
RDM-YOLO: A Lightweight Multi-Scale Model for Real-Time Behavior Recognition of Fourth Instar Silkworms in Sericulture



Abstract
1. Introduction
2. Materials and Methods
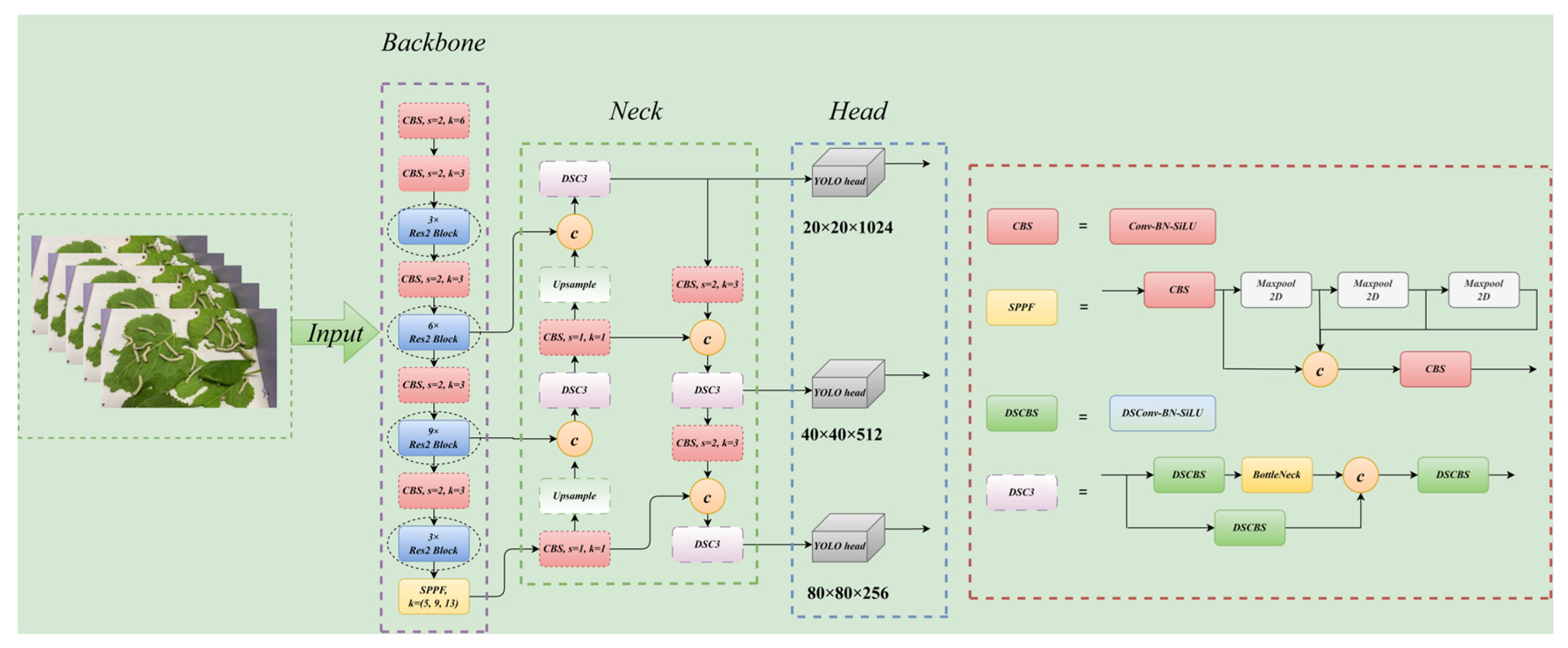
2.1. Overview of the Model Improvements
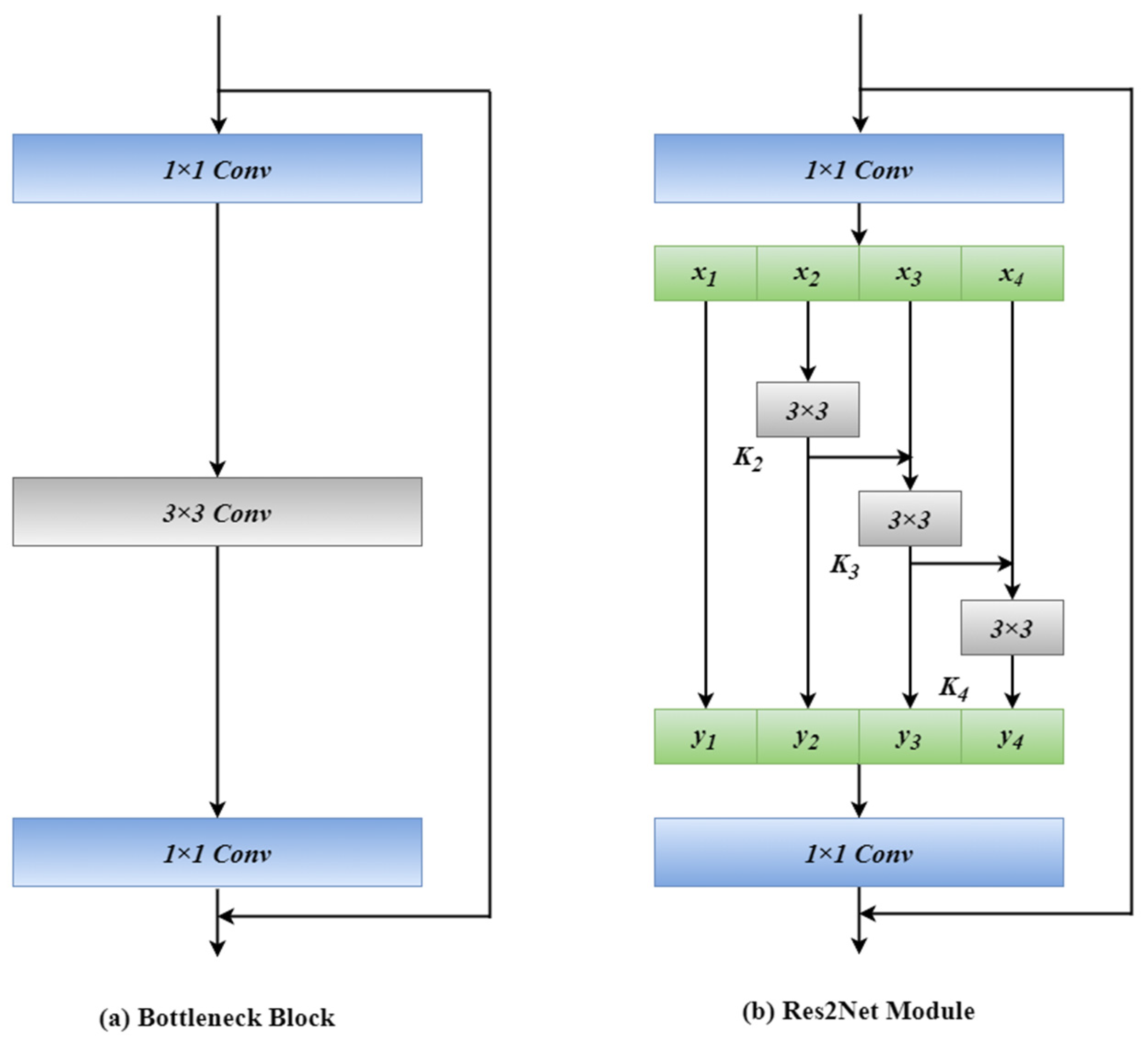
2.2. Res2Net Module
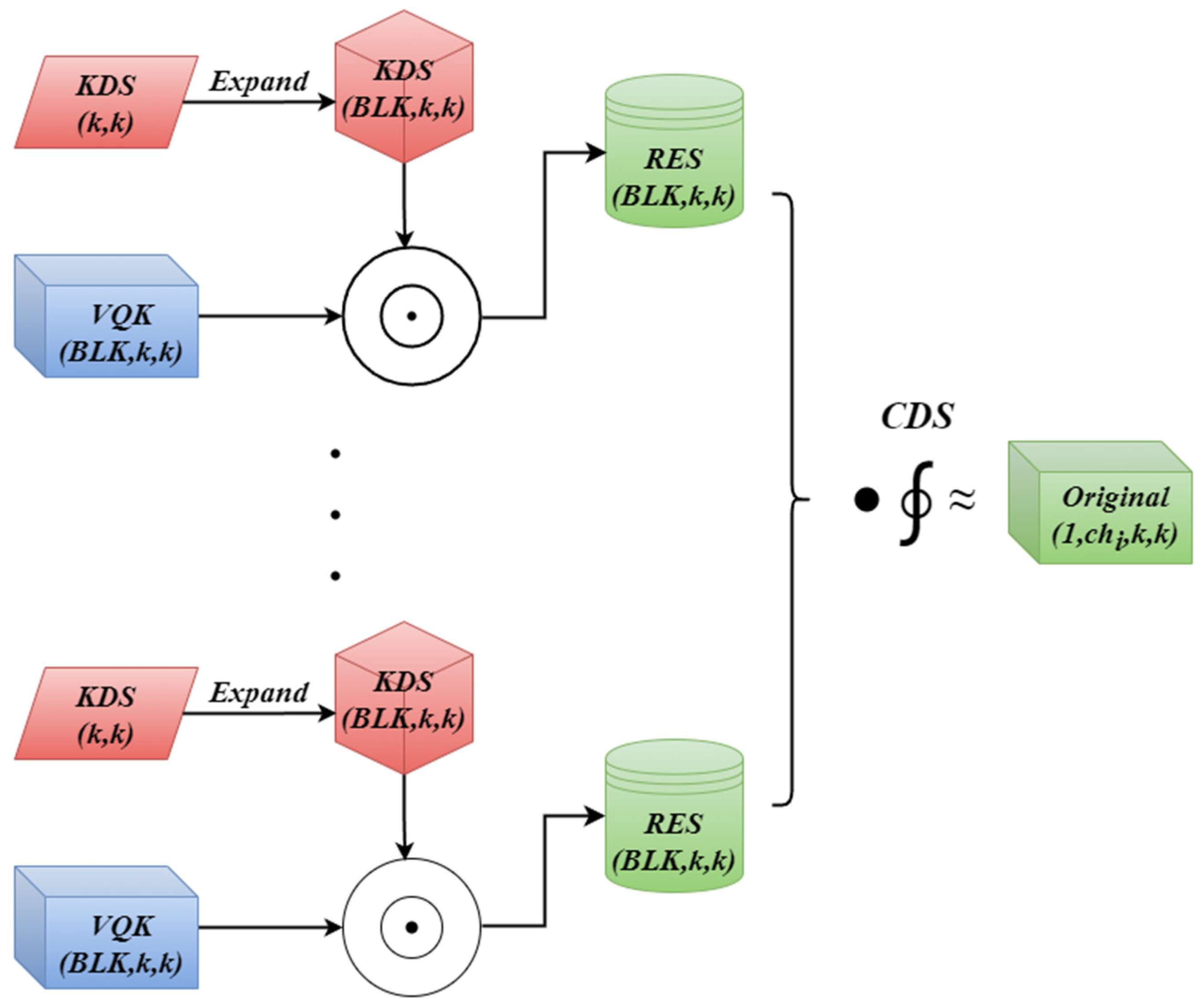
2.3. Distribution Shifting Convolution Module
2.4. Minimum Point Distance Intersection over Union Module
3. Experimental Setup
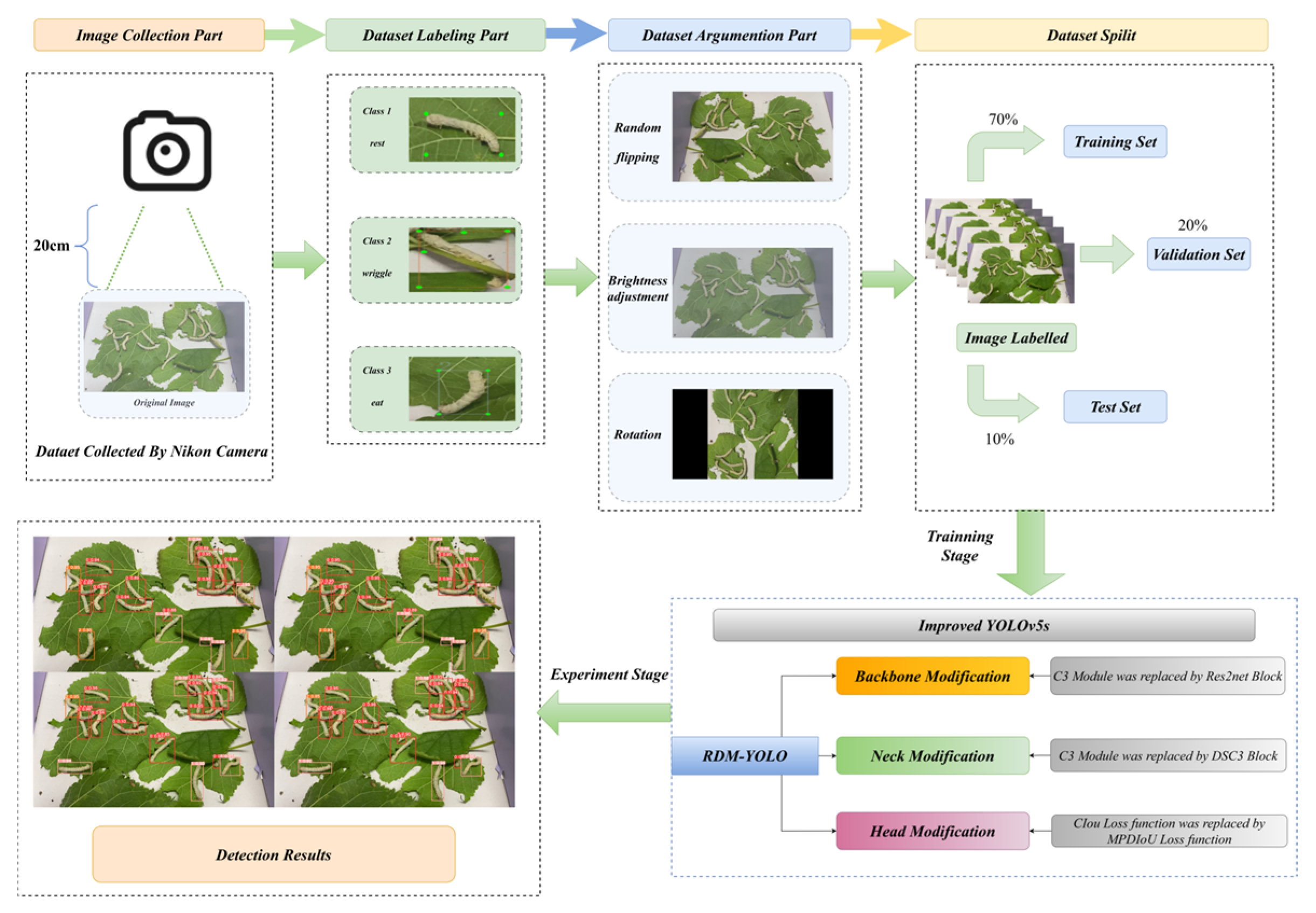
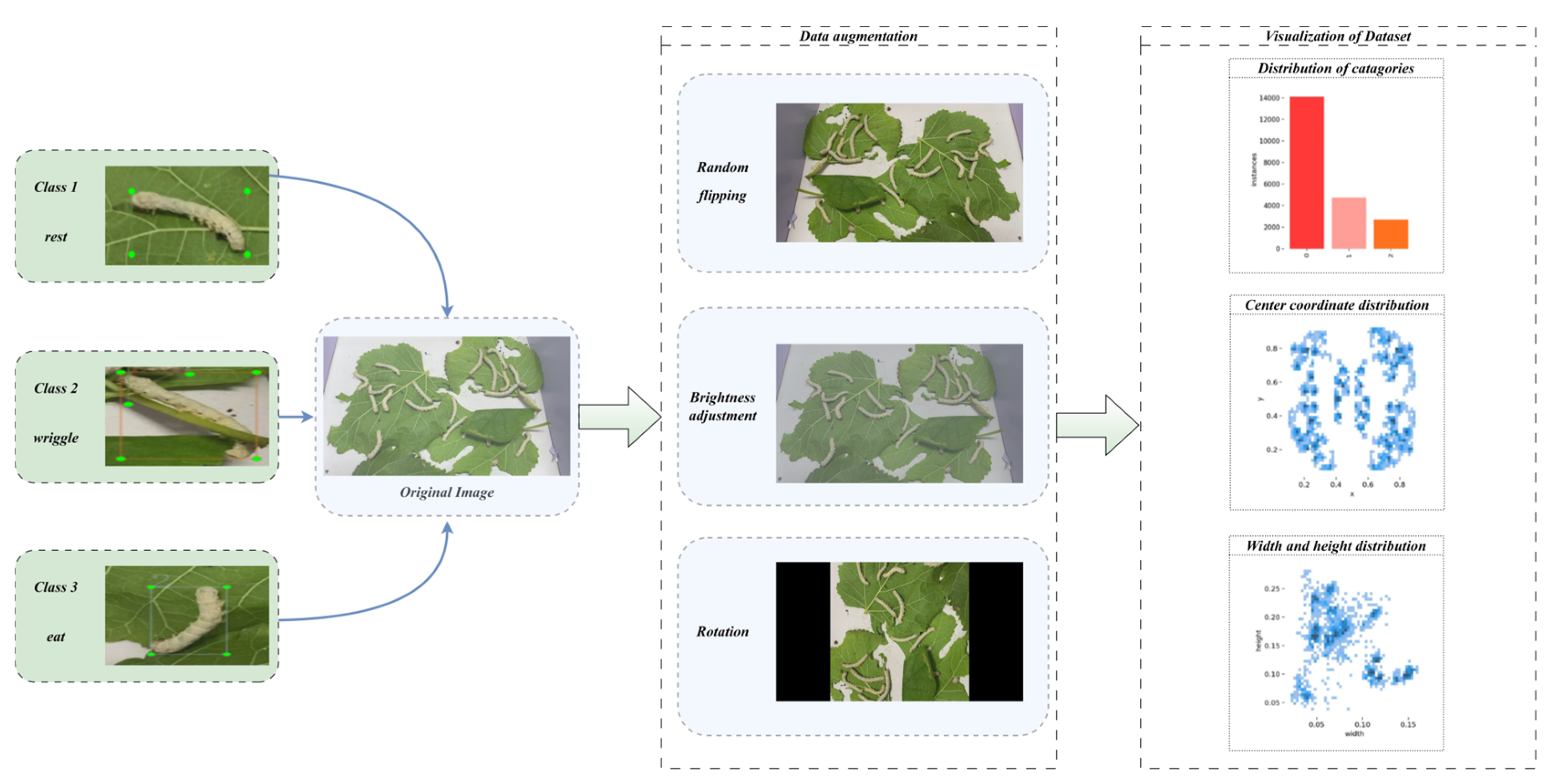
3.1. Dataset
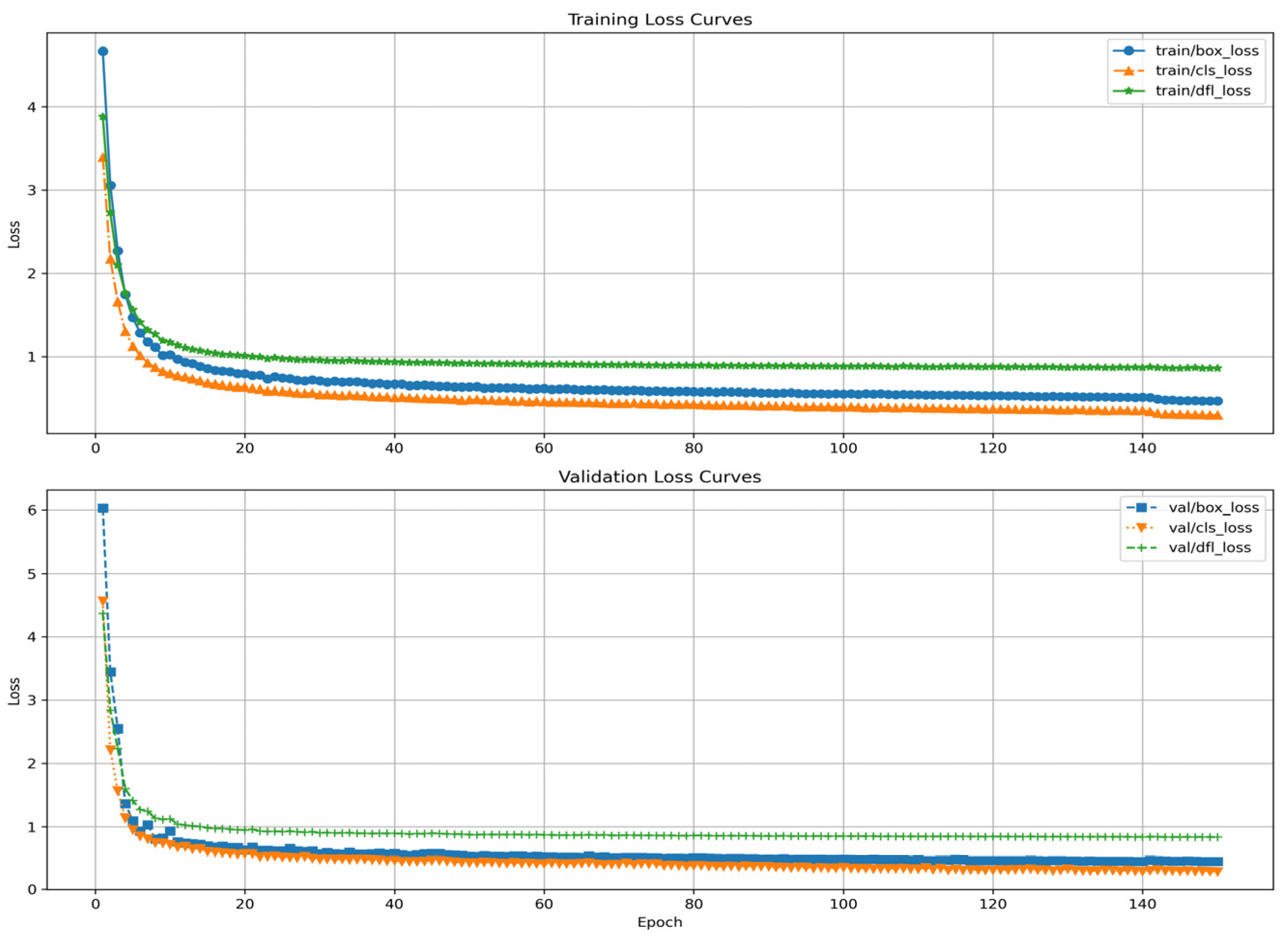
3.2. Implementation Details
3.3. Evaluation Metrics
4. Results
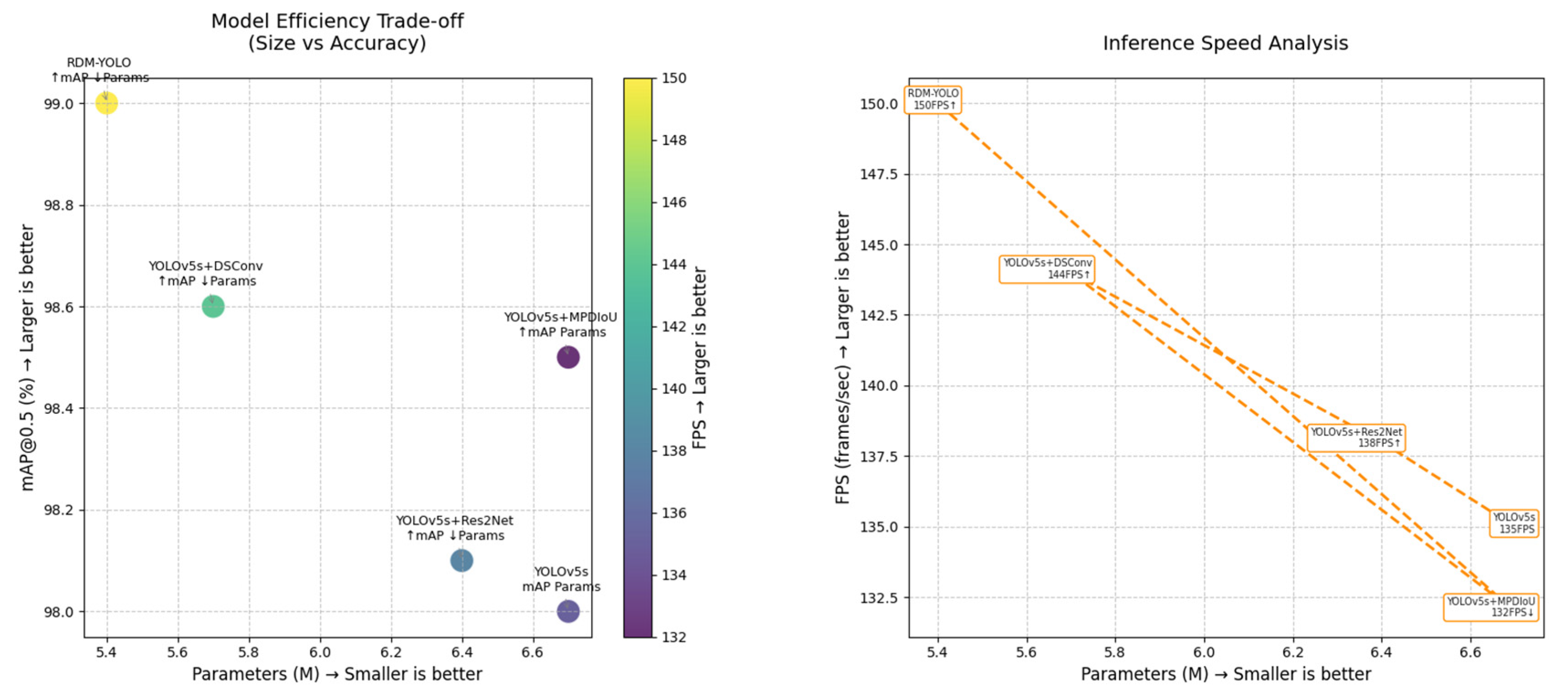
4.1. RDM-YOLO Ablation Study
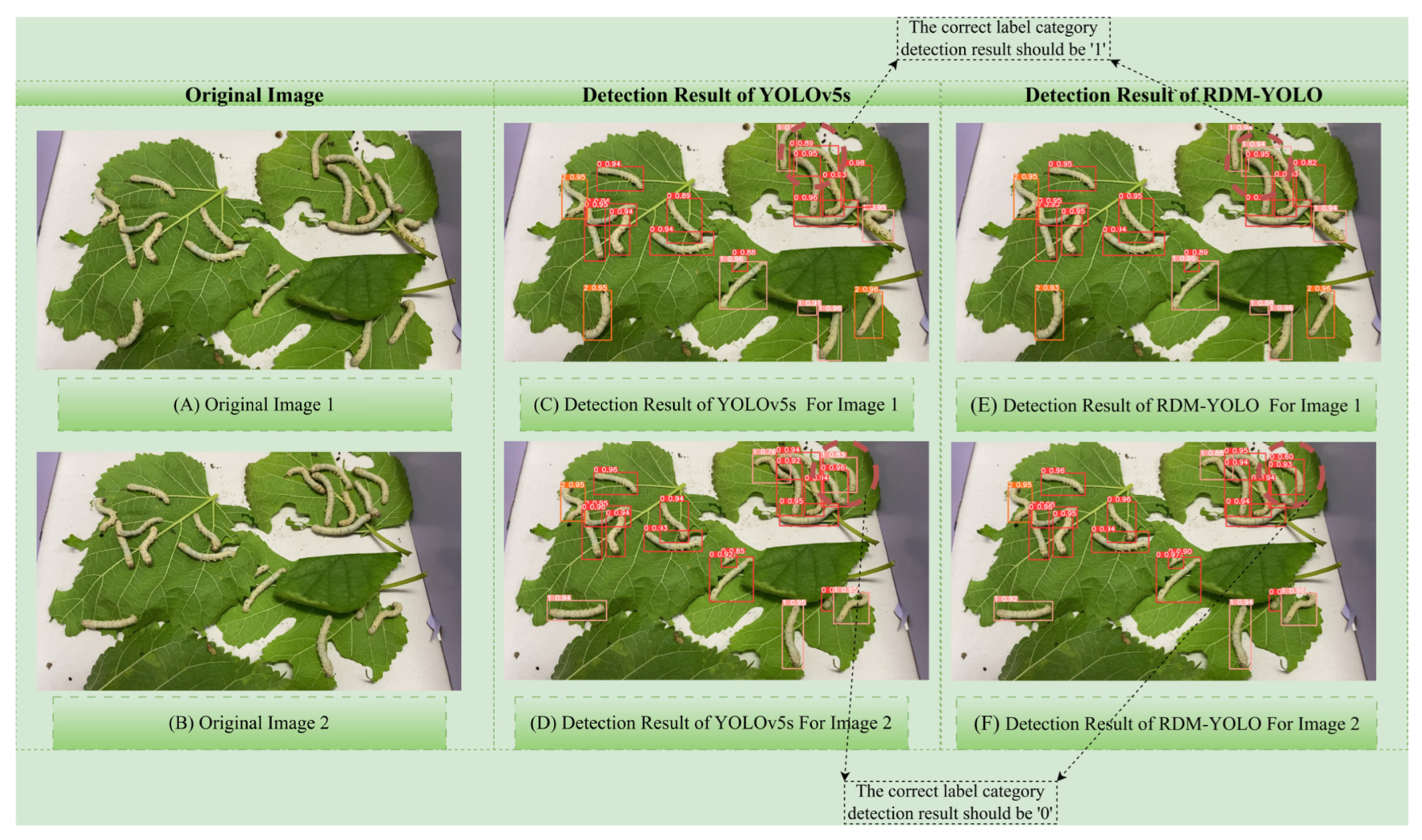
4.2. Comparison Between Baseline YOLOv5s and RDM-YOLO
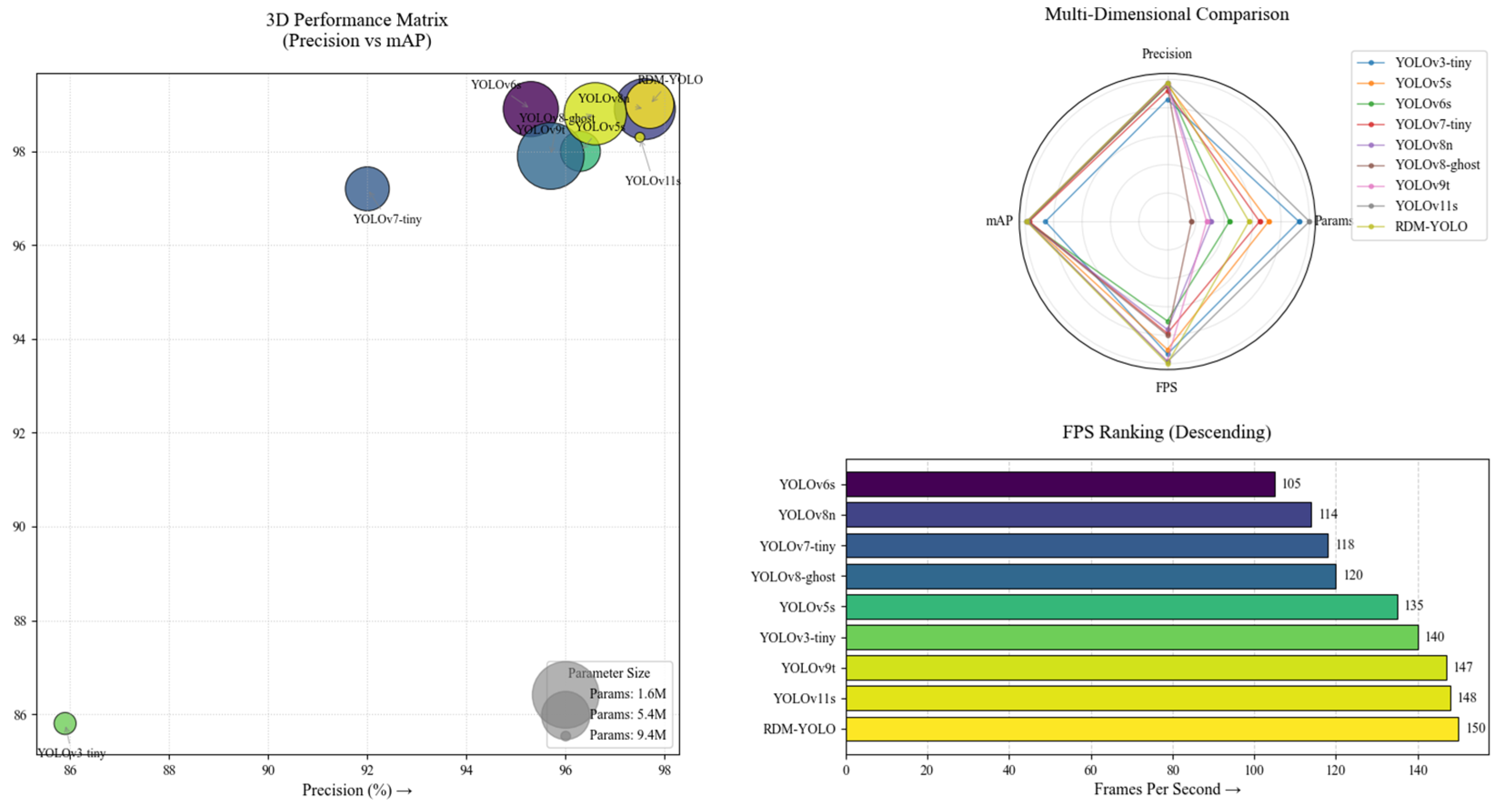
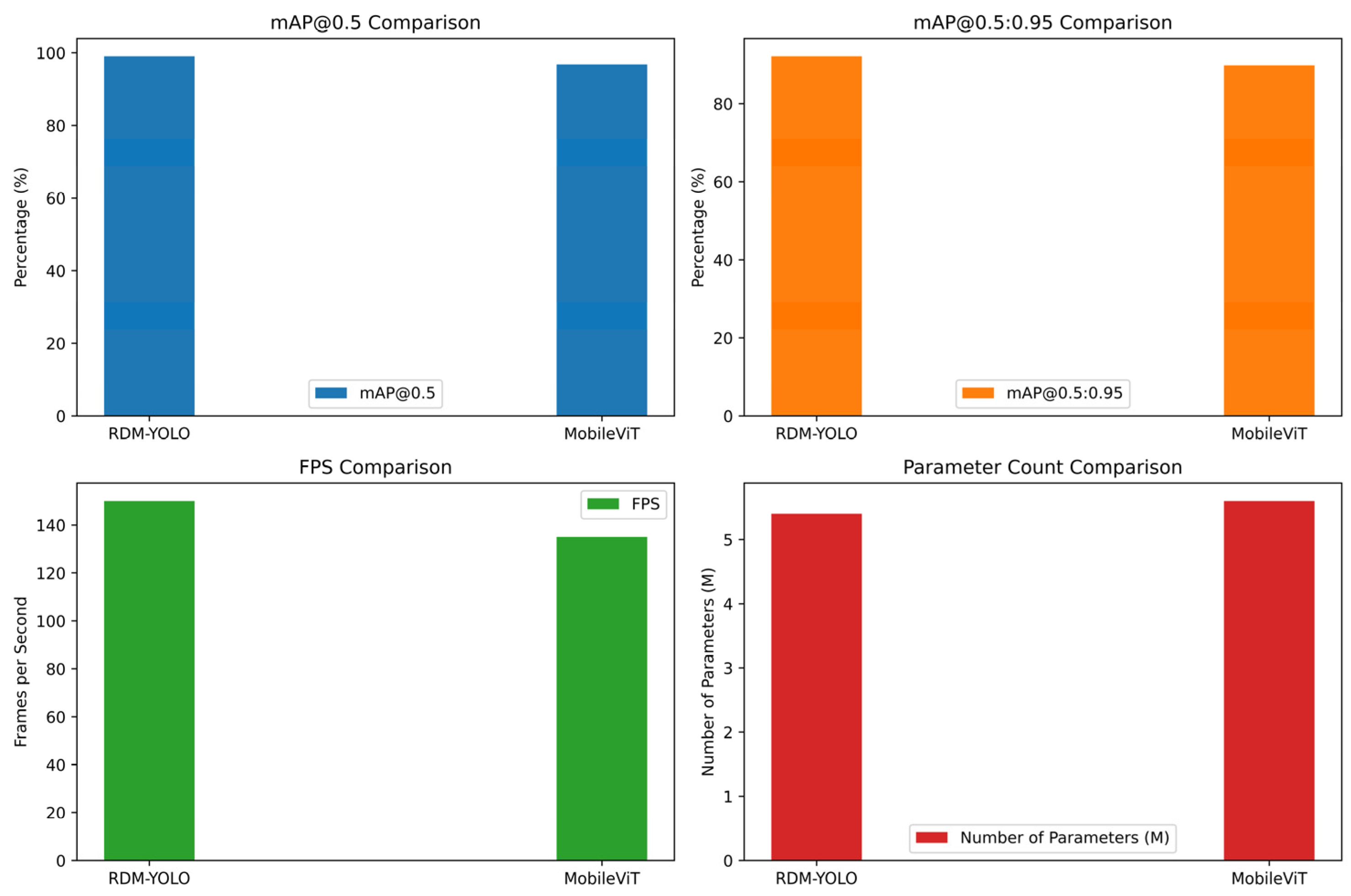
4.3. Comparative Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| DSConv | Distribution shifting convolution |
| MPDIoU | Minimum point distance intersection over union |
| AP | Average precision |
| mAP | Mean average precision |
| CNNs | Convolutional neural networks |
| FPS | Frames per second |
| IoU | Intersection over union |
| TP | True positive |
| FP | False positive |
| FN | False negative |
| Adam | Adaptive moment estimation |
References
- Xu, H.; Pan, J.; Ma, C.; Mintah, B.; Dabbour, M.; Huang, L.; Dai, C.; Ma, H.; He, R. Stereo-hindrance effect and oxidation cross-linking induced by ultrasound-assisted sodium alginate-glycation inhibit lysinoalanine formation in silkworm pupa protein. Food Chem. 2025, 463, 141284. [Google Scholar] [CrossRef]
- Xu, H.; Pan, J.; Dabbour, M.; Mintah, B.; Chen, W.; Yang, F.; Zhang, Z.; Cheng, Y.; Dai, C.; He, R. Synergistic effects of pH shift and heat treatment on solubility, physicochemical and structural properties, and lysinoalanine formation in silkworm pupa protein isolates. Food Res. Int. 2023, 165, 112554. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, X.; Liu, C.; Pan, Q. Development of the precision feeding system for sows via a rule-based expert system. Int. J. Agric. Biol. Eng. 2023, 16, 187–198. [Google Scholar] [CrossRef]
