
Research Status and Development Trends of Deep Reinforcement Learning in the Intelligent Transformation of Agricultural Machinery

 ,
,  , ,
, ,
Abstract
1. Introduction
- (1)
- Dynamic environmental factors (e.g., changing crop distributions, sudden obstacles) demand real-time perception and adaptive responses.
- (2)
- Hybrid task requirements (e.g., coupling continuous control with discrete decision-making) necessitate the development of hybrid intelligent decision systems.
- (3)
- Resource constraints (e.g., limited computational power and energy consumption) impose stricter demands on system efficiency.
2. Deep Reinforcement Learning Technology Framework and Algorithm Architecture
2.1. Deep Reinforcement Learning Algorithm Framework
2.1.1. Value Function-Based DRL Algorithms
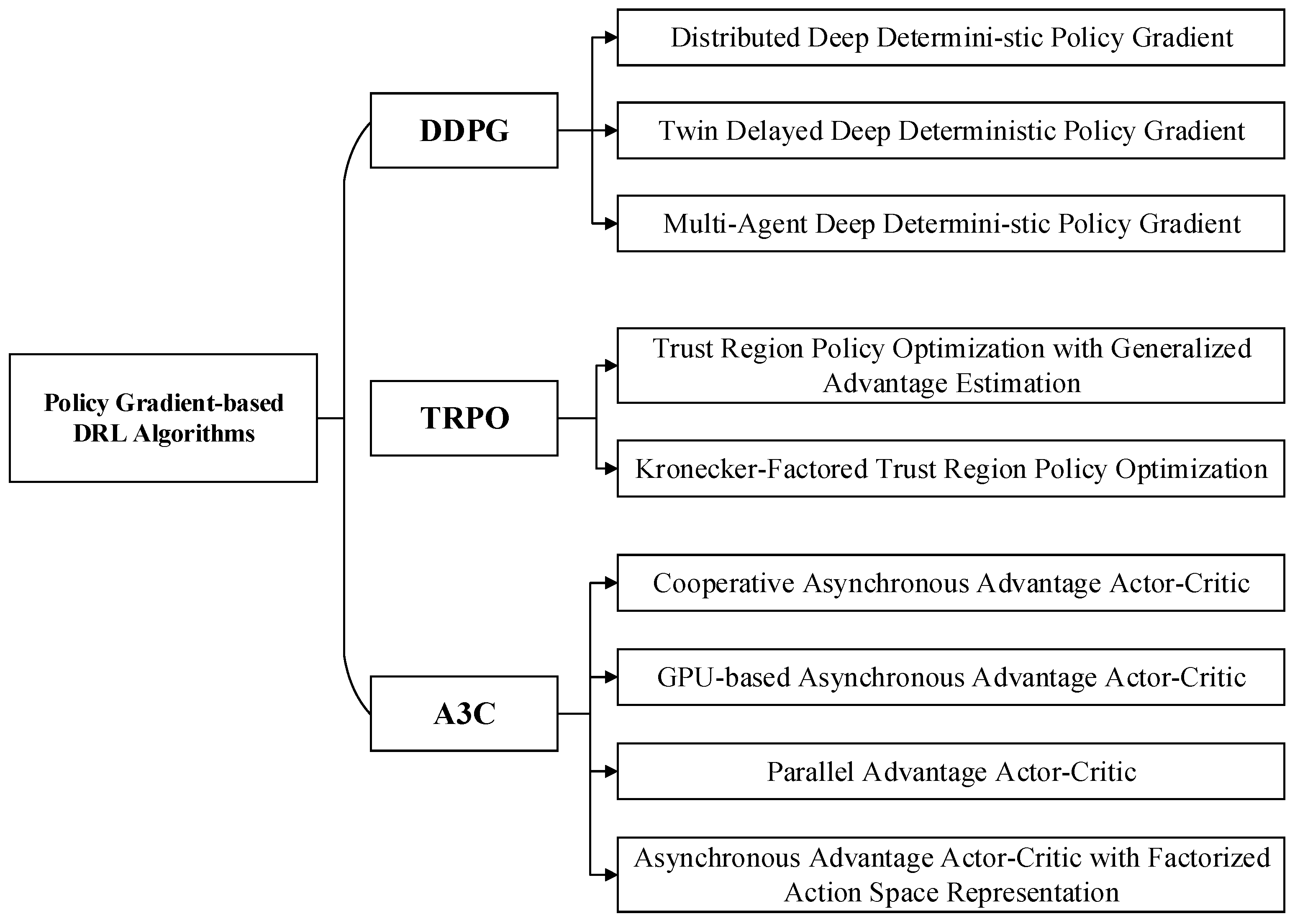
2.1.2. Policy Gradient-Based DRL Algorithms
3. Applications of DRL in Agricultural Production Environments
3.1. Agricultural Ground Platform Navigation
3.1.1. Application Background
3.1.2. DRL-Based Solution and Key Advantages
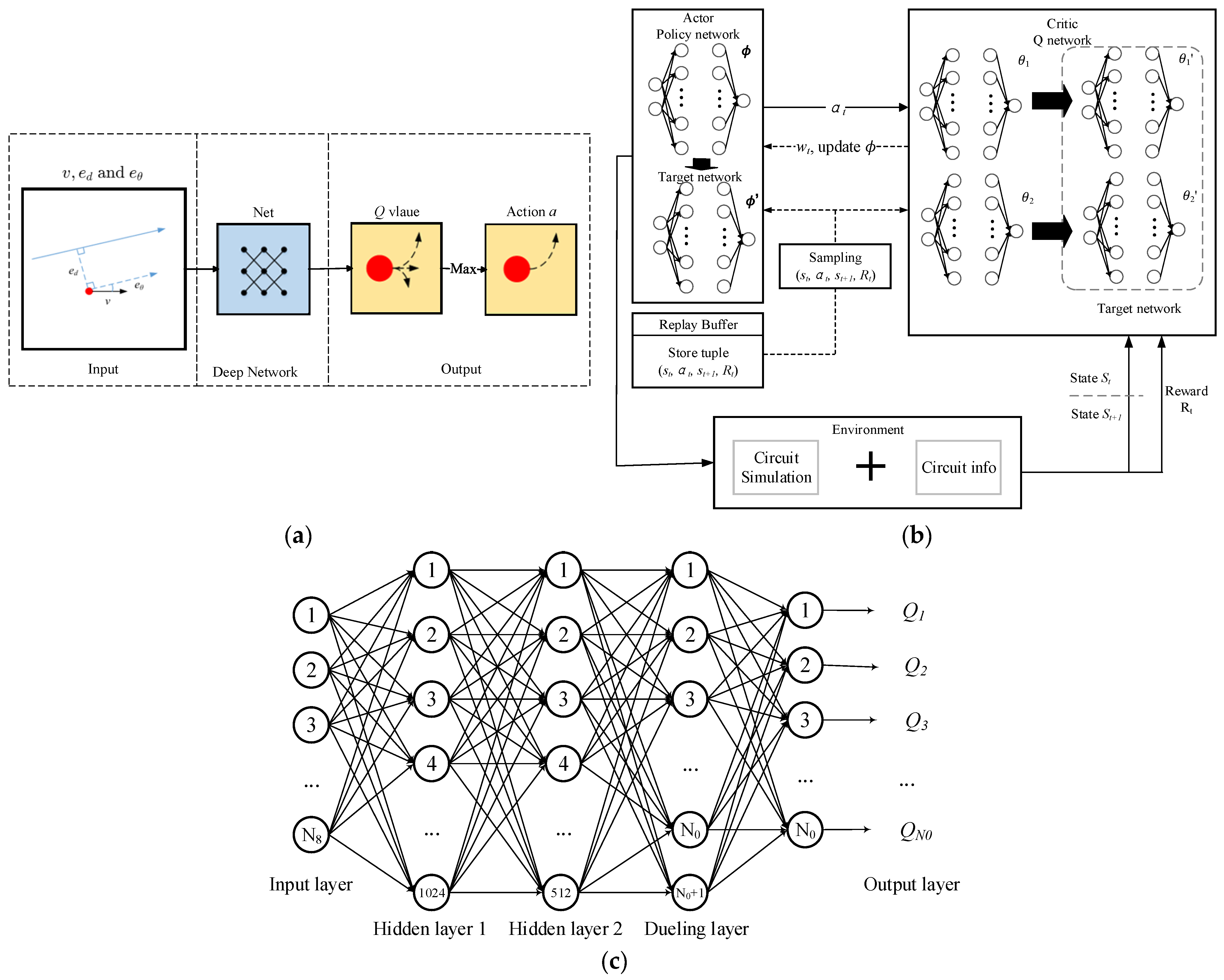
- Double-DQN algorithm (Figure 3a): The Double-DQN is an enhanced algorithm developed from the foundation of DQNs, with the primary objective of addressing the issue of Q-value overestimation inherent in DQNs [49]. The central principle involves decoupling the evaluation of Q-values from the selection of actions, employing two distinct neural networks to execute these tasks independently. This separation enhances the precision of Q-value estimation, thereby enabling the agent to learn an optimal policy with greater stability throughout the decision-making process. As depicted in the leftmost input section of the accompanying figure, the input comprises speed and two error terms. These elements collectively characterize the agent’s current environmental state, serving as the foundational basis for subsequent decision-making. The central component of the figure, the deep network, constitutes the critical processing unit of the Double-DQN. This network accepts the input state and processes it through a multi-layer neural network architecture, performing feature extraction and transformation to map the relationship between states and Q-values. The network’s parameters are iteratively updated to progressively approximate the true Q-value function. In the output phase, the action yielding the highest Q-value is designated as the final decision action. This selection is executed via a “max” operation, identifying the optimal action that drives the agent to perform the corresponding operation within the environment, subsequently receiving a reward, and transitioning to the next state. The figure provides a clear illustration of this workflow: from the input state, through deep network processing to derive Q-values, to the ultimate selection of actions based on these Q-values. This visualization encapsulates the fundamental operational framework and decision-making paradigm of Double-DQNs.
