
A Novel Method to Forecast Nitrate Concentration Levels in Irrigation Areas for Sustainable Agriculture



Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area, Water Sampling, and Analysis
2.2. Observed Data Used
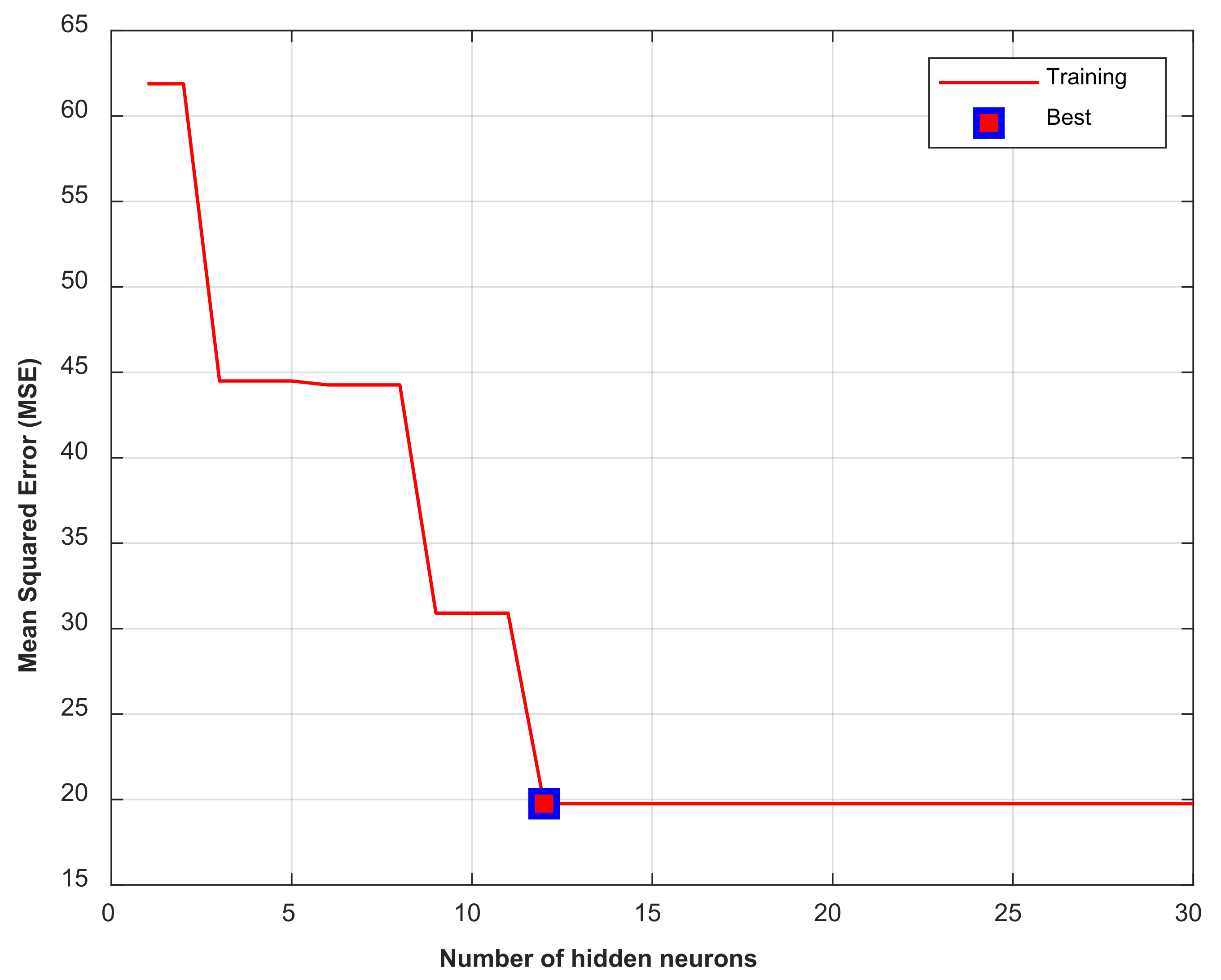
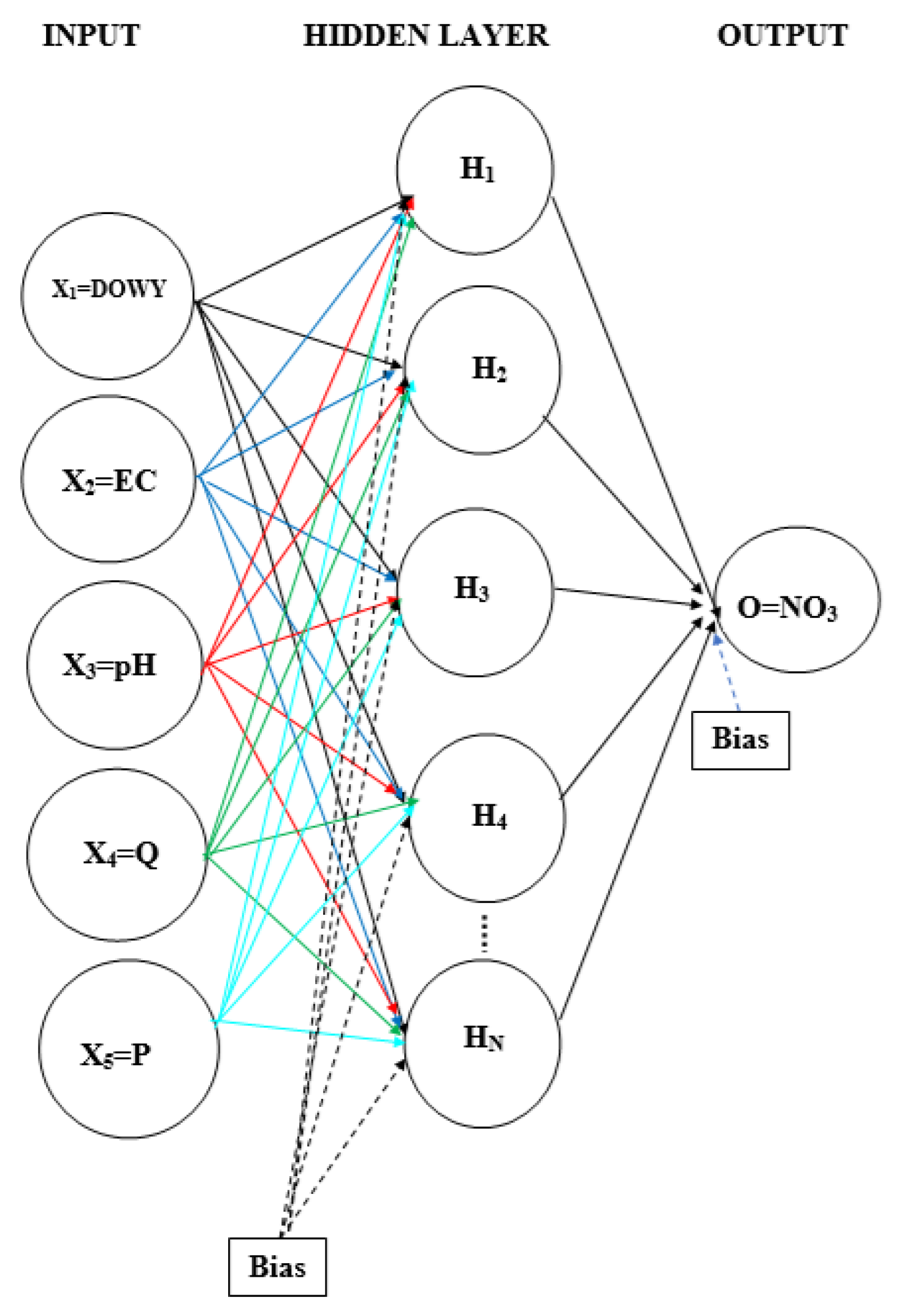
2.3. Developing an ANN Model for Nitrate Concentrations
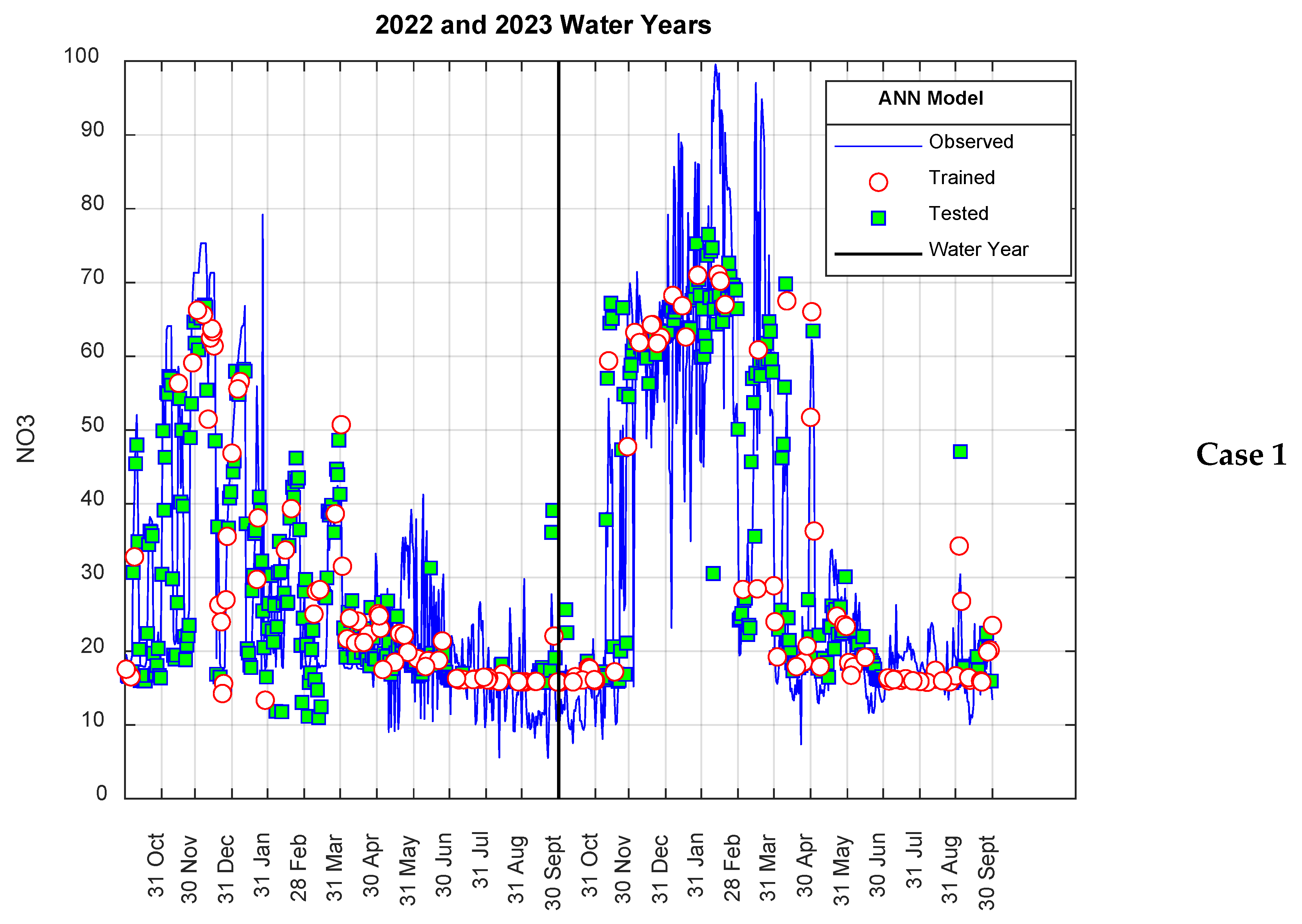
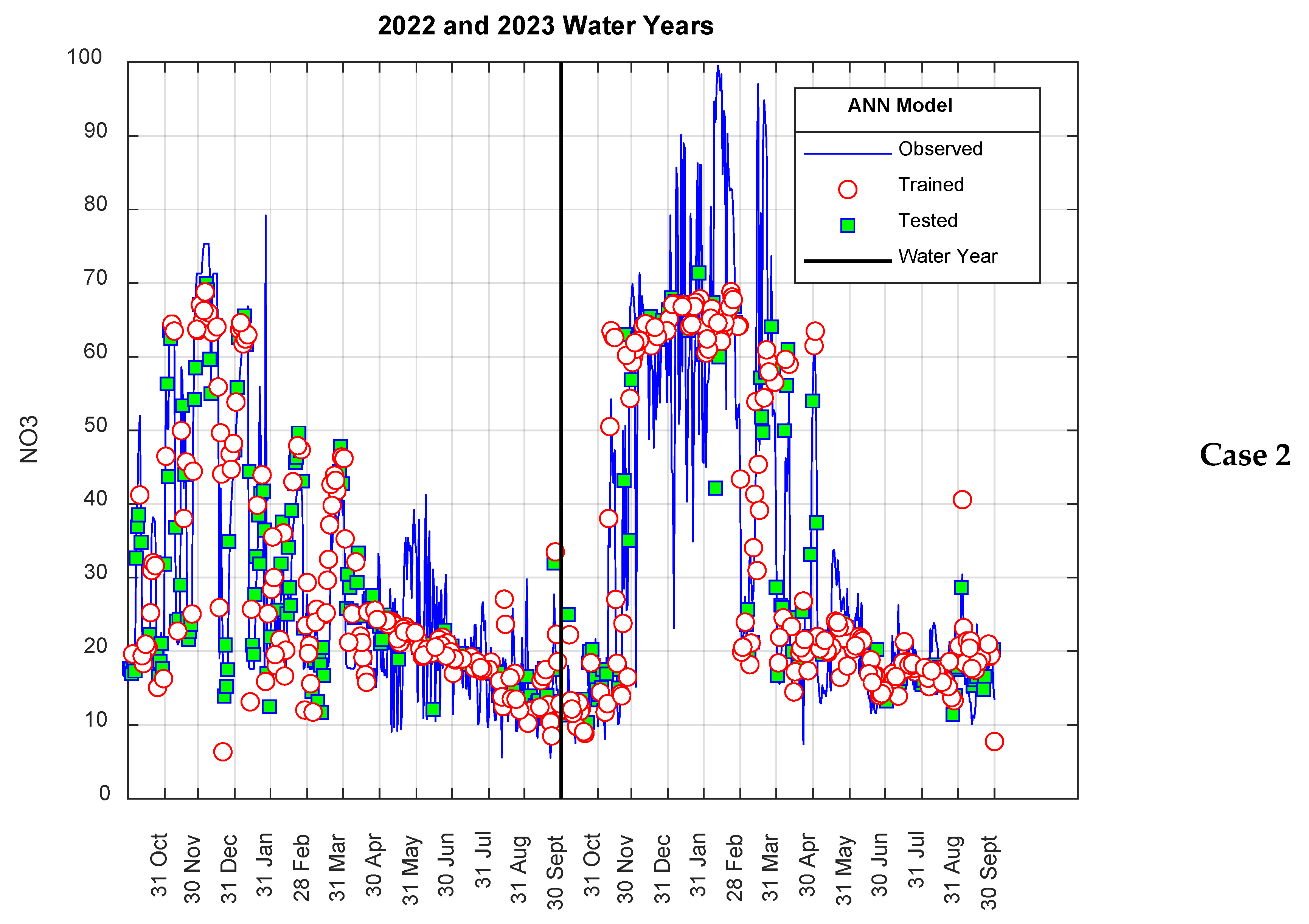
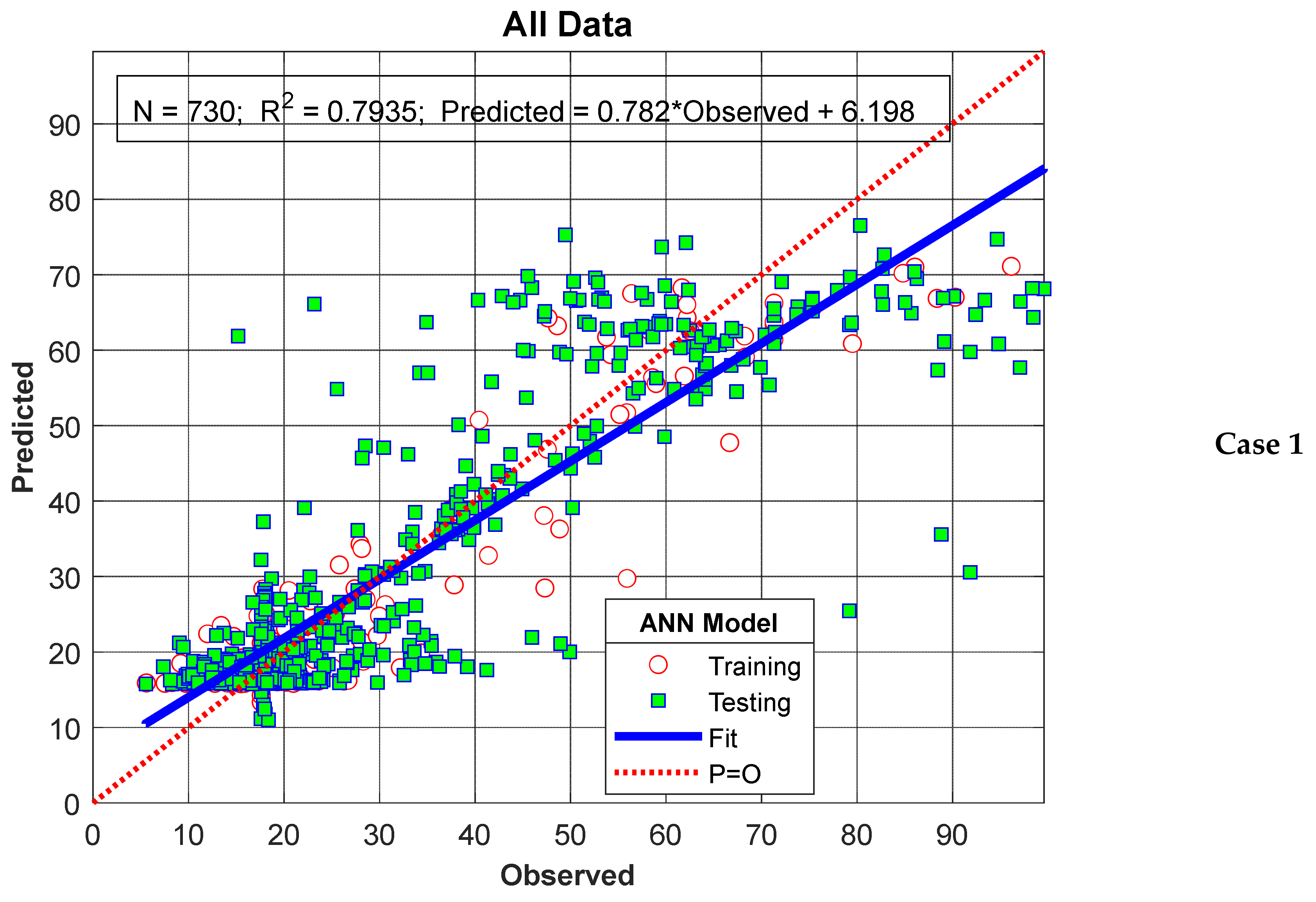
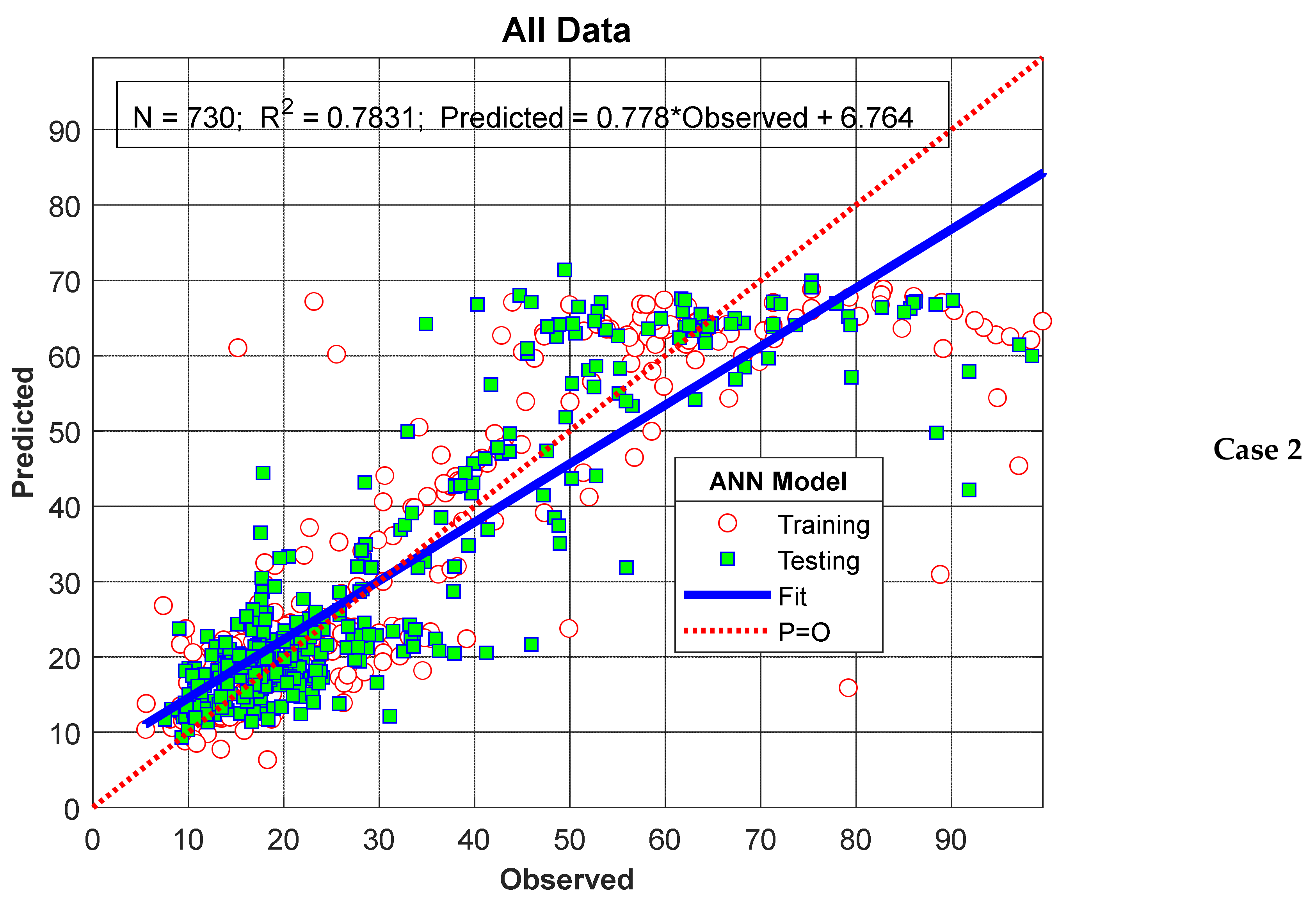
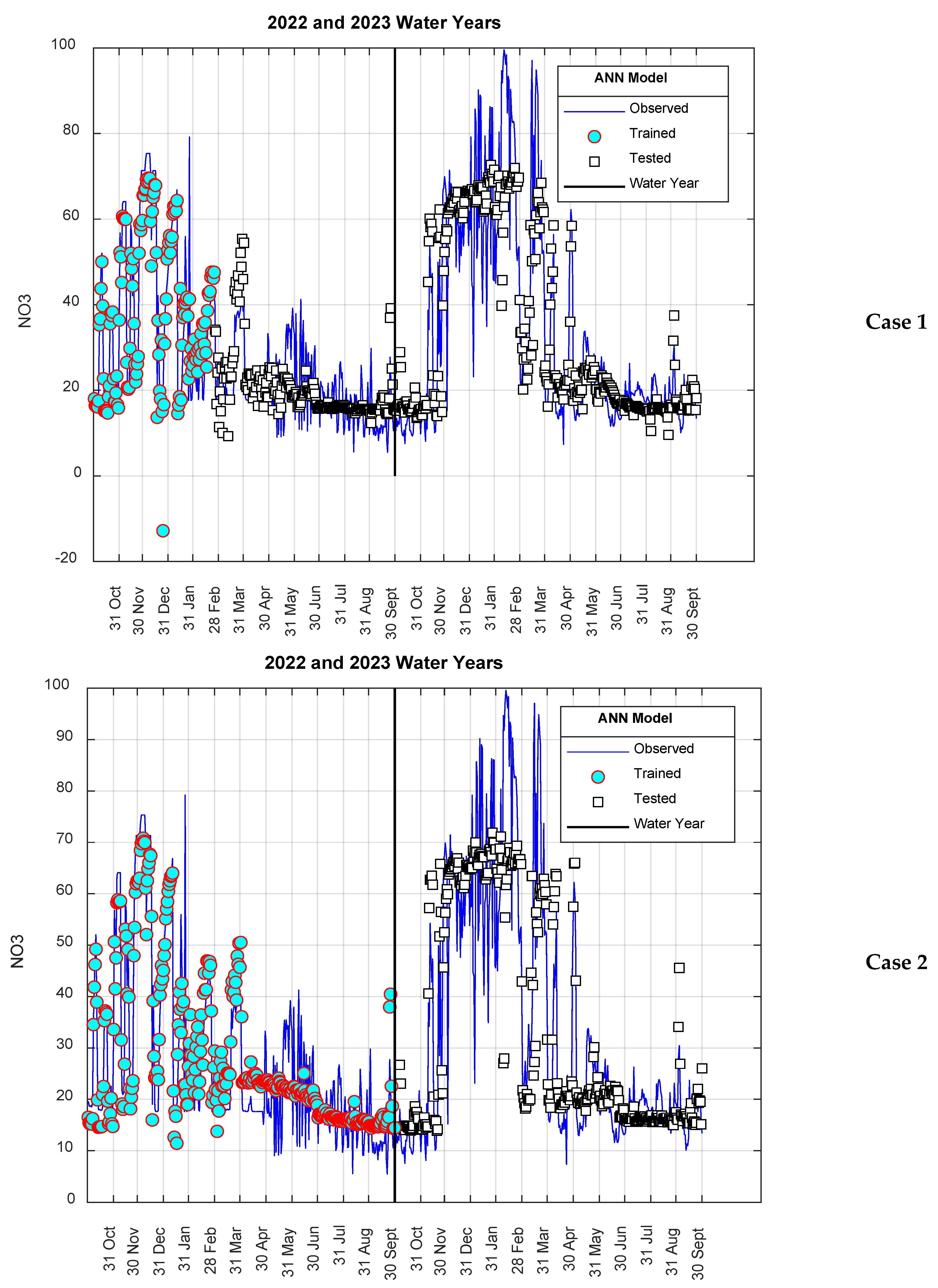
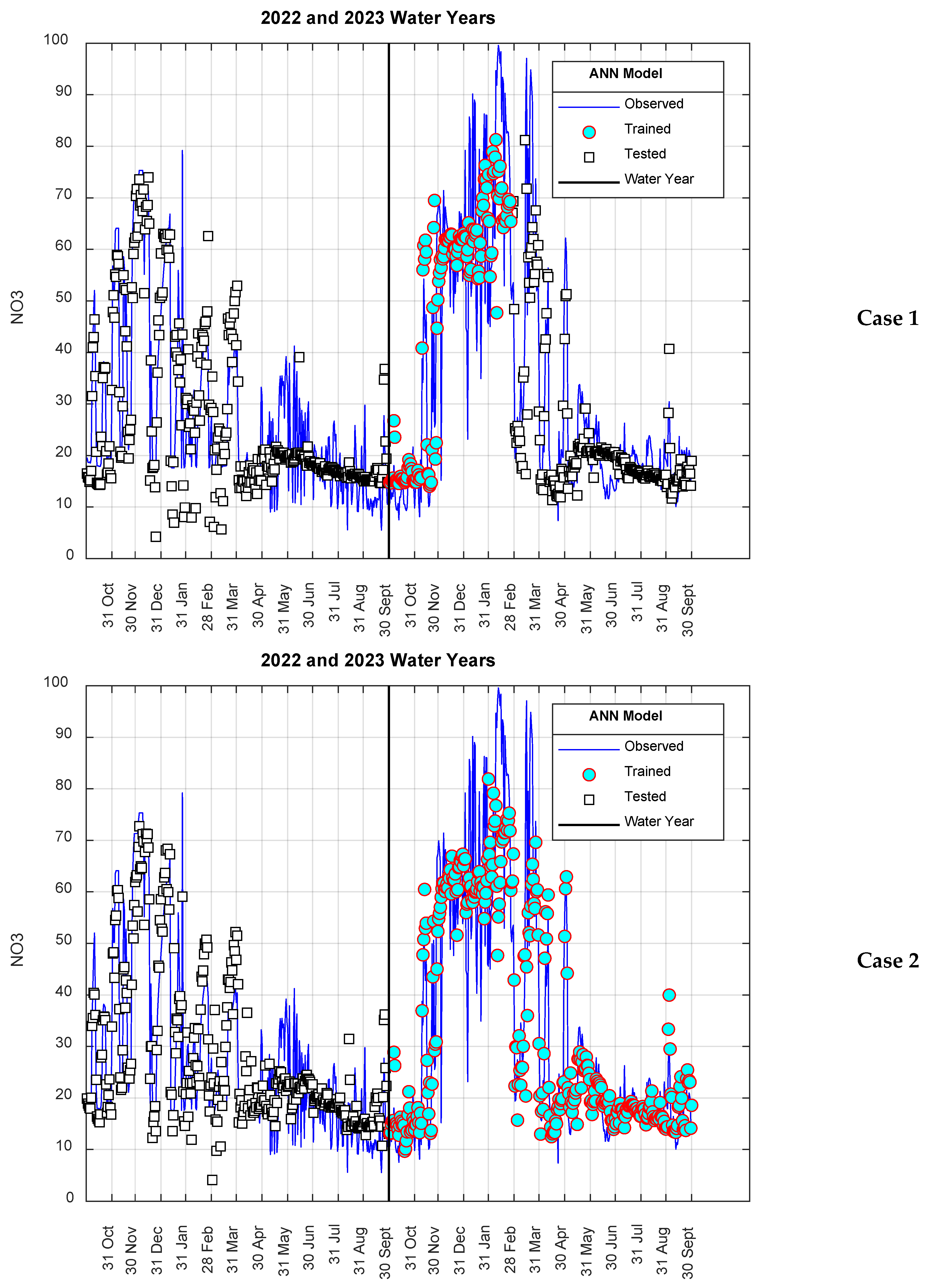
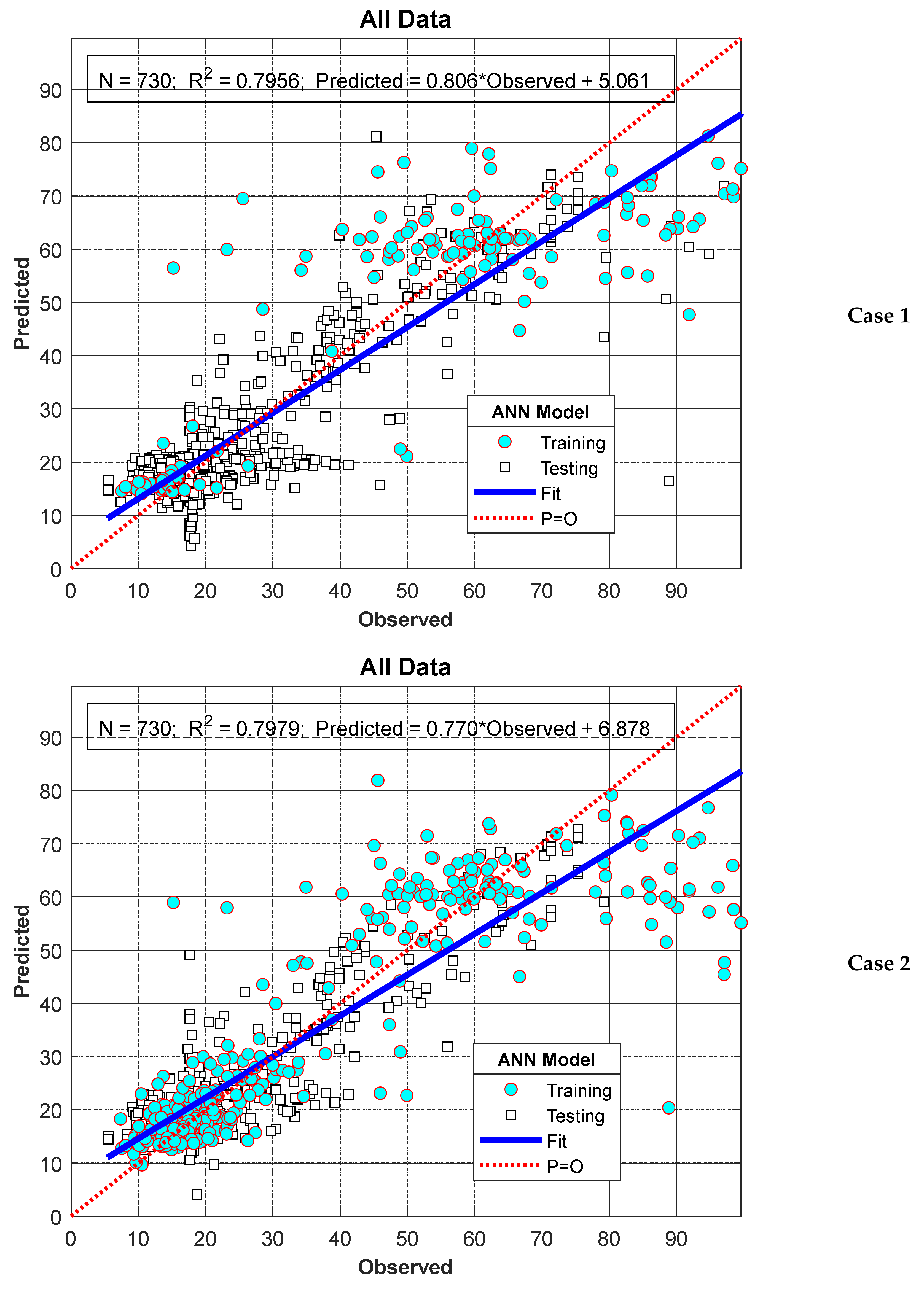
3. Results
4. Discussion
4.1. Optimal Network Selection and Performance Factors in ANN Models
4.2. Data Ratios and Selection Methods in Training and Testing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Definitions of Error Indicators
References
- McNeely, R.N.; Neimanis, V.P.; Dwyer, L. Water Quality Sourcebook: A Guide to Water Quality Parameters; Inland Waters Directorate, Water Quality Branch: Ottawa, Canada, 1979; pp. 1–89. [Google Scholar]
- Hem, J.D. Study and Interpretation of the Chemical Characteristics of Natural Water; Department of the Interior, US Geological Survey: Alexandria, VA, USA, 1985; Volume 2254. [Google Scholar]
- Benzer, S.; Benzer, R. Modelling nitrate prediction of groundwater and surface water using artificial neural networks. J. Polytech. 2018, 21, 321–325. [Google Scholar] [CrossRef]
- Sharma, V.; Negi, S.C.; Rudra, R.P.; Yang, S. Neural networks for predicting nitrate-nitrogen in drainage water. Agric. Water Manag. 2003, 63, 169–183. [Google Scholar] [CrossRef]
- Horsburgh, J.S.; Hooper, R.P.; Bales, J.; Hedstrom, M.; Imker, H.J.; Lehnert, K.A.; Shanley, L.A.; Stall, S. Assessing the state of research data publication in hydrology: A perspective from the Consortium of Universities for the Advancement of Hydrologic Science, Incorporated. Wiley Interdiscip. Rev. Water 2020, 7, e1422. [Google Scholar] [CrossRef]
- McDonough, L.K.; Santos, I.R.; Andersen, M.S.; O’Carroll, D.M.; Rutlidge, H.; Meredith, K.; Oudone, P.; Bridgeman, J.; Goddy, D.C.; Sorensen, J.P.; et al. Changes in global groundwater organic carbon driven by climate change and urbanization. Nat. Commun. 2020, 11, 1279. [Google Scholar] [CrossRef]
- Misstear, B.; Vargas, C.R.; Lapworth, D.; Ouedraogo, I.; Podgorski, J. A global perspective on assessing groundwater quality. Hydrogeol. J. 2023, 31, 11–14. [Google Scholar] [CrossRef]
