1. Introduction
Tomatoes are one of the most widely cultivated solanaceous vegetable crops in the world [
1], is not only rich in nutritional value, but also has unique edible and health care functions; thus, it is widely planted in facility agriculture. With the increasing trend of greenhouse scale cultivation, the traditional manual picking method has been unable to meet the demand for high efficiency and low loss in modern agriculture, which prompts the intelligent upgrade of picking robots to become an inevitable trend [
2]. With the continuous expansion of greenhouse planting scale, automated picking technology and accurate detection of fruits have become the key factors in improving production efficiency and reducing labour costs [
3].
Fruit recognition technology is the key to the realisation of automatic robot picking function. Improving the accuracy of target fruit recognition and reducing the leakage rate of target fruits are crucial for enhancing the stability of the system and improving the overall picking efficiency [
4]. In the initial development stage of fruit recognition technology, traditional image processing methods based on visual features such as colour, texture, and shape are mainly applied, such as the sliding window technique, Histogram of Oriented Gradients (HOG) [
5], Support Vector Machine (SVM) [
6], and Non-Maximum Value Suppression (NMVS) [
7]. These methods can achieve some success under the conditions of uniform illumination and a simple background, but in the complex environment of natural greenhouses, when facing the challenges of a complex background, drastic changes in illumination, and shading and overlapping among fruits, they show obvious defects such as insufficient robustness, weak generalisation ability, and reliance on manual parameter configuration, which make it difficult to satisfy the dual demands of high real-time performance and high accuracy in practical agricultural production [
8].
With the advancement of deep learning, object detection approaches based on Convolutional Neural Networks (CNN) [
9] have become a mainstream direction in fruit recognition. These methods can generally be divided into two categories [
10]: two-stage detectors, such as the R-CNN series [
11], Fast R-CNN [
12], and Faster R-CNN [
13]; and one-stage detectors, including SSD [
14] and the YOLO family. The YOLO algorithm, introduced by Redmon et al., pioneered the single-stage detection paradigm by formulating object detection as a regression problem, significantly improving detection speed [
15]. In the agricultural field, Sa et al. developed a sweet pepper detection system based on deep learning [
16], and Bargoti et al. proposed CNN-based detection methods for apples and mangoes [
17]. Long et al. combined CSPNet with the ResNet Backbone of Mask R-CNN and proposed an improved tomato segmentation approach, which enhanced both the accuracy and speed of cherry tomato recognition [
18].
The proliferation of UAVs and proximal sensing technologies has further accelerated the adoption of deep learning in precision agriculture. Kamilaris et al. conducted a comprehensive review of the application of deep learning in agriculture and systematically analysed the technical paths of this technology in crop monitoring and pest and disease detection, achieving a deep sorting out of the development context of agricultural AI technology [
19]. To address the challenge of limited annotated data, Goodfellow et al. introduced Generative Adversarial Networks (GANs), which generate high-quality synthetic samples through adversarial training, offering an innovative solution for agricultural dataset augmentation [
20]. Based on this, Fawakherji et al. proposed an improved WGAN-GP model that produces spectrally consistent weed images in both RGB and IR domains using a stable gradient penalty, enabling automated generation of high-quality agricultural imagery [
21]. Rana et al. developed an efficient annotation pipeline by integrating YOLOv8 with the Segment Anything Model (SAM), achieving seamless automation of segmentation and detection in cauliflower monitoring tasks [
22]. The SAM, introduced by Kirillov et al., provides powerful zero-shot segmentation capabilities, offering strong support for automatic annotation in complex agricultural environments [
23]. In spectral image analysis, fuzzy classification algorithms have demonstrated superior robustness in environments with overlapping spectral features. Mehrotra et al. applied a Modified Possibilistic C-Means (MPCM) soft classification strategy combined with vegetation indices to effectively address spectral overlap and heterogeneity in agricultural images [
24]. Furthermore, Rana et al. highlighted the challenges posed by spatial–spectral misalignment in multispectral imaging. Their registration error analysis showed that even slight misalignments could significantly degrade CNN detector performance, underscoring the importance of precise spectral registration as a critical preprocessing step [
25].
