
A Track-Type Orchard Mower Automatic Line Switching Decision Model Based on Improved DeepLabV3+


Abstract
1. Introduction
2. Materials and Methods
2.1. Kinematic Model of the Mower
2.2. Image Data
2.2.1. Image Acquisition
2.2.2. Data Augmentation
2.3. Headland Environment Semantic Segmentation Model
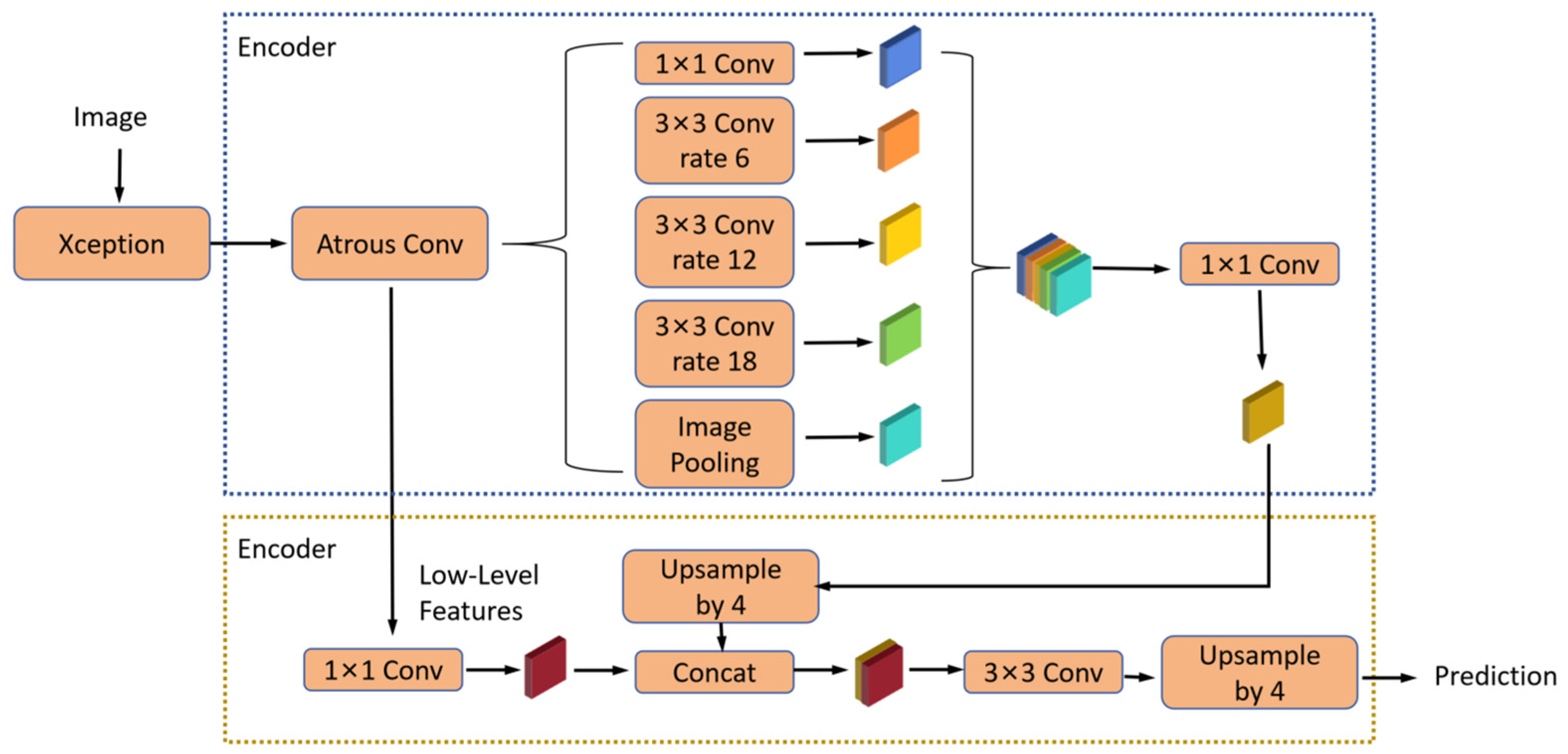
2.3.1. DeepLabV3+ Neural Network Model