- Basu, N.B.; Van Meter, K.J.; Byrnes, D.K.; Van Cappellen, P.; Brouwer, R.; Jacobsen, B.H.; Jarsjö, J.; Rudolph, D.L.; Cunha, M.C.; Nelson, N.; et al. Managing nitrogen legacies to accelerate water quality improvement. Nat. Geosci. 2022, 15, 97–105. [Google Scholar] [CrossRef]
- Foster, S.S.D.; Chilton, P.J. Groundwater: The processes and global significance of aquifer degradation. Philosophical Transactions of the Royal Society of London. Ser. B Biol. Sci. 2003, 358, 1957–1972. [Google Scholar] [CrossRef]
- Jasechko, S.; Perrone, D. Global groundwater wells at risk of running dry. Science 2021, 372, 418–421. [Google Scholar] [CrossRef]
- Torres-Martínez, J.A.; Mahlknecht, J.; Kumar, M.; Loge, F.J.; Kaown, D. Advancing groundwater quality predictions: Machine learning challenges and solutions. Sci. Total Environ. 2024, 949, 174973. [Google Scholar] [CrossRef]
- Palani, S.; Liong, S.Y.; Tkalich, P. An ANN application for water quality forecasting. Mar. Pollut. Bull. 2008, 56, 1586–1597. [Google Scholar] [CrossRef]
- Zare, A.; Bayat, V.; Daneshkare, A. Forecasting nitrate concentration in groundwater using artificial neural network and linear regression models. Int. Agrophysics 2011, 25, 2–187. [Google Scholar]
- Mahlknecht, J.; Torres-Martínez, J.A.; Kumar, M.; Mora, A.; Kaown, D.; Loge, F.J. Nitrate prediction in groundwater of data scarce regions: The futuristic fresh-water management outlook. Sci. Total Environ. 2023, 905, 166863. [Google Scholar] [CrossRef] [PubMed]
- Podgorski, J.; Berg, M. Global analysis and prediction of fluoride in groundwater. Nat. Commun. 2022, 13, 4232. [Google Scholar] [CrossRef] [PubMed]
- Podgorski, J.; Berg, M. Global threat of arsenic in groundwater. Science 2020, 368, 845–850. [Google Scholar] [CrossRef] [PubMed]
- Sarkar, S.; Mukherjee, A.; Chakraborty, M.; Quamar, M.T.; Duttagupta, S.; Bhattacharya, A. Prediction of elevated groundwater fluoride across India using multi-model approach: Insights on the influence of geologic and environmental factors. Environ. Sci. Pollut. Res. 2023, 30, 31998–32013. [Google Scholar] [CrossRef]
- Alengebawy, A.; Abdelkhalek, S.T.; Qureshi, S.R.; Wang, M.Q. Heavy metals and pesticides toxicity in agricultural soil and plants: Ecological risks and human health implications. Toxics 2021, 9, 42. [Google Scholar] [CrossRef]