- Soft Actor–Critic (SAC) algorithm (Figure 3b): The SAC algorithm is a policy gradient method rooted in maximum entropy reinforcement learning [69]. Its core principle involves not only pursuing high cumulative rewards during policy optimization but also maximizing the entropy (uncertainty) of the policy. This encourages the agent to thoroughly explore the environment while maintaining effective control. During training, the agent executes actions determined by the current policy (output by the Actor network), interacts with the environment, and collects experiential data (such as states, actions, and rewards), which is stored in a replay buffer. Data sampled from this replay buffer is then used to update the networks.
- SMO-Rainbow strategy (Figure 3c): The rainbow algorithm integrates multiple improved algorithms into the DQN algorithm [70]. The network architecture uses a fully connected neural network with two hidden layers and a dueling layer, as shown in Figure 2. The network input is the environment state S, with 1024 and 512 neurons in the hidden layers, respectively. The dueling layer includes both a value function network and an advantage function network, which together output the predicted Q-values for each option. The hidden layers and the dueling layer use ReLU (rectified linear unit) activation functions, and the loss function is Huber loss.
3.2. Motion Planning for Intelligent Agricultural End-Effectors
3.2.1. Application Background
3.2.2. DRL-Based Solution and Key Advantages
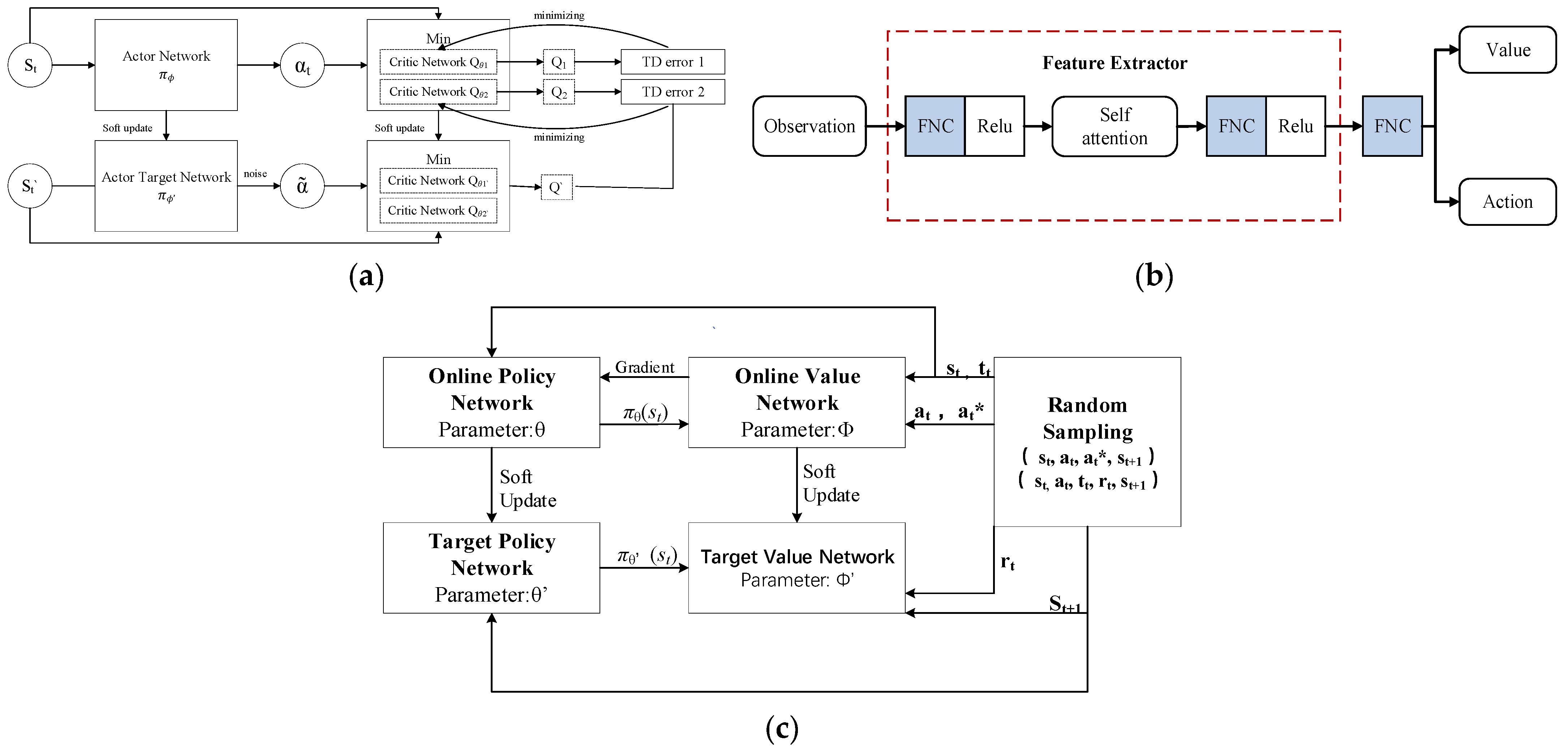
- Twin Delayed Deep Deterministic Policy Gradient (TD3) (Figure 4a): TD3 is an improved deterministic policy gradient algorithm. Its core idea involves enhancing the stability of reinforcement learning by integrating dual critic networks, smooth target network updates, and delayed policy updates. During execution, the agent executes actions (“a”) according to the policy output by the “Actor Network π0”, interacts with the environment, and observes the next state (“s′”). These experiences—including the current state, action, and next state—are then stored (typically in a replay buffer for practical applications).
- A deep reinforcement learning network with self-attention (Figure 4b): This deep reinforcement learning network incorporates a self-attention mechanism. Its core idea is to leverage the self-attention mechanism to capture global dependencies among different features within the input observations, thereby extracting more effective features for value estimation and action selection in reinforcement learning. The agent acquires observational data from the environment and inputs it into a feature extractor. The data first undergo FNC and ReLU processing, performing preliminary feature extraction and nonlinear transformation on the raw observations. The self-attention mechanism then processes these initially extracted features, computing correlation weights between features. By comparing each feature against others, the self-attention mechanism determines the importance of each feature, ultimately generating a new feature representation that highlights the most critical features for the task.
