou, J.; et al. StMAPKK5 Responds to Heat Stress by Regulating Potato Growth, Photosynthesis, and Antioxidant Defenses. Front. Plant Sci. 2024, 15, 1392425. [Google Scholar] [CrossRef]
- Li, Z.; Li, B.; Jahng, S.G.; Jung, C. Improved VGG Algorithm for Visual Prosthesis Image Recognition. IEEE Access 2024, 12, 45727–45739. [Google Scholar] [CrossRef]
- Johri, P.; Kim, S.; Dixit, K.; Sharma, P.; Kakkar, B.; Kumar, Y.; Shafi, J.; Ijaz, M.F. Advanced Deep Transfer Learning Techniques for Efficient Detection of Cotton Plant Diseases. Front. Plant Sci. 2024, 15, 1441117. [Google Scholar] [CrossRef]
- Kong, X.; Ge, Z. Deep PLS: A Lightweight Deep Learning Model for Interpretable and Efficient Data Analytics. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8923–8937. [Google Scholar] [CrossRef]
- Yogheedha, K.; Nasir, A.S.A.; Jaafar, H.; Mamduh, S.M. Automatic Vehicle License Plate Recognition System Based on Image Processing and Template Matching Approach. In Proceedings of the 2018 International Conference on Computational Approach in Smart Systems Design and Applications (ICASSDA), Delhi, India, 15–17 August 2018; IEEE: Kuching, Malaysia, 2018; pp. 1–8. [Google Scholar]
- Li, Y.; Lu, Y.; Liu, H.; Bai, J.; Yang, C.; Yuan, H.; Li, X.; Xiao, Q. Tea Leaf Disease and Insect Identification Based on Improved MobileNetV3. Front. Plant Sci. 2024, 15, 1459292. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, L.; He, Y.; Lv, C.; Liu, Y.; Song, H.; Lv, H.; Du, Z. Online Inspection of Blackheart in Potatoes Using Visible-near Infrared Spectroscopy and Interpretable Spectrogram-Based Modified ResNet Modeling. Front. Plant Sci. 2024, 15, 1403713. [Google Scholar] [CrossRef]
- Lv, Z.; Zhang, W.; Qi, X. Buds Recognition of Potato Images Based on Gabor Feature. Agric. Mech. Res. 2021, 43, 203–207. [Google Scholar] [CrossRef]
- Xi, R.; Hou, J.; Li, L. Fast Segmentation of Potato Sprout Eyes based on Chaos Optimization K-means algorithm. J. Agric. Eng. 2019, 35, 190–196. [Google Scholar]
- Meng, L. Research on Smart cutting Technology of Potato Seed based on Image Processing. Master’s Thesis, Shandong University of Technology, Zibo, China, 2021. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, H. Application of Computer Vision Technology in the Field of Agriculture. Mod. Agric. Sci. Technol. 2024, 4, 178–181. [Google Scholar]
- Huang, J.; Wang, X.; Jin, C.; Cheein, F.A.; Yang, X. Estimation of the Orientation of Potatoes and Detection Bud Eye Position Using Potato Orientation Detection You Only Look Once with Fast and Accurate Features for the Movement Strategy of Intelligent Cutting Robots. Eng. Appl. Artif. Intell. 2025, 142, 109923. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, X.; Zhao, Q.; Xu, Q.; Sun, Y.; Ning, X. Non-Destructive Detection of External Defects in Potatoes Using Hyperspectral Imaging and Machine Learning. Agriculture 2025, 15, 573. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, S.; Wang, C.; Wang, H.; Du, Y.; Zong, Z. Research on a Potato Leaf Disease Diagnosis System Based on Deep Learning. Agriculture 2025, 15, 424. [Google Scholar] [CrossRef]
- Cai, Z.; Zhang, Y.; Li, J.; Zhang, J.; Li, X. Synchronous Detection of Internal and External Defects of Citrus by Structured-Illumination Reflectance Imaging Coupling with Improved YOLO V7. Postharvest Biol. Technol. 2025, 227, 113576. [Google Scholar] [CrossRef]
- Yang, Z.; Yuan, J.; Xu, Y.D. Review of Research on Object Detection Based on YOLO Series. In Proceedings of the 28th Annual Conference on New Network Technologies and Applications of China Computer Users Association Network Application Branch, Beijing, China, 28 December 2024; pp. 263–267. [Google Scholar]
- Doherty, J.; Gardiner, B.; Kerr, E.; Siddique, N. BiFPN-YOLO: One-Stage Object Detection Integrating Bi-Directional Feature Pyramid Networks. Pattern Recognit. 2025, 160, 111209. [Google Scholar] [CrossRef]
- Nghiem, V.Q.; Nguyen, H.H.; Hoang, M.S. LEAF-YOLO: Lightweight Edge-Real-Time Small Object Detection on Aerial Imagery. Intell. Syst. Appl. 2025, 25, 200484. [Google Scholar] [CrossRef]