- Hube, S.; Wu, B. Mitigation of emerging pollutants and pathogens in decentralized wastewater treatment processes: A review. Sci. Total Environ. 2021, 779, 146545. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Ebtehaj, I.; Bonakdari, H.; Deo, R.C.; Mehr, A.D.; Mohtar, W.H.M.W.; Diop, L.; El-shafie, A.; Singh, V.P. Novel approach for streamflow forecasting using a hybrid ANFIS-FFA model. J. Hydrol. 2017, 554, 263–276. [Google Scholar] [CrossRef]
- Sarangi, A.; Singh, M.; Bhattacharya, A.K.; Singh, A.K. Subsurface drainage performance study using SALTMOD and ANN models. Agric. Water Manag. 2006, 84, 240–248. [Google Scholar] [CrossRef]
- Karahan, H.; Ayvaz, M.T. Forecasting aquifer parameters using artificial neural networks. J. Porous Media 2006, 9, 429–444. [Google Scholar] [CrossRef]
- Logan, T.J.; Eckert, D.J.; Beak, D.G. Tillage, crop and climatic effects of runoff and tile drainage losses of nitrate and four herbicides. Soil Tillage Res. 1994, 30, 75–103. [Google Scholar] [CrossRef]
- Strik, D.P.; Domnanovich, A.M.; Zani, L.; Braun, R.; Holubar, P. Prediction of trace compounds in biogas from anaerobic digestion using the MATLAB Neural Network Toolbox. Environ. Modell. Softw. 2005, 20, 803–810. [Google Scholar] [CrossRef]
- Koekkoek, E.J.W.; Booltink, H. Neural network models to predict soil water retention. Eur. J. Soil Sci. 1999, 50, 489–495. [Google Scholar] [CrossRef]
- Co, H.C.; Boosarawongse, R. Forecasting Thailand’s rice export: Statistical techniques vs. artificial neural networks. Comput. Ind. Eng. 2007, 53, 610–627. [Google Scholar] [CrossRef]
- Erzin, Y.; Rao, B.H.; Singh, D.N. Artificial neural network models for predicting soil thermal resistivity. Int. J. Therm. Sci. 2008, 47, 1347–1358. [Google Scholar] [CrossRef]
- Baker, L.; Ellison, D. Optimisation of pedotransfer functions using an artificial neural network ensemble method. Geoderma 2008, 144, 212–224. [Google Scholar] [CrossRef]
- Liu, H.; Xie, D.; Wu, W. Soil water content forecasting by ANN and SVM hybrid architecture. Env. Monit. Assess. 2008, 143, 187–193. [Google Scholar] [CrossRef]
- Patil, S.L.; Tantau, H.J.; Salokhe, V.M. Modelling of tropical greenhouse temperature by auto regressive and neural network models. Biosyst. Eng. 2008, 99, 423–431. [Google Scholar] [CrossRef]
- Xu, L.; Yang, J.; Zhang, Q.; Niu, H. Modelling water and salt transport in a soil–water–plant system under different groundwater tables. Water Environ. J. 2008, 22, 265–273. [Google Scholar] [CrossRef]
