
An Object Detection Algorithm for Orchard Vehicles Based on AGO-PointPillars


Abstract
1. Introduction
- The RGB-D camera is used to replace the lidar as the object sensing hardware for data acquisition, and the acquired depth image data are converted into 3D point cloud data. The 3D point cloud data can lay the foundation for the subsequent object detection algorithm of orchard vehicles;
- An orchard vehicle object detection algorithm is proposed to introduce the ECA module and the EUCB module to enhance the capability of feature extraction for orchard objects;
- An orchard object detection dataset with multiple scenes is constructed based on the KITTI Vision Benchmark. We verify the effectiveness of the object detection algorithm for orchard vehicles by using the constructed dataset and comparing the proposed algorithm with others.
2. Methods
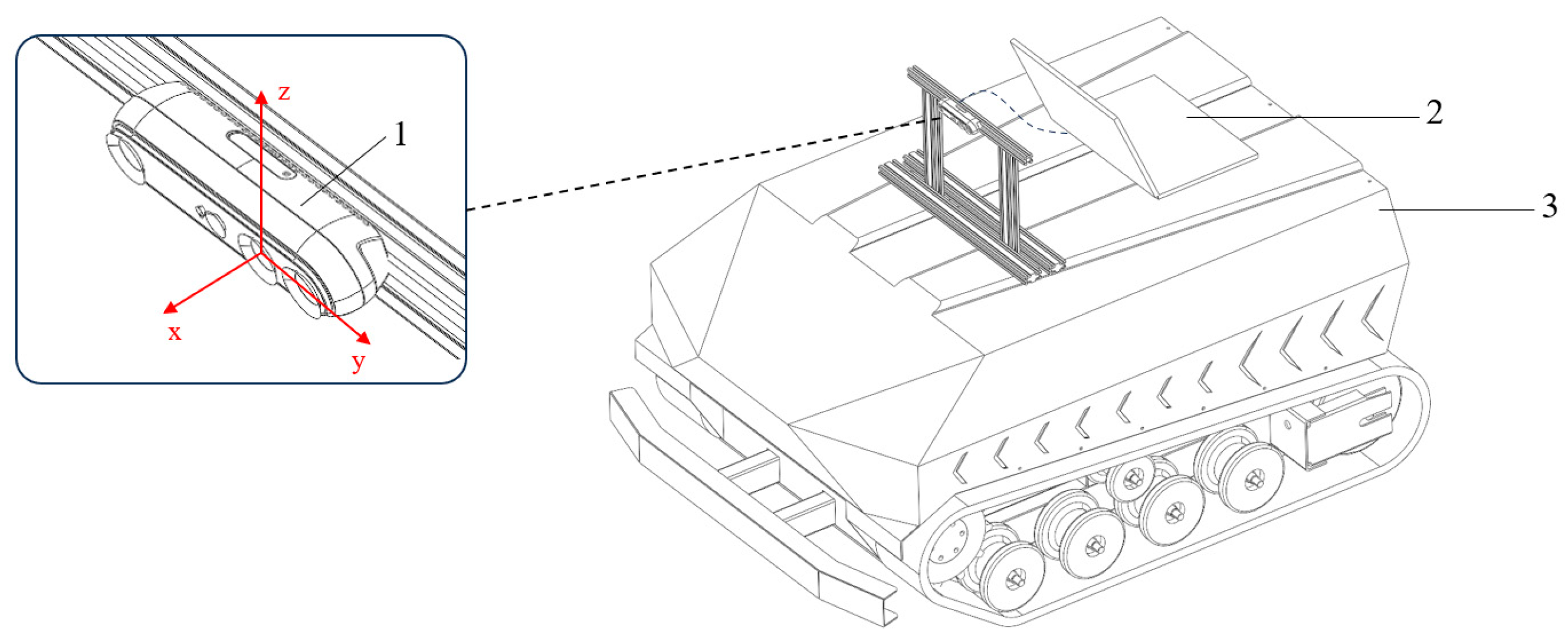
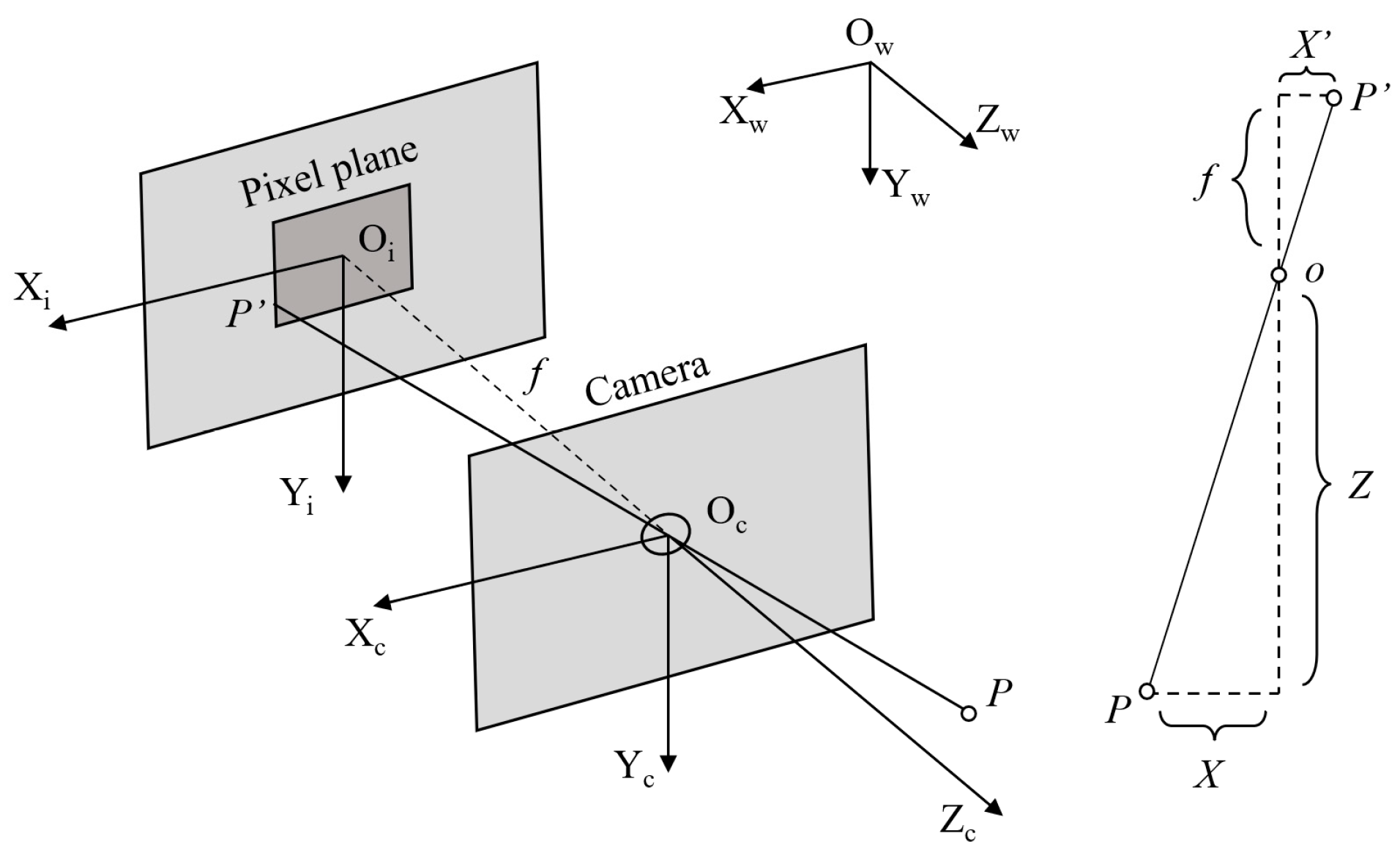