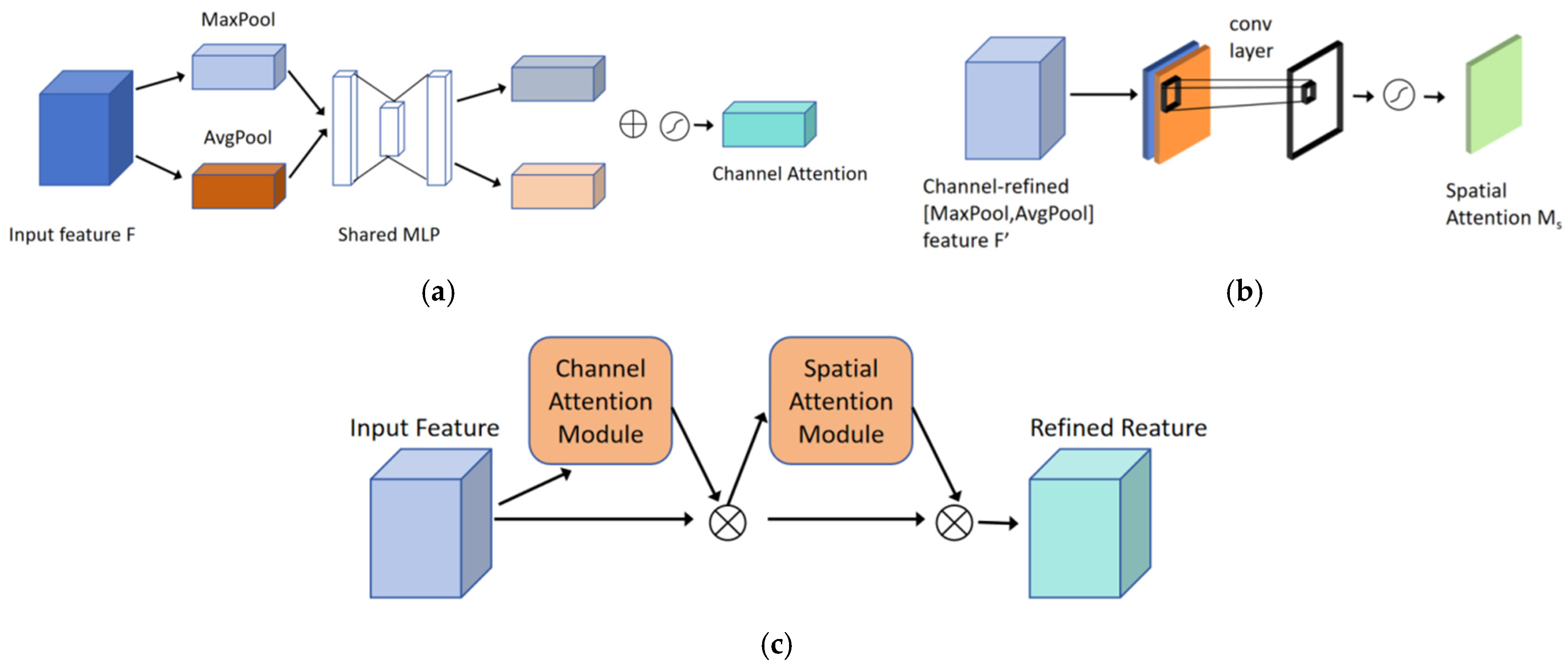
2.3.2. Attention Mechanism Module: CMAM
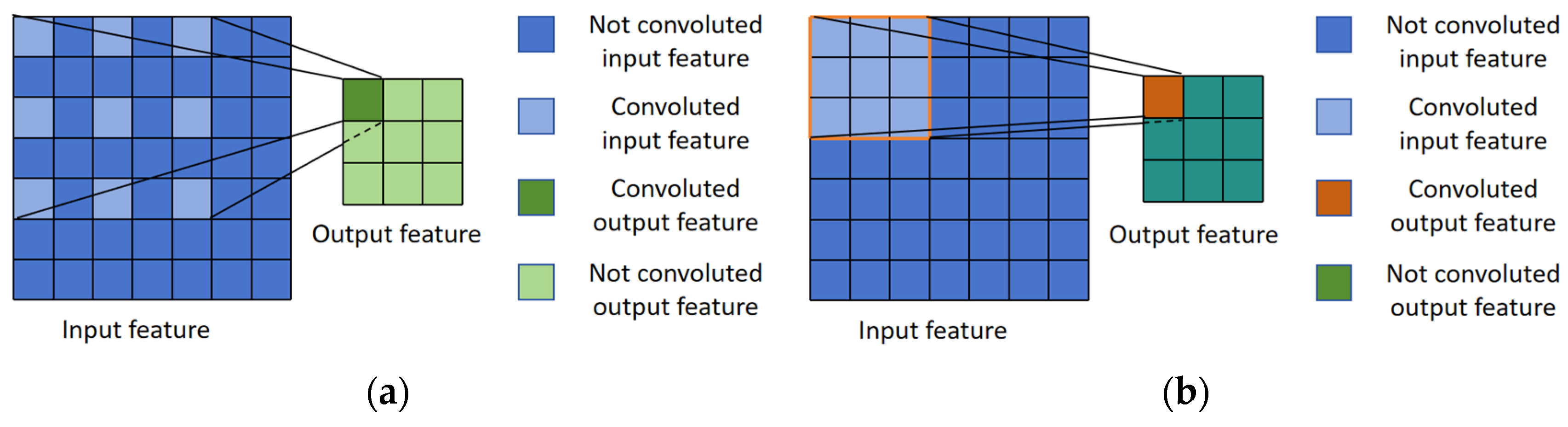
2.3.3. Lightweight Design by MobileNetV2
2.3.4. Improved DeeplabV3+ Model
2.4. Navigation Path Generation
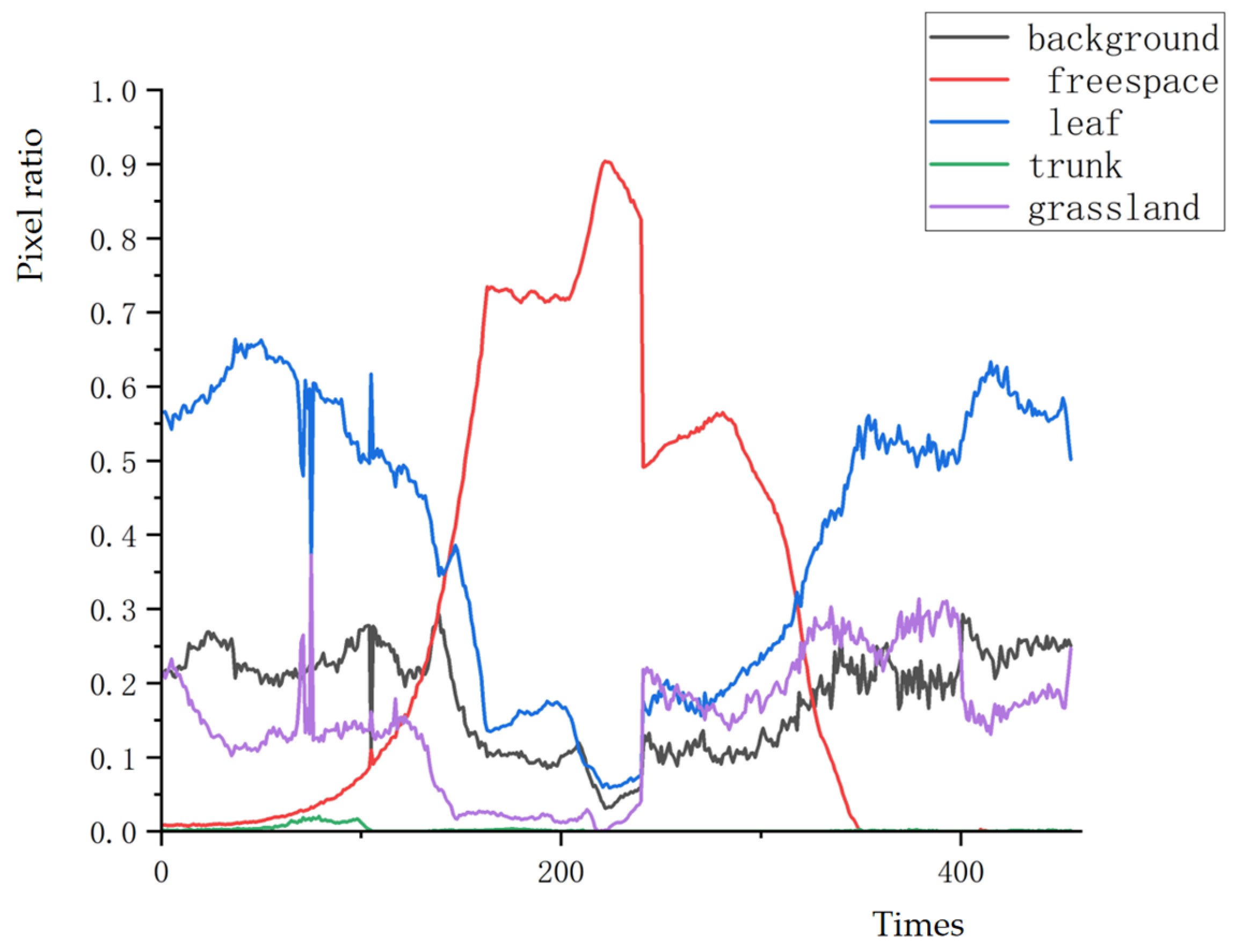
2.4.1. Semantic Segmentation Change Scenario
2.4.2. Navigation Path Generation Principle
- Figure 10a illustrates the first stage of the row-changing process, where the lawnmower is moving between the current rows. The navigation path L1 for this stage is generated from the centroid A (x1, y1) of the grassland area between the current rows and the centroid B (x2, y2) of the freespace, with the calculation process described in formula below:
- 2.