Although the YOLO series performs exceptionally well in terms of speed, standard models still suffer from parameter redundancy and large model sizes, making deployment on resource-constrained embedded devices challenging. To address this, researchers have introduced various lightweight architectures. Howard et al. developed the MobileNets family, which dramatically reduces model complexity by separating standard convolutions into depthwise and pointwise operations [
26]. Likewise, Zhang et al. proposed the ShuffleNet architecture, which employs channel shuffling and group convolution to reduce computation without sacrificing accuracy [
27]. Sun et al. proposed YOLOv5-PRE, a lightweight apple detection framework that integrates ShuffleNet, GhostNet, and attention mechanisms (CA, CBAM) to achieve rapid yield estimation in complex orchards [
28]. Li et al. designed a strawberry maturity detection algorithm using lightweight convolutional modules and attention mechanisms, enabling accurate 3D localization of tea shoots with RGB-D sensors [
29]. Zhang et al. developed the EPSA-YOLO-V5s model to address the challenges of outdoor field environments, achieving accurate estimation of rapeseed survival rates [
30]. Zhao et al. introduced a lightweight version of YOLOv5s optimised for greenhouse conditions to enable efficient tomato detection [
31]. Qiu et al. proposed an enhanced YOLOv8n architecture that combines partial convolution and knowledge distillation to strike a balance between accuracy and efficiency for automated mulberry harvesting [
32]. However, lightweight model designs often lead to compromised detection performance, especially in greenhouse environments with dense fruit occlusion and drastic lighting variations, where false positives and missed detections are common [
33].
