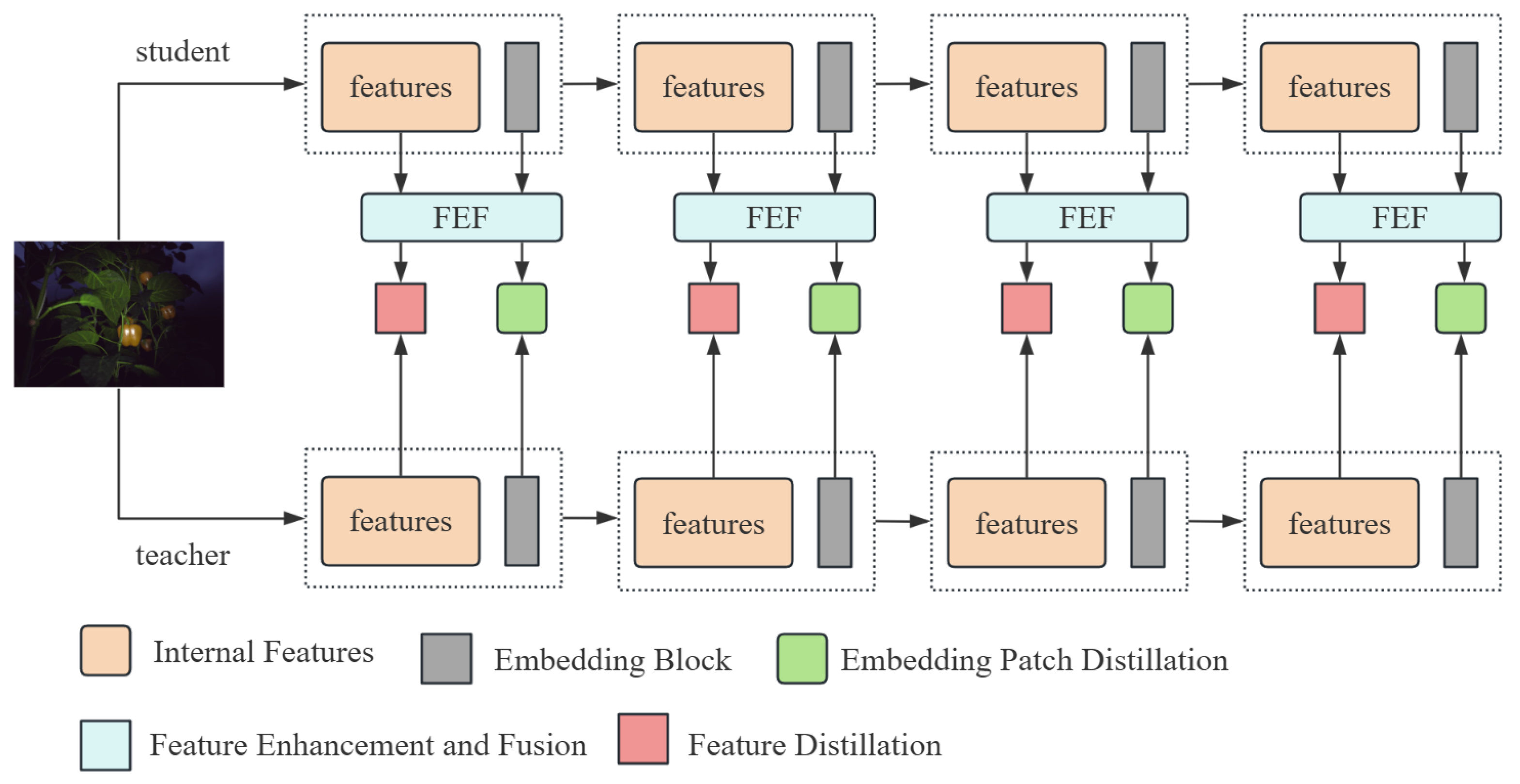
In this study, a Feature Enhancement and Fusion module (FEF) is innovatively proposed. Meanwhile, three efficient distillation methods are designed to optimize the knowledge transfer process, thus enhancing the performance of the student model. The three distillation methods are feature relationship distillation [
29], feature reconstruction distillation, and embedding patch distillation. They were primarily designed to address several key limitations in the existing knowledge distillation approaches, with a particular focus on the practical challenges of agricultural semantic segmentation. For example, the failure of multi-scale information fusion made it difficult for the model to simultaneously recognize large background areas and small crop structures [
25,
26]. Insufficient knowledge transfer led to weak generalization when the student model was applied to complex field environments, such as crop occlusion and weed overlap [
30]. Additionally, the underutilization of low-level features resulted in the poor representation of critical texture details—such as crop edges and stems—which negatively affected the overall segmentation accuracy and stability [
25].