- In the formula, y2 − y1/x2 − x1 represents the slope of path L1, and the navigation path L1 in Stage One is expressed by the linear regression equation of y with respect to x.
- 3.
- As shown in Figure 10b, the mower reaches the edge at the intersection of the current row and the next row, entering the second phase. The navigation path needs to guide the mower to make a turn to enter the next row. Equation (3) represents the generation expression for the navigation path in the second phase. The centroid B1(x3, y3) of the freespace area during this phase has the auxiliary line l2 parallel to the x-axis, and it connects to the centroid Q(x4, y4) of the grassland, forming line l3. The navigation path for the mower in this phase is L2, which is an arc-shaped path that is inscribed between l3 and l2. At this point, the mower deviates to the left from the current row to enter the next row. The calculation process for the inscribed circle of path L2 is described in Equation (3), where A, B, D, E, C1, and C2 are parameters from the function equations of line segments l2 and l3, (xo, yo) represents the coordinates of the center of the arc for path L2, and r denotes the radius of the arc:
- 4.
- As shown in Figure 10c, the tracked mower enters the third phase of the next row section. In this phase, the proportion of the freespace area is the largest, and the shape of the area is relatively regular, making it easier to generate the coordinates of the edge scatter points on the boundary of the freespace area. This phase uses a linear regression approach based on a least squares method to analyze the scatter points on both edges, calculating the linear equations for the left and right boundaries of the freespace area (l4 and l5). Using these two linear equations, the center point is calculated to generate the navigation path L3 for entering the next row section:
- 5.
- In the equation, Y is the regression function concerning X, representing the relationship between the variables (xi, yi), where xi and yi are the coordinate values of the pixel points in the image. a0 and a1 are the correlation coefficients of the regression equation Y. R is the correlation coefficient used to assess the effectiveness of the data points in regression; the closer the value is to 1, the higher the correlation between the data points (xi, yi) and the regression equation. m represents the total number of sampled edge points in the connected regions of the image, and the linear equations for l4 and l5 are both represented by Equation (4).
- 6.
- As shown in Figure 10d, the tracked mower is about to enter the target row at the turning endpoint. As the weedy area between the target rows gradually increases, the proportion of grassland pixel points in the image also increases. The principle for path L4 is the same as that of path L2; in this phase, the tracked mower must execute a turning maneuver to enter the target row, with the calculation method being described by Equation (3). The coordinates of point O are (960, 0), point B2 is the centroid of the freespace area in this phase, and point A1 is the centroid of the grassland area in this phase. Line l6 is drawn through points A1 and B3, and line l7 is drawn through points O and B3. Path L4 is an arc that is tangential to lines l6 and l7.
- 7.
- In Figure 10e, the tracked mower enters the target row, and path L5 represents the driving path of the mower after it has entered the target row. The calculation method for this path is the same as that for path L3, described by Equation (4). In the figure, the linear equations for l8 and l9 are both regression functions of Y concerning X, and the line segment for the navigation path L5 is defined by the midline equation determined by l8 and l9.