- Yuan, H.; Cai, Y.; Liang, S.; Ku, J.; Qin, Y. Numerical Simulation and Analysis of Feeding Uniformity of Viscous Miscellaneous Fish Bait Based on EDEM Software. Agriculture 2023, 13, 356. [Google Scholar] [CrossRef]
- Zhao, Z.; Jin, M.; Tian, C.; Yang, S. Prediction of seed distribution in rectangular vibrating tray using grey model and artificial neural network. Biosyst. Eng. 2018, 175, 194–205. [Google Scholar] [CrossRef]
- Yang, N.; Yuan, M.; Wang, P.; Zhang, R.; Sun, J.; Mao, H. Tea diseases detection based on fast infrared thermal image processing technology. J. Sci. Food Agric. 2019, 99, 3459–3466. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Xu, C.; Hou, W.; McElligott, A.; Liu, K.; Xue, Y. Transformer-based audio-visual multimodal fusion for fine-grained recognition of individual sow nursing behaviour. Artif. Intell. Agric. 2025, 15, 363–376. [Google Scholar] [CrossRef]
- Sun, G.; Liu, T.; Zhang, H.; Tan, B.; Li, T. Basic behavior recognition of yaks based on improved SlowFast network. Ecol. Inform. 2023, 78, 102313. [Google Scholar] [CrossRef]
- Kirsch, K.; Strutzke, S.; Klitzing, L.; Pilger, F.; Thöne-Reineke, C.; Hoffmann, G. Validation of a Time-Distributed residual LSTM–CNN and BiLSTM for equine behavior recognition using collar-worn sensors. Comput. Electron. Agric. 2025, 231, 109999. [Google Scholar] [CrossRef]
- Zhu, C.; Hao, S.; Liu, C.; Wang, Y.; Jia, X.; Xu, J.; Guo, S.; Huo, J.; Wang, W. An Efficient Computer Vision-Based Dual-Face Target Precision Variable Spraying Robotic System for Foliar Fertilisers. Agronomy 2024, 14, 2770. [Google Scholar] [CrossRef]
- Niu, Z.; Huang, T.; Xu, C.; Sun, X.; Taha, M.; He, Y.; Qiu, Z. A Novel Approach to Optimize Key Limitations of Azure Kinect DK for Efficient and Precise Leaf Area Measurement. Agriculture 2025, 15, 173. [Google Scholar] [CrossRef]