In summary, although substantial progress has been made in fruit recognition, several challenges remain. Occlusion and clustering of fruits in complex environments still limit detection accuracy. Technical issues such as spectral feature overlap and misalignment in multispectral imagery further exacerbate detection difficulty. While existing models have undergone lightweight optimisation, their computational demands and storage footprints remain too high for real-time deployment on low-power embedded platforms. Therefore, achieving high accuracy while further reducing model size and improving deployment efficiency remains a central challenge in agricultural visual recognition.
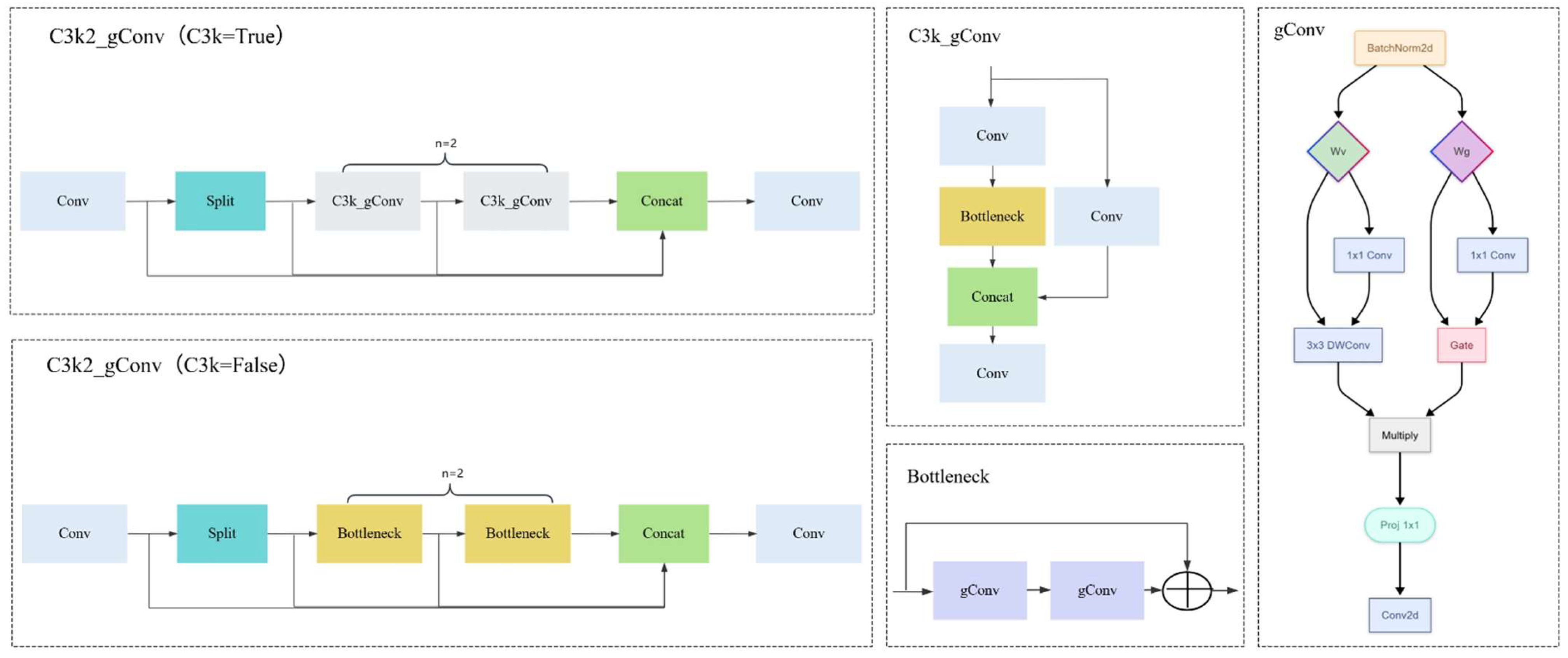
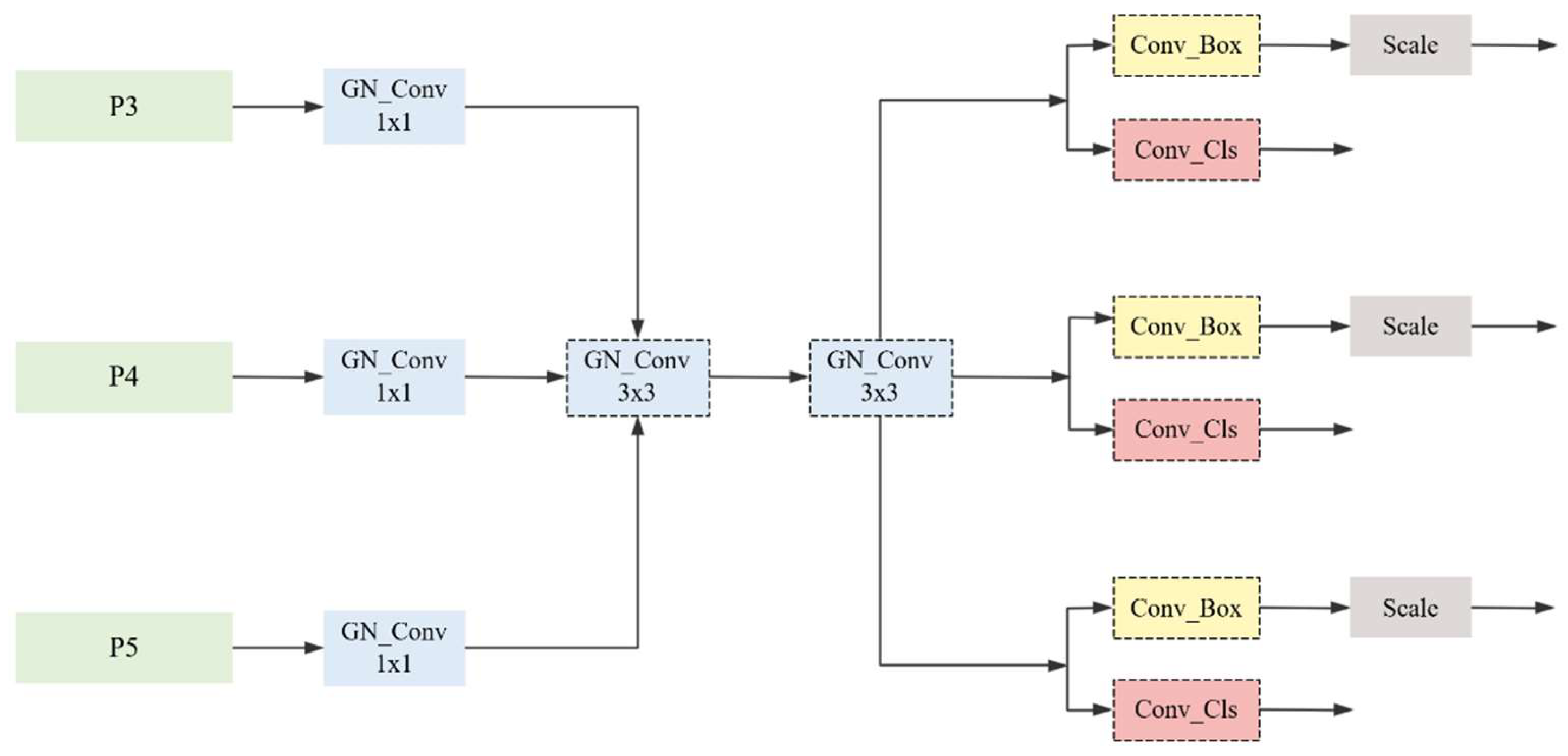
To address these issues, this study proposes a lightweight tomato fruit detection model named ACLW-YOLO, based on an improved YOLOv11n framework. The model retains high detection accuracy while significantly reducing parameters and accelerating inference through architectural optimization. Specifically, traditional downsampling layers are replaced with ADown modules; the C3K2_gConv structure is employed to reduce computational load; LSCD modules are used for refined feature extraction; and the Wise-PIoU loss function is adopted to enhance bounding box regression. This solution enables efficient and accurate tomato fruit detection, demonstrating strong potential for embedded deployment and real-world agricultural applications.
3. Results and Discussion
3.1. Effectiveness of Loss Function Optimization
To gain deeper insights into the impact of loss functions on network performance, this study conducted a series of systematic comparative experiments. Several mainstream bounding box regression loss functions were selected for analysis, including CIoU, PIoU, SIoU, WIoU, Shape-IoU, and Wise-PIoU. The performance comparison of different loss functions is presented in