2.5. Decision-Making Model for Automatic Turning of Orchard Tracked Mower
3. Results
3.1. Model Evaluation Metrics
3.1.1. Comparison of Semantic Segmentation Model Performance
3.1.2. Path Tracking Effect
3.2. Automatic Turning Experiment of the Tracked Mower
4. Discussion
- In the second and fourth phases, the navigation path generated by the line switch decision model for the tracked mower is curved based on the surrounding environment. The average deviation of the yaw angle for these two phases is significantly larger compared to the other three phases. The navigation paths in the other three phases can be generated using information from a single type of area. The parameters required for the calculation of the curved navigation path come from the information on the freespace and grassland areas. Therefore, the increase in segmentation categories from the semantic segmentation model leads to a certain degree of decline in classification accuracy. This complexity in generating curved paths affects the guiding function of the expected navigation path, making it difficult for the automatic line switching control system to adjust the mower’s posture. LiDAR can obtain radar detection data from different areas, and by measuring the time difference between the emitted and received signals, it can determine the distance, orientation, and shape of the target. Combining LiDAR point cloud data with rich semantic segmentation image features is more beneficial for planning paths that map to real-world scenarios, further enhancing the tracked mower’s tracking performance on curved paths. At the same time, the environmental information acquisition system needs laser radar to detect the obstacles in the surrounding environment, such as stones, broken branches, and metal parts, to assist the mower in realizing the function of automatic obstacle avoidance and to avoid damage to the mower.
- In this study, the line switching road in the third phase is a concrete surface, while the line switching road in the orchard headland environment consists of non-concrete surfaces. To improve the robustness of the automatic line switching decision model for the mower in the orchard headland environment, it is necessary to further enrich the dataset used for training the semantic segmentation model. Additionally, the recognition strategy of the semantic segmentation model can be improved by optimizing the feature vectors. By integrating color features, texture features, and shape features into a comprehensive feature vector, more information can be captured, which will help the neural network model classify line change roads in different environments and enhance the transferability of the automatic line change decision model. The method of multi-type data enhancement is beneficial to improve the robustness and generalization of the model. Because the mower works outdoors, the future model design should consider how to improve the anti-interference ability of the model. Therefore, the collected data should include images under different lighting conditions. Data enhancement can also be achieved by changing the contrast of the image to simulate different lighting conditions.