2.1. Feature Enhancement and Fusion Module
In agricultural semantic segmentation tasks, the extraction and accurate recognition of fine-grained features are severely hampered by complex crop structures, large variations in scale, and strong background interference [
31,
32]. To address these challenges, this paper proposes a Feature Enhancement and Fusion (FEF) module, which adaptively highlights key information in images and integrates multi-scale semantic features. By introducing a dynamic gated attention mechanism, the FEF module effectively enhances the representation of small-scale and occluded crop components (such as stems and leaves), significantly improving the model’s segmentation accuracy in complex field environments.
In the attention block, the channel attention module (CA) extracts the importance of different channels in the feature map through the global average pooling and global max pooling strategies, thereby enhancing the feature of channels with rich information [
33,
34]. Suppose
is the input feature map, and the calculation of the channel attention weight is expressed as follows:
where the
is the fully connected layer for dimensionality reduction, and
is the fully connected layer for dimensionality increase.
is the ReLU activation function, and
is the Sigmoid activation function.
represents performing global average pooling on the input feature map
, and
represents performing global max pooling on the input feature map
.
The spatial attention (SA) module is used to highlight the important spatial positions in the feature map. It performs average pooling and max pooling operations on the input feature map along the channel dimension to obtain two single-channel feature maps. These two maps are concatenated along the channel dimension, and then a convolution operation is applied to obtain the spatial attention weights. The calculation can be expressed as follows:
where the
represents a convolution kernel of size
.
To further refine the attention mechanism, we introduce a dynamic gating mechanism that adaptively adjusts the contributions of the channel and spatial attention based on the input [
35]. The final output is computed as a weighted combination of the channel and spatial attention:
where
and
are dynamic gating weights generated from the input features.
Specifically, the combined features from the channel and spatial attention are processed through a 1 × 1 convolution and a Sigmoid activation to generate the gating weights:
where
is the learnable parameter of the gating network.
As shown in
Figure 2, the FEF module adopts a unified attention mechanism that adaptively fuses channel and spatial information from the input features. Through a lightweight structure, the FEF module enhances key regions and prominent crop structures, enabling more precise feature alignment with the teacher model. This design significantly improves the representation of small-scale and occluded crop components, which are particularly challenging in agricultural segmentation tasks.
2.2. Feature Relationship Distillation
In agricultural segmentation tasks, accurately distinguishing crop structures relies not only on global feature relationships but also on fine-grained local features. Traditional pixel-level difference calculations are insufficient to comprehensively capture the structural and semantic distributions among features, resulting in limited model performance in complex field environments. To address this issue, we propose a feature relation loss that compares the relation matrices between the teacher and student models, guiding the student model to learn crop distributions and spatial patterns from the perspective of the overall structural relationships.
When calculating the feature relation loss, we flatten the spatial dimensions of the feature map into a vector. Then we multiply the flattened feature map by its transpose to calculate the autocorrelation matrix. The calculation can be expressed as follows:
where
and
represent the original features of the student and the teacher, respectively.
and
represent the corresponding transpose matrices.
The feature relation loss
can be represented by the MSE between the normalized student relation matrix
and teacher relation matrix
. The complete formula is as follows:
where
is the spatial dimension of the flattened feature map (
), and
and
represent the relation matrices of the student and teacher models, respectively, calculated by the product of the flattened feature map and its transpose.
and
denote the Frobenius norms of the relation matrices, which are used to normalize them to ensure that their values are within a comparable range [
36,
37]. The loss minimizes the difference between the normalized relation matrices using the MSE.
The relation matrix encodes the context relation information within the feature map, and such information is of vital importance. It not only focuses on the similarity of individual features but also has the ability to capture the overall structure and patterns.
We calculate the feature relation loss and utilize its gradient information to optimize the student model. This guiding mechanism enables the student network to better learn and replicate the complex behaviors and patterns of the teacher network, thus enhancing the effect of knowledge distillation.