- Li, H.; Liu, X.; Zhang, H.; Li, H.; Jia, S.; Sun, W.; Wang, G.; Feng, Q.; Yang, S.; Xing, W. Research and Experiment on Miss-Seeding Detection of Potato Planter Based on Improved YOLOv5s. Agriculture 2024, 14, 1905. [Google Scholar] [CrossRef]
- Che, Y.; Bai, H.; Sun, L.; Fang, Y.; Guo, X.; Yin, S. Real-Time Detection of Varieties and Defects in Moving Corn Seeds Based on YOLO-SBWL. Agriculture 2025, 15, 685. [Google Scholar] [CrossRef]
- Zhang, W.; Zeng, X.; Liu, S.; Mu, G.; Zhang, H. Detection Method of Potato Seed Bud Eye Based on Improve YOLOv5s. J. Agric. Mach. 2023, 54, 260–269. [Google Scholar]
- Wu, Y.; Xu, M.; Wang, X.; Menez, P.; Wang, W.; Zhuang, M. Localized Nutrient Management Practices Enhance the Environmental-Economic Sustainability in Potato Production of China. J. Environ. Manag. 2025, 379, 124822. [Google Scholar] [CrossRef] [PubMed]
- Etherton, B.A.; Plex Sulá, A.I.; Mouafo-Tchinda, R.A.; Kakuhenzire, R.; Kassaye, H.A.; Asfaw, F.; Kosmakos, V.S.; McCoy, R.W.; Xing, Y.; Yao, J.; et al. Translating Ethiopian Potato Seed Networks: Identifying Strategic Intervention Points for Managing Bacterial Wilt and Other Diseases. Agric. Syst. 2025, 222, 104167. [Google Scholar] [CrossRef]
- Yayeh, S.G.; Mohammed, W.; Woldetsadk, K.; Bezu, T.; Dessalegn, Y.; Asredie, S. Phenology, Growth, and Seed Tuber Yield in Potato (Solanum Tuberosum L) Varieties as Influenced by Plant Density at Adet, Northwestern Ethiopia. Heliyon 2025, 11, e41244. [Google Scholar] [CrossRef] [PubMed]
- Kalsoom, T.; Ahmed, T.; Azam Khan, M.; Hasanuzzaman, M.; Ahmed, M.P.O.; Werbrouck, S. In Vitro Synthetic Seed Production of Potato under Different Fungicide Levels and Storage Intervals. Phyton 2023, 92, 2429–2450. [Google Scholar] [CrossRef]
- Maulidiyah, R.; Salam, M.; Jamil, M.H.; Tenriawaru, A.N.; Rahmadanih; Heliawaty; Muslim, A.I.; Bakheet Ali, H.N.; Ridwan, M. Determinants of Potato Farming Productivity and Success: Factors and Findings from the Application of Structural Equation Modeling. Heliyon 2025, 11, e43026. [Google Scholar] [CrossRef]
- Sun, T.; Zhang, W.; Miao, Z.; Zhang, Z.; Li, N. Object Localization Methodology in Occluded Agricultural Environments through Deep Learning and Active Sensing. Comput. Electron. Agric. 2023, 212, 108141. [Google Scholar] [CrossRef]
- Li, S.; Huang, H.; Meng, X.; Wang, M.; Li, Y.; Xie, L. A Glove-Wearing Detection Algorithm Based on Improved YOLOv8. Sensors 2023, 23, 9906. [Google Scholar] [CrossRef]
- Yang, H.; Yang, L.; Wu, T.; Yuan, Y.; Li, J.; Li, P. MFD-YOLO: A Fast and Lightweight Model for Strawberry Growth State Detection. Comput. Electron. Agric. 2025, 234, 110177. [Google Scholar] [CrossRef]
- Qiu, Z.; Wang, W.; Jin, X.; Wang, F.; He, Z.; Ji, J.; Jin, S. DCS-YOLOv5s: A Lightweight Algorithm for Multi-Target Recognition of Potato Seed Potatoes Based on YOLOv5s. Agronomy 2024, 14, 2558. [Google Scholar] [CrossRef]
- Li, R.; Li, Y.; Qin, W.; Abbas, A.; Li, S.; Ji, R.; Wu, Y.; He, Y.; Yang, J. Lightweight Network for Corn Leaf Disease Identification Based on Improved YOLO V8s. Agriculture 2024, 14, 220. [Google Scholar] [CrossRef]
- Hussain, I.; Tan, S.; Huang, J. Few-Shot Based Learning Recaptured Image Detection with Multi-Scale Feature Fusion and Attention. Pattern Recognit. 2025, 161, 111248. [Google Scholar] [CrossRef]
- Chen, C.; Li, B. An Interpretable Channelwise Attention Mechanism Based on Asymmetric and Skewed Gaussian Distribution. Pattern Recognit. 2023, 139, 109467. [Google Scholar] [CrossRef]
- Tang, X.; Xie, Y.; Li, X.; Wang, B. Riding Feeling Recognition Based on Multi-Head Self-Attention LSTM for Driverless Automobile. Pattern Recognit. 2025, 159, 111135. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 11531–11539. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 10778–10787. [Google Scholar]
- Liu, Y.; Huang, Z.; Song, Q.; Bai, K. PV-YOLO: A Lightweight Pedestrian and Vehicle Detection Model Based on Improved YOLOv8. Digit. Signal Process. 2025, 156, 104857. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).