- Deep Deterministic Policy Gradient (DDPG) algorithm (Figure 4c): The DDPG algorithm is a reinforcement learning method that combines the Q-learning and policy gradient techniques [28]. It employs two neural networks—a policy network (Actor) and a value network (Critic)—to represent the policy and value function, respectively, utilizing experience replay and target networks to stabilize the training process. At its core, DDPG optimizes the value function via a deterministic policy to identify optimal policies in continuous action spaces. The agent executes actions generated by the online policy network πθ (st) during environmental interaction, observing the next state (st+1) and receiving an immediate reward (rt). These experiences (st, at, rt, and st+1) are stored in an experience replay buffer. Through continuous updates to the online networks and soft updates to the target networks, the agent learns an effective policy to maximize cumulative rewards.
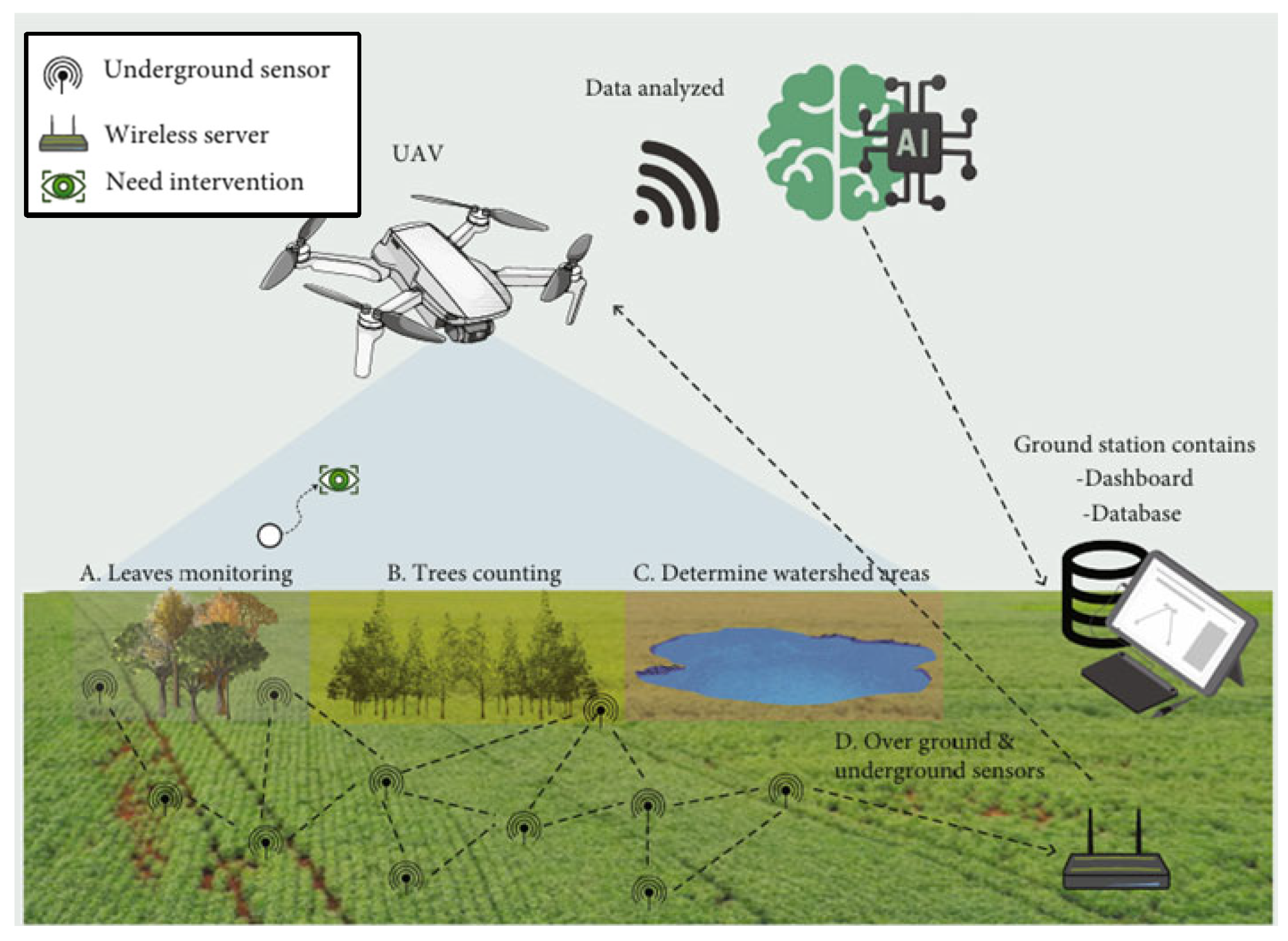
3.3. Agricultural Low-Altitude Drone Operations
3.3.1. Application Background
3.3.2. DRL-Based Solution and Key Advantages
- Neural network-based value function approximator of reinforcement learning (Figure 6a): Hu et al.’s neural network architecture, as shown in Figure 3, consists of two fully connected layers instead of the convolutional layers found in typical Deep Q-Networks. Additionally, the rectified linear unit (ReLU) is used as the activation function, with each layer having 32 neurons. The input is the state S = (U, Xw, w), and the output is the corresponding Q-value.
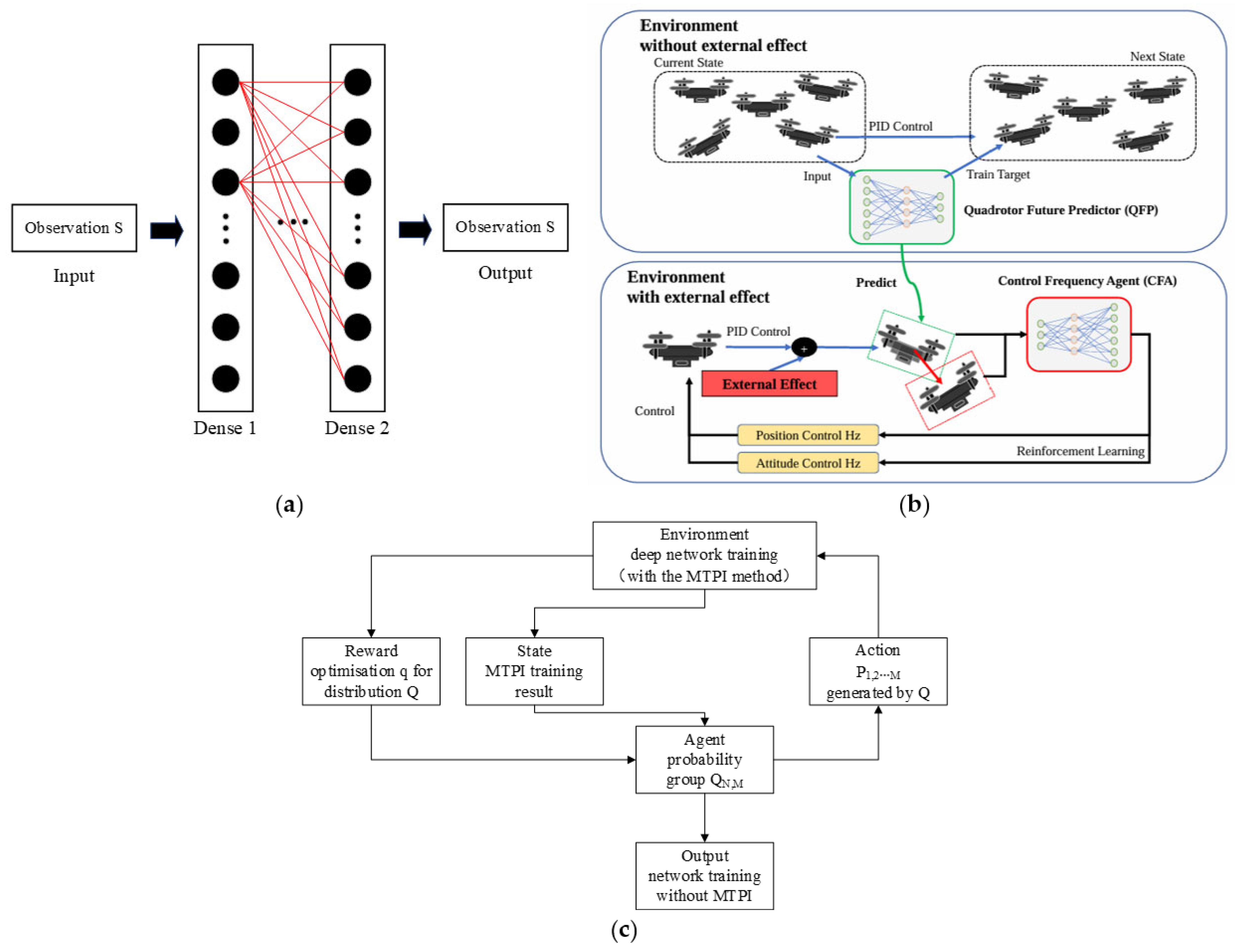
- QFP and CFA models (Figure 6b): QFP is trained to predict the next position of a quadcopter controlled by PID in an environment free from external influences. After training, the estimated next state by QFP is used as input for CFA. Then, CFA is trained to adjust the position and attitude control frequencies against external influences by maximizing a given reward function. The approximate external influence is calculated as the difference between the current state (enclosed in a red dashed box) and the estimated state (enclosed in a green dashed box). CFA is trained to balance the position and attitude control frequencies to achieve time-optimal waypoint tracking control.
