1. Introduction
Cotton is an important economic crop and textile material, playing a significant role in driving economic development and improving people’s well-being [
1]. However, during the cotton cultivation process, various pests and diseases severely threaten its normal growth, such as leaf spot disease, aphids, bollworm, wilt disease, Fusarium wilt, gray mold, and leaf curl disease. These pests and diseases not only pose a challenge to the healthy growth of cotton, but also significantly reduce its yield and quality [
2]. Thus, promptly and accurately detecting cotton pests and diseases in the field, along with correctly identifying their types, is essential for enhancing both cotton yield and quality [
3].
Conventional approaches to detecting cotton pests and diseases primarily depend on manual observation [
4]. This approach is not only inefficient, but also susceptible to human subjective factors, leading to inaccurate judgments. As cotton cultivation expands and the demand for agricultural intelligence grows, manual identification methods are becoming inadequate to meet the practical needs of large-scale pest and disease management. In this context, the advancement of automated recognition and detection technologies that are both cost-effective and highly efficient has emerged as a focal point of research within the field of agricultural intelligence [
5].
Conventional approaches to detecting cotton pests and diseases primarily depend on manual observation [
6]. Traditional image processing methods typically rely on manually designed disease and pest features, which are then classified using classifiers [
7]. These methods typically include processes like image segmentation, edge detection, feature extraction, and classification. Although these methods can achieve certain results in specific scenarios, they face difficulty in meeting the conditions of complex natural environments, leading to limitations in speed and accuracy that cannot fulfill the practical demands of modern agricultural production.
In contrast, deep learning techniques offer considerable advantages in detecting plant pests and diseases. These algorithms can autonomously identify and learn intricate features, which allows them to outperform traditional image processing methods in detection accuracy [
8]. These algorithms can learn from large-scale feature datasets and accurately detect crop pests and diseases with minimal human intervention. For instance, Qi et al. [
9] incorporated the squeeze-and-excitation (SE) module, which utilizes an attention mechanism, into the YOLOv5 model. This enhancement enabled the model to focus on and extract features from crucial regions. As a result, the modified model exhibited robust performance during both the training and testing phases on the dataset. AtoleR et al. [
10] used the AlexNet model to classify three types of rice diseases (including healthy leaves). LiY et al. [
11] proposed a fine-tuned GoogLeNet model for identifying crop disease types, which also integrated several preprocessing techniques to adapt to complex backgrounds. Bao et al. [
12] developed a compact version of the CADenseNetBC40 model, which is based on DenseNet. This model incorporates a coordinated attention mechanism into every submodule of the dense block, thereby improving the extraction of features associated with cotton aphid symptoms.
Object detection is a key area at the convergence of computer vision and deep learning. It involves both classifying objects within images and precisely determining their locations [
13]. Among methods for object detection, the YOLO (You Only Look Once) algorithm can directly predict object categories from feature maps, showing significant advantages in both detection speed and accuracy, making it particularly suitable for detection tasks [
14]. Researchers in this field have proposed many efficient detection models. For example, Li et al. [
15] expanded the receptive field by quadrupling the down-sampling in the feature pyramid to better detect small objects, and incorporated the CBAM attention mechanism into the neural network to mitigate the gradient vanishing problem during training, thereby enhancing detection accuracy and robustness to interference. Chen et al. [
16] introduced a novel Involution Bottleneck module, which reduces both the number of parameters and computational demands, while effectively capturing long-range spatial information. Additionally, an SE module was incorporated to increase the model’s sensitivity to channel-specific features, leading to significant improvement in both detection accuracy and processing speed. Zhang et al. [
17] introduced an efficient channel attention mechanism, Hard-Swish activation function, and Focal Loss function in YOLOX to improve the model’s ability to extract image features and enhance detection accuracy and speed. Liu et al. [
18] proposed the MRF-YOLO algorithm based on deep learning, reconstructing a deep convolutional network suitable for small-to-medium-sized target crop image scenes and complex detection backgrounds. By incorporating multi-scale modules into the backbone, adding multi-receptive field extraction modules, and fusing multi-level features, they improved small-object detection accuracy, achieving a balance between speed and precision. Liu et al. [
19] used the DCNv3 structure to replace the ordinary convolution in the C2f module Bottleneck structure of YOLOv8n [
20], calling it C2f-DCNv3. Secondly, adding high-efficiency channel attention after the last C2f-DCNv3 module of the head keeps real-time detection possible while improving model accuracy. Pan et al. [
21] replaced the Bottleneck structure in the C2f module of the backbone network with Partial Convolution. In the neck network, a thin neck structure was employed, and the C2f module was substituted with the GSConv and VoVGSCSP modules. This approach effectively achieved a balanced trade-off between detection speed, accuracy, and model size.