- Huang, L.; Xu, L.; Wang, Y.; Peng, Y.; Zou, Z.; Huang, P.; Ahmad, M. Efficient Detection Method of Pig-Posture Behavior Based on Multiple Attention Mechanism. Comput. Intell. Neurosci. 2022, 2022, 1759542. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Zhu, W.; Ma, C.; Guo, Y.; Chen, C. Identification of group-housed pigs based on Gabor and Local Binary Pattern features. Biosyst. Eng. 2018, 166, 90–100. [Google Scholar] [CrossRef]
- Wang, Z.; Hua, Z.; Wen, Y.; Zhang, S.; Xu, X.; Song, H. E-YOLO: Recognition of estrus cow based on improved YOLOv8n model. Expert Syst. Appl. 2024, 238, 122212. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, X.; Sun, J.; Yu, T.; Cai, Z.; Zhang, Z.; Mao, H. Low-Cost Lettuce Height Measurement Based on Depth Vision and Lightweight Instance Segmentation Model. Agriculture 2024, 14, 1596. [Google Scholar] [CrossRef]
- Zhang, T.; Zhou, J.; Liu, W.; Yue, R.; Shi, J.; Zhou, C.; Hu, J. SN-CNN: A Lightweight and Accurate Line Extraction Algorithm for Seedling Navigation in Ridge-Planted Vegetables. Agriculture 2024, 14, 1446. [Google Scholar] [CrossRef]
- Jiang, L.; Wang, Y.; Wu, C.; Wu, H. Fruit Distribution Density Estimation in YOLO-Detected Strawberry Images: A Kernel Density and Nearest Neighbor Analysis Approach. Agriculture 2024, 14, 1848. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Romano, D. Novel automation, artificial intelligence, and biomimetic engineering advancements for insect studies and management. Curr. Opin. Insect Sci. 2025, 68, 101337. [Google Scholar] [CrossRef]
- Kariyanna, B.; Sowjanya, M. Unravelling the use of artificial intelligence in management of insect pests. Smart Agric. Technol. 2024, 8, 100517. [Google Scholar] [CrossRef]
- Wang, J.; Wei, T.; Song, Z.; Chen, R.; He, Q. Determination of the equivalent length for evaluating local head losses in drip irrigation laterals. Appl. Eng. Agric. 2022, 38, 49–59. [Google Scholar] [CrossRef]