- Multi-Task State Aggregation (MTSA) algorithm (Figure 6c): The MTSA algorithm aims to enhance the efficiency and performance of reinforcement learning by combining multi-task learning with state aggregation techniques. Its core principle leverages shared information across tasks to accelerate learning while reducing state space complexity through state aggregation, enabling more effective handling of complex environments. The agent interacts with the environment, selecting actions based on the current state. These actions are generated by a Q-network, which guides the agent’s behavior by estimating the value of state–action pairs. During training, state-aggregated training is accelerated using MPI (Message Passing Interface). This approach enables efficient processing of large-scale state spaces.
4. Key Challenges of DRL in Agricultural Applications
4.1. Environmental Complexity Issues
4.2. Algorithm and Computational Resource Limitations
4.3. Safety and Reliability Issues
5. Future Research Directions for DRL in Agricultural Applications
- (1)
- Complex Hybrid Architectures and Algorithmic Innovations: Develop hybrid decision frameworks combining model predictive control with DRL to enhance stability and interpretability; innovate algorithms merging value and policy methods (e.g., SAC + DQN) to boost convergence and generalization; introduce attention mechanisms and multi-scale state representations to improve strategy expressiveness in complex scenarios.
- (2)
- Edge-Cloud Collaborative Computing and Lightweight Deployment: Establish edge-cloud collaborative architectures, training complex models in the cloud while deploying lightweight, quantized models (e.g., TinyDRL, ONNX-quantized) on edge devices for low latency and energy efficiency. Leveraging 5G/6G networks enables real-time model updates and strategy synchronization, reconstructing intelligent farm IT infrastructure.
- (3)
- Meta-Learning and Self-Supervised DRL for Rapid Adaptation: Integrate meta-learning and self-supervised tasks to enable few-shot policy generalization across crop varieties, climates, and regions. Construct self-supervised tasks from historical trajectories and visual representations to achieve plug-and-play agricultural agents.
6. Conclusions
- Autonomous Navigation and Path Planning: Hybrid DRL algorithms integrating value function and policy gradient approaches (e.g., Double-DQN and DDPG) have achieved centimeter-level precision in agricultural vehicle path tracking (e.g., reducing errors to ±3 cm in [44]). Dynamic state representations (e.g., path curvature parameters) significantly improved robustness in complex farmland scenarios. However, the long-term stability of high-precision path tracking requires further validation, particularly under dynamic conditions such as crop growth interference and sudden obstacles.
- UAV Operation Optimization: Multi-objective reward mechanisms (e.g., balancing coverage efficiency and energy consumption) demonstrated preliminary success in pesticide spraying tasks (e.g., a 41.68% increase in coverage in [67]). However, their generalization across heterogeneous farmland scenarios necessitates further validation through cross-regional and multi-crop experiments.
- Multi-Agent Collaboration: Distributed DRL frameworks with attention mechanisms (e.g., MADDPG) reduced task completion time by 10.7% in collaborative harvesting scenarios ([63]). Yet, real-time responsiveness and safety of multi-agent systems require systematic optimization under hardware constraints.
- Hybrid DRL architectures coupled with model predictive control to enhance decision interpretability and robustness;
- Edge-cloud collaborative computing frameworks for deploying lightweight models with low-latency field response and high energy efficiency;
- Cross-scene adaptive agents developed through meta-learning and self-supervised mechanisms to advance agricultural machinery from task-specific to generalized intelligence.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Yin, X.; Wang, Y.X.; Chen, Y.L.; Jin, C.Q.; Du, J. Development of autonomous navigation controller for agricultural vehicles. Int. J. Agric. Biol. Eng. 2020, 13, 70–76. [Google Scholar] [CrossRef]
- Wu, C.C.; Fang, X.M. Development of precision service system for intelligent agriculture field crop production based on BeiDou system. Smart Agric. 2019, 1, 83–90. [Google Scholar]
- Sun, J.L.; Wang, Z.; Ding, S.H.; Xia, J.; Xing, G.Y. Adaptive disturbance observer-based fixed time nonsingular terminal sliding mode control for path-tracking of unmanned agricultural tractors. Biosyst. Eng. 2024, 246, 96–109. [Google Scholar] [CrossRef]
- Hu, J.T.; Gao, L.; Bai, X.P.; Li, T.C.; Liu, X.G. Review of research on automatic guidance of agricultural vehicles. Trans. Chin. Soc. Agric. Eng. 2015, 31, 1–10. [Google Scholar]
- Cui, B.; Cui, X.; Wei, X.; Zhu, Y.; Ma, Z.; Zhao, Y.; Liu, Y. Design and Testing of a Tractor Automatic Navigation System Based on Dynamic Path Search and a Fuzzy Stanley Model. Agriculture 2024, 14, 2136. [Google Scholar] [CrossRef]
- Duan, J.; Wang, M.L.; Jiang, Y.; Zhao, J.B.; Tang, Y.W. A Compound Fuzzy Control Method for Agricultural Machinery Automatic Navigation Based on Genetic Algorithm. In Proceedings of the IEEE 2nd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 December 2017; pp. 1663–1666. [Google Scholar]
- Hameed, I.A. Intelligent Coverage Path Planning for Agricultural Robots and Autonomous Machines on Three-Dimensional Terrain. J. Intell. Robot. Syst. 2014, 74, 965–983. [Google Scholar] [CrossRef]
- Gong, J.L.; Wang, W.; Zhang, Y.F.; Lan, Y.B. Cooperative working strategy for agricultural robot groups based on farmlandenvironment. Trans. Chin. Soc. Agric. Eng. 2021, 37, 11–19. [Google Scholar]
- Li, Y.W.; Xu, J.J.; Wang, M.F.; Liu, D.X.; Sun, H.W.; Wang, X.J. Development of autonomous drivingtransfer trolley on field roads and its visual navigation system for hilly areas. Trans. Chin. Soc. Agric. Eng. 2019, 35, 52–61. [Google Scholar]
- Wan, J.; Sun, W.; Ge, M.; Wang, K.H.; Zhang, X.Y. Robot Path Planning Based on Artificial Potential Field Method with Obstacle Avoidance Angles. J. Agric. Mach. 2024, 55, 409–418. [Google Scholar]
- Zheng, Z.; Yang, S.H.; Zheng, Y.J.; Liu, X.X.; Chen, J.; Su, D.B.L.G. Obstacle avoidance path planning algorithm for multi-rotor UAVs. Trans. Chin. Soc. Agric. Eng. 2020, 36, 59–69. [Google Scholar]
- Zhang, X.H.; Fan, C.G.; Cao, Z.Y.; Fang, J.L.; Jia, Y.J. Novel obstacle-avoiding path planning for crop protection UAV using optimized Dubins curve. Int. J. Agric. Biol. Eng. 2020, 13, 172–177. [Google Scholar] [CrossRef]
- Wu, C.C.; Wang, D.X.; Chen, Z.B.; Song, B.B.; Yang, L.L.; Yang, W.Z. Autonomous driving and operation control method for SF2104 tractors. Trans. Chin. Soc. Agric. Eng. 2020, 36, 42–48. [Google Scholar]