Although deep learning-based crop pest and disease recognition shows ideal detection capabilities, applying these methods directly in practical production is challenging [
22]. Crop pests and diseases vary in size and shape, and the detection process becomes more complex, especially under conditions with significant interference from complicated backgrounds. At the same time, compared to the powerful GPU devices typically used for training and evaluation, the computational capabilities of practical deployment devices are usually much lower [
23]. Moreover, some deep learning models with high detection accuracy tend to have redundant model parameters, which hinder the improvement of detection efficiency in practical applications. Therefore, issues such as complex environmental backgrounds, diverse pest and disease types, and difficulties in deploying large-scale equipment pose significant challenges for crop pest and disease detection [
24].
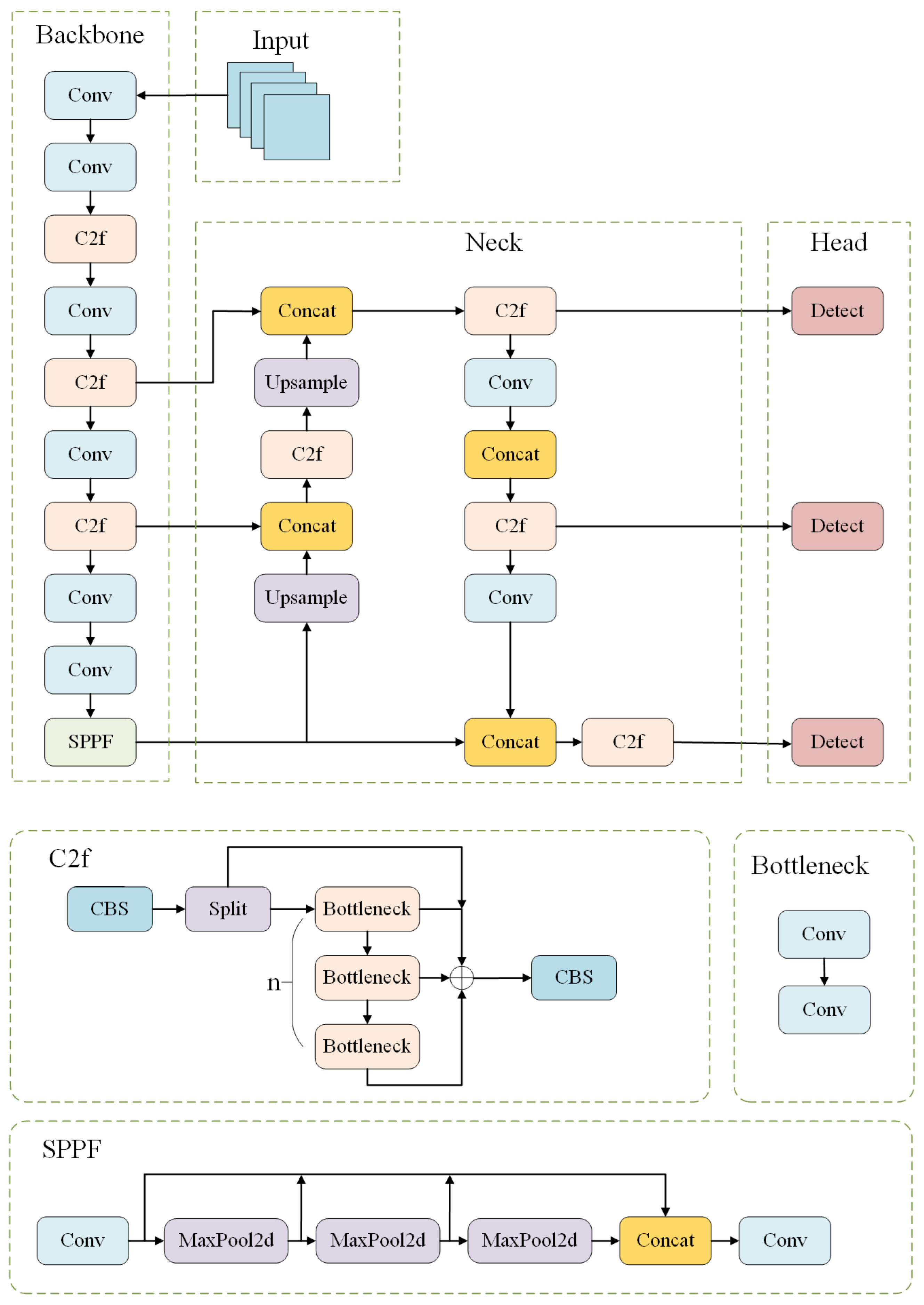
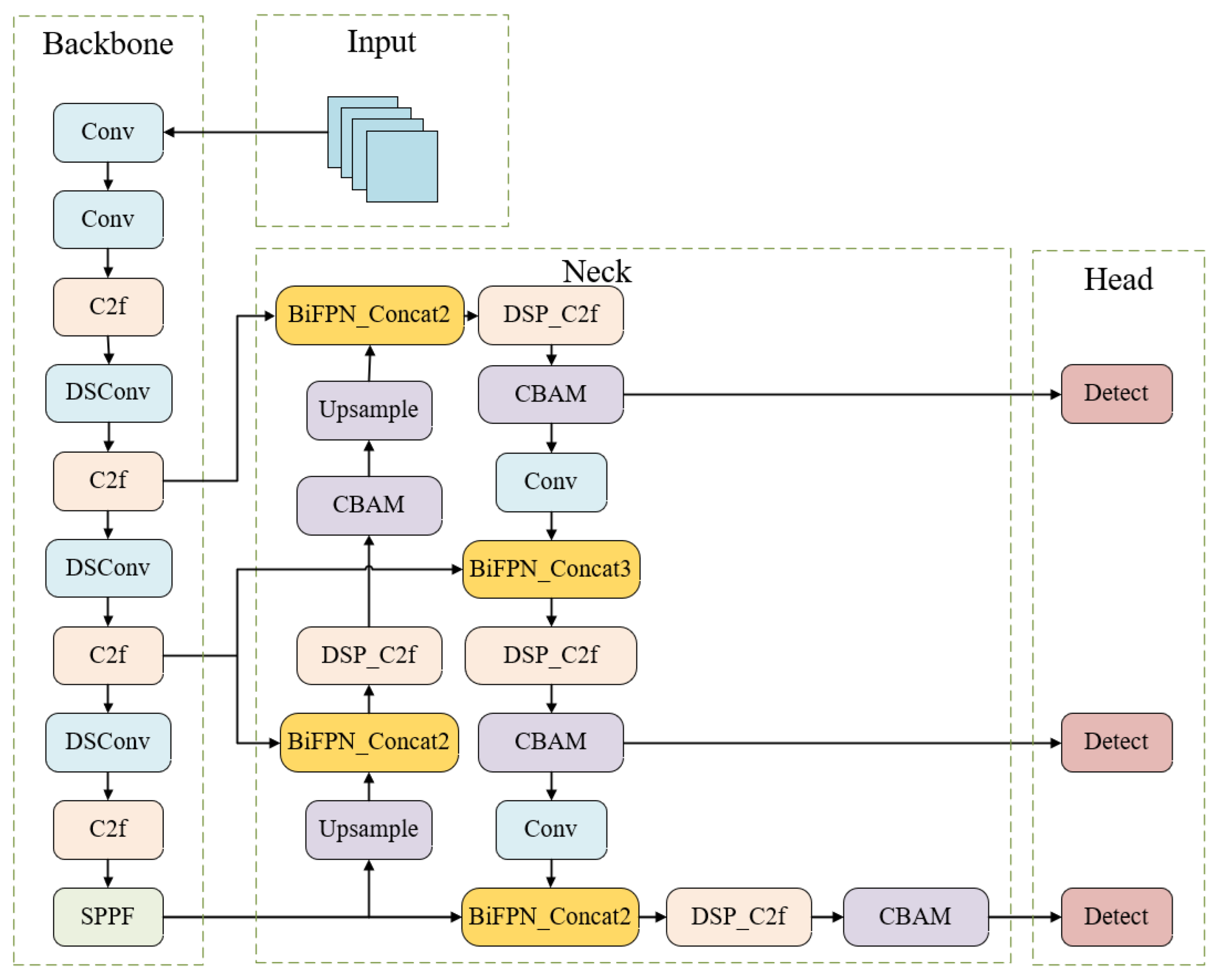
To overcome the aforementioned challenges, this paper introduces the LCDDN-YOLO algorithm, which is built upon the YOLOv8n framework. To adapt to the limited computational resources of devices in practical applications, some convolutional layers in the backbone network are replaced with DSConv, effectively reducing model parameters and computational complexity. The BiFPN network is integrated into the original architecture, incorporating learnable weights to quantify the importance of different input features. Additionally, we innovatively fuse DSConv with the