- The straight-line travel and automatic line switching strategies of mowers need to be further optimized according to their own mowing width and orchard row width. In this study, the automatic line switching decision-making model of the mower does not enter the same working line repeatedly. When the mower’s mowing range is less than the fruit tree row width, the mower needs to enter the task row for the second time or even many times to complete the full-coverage mowing task. Therefore, the decision model is required to automatically divide the mower’s travel lane in the operation row according to the mower’s mowing width and the orchard row width to ensure that the mower can enter the working row many times. The designer may adjust the mowing width of the mower according to the inter-row width so that the mower can complete the task of the working line at one time. And we need to ensure that the mower can complete the task of mowing in the process of normal travel. Depth images assign a value representing the distance to each pixel, reflecting the three-dimensional structure of the scene. Utilizing the depth data from the images can supplement the distance information of the surrounding environmental areas, providing data for the mower’s travel control decision model. This enables precise adjustment of the tracked speed, allowing for the delineation of driving lanes between rows in the orchard, ensuring full coverage cutting, and reducing the occurrence of missed spots.
5. Conclusions
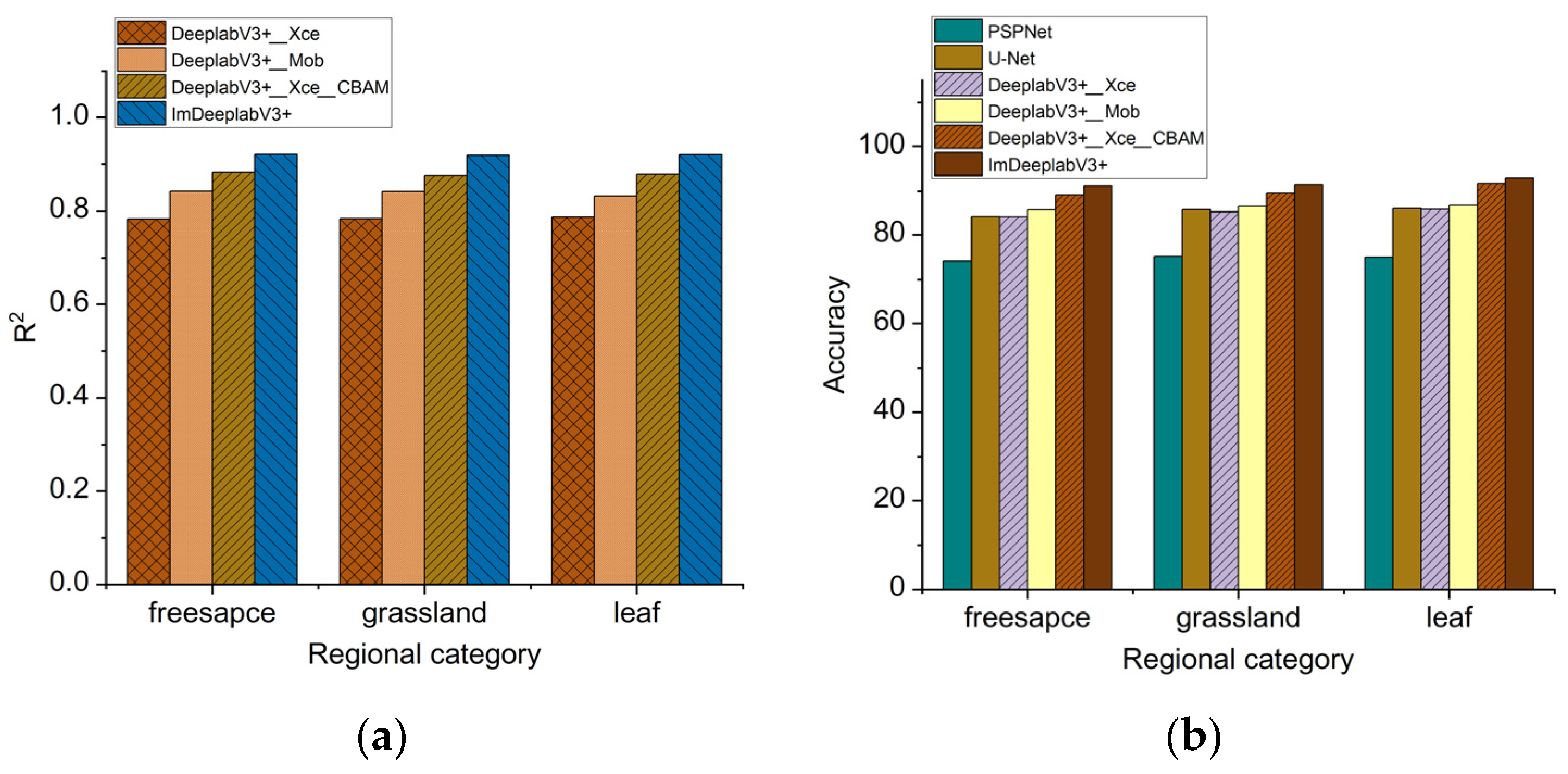
- DeeplabV3+_Xce, DeeplabV3+_Mob, DeeplabV3+_Xce_CBAM, and ImDeeplabV3+ constitute the ablation tests. The Loss value and the Val_Loss value of DeeplabV3+_Mob decreased faster than DeeplabV3+_Xce. The results of the automatic line change tests show that the DeeplabV3+_Mob semantic segmentation model achieves a speed improvement of 39.318 FPS compared to DeeplabV3+_Xce, with an average pass time reduction of 20.25 s. These show that Mobilenet V2 improves the computational efficiency of the model. The final Loss value and the Val_Loss of DeeplabV3+_Xce_CBAM were all smaller than those of DeeplabV3+_Xce. The DeeplabV3+_Xce_CBAM semantic segmentation model shows an improvement of 0.09 in average R2 compared to DeeplabV3+_Xce, an increase of 5.0% in average accuracy, a reduction of 0.145° in average yaw angle deviation, and an increase of 10.8% in average intersection over union (MIoU). These show that the CBAM improves the classification accuracy of the model. The training loss value (Loss) and validation loss value (Val_Loss) for the ImDeeplabV3+ model are minimized at 0.073 and 0.032, respectively. Compared with other models, ImDeeplabV3+ has the best convergence effect.
- The results of the automatic line change tests show that the ImDeeplabV3+ semantic segmentation model achieves a speed improvement of 27.513 FPS compared to DeeplabV3+_Xce_CBAM, with an average pass time reduction of 21.94 s. The image processing efficiency of ImDeeplabV3+ is lower than that of DeeplabV3+_Mob by 21.75%. This suggests that the combination of MobileNet V2, the CBAM model, and the improved parallel Atrous Convolution structure enables the ImDeeplabV3+ model to effectively complete the automatic line switching task.