- Lu, E.; Xu, L.Z.; Li, Y.M.; Tang, Z.; Ma, Z. Modeling of working environment and coverage path planning method of combine harvesters. Int. J. Agric. Biol. Eng. 2020, 13, 132–137. [Google Scholar] [CrossRef]
- Jin, Y.C.; Liu, J.Z.; Xu, Z.J.; Yuan, S.Q.; Li, P.P.; Wang, J.Z. Development status and trend of agricultural robot technology. Int. J. Agric. Biol. Eng. 2021, 14, 1–19. [Google Scholar] [CrossRef]
- Kang, H.W.; Chen, C. Fruit detection, segmentation and 3D visualisation of environments in apple orchards. Comput. Electron. Agric. 2020, 171, 105302. [Google Scholar] [CrossRef]
- Kim, W.S.; Lee, D.H.; Kim, Y.J.; Kim, T.; Hwang, R.Y.; Lee, H.J. Path detection for autonomous traveling in orchards using patch-based CNN. Comput. Electron. Agric. 2020, 175, 105620. [Google Scholar] [CrossRef]
- Li, T.; Yu, J.P.; Qiu, Q.; Zhao, C.J. Hybrid Uncalibrated Visual Servoing Control of Harvesting Robots With RGB-D Cameras. IEEE Trans. Ind. Electron. 2023, 70, 2729–2738. [Google Scholar] [CrossRef]
- Aguilar, W.G.; Luna, M.A.; Moya, J.F.; Abad, V.; Parra, H.; Ruiz, H. Pedestrian detection for UAVs using cascade classifiers with Meanshift. In Proceedings of the 11th IEEE International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 30 January–1 February 2017; pp. 509–514. [Google Scholar]
- Liao, M.; Sen, T.; Elasser, Y.; Al Hassan, H.A.; Pigney, A.; Knapp, E.; Chen, M.J. UAV Fleet Charging on Telecom Towers with Differential Capacitive Wireless Power Transfer. IEEE Trans. Power Electron. 2025, 40, 6370–6384. [Google Scholar] [CrossRef]
- Zhao, D.B.; Shao, K.; Zhu, Y.H.; Li, D.; Chen, Y.R.; Wang, H.T.; Liu, D.R.; Zhou, T.; Wang, C.H. Review of deep reinforcement learning and discussions onthe development of computer Go. Control Theory Appl. 2016, 33, 701–717. [Google Scholar]
- Farias, G.; Garcia, G.; Montenegro, G.; Fabregas, E.; Dormido-Canto, S.; Dormido, S. Reinforcement Learning for Position Control Problem of a Mobile Robot. IEEE Access 2020, 8, 152941–152951. [Google Scholar] [CrossRef]
- Gao, J.L.; Ye, W.J.; Guo, J.; Li, Z.J. Deep Reinforcement Learning for Indoor Mobile Robot Path Planning. Sensors 2020, 20, 5493. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Zhai, J.W.; Zhang, Z.Z.; Zhong, S.; Zhou, Q.; Zhang, P.; Xu, J. A Survey on Deep Reinforcement Learning. Chin. J. Comput. 2018, 41, 1–27. [Google Scholar]
- Wen, H.; Li, H.; Wang, Z.; Hou, X.; He, K. Application of DDPG-based Collision Avoidance Algorithm in Air Traffic Control. In Proceedings of the 2019 12th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 14–15 December 2019; pp. 130–133. [Google Scholar]
- Zhang, J.; Lu, S.; Zhang, Z.; Yu, J.; Gong, X. Survey on Deep Reinforcement Learning Methods Based on Sample Efficiency Optimization. J. Softw. 2022, 33, 4217–4238. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Luo, L.; Li, L.; Yang, R.; Chen, L.L. Vector Antenna Neighborhood Search Tuning Algorithm. Commun. Technol. 2019, 52, 1800–1803. [Google Scholar]
- Yan, D.; Weng, J.Y.; Huang, S.Y.; Li, C.X.; Zhou, Y.C.; Su, H.; Zhu, J. Deep reinforcement learning with credit assignment for combinatorial optimization. Pattern Recogn. 2022, 124, 108466. [Google Scholar] [CrossRef]
- Shi, X.T.; Li, Y.J.; Du, C.L.; Shi, Y.; Yang, C.H.; Gui, W.H. Fully Distributed Event-Triggered Control of Nonlinear Multiagent Systems Under Directed Graphs: A Model-Free DRL Approach. IEEE Trans. Autom. Control 2025, 70, 603–610. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhou, L.C.; Yi, Z.H.; Shi, D.; Guo, M.J. Leveraging AI for Enhanced Power Systems Control: An Introductory Study of Model-Free DRL Approaches. IEEE Access 2024, 12, 98189–98206. [Google Scholar] [CrossRef]
- Herrera, E.M.; Calvet, L.; Ghorbani, E.; Panadero, J.; Juan, A.A. Enhancing carsharing experiences for Barcelona citizens with data analytics and intelligent algorithms. Computers 2023, 12, 33. [Google Scholar] [CrossRef]
- Liu, J.W.; Gao, F.; Luo, X.L. Survey of Deep Reinforcement Learning Based on Value Function and Policy Gradient. Chin. J. Comput. 2019, 42, 1406–1438. [Google Scholar]
- Bravo-Arrabal, J.; Toscano-Moreno, M.; Fernández-Lozano, J.J.; Mandow, A.; Gomez-Ruiz, J.A.; García-Cerezo, A. The internet of cooperative agents architecture (X-ioca) for robots, hybrid sensor networks, and mec centers in complex environments: A search and rescue case study. Sensors 2021, 21, 7843. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Rasmussen, C.E. PILCO: A Model-Based and Data-Efficient Approach to Policy Search; Omnipress: Madison, WI, USA, 2011. [Google Scholar]
- Janner, M.; Fu, J.; Zhang, M.; Levine, S. When to Trust Your Model: Model-Based Policy Optimization. In Proceedings of the Advances in Neural Information Processing Systems 32, Volume 16 of 20: 32nd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, CA, USA, 8–14 December 2019; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2020. [Google Scholar]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents. J. Artif. Intell. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Bae, S.-Y.; Lee, J.; Jeong, J.; Lim, C.; Choi, J. Effective data-balancing methods for class-imbalanced genotoxicity datasets using machine learning algorithms and molecular fingerprints. Comput. Toxicol. 2021, 20, 100178. [Google Scholar] [CrossRef]
- Choi, S.; Park, S. Development of Smart Mobile Manipulator Controlled by a Single Windows PC Equipped with Real-Time Control Software. Int. J. Precis. Eng. Manuf. 2021, 22, 1707–1717. [Google Scholar] [CrossRef]
- Liu, Z.T.; Shi, Y.H.; Chen, H.W.; Qin, T.X.; Zhou, X.J.; Huo, J.; Dong, H.; Yang, X.; Zhu, X.D.; Chen, X.N.; et al. Machine learning on properties of multiscale multisource hydroxyapatite nanoparticles datasets with different morphologies and sizes. npj Comput. Mater. 2021, 7, 142. [Google Scholar] [CrossRef]
- Chen, K.Y.; Liang, Y.F.; Jha, N.; Ichnowski, J.; Danielczuk, M.; Gonzalez, J.; Kubiatowicz, J.; Goldberg, K. FogROS: An Adaptive Framework for Automating Fog Robotics Deployment. In Proceedings of the 17th IEEE International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 2035–2042. [Google Scholar]
- Ou, J.J.; Guo, X.; Lou, W.J.; Zhu, M. Learning the Spatial Perception and Obstacle Avoidance with the Monocular Vision on a Quadrotor. In Proceedings of the IEEE International Conference on Mechatronics and Automation (IEEE ICMA), Takamatsu, Japan, 8–11 August 2021; pp. 582–587. [Google Scholar]
- Saeedvand, S.; Mandala, H.; Baltes, J. Hierarchical deep reinforcement learning to drag heavy objects by adult-sized humanoid robot. Appl. Soft. Comput. 2021, 110, 107601. [Google Scholar] [CrossRef]
- Jembre, Y.Z.; Nugroho, Y.W.; Khan, M.T.R.; Attique, M.; Paul, R.; Shah, S.H.A.; Kim, B. Evaluation of reinforcement and deep learning algorithms in controlling unmanned aerial vehicles. Appl. Sci. 2021, 11, 7240. [Google Scholar] [CrossRef]