PConv module in the neck network’s C2f module, resulting in an enhanced structure referred to as PDS-C2f. Furthermore, to improve the model’s success rate in detecting cotton pests and diseases, the CBAM attention mechanism is incorporated into the neck network to enhance feature representation across different channels and extract critical spatial information from various locations, thus improving model performance. Together, these optimizations improve detection accuracy, while simultaneously reducing both the number of parameters and the computational burden. This makes the deployment of the model on resource-limited devices feasible, and offers a practical solution for detecting cotton pests and diseases. The key contributions of this paper are summarized as follows:
1. A dataset consisting of 6712 images of cotton pests and diseases was established. We collected images of cotton pests and diseases from natural environments for model training, validation, and testing.
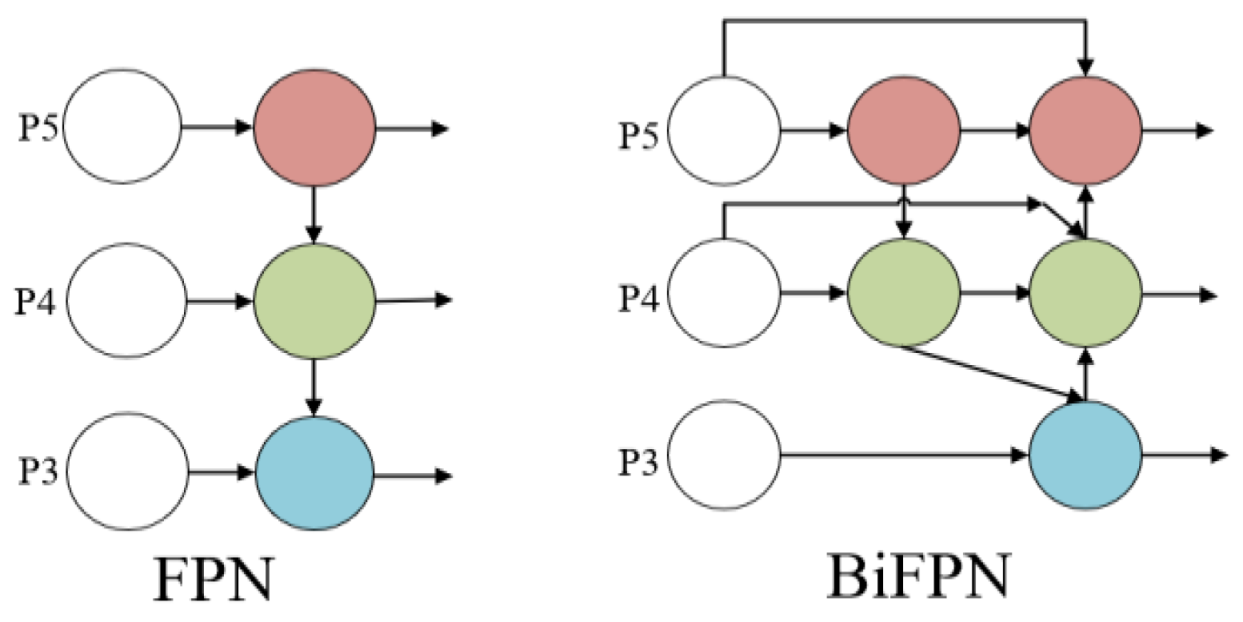
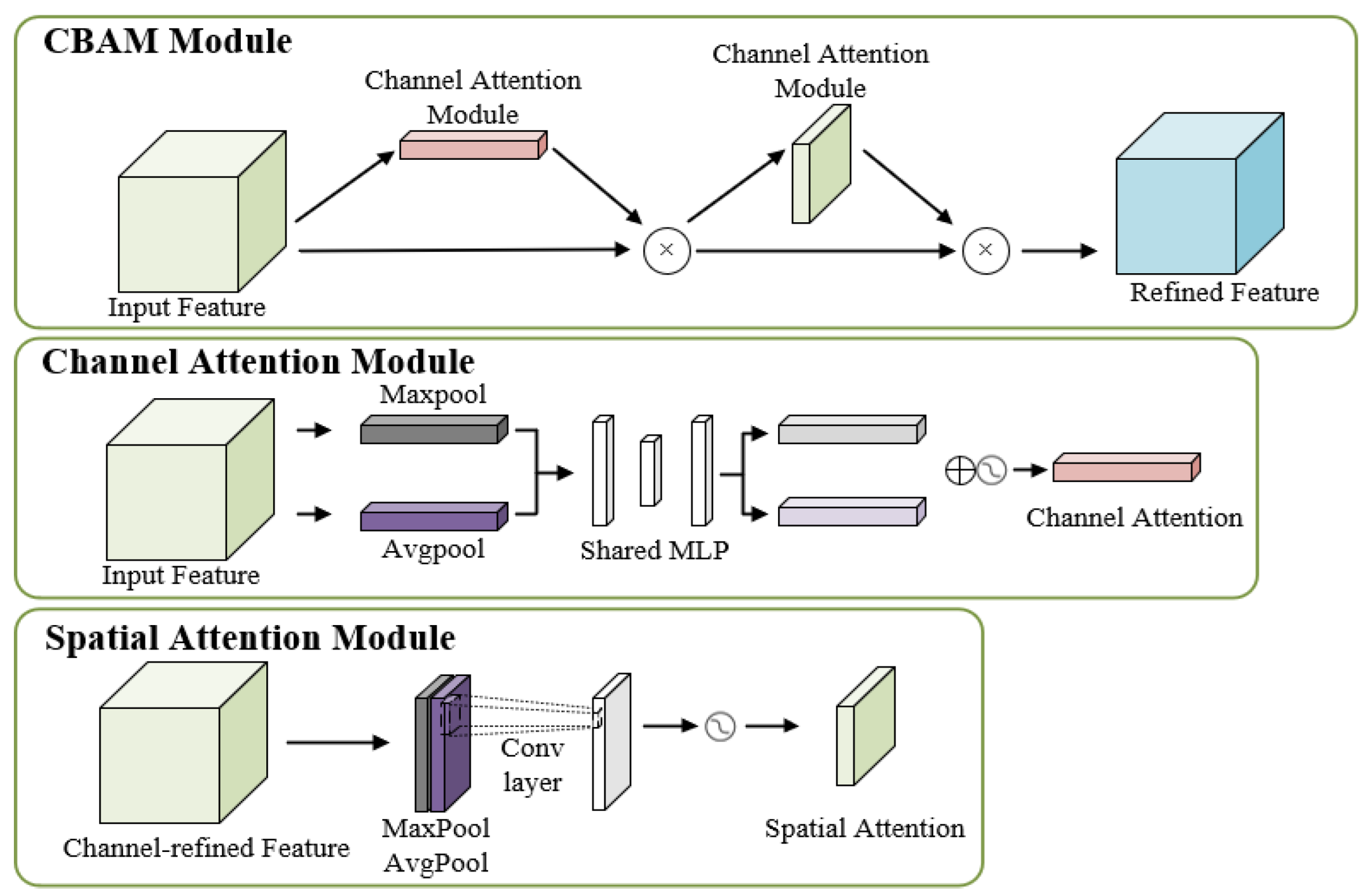
2. This paper introduces the innovative PDS-C2f module to develop a lightweight detection model. The network architecture is restructured by employing the lightweight BiFPN as the neck component of LCDDN-YOLO, and integrating the Convolutional Block Attention Module (CBAM), along with the new PDS-C2f module. By integrating features across various resolutions and scales, this approach enhances the model’s capacity to represent features more effectively. Additionally, it achieves an optimal balance between detection speed and accuracy.