- The ImDeeplabV3+ semantic segmentation model enables relatively accurate classification of various targets in the unstructured orchard headland environment. The automatic line change control system plans a navigation path based on the semantic segmentation image data, controls the tracked speed, and adjusts the mowing posture to complete the automatic line change task, providing a design reference for decision models in the unmanned operation of tracked mowers.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Yan, W.; De, C.; Zhao, S. Unstructured road detection and tracking based on monocular vision. J. Harbin Eng. Univ. 2011, 32, 334–339. [Google Scholar]
- Hou, K.; Sun, H.; Jia, Q.; Zhang, Y. An autonomous positioning and navigation system for spherical mobile robot. Procedia Eng. 2012, 29, 2556–2561. [Google Scholar] [CrossRef]
- Xue, J.L.; Grift, T. Agricultural robot turning in the headland of corn fields. Appl. Mech. Mater. 2011, 63, 780–784. [Google Scholar] [CrossRef]
- Li, J.; Chen, B.; Liu, Y. Image Detection Method of Navigation Route of Cotton Plastic Film Mulch Planter. Trans. Chin. Soc. Agric. Mach. 2014, 45, 40–45. [Google Scholar]
- Liang, H.; Chen, B.; Jiang, Q.; Zhu, D.; Yang, M.; Qiao, Y. Detection method of navigation route of corn harvester based on image processing. Trans. Chin. Soc. Agric. Eng. 2016, 32, 43–49. [Google Scholar]
- Lai, H.; Zhang, Y.; Zhang, B.; Yin, Y.; Liu, Y.; Dong, Y. Design and experiment of the visual navigation system for a maize weeding robot. Trans. Chin. Soc. Agric. Eng. 2023, 39, 18–27. [Google Scholar]
- Li, Y.; Xu, J.; Wang, M.; Liu, D.; Sun, H.; Wang, X. Development of autonomous driving transfer trolley on field roads and its visual navigation system for hilly areas. Trans. Chin. Soc. Agric. Eng. 2019, 35, 52–61. [Google Scholar]
- Yang, Y.; Zhang, L.; Zha, J.; Wen, X.; Chen, L.; Zhang, T.; Dong, Y.; Yang, X. Real-time extraction of navigation line between corn rows. Trans. Chin. Soc. Agric. Eng. 2020, 36, 162–171. [Google Scholar]
- Le, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar]
- Saleem, M.; Potgieter, J.; Arif, K. Automation in agriculture by machine and deep learning techniques: A review of recent developments. Precis. Agric. 2021, 22, 2053–2091. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Zhong, C.; Hu, Z.; Li, M.; Li, H.; Yang, X.; Liu, F. Real-time semantic segmentation model for crop disease leaves using group attention module. Trans. Chin. Soc. Agric. Eng. 2021, 37, 208–215. [Google Scholar]
- Zhang, X.; Gao, H.; Zhao, J.; Zhou, M. Overview of deep learning intelligent driving methods. J. Tsinghua Univ. (Sci. Technol.) 2018, 58, 438–444. [Google Scholar]
- Lin, J.; Wang, W.; Huang, S. Learning based semantic segmentation for robot navigation in outdoor environment. In Proceedings of the 2017 Joint 17th World Congress of International Fuzzy Systems Association and 9th International Conference on Soft Computing and Intelligent Systems (IFSA-SCIS), Otsu, Japan, 27–30 June 2017; pp. 1–5. [Google Scholar]
- Song, G.; Feng, Q.; Hai, Y.; Wang, S. Vineyard Inter-row Path Detection Based on Deep Learning. For. Mach. Woodwork. Equip. 2019, 47, 23–27. [Google Scholar]
- Li, Y.; Xu, J.; Liu, D.; Yu, Y. Field road scene recognition in hilly regions based on improved dilated convolutional networks. Trans. Chin. Soc. Agric. Eng. 2019, 35, 150–159. [Google Scholar]
- Lin, Y.; Chen, S. Development of navigation system for tea field machine using semantic segmentation. IFAC-PapersOnLine 2019, 52, 108–113. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Kang, J.; Liu, L.; Zhang, F.; Shen, C.; Wang, N.; Shao, L. Semantic segmentation model of cotton roots in-situ image based on attention mechanism. Comput. Electron. Agric. 2021, 189, 106370. [Google Scholar] [CrossRef]