- Timmis, I.; Paul, N.; Chung, C.J. Teaching Vehicles to Steer Themselves with Deep Learning. In Proceedings of the IEEE International Conference on Electro Information Technology (EIT), Mount Pleasant, MI, USA, 14–15 May 2021; pp. 419–421. [Google Scholar]
- Yuhas, M.; Feng, Y.L.; Ng, D.J.X.; Rahiminasab, Z.; Easwaran, A. Embedded Out-of-Distribution Detection on an Autonomous Robot Platform. In Proceedings of the Design Automation for CPS and IoT, Nashville, TN, USA, 18 May 2021; pp. 13–18. [Google Scholar]
- van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the 30th Association-for-the-Advancement-of-Artificial-Intelligence (AAAI) Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Zhang, W.Y.; Gai, J.Y.; Zhang, Z.G.; Tang, L.; Liao, Q.X.; Ding, Y.C. Double-DQN based path smoothing and tracking control method for robotic vehicle navigation. Comput. Electron. Agric. 2019, 166, 104985. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, Y.F.; Wang, J.C.; Noguchi, N.; He, Y. Obstacle avoidance method based on double DQN for agricultural robots. Comput. Electron. Agric. 2023, 204, 107546. [Google Scholar] [CrossRef]
- Ren, Z.G.; Liu, Z.J.; Yuan, M.X.; Liu, H.; Wang, W.; Qin, J.F.; Yang, F.Z. Double-DQN-Based Path-Tracking Control Algorithm for Orchard Traction Spraying Robot. Agronomy 2022, 12, 2803. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1889–1897. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Harley, T.; Lillicrap, T.P. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Hu, Z.Y.; Wang, Y. A deep deterministic policy gradient method for collision avoidance of autonomous ship. Command Control Simul. 2024, 46, 37–44. [Google Scholar]
- Takahashi, K.; Tomah, S. Online optimization of AGV transport systems using deep reinforcement learning. Bull. Netw. Comput. Syst. Softw. 2020, 9, 53–57. [Google Scholar]
- Ye, X.F.; Deng, Z.Y.; Shi, Y.J.; Shen, W.M. Toward Energy-Efficient Routing of Multiple AGVs with Multi-Agent Reinforcement Learning. Sensors 2023, 23, 5615. [Google Scholar] [CrossRef]
- Chen, Y.; Schomaker, L.; Cruz, F. Boosting Reinforcement Learning Algorithms in Continuous Robotic Reaching Tasks Using Adaptive Potential Functions. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Melbourne, Australia, 25–29 November 2024; pp. 52–64. [Google Scholar]
- Sasaki, Y.; Matsuo, S.; Kanezaki, A.; Takemura, H. A3C Based Motion Learning for an Autonomous Mobile Robot in Crowds. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 1036–1042. [Google Scholar]
- Lyu, S.; Gong, X.Y.; Zhang, Z.H.; Han, S.; Zhang, J.W. Survey of Deep Reinforcement Learning Methods with Evolutionary Algorithms. Chin. J. Comput. 2022, 45, 1478–1499. [Google Scholar]
- Freitas, G.; Hamner, B.; Bergerman, M.; Singh, S. A practical obstacle detection system for autonomous orchard vehicles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots & Systems, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Blok, P.M.; Kwon, S.H.; Boheemen, K.v.; Hakjin, K. Autonomous In-Row Navigation of an Orchard Robot with a 2D LIDAR Scanner and Particle Filter with a Laser-Beam Model. Inst. Control Robot. Syst. 2018, 24, 726–735. [Google Scholar] [CrossRef]
- Wang, M.; Xu, J.; Zhang, J.C.; Cui, Y. An autonomous navigation method for orchard rows based on a combination of an improved a-star algorithm and SVR. Precis. Agric. 2024, 25, 1429–1453. [Google Scholar] [CrossRef]
- Kiumarsi, B.; Vamvoudakis, K.G.; Modares, H.; Lewis, F.L. Optimal and Autonomous Control Using Reinforcement Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2042–2062. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, R.R.; Zhang, L.H.; Chen, L.P.; Yi, T.C.; Wu, M.Q.; Yue, X.L. DQN-based Path Tracking Control for Intelligent Agricultural Machinery. J. Agric. Mech. Res. 2025, 47, 28–34. [Google Scholar] [CrossRef]
- Zhang, F.; Wan, X.F.; Cui, J.; Liu, H.D.; Cai, T.T.; Yang, Y. UAV path planning strategy for smart tourism agriculture. Comput. Eng. Des. 2022, 43, 1905–1914. [Google Scholar] [CrossRef]
- Hu, G.M. Research on Navigation of Orchard Inspection Robot Based on Deep Reinforcement Learning. Mod. Inf. Technol. 2021, 5, 154–156+160. [Google Scholar] [CrossRef]
- Devarajan, G.G.; Nagarajan, S.M.; Alnumay, G.W. DDNSAS: Deep reinforcement learning based deep Q-learning network for smart agriculture system. Sustain. Comput.-Infor. 2023, 39, 100890. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining Improvements in Deep Reinforcement Learning. In Thirty-Second AAAI Conference on Artificial Intelligence; AAAI: Philadelphia, PA, USA, 2017; Volume 32. [Google Scholar]
- Zhang, Y.H.; Chen, W.B.; Zhang, J.Q.; Ma, H. A flexible assembly strategy for a 6-DOF robotic arm based on deep reinforcement learning. J. Chongqing Univ. Technol. (Nat. Sci.) 2024, 38, 148–154. [Google Scholar]
- Zhang, S.; Shen, J.; Cao, K.; Dai, H.S.; Li, T. Research on 6D Robotic Arm Grasping Method Based on Improved DDPG. Comput. Eng. Appl. 2025, 1–10. [Google Scholar]
- Zhang, X.; Lu, H.M.; Ren, J.K.; Mo, X.M.; Xiao, H.R.; Zhang, W.J.; Yang, X. A Dynamic Target Grasping Method for Manipulator Based on Deep Reinforcement Learning. Ordnance Ind. Autom. 2024, 43, 91–96. [Google Scholar]
- Liu, J.; Yap, H.J.; Khairuddin, A.S.M. Path Planning for the Robotic Manipulator in Dynamic Environments Based on a Deep Reinforcement Learning Method. J. Intell. Robot. Syst. 2024, 111, 3. [Google Scholar] [CrossRef]
- Xie, F.; Guo, Z.; Li, T.; Feng, Q.; Zhao, C. Dynamic Task Planning for Multi-Arm Harvesting Robots Under Multiple Constraints Using Deep Reinforcement Learning. Horticulturae 2025, 11, 88. [Google Scholar] [CrossRef]
- Yang, B.; Wu, X.; Zhang, M.L.; Feng, S.K. Path Planning of Weeding Robot Arm Based on Deep Reinforcement Learning. J. Agric. Mech. Res. 2025, 47, 15–21. [Google Scholar] [CrossRef]
- Zhang, S.C.; Xue, X.Y.; Chen, C.; Sun, Z.; Sun, T. Development of a low-cost quadrotor UAV based on ADRC for agricultural remote sensing. Int. J. Agric. Biol. Eng. 2019, 12, 82–87. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, D.; Mao, H.; Shen, B.; Li, M. Wind-induced response of rice under the action of the downwash flow field of a multi-rotor UAV. Biosyst. Eng. 2021, 203, 60–69. [Google Scholar] [CrossRef]
- Almalki, F.A.; Salem, S.M.; Fawzi, W.M.; Alfeteis, N.S.; Esaifan, S.A.; Alharthi, A.S.; Alnefaiey, R.Z.; Naith, Q.H. Coupling an Autonomous UAV With a ML Framework for Sustainable Environmental Monitoring and Remote Sensing. Int. J. Aerosp. Eng. 2024, 2024. [Google Scholar] [CrossRef]
- Hu, J.; Wang, T.; Yang, J.C.; Lan, Y.B.; Lv, S.L.; Zhang, Y.L. WSN-Assisted UAV Trajectory Adjustment for Pesticide Drift Control. Sensors 2020, 20, 5473. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.T.; Li, Z.; Zhang, W.J.; Feng, Y.X.; Zhu, L.; Fang, X.; Li, J. Research on Path Planning of Agricultural UAV Based on Improved Deep Reinforcement Learning. Agronomy 2024, 14, 2669. [Google Scholar] [CrossRef]