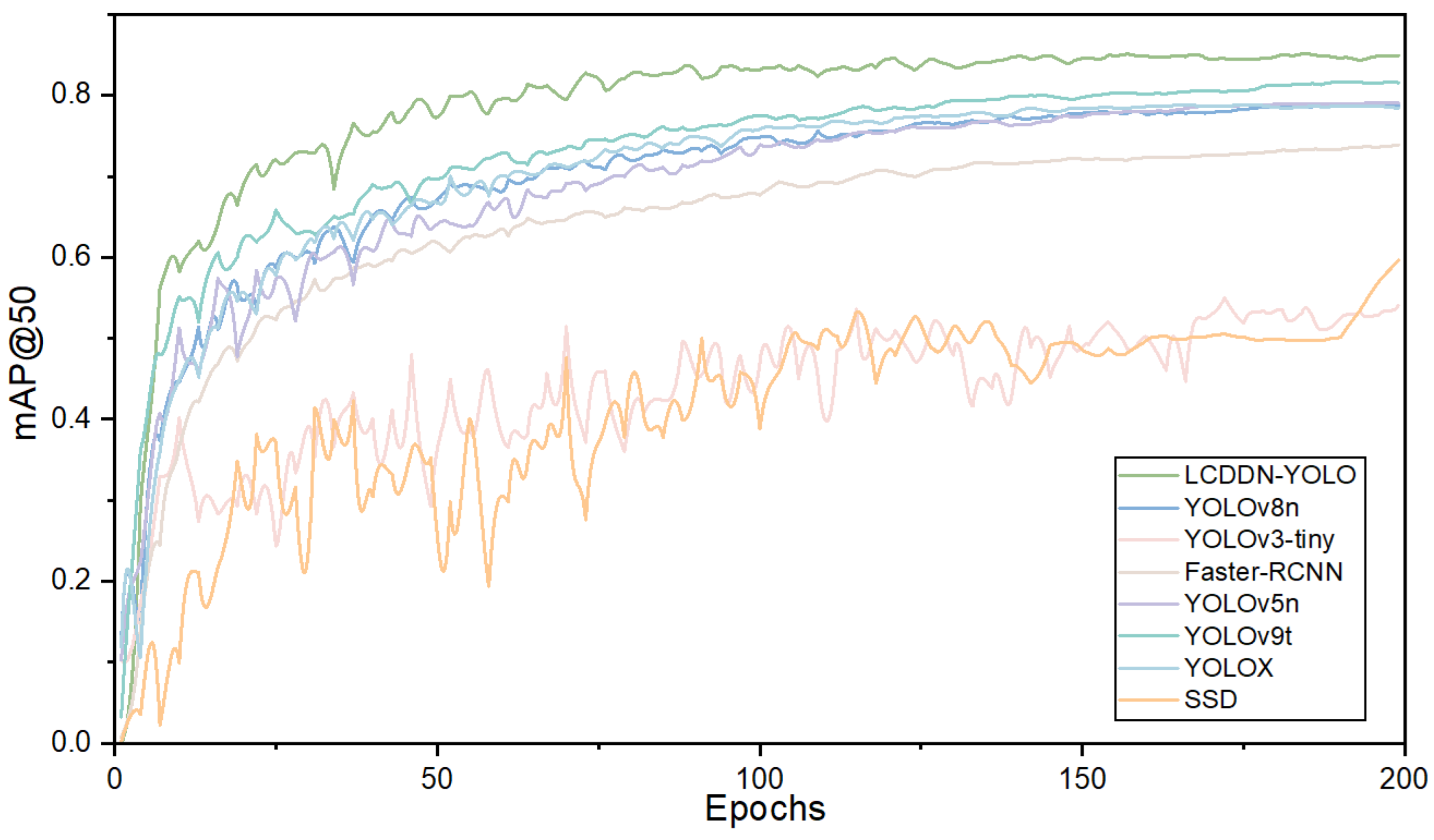
3. The Lightweight Cotton Disease Detection in Natural Environment (LCDDN-YOLO) network is compared with the YOLO series. The comparison validates the model’s performance in detecting pests and diseases, particularly those that are challenging to differentiate.
4. Discussion
4.1. Main Features of Proposed Method
Deep learning models need a lot of computing power to extract features accurately. This is a big challenge for embedded devices with limited resources. The problem is especially clear when using these models on devices like agricultural inspection robots. These devices often cannot handle such heavy computations in a given time. Some detection networks can provide high-precision results. However, their large size and complex calculations put too much pressure on the devices. On the other hand, lightweight detection models are faster and require less computing power, but they usually have lower accuracy, which affects performance. Therefore, when using cotton disease detection models on agricultural robots or other devices with limited resources, a key issue is determining how to make the model lightweight while keeping high detection accuracy.