- Liu, L.; Wang, X.; Liu, H.; Li, J.; Wang, P.; Yang, X. A Full-Coverage Path Planning Method for an Orchard Mower Based on the Dung Beetle Optimization Algorithm. Agriculture 2024, 14, 865. [Google Scholar] [CrossRef]
- Shen, C.; Liu, L.; Zhu, L.; Kang, J.; Wang, N.; Shao, L. High-throughput in situ root image segmentation based on the improved DeepLabv3+ method. Front. Plant Sci. 2020, 11, 576791. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Singh, P.; Kumar, D.; Srivastava, A. A CNN Model Based Approach for Disease Detection in Mango Plant Leaves; Springer Nature: Singapore, 2023; pp. 389–399. [Google Scholar]
- Liu, L.; Wang, X.; Yang, X.; Liu, H.; Li, J.; Wang, P. Path planning techniques for mobile robots: Review and prospect. Expert Syst. Appl. 2023, 227, 120254. [Google Scholar] [CrossRef]
- Chen, J.; Ma, B.; Ji, C.; Zhang, J.; Feng, Q.; Liu, X.; Li, Y. Apple inflorescence recognition of phenology stage in complex background based on improved YOLOv7. Comput. Electron. Agric. 2023, 211, 108048. [Google Scholar] [CrossRef]
- Li, S.; Zhang, S.; Xue, J.; Sun, H. Lightweight target detection for the field flat jujube based on improved YOLOv5. Comput. Electron. Agric. 2022, 202, 107391. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, X.; Liu, J.; Zhang, D.; Lu, Y.; Zhou, Y.; Sun, L.; Hou, S.; Fan, X.; Shen, S.; et al. Multispectral drone imagery and SRGAN for rapid phenotypic mapping of individual chinese cabbage plants. Plant Phenomics 2022, 2022, 0007. [Google Scholar] [CrossRef]
- Ye, Z.; Yang, K.; Lin, Y.; Guo, S.; Sun, Y.; Chen, X.; Lai, R.; Zhang, H. A comparison between Pixel-based deep learning and Object-based image analysis (OBIA) for individual detection of cabbage plants based on UAV Visible-light images. Comput. Electron. Agric. 2023, 209, 107822. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Yaw Angle Deviation/° | |||||
|---|---|---|---|---|---|---|
| Current Line | Starting Point | Road Break | Ending Point | Target Line | Average Gap Between Lines | |
| PSPNet | 1.436 | 2.634 | 1.562 | 3.211 | 1.713 | 2.111 |
| U-Net | 1.271 | 2.188 | 0.935 | 2.212 | 0.983 | 1.518 |
| DeeplabV3+_Xce | 1.266 | 2.176 | 0.947 | 2.332 | 0.973 | 1.539 |
| DeeplabV3+_Mob | 1.197 | 2.088 | 0.914 | 2.157 | 0.962 | 1.464 |
| DeeplabV3+_Xce_CBAM | 0.986 | 1.899 | 0.992 | 1.837 | 0.989 | 1.394 |
| ImDeeplabV3+ | 0.932 | 1.801 | 0.959 | 1.622 | 0.983 | 1.259 |
| Mower | Parameters |
|---|---|
| Model | G33 |
| Length × width × height | 1.07 m × 0.98 m × 0.44 m |
| Linear velocity | 1.5 m/s |
| Angular velocity | 0.2 rad/s |
| Model | MIoU | FPS | Passing Rate/% | Mean Transit Time/s |
|---|---|---|---|---|
| PSPNet | 0.735 | 15.635 | 12 | 38.49 |
| U-Net | 0.826 | 20.148 | 77 | 30.81 |
| DeeplabV3+_Xce | 0.807 | 20.148 | 75 | 31.22 |
| DeeplabV3+_Mob | 0.823 | 58.656 | 78 | 10.97 |
| DeeplabV3+_Xce_CBAM | 0.915 | 18.384 | 87 | 34.52 |
| ImDeeplabV3+ | 0.934 | 45.897 | 94 | 12.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Wang, P.; Li, J.; Liu, H.; Yang, X. A Track-Type Orchard Mower Automatic Line Switching Decision Model Based on Improved DeepLabV3+. Agriculture 2025, 15, 647. https://doi.org/10.3390/agriculture15060647
Liu L, Wang P, Li J, Liu H, Yang X. A Track-Type Orchard Mower Automatic Line Switching Decision Model Based on Improved DeepLabV3+. Agriculture. 2025; 15(6):647. https://doi.org/10.3390/agriculture15060647
Chicago/Turabian StyleLiu, Lixing, Pengfei Wang, Jianping Li, Hongjie Liu, and Xin Yang. 2025. "A Track-Type Orchard Mower Automatic Line Switching Decision Model Based on Improved DeepLabV3+" Agriculture 15, no. 6: 647. https://doi.org/10.3390/agriculture15060647
APA StyleLiu, L., Wang, P., Li, J., Liu, H., & Yang, X. (2025). A Track-Type Orchard Mower Automatic Line Switching Decision Model Based on Improved DeepLabV3+. Agriculture, 15(6), 647. https://doi.org/10.3390/agriculture15060647