- Jin, M.; Zhao, Z.; Che, S.; Chen, J. Improved piezoelectric grain cleaning loss sensor based on adaptive neuro-fuzzy inference system. Precis. Agric. 2022, 23, 1174–1188. [Google Scholar] [CrossRef]
- Fan, X.; Ding, W.; Qin, W.; Xiao, D.; Min, L.; Yuan, H. Fusing Self-Attention and CoordConv to Improve the YOLOv5s Algorithm for Infrared Weak Target Detection. Sensors 2023, 23, 6755. [Google Scholar] [CrossRef] [PubMed]
- Wen, C.; Wen, J.; Li, J.; Luo, Y.; Chen, M.; Xiao, Z.; Xu, Q.; Liang, X.; An, H. Lightweight silkworm recognition based on Multi-scale feature fusion. Comput. Electron. Agric. 2022, 200, 107234. [Google Scholar] [CrossRef]
- Pei, H.; Sun, Y.; Huang, H.; Zhang, W.; Sheng, J.; Zhang, Z. Weed Detection in Maize Fields by UAV Images Based on Crop Row Preprocessing and Improved YOLOv4. Agriculture 2024, 12, 975. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, Z.; Ali, S.; Yang, N.; Fu, S.; Zhang, Y. Multi-class detection of cherry tomatoes using improved YOLOv4-Tiny. Int. J. Agric. Biol. Eng. 2023, 16, 225–231. [Google Scholar] [CrossRef]
- Ji, W.; Gao, X.; Xu, B.; Pan, Y.; Zhang, Z.; Zhao, D. Apple target recognition method in complex environment based on improved YOLOv4. J. Food Process Eng. 2021, 44, e13866. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, Y.; Zhao, Y.; Pan, Q.; Jin, K.; Xu, G.; Hu, Y. TS-YOLO: An All-Day and Lightweight Tea Canopy Shoots Detection Model. Agronomy 2023, 13, 1411. [Google Scholar] [CrossRef]
- Wang, Q.; Qin, W.; Liu, M.; Zhao, J.; Zhu, Q.; Yin, Y. Semantic Segmentation Model-Based Boundary Line Recognition Method for Wheat Harvesting. Agriculture 2024, 14, 1846. [Google Scholar] [CrossRef]
- Tao, D.; Qiu, G.; Li, G. A novel model for sex discrimination of silkworm pupae from different species. IEEE Access 2019, 7, 165328–165335. [Google Scholar] [CrossRef]
- Liu, J.; Abbas, I.; Noor, R. Development of Deep Learning-Based Variable Rate Agrochemical Spraying System for Targeted Weeds Control in Strawberry Crop. Agronomy 2021, 11, 1480. [Google Scholar] [CrossRef]