The LCDDN-YOLO algorithm proposed in this paper is a lightweight approach for cotton pest and disease detection, built upon the YOLOv8n model. This model incorporates several lightweight modules, including DSConv, PDS-C2f, and BiFPN. The advantages of the LCDDN-YOLO model are as follows:
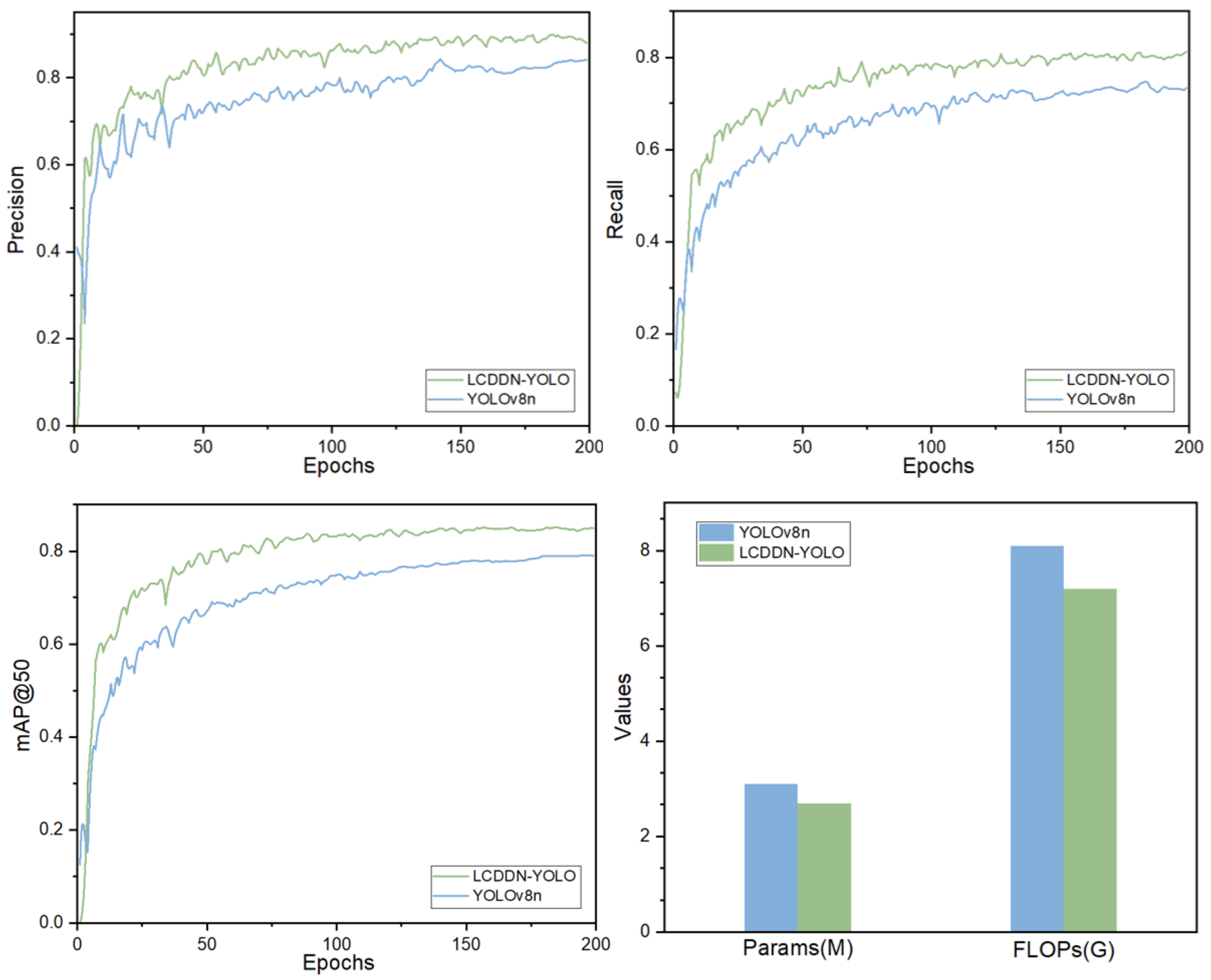
1. The model’s parameter count and floating-point operations are reduced to 2.7 M and 7.2 G, respectively, making it suitable for deployment in agricultural inspection robots and other resource-constrained agricultural devices.