2.1. Data Acquisition and Preprocessing
- (1)
- Data Acquisition
- (2)
- Data Preprocessing
2.2. Attention-Guided Orchard PointPillars
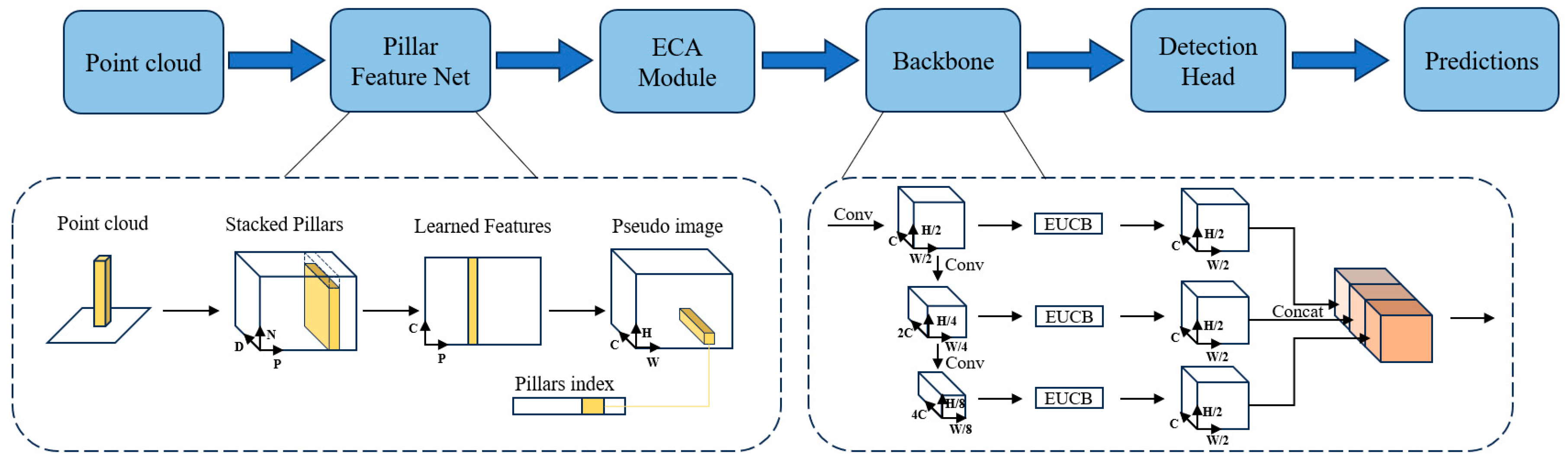
2.2.1. The Architecture of AGO-PointPillars
2.2.2. Pillar Feature Network
2.2.3. Efficient Channel Attention Module
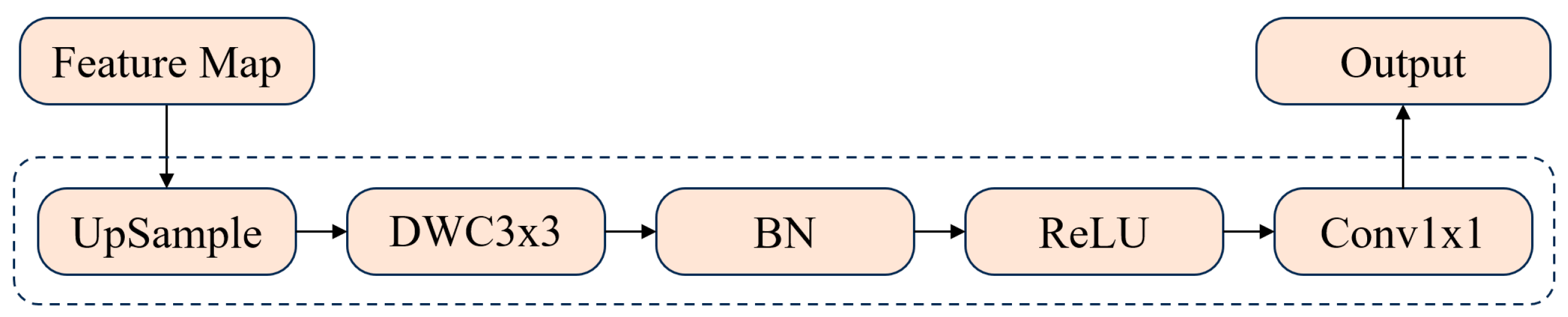
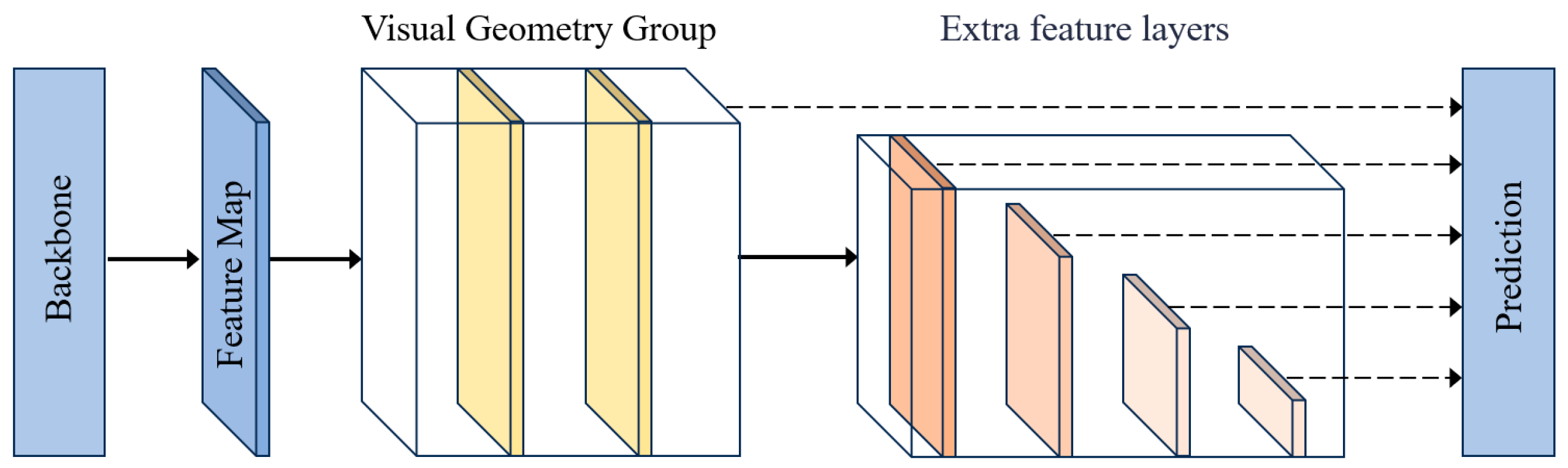
2.2.4. Improved 2D CNN Backbone Network
2.2.5. Detection Head
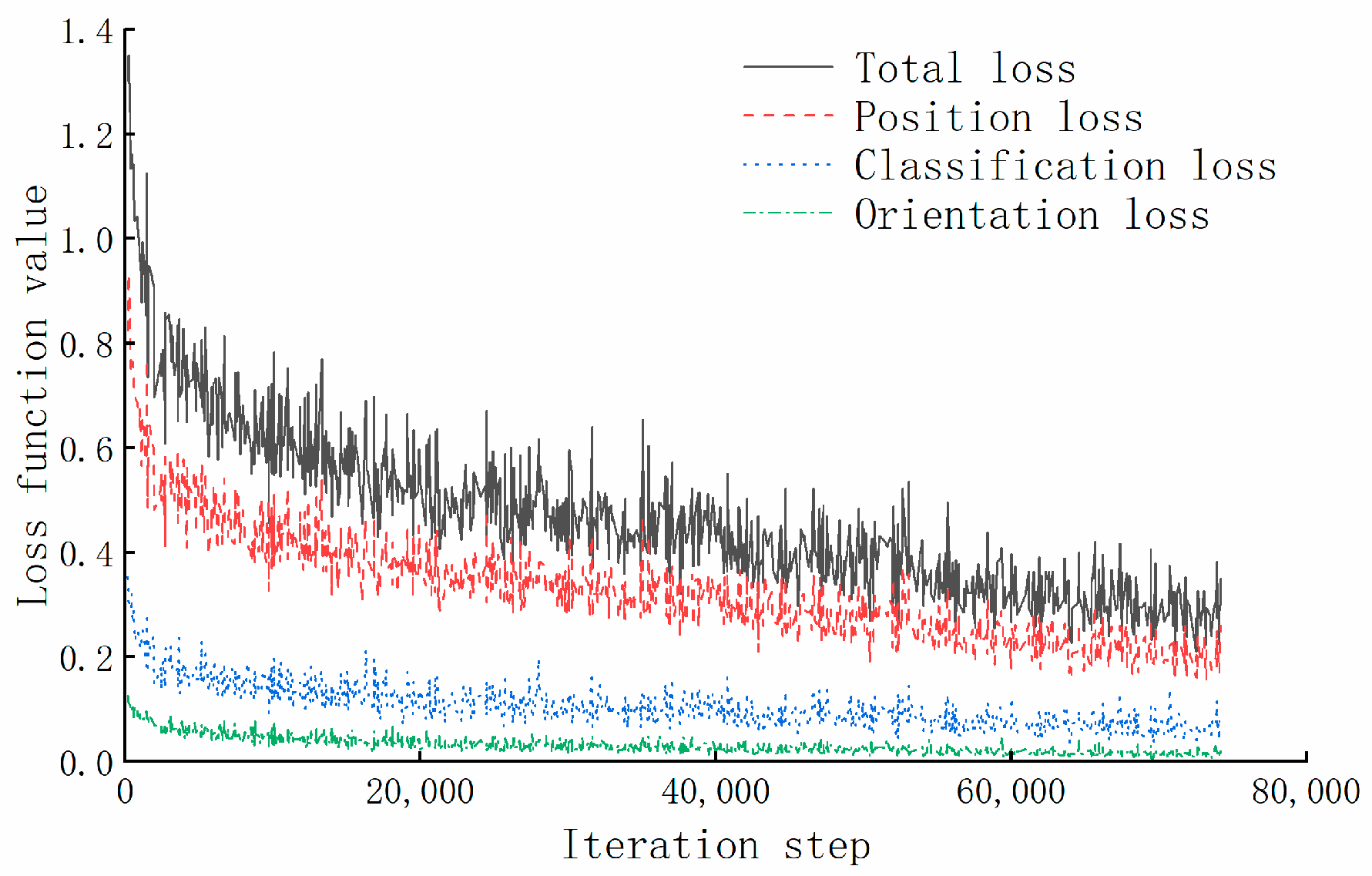
2.3. Training Loss Evaluation Indicators
3. Results and Discussion
3.1. Dataset
3.2. Analysis of Experimental Results
- (1)
- Quantitative Analysis
- (2)
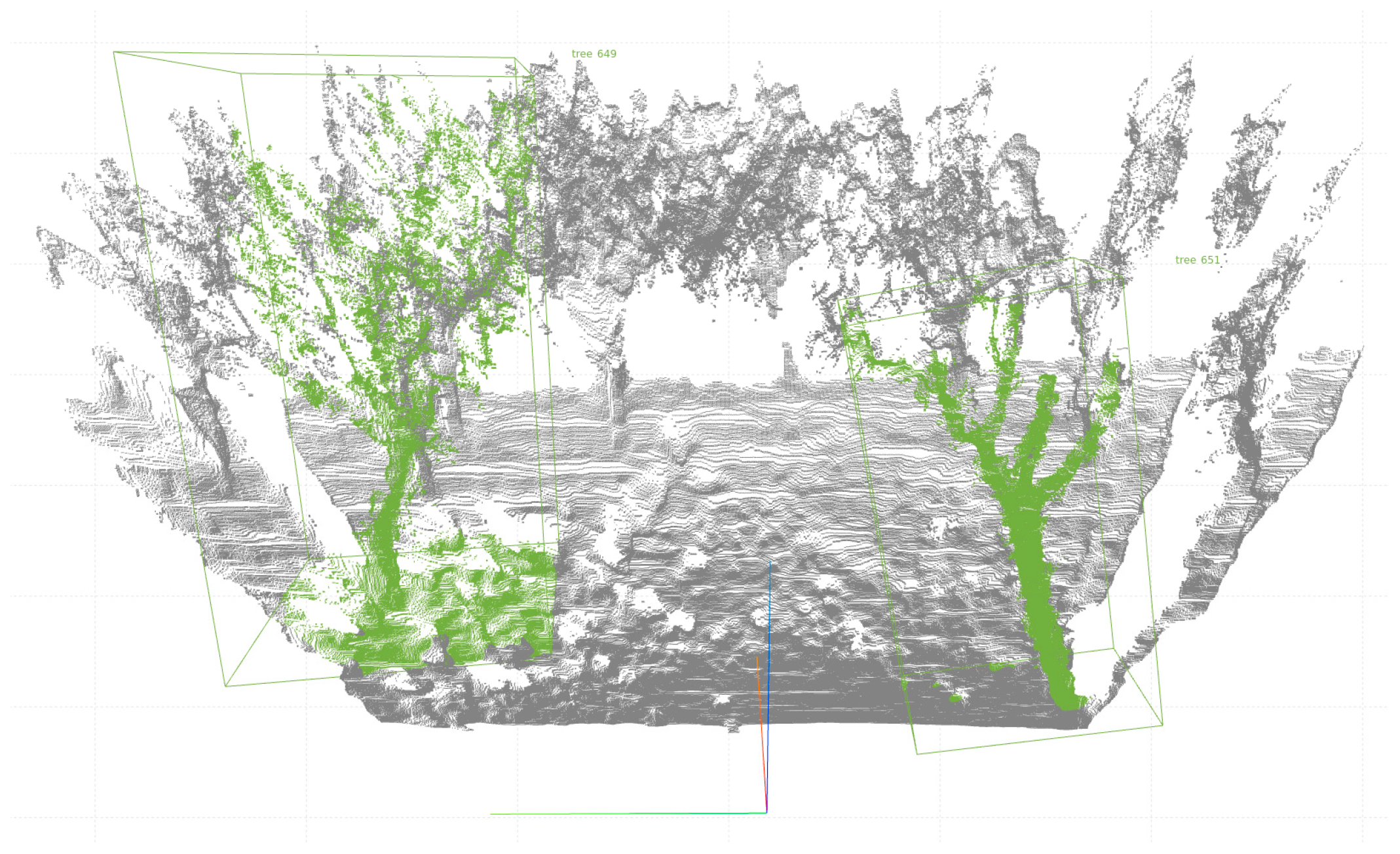
- Qualitative Analysis
- (3)
- Ablation Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, X.; Chen, W.; Wei, X. Improved Field Obstacle Detection Algorithm Based on YOLOv8. Agriculture 2024, 14, 2263. [Google Scholar] [CrossRef]