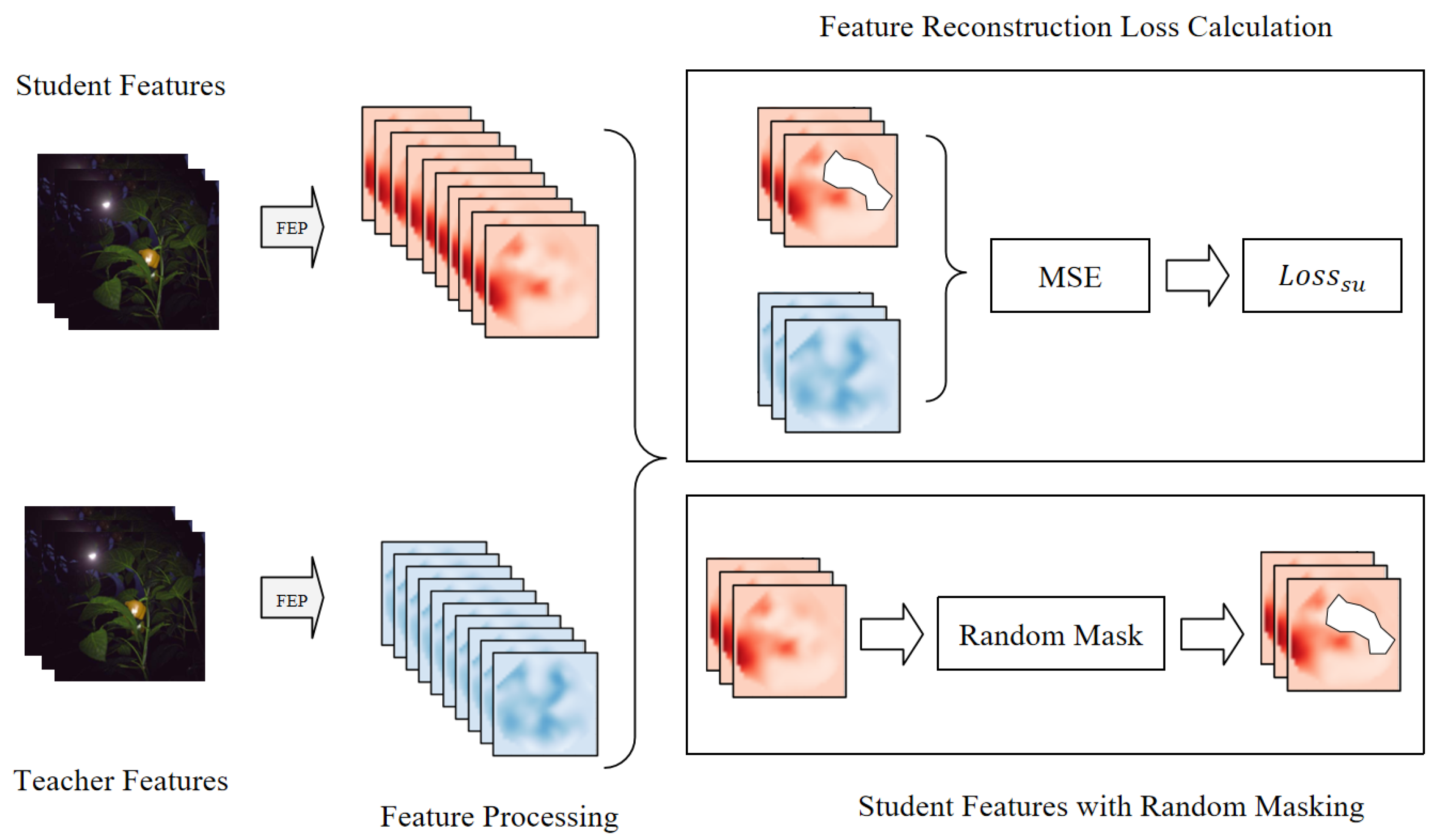
2.3. Feature Reconstruction Distillation
Due to insufficient knowledge transfer, critical information in crop images may be lost during the distillation process, which can negatively impact the accuracy of the student model in crop segmentation and other agricultural image tasks. To address this issue, we innovatively introduced a feature reconstruction mechanism into the knowledge distillation framework, enabling the student model to more effectively replicate the high-quality feature representations extracted by the teacher model, thereby improving the completeness and effectiveness of the knowledge transfer.
As depicted in
Figure 3, we employ a random mask to partially cover the original features, and the masked regions are substituted with a zero matrix. Through this mask design, we simulate the scenario of information loss, thereby compelling the student model to infer the complete feature representation based on partial information. We randomly mask 30% of the areas on the height
and width
of the feature map. The selection of the masked regions is achieved by randomly generating the starting positions
and
in each batch and then applying the mask at these positions. The generated mask is a tensor with the same size as the student features, where the masked regions are set to 0 and the other regions are set to 1.
The reconstruction loss is calculated by using the MSE to compute the Euclidean distance between two tensors. The formula for the reconstruction loss is expressed as follows:
where
represents the student feature matrix that has already been masked, and
represents the teacher’s feature matrix.
For the masked regions, the MSE between the student and the teacher features is used as the reconstruction loss, encouraging the student model to recover missing information and more closely match the teacher’s feature representations. To comprehensively transfer knowledge, this reconstruction loss is computed at each layer of the network, and the final feature reconstruction loss is obtained by averaging the reconstruction losses across all the feature layers. This approach not only enhances the feature learning ability of the student model but also improves the segmentation performance for challenging structures while reducing the reliance on annotated data.
2.4. Embedding Patch Distillation
Most existing knowledge distillation methods for crop segmentation mainly focus on high-level features, often neglecting low-level structures and edge information, which results in limited performance for small object segmentation and complex boundary recognition tasks [
38,
39]. To address this issue, this study leverages the patch embedding mechanism of SegFormer and innovatively proposes a new low-level feature distillation approach that fully exploits the rich texture information contained in embedding patches.