Table 3.
The experimental results indicate that Wise-PIoU outperforms all other loss functions in terms of both precision and recall, demonstrating a clear advantage. Although its mAP50 is 0.1 percentage points lower than that of CIoU, this minor difference is negligible in practical applications. For greenhouse tomato detection, high precision helps reduce false positives, while high recall mitigates missed detections—characteristics that are more practically valuable than marginal gains in the mAP metric. Wise-PIoU features fast convergence and a dynamic focusing mechanism. Through an adaptive weight allocation strategy, it effectively suppresses harmful gradients from low-quality anchors while enhancing the learning capacity of medium-quality anchors, thereby improving the model’s detection accuracy. Considering overall performance, Wise-PIoU is ultimately adopted as the loss function in this study.
3.2. Ablation Experiments
To systematically validate the effectiveness of each proposed optimization strategy, a comprehensive ablation study was conducted on the YOLOv11n model using the self-constructed tomato dataset under a unified training environment. Following the logical order of network structure optimization, four key improvements were introduced sequentially: the ADown downsampling module, the C3k2-gConv feature extraction structure, the LSCD lightweight detection head, and the Wise-PIoU loss function. A hybrid experimental design was adopted, combining isolated single-module validation with cumulative integration. First, the performance contribution of each module was quantified independently; then, modules were progressively combined to assess their synergistic effects. The impact of each component on detection accuracy and inference efficiency was comprehensively evaluated. The ablation results are summarised in
Table 4.