- Tang, P.; Lv, M.; Ding, Z.; Xu, W.; Jiang, M. Pothole detection-you only look once: Deformable convolution based road pothole detection. IET Image Process. 2025, 19, e13300. [Google Scholar] [CrossRef]
- Aljohani, A. Optimized Convolutional Forest by Particle Swarm Optimizer for Pothole Detection. Int. J. Comput. Intell. Syst. 2024, 17, 7. [Google Scholar] [CrossRef]
- Yasmin, S.; Durrani, M.Y.; Gillani, S.; Bukhari, M.; Maqsood, M.; Zghaibeh, M. Small obstacles detection on roads scenes using semantic segmentation for the safe navigation of autonomous vehicles. J. Electron. Imaging 2022, 31, 061806. [Google Scholar] [CrossRef]
- Li, X.; Deng, X.; Wu, X.; Xie, Z. SS-DETR: A strong sensing DETR road obstacle detection model based on camera sensors for autonomous driving. Meas. Sci. Technol. 2025, 36, 025105. [Google Scholar] [CrossRef]
- Pang, F.; Chen, Y.; Luo, Y.; Lv, Z.; Sun, X.; Xu, X.; Luo, M. A Fast Obstacle Detection Algorithm Based on 3D LiDAR and Multiple Depth Cameras for Unmanned Ground Vehicles. Drones 2024, 8, 676. [Google Scholar] [CrossRef]