- Kang, C.; Park, B.; Choi, J. Scheduling PID Attitude and Position Control Frequencies for Time-Optimal Quadrotor Waypoint Tracking under Unknown External Disturbances. Sensors 2022, 22, 150. [Google Scholar] [CrossRef]
- Huang, Y.Y.; Li, Z.W.; Yang, C.H.; Huang, Y.M. Automatic Path Planning for Spraying Drones Based on Deep Q-Learning. J. Internet Technol. 2023, 24, 565–575. [Google Scholar] [CrossRef]
- Zhu, W.; Feng, Z.; Dai, S.; Zhang, P.; Wei, X. Using UAV Multispectral Remote Sensing with Appropriate Spatial Resolution and Machine Learning to Monitor Wheat Scab. Agriculture 2022, 12, 1785. [Google Scholar] [CrossRef]
- Chen, Y.Y.; Zhou, B.B.; Chen, X.P.; Ma, C.K.; Cui, L.; Lei, F.; Han, X.J.; Chen, L.J.; Wu, S.S.; Ye, D.P. A method of deep network auto-training based on the MTPI auto-transfer learning and a reinforcement learning algorithm for vegetation detection in a dry thermal valley environment. Front. Plant Sci. 2025, 15, 1448669. [Google Scholar] [CrossRef] [PubMed]
- Gözen, D.; Özer, S. Visual Object Tracking in Drone Images with Deep Reinforcement Learning. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10082–10089. [Google Scholar]
- Lytridis, C.; Kaburlasos, V.G.; Pachidis, T.; Manios, M.; Vrochidou, E.; Kalampokas, T.; Chatzistamatis, S. An Overview of Cooperative Robotics in Agriculture. Agronomy 2021, 11, 1818. [Google Scholar] [CrossRef]
- Delavarpour, N.; Koparan, C.; Nowatzki, J.; Bajwa, S.; Sun, X. A Technical Study on UAV Characteristics for Precision Agriculture Applications and Associated Practical Challenges. Remote Sens. 2021, 13, 1204. [Google Scholar] [CrossRef]
- Miao, H.; Tian, Y.C. Dynamic robot path planning using an enhanced simulated annealing approach. Appl. Math. Comput. 2013, 222, 420–437. [Google Scholar] [CrossRef]
- Yang, K.J.; Sukkarieh, S. REAL-TIME Continuous Curvature Path Planning of Uavs in Cluttered Environments. In Proceedings of the 5th International Symposium on Mechatronics and its Applications, Amman, Jordan, 27–29 May 2008; pp. 1–6. [Google Scholar]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, J. The Three-Dimension Path Planning of UAV Based on Improved Artificial Potential Field in Dynamic Environment. In Proceedings of the 2013 5th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2013; pp. 144–147. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Yan, F.; Liu, Y.S.; Xiao, J.Z. Path Planning in Complex 3D Environments Using a Probabilistic Roadmap Method. Int. J. Autom. Comput. 2013, 10, 525–533. [Google Scholar] [CrossRef]
- Tsai, J.T.; Chou, J.H.; Liu, T.K. Tuning the structure and parameters of a neural network by using hybrid Taguchi-genetic algorithm. IEEE Trans. Neural Netw. 2006, 17, 69–80. [Google Scholar] [CrossRef]
- Wu, K.Y.; Esfahani, M.A.; Yuan, S.H.; Wang, H. TDPP-Net: Achieving three-dimensional path planning via a deep neural network architecture. Neurocomputing 2019, 357, 151–162. [Google Scholar] [CrossRef]
- Guo, T.; Jiang, N.; Biyue, L.I.; Zhu, X.; Wenbo, D.U. UAV navigation in high dynamic environments: A deep reinforcement learning approach. Chin. J. Aeronaut. 2020, 34, 479–489. [Google Scholar] [CrossRef]
- Tian, S.S.; Li, Y.X.; Zhang, X.; Zheng, L.; Cheng, L.H.; She, W.; Xie, W. Fast UAV path planning in urban environments based on three-step experience buffer sampling DDPG. Digit. Commun. Netw. 2024, 10, 813–826. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P. Soft Actor-Critic Algorithms and Applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Baumgartner, J.; Petric, T.; Klancar, G. Potential Field Control of a Redundant Nonholonomic Mobile Manipulator with Corridor-Constrained Base Motion. Machines 2023, 11, 293. [Google Scholar] [CrossRef]
- Li, L.Y.; Wu, D.F.; Huang, Y.Q.; Yuan, Z.M. A path planning strategy unified with a COLREGS collision avoidance function based on deep reinforcement learning and artificial potential field. Appl. Ocean Res. 2021, 113, 102759. [Google Scholar] [CrossRef]
- Cao, K.; Zhu, Y.; Gao, Q.; Liu, J.H. Research status and prospect of deep reinforcement learning in automatic control. J. Drain. Irrig. Mach. Eng. 2023, 41, 638–648. [Google Scholar]
- Choudhury, M.R.; Das, S.; Christopher, J.; Apan, A.; Chapman, S.; Menzies, N.W.; Dang, Y.P. Improving Biomass and Grain Yield Prediction of Wheat Genotypes on Sodic Soil Using Integrated High-Resolution Multispectral, Hyperspectral, 3D Point Cloud, and Machine Learning Techniques. Remote Sens. 2021, 13, 3482. [Google Scholar] [CrossRef]
- Awais, M.; Li, W.; Cheema, M.J.M.; Zaman, Q.U.; Shaheen, A.; Aslam, B.; Zhu, W.; Ajmal, M.; Faheem, M.; Hussain, S.; et al. UAV-based remote sensing in plant stress imagine using high-resolution thermal sensor for digital agriculture practices: A meta-review. Int. J. Environ. Sci. Technol. 2023, 20, 1135–1152. [Google Scholar] [CrossRef]
- Velusamy, P.; Rajendran, S.; Mahendran, R.K.; Naseer, S.; Shafiq, M.; Choi, J.G. Unmanned Aerial Vehicles (UAV) in Precision Agriculture: Applications and Challenges. Energies 2022, 15, 217. [Google Scholar] [CrossRef]
- Gao, T.; Gao, Z.H.; Sun, B.; Qin, P.Y.; Li, Y.F.; Yan, Z.Y. An Integrated Method for Estimating Forest-Canopy Closure Based on UAV LiDAR Data. Remote Sens. 2022, 14, 4317. [Google Scholar] [CrossRef]
- Zhao, D.A.; Lv, J.D.; Ji, W.; Zhang, Y.; Chen, Y. Design and control of an apple harvesting robot. Biosyst. Eng. 2011, 110, 112–122. [Google Scholar] [CrossRef]
- Feng, R.G.; Hu, J.P.; Wang, M.J.; Niu, X.S.; Li, H.T. Key technologies and application analysis of intelligent agricultural machinery autonomous driving. Agric. Equip. Veh. Eng. 2024, 62, 15–18. [Google Scholar]
- Ahmed, S.; Qiu, B.J.; Ahmad, F.; Kong, C.W.; Xin, H. A State-of-the-Art Analysis of Obstacle Avoidance Methods from the Perspective of an Agricultural Sprayer UAV’s Operation Scenario. Agronomy 2021, 11, 1069. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Model-Based DRL | Model-Free DRL |
|---|---|---|
| Core Concept | Builds a model of environment dynamics for policy optimization | Learns optimal policy directly through interaction with environment |
| Sample Efficiency | High—can generate abundant data via the learned model | Low—requires large amounts of real-world interaction |
| Generalization Ability | Strong—suitable for transfer and multi-task learning | Moderate—relies on experience replay or exploration mechanisms |
| Typical Application Scenarios | Structured environments (e.g., greenhouse climate control) | Complex, unstructured environments (e.g., field navigation) |
| Representative Algorithms | PILCO [37], MBPO [38], Dreamer [39] | DQN, DDPG, TD3 |
| Major Challenges | Model error accumulation, increased training complexity | High data demand, unstable convergence |