- Zou, P.; Yang, J.; Fu, J.; Liu, G.; Li, D. Artificial neural network and time series models for predicting soil salt and water content. Agric. Water Manag. 2010, 97, 2009–2019. [Google Scholar] [CrossRef]
- Stamenković, L.J. Application of ANN and SVM for prediction nutrients in rivers. J. Environ. Sci. Health Part A 2021, 56, 867–873. [Google Scholar] [CrossRef]
- Stamenković, L.J.; Mrazovac Kurilić, S.; Presburger Ulniković, V. Prediction of nitrate concentration in Danube River water by ysing Artificial Neural Networks. Water Supply 2020, 20, 2119–2132. [Google Scholar] [CrossRef]
- Jung, K.; Bae, D.-H.; Um, M.-J.; Kim, S.; Jeon, S.; Park, D. Evaluation of nitrate load estimations using neural networks and canonical correlation analysis with K-Fold Cross-Validation. Sustainability 2020, 12, 400. [Google Scholar] [CrossRef]
- Band, S.S.; Janizadeh, S.; Pal, S.C.; Chowdhuri, I.; Siabi, Z.; Norouzi, A.; Melesse, A.M.; Shokri, M.; Mosavi, A. Comparative analysis of Artificial Intelligence models for accurate estimation of groundwater nitrate concentration. Sensors 2020, 20, 5763. [Google Scholar] [CrossRef]
- Hrnjica, B.; Mehr, A.D.; Jakupovic, E.; Crnkic, A.; Hasanagic, R. Application of deep learning neural networks for nitrate prediction in the Klokot River, Bosnia and Herzegovina. In Proceedings of the 2021 7th International Conference on Control, Instrumentation and Automation (ICCIA), Tabriz, Iran, 23–24 February 2021; IEEE: Tabriz, Iran, 2021; pp. 1–6. [Google Scholar]
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ. Model. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Al-Mahallawi, K.; Mania, J.; Hani, A.; Shahrour, I. Using of neural networks for the prediction of nitrate groundwater contamination in rural and agricultural areas. Environ. Earth Sci. 2012, 65, 917–928. [Google Scholar] [CrossRef]
- Yesilnacar, M.I.; Sahinkaya, E.; Naz, M.; Ozkaya, B. Neural network prediction of nitrate in groundwater of Harran Plain, Turkiye. Environ. Geol. 2008, 56, 19–25. [Google Scholar] [CrossRef]
- Elzain, H.E.; Chung, S.Y.; Senapathi, V.; Sekar, S.; Lee, S.Y.; Roy, P.D.; Hassan, A.; Sabarathinam, C. Comparative study of machine learning models for evaluating groundwater vulnerability to nitrate contamination. Ecotoxicol. Environ. Saf. 2022, 229, 113061. [Google Scholar] [CrossRef]