- Wang, H.; Wang, H.; Liu, Y.-J.; Liu, L. Real-time obstacle perception method for UAVs with an RGB-D camera in low-light environments. Signal Image Video Process. 2025, 19, 256. [Google Scholar] [CrossRef]
- Liu, Z.; Fan, G.; Rao, L.; Cheng, S.; Chen, N.; Song, X.; Yang, D. Positive and negative obstacles detection based on dual-lidar in field environments. IEEE Robot. Autom. Lett. 2024, 9, 6768–6775. [Google Scholar] [CrossRef]
- Qin, J.; Sun, R.; Zhou, K.; Xu, Y.; Lin, B.; Yang, L.; Chen, Z.; Wen, L.; Wu, C. Lidar-based 3D obstacle detection using focal voxel R-CNN for farmland environment. Agronomy 2023, 13, 650. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, K.; Huang, J.; Wang, Z.; Zhang, B.; Xie, Q. Field Obstacle Detection and Location Method Based on Binocular Vision. Agriculture 2024, 14, 1493. [Google Scholar] [CrossRef]
- Talha, S.A.; Manasreh, D.; Nazzal, M.D. The Use of Lidar and Artificial Intelligence Algorithms for Detection and Size Estimation of Potholes. Buildings 2024, 14, 1078. [Google Scholar] [CrossRef]
- Wang, S.; Xie, X.; Li, M.; Wang, M.; Yang, J.; Li, Z.; Zhou, X.; Zhou, Z. An Adaptive Multimodal Fusion 3D Object Detection Algorithm for Unmanned Systems in Adverse Weather. Electronics 2024, 13, 4706. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Le, D.T.; Shi, H.; Rezatofighi, H.; Cai, J. Accurate and real-time 3D pedestrian detection using an efficient attentive pillar network. IEEE Robot. Autom. Lett. 2022, 8, 1159–1166. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, Z.; Tong, J.; Yang, J.; Peng, J.; Zhang, L.; Cheng, W. ET-PointPillars: Improved PointPillars for 3D object detection based on optimized voxel downsampling. Mach. Vis. Appl. 2024, 35, 56. [Google Scholar] [CrossRef]
- Zhang, L.; Meng, H.; Yan, Y.; Xu, X. Transformer-based global PointPillars 3D object detection method. Electronics 2023, 12, 3092. [Google Scholar] [CrossRef]