Experiment 1 corresponds to the baseline YOLOv11n model without any modifications. Although it achieves relatively high accuracy in tomato detection, its large model size and computational overhead render it unsuitable for embedded deployment. From the single-module analysis, it can be observed that the ADown module (Experiment 2) significantly reduces model complexity while maintaining detection accuracy. Compared with the baseline, the precision increased by 1.1% to 93.2%, while recall and mAP50 experienced slight decreases. However, the model size decreased by 17.3%, the parameter count dropped by 19.2%, and FLOPs were reduced by 15.9%. These results indicate that ADown effectively enhances model compactness by optimising the downsampling strategy through a multi-path fusion mechanism. The C3k2-gConv module (Experiment 3) primarily excels in improving detection precision. Compared with the baseline, precision increased significantly by 1.8% to 93.9%, while model size and parameter count were reduced by 11.5% and 15.4%, respectively. This highlights the advantage of the gated convolution mechanism in balancing accuracy and lightweight design. By adopting a dual-branch structure and adaptive feature selection, this module enhances feature representation capacity. The LSCD head (Experiment 4) demonstrates promising lightweighting capabilities, reducing model size by 5.8% and FLOPs by 11.1%, while maintaining stable and slightly improved detection performance. This suggests that the lightweight shared convolutional detection head effectively balances model efficiency and detection accuracy through cross-scale feature fusion. The Wise-PIoU loss function (Experiment 5) mainly contributes to improving regression quality, boosting precision by 1.0% and recall by 0.5%, confirming the effectiveness of dynamic weight adjustment in optimising bounding box regression. In Experiment 6, the integration of ADown and C3k2-gConv modules reduces model size by 28.8%, parameter count by 30.8%, and FLOPs by 27.0% compared to the baseline, demonstrating a positive synergy between the two modules in lightweight optimisation. Experiment 7 adds the LSCD head to the previous configuration, leading to notable improvements in detection performance: precision increases to 93.6%, recall to 91.8%, and mAP50 reaches the highest value of 95.3%, while the model size is further reduced to 3.3 MB and FLOPs to 3.9 G. This indicates that LSCD not only preserves the lightweight advantage but also effectively addresses the recall drop observed in Experiment 6, highlighting the superiority of the decoupled detection head in multi-scale feature integration. Experiment 8 constitutes the final ACLW-YOLO model, in which the Wise-PIoU loss function is applied on top of the configuration from Experiment 7 to further optimise bounding box regression. Compared to Experiment 7, precision increases to 94.2%, recall improves to 92.0%, and mAP50 remains at a high level of 95.2%. Taking all indicators into account, this configuration achieves the optimal balance between accuracy and efficiency. These results comprehensively validate both the individual effectiveness and the synergistic benefits of the proposed improvement modules.
3.3. Performance Analysis of Tomato Maturity Detection Based on ACLW-YOLO
To comprehensively evaluate the improvements of the ACLW-YOLO model over the YOLOv11n baseline and to analyse its detection performance across different tomato maturity stages, a comparative analysis was conducted for each stage using precision, recall, and mAP50 as evaluation metrics.
Table 5 presents the detection performance of the models before and after optimisation for tomatoes at different ripeness levels.
As shown in
Table 5, ACLW-YOLO achieves consistent improvements in overall detection performance. The overall precision increases from 92.1% to 94.2%, representing a 2.1 percentage point gain. Recall improves from 91.7% to 92.0%, and mAP50 rises from 94.9% to 95.2%, each with a 0.3 percentage point improvement. In terms of class-specific performance, the precision for unripe tomatoes increases significantly by 2.4 percentage points to 94.2%, indicating stronger discriminative capability for green tomatoes and a notable reduction in false positives. The improvement for ripe tomatoes is even more substantial, with precision rising by 1.8 percentage points to 94.2%, recall increasing by 0.7 percentage points to 95.6%, and mAP50 climbing by 1.1 percentage points to 97.9%. These results highlight the superior detection performance of the ACLW-YOLO model in the context of tomato maturity classification.