Specifically, we design a dual-texture distillation loss based on embedding patches, which effectively integrates structural texture and statistical texture information. The structural texture loss captures local geometric details—such as crop contours and edges—through multi-scale convolution and decomposition, while the statistical texture loss is based on the mean and the standard deviation, enhancing the model’s perception of global texture features, such as the regional intensity distribution. The combination of these two losses significantly improves the student model’s ability to model and segment fine details in complex agricultural images. The calculation process is illustrated in
Figure 4.
Structural Texture Calculation: The core of structural texture knowledge distillation lies in enhancing the student network’s understanding of the geometric features of images. These features include boundaries, shapes, and directions, which play a crucial role in capturing the details and contours of images [
40,
41]. To achieve this goal, we adopt a multi-scale decomposition method based on the Laplacian pyramid and the directional filter bank [
42].
The embedding patches are processed and reshaped into the image format
. Its smoothed version is obtained through the Gaussian blur operation
G(∙). Then, by calculating the difference between the original image and the blurred image, the Laplacian pyramid layer is obtained. The calculation formula is as follows:
where
represents the reshaped image at the
-th layer, and
G(∙) is the Gaussian blur operation function.
refers to the output of the Laplacian pyramid at the
-th layer, that is, the edge and detail features.
By repeatedly performing this blurring and differencing operation multiple times, we generate a pyramid of multi-scale image representations. To more effectively capture the directional features of the image, we introduce a directional filter bank. This filter bank is capable of decomposing the image into sub-bands in multiple directions, thereby enhancing the representation ability of structural textures. For the output
of each layer of the Laplacian pyramid, we further apply a set of directional filters to extract directional information. The calculation formula is as follows:
where
represents the sub-band in the
-th direction of the
-th layer, and
(∙) represents the directional filter function.
Through this multi-directional decomposition, we are able to capture the edge and texture features of the image in multiple directions. Finally, we calculate the differences between the teacher network and the student network on each directional sub-band and quantify these differences using the MSE. The calculation formula is as follows:
where
represents the total number of directional sub-bands.
The is the loss calculated for the structural texture. This ensures that the student network can gradually approach the performance of the teacher network in terms of the structural texture, thereby enhancing its sensitivity to and understanding of the geometric features of the image.
The Laplacian pyramid enables the multi-scale representation of image details, allowing the model to capture both coarse structures and fine edges in crop images. The directional filter bank supports multi-directional decomposition, enhancing the ability to extract complex crop contours and geometric features. Unlike Gabor filters, which rely on fixed parameters [
43], our proposed method can adaptively model diverse shapes and textures in farmland imagery, providing more expressive and robust texture representation, especially in challenging scenarios, such as overlapping leaves, irregular crop shapes, and blurred boundaries.
Statistical Texture Calculation: To enhance the student network’s ability to recognize texture features in crop images, we incorporate the computation of statistical texture loss into the loss function. The core objective is to strengthen the model’s understanding of the pixel intensity distribution in crop images, thereby enabling a more accurate representation of texture variations, disease-affected regions, and edge structures. By modeling the global statistical properties of image pixels, such as the mean and the standard deviation, we aim to capture the overall texture patterns present in the images.
To extract statistical texture features, we carry out regional block processing on the feature map. For each block, we calculate its mean value and standard deviation so as to depict the intensity distribution pattern of the local area. The specific calculation formulas are as follows:
where
and
are the mean value and the standard deviation of the
-th block, respectively.
represents the
-th data point in the
-th region.
is the number of pixels within the block.
Based on the aforementioned method, we extract the statistical features of each local block. To enable the student network to effectively learn the statistical texture features of the teacher network, we calculate the differences in their statistical features and use the MSE for quantification. The specific calculation is as follows:
The is the statistical texture loss. By minimizing this loss, the student network can better approximate the performance of the teacher network in terms of the statistical texture.
Based on the analysis of the low-level features of the embedding patches, the structural texture loss can effectively capture the edge and detail features of the image, thereby improving the ability to recognize the contours of objects in complex scenes. At the same time, the statistical texture loss promotes the student network’s learning of the global intensity distribution, making it consistent with the teacher network. The combination of the two enhances the overall texture consistency and visual effects, which can be formulated as
where
and
represent the hyperparameters for the weighted tuning of the structural texture loss and the statistical texture loss. In the experiment,
and
are set to 0.6 and 0.4, respectively.
We perform a weighted fusion of the two losses to construct the embedding loss () for knowledge distillation, thereby improving the efficiency of distillation learning at both the local and global levels. This method effectively overcomes the shortcomings of single-feature learning and provides a more balanced and comprehensive distillation framework.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}