- Shu, X.; Zhang, L. Research on PointPillars Algorithm Based on Feature-Enhanced Backbone Network. Electronics 2024, 13, 1233. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Rahman, M.M.; Munir, M.; Marculescu, R. Emcad: Efficient multi-scale convolutional attention decoding for medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 11769–11779. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. 2016; pp. 21–37. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modality | AP (%) | mAP (%) | Speed (Hz) | |
|---|---|---|---|---|---|
| Pothole | Tree | ||||
| VoxelNet | Lidar | 48.93 | 67.42 | 58.18 | 22 |
| SECOND | Lidar | 57.25 | 72.03 | 64.64 | 36 |
| PointPillars | Lidar | 61.53 | 81.39 | 71.46 | 59 |
| AGO-PointPillars | RGB-D camera | 66.68 | 85.52 | 76.10 | 58 |
| Model | AP (%) | mAP (%) | |
|---|---|---|---|
| Pothole | Tree | ||
| PointPillars | 61.53 | 81.39 | 71.46 |
| PointPillars + ECA | 63.58 | 84.52 | 74.05 |
| PointPillars + EUCB | 62.75 | 83.49 | 73.12 |
| AGO-PointPillars | 66.68 | 85.52 | 76.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, P.; Qiu, X.; Gao, Q.; Song, Y. An Object Detection Algorithm for Orchard Vehicles Based on AGO-PointPillars. Agriculture 2025, 15, 1529. https://doi.org/10.3390/agriculture15141529
Ren P, Qiu X, Gao Q, Song Y. An Object Detection Algorithm for Orchard Vehicles Based on AGO-PointPillars. Agriculture. 2025; 15(14):1529. https://doi.org/10.3390/agriculture15141529
Chicago/Turabian StyleRen, Pengyu, Xuyun Qiu, Qi Gao, and Yumin Song. 2025. "An Object Detection Algorithm for Orchard Vehicles Based on AGO-PointPillars" Agriculture 15, no. 14: 1529. https://doi.org/10.3390/agriculture15141529
APA StyleRen, P., Qiu, X., Gao, Q., & Song, Y. (2025). An Object Detection Algorithm for Orchard Vehicles Based on AGO-PointPillars. Agriculture, 15(14), 1529. https://doi.org/10.3390/agriculture15141529