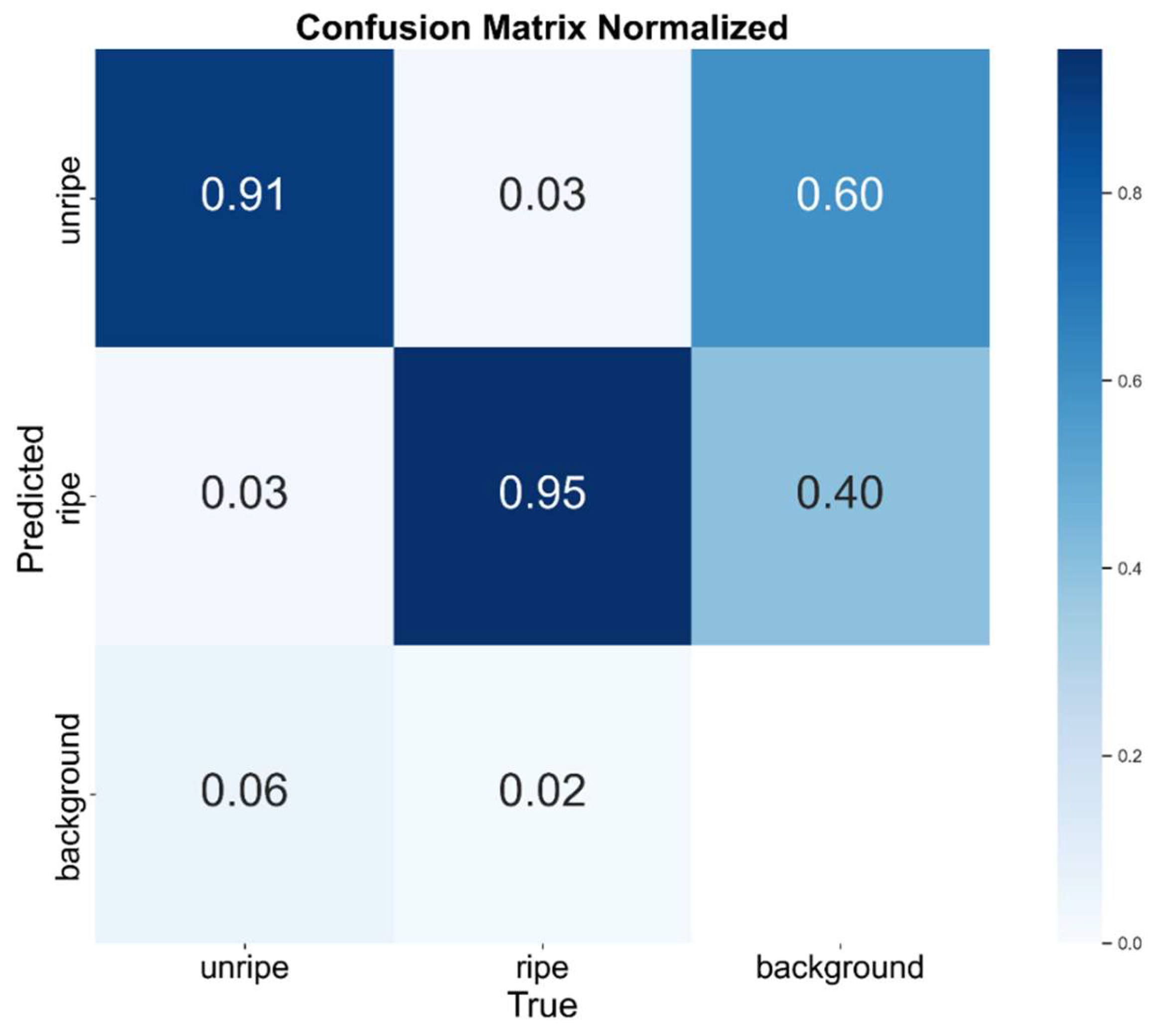
To further investigate the actual detection performance of the ACLW-YOLO model across different tomato categories, an error analysis was conducted based on the confusion matrix. The confusion matrix of ACLW-YOLO is presented in
Figure 7.
As shown in
Figure 7, the ACLW-YOLO model achieves the best recognition performance on the mature tomato category, followed by the immature tomato category. A detailed analysis of misclassified samples reveals that the primary source of errors stems from interference caused by similar background colours, particularly the high colour similarity between green tomatoes and surrounding leaves, which leads to frequent missed detections of immature tomatoes. In the complex greenhouse environment, varying lighting conditions and occlusions further exacerbate the difficulty of distinguishing features.
3.4. Comparison Experiments of Different Algorithms
To verify the validity and superiority of the ACLW-YOLO model, we conducted comparative experiments with various classical models on the same greenhouse tomato dataset. The experimental results are shown in
Table 6.