- Peng, Y.; Zhao, S.; Liu, J. Fused Deep Features-Based Grape Varieties Identification Using Support Vector Machine. Agriculture 2021, 11, 869. [Google Scholar] [CrossRef]
- Xiong, H.; Cai, J.; Zhang, W.; Hu, J.; Deng, Y.; Miao, J.; Tan, Z.; Li, H.; Cao, J.; Wu, X. Deep learning enhanced terahertz imaging of silkworm eggs development. iScience 2021, 24, 103316. [Google Scholar] [CrossRef]
- Xu, B.; Cui, X.; Ji, W.; Yuan, H.; Wang, J. Apple Grading Method Design and Implementation for Automatic Grader Based on Improved YOLOv5. Agriculture 2023, 13, 124. [Google Scholar] [CrossRef]
- Tao, T.; Wei, H. STBNA-YOLOv5: An Improved YOLOv5 Network for Weed Detection in Rapeseed Field. Agriculture 2025, 15, 22. [Google Scholar] [CrossRef]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P. Res2Net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef]
- Zhang, Z.; Mamat, H.; Xu, X.; Aysa, A.; Ubul, K. FAS-Res2net: An Improved Res2net-Based Script Identification Method for Natural Scenes. Appl. Sci. 2023, 13, 4434. [Google Scholar] [CrossRef]
- Ju, H.; Fang, Y.; Yang, H.; Si, F.; Kang, K. Improved Lightweight YOLOv8 With DSConv and Reparameterization for Continuous Casting Slab Detection on Embedded Device. IEEE Trans. Instrum. Meas. 2024, 74, 5003712. [Google Scholar] [CrossRef]
- Ou, J.; Shen, Y. Underwater Target Detection Based on Improved YOLOv7 Algorithm With BiFusion Neck Structure and MPDIoU Loss Function. IEEE Access 2024, 12, 105165–105177. [Google Scholar] [CrossRef]
- Duan, Y.; Han, W.; Guo, P.; Wei, X. YOLOv8-GDCI: Research on the Phytophthora Blight Detection Method of Different Parts of Chili Based on Improved YOLOv8 Model. Agronomy 2024, 14, 2734. [Google Scholar] [CrossRef]
- Wan, J.; Xue, F.; Shen, Y.; Song, H.; Shi, P.; Qin, Y.; Yang, T.; Wang, Q. Automatic segmentation of urban flood extent in video image with DSS-YOLOv8n. J. Hydrol. 2025, 655, 132974. [Google Scholar] [CrossRef]