- Stylianoudaki, C.; Trichakis, I.; Karatzas, G.P. Modeling groundwater nitrate contamination using artificial neural networks. Water 2022, 14, 1173. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model Evaluation Guidelines for Systematic Quantification of Accuracy in Watershed Simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- El Amri, A.; M’nassri, S.; Nasri, N.; Nsir, H.; Majdoub, R. Nitrate concentration analysis and prediction in a shallow aquifer in central-eastern Tunisia using artificial neural network and time series modelling. Environ. Sci. Pollut. Res. 2022, 29, 43300–43318. [Google Scholar] [CrossRef]
- Deng, Y.; Ye, X.; Du, X. Predictive modeling and analysis of key drivers of groundwater nitrate pollution based on machine learning. J. Hydrol. 2023, 624, 129934. [Google Scholar] [CrossRef]
- Sarangi, A.; Bhattacharya, A.K. Comparison of artificial neural network and regression models for sediment loss prediction from Banha watershed in India. Agric. Water Manag. 2005, 78, 195–208. [Google Scholar] [CrossRef]
- Kim, M.Y.; Seo, M.C.; Kim, M.K. Linking hydro-meteorological factors to the assessment of nutrient loadings to streams from large-plotted paddy rice fields. Agric. Water Manag. 2007, 87, 223–228. [Google Scholar] [CrossRef]
- Landeras, G.; Ortiz-Barredo, A.; López, J.J. Comparison of artificial neural network models and empirical and semi-empirical equations for daily reference evapotranspiration estimation in the Basque Country (Northern Spain). Agric. Water Manag. 2008, 95, 553–565. [Google Scholar] [CrossRef]
- Chinh, L.V.; Hiramatsu, K.; Harada, M.; Mori, M. Estimation of water levels in a main drainage canal in a flat low-lying agricultural area using artificial neural network models. Agric. Water Manag. 2009, 96, 1332–1338. [Google Scholar] [CrossRef]
- Chau, K.W. A review on integration of artificial intelligence into water quality modelling. Mar. Poll. Bull. 2006, 52, 726–733. [Google Scholar] [CrossRef]
- Hatzikos, E.; Anastasakis, L.; Bassiliades, N.; Vlahavas, I. Applying neural networks with active neurons to sea-water quality measurements. In Proceedings of the Second International Scientific Conference on Computer Science, Varna, Bulgaria, 11–13 May 2005; IEEE Computer Society: Washington, DC, USA, 2005; pp. 114–119. [Google Scholar]
- Wagh, V.; Panaskar, D.; Muley, A.; Mukate, S.; Gaikwad, S. Neural network modelling for nitrate concentration in groundwater of Kadava River basin, Nashik, Maharashtra, India. Groundw. Sustain. Develop. 2018, 7, 436–445. [Google Scholar] [CrossRef]