As can be seen from the table, YOLOv11n maintains a high recall rate of 91.7%, but the model memory usage and parameter count are large. YOLOv3-tiny has the least satisfactory results, with a model size of 23.3 MB, the highest among all algorithms. YOLOv5 performs mediocrely, with a recall rate of only 90.2%. The results of YOLOv8n were not ideal, While the accuracy is low, the amount of computation reaches 8.1 G. YOLOv9t has a better performance, with mAP50 on par with the improved model, but the computation is 7.6 G, which is not conducive to lightweight deployments. YOLOv10n and YOLOv12 have excellent performance in terms of precision, recall, and average precision mean, yet they still find it hard to reduce the higher model complexity. In contrast, ACLW-YOLO achieves the best detection performance of 94.2% precision, 92.0% recall, and 95.2% mAP50 with the lowest resource consumption of 3.3 MB, 1.6 M parameters, and 3.9 GFLOPs, which provides the optimal detection performance and deployment efficiency, and is more suitable for greenhouse tomato detection.
3.5. Generalisation Experiments on Different Datasets
To verify the generalisation ability and cross-domain adaptability of the proposed algorithm, both the baseline YOLOv11n and the improved ACLW-YOLO were evaluated through comparative experiments on three datasets: a private tomato dataset, the public Laboro Tomato dataset, and the tomatOD dataset. These datasets collectively cover complex greenhouse environments, large-scale standard samples, and multi-variety expert-labelled samples, enabling a comprehensive assessment of the model’s cross-domain performance.
As shown in
Table 7, ACLW-YOLO demonstrates outstanding detection performance across different data distributions. On the private dataset, the model achieves a precision of 94.20%, representing a 2.09 percentage point improvement over YOLOv11n, with an mAP50 of 95.24%, up by 0.37 percentage points. On the Laboro Tomato dataset, ACLW-YOLO reaches a precision of 90.82%, improving by 2.14 percentage points, and an mAP50 of 90.54%, which is comparable to the baseline’s 90.62%. On the tomatOD dataset, the model attains a precision of 91.96% and an mAP50 of 96.23%, up 0.34 percentage points. In terms of model lightweighting, ACLW-YOLO reduces the number of parameters to 1.61 M, representing a 37.6% decrease compared to YOLOv11n. The model size is also compressed to 3.3 and 3.4 MB, further enhancing its deployment feasibility.
These experimental results demonstrate that ACLW-YOLO maintains high detection accuracy while significantly reducing computational complexity and storage requirements, making it well-suited for deployment on resource-constrained edge devices. More importantly, the model maintains stable performance across three datasets with distinct data distributions and scene complexities, confirming its strong cross-domain generalisation capability. This robustness is particularly valuable for adapting to the diversity and complexity of real-world greenhouse environments.
3.6. Comparison of Detection Effects
To more intuitively evaluate the adaptability and robustness of the ACLW-YOLO model in real greenhouse environments, this study selects several typical greenhouse tomato growth scenarios (multiple fruits, occlusion, dim environment, and similar backgrounds) to conduct visualisation and comparison experiments, and compares the algorithms of the ACLW-YOLO model with the YOLOv11n model. The red rectangular box with the “ripe” label indicates the recognised ripe tomato results, and the blue rectangular box with the “unripe” label indicates the recognised unripe tomato results. The visualisation results are shown in
Figure 8.
In the multi-fruit scenario, both models can accurately detect the target, but the improved model has higher confidence, better recognition ability for multi-fruit targets, can better handle the mutual occlusion relationship between fruits, and accurately detects the boundary of each tomato fruit, avoiding the adhesion misdetection between fruits. In the scene where occlusion occurs, the two models did not show any leakage detection, but YOLOv11n’s recognition of green tomato fruits is poor, which is because the fact that the green fruits are similar in colour to the occluded leaves, which has an impact on the model’s recognition, whereas the improved model can use the features of its unobscured part for effective detection and the model can identify the occluded part of the fruits based on the fruit’s local features and its spatial relationship with other fruits, the occluded fruits can be recognised. In the scene with a dim background, the YOLOv11n model has a leakage detection phenomenon, and fails to recognise the green fruits under the condition of insufficient light, while the improved model can still capture the key features of the fruits and has a strong feature extraction capability. In the scene with similar backgrounds, YOLOv11n shows a serious leakage phenomenon, and the model misses all the targets, while the improved model can accurately recognise the three main targets in the near distance, in addition to the small target green tomato in the far distance. Despite the low contrast between the fruit and the background, the model can effectively recognise the location of the fruit through the rich feature information learned. Therefore, to avoid the situation of omission and misdetection of the picking robot in actual production leading to operational errors, the ACLW-YOLO model with higher overall performance is selected for fruit recognition and detection to improve the picking efficiency to adapt to the task requirements.