- do Nascimento, M.; Fawcett, R.; Prisacariu, V. DSConv: Efficient Convolution Operator. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5147–5156. [Google Scholar] [CrossRef]
- Mohammad, S.; Razak, M.; Rahman, A. 3D-DIoU: 3D Distance Intersection over Union for Multi-Object Tracking in Point Cloud. Sensors 2023, 23, 3390. [Google Scholar] [CrossRef]
- Ma, S.; Xu, Y. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar] [CrossRef]
- Cho, Y. Weighted Intersection over Union (wIoU) for evaluating image segmentation. Pattern Recognit. Lett. 2024, 185, 101–107. [Google Scholar] [CrossRef]
- Yuan, H.; Liu, G.; Wang, Y. Defect detection of small targets on fabric surface based on improved YOLOv3-tiny. Manuf. Autom. 2022, 44, 172–176. [Google Scholar]
- Fu, L.; Feng, Y.; Wu, J.; Liu, Z.; Gao, F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model. Precis. Agric. 2021, 22, 754–773. [Google Scholar] [CrossRef]
- Chowdhury, A.; Said, W.; Saruchi, S. Oil Palm Fresh Fruit Branch Ripeness Detection Using YOLOV6 Algorithm. In Intelligent Manufacturing and Mechatronics; Springer Nature: Singapore, 2024; pp. 187–202. [Google Scholar] [CrossRef]
- Wu, E.; Ma, R.; Dong, D.; Zhao, X. D-YOLO: A Lightweight Model for Strawberry Health Detection. Agriculture 2025, 15, 570. [Google Scholar] [CrossRef]
- Al Amoud, I.; Ramli, D. YOLOv7-Tiny and YOLOv8n Evaluation for Face Detection. In Proceedings of the 12th International Conference on Robotics, Vision, Signal Processing and Power Applications; Springer Nature: Singapore, 2024; pp. 477–483. [Google Scholar] [CrossRef]
- Kumar, A.; Kumar, A.; Jayakody, D. Ambiguous facial expression detection for Autism Screening using enhanced YOLOv7-tiny model. Sci. Rep. 2024, 14, 12241. [Google Scholar] [CrossRef]
- Yang, H.; Jiang, H.; Zheng, H.; Cheng, X.; Hu, J.; Du, Y.; Jiang, Z. HE-Yolov8n: An innovative and efficient method for detecting defects in Lithium battery shells based on Yolov8n. Nondestruct. Test. Eval. 2024. [Google Scholar] [CrossRef]