- Latif, S.D.; Azmi, M.S.B.N.; Ahmed, A.N.; Fai, C.M.; El-Shafie, A. Application of artificial neural network for forecasting nitrate concentration as a water quality parameter: A case study of Feitsui Reservoir, Taiwan. Int. J. Des. Nat. Ecodynamics 2020, 15, 647–652. [Google Scholar] [CrossRef]
- Meng, G.; Fang, L.; Yin, Y.; Zhang, Z.; Li, T.; Chen, P.; Liu, Y.; Zhang, L. Intelligent control of the electrochemical nitrate removal basing on artificial neural network (ANN). J. Water Process Eng. 2022, 49, 103122. [Google Scholar] [CrossRef]
- Alsenjar, O.; Çetin, M.; Aksu, H.; Akgül, M.A.; Golpinar, M.S. Cropping pattern classification using artificial neural networks and evapotranspiration estimation in the Eastern Mediterranean region of Turkey. J. Agric. Sci. 2023, 29, 677–689. [Google Scholar] [CrossRef]
- Alsenjar, O.; Cetin, M.; Aksu, H.; Golpinar, M.S.; Akgul, M.A. Actual evapotranspiration estimation using METRIC model and Landsat satellite images over an irrigated field in the Eastern Mediterranean Region of Turkey. Med. Geosc. Rev. 2023, 5, 35–49. [Google Scholar] [CrossRef]
- Cetin, M.; Kaman, H.; Kirda, C.; Sesveren, S. Analysis of irrigation performance in water resources planning and management: A case study. Fresenius Environ. Bull. 2020, 29, 3409–3414. [Google Scholar]
- Dinç, U.; Şenol, S.; Sayın, M.; Kapur, S.; Güzel, N.; Derici, R.; Yeşilsoy, M.Ş.; Yeğingil, D.; Sari, M.; Kaya, Z.; et al. The soils of Southeastern Anatolia Region (GAT) 1. Harran Plain. In TUBİTAK Agriculture and Forestry Group Guided Research Project Final Result Report; Project Number: TOAG-534; TÜBİTAK: Ankara, Türkiye, 1988. (In Turkish) [Google Scholar]
- Karnez, E.; Sagir, H.; Gavan, M.; Golpinar, M.S.; Cetin, M.; Akgul, M.A.; İbrikci, H.; Pintar, M. Modeling Agricultural Land Management to Improve Understanding of Nitrogen Leaching in an Irrigated Mediterranean Area in Southern Turkey; IntechOpen: London, UK, 2017; ISBN 978-953-51-2882-3. [Google Scholar]
- Rice, E.W.; Bridgewater, L. Standard Methods for the Examination of Water and Wastewater; American Public Health Association: Washington, DC, USA, 2012; Volume 10. [Google Scholar]
- Karahan, H.; Iplikci, S.; Yasar, M.; Gurarslan, G. River flow estimation from upstream flow records using support vector machines. J. Appl. Math. 2014, 2014, 714213. [Google Scholar] [CrossRef]
- Karahan, H.; Ayvaz, M.T. Simultaneous parameter identification of a heterogeneous aquifer system using artificial neural networks. Hydrogeol. J. 2008, 16, 817–827. [Google Scholar] [CrossRef]