3.7. Jetson Platform Model Test
To verify the deployment feasibility of the proposed ACLW-YOLO model in a resource-constrained environment, we conducted performance evaluation on the NVIDIA Jetson Orin Nano (4GB) edge computing platform. As shown in
Table 8, the model showed good practicality on this edge device.
Specifically, the model’s single-frame processing latency on the Jetson Orin Nano is 84.4 milliseconds. Although this is an increase from the 10.8 milliseconds of high-performance computing platforms, it still maintains a frame rate of 11.85 FPS, meeting the basic requirements for real-time detection. Notably, this performance is achieved with only 10W of power consumption, a significant improvement over the 140W power consumption of computer platforms. It is worth noting that the current test results are based on the model’s baseline performance and have not yet utilised advanced optimisation techniques such as TensorRT. After integrating these inference optimisation technologies in actual deployment, it is expected to further enhance performance and improve the model’s practicality. In summary, this result fully demonstrates the technical advantages and deployment potential of the ACLW-YOLO model in edge AI applications.
4. Conclusions
Aiming at the problem of a large volume of model parameters and high complexity of network structure in tomato fruit detection, which makes it difficult to deploy the application on inspection equipment, this paper proposes a lightweight greenhouse tomato fruit target detection algorithm (ACLW-YOLO) based on improved YOLOv11n. The main contributions are as follows, the process of downsampling is improved by the ADown module, and gConv is introduced based on the original c3k2 structure, which reduces the number of parameters and computation of the model. Secondly, the LSCD mechanism is used in the detection head, which improves the detection accuracy while reducing the model complexity, and finally, the model is improved by the Wise-PIoU loss function, which effectively improves the performance of the model in the greenhouse tomato detection task.
Experimental results show that, compared with the original YOLOv11n, ACLW-YOLO reduces the number of parameters by 38.7%, decreases computational cost by 39.1%, and compresses the model size by 37.5%. Meanwhile, it achieves a precision of 94.2%, recall of 92.0%, and mean average precision of 95.2%. Cross-dataset testing further verifies its strong generalisation capability. Deployed on the NVIDIA Jetson Orin Nano edge device, the model reaches a real-time inference speed of 11.85 FPS with only 10W of power consumption, demonstrating excellent performance for resource-constrained platforms.
This study effectively addresses the long-standing trade-off between model lightweighting and high detection accuracy in the context of greenhouse tomato detection. The proposed model achieves high-precision detection, low resource consumption, compact size, and real-time edge inference capability, fulfilling the core requirements of tomato fruit detection in automated greenhouse harvesting systems and providing a solid technical foundation for practical deployment.
Despite the notable improvements, several challenges remain. Under extreme conditions—such as strong glare, severe fruit occlusion, or backgrounds with high visual similarity—the detection accuracy may decline. Moreover, current deployment verification is limited to a single hardware platform, lacking systematic evaluation across heterogeneous edge devices. To address these limitations, future research will focus on two main directions: Designing more efficient loss functions to enhance model robustness under challenging scenarios. Expanding compatibility testing across diverse hardware platforms to ensure broad applicability and stable performance in real-world deployment environments. Additionally, future work will include comparative studies with more state-of-the-art models to further validate the feasibility of ACLW-YOLO. Efforts will also be made to establish a standardised evaluation benchmark to promote more objective and comprehensive methodological comparisons in this domain.


 and
and 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}