- Song, Y.; Wu, Z.; Zhang, S.; Quan, W.; Shi, Y.; Xiong, X.; Li, P. Estimation of Artificial Reef Pose Based on Deep Learning. J. Mar. Sci. Eng. 2024, 12, 812. [Google Scholar] [CrossRef]
- Chen, X.; Lin, C. EVMNet: Eagle visual mechanism-inspired lightweight network for small object detection in UAV aerial images. Digit. Signal Process. 2024, 158, 104957. [Google Scholar] [CrossRef]
- Liao, Y.; Li, L.; Xiao, H.; Xu, F.; Shan, B.; Yin, H. YOLO-MECD: Citrus Detection Algorithm Based on YOLOv11. Agronomy 2025, 15, 687. [Google Scholar] [CrossRef]
- Lan, Y.; Lv, Y.; Xu, J.; Zhang, Y.; Zhang, Y. Breast mass lesion area detection method based on an improved YOLOv8 model. Electron. Res. Arch. 2024, 32, 5846–5867. [Google Scholar] [CrossRef]
- Cao, Y.; Yin, Z.; Duan, Y.; Cao, R.; Hu, G.; Liu, Z. Research on improved sound recognition model for oestrus detection in sows. Comput. Electron. Agric. 2025, 231, 109975. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loss Function | Model | mAP@0.5 | Convergence Epochs | Overlap Robustness |
|---|---|---|---|---|
| CIoU | YOLOv5s-CIoU | 96.8% | 150 | Moderate |
| DIoU | YOLOv5s-DIoU | 97.1% | 145 | Moderate |
| MPDIoU | YOLOv5s-MPDIoU | 98.5% | 128 | High |
| Environmental Conditions | Value |
|---|---|
| Temperature | 25 °C ± 1 °C |
| Relative humidity | 80% ± 5% |
| Light–dark #cycle | 16:8 |
| Diet | Fresh mulberry leaves derived from young shoots (10–15 cm in length) with tender leaves |
| Parameter Category | Specific Parameter | Value |
|---|---|---|
| Software environment | Python version | 3.9 |
| PyTorch version | 1.11.0 | |
| CUDA version | 11.4 | |
| Key dependencies | OpenCV version | 4.7.0 |
| NumPy version | 1.23.5 | |
| Training hyperparameters | Batch size | 16 |
| Training epochs | 150 | |
| Optimizer | Adam | |
| Initial learning rate | 0.01 | |
| Momentum | 0.937 | |
| Weight decay | 0.0005 | |
| Hardware configuration | CPU | Intel Core i7-9750H |
| RAM | 64 GB | |