2. In terms of detection accuracy, the LCDDN-YOLO model achieves precision, mAP@50, and recall of 89.5%, 85.4%, and 80.2%, respectively. The LCDDN-YOLO model strikes a balance between improving accuracy and simplifying model efficiency, providing technical support for precision agriculture management.
4.2. Future Work
The experimental results demonstrate that the proposed model exhibits broad application prospects. In practical implementations, the LCDDN-YOLO model can be seamlessly integrated with diverse data acquisition and processing tools to achieve efficient cotton pest and disease detection. Firstly, data collection can be conducted through agricultural inspection robots or unmanned aerial vehicles equipped with high-resolution cameras. These devices autonomously navigate cotton fields to capture real-time images of cotton plants, transmitting the image data to a central processing system via wireless networks. The central processing system, deployable on cloud-based or local servers, utilizes the LCDDN-YOLO model for real-time image analysis. The model’s high efficiency and lightweight design enable operation on resource-constrained devices, while maintaining superior detection accuracy in complex natural environments. Secondly, the LCDDN-YOLO model can be integrated with existing agricultural management systems. Through API interfaces, detection results are directly transmitted to management platforms. Administrators can visualize these results through graphical interfaces and implement appropriate control measures based on model-generated recommendations. Furthermore, the model can be synchronized with automated pesticide spraying equipment to enable targeted pesticide application, thereby reducing chemical usage and environmental contamination. Finally, to enhance model performance continuously, newly acquired field data can be periodically incorporated into training processes for model optimization and updates. This closed-loop data processing workflow not only improves the model’s generalization capability, but also adapts to pest/disease variations across regions and seasons, ensuring the long-term effectiveness of the detection system.
5. Conclusions
Detecting cotton pests and diseases in natural environments presents significant challenges, particularly due to the similarities between the features of these pests and diseases. To address these issues, this study introduces an enhancement to the YOLOv8 algorithm, resulting in an improved version named LCDDN-YOLO. The LCDDN-YOLO model first replaces a subset of traditional convolutional layers in the backbone network with DSConv layers. This modification leads to a significant reduction in both the model’s parameter count and computational complexity, while maintaining or even enhancing its ability to capture features. Consequently, LCDDN-YOLO achieves an optimal balance between detection speed and accuracy, making it a suitable and efficient solution for deployment on embedded devices. Furthermore, the model incorporates the BiFPN structure into its architecture, which enhances its feature representation capabilities and further improves detection accuracy. This addition allows the model to better identify cotton pests and diseases, even in complex environments with varying scales and backgrounds. Additionally, the LCDDN-YOLO algorithm integrates DSConv and PConv modules into the neck network’s C2f module, creating a new module called PDS-C2f. This modification is designed to improve the network’s feature extraction capacity and strengthen multi-level feature fusion, leading to improved identification of cotton pests and diseases. To further enhance the model’s ability to express features, the LCDDN-YOLO model also incorporates the CBAM attention mechanism into the neck network of the YOLOv8n model. These combined improvements increase the model’s sensitivity to subtle differences, reducing both false positives and false negatives in more complex environments. LCDDN-YOLO also uses the Focal-EIoU loss function. This helps to improve the model’s training process. As a result, the model becomes more accurate and robust in detecting cotton pests and diseases. Experimental results show that LCDDN-YOLO outperforms the traditional YOLOv8 model. Compared to YOLOv8n, the LCDDN-YOLO model reduces the parameter count by 12.9% and FLOPs by 9.9%, while increasing precision, mAP@50, and recall by 4.6%, 6.5%, and 7.8%, respectively, allowing them to reach 89.5%, 85.4%, and 80.2%. These results indicate that the LCDDN-YOLO model, with its excellent detection accuracy and efficient computational speed, is already capable of meeting practical application demands, particularly in lightweight computing scenarios. In the future, with further optimization and adjustments, the LCDDN-YOLO model is expected to be applied in a broader range of agricultural detection fields and provide strong technical support for real-time detection and precise control of cotton field pests and diseases.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}