| Agricultural Use Cases | Crop growth modeling, irrigation/fertilization control | Tractor path tracking, UAV spraying missions |
| Method | Path Accuracy | Adaptability | Computational Load | Suitable Terr |
|---|---|---|---|---|
| PPC | Medium | Low | Low | Flat Fields |
| MPC | High | Medium | High | Greenhouses |
| DRL(DQN,PPO) | High | High | Medium | Unstructured fields |
| Metric | Traditional | DRL Solution |
|---|---|---|
| Obstacle reaction time | 42 ms | 12.1 ms |
| Multi-target success rate | 65% | 87% |
| Multi-arm task time | 120 s | 107 s |
| Method | Advantages | Disadvantages | Reference |
|---|---|---|---|
| RRT | Simple, low computation | Static-only; non-optimal paths | Yang et al. [90] |
| A* | Fast search | Static-only; high computational burden; non-smooth | Hart et al. [91] |
| APF | Fast convergence | Local minima problem | Chen & Zhang [92] |
| Dijkstra’s Alg | Easy implementation | High complexity; static-only | Dijkstra et al. [93] |
| PRM | Handles complex spaces | Static-only; non-optimal; time-consuming | Yan et al. [94] |
| Genetic Alg | Solves NP-hard and multi-objective | High complexity; premature convergence | Tsai et al. [95] |
| CNN | Handles dynamic, unknown | High complexity; many hyperparameters; non-optimal | Wu et al. [96] |
| DQN | Adaptive | Non-optimal; hard to implement | Tong et al. [97] |
| DDPG | Supports continuous action spaces; suitable for high-dimensional control | Unstable training; high computational resource demands | Tian et al. [98] |
| TD3 | Improved stability over DDPG; reduces overestimation | Complex parameter tuning; insufficient real-time performance | Liu et al. [74] |
| SAC | Balances exploration-exploitation; adapts to complex dynamic environments | High algorithmic complexity; long training time | Haarnoja et al. [99] |
| PPO | Stable training; suitable for multi-task scenarios | Requires fine hyperparameter tuning; slow convergence | Baumgartner et al. [100] |
| Method | Advantages | Limitations | Applicability Case |
|---|---|---|---|
| RRT | Simple, low computation | Only suitable for static environments, the path is not optimal, and it cannot handle dynamic obstacles | For initial path exploration of static obstacles in farmland (such as avoiding fixed gullies); it should be combined with other methods to optimize the path. |
| A* | Fast search | Training is unstable, requires high computational resources, and has limited real-time performance | For initial global path planning of agricultural machinery; it needs to be combined with local dynamic adjustments. |
| DDPG | Supports continuous action spaces; suitable for high-dimensional control | Parameter tuning is complex, and hardware compatibility is poor | Zhang et al. used DDPG to optimize tractor dynamic path tracking, improving response speed by 30%. |
| TD3 | Improved stability over DDPG; reduces overestimation | High algorithm complexity and long training cycles | Liu et al. implemented dynamic obstacle avoidance path generation for agricultural machinery based on TD3, reducing the response time to 12.1 milliseconds. |
| SAC | Balances exploration–exploitation; adapts to complex dynamic environments | Only applicable for static maps; path is not smooth; high computational burden | Hu adopted an SAC-designed orchard inspection robot navigation strategy to address the issue of sparse GPS signals. |
| Method | Advantages | Limitations | Applicability Case |
|---|---|---|---|
| PPO | Training is stable and suitable for multi-task scenarios | Requires fine-tuning of parameters, with slow convergence speed | Xu et al. achieved dynamic grasping with a 6-degree-of-freedom robotic arm using PPO, improving the success rate by 21% |
| DQN | Strong adaptive learning ability; suitable for discrete action spaces (such as decision-making) | Difficult to handle continuous actions | For discrete task selection of end-effectors (such as spray switch control); it needs to be combined with policy gradient methods |
| MADDPG | Supports multi-agent collaboration | High risk of strategy drift requires complex reward function design | Xie et al. developed a multi-robotic arm Markov game model, reducing task completion time by 10.7% |
| APF | Converges quickly; suitable for local obstacle avoidance | Prone to becoming stuck in local minima; unable to handle complex constraints | Chen et al. combined APF with DDPG to design an obstacle avoidance reward mechanism, reducing the seedling damage rate to 2.82% |
| Method | Advantages | Limitations | Applicability Case |
|---|---|---|---|
| Genetic Alg | Suitable for multi-objective optimization | High computational complexity; prone to premature convergence | For offline global path planning (such as large field area division); but it needs to be combined with online DRL dynamic adjustment |
| DQN + PSO | Combining the adaptability of DQN with the global search capability of PSO to enhance path optimality | Implementation is complex and requires data fusion from multiple sensors | Hu et al. designed a drone trajectory correction system assisted by WSN, which increased pesticide deposition coverage by 41.68% |
| TD3 | Adapt to continuous action space | Insufficient real-time performance; difficulties in deploying at the edge | For drone attitude control in simulation environments, a lightweight model such as TinyDRL is needed to adapt to actual hardware |
| SAC | Supports complex dynamic environments (such as sudden changes in wind speed), with high efficiency | The need for extensive training data makes it difficult to quickly transfer to new scenarios | Almalki et al. combined SAC with Faster R-CNN to achieve vegetation detection in arid river valleys with an accuracy of 98% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Fan, S.; Zhang, B.; Wang, A.; Zhang, L.; Zhu, Q. Research Status and Development Trends of Deep Reinforcement Learning in the Intelligent Transformation of Agricultural Machinery. Agriculture 2025, 15, 1223. https://doi.org/10.3390/agriculture15111223
Zhao J, Fan S, Zhang B, Wang A, Zhang L, Zhu Q. Research Status and Development Trends of Deep Reinforcement Learning in the Intelligent Transformation of Agricultural Machinery. Agriculture. 2025; 15(11):1223. https://doi.org/10.3390/agriculture15111223
Chicago/Turabian StyleZhao, Jiamuyang, Shuxiang Fan, Baohua Zhang, Aichen Wang, Liyuan Zhang, and Qingzhen Zhu. 2025. "Research Status and Development Trends of Deep Reinforcement Learning in the Intelligent Transformation of Agricultural Machinery" Agriculture 15, no. 11: 1223. https://doi.org/10.3390/agriculture15111223
APA StyleZhao, J., Fan, S., Zhang, B., Wang, A., Zhang, L., & Zhu, Q. (2025). Research Status and Development Trends of Deep Reinforcement Learning in the Intelligent Transformation of Agricultural Machinery. Agriculture, 15(11), 1223. https://doi.org/10.3390/agriculture15111223