| GPU | NVIDIA GeForce RTX 3080Ti |
| Experiment | Model | mAP@0.5 | Parameters | FPS |
|---|---|---|---|---|
| 1 | YOLOv5s | 98.0% | 6.7 M | 135 f·s−1 |
| 2 | YOLOv5s+Res2Net | 98.1% ↑ | 6.4 M ↓ | 138 f·s−1 ↑ |
| 3 | YOLOv5s+DSConv | 98.6% ↑ | 5.7 M ↓ | 144 f·s−1 ↑ |
| 4 | YOLOv5s+MPDIoU | 98.5% ↑ | 6.7 M | 132 f·s−1 ↓ |
| 5 | RDM-YOLO | 99.0% ↑ | 5.4 M ↓ | 150 f·s−1 ↑ |
| Model | Parameters | Precision | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|
| YOLOv3-tiny | 8.7 M | 85.9% | 85.8% | 77.8% | 140 f·s−1 |
| YOLOv5s | 6.7 M | 96.3% | 98.0% | 90.1% | 135 f·s−1 |
| YOLOv6s | 4.1 M | 95.3% | 98.9% | 91.2% | 105 f·s−1 |
| YOLOv7-tiny | 6.1 M | 92.0% | 97.2% | 89.5% | 118 f·s−1 |
| YOLOv8n | 2.9 M | 97.6% | 98.9% | 90.9% | 114 f·s−1 |
| YOLOv8-ghost | 1.6 M | 95.7% | 97.9% | 88.9% | 120 f·s−1 |
| YOLOv9t | 2.6 M | 96.6% | 98.8% | 91.1% | 147 f·s−1 |
| YOLOv11s | 9.4 M | 97.5% | 98.3% | 90.6% | 148 f·s−1 |
| RDM-YOLO | 5.4 M | 97.7% | 99.0% | 92.1% | 150 f·s−1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Sun, J.; Wu, X.; Dai, C. RDM-YOLO: A Lightweight Multi-Scale Model for Real-Time Behavior Recognition of Fourth Instar Silkworms in Sericulture. Agriculture 2025, 15, 1450. https://doi.org/10.3390/agriculture15131450
Gao J, Sun J, Wu X, Dai C. RDM-YOLO: A Lightweight Multi-Scale Model for Real-Time Behavior Recognition of Fourth Instar Silkworms in Sericulture. Agriculture. 2025; 15(13):1450. https://doi.org/10.3390/agriculture15131450
Chicago/Turabian StyleGao, Jinye, Jun Sun, Xiaohong Wu, and Chunxia Dai. 2025. "RDM-YOLO: A Lightweight Multi-Scale Model for Real-Time Behavior Recognition of Fourth Instar Silkworms in Sericulture" Agriculture 15, no. 13: 1450. https://doi.org/10.3390/agriculture15131450
APA StyleGao, J., Sun, J., Wu, X., & Dai, C. (2025). RDM-YOLO: A Lightweight Multi-Scale Model for Real-Time Behavior Recognition of Fourth Instar Silkworms in Sericulture. Agriculture, 15(13), 1450. https://doi.org/10.3390/agriculture15131450