- Bilski, J.; Kowalczyk, B.; Marchlewska, A.; Zurada, J.M. Local Levenberg-Marquardt algorithm for learning feedforwad neural networks. J. Artif. Intell. Soft Comput. Res. 2020, 10, 299–316. [Google Scholar] [CrossRef]
- Yan, Z.; Zhong, S.; Lin, L.; Cui, Z. Adaptive Levenberg–Marquardt algorithm: A new optimization strategy for Levenberg–Marquardt neural networks. Mathematics 2021, 9, 2176. [Google Scholar] [CrossRef]
- Haring, M.; Grøtli, E.I.; Riemer-Sørensen, S.; Seel, K.; Hanssen, K.G. A Levenberg-Marquardt algorithm for sparse identification of dynamical systems. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9323–9336. [Google Scholar] [CrossRef]
- Souayeh, B.; Sabir, Z. Designing hyperbolic tangent sigmoid function for solving the Williamson nanofluid model. Fractal Fract. 2023, 7, 350. [Google Scholar] [CrossRef]
- Pérez–Enríquez, L.; Zapotecas–Martínez, S.; Oliva, D.; Altamirano-Robles, L. Hyperbolic tangent sigmoid as a transformation function for image contrast enhancement. In Proceedings of the 2023 IEEE Symposium Series on Computational Intelligence (SSCI), Mexico City, Mexico, 5–8 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 282–287. [Google Scholar]
- Rasamoelina, A.D.; Adjailia, F.; Sinčák, P. A review of activation function for artificial neural network. In Proceedings of the 2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herlany, Slovakia, 23–25 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 281–286. [Google Scholar]
- Parhi, R.; Nowak, R.D. The role of neural network activation functions. IEEE Signal Process. Lett. 2020, 27, 1779–1783. [Google Scholar] [CrossRef]
- Karahan, H.; Cetin, M.; Can, M.E.; Alsenjar, O. Developing a New ANN Model to Estimate Daily Actual Evapotranspiration Using Limited Climatic Data and Remote Sensing Techniques for Sustainable Water Management. Sustainability 2024, 16, 2481. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO3 (mg/L) | EC (ds/m) | pH | Q (m3/s) | P (mm) | |
|---|---|---|---|---|---|
| Min | 5.53 | 0.00 | 6.47 | 0.59 | 0.00 |
| Max | 99.57 | 2.75 | 8.88 | 13.34 | 77.20 |
| Aveg | 31.03 | 1.05 | 8.26 | 3.19 | 1.94 |
| Std. Dev. | 21.32 | 0.74 | 0.28 | 1.96 | 7.49 |
| Inputs | Scenario | Case | MSE | RMSE | MAE | MAPE | Corr. | R2 | NSE |
|---|---|---|---|---|---|---|---|---|---|
| EC, Q | I | 1 | 109.5677 | 10.4675 | 6.5033 | 27.0435 | 0.8717 | 0.7598 | 0.7586 |
| 2 | 106.9859 | 10.3434 | 6.6808 | 24.1393 | 0.8743 | 0.7644 | 0.7643 | ||
| II | 1 | 113.9173 | 10.6732 | 6.6912 | 24.0451 | 0.8655 | 0.7491 | 0.7490 | |
| 2 | 117.4629 | 10.8380 | 6.6498 | 24.9530 | 0.8621 | 0.7433 | 0.7412 | ||
| DOWY, EC, Q | I | 1 | 97.2194 | 9.8600 | 6.4376 | 23.0049 | 0.8868 | 0.7864 | 0.7858 |
| 2 | 100.6939 | 10.0346 | 6.6412 | 23.0714 | 0.8821 | 0.7782 | 0.7782 | ||
| II | 1 | 109.4345 | 10.4611 | 7.1083 | 26.8838 | 0.8712 | 0.7591 | 0.7589 | |
| 2 | 108.3617 | 10.4097 | 6.7181 | 23.1375 | 0.8753 | 0.7661 | 0.7613 | ||
| DOWY, EC, pH, Q, P | I | 1 | 96.8020 | 9.8388 | 6.3569 | 25.8653 | 0.8872 | 0.7871 | 0.7867 |
| 2 | 99.4891 | 9.9744 | 6.6889 | 23.4808 | 0.8837 | 0.7810 | 0.7808 | ||
| II | 1 | 92.2249 | 9.6034 | 6.5131 | 24.2921 | 0.8928 | 0.7972 | 0.7968 | |
| 2 | 94.4068 | 9.7163 | 6.5438 | 22.0906 | 0.8917 | 0.7951 | 0.7920 |
| Obj. Func | Scenario | Case | MSE | RMSE | MAE | MAPE | Corr. | R2 |
|---|---|---|---|---|---|---|---|---|
| MSE | I | 1 | 107.8451 | 10.3849 | 7.1259 | 23.7032 | 0.8736 | 0.7632 |
| 2 | 108.2206 | 10.4029 | 6.5652 | 22.2381 | 0.8734 | 0.7627 | ||
| II | 1 | 98.4615 | 9.9228 | 6.7897 | 23.2057 | 0.8854 | 0.7840 | |
| 2 | 96.2254 | 9.8095 | 6.6149 | 23.3378 | 0.8877 | 0.7881 | ||
| MAE | I | 1 | 100.9913 | 10.0494 | 7.0777 | 24.6614 | 0.8818 | 0.7776 |
| 2 | 102.7251 | 10.1353 | 6.6752 | 23.9452 | 0.8800 | 0.7744 | ||
| II | 1 | 94.2135 | 9.7064 | 6.5363 | 23.3390 | 0.8903 | 0.7927 | |
| 2 | 92.1155 | 9.5977 | 6.4191 | 23.0728 | 0.8929 | 0.7973 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karahan, H.; Erkan Can, M. A Novel Method to Forecast Nitrate Concentration Levels in Irrigation Areas for Sustainable Agriculture. Agriculture 2025, 15, 161. https://doi.org/10.3390/agriculture15020161
Karahan H, Erkan Can M. A Novel Method to Forecast Nitrate Concentration Levels in Irrigation Areas for Sustainable Agriculture. Agriculture. 2025; 15(2):161. https://doi.org/10.3390/agriculture15020161
Chicago/Turabian StyleKarahan, Halil, and Müge Erkan Can. 2025. "A Novel Method to Forecast Nitrate Concentration Levels in Irrigation Areas for Sustainable Agriculture" Agriculture 15, no. 2: 161. https://doi.org/10.3390/agriculture15020161
APA StyleKarahan, H., & Erkan Can, M. (2025). A Novel Method to Forecast Nitrate Concentration Levels in Irrigation Areas for Sustainable Agriculture. Agriculture, 15(2), 161. https://doi.org/10.3390/agriculture15020161